一、MIND [2019]
《Multi-Interest Network with Dynamic Routing for Recommendation at Tmall》
天猫是中国最大的
Business-To-Customer: B2C电商平台,它在线提供十亿规模的商品,服务于十亿规模的用户。2018年11月11日,著名的天猫全球购物节,商品交易总额(Gross Merchandise Volume: GMV)大约为2130亿元,较2017年同期增长26.9%。随着用户和商品的不断增长,帮助每个用户找到他 / 她可能感兴趣的商品变得越来越重要。近年来,天猫在开发个性化推荐系统方面付出了巨大的努力,极大地促进了用户体验的优化以及商业价值的提升。例如,占天猫总流量一半左右的移动天猫App首页(如下图左图所示),就部署了推荐系统来展示个性化商品,从而满足客户的个性化需求。由于拥有十亿规模的用户和
item,天猫的推荐流程分为matching阶段和ranking阶段两个阶段。matching阶段负责检索与用户兴趣相关的数千个候选item,然后ranking阶段负责预测用户与这些候选item交互的精确概率。对于这两个阶段,为了支持对满足用户兴趣的item的高效检索,建模用户兴趣并得到捕获用户兴趣的用户representation至关重要。然而,由于用户兴趣的多样性(diversity),在天猫上建模用户兴趣并非易事。平均而言,十亿级用户访问天猫,每个用户每天与数百种商品进行交互。交互的商品往往隶属不同的类目,暗示了用户兴趣的多样性。例如,如下图右图所示,不同用户的兴趣是不同的,同一用户也可能对不同的item感兴趣。因此,捕获用户多样化兴趣(diverse interests)的能力对天猫的推荐系统而言至关重要。注:下图中,左图的虚线矩形区域是天猫的十亿规模用户的个性化区域;右图是两个用户和不同类目商品的交互。

现有的推荐算法以不同的方式建模和表示用户兴趣:
基于协同过滤的方法通过历史交互
item或潜在因子来表示用户兴趣,这些方法存在数据稀疏问题、或者计算复杂度太高的问题。基于深度学习的方法通常用低维
embedding向量表示用户兴趣。例如,为YouTube视频推荐提出的深度神经网络(YouTubeDNN)通过一个固定长度的向量来表示每个用户,该向量是由用户历史行为转换而来。这可能是建模多样化兴趣的瓶颈,因为它的维度必须很高,从而表达天猫上的、大量的兴趣画像。深度兴趣网络(
Deep Interest Network: DIN)通过注意力机制来捕获用户兴趣的多样性,使得用户在不同目标item上的用户representation不同。然而,注意力机制的采纳也使得具有十亿级item的大规模应用在计算上受到限制,因为它需要重新计算每个目标item的用户representation,使得DIN仅适用于ranking阶段。
论文
《Multi-Interest Network with Dynamic Routing for Recommendation at Tmall》关注于在matching阶段对用户的多样化兴趣进行建模的问题。为了克服现有方法的局限性,论文提出了具有动态路由的多兴趣网络(Multi-Interest Network with Dynamic routing: MIND) 。MIND用于工业级推荐系统在matching阶段学习反映用户的多样化兴趣的representation。为了推断用户
representation向量,论文设计了一个称为多兴趣提取器层(multi-interest extractor layer),它利用动态路由将用户的历史行为自适应地聚合到用户representation中。动态路由的过程可以视为软聚类 (soft-clustering),它将用户的历史行为分为几个簇。每个历史行为簇进一步用于推断对应于一个特定兴趣的用户representation向量。这样,对于特定的用户,MIND输出多个represenation向量,它们共同代表了用户的多样化兴趣。用户representation向量只需要计算一次,就可以用于matching阶段从而在十亿级item中检索相关item。总而言之,这项工作的主要贡献:为了从用户行为中捕获用户的不同兴趣,论文设计了多兴趣提取器层,该层利用动态路由自适应地将用户的历史行为聚合为用户
