一、OneTrans [2025]
《OneTrans: Unified Feature Interaction and Sequence Modeling with One Transformer in Industrial Recommender》
在推荐系统中,
scaling up特征交互模块(如Wukong、RankMixer)或用户行为序列模块(如LONGER)的规模已取得显著成效。然而,这些研究通常沿着独立路径推进,不仅阻碍了双向信息交换,还无法实现unified optimization and scaling。本文提出OneTrans,一种统一的Transformer骨干网络,能够同时执行用户行为序列建模与特征交互。OneTrans采用unified tokenizer,将sequential attributes和non-sequential attributes转换为a single token sequence。堆叠的OneTrans blocks在sequential tokens间共享参数,同时为non-sequential tokens分配token-specific parameters。通过causal attention机制和cross-request KV caching,OneTrans支持intermediate representations的precomputation与caching,大幅降低training和inference阶段的计算成本。工业级数据集上的实验结果表明,OneTrans随着参数增加实现高效的scales,持续优于strong baselines,且在online A/B tests中实现了5.68%的per-user GMV提升。推荐系统在各类
information services中扮演着核心角色,例如电子商务、流媒体、和社交网络。工业级推荐系统通常采用级联排序架构(cascaded ranking architecture)。首先,召回阶段从十亿级别的语料库中筛选出数百个
candidates。随后,排序阶段(通常包含粗排和精排)对每个
candidate进行评分,并返回top-k items。
本文聚焦于排序阶段(
ranking stage)。对于ranking任务,主流方法围绕两个独立模块展开迭代:序列建模(
sequence modeling):通过local attention或Transformer encoders,将user multi-behavior sequences编码为candidate-aware representations;feature interaction:通过因子分解、显式交叉网络、或attention over feature groups,学习non-sequential features(如用户画像、item画像、以及上下文)之间的high-order crosses。
如图
Figure 1(a)所示,这些方法通常将用户行为编码为compressed sequence representation,然后与non-sequential features拼接,并应用feature-interaction module学习高阶interaction。我们将这种设计称为encode-then-interaction pipeline。事实上,
Longer(《LONGER: Scaling Up Long Sequence Modeling in Industrial Recommenders》)采用的就是Figure 1 (b)的方式。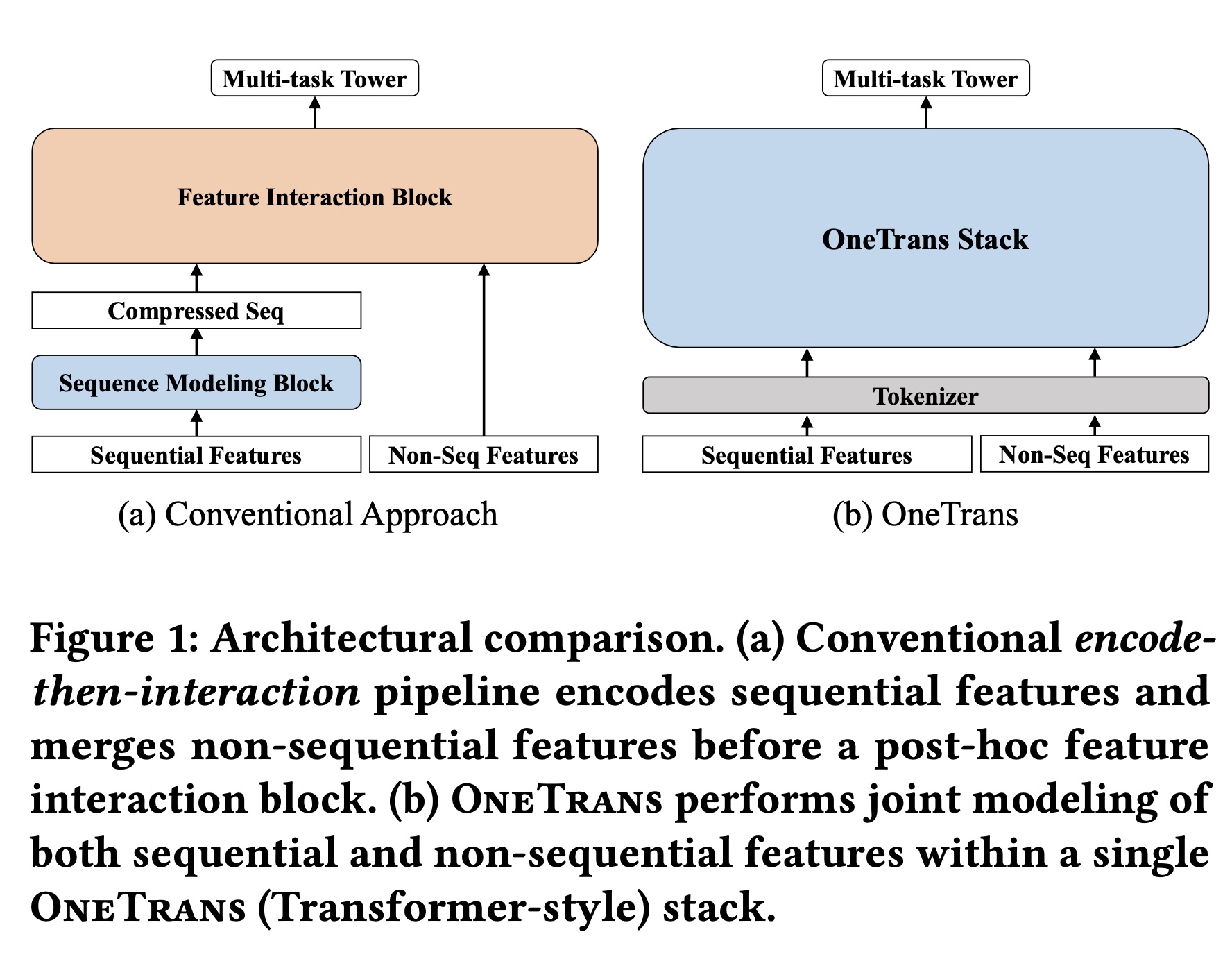
大型语言模型(
large language models: LLMs)的成功表明,扩大模型规模(如参数数量、训练数据)能带来可预测的性能提升(《Scaling laws for neural language models》),这启发了推荐系统领域的类似研究(《LONGER: Scaling Up Long Sequence Modeling in Industrial Recommenders》、《Wukong: Towards a scaling law for large-scale recommendation》、《RankMixer: Scaling Up Ranking Models in Industrial Recommenders》)。在特征交互(
feature interaction)方面,Wukong通过堆叠Factorization Machine blocks with linear compression来捕获高阶feature interactions并建立scaling laws,而RankMixer通过hardware-friendly的token-mixing with token-specific feed-forward networks (FFNs)实现了良好的scaling效果。在序列建模(
sequence modeling)方面,LONGER将causal Transformer应用于long user histories,表明增加depth和width能带来单调提升。
尽管这些方法在实际应用中有效,但将
sequence modeling和feature interaction分离为独立模块的做法存在两个主要局限:首先,
encode-then-interaction pipeline限制了双向的信息流,制约了static/context features对sequence representations的塑造作用(《Interformer: Towards effective heterogeneous interaction learning for click-through rate prediction》)。其次,
module separation导致执行过程碎片化并增加latency,而单一的Transformer-style的骨干网络可复用LLM的优化技术(如KV caching、memory-efficient attention、以及mixed precision),实现更有效的scaling(《Hiformer: Heterogeneous Feature Interactions Learning with Transformers for Recommender Systems》)。
本文提出
OneTrans,一种创新的架构范式(architectural paradigm),其统一的Transformer骨干网络能够联合执行user-behavior sequence modeling与feature interaction。如Figure 1(b)所示,OneTrans在统一骨干网络(unified backbone)中支持双向的信息交换。它采用unified tokenizer,将sequential features(diverse behavior sequences)和non-sequential features(static user/item and contextual features)转换为a single token sequence,随后由stacked OneTrans blocks构成的金字塔结构处理。OneTrans block是一种专为工业级推荐系统定制的Transformer变体。为适应推荐系统中diverse token sources(LLMs中仅含text-only tokens,这与推荐系统不同),每个OneTrans block采用类似于HiFormer的mixed parameterization。具体而言,所有sequential tokens(来自sequential features)共享a single set of Q/K/V and FFN weights,而每个non-sequential token(来自non-sequential features)获得token-specific parameters以保留其独特的语义。与传统的
encode-then-interaction框架不同,OneTrans通过unified causal Transformer backbone消除了sequential features与non-sequential features之间的架构壁垒。这种设计使推荐系统的scaling与LLM实践保持一致:整个模型可通过调整骨干网络的depth和width进行scale,同时无缝继承成熟的LLM optimizations技术,如FlashAttention和mixed precision training。特别是,cross-candidate KV caching和cross-request KV caching将sessions with C candidates的时间复杂度从large-scale OneTrans deployment成为可能。总之,本文的主要贡献包括四个方面:
Unified framework:提出OneTrans,一种用于ranking的single Transformer backbone,配备unified tokenizer(将sequential features和non-sequential features编码为one token sequence)和unified Transformer block(联合执行序列建模与特征交互)。这个思想已经在
