一、MoRec [2023]
《Where to Go Next for Recommender Systems? ID- vs. Modality-based Recommender Models Revisited》
利用
unique identities(简称ID)来表示distinct users and items的推荐模型,在过去十多年中一直是推荐系统(recommender systems: RS)领域的主流且SOTA的技术。与此同时,pre-trained modality encoders(如BERT《Bert: Pre-training of deep bidirectional transformers for language understanding》和Vision Transformer《An image is worth 16x16 words: Transformers for image recognition at scale》)在建模item的原始模态特征(如文本特征和图像特征)方面变得越来越强大。基于此,一个自然的问题出现了:通过用SOTA modality encoder替换itemID embedding,纯基于模态的推荐模型(MoRec)能否优于或匹敌纯基于ID的模型(IDRec)?事实上,这个问题在十年前就有答案,当时IDRec在推荐准确性和效率两方面都大幅领先MoRec。我们旨在重新审视这个“老”问题,并从多个方面系统研究
MoRec。具体来说,我们研究以下几个子问题:(i):MoRec和IDRec这两种推荐范式在实际场景中哪种表现更好,特别是在IDRec具有强优势的general setting和popular item场景下?这种情况对于items with different modality features是否成立?(ii):来自其他社区(即自然语言处理和计算机视觉)的最新技术进展能否转化为MoRec的准确性提升?(iii):如何有效利用item modality representation——是直接使用还是需要用新数据进行调整?(iv):MoRec在实际应用中需要解决哪些关键挑战?
为了回答这些问题,我们对具有两种流行模态(即文本和视觉)的
item recommendations进行了严格的实验。我们提供了第一个经验证据,表明通过昂贵的端到端训练方法,MoRec已经能够与IDRec相媲美,即使在warm item recommendation中也是如此。我们的结果可能意味着IDRec在recommender systems领域的主导地位在未来可能会受到巨大挑战。我们已在https://github.com/westlake-repl/IDvs.MoRec发布了代码和其他材料。推荐系统(
recommender system: RS)模型学习users and items的historical interactions,并推荐用户未来可能交互的items。RS在搜索引擎、广告系统、电子商务网站、视频和音乐流媒体服务以及各种其他互联网平台中发挥着关键作用。现代推荐模型通常使用unique identities(ID)来表示users and items,随后将其转换为可学习的embedding向量。这些基于ID的推荐模型(IDRec)已经确立并主导RS领域超过十年,直至现在。尽管如此,
IDRec有着不可忽视的关键弱点。首先,
IDRec高度依赖ID交互,当users and items的交互很少时无法提供推荐(《Parameter-efficient transfer from sequential behaviors for user modeling and recommendation》、《One person, one model, one world: Learning continual user representation without forgetting》),即cold-start setting。其次,
pre-trained IDRec无法跨平台迁移,因为userIDs和itemIDs在实际中通常不可共享。这个问题严重限制了深度学习社区中新兴范式——大型通用recommender system模型的发展。第三,纯
IDRec无法从其他社区(如NLP和CV领域开发的foundation models: FM《On the opportunities and risks of foundation models》)的技术进步中受益。此外,在工业应用中,为
users and items维护大型且频繁更新的ID embedding matrix仍然是一个关键挑战(《A generic network compression framework for sequential recommender systems》)。最后但同样重要的是,利用
ID特征的推荐模型在可解释性、可视化和评估方面存在明显缺陷。
解决这些问题的一种方法是用
item modality encoder(ME)替换IDRec的ID embedding,尤其是在item modality features(如图像特征和文本特征)可用的情况下。我们将此类推荐模型称为MoRec。事实上,这种MoRec多年前就出现在文献中,但主要用于解决cold-start recommendation或cross-domain recommendation问题(《Fully content-based movie recommender system with feature extraction using neural network》、《Deeply fusing reviews and contents for cold start users in cross-domain recommendation systems》、《Deep content-based music recommendation》)。换句话说,MoRec很少在推荐non-cold items或popular items时被采用,除非与其他有效特征(如itemID features)结合,例如在《VBPR: visual bayesian personalized ranking from implicit feedback》、《Convolutional matrix factorization for document context-aware recommendation》、《Collaborative topic modeling for recommending scientific articles》中。一个关键原因可能是过去几年开发的item modality encoder(例如word embedding《Distributed representations of words and phrases and their compositionality》和一些浅层神经网络《Deep content-based music recommendation》)不如典型的itemID embeddings具有表达力。