representation向量。通过使用多兴趣提取器层、以及新提出的标签感知注意力层(
label-aware attention layer)所产出的用户representation向量,论文为个性化推荐任务构建了一个深度神经网络。与现有的方法相比,MIND在多个公共数据集和一个来自天猫的工业数据集上表现出优越的性能。为了在天猫部署
MIND从而服务于十亿级用户,论文构建了一个系统来实现数据集采集、模型训练、以及在线serving的整个pipeline。部署的系统显著提高了移动天猫App首页的点击率(click-through rate: CTR)。目前MIND已经在Mobile Tmall App首页上部署从而处理主要的在线流量。
相关工作:
深度学习推荐:受深度学习在计算机视觉和自然语言处理中成功应用的启发,人们投入了大量努力来开发基于深度学习的推荐算法。除了
《Deep neural networks for youtube recommendations》和《Deep interest network for click-through rate prediction》之外,各种类型的深度模型也得到了极大的关注。神经协同过滤(
Neural Collaborative Filtering: NCF)、DeepFM、和深度矩阵分解(Deep Matrix Factorization Model: DMF)构建了一个由若干MLP组成的神经网络,从而对用户和item之间的交互进行建模。《Personalized top-n sequential recommendation via convolutional sequence embedding》通过提供一个统一且灵活的网络来捕获更多特征,为top-N序列推荐提供了一个新颖的解决方案。
用户
Representation:将用户表示为向量是推荐系统中常见的做法。传统方法将用户感兴趣的
item、用户感兴趣的关键词、用户感兴趣的主题拼接起来,从而构成用户偏好向量。随着distributed representation learning的出现,通过神经网络获取user embedding得到了广泛的应用。《Learning user and product distributed representations using a sequence model for sentiment analysis》使用RNN-GRU从时间有序的review documents中学习user embedding。《User embedding for scholarly microblog recommendation》从word embedding向量中学习user embedding向量,并将其应用于推荐学术微博(scholarly microblog)。《Modelling Context with User Embeddings for Sarcasm Detection in Social Media》提出了一种新的、基于卷积神经网络的模型,该模型显式地学习和利用user embedding以及从话语(utterances)中获得的特征。
胶囊网络(
