一、 HyFormer [2026]
《HyFormer: Revisiting the Roles of Sequence Modeling and Feature Interaction in CTR Prediction》
工业级大规模推荐模型(
large-scale recommendation models: LRMs)面临着如下的挑战:在严苛的效率约束下,联合建模long-range用户行为序列与异构的non-sequential features。然而,大多数现有架构采用解耦式的流水线:先通过一个
query-token based sequence compressor(如LONGER)对long sequences进行压缩。再通过
RankMixer等token-mixing模块与dense features进行融合。
这种流水线在一定程度上限制了模型的表征能力与交互灵活性。本文提出
HyFormer,一种统一的hybrid的Transformer架构,将long-sequence modeling与feature interaction紧密整合至单一骨干网络中。从序列建模的角度出发,我们重新审视并重新设计了LRMs中的query tokens,将LRM modeling task构建为一个交替的optimization process,该过程整合了两个核心组件:Query Decoding:将non-sequential features扩展为Global Tokens,并基于long behavioral sequences的layer-wise key-value representations执行long sequence decoding。Query Boosting:通过高效的token mixing来增强cross-query and cross-sequence heterogeneous interactions。
这两种互补机制以迭代方式执行,逐层地
refine representations。在十亿级工业数据集上的大量实验表明,在参数数量和浮点运算量(FLOPs)相当的前提下,HyFormer持续优于性能强劲的LONGER和RankMixer基线模型,且随着参数数量和FLOPs的增加,展现出更优异的scaling特性。在高流量生产系统中开展的大规模online A/B tests进一步验证了其有效性,相较于已部署的当前SOTA模型取得了显著的性能提升。这些结果凸显了HyFormer的的实用性和可扩展性,从而作为一个统一的建模框架从而用于工业级LRMs。现代工业级大规模推荐模型(
large-scale recommendation models: LRMs)运行在日益复杂的环境中,其精准预测依赖于对long-range用户行为历史和丰富的异构特征的联合建模。这些异构特征包括:用户画像、上下文信号和交叉特征。随着user engagement在更长的时间范围内不断提升,特征空间持续扩展;如何将long sequential signals与高维non-sequential information有效融合,已成为大规模推荐系统和搜索系统的核心挑战。为应对这一挑战,近期的工业架构在很大程度上趋同于一种分离式的scaling范式,将long sequence modeling与feature interaction相结合。在该范式中,long user behavior sequences由专用的sequence transformers编码,以捕获时序依赖关系(temporal dependencies)和用户兴趣,压缩后的sequence token(s)通过token-mixing or interaction modules与其他异构特征融合,从而实现cross-feature reasoning。这种"Long Sequence Modeling, Then Heterogeneous Feature Interaction"的流水线已被证明是有效的,并成为现代工业级LRMs的scaling up的的主流设计选择。尽管该范式取得了良好的实证性能,但这种主流架构从根本上强制采用了压缩的(
compressed)、后期融合的(late-fusion)、以及单向的交互模式(interaction pattern)。随着序列长度和模型容量的不断增加,这种两阶段设计暴露出根本性的局限性,制约了模型的表达能力和可扩展性。现有架构中的
sequence transformers在序列压缩过程中,往往依赖过于简化的query representations。实际应用中,用于聚合long behavior sequences的query tokens通常由candidate-related or global features的有限子集生成,限制了modeling long-term user interests时可利用的上下文信息总量。而直接增加query tokens的数量,会在KV-Cache和M-Falcon机制下导致serving efficiency的显著下降。单层交叉注意力计算复杂度为
query tokens数量,实时计算量呈线性暴涨:
缓存访存效率大幅降低:
KV-Cache的张量存储在GPU的高带宽显存(HBM)中,query tokens数量增加会导致单次推理的访存次数、访存数据量同步上升,引发显存带宽瓶颈。
sequence-compressed tokens与异构non-sequential tokens之间的交互通常仅发生在模型的后期阶段。在当前范式下,cross-feature reasoning被推迟至sequence compression完成后,导致不同token types之间的交互是shallow的、且implicit的。这种delayed fusion限制了模型捕获细粒度依赖关系的能力(这种依赖关系跨多个behavior sequences和heterogeneous feature groups),也使得early-layer representations无法从cross-domain上下文信息中获益。由于
interaction模块仅对compressed sequence representations进行操作,increasing model capacity or sequence length主要优化的是孤立的组件,而非增强joint representations。因此,scaling up模型深度或参数会导致scaling efficiency降低:性能随计算预算的增加而提升,但是提升的速率放缓,因为计算资源未能有效转化为更丰富的joint representations。
