一、RankMixer [2025]
《RankMixer: Scaling Up Ranking Models in Industrial Recommenders》
大型语言模型(
large language models: LLMs)的最新进展激发了人们对scaling up推荐系统的兴趣,然而仍存在两个实际障碍:首先,工业级的推荐系统上的
training和serving成本必须遵守strict latency的限制和high QPS的需求。其次,
ranking模型中大多数的人工程设计的feature-crossing模块继承自CPU时代,无法充分利用现代GPU,导致模型浮点运算利用率(Model Flops Utilization: MFU)低和可扩展性差。
我们介绍了
RankMixer,一种面向硬件感知(hardware-aware)的模型设计,旨在实现统一且scalable的feature-interaction架构。RankMixer保留了Transformer的高并行性,同时用multi-head token mixing模块替换了平房复杂度的self-attention以提高效率。此外,RankMixer通过Per-token FFNs保持了对distinct feature subspaces的建模、以及cross-feature-space interactions。我们进一步通过稀疏混合专家(Sparse-MoE)变体将其扩展到十亿级参数,以获得更高的投资回报率(ROI)。我们采用动态路由策略(dynamic routing strategy)来解决experts training不足和不平衡的问题。实验表明,在万亿级别的生产级数据集上,
RankMixer具有卓越的扩展能力。通过用RankMixer替换先前diverse handcrafted low-MFU modules,我们将模型MFU从4.5%提升至45%,并将online ranking model参数扩展了两个数量级,同时保持了大致相同的inference latency。我们通过在两个核心应用场景(推荐Recommendation和广告Advertisement)上的online A/B tests来验证了RankMixer的普适性。最终,我们为full traffic serving部署了1B Dense-Parameters RankMixer,且未增加serving成本,这使得用户活跃天数(user active days)增加了0.3%,应用内总使用时长(total in-app usage duration)增加了1.08%。推荐系统(
Recommender System: RS)在信息分发过程中至关重要。作为一个重要的机器学习场景,推荐系统基于大量的multi-field feature data来预测用户对items的行为,这些数据包括数值特征(例如各种各样的统计数据),categorical特征(例如user ID、item ID、用户行为特征、内容特征)。SOTA的推荐方法是基于深度学习推荐模型(Deep Learning Recommendation Models: DLRMs),该类模型基于神经网络灵活地捕获特征交互(feature interactions)。这些feature interactions发生在dense interaction layers中;其中,dense interaction layers位于input embeddings之上。DLRM中的dense interaction layer对推荐系统的性能至关重要,并且人们提出了各种各样的模型结构。受
LLMs从increasing parameters中获益的进展的驱动,scaling up DLRMs以充分利用数据量是一项迫切需求。先前的研究在扩展scaling up DLRMs方面产生了许多成果。早期研究(
《Understanding scaling laws for recommendation models》、《Scaling generative pre-training for user ad activity sequences》、《Scaling law of large sequential recommendation models》)仅仅是在不修改结构的情况下拓宽或堆叠feature interaction layers。这种方式获得的收益有限,有时甚至是负面的。随后的努力,例如
DHEN和Wukong,专注于设计创新的DNN结构以提升scaling的性能。
然而,在推荐系统中利用
model scale来提高性能面临着独特的实际挑战。与NLP任务或视觉任务不同,工业级推荐系统必须遵守严格的latency约束并支持极高的QPS(queries per second每秒查询数)。因此,核心挑战在于找到模型有效性(model effectiveness)和计算效率(computational efficiency)的最佳平衡点。历史上,推荐系统中的
ranking model架构是由CPU时代的设计原则塑造的。这些模型通常依赖于对heterogeneous diverse handcrafted cross-feature modules的组合从而来提取feature interactions,但它们的许多核心算子(core operators)在现代GPU上是内存受限(memory-bound)而非计算受限(compute-bound)的,导致GPU并行性差和极低的MFU(模型浮点运算利用率Model Flops Utilization),通常MFU仅为个位数百分比。此外,由于CPU时代模型的计算成本大致与参数数量成正比,scaling laws所暗示的通过积极地scaling所带来的潜在ROI在实践中难以实现。总之,
DLRMs的scaling laws上的研究必须克服以下问题:架构应与硬件对齐,在现代
GPU上最大化MFU和计算吞吐量(compute throughput)。模型设计必须利用
recommendation data的特性,例如异构的特征空间、以及数百个fields之间的个性化的cross-feature interactions。
为了应对这些挑战,我们提出了一种硬件感知(
hardware-aware)的模型设计方法,RankMixer。RankMixer的核心设计基于两个scalable的组件:Multi-head token mixing仅通过无参数算子(parameter-free operator)就实现cross-token feature interactions。该策略在性能和计算效率方面优于self-attention机制。Per-token feed-forward networks (FFNs)显著扩展了模型容量(model capacity),并通过为不同的feature subspace的modeling来分配独立的参数来解决inter-feature-space的domination的问题。这些FFNs也与recommendation data的模式很好地契合,实现了更好的scaling。
为了进一步提升
large-scale模型的ROI,我们将per-token FFN modules扩展为Sparse Mixture-of-Experts (MoE)结构。通过为不同的数据动态地在每个token仅激活a subset of experts,我们可以在计算成本minimal increase的情况下显著提高模型容量。RankMixer采用了类似于Transformer的高度并行架构,但克服了self-attention based feature-interaction的几个关键限制:训练效率低、modeling cross-space ID similarity时的组合爆炸、以及attention weights matrix引起的严重的memory-bound。同时,在相同Flops下,与Vanilla Transformer相比,RankMixer提供了更大的模型容量和学习能力。modeling cross-space ID similarity时的组合爆炸,这指的是:在推荐系统中,由于ID类特征数量巨大且来自不同语义空间,使用自注意力机制计算所有feature pair之间的相似性会导致计算和存储复杂度呈平方级增长,从而无法在实际系统中高效运行。RankMixer通过去参数化的token mixing机制避免了这一问题,实现了高效且可扩展的heterogeneous feature interaction建模。在抖音的推荐系统的生产部署中,我们证明了在与先前