Capsule Network):”胶囊” 的概念表示一组神经元组装而成的向量,它由Hinton在2011年首次提出。动态路由(dynamic routing)用于学习胶囊之间连接的权重,该学习方法不是基于反向传播,而是基于Expectation-Maximization: EM算法,从而克服几个缺陷并获得更好的准确性。与传统神经网络的这两个主要区别(由一组神经元组成、通过EM算法学习)使得胶囊网络能够对部分和整体之间的关系进行编码,这在计算机视觉和自然语言处理方面是先进的。SegCaps证明,胶囊可以比传统的CNN更好地建模对象的空间关系。《Investigating Capsule Networks with Dynamic Routing for Text Classification》研究了用于文本分类的胶囊网络,并提出了三种提高性能的策略。
1.1 模型
工业推荐系统
matching阶段的目标是为每个用户item库item的item子集,其中该子集中每个item都和用户的兴趣相关。为了实现该目标,我们收集用户历史行为数据从而构建
matching模型。具体而言,每个样本都可以用一个元组item集合,也称作用户行为。target itemitem id、category id。注意:
target itemtarget item
MIND的核心任务是学习将原始特征映射到用户representation的函数,即:其中
representation向量,向量维度为representation向量,就像YouTube DNN一样。此外,通过
embedding函数获得target itemrepresentation向量为:其中
itemrepresentation向量。当学习了用户
representation向量、item representation向量之后,在线serving时根据评分函数检索top N候选item:其中
matching阶段要检索的、预定义的item数。注意:serving阶段,而不用于训练阶段。如下图所示,
MIND将用户行为序列、用户画像、label item等特征作为输入,然后输出用户representation从而用于推荐系统的matching阶段来检索item。MIND主要由以下部分组成:Embedding&Pooling Layer:来自输入层的id特征通过embedding层转换为embedding,然后每个item的各种id embedding由池化层进一步取平均。Multi-Interest Extractor Layer:用户行为embedding被馈入多兴趣提取器层从而产生兴趣胶囊。通过将兴趣胶囊和用户画像embedding拼接,然后经过几个ReLU的全连接层进行转换,可以得到用户representation向量。Label-aware Attention Layer:在训练过程中引入一个额外的标签感知注意力层,从而指导训练过程。
最后在
serving过程中,用户的多个representation向量用于通过最近邻检索来检索item。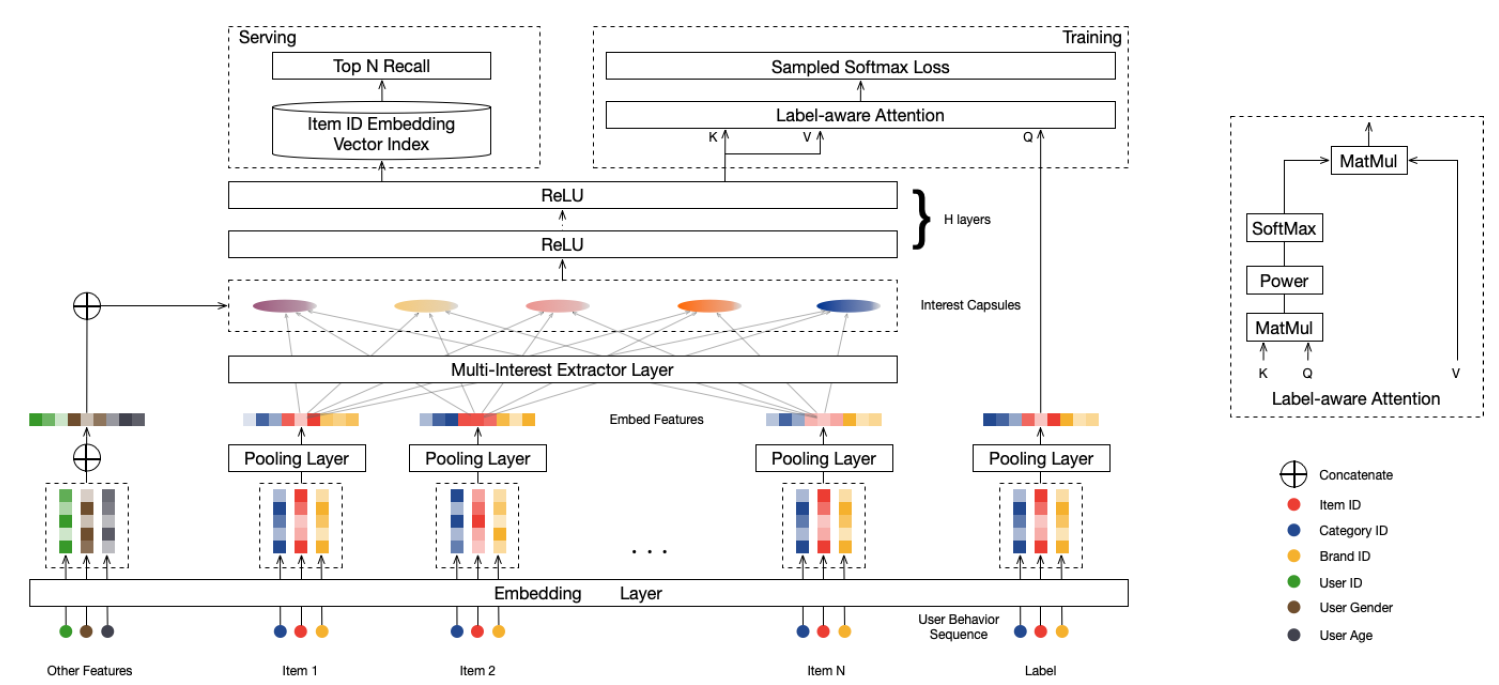
Embedding&Pooling Layer:MIND的输入包含三组:用户画像label itemcategorical id特征。例如,item id的数量约为数十亿个,因此我们采用了广泛使用的embedding技术将这些ID特征嵌入到低维稠密向量(也称作embedding向量)中,从而显著减少了参数数量并简化了学习过程。对于来自用户画像
id特征(性别、年龄等),对相应的embedding进行拼接从而构成用户画像embedding对于
item的item id以及其它categorical id(如品牌id、店铺id等),这些id被证明有助于label itemembedding会进一步通过均值池化层从而形成label item embedding对于来自用户行为
item,收集相应的item embedding从而形成用户行为embeddingembedding构成了用户行为embedding矩阵
1.1.1 Multi-Interest Extractor Layer
我们认为,用一个