这些局限性促使我们重新思考
long-range sequence modeling与heterogeneous feature interaction的融合方式。我们需要一种统一的建模框架,而非将sequence encoding和token mixing视为两个松散耦合的阶段,以实现sequential signals与non-sequential signals之间更深度的、更早期的双向交互。本文提出
HyFormer,一种hybrid transformer架构,将sequence modeling与feature interaction统一在单一骨干网络中。HyFormer引入一组global tokens,作为long behavior sequences与heterogeneous features之间的a shared semantic interface。通过堆叠式设计,HyFormer在两种轻量的且具有表达能力的机制间交替执行:Query Decoding模块利用global query tokens,对long behavioral sequences的layer-wise key–value representations进行注意力计算,使global context能直接塑造(shape)sequence representations。Query Boosting模块通过高效的token mixing,进一步强化cross-query and cross-sequence interactions,逐层丰富semantic representations。
该设计实现了
sequence modeling与feature interaction组件间的信息的双向流动,克服了传统的decoupled pipelines的局限性。在十亿级工业数据集上的大量实验表明,在参数量和FLOPs相当的前提下,HyFormer一致地优于性能强劲的sequence-based and token-mixing baselines。此外,HyFormer在模型FLOPs和参数量方面展现出更优异的scaling特性,且在高流量的生产系统中开展的大规模online A/B tests中取得了显著的性能提升。综上,本文的贡献如下:
指出了工业级大规模推荐系统中,主流的
decoupled sequence modeling and feature interaction范式存在的根本性局限性,并分析了其单向的、后期融合的设计如何制约模型容量和可扩展性。提出
HyFormer,一种统一的hybrid transformer架构,通过Query Decoding和Query Boosting实现long-range behavioral sequences与heterogeneous features之间的双向的、layer-wise的交互,在实际工业场景中取得了SOTA的性能和可扩展性。在十亿级工业数据集上,通过实证验证了所提模型的有效性和优异的
scaling性能。目前,HyFormer已在Bytedance全面部署,每日服务十亿级用户。
1.1 相关工作
传统推荐范式:现代工业级
LRMs通常由两个核心组件构成:behavior-sequence modeling网络和feature-interaction网络。在该范式中,user behavior histories首先由专用的sequence models进行编码,其输出随后与heterogeneous non-sequential features一起馈入下游的interaction模块。近期的工业系统沿此方向大幅提升了
sequence modeling的可扩展性。SIM(《Search-based User Interest Modeling with Lifelong Sequential Behavior Data for Click-Through Rate Prediction》)、ETA(《Efficient long sequential user data modeling for click-through rate prediction》)、TWIN(《TWIN: TWo-stage Interest Network for Lifelong User Behavior Modeling in CTR Prediction at Kuaishou》、《TWIN V2: Scaling Ultra-Long User Behavior Sequence Modeling for Enhanced CTR Prediction at Kuaishou》)、TransAct(《TransAct: Transformer-based Realtime User Action Model for Recommendation at Pinterest》)和LONGER(《LONGER: Scaling Up Long Sequence Modeling in Industrial Recommenders》)等方法,通过高效注意力机制、分层聚合(hierarchical aggregation)、KV caching和易部署的设计,将sequence encoders的处理能力扩展至数百甚至数千个behaviors。这些研究证明,在大规模流量下,建模long-range user behaviors存在明显的power-law缩放趋势,但在很大程度上仍保留了将sequence encoding与feature interaction解耦的两阶段架构。在
feature-interaction方面,DeepFM(《DeepFM: A Factorization-Machine based Neural Network for CTR Prediction》)、xDeepFM(《xDeepFM: Combining Explicit and Implicit Feature Interactions for Recommender Systems》)和DCNv2(《DCN V2: Improved Deep & Cross Network and Practical Lessons for Web-scale Learning to Rank Syst》)等早期模型能at scale地建模低阶的或有界degree的feature crosses,但随着interaction depth的增加,性能提升逐渐趋缓。Wukong(《Wukong: Towards a scaling law for large-scale recommendation》)和RankMixer(《RankMixer: Scaling Up Ranking Models in Industrial Recommenders》)等近期的scaling studies指出,cross-module expansion成为工业级模型性能提升的关键驱动力。这些模型代表了当前大规模feature-interaction设计的最高水平;但在大多数生产级流水线中,interaction stack与sequence encoder仍处于松散耦合的状态,导致late fusion,无法实现heterogeneous signals的联合优化。
