一、 TokenMixer-Large [2026]
《TokenMixer-Large: Scaling Up Large Ranking Models in Industrial Recommenders》
推荐模型的
scaling laws已受到广泛关注,但Wukong、HiFormer、DHEN等现有架构常因设计欠佳、硬件利用率低,限制了实际的可扩展性。我们此前在RankMixer论文中提出的TokenMixer架构,通过轻量级的token mixing operator替代self-attention,实现了效果与效率的平衡;然而,该架构在deeper configurations中遭遇了关键瓶颈,包括residual paths不合理、梯度消失、MoE sparsification不彻底、以及scalability受限等问题。本文提出
TokenMixer-Large,这是一款为超大规模推荐任务设计的、经系统性改进的架构。通过引入mixing-and-reverting操作、inter-layer residuals和辅助损失函数,我们确保了model depth增加时梯度传播的稳定性。此外,我们融入了Sparse Per-token MoE机制,实现了模型参数的高效扩展。TokenMixer-Large成功扩展到7 billion参数规模从而用于线上流量、,离线实验中更是达到15 billion参数。该模型目前已在ByteDance多个业务场景落地部署,取得了显著的性能提升:电商场景中订单量提升
1.66%、人均预览支付商品交易总额(GMV)提升2.98%。广告场景中广告主满意度评分(
ADSS)提升2.0%。直播场景中营收增长
1.4%。
推荐系统在当今互联网生态中占据核心地位,为电商、在线广告、内容信息流、直播等核心应用提供技术支撑。因此,工业界和学术界都在持续迭代与升级推荐模型及架构。随着深度学习的广泛应用,深度学习推荐模型(
Deep Learning Recommendation Models: DLRMs)展现出卓越的效果。这类模型通常先通过embedding layer,将高维稀疏的user, item, and behavioral features转换为低维稠密的embeddings向量;随后设计复杂的feature interaction layers,从而捕获潜在的user-item relationships。受大语言模型(
Large Language Models: LLMs)成功的启发,feature interaction领域的研究开始探索DLRMs的scaling laws,即研究是否能通过增加模型参数和浮点运算量(FLOPs)来实现性能的持续提升。早期研究主要聚焦于单纯扩展model width或interaction layer parameters,缺乏精细化的架构设计,导致效果受限。后续的Wukong、HiFormer、DHEN等研究尝试设计更精细的模型结构,并从size、width和depth等维度进行扩展,但往往忽视了与硬件适配的co-design和optimization,最终性能表现欠佳。目前,工业界领先的
SOTA模型架构是TokenMixer——一种高度简化的Transformer变体。该架构通过轻量级的token mixing操作替代attention,大幅降低了计算复杂度。RankMixer(《Rankmixer: Scaling up ranking models in industrial recommenders》)将其作为骨干网络,验证了该结构在ranking模型中的有效性。通过硬件感知的co-design,TokenMixer在保持scaling效率的同时,显著提升了Model FLOPs Utilization: MFU,大幅改善了硬件使用效率。尽管TokenMixer已在工业界取得成功(如RankMixer),但我们发现其存在若干关键局限性:Residual Design不合理:RankMixer通过mixing机制将original tokens转换为new tokens,要求new tokens数量original tokens数量add & norm操作中,RankMixer直接将mixing之前的tokens和之后的tokens相加,这往往会引发语义错位(semantic misalignment),最终导致性能欠佳。Model Architecture冗余:受历史迭代过程影响,许多已部署的模型即便采用TokenMixer作为骨干网络,仍保留了大量零散的算子,如LHUC(《Learning hidden unit contributions for unsupervised acoustic model adaptation》)、DCNv2。这类算子受内存限制,计算密度低但内存访问和通信开销大,降低了模型的整体MFU。Deep Models的梯度更新不足:在工业场景中,TokenMixer的配置通常较浅(如RankMixer中仅2 layers)。随着模型深度增加,实现训练稳定性和性能提升的难度显著增大,而当前的TokenMixer缺乏针对deep架构的专属设计。MoE Sparsification不充分:尽管RankMixer采用Sparse MoE来优化模型成本,但其依赖"Dense Train, Sparse Infer"的范式,无法降低训练成本。此外,所使用的ReLU-MoE(《ReMoE: Fully Differentiable Mixture-of-Experts with ReLU Routing》)存在activation dynamism的问题,推理时难以预测每一个batch所激活的experts数量,因此需要对activated experts采取截断策略或fallback策略,对inference不友好。RankMixer采用的Sparse MoE仅在Inference阶段启用专家稀疏激活,而Training阶段仍会让所有专家全部参与计算,即训练时保持模型的密集化运行,推理时才通过路由选择部分专家激活以降低推理成本,这一运行逻辑直接定义了其"Dense Train, Sparse Infer"的范式特征。这种设计下,训练过程无法利用MoE的稀疏性优势,所有专家的参数都会被同步更新,硬件计算和内存开销与同规模的密集模型无异,因此无法降低训练成本,仅能在推理阶段通过稀疏激活优化资源消耗。activation dynamism核心指不同batch数据在推理时,被路由机制激活的专家数量、具体专家索引会呈现无规律的动态变化。ReLU-MoE该问题的根源来自其基于ReLU激活的路由设计:ReLU-MoE以ReLU作为路由函数的核心组件,路由对输入样本的特征分布高度敏感。而工业推荐场景的输入(如用户、商品、行为特征)具有高度稀疏性和分布随机性(不同batch的样本特征分布差异大)。这导致推理时,针对不同batch的数据,路由模块输出的激活专家选择结果不稳定 —— 激活的专家数量时多时少、具体激活哪几个专家无固定规律,无法提前预判每一个batch所需激活的专家数量和组合。推理阶段的硬件资源(如
GPU显存、计算核心)是提前固定分配的,而ReLU-MoE的activation dynamism导致单个batch实际激活的专家数量不可控:若某一
batch被激活的专家数量超过硬件提前分配的资源上限,会直接引发显存溢出、计算资源不足,导致推理中断;若无统一的激活专家数量约束,推理引擎无法提前做资源调度和计算优化,会出现资源利用率剧烈波动。
因此必须通过截断策略(将单
batch激活的专家数量强行限制在预设阈值内,超出部分直接舍弃)或fallback策略(当激活专家数量超出阈值时,回退到预设的通用专家 / 密集计算模式),来保证推理过程的稳定性,避免资源异常。Scaling的探索不足:受框架和训练效率的约束,RankMixer的参数规模仅能扩展至约1-Billion。
为解决上述问题,我们设计并深入研究了
TokenMixer-Large。该框架包含Tokenization、TokenMixer-Large Block、Sparse-Pertoken MoE等模块。其中,TokenMixer-Large Block由Mixing & Reverting、Pertoken-SwiGLU、Residual & Normalization、Interval Residual & Residual Loss等组件构成。通过堆叠多个TokenMixer-Large Blocks,我们大幅提升了工业场景下模型的离线性能和在线性能。本文的研究贡献总结如下:提出了
TokenMixer-Large架构。通过重新审视并重新设计TokenMixer中存在缺陷的residual机制,引入Mixing & Reverting操作。针对核心组件的大量消融实验表明,TokenMixer-Large是一种更优的模型架构。我们发现,随着模型规模扩大,
low-level零散算子带来的增益可通过堆叠多个TokenMixer Blocks来实现。移除这类算子能大幅提升model MFU和硬件利用率。我们将这一"pure model"设计理念融入TokenMixer-Large,将广告骨干网络的MFU提升至60%。为了解决
