一、PMF [2008]
《Probabilistic Matrix Factorization》
低维因子模型(
low-dimensional factor model)是最流行的协同过滤方法之一,该模型背后的思想是:用户偏好是由少量未观察到的因子(unobserved factor)决定的。在线性因子模型(
linear factor model)中,我们可以通过采用线性加权item因子向量(item factor vector)来建模用户的偏好,权重为特定于用户的系数 (user-specific coefficient)。例如,对于item因子矩阵训练这个模型等价于:在给定损失函数的意义下,寻找
通常可以采用奇异值分解(
Singular Value Decomposition: SVD)寻找到最小平方和损失下的低秩近似。但是, 大多数真实数据集都是非常稀疏的,即observed entry)(即非缺失值)。这种看起来非常微小的修改将导致难以解决的非凸优化问题,从而使得标准的SVD无法解决。《Maximum-margin matrix factorization》方法并非约束矩阵分解的秩,而是对上面提到的许多协同过滤算法已经应用于
Netflix Prize数据集上建模用户评分。然而,由于以下两个原因,这些方法都不是很成功:首先,除了基于矩阵分解的方法之外,上述方法都无法很好地扩展到大型数据集。
其次,大多数现有算法都难以为评分很少的用户做出准确的预测。
协同过滤任务的一种常见的数据预处理方法为:删除评分数量低于指定阈值的用户(如评分数量低于
3)。事实上,评分数量很低的用户的推荐难度更大。因此大多数协同过滤算法在MovieLens, EachMovie等标准数据集上效果非常好,因为这些标准数据集剔除了最困难的情况。例如,Netflix数据集非常不平衡,低频用户评分少于5部电影、高频用户评分超过10000部电影。由于Netflix Prize数据集规模之大、不活跃用户之多, 使得它成为协同过滤算法更现实的benchmark数据集。论文
《Probabilistic Matrix Factorization》提出了概率矩阵分解(Probabilistic Matrix Factorization:PMF)模型,该模型可以轻松的处理非常大的数据,并且也可以处理评分数量稀少的用户。实验表示PMF模型在Netflix数据集上表现良好。PMF模型的计算复杂度和观察次数成线性,因此具有很好的scalability。并且模型在大型、非常稀疏、非常不平衡的数据集(例如Netflix数据集)上表现良好。论文进一步扩展了
PMF模型,从而得到能够自动调整超参数的自适应PMF,并展示如何自动控制模型容量。最后,论文引入
PMF模型的约束版本,该变种基于以下假设:对相似item集合评分的用户可能具有相似的偏好。该假设得到的模型对于评分数量很少的用户能产生更好的推荐结果。
当多个
