一、MixFormer [2026]
《MixFormer: Co-Scaling Up Dense and Sequence in Industrial Recommenders》
随着工业推荐系统进入
scaling驱动的发展阶段,Transformer架构因其向更大容量和更长序列的scaling models的能力而愈发具有吸引力。然而,现有基于Transformer的推荐模型在结构上仍然存在割裂——sequence modeling与feature interaction被实现为独立的模块,且各自拥有独立的参数化方案。这种设计引入了一个根本性的co-scaling挑战:在有限的计算资源预算下,模型容量必须在dense feature interaction与sequence modeling之间进行次优的分配。本文提出MixFormer,一种专为推荐系统定制的统一的Transformer风格的架构,能够在单一骨干网络内联合建模sequential behaviors与feature interaction。通过统一的参数化方式,MixFormer能够在dense capacity和sequence length两个维度上实现有效的co-scaling,从而缓解了decoupled designs中观察到的trade-off问题。此外,这种一体化架构促进了sequential representations与non-sequential representations之间的深层交互,使得高阶特征语义(high-order feature semantics)能够直接参与sequence aggregation过程,进而增强整体表达能力。为确保工业实用性,我们进一步引入了一种user-item decoupling策略进行效率优化,显著降低了冗余计算和推理延迟。在大规模工业数据集上的广泛实验表明,MixFormer持续展现出优越的准确性与效率。此外,在两个生产级推荐系统——Douyin和Douyin Lite——上进行的大规模在线A/B test显示,user engagement指标(包括active days和in-app usage duration)均获得了一致的提升。Transformer架构已成为现代工业推荐系统中基础性的建模范式。凭借其强大的表征能力和高度的并行性,Transformer在大规模user behavior modeling和复杂feature interaction learning方面尤为有效。与此同时,推荐系统已进入一个规模化驱动(scaling-driven)的发展阶段,在此阶段,性能提升越来越依赖于扩展数据量和模型容量,而非依赖于手工设计的特征或针对特定任务的启发式方法。在这种发展态势下,模型架构不再是次要的设计选择(design choice),而是主要决定因素:它决定了额外计算资源能够多高效地转化为可衡量的性能提升。目前,
Transformer在推荐系统中的应用主要沿着两个互补但又相对独立的方向展开。一个研究方向聚焦于
sequence modeling,利用Transformer捕获user behavior sequences中的长程时序依赖关系(long-range temporal dependencies)。另一个研究方向则强调高阶
feature interaction,采用Transformer风格的架构对heterogeneous dense features之间的复杂关系进行建模。
尽管这两个方向各自都展现了强大的实证收益和良好的
scaling趋势,但它们隐含地假设了sequence modeling和feature interaction可以孤立地进行优化。随着推荐系统向更长的用户历史、更丰富的特征空间和更大的模型容量不断scale,这一假设正变得愈发脆弱。从系统级视角来看,在有限的计算预算下联合地
scalingsequence modeling和dense feature interaction,会暴露出一项根本性的架构压力。sequential Transformer的计算成本随着序列长度的增加而迅速增长,而dense Transformer的规模则主要随特征维度和模型宽度变化。当这两个组件各自独立进行参数化和优化时,它们会竞争共享的计算预算和参数预算,从而导致相互冲突的scaling激励(scaling incentives)。将更多容量分配给
sequence组件可以改善时序建模(temporal modeling)能力,但会不成比例地增加计算成本,从而实质上抑制了dense feature interaction的scaling潜力。反之,优先
scalingdense部分则会限制模型利用long-range behavioral signals的能力。
因此,在强制参数分离的架构下,实现
sequence组件与dense组件全局最优的co-scaling,在结构上变得难以协调。现有的大多数方法通过层次堆叠(
hierarchical stacking)或并行拼接(parallel concatenation)的方式,将一个sequence Transformer和一个dense Transformer组合起来应对这一挑战。在
hierarchical stacking中,sequence Transformer的output被视为dense Transformer的一个input feature。而
parallel concatenation是将两个组件直接拼接。
尽管这些范式设计的简洁性,但它们保留了