deep models中梯度更新不足问题,我们在TokenMixer-Large Block中融入interval residuals、auxiliary loss机制、以及down-matrix small initialization策略,促进deep models更好地收敛。我们将
Rankmixer (TokenMixer)中的relu-MoE升级Sparse-Pertoken MoE,它采用统一的"Sparse Train, Sparse Infer"范式。结合高效的算子设计以及FP8量化、Token Parallel等工程优化手段,Sparse-Pertoken MoE大幅降低了训练成本和推理成本。我们开展了模型
scaling laws的综合研究,验证了TokenMixer-Large的优越性。我们在Douyin的广告和电商场景的离线实验中,成功将模型分别扩展至15B和7B参数;在线上流量实验中,相应扩展至7B和4B参数。目前,TokenMixer-Large已在ByteDance多个线上场景部署,服务数亿用户的同时,实现了ADSS提升2%、GMV提升2.98%的线上收益。
1.1 相关工作
DLRMs的核心在于设计有效的feature interaction架构。Wide and Deep作为经典研究之一,通过集成式方法同时捕获low-order and high-order的feature interactions。这一建模范式在DeepFM、XDeepFM、PNN、DCN、DCNv2、FCN等后续设计中得到体现。但作为早期设计,这类模型仍依赖CPU时代效率低下、延迟较高的算子,无法充分发挥GPU的计算能力。在不同子结构进行集成的基础上,
DHEN和Wukong进一步验证了推荐系统中的scaling laws,证明"unified design, stacked layers"的迭代式模式在推荐任务中也能实现显著的性能提升。
作为基础模型,
Transformer在GPU时代被广泛证实具有强大的通用性(CV、NLP、推荐系统RS)和良好的scaling-law特性。在推荐领域,
AutoInt、HiFormer等模型通过融入attention机制来增强feature interaction能力。RankMixer(《Rankmixer: Scaling up ranking models in industrial recommenders》)和MLPMixer(《Mlp-mixer: An all-mlp architecture for vision》)进一步将注意力机制简化为更轻量的token-mixing操作,降低了标准注意力机制的平方计算成本。LONGER、HSTU、MTGR等研究也在不同程度上证明了基于Transformer的模型(及其变体)在sequential modeling生成式推荐场景中的scaling潜力。
1.2 方法
1.2.1 整体架构
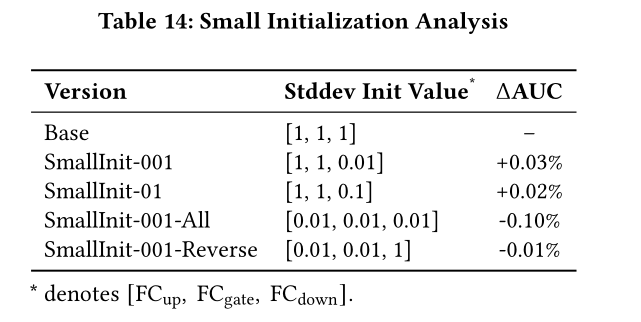
如
Figure 1所示,TokenMixer-Large框架的整体架构由三部分组成:1) Tokenization:将原始高维稀疏的one-hot features转换为dense embeddings,再进一步转换为维度对齐的semantic tokens。2) Token Mixing & Channel Mixing:采用"Mixing and Reverting"范式,解决RankMixer (TokenMixer)中存在的维度不匹配问题;3) Sparse-Pertoken MoE:是RankMixer (TokenMixer)中提及的Pertoken-FFN/relu-MoE的升级版本。
最后,我们采用均值池化方法聚合
output tokens,输出的representation将用于各类任务的预测。这是
RankMixer V2,它的基本架构与RankMixer差别不大。更多的是细节上的优化。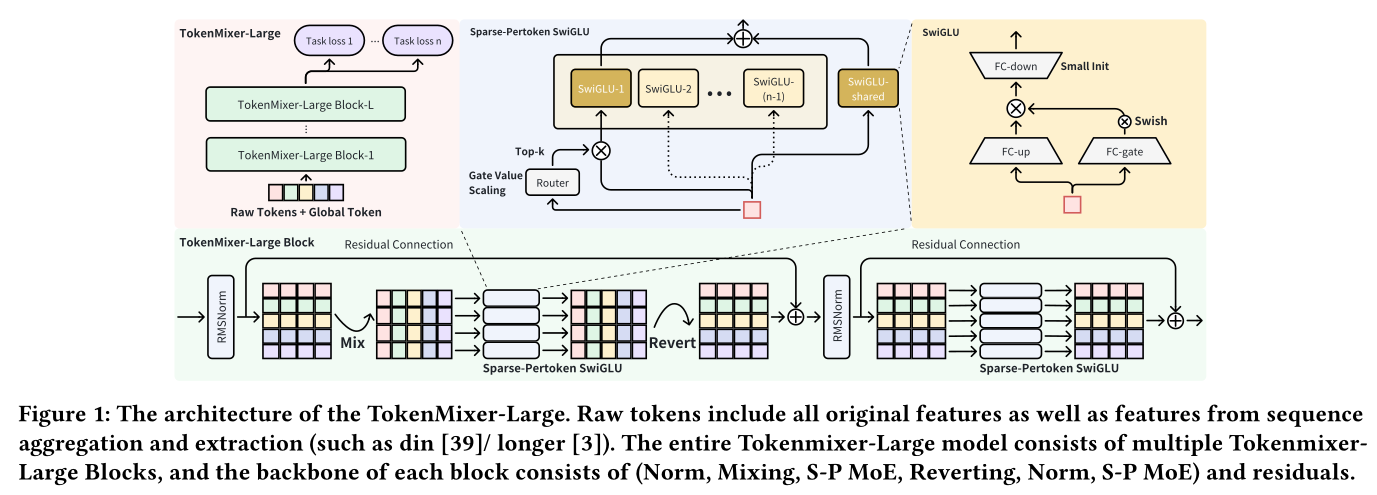
1.2.2 Tokenization
Semantic Group-wise Tokenizer:工业级推荐系统通常包含user features、item features、sequence features和cross features。其中,sequence features包括:覆盖了用户短期兴趣(DIN)、长期兴趣(SIM)、超长期兴趣(LONGER)的行为历史。第一步通过embedding layer将所有这些特征从高维稀疏空间投影到低维稠密空间,特征embedding向量由于
TokenMixer-Large是高度并行的架构设计,需要将变长的embedding representations转换为维度对齐的feature tokens,以便后续计算。为实现这一目标,我们根据semantic meanings对不同特性的embeddings进行分组,得到分组embedding拼接后,执行压缩和对齐操作。考虑到不同semantic groups代表不同的特征属性,我们在压缩和对齐过程中采用不同的DNN mappings,以保留其异构性:其中:
groups。如何分组?作者并未详细说明。根据
RankMixer的论文:对于序列特征,每一种序列都构成一个分组:
短期序列,用一个
Sequence Module来抽取短期兴趣representation长期序列,用另一个
Sequence Module来抽取长期兴趣representation超长期序列,用第三个
Sequence Module来抽取超长期兴趣representation
对于非序列特征,
User features、candidate features、Cross Features分别构成了各自的分组
Global Token:除语义分组的tokens之外,我们还引入了专门用于封装全局信息的global token。受BERT中[CLS] token机制的启发,该global token用于聚合全局信息并将其传播至其他tokens:TokenMixer-Large的final input为global token与enhanced tokens的组合:在实验章节,
Global Token的auc gain较小,仅仅0.02%。
1.2.3 TokenMixer-Large Block
TokenMixer-Large采用multiple TokenMixer-Large blocks的堆叠结构,每个block可分解为mixing module、pertoken SwiGLU、normalization等三个组件。Mixing & Reverting:一个RankMixer (TokenMixer) block可以表示为如下的形式:第一行:对每个
第二行:将每个
第三行:将所有
原始
input的tokens数量为tokens数量为residual connections无法在层间平稳传播。为克服这一限制,我们设计的
TokenMixer-Large采用特殊的双层TokenMixer结构:第一层负责原始
tokens之间的信息混合。第二层专门还原
mixed tokens的维度。注意:这里的残差连接是
这种对称的
"mixing–reverting"设计确保了模块间input and output的维度一致性,从而建立了从initial input到deep network的连续的信号通路。它实现了每层稳定的residual connections,并有效防止了梯度信息的丢失。与RankMixer (TokenMixer)的详细对比见1.3节。mixing阶段实现了信息的cross-token融合。在mixing-reverting阶段引入了操作pSwiGLU,促进了信息融合。Pertoken SwiGLU:RankMixer (TokenMixer)引入了一种参数隔离的feed-forward network: FFN架构,即per-token FFN,旨在建模不同tokens间的特征异构性。在TokenMixer-Large中,我们将per-token FFN升级为pertoken SwiGLU:其中:
MLP,Swish激活函数:当
Swish激活函数简化为token。
实验表明,
Pertoken SwiGLU比pertoken FFN在AUC上提升了0.1%。SwiGLU的门控相当于为每个token的特征分配 “动态权重”,能更精准地捕捉推荐场景中 “用户兴趣 - 物品特征” 的复杂非线性关联,提升模型的CTR/CVR预测准确性。普通
FFN的ReLU激活函数会导致梯度传播中断,尤其在深层模型中,训练后期梯度几乎无法传递到浅层;SwiGLU采用Swish激活,是处处可导的平滑非线性函数,且梯度始终非零,能让梯度更顺畅地在深层模型中传播。
Residual & Normalization:标准残差连接如Figure 1所示。此外,我们用更轻量的RMSNorm替代了标准的LayerNorm。通过移除LayerNorm中的均值中心化(mean-centering)步骤,RMSNorm在保留核心归一化能力的同时,大幅降低了计算开销。然而,在RankMixer (TokenMixer)的Post-Norm设计下,我们经常遇到数值爆炸和梯度不稳定的问题。为解决这些稳定性问题,我们采用Pre-Norm设计替代原有的Post-Norm架构,详细对比见附录A.4。给定一个向量
LayerNorm:其中:
RMSNorm:.