representation向量表示用户兴趣可能是捕获用户的多样化兴趣的瓶颈,因为我们必须将与用户的多样化兴趣相关的所有信息压缩到一个representation向量中。因此,关于用户的不同兴趣的所有信息都被混合在一起,从而导致在matching阶段的item检索不准确。相反,我们采用多个
representation向量分别表达用户的不同兴趣。通过这种方式,我们可以在matching阶段分别考虑用户的多样化兴趣,从而可以更准确地检索各个方面的兴趣。为了学习多个
representation向量,我们利用聚类过程将用户的历史行为分组为几个簇(cluster)。我们预期来自同一个簇的item将密切相关,并且共同代表了用户在某个特定方面的兴趣。这里,我们设计了多兴趣提取器层(multi-interest extractor layer),从而用于聚类历史行为,并得到结果聚类的representation向量。由于多兴趣提取器层的设计受到最近提出的、用于胶囊网络(
capsule network)中representation learning的动态路由(dynamic routing)的启发,因此我们首先回顾基础知识。动态路由(
Dynamic Routing):我们简单介绍用于胶囊网络表示学习的动态路由,这是一种以向量表示的、新型的神经元。假设我们有两层胶囊,分别将第一层胶囊和第二层胶囊称作低层胶囊(
low-level capsule)、高层胶囊(high-level capsule)。动态路由的目标是以迭代的方式在给定低层胶囊值的情况下计算高层胶囊值。在每次迭代中,给定低层胶囊
value vector和高层value vector的维度。则低层胶囊
routing logit其中
当计算好
routing logit之后,高层胶囊value vector更新为:其中:
routing logit进行softmax来计算的。非线性的
squash函数用于获得高层胶囊的值向量。
另外,
整个路由过程通常需要
3轮迭代才会收敛。路由结束后,高层胶囊的值向量layer的输入。B2I动态路由:简而言之胶囊是一种由向量表示的神经元,而不是普通神经网络中标量表示的神经元。我们期待基于向量的胶囊能够代表实体的不同属性,其中向量的方向代表一种属性、向量的长度代表该属性存在的概率。相应地,多兴趣提取器层的目标是学习用于表达用户兴趣、以及是否存在相应兴趣的
representation。胶囊和兴趣representation之间的语义联系促使我们将行为/兴趣representation视为行为/兴趣胶囊,并采用动态路由从行为胶囊(behavior capsule)中学习兴趣胶囊(interest capsule)。然而,针对图像数据提出的原始路由算法并不能用于直接处理用户行为数据。因此,我们提出了
Behavior-to-Interest:B2I动态路由,用于将用户的行为自适应地聚合到兴趣representation向量中,这和原始路由算法在三个方面有所不同:共享双线性映射矩阵:基于两方面的考虑,我们将每对低层胶囊和高层胶囊
pair对之间使用固定的双线性映射矩阵一方面,用户行为序列的长度是可变的,天猫用户的行为序列长度从几十到几百,因此使用共享的双线性映射矩阵更为泛化(
generalizable)。另一方面,我们希望兴趣胶囊位于相同的向量空间中,而不同的双线性映射矩阵会将兴趣胶囊映射到不同的向量空间中。
因此,
routing logit计算为:其中:
behavior itemembedding。interest capsule双线性映射矩阵
pair对之间共享。
随机初始化
routing logit:由于使用了共享的双线性映射矩阵routing logit初始化为零导致所有用户具有相同的初始兴趣胶囊。然后在随后的每一轮迭代中,不同用户之间在当前轮次具有相同的兴趣胶囊。(注:不同迭代步之间的取值不同,但是同一迭代步之内的取值都相同)。为了缓解这种现象,我们从高斯分布
