一、ChatGPTRec [2023]
《Uncovering ChatGPT’s Capabilities in Recommender Systems》
ChatGPT的首次亮相最近引起了自然语言处理(natural language processing: NLP)领域及其他领域的极大关注。现有研究已经证明,ChatGPT在一系列下游NLP任务中表现出显著的进步,但ChatGPT在recommendations方面的能力和局限性仍不清楚。在本研究中,我们旨在通过将ChatGPT与传统的信息检索(information retrieval: IR)ranking能力(包括point-wise ranking、pair-wise ranking和list-wise ranking)对齐,来增强ChatGPT的推荐能力。为了实现这一目标,我们将上述三种推荐策略重新表述为专门针对当前领域的prompt格式。通过在来自不同领域的四个数据集上进行的大量实验,我们分析了这三种推荐策略之间的区别。我们的研究结果表明,当配备list-wise ranking时,ChatGPT在成本和性能之间达到了最佳平衡。这项研究揭示了将ChatGPT与推荐任务对齐的一个有前景的方向。为了促进这一领域的进一步探索,完整代码和详细的原始结果已在https://github.com/rainym00d/LLM4RS上开源。大型语言模型(
Large language Models: LLMs),例如OpenAI开发的ChatGPT,最近引起了自然语言处理领域及其他领域的极大关注。这些LLM具有多功能性和广泛的世界知识,不仅可应用于各种NLP任务,还可应用于教育、医学、搜索和法律等领域。同时,先前的研究表明,通过使用
prompts将推荐任务改编为multi-token完形填空任务,现成的pre-trained语言模型可以直接用作推荐器(《What does bert know about books, movies and music? probing bert for conversational recommendation》、《Zero-Shot Recommendation as Language Modeling》、《Language models as recommender systems: Evaluations and limitations》)。因此,一个自然的研究问题出现了:如何有效地将LLM与推荐能力对齐?推荐系统的主要目标是通过为用户提供个性化的
top-K item ranking lists来减轻信息过载。在信息检索(information retrieval: IR)中,先前的研究通常使用三种方法来构建这些ranking lists:point-wise、pair-wise和list-wise(《Learning to rank for information retrieval》、《Deep learning for matching in search and recommendation》)。因此,在本文中,我们特别关注通过将LLM与这三种ranking视角对齐来探究LLM的推荐能力。为了从这三种
ranking视角研究LLM在推荐任务中的潜力,我们首先将这三种能力重新表述为prompts;这些prompts针对特定领域并用于LLMs的input。然后,我们对来自OpenAI的ChatGPT和其他流行的LLM在来自不同知识丰富领域的四个广泛使用的recommendation benchmarks上进行了实证分析。据我们所知,这是首次从不同ranking视角探究ChatGPT在推荐系统中能力的实证研究。主要发现。总之,经过实证实验,我们有以下主要发现:
ChatGPT在所有三种排序能力上相比其他LLM表现出一致的优势。ChatGPT擅长list-wise ranking和pair-wise ranking,而在point-wise ranking上稍弱。ChatGPT在训练数据有限的情况下可以超越传统推荐模型。考虑到成本、以及所带来的改进,对于
LLM-based recommenders,我们推荐在实际中采用list-wise ranking。ChatGPT在explainable recommendations、以及对item similarity的良好理解方面展现出潜力。
我们希望这次对
ChatGPT在推荐中的初步evaluation能为评估LLM的能力、以及利用LLM(如ChatGPT)来增强推荐系统提供新的视角。
1.1 探究 ChatGPT 的推荐能力
在本节中,我们利用
prompts来适配point-wise ranking、pair-wise ranking和list-wise ranking任务,使现成的LLM能够有效地处理这些任务。
1.1.1 推荐系统中的三种 Ranking 能力
个性化推荐的核心目标是基于用户偏好对
candidate items进行排序。为了实现这一点,当前的learning-to-rank: LTR方法通过相应的loss函数赋予推荐系统不同的能力,包括point-wise排序能力、pair-wise排序能力和list-wise排序能力(《Learning to rank for information retrieval》)。形式上,给定一个用户
