一、DSSM [2013]
《Learning Deep Structured Semantic Models for Web Search using Clickthrough Data》
现代搜索引擎主要通过将
document中的关键词(keywords)和搜索query中的关键词进行匹配(matching)来检索web document。然而,词汇匹配(lexical matching)可能不准确,因为同一个概念通常在document和query中使用不同的词汇(vocabulary)和语言风格(language styles)来表达。潜在语义分析(
latent semantic analysis: LSA)等潜在语义模型(latent semantic models)能够在词汇匹配经常失败的语义级别(semantic level)将query映射到query相关的document。这些潜在语义模型通过将出现在相似上下文中的不同term分组到相同的语义簇 (semantic cluster),从而解决web document和搜索query之间的语义差异。因此,query和document在低维语义空间中表示为两个向量,即使它们不共享任何term,它们仍然可以具有很高的相似度得分(similarity score)。根据
LSA扩展,人们还提出了诸如probabilistic LSA: PLSA、Latent Dirichlet Allocation: LDA之类的概率主题模型(probabilistic topic models)用于语义匹配(semantic matching)。然而,这些模型通常以无监督的方式使用目标函数进行训练,该目标函数与检索任务的评估指标联系不紧密。因此,这些模型在
web搜索任务上的表现并不如最初预期的那么好。最近,已经进行了两个研究方向来扩展上述的潜在语义模型,下面对其进行简要的回顾:首先,由
query及其点击document组成的点击数据集被用于语义建模(semantic modeling),从而弥合搜索query和web document之间的语言差异(language discrepancy)。例如,Gao等人提出使用Bi-Lingual Topic Model: BLTM和线性的判别投影模型(Discriminative Projection Model: DPM)在语义级别进行query-document matching。这些模型使用针对document ranking任务定制的目标函数对点击数据进行训练。具体而言:BLTM是一种生成模型,它要求query及其点击的document不仅共享相同的主题分布,而且还包含分配给每个主题的相似词组。相比之下,
DPM是使用S2Net算法学习的,该算法遵循《Learning to rank using gradient descent》中概述的pairwise learning-to-rank范式。将query和document的term vectors投影到低维语义空间的概念向量(concept vectors)之后,query及其点击document的概念向量比query及其未点击document的概念向量距离更近。
Gao等人报告说,在document ranking任务中,BLTM和DPM的表现都显著优于无监督的潜在语义模型,包括LSA和PLSA。然而,
BLTM的训练虽然使用点击数据,但最大化对数似然函数,这对于document ranking任务的评估指标而言是次优的。另一方面,
DPM的训练涉及大规模矩阵乘法,这些矩阵的大小通常随着词表规模(vocabulary size)的增加而迅速增长。而在web搜索任务中,词表规模可能达到数百万的量级。为了使训练时间可以接受,词表被激进地裁剪。尽管更小规模的词表使得模型使得训练可以进行,但是会导致性能欠佳。其次,
Salakhutdinov和Hinton使用深度自编码器(deep auto-encoder)扩展了语义建模(semantic modeling)。他们证明了嵌入在query和document中的层次语义结构(hierarchical semantic structure)可以通过深度学习来提取。据报道,这种方法的性能优于传统
LSA。然而,他们使用的深度学习方法仍然采用无监督学习方法,其中模型参数针对document的重建进行优化,而不是针对给定的query将相关的document和无关的document区分开。因此,深度学习模型并没有显著优于基于关键词匹配的baseline检索模型。此外,语义哈希模型(
semantic hashing model)还面临大规模矩阵乘法的可扩展性挑战。然而,学习大词表的能力对于在现实世界的web搜索任务中获得良好结果至关重要。
在论文
