一、SSL [2020]
《Self-supervised Learning for Large-scale Item Recommendations》
大型推荐模型从庞大的
catalogs中找到最相关的items,它们在现代搜索系统和推荐系统中发挥着关键作用。为了用large-vocab categorical features对输入空间进行建模,典型的推荐模型通过神经网络从user feedback data中为queries和items学习一个联合的embedding space。然而,由于语料库中有数百万到数十亿个items,用户倾向于为其中很小一部分提供反馈,从而导致幂律分布。这使得长尾items的反馈数据非常稀疏。 受计算机视觉和自然语言理解领域中self-supervised representation learning近期所取得的成功启发,我们提出了一个多任务的自监督学习(self-supervised learning: SSL)框架用于大型的item recommendations。该框架旨在通过学习item features的更好的latent relationship来解决标签稀疏问题。具体而言,SSL不仅改进了item representation learning,并作为额外的正则化来提高泛化能力。此外,我们提出了一种新颖的数据增强方法,该方法利用所提框架内的feature correlations。 我们使用两个分别具有500M和1B个训练样本的真实数据集来评估我们的框架。我们的结果证明了SSL正则化的有效性,并表明其性能优于SOTA的正则化技术。我们还已将所提出的技术应用于互联网规模的商业app-to-app推荐系统,并在实时流量的A/B实验中展示了关键业务指标的显著改进。我们的在线结果也验证了我们的假设,即我们的框架在缺乏监督的样本切片上确实能更大程度地提高模型性能。最近,神经网络模型已成为整个工业界的和学术界的现代推荐系统的主流。与矩阵分解、梯度提升决策树、和基于逻辑回归的推荐器等传统方法相比,这些深度模型能更有效地处理
categorical features。它们还能实现更复杂的data representations,并引入更多非线性,从而更好地拟合复杂数据从而用于推荐模型。本文重点关注的一个特定推荐任务是:从庞大的
item catalog中找出与给定query最相关的items。这种large-scale item recommendations的通用问题已在各种应用中广泛采用。根据query的类型,推荐任务可以分为:(i):个性化推荐:当query是用户时。(ii):item to item推荐:当query也是一个item时。(iii):搜索:当query是一段自由文本时。
为了对
a query and an item之间的交互进行建模,一种广为人知的方法是利用embedding-based neural networks。推荐任务通常被表述为一个极端分类问题,其中每个item在输出空间中表示为一个密集向量。本文聚焦于在许多实际推荐器中流行的双塔
DNN(见Figure 1)。在这种架构中,神经网络将一组item features编码为一个embedding,因此即使对于冷启动items也适用。此外,双塔DNN架构通过将top-k nearest neighbor search转换为具有亚线性复杂度的最大内积搜索(Maximum-Inner-Product- Search: MIPS),能够高效地实时为大量items提供服务。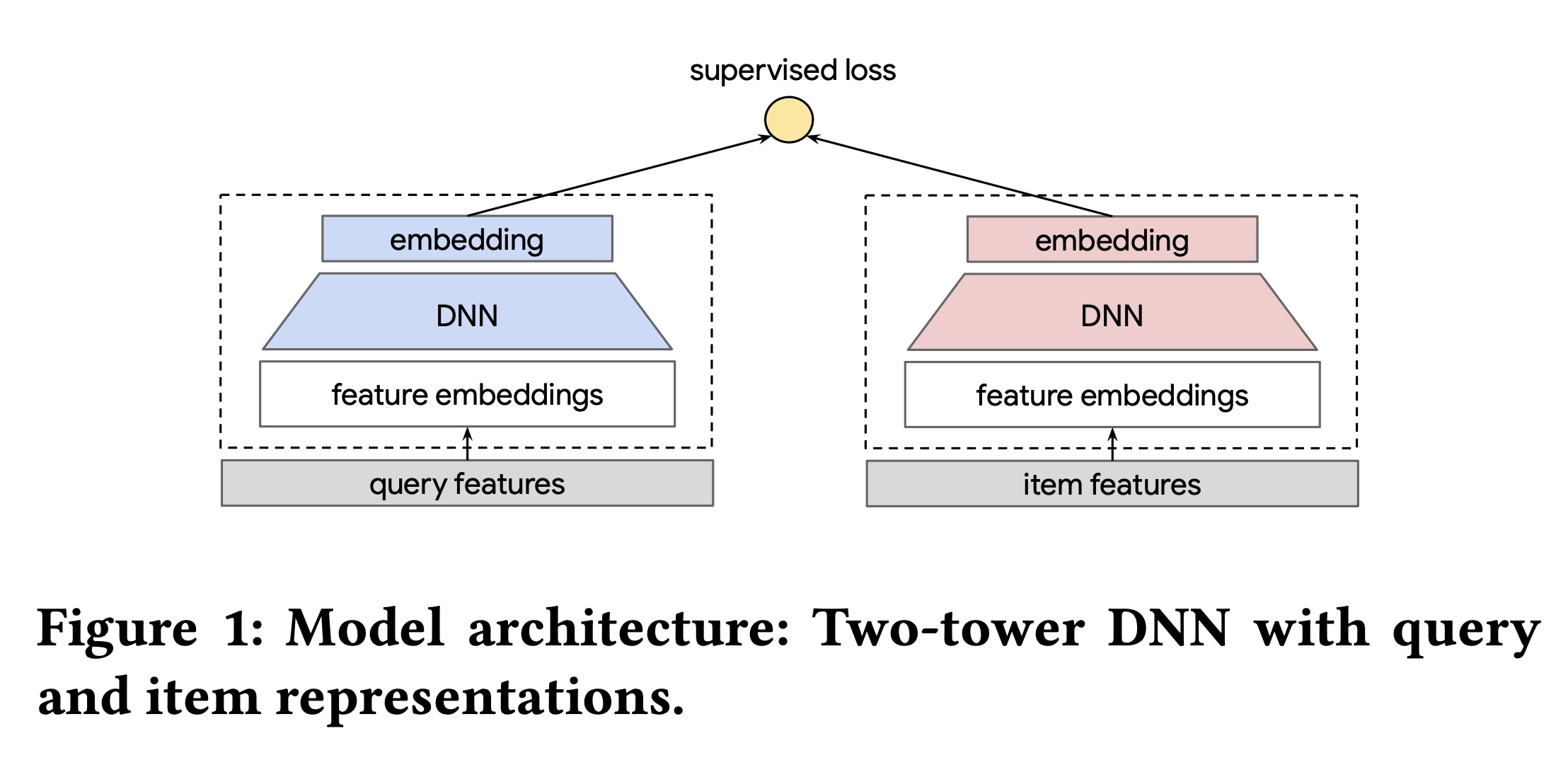
embedding-based的深度模型通常具有大量参数,因为它们是用高维embeddings来构建的,这些embeddings表示high cardinality的稀疏特征,如topics或item IDs。在许多现有文献中,训练这些模型的损失函数被表述为一个监督学习问题。监督信息来自收集到的标签(例如,点击)。现代推荐系统从用户那里收集数十亿到数万亿的行为数据,为构建深度模型提供了大量的训练数据。然而,当对数量在数百万(例如,歌曲和apps)甚至数十亿(例如,YouTube上的视频)量级的庞大catalogue of items进行建模时,由于以下原因,某些data slices仍然可能非常稀疏:高度偏斜的数据分布:
queries and items之间的交互往往呈现幂律分布。因此,一小部分热门items获得了大部分的交互。这总是使得长尾items的训练数据非常稀疏。缺乏显式的用户反馈:用户通常会隐式地提供大量
positive feedback,如点击和点赞。然而,他们不太可能提供显式的反馈,如item ratings、用户满意度反馈、以及relevance scores。
自监督学习(
self-supervised learning: SSL)通过unlabeled data为改进deep representation learning提供了不同的视角。其基本思想是:通过各种数据增强、以及基于predict or reconstitute原始样本的监督任务作为辅助任务,从而来enhance训练数据。自监督学习已广泛应用于计算机视觉和自然语言理解领域。计算机视觉领域的一项示例工作(
《Learning Representations for Automatic Colorization》)提出随机旋转图像,并训练模型预测每个augmented input image的旋转方式。在自然语言理解中,
BERT模型引入了masked language task,以帮助改进语言模型的pre-training。类似地,其他预训练任务,如预测维基百科文章中的周围句子和linked sentences,也被用于改进自然语言理解中的dual-encoder类型的模型。
与传统的监督学习相比,自监督学习提供了补充的目标,消除了手动收集标签的前提条件。此外,自监督学习能够通过利用
input features的内部关系来自动地发现良好的semantic representations。尽管自监督学习在计算机视觉和自然语言理解中得到了广泛应用,但在推荐系统领域的应用研究较少。
最相关的研究方向是研究一组正则化技术,这些技术旨在迫使不同样本的
learned representations(即多层感知器的output layer (embeddings))在整个潜在embedding空间中彼此远离并分散开来。虽然这些技术与自监督学习精神相似,但它们没有显式地构建自监督学习任务。与计算机视觉或自然语言理解的
application中的模型不同,推荐模型的输入极其稀疏,high cardinality的categorical features采用one-hot (or multi-hot)来编码,如item IDs或item categories。在深度模型中,这些特征通常表示为可学习的embedding向量。由于计算机视觉和自然语言理解中的大多数模型处理的是dense input,现有的创建自监督学习任务的方法不能直接应用于推荐系统中的sparse models。最近,一系列研究致力于利用自监督学习改进推荐中的
sequential user modeling。与这些工作不同,本文专注于item representation learning,并展示自监督学习如何在long-tail item distribution的背景下帮助提高泛化能力。此外,与在特定的sequential user feature上使用自监督学习不同,我们设计了新的自监督学习任务,并展示了它们的有效性从而用于具备一组异构categorical features的学习。我们认为这对于其他类型的推荐模型,如multitask ranking models,是更通用的设置。
在本文中,我们提议利用基于自监督学习的辅助任务来改进