Inter-Residual & Auxiliary Loss:如Figure 2所示,除标准的residual connections外,我们还加入了inter-residual connections(通常每隔2层或3层添加),以加强层间的信息流动,其主要作用是解决梯度消失问题。通过增强lower-layer features向higher layers的传递,加速了early layers中参数的收敛,缓解了deep networks中梯度的逐渐衰减。不建议在最后一层添加interval-residual connections,因为最后一层的主要作用是提取高度抽象的、high-level的特征,为后续的分类任务提供精准的支持,引入过多原始的lower-level information可能会干扰这一抽象过程,从而损害最终的任务性能。同时,我们将
lower-layers计算得到的logits与higher layers的logits相结合,计算joint loss,形成轻量级的辅助损失(auxiliary loss)。该机制本质上让lower layers学会"estimate deviations in higher-layer features",从而增强其feature representation能力,有助于防止随着网络深度增加,lower-layer训练不充分的问题,实现更充分的parameter learning,让deep model的性能更稳定。这个
joint loss如何设计?论文并未说明。读者猜测:就是标准的logloss:对于
MainTower:基于main logit来计算logloss。对于
AuxLoss1:Block-6和Block-4的output都馈入到a shared AuxTower1中,然后将它们的logit相加,然后计算logloss。对于
AuxLoss2:Block-6、Block-4和Block-2的output都馈入到a shared AuxTower2中,然后将它们的logit相加,然后计算logloss。
1.2.4 Sparse-Pertoken MoE
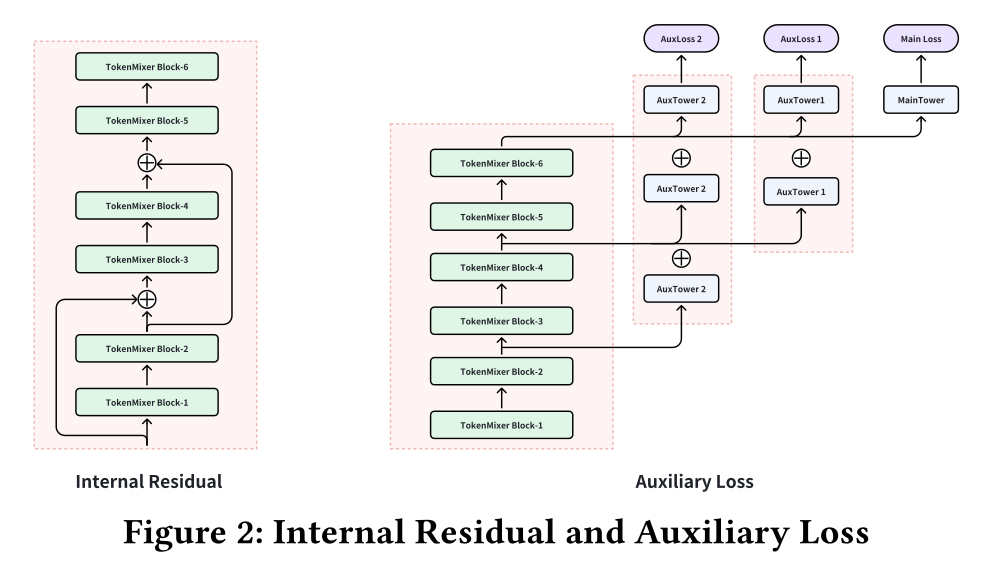
为进一步提升
TokenMixer-Large的成本效益,我们设计了Sparse-pertoken MoE机制,在pertoken SwiGLU的基础上,将每个expert扩展为多个sub-experts并进行稀疏激活。与RankMixer的"dense training and sparse serving"相比,该机制实现了"sparse training and sparse serving",大幅降低了超大规模推荐模型的训练成本和推理成本。First Enlarge, Then Sparse:在迭代策略上,我们采用"first enlarge, then sparse"的思路:先扩大模型规模以提升效果,再对pertoken SwiGLUs进行拆分并稀疏激活,以获得效率收益。Sparse-Pertoken MoE (S-P MoE)可表示为:其中:
token的experts数量。Expert中,先将hidden representation扩张注意:每个
Expert的宽度需要除以Experts来代替一个大的Expert(即,SwiGLU)。token。routertop-k数量。selected experts的可能性进行归一化,代表activated experts的概率之和为1。详细的设计理念和实验结果见附录A.1。给定
tokenexperts,则其中:
训练和推断过程中使用
top-k。但是,top-k操作在训练过程中不可导。此时采用Straight-Through Estimator (STE)方案:前向传播:执行真实的
hard top-k操作(选概率最高的k个experts,其余置0`),保证训练时的激活模式与推理一致。反向传播:忽略
top-k的离散性,梯度仅回传到选中的experts所对应的概率维度。
Shared Expert:目前,多款基于MoE架构的LLMs提及使用shared experts来提升训练的稳定性和效果,我们在实际应用中也采用了这一设计。值得注意的是,此处的shared expert仍为per token的,而非对所有tokens全局可见的shared expert:这段话的含义是:
SharedExpert的结构是每个token共享的,但是它的input-output是per-token的。也就是:给定
tokenSharedExpert的输入仅仅依赖于tokens。给定
tokenSharedExpert的输出仅用于tokens。
SharedExpert代表了一个共享的extractor,用于抽取某种per-token的、共享的属性。“所有
tokens全局可见的”,这句话的意思是SharedExpert的输出被馈入给所有tokens。Gate Value Scaling:在实际应用中,我们发现由于routersoftmax将router logits转换为和为1的概率分布,这一summing = 1的约束会导致SwiGLUs的梯度更新不足。因此,我们在expert networks的更新更充分:根据实验部分的总结,
experts(包含SharedExpert),则这里的稀疏率为Down-Matrix Small Init:受Rezero(《Zero-shot text-to-image generation》)启发,我们降低了SwiGLU中final layer下投影矩阵xavier_uniform,并将默认标准差超参数从1降至0.01。这一调整让训练初期0,使模块在初始阶段表现为近似恒等映射,从而提升训练稳定性;同时也有助于缓解SwiGLU中上投影矩阵output value爆炸的问题。结合上述改进,我们的