统一的推荐架构:为减少
sequence modeling与feature interaction之间的割裂,近期研究开始探索统一的架构(unified architectures),在单一骨干网络中处理异构的信号。HSTU(《Actions Speak Louder than Words: Trillion-Parameter Sequential Transducers for Generative Recommendations》)等分层的生成式架构,通过基于contextual and candidate signals执行sequence transduction,构建了统一的推荐范式。InterFormer(《InterFormer: Effective Heterogeneous Interaction Learning for Click-Through Rate Prediction》)引入可学习的interaction tokens,实现信号的双向交换,弥补了sequence encoders与interaction networks之间的差距。MTGR(《MTGR: Industrial-Scale Generative Recommendation Framework in Meituan》)进一步推进了统一化设计,将user, behavior, real-time, and candidate features重组为heterogeneous tokens,并通过一个Transformer-style backbone进行编码,使sequence information和cross features能被一致地建模(be modeled coherently)。OneTrans(《OneTrans: Unified Feature Interaction and Sequence Modeling with One Transformer in Industrial Recommender》)沿袭了MTGR的研究方向,使用单一Transformer联合捕获sequence dependencies和high-order feature interaction,同时通过pyramid-compression style简化了Transformer结构,可视为MTGR的简化版本。
然而,
MTGR和OneTrans将query tokens的数量直接等同于所有non-sequence tokens的数量,实际应用中会导致serving efficiency显著下降(见第1.3节)。此外,在工业级LRMs中,采用统一的Transformer结构建模feature interaction通常存在表达能力不足的问题(《RankMixer: Scaling Up Ranking Models in Industrial Recommenders》)。总体而言,统一的架构为打破sequence models与feature-interaction stacks之间长期存在的分离状态迈出了一步,但如何以最小的架构开销实现完全统一,仍是一个待解的挑战。
1.2 方法
问题定义:设
user space和item space。对于用户raw behavioral history表示为non-sequential features,包括画像属性、上下文信号和交叉特征。给定candidate itemitem注意:
user, item,也表示它们关联的non-sequential features。其中
interaction是否发生。模型参数通过历史数据集
其中
LRM输出的engagement概率的预测值。整体框架:传统的
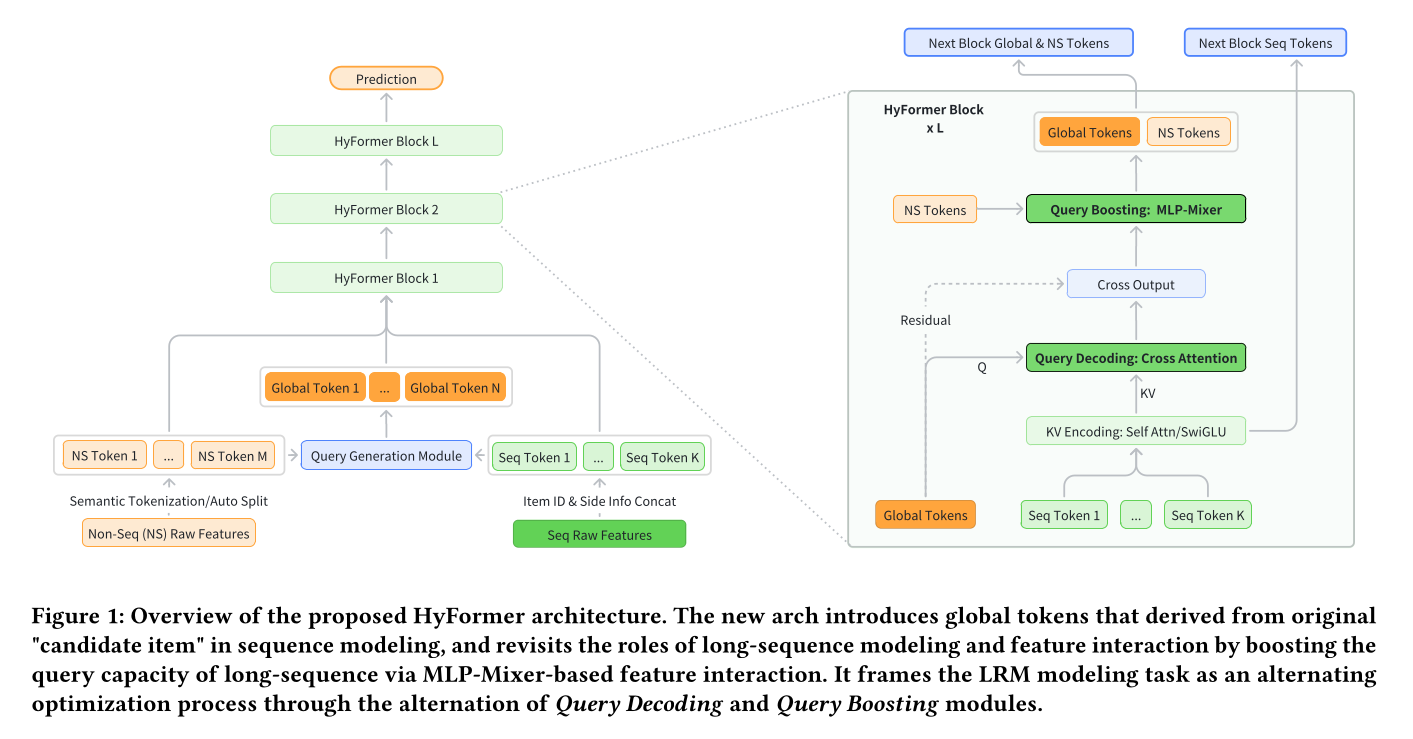
LRM架构通常采用流水线设计,先执行LONGER等sequence modeling操作,再将包含compressed sequence information的query token用于后续的RankMixer等feature interaction操作。如前文所述,这种分离式流水线对sequence modeling和异构feature interaction的建模均存在不足。为克服该局限性,本文提出一种统一的混合框架,通过堆叠的HyFormer layers,联合non-sequential (NS) tokens和long behavioral sequences。HyFormer的整体架构如Figure 1所示。如图所示,每个HyFormer layer整合了两种互补机制:(1):Query Decoding,通过MLP-based query generation,将non-sequential and sequential features扩展为多个semantic global tokens(即sequence queries),并对long-sequence K/V pairs执行cross-attention,使global information能直接塑造representation of sequence tokens。(2):Query Boosting,采用MLP-Mixer-style token mixing,强化decoded queries与non-sequence tokens之间的交互。
通过将
global heterogeneous-feature mixing与高效的long-sequence modeling紧密耦合,所提框架实现了更丰富的heterogeneous interactions、对sequential structure的deeper utilization;且与现有分离式流水线架构相比,在性能和计算成本上更具优势。注意,右图中:
Next Block Seq Tokens:就是NS Tokens:来自于Query Boosting的split结果。Next Block Global:来自于Query Boosting的split结果。
该方法的核心是:
用
Query Generation(初始block)、Query Boosting(后续blocks)来建模feature interaction。然后用所生成的
Global Tokens作为query来执行sequence modeling。
这两步交替执行,从而不断优化。
1.2.1 Query Generation
Input Tokenization:遵循RankMixer中的tokenization策略,input tokens可通过semantic grouping或automatic splitting两种方式组织。semantic grouping根据特征的固有含义(如用户、上下文或behavior语义)对tokens进行划分。而
automatic splitting则将所有features展平为单个embedding,并在无显式语义区分的情况下进行均匀拆分。
实际应用中,鉴于本研究中的
input features具有明确的语义角色(semantic roles),HyFormer采用semantic grouping,以保留结构化的inductive bias并提升模型的可解释性。Query Generation:Query Generation模块将heterogeneous non-sequential features转换为用于解码long behavioral sequences的semantic query tokens。将所有non-sequential feature vectorsfeed-forward network: FFN)进行映射。此外,通过对behavioral sequence representations进行池化操作,得到一个global sequence-level summary,并将其作为额外的shared input,与non-sequential features类似地处理。queries通过如下方式来生成:首先融合non-sequential features和pooled sequence summary,然后通过一个轻量级投影。其中:
hidden representation维度,non-sequential features数量,query tokens数量。behavioral sequence representations。
为保证
serving efficiency,该模块支持feature selection和可选的query compression,在保持generated queries数量稳定的同时,为下游解码保留足够的表征能力。“该模块支持
feature selection和可选的query compression“,这段话如何理解?作者并未说明。基于相同的
Global Info来生成query,这类似于multi-query attention: MQA的思路。在更深的
HyFormer layers中,queries不再通过MLPs来生成。而是每层将前一层的Query Boosting outputs作为updated queries,以逐步丰富的语义对长序列进行查询。在实验章节,作者提到:
HyFormer的query由三个来源生成:global non-sequential features、multiple sequences pooling tokens和original target features。因此,
query还包含了original target features。
1.2.2 Query Decoding
Query Decoding模块负责将non-sequential features转换为semantic queries,并通过cross attention从long behavioral sequences中提取target-aware information。利用Sequence Representation Encoding模块生成的long sequence的layer-wise key–value representations,Query Decoding模块通过multi-query cross attention机制,使用Query Generation模块输出的multiple query tokens对K/V representation进行解码。Sequence Representation Encoding:HyFormer支持多种sequence encoding策略,可在模型容量和效率之间实现不同的权衡。给定behavioral sequencelayer-wise key–value representationsFull Transformer Encoding:在最高建模容量下,采用标准的Transformer encoder:该方式通过
full self-attention捕获细粒度的interactions和长距离的dependencies。LONGER-style Efficient Encoding:为提升long sequences的处理效率,将full self-attention替换为cross-attention(在a compact short sequence和full history之间):其中:
a compact short sequence),它的长度为query,keys和values。该方式替代了
full self-attention,将计算复杂度从这个
short sequence如何得到?作者并未说明。读者猜测:利用最近的actions。Decoder-style Lightweight Encoding:对于对latency要求严苛的场景,通过attention-free feed-forward操作转换sequence representations:它以牺牲
contextual capacity为代价,实现最小的计算成本。其中:
SwiGLU函数:注意:这里
SwiGLU函数是per-token的,并不是"Concat-And-SwiGLU"。
在所有变体中,将所生成的