《Learning Deep Structured Semantic Models for Web Search using Clickthrough Data》中,从上述两个研究方向出发,论文提出了一系列用于web搜索的深度结构化语义模型(Deep Structured Semantic Model: DSSM)。具体而言,论文的最佳模型使用深度神经网络DNN对给定query的一组document进行排序,如下所示:首先,执行非线性投影从而将
query和document映射到公共语义空间。然后,每个
document和给定query的相关性计算为它们在这个公共语义空间中的向量之间的余弦相似度。
神经网络模型使用点击数据进行有区别地 (
discriminatively)训练,从而最大化给定query条件下点击document的条件概率。和之前以无监督方式学习的潜在语义模型不同,DSSM模型直接针对web document ranking进行了优化,因此具有卓越的性能。此外为了处理大型词表,作者提出了所谓的哈希方法(
hashing method),通过该方法将query或document的高维term vectors投影到低维的letter based n-gram vectors,信息损失很小。在论文的实验中,实验表明:通过在语义模型中添加这一个额外的layer,word hashing使得我们能够有区别地学习大词表的语义模型,这对于web搜索至关重要。论文使用真实世界的数据集在
web document ranking任务上评估了DSSM,结果表明:DSSM的最佳模型在NDCG@1中以2.5%-4.3%的显著优势优于所有竞争方法(包括之前被认为是SOTA的方法)。论文的主要贡献在于论文在三个关键方面对先前的潜在语义模型(如
LSA)进行了重大扩展。首先,论文直接针对
document ranking的目标,利用点击数据来优化模型参数。其次,论文使用多个
hidden-representation layer将线性语义模型扩展到非线性语义模型。采用深层架构可以进一步增强建模能力,从而捕获和表达
query和document中更复杂的语义结构。第三,论文使用
letter n-gram based word hashing技术,该技术证明有助于扩展深度模型的训练,以便可以在现实的web搜索中使用非常大的词表。
论文的实验表明上述三个方面的每一个新技术都可以显著提高
document排序任务的性能。三种新技术的组合产生了一个新的SOTA的语义模型,该模型以显著的优势击败了所有之前的baseline模型。相关工作:论文的工作是基于对信息检索(
IR)的潜在语义模型的两个最新扩展。第一个是探索用于以监督方式学习潜在语义模型的点击数据,第二个引入深度学习方法进行语义建模。潜在语义模型以及使用点击数据:使用潜在语义模型进行
query-document mathcing是IR社区中一个长期存在的研究课题。流行的模型可以分为两类:线性投影模型(linear projection model)和生成主题模型(generative topic model)。最著名的
IR线性投影模型是LSA。通过使用document-term矩阵的奇异值分解(singular value decomposition: SVD),可以将document(或者term)映射到低维概念向量(concept vector)。给定documentterm vector其中:
document在
document搜索中,queryterm vectordocumentterm vectorrelevance score),与它们对应的概念向量similarity score)成正比:除了潜在语义模型之外,在点击的
query-document pair对上训练的翻译模型(translation model)提供了另一种语义匹配方法。和潜在语义模型不同,基于翻译的方法直接学习document中的term和query中的term之间的翻译关系。最近的研究表明,给定大量用于训练的点击数据,这种方法非常有效。论文还将通过实验将DSSM和翻译模型进行比较,细节参考后面的内容。深度学习:最近,深度学习方法已经成功地应用于各种语言和信息检索
application。通过利用深度架构,深度学习技术能够从训练数据中发现对任务有用的不同抽象级别(abstractions level)的隐藏结构和特征。在
《Semantic hashing》中,Salakhutdinov和Hinton通过使用深度网络(自编码器auto-encoder)来扩展LSA模型,从而发现嵌入在query和document中的层次语义结构(hierarchical semantic structure)。他们提出了一种语义哈希(semantic hashing: SH)方法,该方法使用从深度自编码器中学到的bottleneck特征进行信息检索。这些深度模型分为两个阶段学习。首先,学习一系列生成模型(即受限玻尔兹曼机