MoE model版本仅激活一半参数,就能实现与fully activated dense model近乎持平的性能。我们还从Figure 7中观察到,引入这些改进后,tokens的负载达到了良好的平衡,无需额外的load-balancing loss,详细分析见附录A.2。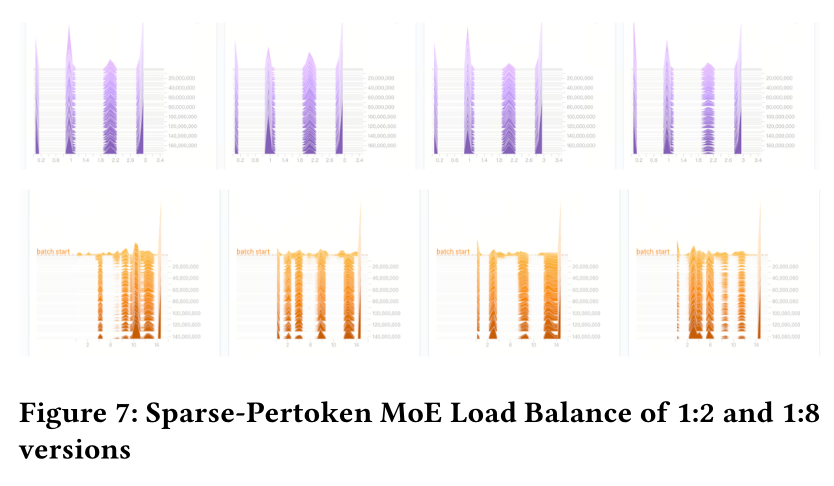
1.2.5 Training/Serving Optimization
我们研发了一套高性能算子,提升
TokenMixer-Large在训练和推理中的效率。高性能自定义算子:整体工作流程如
Figure 3所示。MoEPermute将input从batch-first格式转换为expert-first格式,确保每个expert FFN的input是连续的。随后,
MoEGroupedFFN算子(MoE-GroupedSwiglu and MoEGroupedGemm)通过单个kernel计算所有expert FFNs,减少算子调度(operator scheduling)的开销,提升设备利用率。最后,
MoEUnpermute计算multiple activated experts的输出的加权和,作为final output。
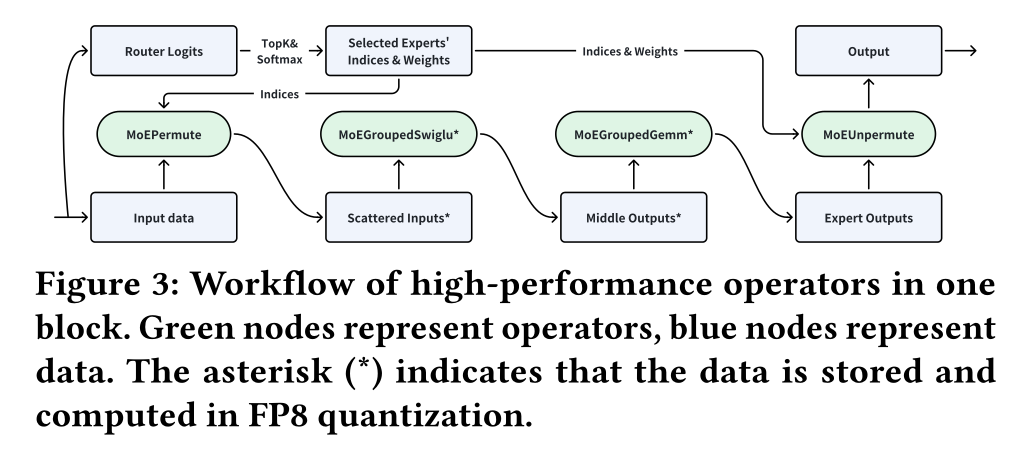
各算子在训练和推理中的耗时如
Table 1所示,其中MoEGroupedFFN是延迟的主要贡献者;MoEGroupedFFN在推理耗时中的占比更高,因为即使推理时采用smaller batch sizes也不会降低其内存访问量。
FP8 Quantization:推理阶段,我们采用FP8 E4M3 post-training quantization;训练全程保持bfloat16精度。线上实验表明,FP8 serving在不损失模型准确性的前提下,实现了1.7倍的加速。如Figure 3所示:input在MoEPermute中完成量化,所有expert weights均已被提前量化。随后,
MoEGroupedSwiglu融合the quantization of outputs,直接生成quantized activations。同理,
MoEGroupedGemm采用FP8进行计算,输出结果为bfloat16格式。
Token Parallel:在分布式multi-device environments中扩展TokenMixer-Large架构会带来显著的瓶颈。对于训练而言,主要挑战是
GPU的显存容量和整体训练时间。随着模型规模扩大,模型的参数和activations可能超出单台设备的显存上限。对于推理而言,问题更为突出:
online inference with small batch sizes使计算成为memory-bandwidth-bound,导致硬件利用率低、吞吐量差。
简单的
model-parallel solution会将pertoken operation weights分片到各设备,每次计算之前和之后都需要执行"all2all" operation以交换sharding layouts,这使得每个block的通信步骤多达四次。为解决这些问题,我们提出Token Parallel,一种专为TokenMixer-Large架构设计的model-parallelism策略,将模型参数(尤其是pertoken operation weights)和计算任务在多个设备间进行划分。实现方式:
Token Parallel的实现将data sharding与TokenMixer-Large block的计算流程(Mixing -> Reverting -> a pertoken operation)对齐。以下所有张量均可视为分布式张量,我们用Shard(dim)表示张量在指定维度上被分片。
采用
Token Parallel后,outputtoken dimension被分片(Shard(token)),并直接被馈入下一个block;而下一个block的initial "split" operation可基于该layout执行,从而省去了两次额外的通信步骤,使layers的通信开销从a final all_to_all来恢复the batch sharding)。Token Parallel策略在训练和推理中均带来了显著的性能提升。在production serving中,采用4-way token parallelism的TokenMixer-Large模型(global batch size = 320),其吞吐量相比non-parallelized baseline提升29.2%;通过将通信与计算重叠(如采用细粒度的micro-batch调度、in-kernel的computation-communication重叠等技术),这一增益进一步提升至96.6%。
1.3 实验
数据集:本研究的离线实验主要基于
Douyin的main feed上电商场景的真实训练数据集。该数据集来源于平台的线上日志和user feedback labels,包含商品点击、转化、商品交易总额(Gross Merchandise Volume: GMV)等指标。训练集包含500余种特征(包括数值特征、ID类特征、交叉特征、序列特征),覆盖数亿独立用户。经采样后,数据集每日约有400 million条记录,数据收集周期为两年。离线实验还包含
Douyin Ads和Douyin Live Streaming场景的真实训练数据。经采样后,它们每日数据量分别达到300 million和17 billion条记录。评估指标:我们以