baseline相比延迟更短的情况下,将模型参数扩展100倍以上是可行的。这得益于RankMixer架构能够将parameter growth与FLOPs解耦,并通过high MFU和engineering optimization将FLOPs growth与实际成本解耦。主要贡献总结如下:
我们提出了一种名为
RankMixer的新架构,遵循硬件感知的模型设计理念。我们设计了multi-head token mixing和per-token FFN策略来高效地捕获heterogeneous feature interactions,并使用动态路由(dynamic routing)策略来提高RankMixer中SparseMoE的scalability。利用
high MFU和performance-optimization的杠杆,我们在不增加推理成本的情况下将模型参数扩展了70倍,包括improving MFU和Quantization。我们在万亿级别的工业级推荐数据集上进行了广泛的离线实验和在线实验,并研究了模型的
scaling law。RankMixer模型已成功部署在抖音Feed Recommendation Ranking中用于full-traffic serving,分别实现了活跃天数(active days)和App使用时长(App duration)的0.3%和1.08%的增长。
1.1 相关工作
现代推荐系统基于
Deep Learning Recommendation Models: DLRMs,如何有效地建模feature interactions是DLRMs的关键因素。Wide&Deep是最早的努力之一,它结合了逻辑回归(wide part)和DNN(deep part)来分别捕获低阶的和高阶的feature interactions。DeepFM是另一个成果,它集成了因子分解机(Factorization Machine: FM)和DNN。此外,
DeepCross是残差网络(residual network)(《Deep residual learning for image recognition》)的扩展,旨在隐式地学习自动的feature interactions。
然而,仅依靠
DNN来学习高阶特征交互已被证明相当具有挑战性。显式的cross methods设计了不同的算子(operators)来显式地捕获高阶特征交互,例如PNN、DCN及其后继者DCNv2、xDeepFM、FGCNN和FiGNN。AutoInt和Hiformer采用带有残差连接的attention机制来学习复杂的交互。DHEN提出将多个interaction operators组合在一起。尽管提高了准确性,但这些新架构增加了模型latency和内存消耗,并且它们的模型规模相对较小。scaling law已成为深度学习的一个基本主题,并且是过去十年中许多突破的关键催化剂,特别是在自然语言处理(NLP)、计算机视觉(CV)和多模态建模领域,这些定律描述了模型性能与scaling factors(如模型大小、数据量和算力)之间的power-law correlations。最近,推荐系统中的scaling laws引起了研究人员的广泛关注。人们研究探索了用于
pre-training user activity sequences(《Scaling generative pre-training for user ad activity sequences》)、general-purpose user representations(《Scaling law for recommendation models: Towards general-purpose user representations》、《Scaling law of large sequential recommendation models》)和online retrieval(《 Scaling laws for dense retrieval》、《Scaling Laws for Online Advertisement Retrieval》)的scaling策略。Wukong堆叠FM和LCB来学习feature interactions。正交地,
《Scaling law of large sequential recommendation models》将一个序列推荐模型扩展到0.8B参数。HSTU提升了Generative Recommenders: GRs的scaling效果。
1.2 方法论
1.2.1 整体架构
RankMixer的整体架构包括T input tokens,这些tokens经过RankMixer block处理,最后是一个output pooling operator。如Figure 1所示,每个RankMixer block有两个主要组成部分:(1):一个Multi-Head Token Mixing层 。(2):一个Per-Token Feed-Forward Network: PFFN层。
首先,
input vectortokenize为feature tokenstoken代表一个feature vector。RankMixer block通过以下方式对token representations进行反复地refine(其中:
layer normalization函数,multi-head Token Mixing模块和per-token FFN模块。RankMixer block的输出;hidden dimension。
output representationfinal layers的representationsmean pooling。prediction。注意,下图中的
feature tokens,在实际中选择mixing前后保持tokens数量不变。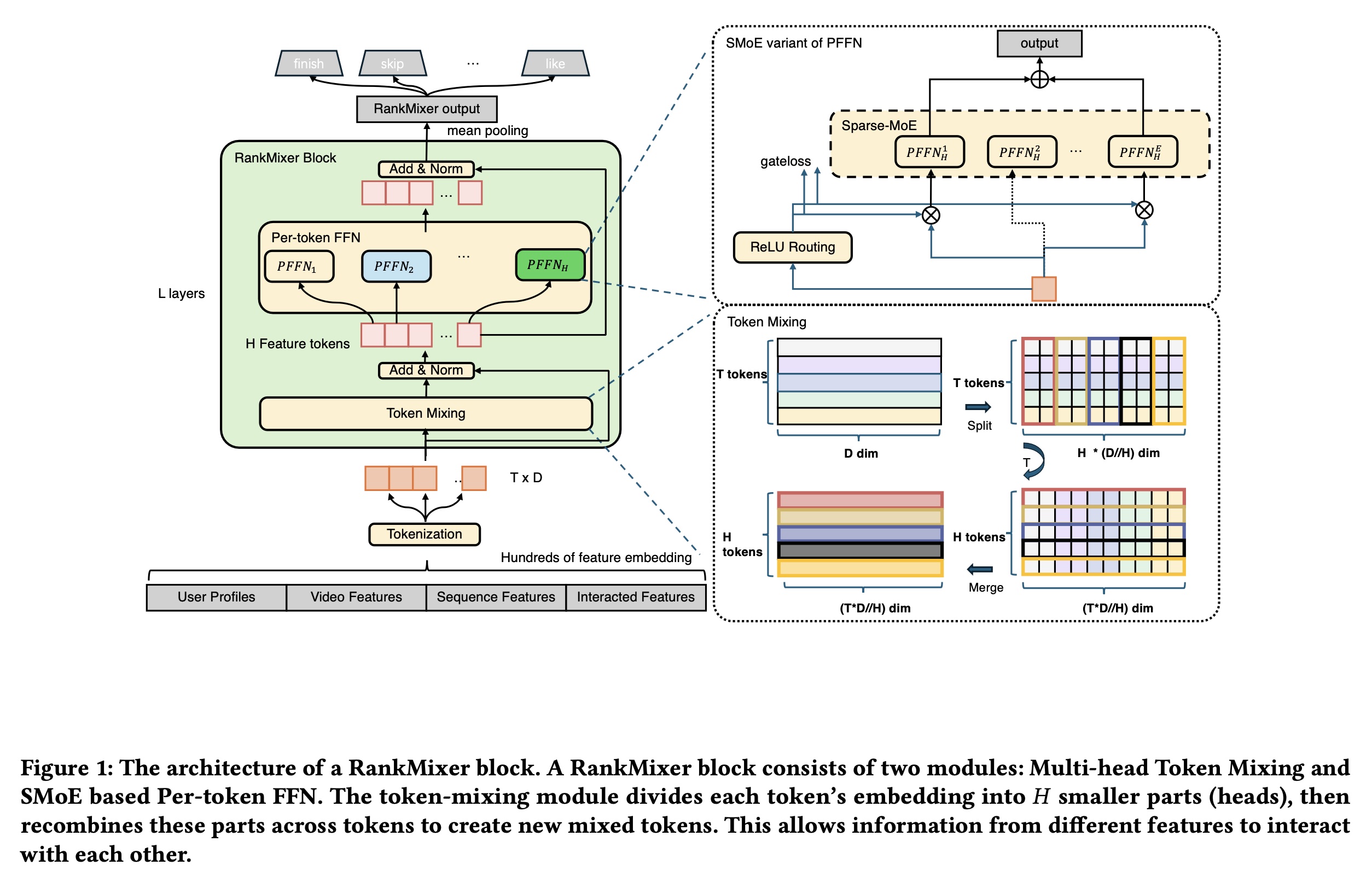
1.2.2 Input Layer and Feature Tokenization
构建
large-scale推荐模型的首要任务是准备好具有丰富信息的inputs,例如:User features:包括user ID和其他的用户信息。candidate features:包括video ID、author ID等等。Sequence Features:由Sequence Module进行处理以捕获时序的兴趣,产生以及
Cross Features:即user和candidate之间的交叉特征。
所有特征都将被转换为具有
diverse dimensions的embeddings。为了实现后续阶段的高效并行计算,必须将不同维度的
embeddings转换为维度对齐的向量,称为feature-tokens。我们将这种embedding alignment过程称为tokenization。最简单的策略是为每个特征分配一个embedding。考虑到通常有数百个特征,这会引入几个挑战:拥有数百个
tokens不可避免地减少了分配给每个token的parameters和computation,使其成为small fragments,导致对重要特征的建模不足以及GPU cores的利用率不足。相反,
tokens太少(例如单个token)会使模型结构退化为简单的深度神经网络(Deep Neural Network: DNN),无法可区分地表达diverse feature spaces,这存在dominant features掩盖其他特征的风险。
这里的挑战仅仅是针对
RankMixer框架的。其它框架可能不存在这两个问题。因为RankMixer涉及到Multi-Head Token Mixing、Per-Token Feed-Forward Network: PFFN。如果
tokens太多:Per-Token Feed-Forward Network: PFFN针对每个token都有一个FFN,因此总参数规模急剧膨胀。如果控制总参数规模不变,那么每个FFN的参数将急剧缩小。如果
tokens只有一个:那么Multi-Head Token Mixing等价于Identify操作、Per-Token Feed-Forward Network: PFFN退化为FFN。整个模型就退化为简单的DNN。
作者的解决方案为:先把所有
