一、 AdaTT [2023]
《AdaTT: Adaptive Task-to-Task Fusion Network for Multitask Learning in Recommendations》
多任务学习(
multi-task learning: MTL)旨在通过同时训练多个任务来提升机器学习模型的性能和效率。然而,MTL研究面临两大挑战:1):如何有效地建模任务间的关系以实现知识共享(knowledge sharing)。2):如何联合学习task-specific knowledge和shared knowledge。
本文提出了一种
Adaptive Task-to-Task Fusion Network: AdaTT的新型模型来应对这两个挑战。AdaTT是一个深度融合网络(deep fusion network),由multiple levels的task-specific and optional shared fusion units构成。通过利用残差机制(residual mechanism)和门控机制(gating mechanism)进行task-to-task fusion,这些units能够自适应地学习shared knowledge和task-specific knowledge。为了评估AdaTT的性能,我们使用不同的任务组在公开benchmark数据集和工业推荐数据集上进行了实验。结果表明,AdaTT的性能显著优于现有的SOTA baselines。此外,我们的端到端实验表明,该模型相比其他模型也表现出更优的性能。这些
fusion units其实就是experts。所谓的残差机制就是:首先对
task-specific experts进行线性组合,门控机制学习的是这个线性组合的残差。在线推荐系统旨在为用户生成个性化的高质量推荐内容。这类系统的有效性通常取决于它准确学习用户偏好的能力,而这往往需要同时优化多个目标(
multiple objectives)。例如,短视频推荐系统既需考虑用户观看视频的可能性,也需关注用户点赞视频的可能性。多任务学习(multi-task learning: MTL)是应对此类场景的典型解决方案。通过在单一框架内联合训练多个任务,多任务学习具有多项优势:首先,它能提升计算效率,这对于大规模在线推荐系统至关重要。
其次,它通过跨任务正则化(
cross-task regularization)和知识共享(knowledge sharing),可增强模型性能。
然而,多任务学习也面临独特的挑战。其中核心挑战之一是建模任务间的关系。由于每个任务与其他任务的相关程度可能存在差异,仅对所有任务的通用共性(
general commonalities)进行建模是不够的。且随着任务数量的增加,该问题的复杂性会进一步加剧。有效的任务关系建模(task relationship modeling)是实现高效的任务自适应知识共享(task-adaptive knowledge sharing)的关键。例如,“分享视频” ("sharing a video")任务的共享知识可重点向“点赞视频”("liking a video")等相似任务倾斜,同时从“观看视频” ("watching a video")等样本丰富的任务中汲取不同方面(different aspects)的知识。而对于高度不相关的任务,则应最小化其共享学习(shared learning)的程度。以往的研究(
《Multitask learning》、《End-to-end multi-task learning with attention》)通常采用static shared representations。其他方法如交叉缝合网络(
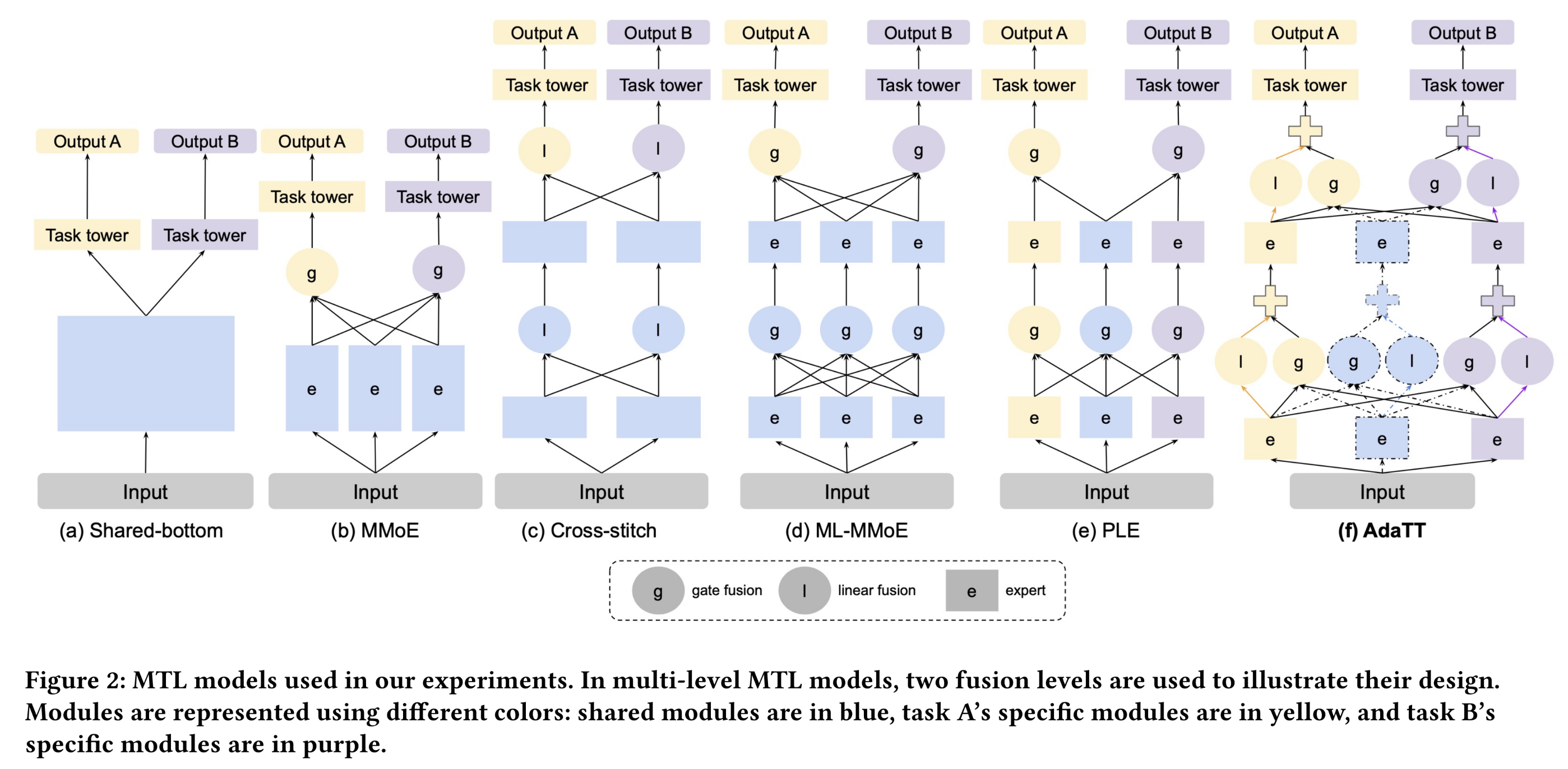
Cross-stitch Networks)(《Cross-stitch networks for multi-task learning》)(如Figure 2(c)所示),通过学习矩阵来建模多个子网络间的关系,但这些权重对所有样本均保持固定,且子网络仅在一定程度上是task-specific的。近年来的方法如多门混合专家模型(
MMoE)(《Modeling task relationships in multi-task learning with multi-gate mixture-of-experts》)(如Figure 2(b)所示)和PLE(《Progressive layered extraction (ple): A novel multi-task learning (mtl) model for personalized recommendations》)(如Figure 2(e)所示),采用专门的门控网络(gating networks)动态组合shared sub-modules以实现灵活共享,但这些方法所建模的任务间关系较为模糊且是间接的。
除
shared learning外,task-specific learning也是多任务学习中不可或缺的部分。在两者之间取得恰当的平衡,对于解决任务冲突(task conflicts)和实现跨任务正则化(cross-task regularization)至关重要。一方面,多任务学习可能会遭遇负向迁移问题(
negative transfer)——即对某一任务的优化会对另一任务的性能产生负面影响,尤其是在任务目标(task objectives)相互冲突的情况下。在此类场景中,多任务学习模型应自适应地侧重task-specific learning。另一方面,过度的
task-specific learning和不足的shared learning可能导致过拟合,从而削弱跨任务正则化(cross-task regularization)的优势。
每个任务的
training data的数量及其分布也会影响学习的侧重点:数据量较多的任务可更多地依赖自身的