AUC和用User-Level AUC: UAUC作为主要的效果指标,以dense parameter数量(不含sparse embeddings参数)、FLOPs(模型处理a single batch of 2048 samples所需的浮点运算次数)和MFU作为效率指标。baselines:我们主要对比以下公认的SOTA基线模型:DLRM-MLP:采用multi-layer perceptrons: MLP来实现feature interaction。DCNv2:"Deep & Cross Network"的改进版本,具备更深的、更强的feature-crossing能力。AutoInt:通过multi-head self-attention机制,自动地、显式地学习高阶feature combinations。HiFormer:对标准的self-attention进行改进,采用heterogeneous self-attention layers和低秩近似(low-rank approximation)。DHEN:采用集成的思想,在单个block中融合多种feature interaction modules(DCN/SelfAttention/FactorizationMachineBlock),并堆叠multiple layers。Wukong:将factorization machine module: FMB和linear compression module: LCB集成在一起,进行多层堆叠,并研究feature interactions的scaling laws。Group Transformer:我们针对建模heterogeneous features而设计的Transformer variant(公司内部研究的版本),通过grouping features并聚合为少量的tokens,降低self-attention机制的计算复杂度,并采用pertoken Q/K/V/O来增强模型的representing heterogeneous features的能力。FAT:Group Transformer的升级版本,在pertoken Q/K/V/O的基础上,采用正交基组合(orthogonal basis combinations)来提升模型性能。RankMixer:以TokenMixer block为核心(替代self-attention机制),大幅降低计算成本。
所有实验均在混合分布式训练框架(
hybrid distributed training framework)中进行;电商场景使用64 GPUs,Feed Ads和Live Streaming使用256 GPUs。该框架对sparse parameters采用异步更新,对dense parameters采用同步更新。所有模型的optimizer hyperparameters保持一致:dense and sparse parts均采用Adagrad optimizer,学习率分别设为0.01和0.05。
1.3.1 与 SOTA 模型的对比
Table 2的结果表明,TokenMixer-Large性能优于所有SOTA模型,相比MLP-500M baseline,其CTCVR的AUC提升了1.14%。值得注意的是,
Wukong, Group Transformer, and RankMixer等模型采用了pertoken network设计,因此它们的每个batch(batch size = 2048)的FLOPs远低于其他baselines。此外,我们发现
Sparse-Pertoken MoE在仅激活一半参数的情况下,性能可与dense版本持平,大幅提升了模型训练/推理的投资回报率(ROI)。
HiFormer也是per-token FFN的,但是它的FLOPs要大得多。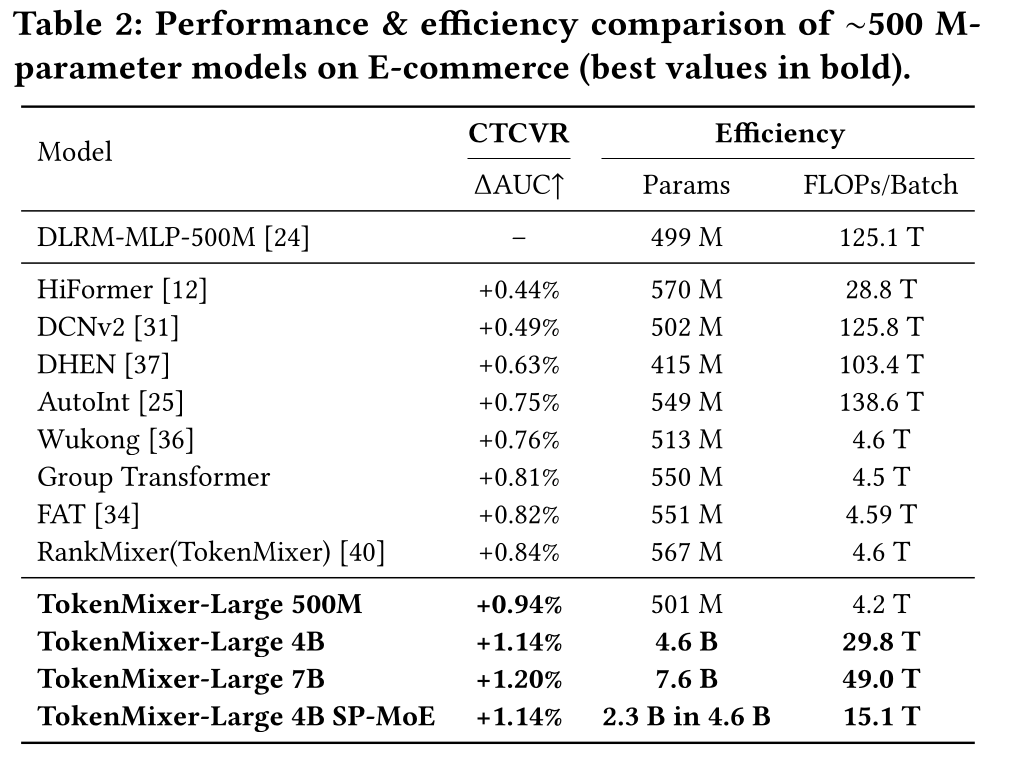
1.3.2 与 Rankmixer (TokenMixer) 的详细对比
我们对
TokenMixer-Large和Rankmixer (TokenMixer)进行了详细对比,对三个关键设计维度定义如下:Standard Residual (SR):表示blocks之间是否存在标准的residual connections。Original Token Residual (OTR):表示原始tokens的语义信息是否被保留并传播至后续层。例如,若an input of 40 tokens被混合成16 new tokens,且后续始终保持16 tokens,那么40 tokens的原始语义信息无法一直保留至final output。Token Semantic Alignment in Residual (TSA):表示残差操作tokens的语义是否保持一致。在RankMixer中,tokens after mixing,而residual inputtokens before mixing,导致语义错位。
由于
Group Transformer的每一层都不会改变input tokens的数量,且在执行attention and pertokenFFN的计算后,token_dim上各位置的语义保持对齐,因此满足所有上述三个特性。相比之下,
RankMixer在residual connections中直接将tokens before mixing和tokens after mixing相加,破坏了token_dim上各位置的semantic alignment;此外,除非刻意设计new tokens数量与original tokens数量一致,否则RankMixer的original token residual无法在网络中有效传播。如
Table 3所示,TokenMixer-Large精准解决了RankMixer中存在的这些问题,满足所有三个设计特性的同时,实现了最优性能。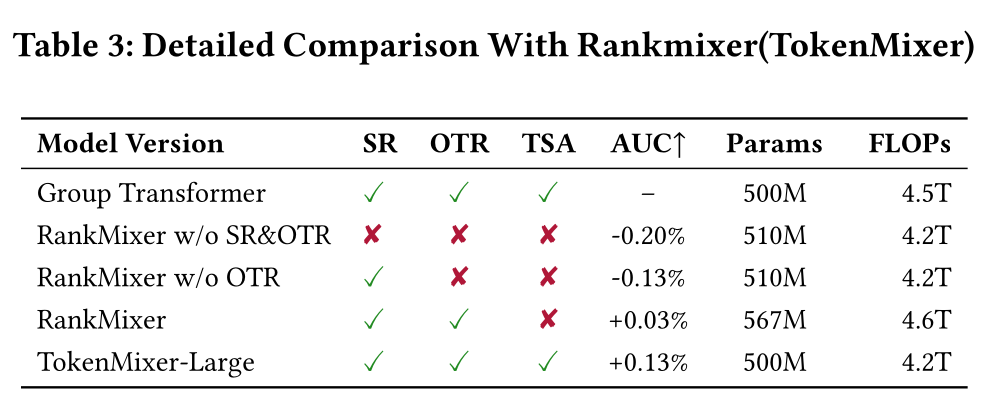
1.3.3 Scaling Laws
Scaling Laws of SOTA Models:在Figure 5中,我们选取了性能最优的两个模型——RankMixer和TokenMixer-Large,分析其scaling laws。结果表明,两个模型的AUC均随参数数量/FLOPs的增加而提升;整体而言,TokenMixer-Large性能最优,且性能提升的斜率更陡。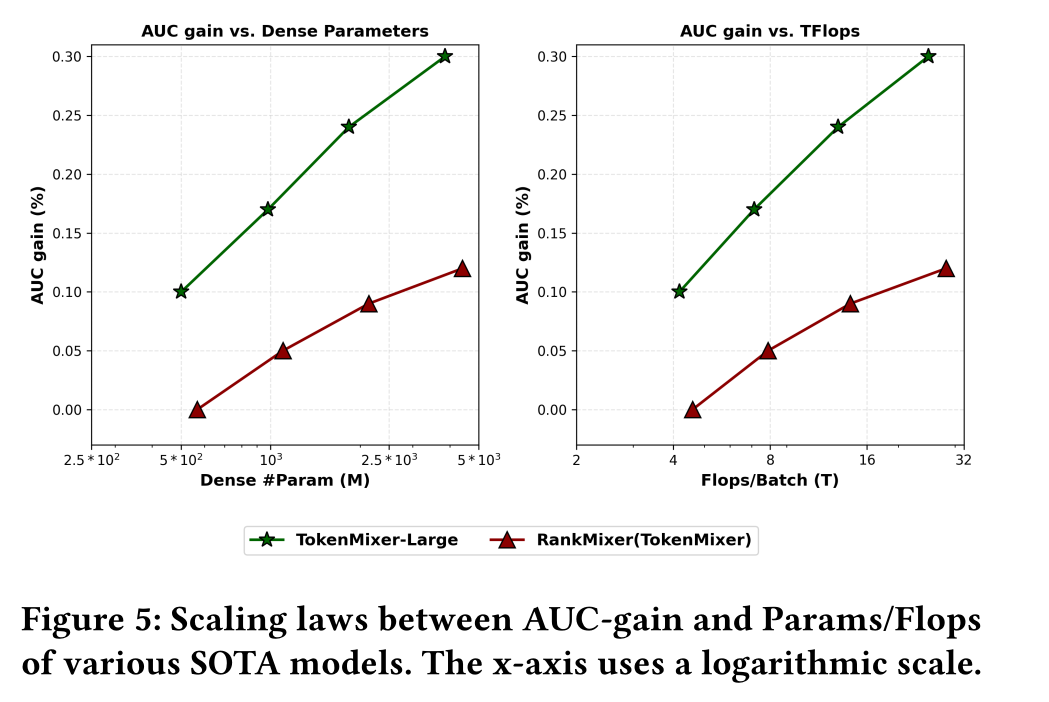