然而,鉴于foundation models最近取得的巨大成功,我们认为现在是时候重新审视现代MoRec和IDRec之间的关键比较,特别是对于常规(或non cold-item)推荐。例如,BERT(《Bert: Pre-training of deep bidirectional transformers for language understanding》)、GPT-3(《Language models are few-shot learners》)和各种Vision Transforme: ViT(《An image is worth 16x16 words: Transformers for image recognition at scale》、《Swin transformer: Hierarchical vision transformer using shifted windows》)在表示文本特征和视觉特征方面彻底改变了NLP领域和CV领域。由它们学到的item representations是否比ID features更适合常规推荐任务仍然未知。在本文中,我们打算重新思考
MoRec的潜力,并研究一个关键问题:对于未来的推荐系统,我们是否应该继续坚持IDRec范式?我们专注于基于文本和视觉模态的item推荐——这是文献中最常见的两种模态。为简洁起见,我们试图解决以下子问题:Q(i):配备强大的modality encoders: ME后,MoRec在常规推荐特别是warm-start item推荐场景中能否与IDRec相媲美甚至超越?为了回答这个问题,我们进行了实证研究,考虑了两种最具代表性的推荐架构,即基于双塔的DSSM(《Learning deep structured semantic models for web search using clickthrough data》、《Neural collaborative filtering vs. matrix factorization revisited》)和基于session的SASRec(《Self-attentive sequential recommendation》),配备了四种强大的modality encoders,并在三个大规模推荐数据集上使用两种模态(文本和视觉)进行评估。新颖性说明:尽管许多先前文献研究了
MoRec并与许多基线进行了比较,但不幸的是,没有任何一项工作在常规推荐甚至warm item推荐场景下对其提出的MoRec与相应的IDRec对应物进行了公平或严格的比较。这里的公平比较意味着MoRec和IDRec至少应该在相同的backbone网络和实验设置(如samplers和loss函数)下进行比较。没有公平的比较,社区就无法真正评估MoRec的进展和modality encoders对推荐的表达能力。Q(ii):如果Q(i)是肯定的,那么NLP和CV领域的最新技术进展能否转化为使用文本特征和视觉特征的MoRec的准确性提升?我们通过三个实验来解决这个问题。首先,我们通过比较较小的
modality encoders与较大的modality encoders来评估MoRec,因为更大模型尺寸的pre-trained modality encoders在各种下游任务中往往比较小的modality encoders表现更好。其次,我们通过比较较弱的
modality encoders与较强的modality encoders来评估MoRec,其中强弱由NLP任务和CV任务来决定。第三,我们比较了在相应的
NLP数据集和CV数据集上进行pre-training与未进行任何pre-training的modality encoders。
Q(iii):这些foundation models学到的representations是否像声称的那样通用?我们如何有效使用来自NLP encoder network或CV encoder network的item modality representations?foundation models研究的一个理想目标是开发能够生成universal representations的模型,这些representations可以直接用于各种下游任务(《Could Giant Pretrained Image Models Extract Universal Representations?》)。我们首先从著名的modality encoders中提取frozen modality features,然后将其作为common features添加到推荐模型中,这通常被称为两阶段(two-stage: TS)范式。由于训练效率考虑,这是大规模工业推荐系统的常见做法(《Deep neural networks for youtube recommendations》、《Image-based recommendations on styles and substitutes》)。然后我们将two-stage与联合或端到端(end-to-end: E2E)训练进行比较,其中后者同时训练recommendation architecture和modality encoders。新颖性说明:尽管最近有几篇文献探索了用于推荐的
end-to-end learning,但很少有人明确讨论two-stage和end-to-end范式之间巨大的准确性和效率差距(超过100倍)。更重要的是,大多数文献只讨论了DSSM架构(或其他双塔变体),而没有考虑更强大且计算上更昂贵的序列到序列(sequence-to-sequence: seq2seq)训练方法(例如SASRec和NextItNet《A simple convolutional generative network for next item recommendation》中使用的)。此外,所有这些工作都仅针对文本推荐,到目前为止,还没有近五年内经过同行评审的文献考虑用于图像推荐的end-to-end学习范式。
除了上述关键问题之外,我们还发现了在使用
end-to-end学习范式时MoRec尚未探索的几个挑战。
1.1 相关工作
ID-based recommender systems (IDRec):在现有的推荐文献中,有无数完全建立在user/item ID之上的模型,从早期的item-to-item collaborative filtering(《Amazon. com recommendations: Item-to-item collaborative filtering》)、浅层factorization models(《Matrix factorization techniques for recommender systems》、《Factorization machines》),到深度神经模型(《Neural collaborative filtering》、《Session-based recommendations with recurrent neural networks》)。它们大致可以分为两类:非序列模型(non-sequential models: NSM)和序列神经模型(sequential neural models: SRM)。NSM进一步包括:各种召回模型,例如
