一、 STAR [2021]
《One Model to Serve All: Star Topology Adaptive Recommender for Multi-Domain CTR Prediction》
传统的工业推荐系统通常使用单个
domain的数据来训练模型,然后为该domain提供服务。然而,大型商业平台往往包含多个domains,其推荐系统通常需要对多个domains进行点击率(click-through rate: CTR)预测。一般来说,不同domains可能共享部分common user groups and items,且每个domain可能拥有自己unique user groups and items。此外,即便是同一用户在不同domains也可能表现出不同的行为。为了充分利用来自不同domains的所有数据,可以训练一个单一模型来服务所有domains。但单一模型难以捕获各个domains的特性,难以很好地服务所有domains。另一方面,为每个domain单独训练一个模型则无法充分利用所有domains的数据。在本文中,我们提出了星形拓扑自适应推荐器(
Star Topology Adaptive Recommender: STAR)模型:同时利用所有
domains的数据。捕获每个
domain的特性并建模不同domains之间的共性。训练一个单一模型来服务所有
domains。
本质上,每个
domain的网络由两个factorized networks组成:一个是所有
domains共享的中心网络(centered network)。另一个是为每个
domain量身定制的domain-specific network。
对于每个
domain,我们将这两个factorized networks组合起来,通过对shared network和domain-specific network的权重进行逐元素相乘(element-wise multiplying),生成一个统一的网络(unified network)。不过,这两个factorized networks也可以通过其他函数进行组合,这一点有待进一步研究。最重要的是,STAR能够从所有数据中学习shared network,并根据每个domain的特性自适应地调整domain-specific parameters。来自生产数据的实验结果验证了所提出的STAR模型的优越性。自2020年末以来,STAR已部署在Alibaba的展示广告系统中,点击率提升了8.0%,每千次展示收入(RPM)增长了6.0%。传统的
CTR prediction模型侧重于single-domain prediction,即CTR模型使用从某个business domain收集的样本来训练后,为该domain提供服务。每个business domain是指在mobile app或电脑端网站中向用户展示items的特定位置(specific spot)。在
Alibaba、Amazon等大型商业公司中,通常有许多business domains需要进行CTR prediction,以提高用户满意度(user satisfaction)和业务收入(business revenue)。例如,在Alibaba,business domains包括Taobao App首页的 “猜你喜欢”(Guess What You Like)、Taobao App首页的横幅广告(Banner)以及其他domains。Figure 1展示了Alibaba的两个代表性的business domains:Banner:在banner,待推荐的items出现在Taobao首页的top banner位置。item可以是单个商品(commodity)、一个店铺(store)或一个品牌(brand)。Guess What You Like:在Guess What You Like,所有items均为单个商品,以左右列的形式(left or right column)展示给用户。
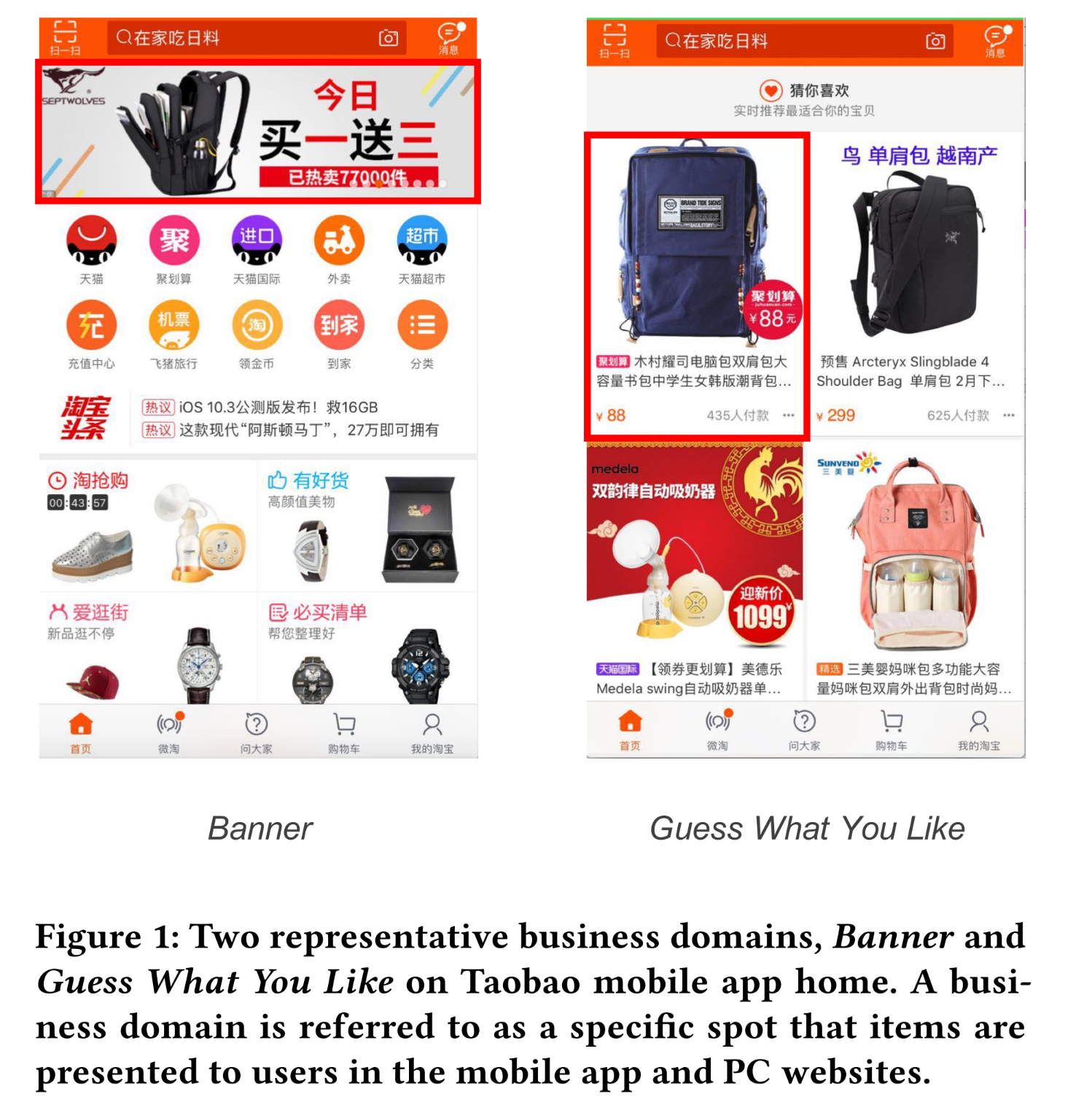
由于不同
business domains存在重叠的user groups and items,这些domains之间存在共性。实现information sharing有助于每个domain的CTR模型的学习。然而,不同domains的specific user group可能不同,用户行为也会发生变化。这些差异导致了domain-specific的数据分布。简单地混合所有数据并训练一个单一的shared CTR model无法在所有domains都表现良好如(Figure 2(a)所示)。除了混合数据并训练一个
shared model外,另一种简单的解决方案是为每个business domain构建一个独立的模型(如Figure 2(b)所示)。这种策略也存在一些缺点:(1):某些business domains的数据量远少于其他domains。splitting数据会忽略领域共性(domain commonalities),导致training data大幅减少,使得模型难以学习。(2):维护多个模型会消耗大量资源,并且需要更多的人力成本。当business domains数量达到数百个时,这将带来过重的负担。
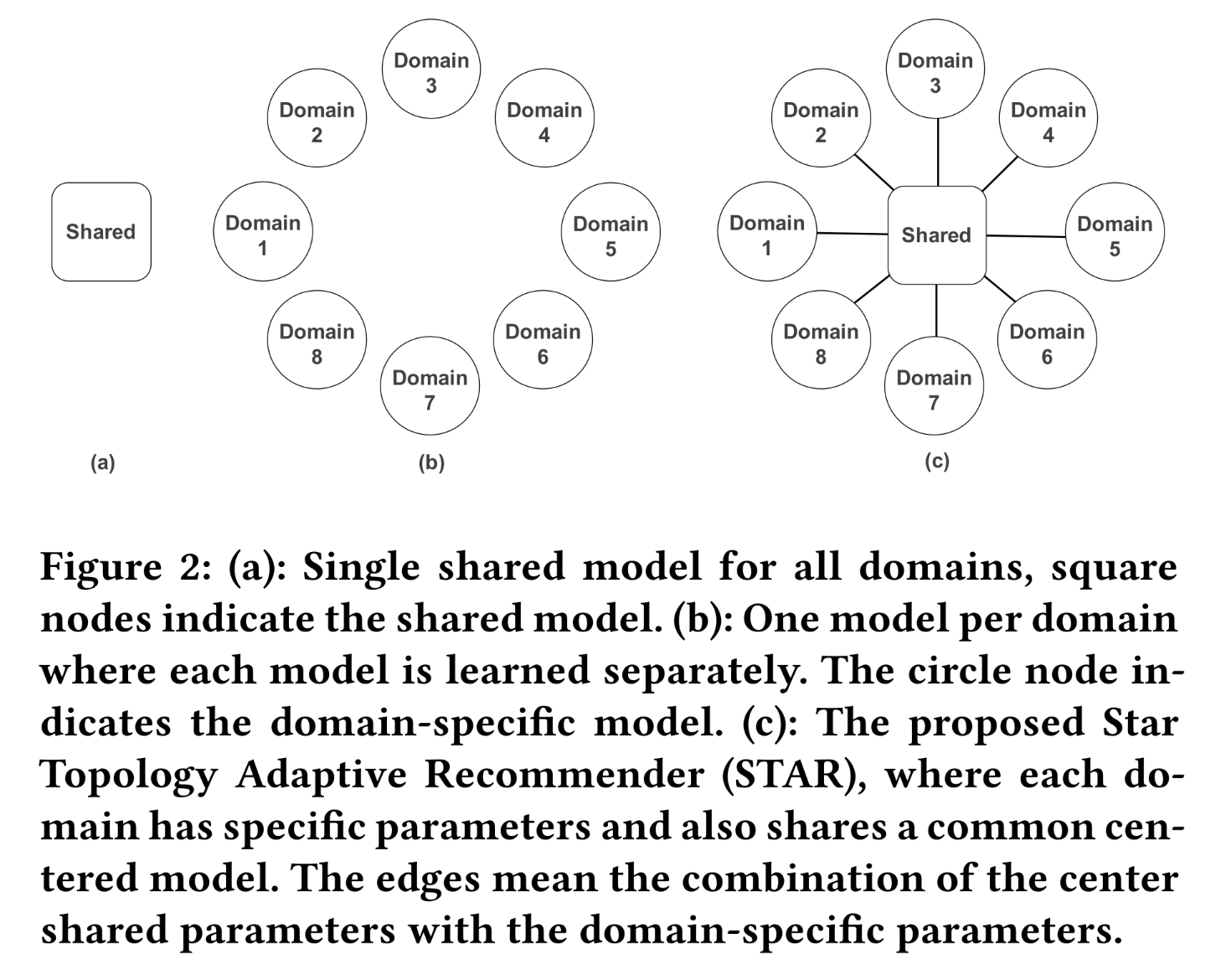
本文旨在学习一种高效的
CTR model,以同时处理多个domains。我们将multi-domain CTR prediction表述为:recommender需要同时为business domainsCTR prediction的问题。模型的输入为business domains使用的common feature,如历史用户行为(historical user behavior)、用户画像特征(user profile feature)、item feature和context feature。clicked label。domain indicator,用于指示该样本来自哪个domain。
需要注意的是,
domain-specific分布domains而变化。multi-domain CTR prediction的目标是:构建一个高效且有效的模型,能够为每个domain提供准确的CTR prediction,同时在资源消耗方面成本极低。为实现这一目标,模型应充分利用领域共性(domain commonalities)并捕获领域差异(domain distinction)。一种可能的利用多个