restricted Boltzmann machine)将document的term vector representation逐层映射到低维的语义概念向量(semantic concept vector)。其次,对模型参数进行微调,从而最小化
document的原始term vector和重构的term vector之间的交叉熵误差。
中间层
activation用作document排序的特征(即bottleneck)。他们的评估表明,SH方法取得了优于LSA的文档检索性能。然而,
SH存在两个问题,并且无法超越基于标准的lexical matching based的检索模型(例如,使用TF-IDF term weighting的余弦相似度)。第一个问题是模型参数针对
document的term vector重建进行了优化,而不是针对给定query从而将相关的document和不相关的document区分开来。第二个问题是为了降低计算成本,
document的term vector仅包含最常用的2000个单词。
接下来论文将展示对这两个问题的解决方案。
1.1 模型
1.1.1 DNN 架构
我们开发的
DNN架构可以将原始的高维稀疏文本特征映射到语义空间中的低维稠密特征,如下图所示。DNN的输入(原始文本特征)是一个高维稀疏的term vector,如query或document中term未归一化的原始计数。输入层500k表示采用500k个单词的大型词表。DNN的第一个隐层有30k个单元,从而完成word hashing。然后通过多层非线性投影来映射经过
word hashed的特征。DNN的输出是低维语义特征空间中的概念向量(concept vector)。
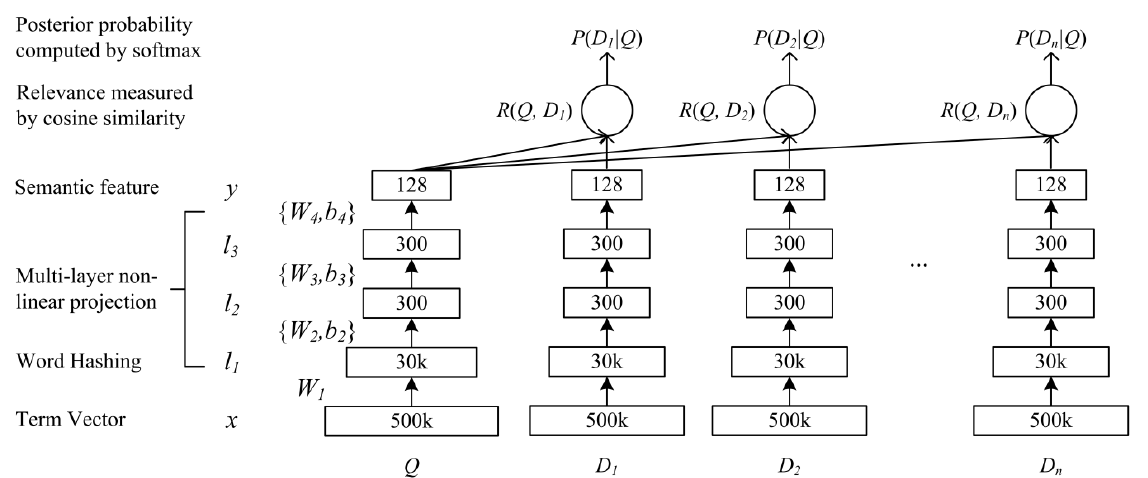
这个
DNN模型用于web document ranking如下:将
term vectors映射到它们对应的语义概念向量(semantic concept vectors)。计算
document和query对应的语义概念向量的余弦相似度(cosine similarity)作为它们之间的相关性得分(relevance score)。
形式化地,假设输入向量为
其中:
tanh激活函数。word hashing layer固定的权重矩阵,不需要学习,详细内容参考后文所述。
对于
querydocumentquerydocument一般而言,
term vector(可以视为IR中的原始bag-of-words特征)的维度与用于索引web document集合的词表大小相同。在现实世界的web搜索任务中,词表大小通常非常大。因此,当使用term vector作为输入时,神经网络输入层的尺寸将无法用于模型推断和模型训练。为了解决这个问题,我们为
DNN的第一层开发了一种称作word hashing的方法,如上图的下半部分所示。word hashing layer仅由线性隐单元组成,其中包含一个不需要学习的、规模很大的权重矩阵。接下来我们将详细描述word hashing方法。
1.1.2 word hash
word hashing方法旨在降低bat-of-word向量的维度。该方法基于letter n-gram,是一种专门为我们的任务开发的新方法。给定一个单词(如good):我们首先为单词添加开始标记、结束标记(如
#good#)。然后我们将单词分解为
letter n-gram(例如letter trigrams:#go, goo, ood, od#)。最后,单词使用
letter n-grams的向量来表示。
这种方法的一个问题是冲突(
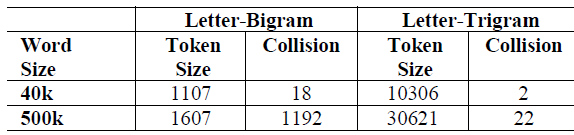
collision),即两个不同的单词可能具有相同的letter n-gram向量表示。下表展示了对两个词表进行
word hashing的一些统计数据。和one-hot向量的原始尺寸相比,word hashing允许我们使用维度低得多的向量来表示query或document。以
40K-word词表为例,每个单词都可以使用letter trigrams由一个10306维的向量来表示,从而在几乎没有冲突的情况下将维度降低了4倍。当该技术应用于更大规模的词表时,维度的降低更为显著。如下表所示,
500K-word词表中每个单词都可以使用letter trigrams由一个30621维的向量来表示,维度降低了16倍,而且冲突率0.0044%(22/500000)几乎可以忽略不计。
虽然英语单词的数量可以是无限的,但是英语(或者其他类似语言)中