DSSM和YouTube DNN《Deep neural networks for youtube recommendations》)。以及
CTR模型,例如DeepFM(《DeepFM: a factorization-machine based neural network for CTR prediction》)、wide & deep(《Wide & deep learning for recommender systems》)和Deep Crossing(《Deep crossing: Web-scale modeling without manually crafted combinatorial features》)。
这些模型通常以
user-item pair以及一些附加特征作为输入,并预测users and items之间的匹配分数。相比之下,典型的
SRM以a sequence of user-item interactions作为输入,并生成next interaction的概率。最具代表性的SRM包括以RNN、CNN、GNN、Transformer和BERT为骨干网络的GRU4Rec(《Session-based recommendations with recurrent neural networks》)、NextItNet(《A simple convolutional generative network for next item recommendation》、《One person, one model, one world: Learning continual user representation without forgetting》)、SR-GNN(《Session-based recommendation with graph neural networks》)、SASRec(《Self-attentive sequential recommendation》)和BERT4Rec(《BERT4Rec: Sequential recommendation with bidirectional encoder representations from transformer》),其中SASRec通常在文献中表现最佳(《Comparison of Transformer-Based Sequential Product Recommendation Models for the Coveo Data Challenge》、《Tenrec: A Large-scale Multipurpose Benchmark Dataset for Recommender Systems》、《Dynamic graph neural networks for sequential recommendation》)。
Modality-based recommender systems (MoRec):MoRec专注于对items的modality content features进行建模,例如文本、图像、视频、音频以及text-image multimodal pairs。先前的工作倾向于采用两阶段(
two-stage: TS)机制:首先从modality encoder中预先提取item modality features,然后将这些fixed features纳入推荐模型。更重要的是,这些工作大多将模态作为辅助特征,以ID为主要特征。E2E-based MoRec直到最近才流行起来,原因如下:(1):two-stage机制在架构上对工业applications非常灵活,并且需要低得多的计算和训练成本。(2):很少有高质量的具有原始item modalities的公共数据集。(3):过去文献中开发的modality encoder(例如word embedding)即使通过End2End训练也不够具有表达能力。
在过去两年中,一些工作开始探索
E2E-based MoRec,然而,其中大多数专注于文本推荐。最近的一篇预印本《End-to-End Image-Based Fashion Recommendation》引入了ResNet作为fashion-based recommendation的modality encoder,但不得不依赖ID特征来获得有竞争力的准确性。据我们所知,这些现有的经过同行评审的文献中,没有一项在公平的实验设置下(例如确保使用相同的骨干网络进行比较)提供了MoRec与其相应IDRec对应物的明确且全面的比较研究,尤其是在non cold-start settings甚至warm-start settings中。
1.2 IDRec & MoRec
推荐模型的一个核心功能是表达
items和users并计算它们的匹配分数。记items集合和users集合。对于itemunique IDunique IDa sequence of interacted items。在
IDRec中,我们初始化一个ID embedding matrixembedding维度。itemitem encoder。在训练和推理期间,IDRec从itemembedding,然后将其馈送到recommendation network中。在
MoRec中,假设items包含模态信息。对于itemMoRec使用modality encoder为representation,并用这个representation来替换IDRec中的ID embedding vector。例如,在新闻推荐场景中,我们可以使用pre-trained BERT or RoBERTa(《Roberta: A robustly optimized bert pretraining approach》)作为text modality encoder,并通过新闻标题的textual representation来表示一条新闻。类似地,当items包含视觉特征时,我们可以简单地使用pre-trained ResNet or ViT作为vision modality encoder。在本文中,我们对两种最常采用的推荐范式进行了严格的实证研究:
DSSM(《Learning deep structured semantic models for web search using clickthrough data》)和SASRec(《Self-attentive sequential recommendation》)。原始的
DSSM模型是一种基于双塔的架构,其中users/items通过各自的encoder networks来编码,而且user iD/item ID作为各自的encoder network的输入。SASRec是一种基于多头自注意力(multi-head self-attention: MHSA)(《Attention is all you need》)的著名序列推荐模型,它通过用户交互过的item ID sequence来描述用户。