item representations,特别是在长尾分布和稀疏数据的情况下。与计算机视觉或自然语言理解的application不同,推荐模型的输入空间高度稀疏,由一组具有large cardinality的categorical features(例如item ids)来表示。对于这样的稀疏模型,我们提出了一种新的自监督学习框架,其关键思想是:(i):通过掩码输入信息来增强数据。(ii):使用双塔DNN对each pair of augmented examples进行编码。(iii):应用对比损失来学习augmented data的representations。contrastive learning的目标是:使来自同一样本的augmented data能够与其它样本区分开来。注意,用于对比学习的双塔DNN和用于编码query and item的双塔DNN可以共享一定数量的模型参数。
我们的贡献有四个方面:
自监督学习框架:我们提出了一种与模型架构无关的自监督学习框架,用于推荐系统中的稀疏神经模型。辅助自监督损失和主体监督损失通过多任务学习框架联合优化。我们专注于使用这个框架对
a large corpus of items进行高效地评分,这在两阶段推荐器中也称为item retrieval。我们相信它也将为其他类型的模型(如ranking models)设计自监督学习提供思路。数据增强:我们提出了一种新颖的数据增强方法,该方法利用
feature correlations,并且是为推荐模型中常见的heterogeneous categorical features量身定制的。离线实验:在一个公共数据集和一个工业规模的推荐系统数据集上,我们证明了引入自监督学习作为辅助任务可以显著提高模型性能,特别是在标签稀缺的情况下。与
SOTA的非自监督学习的正则化技术相比,我们证明了自监督学习始终表现更好,并且即使非自监督学习正则化没有带来任何额外收益时,自监督学习也能提高模型性能。互联网规模的推荐器中的在线实验:我们已经在一个大型的实际系统中,将所提出的自监督学习技术应用于一个相当强大的双塔
app-to-app推荐模型。实时A/B test显示关键指标显著改进。我们特别看到在缺乏大量监督的data slices上有更大的改进。
1.1 方法
我们提出自监督学习框架从而用于具有
large-vocab categorical features的深度神经网络模型。具体来说:首先,我们介绍了一个通用的自监督学习框架。
然后,我们提出了一种数据增强方法来构建自监督学习任务,并详细阐述了它们与分散正则化(
spread-out regularization)的联系。最后,我们描述了如何通过多任务学习框架使用自监督学习来改进
factorized models(即如Figure 1所示的双塔DNN)。
1.1.1 框架
受用于视觉
representation learning的SimCLR框架的启发,我们采用类似的对比学习算法来学习representations of categorical features。基本思想有两个方面:首先,对同一训练样本应用不同的数据增强来学习
representations。然后使用对比损失函数(
contrastive loss function)来促使为同一训练样本学到的representations是相似的。
对比损失也用于训练双塔
DNN,尽管那里的目标是使positive item与其相应的queries一致。考虑一批
item examplesquery、一个item或一个query-item pair。假设有一对变换函数给定样本
inputrepresentationsembeddings,即:我们将
positive pairs,将negative pairs(其中为了促使上述性质成立,我们为一
batch的其中:
softmax temperature。上述损失函数学习一个稳健的
embedding space,使得相似的items在数据增强后彼此接近,而随机样本则被推得更远。整体框架如Figure 2所示。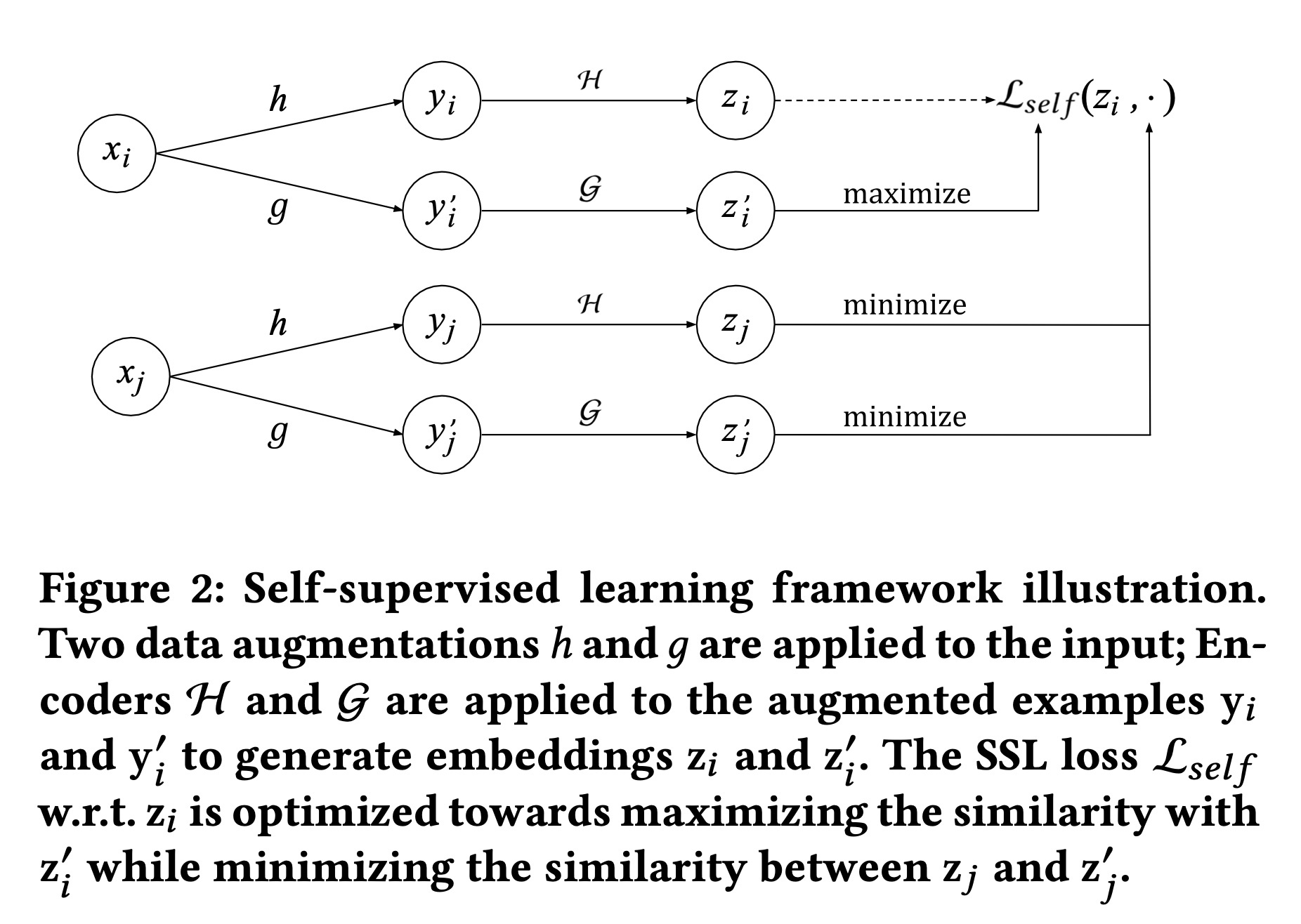
编码器架构:对于具有
categorical features的输入样本,input layer再跟一个多层感知器(multi-layer perceptron: MLP)来构建。输入层通常是normalized dense features和多个sparse feature embeddings的拼接,其中sparse feature embeddings是存储在embedding tables中的learnt representations(相比之下,计算机视觉和语言模型的输入层直接处理原始输入)。为了使自监督学习有助于监督学习任务,我们为神经网络
sparse features的embedding table。根据数据增强技术的不同,注意:
embedding table。那么如何与main task共享?读者认为也是共享embedding table。与分散正则化的联系:在
这促使不同样本的
learned representations具有较小的余弦相似度。该损失与
《Learning Spread-Out Local Feature Descriptors》中引入的分散正则化(spread-out regularization)类似,不同之处在于原始提案使用平方损失,即softmax。分散正则化已被证明可以提高大型检索模型的泛化能力。在实验章节中,我们表明通过引入特定的数据增强,与分散正则化相比,基于自监督学习的正则化可以进一步提高模型性能。
1.1.2 两阶段数据增强
我们介绍
Figure 2中的数据增强,即item features,关键思想是通过掩码部分信息来创建两个augmented examples。一个好的变换和数据增强应该对数据做出最小的假设,以便它可以普遍适用于各种任务和模型。掩码的想法受到BERT中Masked Language Modeling的启发。与sequential tokens不同,通用的features集合是没有顺序的,这使得masking pattern的选择成为一个悬而未决的问题。我们试图通过探索feature correlation来设计掩码模式(masking pattern)。我们提出了相关特征掩码(Correlated Feature Masking: CFM),它针对categorical features并考虑了feature correlations。在深入探讨掩码的细节之前,我们首先介绍一种两阶段增强算法。注意,在没有增强的情况下,
input layer是通过拼接embeddings of all categorical features来创建的。两阶段增强包括:掩码(
Masking):对item features集合应用掩码模式。我们在输入层中使用一个default embedding来表示被掩码的特征。随机丢弃(
Dropout):对于具有多个值的categorical features,我们以一定概率随机丢弃每个值。这进一步减少了输入信息,并增加了自监督学习任务的难度。
masking步骤可以被视为dropout的一种特殊情况,其dropout rate = 100%。假设有 “类别”、“品牌”、“店铺“、”是否免运费“ 等特征:
第一步随机增强:假设随机掩码 “店铺”,那么所有样本的
item都使用default embedding来代替 “店铺”embedding。第二部随机
dropout:对于“类别”特征:随机选择某个
category ID进行丢弃。仅仅包含该category ID的item,这些item使用default embedding来代替 “类别”embedding。对于“品牌”特征:随机选择某个
brand ID进行丢弃。仅仅包含该brand ID的item,这些item使用default embedding来代替 “品牌”embedding。....
