一、SSRNet [2026]
《Beyond Dense Connectivity: Explicit Sparsity for Scalable Recommendation》
最近在
scaling large models方面的进展促使推荐系统增加模型深度和模型容量,以更好地利用海量的behavioral data。然而,推荐系统的inputs是高维的且极其稀疏的,简单地scaling dense backbones(例如,deep MLPs)往往会导致收益递减甚至性能下降。我们对工业级CTR模型的分析揭示了一种implicit connection sparsity的现象:大多数学到的connection weights趋向于零,而只有一小部分保持显著。这表明dense connectivity与sparse recommendation data之间存在结构性的不匹配;通过迫使模型处理大量low-utility connections而非valid signals,dense architecture本身成为了effective pattern modeling的主要瓶颈。我们提出了SSR(Explicit Sparsity for Scalable Recommendation),这是一个将sparsity显式地融入架构的框架。SSR采用了一种multi-view的"filter-then-fuse"机制,将inputs分解为多个并行的视图,从而进行dimension-level sparse filtering,随后进行dense fusion。具体来说,我们通过两种策略实现sparsity:Static Random Filter:通过fixed dimension subsets来实现高效的structural sparsity。Iterative Competitive Sparse: ICS:这是一种可微的动态机制,采用受生物学启发的竞争来自适应地保留high-response dimensions。
在三个公共数据集和来自全球电商平台
AliExpress的十亿级工业数据集上的实验表明,SSR在相似的预算下优于SOTA的基线模型。关键在于,SSR表现出卓越的scalability,在dense models达到饱和之处实现了持续的性能提升。代码可从https://github.com/Atticus666/SSRNet获取。深度学习推荐系统(
Deep learning recommender systems: DLRS)是许多online services的核心排序引擎。受大语言模型成功的启发,我们研究推荐模型是否表现出类似的scaling特性,即随着模型容量和数据规模共同增长,模型性能也随之提升。在实践中,主流的工业级CTR骨干网络,如Wide&Deep(《Wide & deep learning for recommender systems》)和DLRM(《Deep learning recommendation model for personalization and recommendation systems》),仍然相对较浅,通常只有3-4层。简单地scale up这些dense MLP-based的架构的尝试常常导致收益递减甚至性能下降,正如先前研究所报道的那样。这意味着对dense架构进行朴素的scaling并非最优选择。一个根本性问题在于:
dense connectivity与sparse recommendation data之间的不匹配。与具有自然的空间局部性或序列局部性的图像或文本不同,recommendation inputs由数百个heterogeneous feature fields组成,对于任何给定的样本,只有一小部分子集是相关的(《Search-based user interest modeling with lifelong sequential behavior data for click-through rate prediction》、《Deep learning for click-through rate estimation》)。如Figure 1所示,生产环境中的CTR模型学到的权重表现出极端的implicit sparsity:92%的connections被抑制到接近零,80%的权重质量(weight mass)集中在仅4%的维度上。这证实了dense architecture本身成为了effective scaling的瓶颈,我们将在后续章节提供详细的分析和理论基础。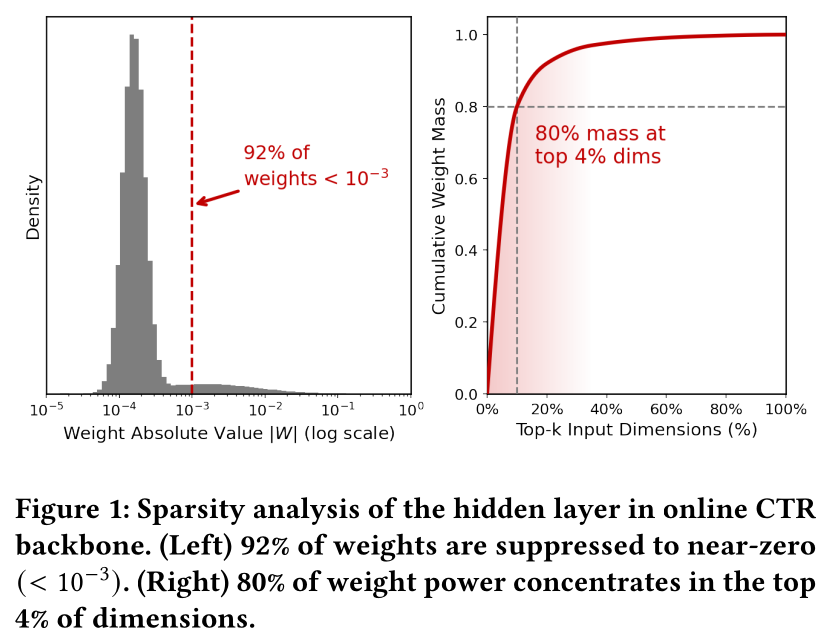
基于这一见解,我们提出了
Explicit Sparsity for Scalable Recommendation: SSR,这是一个为在sparse recommendation data上进行scaling而量身定制的框架。SSR引入了一种从implicit weight suppression到explicit signal filtering的范式转变,建立在一个简单原则之上:先筛选,后融合(first filter, then fuse)。它在进行dense nonlinear fusion之前执行显式的dimension-level sparse filtering。我们通过两种互补策略实现sparsity:静态随机筛选器(
Static Random Filter: SSR-S):通过fixed dimension subsets以zero FLOP成本实现高效的structural sparsity。迭代式竞争稀疏(
Iterative Competitive Sparse: ICS/SSR-D):这是一种可微的动态机制,基于样本上下文来引入sparsity以自适应地筛选dimensions。
与依赖于
soft attention(《FiBiNET: combining feature importance and bilinear feature interaction for click-through rate prediction》)或post-hoc pruning(《Autofis: Automatic feature interaction selection in factorization models for click-through rate prediction》)的现有方法不同(这些方法保持全连接图fully connected graph,因此无法在大规模场景下阻止噪声),SSR强制执行explicit sparsity,从源头上阻止噪声传播(noise propagation),从而为scaling提供更清晰的梯度流(gradient flow)。本文的主要贡献总结如下:我们分析了在
sparse data上scaling dense MLPs的问题,强调implicit weight suppression无法阻止噪声,并在Figure 1中提供了strong sparse connection的证据。我们提出了
SSR,将范式从implicit weight suppression转变为explicit signal filtering。它在dense interaction之前实现explicit sparsity以隔离噪声,确保expanded capacity专用于valid signals。我们引入了两种策略来实现
explicit sparsity,Static Random Filter:用于高效的structural sparsity。ICS:一种可微的动态筛选机制,从而能够实现input-adaptive sparsification以捕获复杂的依赖关系。
在三个公共数据集和一个来自
AliExpress的十亿级工业数据集上的实验表明,SSR在相当的计算预算下达到了更高的准确性,并在scaling size时表现出更稳定的改进。
1.1 相关工作
我们回顾了三个方面的相关工作,作为
SSR框架的背景:特征交互建模(feature interaction modeling)、稀疏性驱动的架构(sparsity-driven architectures)、和动态选择机制(dynamic selection mechanisms)。From Global Dense to Sparse Filtering:捕获高维稀疏特征之间的非线性依赖关系是推荐系统的基础。早期的模型,如因子分解机(Factorization Machines),显式地处理了二阶交互。在深度学习时代,架构通常分为三类:混合模型(例如,
Wide&Deep《Wide & deep learning for recommender systems》、DeepFM《DeepFM: a factorization-machine based neural network for CTR prediction》)结合线性组件和非线性组件以平衡memorization和generalization。自注意力机制(例如,
AutoInt《Autoint: Automatic feature interaction learning via self-attentive neural networks》、AFN《Adaptive factorization network: Learning adaptive-order feature interactions》)利用multi-head attention从而用于high-order correlations。隐式模型(例如,