如前所述,通过用
item modality encoder来替换ID embeddings,我们获得了DSSM和SASRec的MoRec版本。我们在Figure 1中展示了IDRec和MoRec。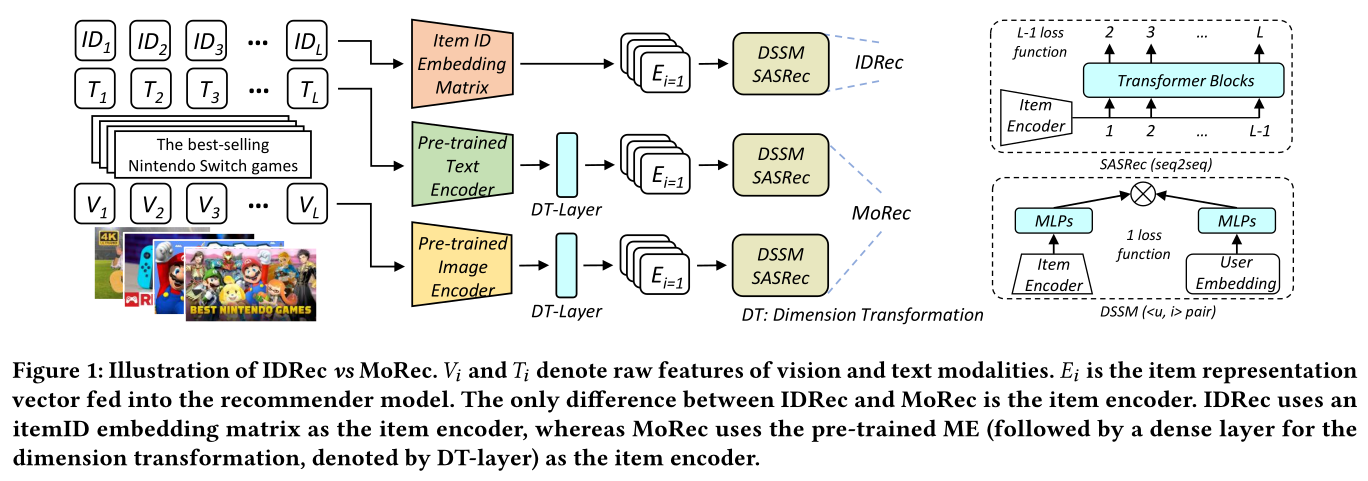
训练细节:记
interactions。对于每个正样本training epoch随机采样一个不在《Neural collaborative filtering》、《BPR: Bayesian personalized ranking from implicit feedback》。positive interactions和sampled negative interactions interactions可以形成训练集《Neural collaborative filtering》、《Self-attentive sequential recommendation》,我们采用广泛使用的二元交叉熵(binary cross entropy: BCE)损失作为DSSM和SASRec及其MoRec版本的目标函数,以实现公平比较:其中:
sigmoid函数。interaction sequence长度。positive item和negative item。user encoder和item encoder的hidden vectors之间的匹配分(matching score)。
注意,
SASRec的user encoder(通过seq2seq训练)在interaction sequence的每个位置产生不同的hidden vector。除非特别说明,在以下实验中,整个推荐模型的所有参数都在训练期间进行优化。
1.3 实验设置
数据集:我们在三个真实世界数据集上评估
IDRec和MoRec,即:来自微软新闻推荐平台的
MIND新闻点击数据集(《Mind: A large-scale dataset for news recommendation》)。来自
H&M平台的HM服装购买数据集。以及来自在线视频推荐平台的
Bili评论数据集。
purchase和comment可以被视为隐式的click信号,因为可以合理地假设用户在购买或发表评论之前已经点击了item。然而,我们不能假设反过来也成立,这是大多数推荐数据集中的一个常见属性,即unobserved items对用户来说可能是正例也可能是负例。为了确保
IDRec和MoRec之间的公平比较,所使用的数据集应保证user对item的clicking decisions完全基于item的模态内容特征。直观上,图像或视频的封面、以及新闻文章的标题,在为用户提供对item的第一印象方面起着至关重要的作用。这种印象显著影响他们对item的click的决定。因此:在
MIND中,我们使用新闻文章标题来表示item。而在
HM和Bili中,我们使用相应的封面图像来表示item。
尽管如此,这些数据集仍可能无法完美满足要求。特别是在
HM数据集的电子商务背景下,item的封面图像、价格和销量等因素可能共同影响用户点击item的决定(参见Figure 2)。这意味着在HM数据集中仅依靠封面图像可能不足以让MoRec有效地捕获这些non-visual features,因为封面图像是item encoder的唯一input。相比之下,众所周知IDRec能够从latent embedding space中隐式地学习这些特征(《Matrix factorization techniques for recommender systems》)。也就是说,如果考虑更理想的数据集或更有用的内容特征,MoRec的性能仍有提升空间。为了构建实验数据集,我们分别从
Bili、HM和MIND中随机选择了大约400K、500K和600K用户。然后,我们进行基本的预处理:将所有图像的大小设置为
224x224。将所有新闻文章的标题设置为最多
30 tokens(覆盖99%的descriptions)。对于
MIND,我们为每个用户选择latest 23 items来构建interaction sequence。对于HM和Bili,我们选择最近的13次interactions,因为encoding images需要更大的GPU内存(尤其是在SASRec架构下)。遵循
《BPR: Bayesian personalized ranking from implicit feedback》,我们删除了interactions少于5次的users,这仅仅是因为本文不考虑cold user settings。

超参数:
对于所有方法,我们采用
AdamW作为默认optimizer,并发现dropout rate = 0.1(即删除10%的parameters))在验证集上提供了最优结果。关于其他超参数,我们遵循常见做法并进行了广泛的搜索。对于
IDRec,我们从embedding/hidden sizeDSSM的batch size1024,SASRec的batch size128。对于
MoRec,我们将DSSM和SASRec的512;由于GPU内存限制,DSSM和SASRec的batch size512和64。鉴于
modality encoder(例如BERT和ResNet)已经具有良好预训练好的参数,我们为modality encoder使用比recommender model其他部分相对更小的pre-trained modality encoder network搜索randomly initialized parameters的部分将最后,我们从
IDRec和MoRec的weight decay对于
DSSM中使用的多层感知机(multilayer perceptron: MLP),我们最初将其中间层大小也设为no hidden layers)总是产生最佳结果。对于
SASRec中使用的Transformer block,我们将2,multi-head attention的head数设为2以获得最优结果。除非另有说明,所有其他超参数在
IDRec和MoRec中保持相同。
Comparison Settings:为了公平比较,我们确保
IDRec和MoRec除了item encoder外具有完全相同的网络架构。对于text encoders和vision encoders,我们将其output item representations传递到一个DT-layer(见Figure 1,dimension transformation layer)进行维度变换。关于超参数设置,我们的原则是确保
IDRec在学习率embedding维度dropout rateMoRec,我们尝试首先使用与IDRec相同的超参数集,然后在best choices附近进行一些基本搜索。因此,除非特别说明,我们不保证MoRec报告的结果是最好的,因为为MoRec搜索所有可能的超参数非常昂贵且耗时,有时比IDRec多花费100倍以上的计算和训练时间(尤其是对于vision,见Table 6)。因此,如何有效找到MoRec的最优超参数是一个重要但尚未探索的研究课题。考虑到