feature embeddings拼接在一起,然后拆分为tokens。为了克服这些问题,我们提出了一种基于语义的
tokenization方法,利用domain知识将特征分组为几个语义连贯的clusters。这些分组后的特征被串行地拼接成一个embedding向量feature group的embedding;feature-groups的数量;;表示向量拼接。注意:因为要先拼接、再拆分、再投影。因此,
feature embeddingsuser features拼接在一起、将item features拼接在一起, 等等。随后
tokens。每个feature tokenfeature embeddings,代表一个similar semantic aspect:其中:
embedding向量,token的固定维度,token数量,Proj函数将分割后的embedding映射到假设
注意,这里是按照固定的窗口
token,而不是按照feature groups来拆分token。是否可以参考CNN的做法,用一组slide window(具有不同的步长)从而获得多组inpu tokens?可以试试。
1.2.3 RankMixer Block
Multi-head Token Mixing:为了促进跨tokens的有效信息交换(这对于feature cross和global information modeling非常重要),我们引入了multi-head Token Mixing模块。每个token被均匀地分成tokenhead表示为这些
heads可以看作是tokenfeature subspace的投影,因为recommendation任务需要考虑不同的视角。Token Mixing用于融合这些sub-space vector以实现global feature interactions。形式上,经过multi-head Token Mixing后,对应于第head的shuffled tokens)构造如下:multi-head Token Mixing模块的输出是shuffled tokensToken Mixing后保持相同数量的tokens用于residual connection。考虑到
经过
residual connection和normalization模块后,我们可以生成:由于
尽管
self-attention在大型语言模型中已被证明非常有效,但我们发现它对于推荐系统并非最优。在self-attention中,attention权重是使用tokens的内积计算的。这种方法对于NLP很有效,因为所有tokens共享一个unified embedding space。然而,在推荐任务中,特征空间本质上是异构的。计算两个异构语义空间(heterogeneous semantic spaces)之间的内积相似性非常困难——尤其是在推荐系统中,来自user侧和item侧的特征的ID space可能包含数亿个元素。因此,将self-attention应用于如此diverse inputs,其性能并不优于无参数的multi-head Token Mixing方法,并且消耗更多的计算、Memory IO操作和GPU memory usage。TokenMixing是可微的。因为它只是对输入进行固定的置换(permutation)操作。在深度学习中,置换操作(例如reshape、transpose、gather等)都是可微的,因为它们的前向传播是确定的元素重排,反向传播时梯度可以按照相反的规则传播回原来的位置。Per-token FFN:先前的DLRM和DHEN模型倾向于在单个interaction模块中混合来自许多不同的语义空间的特征,这可能导致high-frequency fields主导并淹没低频或长尾的信号,最终损害整体的recommendation质量。我们引入了一种参数隔离的feed-forward network架构,称为per-token FFN。在传统设计中,FFN的参数在所有tokens之间共享,但我们的方法使用专用的变换(transformations)来处理每个token,从而隔离了每个token的参数。对于第tokenper-token FFN可以表示为:其中:
per-tokenFFN的第MLP。per-token FFN的hidden dimension。注意:这里的参数
per-token的,因此具有上标Gelu激活函数。token。
我们将
Per-token FFN模块总结为:其中:
与
parameter-all-shared FFN相比,per-token FFN通过引入更多参数来增强建模能力,同时保持计算复杂度不变。这种思想在
Hiformer中已经被引入:field-specific FFN。值得强调的是,
per-token FFN与MMoE experts不同,因为每个Per-token FFN看到的是distinct token input,而MMoE中的所有experts共享相同的输入。与MMoE(许多experts处理相同的输入)和Transformer(不同的输入共享一个FFN)不同,RankMixer同时分割inputs和参数,这有利于在不同feature sub-spaces中学习多样性。
1.2.4 Sparse MoE in RankMixer
为了进一步提高
scaling ROI,我们可以用Sparse Mixture-of-Experts (MoE) blocks来替换the dense FFNs of each pertoken,这样模型的容量增长而计算成本大致保持不变。这段话可以这样理解:用
MoE代替FFN可以带来模型容量的显著增加,因此MOE中的每个expert就相当于一个FFN;同时每次仅仅激活少数的几个experts,从而使得计算量基本保持不变。实验部分缺乏这部分的消融分析。
然而,原始的
Sparse-MoE在RankMixer中性能下降,因为:(i) uniform k-expert routing:Top-k selection平等地对待所有feature tokens,将预算浪费在low-information tokens上,而使high-information tokens缺乏资源,这阻碍了模型捕获tokens间的差异。这段话的意思是:
top-k的feature tokens是相同的。理论上:如果对于low-information tokens采用较小的high-information tokens使用较大的tokens是high/low information的;另一方面也方便设置per-token的(ii) expert under-training:Per-token FFNs已经将expert参数(每个expert就是一个FFN)规模乘以了#tokens;添加non-shared experts进一步爆炸了expert数量,产生高度不平衡的routing和训练不佳的experts。
我们结合两种互补的
training策略来解决上述问题:注意:这里有些符号与原始论文中的不一致。读者发现论文中符号容易混淆,因此做了修改。
ReLU Routing:为了赋予tokens灵活的expert数量并保持可微性,我们用ReLU gate上自适应的penalty(《ReMoE: Fully Differentiable Mixture-of-Experts with ReLU Routing》)替换了常见的Topk+softmax。给定第experttokenrouter其中:
token的experts的数量。router函数expert函数token-specific的,而不是全局共享的。ReLU Routing将为high-information tokens激活更多experts,并提高参数效率。稀疏性(Sparsity)由带有系数active-expert ratio保持在预算附近:tokens数量。Dense-training / Sparse-inference (DTSI-MoE):受《Ads recommendation in a collapsed and entangled world》的启发,我们采用了两个routersDS-MoE使得experts不会遭受under-training的问题,同时降低了推理成本。双路由方式:
其中:
experts充分训练;routing的稀疏性,控制inference成本。虽然论文没有明确说明,但实践中通常会有隐式的对齐,确保
cos相似度)。例如:.
