一、UniMixer [2026]
《UniMixer: A Unified Architecture for Scaling Laws in Recommendation Systems》
近年来,推荐模型的
scaling laws受到越来越多的关注,它决定了推荐系统性能与参数、计算量(FLOPs)之间的关系。当前,实现推荐模型scaling的主流架构主要有三种,分别是attention-based方法、TokenMixer-based方法以及factorization-machine-based方法,这些方法在设计理念与架构结构上存在本质差异。本文提出一种面向推荐系统的统一的scaling架构——UniMixer,旨在提升scaling效率,并构建一个统一了主流scaling blocks的理论框架。通过将rule-based TokenMixer转化为等价的参数化结构,我们构建了一个通用的参数化的feature mixing模块,使token mixing模式可在模型训练过程中被优化和被学习。同时,通用的参数化的token mixing移除了TokenMixer中要求heads数量与tokens数量相等的约束。此外,我们为推荐系统建立了统一的scaling module设计框架,打通了attention-based方法、TokenMixer-based方法、以及factorization-machine-based方法之间的联系。为进一步提升scaling ROI,我们设计了轻量级UniMixing模块——UniMixing-Lite,在大幅压缩模型参数与计算成本的同时显著提升模型性能。scaling curves如下图所示。本文通过大量离线与在线实验验证了UniMixer优异的scaling能力。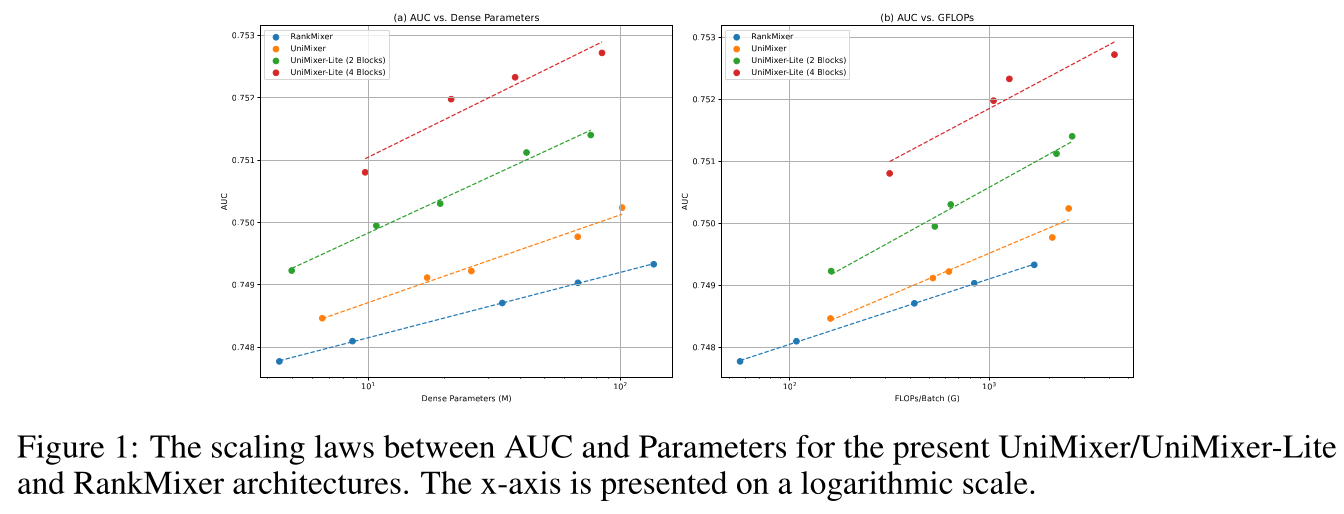
大语言模型(
Large language models: LLMs)展现出一个令人瞩目的现象:随着模型规模、数据量与计算资源的增加,性能稳步提升,这一现象被称为scaling laws。LLMs中显著的性能scaling效果启发了推荐系统领域,研究者开始探索适配推荐任务的scaling框架。近年来,研究人员尝试设计scaling模块并多层堆叠,以提升ranking模型复杂度,从而实现模型性能与模型规模、计算成本(如参数、FLOPs)之间的scaling laws。推荐系统基于大量的
multi-field的user and item features,预测用户行为,为用户展示最相关的内容,提升用户对推荐结果的positive engagements。这些multi-field features通常包含categorical features与dense features,具备更动态的embedding representations,可从多视角捕获信息。与自然语言处理(natural language processing: NLP)领域不同(在NLP中,所有tokens共享一个统一的embedding space),推荐任务的feature space天然具有异构性(heterogeneous)。因此,learning heterogeneous features interactions是推荐领域与NLP领域的根本区别。得益于
Transformer在LLMs中的巨大成功,一个自然的思路是修改Transformer模块以适配推荐任务,因为直接将Transformer模块作为推荐系统scaling laws的fundamental block通常不可行。为解决heterogeneous feature interaction problem,当前推荐模型的主流scaling架构可分为三类:attention-based方法、TokenMixer-based方法以及factorization-machine-based方法。attention-based方法为每个input token构建token-specific query, key, and value projections。如HiFormer(《Hiformer: Heterogeneous feature interactions learning with transformers for recommender systems》)、FAT(《From scaling to structured expressivity: Rethinking transformers for ctr prediction》)、HHFT(《Hhft: Hierarchical heterogeneous feature transformer for recommendation systems》) 等等。与
attention-based方法不同,TokenMixer-based方法采用rule-based token mixing操作实现heterogeneous feature interactions,避免计算两个heterogeneous semantic spaces之间的内积相似度。如RankMixer(《Rankmixer: Scaling up ranking models in industrial recommenders》)、TokenMixer-Large(《Tokenmixer-large: Scaling up large ranking models in industrial recommenders》)等等。而
factorization-machine-based方法则通过引入因子分解机(Factorization Machine: FM)模块,建模每层input embeddings之间的feature interactions。如Wukong(《Wukong: Towards a scaling law for large-scale recommendation》)、Kunlun(《Kunlun: Establishing scaling laws for massive-scale recommendation systems through unified architecture design》)等等。
这些框架基于完全不同的
scaling blocks来构建,却均具备模型性能scaling up的能力。这引发了一个根本性问题:我们能否为推荐系统构建一个统一的scaling module,融合现有主流scaling components的优势?为打通这些
scaling modules间的联系,我们首先为rule-based TokenMixer操作建立parameterized formulation。通过进一步优化计算流程,我们推导出计算成本更低的UniMixing模块。基于该设计与实验结果,我们提出一个统一的理论框架,整合推荐系统主流的scaling modules。此外,我们设计了轻量级的UniMixer模块,结合现有主流scaling blocks的优势,实现最优的参数效率与计算效率。我们希望该统一架构能助力推荐系统领域迎来属于自己的"attention moment"。本文主要贡献总结如下:
通过对
rule-based TokenMixer进行等价的参数化,揭示其feature interaction模式。提出统一的