MoRec的FLOPs要大得多,因此其online inference会是一个瓶颈。
评估:
我们采用标准的留一法(
leave-one-out)策略将数据集划分为训练集、验证集和测试集。具体来说,每个用户的latest interaction用于评估,倒数第二次interaction用作验证以搜索超参数,所有其他interactions用于训练。我们使用两个流行的
top-N ranking metrics评估所有模型:HR@N(命中率Hit Ratio)和NDCG@N(归一化折损累积增益Normalized Discounted Cumulative Gain),其中10。我们通过将
ground-truth target item与item pool中所有剩余items进行比较来对ground-truth target item进行排序。最后,我们在测试集上报告结果,但通过验证集找到最佳超参数。
1.4 实验结果
1.4.1 Comparative Studies (Q(I))
根据现有文献,
MoRec在new item recommendation settings或cold-start item recommendation settings中可以轻松击败IDRec(《Content-aware neural hashing for cold-start recommendation》、《Visually-aware personalized recommendation using interpretable image representations》、《Adversarial training towards robust multimedia recommender system》)。我们在附录A.1中报告了这些结果。本文我们专注于在更具挑战性的setting中评估它们:常规推荐场景(mixture of warm and cold items)和warm-start item recommendation场景,在这些场景中IDRec通常非常强大。据我们所知,现有文献中尚未明确讨论过此类比较。如前所述,我们使用两种最重要的推荐架构(即
DSSM和SASRec)来评估IDRec和MoRec。当物品具有文本特征时,我们使用
pre-trained BERT and RoBERTa作为modality encoders。当物品具有视觉特征时,我们使用
pre-trained ResNet and Swin Transformer作为modality encoders。
注意对于
BERT和RoBERTa,我们在[CLS] token的final representation上添加了DT-layer(见Figure 1)。我们在Table 2中报告了regular setting(即原始分布)下测试集的结果,在Table 3中报告了warm-start setting(删除cold items后)的结果。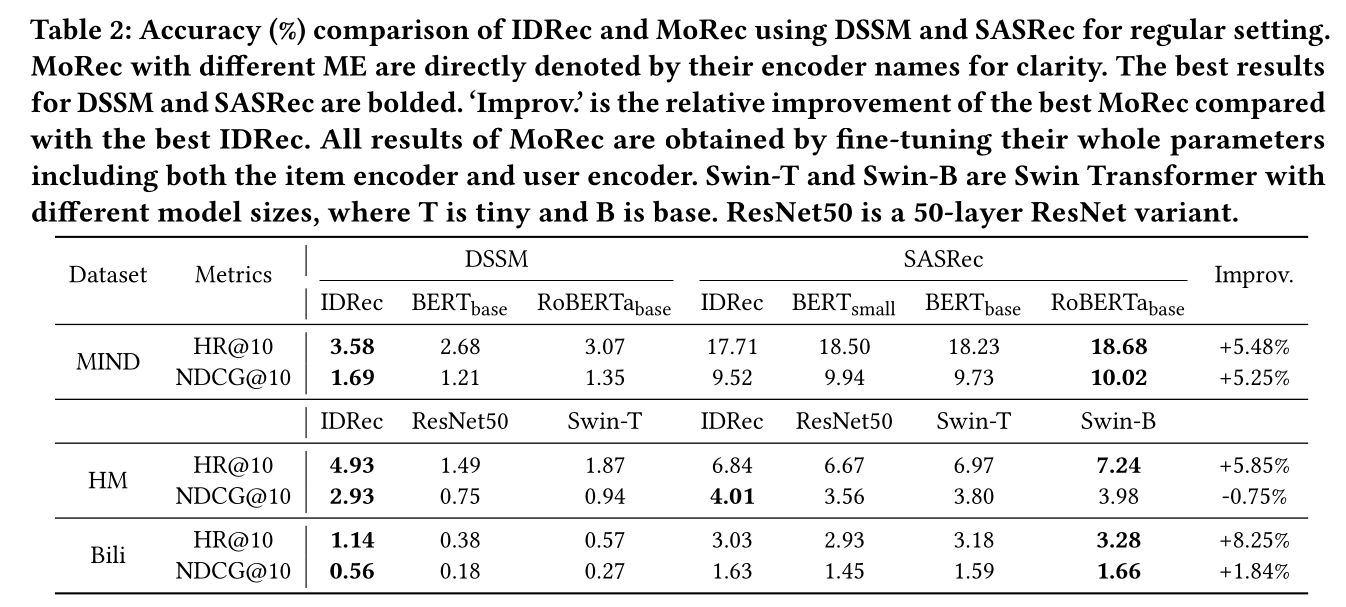
MoRec vs IDRec (Regular Setting):如Table 2所示:我们观察到无论使用何种
item encoding策略,DSSM始终大幅逊于SASRec。例如,基于
SASRec-based IDRec在新闻推荐的HR@10上比基于DSSM-based IDRec好约4.9倍,尽管它们的训练集、验证集和测试集完全相同。图像推荐的性能差距相对较小,在
HM和Bili上分别约为1.4倍和2.7倍。
这与许多先前文献
《Session-based recommendations with recurrent neural networks》、《Self-attentive sequential recommendation》一致,即用interacted item sequence来representing and modeling users,通常比将它们作为单个userID处理更强大。其次,我们注意到:
在
DSSM架构下,即使使用SOTA的modality encoder,MoRec在所有三个数据集上的表现都远差于IDRec,尤其是在视觉推荐场景中。相比之下,在
SASRec架构下,MoRec在MIND上使用三种文本编码器(即BERT_small、BERT_base和RoBERTa_base)中的任意一种都持续取得优于IDRec的结果。例如,使用RoBERTa_base文本编码器时,MoRec在两个评估指标上比IDRec高出超过5%。同时,当使用Swin Transformer作为modality encoder时,MoRec表现与IDRec相当;但在使用ResNet50时表现相对较差。
MoRec在DSSM和SASRec之间的性能差异可能暗示,需要一个强大的recommendation backbone(SASRec vs DSSM)和训练方法(seq2seq vs <u,i> pair)来充分发挥modality-based item encoder的优势。鉴于MoRec在DSSM上的糟糕结果,我们后续主要关注SASRec架构。
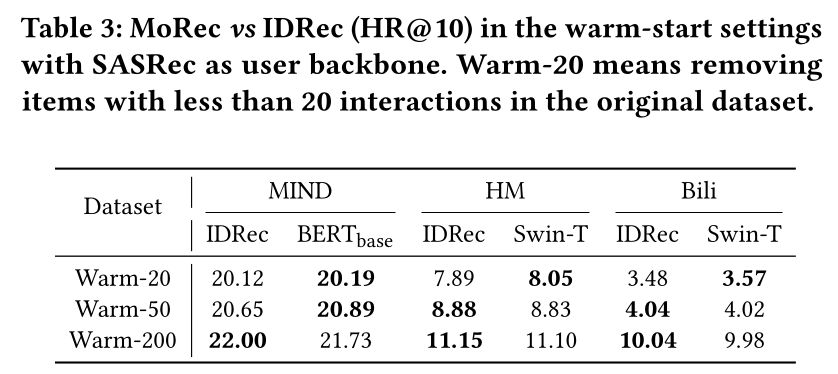
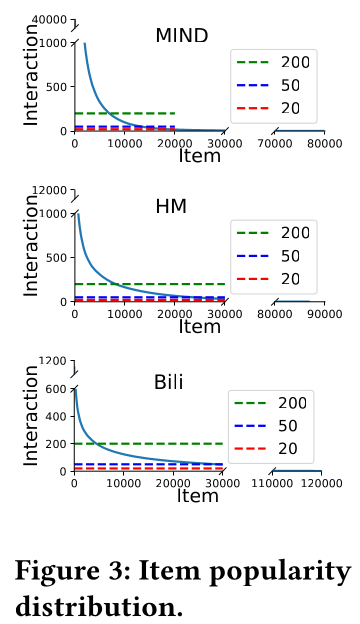
MoRec vs IDRec (Warm Item Settings):为了验证MoRec和IDRec在warm item recommendation中的性能,我们构建了具有不同item popularity的新数据集。我们在Figure 3中展示了原始数据集的item popularity分布。对于每个数据集,我们从原始数据集中删除interactions次数少于20、50、200次的items。我们在Table 3中报告了所有三个数据集的推荐准确性。可以看出:从
warm-20、warm-50到warm-200,IDRec变得越来越强。在warm-20数据集中,MoRec略优于IDRec,而在warm-200中,对于文本推荐,MoRec略差于IDRec。根据现有文献(《Autodebias: Learning to debias for recommendation》、《Sampling-bias-corrected neural modeling for large corpus item recommendations》、《Lambdafm: learning optimal ranking with factorization machines using lambda surrogates》),这是合理的,因为众所周知IDRec擅长对popular items进行建模。但即使在这些
warm-start setting中,MoRec仍然与IDRec相当。这一特性很有吸引力,因为众所周知MoRec在cold-start setting中可以轻松击败IDRec(见附录),并且在tranfer learning或cross-domain recommendation方面具有天然优势。更进一步,最近的工作表明,大型
