一、BPR [2009]
《BPR: Bayesian Personalized Ranking from Implicit Feedback》
内容推荐是很多信息系统中的一项重要任务,例如像
Amazon这样的在线购物网站为每个客户提供用户可能感兴趣商品的个性化推荐。其它例子像YouTube这样的视频门户网站,为用户推荐电影。个性化对于内容提供商和用户都很有吸引力,前者可以增加销售额或者浏览量,后者可以更容易找到有趣的内容。这里我们专注于item推荐。item推荐任务是为一组item创建user-specific排序。用户对item的偏好是从用户历史行为中获悉的,如用户的购买历史、观看历史等等。推荐系统是一个活跃的研究课题。最近的工作是关于用户提供显式反馈的场景,例如在评分方面。然而,在现实世界的场景中,大多数反馈不是显式而是隐式的。隐式反馈会自动跟踪,例如跟踪点击次数、浏览次数、购买次数等等。隐式反馈的收集要容易的多,因为用户不需要显式表达他的口味。事实上,几乎任何信息系统都已经可以使用隐式反馈,例如
web服务器在日志文件中记录的任何页面浏览行为。在论文
《BPR: Bayesian Personalized Ranking from Implicit Feedback》中,作者提出了一种用于学习个性化排序模型的通用方法。这项工作的主要贡献是:论文提出了从最大后验估计导出的、用于最佳个性化排序的通用优化标准
BPR-Opt。论文展示了BPR-Opt与AUC的类比。为了最大化
BPR-Opt,论文提出了通用学习算法LearnBPR,它基于随机梯度下降、以及对训练三元组的bootstrap采样。论文表明作者的算法在优化BPR-Opt方面优于标准的梯度下降方法。论文展示了如何将
LearnBPR应用于两个SOTA的推荐模型族。论文的实验表明,对于个性化排序任务,使用
BPR学习的模型优于其它学习方法。
相关工作:
推荐系统最流行的模型是
k-nearest neighbor: KNN协同过滤。传统上,KNN的相似度矩阵是通过启发式计算的,例如Pearson相关性。但是在最近的工作《Factorization meets the neighborhood: a multifaceted collaborative filtering model》中,相似度矩阵被视为模型参数,并为任务专门学习。最近,矩阵分解
matrix factorization: MF在隐式反馈和显式反馈的推荐系统中变得非常流行。在早期的工作《Incremental singular value decomposition algorithms for highly scalable recommender systems》中,作者已经提出奇异值分解(singular value decomposition: SVD)来学习特征矩阵。SVD学习的MF模型已经被证明非常容易过拟合,因此人们使用正则化技术。对于item预测,《Collaborative filtering for implicit feedback datasets》和《One-class collaborative filtering》提出了一种带有样本权重正则化的最小二乘优化(WR-MF)。样本权重可用于减少负样本的影响。《Latent semantic models for collaborative filtering》提出了一种用于item推荐的概率潜在语义模型。《Compound classification models for recommender systems》将问题转变为多分类问题,并使用一组二分类器解决它。
尽管上面讨论的所有
item预测工作都是在个性化排序数据集上进行评估的,但是这些方法都没有为排序任务直接优化模型参数。相反,他们优化模型参数从而预估用户是否会选择某个item。在我们的工作中,我们导出了一个基于item pair(即特定用户的两个item之间的顺序)的个性化排序优化标准。我们将展示如何根据该标准优化MF或者自适应kNN等SOTA模型,从而提供比常规的学习方法更好的排序质量。我们还详细讨论了
《Collaborative filtering for implicit feedback datasets》和《One-class collaborative filtering》的WRMF方法、以及《Improving maximum margin matrix factorization》的maximum margin matrix factorization: MMMF方法与我们方法之间的关系。我们还将讨论我们的优化准则和AUC优化准则的关系。在本文中,我们专注于模型参数的离线学习。在评分预测相关的任务中,