1.2.5 Scaling Up Directions
RankMixer本质上是一个高度并行和可扩展的架构。其参数数量和计算成本可以沿着四个正交轴来扩展:tokens数量experts数量full-dense-activated版本,一个样本的参数和前向FLOPs可以计算为:FFN的hidden dimension的缩放比率。在
Sparse-MoE版本中,每个token的有效的参数和计算量进一步按sparsity ratio
1.3 实验
数据集:离线实验使用抖音推荐系统的训练数据进行。这些数据源自抖音的在线日志和
user feedback labels。训练数据集包括超过300个特征,例如数值特征、ID特征、交叉特征和序列特征,涉及数十亿user IDs和数亿video IDs。所有这些特征都被转换为embeddings。数据覆盖每天数万亿条记录,实验是在两周内收集的数据上进行的。评估指标:
AUC (Area Under the Curve)、UAUC (User-level AUC)作为主要性能指标;Parameter count、FLOPs、MFU作为效率指标。Finish/Skip AUC/UAUC:finish=1/0或skip=1/0标签指示用户是否在短时间内看完了一个视频或滑到了下一个视频。我们评估此finish label的AUC和UAUC。AUC增加0.0001可以被认为是一个显著且置信的改进。Dense-Param:dense part中的参数数量,不包括sparse embedding参数。Training Flops/Batch:运行一个512 batch-size的batch通过模型所需的floating-point operations: FLOPs次数,代表训练的计算成本。MFU:MFU(Model FLOPs Utilization)是一个衡量模型如何有效利用硬件提供的浮点运算的指标,通过将模型的实际FLOPs消耗除以硬件的理论FLOPs容量来计算。
baselines:我们与以下广泛认可的SOTA基线进行比较:DLRM-MLP:原始MLP用于feature crossing,这作为实验的baseline。DCNv2, RDCN:feature cross模型的SOTA。MoE:通过使用多个并行experts进行scale up。AutoInt, Hiformer:结合了heterogeneous self-attention layer和low-rank approximation matrix computation。DHEN:结合了不同类型的feature-cross block(DCN/self-attention/FM/LR)并堆叠了多个层。Wukong:研究了feature interaction的scaling law,遵循带有Factorization Machine Block (FMB)和Linear Compress Block (LCB)的DHEN架构。
所有实验都是在数百个
GPU上进行的,采用hybrid distributed training框架,其中sparse部分异步更新,而dense部分同步更新。所有模型的optimizer hyperparameters保持一致。对于
dense部分,我们使用RMSProp优化器,学习率为而
sparse部分使用Adagrad优化器。
在论文中,
sparse部分和dense部分采用不同的优化器,这是工业级推荐系统训练中的常见做法。原因如下:数据分布和更新频率不同:
sparse部分:参数数量巨大(通常有数十亿甚至数百亿的ID类特征),但每个训练样本只更新极少一部分embedding向量(即出现过的ID对应的embedding)。这些embeddings的更新非常稀疏,而且每个embedding向量的更新频率与其在训练数据中出现的频率相关。dense部分:参数数量相对较少(几百万到几十亿),每个训练样本都会更新所有dense参数。
优化器的适应性:
对于
sparse embedding,通常使用自适应优化器(如Adagrad、Adam、FTRL等)来为每个特征(每个ID)单独调整学习率。这是因为不同ID的出现频率差异很大,自适应优化器可以为低频ID设置较大的学习率,为高频ID设置较小的学习率,从而更好地训练sparse embedding。对于
dense layer,通常使用SGD、RMSProp、Adam等优化器。在论文中,dense layer使用了RMSProp,这可能是因为RMSProp在推荐系统任务中表现稳定。
训练效率:
sparse embedding layer由于参数量巨大,通常存储在参数服务器(Parameter Server)或使用其他分布式存储方式,并采用异步更新。为了减少通信开销,sparse embedding的更新可能采用延迟更新或更高效的优化算法。dense layer则可以使用同步更新,因为参数量相对较小,同步更新的开销不大。
收敛性考虑:
sparse embedding和dense layer通常具有不同的梯度分布和收敛速度。使用不同的优化器(甚至不同的学习率)可以分别调整两部分参数的学习过程,使训练更稳定、收敛更快。
1.3.1 与 SOTA 方法的比较
为了探索如何
scale up模型,我们比较了参数大小相似(大约100 million)的模型,以确定在相同计算成本下哪种模型结构表现最佳。我们的方法和基线性能的主要结果总结在Table 1中。我们可以观察到:RankMixer在多个目标和指标上显著优于其他SOTA模型。我们仔细看一下每个模型:
首先,仅仅将
DLRM扩展到100 million参数只能带来有限的收益,这强调了设计针对recommendation data特性的模型以获得更好scaling性能的必要性。然后,我们将
RankMixer模型与其他经典的cross-structure设计(如DCN、RDCN、AutoInt和DHEN)进行比较,发现它们在模型参数和计算成本之间存在不平衡。即使参数规模相对较小,这些模型已经表现出较大的FLOPs,表明设计缺陷限制了它们在Table中的结果。同时,尽管
RankMixer实现了最佳性能;而且当扩展到100 million参数时,其FLOPs在所有模型中仍然相对适中,反映了模型容量和计算负载的平衡方法。我们还将
RankMixer与几种常用的SOTA的scaling-up模型(如Hiformer和Wukong)进行了比较,发现在相似的参数设置下,RankMixer不仅性能更好,而且计算需求更低。
Hiformer的性能排第二,而且参数规模、FLOPs/Batch也适中。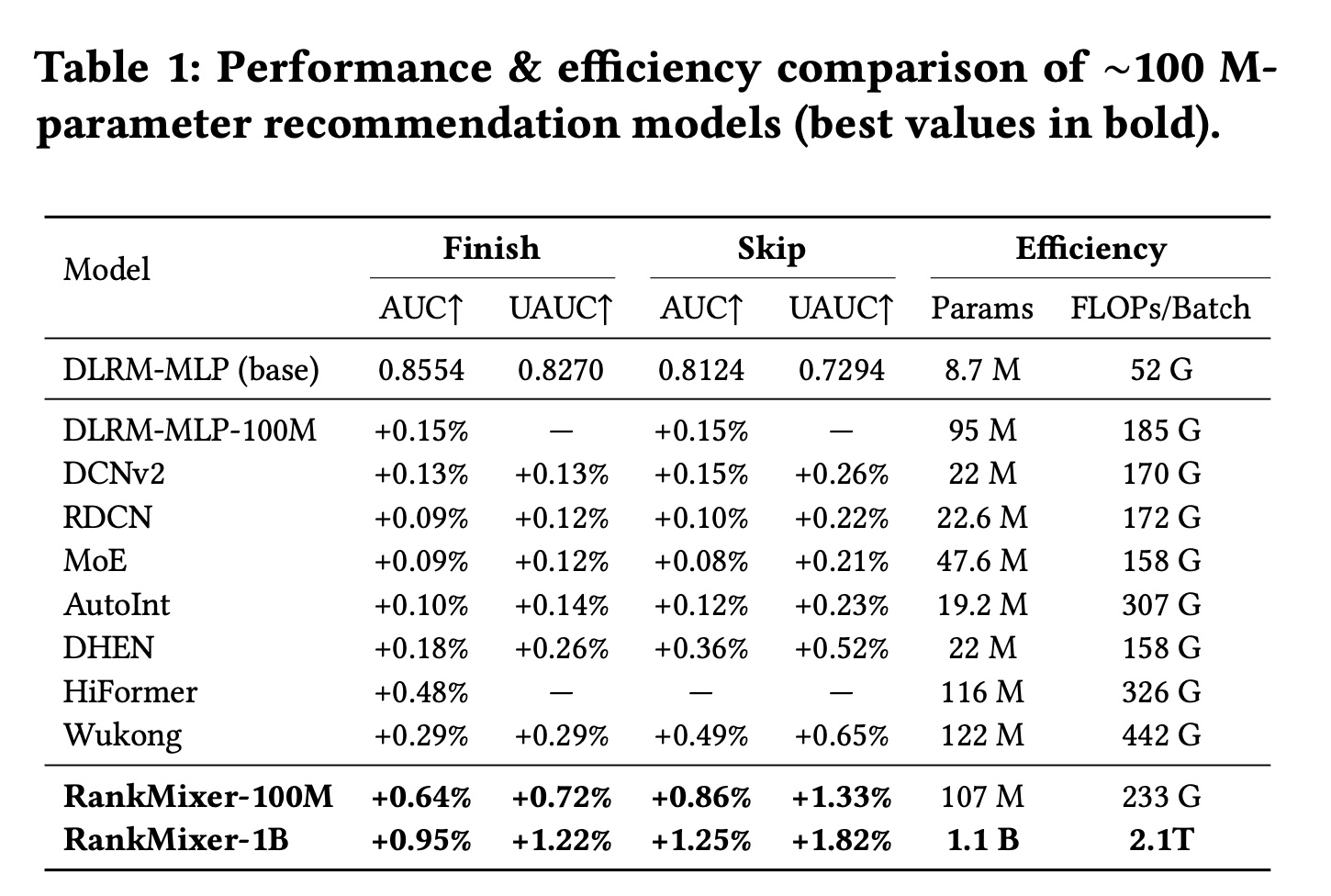
1.3.2 不同模型的 Scaling Laws
在
Figure 2中,我们展示了从参数大小和Flops观察到的scaling law曲线。RankMixer模型在参数和FLOPs方面都显示出最陡峭的scaling law。RankMixer始终优于其他模型。尽管