MoRec模型有潜力成为foundation recommendation models(《One4all user representation for recommender systems in e-commerce》、《Scaling law for recommendation models: Towards generalpurpose user representations》),能够实现"one model for all"的雄心勃勃的目标(《One4all user representation for recommender systems in e-commerce》、《TransRec: Learning Transferable Recommendation from Mixture-of-Modality Feedback》)。
上述结果揭示了以下见解:
(1):MoRec的推荐架构(seq2seq SASRec或two-tower DSSM)对其性能影响非常大。(2):其item modality encoder也影响MoRec的性能。(3)(问题Q(i)的答案):配备最强大的modality encoder,在使用sequential neural network recommendation architecture时,MoRec在文本推荐(包括cold item settings和warm item settings)中基本上可以击败其对应的IDRec,并在视觉推荐中与IDRec相当。然而,在regular setting或warm-start setting中,MoRec似乎不太可能通过典型的DSSM训练方法取代IDRec。(4):尽管MoRec在very popular item recommendation中不能击败IDRec,但它们仍然表现出非常有竞争力的结果。据我们所知,这是第一篇明确声称pure MoRec可以与pure IDRec相媲美的论文(当它们在相同的sequential recommendation architecture下进行比较时),即使在极具挑战性的warm item recommendation中也是如此。
1.4.2 Inherit Advances In NLP & CV? (Q(II))
直观上,
MoRec有潜力将来自其他社区(如NLP和CV)的强大的representation learning技术引入推荐任务。然而,这尚未得到正式研究。在此,我们问:NLP和CV的最新进展能否转化为推荐任务准确性的提升?我们试图从以下角度回答这个问题。首先,我们研究更大的
pre-trained modality encoder是否能带来更好的推荐准确性,因为在NLP和CV中,更大的pre-trained models在相应的下游任务中通常提供更高的性能。如Figure 4所示,更大的vision item encoder总是能实现更好的图像推荐准确性,即:ResNet18-based MoRec < ResNet34-based MoRec < ResNet50-based MoRecSwin-T based MoRec < Swin-B based MoRec类似地,我们发现:
xxxxxxxxxxBERTtiny-based MoRec < BERTbase-based MoRec < BERTsmall-based MoRec一个不同之处是,
BERTbase-based MoRec并未优于基于BERTsmall-based MoRec,尽管后者是更小的BERT变体。我们得出结论,一般来说,来自NLP和CV的更大、更强大的modality encoder往往会提高推荐准确性,但这可能并不严格适用于所有情况。
其次,我们研究更强的
encoder network是否能带来更好的推荐。例如,公认的是RoBERTa优于BERT(《Roberta: A robustly optimized bert pretraining approach》),而BERT优于单向GPT(《Improving language understanding by generative pre-training》)(如OPT(《Open pre-trained transformer language models》)),用于大多数NLP理解任务(而非NLP生成任务),在相似的模型大小下;并且Swin Transformer通常在许多CV任务中优于ResNet(《Swin transformer: Hierarchical vision transformer using shifted windows》)。此外,这些现代pre-trained NLP foundation models轻松优于TextCNN(《Convolutional Neural Networks for Sentence Classification》)和GloVe(《Glove: Global vectors for word representation》),这两个约十年前开发的著名浅层模型。如Figure 4所示,MoRec的性能与NLP和CV中的发现保持一致,即:xxxxxxxxxxRoBERTabase-based MoRec > BERTbase-based MoRec > OPT125M-based MoRec > TextCNN-based MoRec > GloVe-basedMoRecSwin-T based MoRec > ResNet50-based MoRec(
Swin-T与ResNet50具有相似的模型大小,RoBERTa_base、BERT_base和OPT125M也是如此)。第三,我们研究
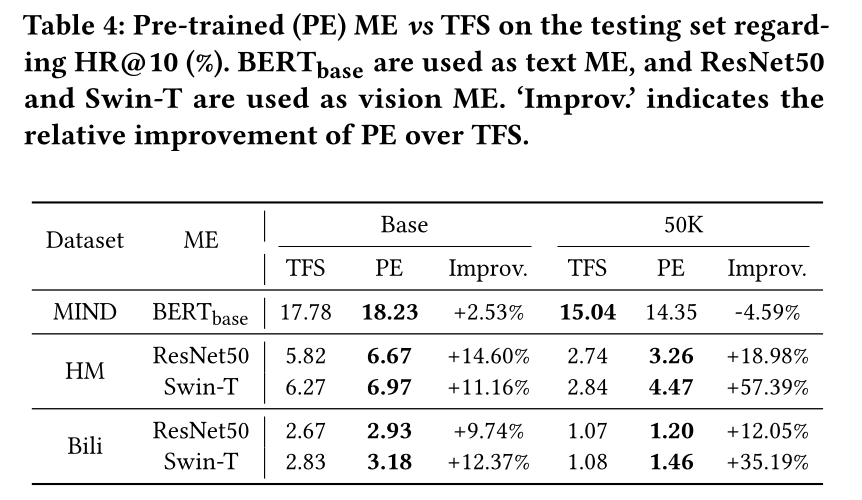
pre-trained modality encoder是否比其从头训练(training-from-scratch: TFS)版本(即随机初始化)产生更高的推荐准确性。毫无疑问,pre-trained BERT, ResNet, and Swin相对于它们的TFS版本大幅提升了相应的NLP和CV任务。我们在Table 4中报告了测试集上的推荐结果。可以清楚地看到,
pre-trained MoRec获得了更好的最终结果。特别是,在HM和Bili上,使用pre-trained modality encoder(ResNet和Swin)的MoRec实现了约10%的提升,这也与NLP和CV领域的发现一致。我们还通过从
MIND、HM和Bili中随机抽50K users构建了较小版本的数据集。可以看出,pre-trained modality encoder相对于TFS的优势在小数据集上更为明显。然而,我们发现pre-trained BERTbase在MIND-50K上甚至比其TFS版本更差。
根据上述实验,我们得出结论(问题
