一、ComiRec [2020]
《Controllable Multi-Interest Framework for Recommendation》
近年来,电商的发展彻底改变了我们的购物方式。推荐系统在电商公司中扮演着重要的角色。传统的推荐方法主要使用协同过滤来预测用户和
item之间的得分。近年来,由于深度学习的快速发展,神经网络在电商推荐系统中得到了广泛的应用。神经推荐系统为用户和item生成representation,并且优于传统的推荐方法。然而,由于电商用户和item的规模较大,很难使用深度模型直接给出每对user-item之间的点击率(CTR)预估。当前的业界实践是使用fast KNN(如Faiss)来生成候选item,然后使用深度模型结合用户属性和item属性来优化业务指标(如点击率)。最近的一些工作使用
graph embedding方法来获取user representation和item representation,然后用于下游application。例如,PinSage建立在Graph-SAGE基础之上,并将基于图卷积的方法应用于具有数十亿节点和边的生产级数据。GATNE考虑了不同的用户行为类型,并利用异质图embedding方法来学习user representation和item representation。然而,这些方法忽略了用户行为中的序列信息,无法捕获到用户的相邻行为之间的相关性。最近的研究将推荐系统形式化为一个序列推荐(
sequential recommendation)问题。序列推荐任务是根据用户的行为历史,预测用户可能感兴趣的next item。该任务反映了现实世界的推荐情况。许多近期提出的模型可以从每个用户的行为序列中给出该用户的整体embedding。然而,统一的用户embedding很难代表多种兴趣(multiple interests)。例如在下图中,点击序列显示了Emma的三种不同兴趣。作为一个现代女性,Emma对珠宝(jewelry)、手提包(handbags)、化妆品(make-ups)很感兴趣。因此,她可能会在这段时间内点击这三个类目的item。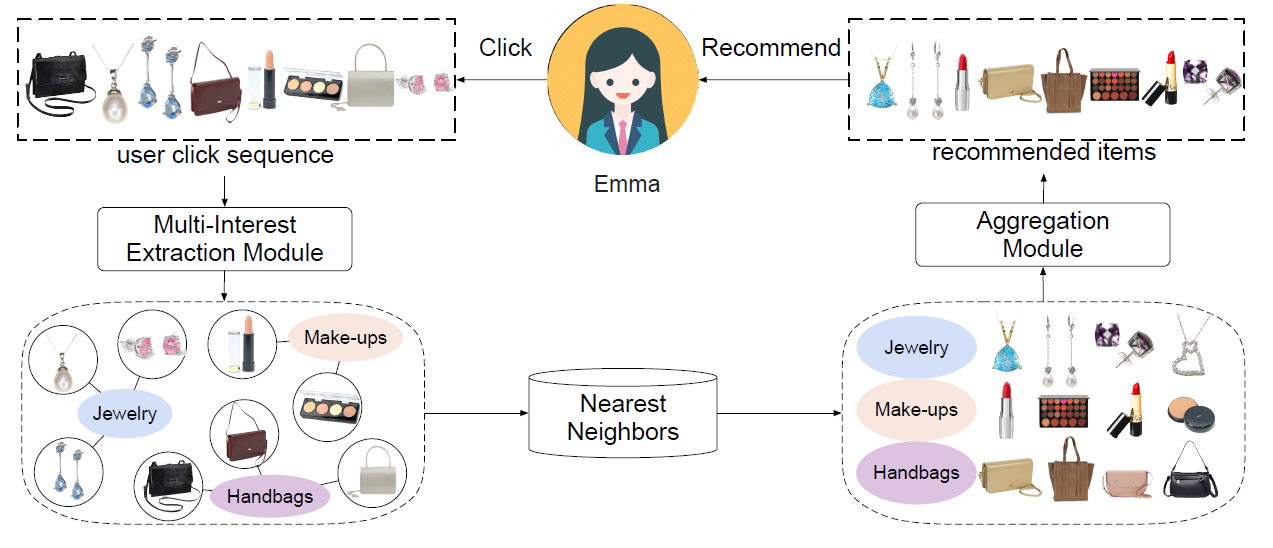
在论文
《Controllable Multi-Interest Framework for Recommendation》中,作者提出了一种新的、可控的多兴趣框架(multi-interest framework),称作ComiRec。上图展示了ComiRec多兴趣框架的一个示例。ComiRec的多兴趣模块(multi-interest module)可以从用户行为序列中捕获用户的多种兴趣,这些兴趣可独立地从大规模item池中检索候选item。ComiRec的聚合模块(aggregation module)将这些来自不同兴趣的item组合在一起,并输出整体top-N推荐。聚合模块利用可控的因子来平衡推荐的准确性(accuracy)和多样性(diversity)。
论文对序列推荐进行了实验。另外,
ComiRec框架也成功地部署在阿里巴巴分布式云平台上。十亿级工业数据集的结果进一步证明 了ComiRec在实践中的效果(effectiveness)和效率(efficiency)。总而言之,本文的主要贡献是:
提出了一个综合的框架
ComiRec,将可控性(controllability)和多兴趣组件集成在一个统一的推荐系统中。通过在线推荐场景中的
implementing和studying来调研可控性在个性化系统中的作用。ComiRec框架在两个具有挑战性的真实数据集上为序列推荐实现了SOTA的性能。