representations进行线性投影,得到layer-specific key–value states:key–value states在每层重新计算,使sequence features能与decoder depth协同演化,同时支持灵活的deployment configurations。注意:
Seq Tokens。Query Decoding via Cross-Attention:给定sequence-specific query tokens和对应的layer-wise key–value representations,HyFormer通过cross-attention执行Query Decoding。对于第behavioral sequencedecoded query representations计算如下:其中:
multi-head cross-attention操作。query token。
该
decoding步骤使得全局的non-sequential的特征能够直接对long behavioral sequences执行注意力计算,将上下文信号注入到sequence-aware query representations中。decoded queryinteraction模块和boosting模块。注意:在
Figure 1中,作者对CrossAttn的输出叠加了一个residual connection。
1.2.3 Query Boosting
Query Boosting模块在query representations被馈入后续cross-attention layer之前,对query representations进行增强。decoding步骤完成后,queries已编码了sequence-aware information,但其与静态的non-sequential heterogeneous features之间的交互仍未被充分挖掘。Query Boosting模块通过显式地在query tokens之间混合信息,并注入额外的non-sequence-feature signals,解决这一局限性。基于
decoded output,unified query representation定义为:其中:
decoded query tokens,剩余tokens为non-sequential feature embeddings。具体而言,
boosting模块采用受RankMixer启发的MLP-Mixer-style的轻量级token-mixing操作,从而增强decoded queries。首先将每个
query token对于每个子空间索引
MLP-Mixer通过拼接对应子空间的信息,聚合所有token positions的特征:整合所有
mixed tokens,得到token-mixed representation:通过轻量级的
per-toke feed-forward模块,对mixed queries进行进一步优化:其中:
query token执行独立的前馈变换,在保留线性计算复杂度的同时,实现子空间特定的优化(subspace-specific refinement)。最后,引入残差连接(
residual connection)以稳定optimization过程,并保留原始的decoded semantics:
boosted queries随后馈入下一个HyFormer layer,使更deeper layers能以逐步丰富、更具表达能力的representations对long behavioral sequences进行查询。注意:在
Figure 1中,residual connection是叠加在Cross Attention的output上。注意:
Global Token和NS Tokens从而被馈入下一层。
1.2.4 HyFormer Module
HyFormer模块由多层堆叠构成,每层包含一个Query Decoding块和一个Query Boosting块。在每层中,semantic queries通过cross-attention与long behavioral sequence交互;所生成的sequence-aware representations经进一步优化后,作为deeper layers的输入。形式化地,在第
Query Decoding块接收global querieslayer-wise key–value representationslong sequence派生而来)执行cross-attention:decoded queriesnon-sequential tokens拼接后,馈入Query Boosting块,通过轻量级的token-wise transformation来增强query representations:通过堆叠多层上述结构,
HyFormer逐步优化semantic queries,使deeper layers能以更具表达能力的representations对long sequence进行总结。HyFormer顶层的output被馈入下游的MLPs,得到最终预测结果,实现了LRMs中heterogeneous non-sequential features与long behavioral sequences的高效的、灵活的融合。NS Tokens:来自于上一层的
1.2.5 Multi-Sequence Modeling
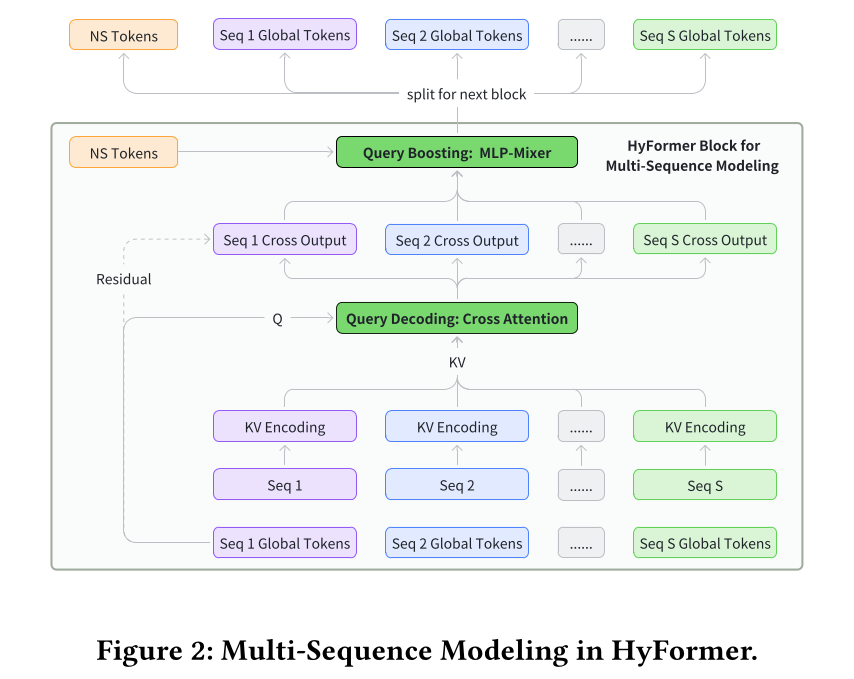
在工业推荐场景中,
user behaviors通常被组织为多个异构序列,例如video-watch sequence和product-purchase sequence。由于实际的multi-sequences通常具有不同的特征空间和semantic representations,我们通过实证发现:MTGR或OneTrans采用的简单的sequence-merge会导致模型性能显著下降(见1.3节)。因此,HyFormer并未将不同序列合并为单个unified stream,而是在每个HyFormer块中独立地处理每个behavior sequence,兼顾模型的效率和有效性。如
Figure 2所示,对于每个序列,构建一组专用的query tokens,并用于对对应的sequence representations执行Query Decoding。该设计在decoding过程中保留了sequence-specific semantics,同时通过query-level token mixing,在后续步骤中处理cross-sequence interaction,无需对序列进行显式拼接。这种做法比较巧妙。
