一、ItemBased CF [2001]
《Item-Based Collaborative Filtering Recommendation Algorithms》
世界上信息量的增长速度远远超过我们处理信息的能力。我们都有体会:被每年出版的海量的新书、期刊文章和会议纪要所淹没的感觉。技术大大降低了发布(
publishing)和分发(distributing)信息的障碍。现在是时候创造新的技术,从而可以帮助我们从所有可用信息中找到最有价值的信息。此类最有前途的技术之一是协同过滤(
collaborative filtering)。协同过滤的工作原理是建立用户对item的偏好数据库。对于一个新用户,假设叫做Neo,我们从数据库中匹配邻居,这些邻居是历史上与Neo有相似品味(taste)的其它用户。然后我们将邻居喜欢的item推荐给Neo,因为Neo可能也会喜欢这些item。协同过滤在研究和实践中都非常成功,在信息过滤应用和电商应用中都非常成功。然而,协同过滤推荐系统有两个基本挑战仍然未能克服:可扩展性(
scalability):这些算法能够实时搜索数以万计的潜在邻居,但是现代系统需要搜索数千万个潜在邻居。由于整体计算复杂度为item数量,因此随着用户规模的增加其计算复杂度难以忍受。此外,现有算法对于拥有大量历史行为的单个用户(
individual user)也存在性能问题。例如,某些用户可能在成千上万个item上有过行为,那么这批用户会拖慢每秒可以搜索的相似用户的数量(因为计算用户之间的相似度的计算复杂度为item数量),从而进一步降低了可扩展性。推荐质量(
quality):用户需要他们可以信任的推荐,从而帮助他们找到感兴趣的item。对于质量较差的推荐,用户一般都是“用脚投票”,直接拒绝使用该推荐系统。
某种程度上这两个挑战是相互冲突的:算法花在搜索邻居上的时间越少,它的可扩展性就越强、推荐质量也就越差。出于这个原因,同时处理这两个挑战很重要,这样的解决方案既有效又实用。 论文
《Item-Based Collaborative Filtering Recommendation Algorithms》提出了Item-Based CF来同时解决这两个挑战。传统的协同过滤算法的瓶颈是在大量用户中搜索邻居,而
Item-Based算法通过首先探索item之间的关系、而不是用户之间的关系来避免这个瓶颈。通过查找用户喜欢item相似的其它item来获取对用户的推荐。 由于item之间的关系是相对静态(static)的,Item-Based算法可以减少在线计算的数量,同时保持与User-Based算法相同的推荐质量。论文主要贡献:
分析
Item-Based的预测算法,并识别(identification)实现其子任务的不同方法。形式化
item相似度的预计算模型(pre-computed model),从而提高Item-Based推荐的在线可扩展性。几种不同的
Item-Based算法与经典的User-Based算法(最近邻)的实验效果比较。
相关工作:这里我们简要介绍一些与协同过滤、推荐系统、数据挖掘、以及个性化相关的研究文献。
