一、MF [2009]
《Matrix factorization techniques for recommender systems》
现代消费者被各种选择所淹没。电商和内容提供商提供种类繁多的产品,有前所未有的机会来满足各种特殊需求和口味。为消费者匹配最合适的产品是提高用户满意度和忠诚度的关键。因此,越来越多的电商对推荐系统感兴趣,其中推荐系统分析用户对产品的兴趣模式,从而提供适合用户口味的个性化推荐。由于良好的个性化推荐可以提升用户体验,因此
Amazon.com和Netflix等电商领导者已经将推荐系统作为他们网站的重要组成部分。这样的系统对于诸如电影、音乐、电视节目之类的娱乐产品也特别有用。许多不同的用户将观看同一部电影,而每个用户可能会观看许多不同的电影。事实证明,客户愿意表明他们对特定电影的满意度,因此有大量的、关于哪些电影吸引哪些用户的数据是可用的。公司可以分析这些数据,从而向特定用户推荐电影。
推荐系统策略:广义上讲,推荐系统基本上有两种策略:
基于内容过滤(
content filtering)的推荐:为每个用户创建用户画像,或为每个商品创建商品画像,然后系统基于用户画像和商品画像进行匹配。如:用户画像包括人口统计信息、调查问卷及其答案;电影画像包括电影类型、演员、票房热度等。然而,基于内容过滤的推荐需要搜集大量的外部信息从而构建画像系统,这些信息可能很难收集或者根本无法收集。
基于内容过滤推荐的一个成功案例是
Music Genome Project项目,该项目用于互联网广播服务Pandora.com。在该项目中,受过训练的音乐分析师会根据数百种不同的音乐特征对每首歌进行打分,从而构建音乐画像。这些特征不仅捕获了歌曲的音乐特性,还捕获了与听众的喜好相关的很多其它特性。基于协同过滤 (
collaborative filtering)的推荐:它根据用户之间的相关性,或者商品之间的相关性进行推荐。这个过程中不需要创建用户画像或商品画像,仅依赖于历史的用户行为,例如历史的交易或者评分。协同过滤的主要优点在于它是领域无关(
domain free)的,并可以解决内容画像难以描述的一些用户行为模式。协同过滤虽然通常比内容推荐更为准确,但无法解决冷启动问题(cold start problem) 。在冷启动方面,基于内容推荐的表现更好。
协同过滤的两个主要方向是邻域方法(
neighborhood method)和潜在因子模型(latent factor model)。邻域方法的重点是计算
item之间的相关性,或用户之间的相关性。ItemBased CF根据同一个用户在相似的item上的评分,来评估该用户对新item的偏好。UserBased CF根据相似用户在同一个item上的评分,来评估新用户对该item的偏好。
潜在因子模型根据所有用户的
item评分模型,从而推断出item。从某种意义上讲,这些因子包括上述人类创造歌曲基因的、计算机化的替代方案。对于电影,因子可能是某些显著的维度(如:电影流派、是否适合儿童等等),也可能是不显著的维度(如:演员的气质),甚至也可能是完全无法解释的维度。对于用户,这些因子衡量用户对相应因子电影上的喜欢程度。
潜在因子模型的一些最成功的实现是基于矩阵分解(
matrix factorization:MF)。在矩阵分解的基本形式中,它通过从item评分模式中推断出的因子向量来表征用户和item。然后我们基于用户因子向量和item因子向量的内积来进行推荐。近年来,这些方法因为具有良好的可扩展性、预测准确性从而变得流行。此外,它们为建模各种现实情况提供了很大的灵活性 ,它允许结合额外信息,例如隐式反馈、时间效应、以及置信度水平。论文
《Matrix factorization techniques for recommender systems》对协同矩阵分解模型进行了详细的讨论。推荐系统依赖于不同类型的输入数据,这些数据通常放置在一个矩阵中,一个维度代表用户、另一个维度代表感兴趣的