对于
Masking,一种策略是互补的掩码模式,即我们将feature set划分为两个互斥的feature set,并分别应用到两个augmented examples中。具体来说,我们可以随机将feature set划分为两个不相交的子集。我们将这种方法称为随机特征掩码(Random Feature Masking: RFM),并将其用作我们的基线方法之一。现在我们介绍相关特征掩码(Correlated Feature Masking: CFM),在创建掩码模式时,我们进一步探索feature correlations。为什么要互斥,这是因为自监督学习需要两个数据增强操作
learned representations。Categorical Features的互信息:如果masked features的集合是随机选择的,那么feature set上的augmented examples之间高度相关的特征从而走捷径,从而使自监督学习任务变得过于简单。为了解决这个问题,我们建议根据互信息所刻画的feature correlation来划分特征。两个categorical features的互信息由下式给出:其中:
pairs of features的互信息可以预先计算出来。Correlated Feature Masking:有了预先计算好的互信息,我们提出相关特征掩码(Correlated Feature Masking: CFM),它利用feature-dependency patterns来构建更有意义的自监督学习任务。对于masked features的集合,我们试图将高度相关的特征一起掩码。我们首先从所有可用特征
top-n最相关的特征最终
我们选择
batch都改变种子特征,以便自监督学习任务能够学习各种掩码模式。
1.1.3 多任务训练
为了使自监督学习所学到的
representations有助于改进主体监督任务(如回归或分类)的学习,我们采用多任务训练策略,将主体监督任务和辅助自监督学习任务联合优化。具体来说,设batch的query-item pairs,设item分布batch的items。那么联合损失为:其中:
query和item之间交互的主要任务的损失函数,异构样本分布:来自
marginal item distribution通常遵循幂律分布。因此,在training item distribution会导致学到的feature relationship偏向于头部items。相反,我们从语料库中均匀采样items从而用于item distribution。在实践中,我们发现对主体任务和自监督学习任务使用异构分布对于自监督学习实现卓越性能至关重要。items不是batch中的items。主体任务的损失:根据目标的不同,主体损失有很多选择。在本文中,我们考虑在推荐器和自然语言处理中都使用的
batch softmax loss,以优化top-k accuracy。具体来说,设query and item examplesembeddings,那么对于一个batch的pair对batch softmax交叉熵损失为:其他基线:如前所述,我们使用双塔
DNN作为主体任务的基线模型。与经典的矩阵分解(matrix factorization: MF)和分类模型相比,双塔模型在编码item features方面具有独特的属性。矩阵分解和分类模型虽然也适用于大规模item retrieval,但它们仅基于IDs来学习item embeddings,因此不适合我们利用自监督学习探索item feature relations的提议。
