一、 TALLRec [2023]
《TALLRec: An Effective and Efficient Tuning Framework to Align Large Language Model with Recommendation》
大语言模型(
Large Language Models: LLMs)已在多个领域展现出卓越的性能,这促使研究人员探索其在推荐系统中的潜在应用。人们初步尝试利用了LLMs的卓越能力,例如通过上下文学习(In-context Learning)实现的丰富知识和强大泛化能力,该方法将推荐任务构建为提示词(prompts)。然而,由于LLM的训练任务与推荐任务之间存在巨大差异,以及在pre-training期间推荐数据的不足,LLM在推荐任务中的表现仍然不够理想。为了弥合这一差距,我们考虑通过使用推荐数据微调LLM来构建一个大型推荐语言模型(Large Recommendation Language Model)。为此,我们提出了一个有效且高效的、用于将LLMs与推荐任务对齐的微调框架,即TALLRec。我们已经证明,即使在少于100个样本的有限数据集上,所提出的TALLRec框架也能显著提升LLM在电影和图书领域的推荐能力。此外,所提出的框架非常高效,可以在单张RTX 3090显卡上使用LLaMA-7B模型执行。更重要的是,微调后的LLM展现出了强大的跨域泛化能力。我们的代码和数据可在https://github.com/SAI990323/TALLRec获取。大语言模型(
Large Language Models: LLMs)在生成接近人类语言的文本以及执行广泛任务方面展现出了卓越的能力(《A Survey of Large Language Models》),这些任务包括自然语言处理、机器人技术和信息检索。先前的研究也证明了LLMs具有知识丰富和组合泛化(compositional generalization)的能力。只要给予适当的指令,这些模型能够学习如何解决未见过的任务,并激发自身的知识以达到高性能水平(《Few-shot learning with multilingual language models》)。LLM的上述能力为解决当前推荐领域的挑战提供了有前景的机会,其中这些挑战需要强泛化能力和丰富知识。鉴于此,探索将LLM集成到推荐系统中是很有价值的,而这在先前的研究中受到的关注有限。在最近的初步尝试中(
《Chat-REC: Towards Interactive and Explainable LLMs-Augmented Recommender System》、《Zero-Shot Next-Item Recommendation using Large Pre-trained Language Models》),achieving the target依赖于上下文学习(In-context Learning)(《Language models are few-shot learners》),这通常通过OpenAI官方API来实现。他们将LLM视为传统推荐模型(如MF《Matrix factorization techniques for recommender systems》和LightGCN《Lightgcn: Simplifying and powering graph convolution network for recommendation》)的工具(toolformer)(《Toolformer: Language models can teach themselves to use tools》),即LLM用于对这些模型筛选出的candidate items进行re-ranking。然而,这些方法仅达到了与传统模型相当的性能。更糟糕的是,仅使用In-context Learning可能无法进行推荐。如Figure 1所示,我们发现ChatGPT要么拒绝回答,要么总是给出肯定的预测(喜欢)。因此,探索一种更合适的方式来更有效地在推荐中利用LLM至关重要。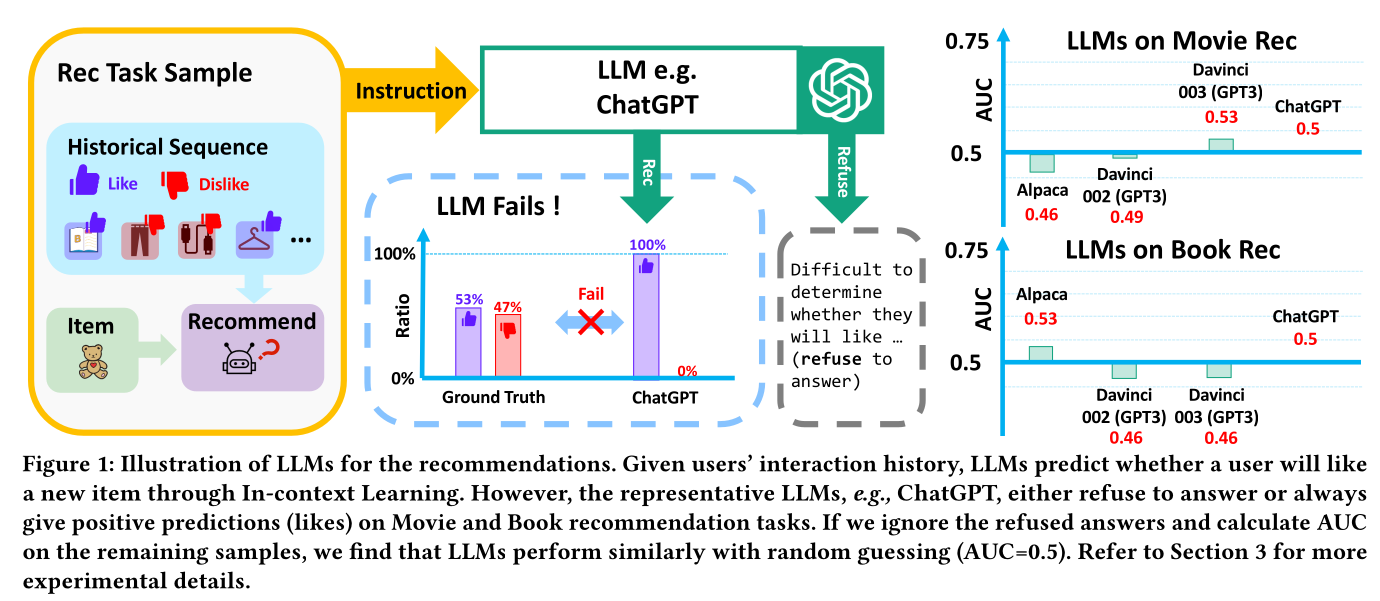
我们推测仅使用