domains来改进learning的策略是多任务学习(multi-task learning)。如Figure 3所示,multi-domain CTR prediction与多任务学习的区别在于:multi-domain CTR prediction在不同domains解决相同的任务(即CTR prediction),不同domains的label spaces相同,但数据分布不同。而大多数
multi-task learning方法在同一domain处理不同的任务,label space可能不同,例如联合估计CTR和转化率(conversion rate: CVR)。由于任务的异质性,现有的多任务学习方法侧重于在bottom layers共享信息,而保留独立的task-specific output layers(《An Overview of Multi-Task Learning in Deep Neural Networks》)。将多任务学习方法直接应用于multi-domain CTR prediction无法充分利用label space中的domain relationship,且忽略了不同domains的独特的数据分布。
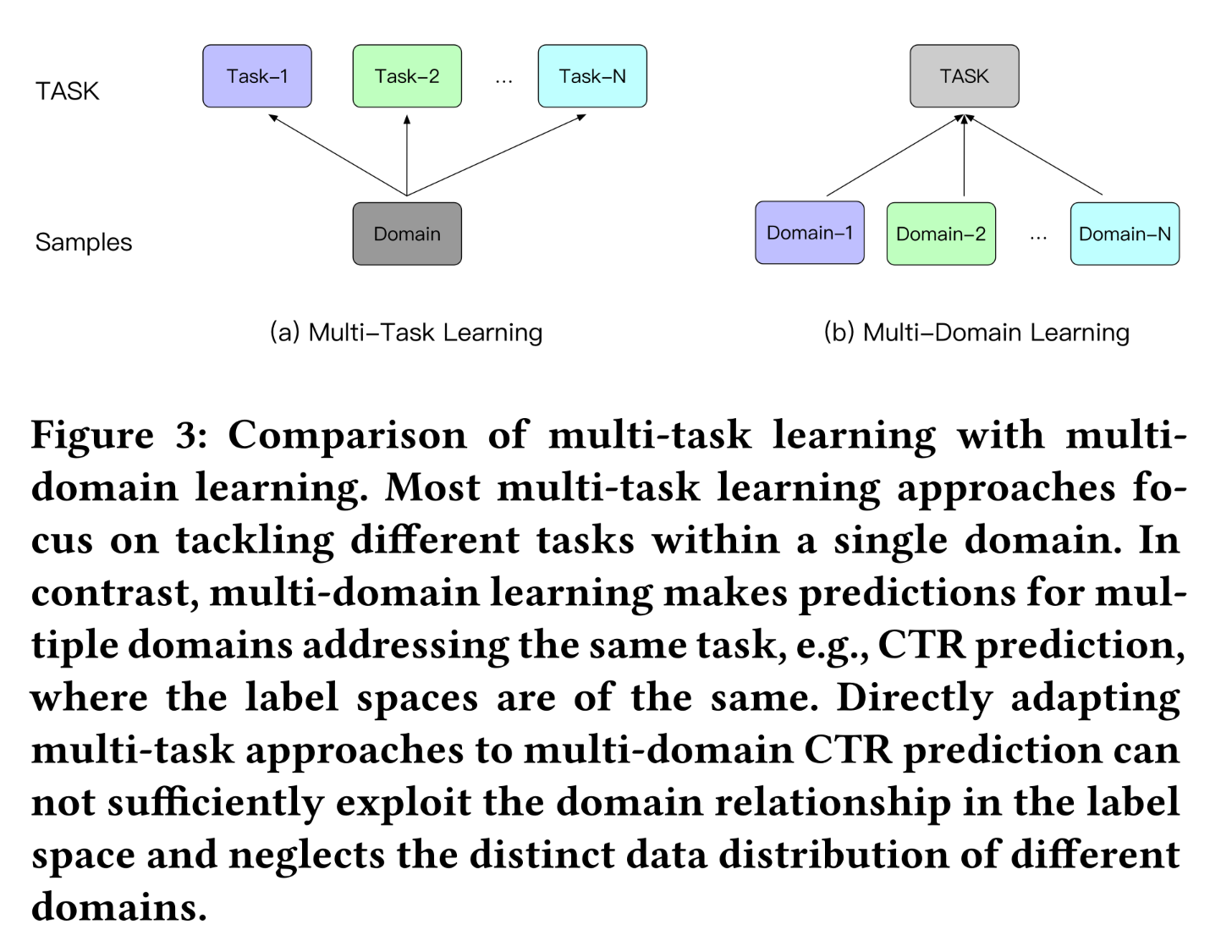
为了充分利用
domain relationship,我们提出了Star Topology Adaptive Recommender: STAR用于multi-domain CTR prediction。所提出的STAR模型具有星形拓扑结构(star topology),如Figure 4所示。STAR由shared centered parameters和multiple sets of domain-specific parameters组成。每个domain的final model通过组合shared centered parameters和domain-specific parameters得到。centered parameters用于学习所有domains的通用行为(general behaviors),其中的共性知识(common knowledge)可以在所有domains之间学习和迁移。domain-specific parameters捕获不同domains的特定行为,以促进更精细的CTR prediction。
星形拓扑结构有助于在多个
domains之间进行有效的信息传递,从而学习domain共性(commonalities)和差异(distinctions)。本文通过每层权重的逐元素相乘作为组合策略(combination strategy)来实现STAR模型。由于embedding layers在工业推荐系统中占据大部分参数,新增的domain-specific parameters相对于总参数数量而言可以忽略不计。因此,使用STAR模型服务多个domains仅会增加少量计算和内存成本,同时带来更好的性能。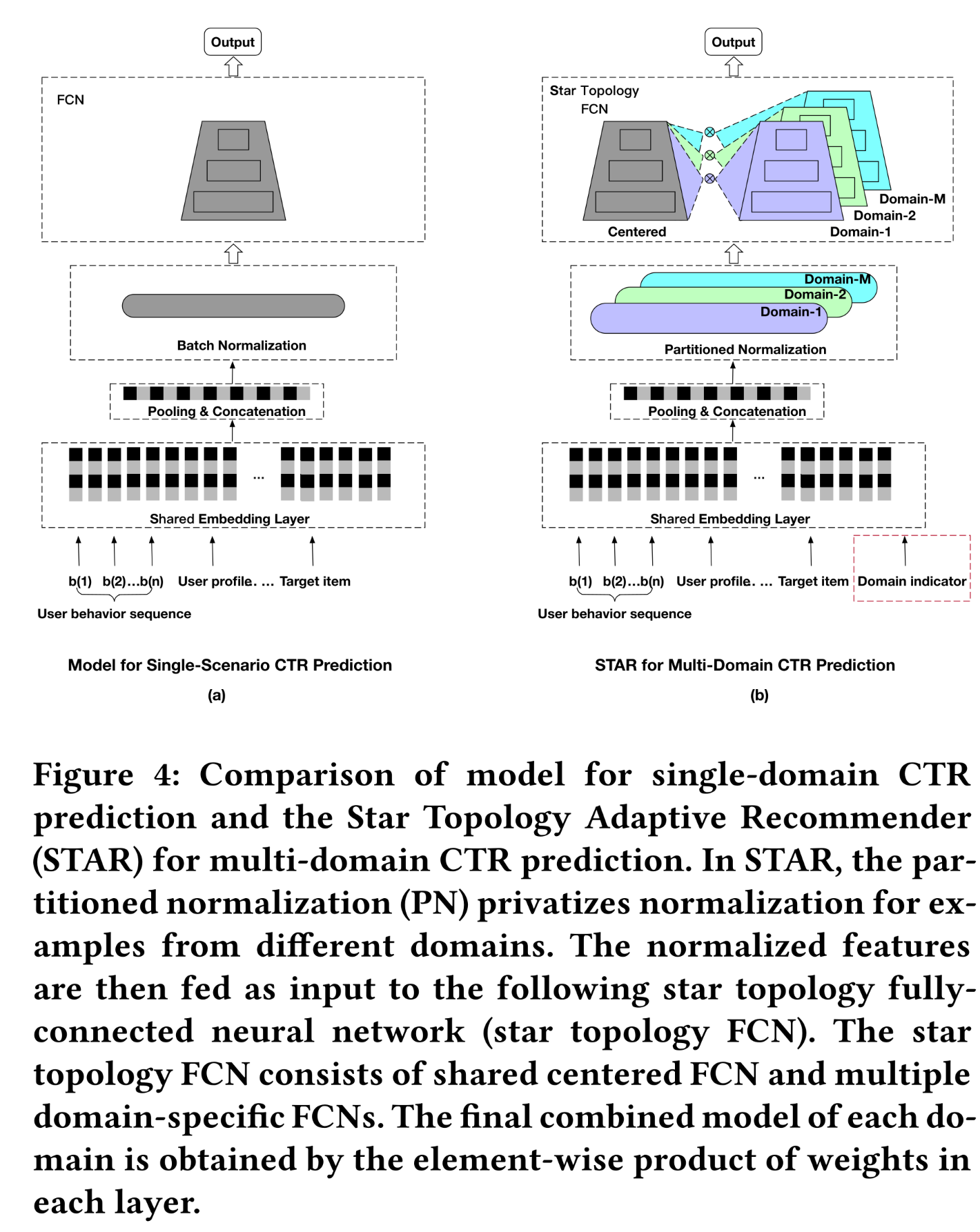
本文的主要贡献如下:
提出了
Star Topology Adaptive Recommender: STAR来解决multi-domain CTR prediction问题。星形拓扑结构有助于在多个domains之间进行有效的信息传递,从而学习领域共性(domain commonalities)并捕获领域差异(domain distinction)。不同
domains具有不同的数据分布,这导致使用Batch Normalization时统计结果不准确。为解决此问题,我们提出了分区归一化(Partitioned Normalization: PN),为来自不同domains的样本提供私有化的normalization。PN可以获得更准确的domain内的统计矩(moments),从而提升模型性能。在
multi-domain CTR prediction中,描述domain information的features至关重要。我们提出了一个辅助网络(auxiliary),将domain indicator直接作为输入,并学习其embedding以描述domain。然后将该embeddings馈入到辅助网络中,该辅助网络比原始网络简单得多。这使得domain indicator能够以直接的方式影响final prediction。我们在工业生产数据集上对
STAR进行了评估,并于2020年将其部署在Alibaba的展示广告系统中。一致的优越性验证了STAR的有效性。截至目前,STAR的部署使CTR提升了6%,每千次展示收入(RPM)提升了8%。我们相信,在部署过程中获得的经验可以推广到其他场景,因此对研究人员和工业从业者具有参考价值。
1.1 相关工作
本文的工作与传统的
single-domain CTR prediction密切相关,即:推荐器在单个business domain上训练好之后为该business domain提供服务。此外,本文的工作还与multi-task learning和multi-domain learning相关。本节将对此进行简要介绍。
1.1.1 Single-Domain CTR Prediction
受
deep learning成功的启发,近年来CTR prediction模型已从传统的浅层方法转变为现代的深层方法。大多数deep CTR models遵循embedding and MLP范式。Wide & Deep(《Wide & deep learning for recommender systems》)和DeepFM(《Deepfm: a factorization-machine based neural network for ctr prediction》)结合了低阶特征和高阶特征,以提高模型的表达能力。PNN(《Product-based neural networks for user response prediction》)引入了一个乘积层(product layer)来捕获跨字段类别(inter-field categories)之间的交互模式(interactive patterns)。
在上述这些模型中,用户的历史行为(