routing logit,使得初始兴趣胶囊彼此不同。这和著名的K-Means聚类算法的随机初始化类似。动态兴趣数量:由于不同用户的兴趣数量可能不同,因此我们引入了一种启发式规则,用于针对不同用户自适应地调整
具体而言,用户
这种调整兴趣数量的策略可以为那些兴趣较少的用户节省一些资源,包括计算资源、内存资源。
B2I Dynamic Routing算法:输入:
用户
embedding集合迭代轮次
兴趣胶囊数量
输出:用户
算法步骤:
计算自适应的兴趣胶囊数量:
对于所有的行为胶囊
迭代
对于所有行为胶囊
对于所有兴趣胶囊
对于所有兴趣胶囊
对于所有的行为胶囊
返回
注:本质上它是在给定
a. 兴趣胶囊
b. 行为胶囊
softmax得到。这类似于二部图上的消息传递机制,因此迭代若干轮之后就会收敛。
这里
注二:这里使用胶囊网络来进行聚类,本质是一个聚类过程。
1.1.2 Label-aware Attention Layer
通过多兴趣抽取层,我们从用户的行为
embedding中生成了多个兴趣胶囊。不同的兴趣胶囊代表了用户兴趣的不同方面,而且相关的兴趣胶囊用于评估用户对特定item的偏好。因此,在训练过程中我们基于scaled dot-product attention设计了标签感知注意力层(label-aware attention layer)。具体而言,对于一个目标
item:首先,我们计算每个兴趣胶囊和目标
item embedding之间的相似性。然后,我们计算兴趣胶囊的加权和作为针对目标
item的用户representation向量,其中每个兴趣胶囊的权重由相应的相似性来确定。
在标签感知注意力层中,
label item是query,兴趣胶囊同时作为key和value。用户itemrepresentation为:其中:
pow()函数表示逐元素的指数函数。p是一个超参数作为指数函数的指数项,它用于调整注意力分布:当
当
1时,随着dot-product的兴趣胶囊将获得越来越大的权重。考虑极端情况下当
hard attention):选择注意力最大的兴趣胶囊并忽略其它兴趣胶囊。这意味着挑选和目标
item最相似的兴趣来作为标签感知的兴趣representation。此时无需进行复杂的attention计算,直接利用最近邻检索来获取。
在我们的实验中,我们发现
hard attention可以加快收敛速度。
1.1.3 其它
Training:得到用户representation向量label item embeddinglabel item训练
MIND的目标函数为:其中
user-item交互的训练数据的集合。注意,这里通过
softmax函数变为一个多分类问题,因此没有负样本的概率。在多分类问题中,不存在负样本,只有二分类问题存在负样本。由于
item规模在数十亿级,因此softmax技术(sampled softmax technique)。我们使用
Adam优化器来训练MIND。Serving:除了标签感知注意力层之外的MIND网络即为用户representation映射函数serving期间:用户的行为序列和用户画像馈入
representation向量。然后,我们使用这些
representation向量通过最近邻方法检索top N个item,从而构成推荐系统matching阶段的最终候选item集。
注意:
当用户有新的行为时,这将改变用户的行为序列以及相应的用户
representation向量,因此MIND对于mathcing阶段拥有实时个性化的能力。每个用户有
部署:天猫上
MIND的实现和部署如下所示:当用户启动天猫
APP时,推荐请求发送到天猫个性化平台 (Tmall Personality Platform),该服务器集群集成了很多插件模块并提供天猫在线推荐服务。天猫个性化平台检索用户的近期行为,并将其发送到用户兴趣提取器(