scaling框架UniMixer,打通attention-based方法、TokenMixer-based方法、FM-based方法之间的差异与联系。通过优化计算流程,UniMixer显著降低训练与推理阶段的计算复杂度与GPU内存消耗。为进一步减少模型参数与计算成本,设计轻量级的
UniMixing模块——UniMixing-Lite,可同时利用attention-based架构与TokenMixer-based架构的优势,实现更优的scaling效率。开展大量离线与在线实验,证明
UniMixer具备优异的scaling能力。
1.1 相关工作
当前,面向大规模推荐系统建立
scaling laws的建模范式主要有三种:attention-based方法、TokenMixer-based方法、以及FM-based方法。Attention-Based Framework:近年来,推荐系统领域将Transformer适配用于CTR prediction。该范式的核心挑战是弥合token sequence的异构性与语言建模假设的sequential compositionality之间的差距。为此,
《Hiformer: Heterogeneous feature interactions learning with transformers for recommender systems》提出heterogeneous attention layer解决heterogeneous feature interaction问题,并设计HiFormer,将heterogeneous tokens展平为a single vector representation,显式建模高阶交互。此外,
Field-Aware Transformers: FAT通过factorized contextual alignment与cross-field modulation,将field-aware interaction的先验知识注入attention机制,进一步建立CTR prediction的经验scaling law(《From scaling to structured expressivity: Rethinking transformers for ctr prediction》)。HHFT通过交替使用heterogeneous Transformer blocks(保留domain-specific semantics)与HiFormer blocks(学习高阶交互),验证了这些scaling特性(《Hhft: Hierarchical heterogeneous feature transformer for recommendation systems》)。此外,在
dynamic user behavior modeling中,HSTUV1/V2、MARM、OneTrans、Climber、Hyformer、LLaTTE等方法利用attention机制捕获长程时序依赖。
这些方法凸显了统一
feature interaction与sequential behavior modeling以实现更鲁棒scaling laws的潜力。TokenMixer-Based Framework:尽管attention机制具备强大的feature interaction表达能力,但attention score computation的二次复杂度会带来高昂的计算成本。受计算机视觉领域MLP-Mixer(《Mlp-mixer: An all-mlp architecture for vision》)成功的启发,工业级推荐系统出现了向token-mixing架构的范式转变,诞生了RankMixer(《Rankmixer: Scaling up ranking models in industrial recommenders》)、Lemur(《Lemur: Large scale end-to-end multimodal recommendation》)、TokenMixer-Large(《Tokenmixer-large: Scaling up large ranking models in industrial recommenders》)等先进模型。例如,
RankMixer用静态的、无参数的token-mixing操作替代dynamic attention,在保持相当的FLOPs的同时,实现了有竞争力的CTR预测性能。在此基础上,
TokenMixer-Large通过引入辅助的residual connections与定制的loss functions,将该架构扩展至13 Billion参数规模,在various model dimensions上展现出良好的scaling laws。
尽管如此,当前
token-mixing算子的设计仍高度依赖经验规则,缺乏与传统FM-based方法或attention-based方法的严谨理论桥梁。FM-Based Framework:FM-based的开创性方法采用低阶pairwise modeling来实现推荐系统的feature interactions(《Factorization machines》),后续经过Field-aware FMs来泛化(《Field-aware factorization machines for ctr prediction》),可捕获field-specific and context-sensitive interactions。这类模型具备高可解释性与高效性,但固有地受限于低阶交互能力。为解决该局限,
DeepFM(《Deepfm: a factorization-machine based neural network for ctr prediction》)、AutoInt(《Autoint: Automatic feature interaction learning via self-attentive neural networks》)、DCN(《Deep & cross network for ad click predictions》、《Dcn v2: Improved deep & cross network and practical lessons for web-scale ctr prediction》)等多种神经网络扩展方法,融合MLP或transformer attention以捕获高阶交互。近期,
Wukong(《Wukong: Towards a scaling law for large-scale recommendation》)通过堆叠FM-style interaction blocks with linear compression,展现出良好的scaling特性。然而,
FM-based方法对显式低阶交互的依赖,仍限制了模型在参数量与FLOPs扩大时的性能提升,这与LLMs中观察到的predictive scaling laws形成对比。
1.2 预备知识
考虑一类判别式推荐任务,如
rating预测、点击率(click-through rate: CTR)预测、点击后转化率(post-click conversion rate: CVR)预测等,这类任务通常被建模为监督学习问题。数据集定义为feature fields。通常,输入特征categorical featuresdense featurescategorical features数量与dense features数量。