相关工作:这里我们将介绍有关推荐系统和推荐多样性的相关文献,以及我们在论文中使用的胶囊网络和注意力机制。
协同过滤方法已经在现实世界的推荐系统中被证明是成功的,它可以找到相似的用户和相似的
item,并在此基础上做出推荐。矩阵分解(
Matrix Factorizaion: MF)是经典推荐研究中最流行的技术,它将用户和item映射到联合潜在因子空间(joint latent factor space)中,这样user-item交互被建模为该空间中的内积。分解机(
Factorization Machine: FM)使用分解的参数(factorized parameters)对变量之间的所有交互进行建模,因此即使在推荐系统等具有巨大稀疏性的问题中也可以估计交互(estimate interaction)。
神经推荐系统(
Neural Recommender System):神经协同过滤(
Neural Collaborative Filtering: NCF)使用神经网络架构对用户和item的潜在特征进行建模。NFM无缝地结合了FM在建模二阶特征交互时的线性、以及神经网络在建模高阶特征交互时的非线性。DeepFM设计了一个端到端的学习模型,同时强调了低阶特征交互和高阶特征交互以进行CTR预测。xDeepFM扩展了DeepFM,可以显式地学习特定的、阶次有界(bounded-degree)的特征交互。深度矩阵分解(
Deep Matrix Factorization: DMF)使用深度结构学习的架构(deep structure learning architecture),基于显式评分和非偏好(non-preference)的隐式反馈,学习user representation和item representation的通用低维空间。DCN保留了深度模型的优点,并引入了一种新颖的交叉网络,该网络在学习特定的、阶次有界的特征交互方面更有效。CMN利用潜在因子模型的全局结构和基于局部邻域的结构的优势,以非线性方式使用深度架构来统一两类CF模型。
序列推荐(
Sequential Recommendation):序列推荐是推荐系统的关键问题。最近很多关于推荐系统的工作都集中在这个问题上。FPMC对于序列basket数据同时包含了一个常见的马尔科夫链和一个普通的矩阵分解模型。HRM扩展了FPMC模型,并采用两层结构来构建最近一次交互的user和item的混合representation。GRU4Rec首次引入了一种RNN-based方法来建模整个session,以获得更准确的推荐。DREAM基于RNN,学习用户的动态representation以揭示用户的动态兴趣。Fossil将similarity-based方法和马尔科夫链平滑地结合在一起,从而对稀疏和长尾数据集进行个性化的序列预测。TransRec将item嵌入到向量空间中,其中用户被建模为在item序列上进行的向量操作(vectors operating),从而用于大规模序列的预测。RUM使用了一个memory-augmented神经网络,融合了协同过滤的洞察(insights)来进行推荐。SASRec使用基于self-attention的序列模型来捕获长周期(long-term)语义,并使用注意力机制来基于相对较少的动作进行预测。DIN设计了一个局部激活单元(local activation unit)来自适应地从历史行为中学习关于目标广告的用户兴趣的representation。SDM使用multi-head self-attention模块对行为序列进行编码以捕获多种类型的兴趣,并使用长短期门控融合模块(long-short term gated fusion module)来融入长期偏好。