history behaviors)经过embedding和pooling后转换为低维向量。DIN(《Deep interest network for click-through rate prediction》)采用attention机制,针对给定的target item局部地激活历史行为,成功捕获了用户兴趣的多样性的特点(diversity characteristic)。DIEN(《Deep Interest Evolution Network for Click-Through Rate Prediction》)进一步提出了一个辅助损失(auxiliary loss),以从历史行为中捕获潜在兴趣(latent interest)。此外,DIEN将attention机制与GRU相结合,以建模用户兴趣的动态演变(dynamic evolution)。MIND(《Multi-Interest Network with Dynamic Routing for Recommendation at Tmall》)和DMIN(《Deep Multi-Interest Network for Click-through Rate Prediction》)认为,单一向量可能不足以捕获user and items中复杂的模式。MIND中引入了胶囊网络(capsule network)和动态路由(dynamic routing)机制,以学习多个representations来聚合原始特征。此外,受
self-attention架构在sequence to sequence learning任务中的成功的启发(《Attention is All you Need》),《Deep Session Interest Network for Click-Through Rate Prediction》中引入了Transformer用于feature aggregation。MIMN(《Practice on Long Sequential User Behavior Modeling for Click-through Rate Prediction》)提出了一种memory-based的架构来聚合特征,并解决long-term user interest modeling的挑战。SIM(《Search-based User Interest Modeling with Lifelong Sequential Behavior Data for Click-Through Rate Prediction》)通过两个级联的搜索单元(search units)来抽取用户兴趣,在可扩展性(scalability)和准确性方面均实现了更好的modeling lifelong sequential behavior data的能力。
1.1.2 Multi-Task Learning
多任务学习(
multi-task learning)旨在通过在多个相关任务(related tasks)之间共享知识(shared knowledge)来提高泛化能力。探索shared knowledge和task-specific knowledge有助于每个任务的learning。多任务学习已成功应用于多个application领域,包括自然语言处理、语音识别、推荐系统、以及计算机视觉。在早期的线性模型多任务学习文献中,
《Convex multi-task feature learning》提出了一种方法来学习跨多个任务共享的sparse representations。在
deep learning背景下,多任务学习通常通过hidden layers的参数共享来实现。《Cross-Stitch Networks for Multi-task Learning》提出了交叉拼接单元(cross-stitch units),为每个任务学习task-specific hidden-layers的unique combinations。《Modeling Task Relationships in Multi-task Learning with Multi-gate Mixture-of-Experts》提出了多门混合专家模型(Multi-gate Mixture-of-Experts: MMoE),通过在所有任务之间共享expert sub-models,并训练一个门控网络(gating network)来优化每个任务,从而建模task relationships。《Multi-task learning using uncertainty to weigh losses for scene geometry and semantics》提出了multi-task deep learning的一种原则性方法(principled approach),通过考虑每个任务的同方差不确定性(homoscedastic uncertainty)来权衡多个损失函数。在多任务学习中,不同任务可能存在冲突,需要进行权衡,优化下面的代理目标(
proxy objective)可能并非最优:最小化每个任务loss的加权线性组合。为解决此问题,《Multi-Task Learning as Multi-Objective Optimization》显式地将多任务学习视为多目标优化(multi-objective optimization),其overall objective是找到帕累托最优解(Pareto optimal solution)。
需要注意的是,
《Multi-task learning using uncertainty to weigh losses for scene geometry and semantics》、《Multi-Task Learning as Multi-Objective Optimization》与本文的工作是互补的,有可能结合起来以实现更好的性能。
1.1.3 Multi-Domain Learning
在实际
applications中,数据通常来自多个domains。multi-domain learning支持domains之间的知识转移(knowledge transfer),以改进学习效果。因此,它与领域自适应(domain adaptation: DA)问题不同,在领域自适应中,知识转移只是单向的,即从source domain到target domain。《Transferable Normalization: Towards Improving Transferability of Deep Neural Networks》提出了可迁移归一化(Transferable Normalization)来替代现有的normalization技术从而用于领域自适应(domain adaptation),并揭示批量归一化(batch normalization: BN)(《Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift》)是可迁移性(transferability)的约束因素。
