一、PLE [2020]
《Progressive Layered Extraction (PLE): A Novel Multi-Task Learning (MTL) Model for Personalized Recommendations》
多任务学习(
multi-task learning: MTL)已成功应用于众多推荐场景。然而,在实际推荐系统中,由于任务间存在复杂的且相互竞争的关联关系(correlation),多任务学习模型常因负向迁移问题(negative transfer)导致性能下降。此外,通过对现有SOTA的多任务学习模型的大量实验,我们发现了一种有趣的“跷跷板现象” (seesaw phenomenon)——提升某一任务的性能往往会以损害其他任务的性能为代价。为解决这些问题,我们提出了一种具有新颖的
sharing structure design的Progressive Layered Extraction: PLE模型。该模型显式地分离了shared components与task-specific components,并采用渐进式的路由(progressive routing)机制,从而渐进式地提取和分离deeper semantic knowledge,在general setup下提高了任务之间的joint representation learning和information routing的效率。我们将
PLE同时应用于关联关系复杂的任务和关联关系正常的任务中,涵盖双任务场景到多任务场景,实验基于Tencent视频推荐的真实数据集(含1 billion样本)。结果表明,在不同task correlations和task-group size下,PLE的性能显著优于SOTA的多任务学习模型。此外,在
Tencent大型内容推荐平台上的在线评估显示,与现有SOTA多任务学习模型相比,PLE使观看次数提升2.23%,观看时长提升1.84%。这表明改进效果显著,验证了其有效性。最后,在公开的
benchmark数据集上的大量离线实验表明:除推荐场景外,PLE还可应用于多种场景以消除跷跷板现象。目前,PLE已成功部署到Tencent在线视频推荐系统中。个性化推荐在
online applications中发挥着至关重要的作用。推荐系统(recommender systems: RS)需要整合各种user feedbacks来建模用户兴趣(user interests),以最大化user engagement and satisfaction。然而,由于问题的高维特性,用户满意度(user satisfaction)通常难以通过a learning algorithm来直接建模。同时,user satisfaction and engagement受多个主要因子的影响(这些因子可以被直接学习),例如clicking, finishing, sharing, favoriting, and commenting的可能性等等。因此,将多任务学习(Multi-Task Learning: MTL)应用于推荐系统,以同时建模user satisfaction or engagement的多个方面,已成为一种日益普遍的趋势。事实上,它已成为主流行业applications中的主流方法。多任务学习在单个模型中同时学习多个任务,并通过任务间的信息共享(
information sharing)来提高学习效率(《Multitask learning》)。然而,实际推荐系统中的任务往往关联松散(loosely correlated),甚至相互冲突,这可能导致性能下降,即所谓的负向迁移(negative transfer)(《Transfer learning》)。通过在真实大规模视频推荐系统和公开基准数据集上的大量实验,我们发现:当task correlation是复杂的且有时是sample dependent的时候,现有多任务学习模型往往会以牺牲其他任务的性能为代价来提升某些任务的性能。即,与对应的单任务模型相比,多个任务无法同时得到改善。本文将这种现象称为“跷跷板现象”(seesaw phenomenon)。以往的研究更多地致力于解决负向迁移问题,却忽略了跷跷板现象。
例如,交叉缝合网络(
cross-stitch network)(《Cross-stitch networks for multi-task learning》)和水闸网络(sluice network)(《Sluice networks: Learning what to share between loosely related tasks》)提出通过学习静态的线性组合(static linear combinations)来融合不同任务的representations,但无法捕获样本依赖性(sample dependence)。MMOE(《Modeling task relationships in multi-task learning with multi-gate mixture-of-experts》)基于input来应用gating networks从而组合bottom experts以处理任务差异(task differences),但忽略了experts之间的差异(differentiation)和交互(interaction),在我们的工业实践中被证明存在跷跷板现象。
因此,设计一种更强大的、更高效的模型来处理复杂的关联关系(
correlations)并消除棘手的跷跷板现象至关重要。为实现这一目标,我们提出了一种新型的多任务学习模型,称为
Progressive Layered Extraction: PLE。该模型在design of shared network中更好地利用先验知识(prior knowledge)来捕获复杂的任务关联(task correlations)。与
MMOE中粗略的shared parameters不同,PLE显式地分离shared experts和task-specific experts,以减轻common knowledge和task-specific knowledge之间有害的参数干扰(parameter interference)。此外,
PLE引入multi-level的experts and gating networks,并应用渐进式分离路由(progressive separation routing),从lower-layer experts中提取deeper knowledge,并在higher levels渐进式地分离task-specific parameters。
为评估
PLE的性能,我们在真实的工业推荐数据集和主要的公开数据集(包括census-income、synthetic data、以及Ali-CCP数据集)上进行了大量实验。实验结果表明,PLE在所有数据集上均优于现有SOTA的多任务学习模型:不仅在具有复杂关联关系(omplex correlations)的task groups上,而且在不同场景中具有正常关联关系(normal correlations)的task groups上都取得了一致的改进。此外,在Tencent大规模视频推荐系统上的在线指标显著提升,证明了PLE在实际推荐applications中的优势。本文的主要贡献总结如下:
通过在
Tencent大规模视频推荐系统和公开基准数据集上的大量实验,观察到一种有趣的跷跷板现象:由于复杂的inherent correlations,现有SOTA的多任务学习模型往往以牺牲其他任务的性能为代价来提升某些任务的性能,且并未优于对应的单任务模型。提出了一种具有新颖的
shared learning structure的PLE模型,从joint representation learning和information routing的角度,提高shared learning的效率,进而解决跷跷板现象和负向迁移问题。除recommendation applications外,PLE还可灵活应用于多种场景。在工业数据集和公开基准数据集上进行了大量离线实验,以评估
PLE的有效性。在Tencent某大型内容推荐平台上的online A/B test结果也表明,在实际应用中,PLE相比现有SOTA多任务学习模型有显著改进,观看次数提升2.23%,观看时长提升1.84%,产生了显著的商业收益。目前,PLE已成功部署到该推荐系统中,并有望应用于许多其他推荐场景。
1.1 相关工作
高效的多任务学习模型、以及多任务学习模型在推荐系统中的应用,这是与本文相关的两个研究领域。在本节中,我们简要讨论这些领域的相关工作。
1.1.1 Multi-Task Learning Models
如
Figure 1a所示,硬参数共享(Hard parameter sharing)(《Multitask learning》)是最基本的且常用的多任务学习结构,但由于任务间直接共享参数,可能会因任务冲突而遭受负向迁移(negative transfer)。为解决任务冲突,交叉缝合网络(
cross-stitch network)(《Cross-stitch networks for multi-task learning》)(如Figure 1f所示)和水闸网络(sluice network)(《Sluice networks: Learning what to share between loosely related tasks》)(如Figure 1g所示)均提出通过学习weights of linear combinations来选择性地融合不同任务的representations。然而,在这些模型中,所有样本都使用相同的static weights来组合representations,并未解决跷跷板现象。本文提出的Progressive Layered Extraction: PLE模型应用带有门结构(gate structures)的渐进式路由机制(progressive routing mechanism),基于input来融合知识,实现了对不同inputs的自适应组合(adaptive combinations)。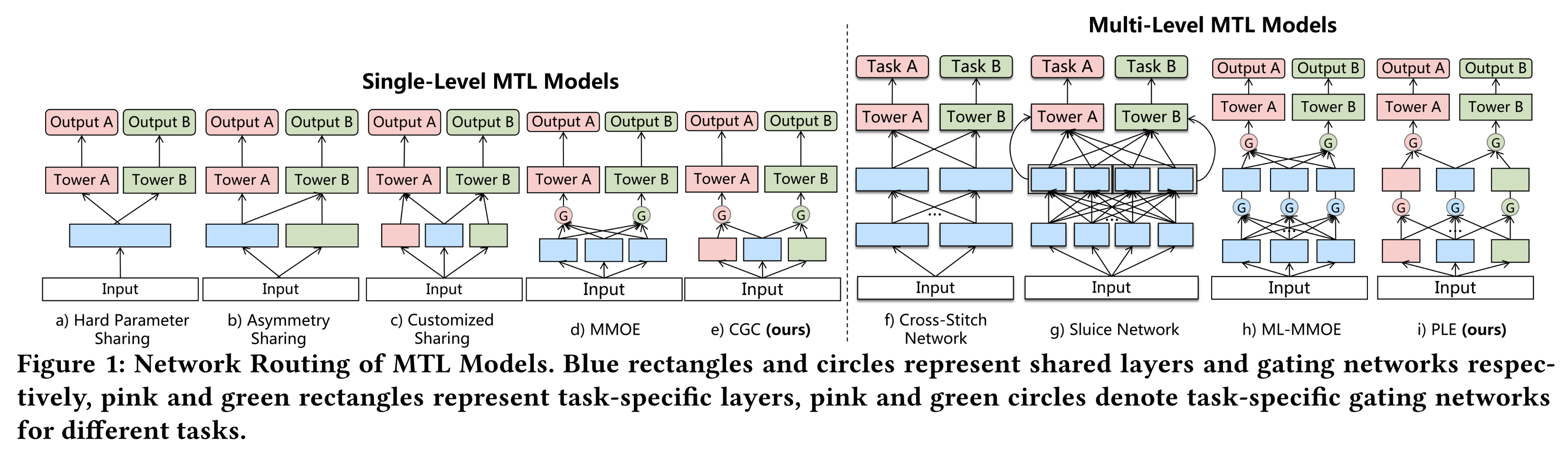
已有一些研究将门结构和注意力网络(
attention network)应用于信息融合。混合专家模型(
MOE)(《Adaptive mixtures of local experts》)首次提出在底层共享一些experts,并通过一个门控网络(gating network)来组合experts。MMOE(如Figure 1所示)(《Modeling task relationships in multi-task learning with multi-gate mixture-of-experts》)扩展了MOE,在多任务学习中为每个任务利用不同的gates来获得不同的fusing weights。类似地,多关系注意力网络(
MRAN)(《Multiple Relational Attention Network for Multi-task Learning》)应用multi-head self-attention在不同feature sets上学习不同的representation subspaces。
在
MOE、MMOE和MRAN中,expert和attention module在所有任务间共享,没有task-specific的概念。相比之下,我们提出的Customized Gate Control: CGC和PLE模型显式地分离task-common参数和task-specific参数,以避免因复杂的task correlations导致的参数冲突(parameter conflicts)。尽管MMOE在理论上有可能收敛到我们的网络设计(network design),但网络设计中的先验知识(prior knowledge)至关重要,而MMOE在实践中很难找到收敛路径(convergence path)。《End-to-end multi-task learning with attention》应用task-specific attention networks选择性地融合shared features,但不同任务在attention network中融合之前仍然共享相同的representation。
以往的工作均未显式地解决
representation learning和routing的联合优化(joint optimization)问题,尤其是它们以不可分离的联合方式(inseparable joint fashion);而本文首次尝试在joint learning and routing的通用框架上提出一种新型的渐进式分离方式(progressive separation fashion)。也有一些工作利用自动机器学习(
AutoML)方法寻找良好的网络结构。子网络路由(
SNR)框架(《SNR: Sub-Network Routing for Flexible Parameter Sharing in Multi-task Learning》)通过二元随机变量(binary random variables)控制子网络之间的连接,并应用神经架构搜索(NAS)(《Neural architecture search with reinforcement learning》)寻找最优结构。类似地,
Gumbel-matrix routing framework(《Gumbel-Matrix Routing for Flexible Multi-task Learning》)利用Gumbel-Softmax trick,将多任务学习模型的routing建模为二元矩阵。《Routing networks: Adaptive selection of non-linear functions for multi-task learning》将routing过程建模为马尔可夫决策过程(MDP),应用多智能体强化学习(MARL)(《Multi-agent reinforcement learning: a critical survey》)训练routing network。