1.2.6 Training and Deployment Optimization
Long-Sequence的GPU Pooling:user long-sequence features的数据量可能极大,导致显著的data-transfer开销(如主机到设备的内存拷贝)和主机端的高内存压力。幸运的是,此类序列中真正unique feature IDs数量有限(通常为total tokens的25%)。我们利用这种稀疏性对特征进行去重,大幅降低传输成本和主机内存占用。具体而言,在
graph execution前,将特征存储在compressed embedding-table中;执行过程中,构建高性能的前向算子,直接在GPU上重构original sequence features。在反向传播过程中,配套的反向算子将sequence features的梯度聚合为embedding table的梯度,随后将这些梯度向上传播,更新sparse parameters。Asynchronous AllReduce:为缓解synchronous gradient aggregation带来的设备空闲时间,本系统启用了asynchronous AllReduce,使第gradient synchronization能与第GPU的利用率。但这一设计的权衡是,dense parameters的梯度会引入一步延迟:由于dense parameters的梯度需在asynchronous reduction完成后才能获取,其更新规则变为:即,第
dense parameter使用前一步的梯度来更新。相比之下,
sparse parameters在本地梯度计算完成后即可立即更新,更新规则为:因此其更新比
dense parameter领先一步。尽管这种混合更新策略导致
dense and sparse parameter states存在轻微的时间不一致性,但实证结果表明,这种延迟在实际应用中不会降低模型的收敛质量和性能。
1.3 实验
数据集:我们在
ByteDance的Douyin Search System中,针对点击率(Click Rate: CTR)预测任务评估模型性能,该场景是真实的大规模工业搜索推荐场景。实验数据集来源于70个连续自然日的在线user interaction logs的子集,包含3 billion条样本。每条样本整合了user features、query features、document features、cross-features和多个sequential features。模型中使用的三个主要序列定义如下:long-term sequence:用户的长期search and click behavior sequence,长度可按需调整,本研究中设置上限为3000。Search sequence:经Query Search模块筛选后的用户top-50 search behavior items。Feed sequence:经Query Search模块筛选后的用户top-50 feed behavior items。
Baselines:我们将所提模型与多个性能强劲的基线模型进行对比,这些基线模型可分为两种架构范式:传统两阶段模型(Traditional Two-Stage Models)和统一架构模型(Unified-Architecture Models)。Traditional Two-Stage Models:遵循主流的设计思路,将sequence modeling和feature interaction分为两个连续的阶段。具体而言,先通过专用的sequence modeling模块生成sequential representations,再将其与其他特征的token-level representations进行交叉融合。long-sequence modeling采用LONGER或Full Transformer架构。为捕获
tokenized features间的交互,采用RankMixer、Full Transformer和Wukong等成熟的feature interaction架构。
Unified-Architecture Models:将sequential features和non-sequential features均进行令牌化,并在单个model block中同时处理,将sequence modeling和heterogeneous feature interaction整合为一个统一阶段。例如:MTGR:将所有特征令牌化后,通过Transformer风格的骨干网络进行联合建模。OneTrans:采用类似的简化设计,以pyramid-compressed structure作为骨干网络。
在本研究的
MTGR/OneTrans模型实现中,仅在non-sequential features和sequential features之间执行cross-attention计算,即MTGR/OneTrans (LONGER),不计算序列内部的self-attention。同时,为提升性能并增加FLOPs,我们也实现了包含序列full self-attention的MTGR/OneTrans模型,即MTGR/OneTrans (Full Transformer)。
评估指标:离线评估采用
Query-level AUC,即先计算每个query下样本的AUC,再对所有queries的AUC取平均值。同时,我们报告模型的dense parameters数量和training FLOPs,其中FLOPs基于batch size = 2048来计算。实现细节:
为方便实验,推荐模型在离线评估时采用冷启动方式,在线评估时通过
checkpoints进行预热。所有基线模型均使用相同的
batch size = 2048和optimizer settings。所有
MLP-Mixer模块的input token数量均对齐为16。在
multi-sequence HyFormer的实现中,包含13个non-sequential tokens和3个global tokens(每个序列对应1个global tokens),tokens总数为16。所有模型均采用相同的超参数调优策略,实验在一个
64-GPUs cluster上完成。
1.3.1 整体性能
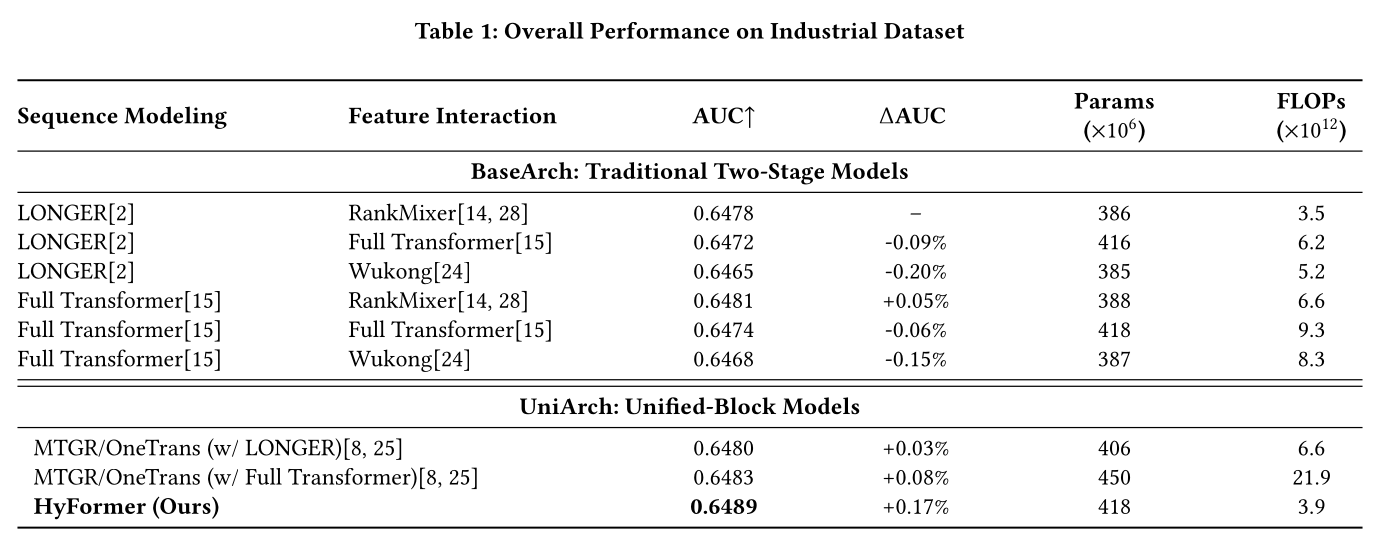
现有方法对比:所提的