User Interest Extractor),后者是实现MIND的主要模块,用于将用户行为转换为多用户兴趣(multiple user interest)。随后,召回引擎(
Recall Engine)将搜索和用户兴趣的embedding向量最邻近的item。由不同兴趣触发的item将融合为候选item,并根据它们与用户兴趣的相似性进行排序。由于基于
MIND服务的有效性,通过用户兴趣提取器和召回引擎从数十亿个item库中选择数千个候选item的整个过程可以在不到15ms的时间内完成。Ranking Service对这些候选item中的top 1000个item进行打分(在item数量和延迟时间之间进行权衡),该服务通过一系列特征来预测CTR。最后天猫个性化平台完成推荐列表,并向用户展示推荐结果。
用户兴趣提取器和
Ranking Service都是在Model Training Platform上使用100个GPU进行训练,训练可以在8个小时内完成。得益于Model Training Platform的出色性能,深度模型天级更新。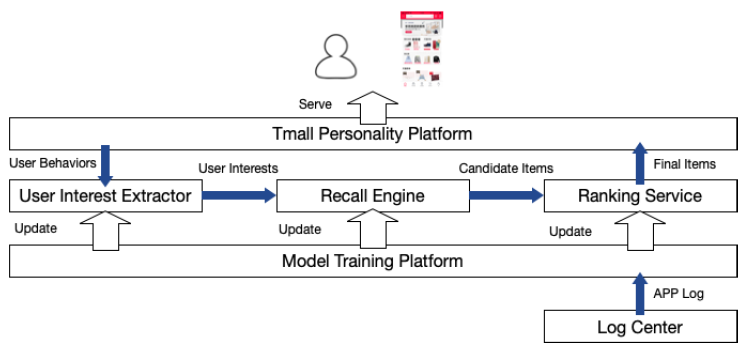
这里我们对
MIND和两种现有方法之间的关系做一些说明,说明它们的相似之处和不同之处。YouTube DNN:MIND和YouTube DNN都利用深度神经网络对行为数据进行建模从而生成用户representation。这些representation用于工业推荐系统matching阶段的大规模item检索。但是,
YouTube DNN使用一个向量来代表用户,而MIND使用多个向量。当用户兴趣数量K=1时,MIND会退化为YouTube DNN,因此MIND可以视为YouTube DNN的推广。DIN:在捕获用户的多样化兴趣方面,MIND和DIN具有相同的目标。但是,这两种方法在实现目标的方式和适用性方面有所不同。为了处理多样化兴趣,
DIN在item-level应用了注意力机制;而MIND使用动态路由生成兴趣胶囊,并在interest-level考虑了多样性。(interest比item更高一个level)。此外,
DIN重点聚焦于ranking阶段,因为它处理上千个item;而MIND作用于matching阶段,处理数十亿个item。
未来方向:
第一个方向是融合有关用户行为序列的更多信息,如行为时间等。
第二个方向是优化动态路由的初始化方案,参考
K-means++初始化方案,从而实现更好的用户representation。
1.2 实验
1.2.1 离线评估
这里我们在多个数据集上离线评估了
MIND和现有方法的推荐准确率。数据集:
Amazon Books数据集:它是电商推荐领域中使用最广的公共数据集之一。我们仅保留至少评论10次的item、以及至少评论10个item的用户。Tmall Data数据集:它是从Mobile Tmall App中随机采样的200万天猫用户,并获得这些用户在10天内的历史行为。我们保留至少600个用户点击的item。
这些数据集的统计信息如下表所示:

评估指标:我们选择
next item prediction问题(即预测用户的下一个交互)来评估方法的性能,因为这是推荐系统mathcing阶段的核心任务。我们将每个数据集的
user-item交互数据按照19:1的比例随机划分为训练集、测试集。然后对于每个用户,我们将用户交互的、测试集中的item作为目标item,该item之前所有交互的item作为用户历史行为。我们根据用户历史行为来预测目标item。我们采用命中率(
hit rate)作为衡量推荐效果的主要指标,定义为:其中:
target itemtarget item occurs in top N表示目标item是否在预估多分类概率中的top N。由于模型采用softmax输出层,因此可以考虑目标item的输出概率在所有item输出概率中的位置。
我们在每个数据集上对