specific learning。而数据量较少或分布高度倾斜的任务则可更多地专注于
shared learning。
考虑样本间的差异,则能让两者的权衡更具动态性。因此,自动地
learn to balance这两种学习的类型具有重要意义。许多soft parameter sharing模型能够实现这一点,无需繁琐的人工调优(《Multitask learning》),也无需在简化假设下为所有样本学习static structures(《Beyond shared hierarchies: Deep multitask learning through soft layer ordering》、《Adashare: Learning what to share for efficient deep multi-task learning》、《Branched multi-task networks: deciding what layers to share》)。然而,如何建模shared learning与task-specific learning之间的交互以提升性能,仍需进一步研究。为同时应对这些挑战,我们提出一种新型多任务学习模型——
Adaptive Task-to-Task Fusion Network: AdaTT。为提升
shared learning效果和模型可解释性,我们引入task-specific experts、shared experts和gating modules,以同时在task-pair levels和all-task levels显式地建模task-to-task interaction。为实现
task-specific learning与shared learning的协同作用,我们在独立的fusion modules中对二者进行区分和建模,并在每个fusion module中采用不同的experts和融合策略。fused results随后通过残差机制(residual mechanism)进行组合。此外,我们采用multiple levels of fusion,每个level专注于不同的功能,以提升学习性能。所谓的残差机制就是:首先对
task-specific experts进行线性组合,门控机制学习的是这个线性组合的残差。
为评估
AdaTT的性能,我们在真实世界的短视频推荐系统上进行了实验。通过设置不同的实验组,检验其对不同task relationships的适应性(adaptability)。同时,我们利用公共基准数据集进一步验证其泛化能力。在所有实验中,AdaTT在不同数据集和task groups上均一致地优于baseline模型。为评估
AdaTT的大规模性能,我们对其超参数(重点关注fusion levels数量、experts数量)展开了研究。此外,我们设计了消融实验和可视化分析,以深入探究AdaTT的内部机制。消融实验验证了残差设计(residual design)以及独立建模的融合模块(fusion modules)在实现互补的task-specific learning和shared learning方面的有效性。通过对deep fusion levels和shallow fusion levels的expert weights进行可视化,我们更深入地理解了不同fusion levels, tasks, and task groups所学到的独特且有意义的共享模式(sharing patterns)。fusion levels就是网络层数。总之,本文的贡献如下:
提出一种新型多任务学习模型——
Adaptive Task-to-Task Fusion Network: AdaTT,该模型能够同时实现自适应的task-to-task knowledge sharing和稳健的task-specific learning。通过在真实世界
benchmark数据和大规模视频推荐系统上进行全面实验,评估了AdaTT相较于多种baselines的有效性。通过对各个
fusion modules进行消融实验,并研究其fusion units在shallow and deep knowledge的处理中的运作机制,验证了模型的可解释性。
AdaTT就是PLE的变体。
1.1 相关工作
多任务学习在计算机视觉、自然语言处理、语音识别、机器人技术、以及推荐系统等多个领域具有广泛应用。众多研究致力于开发创新的多任务学习架构,这些模型可分为硬参数共享(
hard parameter sharing)和软参数共享(soft parameter sharing)两大类。hard parameter sharing:hard parameter sharing采用预定义的模型架构,其中某些层(certain layers)为所有任务所共享,而其他层(other layers)则为单个任务所专用。共享底部模型(
shared-bottom model)(《Multitask learning》)是hard parameter方法中应用最广泛的模型之一,该模型利用shared lower layers来进行representation learning,并在底层之上设置task-specific layers。多线性关系网络(
Multilinear Relationship Networks)(《Learning multiple tasks with multilinear relationship networks》)通过在task specific layers的参数上施加张量正态先验(tensor normal priors),对该结构进行了改进。另一个例子是