《Online updating regularized kernel matrix factorization models for large-scale recommender systems》已经为MF研究了将学习方法扩展到在线学习的场景(如,添加一个新用户,然后新用户的历史行为记录从0增加到1,2,...)。相同的方法可用于BPR。还有关于学习使用非协同过滤模型进行排序的相关工作(
《Efficient inference for distributions on permutations》,《《Multiobject tracking with representations of the symmetric group》)。一个方向是对排列的分布进行建模。《Learning to rank using gradient descent》针对排序任务,使用梯度下降优化了一个神经网络模型。所有这些方法只学习一个排序,即它们是非个性化的。相反,我们的模型是学习个性化排序的协同过滤模型,即每个用户一个单独的排序。在我们的评估中,我们根据实验表明,在典型的推荐设置中,我们的个性化BPR模型甚至优于非个性化排序的理论上限。个性化排序(
personalized ranking)任务是为用户提供一个排序的item列表,这也被称作item推荐(item recommendation)。例如,一家在线商城会向用户推荐用户可能想要购买的商品的个性化排序列表。在本文中,我们研究了从隐式反馈中推断ranking的场景。隐式反馈有意思的地方在于,只有正的观察值是可用的。未观察到的user-item pair(例如,用户尚未购买的商品)的真实反馈是未知的,可能是用户不喜欢(负反馈)、也可能是用户喜欢但是尚未见过。
1.1 BPR 准则
令
item集合。推荐系统的任务是针对用户完备性(
totality):反对称性(
antisymmetry):传递性(
transitivity):
常规的
item推荐思路是预测用户itemitem的偏好。然后根据预估评分对item进行排序。令隐式反馈数据
在隐式反馈系统中,系统只能观察到用户的
postive行为,剩余的数据是缺失值。一种解决缺失值的方法是忽略这些缺失值。但是直接忽略缺失值使得我们没有
negative样本,从而模型无法学习。另一种解决缺失值的方法是将缺失值都是为
negative行为。这意味着模型对1、对0。考虑到item就是我们候选的、需要向用户推荐的item,因此一个学习能力强的模型会根据这些negative数据学到目前该方法之所以有一定效果的原因是模型采取了一些缓解过拟合的策略,如正则化。
我们采用了不同的思路:使用
item pair来训练模型从而优化item pair的排名,而不是优化单个item的得分。这相比使用negative来代替缺失值更好地刻画了问题。我们从
如果
itemitem,用户item如果
item如果
item
因此我们构建训练集:
其中
对于任何三元组
itemitem这种方式有两个优点:
训练集包含
postive pair、negative pair。 测试集包含所有缺失item pair,这个刚好就是我们希望进行排序的目标item pair。这意味着从pair-wise角度来看,训练集训练集包含的是 “(观测样本,未观测样本)” 的
pair,而测试集是 “(未观测样本,未观测样本)” 的pair,因此二者是不相交的。训练数据是为真实的
ranking目标而构建的。
在贝叶斯分析框架下,个性化排名的任务是:为每个
item考虑到
其中
假设用户之间彼此独立,并且假设用户
item pair之间的顺序也是相互独立的。因此其中
进一步地,根据完备性和反对称性,我们有:
目前为止,我们还无法确保得到个性化排序。为满足完备性、反对称性、传递性,我们定义用户
item其中:
sigmoid函数;itemitem即:我们的
BPR通用框架把对kNN之类的基础模型,由这些模型来预估BPR框架,我们可以对个性化排序我们引入先验概率密度函数
为减少超参数数量,我们选择
BPR-OPT:个性化排名通用准则BPR-OPT是最大化后验估计其中
itemitem
1.2 BPR 学习
和
AUC的联系:我们将BPR和AUC进行类比。用户维度的AUC定义为:即在所有