In-context Learning的失败有两个原因:1):由于训练LLM的语言处理任务与推荐任务之间存在巨大差距,LLM可能与推荐任务不能很好地对齐。此外,在LLM的训练阶段,面向推荐的语料库非常有限。2):LLM的效果受到底层推荐模型的限制,这些模型可能由于自身能力有限而无法将target items包含在其candidate lists中。
因此,我们考虑构建一个
Large Recommendation Language Model: LLRM来弥合LLM与推荐任务之间的差距,并在In-context Learning之外,更好地激发LLM的推荐能力。为了实现这一目标,我们专注于使用推荐任务来微调
LLM。考虑到instruction tuning是让LLM学习解决不同任务并具有强大泛化能力的核心,我们提出了一个轻量级的微调框架,以使LLM适配推荐任务,名为TALLRec。具体来说,TALLRec将推荐数据构建为instructions,并通过一个额外的instruction tuning过程来微调LLM。此外,考虑到LLM训练需要大量的计算资源,TALLRec采用轻量级微调方法,以高效地将LLM适应于推荐任务。具体而言,我们将
TALLRec框架应用于带有LoRA(《LoRA: Low-Rank Adaptation of Large Language Models》)架构的LLaMA-7B模型(《LlaMA: Open and efficient foundation language models》)上,这确保了该框架可以在NVIDIA RTX 3090 (24GB) GPU上部署。此外,为了研究所需的最少计算资源,我们在few-shot setting下进行了实验,仅使用了有限数量的微调样本。我们在电影和图书这两个知识密集的推荐场景中进行了详细实验,微调后的LLaMA-7B模型表现优于传统推荐模型、以及In-context Learning Learning with GPT3.5(一个比LLaMA-7B强大得多的LLM)。结果验证了我们框架的效率和鲁棒性:1):我们的TALLRec框架可以在few-shot setting下快速激发LLM的推荐能力。2):通过TALLRec框架训练的LLM在不同领域(例如,movie --> book)之间具有强大的泛化能力。
总的来说,我们的贡献总结如下:
我们研究了推荐中的一个新问题——将
LLM与推荐对齐,揭示了In-context Learning-based方法的局限性,并强调了instruction tuning的重要性。我们引入了一个新的
TALLRec框架来构建大型推荐语言模型,该框架能够以低GPU成本和少量微调样本,有效且高效地对LLM进行推荐任务的微调。我们进行了广泛的实验,验证了所提出框架的有效性和效率,并揭示了其在不同领域之间无缝切换的卓越鲁棒性。
1.1 相关工作
LMs for Recommendation:已经有一些尝试将语言模型(language models: LMs)与推荐系统集成。尽管整合了LMs(《Recommendation as language processing (rlp): A unified pretrain, personalized prompt & predict paradigm (p5)》、《Personalized prompt learning for explainable recommendation》),一些尝试仍然坚持使用传统的user/item IDs来表示users/items。因此,它们忽略了LMs的语义理解能力,例如评论;而其他工作则已将语言信息作为users/items embedding的一部分纳入其中(《Towards Universal Sequence Representation Learning for Recommender Systems》)。此外,其他方法要么利用已经具备初步推荐能力的未公开模型(《M6-Rec: Generative Pretrained Language Models are Open-Ended Recommender Systems》),要么使用小模型在大规模下游任务数据上进行训练(《Prompt Learning for News Recommendation》)。此外,上述模型也限于小模型,而本文关于如何使大语言模型适应推荐任务的问题是正交的。在推荐系统中,目前将