推荐多样性(
Recommendation Diversity):研究人员已经意识到,只遵循最准确(most accurate)的推荐可能不会产生最好best的推荐结果,因为最准确的结果往往会向用户推荐相似的item,从而产生无聊的推荐结果。为解决这些问题,推荐item的多样性(diversity)也起着重要作用。在多样性方面,有聚合多样性(
aggregated diversity),指的是向用户推荐长尾item的能力。很多研究聚焦于提高推荐系统的聚合多样性。另外有一些工作聚焦于推荐给单个用户的
item多样性,这指的是推荐给单个用户的item dissimilarity。注意力(
Attention):注意力机制的起源可以追溯到几十年前的计算机视觉领域。然而,它在机器学习的各领域中的普及只是近年来才出现的。它最早是由《Neural machine translation by jointly learning to align and translate》引入机器翻译的,后来作为tensor2tensor成为一种突破性的方法。BERT利用tensor2tensor并在NLP方面取得了巨大成功。注意力机制也适用于推荐系统,并在现实世界的推荐任务中相当有用。胶囊网络(
Capsule Network): 胶囊的概念最早由《Transforming auto-encoders》提出,并且自从动态路由方法被提出以来就广为人知。MIND将胶囊引入推荐领域,并利用胶囊网络基于动态路由机制来捕获电商用户的多个兴趣,可以用于聚类(clustering) 历史行为并提取多样化的兴趣。CARP首先从用户和item评论文档中抽取观点和aspect,并根据每个逻辑单元的组成观点和aspect推导出每个逻辑单元的representation,从而用于评分预测。
1.1 模型
序列推荐问题:假设有用户集合
item集合historical behaviors sequence)(根据行为发生时间来排序)item。给定历史交互数据,序列推荐的问题是预测用户可能交互的下一个item。在实践中,由于对延迟和性能的严格要求,工业推荐系统通常会包含两个阶段,即
matching阶段和ranking阶段。matching阶段对应于检索top-N个候选item,而ranking阶段用于通过更精确的score对候选item进行排序。我们的论文主要聚焦于提高matching阶段的有效性。在本节的剩余部分,我们将介绍我们的可控多兴趣框架ComiRec,并说明ComiRec框架对于序列推荐问题的重要性。由于工业推荐系统的
item池通常由数百万甚至数十亿的item组成,matching阶段在推荐系统中起着至关重要的作用。具体而言,matching模型首先根据用户的历史行为计算user embedding,然后根据user embedding为每个用户检索候选item集合,最后借助于fast KNN算法从大规模item池中选择最近邻的item为每个用户生成候选集合。换句话讲,matching阶段的决定性因素是根据用户历史行为计算的user embedding的质量。现有的
matching模型通常使用RNN来计算用户的embedding,大多数只为每个用户生成一个embedding向量。但是单个embedding缺乏表达能力,因为单个embedding无法代表用户的多种兴趣。为此我们为序列推荐提出了一个多兴趣框架ComiRec,整体如下图所示:模型的输入是一个用户行为序列,其中包含一个