DCN v2《Dcn v2: Improved deep & cross network and practical lessons for web-scale learning to rank systems》、RankMixer《Rankmixer: Scaling up ranking models in industrial recommender》)依赖深度堆叠的fully connected layers来捕获交互。
然而,这些全局稠密的架构与固有的
data sparsity之间存在根本性的不匹配。尽管像IntentGC(《Intentgc: a scalable graph convolution framework fusing heterogeneous information for recommendation》)这样的Graph Neural Networks: GNN试图通过利用graph topology来指导interactions以解决sparsity问题,但在工业环境中它们通常会带来与graph construction和neighbor sampling相关的成本。类似地,
self-attention模型(例如,AutoInt《Autoint: Automatic feature interaction learning via self-attentive neural networks》)理论上可以捕获细粒度的相关性。然而,标准的Softmax操作产生严格为正的权重,本质上是保留了一个全连接图(fully connected graph)。尽管人们已经提出了Sparse Attention机制(《Generating long sequences with sparse transformers》)来限制感受野(receptive fields),但它们通常会引入复杂的indexing开销。相比之下,SSR采用了"filter-then-fuse"的范式。SSR不依赖繁重的graph structures或复杂的sparse attention indices,而是采用显式的signal filtering。通过将inputs分解为并行视图(parallel views)并在fusion前阻断噪声,SSR使模型能够有效scale up,避免了dense baselines中观察到的饱和现象。From Pruning to Structural Sparsity:为了减轻高维特征的计算负担,explicit sparsity已成为一个活跃的研究方向。传统方法主要分为两类:Feature Selection:它剪枝冗余的字段,例如AutoFIS(《Autofis: Automatic feature interaction selection in factorization models for click-through rate prediction》)。Mixture-of-Experts: MOE:它使用conditional routing来扩展容量,例如MMOE(《Modeling task relationships in multi-task learning with multi-gate mixture-of-experts》)、PLE(《Progressive layered extraction (ple): A novel multi-task learning (mtl) model for personalized recommendations》)。
这些方法存在局限性。
Feature Selection通常遵循"model-then-prune"的逻辑——试图在dense interactions已经发生后再移除冗余。MoE模型虽然增加了容量,但面临路由坍缩(routing collapse)和负载均衡(load balancing)的挑战。
最近的进展已转向固有的
sparsity。例如,最近的研究 (《Dynamic sparse learning: A novel paradigm for efficient recommendation》)提出了一种Dynamic Sparse Learning范式,从头开始训练sparse models,有效避免了redundancy of post-hoc pruning。类似地,后续研究(《Scalable approximate nonsymmetric autoencoder for collaborative filtering》)利用sparse approximate inverses来增强collaborative filtering autoencoders的scalability。SSR与传统的post-hoc pruning和soft attention不同,它引入了一种hard-filtering范式。SSR不是"learning then deleting",也不是通过严格为正的权重来保留噪声,而是从一开始就实现了一种"learn-while-filtering"的机制。最重要的是,通过强制执行截断(zero-weight connections),SSR实现了signal isolation从而阻隔noise propagation。From Gating to Global Inhibition:为了实现input-aware adaptivity,动态机制是必不可少的。现有工作已经探索了多种技术来动态地处理data sparsity。MaskNet(《Masknet: Introducing feature-wise multiplication to CTR ranking models by instance-guided mask》)和LHUC(《Learning hidden unit contributions for unsupervised speaker adaptation of neural network acoustic models》)引入了Instance-Aware Masks,通过element-wise gating来突出informative features。其他方法利用
Locality-Sensitive Hashing(《Improved LSH for privacy-aware and robust recommender system with sparse data in edge environment》)在edge environments中进行高效检索,或采用embedding compression(《The Future is Sparse: Embedding Compression for Scalable Retrieval in Recommender Systems》)来为scalable retrieval生成sparse activations。
然而,大多数现有方法依赖于
independent gating或static projections,其中feature selection decisions是局部进行的或通过简单的点积实现。SSR通过提出Iterative Competitive Sparse: ICS机制来推进这一领域。ICS将feature selection建模为一个受生物学全局抑制(biological global inhibition)所启发的动态系统。它引入了竞争机制,其中dominant features抑制较弱的邻居,而不是independent gating。这使得SSR能够学习一个鲁棒的、全局的selection策略,该策略能够根据input context进行迭代式的自适应。
1.2 动机与理论基础
在介绍
SSR框架之前,我们提供支撑我们design choices的分析和理论动机。
1.2.1 为什么 Dense MLPs 不适合 Recommendation
Recommendation inputs与语言数据或视觉数据有根本不同。它们维度高但极其稀疏,每个实例通常只激活a large feature space中的一小部分informative dimensions(《Search-based user interest modeling with lifelong sequential behavior data for click-through rate prediction》)。与图像或文本(其inputs表现出自然的空间局部性或序列局部性,CNN和Transformer等架构利用了这一点)不同。Recommendation inputs由数百个heterogeneous feature fields组成,例如user profiles、item attributes、contextual signals和behavioral sequences,这些字段被拼接成一个no inherent adjacency或no ordering among dimensions的扁平向量。对于特定的impression或purchase,只有少数contextual signals和historical preferences是真正相关的,而绝大多数字段对于该特定样本是弱相关的。这种sparsity pattern意味着模型的有效响应(例如,weight mass)集中在input dimensions的很小一部分上。相比之下,全连接层(