LLM应用于推荐场景的研究很少。那些工作利用GPT3.5系列模型的交互能力并应用In-context Learning(《Chat-REC: Towards Interactive and Explainable LLMs-Augmented Recommender System》、《Zero-Shot Next-Item Recommendation using Large Pre-trained Language Models》)。具体来说:Chat-Rec(《Chat-REC: Towards Interactive and Explainable LLMs-Augmented Recommender System》)努力利用ChatGPT的交互能力,并将ChatGPT与传统推荐模型(例如MF《Matrix factorization techniques for recommender systems》,LightGCN《Lightgcn: Simplifying and powering graph convolution network for recommendation》)连接起来,以构建一个对话式推荐系统。NIR(《Zero-Shot Next-Item Recommendation using Large Pre-trained Language Models》)与Chat-Rec概念相似,它采用传统的推荐模型生成candidate items,然后对这些candidate items进行三阶段multi-step prompting process以进行re-ranking。
Sequential Recommendation:我们的设置接近于序列推荐(sequential recommendation),其目的是基于用户的historical interaction sequences来推断用户的next interaction。早期,马尔可夫链在序列推荐中扮演着重要角色。最近,基于深度学习的方法成为主流。大量工作使用不同类型的神经网络结构,如
RNN、CNN和注意力机制,来建模user interaction sequences。然而,由于仅使用ID来表示users and items,这类工作无法快速适配和泛化到新场景。因此,一些工作通过pre-training(《Perceive Your Users in Depth: Learning Universal User Representations from Multiple E-commerce Tasks》、《Parameter-Efficient Transfer from Sequential Behaviors for User Modeling and Recommendation》)、data augmentation(《Contrastive Learning for Representation Degeneration Problem in Sequential Recommendation》、《Multi-level Contrastive Learning Framework for Sequential Recommendation》、《Contrastive Learning for Sequential Recommendation》)、debiasing(《Interpolative Distillation for Unifying Biased and Debiased Recommendation》、《Unbiased Sequential Recommendation with Latent Confounders》、《Causal Intervention for Leveraging Popularity Bias in Recommendation》、《Disentangling User Interest and Conformity for Recommendation with Causal Embedding》)和robust optimization(《Distributionally-robust Recommendations for Improving Worst-case User Experience》、《A Generic Learning Framework for Sequential Recommendation with Distribution Shifts》)来关注序列推荐模型的泛化能力。然而,它们忽略了现有LLM的强大泛化能力,导致探索不足。