item。显式反馈数据:最方便的数据是高质量的显式反馈,其中包括用户对
item兴趣的显式输入。例如,Netflix收集电影的星级评分,TiVo用户通过thumbs-up和thumbs-down按钮来表明他们对于电视节目的偏好。我们将明确的用户反馈称作评分。通常,显式反馈包含一个稀疏矩阵,因为任何单个用户可能只对所有
item中的一小部分进行了评分。隐式反馈数据:矩阵分解的优势之一是它允许融合附加信息。当显式反馈不可用时,推荐系统可以使用隐式反馈推断用户偏好,通过观察用户行为(包括购买历史、浏览历史、搜索历史、甚至鼠标移动历史)来间接反映用户的意见。隐式反馈通常表示事件的存在或不存在,因此它通常由稠密矩阵来表示。
1.1 基本形式
给定
user-item评分矩阵item因子向量。假设用户
itemitem因子向量item求解该模型的传统方法是奇异值分解
SVD,由于评分矩阵SVD方法是未定义的。一种方法是仅拟合数量稀少的非缺失评分,但这会导致模型很容易陷入过拟合。
另一种方法是通过插值填补来补全缺失的评分,使得
因此最近的工作直接对非缺失项进行建模,同时利用正则化来缓解过拟合:
其中:
user-item pair集合,item集合,《Probabilistic Matrix Factorization》为正则化提供了概率论上的理论解释。item因子矩阵。
训练算法:
随机梯度下降:
Simon Frunk提出了该目标函数的随机梯度下降优化算法。算法在迭代过程中遍历训练集的所有user-item评分。对于每个已知评分然后算法根据梯度进行参数更新:
其中
这种训练算法易于实现,并且训练时间相对较快。
交替最小二乘法(
Alternating Least Squares:ALS):另一种训练算法是交替最小二乘法。由于因此,
ALS交替固定ALS更容易实现、收敛更快,但是至少在两种情况下ALS是有利的:首先,
ALS是可以并行化的。当固定其次,对于隐式反馈系统,因为存在大量的隐式反馈数据,因此像随机梯度下降那样遍历每个评分是不现实的。而
ALS可以有效处理这类场景。
1.2 bias 形式
我们观察到很多评分的差异是由用户本身或者
item本身导致的,称作bias偏差。如,某些用户比较吹毛求疵,其评分普遍低于所有用户的平均分;有些电影比较热门,其评分普遍高于所有电影的平均分。因此,系统可以对
bias建模为:其中
bias的评分预估,bias,itembias。如:假设所有用户在所有电影上的平均评分为
0.3分;电影 “流浪地球” 比较热门,其评分普遍比平均水平高0.5分。则“张三” 对于 “流浪地球” 的评分预估为我们可以用
bias来改进矩阵分解。我们将预估评分分解为四个部分,每个部分分别捕获对应的信号:全局均值
item上的整体评分情况。user biasuser偏离均值的部分,与item无关。item biasitem偏离均值的部分,与user无关。user-item交互部分user对于特定item的兴趣。
即:
基于
bias形式的矩阵分解模型,其目标函数为:其中
bias参数
1.3 多输入源
推荐系统经常会遇到冷启动问题,即用户提供的评分数据非常稀疏。解决冷启动问题的一种有效方法是:合并有关用户的其它信息来源,如隐式反馈数据。
为方便讨论,考虑使用二元隐式反馈数据。假设
item集合。对于每个itemitem隐式反馈因子向量item来刻画:考虑到不同用户的隐式数据规模不同,因此这里对其进行归一化:
另一种信息源是已知的用户属性,例如人口统计信息。为简单起见,这里也考虑二元属性。
假设用户
1的属性的集合) ,该集合可以描述性别(是否女性)、年龄组(是否老年人)、地域(是否一线城市)、收入水平(是否年薪超过百万)等等。对于每个属性
融合了多个数据源之后,矩阵分解模型进化为:
尽管这里给出的是提升用户表达的能力,但是必要的时候也可以对