sequence parameters与non-sequence parameters之间的严格分离,导致跨组件交互受限且优化过程割裂。更重要的是,这种分离从根本上制约了co-scaling行为:sequence module迅速增长的计算开销主导了资源分配决策,阻碍了dense component按比例scaling,从而导致在现实部署约束下的全局性能次优。在本文中,我们认为,在大规模推荐系统中实现有效的
co-scaling,需要一种根本不同的架构原则:sequence modeling与feature interaction必须在单一参数空间内统一,并在整个网络中进行联合优化。为此,我们提出MixFormer——一种完全统一的Transformer风格的大型推荐模型,它采用一组共享的参数来同时对sequence和dense feature interaction进行建模。通过消除严格的参数边界,MixFormer使得sequential and non-sequential co-modeling能够相互增强,允许高阶feature semantics直接参与sequential aggregation,同时保留细粒度的behavioral signals。这种统一的参数化方式从根本上解决了parameter allocation的困境,并为co-scaling奠定了连贯一致的基础。此外,为使
unified scaling在工业环境中切实可行,我们引入了一种user-item decoupling策略,利用request-level batching技术来复用计算结果,从而显著提升计算效率。该机制是在有限资源预算下scaling unified Transformer architectures的关键因素,有效地提升了可在生产系统中部署的模型容量和序列长度的上限。综上所述,本文的贡献包含以下三个方面:
我们提出
MixFormer,一种用于推荐系统的完全统一的Transformer架构,它在单一参数空间内联合建模sequence dynamics和dense feature interaction,解决了现有混合设计的结构局限性,并实现了有效的global co-scaling。我们引入了一种
user-item decoupling策略,用于request-level computation sharing and reduction,使得unified Transformer scaling在大规模工业环境中成为可能。在大规模工业数据集上的广泛实验表明,
MixFormer实现了更优的准确性和效率,并且在增加模型容量和序列长度时展现出更有利的co-scaling behavior。
1.1 相关工作
sequence modeling:对user behavior sequences进行建模是推荐系统中的一个基础性问题,因为它能够捕获用户的动态且不断演变的兴趣。早期且具代表性的方法侧重于使用
target-attention-based的架构来建模用户近期的行为,包括DIN(《Deep Interest Network for Click-Through Rate Prediction》)、DIEN(《Deep interest evolution network for click-through rate prediction》)和BST(《Behavior sequence transformer for e-commerce recommendation in Alibaba》)。这些方法通常通过关注近期有限窗口内的行为来强调用户的短期兴趣。然而,这样的短序列往往不足以充分刻画用户的长期偏好。为解决这一局限,
SIM(《Search-based User Interest Modeling with Lifelong Sequential Behavior Data for Click-Through Rate Prediction》)引入了面向extremely long sequence modeling的检索式范式。具体而言,SIM采用了一个两阶段框架,包括一个用于检索relevant historical behaviors的General Search Unit: GSU、以及一个用于对retrieved subsequence进行建模的Extract Search Unit: ESU。在此范式基础上,后续工作进一步对
SIM进行了优化,如实现端到端训练(《End-to-end user behavior retrieval in click-through rateprediction mode》)、采用基于BM25算法来增强检索策略(《Learning to Retrieve User Behaviors for Click-through Rate Estimation》),以及通过一致性保持(consistency-preserving)机制改进GSU模块(《TWIN: TWo-stage Interest Network for Lifelong User Behavior Modeling in CTR Prediction at Kuaishou》),等等。随着
GPU硬件和large-scale training基础设施的快速发展,近期研究重新审视了端到端的long sequence modeling。Longer(《LONGER: Scaling Up Long Sequence Modeling in Industrial Recommenders》)提出了一种hierarchical attention architecture,以降低长序列上self-attention机制的二次方复杂度。同时,GR(《Actions Speak Louder than Words: Trillion-Parameter Sequential Transducers for Generative Recommendations》)和MTGR(《MTGR: Industrial-Scale Generative Recommendation Framework in Meituan》)通过采用Transformer-decoder-style架构,将CTR prediction重新构建为生成式任务。