对于
CTR prediction与CVR prediction任务,核心目标是建立模型从而预测click或conversion的概率embedding representations更具动态性。与语言模型input tokens不同,推荐系统中的feature spaces天然具有异构性。因此,直接将大语言模型所用的Transformer架构迁移至推荐建模并不合适。迄今为止,推荐领域的
scaling laws主要通过三类foundational blocks及其变体实现。Heterogeneous Attention Layer:Heterogeneous-attention-based架构通常采用field-specific query, key, and value projections来实现heterogeneous feature interaction。给定input hidden statesheterogeneous attention layer的公式如下:其中:
query, key, and value projections的token-specific weights。这里
heterogeneous tokens数量,head编号。multi-head heterogeneous attention layer的输出计算如下:将
multi-head heterogeneous attention的输出进行拼接后,通过线性投影使output维度与inputTokenMixer:TokenMixer-based框架采用无参数的、基于规则的mixing操作实现feature interaction。给定input hidden statesTokenMixer首先将每个input tokenheads:其中
head。然后,第
tokenTokenMixer的输出可以公式化为:其中:其中要求
Wukong:Wukong-based的模型将一个因子分解机块(Factorization Machine Block: FMB)的输出与一个线性投影层的输出进行拼接,以提升interaction component:其中:
interaction matrixLayer Normalization。
本文聚焦于为推荐系统建立一个统一的结构基础,融合当前
scaling blocks的优势,进一步提升scaling ROI。
1.3 UniMixer
本文构建了用于推荐系统
scaling的统一模块——UniMixer block,在统一理论框架下整合了attention-based模块、TokenMixer-based模块、Wukong-based模块等推荐系统主流scaling模块。如Figure 2所示,整体架构包含feature tokenization、Siamese norm and Sparse-Pertoken MoE的UniMixer blocks。通过对rule-based TokenMixer进行参数化,我们打通了attention-based方法、TokenMixer-based方法、Wokong-based方法之间的联系,使所提出的UniMixer同时具备这些方法的优势。此外,我们开发了一个轻量级UniMixing模块,进一步压缩模型参数与计算成本,同时显著提升模型性能。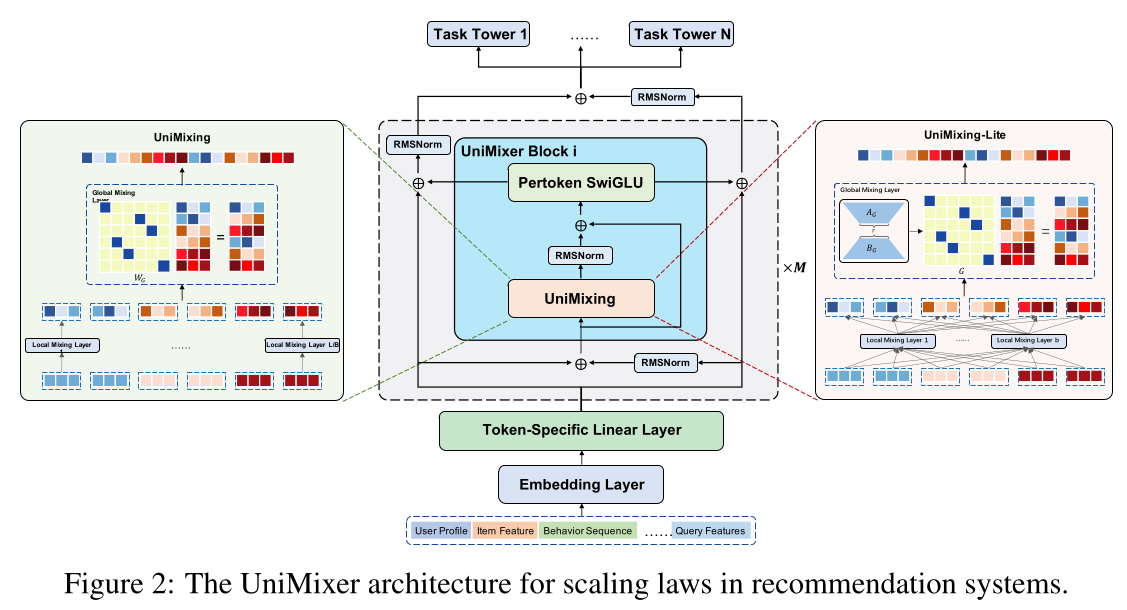
1.3.1 Feature Tokenization
根据
input feature fields的semantic categories,首先将input featuresfeature domains。每个
feature domain通过embedding layers转化为不同维度的embedding vectors:其中:
feature domain内某个feature的one-hot embedding,feature domain对应的embedding维度。将所有
obtained feature domain embeddings拼接为一个embedding向量RankMixer类似,我们将embedding向量blocks,再通过token-specific linear layer将每个block投影为token embedding:其中:
block的待学习的参数。block的维度。按列堆叠
input hidden states如果不按照
feature domains来组织“将
embedding向量blocks“,这一步其实就是sparsify操作,参考论文SSRNet(《Beyond Dense Connectivity: Explicit Sparsity for Scalable Recommendation》)。注意:这里要求
blocks,而不是采用原始的feature-level embedding的原因。
1.3.2 UniMixer Block
Heterogeneous Feature Interactions:如 ”预备知识“ 章节所述,heterogeneous attention通过采用token-specific query, key, and value weights,解决两个heterogeneous semantic spaces的feature interaction问题。然而,通过内积相似度得到的attention pattern通常带有对角占优先验(diagonally dominant prior)。在训练初期,权重矩阵attention weights(即input token valuesattention weights集中在少数tokens上,如Figure 3(a)所示。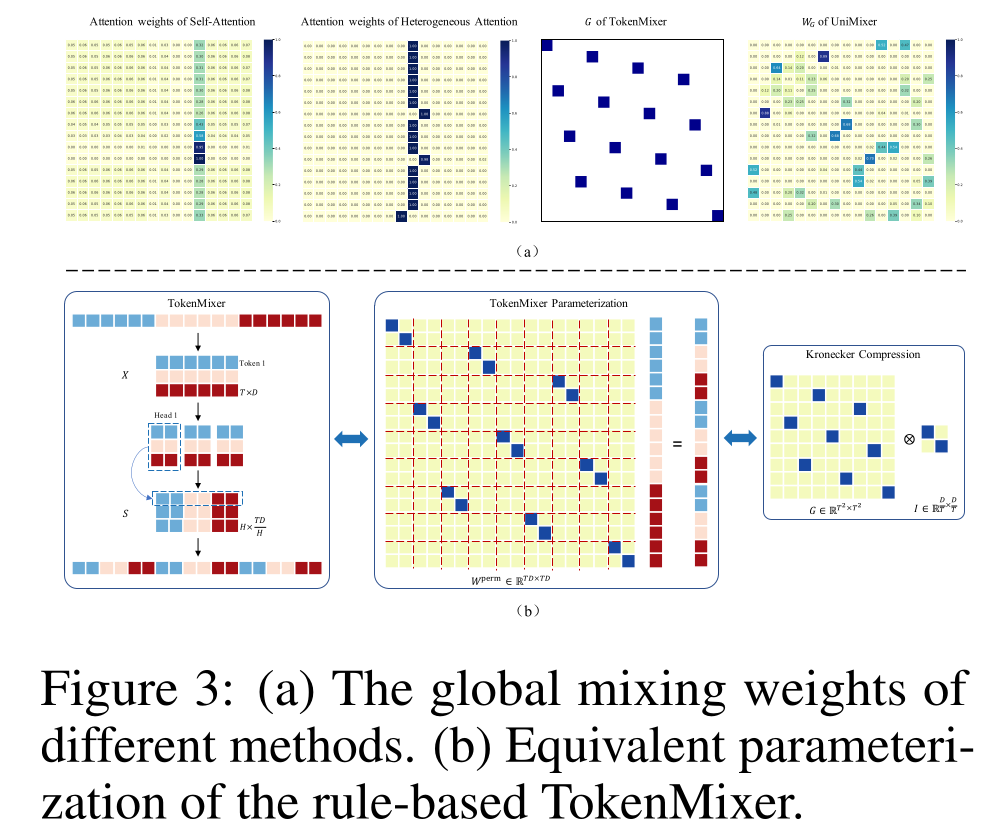
由
Figure 3(a)可见,heterogeneous attention的attention weights尖锐且稀疏,给梯度反向传播带来风险,导致query and key weights训练困难,甚至可能停滞(如Figure 3(a)中heterogeneous attention的attention weights的第10行与第15行)。同时,在大规模heterogeneous feature inputs下,这类attention模式可能导致feature interactions趋同,即attention scores极小且缺乏区分度,可能产生噪声信号,掩盖关键feature interaction模式。另一方面,无参数的、基于规则的
TokenMixer操作缺乏可学习性与场景适应性,可能导致heterogeneous feature interactions不足或错误。此外,要求heterogeneous feature interaction模式的选择。通过深入分析TokenMixer操作,我们得到一些有趣的发现,使TokenMixer操作参数化成为可能。如Figure 3(b)所示,我们发现:TokenMixer操作可视为置换矩阵(permutation matrix)flattened input embedding其中:
A给出具体数值示例。一个自然的思路是通过参数化置换矩阵
rule-based TokenMixer具备可学习性与可优化性。但TokenMixer置换矩阵可压缩性:置换矩阵
Kronecker product),即克罗内克积
.