embedding向量维度baseline方法:WALS:即加权最小二乘法(Weighted Alternating Least Square)。它是一种经典的矩阵分解算法,用于将user-item交互矩阵分解为用户的隐藏因子(hidden factor)和item的隐藏因子 。然后基于用户的隐藏因子和target item的隐藏因子之间的相似性进行推荐。YouTube DNN:它是用于工业推荐系统的最成功的深度学习方法之一。MaxMF:它引入了一种高度可扩展的方法来学习非线性潜在因子分解,从而对用户的多个兴趣进行建模。
实验结果如下表所示,我们给出了不同方法在两个数据集上
N=10,50,100的命中率结果。其中:黑体表示最佳性能;HP表示性能最佳的超参数,K表示兴趣数量,d表示embedding维度;括号中的百分比表示相对于YouTube DNN的相对提升。可以看到:
矩阵分解方法
WALS被其它方法击败,这表明深度学习方法对于改进推荐系统matching阶段的强大作用。但是,即使没有使用深度学习方法,
MaxMF的性能也要比WALS好得多。这可以用以下事实来解释:MaxMF将标准MF泛化为非线性模型,并对于每个用户采用了多个representation向量。可以观察到:采用用户的多个
representation向量的方法(MaxMF-K-interest、MIND-K-interest) 通常要比其它方法(WALS、YouTube DNN、MIND-1-interest)表现更好。因此,事实证明:使用用户的多个
representation向量是一种对用户的不同兴趣进行建模、并提高推荐准确性的有效方法。此外,我们可以观察到,由于天猫的用户倾向于表现出更多的兴趣,因此由于用户的多个
representation向量引入的改善对于TmallData更为显著。多样性的增加也可以通过每个数据集的最佳
K值来反映,其中TmallData的最佳K大于Amazon Books的最佳K值。
和
YouTube DNN相比,MIND-1-interest的提高表明:动态路由是一种比均值池化更好的池化策略。对比
MaxMF和MIND-K-interest的结果,这验证了通过动态路由从用户行为中提取多个兴趣优于在MaxMF中使用非线性建模策略。这可以归结于两点:多兴趣提取器层利用聚类过程生成兴趣的
representation,从而实现用户的更精确的representation。标签感知注意力层使
target item在用户的多个representation向量上分配注意力,从而使得用户兴趣和target item之间的匹配更加准确。

这里我们在
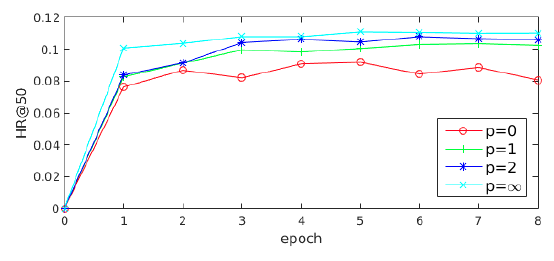
Amazon Books上进行两个实验,从而研究多兴趣提取器层和标签感知注意力层中超参数的影响。routing logit的初始化:多兴趣提取器层采用的routing logit的随机初始化和K-means质心的初始化相似,其中初始聚类中心的分布对于最终聚类结果的影响很大。由于routing logit是根据高斯分布0.1, 1, 5)来初始化routing logit实验结果如下图所示。可以看到:不同
MIND对于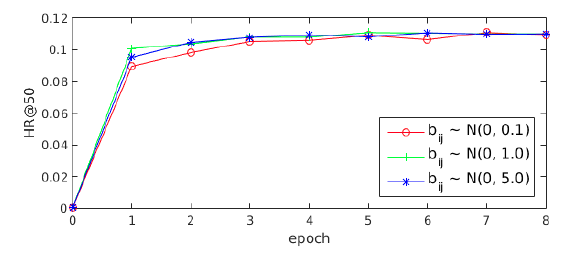
标签感知注意力层的幂次:如前所示,标签感知注意力中的幂次
label-aware interest representation)中所占的比例。为了研究MIND的性能变化。实验结果如下图所示。可以看到:
p=0时的性能相对而言要差很多。原因是当combined interest representation)等于没有参考label时的兴趣representation均值。当
representation向量和目标item的embedding之间相似度成比例,这使得组合的兴趣representation为所有兴趣representation的加权和。另外,随着