Q(ii)的答案):MoRec为recommendation system和其他多媒体社区建立了联系,并且通常可以继承来自NLP和CV领域的最新进展。这是一个非常好的特性,意味着一旦未来相应研究领域出现新的突破,MoRec将有更多的机会和更大的改进空间。
1.4.3 Are Modality Rpresentations Universal For RS? (Q(III))
NLP和CV中的foundation models被期望生成generic representation,然后可以直接用于zero-shot setting下的下游任务。然而,它们大多数仅在部分传统任务(《Grounded language-image pre-training》、《Learning transferable visual models from natural language supervision》)(如图像和文本分类)上进行了评估。我们认为预测user preference比这些客观任务更具挑战性。为了清楚地看到这个问题,我们评估了两种训练方法。
第一种方法是预先通过
modality encoder提取modality features,然后将它们添加到推荐模型中(《Ups and downs: Modeling the visual evolution of fashion trends with one-class collaborative filtering》、《VBPR: visual bayesian personalized ranking from implicit feedback》),称为两阶段(two-stage: TS)流水线。由于训练效率高,TS在真实世界的工业applications中特别流行,这些applications通常有数亿个训练样本。第二种方法是上述所有实验中使用的,以端到端方式同时优化
user and item encoders。
如
Table 5所示,我们发现TS-based MoRec显示出惊人的差的结果,相比IDRec和E2E-based MoRec。特别是,使用ResNet时,在HM和Bili上它仅达到E2E MoRec性能的约60%和25%。为了更好地适配,我们还在这些fixed modality features之上添加了许多dense layers。如Table 5所示,这确实可以提高TS的性能;然而,它仍然远差于IDRec和E2E-based MoRec,尤其是对于视觉推荐。结果表明,通过这些
NLP和CV任务学到的modality features对于推荐问题来说不够通用,因此与新数据上的重新训练(即End2End范式)相比,推荐结果更差。好消息是,通过适当的适配(即TS-DNN),基于TS-based MoRec在未来有潜力与E2E MoRec在文本推荐上竞争(16.66 vs 18.23)。因此,我们想明确提醒
Recommendation System研究人员和从业者(问题Q(iii)的答案):首先,流行的两阶段推荐机制会导致显著的性能下降(尤其是对于图像推荐),这在实践中不应被忽视。
其次,对于
NLP和CV研究人员,我们想向他们展示,尽管Foundation Model取得了革命性的成功,但到目前为止,它们的representation features还不够通用,至少对于item recommendation而言。
注意:这里的
E2E采用了pre-trained encoder,而不是从头开始训练。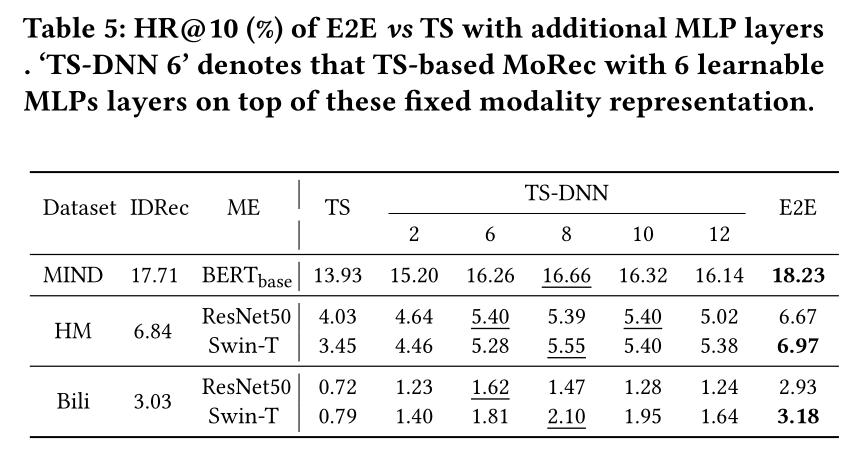
1.4.4 Key Challenges (Q(IV))
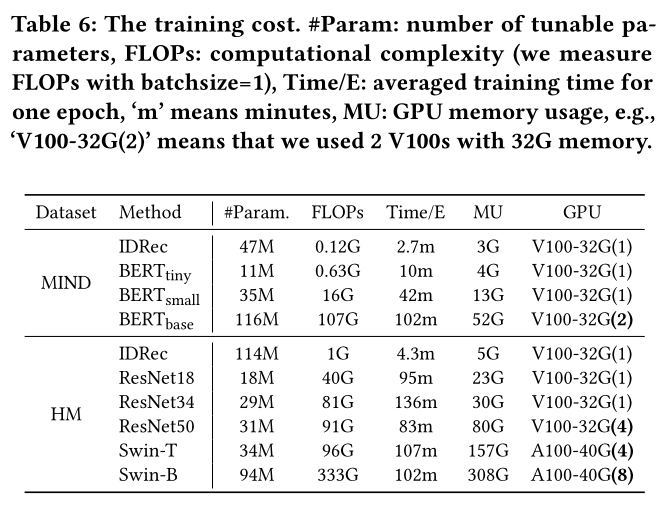
E2E-based MoRec以前研究较少,尤其是对于视觉推荐。在此,我们提出几个关键挑战和一些社区可能没有意识到的意外发现。Training cost。如Figure 4所示,具有更大modality encoder的MoRec往往比较小modality encoder表现更好,然而,训练计算量、时间和GPU内存消耗也会增加,特别是对于具有很长交互序列的seq2seq架构。我们在
Table 6中报告了HM(接近Bili)和MIND上的训练成本细节。事实上,不难想象MoRec会比IDRec消耗更多的计算资源和时间。然而,很难想象最佳的MoRec(以SASRec为user encoder,Swin-B为modality encoder)比IDRec多花费超过100倍的计算和训练时间。这在文献中尚未被明确揭示。这也可能是为什么没有正式的出版物将seq2seq user encoder和E2E-learned item modality encoder结合用于MoRec,特别是对于图像推荐。注意,在实践中,不一定需要优化modality encoder的所有参数,对于某些数据集,微调modality encoder的少数top layers可以达到相当的结果。另一方面,尽管
E2E-based MoRec在训练时非常昂贵(类似于NLP和CV中的Foundation Model),但它已被证明能够实现foundation recommendation models,从而释放更多用于训练特定模型的劳动力(《One4all user representation for recommender systems in e-commerce》、《Scaling law for recommendation models: Towards generalpurpose user representations》)。Extra pre-training:使用下游数据集对modality encoder进行第二轮pre-training在许多机器学习文献中通常效果良好(《Don’t stop pretraining: adapt language models to domains and tasks》、《How to fine-tune bert for text classification?》)。在此,我们探索这是否能为MoRec带来改进的结果。遵循BERT的pre-training,我们采用masked language model: MLM目标在MIND上训练MoRec的文本编码器(记为BERTbase-MLM)并在Table 8中报告结果。如结果所示,BERTbase-MLM在TS模型和E2E模型上都获得了比BERTbase更高的准确性。类似地,我们探索这在视觉编码器上是否成立。注意,之前实验中使用的
ResNet和Swin Transformer是以监督方式预训练的,但HM和Bili都不包含supervised image labels。为此,我们转而使用MAE(《Masked autoencoders are scalable vision learners》),这是一种以无监督方式预训练的SOTA的图像编码器,类似于MLM。我们发现:MAEbase-MLM在HM上使用TS模型时明显优于标准MAEbase,但在E2E模型上获得微小增益。相比之下,在
Bili上没有观察到准确性提升。
通过检查