UberNet(《Ubernet: Training a universal convolutional neural network for low-, mid-, and high-level vision using diverse datasets and limited memory》),它采用图像金字塔(image pyramid)方法,联合解决多种low-, mid-, and high-level视觉任务。UberNet通过task-specific layers和shared layers来处理金字塔中的每个分辨率(resolution)。
hard parameter sharing模型通常结构紧凑,但需要大量人工工作来确定共享内容,且缺乏适应性(adaptability)。此外,在不相关的或冲突的任务(irrelevant or conflicting tasks)之间过度共享可能导致负向迁移(negative transfer),从而对模型性能产生负面影响。soft parameter sharing:为更好地应对这些挑战,研究人员提出了多种soft parameter sharing多任务学习模型。交叉缝合网络(
Cross-stitch network)(《Cross-stitch networks for multi-task learning》)和水闸网络(Sluice network)(《Latent multi-task architecture learning》)利用trainable parameters对各层的输出进行线性组合。然而,它们所采用的线性组合是固定的,无法充分反映单个样本上任务关系的差异性(task relationship distinction)。其他研究提出利用基于
inputs的attention modules或门控模块(gating modules),为每个任务动态地组合或提取知识。例如:MTAN(《End-to-end multi-task learning with attention》)采用attention modules生成elementwise masks,从一个shared representation中提取task-specific knowledge。多门混合专家模型(
MMoE)(《Modeling task relationships in multi-task learning with multi-gate mixture-of-experts》)引入a mixture of experts,并利用门控网络(gating networks)为每个任务动态地融合这些experts。最近提出的
PLE(《Progressive layered extraction (ple): A novel multi-task learning (mtl) model for personalized recommendations》)进一步增强了knowledge sharing的灵活性。PLE模型显式地引入task-specific experts和shared experts,并提出带有门控模块的渐进分离路由(progressive separation routing)策略,以选择性地、动态地融合知识。
在这类工作中,
PLE与本文提出的模型最为相关。不同之处在于:本文引入了两种互补的
fusion modules,分别对task-specific learning和shared learning进行建模。此外,除了显式地引入
shared modules从而用于学习所有任务的共性之外,我们还基于inputs进行直接的task-pair fusion,以最大化knowledge sharing的灵活性。
神经架构搜索(
Neural Architecture Search: NAS):NAS方法已被应用于多任务学习,以自动学习模型结构。分支多任务网络(
Branched Multi-Task Networks)(《Branched multi-task networks: deciding what layers to share》)通过基于affinity scores对任务进行聚类,生成树状结构(tree structure),并将不相似的任务分配到不同的分支(branches)。《Learning to branch for multi-task learning》利用Gumbel-Softmax sampling进行分支(branching)操作,而非预先计算的affinity scores,从而支持端到端训练。软层排序技术(
Soft Layer Ordering)(《Beyond shared hierarchies: Deep multitask learning through soft layer ordering》)指出了传统fixed-order sharing方法在多任务学习模型中的局限性,并提出学习task-specific scaling parameters,从而实现针对每个任务的a flexible ordering of shared layers。AdaShare(《Adashare: Learning what to share for efficient deep multi-task learning》)提出一个task-specific policy,为每个特定任务选择要执行的layers。子网络路由(
Sub-Network Routing: SNR)(《Snr: Sub-network routing for flexible parameter sharing in multi-task learning》)将shared layers划分为sub-networks,并通过latent variables学习它们之间的连接。