1.2 实验
我们提供实证结果,以证明我们提出的自监督学习框架在学术公共数据集和实际大规模
recommendation products中的有效性。实验旨在回答以下研究问题:RQ1:所提出的自监督学习框架是否能改进推荐系统的深度模型?RQ2:自监督学习旨在通过在unlabeled examples上引入自监督学习任务来改进主体监督任务。训练数据量对自监督学习带来的改进有何影响?RQ3:自监督学习参数,即损失乘子dropout rate,如何影响模型质量?RQ4:随机特征掩码(RFM)与相关特征掩码(CFM)相比表现如何?在数据增强中利用feature correlations有何好处?
数据集:我们在两个大规模数据集上进行实验,这两个数据集都带有丰富的
item metadata features。我们将它们的主体监督任务表述为item-to-item recommendation问题,以研究自监督学习对训练推荐器(在这种情况下为retrieval)模型的影响。Wikipedia:第一个数据集专注于维基百科页面之间的link prediction问题。它由页面之间的pairscategorical的,其中:page URL的one-hot encoding。n-grams集合的bag-of-words representation。bag-of-words representation。
我们按照
《Efficient Training on Very Large Corpora via Gramian Estimation》和《Sampling-Bias-Corrected Neural Modeling for Large Corpus Item Recommendations》中的相同处理方式,将数据集按 (90%,10%) 的比例划分为训练集和评估集。App-to-App Install (AAI):AAI数据集是从一个商业移动应用商店的app landing pages收集的。在特定app(seed app)的landing page上,收集了recommended apps部分中的app installs(candidate apps)数据。每个训练样本表示一个seed-candidate pairsseed app,推荐高度相似的apps。这也被表述为:基于multi-class classification loss的item-to-item recommendation问题。请注意,我们只收集正样本,即是从landing page来安装的apprecommended apps都被忽略,因为我们认为它们更像是weak positives,而不是构建retrieval模型的负样本。每个item (app)由具有以下特征的特征向量正样本:曝光且安装的
app。weak positives:曝光且未安装的app。id:Application ID,作为one-hot categorical feature。developer_name:app开发者的名称,作为one-hot categorical feature。categories:app的语义类别,作为multi-hot categorical feature。title_unigram:ap标题的uni-grams,作为multi-hot categorical feature。