fully connected layer)通过将每个output神经元与所有input dimensions耦合,强制执行全局稠密连接性(globally dense connectivity)。这迫使模型处理大量的低效用连接(low-utility connections),从而稀释了valid signals,并使得optimizer负担了suppressing noise而非learning complex patterns的任务(《Autoint: Automatic feature interaction learning via self-attentive neural networks》)。我们认为这构成了inductive bias的错位:dense connectivity假设所有dimension pairs都是等可能性地交互,而数据表现出高度集中的、subset-based的交互。为了支持这一分析,我们可视化了一个在线工业级
CTR模型中全连接层学到的权重(Figure 1)。该模型在没有任何sparsity-inducing约束(例如,L2 regularization)的情况下进行训练。尽管其设计是dense的,但学到的权重表现出高度稀疏的运行模式:超过92%的connections被隐式地抑制到接近零的值(80%的weight mass集中在top 4%的input dimensions上。虽然这证实了由data distribution所驱动的强sparsity preference,但这种implicit suppression是低效的:许多权重仅仅被驱动到接近零,这既不能消除噪声的干扰,也不能提供signal filtering的机制。使这种sparsity显式化(即:将其从implicit的训练副产品转变为可控的架构设计),是克服scaling瓶颈的关键。然而,什么构成噪声因用户而异,因此所有样本共享的static sparse structure忽略了recommendation的context dependence。为了有效地scale up,我们需要structural和dynamic, sample-conditional的sparsity。
1.2.2 Sparsity as Inductive Bias Alignment
从
inductive bias的角度来看,模型架构隐式地编码了关于其input data结构的假设。CNN通过卷积核(convolutional kernels)编码了空间局部性(spatial locality)。Transformer通过自注意力编码了序列依赖性(sequential dependencies)。
这两者都成功,因为它们的结构设计与数据的自然结构相匹配。
然而,
recommendation inputs缺乏这种自然局部性。数百个heterogeneous feature fields被拼接成一个缺乏固有空间顺序或时间顺序的扁平向量。Dense MLP的全连接拓扑没有施加任何结构先验(structural prior),将所有的dimension pairs视为等可能性地交互。当数据的有效interactions集中在小的特征子集上时(正如我们的实证分析所证实的,Figure 1)。这种设计变成了一种错位的inductive bias,迫使optimizer将大部分容量用于学习哪些connections需要抑制,而不是学习哪些模式需要建模。最近关于
structured sparsity的理论工作支持了这一观点。《Understanding MLP-Mixer as a wide and sparse MLP》证明,MLP-Mixer(《Mlp-mixer: An all-mlp architecture for vision》)在数学上等价于一个宽且稀疏的MLP。其Token-Mixing layer和Channel-Mixing layer可以通过Kronecker product结构来表示:假设输入
Kronecker product,
这种结构产生了
non-zero weight ratio,这本身就是高度稀疏的。此外,这种Kronecker product parameterization带有一种隐式的Golubeva假设(《Are wider nets better given the same number of parameters?》)(即在固定参数数量下,增加宽度(从而增加sparsity)能够持续提高泛化能力),这些发现为structured sparsity为何能作为有益的inductive bias提供了理论基础。SSR将这一原则从视觉领域扩展到推荐领域。MLP-Mixer依赖于固定的数学结构(Kronecker products),该结构利用了image patches的空间规律性,而recommendation data缺乏这种规律性:哪些feature interactions是informative的,高度依赖于数据和样本。这促使SSR设计了两种互补的explicit sparsity机制,即:用于高效structural sparsity的static random filtering、以及用于sample-adaptive selection的dynamic competitive filtering。因此,从MLP-Mixer到SSR的转变代表了一个进步:从嵌入在fixed mathematical structure中的implicit sparsity,转向为数据固有属性而设计的explicit sparsity。这激发了下一节详述的"filter-then-fuse"范式。
1.3 SSR 框架
我们提出
Explicit Sparsity for Scalable Recommendation: SSR框架,以解决globally dense connectivity与sparse input data之间的不匹配。在本节中,我们将详细阐述单个SSR Layer的设计,该层包含两个cascaded stages:(1):Multi-view Sparse Filtering。(2):Intra-view Dense Fusion。
Figure 2展示了该框架的概览。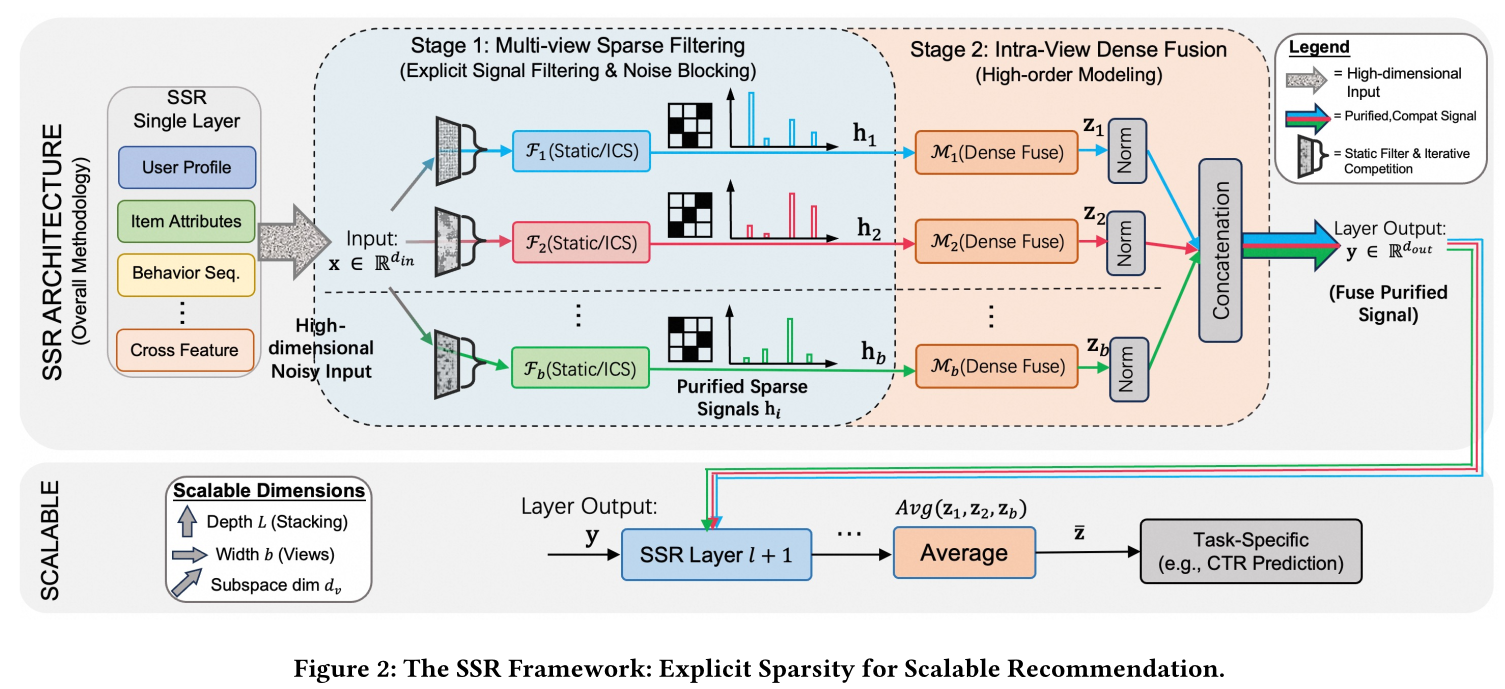
1.3.1 概述
为了克服传统
densely connected layers中无差别mixing和signal dilution所导致的scaling问题,SSR引入了一种基于explicit signal filtering的新计算范式。首先,模型将原始特征(包括
user profiles、candidate item attributes、cross-feature statistics和behavior sequences)转换为embeddings。这些embeddings被拼接起来形成初始输入向量与学习全局映射的标准
dense layer不同,SSR将建模任务分解为purification views)。对于每个视图view-specific的的映射input处理成一个local subspace representationfull inputSparse Filtering(随后是
Dense Fusion(
然后聚合
view outputslayer output。intermediate layers和final layer的具体聚合策略有所不同。
1.3.2 Multi-view Sparse Filtering
该阶段构成了
SSR框架的"Filter"阶段,实现了严格的dimension-level signal filtering。我们定义一组sparse filter operatorspurified representation这个过程本质上是执行
filtering操作。我们为structural sparsity和context-aware dynamic sparsity之间进行权衡。注意,
Static Random Filter和Iterative Competitive Sparse二者是互斥的,无法结合在一起使用。SSR-S: Static Random Filter (Static Instantiation):该策略将structural sparsity。我们使用一个binary selection matrixone-hot vector。此外,该矩阵在初始化后保持固定。为了构建input dimension范围feature indices。在每个视图内,采样无放回地均匀进行,确保单个子空间内的特征不同。然而,不同视图之间的采样是独立的,允许特征重叠。这种独立性产生了一种"Feature Bagging"效应(《Random forests》),促进了并行视图之间的structural diversity和鲁棒性。筛选后的特征计算如下:由于