PMF模型的预测与受限玻尔兹曼机模型的预测线性组合时,论文实现了0.8861的RMSE,这比Netflix自己的系统得分好了将近7%。
1.1 模型
1.1.1 PMF
假设有
item。假设评分为:从整数item定义
item因子矩阵,第item定义观测值的条件分布为:
其中:
进一步的,我们假设用户因子向量和
item因子向量采用零均值的球形高斯先验分布(spherical Gaussian):其中
则后验概率分布的对数为:
其中
当固定
其中:
Frobenius范数。我们可以通过对
PMF模型可以视为SVD模型的概率扩展。当我们能够观察到所有的user-item评分时,在先验方差PMF模型退化为SVD模型。事实上,上述推导过程存在一个问题:预测结果
PMF使用logistic函数来限定评分范围:在训练过程中我们将评分
[0,1];在预测过程中我们使用可以通过最速下降法优化
PMF的目标函数,其计算复杂度和观察值的规模成线性关系。在
Matlab实现中,当Netflix数据集的1个epoch。训练
PMF模型的高效率来自于:仅找到模型参数和超参数的点估计,而不是推断他们的完整后验分布。如果我们采用完全贝叶斯方法,则计算上更为昂贵,但是初步结果强烈表明:对PMF模型的完全贝叶斯处理将导致预测准确性的显著提高。
1.1.2 自适应 PMF
模型容量对于
PMF模型的泛化至关重要。超参数
PMF模型能够逼近任何给定的矩阵。因此,控制PMF模型容量的最简单直接的方法是限制但是,当数据集不平衡时(即观察值的规模在不同的行或者列之间显著不同),则该方法行不通。因为无论怎么选择
另一种方式是采用正则化来控制模型容量,如
选择合适正则化系数,最简单直接的方法是进行超参数搜索,如
GridSearch, RandomSearch。这种方式的主要缺点是计算量太大:除了训练最终的模型之外,我们必须训练多个模型来确定最佳的正则化系数。
这里我们提出了一个自动确定
PMF正则化系数的变种,称作自适应PMF。这种方式可以自动选择合适的正则化系数,并且不会显著影响模型训练时间。其基本原理是:引入超参数的先验分布,并最大化模型在参数其中:
item因子向量的先验分布的超参数。它们本身也是一个随机变量,分别服从分布当先验分布
其中
根据偏导数为零,则我们得到超参数的闭式解:
当先验分布
在求解超参数时固定参数
在求解优化参数时固定超参数,此时通过梯度下降法求解。
当先验分布是混合高斯分布时,我们可以通过执行单步
EM算法来更新超参数(参数的更新仍然是通过梯度下降法)。
1.1.3 约束 PMF
上述
PMF模型存在一个问题:对于评分非常少的用户,他们的用户因子向量将趋近于先验均值(或者说用户因子向量的均值),因此这些用户的预测评分将接近所有评分的均值。这里我们提出了一种约束用户因子向量的方法,该方法对于评分稀少的用户具有很强的效果。
定义
latent similarity constraint matrix),定义用户其中
直观的看:
矩阵
item评分,则用户因子先验均值受到的影响。因此,看过相同(或者相似)电影的用户,其用户因子向量将具有相似的先验分布。如果两个用户评分的item集合相同,则他们具有相同的用户因子向量。
事实上,这里假设有
item因子向量,但是item。下图中,左图为无约束
PMF,此时先验均值固定为零,因此PMF,此时先验分布非零。(注意下图为原始论文,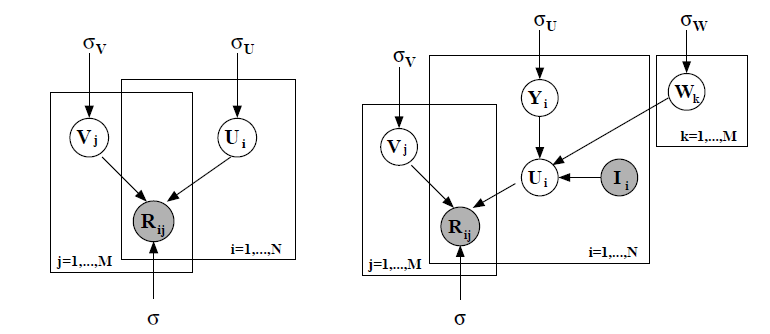
我们定义观察值的条件分布为:
假设
则有:最大化对数后验概率,等价于最小化带正则化项的误差平方和:
其中:
我们可以对
实验表明,这种方式的效果比简单的无约束
PMF模型效果好得多,尤其是针对评分数量稀少的用户。
1.2 实验
数据集:
Netflix数据集。该数据集收集了1998年10月到2005年12月之间Netflix网站上用户的所有评分数据。训练数据集包含来自
480189个 随机选择的匿名用户的100480507个评分,涉及17770个电影标题。作为训练数据的一部分,Netflix还提供了包含1408395个评分的验证数据集。除了训练集和验证集之外,
Netflix还提供了一个包含2817131个user-movie pair的测试集,这些pair是从训练集中部分用户的最新评分中选择的。Netflix给出了测试集中一半数据的评分,另一半数据的评分是未给出的。研究人员需要向官方上传另一半(未知部分)数据的评分结果,并由官方返回该部分的RMSE指标。这种方式是为了防止模型对测试集过拟合。作为Baseline,Netflix给出了他们自己模型在测试集上的RMSE指标为0.9514。为了进一步了解不同算法的性能,我们通过随机选择
50000个用户和1850部电影,从而创建了一个更小、难度更高的数据集。这个小数据集包含1082982个训练数据、10462个验证数据,其中训练数据中超过50%的用户的评分数量少于10。
训练配置:为加快训练速度我们采用随机梯度下降,其中
batch size = 100000。为选择合适的学习率和动量,我们在各种超参数组合上进行实验,最终选择学习率为
0.005、动量为0.9,因为这组配置对所有维度
1.2.1 自适应 PMF
为评估自适应
PMF模型的性能,我们选择SVD模型仍然可能过拟合,并且通过自动正则化会有一些性能的提升。模型:
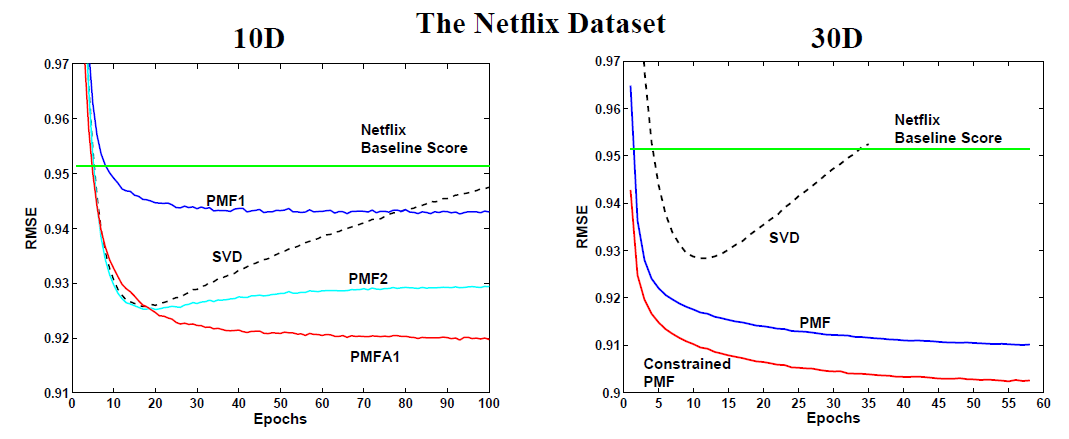
SVD模型:该模型的损失函数为观察值误差的平方和,其中没有采用任何形式的正则化。固定正则化系数的
PMF模型:模型损失函数为观察值误差的平方和,带固定系数的正则化。其中PMF1的正则化系数为PMF2的正则化系数为自适应
PMF模型:模型损失函数为观察值误差的平方和,带正则化。其中PMFA1的PMFA2的在这种情况下,自适应先验具有可调整的均值。
先验参数和噪音协方差每隔
10到100个
我们在完整的