NAS方法减少了大量人工工作,并提高了多任务学习模型中sharing patterns的灵活性。然而,由于穷尽搜索所有可能的model configurations在组合上具有复杂性,这些方法通常依赖于简化假设来限制搜索空间,如branching(Branched Multi-Task Networks、《Learning to branch for multi-task learning》)、routing(Sub-Network Routing)、layer ordering(Soft Layer Ordering)、layer selecting(AdaShare)等等。此外,generated structures无法根据单个样本进行调整。除了专注于多任务学习的架构设计(
architecture design)的研究外,另一类研究旨在改进多任务学习的优化过程(optimization)。基于不确定性的加权方法(
uncertainty-based weighting)(《Multi-task learning using uncertainty to weigh losses for scene geometry and semantics》)根据任务的不确定性来学习每个任务的权重。GradNorm(《Gradient normalization for adaptive loss balancing in deep multitask networks》)通过控制不同任务的梯度幅度(gradient magnitudes)来平衡它们的训练速度。GradDrop(《Just pick a sign: Optimizing deep multitask models with gradient sign dropout》)通过概率性的方式选择a sign,并移除相反符号(opposite sign)的梯度。梯度手术(
PCGrad)(《Gradient surgery for multi-task learning》)将conflicting task gradients投影到彼此的法平面上。RotoGrad(《RotoGrad: Gradient Homogenization in Multitask Learning》)通过操纵任务梯度(task gradients)的幅值和方向来缓解冲突。《Multi-task learning as multi-objective optimization》将多任务学习视为一个multi-objective optimization问题,旨在寻找一个帕累托最优解(Pareto optimal solution)。《Can Small Heads Help? Understanding and Improving Multi-Task Generalization》引入under-parameterized small towers的自辅助损失(self-auxiliary losses),以平衡帕累托效率(Pareto efficiency)和跨任务泛化能力。
尽管这些方法能够带来性能提升,但仅依靠它们而缺乏强大的模型架构,可能会限制模型性能的上限。
1.2 模型架构
为联合学习
adaptive shared representations并增强task-specific learning,我们提出一种新型模型——Adaptive Task-to-Task Fusion Network: AdaTT。AdaTT利用门控机制(gating mechanism)和残差机制(residual mechanism),在多个fusion levels中自适应地融合experts。考虑包含两个
prediction tasks的多任务学习场景,我们通过Figure 1展示了具有两个fusion levels的AdaTT架构。AdaTT由一个multi-level fusion network和多个task towers来组成:fusion networks由task-specific units和可选的shared fusion units构成。这些
units其实就是experts。task towers构建在fusion network之上,并与final fusion level的task-specific units相连。
我们的框架具有通用性,支持灵活地选择
expert modules、task tower networks、gating modules,并可配置experts数量和fusion levels数量。在以下章节中:我们首先介绍
AdaTT的一个特例(名为AdaTT-sp),该特例仅使用task-specific fusion units(如Figure 1(a)所示)。这个模型没有
shared fusion units。随后,我们将描述通用的
AdaTT设计(如Figure 1(b)所示)。
模型的整体思想非常类似于
PLE,仅仅只有少量的改动(如何融合experts)。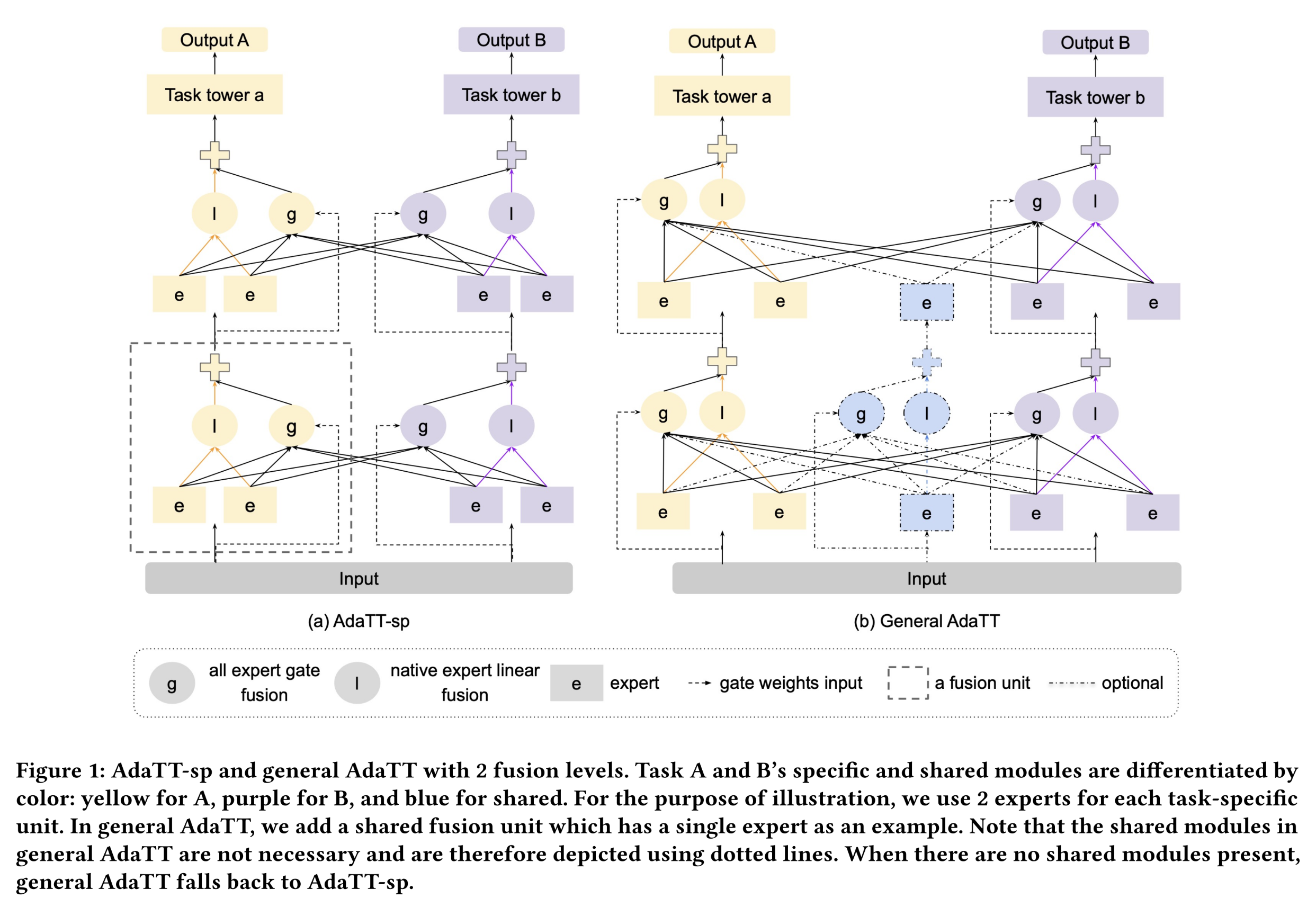
1.2.1 AdaTT-sp
AdaTT-sp的详细设计如下:给定其中:
fusion levels数量。task tower。fusion level的fusion unit的输出。此处,fusion layer(s):其中,
fusion unit。一个
fusion unit就是一个layer,并且上一层的输出作为下一层的输入。
a. Fusion Unit
下面详细介绍
fusion level的所有输出input其中:
expert representation的维度。第
expert network都会生成一个长度为experts的垂直拼接、以及所有任务的experts的垂直拼接,具体而言:其中:
由于一个任务与其他任务可能具有不同的相关程度(
degrees of correlation),gating module)task-to-task knowledge fusion,该模块组合所有任务的expertsnative experts从概念上讲,门控模块用于建模
shared learning,而native experts的线性组合用于建模task-specific learning。具体而言,任务specific unit的输出公式为:其中:
gate weights,用于组合注意:
本质上:线性组合
task-specific experts,再叠加selected all experts。由于每一层都有线性组合,因此这相当于线性组合了不同level的experts。具体而言,
experts的融合方式如下:其中:
在
softmax激活函数的单层MLP:其中:
而在
当
fusion units仅包含一个expert)时,为简化起见,native expert分配单位权重。
b. 简化
为提高实现效率,我们实际上可以用零填充
experts。因此,可见,线性融合模块(
linear fusion module)的引入仅导致计算量的微小增加。
1.2.2 General AdaTT
在通用形式中(如
Figure 1(b)所示),AdaTT采用可选的shared fusion units。从概念上讲,task-specific module pairs之间的fusion用于建模细粒度共享(fine-grained sharing),而task-specific modules与shared modules之间的fusion用于迁移适用于所有任务的广泛知识,从而实现高效且灵活的task-to-task knowledge sharing。general AdaTT的计算过程与AdaTT-sp类似,但在final fusion level中,shared fusion units不执行任何融合操作,仅生成expert outputs从而供task-specific fusion units来处理。这相当于在每一层都增加一组
shared-experts,并逐层提取shared information,类似于PLE。总之,
AdaTT显式地学习task specific knowledge,并将其与shared knowledge进行自适应地融合。这种融合具有任务适应性(task-adaptive),原因如下:1):门控模块(gating modules)学习相对于任务的native experts的残差(residual)。2):每个task-specific unit融合experts,利用基于input的specialized gating module(从第二个fusion level开始,input是unique的)。
通过允许每个任务直接且灵活地从其他任务中学习
shared knowledge,AdaTT相较于仅依赖shared expert(s)作为媒介的PLE具有更高的灵活性。此外,AdaTT可选择仅使用task-specific experts。与PLE(在单个门控模块中处理所有selected experts)不同,AdaTT在每个fusion unit内的不同线性融合模块(linear fusion module)中分别融合native experts。这种设计增强了每个level of fusion后task-specific learning的稳健性。尽管结构简洁,但实验结果表明,AdaTT优于PLE——PLE在不同fusion units中对experts进行选择,并通过不同的路由路径(routing paths)区分这些experts。AdaTT考虑了task-specific experts的线性组合,而PLE没有这一项。AdaTT的task-specific gates考虑所有的experts,而PLE仅考虑shared experts和当前任务的experts。AdaTT可以剔除shared experts,而PLE必须包含shared experts。
1.3 实验
在本节中,我们呈现全面的实验结果,以突显所提出的
AdaTT模型的有效性,并提供对该模型的更深入理解。本节分为四个部分:
首先,我们简要描述
baseline模型。其次,通过在真实世界的工业级数据集和公共数据集上进行实验,评估
AdaTT相较于SOTA的多任务学习模型的有效性。对于工业级数据集,我们使用三组不同的prediction tasks,以检验这些多任务学习模型在各种场景下的性能。接下来,我们进行单个组件的研究:通过消融
AdaTT中包含residual design的重要性,其中residual design用于组合独立的模块来融合不同的experts。同时,可视化每个task-specific unit中学到的expert weights,以展示AdaTT如何学习任务间的适当交互(这对于有效的knowledge sharing至关重要)。最后,我们对
AdaTT的超参数进行研究,以理解fusion levels数量和experts数量与AdaTT性能之间的关系。
1.3.1 Baseline Models
我们采用
Shared-bottom、MMoE、Multi-level MMoE(原始single-level MMoE的扩展)、PLE、以及Cross-stitch Networks作为基线模型。在这些模型中,MMoE、PLE和Cross-stitch Networks均采用soft-parameter sharing技术。MMoE:该模型为每个任务学习专用的门控模块,以融合多个shared experts。给定expert模块task tower模块其中:
Multi-level MMoE (ML-MMoE):该模型通过引入多个levels of fusion,扩展了原始的single-level MMoE。在ML-MMoE中,higher level experts将lower level experts作为输入,其中lower level experts由不同门控模块融合而来。与原始MMoE类似,所有门控模块均基于相同的原始input。Cross-Stitch:该模型引入cross-stitch units,通过学到的权重对不同任务的hidden layers进行线性组合。PLE:该模型显式地引入task specific experts和shared experts,并采用渐进分离路由(progressive separation routing)策略。门控模块用于融合task-specific and shared units中选定的experts。在PLE中,shared units可融合同一level的所有experts,而task-specific units仅融合shared experts以及该任务的native experts。该模型与AdaTT最为接近。