postive item和missing item组合中,模型预估对postive item和missing item能够正确区分的概率。因此所有用户的平均
AUC为:根据
其中
这和
BPR-OPT准则非常类似。BPR-OPT的目标函数为:如果将这个代价函数视为损失函数(第一项)和正则化项(第二项),则
BPR-OPT的损失函数为:这和
AUC有两个区别:AUC使用了归一化常数AUC使用不可导的示性函数Heaviside函数:通常在优化
AUC时我们使用可导的Heaviside函数。而
BPR-OPT使用可导的损失函数
学习算法:虽然我们已经导出了个性化排名的优化准则,并且该准则是可微的,但是我们无法利用标准的梯度下降算法来求解该最优化问题。为解决该最优化问题,我们提出了基于
bootstrap采样的随机梯度下降算法LearnBPR。BPR-OPT目标函数的梯度为:在
full随机梯度下降算法中,在每个step需要计算所有训练样本的梯度,然后更新参数:这种方法可以确保每次参数更新的方向是正确的,但是缺点是计算复杂度太高:
step中计算完整的梯度不可行。另外,使用完整的梯度优化也会存在梯度倾斜问题,这也会拖慢训练的收敛速度:
不同的
item为postive的分布不同,因此我们很难选择一个合适的学习率:对于postive较多的item(梯度较大), 我们必须选择一个较小的学习率;对于postive较少的item(梯度较小) ,我们必须选择一个较大的学习率。另外梯度分布差距太大,导致正则化系数的选择非常困难。
在随机梯度下降算法中,我们对单个三元组
这可以解决梯度倾斜问题。但是,随机梯度下降依赖于样本的遍历顺序,需要确保每次都是随机选择
LearnBPR学习算法采用每次均匀随机选择三元组step中选择相同user-item组合的机会很小。我们建议使用bootstrap采样方法,这样可以在任何step来停止。在我们的案例中,放弃完整epoch循环的想法特别有用,因为样本数量巨大,并且只需要整个epoch的一小部分模型就能收敛。这就是
batch随机梯度下降,并且batch是随机选择(而不是user-wise或者item-wise选择)。下图给出了典型的
user-wise随机梯度下降,以及LearnBPR随机梯度下降的收敛速度。可以看到learnBPR随机梯度下降的收敛速度更快。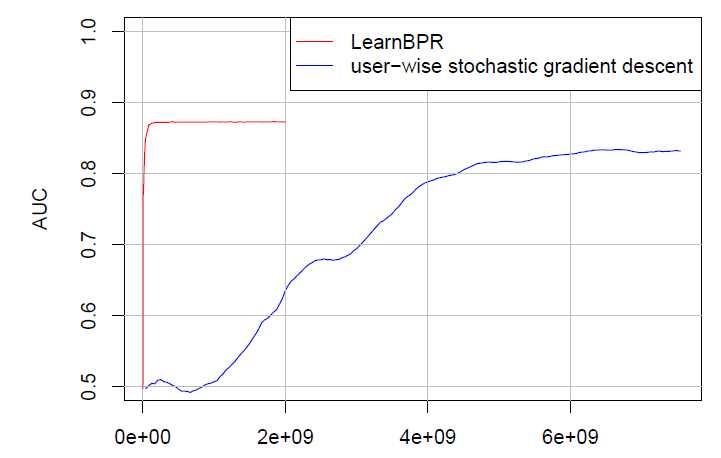
1.3 模型结合 BPR
这里我们展示如何将
BPR和经典的矩阵分解、kNN模型融合。在
BPR-OPT通用框架中,我们需要利用其它模型来预估现在我们可以使用标准的协同过滤算法来预估
即使我们使用了和别人一样的模型,我们和它也有本质的不同:我们采用了另一个准则来优化模型,这会导致更好的排序结果。因为我们的准则是直接优化个性化排名。
我们的准则并不是尝试通过单个预估值
矩阵分解结合
BPR:假设每个用户representation向量itemrepresentationrepresentation向量维度。用户item则有:
其中
item向量item的数量,该模型称作矩阵分解
Matrix Factor,模型的参数为可以通过奇异值分解
SVD来求解参数non-negative MF)、最大裕量矩阵分解 (maximum margin factorization)等等。对于个性化排名任务,更好的方法是采用
BPR-OPT准则进行优化,称作BPR-MF。对于使用了
BPR-OPT准则的矩阵分解模型,LearnBPR优化时使用的梯度为:另外我们还引入三个正则化约束:
使用
representation矩阵使用
positive更新 。使用
negative更新。之所以拆分postive样本和negative样本的规模差异巨大。
自适应
kNN结合BPR:kNN可以基于item之间的相似或者user之间的相似来建模,这里我们介绍基于item相似的kNN方法,但是基于user相似性的kNN方法原理类似。基于
item相似的kNN的基本思想是:用户itemitemitem的相似性。通常我们仅使用itemtop k个item,即kNN。最终基于
item的kNN模型为:其中
item之间的相似度矩阵,它也是模型的参数注意:这里假设
postive得分为1、negative得分为0。因此最终预估评分就是top k个item的相似度之和。另外,有的方法也对相似度矩阵按行进行归一化。大多数方法使用启发式的相似度函数,如余弦相似度:
一个更好的方法是通过学习相似度矩阵
我们考虑通过