Scaling Laws of TokenMixer-Large on Different Scenarios:我们通过增加宽度scaling factorSwiGLU hidden expansion)来扩大模型规模,得出两个关键结论:多维度均衡扩展的收益更高:与
1B参数以下的RankMixer早期实验不同,我们发现单独扩展任意一个维度(宽度、深度、scaling factor)虽能带来收益,但会逐渐遭遇瓶颈;当参数规模超过1B时,需要对所有维度进行均衡扩展,才能实现更优的收益。更大的模型需要更多数据实现收敛:如
Table 4所示,模型从30M参数扩展至90M参数时,仅需14天的训练样本即可收敛;而从500M参数扩展至2B参数时,需要60天的样本才能完全收敛。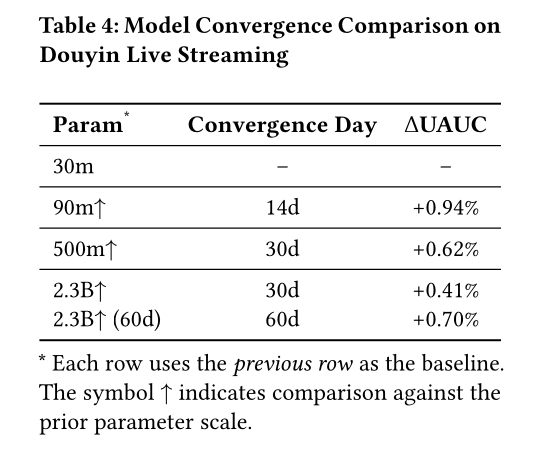
我们还在不同的业务场景中验证了
TokenMixer-Large的scaling laws,发现每个场景均存在显著的scaling law效应。最终,在Feed Ads、电商、Live Streaming的离线实验中,我们成功将模型分别扩展至15B、7B、4B参数;在线上流量实验中,相应扩展至7B、4B、2B参数,实现了显著的scaling收益。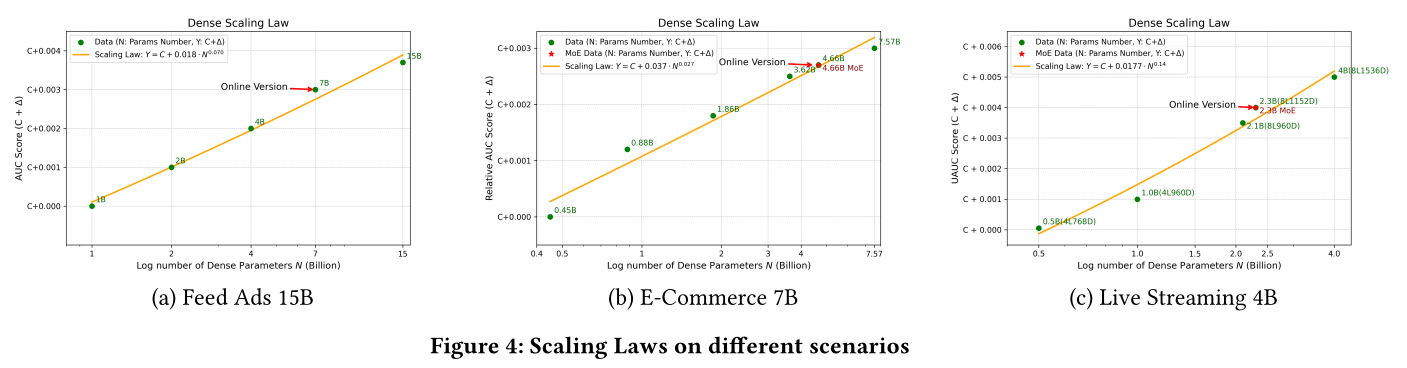
1.3.4 消融实验
TokenMixer-Large Block的消融实验:如Table 5所示,我们对TokenMixer-Large中的不同模块进行了消融实验,包括Tokenization、mixing & reverting、pertoken SwiGLU、residual connections等。结果表明,移除任何一个模块都会导致性能下降,其中"mixing & reverting"和Pertoken-SwiGLU对整体性能的影响最为显著。Pure Model Design:随着TokenMixer-Large参数数量的持续增加,大量的small, I/O-bound, fragmented operators(如DCN、LHUC)带来的收益,均可由TokenMixer-Large自身实现。此外,由于TokenMixer-Large仅包含无参数(parameterless)的mixing and reverting操作,以及大量的GroupedGemm操作,其效率极高,详细分析见附录A.3。Normalization:我们对归一化的应用位置进行了全面分析,包括pre-norm、post-norm、sandwich norm,详细分析见附录A.4。Mixing Strategy:最后,我们对mixer的splitting策略进行了详细研究,详细分析见附录A.5。

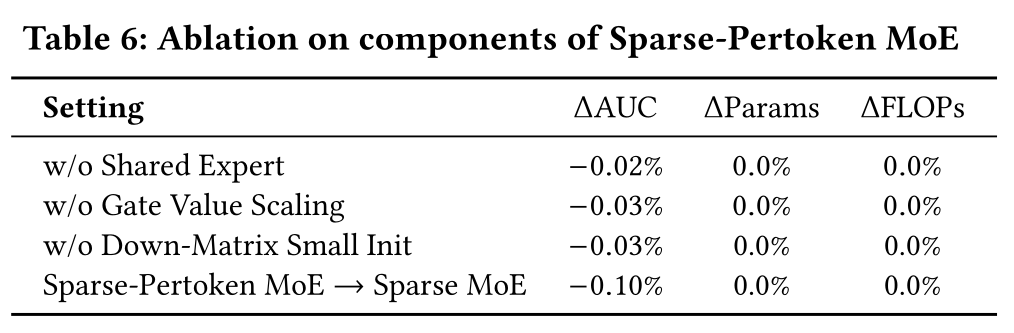
Sparse-Pertoken MoE的消融实验:如Table 6所示,我们对Sparse-Pertoken MoE的不同模块进行了消融实验,包括shared expert、Gate Value Scaling、Down-Matrix Small Init,发现每个模块均对最终的性能提升有积极贡献。上述操作不会引入额外的参数或计算开销(FLOPs),因此是无代价(cost-free)的改进。此外,在总参数数量和激活参数数量均对齐的条件下,我们将
sparse-pertoken MoE与standard MoE进行对比,发现standard MoE的性能显著下降。这是因为sparse-pertoken MoE相当于为standard MoE赋予了一种路由先验(routing prior),即每个token可激活的experts并非共享的,从而避免了训练初期routers难以学习的问题。注意:“在总参数数量和激活参数数量均对齐的条件下”,这意味着
sparse-pertoken MoE与standard MoE具有不同的参数配置。Gate Value Scaling:同时,我们对Gate Value Scaling进行了全面实验,发现最优的scaling factor因模型稀疏率(activated parameters/total parameters)不同而变化:稀疏率(sparsity ratios)为1:2的模型在scaling factor = 2时性能最优;而稀疏率为1:4的模型在scaling factor = 4时达到最优效果。scaling factor与稀疏率呈反比关系。详细分析见附录A.6。Down Matrix Small Initialization:将SwiGLU中last down matrix0.01倍,可显著提升模型性能和训练稳定性,详细分析见附录A.7。
1.3.5 线上性能
为验证
TokenMixer-Large的有效性,我们已将其在Douyin的多个场景落地部署,包括信息流广告(feed advertising)、直播电商(live streaming e-commerce)、普通直播(live streaming),这些部署覆盖了Douyin的大部分核心业务,服务数亿用户。针对每个业务场景,我们采用不同的关键性能指标:Douyin Live-Streaming E-Commerce:以商品交易总额(Gross Merchandise Volume: GMV)和订单量作为核心线上业务指标。Douyin Feed Advertising:以广告主满意度评分(Advertiser Satisfaction Score: ADSS)和广告主价值(Advertiser Value: ADVV)作为主要线上业务指标。Douyin Live Streaming (Non-E-Commerce):以总支付金额(Total Payment Amount)作为核心线上业务指标。