双随机性:置换矩阵
1,满足行和、列和归一特性。稀疏性:该置换矩阵的每一行、每一列仅有唯一一个非零元素。
对称性:若维度参数
这里有一个前提:要求
input hidden states的tokens数量,input hidden states的维度。
根据
TokenMixer置换矩阵的特性,通过参数化矩阵token mixing的参数数量大幅降低,即TokenMixer参数化仍面临三大挑战:直接用参数化的
size为GPU内存要求极高。因为需要生成
如何保证学到的参数满足双随机性、稀疏性与对称性。
如何设计融合了现有
scaling模块的优势的unified recommendation scaling module,为推荐系统建立更优的scaling效率。
Unified Token Mixing Module:受Figure 3启发,unified token mixing module不再使用block num与block size。block size记为block num为input embedding维度(即,block size换成前面的符号,即:
将
parameterized weights记为heterogeneous feature interactions,我们为distinct parameterized weightblock具备不同的feature interaction模式,通过学习参数矩阵其中:
generalized Kronecker product)。即:每一列采用不同的
也可以对
接下来优化
GPU内存需求。首先将
embedding vectorsize为然后将
block weightsblock-wise vectorslocal feature interaction vector:最后,
UniMixing模块的输出为:
与直接使用
reconstructed matrixB。根据优化后的公式,block内的交互模式,block之间的交互模式。对于维度为embedding inputs,不再要求TokenMixer操作相比,UniMixing模块具备更多样的local and global feature mixing patterns and interaction scales,同时保留优势:它是可学习的、可优化的。为保证学到的置换矩阵满足双随机性,采用
Sinkhorn-Knopp迭代,通过指数算子(exponent operator)使rows and columns使其和为1,进行迭代归一化。此外,引入温度系数控制参数矩阵的稀疏性。最后,用当
1.0)时:除法后元素差异被缩小,指数运算后分布比较均匀,最终的双随机矩阵元素值差异不大(接近均匀分布)。当0.05)时:除法放大了元素之间的原始差异,指数运算后大的元素更大,小的元素更小,最终的双随机矩阵变得尖锐:少数元素接近1,其余接近0。在极限情况下(1,其余为0)。实验章节表明:
其中
Sinkhorn‑Knopp迭代(也称Sinkhorn缩放算法)是一种将任意正矩阵转化为双随机矩阵(doubly stochastic matrix)的经典数值方法。所谓双随机矩阵,是指一个方阵满足:所有元素非负(通常为正)、每行之和为1、每列之和也为1。算法基本步骤:给定一个初始的正矩阵
Sinkhorn‑Knopp迭代通过交替缩放行和列,使其逼近一个双随机矩阵:重复迭代直到收敛(或固定次数):
行归一化:将每一行除以其行和,使每行和为
1。列归一化:将每一列除以其列和,使每列和为
1。
经过足够多的迭代后,矩阵
exp),以保证元素为正,然后再应用上述缩放迭代。随后用残差连接与归一化模块处理
UniMixing block的输出:.
A Unified Perspective of Heterogeneous Feature Interaction:观察blocks数量UniMixer的local interaction projection等价于value projection of the heterogeneous attention layer。另一方面,attention weights相同;此外,Wukong的feature interaction基于FM组件。其中:
feature interaction模块attention模块中,当value矩阵不依赖hidden state inputattention机制退化为FM模块。因此,attention-based机构、TokenMixer-based架构与Wukong-based架构可统一于单一理论框架:其中:
heterogeneous feature interaction projection,衡量token-to-token/block-to-block的interaction强度。为便于分析各类方法的差异与联系,我们考虑
single-head attention setting。在统一理论框架下(即,Table 1。对于self-attention、heterogeneous attention与FM,global mixing patterntokens的内积相似度得到;而TokenMixer的global mixing pattern与input token embedding无关。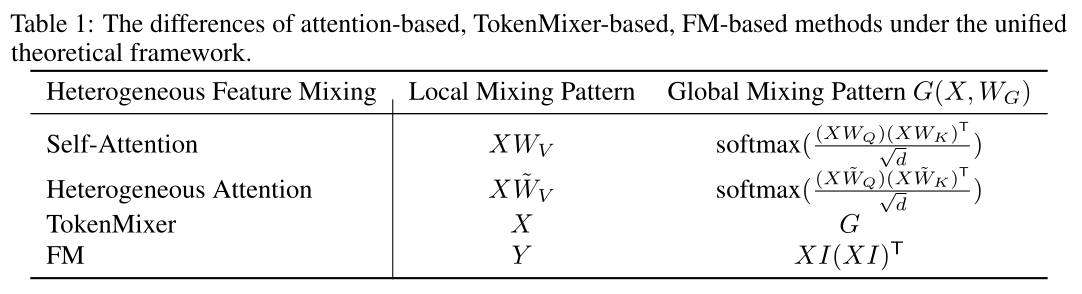
UniMixing-Lite:如Figure 3所示,block粒度越细(即,local interaction parameter matricesglobal interaction parameter matrixlocal interaction patterns。同时,更大的global interaction matrix在reducing the number of parameters上的效率较低。因此,基于UniMixing block,我们设计了一个轻量级的UniMixing模块——UniMixing-Lite,从而进一步减少module parameters与计算成本,提升模型的scaling效率。为解决
local interaction pattern的冗余性问题,我们引入一个basis-composed module,动态地生成block-specific local mixing weight。定义basis matrices的集合为basis matrices上的block-specific weight vectors为basis local mixing weight的数量,global interaction parameterUniMixing-Lite模块可表示为:其中:
low-rank approximation)的秩。
UniMixing-Lite模块同时保留了TokenMixer的低参数的global interaction pattern、以及attention的针对heterogeneous features的local interaction能力,可同时利用attention-based方法与token-mixer-based方法的优势。同时对
Pertoken SwiGLU:在UniMixing block之后,与TokenMixer-Large类似,我们引入pertoken SwiGLU来建模不同tokens之间的feature heterogeneity。对于每个input tokenSwiGLU公式如下:其中:
token的UniMixing output。
1.3.3 SiameseNorm
当前
RankMixer架构缺乏针对deep architectures的专门设计,主要体现在model depth的scaling效果有限。尽管TokenMixer-Large尝试通过在block内加入interval residuals与auxiliary loss来解决该问题,但未触及根本。为实现model depth增加时的训练稳定性与性能提升,我们将孪生归一化(SiameseNorm)引入UniMixer架构,如Figure 2所示。如相关工作所述(《Siamesenorm: Breaking the barrier to reconciling pre/post-norm》),SiameseNorm通过在每层引入两个耦合流(coupled streams),解决预归一化(Pre-Norm)与后归一化(Post-Norm)的矛盾。本节将这两个耦合流记为input embeddings初始化block,SiameseNorm执行如下更新:pre-norm,post-norm。对于第