multi-domain CTR prediction可以看作是一种特殊的multi-domain learning,其中每个domain对应一个business domain,任务是CTR prediction。与传统的multi-domain learning相比,我们的工作专注于CTR prediction。所提出的模型充分利用了domain indicator:其中,domain indicator直接作为ID feature被馈入模型,并学习domain indicator的semantic embeddings来促进模型学习。而这一点(即,利用domain indicator)在以往的文献中被忽略了。multi-domain learning与multi-task learning的区别在于:multi-domain learning针对多个domains解决相同的问题,例如CTR prediction,这些问题的label spaces是相同的。相比之下,
multi-task learning则专注于解决不同的问题(《A Unified Perspective on Multi-Domain and Multi-Task Learning》)。
例如,在视频推荐领域,
multi-task learning问题可以是同时预测单个business domain中视频的CTR和预期观看时间(expected watch time);而multi-domain CTR prediction则针对多个business domains(例如多个视频平台)进行CTR predictions。
1.2 The Proposed Approach
本节首先简要介绍
multi-domain CTR prediction的背景。接下来概述本文提出的multi-domain CTR prediction方法——星型拓扑自适应推荐器(star topology adaptive recommender: STAR)的架构。然后详细介绍STAR,包括所提出的星型拓扑网络(star topology network)、分区归一化(partitioned normalization)和辅助网络(auxiliary network)。
1.2.1 Multi-Domain CTR Prediction
在序列推荐系统(
sequential recommender systems)中,模型以用户历史行为(user historical behavior)、用户画像特征(user profile feature)、target item feature以及其他特征(例如上下文特征context feature)作为输入。用户itempredicted CTR其中:
user features集合,包括用户历史行为和用户画像特征。target item feature集合。other features集合。embedding layer,它将sparse IDs映射到learnable dense vectors。
将原始特征映射到低维
embedding之后,通常的做法是将这些embeddings聚合以获得fixed-length vectors。可以使用诸如《Deep Interest Evolution Network for Click-Through Rate Prediction》、《Deep interest network for click-through rate prediction》之类的不同聚合方法来聚合这些embeddings,从而提取用户兴趣并获得fixed-length representation。然后,将所获得的representation馈入到深度神经网络(例如,多层全连接网络fully-connected network: FCN)中,以获得final CTR prediction。传统的
CTR模型通常使用来自单一business domain的数据进行训练。然而,现实世界的推荐系统通常需要处理多个business domains。具体来说,推荐系统需要同时对domainsCTR prediction。该模型以domains的common feature,例如用户历史行为、用户画像特征、以及target item feature。clicked label。domain indicator,用于指示此样本采集自哪个domain。
需要注意的是,
domain-specific distributiondomains的分布各不相同。multi-domain CTR prediction的目标是构建一个单一的CTR模型,该模型能够以较低的资源消耗和人力成本,为所有domains提供准确的CTR prediction。
1.2.2 Architecture Overview
如上所述,忽略
domain indicatorshared CTR model会忽略领域差异(domain differences),导致模型性能下降。另一方面,为每个domain训练单独的模型导致性能更差,因为领域拆分(domains splitting)会减少每个模型所需的数据量。此外,考虑到资源消耗和人力成本,在生产环境中为每个domain维护单独的模型是不切实际的。为此,我们提出了星型拓扑自适应推荐器(
Star Topology Adaptive Recommender: STAR)用于multi-domain CTR prediction,以更好地利用不同domains之间的相似性,同时捕获领域差异(domain distinction)。如Figure 4所示,STAR由三个主要部分组成:(1):分区归一化(partitioned normalization: PN),用于对来自不同domains的样本执行私有归一化(privatizes normalization)。(2):星型拓扑的全连接神经网络(star topology FCN)。(3):辅助网络(auxiliary network),直接将domain indicator作为输入特征,并学习domain indicator的semantic embeddings以捕获domain distinction。
在训练过程中:
首先采样得到一个