Tapestry是基于协同过滤的推荐系统的最早实现之一。该系统依赖于来自紧密社区(close-knit community)(如办公室工作组)的人们的显式意见(explicit opinion),其中每个用户都了解其它用户。但是大型社区的推荐系统不能依赖于每个用户都了解其它用户。后来,人们开发了几个基于评级(
ratings-based)的自动推荐系统。GroupLens研究系统为Usenet新闻和电影提供了匿名协同过滤解决方案。Ringo和Video Recommender是分别生成音乐推荐和电影推荐的email-based系统和web-based系统。
ACM的通讯特刊《Recommender Systems》介绍了许多不同的推荐系统。其他技术也已经应用于推荐系统,包括贝叶斯网络、聚类(
clustering)、以及Horting。贝叶斯网络创建一个基于训练集的模型,每个节点都有一个决策树,边代表用户信息。该模型可以在几个小时或者几天内离线构建。生成的模型非常小,速度非常快,并且基本上与最近邻方法一样准确。
贝叶斯网络被证明可能适用于用户偏好缓慢变化(相对于构建模型所需的时间)的环境,但是不适用于必须快速或频繁更新用户偏好模型的环境。
聚类技术通过识别似乎具有相似偏好的用户组(
user group)来工作。一旦创建了簇(cluster),就可以通过对该簇中其它用户的意见进行平均来对单个用户进行预测。某些聚类技术将每个用户划分到多个
cluster,然后预测时按照跨cluster取加权平均值,权重是参与这个cluster的程度。聚类技术通常比其它方法产生较少个性化的推荐,并且在某些情况下聚类的准确性比最近邻算法更差。然而,一旦聚类完成,性能就会非常好,因为必须分析的组的数量要小得多。
聚类技术也可以作为
first step来应用,用于在最近邻算法中缩小候选集、或者在多个推荐引擎之间分配最近邻计算。虽然将用户划分为clusters可能会损害cluster边缘附近用户的准确性或推荐,但是pre-clustering可能是准确性和吞吐量之间的一个值得的trade-off。Horting是一种graph-based技术,其中节点是用户、节点之间的边表示两个用户之间的相似程度。预测是通过游走到附近节点,然后结合附近用户的意见来产生的。Horting和最近邻不同,因为它探索了graph上的高阶关系而最近邻仅探索graph上的一阶关系(直接关系),从而探索最近邻算法中没有考虑的信息传递。在一项使用人工合成数据的研究中,Horting产生了比最近邻更好的预测算法。
《Recommender Systems in E-Commerce》展示了电商中使用的推荐系统的详细分类和示例,以及它们如何提供一对一的个性化,同时可以捕获客户忠诚度(loyalty)。
尽管这些系统在过去取得了成功,但是它们的广泛使用暴露了它们的一些局限性,例如数据集的稀疏性问题、与高维相关的问题等。
推荐系统中的稀疏性问题已经在
《Using Filtering Agents to Improve Prediction Quality in the GroupLens Research Collaborative Filtering System》和《Combining Collaborative Filtering With Personal Agents for Better Recommendations》中得到解决。推荐系统中与高维相关的问题已经在