Table 1显示了Wikipedia和AAI数据集的一些基本统计数据。Figure 4显示了这两个数据集中最常见项目的累计密度函数(CDF),表明数据分布高度倾斜。例如,AAI数据集中top 50 items在训练数据中的出现率总计约为10%。如果我们考虑一个简单的基线(即TopPopular recommender),为每个query推荐最热门的top-K items,那么K-th frequent item的CDF基本上代表了这种基线的Recall@K指标。这表明一个简单的TopPopular推荐器在AAI上实现了Recall@50 ≈ 0.1,在Wikipedia上实现了Recall𝑙@50 ≈ 0.05。我们在实验章节中展示了所有提出的方法都大大超越了这一基准。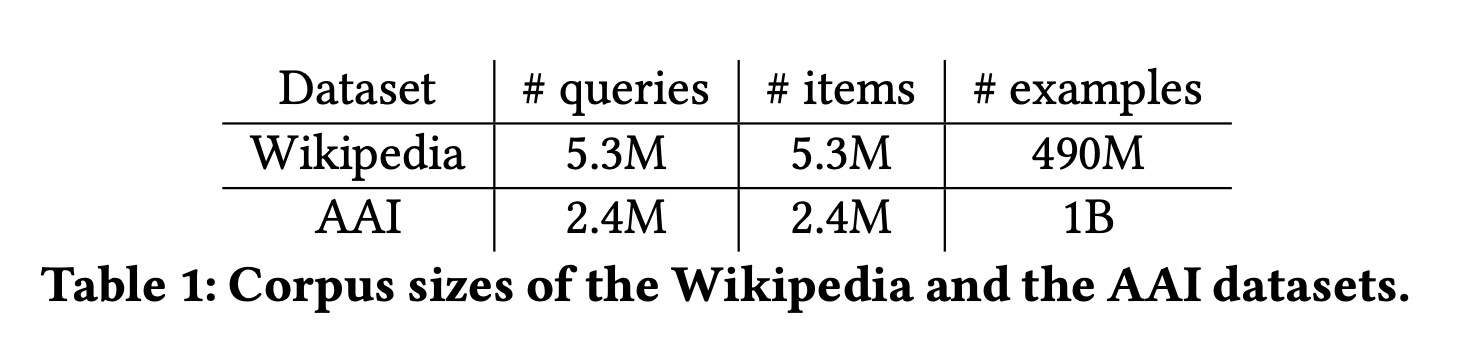
实验设置:
骨干网络:对于根据
query预测relevant items的主体任务,我们使用双塔DNN对query特征和item特征进行编码(见Figure 1)作为骨干网络。item-to-item recommendation问题被形式化为一个多类分类问题,使用batch softmax loss作为损失函数。关于骨干网络选择的讨论,请读者参考前面的章节。超参数:对于骨干双塔
DNN,我们搜索一组超参数,如学习率、softmax tem-perature(Recall@50达到最高。请注意,
batch softmax中的training batch size对模型质量至关重要,因为它决定了每个正样本使用的负样本数量。在本节中,我们对Wikipedia数据集使用batch size = 1024、对AAI数据集使用batch size = 4096。我们还调优了基线模型的隐层数、隐层大小和
softmax temperature对于
Wikipedia数据集,我们使用softmax temperaturehidden_layers = [1024, 128]。对于
AAI数据集,我们使用hidden_layers = [1024, 256]。
请注意,最后一个隐层的维度也是
final query and item embeddings的维度。所有模型都使用Adagrad优化器进行训练,学习率为0.01。我们考虑自监督学习的两个超参数:
1):公式2):数据增强第二阶段中的feature dropout rate,记为
对于每种增强方法(例如,
CFM,RFM),我们在
评估:为了评估给定
seed item的推荐性能,我们从整个语料库中计算并找出余弦相似度最高的top K items,并根据K retrieved items来进行评估。考虑到数据集的稀疏性和语料库中items的大量数量,这是一个相当具有挑战性的任务。我们采用流行的标准指标Recall@K和平均精度均值(MAP@K)来评估推荐性能。对于每个实验结果配置,我们运行实验5次并报告平均值。
1.2.1 基于 Correlated Feature Masking 的自监督学习的有效性
为了回答
RQ1,我们首先评估自监督学习对模型质量的影响。我们专注于使用CFM然后紧跟着dropout作为数据增强技术。我们将后续章节展示CFM相对于其他变体的卓越性能。我们考虑三种基线方法:
Baseline:具有双塔DNN架构的普通骨干网络。Feature Dropout(FD):在监督学习任务中,对item tower进行random feature dropout的骨干模型。对item features的feature dropout可以视为数据增强。与我们的方法相比,FD没有额外的自监督学习正则化。Spread-out Regularization: SO:对item tower应用分散正则化(spread-out regularization)作为正则化的骨干模型。SO正则化与我们的自监督学习框架中的contrastive loss相似。然而,它在原始样本上应用对比学习,没有任何数据增强,因此与我们的方法不同。