domain indicatordomain中采样一个mini-batch(包含STAR模型首先通过an embedding layer将这些input features嵌入为低维向量。在工业界的recommender中,模型通常使用数十亿个特征进行训练(《XDL: An Industrial Deep Learning Framework for High-Dimensional Sparse Data》),并且embedding的参数通常远多于模型的其他部分。这使得不同domains难以在数据有限的情况下学习domain-specific embeddings。例如,在我们日常任务中使用的模型中,embeddings parameters是全连接层参数的10000倍(《XDL: An Industrial Deep Learning Framework for High-Dimensional Sparse Data》)。因此,在提出的STAR模型中,我们让所有business domains共享同一个embedding layer,即不同domains中相同的ID features共享同一个embedding。跨多个domains来共享embedding layer可以显著降低计算和内存成本。然后,将
embeddings进行池化和拼接,得到representations。之后,所提取的
representations由我们提出的分区归一化 (partitioned normalization: PN)layer进行处理。PN layer针对不同的domains对normalization statistics进行私有化。normalized vectors随后作为input馈入到我们所提出的星形拓扑FCN(star topology FCN)以获得输出。star topology FCN由shared centered FCN和多个domain-specific FCNs组成。每个domain的final model是通过组合shared centered FCN和domain-specific FCN来得到的。
在
multi-domain CTR prediction中,能够描述domain information的特征至关重要。在STAR模型中,auxiliary network将domain indicator作为输入,并与描述domain的其他特征一起馈入auxiliary network。auxiliary network的输出与star topology FCN的输出相加,得到final prediction。我们使auxiliary network比star topology FCN简单得多,以便模型能够以直接简便的方式捕获domain distinction。接下来我们将详细介绍这些组成部分。注意:
auxiliary network的结果与star topology FCN进行相加。在
star topology FCN内部,shared parameters和domain-specific parameters进行诸元素相乘。
1.2.3 Partitioned Normalization
如前所述,原始特征首先转换为低维
embeddings,然后经过池化和聚合从而得到中间表征(intermediate representation)。设实例的intermediate representation为deep networks,标准做法是对intermediate representationnormalization layer。在所有normalization方法中,batch normalization: BN是一种代表性方法,被证明对深度神经网络的成功训练至关重要。BN对所有样本进行全局归一化(global normalization),累积normalization moments,并学习跨所有样本共享的参数。具体来说,训练过程中BN的归一化公式如下:其中:
output。scale和bias参数。mini-batch的均值和方差(它们也是向量,通过诸元素计算得到)。
在测试时,使用所有样本的均值
换句话说,
BN假设所有样本是独立同分布的(i.i.d.),并使用跨所有训练样本共享的统计量。然而,在
multi-domain CTR prediction中,样本仅被假设在特定domain内是局部独立同分布的。因此,来自不同domains的数据具有不同的normalization moments。在测试时共享BN layers的global moments and parameters,会掩盖领域差异(domain differences),导致模型性能下降。为了捕获每个
domain的独特的数据特性(data characteristic),我们提出了分区归一化(partitioned normalization: PN),为不同domains提供私有化的normalization statistics and parameters。具体来说,在训练过程中,假设当前mini-batch来自第domain,我们计算当前mini-batch的均值和方差,并对特征进行归一化:其中:
global scale and bias parameters,domain-specific scale and bias parameters。对于每个
mini-batch,通过将共享的domain-specific的final scale,即PN根据domain indicator自适应地缩放representation。类似地,
PN的bias也是基于domain来自适应的,通过将global biasdomain-specific bias
需要注意的是,与
BN相比,PN在训练过程中也使用当前mini-batch的moments(即,均值和方差),但PN引入了domain-specific scale and biasdomain distinction)。在测试期间,除了
scale and bias的修改外,PN还让不同domains累积domain-specific的统计量(均值和方差)的移动均值:domain的实例从这个公式可以看出,
PN使用domain-specific的均值intermediate representationPN根据domain indicator自适应地调整intermediate representation,以捕获独特的domain characteristics。
1.2.4 Star Topology FCN
经过