Wukong模型表现出相对陡峭的参数曲线,但其计算成本增长更快;因此,在AUC与FLOPs曲线上,它与RankMixer和Hiformer的差距更大。此外,
Hiformer的性能略逊于RankMixer,反映了其在feature level上对token segmentation和Attention的依赖影响了其效率。DHEN的scaling不理想,反映了其cross structure的有限的scalability。此外,
MoE通过添加experts进行扩展的策略在保持expert balance方面带来了挑战,导致scaling的性能不佳。
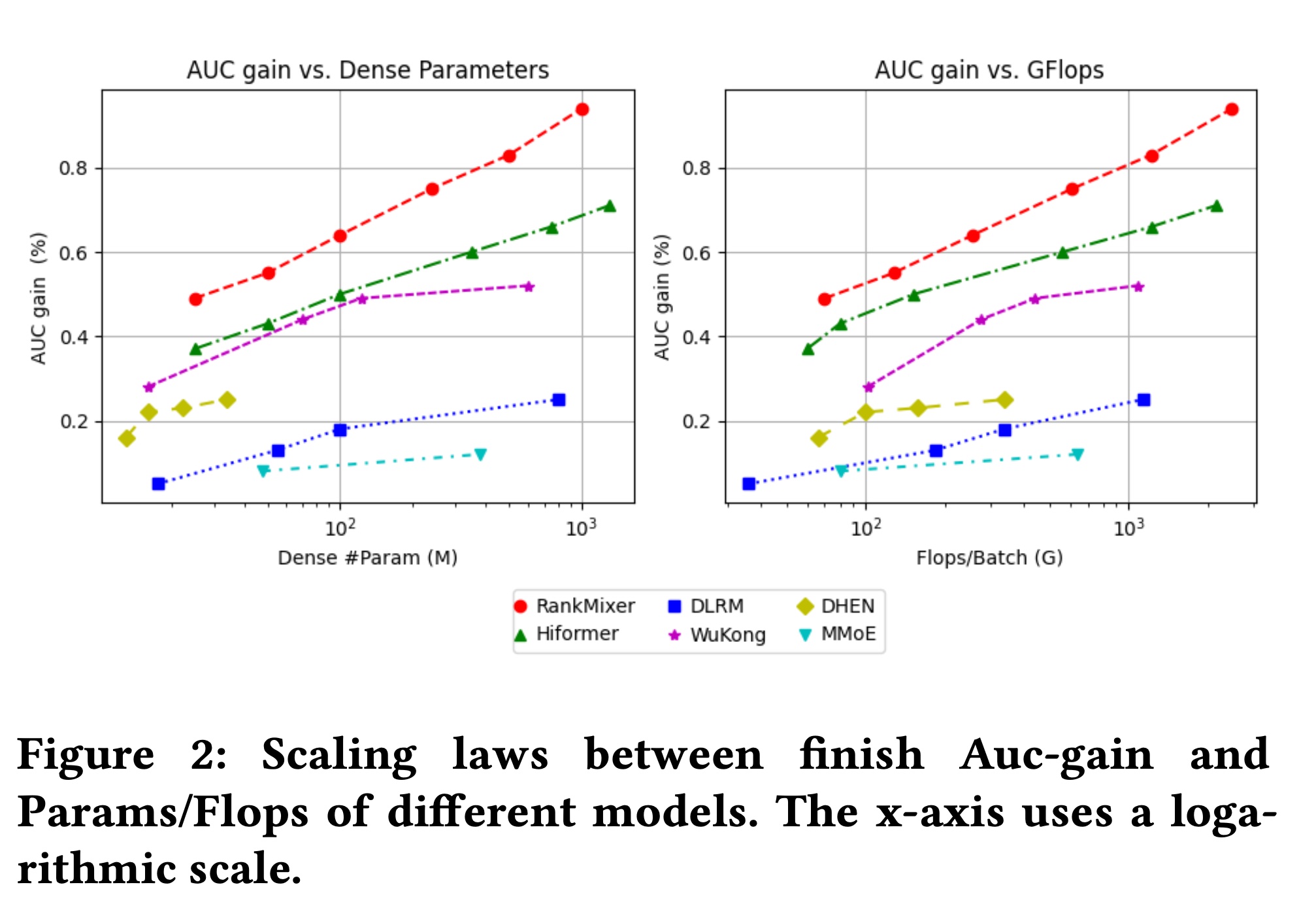
具体来说,我们可以通过增加宽度 (
feature token(RankMixer模型。在我们的实验中,我们观察到一个与LLM的scaling laws共享的结论:模型质量主要与参数总数相关,并且不同的scaling方向(深度tokens从计算效率的角度来看,更大的
hidden-dim会产生更大的matrix-multiply shapes,因此比堆叠更多层实现更高的MFU。因此,100M和1B的最终配置分别设置为: (
1.3.3 消融研究
在
RankMixer-100M模型中,我们对residual connections、Multi-Head Token-Mixing进行了消融研究。从Table 2中,我们可以看到:移除这些组件显著降低了模型的性能。移除
Multi-Head Token-Mixing会丢失全局信息,因为每个FFN只建模部分特征而没有interaction。移除
residual connections和LayerNorm也会降低性能,降低训练稳定性,并使梯度爆炸或梯度消失问题更可能发生。
这里缺乏
Sparse MoE组件的消融研究:使用Per-token Dense FFN而不是Per-token Sparse-MoE的效果。
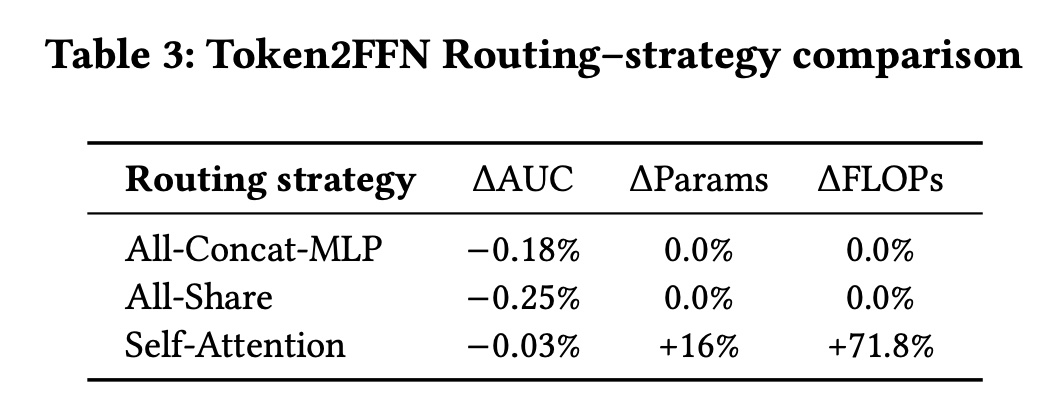
我们进一步分析了
token mixing策略,即从feature tokens到FFNs的routing策略,见Table 3。与Multi-Head Token Mixing比较的routing策略包括:All-Concat-MLP:将所有tokens拼接起来,通过一个大型MLP来处理,然后将它们分割成相同数量的tokens。性能下降显示了learning large matrices、以及削弱local information learning的挑战。All-Share:不分割,整个input向量被共享并馈送到每个per-token FFN,类似于MoE。性能显著下降,这表明与all- shared input相比,feature subspace split和independent modeling的重要性。Self-Attention:在tokens之间应用self-attention进行routing。其性能略逊于Multi-Head Token-Mixing,并且还遭受高计算成本的困扰,这表明了跨越数百个不同feature subspaces来学习相似性的困难。
1.3.4 Sparse-MoE Scalability 和 Expert Balance
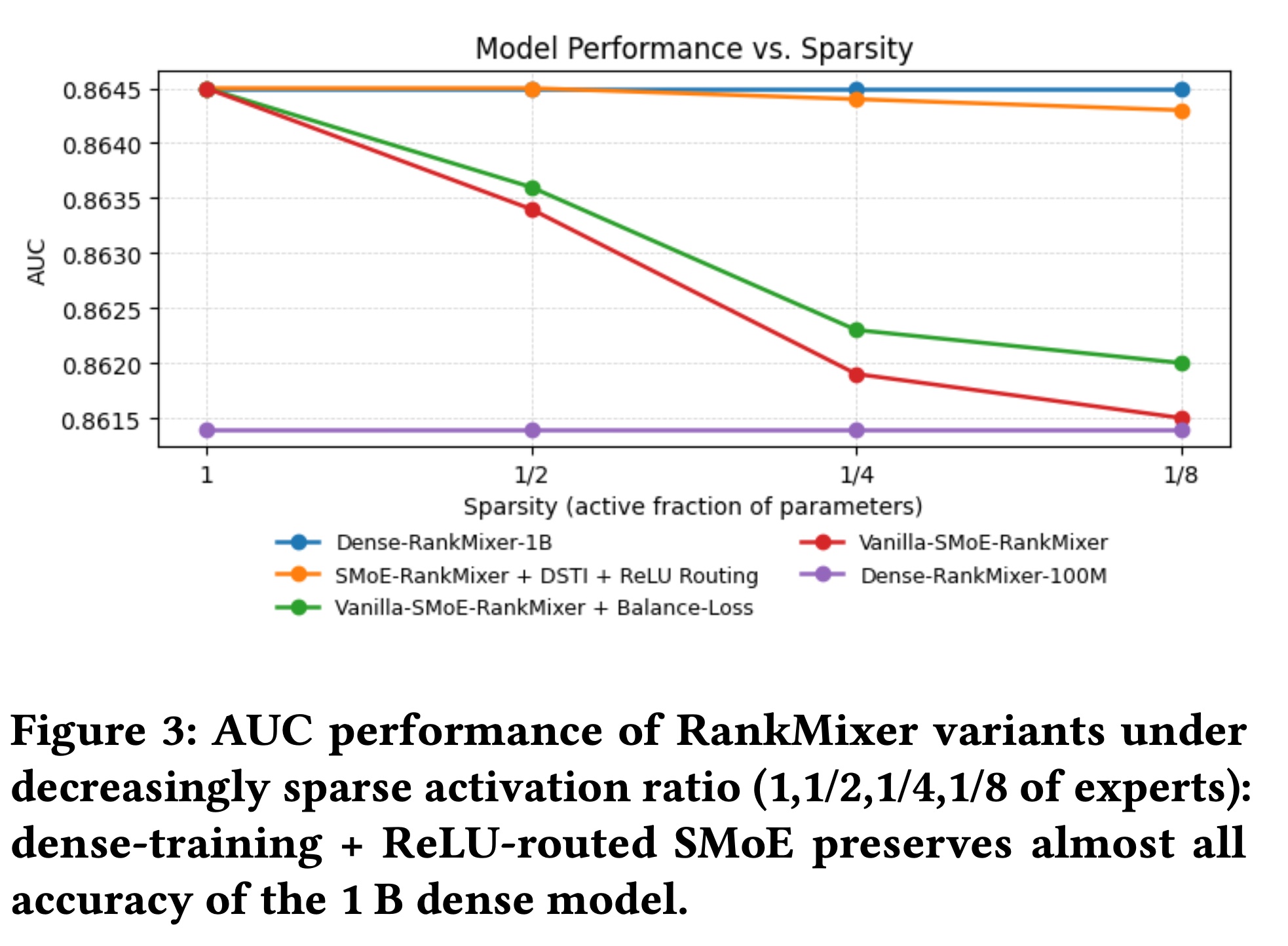