《Learning Collaborative Information Filters》中讨论过,在《Application of Dimensionality Reduction in Recommender System -- A Case Study》中已经研究了应用降维技术解决这些问题。
我们的工作探索了
Item-Based推荐算法(一类新的推荐算法)能够在多大程度上解决这些问题。
1.1 模型
1.1.1 CF-Based 推荐系统
推荐系统主要解决以下问题:通过为给定用户生成预测的可能性得分、或者
top-N的推荐item列表,从而帮助用户找到他们想在电商网站上购买的item。可以使用不同的方法进行
item推荐,例如基于用户的人口统计(demographics)、热门item、或者用户历史购买习惯。协同过滤(Collaborative Filtering: CF)是迄今为止最成功的推荐技术。基于CF的算法的基本思想是:根据其他志趣相投用户的意见提供item推荐或预测。用户的意见可以显式(explicitly)地从用户那里获取,也可以通过一些隐式(implicit)的手段获取。协同过滤处理
Overview:协同过滤算法的目标是根据用户历史偏好、或者其他志趣相投用户的意见,为目标用户推荐新item或者预测某个item的效用 (utility)。在典型的
CF场景中,有一个item的列表item列表item,用户opinion)。 意见可以由用户显式给出(如位于某个数字区间的评级分数rating score),也可以通过分析日志从购买记录中隐式地获取。注意,给定目标用户
item偏好(item likeliness)。这种偏好有两种形式:预测:预测用户
item推荐:为用户
item组成的列表item上,即Top-N推荐。
下图给出了协同过滤任务的示意图。
CF算法将整个user-item数据表示为一个评分矩阵user在第item上的评分。每个评分在一定范围之内(如1~5),也可以为0,表示用户尚未对该item评分。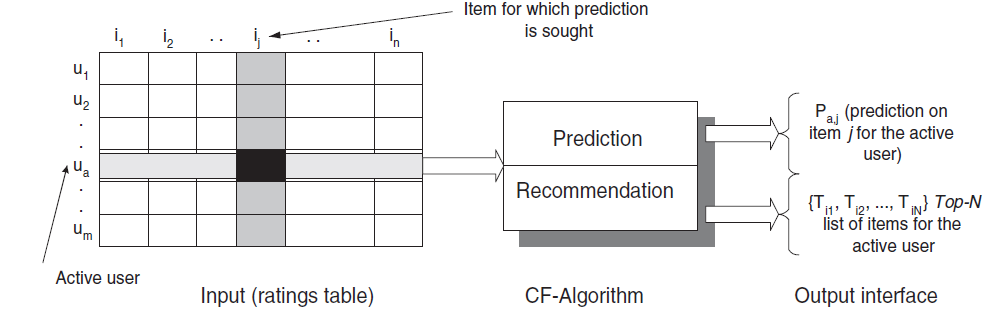
协同过滤算法可以分为两类:
memory-based基于内存的(也称作user-based)协同过滤:利用整个评分矩阵来生成预测。该算法采用统计技术来找出与目标用户最相似的一组用户(称作邻居),然后使用不同的组合方式来组合这些邻居的偏好,从而为目标用户生成推荐或
Top-N推荐。因此该技术也被称为最近邻(nearest-neighbor)或者UserBased CF技术。model-based基于模型的(也称作item-based)协同过滤:通过建立用户打分模型来提供item推荐。这些方法首采用概率性的方法(
probabilistic approach),然后根据给定用户在其它item评分的条件下来预测未打分item上的评分。模型构建过程由不同的机器学习算法执行,例如贝叶斯网络、聚类、以及基于规则(rule-based)的方法。贝叶斯网络模型为协同过滤问题形式化了概率模型。