UniMixer block,我们融合final representation,公式如下:根据离线实验表面,
PostNorm -> SiameseNorm能带来0.027%的AUC提升。因此,它并不是核心设计。
1.3.4 UniMixer 训练策略
为使
parameter matricesoptimization陷入局部最优。另一方面,我们的实验表明weight parameters的稀疏性对模型性能有显著正向影响,如Table 3所示。因此,该稀疏性不可或缺。常用方法是在训练过程中采用线性温度退火(
linear temperature annealing):从较高初始温度(如training iterations次数增加,线性退火至其中:
数据量不足时,线性退火可能导致高温阶段探索不充分,或低温阶段优化效果不佳。为解决该问题,可先用较高温度系数(如
initialization,重新训练低温模型。根据实验部分的描述,训练策略对
UniMixer模型性能的影响最大。众所周知,dnn模型的训练策略、模型架构都对最终模型性能产生重大影响。那么,UniMixer的优秀性能是来自于它的训练策略,还是来自于它的模型架构?
1.4 实验
本节开展大量实验,对比所提出的
UniMixer架构与SOTA方法的性能,并回答以下问题:Q1:UniMixer架构的scaling效率是否优于SOTA架构?Q2:所提出的方法在different settings of global and local mixing pattern下性能如何变化?Q3:轻量级模块UniMixing-Lite是否进一步提升scaling效率?Q4:部署至真实在线系统后,UniMixer/UniMixing-Lite是否在A/B测试中提升业务指标?
数据集与评估指标:我们采用
Kuaishou的广告投放场景的真实训练数据集日志,建模用户留存(user retention),开展离线与在线评估。数据集包含一年收集的超0.7 billion的用户样本,涵盖数值特征、ID特征、交叉特征、序列特征等数百个heterogeneous features。二元标签(User Retention = 1/0)表示users’ first activation的次日是否返回Kuaishou application。推荐模型的scaling evaluation的指标采用行业常用的AUC、UAUC(User-Level AUC)以评估模型性能,用dense parameter数量、FLOPs、MFU来评估模型效率。基线与实验细节:将本文的
2-blocks/4-blocks UniMixer/UniMixing-Lite架构与以下代表性SOTA框架对比,按建模范式分类:Attention-Based架构:Heterogeneous Attention(《Hiformer: Heterogeneous feature interactions learning with transformers for recommender systems》)、HiFormer(《Hiformer: Heterogeneous feature interactions learning with transformers for recommender systems》)、FAT(《From scaling to structured expressivity: Rethinking transformers for ctr prediction》),采用field-specific query, key, and value projections实现heterogeneous feature interaction。TokenMixer-Based框架:RankMixer(《Rankmixer: Scaling up ranking models in industrial recommenders》)、TokenMixer-Large(《Tokenmixer-large: Scaling up large ranking models in industrial recommenders》),采用rule-based token mixing operation实现feature interaction。FM-Based框架:Wukong(《Wukong: Towards a scaling law for large-scale recommendation》),将outputs of a FMB and a linear projection layer拼接起来,从而提升interaction component。