column-wise one-hot vectors组成,该操作不是作为矩阵乘法实现的,而是作为zero-FLOP的并行的gather操作(即直接index slicing)。这从源头上阻止了unselected dimensions的传播。现有方法如
Statistical Top-k,甚至我们自己的dynamic ICS,都利用逻辑稀疏性(logical sparsity):它们将non-informative features乘以零,但物理计算图(computation graph)仍然保持宽的,即SSR-S强制执行hard dimension reduction。通过在计算之前严格地对input indices进行slicing,它将dimension selection成本与inference成本解耦。SSR-D: Iterative Competitive Sparse (Dynamic Instantiation):为了捕获context-aware dependencies,我们采用ICS(详见下一节描述),这是一种动态机制。ICS根据input的semantic context来动态调整focus。它通过主动将输入向量high-response values,来对input进行稀疏化。其中:
view dimension通常会扩展(例如,adaptive dimension sparsity,这与静态策略不同。
outputsparse representation,位于
1.3.3 Intra-view Dense Fusion
在
dimension-level sparse filtering之后,input已被提炼成purified vectorssparsity,在refined signal环境中实现高效的高阶建模。仅应用于refined subspaces内,可以防止low-utility connections的re-aggregation,从而解决了globally dense architectures中固有的signal dilution问题。数学上,此操作等效于将一个块对角权重矩阵(
Block-Diagonal weight matrix)concatenated input。与所有dimension pairs都交互的标准dense layer不同,block-diagonal structure强制视图之间保持严格的语义隔离(semantic isolation),确保来自第static)或dynamic)进行变换。在实践中,这通过zero-valued的非对角块。第其中:
GELU)。对于中间层(
intermediate layers),来自所有视图的outputs经过Layer Normalization处理后,通过concatenation进行重组:这种结构的参数数量为
SSR将复杂度降低了注意:当前
SSR层产生的outputs会被拼接成一个长向量,作为下一层的输入。而下一层会重新将自己的输入(这个拼接好的向量)分解为"sparse filtering" -> "dense fusion" -> "concat outputs"的完整流程。
1.3.4 Last-Layer Aggregation
在
intermediate layers,view outputs被拼接起来并传递到下一层。然而,对于产生prediction logits(例如CTR/CVR scores)的final layer,aggregation策略从拼接切换为取平均:每个视图独立完成
dense fusion以获得shared representationtask-specific prediction heads(例如,通过全连接层):Averaging相比concatenation有两个优势:首先,它推动所有视图朝向一个共享的
semantic space,而不是让它们独立漂移。concatenation保留了视图之间的差异,但averaging鼓励了视图之间的一致性。其次,无论视图数量多少,
averaging都将prediction head input dimension固定为concatenation时,维度将增长到prediction head随视图数量而线性扩展。
1.4 Iterative Competitive Sparse
作为
SSR中动态实例化的核心机制,Iterative Competitive Sparse: ICS是一个可微算子,它不同于传统的sparsification(通常由离散的TopK sorting来处理),而是视为一个连续动力系统。这种公式化使得端到端、自适应的dimension-level sparse filtering成为可能。我们将
inputfeature intensities)代表活力。这个框架将sparsification重新定义为一个离散时间的非线性动力系统,而不是一个静态的排序任务。它包含三个连续阶段:initialization、iterative competition和signal recovery。ICS的前向传播是完全可微的,能够集成到基于梯度的optimization中。标准流程如Algorithm 1所示。核心思想:将
ReLU)。
1.4.1 Initialization and Competitive Dynamics
动态竞争(
Dynamic competition)要求特征强度(feature intensity)具有非负的物理意义。因此,我们首先将input校正为非负。我们定义初始系统状态为:然后,系统进入一个迭代过程,进行
mean-field global inhibition force)驱使特征走向灭绝。我们在stepglobal inhibition field)state update遵循“适者生存”("survival of the fittest")法则。只有明显强于抑制场(inhibition field)的特征才能存活。其余特征将收敛到true zero,实现hard sparsity。具体的更新方程为:其中:
extinction rates),不同的iterations使用不同的关键在于,
iterative designstatistical distribution并不稳定。一个single-step thresholdingnoise floor的静态估计。通过refined以反映true signal baseline。这使得模型能够执行渐进式filtering:首先去除粗噪声(coarse noise),然后进行微调,从而逼近一个复杂的非线性sparsification(而这是单次线性filtering无法实现的)。注意,在训练过程的每个
training step的前向传播中,ICS都会迭代在每次迭代中,我们只执行加法和减法以及计算平均值,这些都是
update rule确保没有feature intensity可以增加。该系统形成一个单调非增序列:这个不等式意味着系统的总能量随时间
1.4.2 Signal Recovery
为了抵消这种固有的衰减,我们引入了一个可学习的
scale参数sparse statefinal output我们引入
rescaling参数。我们将recovery与transformation进行解耦。参数numerical stability)和optimal dynamic range。
1.4.3 Comparison with Other Top-k Mechanisms
我们的
ICS机制相比现有的可微的selection策略具有明显优势。首先,与基于直通估计器(
Straight-Through Estimator: STL)(《Estimating or propagating gradients through stochastic neurons for conditional computation》)的Top-k方法相比,ICS消除了梯度不匹配问题。通过将sparsification表述为一个连续动力系统而非discrete truncation,ICS确保了梯度流的一致性,从而稳定了训练。其次,与通常涉及超线性
Soft Top-k relaxations或NeuralSort(《Stochastic optimization of sorting networks via continuous relaxations》)不同,ICS通过并行竞争抑制(parallel competitive inhibition)来实现sparsity。这导致了严格的线性recommendation features)时的计算瓶颈,同时确保noise dimensions被驱动到true zero,而不仅仅是分配低概率。
1.5 实验
本节旨在解决以下核心研究问题:
RQ1 Effectiveness & Efficiency:SSR在主流benchmarks上是否优于SOTA模型,无论是在预测准确性还是计算效率方面?Q2 Scalability:SSR是否能够有效scale up,即随着模型规模的增加,性能是否持续提升?RQ3 Ablation & Mechanism:sparse filtering design和dense fuse各自的贡献是什么?ICS是否真正实现了dynamic sparsity?RQ4 Online A/B Tests:在线部署SSR是否能在延迟约束下带来关键业务指标的显著提升?