上述所有模型的对比如
Figure 2所示。
1.3.2 Evaluation on Large-scale Short Video Recommendation
在本节中,我们呈现短视频推荐系统上的实验结果。该系统展示推荐视频列表,这些视频基于多个任务的分数进行排序。这些任务大致可分为两类:
engagement任务:考虑用户的显式反馈,如评论视频。consumption任务:反映用户的隐式反馈,如观看视频。
Task groups:我们创建三组任务,以全面评估这些模型在不同任务关系下的性能:第一组包含一个
engagement任务和一个consumption任务,预计它们的任务相关性(task correlation)相对较低。第二组由两个相关性较高的
consumption任务组成:第一个
consumption任务与第一组中的consumption任务相同。第二个
consumption任务选择为与第一组中的engagement任务具有相近的正例率。
第一组和第二组均仅包含二分类任务。
第三组增加任务数量至五个,并选择高度多样化的任务:其中三个为
consumption任务,两个为engagement任务。一个
consumption任务为回归任务,其余四个任务为二分类任务。在用户情感方面,包含一个负向任务(反映用户不喜欢)、以及四个正向任务。
其中一个正例极为稀疏的
engagement任务用作辅助任务。辅助任务参与训练,但是不参与评估。
在报告所有
task groups的结果时,我们首先呈现回归任务(若存在),随后按正例率从高到低的顺序呈现二分类任务。实验设置:
我们收集了约
70 billion个样本的数据集用于训练模型,并在约10 billion个样本的测试集上测试其性能。在特征处理中,我们将所有
sparse features转换为dense embeddings,并与dense features拼接起来。所有任务使用相同的输入。
所有模型在相同的框架下进行训练和测试,采用相同的
optimization settings(如optimizer、learning rate和batch size)。训练时,二分类任务使用
Cross Entropy loss,回归任务使用MSE loss;所有任务的loss相加,并以相等权重进行优化。测试时,二分类任务使用归一化熵(Normalized Entropy: NE),回归任务使用MSE。归一化交叉熵:
首先定义背景正例率为样本集合的经验正例率
其次,用所有样本的平均损失函数除以背景熵,即可得到归一化熵。
模型超参数:在实验中,所有模型均具有
3 hidden layers,激活函数为ReLU。对于每组实验,我们进行两组对比:第一组将
MMoE、PLE、AdaTT与shared-bottom模型进行对比。为保证公平性:PLE、ML-MMoE和AdaTT均设置2 levels of fusion,这2 levels of fusion分别使用single-layer MLP experts,第一层hidden dimensions为256、 第二层为128。MMoE采用hidden dimensions = [256,128]的2-layer MLP experts。
此外:
同时,我们对每个
level of fusion的experts总数进行限制。这些模型中的所有门控模块均采用带有
softmax激活函数的1-layer MLP。值得注意的是,与expert模块相比,门控模块所需的计算量显著更小——尽管两类模块的input维度相同,但门控模块的总output维度几乎小两个数量级。所有模型的
task towers均为a single hidden layer of 64 units。
在该设置下,所有模型的计算量具有可比性(
task towers和expert模块主导计算过程)。在实验中,我们调优PLE和AdaTT的task-specific experts数量和shared experts数量,同时调优MMoE的experts总数。第二组将
AdaTT、cross-stitch model与shared-bottom模型进行对比。为与
cross-stitch model具有可比性,AdaTT采用与前一组实验类似的超参数,但每个任务仅使用1 expert,且不使用shared expert。cross-stitch model具有2 cross-stitch units,且hidden layers与AdaTT相同。
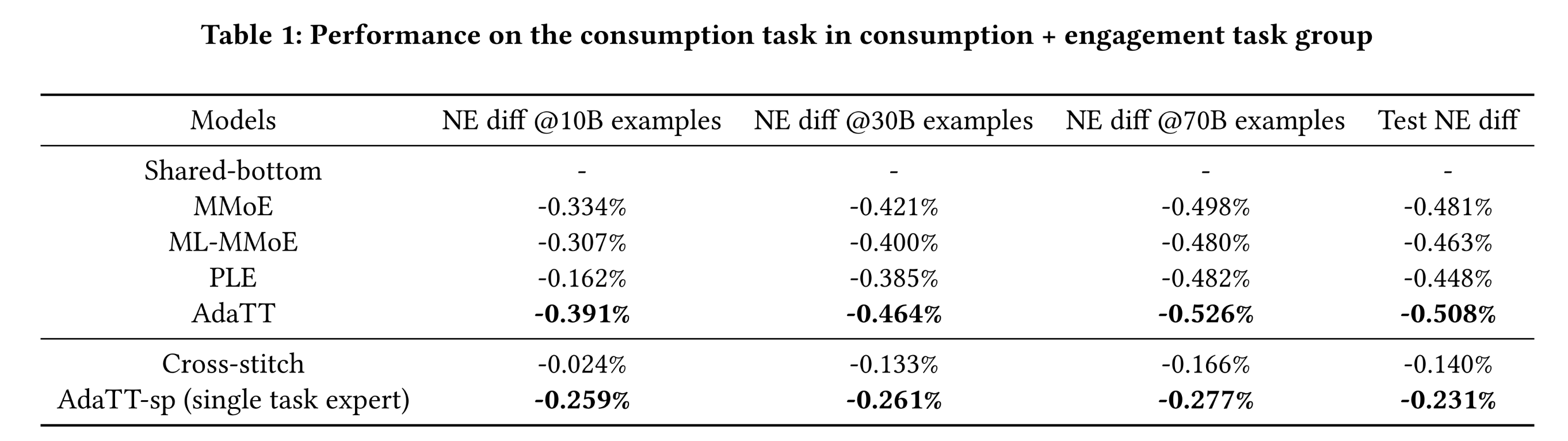
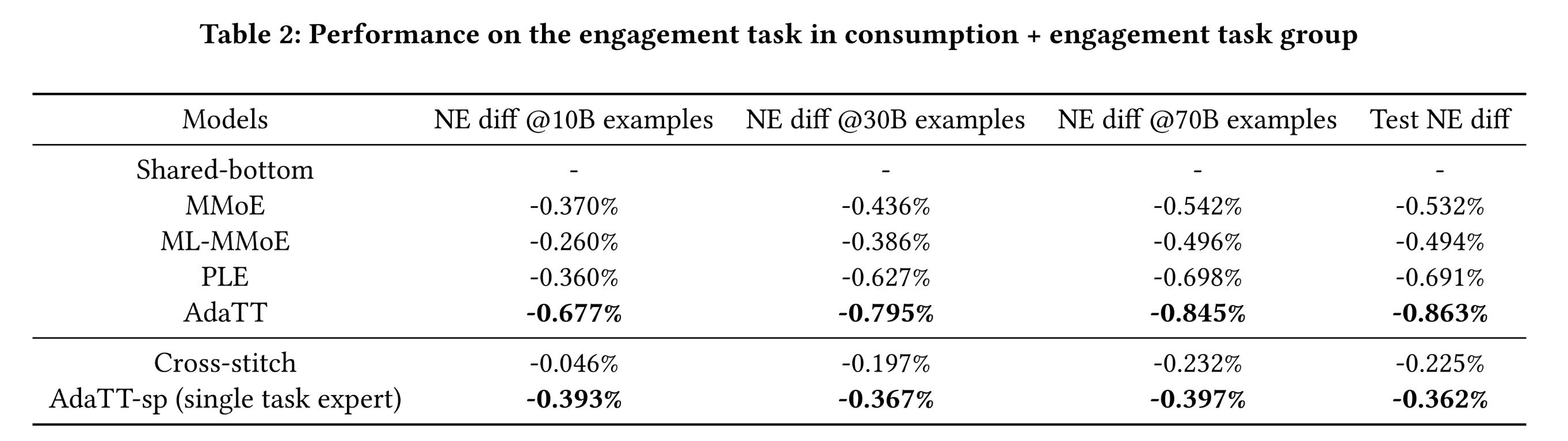
task group of engagement and consumption的实验:对于该task group,我们呈现了每个模型在训练10 billion、30 billion和70 billion个样本后,相对于hared-bottom model的NE差异,以及测试结果。Table 1和Table 2分别展示了consumption任务和engagement任务的结果。结果表明:AdaTT在两个任务中均优于所有其他模型,不仅收敛速度更快,而且性能质量更高。训练10 billion个样本后,两个AdaTT模型已在两个任务中展现出显著的NE提升。对于基线模型,