candidate itemsuser-item pair的representation被编码为定义
1(point-wise排序能力):推荐系统学习通过一个point-wise评分函数itemitems进行排序。point-wise ranking中常用的loss函数包括均方误差(mean squared error: MSE)和二元交叉熵(binary cross entropy: BCE)。定义
2(pair-wise排序能力):推荐系统学习为每个用户pairs of itemspair-wise评分函数item更受偏好,即relative preference score)items进行排序。pairwise hinge loss(《Optimizing Search Engines Using Clickthrough Data》)或Bayesian personalized ranking loss: BPR(《BPR: Bayesian personalized ranking from implicit feedback》)是pair-wise ranking中使用的典型loss函数。定义
3(list-wise排序能力):推荐系统学习通过一个list-wise评分函数a list of itemspredicted scores对items进行排序。list-wise loss,例如,sampled softmax loss(《Deep Neural Networks for YouTube Recommendations》) ,被用于优化推荐模型。
1.1.2 用 Prompts 重新表述和适配 Recommendation
为了获得上述推荐能力,当前的推荐模型采用相应的
loss函数进行supervised learning。然而,supervised learning模式在数据稀疏场景(例如,冷启动问题《A survey on solving cold start problem in recommender systems》和long-tailed items《The long tail of recommender systems and how to leverage it》)中常常失败。相比之下,LLM在这些数据稀疏场景中具有更强的泛化能力,并在few-shot任务甚至zero-shot任务中取得了有前景的性能。在这项实证研究中,我们假设LLM已经具备上述三种能力,我们只需要通过prompt tuning来触发这些能力。为此,我们采用了近期成功的in-context learning(《Language models are few-shot learners》)和instruction tuning(《Scaling instruction-finetuned language models》)实践,并将上述三种能力表达为具有domain-specific prompts的三个任务。Figure 1说明了我们如何使用prompt tuning从LLM中激发三种排序能力。如Figure 1 (left)所示,我们的prompt由三个部分组成:(i) Task descriptionLLM能够理解特定领域的过程,其中在这个领域中需要执行推荐任务。task description被设计为具有domain-aware,这增强了LLM对相关知识的感知。(ii) Demonstration examplesin-context learning),其中:historical interacted items。candidate items。LLM给出的predictions。注意:
labels。examples转换为designed prompt templates的函数。
demonstration examples有助于LLM理解当前任务。(iii):对于给定用户的一个new input queryquery是需要LLM回答的。
对于三个排序任务,相应的
candidate items如
Figure 1 (right)所示,LLM将利用通过不同prompts所激发的不同排序能力来得到prediction然后,
the output answer将被手动检查,有效的答案将用于进一步评估,而无效的答案将被排除。有关prompts的更多详细信息,请参阅链接https://github.com/rainym00d/LLM4RS/blob/main/assets/prompts.pdf。logit_bias方法参考这里:https://platform.openai.com/docs/api-reference/completions/create#completions/create-logit_bias。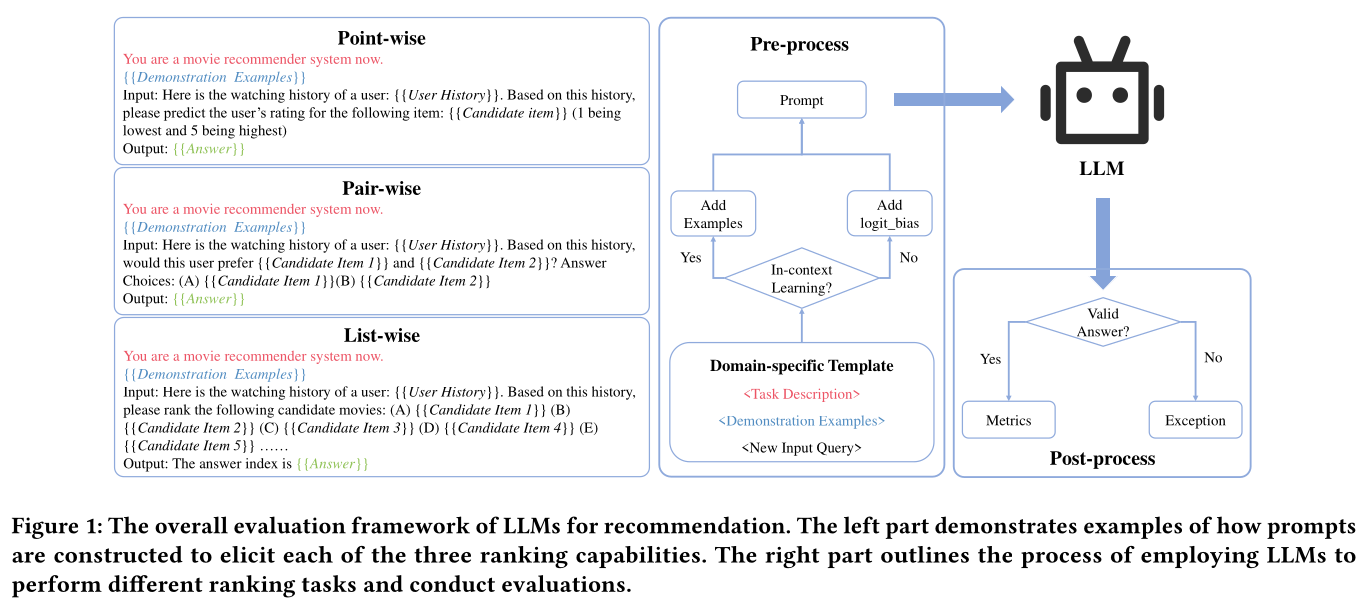
1.2 实验
在本节中,我们进行实验以评估
ChatGPT和GPT-3.5s,以回答以下研究问题:RQ1:这些LLM在不同的推荐领域的各种排序能力上表现如何?RQ2:基于LLM的recommenders与传统的协同过滤(collaborative filtering)方法相比如何?RQ3:这些基于LLM的recommenders在不同排序能力上的成本是多少?