PN layer之后,representationstar topology FCN)。如Figure 5所示,所提出的star topology FCN由一个shared centered FCN和每个领域独立的FCNs组成,因此FCN的总数为domains数量)。第domain的final model通过组合shared centered FCN和domain-specific FCN来得到,其中centered parameters学习所有domains的通用行为(general behaviors),domain-specific parameters捕获不同domains的特定行为(specific behaviors),以促进更精细的CTR prediction。具体来说,对于
shared FCN,设某一层的权重为bias为domain的specific FCN,设对应层的权重为bias为input维度为output维度为domain的final weightsbias其中:
设
domain的该神经网络层的输入,则final output其中:
在所有层中都采用了
shared parameters与domain-specific parameters的组合。通过这种方式,STAR可以根据domain调整其参数。shared parameters与domain-specific parameters为什么要用这种组合方式?论文并未给出说明。读者猜测,这类似于参数分解的思路:每个参数可以分解为
shared-parameters和task-specific paramters。此外,这种分解的方式在online serving的时候可以预先计算好online serving和base model的结构完全相同。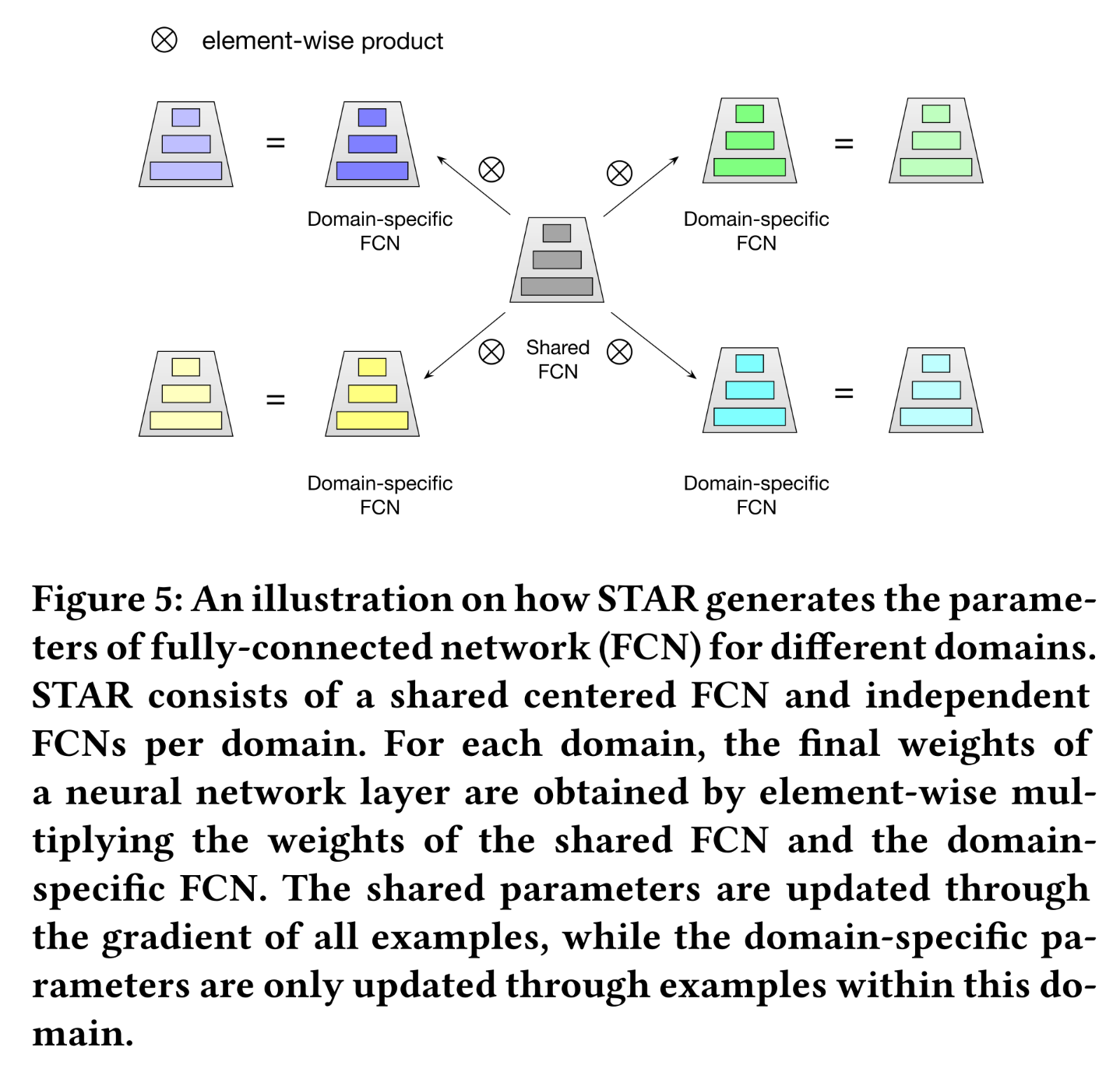
需要注意的是,我们通过如下的方式来实现
shared centered FCN和domain-specific FCN的组合策略(combination strategy):对每一层中的权重进行逐元素乘积、对每一层中的bias进行逐元素相加。也可以进一步研究其他策略以获得更好的性能。
shared parameters通过所有样本的梯度进行更新,而domain-specific parameters仅通过该domain内的示例进行更新。这有助于捕获领域差异(domain differences),从而实现更精细的CTR prediction,同时通过shared centered parameters来学习领域共性(domain commonality)。如前所述,工业推荐系统中的大部分参数都由embedding layer所贡献,增加的FCNs对参数总量的影响可以忽略不计。因此,STAR使用一个模型即可高效地服务于所有business domains,且参数高效且内存友好。
1.2.5 Auxiliary Network
在传统的
CTR modeling方法中,所有特征都被平等对待并馈入到复杂的模型中。然而,在multi-domain CTR prediction中,模型可能难以自动学习领域差异(domain distinction)。我们认为,一个好的good multi-domain CTR model应具备以下特性:(1):包含与domain characteristic相关的有效特征。(2):使这些特征能够直接且有效地影响final CTR prediction。
其背后的逻辑是:能够描述
domains信息的特征至关重要,因为它们可以降低模型捕获领域差异(domain distinction)的难度。为此,我们提出了一种辅助网络(
auxiliary network)来学习domain distinction。为了增强与domain characteristic相关的informative features,我们将domain indicator直接作为ID feature input。首先,将
domain indicator映射到embedding向量,并与其他特征拼接起来。这里的 “其他特征”, 读者猜测主要是
domain相关的特征。也可以采用所有可用的特征,这类似于FinalMLP的思路。然后,
auxiliary network对concatenated features进行前向传播,得到一维的output。将
star topology FCN的一维输出记为auxiliary network的输出记为final logit。然后应用sigmoid函数得到CTR prediction:
在我们的实现中,
auxiliary network比main network简单得多。auxiliary network是一个两层全连接神经网络。这种简单的架构使得domain features能够直接影响final prediction。记
domain中第predicted probability,domains中其中:
domains总数;domain的样本总数。
1.3 实验
本节评估
STAR的有效性。首先,我们介绍实验设置,包括所使用的生产数据集(production dataset)、对比方法和实现细节。然后详细阐述结果和讨论。接着我们进行了深入的消融研究。最后我们展示了生产环境下的实验结果。数据集:由于缺乏公开的
multi-domain CTR prediction数据集,我们使用Alibaba在19 business domains上的用户点击行为(即,production data)进行离线评估。训练数据来自Alibaba在线展示广告系统的流量日志。我们使用19 business domains一天的数据进行训练,并使用第二天的数据进行测试。训练数据集包含数十亿个样本。Table 1显示了训练集中每个domain的样本百分比和平均CTR(# Click/# Impression,即正样本比例)。如Table 1所示:不同
domains的数据分布存在差异,这可以从不同的CTR中反映出来。可以看出,
CTR最高的domain(domain #15)为12.03%,而CTR最低的domain(domain #13)仅为1.27%。
在这个数据集中,大多数
items在大多数business domains中都可用,而只有部分users是重叠的。例如,domain 1和domain 2拥有相同的items set,但只有8.52%的用户重叠。