然而,现有的
sequence modeling方法主要集中于sequential signals本身,这可能导致query expressiveness能力不足以及细粒度behavioral information的丢失。feature interaction:feature interaction长期以来一直是推荐系统的核心研究课题,旨在通过组合heterogeneous input features来构建high-order representations。因子分解机(
Factorization Machines)(《Factorization Machines》)是最早显式地建模二阶feature interactions的方法之一。随后出现了大量扩展方法,利用神经网络探索
higher-order interactions和implicit cross features。然而,最近的研究表明,许多现有的神经交互模型(neural interaction models)难以有效扩展到工业级场景。为解决这一挑战,人们提出了WuKong(《Wukong: towards a scaling law for large-scale recommendation》)作为large-scale feature interaction backbone,展示了强大的scalability和表达能力。在此基础上,
RankMixer(《RankMixer: Scaling Up Ranking Models in Industrial Recommenders》)进一步引入了一种高效、Transformer风格的架构,专为大规模工业ranking系统设计。尽管取得了成功,但这些
feature interaction方法通常将sequential features视为compressed or static representations。因此,interaction模块所产生的高阶特征与sequence modeling过程脱节,限制了sequential representations的表达能力。工业推荐系常采用
hierarchical stacking或parallel combination范式来结合sequential modules和non-sequential modules。最近,OneTrans(《OneTrans: Unified Feature Interaction and Sequence Modeling with One Transformer in Industrial Recommender》)试图通过在Transformer backbone中使用designed attention masks和独立参数,将sequential features和non-sequential features建模为heterogeneous token sequence,从而统一两者。然而,平方复杂度引入了严重的计算开销,而分离的参数导致了dense capacity和sequence length的co-scaling挑战。
1.2 方法
MixFormer是专为多任务推荐系统设计的高效的decoder-only Transformer模型,由input layer、MixFormer blocks、以及若干task networks构成。input layer负责feature embedding与split:首先将user, item, and context features映射为embedding vector,再将该向量切分为heads。整体架构如Figure 1所示。核心思想:不停地
refinequery representation,然后采用cross-attention。但是有个缺点:在每一层,它都是使用原始的用户行为序列,可能没有很好地捕获序列之间的时序依赖性。因此,它重点聚焦于feature interaction modeling,即《InterFormer: Effective Heterogeneous Interaction Learning for Click-Through Rate Prediction》中提到的:sequence modeling -> feature interaction modeling的单向流动,不是最优的。整体思想类似于
《Make It Long, Keep It Fast: End-to-End 10k-Sequence Modeling at Billion Scale on Douyin》的single-query cross-attention model: STCA。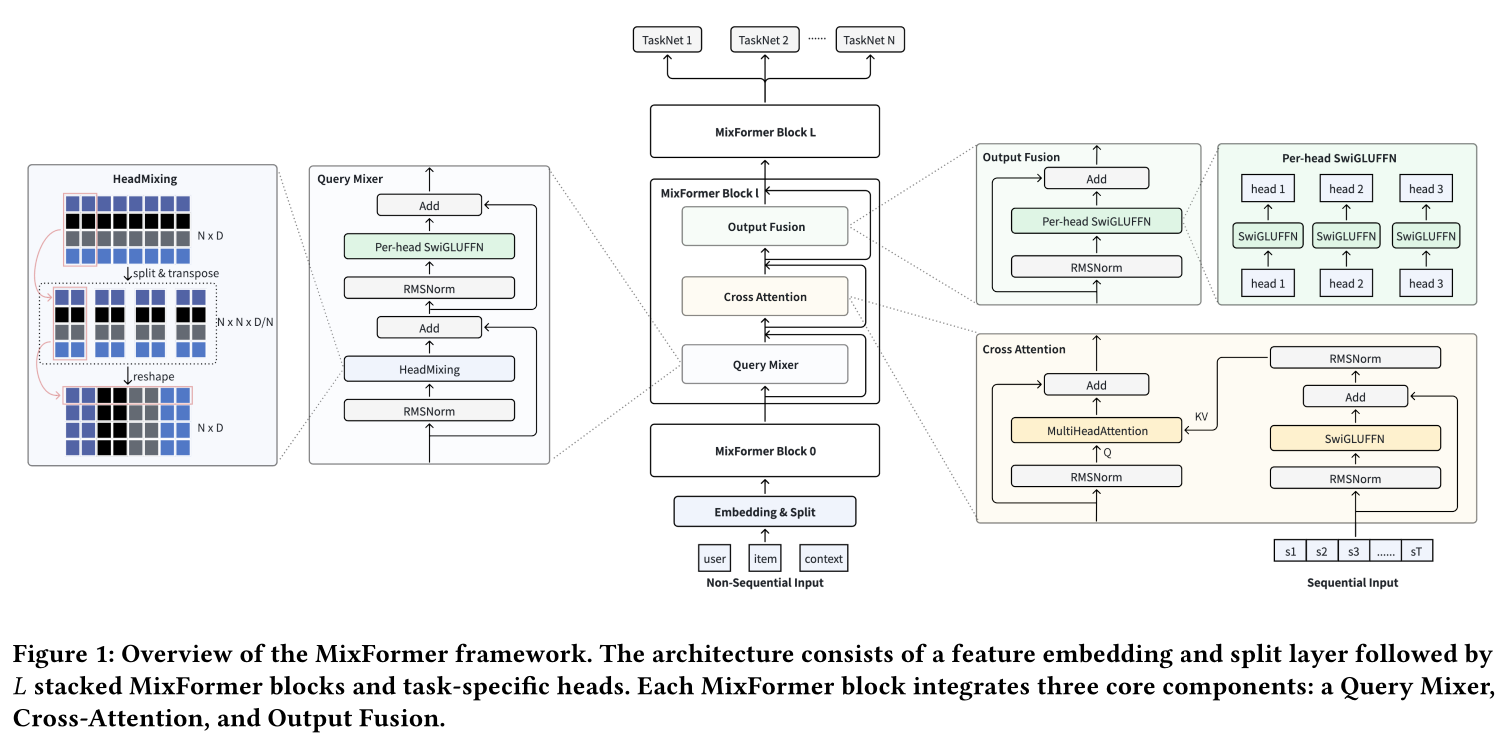
1.2.1 Feature Embedding and Splitting
Input features可划分为两类:sequential features与non-sequential features。sequential features表征用户的historical interaction sequence,由用户对items按时间顺序产生的actions构成。每个action均通过item id、action type、时间戳、以及部分可用的辅助信息进行刻画。针对time stepaction,我们采用专用的embedding layers对其各组成特征进行嵌入,并将resulting vectors进行拼接,形成action representationuser behavior sequence可表示为:该序列作为模型的