item相似度更高的兴趣representation获得了更大的注意力。最后,当
hard attention scheme。此时和目标item最相似的兴趣representation将主导组合的兴趣representation,从而使得MIND收敛得更快并且表现最好。
1.2.2 在线评估
我们在线部署
MIND来处理天猫首页上的实际流量从而进行在线实验,为期一周。为了公平地进行比较,在matching阶段部署的所有方法后续都使用相同的ranking过程。我们评估指标是最终的CTR效果指标。baseline方法:item-based CF:它是服务于在线主流量的基本matching方法。YouTube DNN:它是著名的基于深度学习的matching方法。
我们将所有对比方法部署在
A/B test框架中,每种方法检索一千个候选item,然后将候选item送入ranking阶段以进行最终推荐。实验结果如下图所示,我们得出以下结论:
MIND优于item-based CF和YouTube DNN,这表明MIND产生了更好的用户representation。通过长期的实践优化,
item-based CF的效果要比YouTube DNN更好,而MIND-1-interest也超越了YouTube DNN。一个非常明显的趋势是:随着兴趣数量从
1增加到5,MIND的性能会变好。当兴趣数量达到5时,MIND性能达到峰值,随后继续增加K值则CTR保持不变。例如,K=7相对于K=5带来的提升几乎可以忽略。因此对于天猫用户来讲,最佳的用户兴趣数量是
5~7,这表明了用户兴趣的平均多样化程度。具有动态兴趣数的
MIND与K=7的MIND性能相当。因此动态兴趣数机制不会带来CTR收益,但是在实验过程中我们发现该方案可以降低serving的成本,这有利于大规模的service(如天猫),并且在实践中更易于采用。
总而言之,在线实验证明了
MIND可以实现更好的解决方案,从而为具有不同兴趣的用户建模,并且可以显著提高整个推荐系统的效果。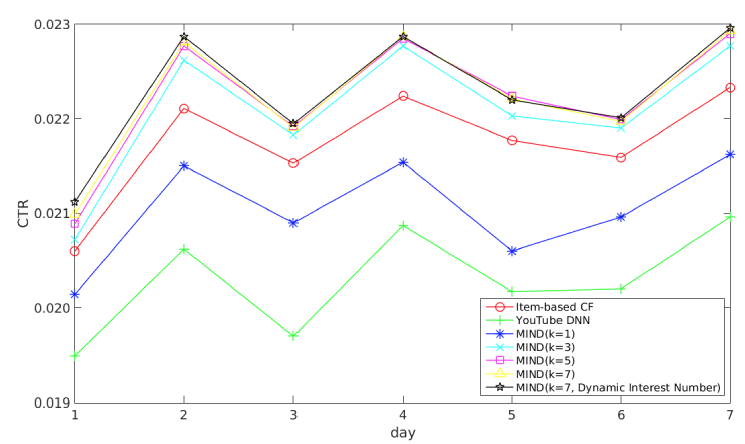
1.2.3 Case Study
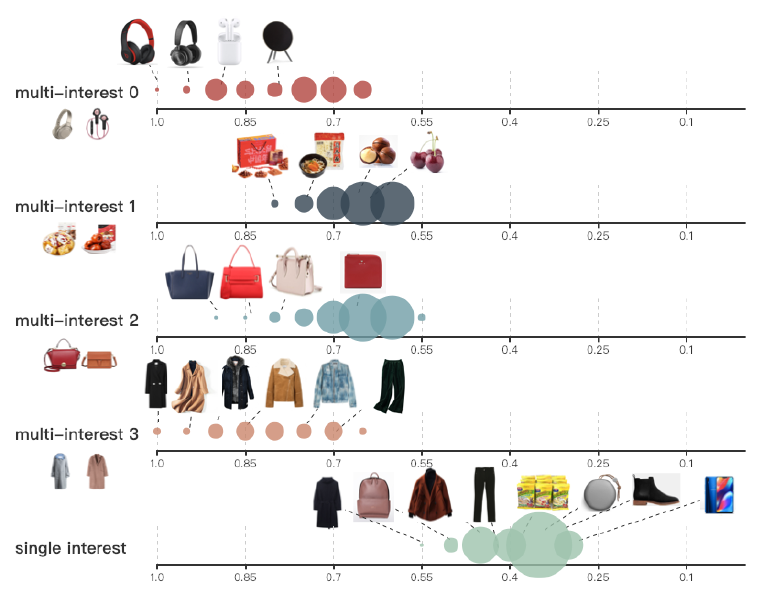
耦合系数(
coupling coefficient):行为胶囊和兴趣胶囊之间的耦合系数可以衡量行为对于兴趣的隶属程度。这里我们将这些耦合系数可视化,从而表明兴趣提取过程是可解释的。下图给出了从天猫每日活跃用户中随机选择的两个用户相关的耦合系数,每一行对应一个兴趣胶囊、每一列对应一个行为。每一类行为在相应的兴趣上具有最大的耦合系数。注意:这两个用户具有不同粒度的兴趣。
可以看到:
用户
C(上部)已经和4类商品(耳机、小吃、手提包、衣服)进行了交互,每类商品在一个兴趣胶囊上具有最大的耦合系数,并形成了相应的兴趣。用户
D(下部)仅对衣服感兴趣,但是可以从行为中解析到3个细粒度的兴趣(毛衣、大衣、羽绒服)。
从这些结果中我们可以看到:用户行为的每个类别被聚类在一起,并形成了相应的兴趣
representation向量。
item分布:在serving阶段,和用户兴趣相似的item将通过最近邻搜索来被检索到。我们根据兴趣检索的item和对应兴趣的相似度,从而可视化相似度的分布。下图给出了用户
C检索的item的结果。其中:上面的四个轴显示了基于MIND的四个兴趣召回的item;最下面的轴显示了基于YouTube DNN召回的item。item根据它们和兴趣的相似性在轴的相应位置上。我们已经通过min-max归一化将相似性缩放到0.0 ~1.0之间,并四舍五入到最近的0.05。图中每个点都是由该区域内
item组成,因此每个点的大小表示具有相应相似度的item数。 我们还给出了从所有候选item中随机选择的一些item。不出所料:
MIND召回的item和相应的兴趣密切相关;而YouTube DNN召回的item类别相差很大,并且与用户行为的相似性较低。