BPR-OPT准则和LearnBPR学习方法来利用kNN对个性化排序进行建模,称作kNN-BPR。LearnBPR优化时采用的梯度为:另外我们还引入两个正则化约束:
1.3 BPR VS WR-MF 、MMMF
这里我们讨论
BPR和WR-MF以及MMMF模型之间的联系。Weighted Regularized Matrix Factorization:WR-MF用于从隐式反馈数据中执行矩阵分解(参考Implicit Feedback CF章节),其模型为:其中
F范数,user-item组合的先验权重。例如,对于所有postive样本选择negative样本选择这里假设正样本的评分为
1、负样本评分为0,因此和
BPT-OPT的BPT-OPT是对每个用户item pair,而WR-MF优化的是单个item。BPT-OPT的损失函数为逻辑回归损失,而WR-MF的损失函数为最小平方误差。但是
item预测实际上不是回归任务(定量分析),而是分类任务(定性分析),因此用逻辑回归损失更合适。BPT-OPT对每个损失的权重为1,而WR-MF对每个损失的权重为
Maximum Margin Matrix Factorization:MMMF并不适合于隐式反馈数据集。我们可以将缺失值设置为0、将非缺失值设置为1。通过这些修改,MMMF的目标函数为:和
BPT-OPT的BPT-OPT的损失函数为逻辑回归损失,而MMMF的损失函数为hinge损失。BPT-OPT准则是通用的,可应用于多种模型;而MMMF方法仅针对矩阵分解。
MMMF:正负样本预估得分之间的差距尽可能大;BPT-OPT:正样本预估得分大于负样本预估得分的概率尽可能大。二者都是排序关系,因此思想上是相近的。如果将Hinge损失替换为逻辑回归损失,则MMMF等价于BPT-OPT。
1.4 实验
数据集:
Rossmann数据集:一个在线商店数据集,包含10000个用户在4000个item上的购买历史,总共有426612条购买记录。我们的任务是为用户推荐该用户下一次可能购买的商品的列表。Netflix数据集:一个DVD出租数据集,包含用户在电影上的显式评分,评分从1~5共五个等级。由于我们需要解决隐式反馈任务,因此我们从数据集中删除了评分分数。现在的任务是预测用户是否可能为电影评分。我们从原始数据集中采样了
10000个用户、5000个item,包含565738个评分。采样时,我们选择至少对10部电影进行评分的用户item至少有10个用户观看
baseline模型:我们选择了矩阵分解MF和kNN这两种流行的模型。对于矩阵分解模型,我们采用三种不同的方法来实现:标准矩阵分解
SVD-MF、带权重矩阵分解WR-MF、基于BPR-OPT优化准则的矩阵分解BPR-MF。对于
kNN模型,我们采用两种不同的方法来实现: 基于余弦相似度的kNN方法cosin-kNN、基于BPR-OPT优化准则的自适应kNN方法BPR-kNN。另外我们还比较了基于热门程度的
baseline方法:根据item热门程度排名,然后为每个用户top热门的item。这也是一种非个性化的推荐,即所有用户推荐的item都相同。
实验配置:我们使用留一法(
leave one out)来评估。对于每个用户随机删除一条历史记录,并将该历史记录作为测试集。这样我们得到了不相交的训练集AUC:其中
item,以及所有的缺失item组成:AUC的值越高表明模型效果越好。随机猜测的AUC为0.5, 最好的AUC为1.0。即对每个用户
我们还给出了非个性化推荐方法的理论
AUC上界对于每种实验配置,随机重复执行
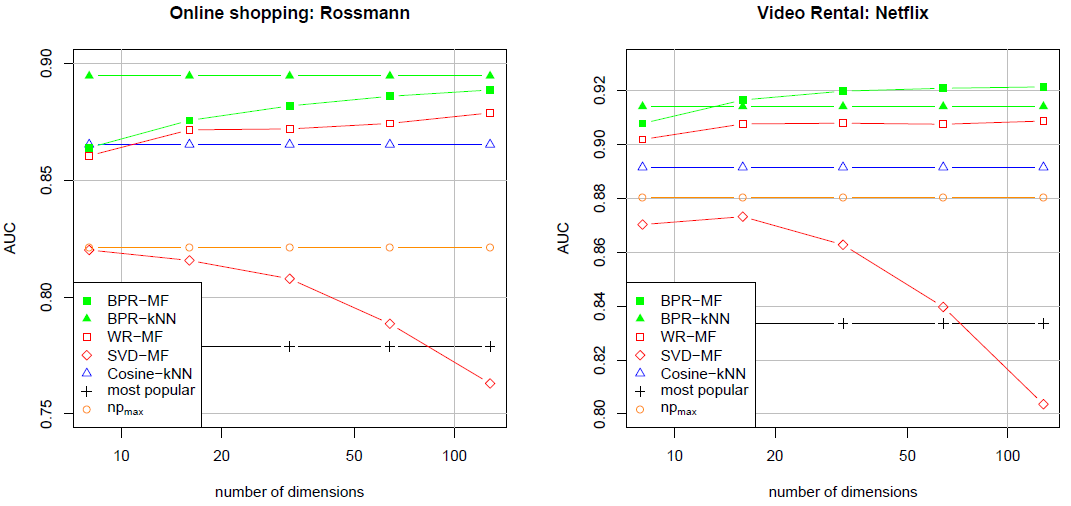
10次,在每一次都随机拆分训练、测试集。所有模型的超参数都在第一次执行时采用grid search搜索,并在剩余9次保持不变。在两个数据集上所有模型的效果如下。结论:
BPR-MR和BPR-kNN均优于其它所有方法。这表明我们的BPR-OPT准则以及对应的LearnBPR学习方法在个性化排序任务中的效果。尽管所有的矩阵分解方法
SVD-MF,WR-MF,BPR-MF采用完全相同的模型(即MF),但是它们的效果差别很大。SVD-MF可以对训练数据拟合的更好,但是它会陷入严重的过拟合。这可以从SVD-MF随着维度的增加,测试AUC反而下降来观察到。WR-MF相比之下更为成功。由于正则化的效果,当维度增加时WR-MF的效果并未下降。BPR-WF在所有数据集上都超越了SVD-MF和WR-MF。
即使是
cosin-kNN这样最简单的个性化推荐方法也超越了非个性化的