PLE在consumption任务上的收敛速度明显较慢;而cross-stitch model则大幅落后于AdaTT,这表明adaptive fusion在任务关系建模中至关重要。值得注意的是,相较于
consumption任务,PLE和AdaTT在正例较少的engagement任务上的提升更为显著——但这种趋势在MMoE和ML-MMoE中并不明显,这突显了task-specific learning的重要性。有趣的是,尽管
ML-MMoE通过额外的fusion操作具有更高的灵活性,但在两个任务中均表现不如MMoE,表明其在expert fusion方面的性能较差。这可能是由于ML-MMoE的设计缺乏区分性(distinction)且存在先验知识(prior knowledge)约束:shared experts具有高度对称性,均被每个门控模块使用,且没有显式建模的task specific experts;此外,所有门控模块均接收相同的原始input。fusion levels的增加导致路由(routes)增多,使得ML-MMoE更难学习到用于预测每个特定任务的不同weight combinations。
注意,对于
PLE模型:首先,
PLE并不能在所有任务中超越MMOE,这违背了PLE论文的结论(PLE在每个任务中都大幅超越MMOE)。其次,
PLE收敛速度较慢,在训练早期的性能太差。这也带来了一个疑问:实验结论是否是在每个模型都收敛的情况下进行比较的?最后,这里没有比较
AUC。读者猜测,实验结论跟评估指标强烈相关。如果切换到AUC指标,可能结论会有不同。
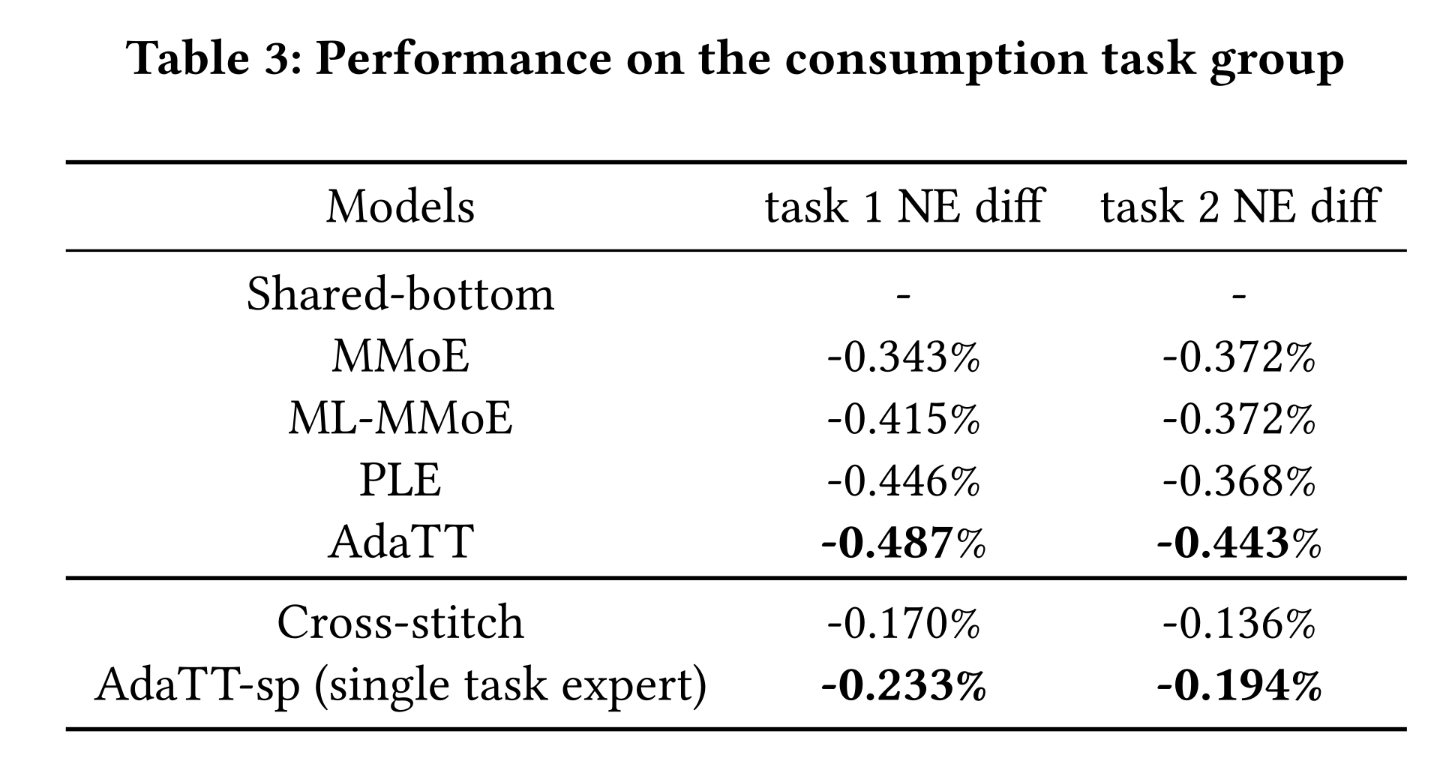
task group of two consumption tasks的实验:由于多任务学习模型的性能可能对任务相关性(task correlations)敏感,我们设计了一组实验,评估这些模型在两个相关的consumption任务上的性能(与task group 1中的低相关性任务形成对比)。Table 3所示的结果表明:与基线模型相比,该组中所有模型在两个任务上的提升更为相似。这一结果并不令人意外——当任务相关性较高时,负向迁移的影响较小,两个任务均能从
higher level of shared knowledge中获益。即使是具有较简单共享机制的多任务学习模型也能取得良好性能,导致
NE差异不太显著。然而,
AdaTT在所有多任务学习模型中仍表现最佳。
five diverse tasks的实验:在该task group中,我们利用5个高度多样化的任务,评估模型处理复杂的cross-task relationships的能力。我们针对4 main tasks调优模型,并在Table 4中呈现结果(由于正例稀疏的auxiliary task噪声较大且性能不稳定,未将其纳入)。结果表明,
AdaTT在所有main tasks中均显著优于所有baseline模型,彰显了其在处理复杂任务关系方面的优越性。auxiliary task效果差就剔除,感觉有点说不过去。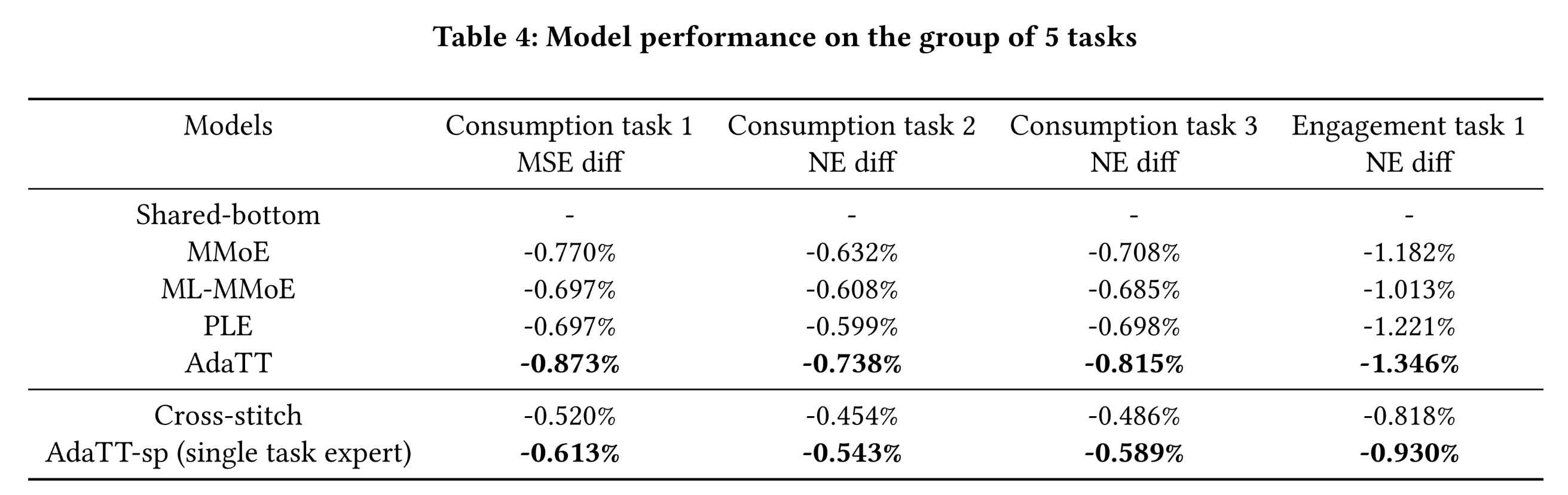
1.3.3 Evaluation on a Public Dataset
数据集:我们使用来自
1994年和1995年当前人口调查的人口普查收入数据集(Census Income dataset)。该数据集包含40个特征和299,285个样本,其中训练样本199,523个,测试样本99,762个。我们将测试样本随机等分为验证集和测试集。任务包括:1):预测收入是否超过50K。2):预测婚姻状况是否为从未结婚。3):预测教育程度是否至少为大学水平。
模型超参数:
本实验采用基于
《Heterogeneous Multi-task Learning with Expert Diversity》的框架,训练和测试ML-MMoE、PLE和AdaTT。模型结构与
Evaluation on Large-scale Short Video Recommendation章节类似,但调整了hidden dimensions和experts数量。实验分为两组,每个
fusion level分别设置6 experts和9 experts。调优PLE和AdaTT的shared experts数量task-specific experts数量计算为为保证公平性,所有其他超参数在各模型间保持一致。
调优
100次,并报告测试集上的平均AUC。
Table 5所示的结果表明,AdaTT在所有任务中均优于基线模型。PLE效果不如ML-MMOE,违背了PLE论文的结论。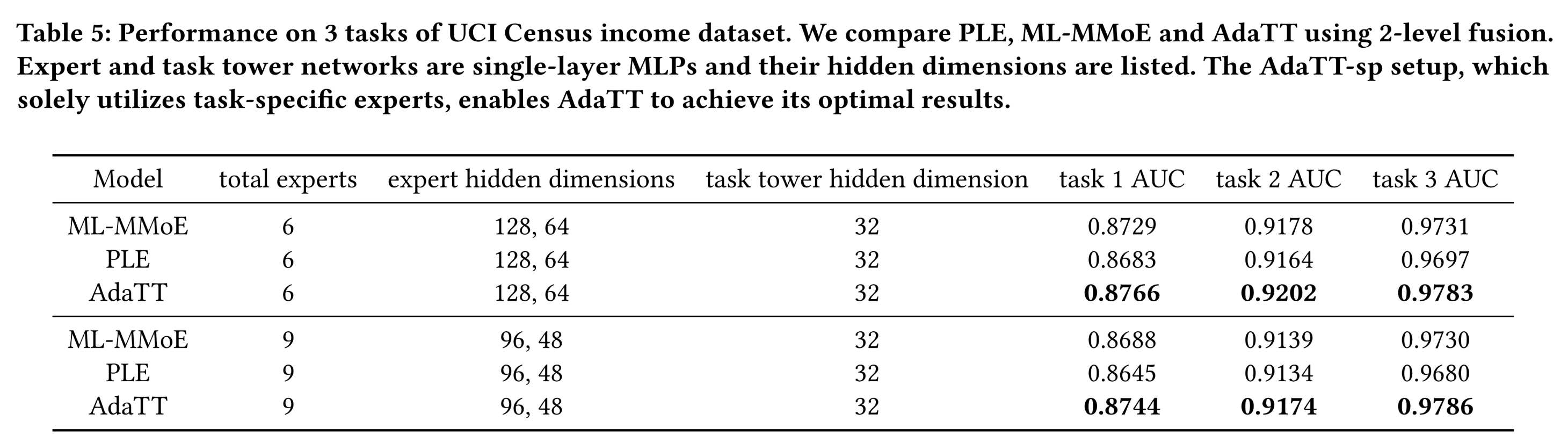
1.3.4 NativeExpertLF 模块的消融实验
在本节中,我们研究
fusion units中带有residual mechanism)的效果。我们通过消融fusion unit中所有experts的输出。我们采用与
Evaluation on a Public Dataset章节类似的模型结构,每个任务固定设置3 experts,且不使用shared expert。两个模型均在70 billion个样本上进行训练,并在10 billion个样本上进行测试,结果如Table 6所示。尽管
expert combinations,但实验结果表明:单独组合native experts并将residual来添加,这是至关重要的。具体而言,消融NE增加0.107%-0.222%,回归任务的MSE增加0.158%。
1.3.5 gating module expert weight distribution 的可视化
在
Figure 3中,我们可视化了distribution of expert weights),以探究AdaTT的内部融合机制。task-specific experts的线性权重;all experts的非线性权重。为评估专家利用率(