HyFormer架构在所有评估模型中取得了最高的AUC值,性能优于传统两阶段模型(记为BaseArch)和其他unified-block模型(记为UniArch)。结果如Table 1所示。在传统两阶段模型组中,性能随组件选择的不同存在显著差异:
在
feature interaction方面,RankMixer的性能始终优于Self-Attention和Wukong。在
sequence modeling方面,在序列中引入full self-attention通常能带来性能提升。值得注意的是,传统两阶段模型中性能最优的组合 ——Full Transformer的sequence modeling配合RankMixer的feature interaction,仍不如HyFormer,这源于其固有的局限性:信息单向流动。
此外,实验结果表明
HyFormer具有优异的计算效率:尽管取得了最高的准确性,但其训练过程(含前向传播和反向传播)的total FLOPs仅为MTGR等其他高性能模型。整体性能结果凸显了传统两阶段范式的固有局限性。HyFormer和MTGR等统一架构的实验结果表明,将sequence modeling与feature interaction整合为一个连贯的设计,能提升模型的整体有效性。但如Table 1所示:MTGR/OneTrans依赖Self-Attention进行feature interaction。这种方式往往会导致AUC下降,且会显著降低interaction模块的计算效率。而
HyFormer无需采用此类高成本的方案,也无需在sequence key-value side进行复杂建模,即可取得最优的准确性,验证了其在unified block中迭代式地执行query decoding和query boosting这一核心设计原则的有效性。
此外,
MTGR/OneTrans将Global Tokens and Seq Tokens共同作为keys,仅将Global Tokens作为queries,这一设计使Global Tokens更容易对自身执行注意力计算,而非对sequence tokens执行注意力计算。相比之下,HyFormer采用分离的信息流设计:先将具体的sequence item information压缩并融入Global Tokens,再在不同的abstract Global Tokens间执行交互,该two-step过程在各层中反复堆叠。同时,HyFormer的混合架构为未来的scaling提供了更高的灵活性,可独立调整interaction layers/dimensions和sequence modeling layers/dimensions,相比将feature interaction and sequence modeling严格绑定在单个标准attention layer中的方法,是一种更具适应性的框架。对于
MTGR/OneTrans,它在一个CrossAttention操作中同时建模sequence modeling和feature interaction。而Hyformer,Query Boosting建模feature interaction,而Query Decoding建模sequence modeling。
消融研究:
Table 2展示了HyFormer性能提升主要贡献因素的消融实验结果。首先,我们对
query的组成部分进行消融。HyFormer的query由三个来源生成:global non-sequential features、multiple sequences pooling tokens和original target features。实验表明:将
query恢复为仅包含原始的target-feature-only state,会严重限制后续的deep feature interaction,导致AUC下降0.08%。从
full query中移除cross-sequence pooling tokens,也会使AUC损失0.05%,证明inter-sequence interaction在HyFormer的结构中能产生有意义的性能增益。
其次,我们评估整体架构变更的影响。
恢复基线架构(
LONGER + RankMixer,即先sequential modeling再独立的feature interaction)后发现,即使增强了query information,由于缺乏deepened interaction,性能提升也受到限制,仅实现了0.03%的AUC提升(-0.14% vs -0.17%)。相比之下,在专为
strengthen interaction设计的HyFormer框架中,扩展query information能带来显著的0.08%的AUC提升。
第三,我们在
HyFormer中对multi-sequence modeling策略进行消融实验。处理multiple sequences主要有两种范式:通过维度对齐和拼接,从而将多个序列合并为一个整体并进行联合建模。
保持多个序列分离并独立建模。
HyFormer采用后一种方式,为每个序列分配独立的query tokens。实验发现,sequence merging and query sharing的方式会导致AUC显著下降0.06%。这一结果体现了HyFormer在expanding queries and enabling broader feature interaction方面的优势;此外,sequence merging会迫使多个序列共享global tokens,忽略了序列的独特性,generated representations所捕获的差异化信息远少于HyFormer的针对序列的separate modeling的方式。我们推测,sequence merging的这种固有局限性,也是MTGR和OneTrans等模型性能不如HyFormer的部分原因。
综上,
HyFormer架构通过为不同序列分配独立的tokens,构建了一个通用的multi-sequence modeling框架,无需对不同序列的side information或sparse dimensions进行强制对齐。该设计不仅在很大程度上保留了序列之间的固有差异,还能为更重要的序列自适应地分配更多global tokens,这一点在我们的离线实验中已取得了可量化的性能增益。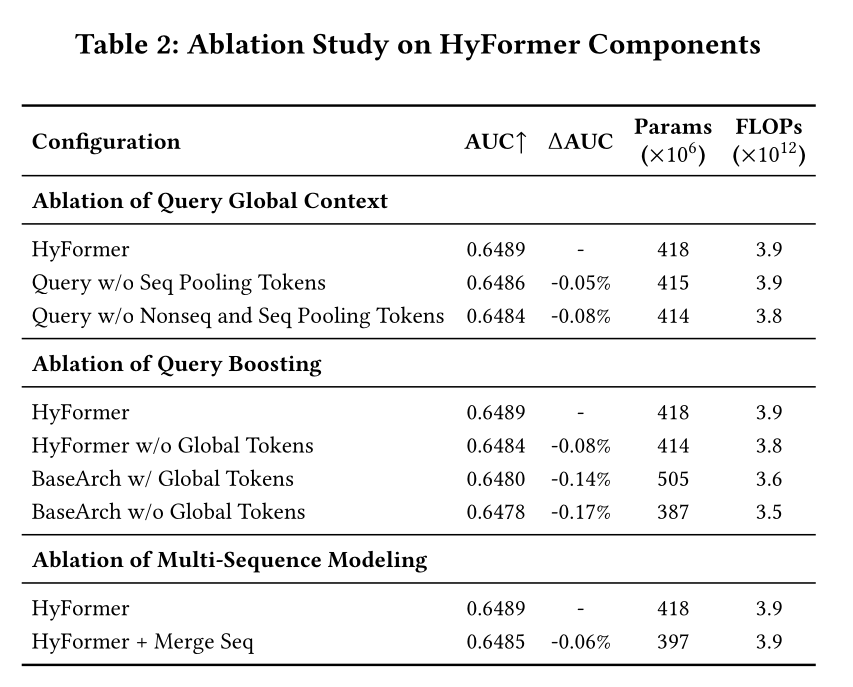
1.3.2 Scaling Analysis
本节分析模型性能随