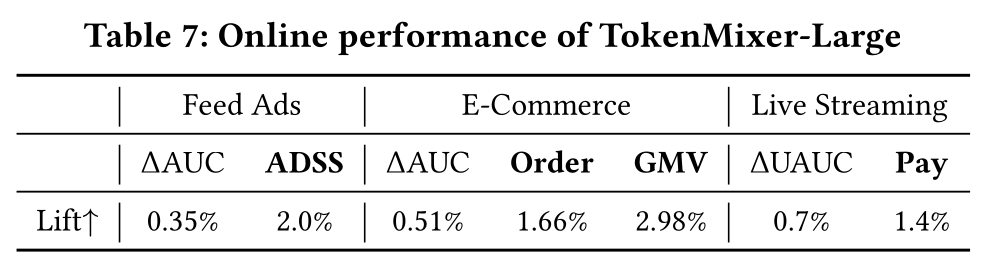
广告、电商、直播场景的线上基线模型分别为
RankMixer-1B、RankMixer-150M、RankMixer-500M。我们将TokenMixer-Large相应扩展至7B、4B、2B参数。如Table 7所示,结果表明:电商场景中,
TokenMixer-Large实现订单量提升1.66%、人均预览支付GMV(per-capita preview payment GMV)提升2.98%。广告场景中
ADSS提升2.0%。直播场景中营收增长
1.4%。
1.4 结论
本文提出了
TokenMixer的升级版本——TokenMixer-Large。我们深入分析了原始TokenMixer设计中的局限性,并对deep layer modeling和Sparse-Pertoken MoE进行了详细的研究与探讨。在工程层面,我们实现了一套高效的MoE operators,以及专为Pertoken experts设计的Token-Parallel策略。TokenMixer-Large已在ByteDance多个场景实现了显著的离线和线上性能提升,服务数亿用户。
二、附录
A.1 First Enlarge Then Sparse
MoE的传统应用方式是在保持activated experts数量不变的前提下,直接增加总参数数量。但我们认为,这种增加experts数量的方式相当于在单一维度上扩展Pertoken SwiGLU的hidden expansion,其上限极易达到。因此,我们选择先设计性能最优的dense模型,再通过稀疏化来实现效率收益,同时将性能损失降至最低。为此,我们采用
"First Enlarge, Then Sparse"的策略,具体而言,将TokenMixer-Large中SwiGLU内的所有FC networks细化为细粒度版本,再进行sparse activation。Figure 6展示了dense model、1:2 sparsity MoE、1:4 sparsity MoE的具体形式。目前:在
1:2 sparsity下,我们能实现offline/online性能近乎零损失。在
1:4 sparsity下,性能仅有轻微下降。但随着
sparsity的增加,SwiGLU中的GEMM组件占比会进一步降低,因此更高的sparsity gains依赖于更大的模型规模和更高的GEMM占比。
因此,我们选择投资回报率(
ROI)最高的1:2版本进行线上部署。能否在保持性能无损失的前提下实现超过1:8 sparsity,仍在探索中。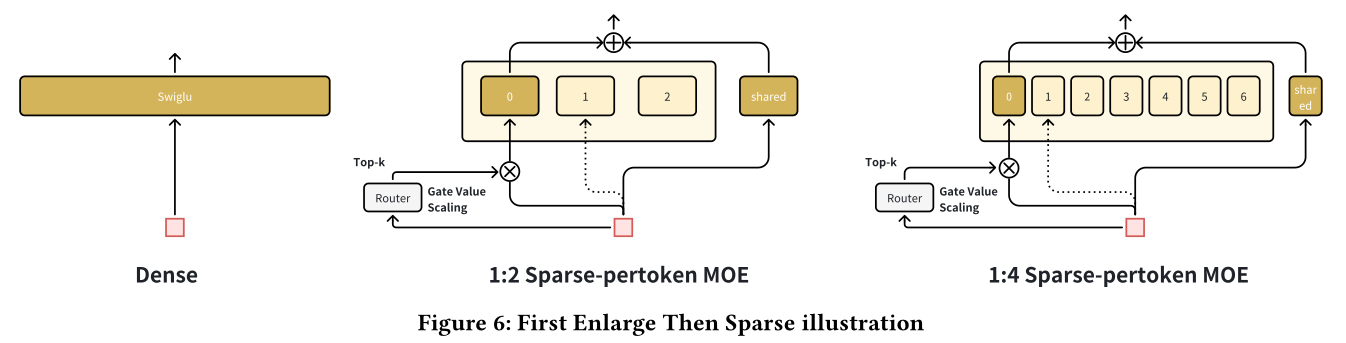
A.2 Load Balance
Figure 7上半部分展示了电商场景下4.6B Sparse-Pertoken MoE的load balancing示例。我们使用one shared expert和three routing experts,共激活two experts。在1:2 sparsity下,该模型的总参数数量与MoE一致,且offline/online性能与dense model (4.6B dense)持平。如图所示,我们展示了每个token的activation状态,其中索引0-2代表routing experts,索引3代表shared expert。可见整体负载达到了良好的平衡。由于索引3为始终激活的shared expert,其激活程度高于索引0-2。然而,随着
sparsity增加(从1:2至1:8),Figure 7下半部分显示模型的负载平衡出现一定程度的恶化。我们也尝试了Switch Transformer(《Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity》)和Z-loss(《St-moe: Designing stable and transferable sparse expert models》)的负载平衡方法,能带来一定收益;但考虑到目前上线的1:2 sparsity版本的投资回报率最高,且不存在负载平衡问题,该部分内容将在未来进一步探索。
A.3 Pure Model Design
在我们的
baseline模型中,我们手动对序列的pooling results进行过滤,并馈入到一个DCN模块进行特征交叉。DCN模块的输出作为additional tokens,补充至骨干网络TokenMixer的输入中。但该设计存在一个主要问题:随着骨干网络TokenMixer复杂度的持续提升,前端DCN带来的增益逐渐降低。实验数据如Table 9所示:在
150M参数的模型中,DCN能带来0.09%的增益。而当模型参数扩展至
700M时,移除DCN结构不再造成任何效果损失。
除
DCN外,我们还尝试将DHEN、LHUC等结构与TokenMixer-Large融合,采用并行和串行两种配置方式。实际结果表明,随着TokenMixer-Large参数规模的扩大,这些small, numerous, and IO-bound fragmented operators带来的收益,可完全由TokenMixer-Large自身实现。此外,TokenMixer-Large block的Model FLOPs Utilization: MFU可达60%,表现优异。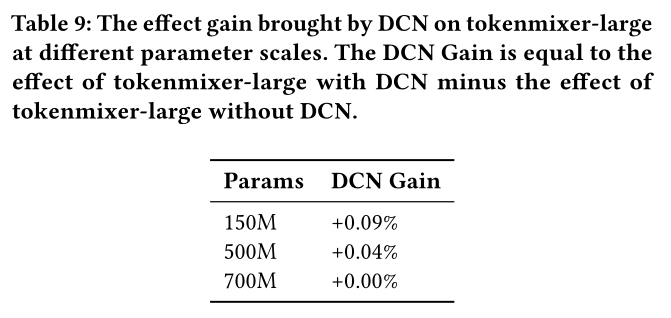
A.4 Normalization and Position
RMSNorm可表示为:其中:
normalization的可学习参数。考虑到
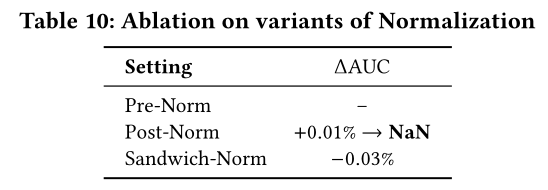