Longer中被提出。Customization for recommenders:为弥合LLMs与推荐系统任务之间的差距,OneTrans引入mixed parameterization,为diverse non-sequential tokens分配token-specific parameters,同时为all sequential tokens共享parameters。这个思想借鉴了
Hiformer。Efficient training and serving:通过逐步裁剪sequential tokens的金字塔策略(pyramid strategy)、以及cross-request KV Caching(跨candidates来复用user-side computations)来提升效率。此外,采用FlashAttention、mixed-precision training和half-precision inference等LLM optimizations进一步减少内存占用和计算量。Scaling and deployment:OneTrans随着模型规模增大呈现near log-linear的性能提升,为real production data中的scaling law提供了实证。在线部署时,它在保持工业级latency的同时,实现了业务KPIs的显著提升。
1.1 相关工作
早期推荐系统如
DIN及其session-aware变体DSIN采用local attention学习user histories的candidate-conditioned summaries,但会将behaviors压缩为fixed-length vectors per candidate,限制了long-range dependency modeling(《Deep Interest Evolution Network for Click-Through Rate Prediction》)。SASRec、BERT4Rec和BST等self-attentive方法通过允许每个position关注full history来消除了这一瓶颈,并通过双向掩码(bidirectional masking)提高了样本效率。近年来,随着推荐系统中
scaling laws的研究日益深入,LONGER通过高效的attention和serving-friendly的设计,将sequence modeling推向工业级规模,以处理超长的behavioral histories。然而,在
mainstream pipelines中,这些sequence encoders通常与feature-interaction stack是分离的,导致与static contextual features的后期融合(late fusion)而非联joint optimization(《Interformer: Towards effective heterogeneous interaction learning for click-through rate prediction》)。Longer是联合优化的。在
feature-interaction方面,早期推荐系统依赖人工设计的cross-features或automatic multiplicative interaction layers。Wide&Deep、FM/DeepFM和DCN/DCNv2等经典模型提供了高效的low-order interactions或bounded-degree interactions。然而,近期
scaling研究发现(《Wukong: Towards a scaling law for large-scale recommendation》),一旦模型堆叠了足够多的cross layers,继续增加层数将不再带来提升:模型性能会趋于平稳而非持续改善。为克服预设的cross forms的僵化(rigidity),attention-based的方法可自动学习high-order interactions。AutoInt学习任意阶次的关系,HiFormer引入group-specific projections以更好地捕捉异构的、非对称的interactions。scaling up越来越多地应用于feature-interaction模块:Wukong等large-scale systems通过堆叠FM-style interaction blocks with linear compression实现可预测的性能提升。而
RankMixer在严格的latency budgets下,通过parallel token mixing和sparse MoE实现了良好的scaling。
然而,这些
interaction模块通常遵循encode-then-interaction的范式,将interactions推向独立的阶段,阻碍了与user sequence modeling的unified optimization(《Towards effective heterogeneous interaction learning for click-through rate prediction》)。迄今为止,推荐系统的进展主要沿着两条独立路径推进:
sequence modeling和feature interaction。InterFormer(《Towards effective heterogeneous interaction learning for click-through rate prediction》)试图通过summary-based的bidirectional cross架构来弥合这一差距,实现两个组件之间的mutual signal的交换。但它仍将两者保持为独立模块,且cross architecture引入了架构复杂性和碎片化执行(fragmented execution)的问题。缺乏用于联合modeling和optimization的unified backbone,使得系统难以作为一个整体进行有效地scaling。
1.2 方法
在详细介绍方法之前,先简要描述
task setting。在级联的工业级推荐系统中,每次召回阶段(recall stage)都会为用户candidate set(通常包含数百个candidate items)。ranking model随后为每个candidate item其中:
user、candidate item和context的non-sequential特征集合。historical behavior sequences的集合。
常见的
task predictions包括点击率(click-through rate: CTR)和点击后转化率(post-click conversion rate: CVR):
1.2.1 OneTrans Framework Overview
如
Figure 2(a)所示,OneTrans采用unified tokenizer,将sequential featuresS-tokens,将non-sequential featuresNS-tokens。然后,金字塔堆叠的Transformer在single computation graph中联合处理该unified token sequence。我们将initial token sequence表示为:该
token sequence由S-tokens和NS-tokens拼接而成,所有tokens的维度均为S-tokens中插入了可学习的[SEP] tokens,用于分隔不同类型的user-behavior sequences。注意,这里的
[SEP] tokens用于分隔不同类型的用户行为,采用的是Timestamp-agnostic方案。根据论文的描述,也可以采用Timestamp-aware方案,此时没有[SEP] token,而是用sequence-type indicator。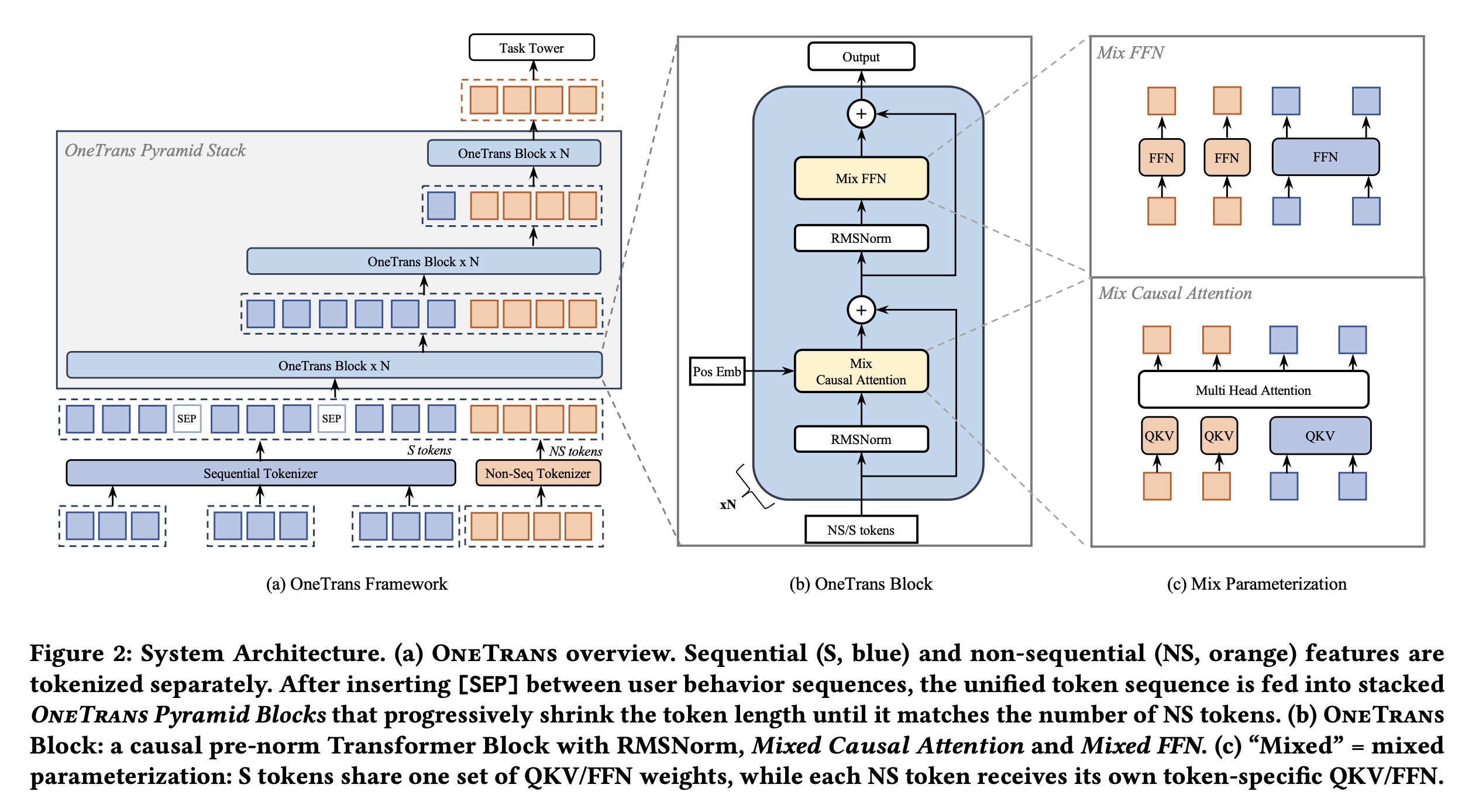
如
Figure 2(b)所示,每个OneTrans block通过以下步骤逐步refines the token states:其中,
MixedMHA(Mixed Multi-Head Attention)和MixedFFN(Mixed Feed-Forward Network)采用混合参数化(mixed parameterization)策略(见Figure 2(c)):在
attention layer(以及feed-forward layers)中,在sequential tokens间共享权重。在
attention layer(以及feed-forward layers)中,为non-sequential tokens分配独立参数。
注意:这里的