实验设置:为了更好探究
ChatGPT和GPT-3.5s(text-davinci-002和text-davinci-003)在个性化推荐上的不同能力,我们在来自四个不同领域的数据集上进行了评估,包括Movie, Book, Music, and News。关于数据集的描述和处理细节,请参阅我们的GitHub仓库。处理后,由于成本高昂,我们在每个数据集上随机采样了
500条记录进行评估。对于所有实验,我们遵循现有实践(《Zero-Shot Recommendation as Language Modeling》),将一个positive item与四个随机采样的negative items配对作为candidate item list。我们将pair-wise和list-wise的示例数(shots)设置为1,将point-wise的示例数设置为2。我们报告
top-K Normalized Discounted Cumulative Gain: NDCG@K和Mean Reciprocal Rank: MRR@K,其中LLM可能生成一些非法输出(illegal output),即不在candidate set中的结果,我们引入指标“合规率” ("Compliance Rate")来比较不同模型之间的合规率,其定义为所生成的有效结果数量占所有测试样本的比例,即:这些数据集和评估方法距离工业界实际场景很远,因此该论文的方法距离实际应用很远。
1.2.1 RQ1: 整体表现
Table 1显示了不同LLM在四个不同领域的结果。我们有以下观察和结论:ChatGPT和GPT3.5s在几乎所有情况下的表现都远优于随机推荐。具体来说,在四个领域上,所有三种LLM都比随机推荐策略有显著的改进,例如,在Movie数据集上,point-wise任务的NDCG@3平均提高了24.71%。此外,由于in-context learning的能力,LLM的大多数答案都是合规的。这些结果表明,LLM有潜力从而促进推荐系统。与
text-davinci-002和text-davinci-003相比,ChatGPT在几乎所有评估指标上对所有三种排序能力都表现出更好的性能。例如,ChatGPT在24次比较中的22次中优于其他LLM,这包括两个排序指标、三种排序能力和四个领域数据集。仅有的两个例外是新闻领域中point-wise ranking与text-davinci-003的比较。我们将ChatGPT的强大性能归因于其卓越的语言理解和推理能力,这使其能够有效地理解item similarity并做出明智的排序决策。ChatGPT在除电影领域外的list-wise排序上表现更好。