item ID列表,代表用户和item根据发生时间排序的交互。模型的输入都是
item ID,没有任何用户侧辅助信息,也没有任何item侧辅助信息,甚至也没有user ID。item ID被馈入embedding layer并被转换为item embedding。多兴趣抽取模块(
multi-interest extraction module)接收item embedding并为每个用户生成多个兴趣,然后这些兴趣可用于模型训练和serving。对于模型训练,将选择与目标
item embedding最近的兴趣embedding来计算sampled softmax损失。对于模型
serving,每个兴趣embedding将独立检索top-N个最近邻的item,然后将其馈入聚合模块(aggregation module)。聚合模块通过平衡推荐准确性(accuracy)和多样性(diversity)的可控过程来生成整体的top-N个item。
有多种可选的方法用于构建多兴趣抽取模块,在本文中我们探索了两种方法:动态路由(
dynamic routing)方法和(self-attention)方法,对应的框架分别命名为ComiRec-DR和ComiRec-SA。ComiRec是基于interest-level来检索item,trigger为用户的各个兴趣。传统的Item CF是基于interest-level来检索item,trigger为用户的历史互动item。如果获取
interest则有各种不同的方法,因此本论文并没有多少创新点。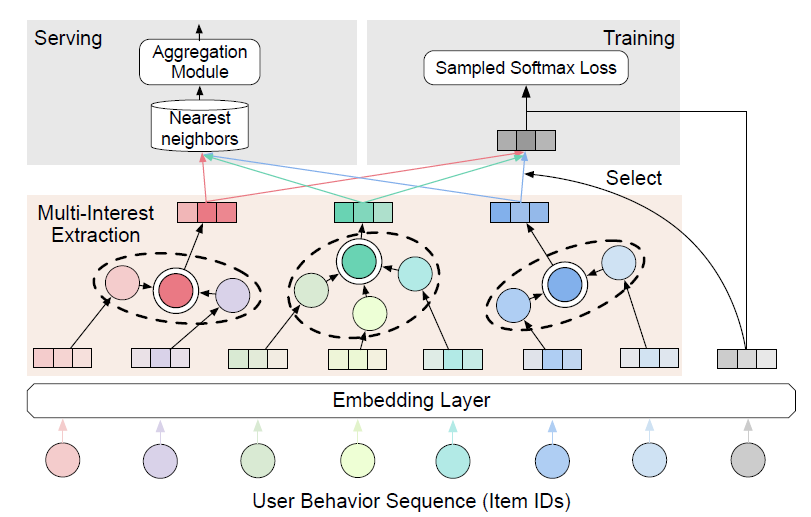
动态路由方法(
Dynamic Routing):我们利用动态路由方法作为多兴趣抽取模块。用户序列的item embedding可以视为主胶囊(primary capsules),多个用户兴趣可以视为兴趣胶囊(interest capsules)。我们使用CapsNet中的动态路由方法。这里我们简要介绍计算胶囊向量输入(
vector inputs)和向量输出(vector outputs)的动态路由。胶囊是一组神经元,其激活向量(activity vectors)代表特定类型实体(例如对象或者对象的一部分)的实例化参数(instantiation parameters)。胶囊向量的长度表示胶囊所代表的实体在当前输入条件下的概率。令primary layer中的胶囊item的embedding),然后我们根据primary capsules来计算兴趣胶囊我们首先计算预测向量(
prediction vector)为:然后兴趣胶囊
iterative)的动态路由过程所确定的耦合系数 (coupling coefficients)。注意:
primary胶囊1,即我们使用
routing softmax来计算耦合系数,并使用初始logits其中
primary胶囊log prior probability)。《Dynamic routing between capsules》提出了一种非线性squashing函数来确保短向量收缩到几乎为零的长度、长向量收缩到略低于1的长度。然后兴趣胶囊
动态路由算法:
输入:
primary capsules迭代次数
兴趣胶囊数量
输出:兴趣胶囊
算法步骤:
对于每个
primary胶囊迭代:
对每个
primary胶囊对每个兴趣胶囊
对每个兴趣胶囊
对每个
primary胶囊
返回
self-attention方法:self-attention方法也可以应用于多兴趣抽取模块。给定用户行为的