这些工作中的网络结构设计基于某些简化假设,不够通用。
《Routing networks: Adaptive selection of non-linear functions for multi-task learning》中的routing network在每个depth为每个任务选择不超过一个功能块(function block),这降低了模型的表达能力。Gumbel-matrix routing network对representation learning施加了约束,即每个任务的inputs需要在每一层合并为一个representation。此外,这些框架中的
fusing weights无法针对不同inputs进行调整,且昂贵的搜索成本是这些方法寻找最优结构的另一个挑战。
1.1.2 Multi-Task Learning in Recommender Systems
为了更好地利用各种
user behaviors,多任务学习已被广泛应用于推荐系统,并取得了显著的改进。一些研究将协同过滤(collaborative filtering: CF)和矩阵分解(matrix factorization: MF)等传统推荐算法与多任务学习相结合。《Why I like it: multi-task learning for recommendation and explanation》和《Explainable recommendation via multi-task learning in opinionated text data》对recommendation任务和explanation任务所学到的latent representations施加正则化,以联合优化它们。《Online multi-task collaborative filtering for on-the-fly recommender systems》将协同过滤与多任务学习相结合,更高效地学习user-item similarity。
与本文中的
PLE相比,这些基于分解的模型的表达能力较低,无法充分利用任务间的共性(commonalities)。作为最基本的多任务学习结构,硬参数共享(
hard parameter sharing)已被应用于许多基于深度神经网络(DNN)的推荐系统中。ESMM(《Entire space multi-task model: An effective approach for estimating post-click conversion rate》)引入了点击率(Click-Through Rate: CTR)和CTCVR两个辅助任务,并在CTR和转化率(Conversion Rate: CVR)之间共享embedding parameters,以提高CVR prediction的性能。《Rank and rate: multi-task learning for recommender systems》提出了一个多任务框架,同时学习ranking任务和rating任务的参数。《Ask the gru: Multi-task learning for deep text recommendations》中的文本推荐任务通过在底层共享representations得到改进。
然而,在任务关联(
task correlations)松散或复杂的时候,hard parameter sharing通常会遭受负向迁移和跷跷板现象。相比之下,我们提出的模型引入了一种新型的共享机制,以实现更通用的、更高效的信息共享。除
hard parameter sharing外,已有一些推荐系统应用了具有更高效shared learning机制的多任务学习模型。为了更好地利用任务间的关联关系,
《Multi-pointer co-attention networks for recommendation》利用hierarchical multi-pointer co-attention来提高recommendation任务和explanation任务的性能。然而,模型中每个任务的tower networks共享相同的representation,可能仍然会遭受任务冲突(task conflicts)。YouTube视频推荐系统(《Recommending what video to watch next: a multitask ranking system》)应用MMOE(《Modeling task relationships in multi-task learning with multi-gate mixture-of-experts》),通过为每个任务采用不同的gating networks来组合shared experts,能够更好地捕获task differences并高效地优化多个objectives。与
MMOE平等对待所有experts而不加以区分不同,本文中的PLE显式地分离task-common experts和task-specific experts,并采用新型渐进式的separation routing,在真实世界的视频推荐系统中实现了相比MMOE的显著改进。
1.2 推荐系统多任务学习中的跷跷板现象
负向迁移(
negative transfer)是多任务学习中常见的现象,尤其是在关联松散的任务中(《Transfer learning》)。对于复杂的任务关联(task correlation),特别是sample dependent的关联模式,我们还观察到跷跷板现象:当前的多任务学习模型难以提高shared learning的效率,并难以在所有任务上显著优于对应的单任务模型。在本节中,我们基于Tencent的大规模视频推荐系统,详细介绍和研究跷跷板现象(seesaw phenomenon)。
1.2.1 视频推荐的多任务学习 Ranking 系统
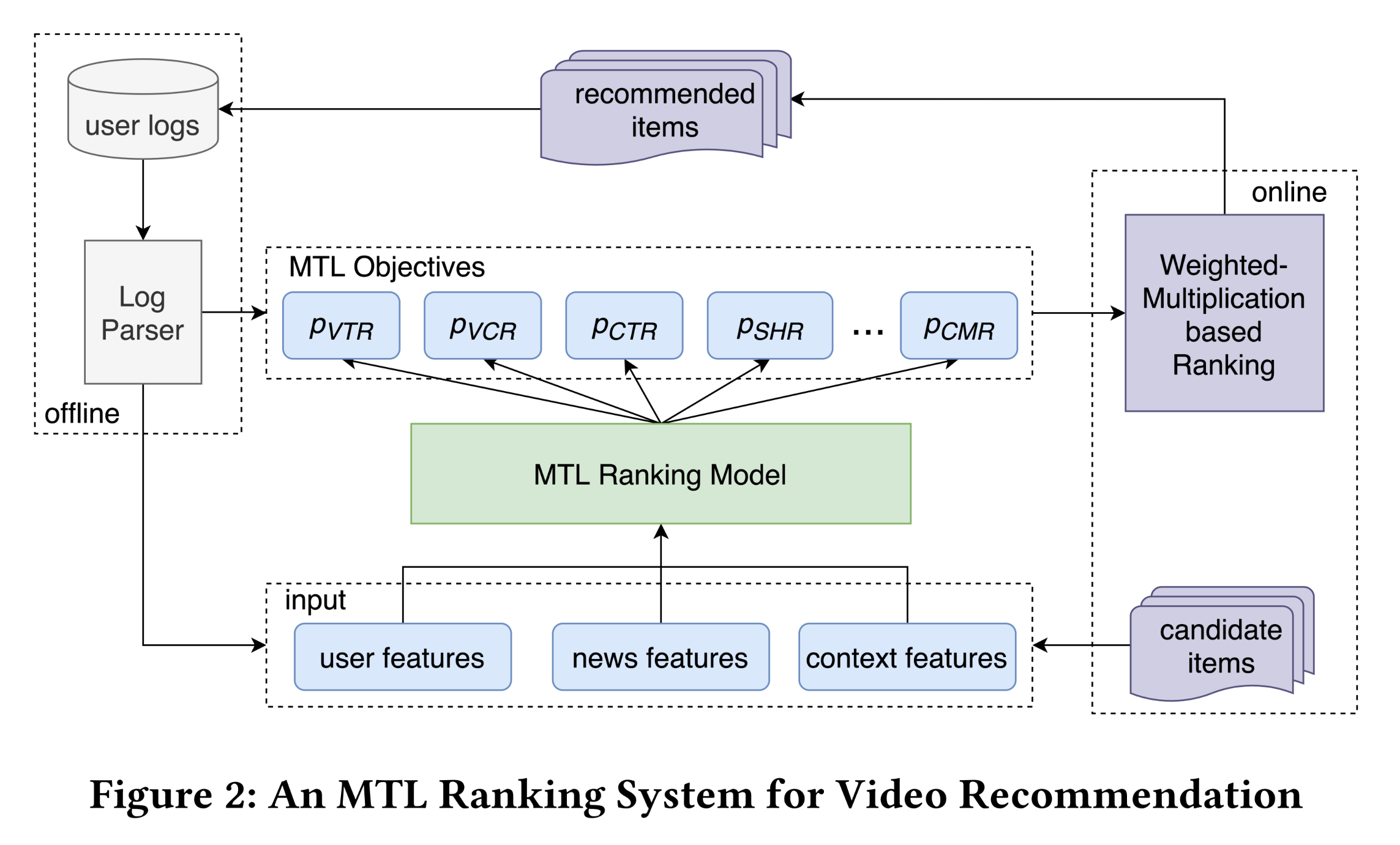
在本节中,我们简要介绍服务于
Tencent新闻的多任务学习ranking系统,该系统是全球最大的内容平台之一,基于多样化的user feedbacks向用户推荐新闻和视频。如Figure 2所示,多任务学习ranking系统中有多个objectives,用于建模不同的user behaviors,如点击(click)、分享(share)和评论(comment)。在离线训练过程中,我们基于从user logs中提取的user actions来训练多任务学习ranking模型。每次online request后,ranking模型输出每个任务的predictions,然后基于加权乘法的ranking模块通过下面所示的组合函数将这些predicted scores组合为final score,并最终向用户推荐排名靠前的视频:其中:
predicted score的相对重要性。它们是通过在线实验搜索来优化的超参数,以最大化在线指标。video duration)的非线性转换函数,如sigmoid()函数或log()函数。