选择后两种方法是因为它们:
(1):与模型无关,并且可扩展到工业规模的推荐系统。(2):与categorical sparse features兼容,可用于提高泛化能力。
此外,
FD可以视为一项消融研究,以分离对比学习可能带来的改进。同样,包含SO是为了分离feature augmentation带来的改进。我们观察到:
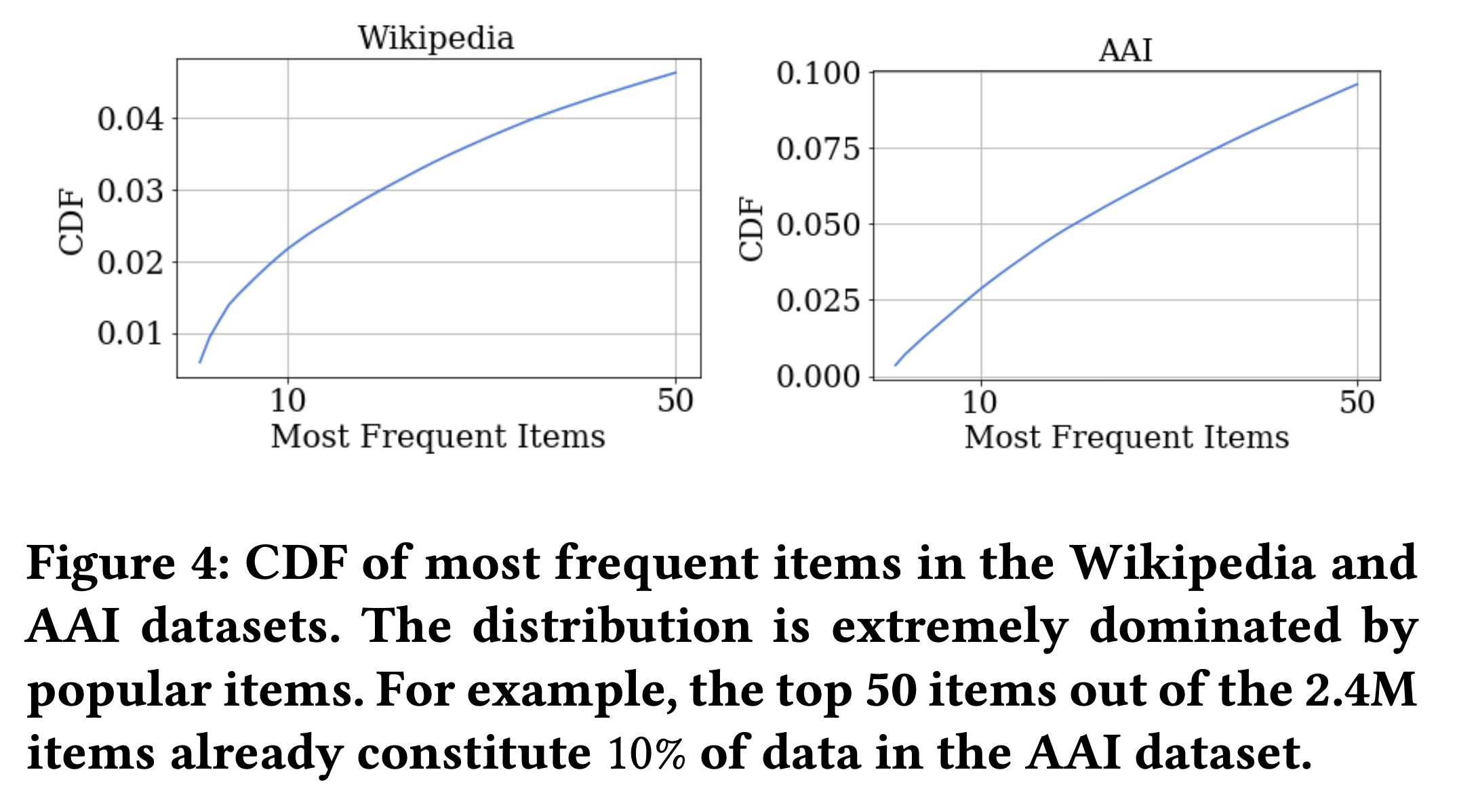
在使用完整数据集时(见
Table 2),与非自监督学习正则化技术相比,CFM始终表现最佳。在
AAI数据集上,CFM相对性能第二好的方法提升了8.69%。在
Wikipedia数据集上,CFM相对性能第二好的方法提升了3.98%。
这有助于回答
RQ1,即:所提出的自监督学习框架和任务确实提高了推荐器的模型性能。通过比较
CFM和SO,结果表明数据增强对于自监督学习正则化获得更好的性能至关重要。当没有任何数据增强时,所提出的自监督学习方法就退化为SO。通过比较
CFM和FD,我们发现特征增强应用于自监督学习任务,比作为标准正则化技术应用于监督任务更有效。请注意,FD作为一种在某些情况下提高泛化能力的知名方法,是在监督训练的同时应用feature augmentation。
Head-tail分析:为了理解自监督学习带来的提升,我们通过按item popularity查看不同item slices来进一步分解整体性能。基于
ground-truth item的流行度,我们将整个测试数据集进行划分。对于
AAI测试数据集,Head数据集包含ground-truth items位于top 10% most frequent items的样本,其余测试样本被视为Tail。对于
Wikipedia测试数据集,我们遵循《Efficient Training on Very Large Corpora via Gramian Estimation》中的数据分区,其中ground-truth items不在训练集中的测试样本被视为Tail,其余测试样本被视为Head。
我们的假设是:自监督学习通常有助于提高缺乏大量监督的
item slices(例如,tail items)的性能。在Head和Tail测试集上评估的结果报告在Table 3中。我们观察到:所提出的自监督学习方法在Head和Tail的item recommendations上都提高了性能,在tail items上的提升更大。例如,在AAI数据集中,CFM在tail items上的Recall@10提升超过51.5%,而在head items上的提升为8.57%。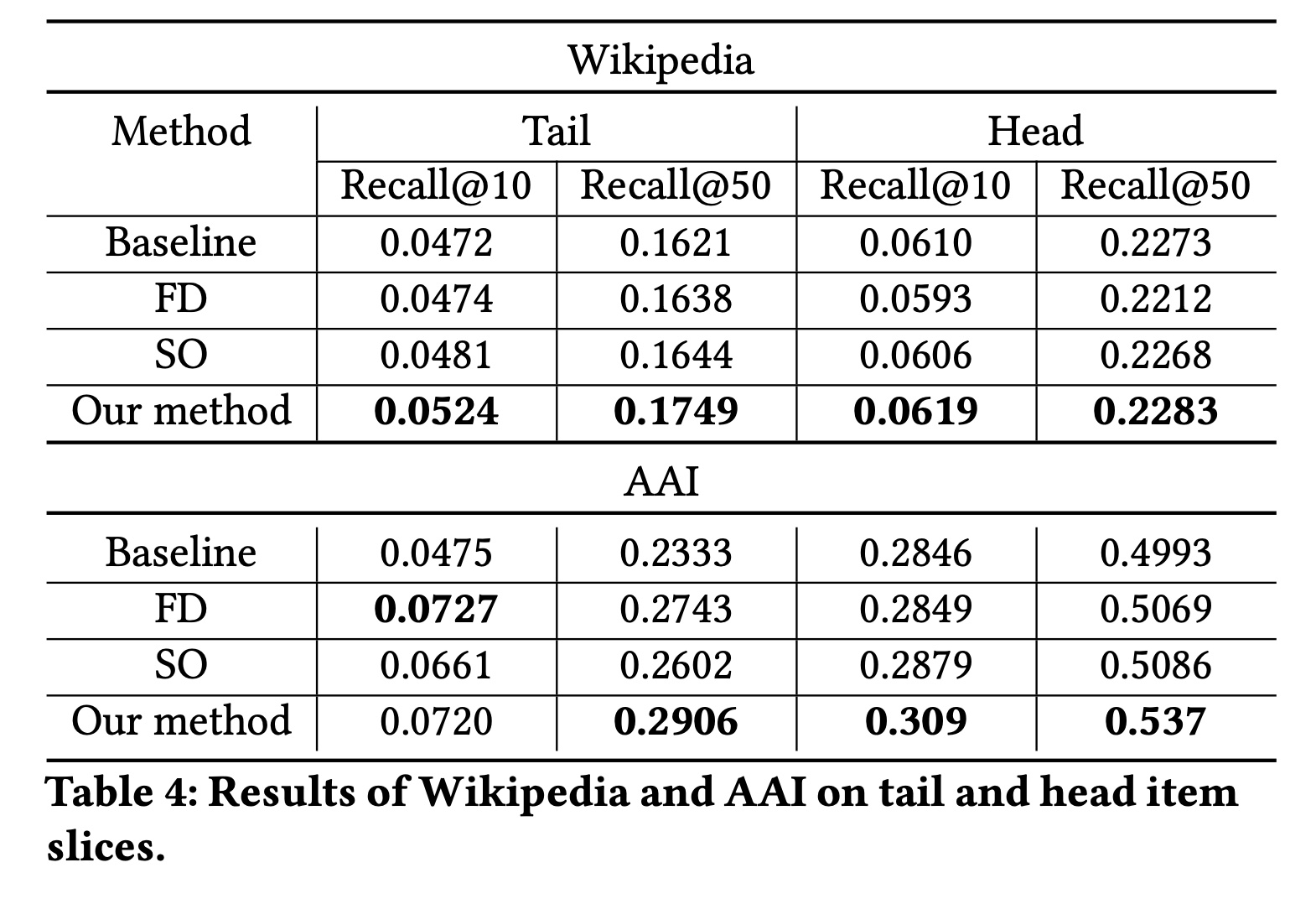
自监督学习的超参数的影响(
RQ3):Figure 5总结了在Wikipedia和AAI数据集上评估的Recall@50相对于正则化强度SO的结果,SO使用相同的正则化参数。我们观察到:随着
通过进一步将我们的方法与
SO进行比较,我们发现在广泛的SO。
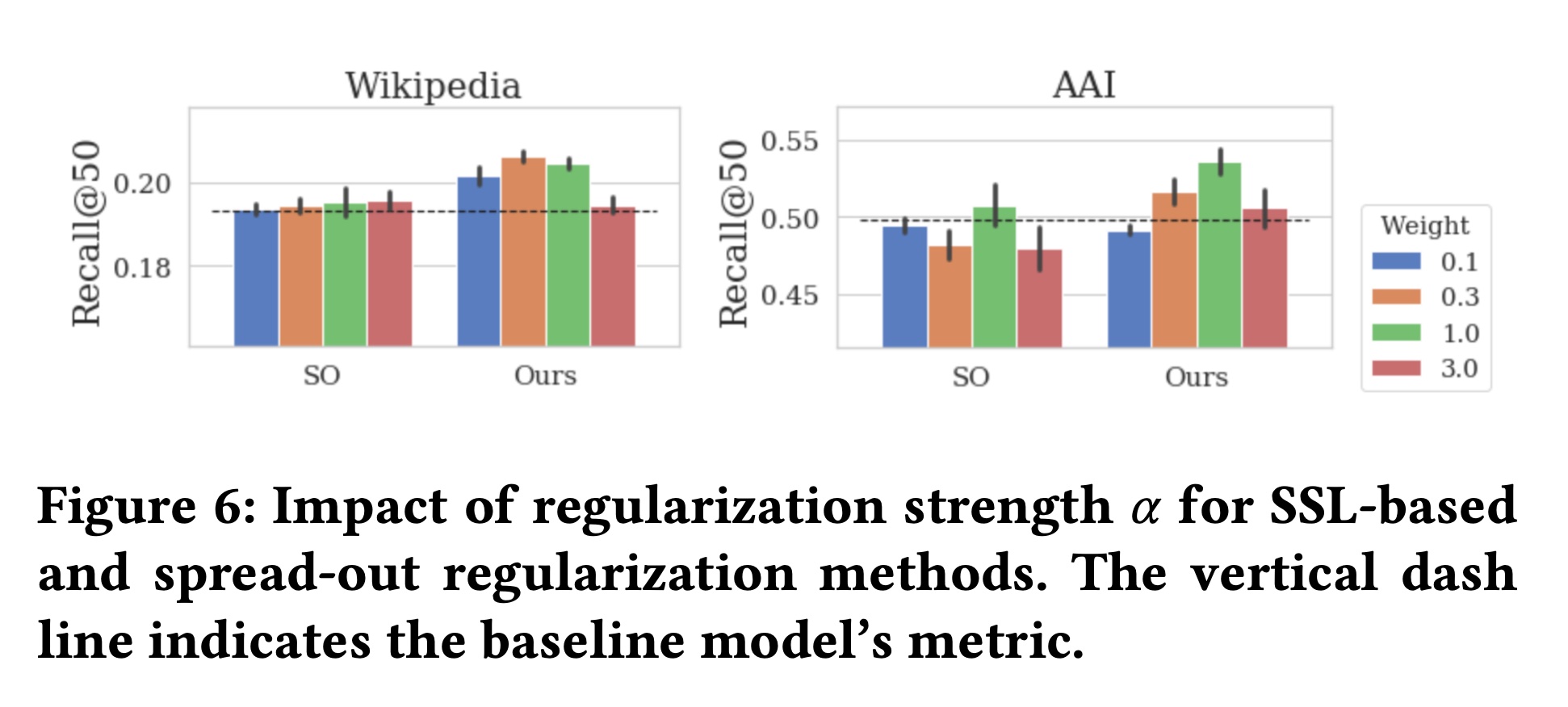
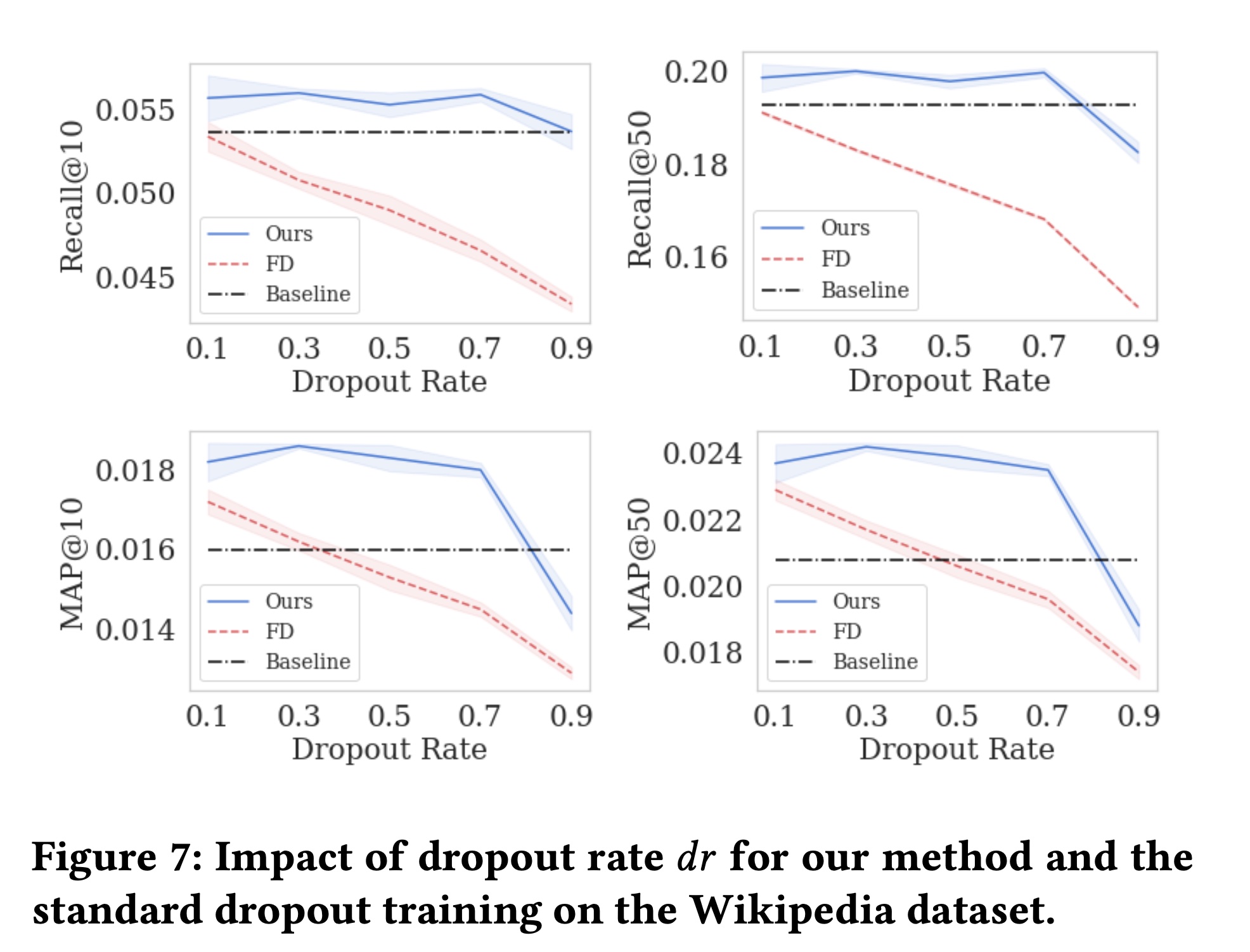