sequential input。non-sequential features包含user features、item features与contextual features。令non-sequential features的集合。每个特征feature-specific embedding table映射为dense embedding vectorembeddings拼接为单个复合表征(composite representation):其中:
non-sequential features的总的embedding维度。non-sequential features随后作为整个backbone的query input。
在标准
Transformer decoder中,attention模块(self-attention或cross-attention)被拓展为multi-head形式,即:将query向量划分至多个子空间。为实现Transformer架构内的统一建模,我们进一步将feature heads。具体而言,我们将其中:
non-sequential feature head。最终得到的矩阵
MixFormer模块的non-sequential input head。与将所有特征压缩为单个
head相比,将embedding空间划分为多个heads能够保留representation的多样性,使模型在不引入过多结构复杂度的前提下捕获heterogeneous feature semantics。此外,下文将介绍的MixFormer模块中的三个核心模块(Query Mixer、Cross Attention、Output Fusion)均采用multi-head设计。因此,non-sequential feature multi-head设计为下游模块提供了灵活且计算高效的接口,使高阶feature interactions能在后续阶段与sequence modeling无缝融合。
1.2.2 MixFormer Block
MixFormer采用与Transformer decoder结构一致的Transformer风格的架构。每个MixFormer模块包含三个核心组件:Query Mixer、Cross Attention与Output Fusion,这三者在设计思想上分别对应标准Transformer decoder block中的Self-Attention、Cross-Attention与Feed-Forward Network: FFN。该设计在保留Transformer-based架构表达能力的同时,针对大规模工业推荐系统进行了customized operations的适配。Query Mixer:self-attention在大语言模型中效果显著,在这类模型中所有tokens均被嵌入到统一的语义空间,且token-to-token similarity可通过内积运算可靠建模。然而受RankMixer(《Scaling Up Ranking Models in Industrial Recommenders》)启发,在推荐场景中query来源于高度异构的feature fields,包括user attributes、item attributes以及contextual signals。这些特征源自不同的语义空间,且通常对应规模极大、高度稀疏的ID domains。在这种异构性下,通过inner-product similarity计算attention weights本身就缺乏可靠性,因为很难在不同特征空间之间建立有意义的alignment。因此,self-attention不仅无法持续提升建模效果,还会引入巨大计算开销。为此,我们受前人工作 (
《MLP-mixer: an all-MLP architecture for vision》、《Scaling Up Ranking Models in Industrial Recommenders》)启发,采用轻量且硬件友好的Query Mixer模块替代self-attention。与multi-head self-attention模块类似,Query Mixer可实现cross-head之间的信息交互,却无需依赖similarity-based attention,使其更适合在严格的效率约束下对异构特征进行建模。形式上,给定
input queryQuery Mixer定义为:其中:
reshape为Figure 1所示。该操作能够以无参数的方式实现高效的cross-head信息交换。Normalization操作。在
Transformer中,通常采用轻量级的RMSNorm。这个定义拷贝自
TokenMixer-Large的论文。
值得注意的是,