letter n-gram的数量通常是有限的。此外,word hashing能够将同一个单词的形态变化映射到letter n-gram空间中彼此靠近的点。更重要的是,letter n-gram based representation可以解决在训练集中看不到的单词(即out-of-vocabulary: OOV)的问题。唯一的风险是
representation冲突,虽然冲突比例较小。因此,基于letter n-gram的word hashing对OOV问题具有鲁棒性,使得我们能够将DNN解决方案扩展到词表非常大的web搜索任务中。我们将在实验部分演示该技术的好处。在我们的实现中,基于
letter n-gram的word hashing可以被视为一种固定的(不需要学习的)线性变换。通过该变换,输入层中的term vector将被投影到下一层的letter n-gram vector。由于letter n-gram vector的维度要低得多,因此可以有效地进行DNN学习。
1.1.3 DSSM 学习
点击日志由
query及其点击的document组成。我们假设每个query与对应的点击document至少部分相关。受语音和语言处理中判别式训练(
discriminative training)方法的启发,我们提出了一种监督训练方法来学习我们的模型参数(即模型中的权重矩阵query的条件下点击document的条件概率。给定
querydocumentsoftmax函数从query-document之间的语义相关性得分得到后验概率:其中:
document集合。理论上应该考虑所有的候选文档,但是实际应用中给定一对点击样本我们选择
我们的目标函数是在给定
query的情况下最大化点击document的可能性,即:其中
该模型很容易使用基于梯度的数值优化算法进行训练,限于篇幅我们省略了梯度的推导过程。
注意:这里并没有计算负样本的概率
DSSM模型配置:为了训练模型并避免过拟合,我们将点击数据分为训练集和验证集。模型在训练集上训练,超参数在验证集上优化。
在实验中,我们的
DSSM使用了具有三层隐层的架构。第一层隐层是word hashing layer,包含大约30k个节点(letter-trigramms);接下来的两层隐层各有300个隐节点。此外,输出层包含
128个节点。word hashing基于固定的投影矩阵,相似性度量基于维度为128的输出层。我们初始化网络权重为
实验结果表明:在采用逐层预训练时我们没有观察到更好的性能。
在训练阶段我们使用基于
mini-batch的随机梯度下降SGD优化模型,每个mini-batch包含1024个训练样本。我们观察到模型训练通常会在20个epoch内收敛。
1.2 实验
数据集:我们在大规模真实世界数据集(称作评估数据集)的
web document排序任务中评估了DSSM。评估数据集包含
16510个英语query,这些query来自商业搜索引擎的一年的query日志文件。平均而言,每个query都和15个web document(URL)相关联。我们仅使用web document的标题字段进行排序。我们使用了大约1亿对的随机采样子集,这些document很受欢迎并且具有丰富的点击信息。每个
query-title pair都有一个人工生成的相关性标签,标签等级从0 ~ 4一共五级相关性:4级表示document和query最相关,0级表示document和query最不相关。所有
query和document都经过预处理:单词被空格分开,字母小写,数字被保留,并且不执行词干化。评估方式:评估指标是
Normalized Discounted Cumulative Gain: NDCG。我们在这里报告NDCG@1, NDCG@3, NDCG@10。我们还使用
paired t-test来进行显著性检验,当本文中使用的所有排序模型(即
DSSM模型、主题模型、线性投影模型)都包含很多需要凭经验设置的超参数,我们使用2-fold交叉验证来调优超参数。baseline方法:我们将DSSM和三组baseline模型进行比较。第一组
baseline方法包括一些广泛使用的lexical matching方法,如TF-IDF和BM25。TF-IDF和BM25都是基于lexical matching的SOTA的document ranking模型。在
TF-IDF方法中,query和document都表示为具有TF-IDF权重的term-vector。给定query,document按照query vector和document vector之间的余弦相似度排序。在
BM25方法中,query和document相关性表示为:query中每个term和document/query相关性的加权和,权重为term的重要性,即:其中:
queryterm;document的相关性;query的相关性。
第二组