Scalability:Figure 3绘制了离线AUC增益与Sparse-MoE稀疏度的关系。将
Dense-Training-Sparse-Inference与ReLU routing相结合,对于在aggressive sparsity下保持准确性至关重要,使RankMixer能够将参数容量(和内存占用)扩展AUC几乎没有损失,并且推理时间显著节省(吞吐量提高+50%)。原始
Sparse-MoE的性能随着activated experts数量的减少而单调下降,说明我们指出的expert-imbalance和under-training问题。添加
load-balancing loss相对于原始Sparse-MoE减少了性能下降,但仍然不及DTSI + ReLU版本,因为问题主要在于expert training而不是router。这验证了Sparse-MoE作为将RankMixer从当前的1B参数扩展到未来10B规模部署而不超出成本预算的路径。
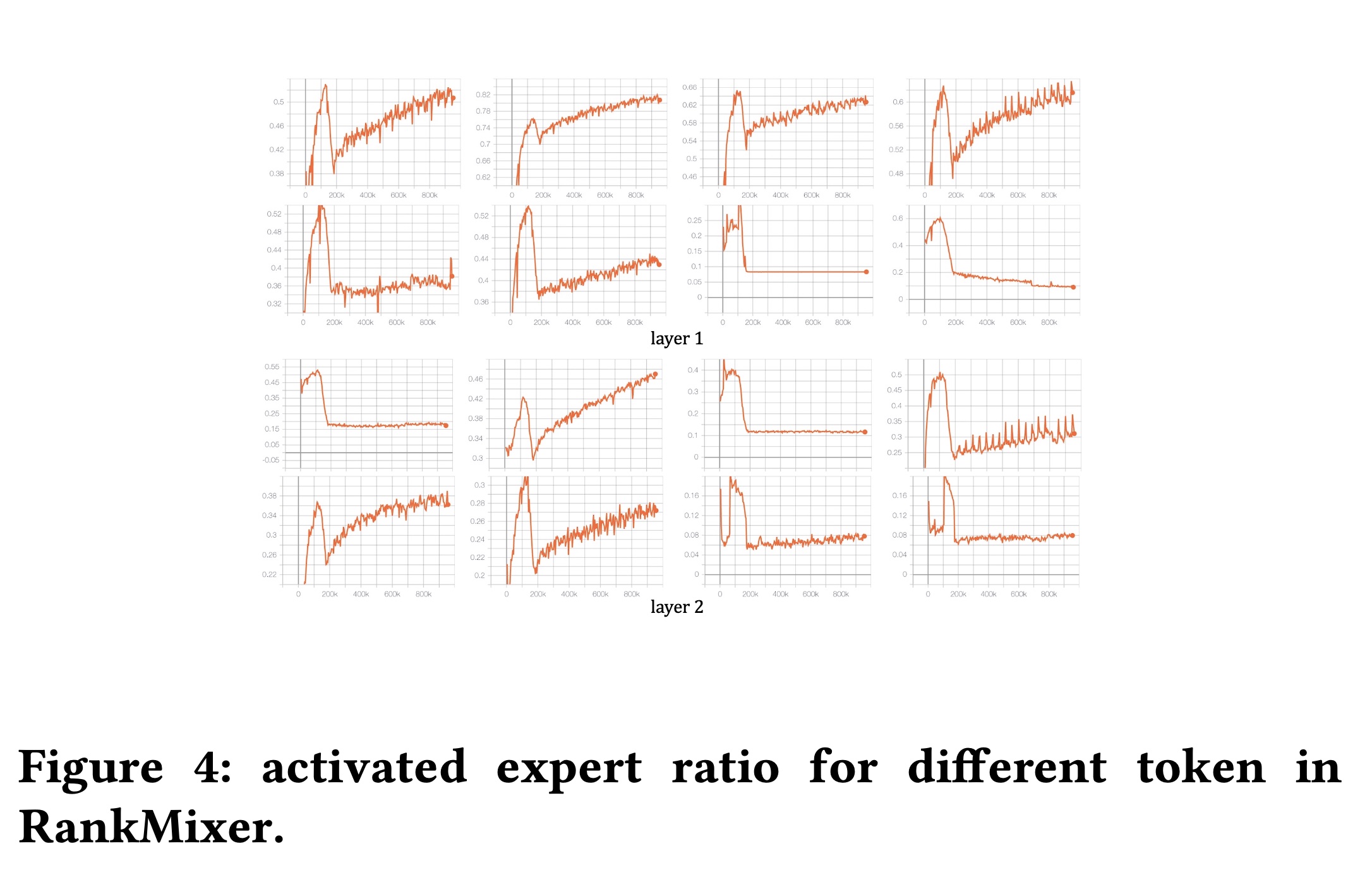
Expert balance and diversity:原始Sparse-MoE经常遭受expert imbalance的困扰,这反过来导致一些experts under-trained,最终导致"dying experts"(几乎从未被激活的experts),并且只有少数固定的experts被constantly activated。Figure 4显示,将DTSI(dense-training, sparse-inference)与ReLU routing相结合,可以有效地解决了这个问题:dense-training保证了大多数experts获得足够的梯度更新,防止expert饥饿。ReLU routing使得不同tokens的activation ratio是动态的——图中显示的activation ratio根据其信息内容自适应变化,这与recommendation data多样且高度动态的分布非常吻合。
1.3.5 Online Serving 成本
我们如何防止
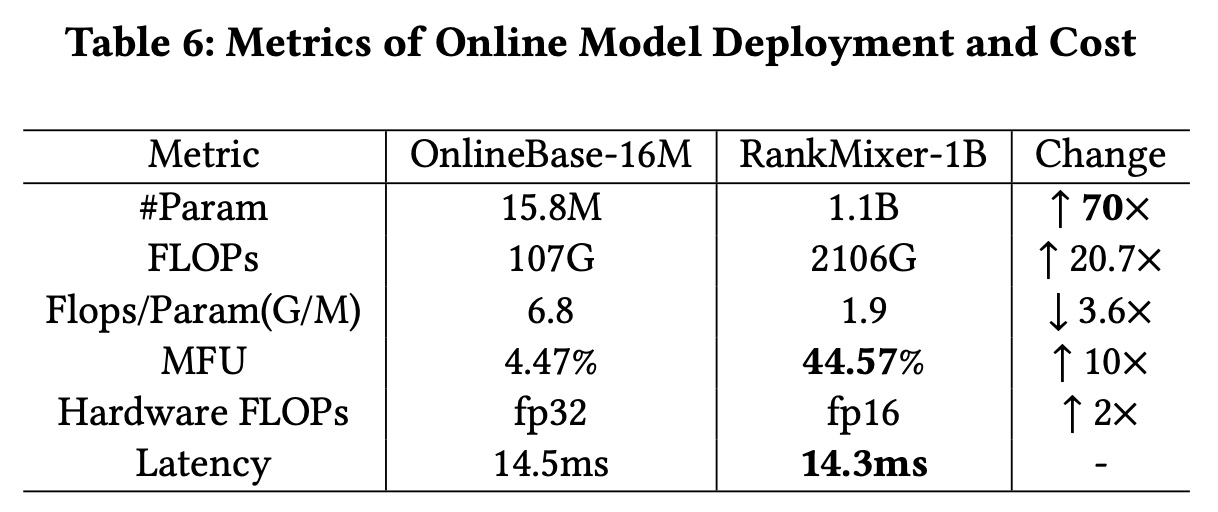
inference latency随着参数增加两个数量级而爆炸?在实际系统中,latency与吞吐量成反比,与serving machine resources的成本成正比。与我们之前的fully-deployed 16M-parameter model(采用集成了DLRM和DCN的结构)相比,我们的RankMixer模型将参数扩展了约70倍至1B。尽管参数显著增加,但由于我们hardware-aligned的模型设计和optimization策略,最终inference latency保持稳定。当大幅增加模型参数时,
latency可以分解为以下公式:如
Table 6所示,两个数量级的参数增长被decrease of FLOPs/Param ratio、increase of MFU和Quatization-based的Hardware FlOPs improvements所抵消。FLOPs/Param ratio:Table 6的第三行报告了per parameter所需的floating-point operations: FLOPs。由于模型设计,RankMixer实现了70倍的参数增加,而FLOPs仅增加了约20倍,实现了仅为基线三分之一的FLOPs/Param ratio:efficiency gain。