在所有任务中,观看完成率(
View Completion Ratio: VCR)和有效观看率(View-Through Rate: VTR)是两个重要的目标,分别建模观看次数(view-count)和观看时长(watch time)的关键在线指标。具体来说:VCR prediction是一个回归任务,使用MSE loss进行训练,用于预测每次观看的完成率(completion ratio)。VCR衡量用户观看视频的相对强度。例如,是100%观看、还是50%观看?给定不同总时长的两个视频,假设分别为
100分钟和10分钟,50%的VCR代表了不同的观看时间。VTR prediction是一个二分类任务,使用cross-entropy loss进行训练,用于预测有效观看(valid view)的概率。有效观看定义为:观看时长超过某个阈值的播放行为。VTR衡量用户观看视频的绝对强度。例如,是否观看超过10分钟。给定不同总时长的两个视频,假设分别为
100分钟和10分钟,那么观看超过1.0的VTR代表用户把第二个视频看完了。
VCR和VTR之间的关联模式复杂。首先,
VTR的label是播放行为(play action)和VCR的耦合因素,因为只有观看时长超过阈值的播放行为才会被视为有效观看。给定视频
VTR阈值即:视频总时长乘以观看完成率,载于
VTR阈值进行比较。其次,播放行为的分布更为复杂:
WiFi环境下自动播放场景的样本具有更高的平均播放概率(probability of play),而其他无自动播放的显式点击场景的样本具有更低的播放概率。这意味着不同
context下,样本具有不同的label分布。
由于这种复杂且强烈依赖于样本的关联模式,在联合建模
VCR和VTR时观察到了跷跷板现象。
1.2.2 多任务学习中的跷跷板现象
为了更好地理解跷跷板现象,我们在我们的
ranking系统中,针对VCR和VTR这一具有复杂关联的任务组(task group),使用单任务模型和SOTA多任务学习模型进行了实验分析。除了hard parameter sharing、cross-stitch、sluice network和MMOE外,我们还评估了两种创新提出的结构:非对称共享(asymmetric sharing)和定制共享(customized sharing):Asymmetric Sharing:是一种新型的共享机制,用于捕获任务间的非对称关系。如Figure 1b所示,bottom layers在任务间非对称地共享,共享哪个任务的representation取决于任务间的关系。可以应用拼接(concatenation)、求和池化(sum-pooling)和平均池化(average-pooling)等常见融合操作来组合不同任务的bottom layers的输出。Customized Sharing:如Figure 1c所示,customized sharing显式地分离shared parameters和task-specific parameters,以避免固有的task conflicts和negative transfer。与单任务模型相比,customized sharing添加了一个shared bottom layer来提取sharing information,并将shared bottom layer和task-specific layer的concatenation结果馈入到对应任务的tower layer中。与
CGC相比,Customized Sharing缺少了门控网络。
Figure 3展示了实验结果,其中越靠近右上方向的气泡表示性能越好(AUC越高,MSE越低)。值得注意的是,在我们的系统中,AUC或MSE改善0.1%会对在线指标产生显著改进。可以看出:hard parameter sharing和cross-stitch network遭受了显著的负向迁移,在VTR上表现最差。通过创新的共享机制捕获非对称关系,
asymmetric sharing在VTR上取得了显著改进,但在VCR上表现出显著下降。sluice network与asymmetric sharing类似。由于显式地分离了
shared layers和task-specific layers,customized sharing在VCR上优于单任务模型,但在VTR上仍然略有下降。MMOE在两个任务上都优于单任务模型,但VCR的改进仅为+0.0001,处于临界水平。
尽管这些模型在这两个具有挑战性的任务上表现出不同的学习效率,但我们清楚地观察到跷跷板现象:一个任务的改进往往导致另一个任务的性能下降,因为没有一个
baseline多任务学习模型完全位于第二象限。在公开benchmark数据集上使用现有SOTA模型进行的实验也表现出明显的跷跷板现象。详细信息将在实验章节中提供。如前所述,
VCR和VTR之间的关联模式复杂且依赖于样本。具体来说,VCR和VTR之间存在一些偏序关系(partially ordered relations),不同样本表现出不同的关联关系。因此,cross-stitch network和sluice network为所有样本使用相同的static weights来组合shared representations,无法捕获样本依赖性(sample dependence),从而遭受跷跷板现象。MMOE通过gates基于input获得fusing weights,在一定程度上处理了任务差异和样本差异,优于其他baseline多任务学习模型。然而,MMOE中所有任务共享experts而不加以区分,无法捕获复杂的任务关联,可能会给某些任务带来有害噪声。此外,MMOE忽略了不同experts之间的交互,进一步限制了joint optimization的性能。除了
VCR和VTR外,工业推荐applications中还有许多关联复杂的任务,因为人类行为通常微妙且复杂,例如在线广告和电子商务平台中的CTR prediction和CVR prediction。因此,一个考虑experts之间区分度(differentiation)和交互(interactions)的强大网络对于消除棘手的跷跷板现象至关重要,这个跷跷板现象由复杂的task correlation所导致。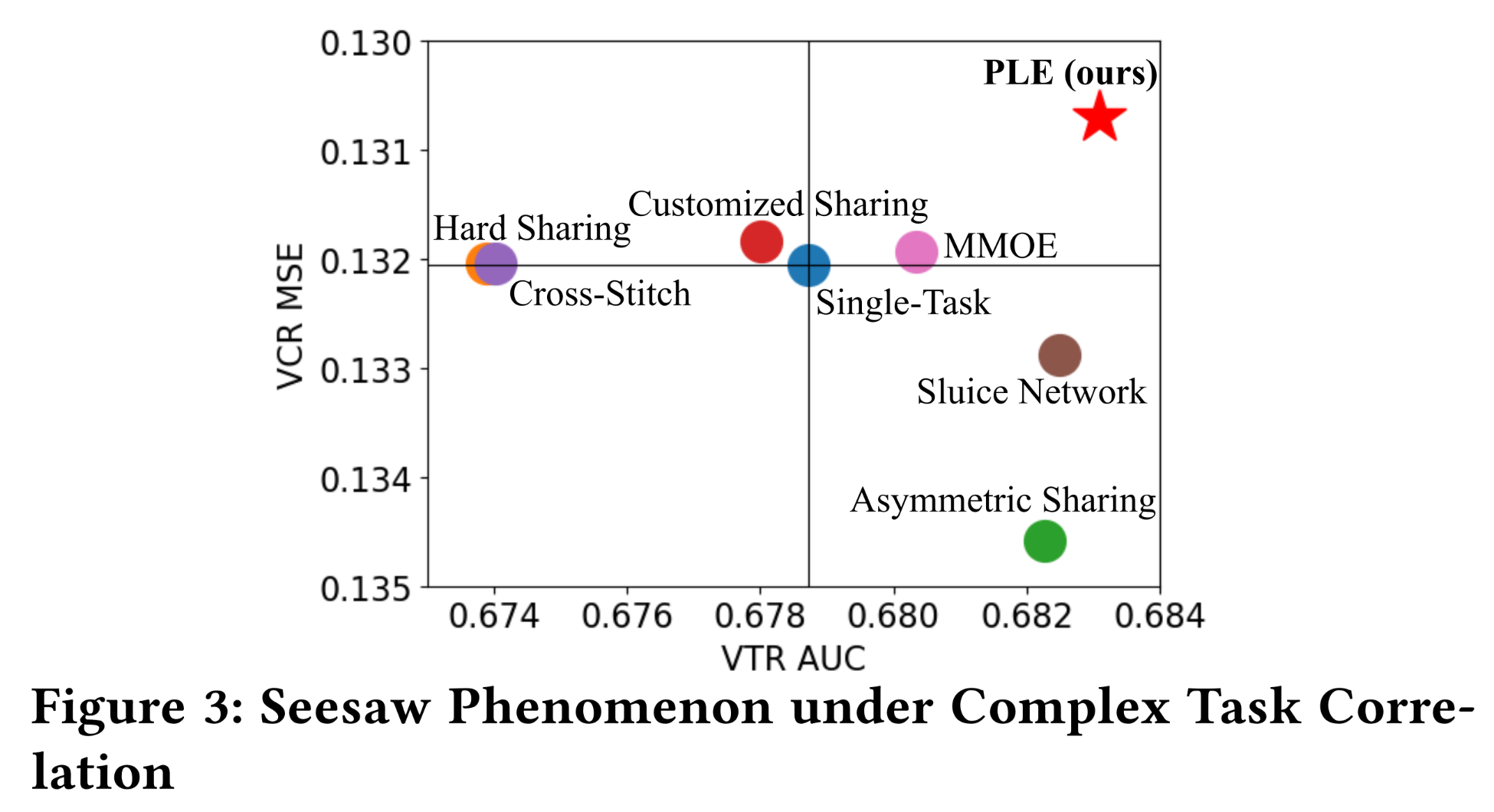
在本文中,我们提出了一种
Progressive Layered Extraction: PLE模型来解决跷跷板现象和负向迁移问题。PLE的核心思想如下:首先,显式地分离
shared experts和task-specific experts,以避免有害的参数干扰(parameter interference)。其次,引入
multi-level的experts and gating networks,以融合更抽象的representations。最后,采用一种新型的渐进式
separation routing来建模experts之间的交互,并在关联复杂的任务间实现更高效的知识迁移(knowledge transferring)。“渐进式“ 的含义:
PLE中不同任务的参数不像CGC那样在early layer完全地分离,而是在upper layers渐进式地地分离。
如
Figure 3所示,PLE在两个任务上都取得了相比MMOE的显著改进。结构设计和实验的详细信息将分别在后续章节给出。
1.3 PLE
为解决跷跷板现象和负向迁移问题,本节提出了一种具有新型
sharing structure design的Progressive Layered Extraction: PLE模型。首先,我们提出了一种显式地分离
shared experts和task-specific experts的Customized Gate Control: CGC模型。其次,将
CGC扩展为具有multi-level gating networks and progressive separation routing的通用PLE模型,以实现更高效的information sharing和joint learning。最后,优化
loss function,以更好地处理多任务学习模型中joint training的实际挑战。
1.3.1 CGC
受
customized sharing的启发(通过显式地分离shared layers和task-specific layers,实现了与单任务模型相当的性能),我们首先引入Customized Gate Control: CGC模型。如Figure 4所示:bottom layer有一些expert模块,top layer有一些task-specific tower networks。每个
expert模块由多个称为"experts"的子网络组成,每个模块中的experts数量是需要调优的超参数。类似地,
a tower network也是一个multi-layer network,其width和depth作为超参数。
具体来说,
CGC中的shared experts负责学习shared patterns,而patterns for specific tasks由task-specific experts提取。每个tower network同时从shared experts和其自身的task-specific experts中吸收知识,这意味着shared experts的参数受所有任务影响,而task-specific experts的参数仅受对应特定任务的影响。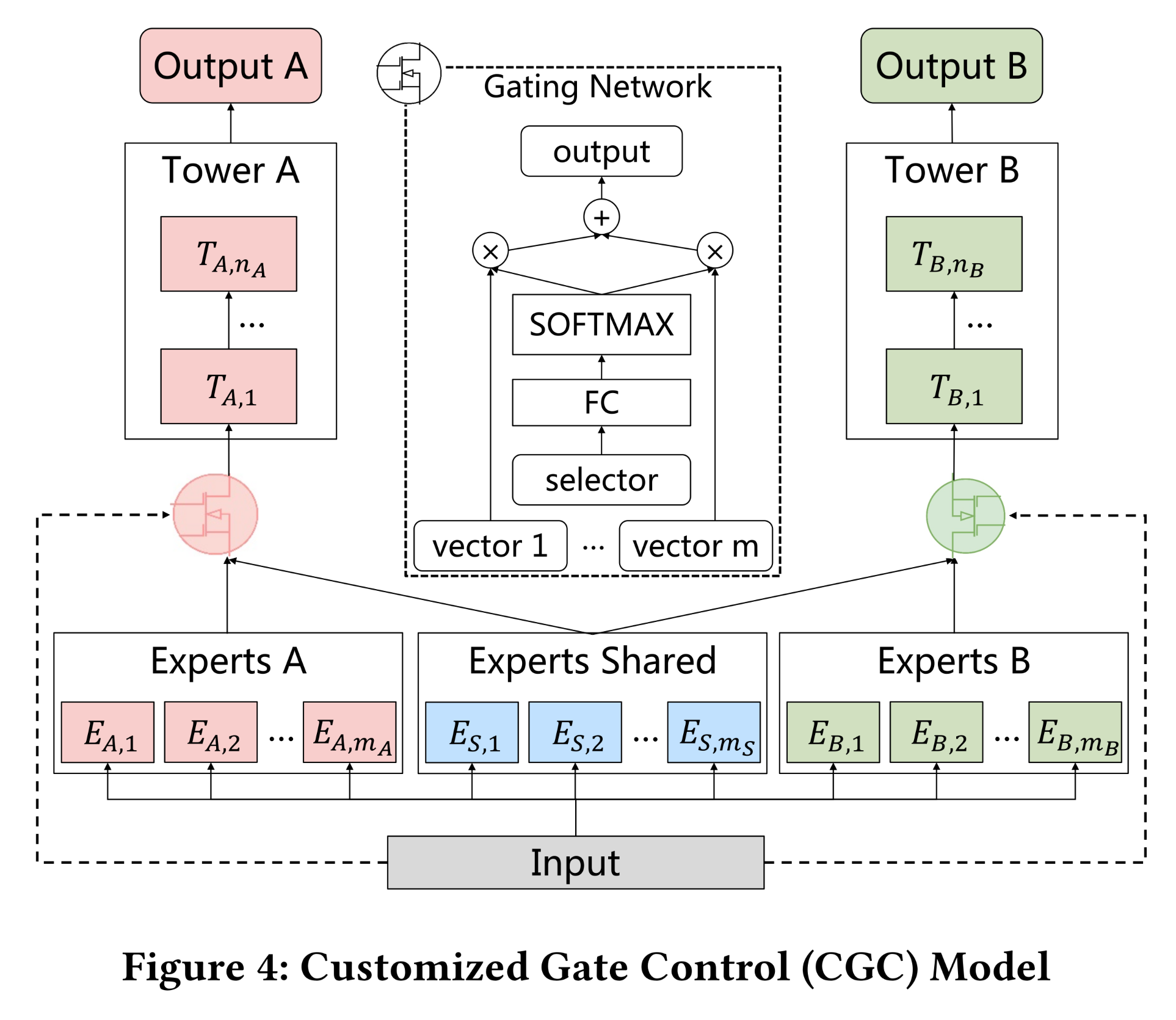
在
CGC中,shared experts和task-specific experts通过一个门控网络(gating network)进行组合,以实现选择性的融合(selective fusion)。如Figure 4所示,门控网络的结构基于单层前馈网络,使用SoftMax作为激活函数,input作为选择器(selector)来计算selected vectors(即outputs of experts)的加权和。更精确地说,任务其中:
input representation。input representation维度。weighting function,它通过线性变换和SoftMax layer计算任务weight vector:其中:
shared experts数量;task-specific experts数量。selected matrix,由所有selected vectors(包括shared experts和任务task-specific experts)组成:其中:
shared experts的output vector,task-specific expert的output vector,
最后,任务
其中:
tower network。注意,可能有多个任务,如任务
shared experts,其它信息是独立的。与
MMOE相比,CGC移除了任务的tower network与task-specific experts of other tasks之间的连接,使不同类型的experts能够高效地专注于学习不同的知识,而不受干扰。结合动态地融合representations的优势(通过基于input的gating networks),CGC实现了任务间更灵活的平衡,并更好地处理了任务冲突(task conflicts)和sample-dependent correlations。
1.3.2 PLE
CGC显式地分离了task-specific components和shared components。然而,在深度多任务学习中,learning需要渐进式地塑造(shape)越来越深的semantic representations,而通常并不清楚中间表征(intermediate representations)是否应被视为shared的或task-specific定的。为解决这一问题,我们通过
Progressive Layered Extraction: PLE对CGC进行了泛化。如Figure 5所示:PLE中有multi-level extraction networks,用于提取higher-level shared information。除了
task-specific experts的gates之外,extraction network还为shared experts采用一个门控网络(gating network),以组合该层所有experts(包括shared experts和task-specific experts)的知识。因此,PLE中不同任务的参数不像CGC那样在early layer完全地分离,而是在upper layers渐进式地地分离。higher-level extraction network中的门控网络将lower-level extraction network中fusion results of gates(而不是raw input)作为selector,因为这样做或许能为从higher-level experts那里提取抽象知识(abstract knowledge)提供更好的信息。
注意:对于第
extraction network:任务
A的门控网络的输入:来自于第extraction network的任务A的门控网络的输出。任务
A的experts的输入:读者猜测是跟门控网络的输入相同(作者在论文中没有说明)。
注意:读者在实现
PLE的过程中发现有一个变体表现良好:Experts A的input来自于上一层Experts A的输出。Experts Shared的input来自于上一层所有task输出的拼接,并且Experts Shared不需要门控输出。
这意味着:
Experts Shared在每一层中抽取shared information,而不是跨层传递shared information。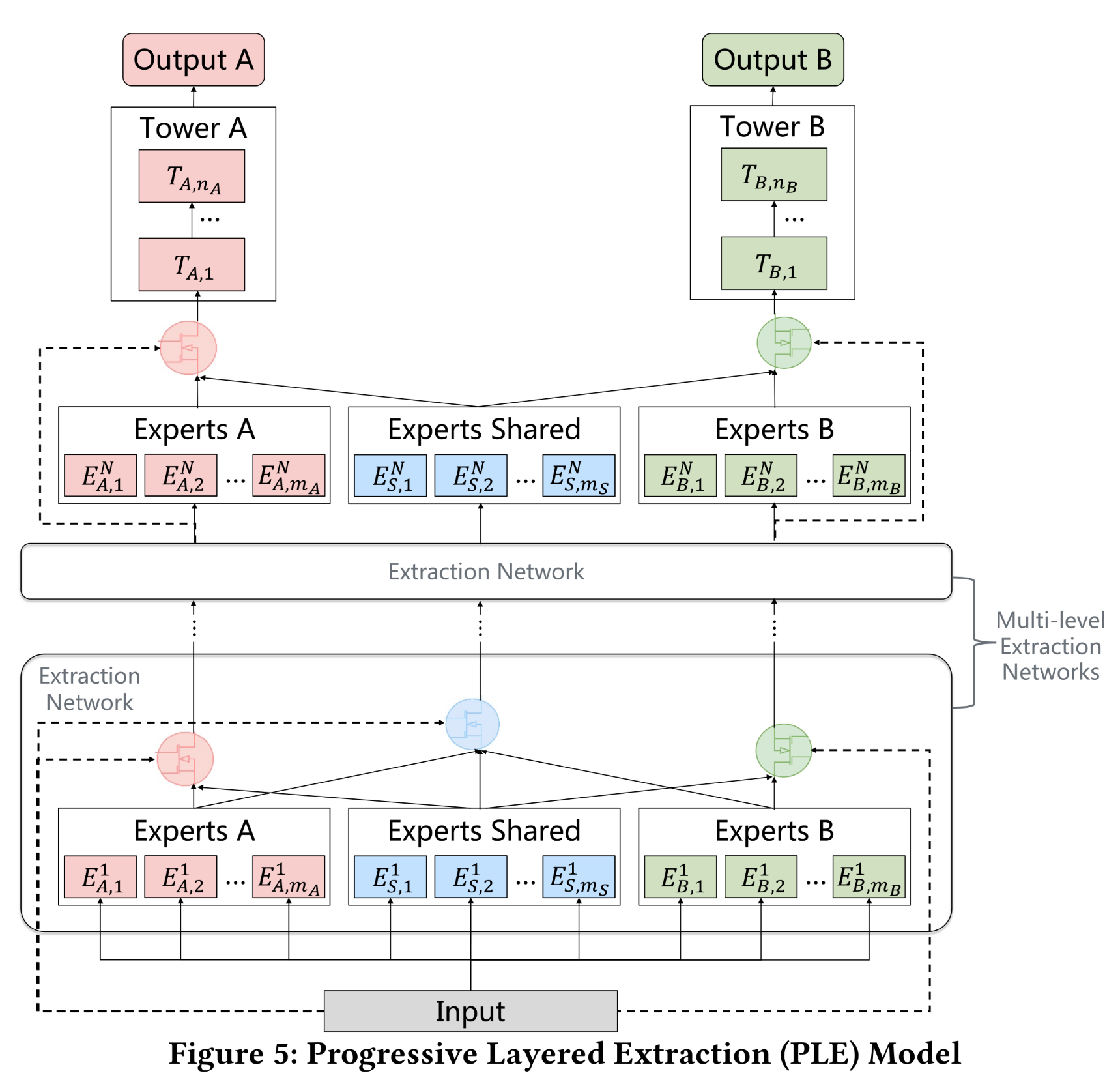