baseline是单词翻译模型,如WTM,它旨在通过学习query单词和document单词之间的lexical mapping来直接解决query-document语言差异问题。第三组
baseline是SOTA的潜在语义模型,这些模型包括无监督方法(如LSA, PLSA, DAE)以及有监督方法(BLTM-PR, DPM)。对于
LSA,我们使用PCA而不是SVD来计算线性投影矩阵。query和title被视为单独的文档,因此模型中并未使用来自点击数据的pair信息。PLSA仅针对document(即title)进行训练,另外我们的PSLA版本是使用MAP估计学习的。DAE是基于深度自编码器的语义哈希模型的实现。由于模型训练的复杂性,输入的term vector基于40k的词表。DAE架构包含四个隐层,每个隐层包含300个节点。中间有个bottleneck layer,它包含128个节点。该模型仅以无监督的方式对document进行训练。在微调阶段,我们使用交叉熵误差作为目标函数。bottleneck激活用作计算query和document之间余弦相似度的特征。BLTM是PLSA的扩展。DPM也可以视为LSA的扩展,其中线性投影矩阵是使用点击数据以监督方式训练的。
为了使得结果具有可比性,我们按照
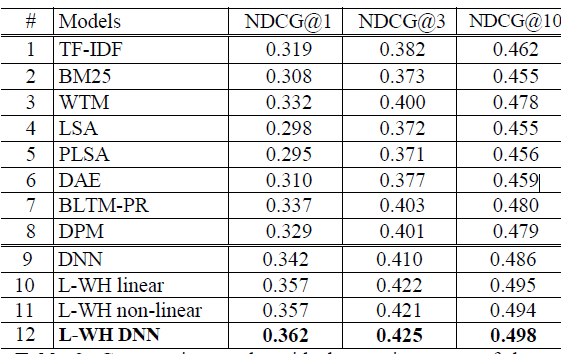
《Clickthrough-based latent semantic models for web search》中的描述重新实现了这些模型。例如,由于模型复杂性的限制,LSA和DPM的模型使用40k-word的词表进行训练,其它模型采用500k-word的词表进行训练。实验结果如下表所示。第
9行到第12行显式了DSSM不同设置的结果。DNN(第9行)是一个不使用word hashing的DSSM。它使用与DAE相同的结构,但是在点击数据上以监督方式进行训练。输入term vector基于DAE使用的40k词表。L-WH linear(第10行)是使用letter trigram based word hashing和监督训练构建的单隐层模型。它和L-WH no-linear的不同之处在于:我们没有对L-WH linear输出层采用任何非线性激活函数,例如tanh。注:但是隐层还是使用了非线性激活函数。L-WH DNN(第12行)是我们最好的、基于DNN的语义模型。它使用三层隐层,包括具有Letter-trigram-based Word Hashing: L-WH的层和一个输出层,并在query-title pair上进行有区分性地地训练。虽然基于letter n-gram的word hashing方法可以应用于任意大的词表,但是为了和其它方法进行公平地比较,该模型使用了500-k word的词表。它和
L-WH no-linear的不同之处在于:L-WH no-linear是单隐层,但是L-WH DNN是三层隐层。
可以看到:
WTM显著优于TF-IDF和BM25,这证明了《Clickthrough-based translation models for web search: from word models to phrase models”》中得到的结论。DAE的结果与之前在《Semantic hashing》中报告的结果一致。基于DNN的潜在语义模型(如DAE)优于线性投影模型(如LSA)。然而,LSA和DAE都是以无监督方式训练,因此无法超越SOTA的lexical matching排序模型。引入点击数据进行监督训练会带来一些显著的提升,
BLTM-PR和DPM都优于baseline模型。DSSM模型表现最佳,在NDCG中以统计显著的优势超越了其它方法。这证明了使用DNN进行语义匹配的有效性。
此外,我们还有以下结论:
很明显,对点击数据的监督学习,再加上
IR-centric优化准则的排序,对于获得卓越的document排序性能至关重要。例如
DNN(第9行)和DAE(第6行)使用相同的40k-word词表并采用相同的深度架构,前者在NDCG@1中比后者高出0.032。word hashing允许我们使用非常大的词表进行建模。例如第
12行中的模型使用500k-word词表,显著优于第9行中使用`40k-word词表的模型,尽管前者的参数规模更少(因为word hashing layer的权重矩阵是固定的)。深层架构比浅层架构在对嵌入在
query和document中的语义信息建模方面效果更好。例如在无监督模型中,
DAE(第3行) 深层模型优于LSA(第2行) 浅层模型。在监督模型中我们也观察到类似的结果:比较第
11行和12行,我们观察到将非线性层从1增加到3会使得NDCG得分提高0.004 ~ 0.005,这在统计上是显著的。比较第
10行和11行(它们都是一层隐层的浅层模型),我们观察到线性模型和非线性模型之间没有显著差异。