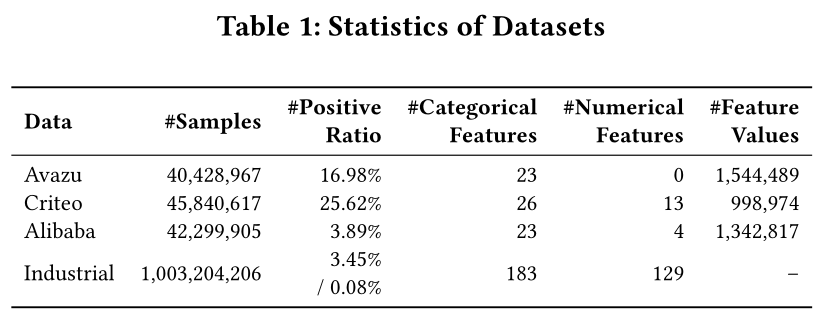
数据集:我们在一个大规模工业数据集以及三个公开数据集(
Criteo、Avazu、Alibaba数据集)上开展了实验评估。Table 1汇总了各数据集的统计信息。该工业数据集包含阿里巴巴国际数字商业集团(
Alibaba International Digital Commerce Group)旗下全球跨境电商平台速卖通(AliExpress)超1 billion条生产日志数据。数据来源于其推荐系统,该系统面向全球用户提供个性化商品推荐服务。数据集包含300多个特征字段,涵盖user profiles、item attributes及contextual signals信息。对于工业数据集,我们采用
time-based split:选取最近一天的数据作为验证集和测试集,以模拟线上真实应用场景。对于公开数据集,我们沿用业界标准的random split(8:1:1)。所有数值特征均经过对数变换与离散化处理,同时剔除出现频次不超过
5的categorical features。
评估方式:为评估所提方法的性能,本文同时从预测效果与计算效率两个维度开展评测。
在预测效果方面,所有数据集统一采用
AUC与LogLoss作为评价指标。针对工业数据集,额外引入GAUC指标,从而缓解user activity bias,重点衡量用户内排序(intra-user ranking)性能。该工业数据集包含click、pay两大任务;其中pay任务在全量样本空间上进行评估。在效率与
scalability方面,本文汇报参数量(Params)与浮点运算量(FLOPs)两项指标。需说明:参数量仅统计骨干网络部分(不包含embedding tables),从而将模型结构评估与dataset-specific feature cardinality解耦。此外,FLOPs基于神经网络模块单次前向推理进行计算,以此近似刻画training阶段的计算开销。
Baselines:本文将SSR模型与四组代表性方法进行对比:(1) Classic Deep Models:DeepFM(《DeepFM: a factorization-machine based neural network for CTR prediction》)、DCN v2(《Dcn v2: Improved deep & cross network and practical lessons for web-scale learning to rank systems》),作为utilizing dense feature interactions的标准基线。(2) Attention-based & Dynamic models:AutoInt(《Autoint: Automatic feature interaction learning via self-attentive neural networks》)、MMOE(《Modeling task relationships in multi-task learning with multi-gate mixture-of-experts》),采用自注意力或门控机制实现adaptive feature learning。(3) Feature Selection (AutoML):AutoFIS(《Autofis: Automatic feature interaction selection in factorization models for click-through rate prediction》)、AFN(《Adaptive factorization network: Learning adaptive-order feature interactions》),为当前的SOTA方法,通过裁剪冗余interactions来提升模型效率。(4) SOTA scalable architectures:Wukong(《Wukong: Towards a scaling law for large-scale recommendation》)、RankMixer(《Rankmixer: Scaling up ranking models in industrial recommenders》),代表高性能工业推荐场景的最新研究进展。
所有模型均基于
TensorFlow实现,并在NVIDIA A100集群上完成训练。为保证对比公平性,所有模型统一设置embedding维度为16,优化器采用Adam,batch size = 1024,并启用early stopping。ICS模块迭代次数5,learnable extinction rates0.1,learnable scale1向量。
1.5.1 Effectiveness & Efficiency (RQ1)
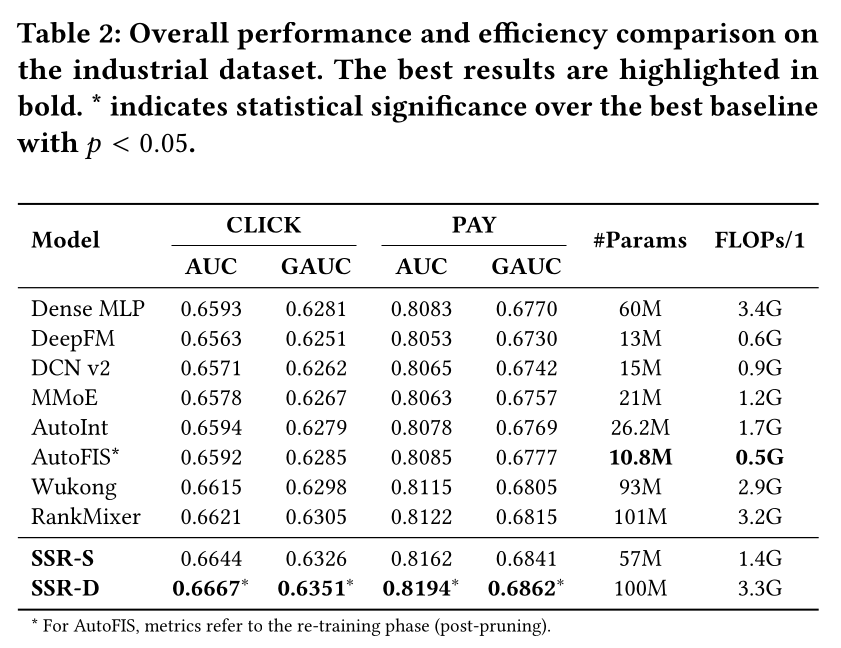
在工业数据集上的性能表现:
Table 2给出了模型在工业数据集Click任务与Pay任务上的实验结果。本文将三组基线模型,分别与静态随机策略SSR-S、动态ICS策略SSR-D进行对比。这里有两个任务,可能用一个