RMSNorm是pre-norm方法,它仅仅对MixedMHA和MixedFFN的输入进行归一化,不会影响residual。unified causal mask施加了自回归约束(autoregressive constraints),限制每个position仅关注preceding tokens。具体而言,NS-tokens允许关注S-tokens的所有历史,从而实现全面的cross-token interaction。通过堆叠此类
blocks并对S-tokens应用金字塔式尾部截断(pyramid-style tail truncation),模型逐步将紧凑的高阶信息提取到NS-tokens中。final token states随后被传入task-specific heads从而用于预测。在
Figure 2 (c)中,用户行为序列按照时间的逆序排列,前面的engagement距离现在最近、后面的engagement距离现在最远。每个position仅仅关注它当前及其它后面的位置(参考Longer模型的论文)。每次截断时,仅选择
NS-tokens、以及最近的S-tokens的并集作为query,但是key/value为所有tokens。通过将
non-sequential features和sequential features统一为unified token sequence,并使用causal Transformer进行建模,OneTrans摆脱了传统的encode-then-interaction pipeline。这种unified design自然支持:(i):每个behavior sequence内部的intra-sequence interactions。(ii):跨多个序列之间的cross-sequence interactions。(iii):item features、user features和contextual features之间的multi-source feature interactions。(iv):sequence-feature interactions。
所有这些均在
single Transformer stack中完成。这种统一形式使我们能够无缝继承成熟的
LLM engineering optimizations,包括KV caching和memory-efficient attention,从而大幅降低inference latency。我们认为,这种统一形式非常适合在single, and scalable architecture中解决multi-sequence and cross-domain recommendation的挑战。接下来,将详细介绍具体设计。
1.2.2 Features and Tokenization
为构建
initial token sequenceOneTrans首先应用feature preprocessing pipeline,将所有raw feature inputs映射为embedding向量。然后将这些embedding向量划分为:(i):一个multi-behavior sequential subset。(ii):一个non-sequential subset,代表user, item, or context features。
对每个子集应用独立的
tokenizers。Non-Sequential Tokenization:Non-sequential featuresnumerical inputs(如price、CTR)和categorical inputs(如user ID、item category)。所有特征均经过bucketized或one-hot encoded之后被embedded。由于工业系统通常涉及数百个重要性各异(varying importance)的特征,控制non-sequential tokens数量Group-wise Tokenizer(与RankMixer一致):将特征手动划分为语义组(semantic groups)group-specific MLP:即,先将组内的
embeddings拼接起来,再进行投影。这里如何分组是一个关键。Auto-Split Tokenizer:另一种方式是将所有特征拼接后通过单个MLP进行一次投影,然后分割:Auto-Split Tokenizer通过使用a single dense projection,与Group-wise Tokenizer相比减少了kernel launch开销。
我们将通过实验评估这两种选择。最终,
non-sequential tokenization生成non-sequential tokens,每个token的维度为这两种方法都大幅降低了
NS-Tokens的数量Attention的复杂度。论文在实验部分选择的是Auto-Split Tokenizer。在
Longer模型中,它通过Group-wise Tokenizer对S-Tokens也进行分组,从而支持超长序列建模。Sequential Tokenization:OneTrans接受multi-behavior sequences,记作:其中:
event embeddings:每个序列代表不同的行为类型,例如:点击行为序列、转化行为序列。
event的embedding,由item ID与其对应的辅助信息(如item category和item price)拼接而成。
Multi-behavior sequences的原始维度可能不同。因此,对于每个序列对齐后的序列
a single token sequence:1) Timestamp-aware:按时间交错所有事件,并添加sequence-type indicators。sequence-type indicators类似于position embedding:它引入一个sequence-type embedding,然后加入到每个token embedding上。注意:对于
OneTrans block,sequence按照时间递增来排序。这与Longer相反。2) Timestamp-agnostic:按事件影响力(event impact)来拼接序列(如purchase -> add-to-cart -> click),在序列之间插入learnable [SEP] tokens。最重要的序列放在左边,因为
causal masking使high-intent signals能够指导和过滤后续的low-intent behaviors。
在后一种情况下,
behaviors with higher user intent被置于序列前端。消融实验结果表明,当时间戳可用时,timestamp-aware rule优于timestamp-agnostic的方案。形式上,有:
注意:对于
Timestamp-aware方案,Timestamp-agnostic方案中,
1.2.3 OneTrans Block
如
Figure 2(b)所示,每个OneTrans block是一个pre-norm causal Transformer,应用于一个normalized token sequence之上。这个sequence包含sequential S-tokens,后跟non-sequential NS-tokens。受heterogeneous feature groups相关研究结果(《Hiformer: Heterogeneous Feature Interactions Learning with Transformers for Recommender Systems》)启发,我们对Transformer进行轻量级修改,以支持mixed parameter方案(见Figure 2(c))。具体而言,homogeneous S-tokens共享一组参数。而来自不同来sources/semantics的heterogeneous NS-tokens则获得token-specific parameters。与
LLM inputs不同,推荐系统中的token sequence结合了sequential S-tokens和diverse NS-tokens,这些tokens的数值范围和statistics的差异显著。post-norm setups可能因这些差异导致注意力崩溃(attention collapse)和训练不稳定性(training instability)。为避免这种情况,我们对所有tokens应用RMSNorm作为pre-norm,跨不同token types对齐scales并稳定optimization过程。RMSNorm是LayerNorm的变体。对于LayerNorm,给定变量其中:
RMSNorm定义为:RMSNorm没有减去均值的操作(即,没有中心化操作),只有缩放操作,因此计算效率更高。实践表明,RMSNorm的效果与LayerNorm没有明显差异,因此目前主流的LLM均采用RMSNorm方法。Mixed (shared/token-specific) Causal Attention:OneTrans采用标准multi-head attention: MHA并配备一个causal attention mask;唯一的修改在于Q/K/V的参数化方式。设token。为计算Q/K/V,对S-tokens(NS-tokens(token-specific projections:其中:
mixed parameterization方案:Attention使用标准的因果掩码(causal mask);此外,NS-tokens位于S-tokens之后。这导致:(1) S-side:每个S-token仅关注positions(在Figure 2a上表现为该token右侧的tokens)。对于
timestamp-aware sequences,每个event均以其历史为条件。对于
timestamp-agnostic sequences(按intent来排序,如purchase -> add-to-cart -> click/impression),causal masking使high-intent signals能够指导和过滤后续的low-intent behaviors。
注意:对于
OneTrans block,sequence按照时间递增来排序。这与Longer相反。(2) NS-side:每个NS-token关注完整的sequence evidence的target-attention aggregation),并关注preceding NS-tokens,增加token-level interaction diversity。问题是,
NS-tokens之间如何排序?论文并未详细说明。是否在NS-tokens之间采用non-causal mask,使得它们之间可以相互关注?可以做消融实验来研究。(3) Pyramid support:在S-side和NS-side,causal masking均逐步将信息集中到later positions,自然支持pyramid schedule(逐层裁剪tokens),这在后续将详细介绍。
Mixed(shared/token-specific) FFN:类似地,feed-forward network: FFN遵循相同的parameterization策略:NS-tokens使用token-specific FFNs,S-tokens使用一个共享的FFN:其中:
mixed parameterization方案:总之,与标准
causal Transformer相比,OneTrans仅修改了parameterization:NS-tokens使用token-specific的QKV和FFN。S-tokens共享一组parameters。
每个
sequence对应于单个causal mask,允许NS-tokens聚合完整的behavior history,同时保留高效的Transformer-style的计算。“每个
sequence对应于单个causal mask” 怎么理解?读者认为是:在
S-tokens上应用了causal mask,使得每个事件只能关注它发生之前的事件、以及所有的NS-tokens。在
NS-tokens之间采用non-causal mask,使得它们之间可以相互关注?可以做消融实验来研究。
1.2.4 Pyramid Stack
如前面章节所所述,
causal masking将信息集中到later positions。利用这种recency structure,我们采用金字塔调度(pyramid schedule):在每个OneTrans block layer,仅将most recent S-tokens的一个子集来生成queries,而keys/values仍基于full sequence来计算;query set随depth来缩小。这里借鉴了
Longer模型的思想。设
input token list,Mixed (shared/token-specific) Causal Attention,我们将queries修改为:而
keys和values照常基于full sequenceattention计算后,只有token length缩减至pyramidal hierarchy)。这种设计带来两个好处:
(i) Progressive distillation:长的behavioral histories被汇集到少量的尾部queries中,将模型能力集中于most informative events,并将信息整合到NS-tokens。(ii) Compute efficiency:attention cost变为FFN随scales。缩小query set直接减少了FLOPs和activation memory。
在模型配置中,实际上配置的是
1.2.5 Training and Deployment Optimization
Cross Request KV Caching:在工业推荐系统中,来自同一request的样本在training和serving期间均被连续地处理:其S-tokens在所有candidates之间保持一致,而NS-tokens因candidate item而异。利用这一结构,我们将广泛采用的KV Caching集成到OneTrans中,形成a unified two-stage paradigm:Stage I (S-side, once per request):使用causal masking处理所有S-tokens,并缓存其key/value pairs和attention outputs。该阶段每个request执行一次。Stage II (NS-side, per candidate):对于每个candidate,计算其NS-tokens,并与cached S-side keys/values进行cross-attention计算,随后通过token-specific FFN layers。特别地,candidate-specific sequences(如SIM,《Search-based user interest modeling with lifelong sequential behavior data for click-through rate prediction》)通过pooling来被预聚合为NS-tokens,因为它们无法复用shared S-side cache。
KV Caching将S-side computation在candidates之间分摊,使per-candidate work轻量化,并消除冗余计算,显著提升吞吐量。由于
user behavioral sequences是追加式(append-only)的,我们将KV Caching扩展到跨requests的场景:每个new request复用previous cache,仅对新增的behaviors计算增量的keys/values。这将per-request sequence computation从request以来的新增behaviors数量。注意:跨
requests的场景需要谨慎处理position-embedding,因为position在增加。此外,如果序列考虑
time-embedding,那么随着新的request的到来,previous cache将会失效。因为在新request中,历史behaviors距离当前request的时间发生了改变。Unified LLM Optimizations:我们采用FlashAttention-2,通过分块(tiling)和内核融合(kernel fusion)减少attention I/O和vanilla attention的quadraticme activation footprint,在training和inference中均实现更低的内存使用和更高的吞吐量。为进一步缓解内存压力,我们使用
mixed-precision training(BF16/FP16)结合activation recomputation,即在前向传播中丢弃selected forward activations,并在反向传播期间重新计算。这种组合以少量额外计算为代价,大幅节省内存,无需架构修改即可支持更大的batches和更深的模型。
1.3 实验
通过离线评估和在线测试,我们旨在回答以下
Research Questions: RQs:RQ1:Unified stack vs. encode–then–interaction:在计算量相当的情况下,single Transformer stack是否能带来持续的性能提升?RQ2:哪些design choices至关重要?通过对input layer(如tokenizer、sequence fusion)和OneTrans block(如parameter sharing、attention type、pyramid stacking)进行消融实验,评估不同design choice对性能和效率的重要性。RQ3:系统效率:pyramid stacking、cross-request KV Caching、FlashAttention-2以及mixed precision with recomputation,在相同OneTrans graph下是否能减少FLOPs/memory和latency?RQ4:Scaling law:当增加length(token sequence length)、width(模型维度depth(层数)时,loss/performance是否呈现预期的log-linear趋势?RQ5:Online A/B Tests:在production latency约束下,在线部署OneTrans是否能在关键业务指标(如order/u、GMV/u)上实现显著提升?