FFN针对每个head独立地实例化,以显式地考虑特征的异质性,这被命名为per-head FFN。在先前的工作(《RankMixer: Scaling Up Ranking Models in Industrial Recommenders》)中,该设计已被证明在保持良好效率的同时具备强大的表达能力。Cross Attention:尽管similarity-based self-attention在建模异构non-sequential features时并非最优选择,但它仍然是将structured query representations与sequential behavioral signals对齐的有效机制。在MixFormer中,Cross Attention模块被设计用于在Query Mixer所生成的高阶feature representations的指导下聚合user sequences。具体而言,Query Mixer的output heads被直接用作cross attention的heads,其中每个head作为一个语义上专门化的sub-query,聚焦于non-sequential features的不同子空间。这种设计使得用户偏好的不同方面能够以解耦但又协调的方式关注behavioral sequences,避免了为query splitting引入额外的投影矩阵,并降低了head collapse的风险。我们首先将
behavioral sequence中的每个action变换为一个隐向量query input对齐,该变换通过一个per-layer SwiGLU-activated FFN完成,随后将其投影为key和value:其中:
MixFormer block中的SwiGLUFFN。head对应的key投影矩阵和value投影矩阵。
与
Transformer decoder中依赖shared hiddens的标准cross-attention机制不同,这些per-layer SwiGLUFFN在每一层独立地参数化,使模型能够随深度逐步提炼(refine)sequence representations。“与
Transformer decoder中依赖shared hiddens的标准cross-attention机制不同”,不知道作者这句话什么意思。实际上Transformer中,层与层之间的参数是独立的,并不是共享的。第
query head的输出计算如下:所得的
representationssummaries of the user sequence,并作为aggregated sequential outputs从而用于后续的fusion。Output Fusion:在从Query Mixer获得高阶non-sequential representations,并从Cross Attention模块获得feature-conditioned sequential aggregations之后,Output Fusion layer对这些信号执行深度集成,以产生final representations。具体而言,每个
cross-attention outputnon-sequential information,也包含与相应high-order query head对齐的sequential information。然而,由于query head的异质性以及previous modules中引入的残差连接,a shared feed-forward transformation不足以充分捕获head-specific interactions。因此,我们采用
a per-head SwiGLU-activated Feed-Forward Network来独立地进一步细化每个representation。形式上,Output Fusion定义为:其中:
head-specific SwiGLUFFN。这种设计使得
MixFormer能够在显式考虑特征异质性(feature heterogeneity)的同时,对sequential signals与non-sequential signals执行深度的非线性融合。通过对每个head应用独立的变换,模型保留了head-level specialization,并避免了heterogeneous feature subspaces之间的表征干扰(representational interference),从而得到更具表达力和更稳定的representations。该output随后作为下一个MixFormer block的input,实现了渐进式的统一feature interaction and sequence modeling。值得注意的是,
Output Fusion和Query Mixer中的per-head FFNs同时服务于sequential features和non-sequential features,形成了一种统一的参数化范式,解决了在组合两个独立模块时参数分配的难题。
1.2.3 User-Item Decoupling
Request Level Batching: RLB已成为提升推荐系统训练与推理效率的有效范式,它通过在单次request内对多个targets共享用户侧计算,从而实现计算成本的大幅削减。然而,original unified MixFormer中mixed user-item computations限制了RLB的应用。为解决此问题,我们提出了User-Item decoupled MixFormer变体,即UI-MixFormer,如Figure 2所示。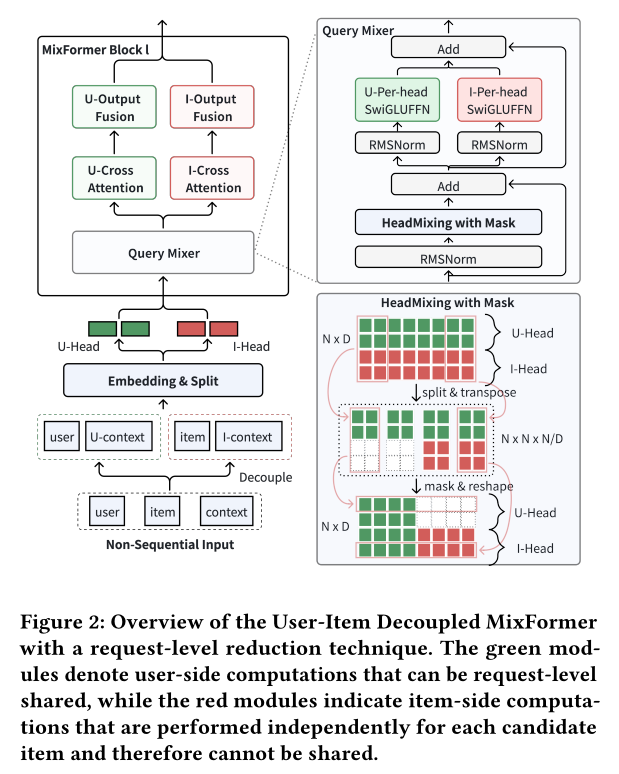
Feature Decoupling:我们将non-sequential features划分为不相交的用user-side子集和item-side子集,分别将它们投影到heads中,作为MixFormer的输入。为保持模型容量,total head number保持不变,embedding维度计算:其中:
item-side non-sequential features的embedding维度。实践中,1:1。Query Mixer with Mask:由于HeadMixing操作跨越distinct heads进行,其output不再保持纯粹的user-side representation,这使得通过RLB进行加速变得不可行。受Self-Attention中causal masks的启发,我们为Mixformer中的单向的user-to-item fusion设计了一个mask。如Figure 2所示,为确保user-side heads能够在单次request内被复用,我们使用一个掩码矩阵user side heads中的item-side signals,该矩阵定义为:最后,将掩码矩阵
the output of original HeadMixing operation进行逐元素乘法,即可得到一个user-item decoupled HeadMixing module,从而得到一个具有显式user-item decoupling特性的query mixer:与双塔架构相比,所提方法保留了从
user side到item side的信息传播,从而确保了user-item feature interaction的有效建模。值得注意的是,
user historical behaviors的sequential features同样适用于request-level sharing。因此,user-side heads and sequences之间cross-attention computation所产生的计算开销可以被大幅削减。这一观察进一步凸显了将sequence modeling和feature interaction整合到a unified backbone中的统一建模范式的优点。
1.3 实验
数据集:我们在从
Douyin推荐系统收集的大规模离线数据集上进行实验。该数据集涵盖连续两周的时间跨度,包含数万亿条user-item interaction记录。每条样本关联超过300个特征,这些特征可大致分为non-sequential features和sequential features。non-sequential features包括源自user profiles、item attributes和上下文信息的categorical, numerical, and cross features。sequential features对应用户的历史行为,其中每个action由item id、action type、时间戳和side attributes表示。
评估指标:我们从准确性和效率两个角度评估模型性能。
对于准确性评估,我们将任务建模为
CTR Prediction任务。我们采用AUC和user-level AUC: UAUC作为主要评估指标,因为它们广泛用于工业推荐系统中以评估排序质量和user-level一致性。对于效率评估,我们报告模型参数量和
FLOPs,它们作为计算复杂度的代理指标,能够反映模型在真实系统中的scalability和部署成本。
Baselines:我们将MixFormer与两类SOTA的基线模型进行比较。1) Stacked methods:此类方法首先将sequential features聚合成一个紧凑的representation,然后将其馈入专门的feature interaction模块。对于
sequence modeling,我们采用了多种变体,包括简单的target attention: TA和SOTA的Stacked Target Cross Attention: STCA架构(《Keep It Fast: End-to-End 10k-Sequence Modeling at Billion Scale on Douyin》)。对于
feature interaction,我们考虑了几种代表性方法,包括DLRM(原始MLP)、DCNv2(《DCN V2: Improved Deep & Cross Network and Practical Lessons for Web-scale Learning to Rank Systems》)、Wukong(《Wukong: towards a scaling law for large-scale recommendation》)、DHEN(《DHEN: A Deep and Hierarchical Ensemble Network for Large-Scale Click-Through Rate Prediction》)和RankMixer(《RankMixer: Scaling Up Ranking Models in Industrial Recommenders》)。
"A --> B"表示将A模块的输出作为B模块的输入。2) Parallel methods:此类方法将non-sequential module和sequential module并行拼接,其中两个模块的参数相互独立。我们选择RankMixer⊕ STCA和OneTrans(《OneTrans: Unified Feature Interaction and Sequence Modeling with One Transformer in Industrial Recommender》)作为此类别的代表性基线。"A⊕B"表示将A模块的输出和B模块的输出拼接后馈入task networks。对于
MixFormer,我们进行了两种规模的实验,分别记为MixFormer-small和MixFormer-medium。
实现细节:
所有实验均在数百个
GPU上采用hybrid distributed training framework进行,其中sparse part异步更新,dense part同步更新。optimizer hyperparameters在所有模型中保持一致。对于dense part,我们使用学习率为0.01的RMSProp optimizer;对于sparse part,使用Adagrad optimizer。所有实验的