2-task model、或者两个single-task model。作者并未说明是哪种方式。如果是2-task model,那么task loss之间的权重比例对于model performance至关重要。不同模型需要调优task loss weight。读者猜测,这里应该是对每个任务一个单独的模型。
SSR整体性能始终优于经典feature interaction模型。例如,静态版本SSR-S的Click AUC达到0.6644,超越了DeepFM、DCN v2等标准基线模型。值得注意的是,SSR-S性能优于参数量相当的Dense MLP,说明性能提升源于sparse architecture本身,而非模型参数量带来的容量增益。在与自动特征选择模型及
attention-based模型的对比中:尽管
AutoFIS在re-training阶段参数量更低,但模型表达能力受限,Click AUC仅为0.6592,并非最优。同样地,
AutoInt的FLOPs高达1.7G,而SSR-S仅为1.4G,但AutoInt的Click AUC仅有0.6594,低于SSR-S。
这类
self-attention机制通过Softmax为所有feature pairs分配恒为正的权重(dense fully connected layer的全连接特征图(fully connected graph)。在与当前
SOTA架构的对比中,动态版本SSR-D取得了最优综合性能。RankMixer是表现最强的基线模型,其Click AUC为0.6621;而SSR-D在所有指标上均全面超越它,Click AUC达0.6667,Pay AUC达0.8194。此外,
SSR实现了更优的准确性--效率权衡:SSR-S仅使用RankMixer的56%的参数量、44%的FLOPs,性能却更优,验证了structured sparsity的优势。SSR-D在与RankMixer计算开销相近的前提下,实现了显著性能提升,进一步验证了Iterative Competitive Sparse: ICS机制的有效性。
在公共
benchmarks上的泛化能力:为验证SSR模型在不同数据分布与业务领域下的鲁棒性,本文在三个主流公开基准数据集Avazu、Criteo、Alibaba上开展实验。这三个数据集在feature sparsity与语义复杂度上存在明显差异。如
Table 3总结所示:本文所提
SSR框架在所有数据集上,相比各类基线模型均取得了稳定性能提升。其中,动态版本SSR-D在AUC和LogLoss两项指标上均达到最优水平。与最强基线模型RankMixer相比,SSR-D在Avazu数据集上AUC提升0.63%,在Criteo上提升0.03%,在Alibaba上提升0.43%。这表明模型性能增益来源于自身架构设计,而非针对特定数据集的调优,具备跨数据集的泛化能力。除预测准确性外,静态版本
SSR-S在Avazu、Alibaba、Criteo所有基准数据集上均展现出优异的计算效率。以Avazu数据集为例:SSR-S的AUC为0.7827,优于RankMixer的0.7772;同时仅需0.33M参数量、688.7M FLOPs。相较于RankMixer,SSR-S将参数量与计算量均缩减近一半,在提升AUC的同时剔除了冗余计算,做到准确性无损、效率大幅优化。Criteo是一个性能竞争充分、模型效果已趋于饱和的基准数据集,性能提升空间本就十分有限。即便如此,SSR-S与SSR-D仍取得0.8098的优异AUC,优于RankMixer(0.8093)、Wukong(0.8073)等强基线模型。该结果证明:即便在性能趋于饱和的场景下,SSR仍能挖掘出传统模型忽略的精细化的高阶dependencies,充分验证了该模型在各类数据环境下的有效性。
1.5.2 Scalability Analysis (RQ2)
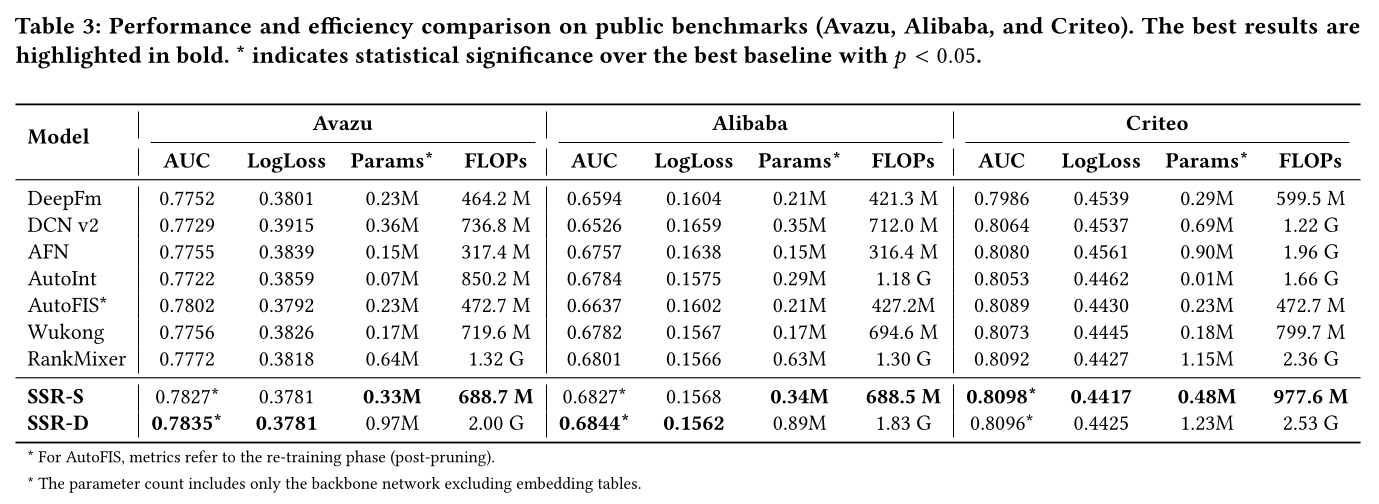
内部效率分析:我们在
Figure 3中分析scaling特性,以确定最优的资源分配策略。结果表明:增加视图数量(scaling维度,尽管在不同数据集上表现出不同的行为。在较小的
Avazu数据集(Figure 3b)上,饱和(saturation)在所有维度上都普遍存在。当视图数量从
子空间宽度(
这表明在有限的数据上,无论选择哪个
scaling维度,模型都容易达到容量上限。相比之下,十亿级的工业数据集(
Figure 3a)表现出不同的模式,其主要瓶颈是欠拟合而非冗余。scaling视图数量的性能曲线保持稳定的上升趋势,直到Avazu中看到的饱和现象。scaling宽度(scale up。然而,它最终在高复杂度时会呈现收益递减,其曲线相比于view scaling的持续增长趋于平缓。
相反,
scaling深度(returns per FLOP, 最早达到饱和并且得到很小的增益。
因此,
scaling width仍然是一个可行的次要选择,我们优先考虑scaling视图数量作为SSR骨干网络的主要机制,因为它在大规模数据上具有长期可扩展的潜力。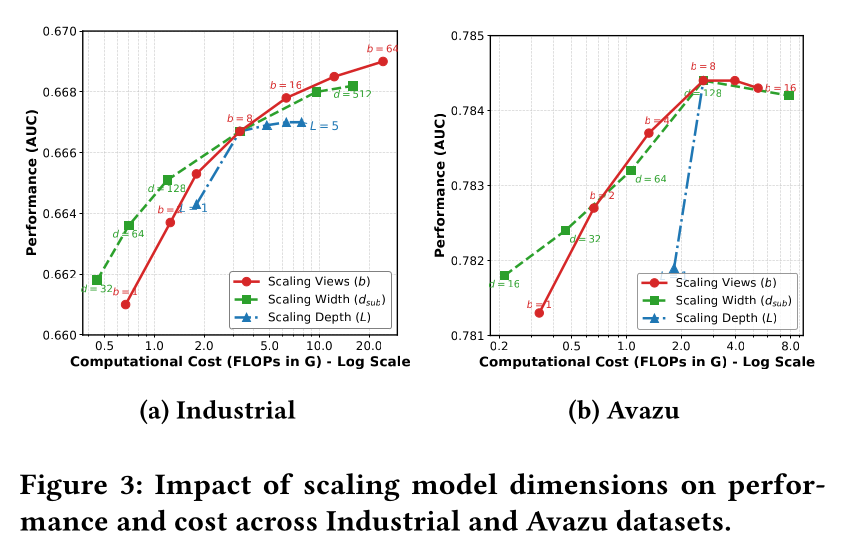