item进行类似的处理。即可以通过用户隐式反馈因子向量、item属性因子向量来刻画item。事实上这就是
Embedding的基本思想:对历史行为item进行embedding、对用户属性进行embedding,然后对应的取加权均值池化或者sum池化。
1.4 时间效应
目前为止所有的模型都是静态的,实际上随着新的用户、新的产品、新的评分不断加入,产品的认知和热门程度会不断发生变化。同样地,用户的喜好也在不断发生变化,这导致用户的偏好被重新定义。
因此,系统应该考虑
user-item交互的动态的 (dynamic) 、随时间漂移(time-drifting)的时间效应。通过在矩阵分解模型中引入时间效应可以显著提高模型的准确性。我们将评分分解为不同的部分,然后处理每一部分的时间效应。具体而言,下列部分会随着时间变化:
item biasitem biasuser bias5分的用户(非常乐观)可能因为家庭变故,使得平均评分降低到2分。因此,模型将user biasuser-item交互:用户可能随着时间的发展而改变其口味。如:可能年轻的时候喜欢啤酒,但是随年龄增长更偏好白酒。和人类不同,商品本质上是静态的,因此系统将
item因子
因此,考虑时间效应的矩阵分解模型为:
1.5 置信度水平
并非所有观察到的评分都应该具有相同的权重或者置信度。如:系统可能会遇到某些刷好评的用户,这些好评并不能反应商品的特征。
另外,在隐式反馈系统中,很难准确地量化用户的偏好,因此系统使用粗糙的二元变量来表示 ”喜欢“ 和 ”不喜欢“ 。如:有过购买行为认为是 ”喜欢“ 。但是用户购买
10次和用户购买1次的行为是不同的,前者更能够反应用户的偏好。因此可以考虑对用户的偏好关联一个置信度得分, 该得分可以来自于用户的行为频次, 如购买行为的频次。可以考虑对矩阵分解模型引入置信度,这使得模型对于没有意义的观察到的评分降低权重。令
1.6 效果
Netflix Prize竞赛:在2006年,在线DVD租赁公司Netflix宣布了一项竞赛来改善其推荐系统。为此,该公司发布了一个包含超过1亿个评分的训练集,覆盖了大约50万匿名用户、以及他们对超过1.7万个电影的评分,评分范围是1 ~ 5分。参赛团队需要为测试集提交预测评分,其中测试集规模为300万个user-item pair。Netflix根据持有的、未公开的真实评分来计算各团队测试集的RMSE。第一个能够将Netflix算法的RMSE性能提升10%或者更高的团队将赢得100万美金的奖金。如果没有团队能够达到10%的目标,那么Netflix将在每年的比赛结束后向第一名的团队提供5万美金的进步奖。该比赛在协同过滤领域引起了轰动。在此之前,用于协同过滤研究唯一公开可用的数据集要小几个数量级。
Netflix Prize数据的发布、以及比赛的吸引力激发了协同过滤领域的活力。根据比赛网站,来自182个不同国家的4.8万多个团队下载了数据。我们团队的参赛作品,原名叫
BellKor,在2007年夏天夺得了比赛的第一,并且以当时最好的成绩获得了2007年的进步奖:比Netflix好8.43%。后来,我们与Big Chaos团队联盟,以9.46%的提升赢得了2008年的进步奖。在撰写本文时,我们仍居第一,朝着10%的里程碑前进。我们的获奖作品包含
100多个不同的预测器集合,其中大部分是使用本文描述方法的一些变体的矩阵分解模型。我们与其他顶级团队的讨论,以及公开比赛论坛上的帖子表明:这些是最流行、最成功的预测评分的方法。我们在
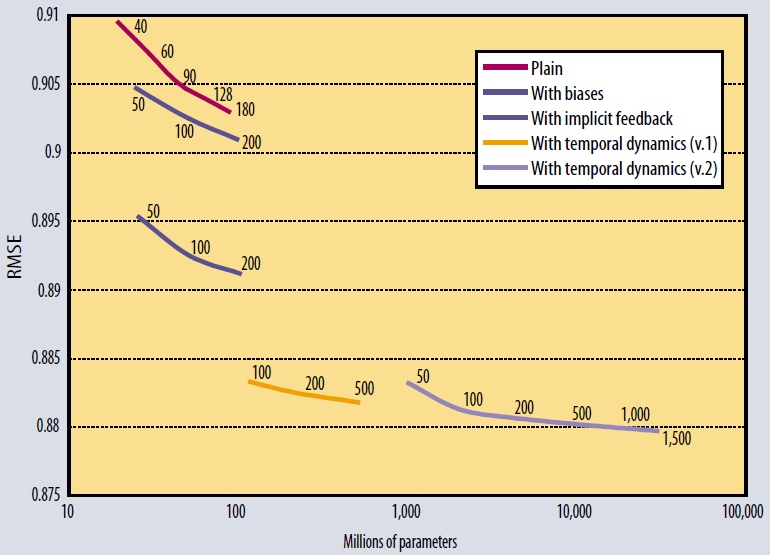
Netflix数据集上尝试了多种不同形式的矩阵分解,下图给出了不同模型、不同参数数量的RMSE。结论:通过增加因子数量,每个模型的准确性都得到提高。
更复杂的因子模型准确性更高。
时间效应对于模型尤为重要,因为数据中存在明显的时间效应。