另一方面,text-davinci-002和text-davinci-003在大多数情况下在pair-wise排序上表现更好。为了提供清晰的比较,我们在Table 2中总结了三种LLM在不同排序能力下的排名。注意,在大多数情况下(12次中的11次),pair-wise ranking往往优于point-wise ranking;尽管由于需要pair-wise comparisons,其推理成本更高。我们将在RQ3中深入分析成本。所有基于
LLM的recommenders在推荐电影、书籍和音乐方面都优于popularity推荐策略,但在新闻领域表现不佳。这种现象可以解释为新闻推荐更依赖于popularity,而其他领域更个性化。新闻传递的速度是另一个可能的因素。由于新闻推荐的时效性和快速变化性,LLM训练语料库中通常没有足够的每个新闻的交互数据。相反,在其他三个领域,item描述和交互数据更丰富,使得LLM在其上工作得更好。总的来说,这一观察表明,虽然现成的基于LLM的recommenders在许多领域可能有效,但它们可能不适用于某些领域,可能需要进一步探索。
我们还使用
zero-shot prompts(即没有示例)进行了实验。然而,使用原始的zero-shot prompt,我们发现超过50%的案例是无效的且难以评估。为了解决这个问题,我们利用logit_bias(https://platform.openai.com/docs/api-reference/completions/create#completions/create-logit_bias)来控制output tokens。由于篇幅限制,我们在链接https://github.com/rainym00d/LLM4RS/blob/main/assets/Supplementary_Material.pdf中提供了详细结果。总的来说,结果突出了
LLM作为推荐系统的潜力,因为它们在zero-shot setting下优于随机策略和基于popularity的策略。此外,正如预期的那样,few-shot settings下的LLM在大多数情况下优于zero-shot settings下的LLM,证明了few-shot prompts in-context learning的有效性。注意,论文并未给出
zero-shot setting的结果,而是在补充材料里提供的。注意,
baseline是random/pop策略,太弱了。LLM-based方法效果并没有比它们强太多,因此LLM-based方法也比较弱。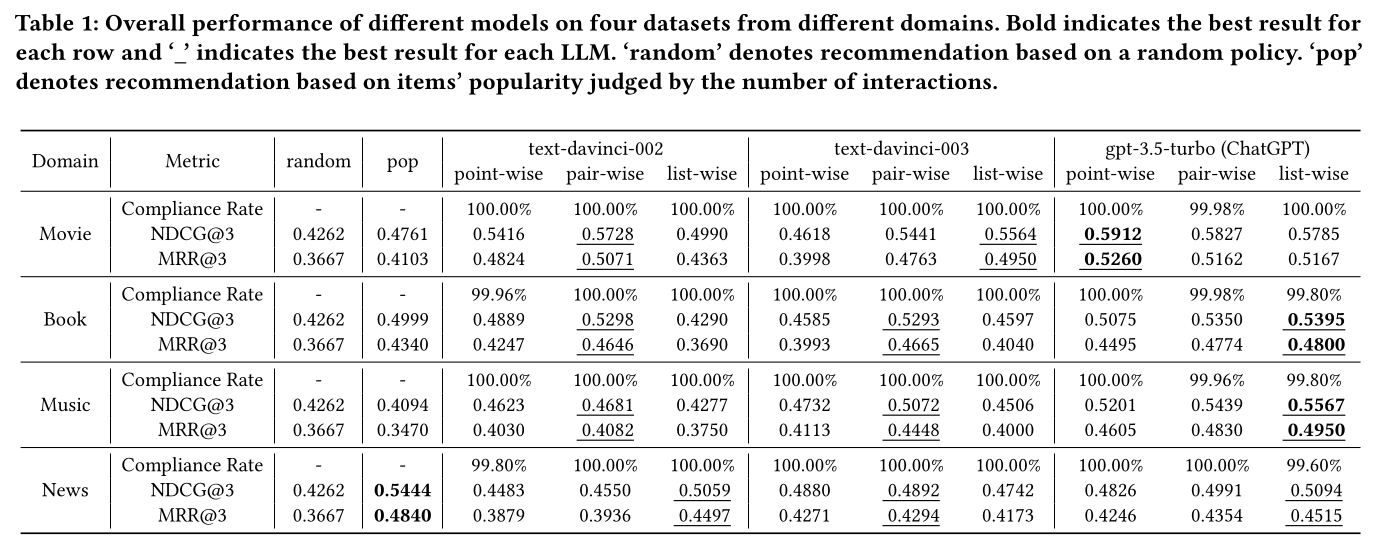

1.2.2 RQ2: 与协同过滤模型的比较
考虑到先前实验中使用的