embeddingself-attention机制获得权重向量其中
我们根据注意力权重
sum用户行为embedding,从而得到用户的向量representation:我们将可训练的
positional embeddings添加到输入embedding中,从而利用用户行为序列的顺序(order)。positional embedding和item embedding具有相同的维度为了表示用户的整体兴趣,我们需要从用户行为序列中得到聚焦于不同兴趣的多个
attention。为此我们将attention权重向量变成一个attention矩阵最终的用户兴趣矩阵
其中
模型训练:在通过多兴趣抽取模块计算用户行为的兴趣
embedding之后,我们使用argmax算子为target itemembedding向量:其中
target itemembedding。给定一个训练样本
item模型的目标函数是最小化以下负对数似然:
其中
item集合。由于计算
sampled softmax technique来训练我们的模型。online serving:对于在线serving,我们使用我们的多兴趣抽取模块来计算每个用户的多个兴趣。用户的每个兴趣向量都可以通过最近邻library(如Faiss)从大规模item池中独立检索top-N个item。由多个兴趣检索的item被馈送到聚合模块中,以确定整体的item候选。最后,在ranking模块中ranking score较高的item被推荐给用户。聚合模块(
Aggregation Module):在多兴趣抽取模块之后,我们根据用户的历史行为从而为每个用户获取多个兴趣embedding。每个兴趣embedding可以根据内积邻近性独立检索top-N个item。但是,如何将这些来自不同兴趣的item聚合起来,从而得到整体的top-N个item?一种
basic且直接的方法是根据item和用户兴趣的内积邻近性来合并merge和过滤item,这可以形式化为:其中
embedding。这是聚合过程最大化推荐准确性(
accuracy)的有效方法。但是,当前推荐系统不仅仅关注准确性,还关注多样性。这个问题可以形式化为:给定用户item的一个集合item的集合我们的框架使用一个可控的过程(
controllable procedure)来解决这个问题。我们使用以下价值函数controllable factor)其中
其中
cat(i)为item如果追求准确性
accuracy,即item。如果追求多样性,即
controllable module)为用户找到最多样化的item。
我们提出了一种贪心推断算法来近似最大化值函数
最后,我们在实验中研究了可控因子。
贪心推断(
Greedy Inference)算法:输入:
候选
item集合输出
item数量
输出:
item集合算法步骤:
初始化
迭代
返回
和已有模型的关联:我们将我们的模型和现有模型进行比较。
MIMN:MIMN是ranking阶段的近期代表性工作,它使用memory网络从长的序列行为数据中捕获用户兴趣。MIMN和我们的模型都是针对用户的多种兴趣。对于非常长的序列行为,memory-based架构也可能不足以捕获用户的长期兴趣。和MIMN相比,我们的模型利用多兴趣抽取模块来利用用户的多种兴趣,而不是一个具有memory utilization正则化和memory induction unit的复杂memory网络。MIND:MIND是matching阶段的近期代表性工作,它提出了一种行为到兴趣(Behavior-to-Interest: B2I)的动态路由,用于自适应地将用户的行为聚合到兴趣representation向量中。和MIND相比,ComiRec-DR沿用了CapsNet使用的原始动态路由方法,可以捕获用户行为的序列信息。我们的框架还探索了一种用于多兴趣抽取的self-attention方法。此外,我们的框架还利用可控聚合模块来平衡基于用户多种兴趣的推荐准确性和多样性。