baselines:为了验证我们方法的有效性,我们将STAR模型与以下几种方法进行比较:Base:我们称Base模型为:由embedding layer、pooling & concatenation layer、batch normalization、以及一个7-layer fully-connected network组成的模型。具体来说,pooling & concatenation layer基于DIEN,用于在embedding layer之后提取用户兴趣。我们将来自不同domains的样本混合,并训练base模型。Shared Bottom:Shared Bottom模型是一个多任务模型,它共享bottom layers的参数。在我们的实现中,Shared Bottom模型共享embedding layer。每个domain还有一个特定的、不共享的7-layer fully-connected network。MulANN:MulANN(《Multi-Domain Adversarial Learning》)在Base模型的基础上添加了领域判别器(domain discriminator)模块。domain discriminator用于区分样本所属的domain。MulANN采用对抗损失函数(adversarial loss),使domain discriminator对domains的shift无法区分。MMoE:MMoE隐式地对多任务学习中的任务关系(task relationships)进行建模,其中不同的任务可能具有不同的标签空间(label spaces)。本文将MMoE应用于multi-domain CTR prediction,其中每个expert都是一个7-layer fully-connected network。experts的数量等于domains的数量。此外,
MMoE还为每个domain学习门控网络(gating network),该网络以input features为输入,输出softmax gates。这些softmax gates将experts以不同的权重组合在一起。Cross-Stitch:Cross-Stitch(《Cross-Stitch Networks for Multi-task Learning》)使用线性交叉缝合单元(linear cross-stitch units)来学习task-specific representations的最优组合。在cross-stitch方法中,每个domain都有一个7-layer fully-connected network,并在每个hidden layer中添加cross-stitch units以学习task-specific representations。
为了进行公平的比较,所有比较方法和
STAR模型均使用我们提出的auxiliary network进行训练。关于auxiliary network的消融研究在后续章节中进行。实现细节:
所有模型均使用
Adam进行训练,学习率设置为0.001,batch size = 2000。我们最小化来自所有
domains的样本的交叉熵损失来训练模型。
模型结构的超参数(比如
embedding size、这个七层全连接网络每一层的size多大),作者都未说明。评估指标:
AUC是评CTR prediction性能的常用指标。用户加权AUC通过对用户的AUC进行平均来衡量用户内部排序的优劣,并且已被证明与推荐系统的在线性能更相关。其计算公式如下:其中:
AUC。我们使用这种加权
AUC作为评估指标,为简便起见,仍将其称为AUC。具体而言,我们使用每个domain的AUC和overall AUC(混合所有domains的样本来计算overall AUC)作为评估指标。
1.3.1 实验结果
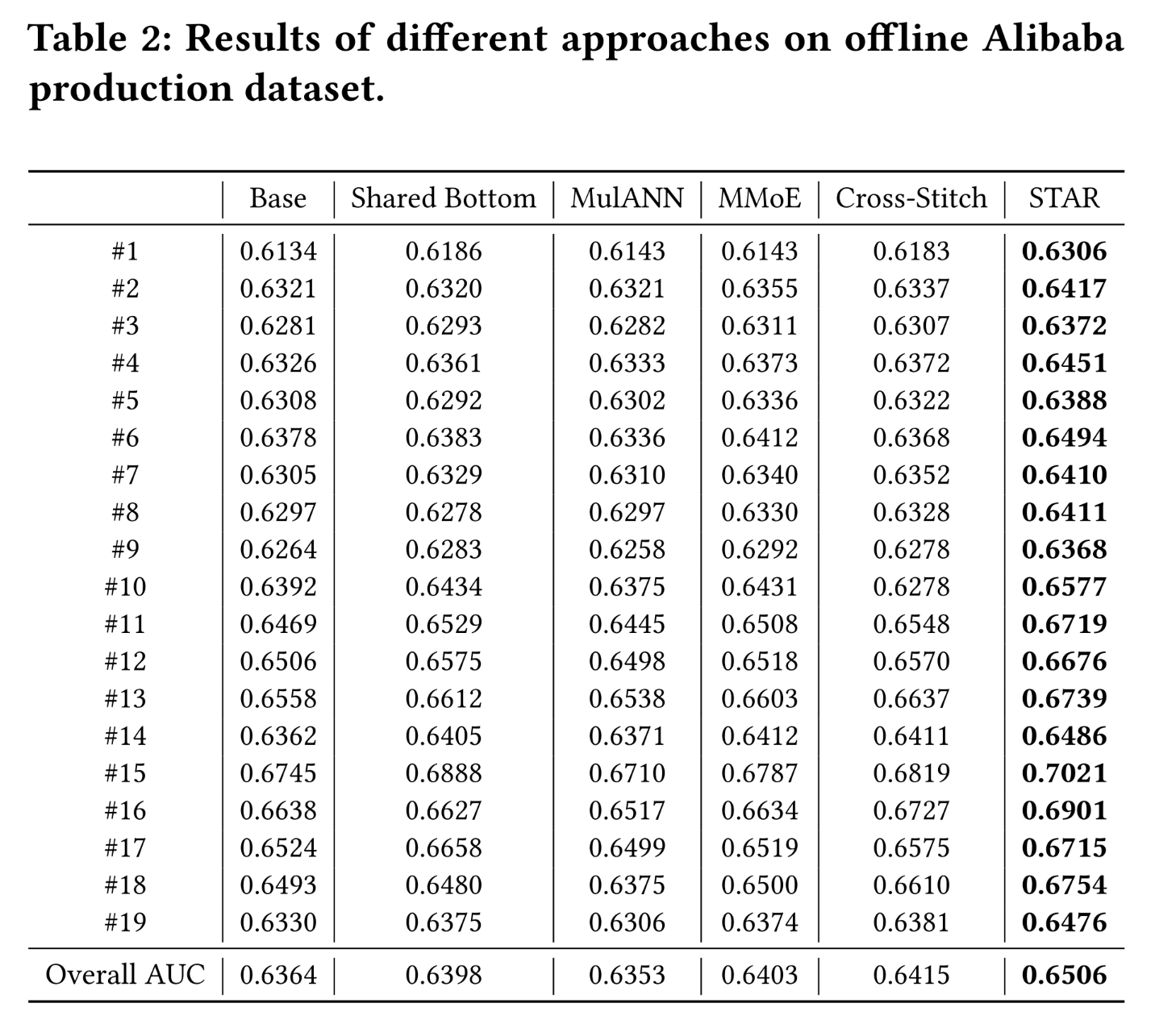
我们在
Alibaba生产数据集上评估了所有方法。为了公平比较,所有baseline方法和STAR模型均使用我们提出的auxiliary network进行训练。如Table 2所示:性能的一致的提升验证了
STAR的有效性。值得注意的是,
MulANN的性能不如Base模型,这表明模糊domain difference会损害multi-domain CTR prediction的建模。此外,
shared Bottom model、MMoE、Cross-Stitch和STAR的整体性能均优于Base模型。这表明利用domain relationship和捕获domain distinction对于提升预测性能至关重要。尽管
Shared Bottom、MMoE和Cross-Stitch的整体性能优于Base模型,但值得注意的是,在某些domains中,Shared Bottom, MMoE, and Cross-Stitch的AUC值低于Base模型,例如domain # 5, #6, and #16。我们推测这是因为这些模型在不同domains中的学习存在冲突。相比之下,
STAR通过其star topology避免了这个问题,其中domain-specific parameters仅通过该domain内的示例进行更新。与Base模型相比,所提出的STAR模型在所有domains上均表现出更优的性能。STAR也一致地优于Shared Bottom模型,这表明在multi-domain learning中,top specific layers的information sharing至关重要,因为所有domains共享相同的label space。STAR的性能也优于MMoE和Cross-Stitch模型,这表明显式地建模domain relationships比通过gate networks或cross-stitch units来隐式建模domain relationships更具优势。
1.3.2 消融研究
为了分析
STAR模型各个组件的作用,我们进行了一些消融实验。STAR Topology FCN and PN:我们分析了STAR中不同组件的影响。具体而言,我们研究了star topology FCN和PN各自的效果。我们比较了以下模型(a):使用BN训练的Base模型。(b):使用PN训练的Base模型。(c):使用BN训练的STAR FCN。(d):STAR模型(STAR FCN + PN)。
结果如
Table 3所示。我们观察到:单独使用
star topology FCN和PN均可优于Base模型。将它们结合起来可以进一步提升性能。
该结果验证了
star topology FCN和PN的有效性。目前看来,仅仅利用
PN就能得到大部分的贡献(+0.0121)。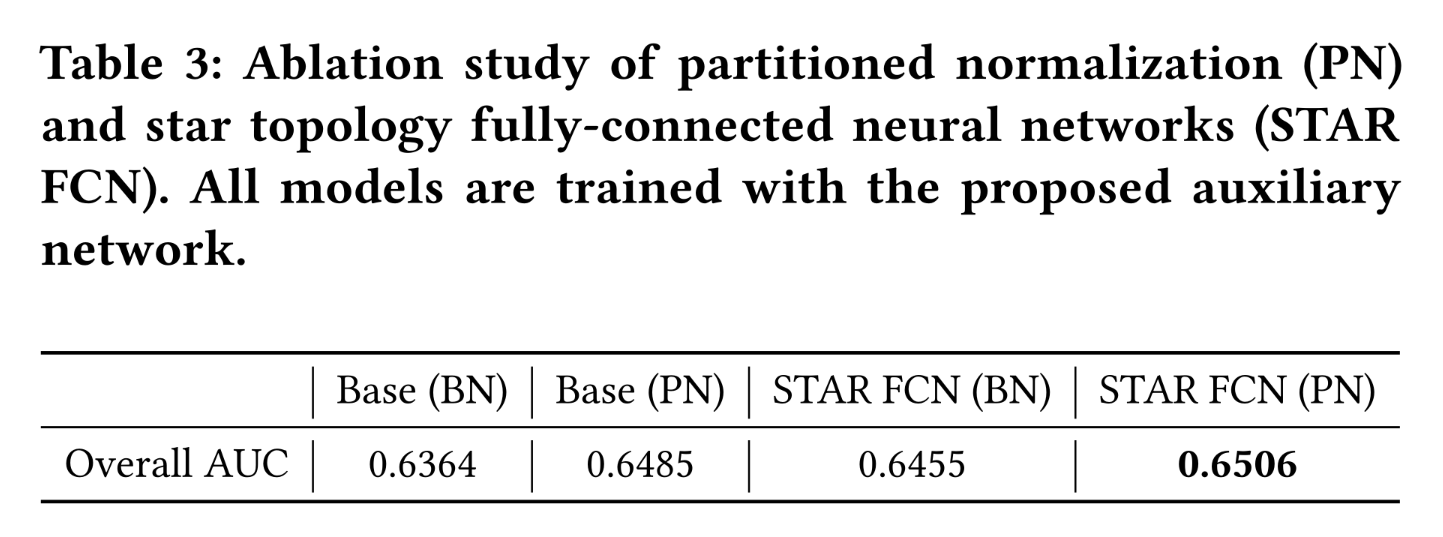