聚类模型将协同过滤视为分类问题,并通过将相同类别的相似用户聚类,并估计给定用户属于特定类别
基于规则的方法应用关联规则挖掘(
association rule discovery)算法来发现共同购买(co-purchase)的item之间的关联,然后根据item之间的关联强度生成item推荐。
User-Based CF的挑战:User-Based协同过滤系统在过去非常成功,但是它们的广泛使用暴露了一些潜在的挑战,例如:稀疏性(
Sparsity):在实践中,许多商业推荐系统用于评估大型item集合(如Amazon.com推荐书籍、CDnow.com推荐音乐专辑)。在这些系统中,即使是活跃用户购买的item也可能占比远低于1%(200万本书的1%是2万本书)。因此,基于最近邻算法的推荐系统,其推荐的准确性可能很差。注意:因为
user的行为太稀疏,导致user-to-user的相似度不可置信。可扩展性(
Scalability):最近邻算法的计算复杂度随着用户数量和item数量的增长而增长。对于数以百万的用户和item,运行现有算法的、典型的web-based推荐系统将面临严重的可扩展性问题。
最近邻算法在大型稀疏数据集上的弱点促使我们探索替代的推荐系统算法。
我们的第一种方法试图将半智能过滤代理 (
semi-intelligent filtering agent)结合到推荐系统中来,从而弥合稀疏性。这些代理使用文法特征(syntactic feature)对每个item进行评估和打分。通过提供稠密的评分集合,它们有助于缓解覆盖度(coverage)并提高推荐质量(quality)。然而,过滤代理解决方案并没有解决志趣相同、但是评分稀疏的用户之间关系不佳的根本问题。为了探索这一点,我们采用了一种算法方法,并使用潜在语义索引(Latent Semantic Indexing: LSI)来捕获降维空间中用户和item之间的相似度。在本文中我们研究了另一种技术,即
model-based方法,来应对这些挑战,尤其是可扩展性挑战。这里的主要思想是分析user-item表示矩阵 (representation matrix)来识别不同item之间的关系,然后利用这些关系来计算目标user-item pair的预测分。这种方法背后的直觉是:用户有兴趣购买历史喜欢item类似的item,并倾向于厌恶历史不喜欢item类似的item。这些技术不需要在请求推荐时识别用户的相似用户,因此它们往往会更快地给出推荐。已经有很多不同的方案来计算
item之间的关联,从概率性方法到更传统的item-item相关性。接下来我们将详细分析我们的方法。
1.1.2 Item-Based CF
这里我们研究了一类
Item-Based的推荐算法,用于对用户进行推荐预测。与前面讨论的User-Based CF算法不同,Item-Based的方法查看目标用户历史评分item集合并计算它们与目标itemtop-k最相似的itemtop-k一旦得到最相似的