所有实验在由
40 GPUs组成的a hybrid distributed training framework下进行。所有模型使用一致的optimizer hyperparameters:dense and sparse parts均用Adam优化,学习率设为0.001。
1.4.1 Performance Comparison (for Q1)
采用参数约
100 million的SOTA scaling architectures与UniMixer、UniMixing-Lite对比,探索其scaling laws。heterogeneous attention架构作为base model。Table 2展示本文模型与SOTA模型的主要性能结果。可以看到:在更小的参数预算与计算成本下,
UniMixer与UniMixing-Lite架构在多个指标上均显著优于其他SOTA模型。TokenMixer-Large的效果还不如RankMixer?有点奇怪。
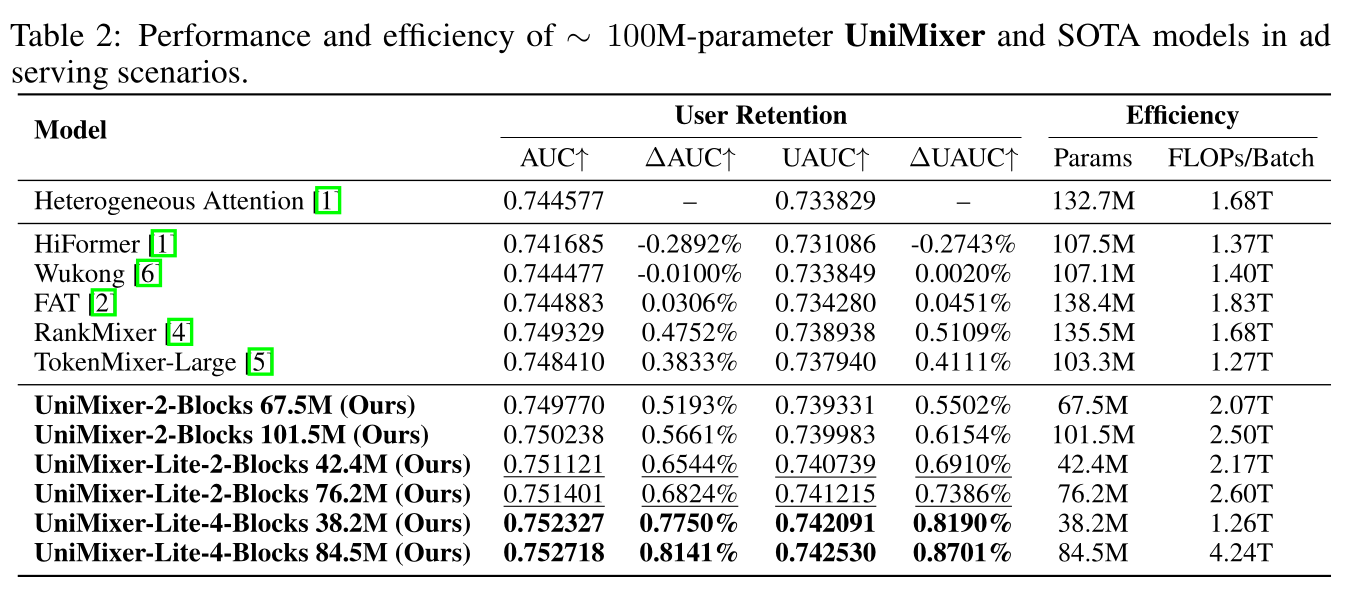
此外,该广告投放场景中,除
UniMixer/UniMixing-Lite外,RankMixer性能优于所有其他SOTA模型。因此,我们选择该最强的SOTA模型与UniMixer/UniMixing-Lite进行scaling laws的对比。所有模型在相同数据集、一致超参数下进行训练,其参数量与FLOPs的scaling curves如Figure 4所示。可以看到:随
number of parameters/FLOPs增加,三个模型的AUC均呈现清晰的power-law趋势。UniMixer-Lite实现最优的scaling效率,提升斜率更陡。
根据
Figure 4,RankMixer、UniMixer、UniMixing-Lite的AUC与Parameters/FLOPs的良好的scaling laws公式如下:scaling laws中的两个常数里,scaling exponent常数对性能增长影响最大,是scaling效率的主导因素。UniMixer-Lite展现出最强的scaling效率,在参数量与FLOPs上均取得最大的scaling exponent与scaling coefficient,说明其从increased model capacity中获益最大。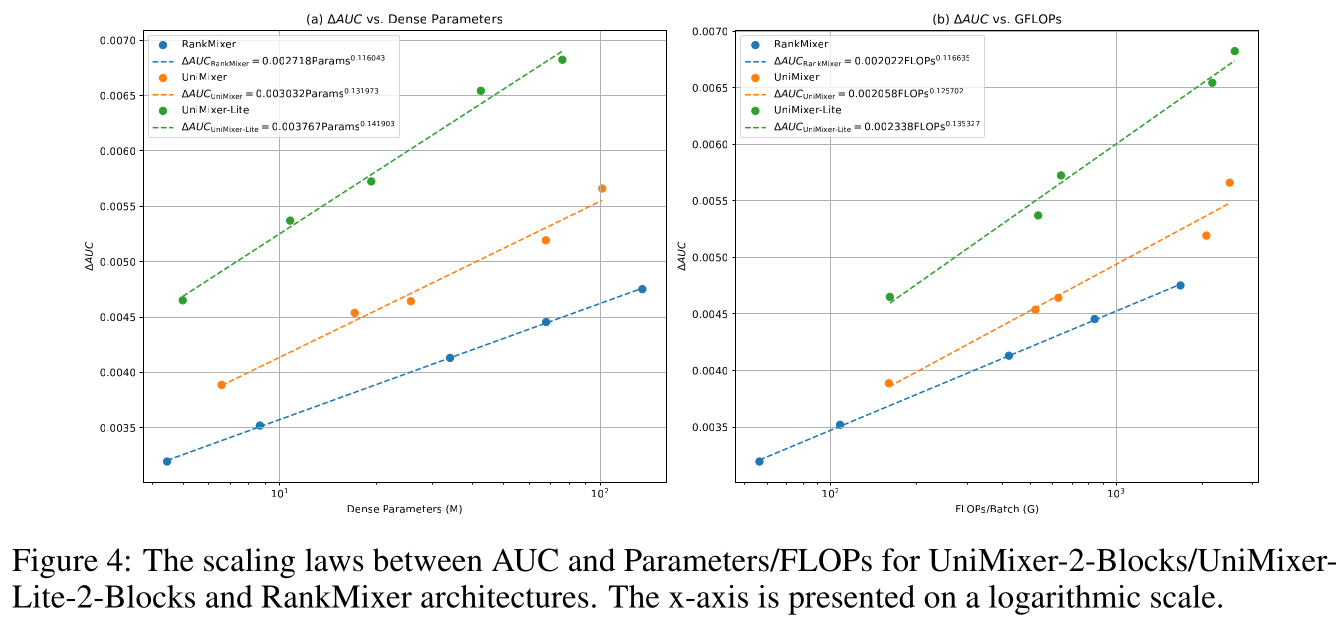
1.4.2 Ablation Studies (for Q2)
为探索
global and local mixing weights的特性,以及UniMixer中各模块对AUC gains的贡献,我们对多种UniMixer变体开展消融实验,测量其相对full UniMixer model的AUC变化。所有变体在相似设置下训练。结果如Table 3所示,移除任意模块或违反参数约束(parameter constraints)均会导致性能下降,其中low temperature coefficient与model warm-up对整体性能影响最显著。model warm-up就是正文章节提到的线性温度退火.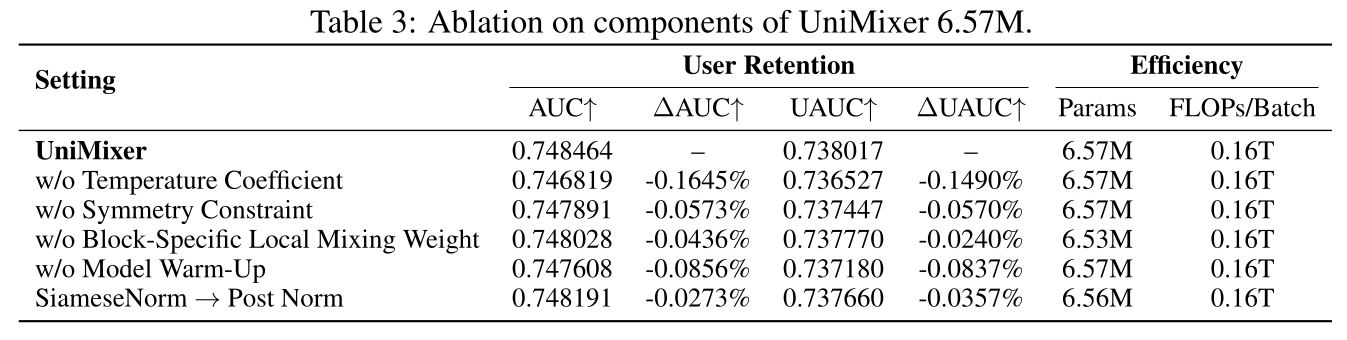
1.4.3 Performance of the UniMixing-Lite Module (for Q3)
根据
Figure 4的scaling趋势可见,本文UniMixing-Lite架构具备最优的参数效率与计算效率。本节开展实验,探究基矩阵集合UniMixer block数量的影响。如Table 4所示:随基矩阵数量
但在参数效率方面,增加基矩阵数量