LLM没有在推荐数据上进行训练,我们研究了传统推荐模型需要多少训练数据才能达到与LLM相当或更好的性能。具体来说,我们选择了最具代表性的传统推荐模型,矩阵分解(Matrix Factorization: MF)(《Matrix factorization techniques for recommender systems》)以及神经协同过滤(Neural Collaborative Filtering: NCF)(《Neural collaborative filtering》),并评估了它们在训练不同比例数据后的性能。为了公平比较,我们仔细调优了MF和NCF的超参数。然后我们将它们的性能与LLM进行了比较。所有实验在Movie数据集上进行了5次,平均结果及其95%置信区间的NDCG@3如Figure 2所示。正如预期,
MF和NCF的性能随着训练数据量的增加而提高。此外,我们可以观察到,当只有少量训练数据可用时,即少于完整训练集的
40%时,现成的基于LLM的模型优于MF和NCF(对于ChatGPT在所有三种排序能力上)。请注意,基于LLM的推荐模型不需要训练数据,而是在prompt中需要少量样本来帮助理解推荐任务。
因此,我们得出结论,基于
LLM的推荐模型可以在实践中应用以缓解冷启动问题。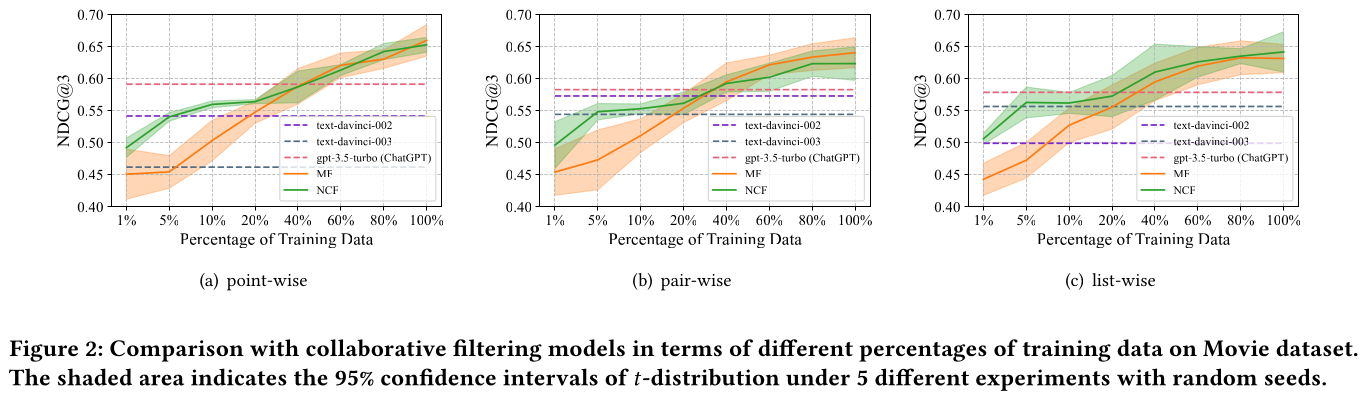
1.2.3 RQ3: Performance Scaling by Cost
尽管如
Table 1所示,LLM在pair-wise ranking或list-wise ranking上具有更好的性能,但我们需要考虑与这些性能改进相关的成本。具体来说,我们计算每个LLM的每单位成本改进:其中:
LLM的指标值,candidate item list进行排序的成本。
参考
Figure 1 (left),我们定义对于
list-wise ranking,只需要一个prompt input即可获得LLM对所有candidate items的排序。对于
point-wise ranking,需要prompt inputs才能获得LLM对所有candidate items的排序。其中candidate items的数量。对于
pair-wise ranking,需要prompt inputs才能获得所有排序结果。
在我们的实验设置中,
point-wise ranking、pair-wise ranking和list-wise ranking的成本分别表示为5x、10x和1x。Figure 3展示了每个LLM的每单位成本改进。可以发现:几乎所有三个
LLM在list-wise ranking中都具有最佳的每单位成本改进,除了text-davinci-002在Book数据集上。此外,