PLE中的加权函数(weighting function)、selected matrix和gating network的计算与CGC相同。具体来说,PLE的第extraction network中任务gating network公式如下:其中:
weighting function,它的输入为注意门控网络的输入是给定任务的上一个
level的gating network输出。extraction network中的selected matrix。即,在第extraction network中,shared experts的output vectors、以及任务task-specific experts的output vectors组成。注意:这里假设每层都有
task-specific experts、都有shared-experts。也可以设定layer-specific的数量。注意:这里没有给出任务
expert网络的输入。读者猜测:跟门控网络的输入相同,即值得注意的是,
PLE中shared module的selected matrixtask-specific模块略有不同,因为它由该层的所有shared-experts和task-specific experts组成:其中:
task-specific experts数量。
计算完所有
gating networks和experts后,最终可以得到PLE中任务其中:
extraction network的数量;tower network。通过
multi-level的experts and gating networks,PLE为每个任务提取和组合deeper semantic representations,以提高泛化能力。如Figure 1所示:MMOE的路由策略(routing strategy)是全连接的。CGC的路由策略是早期分离(early separation)。
不同的是,
PLE采用渐进式分离路由(progressive separation routing),从所有lower-layer experts吸收信息,提取higher-level shared knowl-edge,并渐进式地分离task-specific parameters。这种渐进式分离(progressive separation)过程类似于化学中从化合物中提取所需产物(desired product)的过程。在
PLE的knowledge extraction and transformation过程中,lower-level representations在higher-level shared experts中被联合地extracted/aggregated and routed,获得shared knowledge并渐进地分配到specific tower layers层,从而实现更高效的、更灵活的joint representation learning and sharing。尽管MMOE的全连接routing似乎是CGC和PLE的通用设计,但实验章节的实际研究表明:尽管存在可能性,MMOE仍无法收敛到CGC或PLE的结构。
1.3.3 Joint Loss Optimization for MTL
设计了高效的网络结构后,我们现在专注于以端到端的方式联合训练
task-specific layers和shared layers。在multi-task learning中,joint loss的常见公式是每个单独任务的损失的加权和:其中:
shared parameters。loss权重、以及task-specific parameters。
然而,在实际应用中,多任务学习模型的联合优化(
joint optimization)面临一些挑战。在本文中,我们优化了joint loss function,以解决真实世界推荐系统中遇到的两个关键问题。第一个问题是由于用户行为的序列性(
sequential)导致的异构样本空间(heterogeneous sample space)。例如,用户只有在点击某个item之后才能对其进行分享或评论,这导致了不同任务的样本空间不同,如Figure 6所示。为了联合训练这些任务,我们将所有任务的样本空间的并集作为整个训练集,并在计算每个单独任务的loss时忽略其自身样本空间之外的样本:其中:
loss function,基于预测值
另一种方法是:为每个任务维护独立的
dataloader,每个batch只包含该任务的样本。在训练时,循环或交替地从不同任务的dataloader中获取batch。注意:论文没有做消融研究来这个方法的效果。
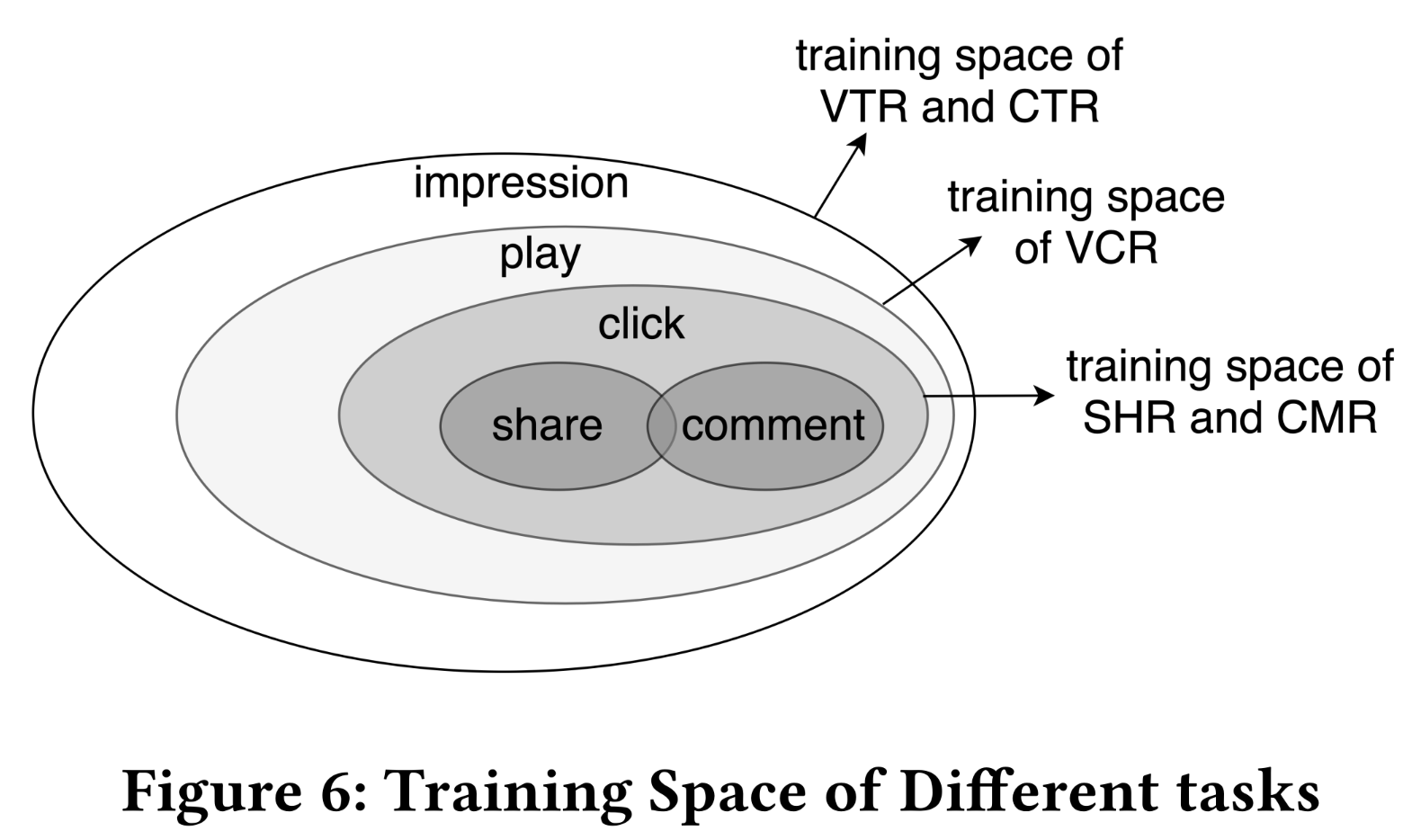
第二个问题是,多任务学习模型的性能对训练过程中
loss weight的选择很敏感(《Multi-task learning using uncertainty to weigh losses for scene geometry and semantics》),因为它决定了每个任务在joint loss中的相对重要性。在实践中,观察到每个任务在不同training phases可能具有不同的重要性。因此,我们将每个任务的loss weight视为动态权重,而不是静态权重。首先,为任务
loss weight然后在每个
step后基于updating ratioloss weight。其中:
training epoch;
注意:任务
采用动态权重的原因:早期训练阶段,某些任务(如
CTR)收敛快,应降低权重避免主导;后期训练阶段,困难任务(如VCR)需要更多关注,应增加权重。
1.4 实验
在本节中,我们在
Tencent的大规模推荐系统和公开benchmark数据集上进行了大量的离线和在线实验,以评估所提出模型的有效性。我们还分析了所有gate-based的多任务学习模型中的专家利用率(expert utilization),以更好地理解门控网络(gating networks)的工作机制,并进一步验证CGC和PLE的结构价值(structure value)。实验部分缺少消融分析。
1.4.1 Evaluation on the Video Recommender System in Tencent
在本节中,我们在
Tencent视频推荐系统中,针对具有复杂和正常关联关系(complex and normal correlations)的task groups以及多任务场景进行了离线和在线实验,以评估所提出模型的性能。数据集:我们通过对服务于
Tencent新闻的视频推荐系统连续8天的用户日志进行采样,收集了一个工业数据集。该数据集包含46.926 million用户、2.682 million视频和0.995 billion条样本。如前所述,VCR、CTR、VTR、分享率(Share Rate: SHR)和评论率(Comment Rate: CMR)是该数据集中modeling other preferences的任务。baselines:在实验中,我们将CGC和PLE与单任务模型(single-task model)、非对称共享(asymmetric sharing)、定制共享(customized sharing)、以及SOTA多任务学习模型(包括cross-stitch network、sluice network和MMOE)进行了比较。由于