换句话说,在相同的FLOPs预算下,RankMixer可以容纳比基线多三倍的参数。Model FLOPs Utilization (MFU):同样 在Table 6中显示,MFU表示machine computing的利用率。通过使用large GEMM shapes、良好的并行topology(将并行的per-token FFNs融合到一个kernel中)、减少内存带宽成本和开销,RankMixer将MFU提高了近Memory-bound状态转变为Compute-bound状态。Quantization:半精度(fp16)inference将使GPU的理论峰值硬件FLOPS提高RankMixer中的主要计算由几个大型矩阵乘法组成,如前所述,这些运算非常适合半精度(fp16)的inference。
1.3.6 Online 性能
为了验证
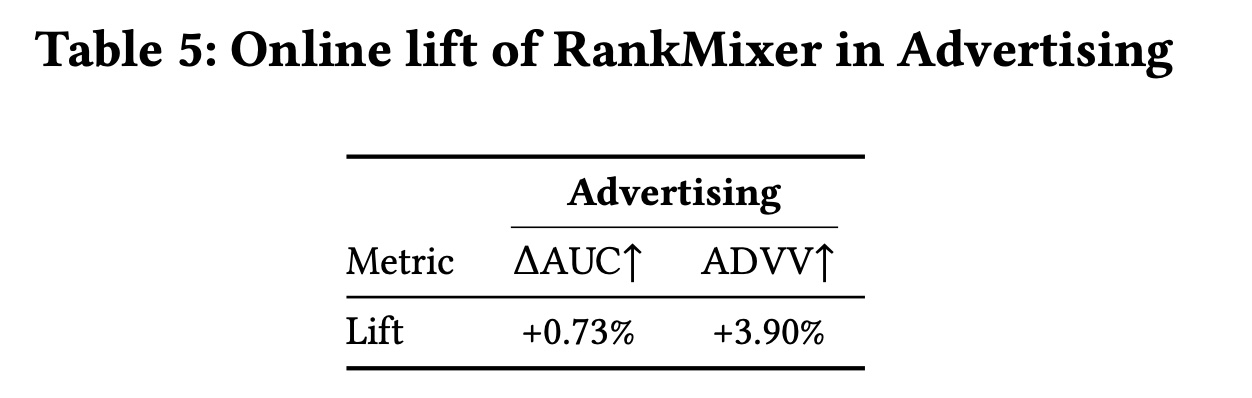
RankMixer作为scaling的推荐模型框架的普适性,我们在个性化ranking的两个核心应用场景——feed recommendation和advertising——中进行了在线实验,涵盖了个性化ranking的主要用例。对于每个场景,我们监控以下关键性能指标:Feed–Recommendation:Active Days是实验期间每个用户的平均活跃天数,是DAU增长的替代指标;Duration衡量在App上的累计停留时间;Finish/Like/Comment是用户的总完成播放、点赞、以及评论。Advertising:我们报告模型质量指标(ADVV(Advertiser Value)。
在这些场景中,先前的基线是结合了
DLRM和DCN的16M参数的模型。我们用RankMixer-1B模型替换了Dense部分,将AUC提高了0.7%。我们在Feed Recommendation和Advertising上进行了online A/B test实验。Table 4显示了FeedRecommendation在8个月的A/B test的长期观察结果,Table 5显示了Advertising的效果。RankMixer在三个personalised-ranking application中部署和评估,包括Feed Recommendation(RankMixer-1B)和Advertising(RankMixer-1B)。RankMixer在所有业务关键指标上都提供了统计显著的提升。我们还可以从Table 4中观察到,与其它activeness level的用户组相比,Low-active用户的改进最大,Active Days提高了超过1.7412%,这证明了模型的强大泛化能力。这些结果表明,
RankMixer作为一个unified backbone,能够可靠地泛化到不同的应用场景。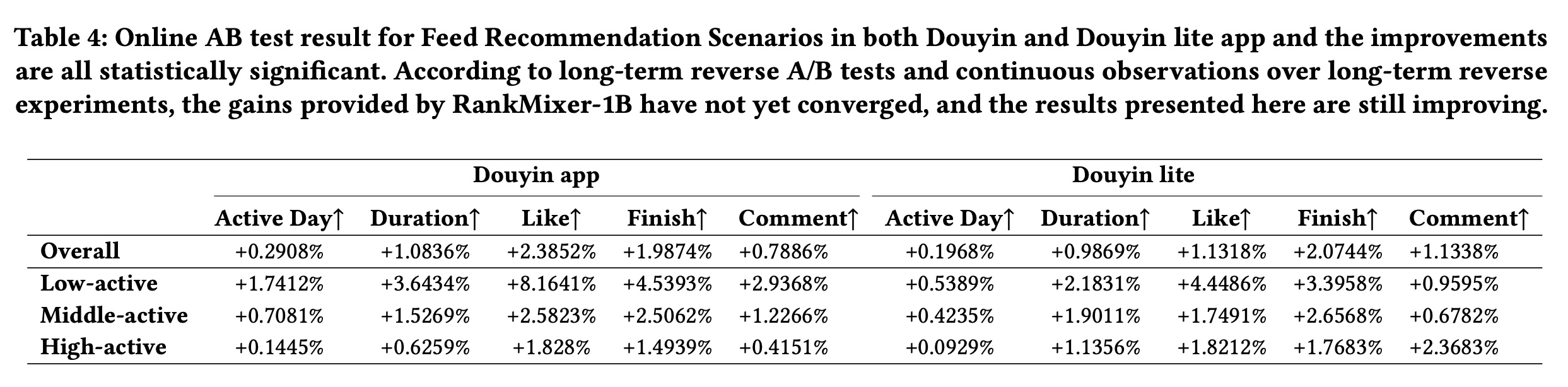
1.4 结论
在本文中,我们介绍了我们最新的
RankMixer模型,该模型已完全部署在抖音Feed ranking中。它结合了用于heterogeneous feature interactions的模型设计和高并行化架构以实现serving效率。实验证明了其卓越的性能和陡峭的scaling law。在抖音App上全面部署后,它获得了0.3%的active days增长、以及1%的App duartion增长。