item及其相似度,我们可以通过目标用户对这些相似item已有评分的加权均值来执行预测。我们这里详细描述了这两个方面,即相似度计算和预测生成。Item相似度计算:Item-Based CF最关键的步骤之一是如何计算item之间的相似度。计算itemuser、列代表item。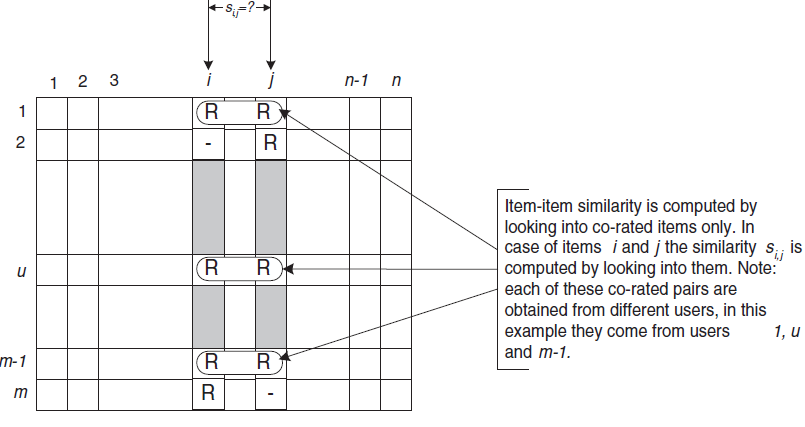
其中有多种方法可以计算
item之间的相似度,我们这里介绍三种方法,即基于余弦(cosine-based)的相似度、基于相关系数(correlation-based)的相似度、基于修正余弦(adjusted-cosine based)的相似度。基于余弦的相似度(
cosine-based similarity):两个item被认为是其中
item基于相关系数的相似度(
correlation-based similarity):两个item之间的相似度是通过计算Pearson-r相关系数其中
item如果令
基于修正余弦的相似度(
adjusted-cosine similarity):基于余弦的相似度有个缺陷:未考虑不同用户之间的打分差异。修正的余弦相似度通过从每个用户的打分中减去该用户的打分均值来修复这个问题:其中
item上的打分均值。如果令
itemitem
预测:协同过滤系统中最重要的一步是生成预测。一旦我们根据相似性得到了目标
itemitem,则下一步是为用户执行打分预测。这里我们考虑两种技术:加权和(
weighted sum):该方法通过计算用户itemitem给出的评分的加权和,从而计算用户itemitem使用下图中的概念,我们可以将预测
这种方式捕获了目标用户
item的评分。加权的权重进行了归一化,从而确保预测打分在预定范围内。下图中,使用了
5个相似的item来进行预测。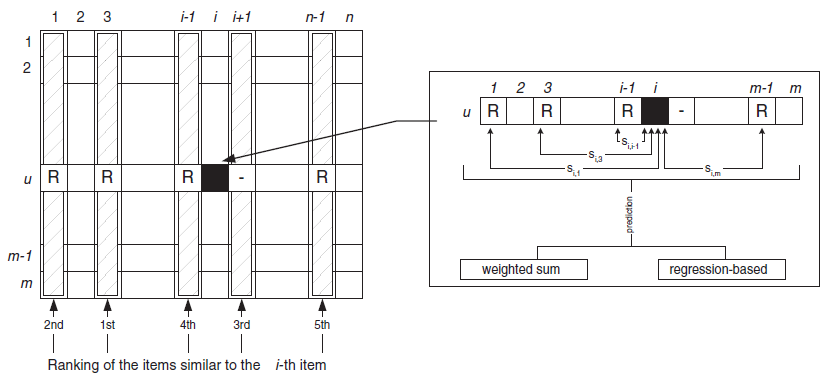
回归(
regression):这种方式类似于加权和,但是不是直接使用相似item的打分,而是基于回归模型来拟合的修正打分。实践中使用余弦相似度或者相关系数相似度可能导致两个向量相似度很高,但是实际上差距很远(夹角相同,长度差异较大)。这种情况下使用原始评分来计算,可能会导致预测不佳。
回归方法的思想是:采用加权和相同的公式,但是不使用原始打分
itemitem然后根据
性能分析:
User-Based CF中,邻域的生成过程,尤其时user-user相似度计算步骤被证明是性能瓶颈,从而使得整个过程不适合实时推荐。在本文中,我们提出了一种model-based方法来预计算item-item相似度得分。相似度计算方案仍然是基于相关性的(如基于相关系数或者基于余弦),但是计算是在item空间上执行的。在典型的电子商务场景中,与经常变化的用户数量相比,item数量相比之下更为静态(static)。item的静态属性使得我们想到了预计算item相似性的想法。预计算
item相似度的一种可能方法是计算所有item之间的相似度,然后执行快速查表从而检索到所需的相似度。这种方法虽然节省时间,但是对于item需要item,我们只需要一小部分最相似的item来预测,这使得我们找到了一种替代的mode-based方案。因此对于每个item,我们仅计算item,其中基于这个模型构建步骤,为目标用户
item邻域生成过程:首先检索与目标
itemitem。这里的