Netflix训练集上训练模型,然后评估模型在Netflix验证集上的效果。可以看到:SVD模型的表现几乎和具有适当正则化的PMF模型(PMF2)效果一样好,但是SVD模型在训练结束之前陷入严重过拟合。PMF1模型虽然没有陷入过拟合,但是它仅达到0.9430的RMSE,明显欠拟合。自适应
PMF明显优于其它模型。这里没有给出PMFA2(RMSE为0.9204),因为它的曲线和PMFA1几乎相同(RMSE为0.9197)。这表明:通过自适应先验来自动正则化在实践中效果良好。我们比较了
另外,尽管对角协方差矩阵的使用并未比球形协方差矩阵的版本有明显改善,但是对角协方差可能非常适合自适应
PMF训练的greedy算法,在该算法中模型每次学习一个因子向量。
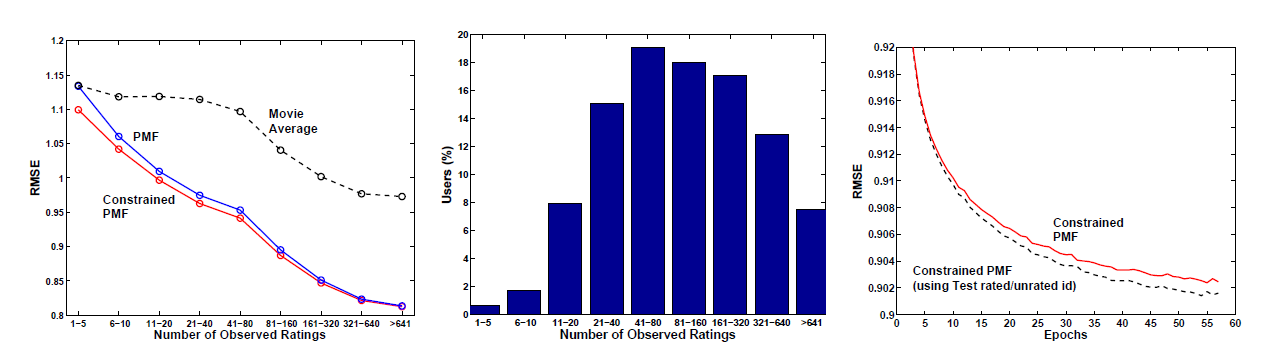
1.2.2 约束PMF
在约束
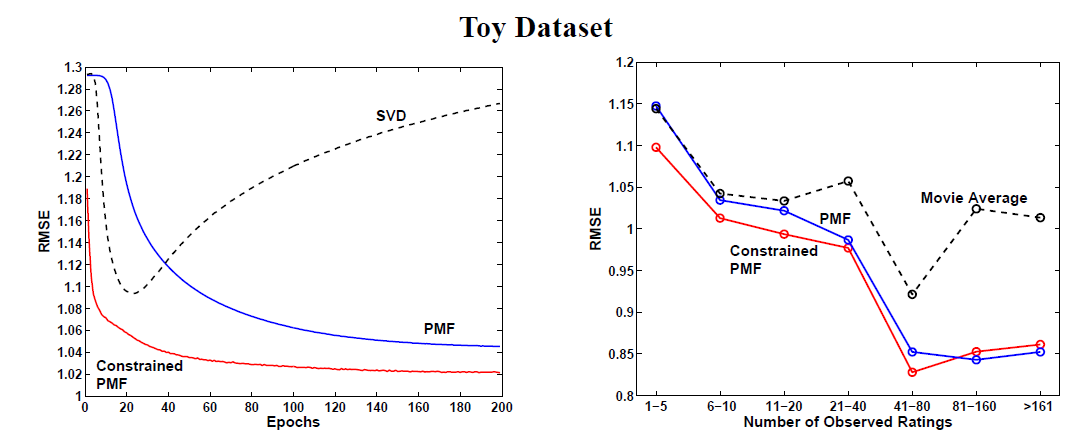
PMF上我们使用30维特征,因为PMF和约束PMF我们设置正则化参数为我们在完整的
Toy训练集(我们构造的小数据集)上训练模型,然后评估模型在Toy验证集上的效果。可以看到:SVD模型明显的陷入了过拟合。约束
PMF模型相比无约束PMF模型具有更好的性能,并且收敛速度更快。右图给出了不同评分数量的用户的评估结果。可以看到:
对于训练集中评分数量少于
5个的一组用户,PMF模型性能与均值算法(电影约束
PMF模型在评分较少的用户上的性能要好得多。随着评分数量的增加,
PMF和约束PMF的性能相差无几。
约束
PMF模型的另一个有趣的性质是:即使我们仅知道用户曾经评分的电影,但是不知道评分的值,模型也能够利用该信息从而得到更好的效果。对于用户对于我们的
toy数据集,我们随机增加了额外的50000个用户来训练,并丢弃这些用户的实际评分。最终约束PMF方法在验证集上的RMSE为1.0510,而简单平均算法的RMSE为1.0726。这表明:仅了解用户评分的电影而不知道具体评分,仍然可以帮助我们更好的建模用户的偏好。
约束
PMF在整个Netflix数据集上的表现与Toy数据集的结果相似。对于PMF和约束PMF我们设置正则化参数为结果表明:
SVD模型的RMSE为0.9280,大约10个epoch开始过拟合。约束
PMF模型对于评分数量很少的用户可以有更好的泛化,其中训练集中超过10%的用户其评分不足20个;随着评分数量的增加,PMF和约束PMF性能趋同。考虑到
Netflix数据还有一个额外的信息来源:Netflix会告诉我们测试集中还有哪些user-movie pair,因此我们还知道一个信息:用户已经评分、但是不知道评分大小的电影。约束
PMF可以很容易考虑该信息,如右图所示,这将进一步提高模型的性能。
当我们将
PMF、自适应PMF、约束PMF线性组合在一起时,我们在测试集上达到了0.8970的RMSE,这比Netflix官方Baseline 0.9514提高了将近6%。