input经过normalization layer后,kernel matrix的bias在数学层面失去实际意义,同时受Llama系列模型的设计启发,我们移除了所有bias kernel matrices,并将TokenMixer-Large中所有Norm由LayerNorm替换为RMSNorm。实测结果显示,该改动在保持模型性能完全不变的前提下,实现了端到端吞吐量8.4%的提升。我们针对
normalization的应用位置开展了全面的对比分析,涵盖前归一化(Pre-Norm)、后归一化(Post-Norm)和三明治归一化(Sandwich-Norm)三种方式,结果如Table 10所示。从效果来看:Post-Norm能带来更优的性能表现,但极易引发梯度爆炸问题。Pre-Norm的效果虽略逊于Post-Norm,却能保障模型训练的稳定性。
A.5 Mixing Strategy
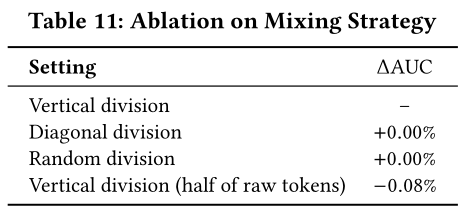
我们针对
mixer的splitting策略开展了详细的研究,结果如Table 11所示。研究发现,只要每个newly mixed token都包含全部original token information,不同的split-concat策略对模型性能无显著影响。作为对照实验,我们尝试仅对一半original token information进行混合,模型性能出现了明显的下降。给定
tokens的embedding的序列垂直划分:即论文中介绍的方式,第
mixed token包含对角线划分:第一个
mixed token包含:第一个token的第一个元素、第二个token的第二个元素、第三个token的第三个元素,...。随机划分:随机指定一个映射方式,从而进行划分。
A.6 Gate Value Scaling Analysis
在将
dense model转换为MoE架构的过程中,我们发现在router functionrouter’s output以增强selected (routed) experts的gradient updates——能显著提升模型性能。在引入a shared expert的情况下,MoE formulation可表示为:其中:
routing weights;expert network;shared expert network。由此,
Sparse-pertoken MoE的数学表达式为:实际实验中我们发现,缩放因子(
scaling factor)sparsity密切相关,具体而言,将sparsity ratio的倒数时,模型能取得最佳性能,结果如Table 12所示。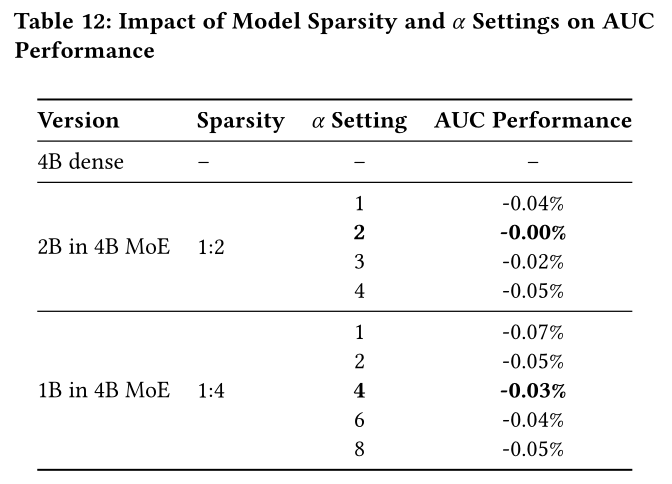
我们认为
Gate Value Scaling操作具备有效性的原因,以及将sparsity ratio倒数的核心逻辑如下:SwiGLU中每个全连接层(fully connected: FC)的梯度更新,需要与原始dense model保持一致。我们所采用的"first enlarge, then sparse"策略,将SwiGLU中的一个large kernel拆分为多个smaller kernels——这一思路与DeepSeek-MoE(《Deepseekmoe: Towards ultimate expert specialization in mixture-of-experts language models》)中的fine-grained expert设计相似,但核心区别在于我们并未增加activated parameters的数量(topk值)。这意味着,模型的拆分粒度越细,每个expert被更新的概率就越低。因此,我们需要在an expert被激活时放大其梯度幅度,而Gate Value Scaling操作恰好实现了这一目标。另一种可能性是,
Gate Value Scaling提升了weighted sum-pooling的结果,进而增大了模型每层输出的方差。为此,我们尝试通过直接增大Expert kernel的初始方差(initial variance),从另一角度模拟放大输出Table 13所示,直接增大Expert kernel的初始方差不仅未提升性能,反而导致结果出现显著恶化。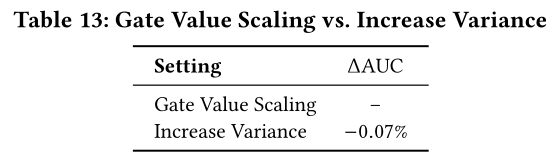
A.7 Down-Matrix Small Initialization
为了解决
deeper models的收敛难题,除引入standard residual connections、interval residual connections和residual loss (resloss)外,我们还借鉴了Rezero的设计理念。本研究中我们采用
Xavier Normal Distribution初始化,其计算公式为:其中:
kernal矩阵;input单元数量和output单元数量;initialization scale,它的默认取值为1。我们将
SwiGLU block中final down-projection matrixinitialization scale直接降至0.01,而保持initialization scale为1。如Figure 8所示,该调整让deep models的收敛。此外,SwiGLU结构中的intermediate hidden layer)的activations和梯度幅度,进而引发局部不稳定性,降低initialization scale也有助于约束这些intermediate representations的幅值,提升训练的稳定性。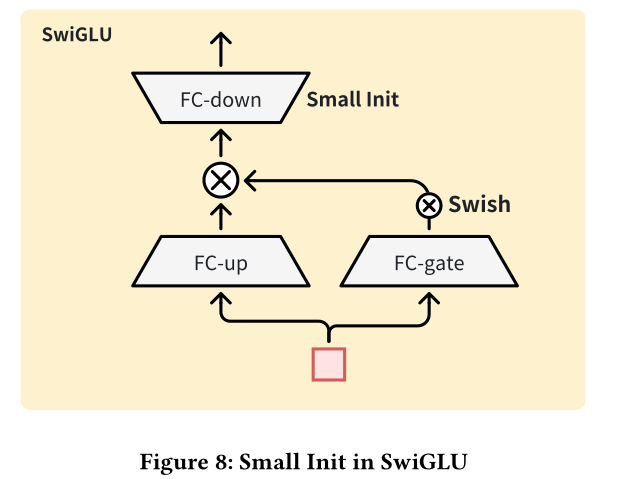
如
Table 14所示,我们严格评估了在不同scale(从1到0.01)和不同位置(从all layers到reverse ordering)下的small initialization。结果表明,专门对small initialization实现了最佳性能。