Normalization:Normalization方法是深度学习中非常有效的组成部分,许多实践表明,它可以ease optimization,并使非常深的网络能够收敛。我们分析了不同normalization方法(包括Batch Normalization: BN、Layer Normalization: LN和我们提出的Partitioned Normalization: PN)对multi-domain CTR prediction的影响。BN累积global statistics并学习来自所有domains的样本的global parameters。LN是一种代表性的instance-based normalization方法,它沿通道维度(channel dimension)进行操作,避免了来自不同domains的样本的mixing statistics。
结果如
Table 4所示。我们的第一个观察结果是,
LN和PN的性能均优于BN。这一观察结果验证了来自不同domains的数据具有不同的分布,需要特定的normalization。使用global normalization会掩盖domain differences,从而降低multi-domain CTR prediction的性能。我们还观察到
PN的性能优于LN,这验证了domain-specific normalization优于instance-specific normalization,因为PN能够获得domain内更精确的moments。

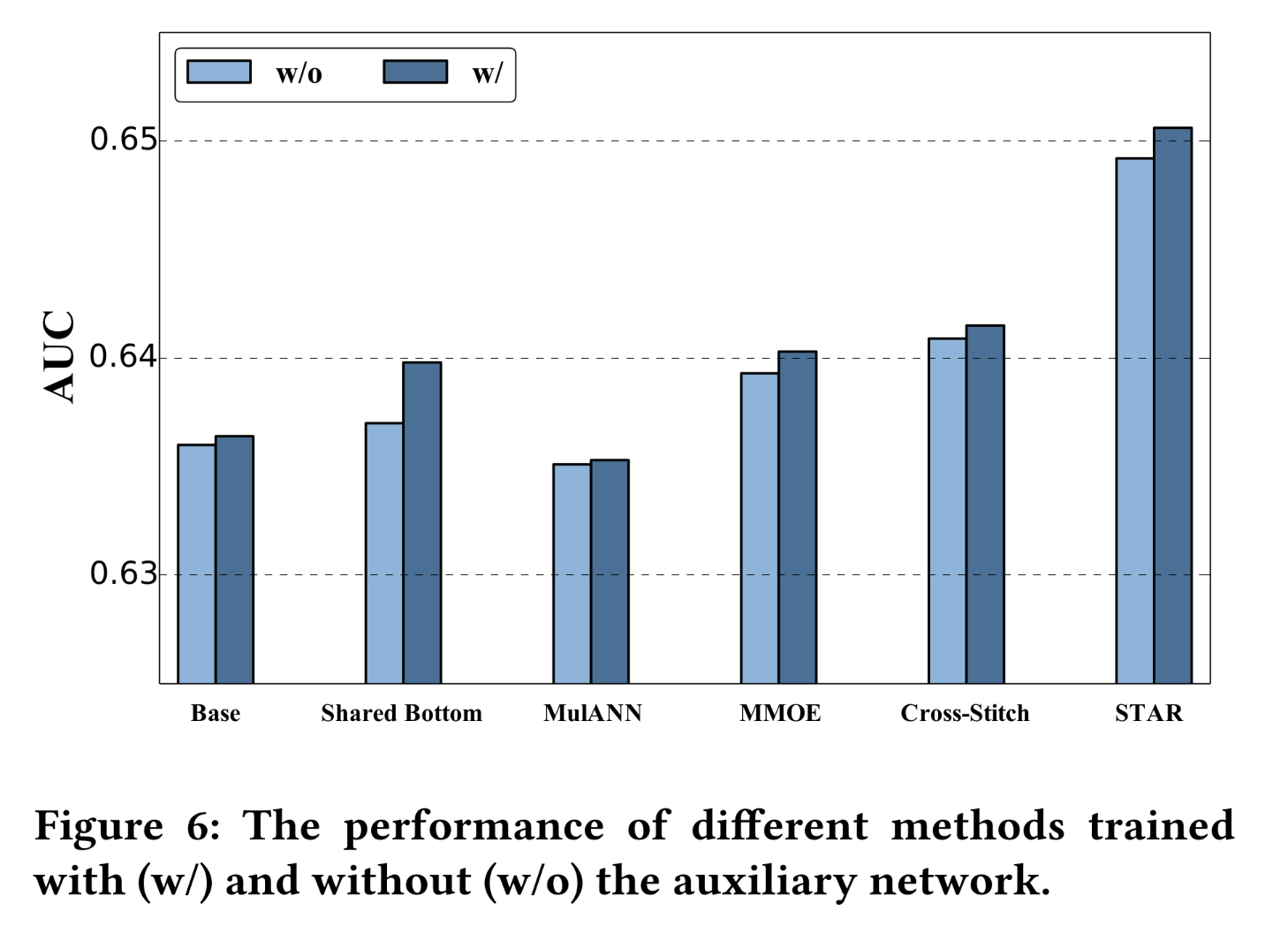
Auxiliary network:我们进行了实验,以评估auxiliary network对不同模型的影响。所有方法均分别在with and without所提出的auxiliary network的情况下进行训练。结果如Figure 6所示。我们观察到,
auxiliary network能够一致地改进所有方法。该结果验证了充分利用domain features并将其用于捕获domain distinction的重要性。我们还观察到,
auxiliary network对MulANN的改进效果略弱于其他方法。原因可能是,用于掩盖domain differences的adversarial loss与用于捕获domain differences的domain feature相矛盾。
Ability to Capture Domain Distinction:每次点击成本 (Cost-per-click: CPC) 是展示广告中广泛使用的一种基于效果的付费模式,广告商针对clicks出价。在CPC模式下,展示系统将每千次展示有效成本 (effective cost per mille: eCPM) 计算为:bid * CTR。系统根据eCPM的降序排列来分配impressions。在CPC中,为了实现具有竞争力的广告系统,CTR模型需要进行良好的校准(《On Calibration of Modern Neural Networks》),也就是说,predicted CTR应该尽可能接近actual CTR。我们证明
STAR模型校准得更好,并且能够捕获到domain distinctions。我们计算了每个domain的predicted CTR over CTR (PCOC)。需要注意的是,PCOC越接近1.0,CTR prediction就越准确。为了便于说明,我们在Figure 7中展示了Base模型和STAR模型的PCOC。我们可以看到,与
Base模型相比,STAR模型在不同domains的PCOC更加集中,且集中在1.0附近。该结果验证了STAR模型捕获domain distinction的能力。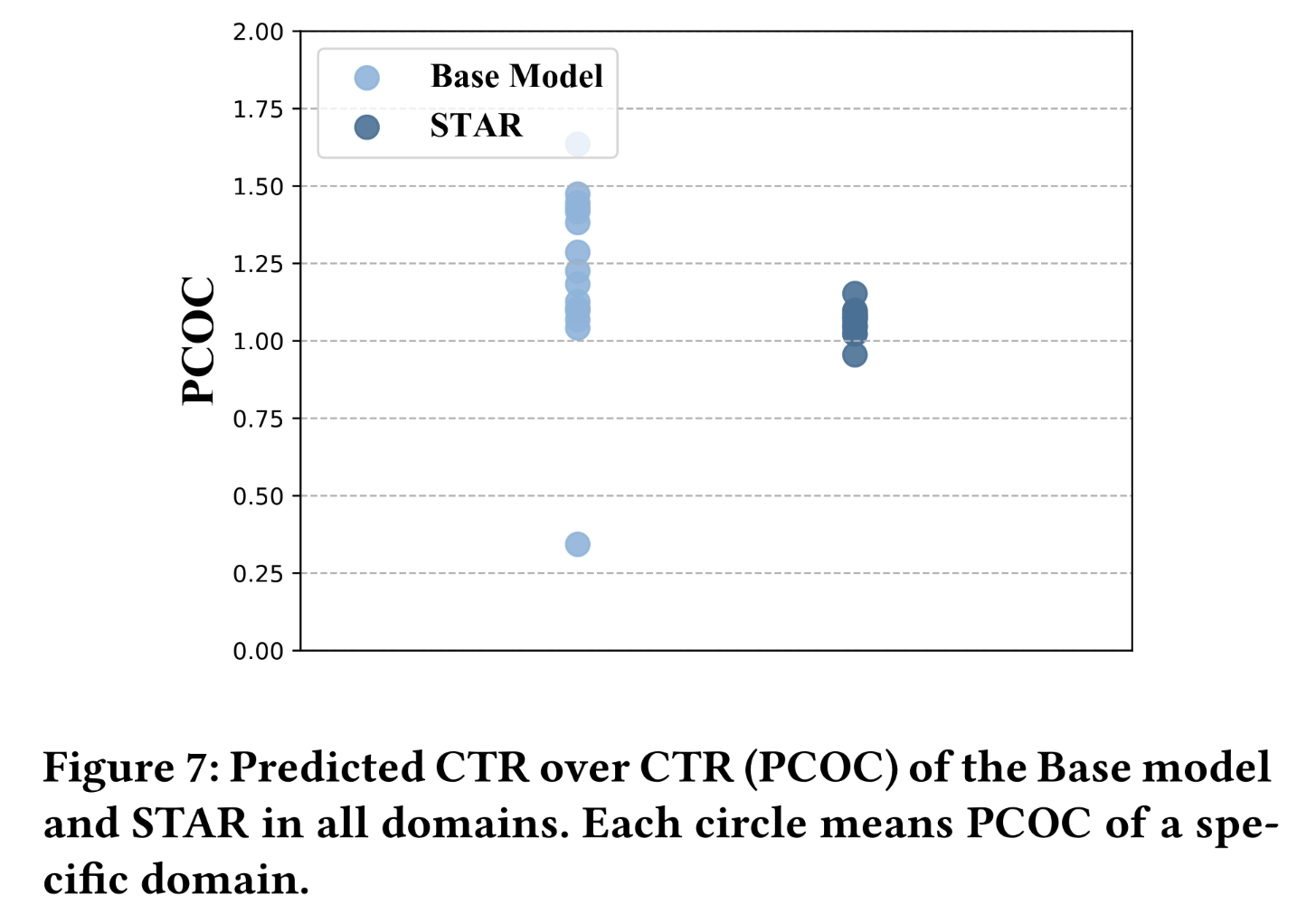
1.3.3 Production
Online serving及挑战:工业推荐系统面临的挑战之一是特征分布和CTR会随时间发生显著变化。为了实时捕获数据的动态变化,持续使用实时样本更新CTR models至关重要,以防止模型过时。然而,对于multi-domain CTR prediction,每个domain的样本比例会随时间变化。例如,某些business domains在早上流量高峰,而另一些business domains在晚上流量高峰。如果我们直接按时间顺序来训练模型,数据比例随时间的变化会导致模型学习不稳定。为了解决这个问题,我们重新设计了data pipeline,并维护一个buffer来存储历史样本的一个滑动窗口,以避免样本比例(example percentage)的突变。具体来说,
buffer中的样本首先被随机混洗,然后进行采样以构建一个mini-batch。将mini-batch样本馈入模型后,将这个mini-batch从buffer中移除,并将新到达的数据添加到该buffer中。我们通过实证研究发现,这种训练方式比传统的online updates更加稳定。值得注意的是,在
serving过程中,每个domain的FCN的权重都会被预先计算(pre-computed),以加快推理速度。这样一来,STAR的计算时间与Shared Bottom model相当。这种系统化的优化使得STAR能够稳定地服务于多个business domains的主流量。自
2020年以来,STAR已部署在Alibaba的展示广告系统中,服务于超过60 business domains。我们计算了所有domains的整体性能提升。Table 5展示了STAR相对于之前的production模型(即Base模型)的改进。在我们的online A / B test中,STAR的引入带来了8.0%的整体CTR提升和6.0%的整体RPM提升。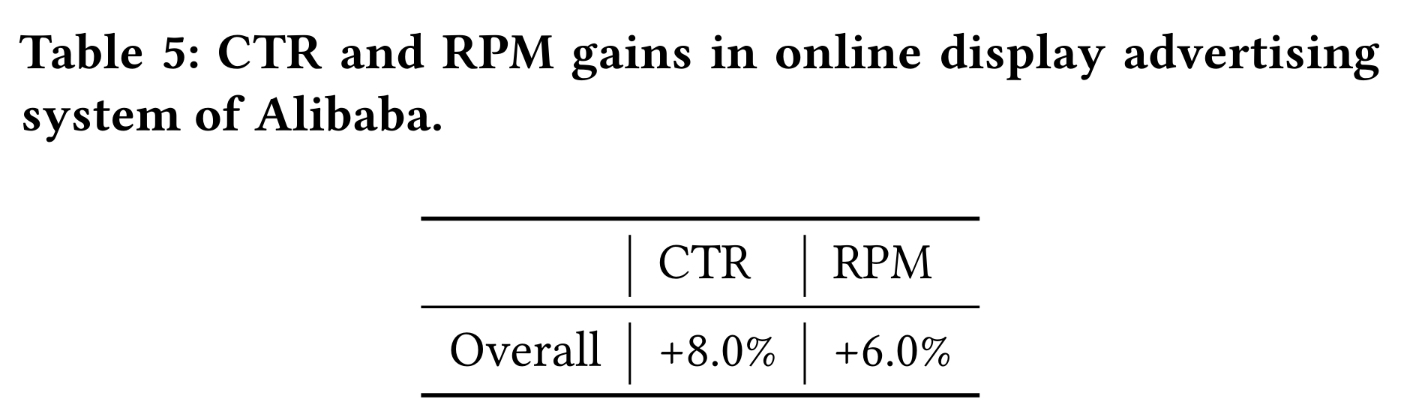
1.4 结论
本文提出了
star topology adaptive recommender: STAR来解决multi-domain CTR prediction问题。STAR并非为不同domains分别构建独立模型,也并非简单地混合所有样本并维护一个共享模型,而是采用star topology:由shared centered parameters和domain-specific parameters组成。shared parameters学习domains之间的共性,并通过所有样本进行更新。domain-specific parameters则捕获domains之间的差异,从而实现更精细的预测,这些参数通过特定domain内的样本进行学习。
通过这种方式,
STAR可以根据domain来自适应地调整其参数,以获得更精确的预测结果。实验结果表明,STAR在multi-domain CTR prediction方面具有显著优势。自2020年以来,STAR已部署在Alibaba的广告系统中,CTR提升了8.0%,RPM提升了6.0%。