batch size均设为1500。MixFormer-small的超参数设置为MixFormer-medium设置为
与
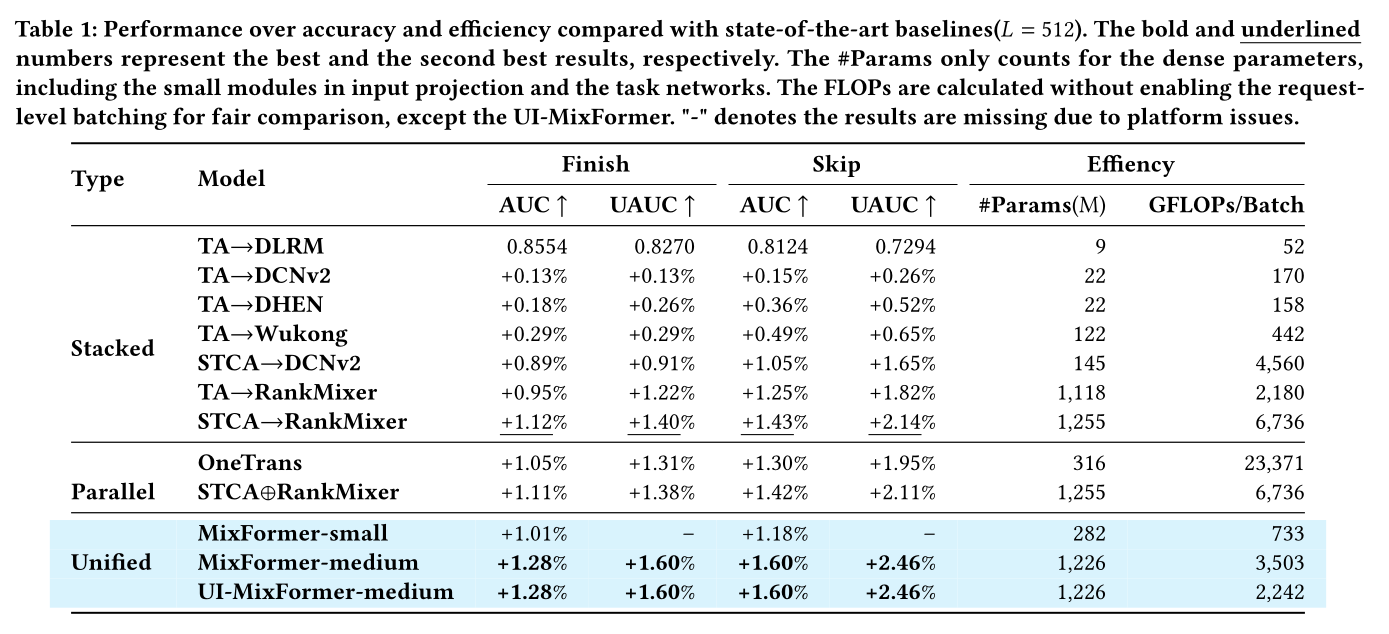
baselines的对比:为证明所提统一模型在准确性和效率方面的性能,我们将MixFormer与SOTA的方法进行比较,包括hierarchical stacked methods和两种代表性方法。结果如Table 1所示,从中我们得出以下结论:SOTA的sequence modeling和feature interaction方法,如STCA和RankMixer,始终以明显优势优于其他架构(包括TA、DCN和Wukong)。这一结果实证验证了Transformer-style架构在capturing complex dependencies和modeling large-scale user behavior patterns方面的有效性,凸显了其在工业推荐系统中的优势。在
comparable sub-structure configurations下,堆叠式设计范式和并行式设计范式仅表现出微小的性能差异。这一观察表明,当两个组件分别参数化时,sequence modeling和feature interaction之间的交互仍然相对较浅。因此,仅仅修改连接模式不足以产生显著的性能提升,表明需要更深度地整合两个模块,以充分发挥其互补优势。得益于统一的架构,所提的
MixFormer持续优于所有基线方法。提升主要来源于feature interaction组件和sequence modeling组件之间的参数共享,这促进了enhanced cross-module representation learning。值得注意的是,在与最强基线STCA + RankMixer相当的参数预算下,MixFormer在两个任务上均实现了显著的AUC提升。此外,采用User–Item Decoupling的效率优化的变体大幅降低了计算开销,实现了约36%的FLOPs减少,同时保持了几乎相同的性能。
Ablation Study:为验证MixFormer中所提出的每个模块的有效性,我们通过替换或删除某些设计进行了一系列实验,具体如下:[QM] wo HM:删除Query Mixer中的HeadMixing。[QM] HM --> SA:将Query Mixer中的HeadMixing替换为SelfAttention模块。[QM] wo FFN:删除Query Mixer中的per-head FFN。[CA] PL-FFN --> FFN:将CrossAttention中action projection的per-layer FFN替换为a shared FFN。[OF] PFFN --> FFN:将Output Fusion中的per-head SwiGLUFFN替换为a head-shared SwiGLUFFN。Pre-RN --> Post-LN:将每个block中的pre-RMSNorm替换为post-LayerNorm。Pre-RN替换为Post-LN,仅仅带来万分之一的auc loss。
消融结果如
Figure 3所示。结果表明,
Query Mixer中的HeadMixing和per-head FFN对性能提升贡献显著,这凸显了在构建用于sequence modeling的queries时,high-order feature representations的重要性。值得注意的是,将
HeadMixing替换为计算成本更高的self-attention并未带来可观的性能增益,这实证验证了在处理推荐系统中heterogeneous heads时,零成本的HeadMixing的效率与有效性。此外,结果表明,在
cross-attention blocks内,使用per-layer FFNs能够在various layers产生更具区分度的representations,在不增加计算成本的前提下提升模型表达能力。在输出端,将
standard FFN升级为per-head FFN进一步增强了模型在heterogeneous heads上的表达能力,且未增加FLOPs,带来了明显的性能提升。
总体而言,这些结果表明,为推荐系统量身定制的这些
refinements在有效性和效率两方面均取得了良好的提升。注意,下图中第一行、第二行的
TM实际上是HM。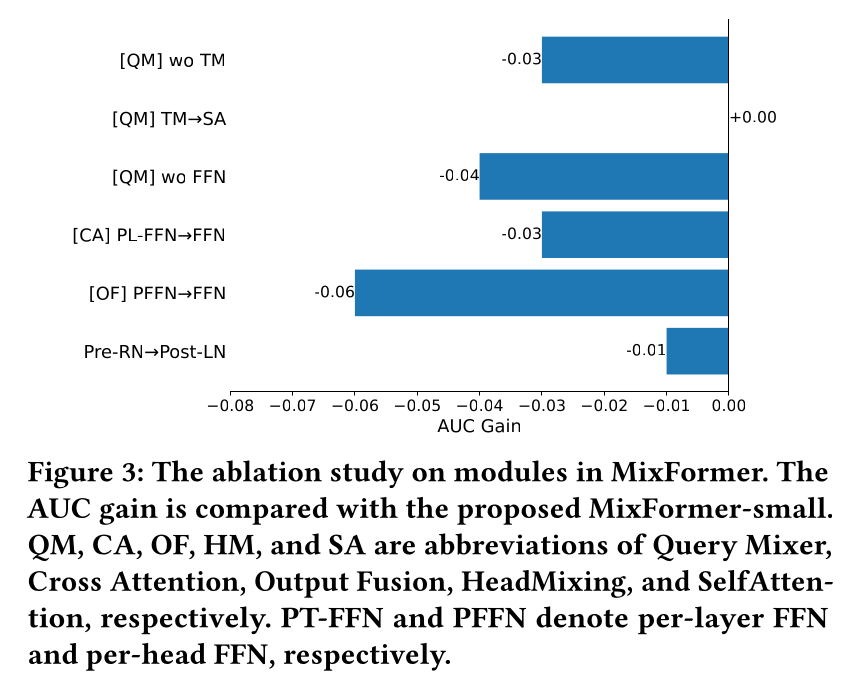
Scaling Analysis:为评估所提模型的co-scaling能力,我们通过在fixed inputs(即,固定序列长度)下scaling dense parameters,以及在fixed model size下增加序列长度,来评估其性能。Scaling of Dense:由于sequence modeling的计算成本对sequence length高度敏感,仅基于参数量来比较dense scaling behavior对于non-sequential models是不公平的。实践中,serving成本主要由FLOPs决定;因此,Figure 4报告了AUC gain随FLOPs变化的函数关系。我们比较了一个SOTA的序列模型STCA(带轻量级DCNv2 head)、一个non-sequential RankMixer模型(带单层Target Attention)、以及它们按1:1 FLOPs比例的组合。在固定序列长度的设置下,