PLE中共享multi-level experts,我们通过添加multi-level experts将MMOE扩展为multi-layer MMOE: ML-MMOE)(如Figure 1h所示),以进行公平比较。在ML-MMOE中,higher-level experts通过gating networks组合来自lower-level experts的representations,并且所有gating networks共享相同的selector。selector指的是门控网络的输入:对于第一层,它就是原始的
inputs。对于第
selector作者并未说明。个人猜测就是所有门控网络第
实验设置:
在实验中,
VCR prediction是一个回归任务,使用MSE loss进行训练和评估;其他modeling other actions的任务均为二分类任务,使用cross-entropy loss进行训练,并使用AUC进行评估。前
7天的样本用于训练,其余样本作为测试集。在多任务学习模型和单任务模型中,我们为每个任务采用了一个
three-layer MLP network(即,task tower),激活函数为ReLU,hidden layer size为[256, 128, 64]。对于多任务学习模型,我们将
expert实现为a single-layer network,并调优以下model-specific的超参数:shared layers的数量。hard parameter sharing and cross-stitch network中的cross-stitch units。所有
gate-based models中的number of experts。
为了公平比较,我们将所有
multi-level多任务学习模型实现为two-level models,以保持相同的网络深度。
评估指标:除了
AUC和MSE等常见评估指标外,我们定义了一个MTL gain指标,以定量评估multi-task learning相比单任务模型在特定任务上的收益。如下面的公式所示,对于给定的一个task group和一个多任务学习模型A上的MTL gain定义为:在相同的网络结构和训练样本下,多任务学习模型A上的性能提升。在复杂关联(
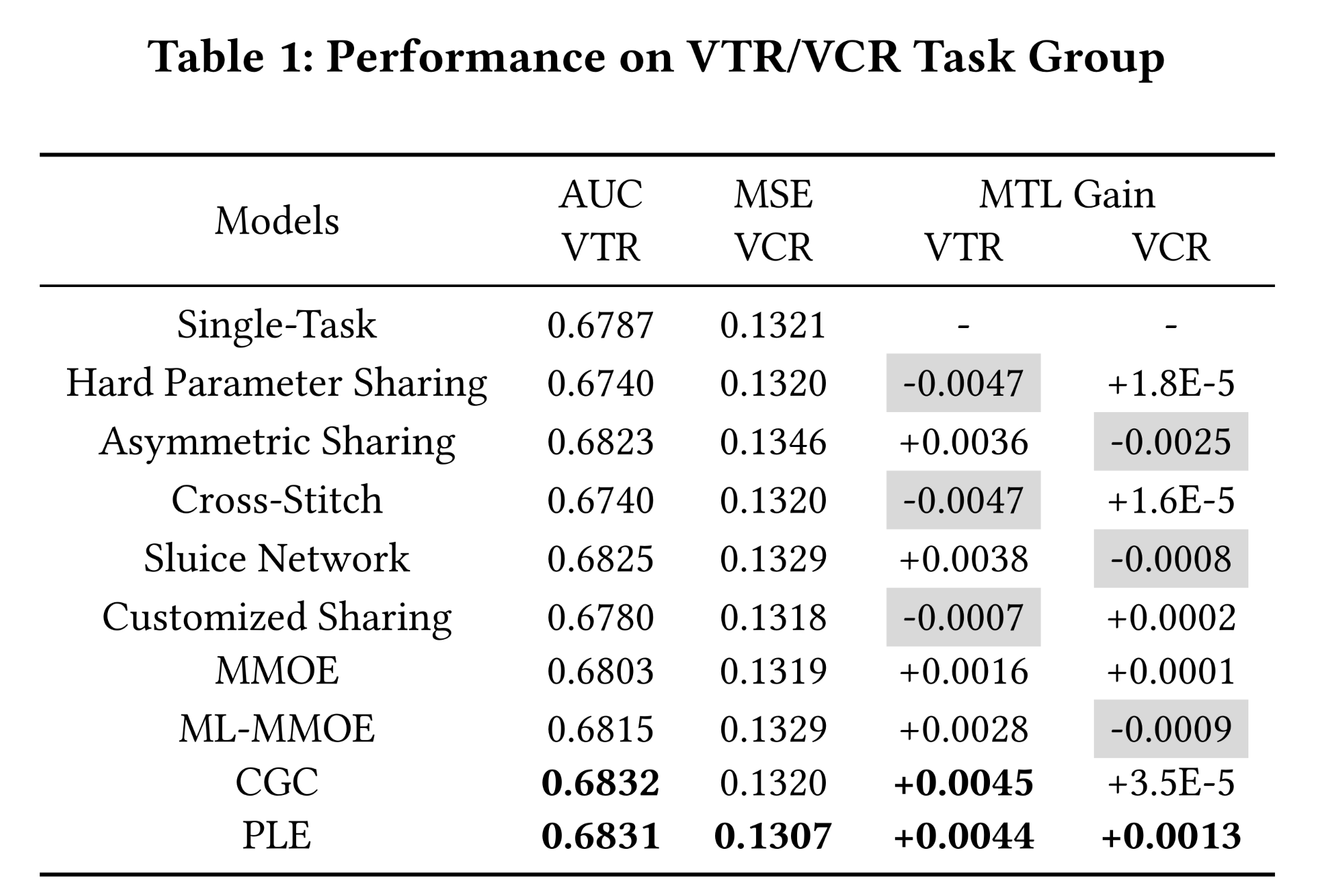
complex correlation)任务上的评估:为了更好地捕获主要的在线engagement指标(如观看次数、观看时长),我们首先在VCR/VTR这个task-group上进行了实验。Table 1展示了实验结果,其中加粗字体标记了最佳分数,灰色标记了性能下降(negative MTL gain)。结果表明,
CGC和PLE在VTR上显著优于所有baseline模型。由于VTR和VCR之间的复杂关联,我们可以通过锯齿状的灰色分布清楚地观察到跷跷板现象:一些模型提升了VCR但损害了VTR,而另一些模型提升了VTR但损害了VCR。具体来说:MMOE在两个任务上都优于单任务模型,但改进并不显著,而ML-MMOE提升了VTR但损害了VCR。与
MMOE和ML-MMOE相比,CGC在VTR上的提升更为显著,在VCR上也略有提升。最后,
PLE以相似的收敛速度收敛,并在上述模型中取得了显著改进,具有最佳的VCR MSE、以及最佳的VTR AUCs之一。
在正常关联任务(
Normal Correlation)上的评估:尽管CGC和PLE在关联非常复杂的任务上表现良好,我们进一步在具有正常关联模式的通用任务组CTR/VCR上验证了它们的通用性。由于CTR和VCR旨在建模不同的用户行为,它们之间的关联相对简单。如
Table 2所示,除cross-stitch network外,所有模型在两个任务上均表现出positive MTL gain,这表明CTR和VCR之间的关联模式并不复杂,不存在跷跷板现象。在这种情况下,CGC和PLE仍然在两个任务上显著优于所有SOTA模型,具有出色的MTL gain。这验证了CGC和PLE的收益具有通用性,能够提高shared learning的效率,并在各种任务关联(task correlation)情况下一致地提供增量的性能改进,不仅适用于难以协作的复杂关联任务,也适用于正常关联的任务。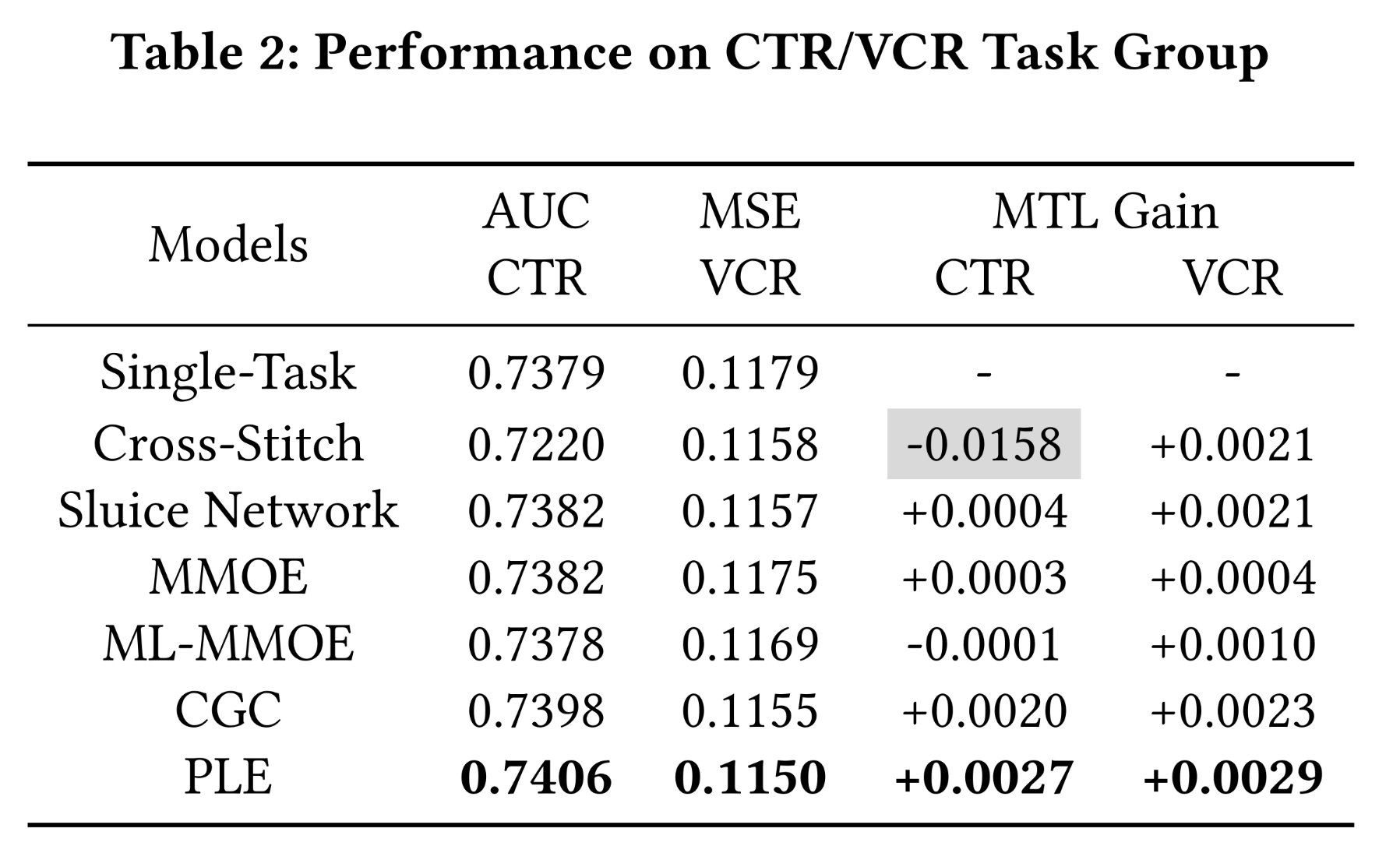
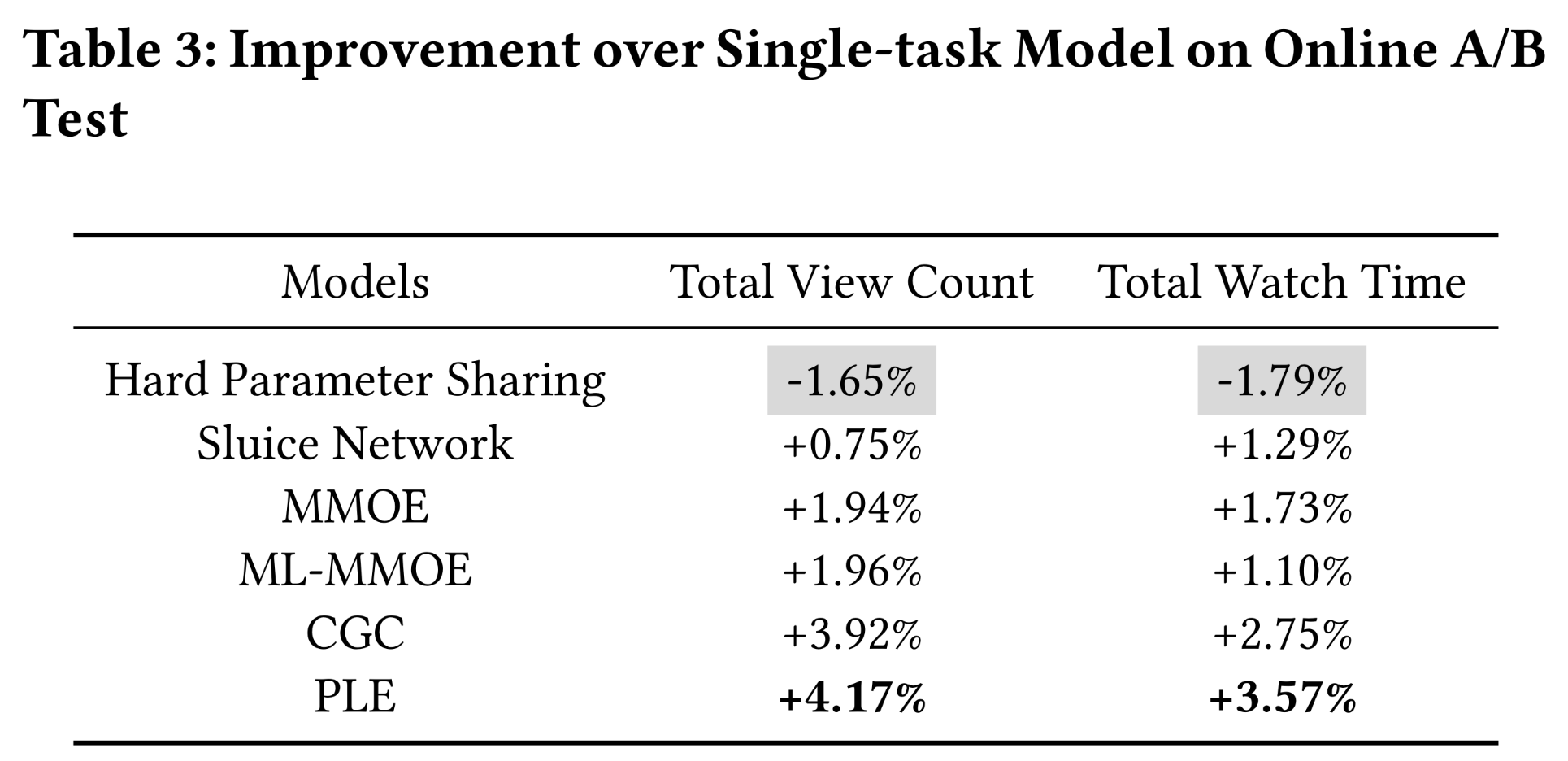
Online A/B Testing:我们在视频推荐系统中针对task-group of VTR and VCR进行了为期4周的精细online A/B test。我们在基于C++的深度学习框架中实现了所有多任务学习模型,将用户随机分配到多个buckets中,并将每个模型部署到其中一个bucket。final ranking score通过前面章节中描述的combination function of multiple predicted scores来获得。Table 3显示了多任务学习模型相比单任务模型在total view count per user和total watch time per user(系统的最终目标)这两个在线指标上的改进。结果表明:CGC和PLE在所有在线指标上都比所有baseline模型有显著提升。此外,
PLE在所有在线指标上都显著优于CGC,这表明多任务学习中AUC或MSE的小幅改进会带来在线指标的显著提升。
从那时起,
PLE已部署到该平台。total view count per user:人均观看次数。在统计周期内,平均每个用户成功播放的视频数量。成功播放的定义为:播放时长超过给定阈值。这个指标对应于VTR。total watch time per user:人均观看时长。在统计周期内,平均每个用户观看视频的总时长。
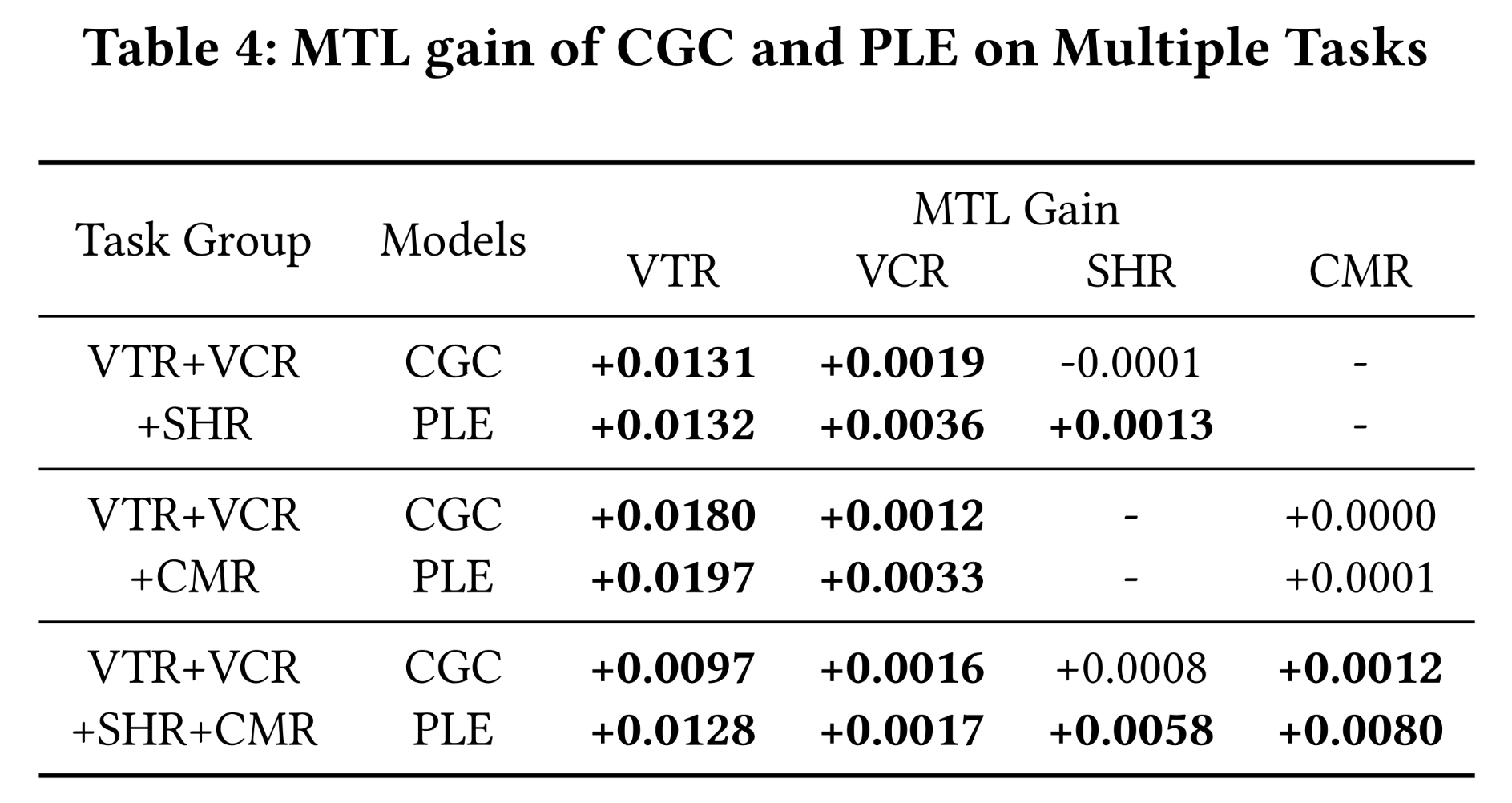
Evaluation with Multiple Tasks:最后,我们在更具挑战性的多任务场景中探索了CGC和PLE的可扩展性(scalability)。除了VTR and VCR外,我们引入了分享率(SHR)和评论率(CMR)来建模user feedback行为。将CGC和PLE扩展到多任务场景很灵活,只需为每个任务添加一个task-specific expert module、一个gating network和一个tower network。如
Table 4所示:CGC和PLE在所有task groups的几乎所有任务上都比单任务模型有显著改进。这表明,对于具有两个以上任务的一般情况,CGC和PLE仍然表现出促进任务协作、防止负向迁移迁移、以及防止跷跷板现象的优势。在所有情况下,
PLE都显著优于CGC。因此,PLE在不同size的task groups中,在提高shared learning效率方面表现出更强的优势。