Figure 7显示了不同dropout ratesFD的结果,FD使用相同的超参数。随着
FD的模型性能持续下降。对于大多数
FD比基线更差。对于带有
feature dropout的自监督学习任务,当dropout rate的进一步提高而下降。当
dropout rate太大时,输入信息变得太少,自监督学习无法学习到有意义的representations。
Item Representations的可视化:除了更好的模型性能之外,我们还期望使用SSL学到的representations比没有使用SSL的representations具有更好的质量。为了验证我们的假设,我们采用在AAI数据集上训练的模型中学到的app embeddings,并使用t-SNE在Figure 5中绘制它们。不同类别的Apps以不同的颜色绘制,如Figure 5中的图例所示。与
Figure 5a中的apps相比,最佳SSL模型(Figure 5b)中的apps倾向于与同一类别中的相似apps更好地分组,并且不同类别的分界看起来更加清晰。例如,我们可以看到Figure 5a中的“Sports & Recreation” apps(红色)与“Law & Government” and “Travel” apps混合在一起。而在Figure 5b中,我们清楚地看到4个类别的apps各自分组在一起。这表明使用SSL学到的representations携带更多的语义信息,也是为什么SSL在我们的实验中导致模型性能更好的原因。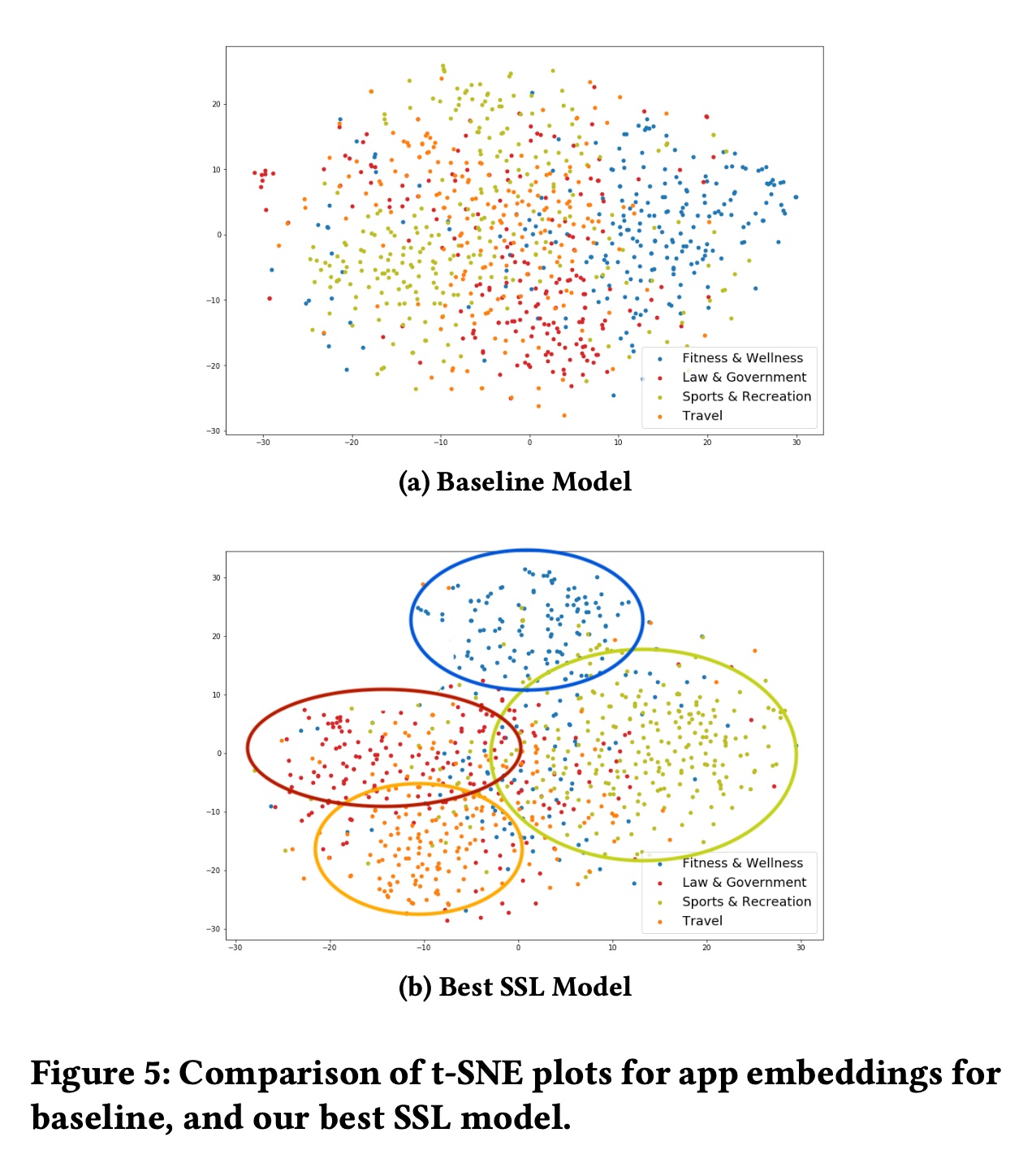
1.2.2 数据稀疏性
我们研究在数据稀疏的情况下
CFM的有效性,以解决RQ2。我们均匀下采样10%的训练数据,并在相同(完整)的测试数据集上进行评估。实验结果报告在Table 3中。随着数据稀疏性的增加,
CFM在Wikipedia和AAI数据集上分别显示出更大的改进。特别是,在完整的Wikipedia数据集上,CFM相对于基线在Recall@10上提高了6.1%,而在10%的数据子集上相对改进为20.6%。在AAI数据集上也观察到类似的趋势(在完整数据集上10.2%、在降采样数据集上为25.7%)。值得注意的是,
CFM始终优于FD,并且随着数据变得更稀疏,差距更大。这表明在SSL任务中使用dropout进行数据增强比直接在监督任务中应用dropout更有效。这是因为:
SSL中的dropout并没有破坏main task中的输入信息,而仅仅破坏了辅助任务的输入信息。
总之,这些发现回答了
RQ2中提出的研究问题:即,所提出的SSL框架在监督更少的情况下能更大程度地提高模型性能。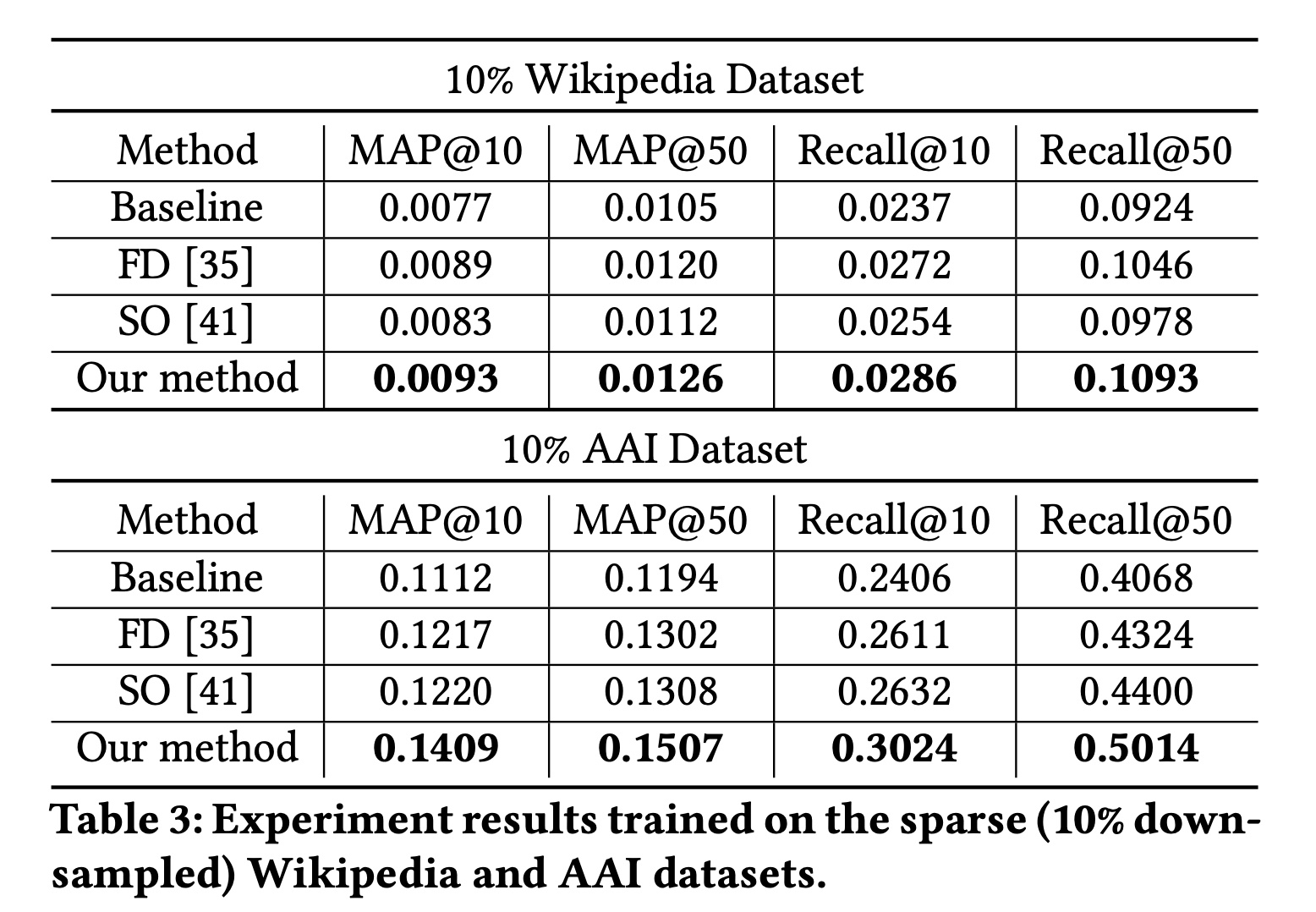
1.2.3 不同数据增强方法的比较
在本节中,我们将几种特征增强方法与
CFM进行比较,通过研究以下两点来回答RQ4:1):在masking中利用feature correlation的好处。2):使用dropout作为增强的一部分的好处。
具体来说,我们考虑以下替代方法:
RFM:Random Feature Masking。在这种方法中,随机选择一组特征进行掩码,而不是像CFM那样由互信息来进行指导。RFM_no_compl:没有补集的Random Feature Masking。在这种方法中,随机独立地掩码两组特征,而不是像CFM那样使用互补的pair of masks。CFM_no_dropout:不应用dropout的Correlated Feature Masking。换句话说,在SSL任务中仅应用correlated masking作为增强。NoMasking:跳过增强中掩码阶段的Correlated Feature Masking。换句话说,我们仅对特征应用dropout作为增强。