Scalability Efficiency分析:我们评估了SSR框架相对于两类基线的scalability。为了确保严格的比较,我们在每个参数规模下对所有基线进行了独立的超参数网格搜索。首先,我们比较了SOTA的架构,如RankMixer和Wukong,以建立一个强参考点。其次,我们纳入了一个标准的Dense MLP,以验证我们sparse filtering的结构优势。Figure 4绘制了每个模型在从5M到近900M的参数规模范围内的性能轨迹。与最强的基线
RankMixer和Wukong相比,SSR不仅表现出更高的准确性,而且具有更陡峭的scaling轨迹。如Figure 4所示,虽然RankMixer随着参数增加保持稳定提升,但其增长率比SSR更平缓。因此,SSR与SOTA模型之间的性能差距随着模型规模的扩大而扩大。在接近900M参数的大规模increases中,SSR将额外容量转化为性能增益的效率远高于基线,从而产生了更大的差距。这表明multi-view architecture比现有方法更能利用大规模参数预算。将我们的模型与
Dense MLP进行比较对于验证我们的design choices至关重要。我们观察到,即使经过精心调优的正则化(例如,Dropout,weight decay),Dense MLP也表现出过早的饱和,参数数量翻倍只会产生递减的收益。这种平台效应(plateauing effect)表明:如果没有explicit selection机制,dense backbone难以利用额外容量来捕获更精细的interaction模式。相比之下,
SSR在整个规模范围内都保持着稳定的上升趋势。这证实了sparse filtering机制对于scaling至关重要。通过用selective views替代无差别的dense connections,SSR将扩展的容量分配给modeling the most informative signals,从而缓解了saturation瓶颈(这个瓶颈限制了传统dense网络)。
1.5.3 Ablation Studies & Mechanism Analysis (RQ3)
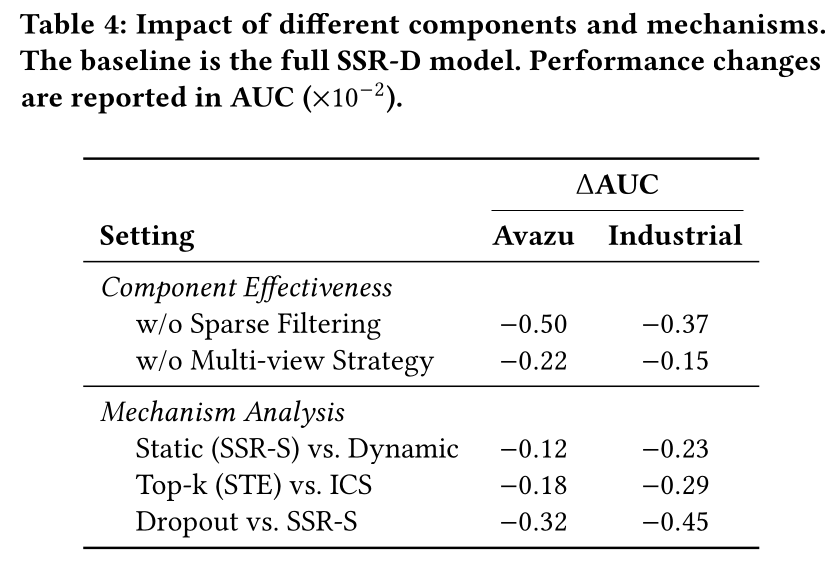
消融研究:为了验证
SSR框架,我们在Avazu数据集和工业数据集上进行了全面的消融研究。我们通过追踪相对于SSR-D基线的AUC性能下降来衡量每个设计元素的贡献,总结于Table 4。dimension-level sparse filtering被证明对我们的架构至关重要。移除此模块(即直接将input暴露给dense blocks)导致了最显著的性能下降,在Avazu数据集上AUC下降了0.50个百分点,在工业数据集上下降了0.37个百分点。这种急剧下降证实了我们的中心假设,即globally dense connectivity不适合recommendation inputs,因为强迫backbone无差别地处理所有input dimensions会稀释effective patterns并引入irrelevant connections。与此相辅相成的是,
multi-view decomposition策略在维持模型容量方面起着至关重要的作用。将模型限制在单一representation subspace(Avazu数据集上性能损失0.22个百分点,工业数据集上损失0.15个百分点,表明parallel view projections对于捕获多样化的和互补的feature interactions至关重要。除了组件存在性(
component existence)之外,我们还检查了底层的实现机制。dynamic adaptation的必要性通过将动态SSR-D替换为静态SSR-S变体时所导致的0.12和0.23个百分点的性能下降得以证明,这表明fixed sparsity patterns无法考虑sample-specific variability。此外,我们的可微
ICS算子相对于标准Top-k selection策略(STE,Top-k truncation的不可微性质导致了大约0.18和0.29个百分点的AUC性能损失。相比之下,我们的ICS提供了稳定的梯度传播,并能更有效地保留critical feature information。最后,我们使用
Dropout替换我们的sparse filtering,以验证我们的增益不仅仅是由于正则化。由此产生的0.32和0.45个百分点的剧烈性能下降表明SSR学到了有意义的sparsity。
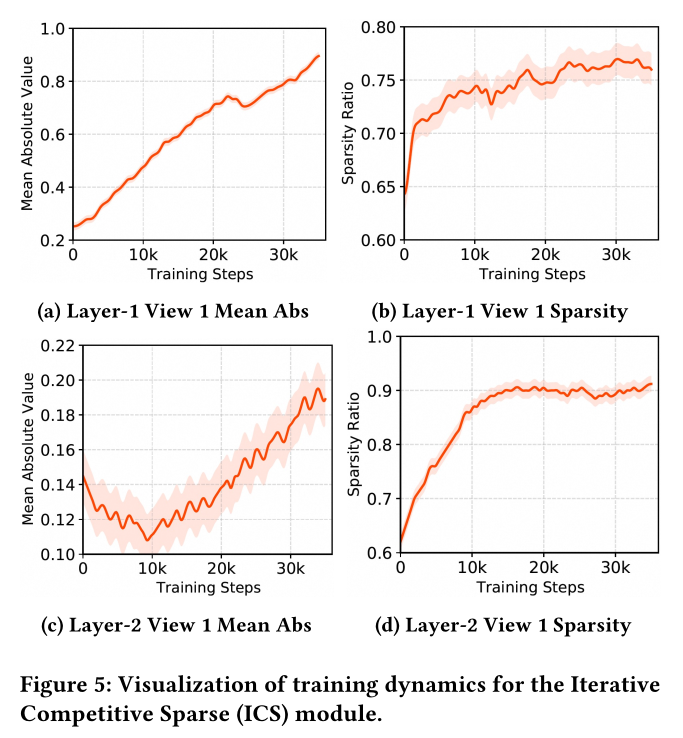
ICS分析:为了理解Iterative Competitive Sparse: ICS模块在optimization过程中的学习方式,我们在Figure 5中可视化了前两层。我们追踪了sparsity ratio和mean absolute magnitude在35,000 steps内的变化。如
Figure 5b和Figure 5d所示,sparsity早期快速上升,然后趋于平稳。第2层收敛到的sparsity(约90%)远高于第1层(约75%),表明deeper layers变得更加selective并产生更抽象的且稀疏的representations。后期观察到的stability证实了是稳定收敛,而不是在feature subsets之间持续切换。同时,