AUC gain。
注意:
RankMixer的层数越多,效果反而下降了。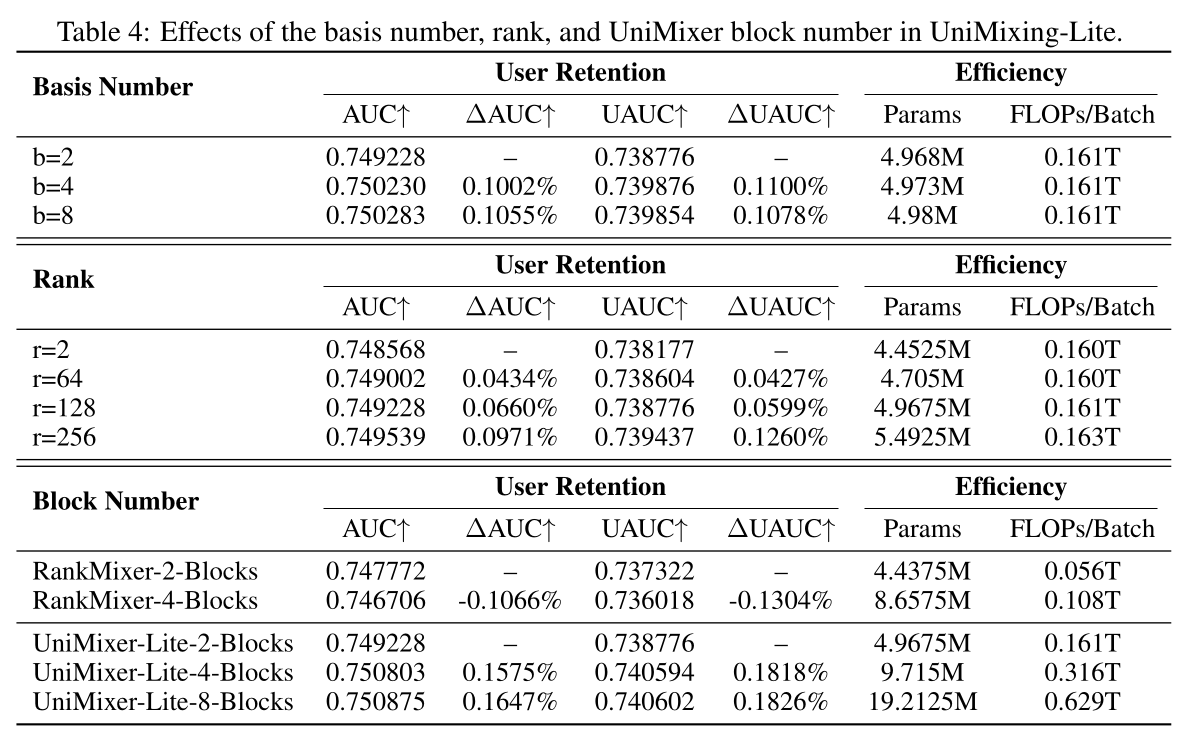
为观察低秩近似
Sinkhorn–Knopp操作的基矩阵global and local mixing matrices的影响,在2-blocks-UniMixer-Lite架构中,我们可视化温度系数UniMixer block的reconstructed global matrixlocal mixing matricesFigure 5所示。input embedding维度为768,block大小为B = 6,因此由
Figure 5可见,尽管模块中使用了低秩近似与basis matrices,Sinkhorn–Knopp操作仍能保证矩阵接近满秩。此外,对比Figure 5(a)(b) and (c)(d),更低的温度系数下的global and local mixing matrices,interaction distributions比更高的温度系数下更尖锐。由消融实验结果可知,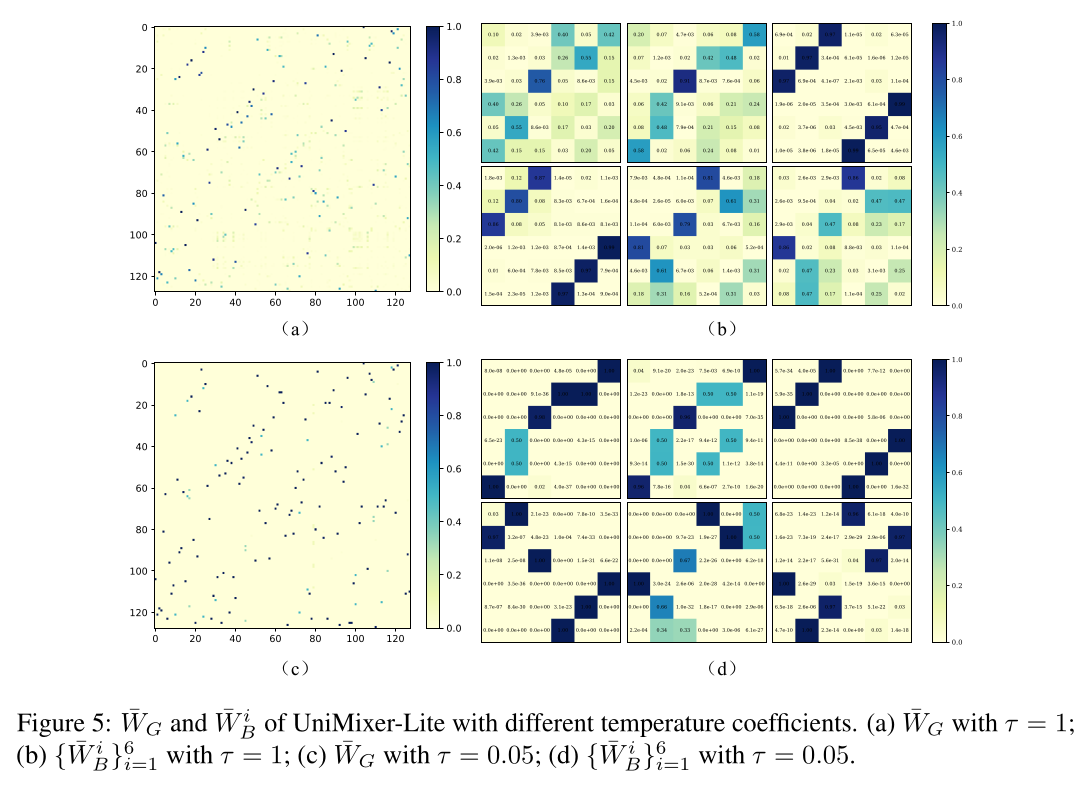
另一方面,由
Table 4可见,随UniMixer的深度的增加,所提出的模型持续呈现清晰的scaling-up趋势,而RankMixer随深度的增加出现性能下降。UniMixing-Lite with 2 blocks and 4 blocks的scaling curves如Figure 6所示,说明沿depth缩放比沿width缩放更高效。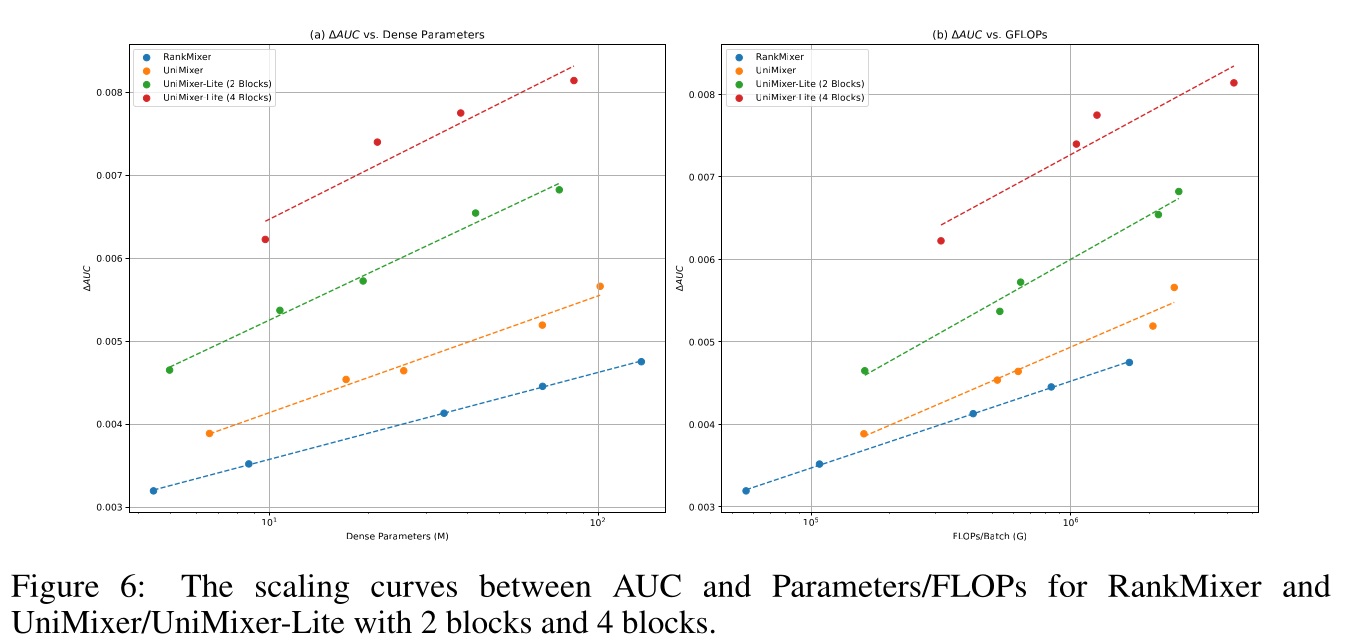
1.4.4 Online A/B Test Results (for Q4)
为验证所提出的
UniMixer架构的在线性能,我们将UniMixer与UniMixing-Lite部署至Kuaishou的多个广告投放场景。在线A/B测试中,以30天观察窗口内的累计活跃天数(Cumulative Active Days: CAD)衡量user engagement(排除installation day,即day 0)。在多个场景中,D1-D30的CAD平均提升超15%。没有详细的图表来说明?
base model是啥?有没有上线?这些都没讲。
1.5 结论
本文为推荐系统的
scaling laws建立了一个统一的scaling框架,打通了attention-based方法、TokenMixer-based方法与FM-based方法的联系,使融合各自优势成为可能。从得到的scaling laws可见,与SOTA架构相比,本文的UniMixing-Lite实现了最优的参数效率与计算效率。我们已将该架构部署至Kuaishou的多个场景,取得显著的离线与在线收益。本工作不再孤立看待推荐系统中现有的
scaling模块(如Heterogeneous Attention、TokenMixer、Wukong),而是建立统一理论框架,为推荐系统的scaling design提供指导。我们相信该统一架构能助力推荐系统领域迎来属于自己的"attention moment"。这个统一模块,UniMixer,是专为推荐领域设计的fundamental block,其适用性可进一步扩展至user behavior sequence modeling任务与generative recommendation任务。
二、附录
2.1 附录 A:TokenMixer 等价变换数值示例
给定如下
input hidden stateinput hidden stateTokenMixer操作后被变换为:TokenMixer的输出可以被展平为一个向量:另一方面,向量
根据上式,本数值例子中的
TokenMixer操作被等价变换为矩阵乘法形式。此外,置换矩阵Kronecker product):.
2.2 附录 B:UniMixing 模块的计算流程优化
定义
其中
根据公式
其中:
根据
UniMixing的原始表达式另一方面,我们可以得到下面的表达式:
上式中的元素满足:
因此有:
由于
computation pipeline optimization后的UniMixing模块可以写作:.