我们在
SSL框架中应用这些特征增强函数,并在AAI数据集上报告结果,见Table 5。首先,我们观察到所有变体都比
CFM差,但仍然优于基线模型。特别是,我们发现selecting the masking set时使用互信息对模型改进至关重要,因为我们看到性能下降最大的是RFM,它是随机选择掩码集的。通过将
CFM与两种方法(RFM_no_compl和NoMasking,其中这两种方法允许两个增强样本之间通过独立的droptout从而存在feature overlap)的结果进行比较,我们发现对比学习任务在具有互补信息时更有帮助,这可能避免了学习中的捷径。最后,通过比较
CFM_no_dropout和CFM,我们发现第二个阶段(即,随机丢弃feature values)也有帮助,这可能是因为在SSL任务中引入了更多的feature variants。
直接独立地应用
RFM_no_compl,效果也还可以,而且更容易实现。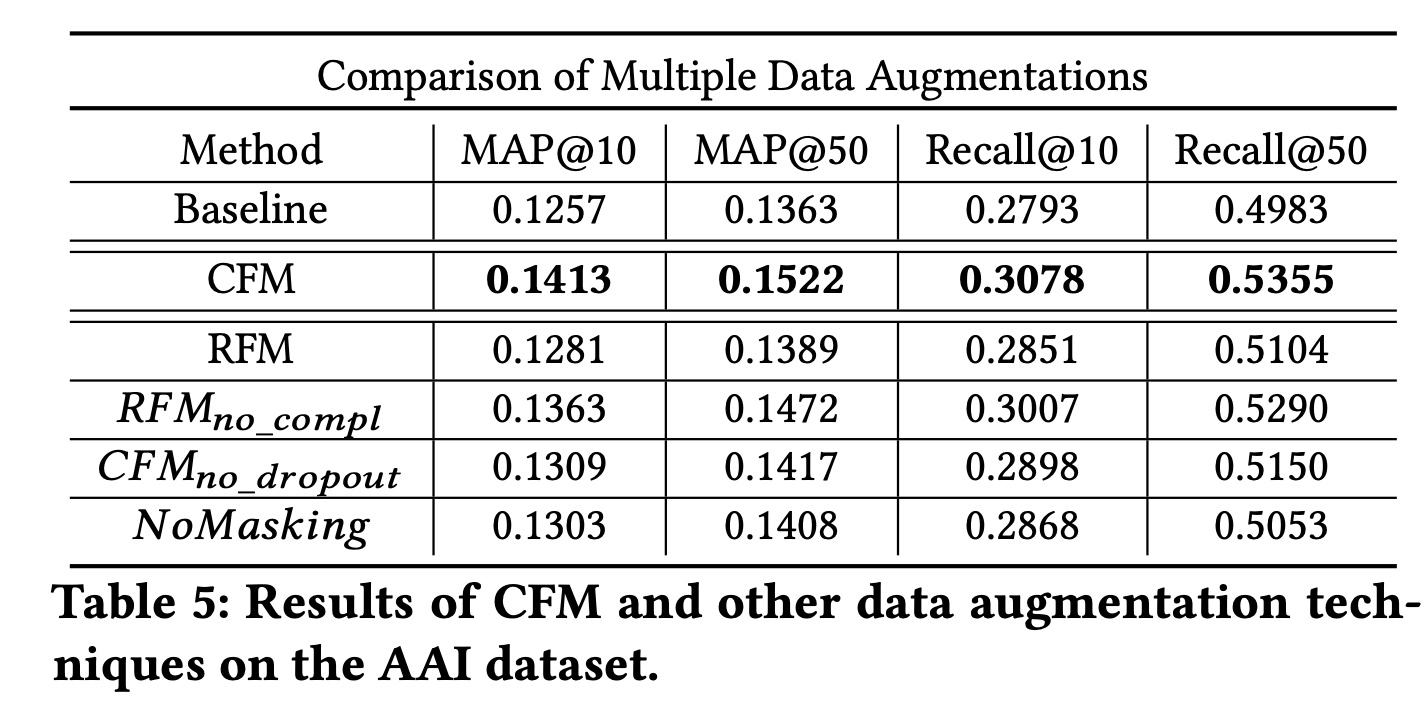
1.2.4 在线实验
在本节中,我们描述如何将我们提出的
SSL框架应用于一个互联网规模的商业app recommender系统。具体来说,给定一个app作为query,系统识别与该query相似的apps。其中一个用于提供此推荐的模型是在前面章节中描述的AAI数据集上进行训练的,其骨干网络结构与Figure 1中的双塔DNN结构相同(有一些修改)。作为AAI实验离线实验的自然扩展,我们进行了A/B实验,以研究在线部署最佳的基于SSL的模型的协同效应。虽然我们已经在这个数据集上展示了离线指标的改进,但在许多实际系统中,离线研究可能与实际影响不一致,原因如下:1):缺乏隐式反馈,因为离线评估数据是根据生产系统中的用户的engagement history收集的。2):未能捕获商品的多目标优化目标(multiple objectives optimization goal),在这种情况下,推荐更具吸引力的apps很可能会损害其他业务目标。
因此,这个实验对于在实际场景中证明所提出框架的有效性至关重要。
在我们的实时
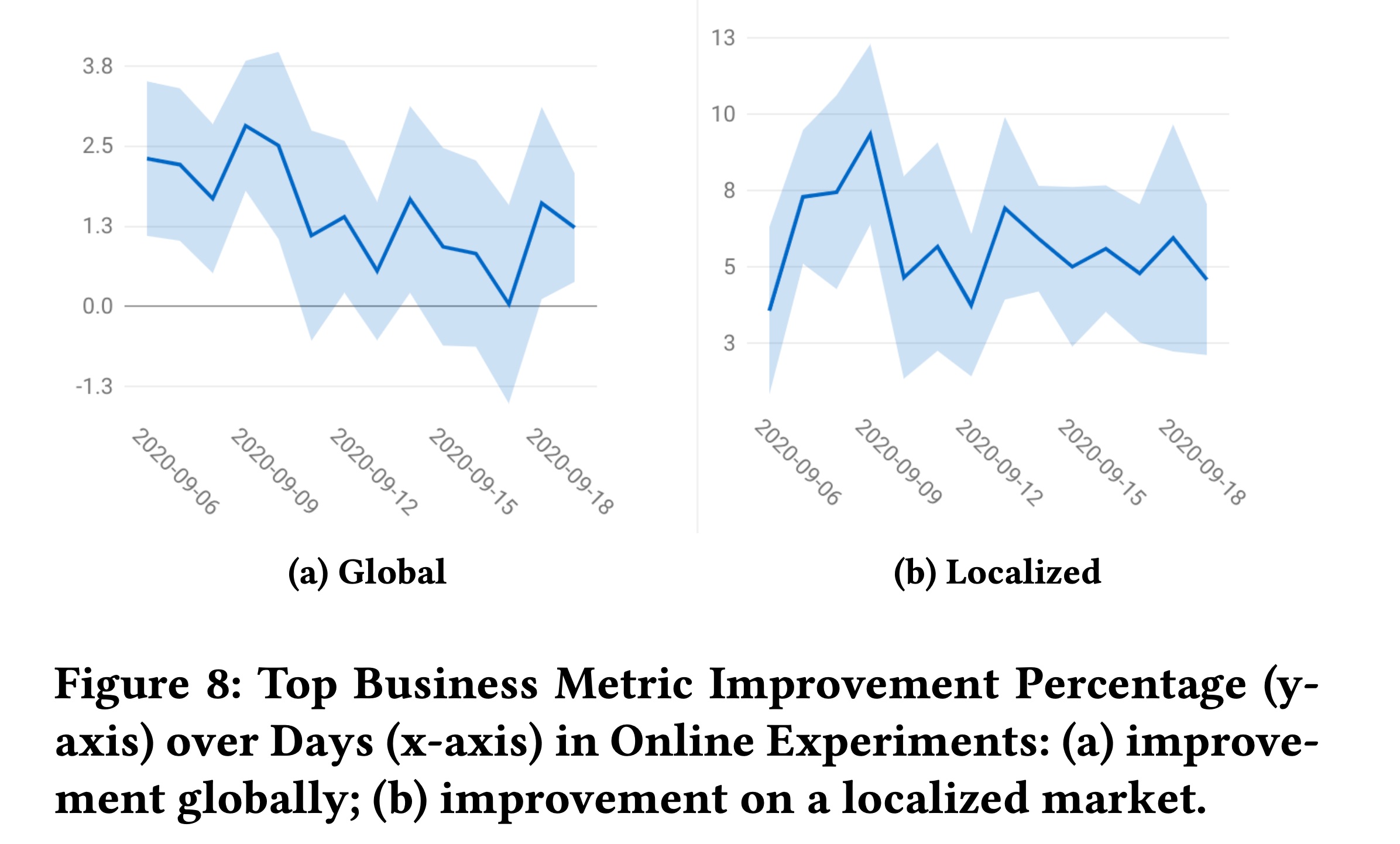
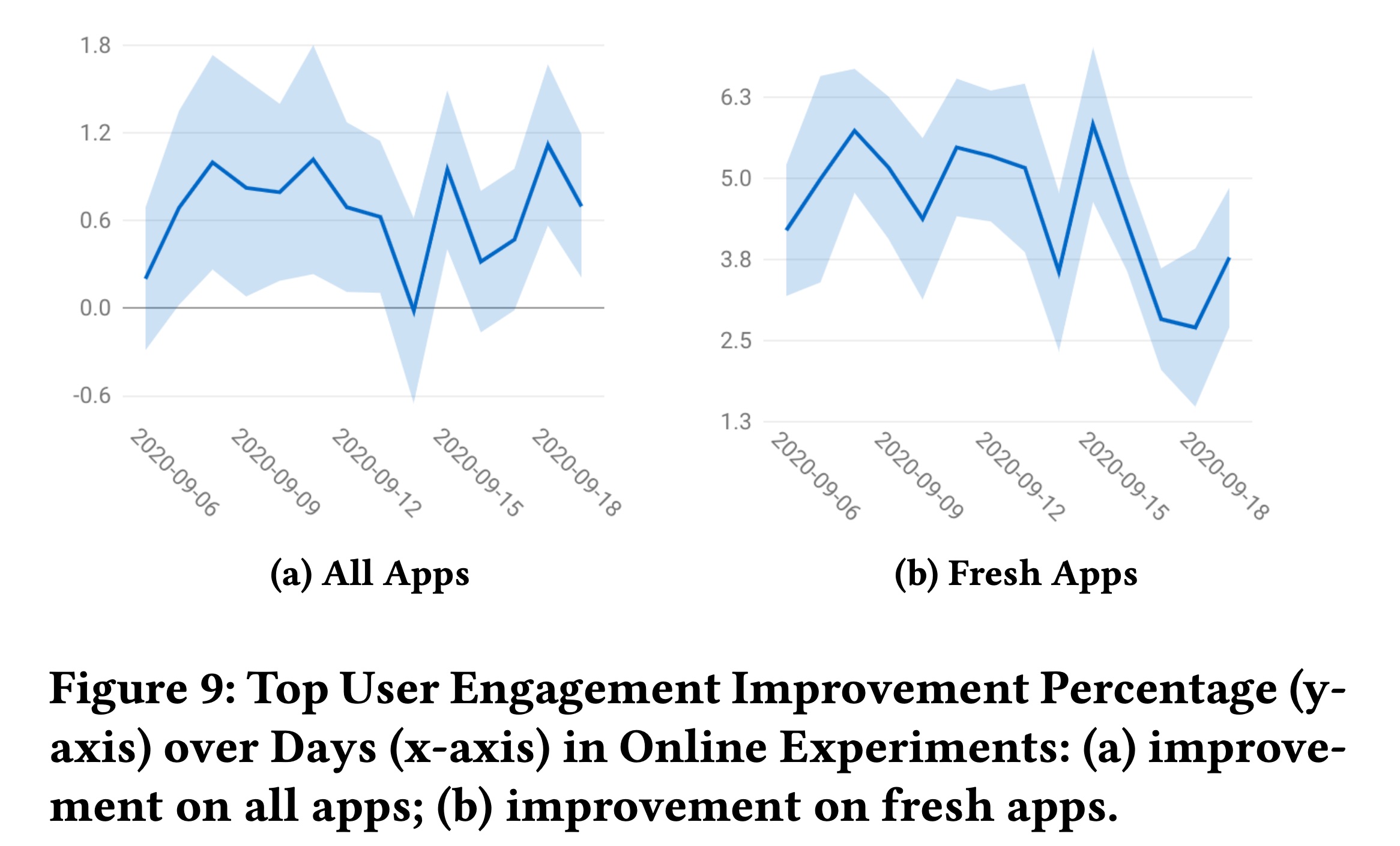
A/B test中,我们在双塔DNN模型(这是生产中使用的现有经过良好调优的模型)之上添加性能最佳的SSL任务,并使用相同的超参数集合。在14天的时间内,该模型显著改善了整体业务指标,关键的user engagement提高了+0.67%(Figure 9a),关键业务指标提高了+1.5%(Figure 8a)。为了呼应前面章节中的
Head-tail分析和数据稀疏性分析,我们在两个data slices上看到了显著的改进:1):新apps的冷启动:该模型使新apps的user engagement提高了+4.5%(Figure 9b)。2):与主要市场相比,训练数据更稀疏的国际国家:我们看到关键业务指标显著提高了+5.47%(Figure 8b右侧)。
同样,这些结果都证实了我们的假设,即我们的
SSL框架确实显著提高了缺乏大量监督的data slices的模型性能。鉴于这些结果,采用SSL的模型已经成功部署到当前的生产系统中。