scaling RankMixer比scaling the sequential component带来更大的边际AUC gains,这突显了在序列长度固定时target-item feature interaction的重要性。combined baseline模型在两者之间呈现出明显的trade-off。相比之下,
MixFormer得益于其统一的参数化方式以及sequential components与non-sequential components之间的深度交互,实现了更大的截距和具有竞争力的scaling斜率。因此,MixFormer在不同的FLOPs预算下均持续优于其他设计。
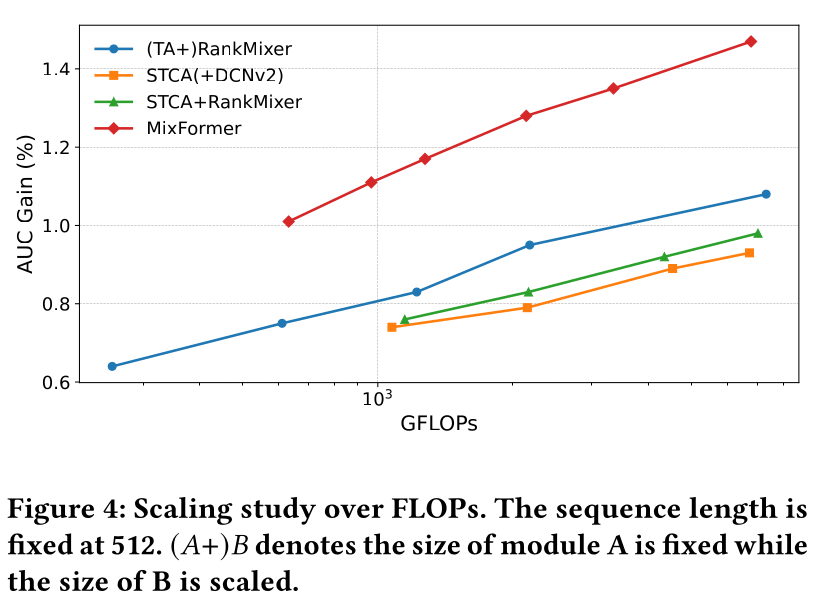
Scaling of Sequence:从另一角度,我们考察了在固定dense parameter budget下,不同方法的sequence-length scaling behavior。为公平起见,我们选取了在序列长度为512时FLOPs相当的若干模型配置(在Figure 4中以圆圈突出显示)。随后,我们遵循《Keep It Fast: End-to-End 10k-Sequence Modeling at Billion Scale on Douyin》的方法,将输入序列长度扩展至{512, 2,048, 8,192, 10,000}进行behavior sequences评估。结果如Figure 5所示。有趣的是,序列长度的
scaling趋势与dense scaling呈现出相反的模式。为序列组件分配更多计算的sequential models(如STCA),比non-sequential models从更长序列中获益更多,这与《Keep It Fast: End-to-End 10k-Sequence Modeling at Billion Scale on Douyin》中的观察结果一致。值得注意的是,
MixFormer受益于其在sequential components与non-sequential components上的统一参数化,实现了与SOTA的STCA相当的scaling斜率。
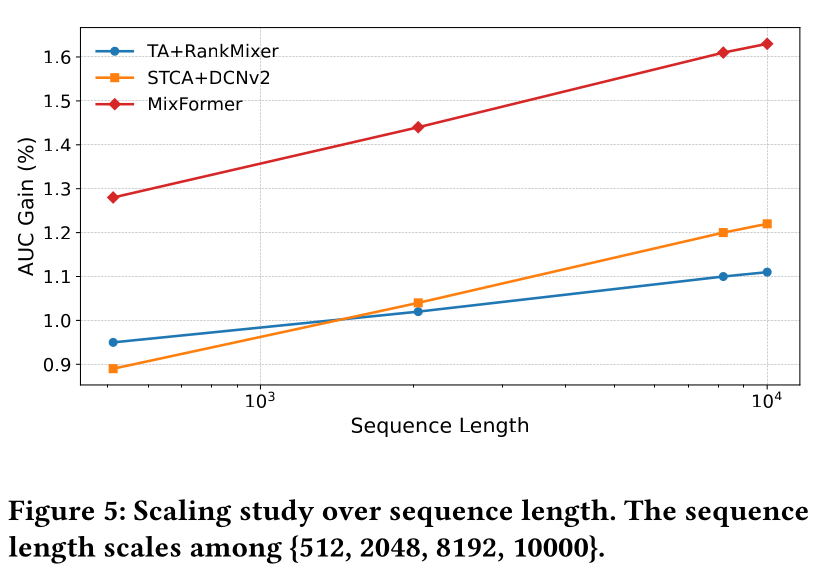
总体而言,我们观察到,具有独立参数化的
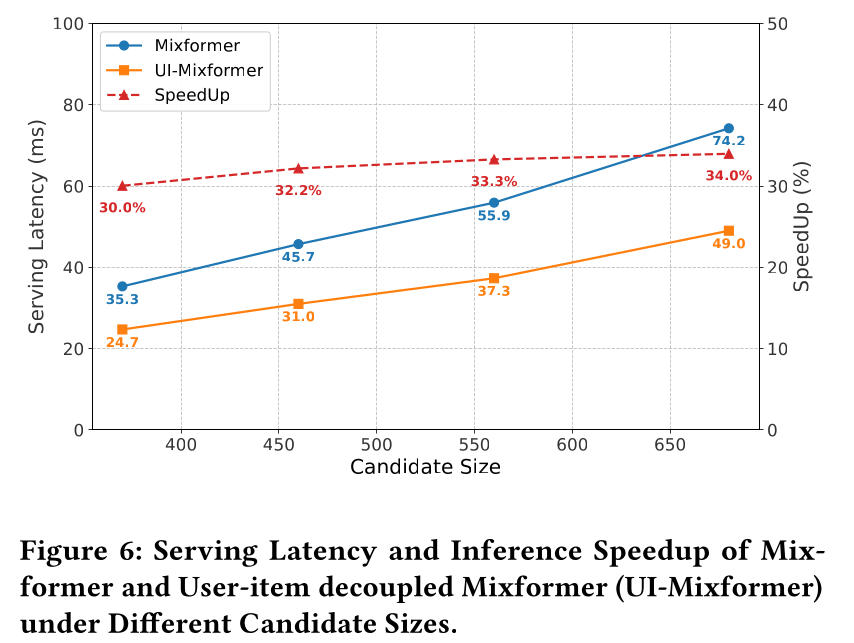
sequential and non-sequential components的模型面临着明显的co-scaling trade-off。在有限的计算预算下,此类模型必须谨慎地在non-sequential modules(FLOPs效率更高)与sequential modules(从sequence-length scaling中获益更多)之间分配容量。相比之下,凭借其一体化的参数设计,MixFormer在dense scaling和sequence scaling两方面均展现出SOTA的scaling行为,进一步验证了该架构的有效性。Serving Latency Anaysis:我们还进行了serving latency测试以验证user-item decoupling策略的效率。如Figure 6所示:当与
Request Level Batching结合使用时,user-item decoupled MixFormer实现了超过30%的serving speedup。此外,随着
ranking阶段待预测candidate items数量的增加,GPU利用率趋于饱和,这进一步加剧了计算瓶颈。幸运的是,我们的user-item decoupling设计能够在单次request内对多个candidate items共享user-side computation。这导致decoupled MixFormer的latency growth远低于原始模型,从而在large candidate sizes下提升了serving效率。
Online A/B Tests:为验证MixFormer作为co-scaling推荐模型框架的普适性,我们在personalised ranking的核心场景——两个Apps的feed recommendation——中进行了在线实验。对于Feed Recommendation,我们监测以下关键性能指标:Active Days:是实验期间每用户的平均活跃天数,可作为DAU增长的替代指标。Duration:衡量App内累计停留时间。Finish/Like/Comment:用户的完整播放次数、点赞数和评论数。
我们与先前基线模型——参数量超过
1 Billion的stacked STCA --> RankMixer——进行了在线A/B测试对比实验。在Feed Recommendation上为期两周的A/B测试结果观察如Table 2所示,且提升幅度仍在持续增长,表明收益尚未达到饱和。
1.4 结论
本文提出了一种专为推荐系统设计的新型
Transformer-style的统一架构。所提模型将现代推荐系统的两个核心组成部分——sequence modeling和feature interaction——整合到一个单一的、统一的参数化框架中,实现了高效且易于co-scalable的设计。此外,我们引入了实质性的user-item decoupling优化,显式地利用request-level computation reduction来提高计算效率。大量实验表明,与强基线模型相比,所提架构持续实现了更优的有效性和效率。我们进一步分析了模型在
FLOPs和序列长度上的scaling效应,并在工业环境中进行了大规模在线A/B测试,为模型在真实推荐系统中的co-scaling潜力和实际有效性提供了有力证据。