1.2 实验
这里我们对序列推荐进行实验,以验证我们框架和其它
SOTA方法相比的性能。此外,我们还报告了我们框架在十亿级工业数据集上的实验结果。我们在强泛化(
strong generalization)下评估所有方法的性能。我们将所有用户按照8:1:1的比例分为训练集、验证集、测试集。我们使用训练用户的完整点击序列来训练模型。为了评估,我们从验证用户和测试用户中获取每个用户前80%的行为,以从训练好的模型中推断用户embedding,并通过预测剩余的20%的行为来计算指标。这种设置比弱泛化(weak generalization)更困难,弱泛化指的是用户行为序列同时用于训练和评估。具体而言,我们采用了训练序列推荐模型的通用设置。设用户
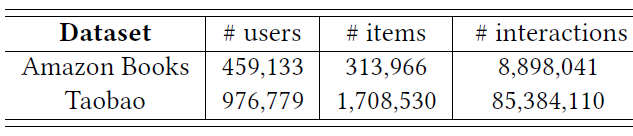
数据集:我们在两个具有挑战性的公共数据集上进行了实验,这些数据集的统计数据如下表所示。
Amazon数据集:包含来自Amazon的商品评论和元数据。在我们的实验中,我们使用Amazon Book子集。每个训练样本的用户行为序列被截断为长度20。Taobao数据集:包含来自淘宝推荐系统中收集的用户行为。在我们的实验中,我们仅使用点击行为并按时间对单个用户的所有行为进行排序。每个训练样本的用户行为序列被截断为长度50。
baseline方法:我们将我们提出的模型ComiRec-SA/ComiRec-DR和SOA的模型进行比较。在我们的实验设置中,模型应该为验证集和测试集中的、训练期间未见过的用户提供预测,因此基于分解的方法不适合这种设置。MostPopular:是一种传统的推荐方法,向用户推荐最后热门的item。YouTube DNN:是工业推荐系统最成功的深度学习模型之一。GRU4Rec:是第一个为推荐引入循环神经网络的工作。MIND:是与我们模型相关的、最新的、SOA的模型。它基于胶囊路由机制设计了一个多兴趣抽取器层(multi-interest extractor layer),适用于对历史行为进行聚类(clustering)并抽取不同的兴趣。
实现:我们的实验是基于
TensorFlow 1.14以及Python 3.6。一些关键的超参数为:embedding维度sampled softmax loss的样本数为10,最大训练迭代次数设置为100万次,多兴趣模块的兴趣embedding数量设置为K = 4。我们使用学习率0.001的Adam优化器进行优化。评估指标:我们使用以下三个常用指标来评估我们提出的模型的性能。
召回率(
Recall):为了更好的可解释性,我们使用user粒度的均值而不是全局均值:其中
top-N推荐item集合,item集合。命中率(
Hit Rate: HR):HR衡量推荐item中包含至少一个用户交互的、正确的item的比例,这在以前的工作中被广泛使用:其中
Normalized Discounted Cumulative Gain: NDCG:NDCG考虑到了正确推荐item的位置:其中
item。Ideal Discounted Cumulative Gain: IDCG@N,它是DCG@N的最大可能值。