Figure 2中的图像案例,我们发现Bili中的图片主题非常多样,比HM(仅包含非常简单的时尚元素)更具挑战性。我们的结论是,第二轮预训练的有效性取决于具体数据集;更重要的是,对于
E2E MoRec似乎很难获得较大的准确性提升。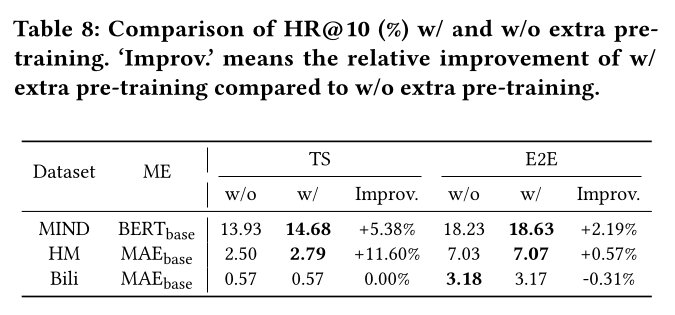
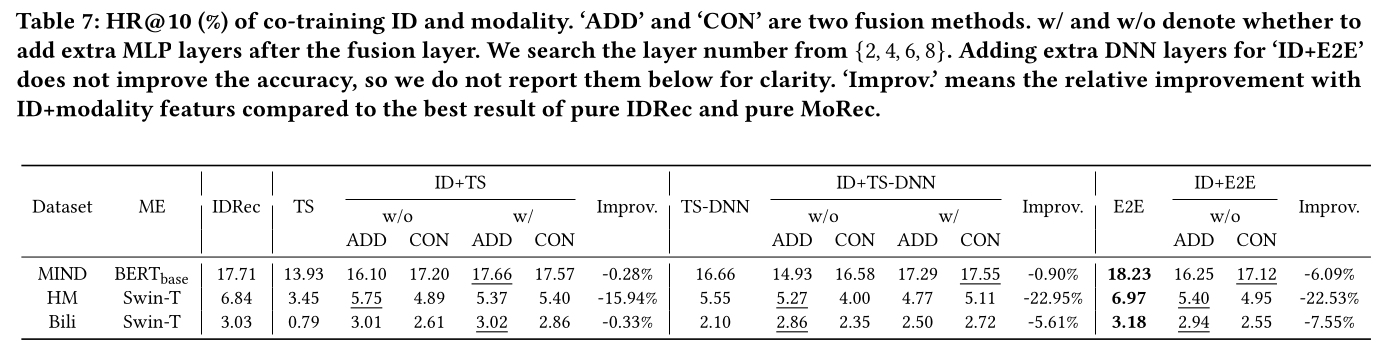
Combing ID & modality features:鉴于IDRec和E2E-based MoRec都表现良好,一个自然的想法是将这两种特征(即ID和modality)结合在一个模型中。我们对此进行了评估,如Table 7所示。我们考虑了两种特征组合方式:加法和拼接。令人惊讶的是,我们发现基于TS-based MoRec和E2E-based MoRec相比IDRec和MoRec之间的最佳结果都没有提升。通过添加ID特征,E2E-based MoRec甚至比pure IDRec和pure MoRec表现更差。我们的结果与之前的文献有些矛盾,后者通常声称通过为IDRec添加modality features或multimedia features可以获得更好的结果(《Ups and downs: Modeling the visual evolution of fashion trends with one-class collaborative filtering》、《VBPR: visual bayesian personalized ranking from implicit feedback》、《Metadata embeddings for user and item cold-start recommendations》)。一个原因可能是,在
regular (vs cold-start) setting中,E2E-based MoRec和IDRec都从user-item interaction data中学习user preference,因此它们无法互补;而对于TS-based MoRec,由于ID embeddings远好于frozen modality features,它们的结合也没有提升结果。第二个原因可能是,结合
ID和modality features需要更先进的技术。事实上,从另一个角度看,MoRec with ID features将失去MoRec的许多优势(见引言章节)。例如,MoRec with ID features不适合构建foundation recommendation models,因为ID由于隐私问题和overlapping问题从而不易迁移。
Model collapse:与IDRec不同,我们发现一个非常令人惊讶的现象:在没有适当超参数(主要是学习率MoRec很容易导致模型坍塌(model collapse)。如Figure 5所示:当
0.0001时,MoRec在MIND上的性能从16%急剧下降到0。更糟糕的是,当
MoRec从一开始就坍塌了。类似地,
MoRec在HM上进行图像推荐时也存在这个问题。
然而,通过仔细搜索超参数,我们发现
MoRec通常可以通过适当的学习率item modality encoder和其他模块设置不同的学习率。这可能是因为item modality encoder已经在NLP和CV数据集上进行了预训练,其learning stride可能与从头训练的其他模块不同。相比之下,即使使用许多不同的IDRec也不会坍塌。据我们所知,我们的这些发现尚未在文献中报道。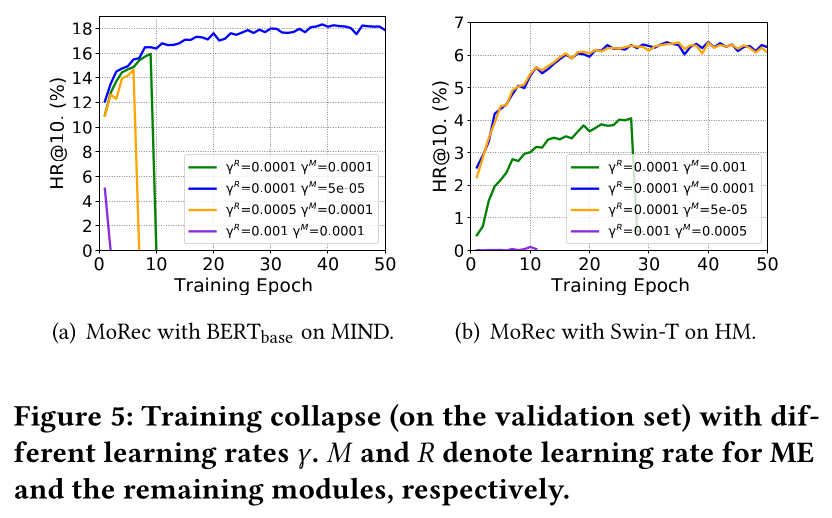
1.5 结论与未来工作
在本文中,我们研究了一个雄心勃勃但未被充分探索的问题:
MoRec是否有机会结束IDRec的主导地位。显然,这个问题无法在一篇论文中完全回答,需要来自Recommendation System甚至NLP和CV社区的更多研究和努力。然而,这里的一个主要发现是,使用SOTA的E2E-trained modality encoder,即使在non cold-start item recommendation setting中,现代MoRec在典型的推荐架构(即Transformer骨干网络)下已经可以表现得与IDRec相当或更好。此外,MoRec可以很大程度上受益于NLP和CV领域的技术进步,这意味着它在未来有更大的准确性改进空间。鉴于此,我们相信我们的研究是有意义的,并可能激发更多关于E2E-based MoRec的研究,例如开发更强大的推荐架构(特别是对于CTR预测任务)、更具表现力和泛化能力的item encoders、更好的item & user fusion策略,以及更有效的优化以减少compute & memory costs and the longer training time。我们还设想,从长远来看,当item raw modality features可用时,Recommendation System的主流范式有可能从IDRec转向MoRec。如上所述,本研究仅是对
MoRec的初步探索,存在几个局限性:(1):我们只考虑了仅包含文本和视觉的Recommendation System场景,而MoRec在其它模态(如语音和视频)上的行为仍然未知。(2):我们只考虑了single-modal item encoders,而multimodal MoRec的行为未知。(3):我们只考虑了一种非常基本的将modality encoder融合到推荐模型中的方法,因此MoRec可能未达到最优性能。(4):我们的观察是在三个中等规模的数据集上进行的,如果像真实工业系统中那样将训练数据扩展到100倍或1000倍,关键发现是否仍然成立尚不可知。
二、附录
2.1 MoRec vs IDRec on cold-start settings
MoRec天然适合cold item recommendation,因为它们的modality encoder是专门为建模item的raw modality features而开发的,无论item是否冷门。为了验证这一点,我们在两种场景下评估IDRec和MoRec:COLD item setting和NEW item setting。具体来说,我们统计了训练集中所有
items的interactions次数,将出现少于10次的视为cold items。我们发现原始测试集中的cold items数量非常少。因此,我们再次进行了一个月的数据爬取,然后选择了包含这些cold items(作为cold item setting)和未出现在训练集中的items(作为new item setting)的用户序列。我们在Table 9中报告了结果。正如预期,
MoRec在所有三个数据集的文本和视觉模态下,在cold item setting和new item setting中始终且大幅优于IDRec。MoRec的优越性来自于modality encoder的强大representations,这些modality encoder事先在大型文本和图像数据集上进行了预训练。