数据集:对于离线评估,我们在大规模工业排序场景中使用生产日志评估
OneTrans,严格遵守隐私合规要求(所有个人身份信息均经过匿名化和哈希处理)。数据按时间顺序分割,所有特征均在impression时刻被快照,以防止时间泄露并确保online-offline一致性。label(如clicks和orders)在与production settings对齐的fixed windows内聚合。Table 1总结了数据集统计信息。ho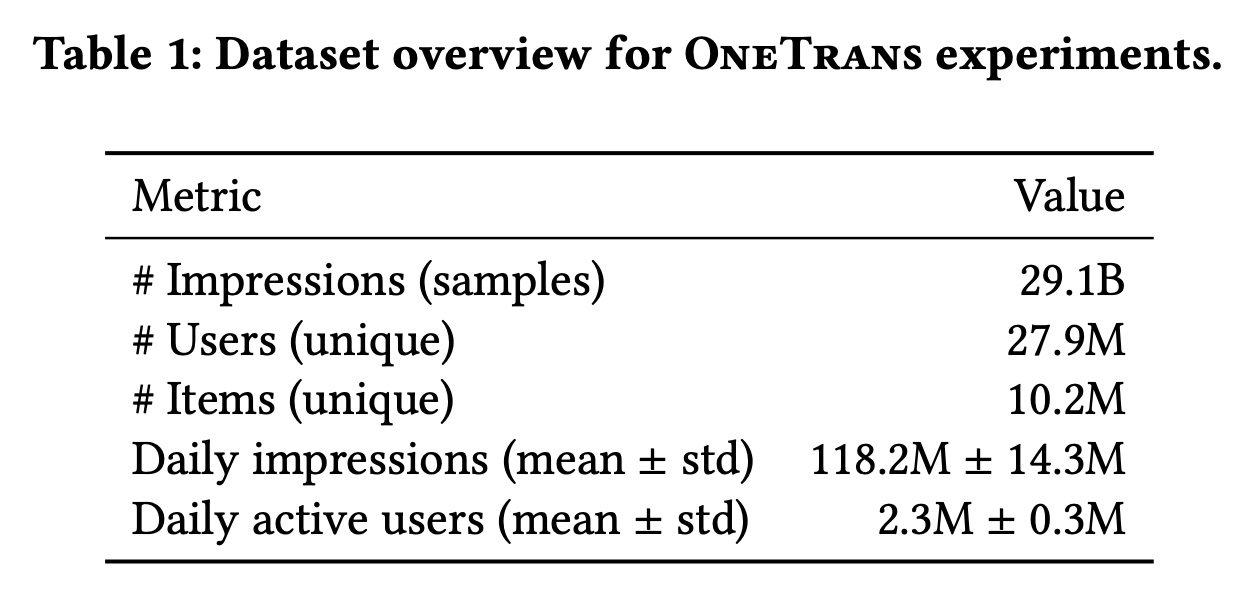
任务和评估指标:我们评估两个二分类
ranking任务:CTR和CVR。性能通过AUC和UAUC(impression-weighted user-level AUC)来衡量。Next-batch evaluation:数据按时间顺序处理。对于每个mini-batch:(i)在eval mode下记录predictions;然后(ii)在同一mini-batch上训练。即:训练时评估。
AUC和UAUC每日根据当天的predictions来计算,最终按天进行宏观平均。是否要在训练
N天之后再开始评估?如果第一个mini-batch就开始评估,那么模型显然还没有训练好。这时候的评估结果是没有意义的。此外,当模型训练到第二个
epoch的时候,模型已经见过这个batch的样本。因此,读者怀疑论文仅仅训练了一个epoch,使得每个batch在评估的时候都是模型未见过的。效率指标:报告参数数量(不包括
sparse embeddings的模型参数)和TFLOPs(batch size 2048时的训练计算量,以TFLOPs为单位)。
baselines:我们使用相同features和matched compute budgets,构建industry-standard model combinations作为基线。在encode-then-interaction范式下,从广泛使用的production基线DCNv2+DIN开始,逐步增强feature-interaction模块:DCNv2 -> Wukong -> HiFormer -> RankMixer。固定RankMixer后,改变sequence-modeling模块:StackDIN -> Transformer -> LONGER。Hyperparameter Settings:我们报告两种settings:6 stacked OneTrans blocks,宽度heads数量100M。8层,宽度heads数量仍然为
此外:
Inputs通过a unified tokenizer来处理:multi-behavior sequences以timestamp-aware方式来融合;non-sequential features通过Auto-Split来tokenize。pyramid schedule将tokens数量从1190线性地缩减至12。
Optimization and infrastructure:采用
a dual-optimizer strategy without weight decay:sparse embeddings使用Adagrad优化,dense parameters使用RMSPropV2优化,lr=0.005, momentum=0.99999。
训练期间:
per-GPU batch size设置为2048;dense layers的梯度裁剪阈值为90,sparse layers的梯度裁剪阈值为120,以确保稳定优化。在
online inference时:per-GPU batch size设置为更小的100,以平衡吞吐量和latency。训练在
16 H100 GPUs上使用data-parallel all-reduce。
1.3.1 RQ1: 性能评估
我们以
DCNv2+DIN(我们场景中的pre-scaling production baseline)为基准进行比较(Table 2)。在
encode-then-interaction范式下,独立扩大任一组件均有益:升级feature interaction模块(DCNv2 -> Wukong -> HiFormer -> RankMixer)或sequence modeling模块(StackDIN -> Transformer -> LONGER),均能持续提升CTR AUC/UAUC和CVR AUC。在我们的系统中,这些指标提升超过