为了和其它模型进行公平地比较,我们在聚合模块中设置
%)。可以看到:我们的模型在所有评估指标上都大大优于所有
SOA的模型。GRU4Rec的性能优于其它仅为每个用户输出单个embedding的模型。和
MIND相比,由于动态路由方式的不同,ComiRec-DR获得了更好的性能。ComiRec-SA展示了通过self-attention机制捕获用户兴趣的强大能力,并获得了与ComiRec-RD相当的结果。
注意:
MIND检索top-N titem的方式和ComiRec相同。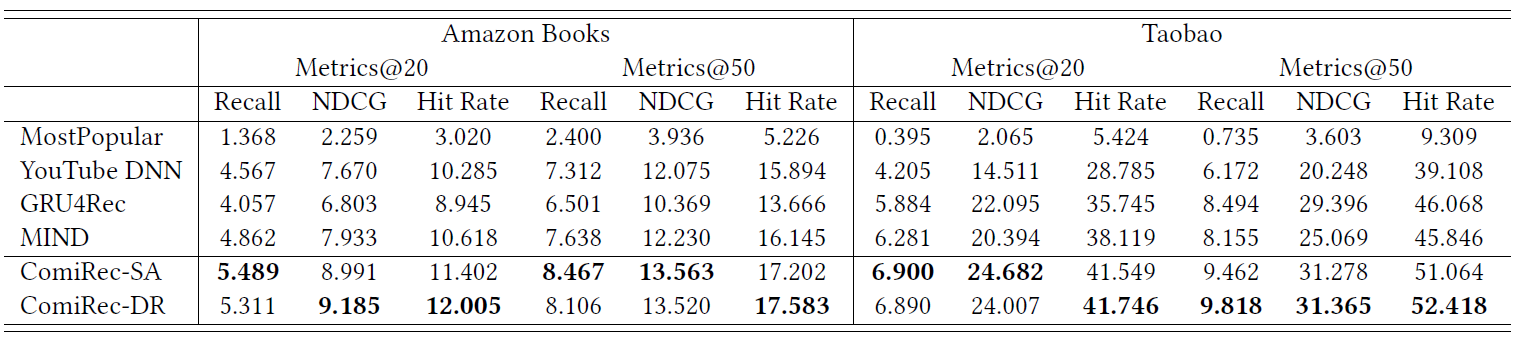
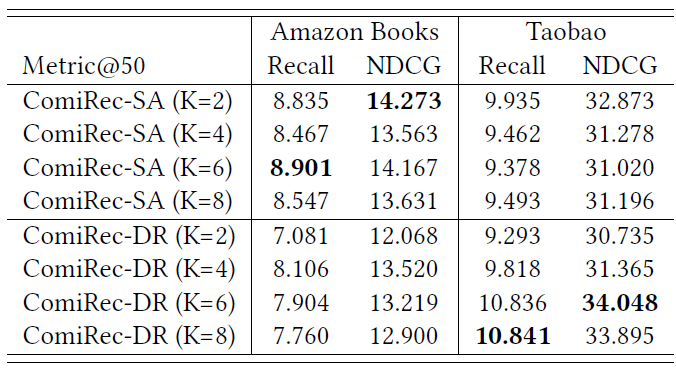
参数敏感性:我们研究了兴趣数量
%)。可以看到:这两个模型显示出了对超参数对于
Amazon数据集:ComiRec-SA在K=2 or 6时性能最好,而ComiRec-DR在K=4时性能最好。对于
Taobao数据集:当K从2增加到8时ComiRec-DR性能越来越好,但是ComiRec-SA在K=2时性能最好。
可控性研究:推荐多样性在当前的推荐系统中扮演着更重要的角色,许多研究目标是提高推荐多样性(
diversity)。我们提出的聚合模块可以控制推荐准确性和多样性的平衡。我们使用以下基于
item类目的个体多样性(individual diversity)定义:其中
cat(i)为itemitem,下表展示了当我们控制因子
Amazon数据集的模型性能。粗体是每列的最佳性能,表中所有数字均为百分比数字(省略了%)。可以看到:当可控因子trade-off。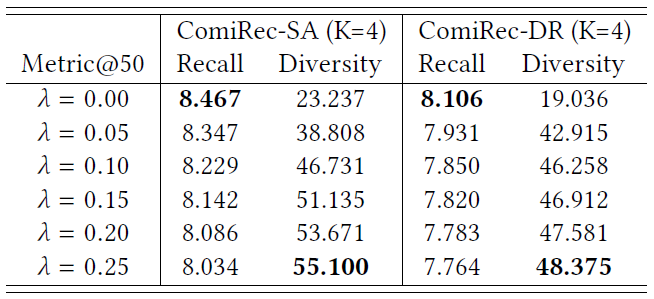
工业数据集:我们在
2020年2月8号手机淘宝App采集的工业数据集上进行了进一步实验,数据集的统计数据如下表所示。工业数据集包含2200万个优质item、1.45亿用户、40亿条user-item交互。
我们的框架已经部署在阿里巴巴分布式云平台上,其中每两个
worker共享一个具有16GB内存的NVIDIA Tesla P100 GPU。我们拆分用户为训练集、验证集、测试集,并使用训练集用户的点击序列来训练我们的模型。为了进行评估,我们使用我们的模型来计算测试集中每个用户的多个兴趣。用户的每个兴趣向量通过fast KNN方法独立地从大规模item池中检索top-N个item。由不同用户兴趣检索的item被馈入到我们的聚合模块。在聚合模块之后,item中的top-N个item是最终候选item,用于计算评估指标recall@50。我们在我们的框架和
SOA的序列推荐方法MIND之间进行了离线实验,结果表明我们方法的显著提升:和MIND相比,我们的ComiRec-SA和ComiRec-DR分别将Recall@50提高了1.39%和8.65%。ComiRec并未进行在线A/B test实验。案例研究:下图给出了一个电商用户的案例研究。通过我们的模型,我们从用户的点击序列中生成四个兴趣
embedding,代表四种不同的兴趣。我们发现用户的四个兴趣是关于糖果、礼品盒、手机壳、配件。左图展示了用户点击行为序列中,分别与这四个兴趣相对应的点击
item。右图展示了通过兴趣
embedding从工业item池中检索到的item。
值得注意的是,我们的模型仅使用
item ID进行训练,并没有使用人工定义的item类目信息。尽管如此,我们的模型仍然可以从用户行为序列中学习item类目。 我们的模型学习到的每个兴趣大约对应于一个特定类目,并且可以从大规模工业item池中检索同一类目的相似item。