sequence side information、FLOPs和参数数量变化的scaling特性。如Table 1的整体性能所示,在first performing sequential modeling and then performing heterogeneous feature interaction的范式下,LONGER + RankMixer取得了最优性能,也是当前的production baseline模型。因此,我们将其作为scaling实验中的对照组(BaseArch),对比HyFormer架构的scaling性能。Parameters & FLOPs:我们在
200M至1B+参数的模型规模范围内,验证了HyFormer架构的scaling law,结果如Figure 3(a)所示。可以看到,HyFormer不仅在初始阶段性能优于基线模型LONGER + RankMixer,且整体保持了强劲的scaling增益,其性能曲线的斜率比基线模型更陡峭。这表明,HyFormer中LONGER和RankMixer的alternating stacked layers实现了信息的双向流动,使其在相似的参数规模下,能从increasing depth中获得比基线模型显著更多的性能增益。从计算成本(
FLOPs)的角度分析scaling law时,也能观察到类似的规律。如Figure 3(b)所示,AUC随FLOPs的增加稳步提升,呈现出明显的power-law趋势。这表明,增加计算资源能使模型处理具备更丰富信息的序列,得益于initial query的扩展,以及通过MLP-Mixer的feature interaction对query进行的反复增强,最终实现了更显著的AUC提升。
这些结果表明,
HyFormer的架构设计优先考虑了scaling效率,通过丰富的heterogeneous feature interactions,使每个参数能产生更大的性能增益,从而形成了更陡峭的性能缩放曲线。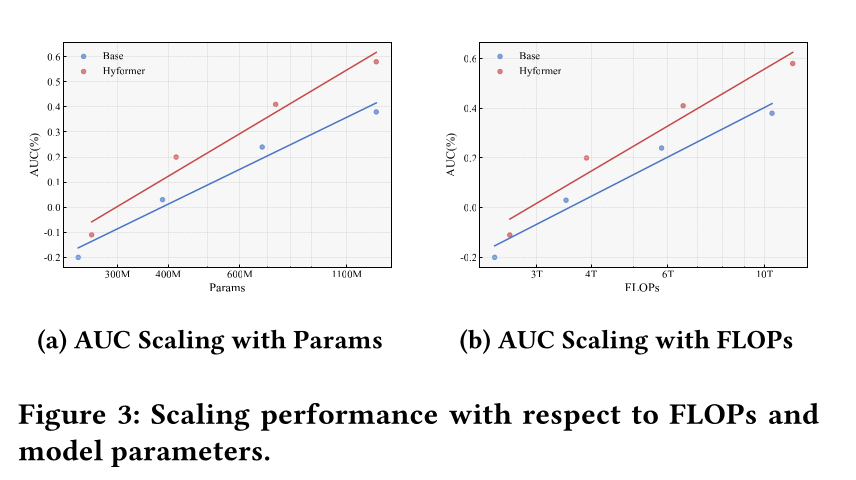
Sparse Dim:我们还分析了模型性能随sequence token input dimension(sparse embedding dim)—— 即sequence side information丰富度 —— 扩展的变化规律。实验表明,无论序列长度如何,丰富sequence side information为HyFormer框架带来的性能增益,始终大于基线框架LONGER + RankMixer。如
Table 3所示,对于长度为1000的序列,将sparse dimension从原始的64维(包含item ID, search query textnet classification, and timestamp等3种side information types)扩展至224维(新增search query ID, author ID, event ID, and playtime,一共共7种side information types),基线模型的AUC提升了0.09%,而HyFormer的AUC提升了0.12%。HyFormer的性能提升幅度显著更大,这一趋势在实验中的其他序列长度下均保持一致。此外,随着序列长度的增加,
HyFormer与传统两阶段模型之间的性能差距逐渐扩大,dimension expansion带来的额外增益从1000序列长度时的0.03%,增加至3000序列长度时的0.06%。这些结果表明,扩展
sequence key/value information能为HyFormer框架带来更大的价值,且这一优势随序列长度的增加而更加显著。该优势源于HyFormer能将更丰富的global information整合到sequence queries中,同时其LONGER模块和Mixer模块之间的信息双向流动,共同实现了更充分的feature interaction。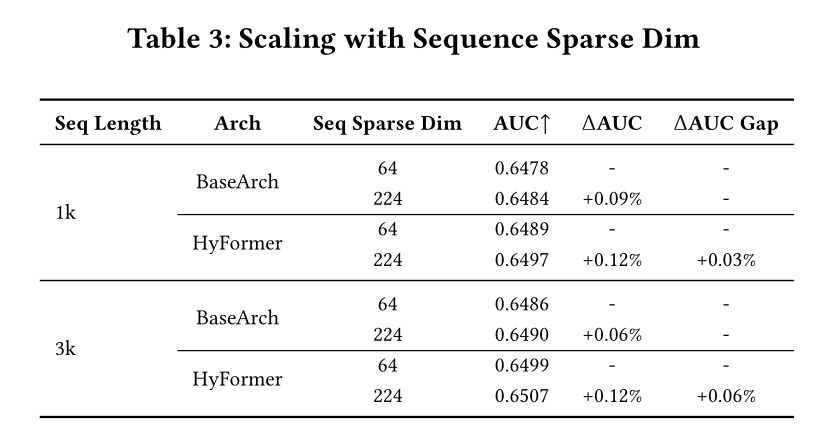
1.3.3 Online A/B Tests
本节展示
HyFormer模型在Douyin Search平台的online A/B test结果,对照组为性能强劲的现有RankMixer基线模型。在线评估采用三个核心指标:人均平均观看时长(Average Watch Time Per User)、人均视频完播数(Video Finish Play Count Per User)和Query Change Rate。其中,Query Change Rate用于量化用户手动将一个search query细化为更具体search query的概率(例如从"iPhone"修改为"iPhone 17 Pro"),计算方式如下:其中:
query reformulation的distinct user-query pairs数量,distinct user-query pairs总数量。该指标可作为用户搜索体验不佳的衡量标准。如
Table 4所示,online A/B Test验证了HyFormer在核心指标上的显著提升:人均平均观看时长提升0.293%,人均视频完播数提升1.111%,query change rate下降0.236%。这些显著的增益证明了HyFormer在十亿级用户的实际平台环境中的实用价值和有效性。
1.4 结论
本文提出了
HyFormer架构。与主流的信息单向流动的"Long Sequence Modeling, Then Feature Interaction"范式不同,HyFormer引入Global Tokens,通过feature interaction来增强query capacity,重新定义了long-sequence modeling and feature interaction的角色。该架构在两个核心组件间交替执行:Query Decoding和Query Boosting。从sequential modeling的角度来看,这对应于一个iterative optimization过程 —— 先用Global Tokens解码long sequences,再通过cross-feature interaction来增强Global Tokens。该设计为更充分的
sequence modeling and feature interaction提供了一种新颖且有效的框架,同时也为multi-sequence modeling提供了灵活的范式。大量的离线和在线实验验证了,从信息单向流动升级为双向的、协同演化的范式具有优越性,同时也为未来工业级LRMs提升了scaling上限。