Figure 5a和Figure 5c显示,mean absolute feature magnitude在训练过程中增加。在第2层,它在最初的10,000 steps内短暂下降,随后增加;这与早期抑制weak or redundant features,随后加强remaining features的过程一致。
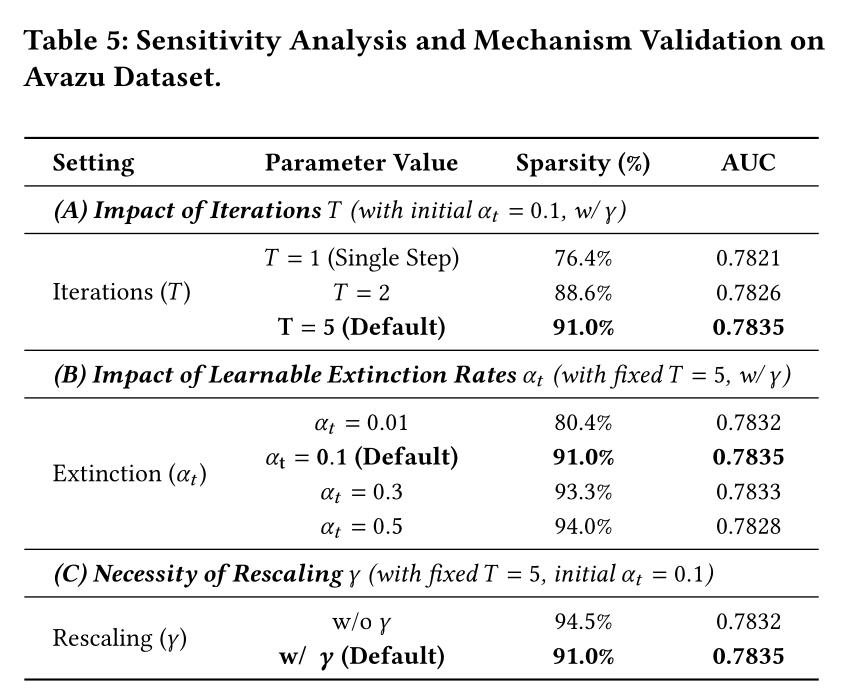
为了评估
ICS机制的敏感性,我们在Avazu数据集上进行了受控的网格搜索(Table 5),变化迭代次数rescaling因子结果支持了渐进式筛选(
progressive filtering)的必要性,单步thresholdingsparsity有限且AUC次优,而将5则产生更cleaner representations,并在91.0%的sparsity下实现了0.7835的最佳AUC。我们还发现
sparsity regulator,在初始值(80.4%平滑地改变到94.5%,同时保持性能稳定,表明该机制是鲁棒的而非脆弱的。最后,
AUC降至0.7832。这与我们的分析一致:需要explicit magnitude rescaling来抵消信号衰减。
View Diversity:为了验证multi-view architecture是否真正学到了互补模式(complementary patterns)而非冗余信息,我们在Figure 6中可视化了不同视图间投影矩阵pairwise cosine similarity。第
1层和第2层的热力图在非对角线元素上都表现出持续的低similarity scores。这表明不同视图所生成的feature vectors在很大程度上保持正交。这种distinct separation证实了parallel views已成功收敛到不同的子空间,每个视图捕获feature interactions的一个独特方面(unique aspect)。通过避免mode collapse(其中,视图变得相同),该框架最大化了representational capacity,并确保了final fusion step整合来自input data的全面的且非冗余的信号。SSR不需要显式的多样性正则化。由于所有view outputs都被拼接起来并在相同的loss下进行优化,训练自然地抑制了冗余视图,并偏向于那些捕获了互补模式(complementary patterns)的视图。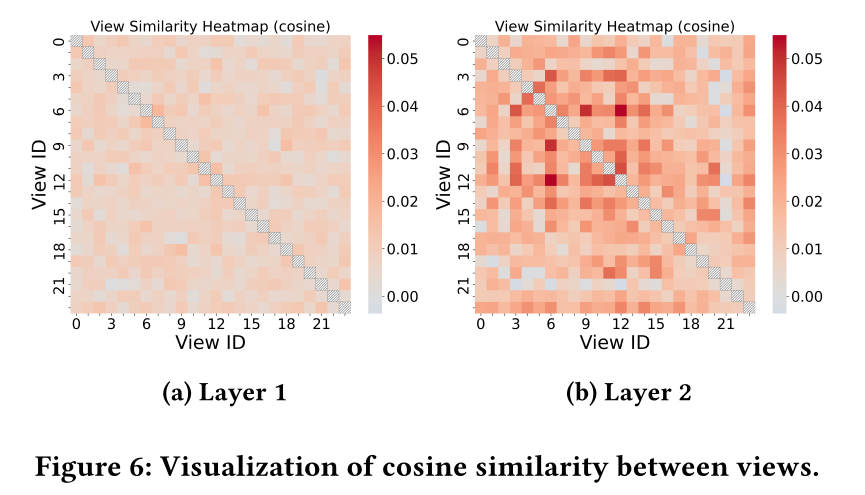
1.5.4 Online A/B Testing (RQ4)
我们在一个核心推荐场景中进行了在线
A/B测试,以验证SSR的实际价值。基线模型是具有相同参数的RankMixer,它代表了当前的production标准。我们在两周内将其与SSR-D进行比较,以评估在真实流量下的性能。如Table 6所示,SSR-D在所有关键业务指标上均实现了持续改进。该模型CTR提升了2.1%,同时推动了conversion的显著增长,人均订单量增长了3.2%,Gross Merchandise Value: GMV增长了3.5%。这些结果证实了
SSR学到的高质量representations直接转化为更好的ranking decisions和更高的商业价值。至关重要的是,这些性能增益的实现没有增加系统延迟。如效率统计数据所详述,基线RankMixer和所提出的SSR-D的平均响应时间均为25ms。这种对等性证实了SSR通过卓越的结构设计提高了推荐质量,而不是增加serving系统的推理时间负担。
1.6 结论
在这项工作中,我们重新审视了推荐系统的
scaling laws,并识别了导致dense backbones性能饱和的不匹配(mismatch)问题。我们的分析揭示,标准dense layers中的无差别mixing常常导致信号稀释,需要从被动的implicit suppression转向显式的signal filtering。SSR通过"filter-then-fuse"拓扑实现了这一范式。通过采用Iterative Competitive Sparse: ICS等机制,SSR从源头上阻断了noise propagation,确保expanded model capacity专用于高信噪比的子空间。我们的实证结果表明,这种
sparsity成功地打破了dense models saturate的scaling天花板。更广泛地说,这项工作例证了一个通用原则:有效的架构需要将其inductive biases与数据的内在结构对齐。正如卷积核(
convolutional kernels)之所以成功是因为它们匹配了图像的空间局部性。自注意力之所以成功是因为它捕获了序列中的长程依赖关系。
SSR的explicit sparsity之所以成功,是因为它匹配了recommendation data中固有的高维的、基于子集的interaction patterns。
这一视角挑战了当前对
globally dense connectivity的依赖,并为未来的研究指向一个有原则的方向:设计那些structural priors能够反映user behaviors的sparse, combinatorial nature的架构。我们预计,explicit filtering机制将有助于为推荐系统开发更大的、更具基础性的模型,这些模型既具有scalable,又具有计算效率。