+0.1%被认为是有意义的,而提升超过+0.3%通常对应online A/B tests中的统计显著效果。然而,由于per-user sample sizes更小、且波动性更高,CVR UAUC的解读需谨慎。转向
unified design后,CTR AUC/UAUC上比基线提升+1.13%/+1.77%,在CVR AUC/UAUC上提升+0.90%/+1.66%。在参数规模相当的情况下,它还优于training FLOPs相近的RankMixer+Transformer(2.64T vs 2.51T),证明了unified modeling的优势。进一步
scaling后,CTR AUC/UAUC提升+1.53%/+2.79%,CVR AUC/UAUC提升+1.14%/+3.23%,表明随着模型容量增长,性能呈现可预测(predictable)的提升。
总之,在
single Transformer中统一sequence modeling和feature interaction,比独立扩大任一组件更能实现可靠的且计算高效的改进。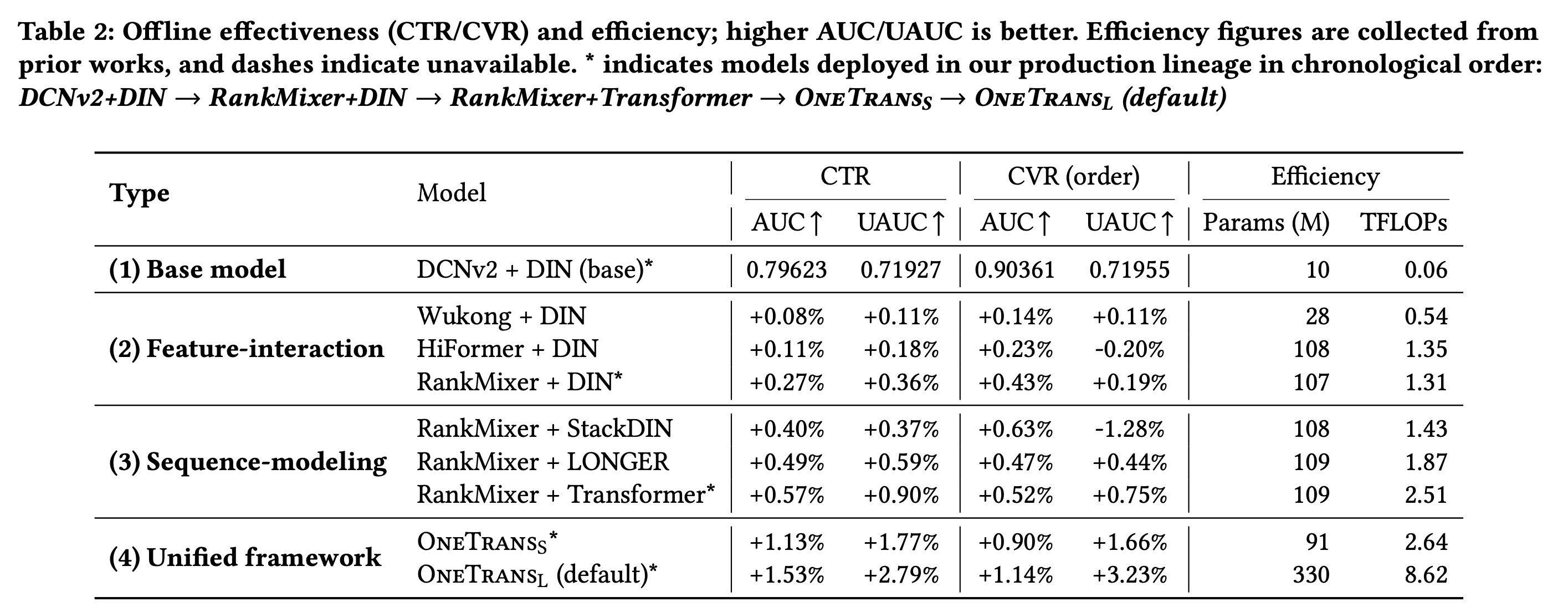
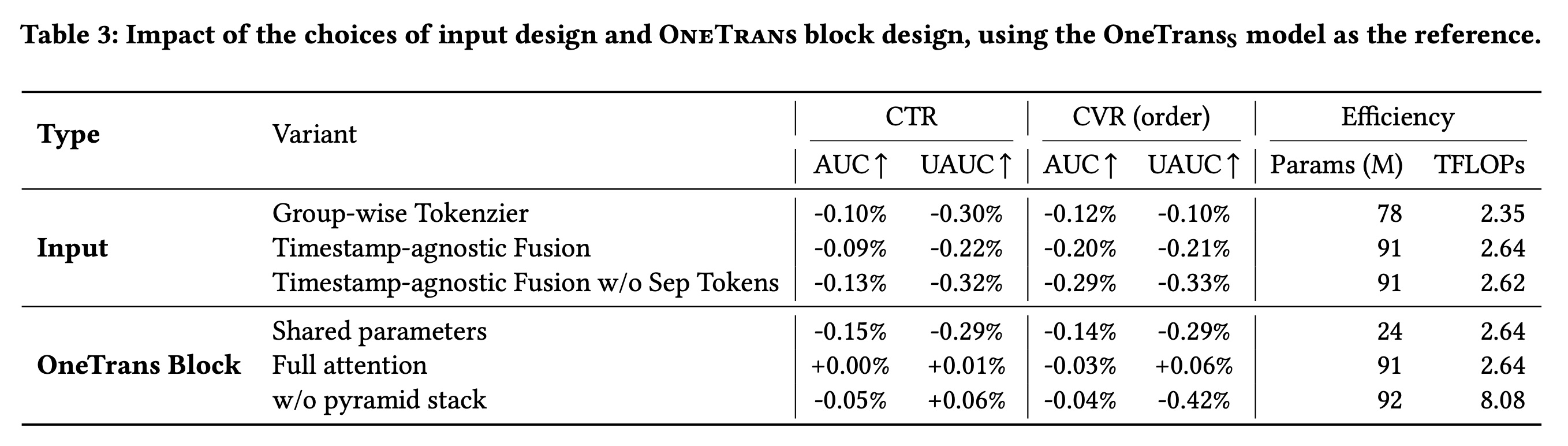
1.3.2 RQ2: 基于消融实验的 Design Choices
我们对所提出的
key design choices的贡献。完整结果总结在Table 3中。我们评估了以下变体:Input变体:i):将Auto-Split Tokenizer替换为Group-wise Tokenizer(第1行)。ii):使用timestamp-agnostic的融合策略替代timestamp-aware sequence fusion(第2行)。iii):在timestamp-agnostic fusion中移除[SEP] tokens(第3行)。
OneTrans block变体:i):所有tokens共享一组Q/K/V和FFN参数,并没有为NS-tokens分配独立参数(第4行)。ii):将causal attention替换为full attention(第5行)。iii):禁用pyramid stack,在所有层保留full token sequence(第6行)。
总之,消融实验表明:
1):Auto-Split Tokenizer比手动将non-sequential features分组为tokens更具优势,表明了模型自动构建的non-sequential tokens比人工定义的feature grouping更有效。2):当时间戳可用时,Timestamp-aware fusion优于intent-based ordering,表明应优先考虑时间顺序而非事件影响(event impact)。3):在timestamp-agnostic fusion下,learnable [SEP] tokens帮助模型区分sequences。4):为NS-tokens分配token-specific parameters比all tokens共享一组参数带来明显提升,证明modeling non-sequential features with individualized projections能实现更好的feature discrimination。5):Causal attention和full attention取得相似结果,表明在该setting中允许tokens关注future positions并非关键。值得强调的是,full attention禁止使用KV caching等standard optimizations。采用
Causal attention的优势是支持KV caching。6):在每一层保留full token list并无益处:OneTrans能有效将信息汇总到a small tail of tokens中,因此pyramid design可安全地裁剪queries以节省计算。
1.3.3 RQ3: 系统效率
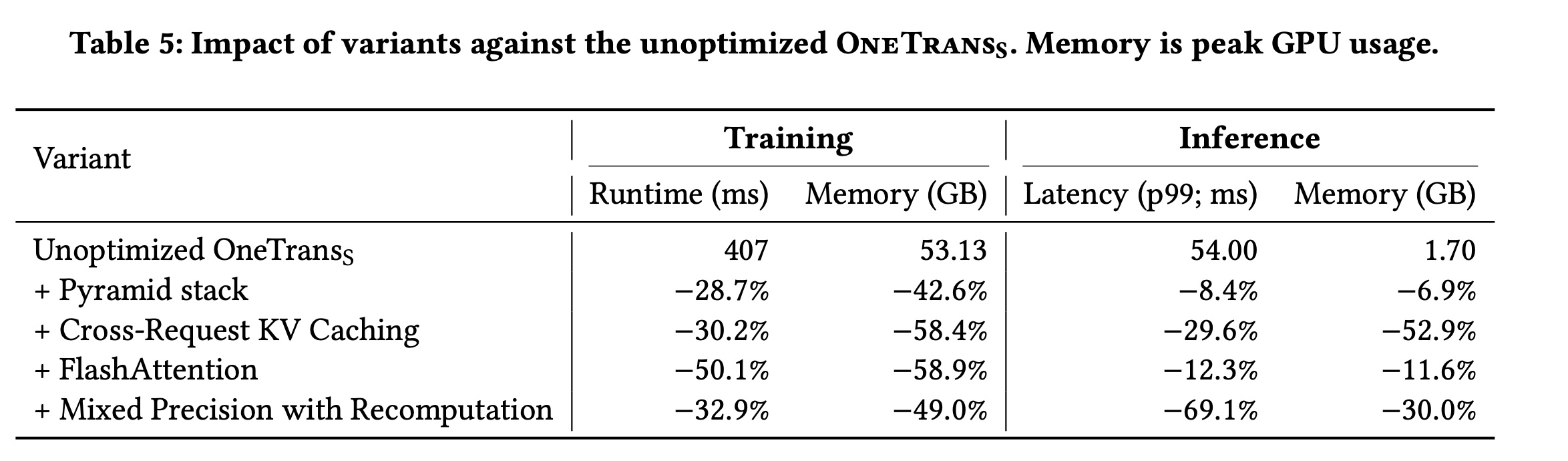
为量化