expert utilization),我们选择了三个任务:两个consumption任务和一个engagement任务。具体而言,在consumption任务中选择一个回归任务,在engagement任务和consumption任务中选择两个正例率最高的二分类任务。我们设置two levels of fusion,每个任务仅使用one expert,且不使用shared expert。two fusion levels的experts分别为hidden dimensions为256和128的single-layer MLP。模型训练完成后,将其应用于测试数据集,计算所有测试样本的平均权重,并为每个fusion level可视化3x3的权重矩阵。观察结果如下:首先,在
lower level of fusion(level 0),模型能够区分任务间的关系:consumption任务组和engagement任务组之间存在明显界限。此外,两个
consumption任务之间存在非对称的共享模式(sharing pattern):consumption二分类任务主要使用expert 2,而consumption回归任务大致同等使用expert 1和expert 2。在
higher level of fusion(level 1),由于更接近监督信号且捕获了丰富的语义信息,模型通过跨任务的shared pattern展现出soft-parameter sharing的优势:尽管native experts在tasks-pecific learning中发挥重要作用,但所有experts均被灵活利用,为shared learning做出贡献。在该level:consumption二分类任务通过利用engagement二分类任务特定的expert 3、以及consumption回归任务特定的expert 1,实现学习的多样化。同时,正例信号较少的
engagement任务从两个consumption任务中获益于知识迁移。相比之下,
consumption回归任务主要依赖其native expert 1和另一个consumption任务特定的expert。在所有
experts中,expert 1(从level 0的expert 1和expert 2的mixture中获得了最多样化的学习)在所有任务中均被赋予较高权重。
总体而言,我们可以观察到明显的专业化(
specialization):在每个任务、task grouping和level of fusion,模型均学到独特的权重分布模式。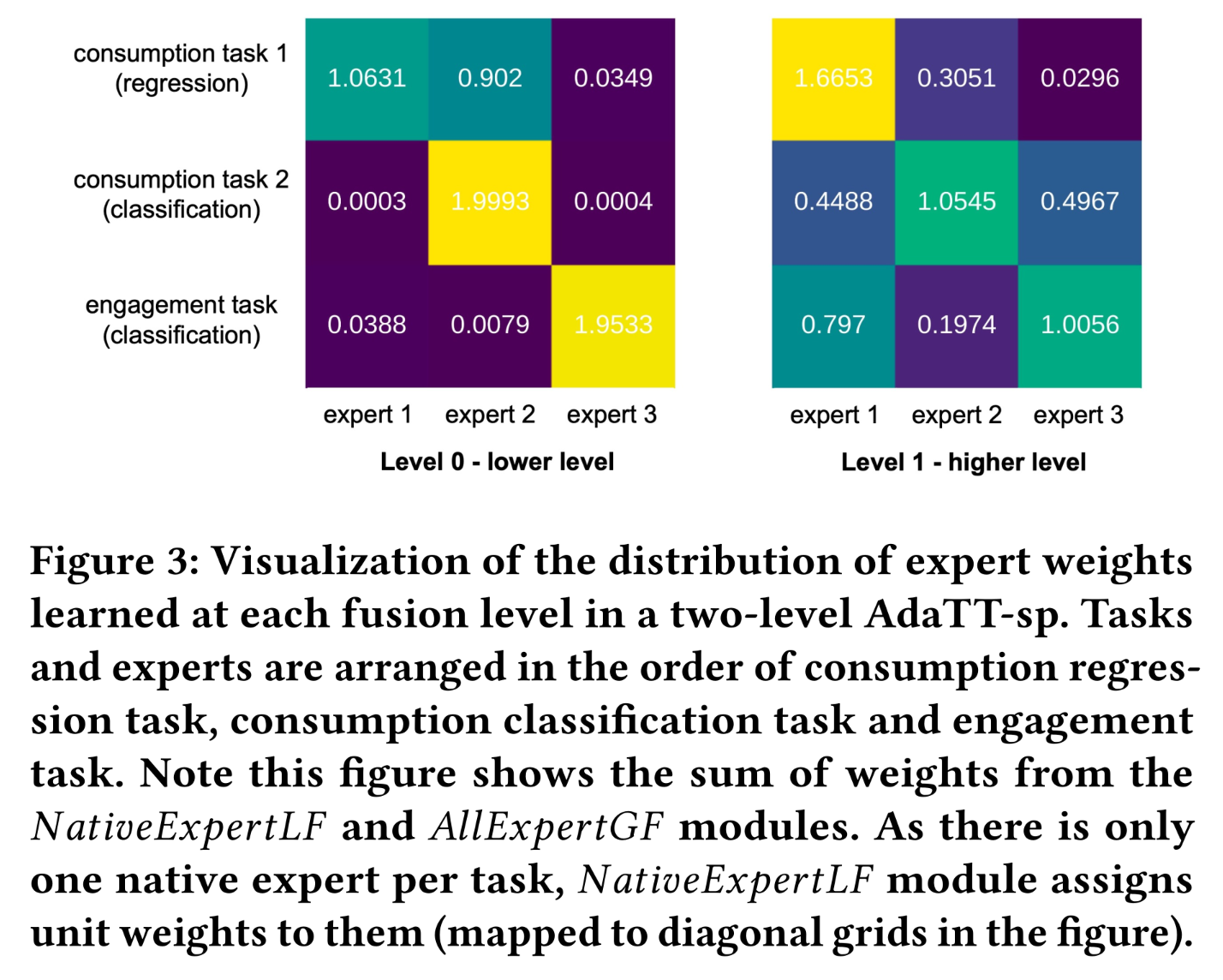
1.3.6 超参数研究
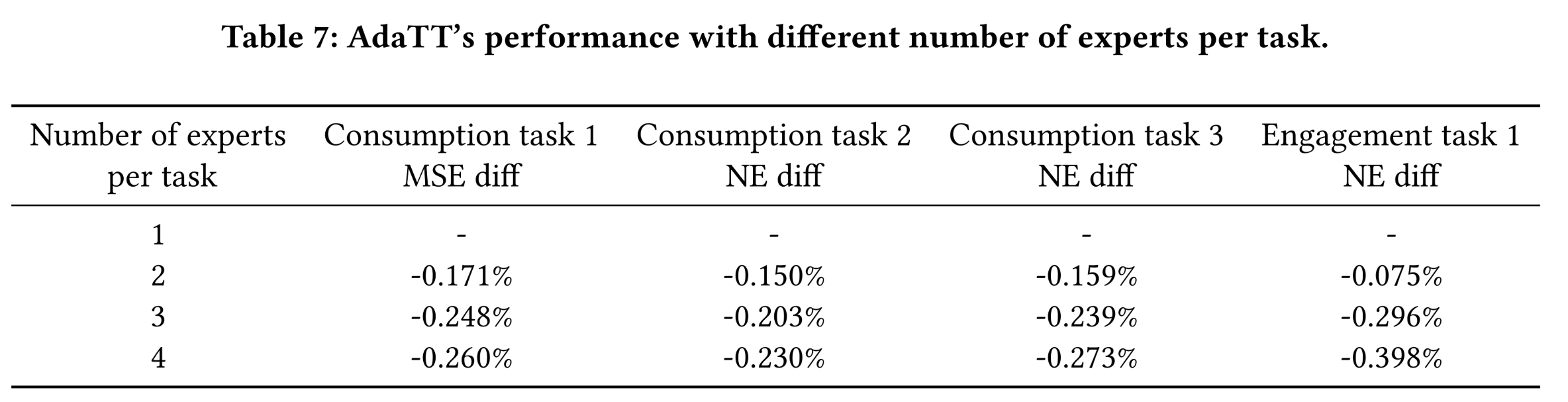
我们进行超参数研究,以探究
experts数量和fusion levels数量的影响。两项研究均使用与Evaluation on Large-scale Short Video Recommendation章节类似的5 prediction tasks,训练样本70 billion个,测试样本10 billion个,模型采用AdaTT-sp。task-specific experts数量的影响:为探究task-specific experts数量的影响,为简化起见,我们保持所有任务的task-specific experts数量一致,并在1 ~ 4之间变化。这些experts通过两个fusion levels的one-layer MLPs来构建,hidden dimensions分别为256和128。分析结果如Table 7所示:随着
experts数量的增加,所有任务的性能均有所提升。然而,提升并不均衡——在本研究中,当
experts数量增加到2时,engagement任务的NE提升相较于consumption任务更为微弱;但当experts数量进一步增加到3和4时,趋势发生逆转,engagement任务的指标提升更为显著。
fusion levels的影响:我们还通过每个任务仅使用1 expert,探究了不同fusion levels配置的效果。逐步增加fusion levels数量,每个level采用single-layer MLP。训练四个模型,不同fusion levels的MLP expert的hidden dimensions分别为[256,128]、[512,256,128]、[1024,512,256,128]和[2048,1024,512,256,128]。所有模型的task towers均采用hidden dimension = 64的single-layer MLPs。这种
hidden dimensions是个梯形,导致fusion levels越大而模型参数扩张的更多,因此很难说是因为模型参数导致的性能提升,还是因为模型更深导致的性能提升。Table 8所示的结果表明,正如预期的那样,增加fusion levels数量能够带来更大的性能提升。即使将fusion levels数量增加到5,所有任务仍能观察到显著的性能改进。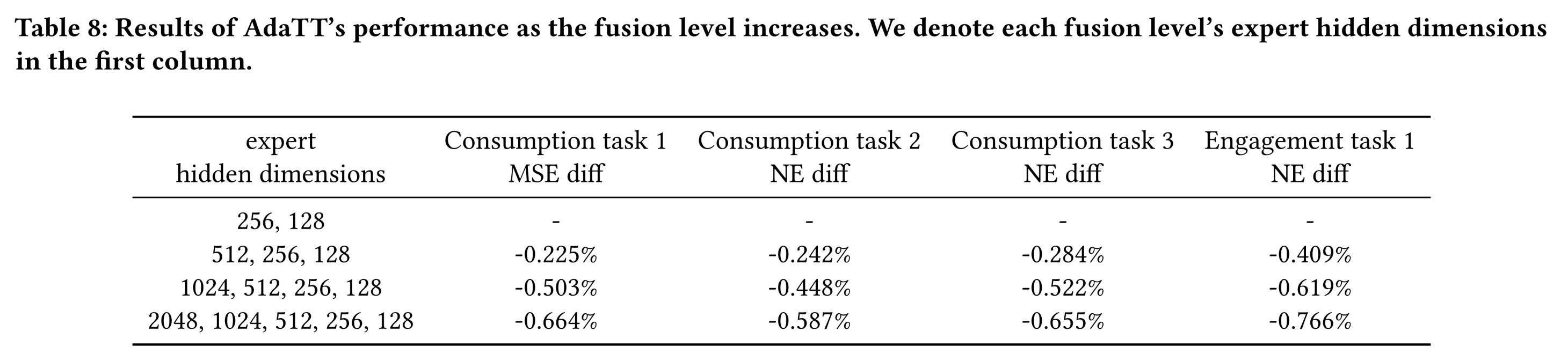
1.4 结论
在本研究中,我们提出一种新型多任务学习模型——
Adaptive Task-to-Task Fusion Network: AdaTT。通过利用其adaptive fusion机制,AdaTT能够有效建模复杂的task relationships,并促进task-specific knowledge与task-specific knowledge的联合学习。通过在公共数据集、以及具有
diverse task groups的真实世界工业级数据集上进行全面评估,我们验证了AdaTT的有效性和泛化能力。结果表明,AdaTT显著优于SOTA的多任务学习模型。我们期望本研究能够惠及多任务学习之外的更广泛应用场景,在这些场景中,不同的relevant specialized modules能够协同学习。