item数量,它不同于模型大小item数量)。预测生成过程:查看用户
item中的多少个,基于此交集使用Item-Based CF预测算法。
这里有质量和性能的权衡(
quality-performance trade-off):为了确保高质量,我们必须有较大的模型大小Item-Based CF完全相同的质量,但是具有很高的空间复杂度。然而,我们的替代方案确保我们保留最相似的item,在生成预测时这些item对预测结果的贡献最大。因此,我们假设这种替代方案即使在我们后续实验验证了我们的假设。具体而言,我们通过改变
读者注:理论上也可以将
User-Based CF拆分为两阶段:邻域生成 + 预测生成。考虑到用户行为非常稀疏,因此用户的任何新的行为对user-user相似度影响较大。因此user-user相似度必须根据最近的用户行为在线实时计算。相对来说,用户的任何新的行为对
item-item相似度影响较小,因此item-item相似度相对静态,可以离线计算。如:假设
user-item矩阵规模为1000万用户、100万item。假设平均每个用户对5个item进行打分,则平均每个item包含50个用户。假设某个用户itemu的user-user相似度,相似度波动范围大致为20%;它也会影响所有涉及到item-item相似度,但是相似度波动范围大致为2%。因此相对而言,item-item相似度要稳定得多。其本质是
user-item矩阵的行比列更为稀疏。
1.2 实验
数据集:我们使用
MovieLens数据集来评估Item-Based CF的效果。MovieLens是一个web-based的研究(research)推荐系统,于1997年秋季首次亮相。每周都有数百名用户访问MovieLens来评估和接受电影推荐。该网站现在拥有超过43000名用户,他们对3500多部电影进行评分。我们随机选择打分超过20部电影的用户及其对应的电影评分,得到十万个打分,其中包括943个用户、1682部电影。即我们的user-item矩阵我们将数据集随机拆分为训练集和测试集,拆分比例为
80%的训练集和20%的测试集。实验中我们还考虑了数据集的稀疏水平(sparsity level)。给定一个矩阵,我们定义它的稀疏水平为:其中
评估指标:推荐系统用来评估推荐质量的指标主要可以分为两类:
统计准确性指标(
statistical accuracy metrics):通过测试集上user-item的真实打分和预测打分的对比,从而评估推荐的准确性。平均绝对误差
MAE是其中应用广泛的指标。对每个真实打分和预测打分pair对MAE越低则推荐质量越好。另外,均方误差(
RMSE)、相关系数(Correlation)也是类似的统计意义上的准确率指标。决策支持准确性指标(
decision support accuracy metrics):评估推荐系统帮助用户筛选高质量item的有效性。事实上给用户推荐
item之后,用户会在被推荐item上给出反馈:推荐有效(用户感兴趣)还是推荐无效(用户不感兴趣)。因此这是一个典型的二元分类:有效推荐则为1、无效推荐则为0。我们认为用户打分在4.0分及以上的item是有效推荐(5分制),从而根据预测的二元标签和真实的二元标签得到precision、recall、auc等指标。这种做法基于我们的观察:对于一个无效推荐的item,算法预测它是1.5分还是2.5分没有任何意义。