1.4.2 Evaluation on Public Datasets
在本节中,我们在公开
benchmark数据集上进行了实验,以进一步评估PLE在推荐之外场景的有效性。数据集:
合成数据集(
Synthetic Data):合成数据集是根据《Modeling task relationships in multi-task learning with multi-gate mixture-of-experts》中的数据合成(data synthesizing)过程生成的,用于控制task correlations。由于《Modeling task relationships in multi-task learning with multi-gate mixture-of-experts》中未提供数据合成的超参数,我们遵循标准正态分布来随机采样的correlation生成了1.4 million个带有两个连续标签的样本(samples with two continuous labels)。人口普查收入数据集(
Census-income Dataset):人口普查收入数据集(《UCI Machine Learning Repository》)包含299,285个样本和40个特征,提取自1994年人口普查数据库。为了与baseline模型进行公平比较,我们考虑了与《Modeling task relationships in multi-task learning with multi-gate mixture-of-experts》相同的task-group。具体来说:task 1:旨在预测收入是否超过50K。task 2:旨在预测该人的婚姻状况是否为从未结婚(never married)。
Ali-CCP Dataset数据集:该数据集是一个公开数据集,包含84 million个样本,提取自淘宝推荐系统。点击率(CTR)和转化率(Conversion Rate: CVR)是该数据集中建模点击行为和购买行为的两个任务。
实验设置:
census-income dataset的设置与《Modeling task relationships in multi-task learning with multi-gate mixture-of-experts》相同。对于
synthetic data和Ali-CCP dataset数据集,在多任务学习模型和单任务模型中,我们为每个任务采用了一个three-layer MLP network with RELU activation,hidden layer size为[256, 128, 64]。
超参数的调优与
Evaluation on the Video Recommender System in Tencent章节中的实验类似。实验结果:
synthetic data数据集上的实验结果如Figure 7所示:hard parameter sharing和MMOE有时会遭受跷跷板现象,表明在两个任务之间失去平衡。相反,
PLE在不同correlation下对两个任务的表现始终最佳,相比MMOE的MTL gain平均提高了87.2%。
<img src="https://pub-c2a3235ca2d249df90938ab3664d2a08.r2.dev/applications/recommendation/general_recommendation/imgs/PLE/PLE_result6.png" width="700px" />
如
Table 5所示,Ali-CCP数据集和census-income数据集上的结果表明,PLE消除了跷跷板现象,在两个任务上始终优于单任务模型和MMOE。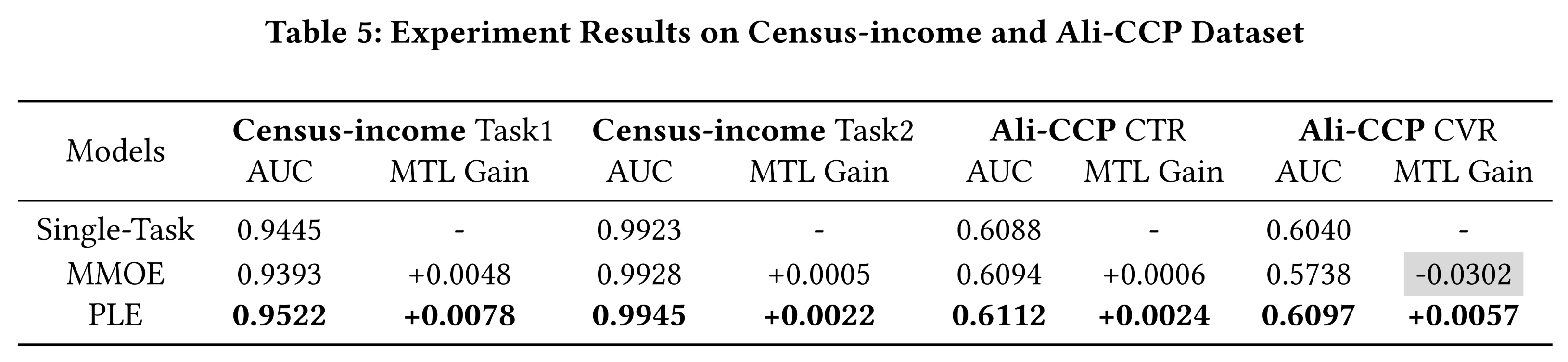
结合之前在工业数据集和 online A/B test 中的实验,PLE 在不同 task correlation 模式和不同 applications 中,在提高多任务学习效率和性能方面表现出稳定的通用优势(general benefit)。
1.4.3 Expert Utilization Analysis
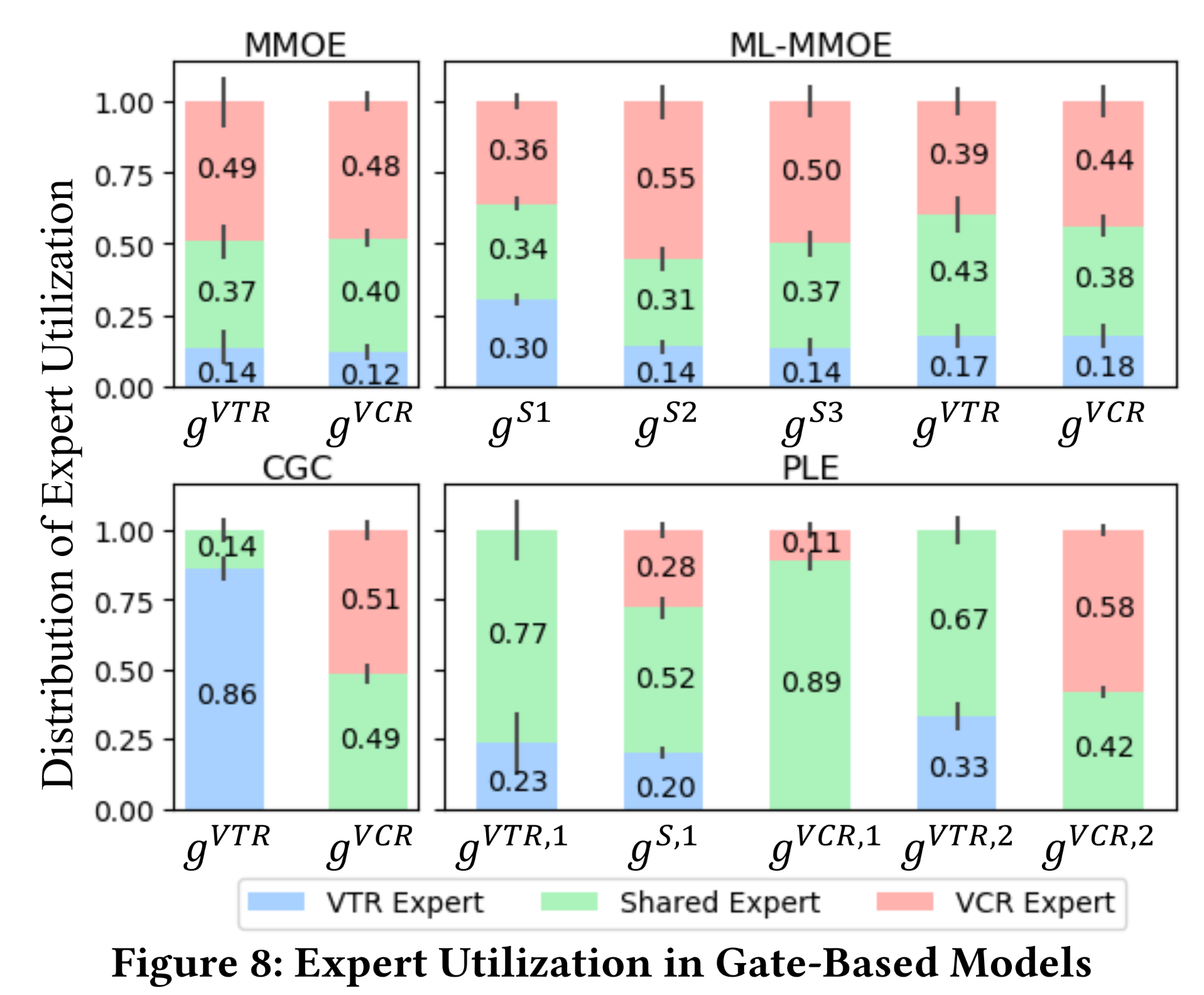
为了揭示不同
gates如何聚合专家,我们在工业数据集的VTR/VCR task group中研究了所有gate-based models的专家利用率(expert utilization)。为简单起见并进行公平比较,我们将每个expert视为a single-layer network,在CGC和PLE的每个expert module中仅保留一个expert,而在MMOE和ML-MMOE的每一层中保留三个experts。Figure 8显示了所有测试数据中每个gate所利用的weight distribution of experts,其中条形图的高度和垂直短线分别表示权重的均值和标准差。结果表明:在
CGC中,VTR和VCR以显著不同的权重来组合experts,而在MMOE中,不同experts的权重则非常相似。这表明CGC的精心设计结构(well-designed structure)有助于实现不同experts之间更好的区分。此外,在
MMOE和ML-MMOE中,所有experts的权重都不为零。这进一步表明,尽管存在理论可能性,但在没有先验知识(prior knowledge)的情况下,MMOE和ML-MMOE很难收敛到CGC和PLE的结构。理论上,
MMOE的权重分布可以拟合到CGC;ML-MMOE的权重分布可以拟合到PLE。与
CGC相比,PLE中的shared experts对input of tower networks影响更大,尤其是对于VTR任务。PLE的性能优于CGC,这表明shared higher-level deeper representations是有价值的。换句话说,需要在任务间共享某些deeper semantic representations,因此渐进式分离路由(progressive separation routing)提供了更好的joint routing and learning scheme。
1.5 结论
在本文中,我们提出了一种新型的多任务学习模型,即
Progressive Layered Extraction: PLE。该模型显式地分离task-sharing parameters和task-specific parameters,并引入创新的渐进式路由方式(progressive routing manner),以避免负向迁移和跷跷板现象,实现更高效的information sharing and joint representation learning。在工业数据集和公开
benchmark数据集上的离线和在线实验结果表明,PLE相比SOTA多任务学习模型有显著且一致的改进。未来的工作将重点探索hierarchical task-group correlations。