Training and Deployment Optimization章节中的optimizations的效果,我们在unoptimized的optimizations进行消融,并在Table 5中报告training/inference指标。unoptimized的training runtime为407 ms,峰值training memory为53.13 GB;p99 inference latency为54.00ms,inference memory为1.70 GB。其中,p99表示尾部99分位的延迟,是高可用性online services的标准服务等级目标(SLO)指标。这些差异反映了不同的运行条件:offline training使用较大的per-device batches,而online inference在多台机器上分配micro-batches以保证稳定性。如表所示:
1):Pyramid stack通过将long behavioral histories压缩为紧凑的query sets,实现了显著节省:训练时间减少28.7%,训练内存减少42.6%,inference latency减少8.4%,inference memory减少6.9%。2):Cross-request KV caching消除了冗余的sequence-side computation,在training and serving中均减少了约30%的runtime/latency和约50%的内存。3):FlashAttention主要有益于training,runtime减少约50%,activation memory减少约58%。inference收益适中(latency和内存各减少约11-12%),因为attention在training中因更大batch size和反向传播从而占据主导计算成本。4):Mixed precision with recomputation带来了最大的serving收益:p99 latency改善约69%,inference memory减少约30%,因为inference可完全在低精度下端到端运行。相比之下,training必须保留full-precision optimizer states and gradient accumulators;即便如此,training runtime和内存仍分别改善约32%和49%。
这些结果证明了
LLM optimizations在大规模推荐系统中的有效性。在DCNv2+DIN基线(该基线比online efficiency(Table 4)。这再次证明,将推荐系统重构为a unified Transformer backbone,能够无缝采用LLM optimizations,解锁了传统encode-then-interaction架构此前无法实现的effective scaling。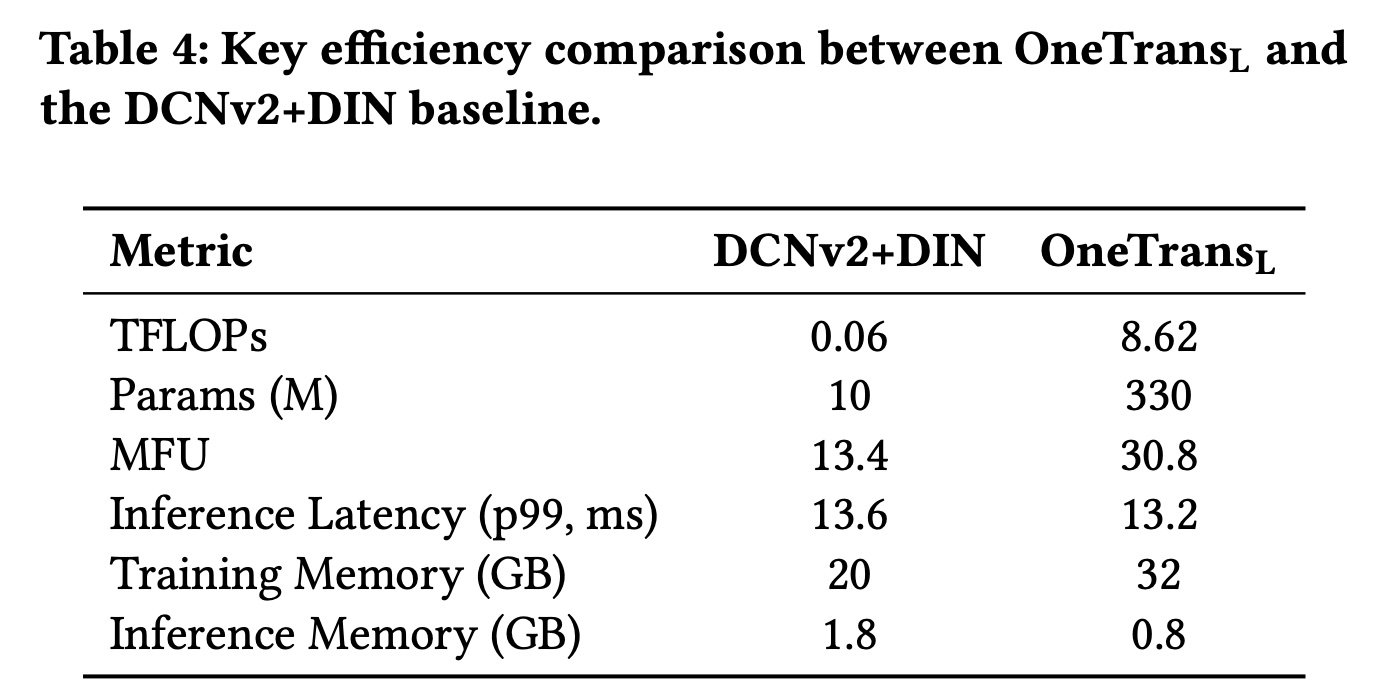
1.3.4 RQ4: Scaling-Law 验证
我们从三个维度探究
OneTrans的scaling laws:1):length,即input token sequence length。2):depth,即stacked blocks数量。3):width,即hidden-state维度。
如
Figure 3(a)所示,增加length带来的收益最大,因为引入了更多behavioral evidence。在depth和width之间,我们观察到明显的权衡:增加
depth通常比单纯增加width带来更大的性能提升,因为更深的stacks能提取更高阶的interactions和更丰富的abstractions。然而,更深的模型也会增加
serial computation,而增加宽度更适合并行化。
因此,
depth和width的选择应在target hardware budget下平衡性能收益与系统效率。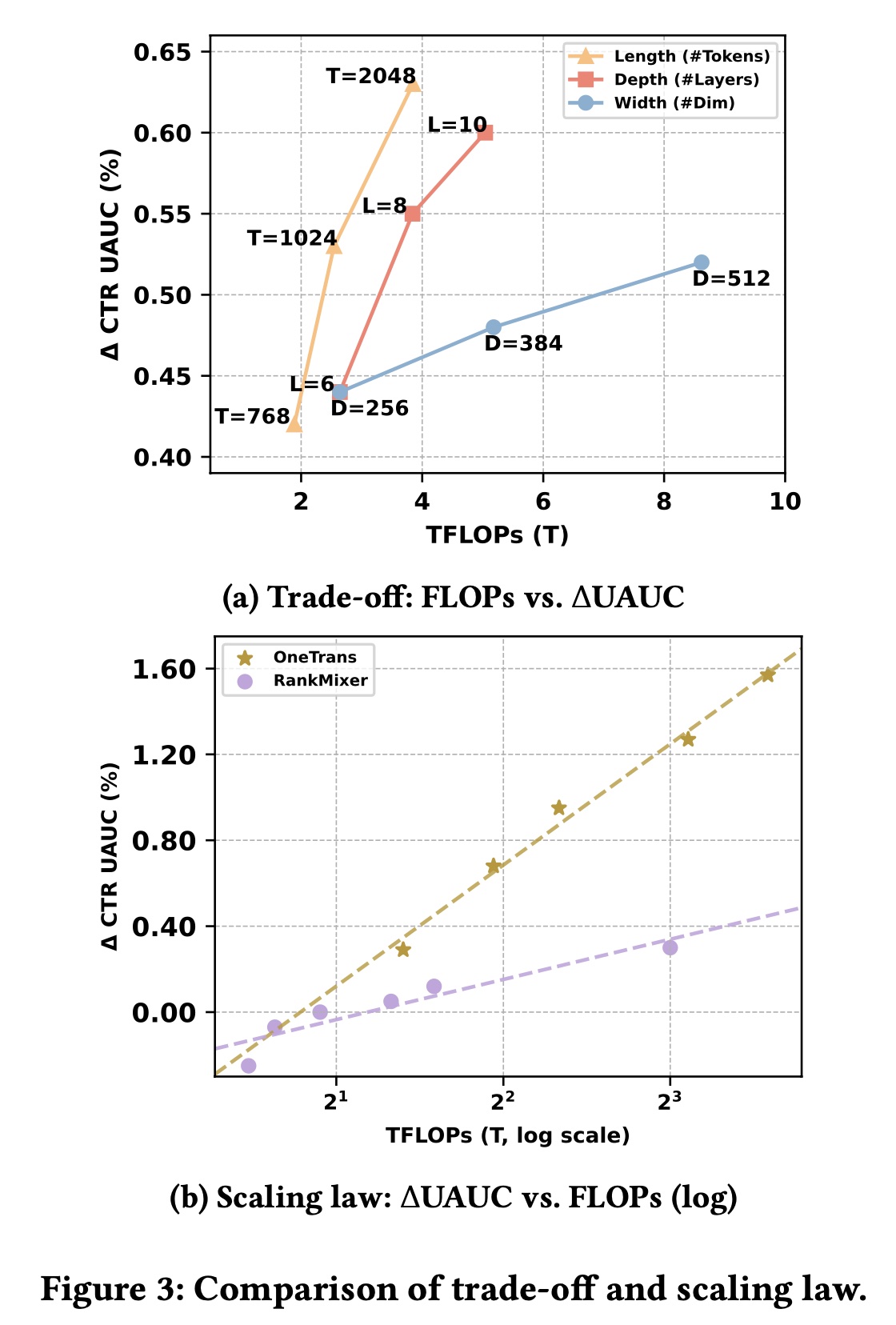
我们通过同时增加
OneTrans的宽度和深度,进一步分析scaling-law行为。为进行比较,我们还将RankMixer+Transformer基线在RankMixer侧扩展至1B参数;然后在对数尺度上绘制UAUC增量(training FLOPs的关系。如Figure 3(b)所示,OneTrans和RankMixer均呈现明显的log-linear趋势,但OneTrans的斜率更陡——这可能是因为RankMixer主导的scaling缺乏a unified backbone,其MoE-based expansion主要增加了FFN的hidden dimension。这些结果共同表明:
OneTrans在参数和计算方面更高效,为工业部署提供了更优的performance–compute权衡。
1.3.5 RQ5: Online A/B Tests
我们在两个大规模工业场景中评估
OneTrans的业务影响:(i):信息流(Feeds),即home feeds。(ii):商城(Mall),包含Feeds和其他子场景的overall setting。
流量通过
hashing和user-level randomization在user/account level拆分。control模型和treatment模型均使用过去1.5年的production数据进行训练和部署,以确保公平比较。我们之前的
production baseline(RankMixer+Transformer)作为control组(约100M神经网络参数),且不使用sequence KV caching。treatment组部署了带有serving optimizations(Training and Deployment Optimization章节所描述的)的33倍)。我们报告
user-level order/u and gmv/u相对于control组(即,RankMixer+Transformer)的相对增量(95%置信区间,基于user-level stratified bootstrap);以及端到端latency——以从请求到达至响应发出的p99 per-impression time的相对变化(如
Table 6所示,在
Feeds场景中,order/u提升4.3510%,gmv/u提升5.6848%,latency降低3.91%。在
Mall场景中,order/u提升2.5772%,gmv/u提升3.6696%,latency降低3.26%
这表明:相比强大的
non-unified baseline,该unified modeling framework在提升业务指标的同时减少了serving时间。我们还观察到用户活跃天数(
user Active Days)增加了0.7478%,cold-start product order/u显著提升了13.59%,突显了该proposed model强大的泛化能力。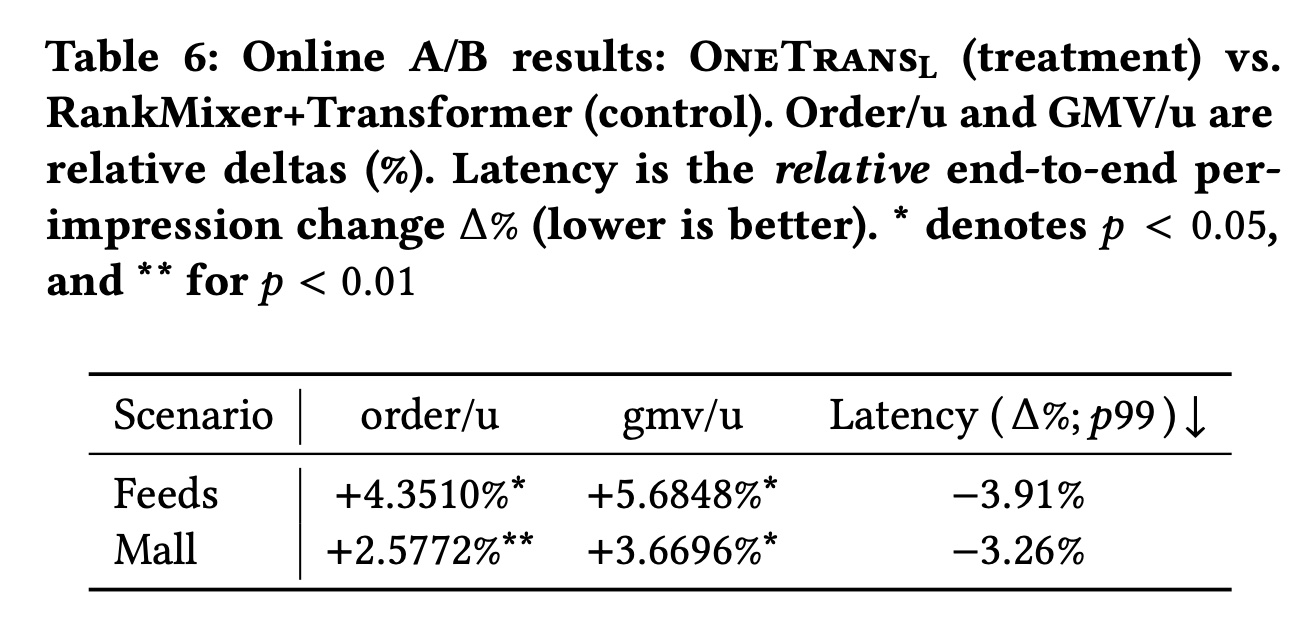
1.4 结论
本文提出
OneTrans,一种用于personalized ranking的unified Transformer backbone,以替代传统的encode–then–interaction架构。A unified tokenizer将sequential attributes和non-sequential attributes转换为one token sequence。A unified Transformer block通过为homogeneous (sequential) tokens共享参数、为heterogeneous (non-sequential) tokens分配token-specific parameters,联合执行sequence modeling与feature interaction。为使
unified stack在大scale下高效地运行,我们采用了pyramid schedule(它逐步裁剪sequential tokens)和cross-request KV Caching(它复用user-side computation)。该设计还受益于LLM-style的systems optimizations(如FlashAttention、mixed precision)。
large-scale evaluations表明,OneTrans随着width/depth增加呈现近log-linear的性能提升,并在保持production-grade latency的同时实现了统计显著的业务指标提升。我们相信,这种unified design为推荐系统的scale up提供了一种实用方法,同时可复用那些推动近期LLM进步的system optimizations。