实验中我们使用
MAE来报告实验结果,因为它最常用并且最容易直观的解释。另外我们每次随机选择不同的训练集和测试集,重复进行10-fold交叉验证并报告MAE的均值。baseline模型:一个User-Based CF模型(基于Pearson最近邻算法 ),该模型召回全量的user-user相似度而不考虑计算代价。我们调优了该算法的超参数,从而得到最好的Pearson最近邻算法。实验配置:我们首先将数据集划分为训练集和测试集 。在开始对不同算法进行全面的实验评估之前,我们确定了不同算法对不同超参数的敏感性,并从敏感性实验中确定了这些超参数的最佳值,并且将这些最佳超参数用于剩余的实验。
为了确定超参数敏感性,我们仅使用训练集,并将其进一步细分为 “训练--训练集” 和 “训练--验证集”,并对其进行实验。
所有的实验都是使用
C语言实现,在基于linux的PC上运行实验。PC配置为600M HZ的Intel Pentium III处理器以及2GM内存。实验结果主要分为推荐质量结果和推荐性能结果两部分。为了得到较高的推荐质量,我们首先确定了一些超参数敏感性,包括:邻域大小
超参数敏感性:为了确定各种超参数的敏感性,我们仅关注训练集,并将原始的训练集进一步拆分为 “训练--训练集” 和 “训练--验证集”。
相似度算法的影响:我们实现了三种不同的相似度算法,包括基础的余弦相似度、修正的余弦相似度、相关性相似度,并在我们的数据集上测试它们。对于每种相似度算法,我们基于加权和算法来生成预测。实验结果如下图所示,我们给出了验证集的
MAE。可以看到:修正的余弦相似度效果最好,因为它的MAE明显更低。因此,在接下来的实验中我们选择修正的余弦相似度。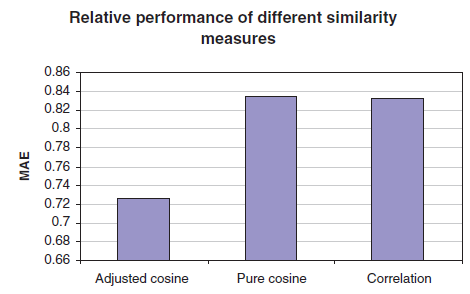
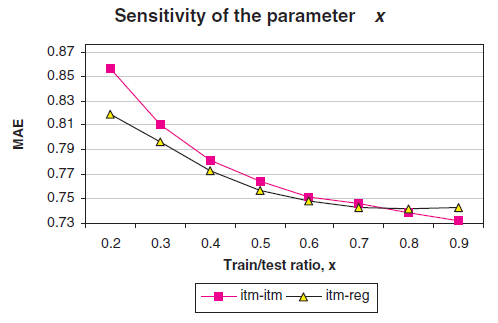
训练集测试集拆分比例的影响:为了确定数据集密度的敏感性,我们以
0.1的增量将0.2增加到0.9。我们分别使用两种预测生成技术:最简单的加权和,以及基于回归的加权和。实验结果如下图所示。可以看到:预测质量随着
我们从曲线图中选择
邻域大小
MAE。我们分别使用两种预测生成技术:最简单的加权和,以及基于回归的加权和。实验结果如下图所示。可以看到:邻域大小
10增加到30时:简单加权和的方法的推荐质量一直得到改善,但是改善的速度逐渐降低,
MAE曲线趋于平缓。基于回归的加权和的方法推荐质量反而逐渐下降。
我们选择
注意:这里离线预计算
item-item相似度时,保留全量的相似度(即模型大小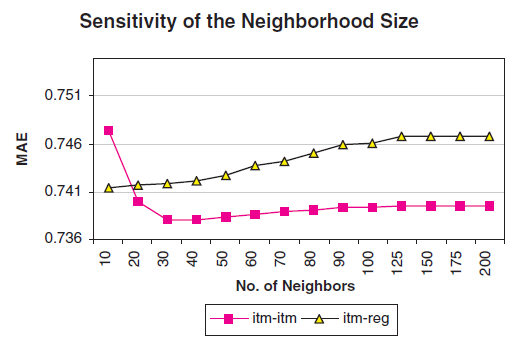
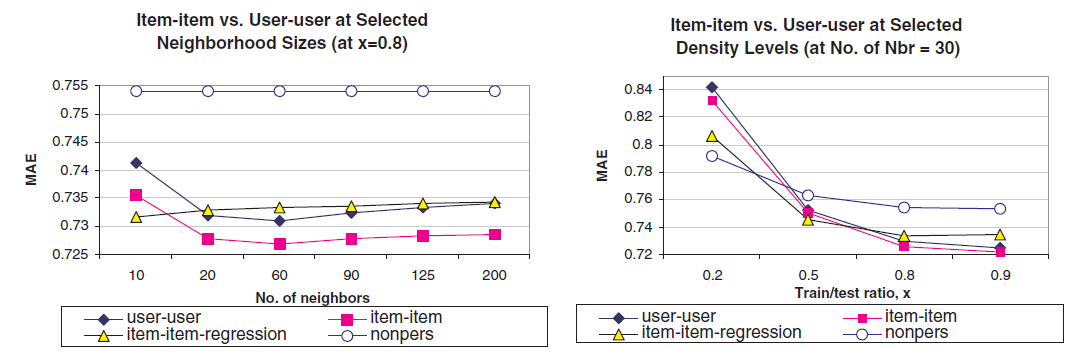
推荐质量:一旦获得了最佳超参数,我们将
User-Based CF和Ite-Based CF进行比较,我们也比较了非个性化算法(non-personalized)(如推最热门的),结果如下所示。可以看到:
简单加权和的
Item-Based CF在所有30)、以及所有邻域尺寸(30)时,User-Based CF的测试MAE = 0.755,而简单加权和Item-Based CF的测试MAE = 0.749;而在邻域大小为60(User-Based CF的测试MAE = 0.732,而简单加权和Item-Based CF的测试MAE = 0.726。回归加权和的
Item-Based CF的表现比较有趣:它在非常小的User-Based CF效果都要差。我们还将我们的算法与朴素的非个性化算法进行了比较。
我们从这些结果中得出两个结论:
首先,简单加权和的
Item-Based CF算法在所有稀疏级别上都比User-Based CF算法提供更好的推荐质量。其次,回归加权和的
Item-Based CF算法在非常稀疏的数据集上表现更好,但是随着我们添加更多数据,推荐质量会下降。我们认为这是由于模型过拟合。
推荐性能:在表明
Item-Based CF算法比User-Based CF算法提供更好的预测质量之后,我们将重点放在可扩展性问题上。如前所述,Item-Based的相似度更加静态,并允许我们预计算item邻居。模型的这种预计算具有一定的性能优势。为了提高系统的可扩展性,我们研究了模型大小推荐质量对模型大小
item数量25增加到200,增量为25。模型大小item来构建模型,然后使用其中的item。下图给出了不同MAE。另外我们还给出全量MAE(虚线之后的最后一个点)。可以看到:
随着
MAE的值会改善,但是改善的效果逐渐降低。仅仅使用一小部分
item即可实现高准确性。在1.5%的模型大小(MAE=0.754)即可得到全尺寸模型(MAE=0.726)96%的准确性;保留3%的模型大小(MAE=0.738)即可得到全尺寸模型98.3%的准确率。这种模型大小敏感性具有重要的性能影响,这表明仅使用一小部分
item来预计算item相似度很有效,并且仍然可以获得良好的预测质量。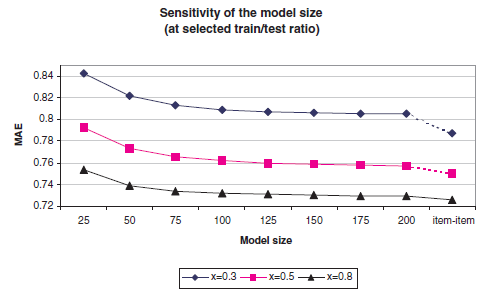
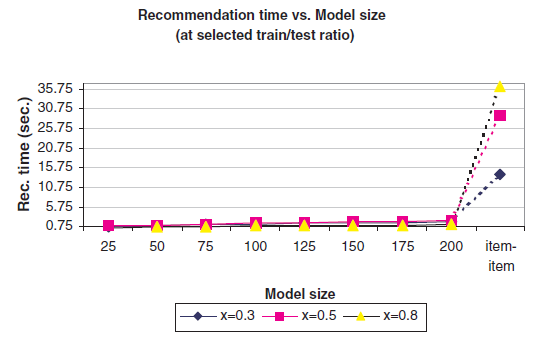
模型大小
可以看到:小尺寸模型和全尺寸模型的预测结果生成时间存在很大差异。
当
7.5万)2.002秒,而全尺寸模型为14.11秒。当
2万)1.292秒,而全尺寸模型为36.34秒。
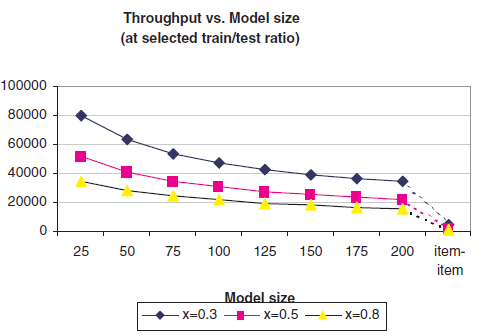
由于不同
当
1.487秒完成7万个测试样本的打分,即47361个/秒,而全尺寸模型只有4961个/秒。当
21505个/秒,全尺寸模型只有550个/秒。
讨论:从
Item-Based CF的试验评估中,我们得出了一些重要的观察:首先,
Item-Based CF比使用User-Based CF提供更好的预测质量。预测质量的提高在不同邻域大小其次,
item邻域是相当静态的,可以预计算,这会导致非常高的在线性能。此外,
model-based方法可以只保留一小部分item并产生相当好的预估质量。我们的实验结果支持这一说法。因此,Item-Based CF能够解决电商推荐系统中的两个最重要的挑战:预测质量和预测性能。