point-wise ranking和pair-wise ranking具有相似的每单位成本改进。尽管pair-wise ranking在绝对指标上可能比point-wise ranking取得更好的性能,但为pair-wise ranking运行multiple prompts的需求导致了额外的成本。
总的来说,我们建议在实践中对推荐任务采用
list-wise ranking,因为它具有不错的性能和较低的成本。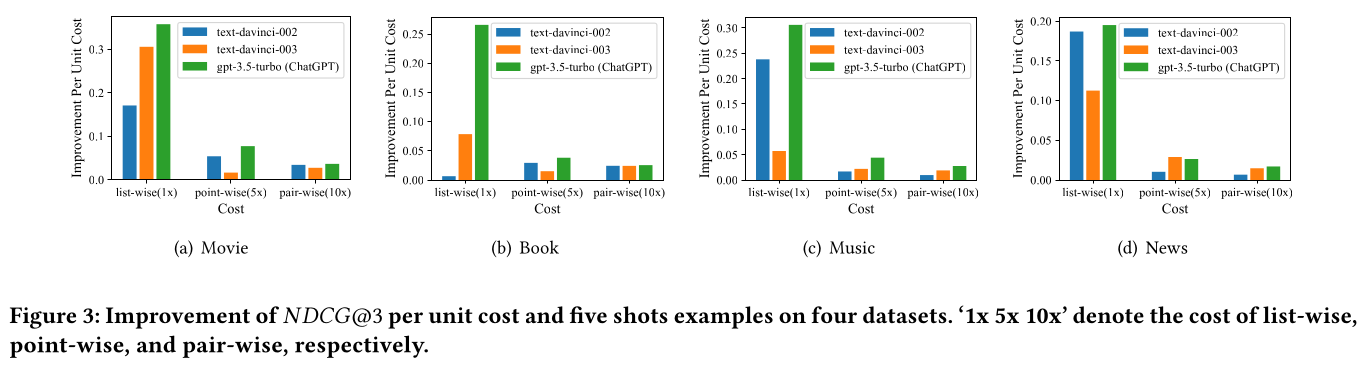
1.2.4 异常案例的研究
值得注意的是,即使在
few-shot in-context learning下,LLM也可能生成一些无效答案,导致合规率可能低于100%,如Table 1所示。例如,Table 3突出了来自ChatGPT with pair-wise ranking的两个异常案例,这两个案例都缺乏正确答案,因为它们是the pair of two negative samples。令人惊讶的是,ChatGPT并没有像在in-context learning examples中看到的那样简单地回答"A"或"B"。相反,它识别出这两个items是不相关的且与user history interactions不相似。例如,在case 1中,用户的观看历史都是科幻电影,但答案选项都是卡通片。这些响应表明ChatGPT理解如何根据user interaction histories进行推荐以及items之间的相似性是什么。然而,受限于我们现有的评估方法,这些答案被认为是不合规的。因此,我们建议从learning to rank之外的其他角度来探索评估LLM作为recommenders的方法,因为LLM有可能在explainable recommendation中发挥更大的作用。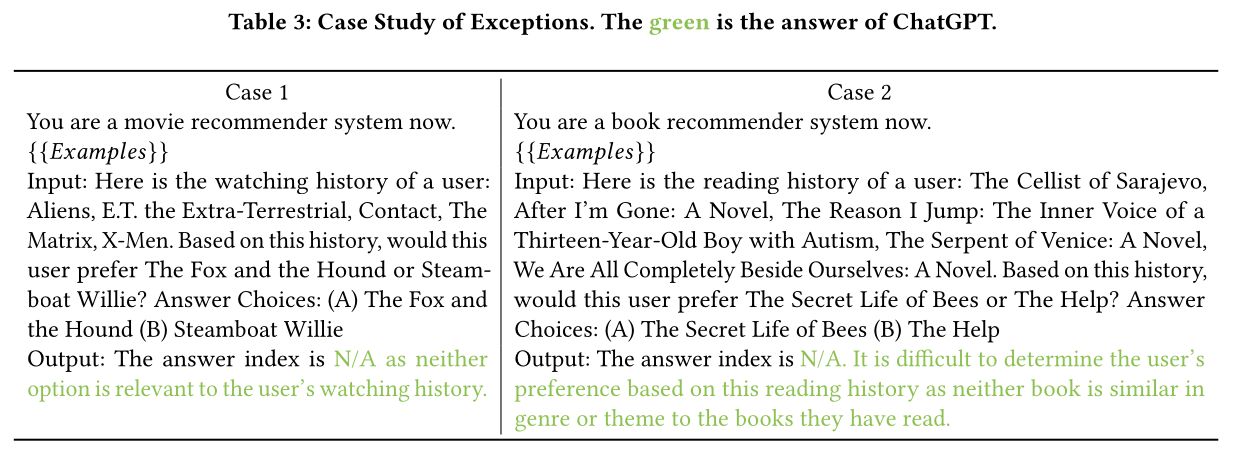
1.3 结论
在本文中,我们对从
point-wise、pair-wise和list-wise角度探究现成LLM进行推荐进行了初步评估。具体来说,我们将上述排序能力重新表述为相应的domain-aware prompts,并评估了ChatGPT在不同领域的每种排序能力上的表现。在四个数据集上的结果表明,ChatGPT在所有三种排序能力上在推荐方面都具有优越性。我们还观察到,LLM擅长list-wise ranking和pair-wise ranking,但在大多数情况下不擅长point-wise ranking。此外,ChatGPT显示出缓解冷启动问题和explainable recommendation的潜力。