1.2 TALLRec
在本节中,我们首先介绍微调
LLM的预备知识和我们的任务表述,然后提出TALLRec框架。
1.2.1 预备知识
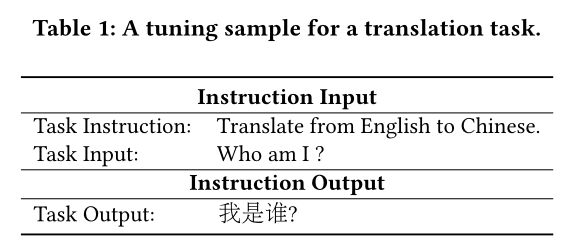
指令微调(
Instruction Tuning):是一项使用人工标注的instructions和responses来训练LLM的关键技术(《Training language models to follow instructions with human feedback》)。通常,指令微调包含四个步骤(见Table 1中的示例)。具体来说:Step 1:定义一个任务,并使用自然语言阐述一个"Task Instruction",其中通常包含对任务的清晰定义以及解决该任务的具体方法。Step 2:用自然语言表述并构建任务的输入和输出,称为"Task Input"和"Task output"。Step 3:将"Task Instruction"和"Task Input"整合在一起形成"Instruction Input",并将"Task output"作为相应的"Instruction Output",用于每个tuning sample。Step 4:基于格式化后的("Instruction Input" "Instruction Output") pair,对LLM进行指令微调。
Rec-tuning Task Formulation:我们的目标是利用LLM,记作LRLM,它可以预测一个new item是否会受到用户的喜爱。为了实现这一目标,我们使用推荐数据对LLM进行推荐微调(rec-tuning)。如Table 2所示,我们将推荐数据格式化为instruction tuning的模式。我们首先编写一个
"Task Instruction",指导模型根据用户的historical interactions来判断用户是否会喜欢target item,并用"Yes" or "No"的二元答案进行回应。为了格式化
"Task Input",我们根据评分将用户历史交互过的items分为两类:用户喜欢的items、以及不喜欢的items,其中items按交互时间顺序排列,并用文本描述(例如,标题和简短介绍)表示。此外,"Task Input"还包括用户从未见过的target new item。最后,我们合并
"Task Instruction"和"Task Input"来创建"Instruction Input",然后将预期的"Instruction Output"设置为"Yes" or "No"用于rec-tuning。

1.2.2 TALLRec Framework
在本小节中,我们介绍
TALLRec框架,该框架旨在促进LLM与推荐任务的有效且高效对齐,特别是在低GPU内存消耗的情况下。具体来说,我们首先介绍具有轻量级实现的两个TALLRec微调阶段,然后介绍骨干模型的选择。如Figure 2所示,TALLRec包含两个微调阶段:alpaca tuning和rec-tuning。alpaca tuning阶段是LLM的常见训练过程,增强了LLM的泛化能力。而
rec-tuning阶段模拟instruction tuning的模式,并为推荐任务微调LLM。
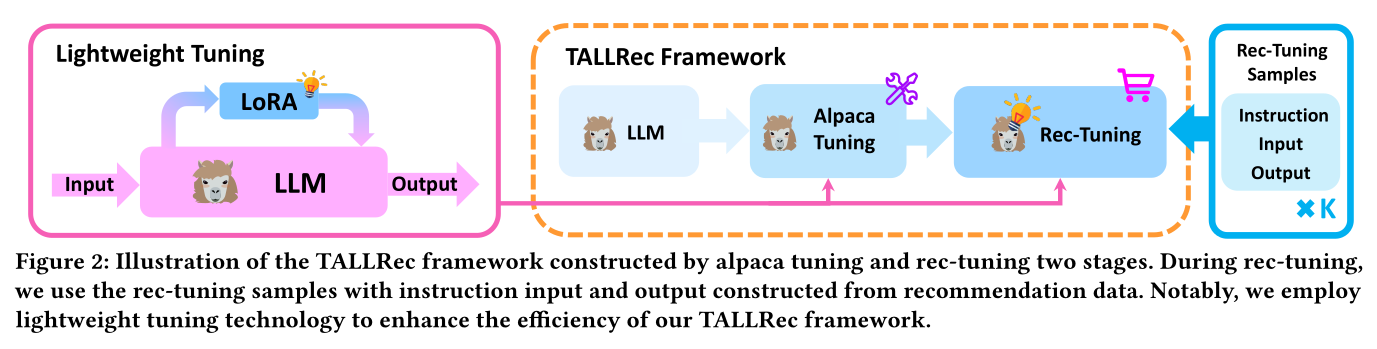
TALLRec Tuning Stages:对于
alpaca tuning,我们使用Alpaca(《Stanford Alpaca: An Instruction-following LLaMA model》)提供的self-instruct data来训练LLM。具体来说,我们在alpaca tuning期间使用conditional language modeling objective,如Alpaca仓库中所例示的。正式地,其中:
self-instruct data中的"Instruction Input"和"Instruction Output"。token,tokens。
在
few-shot learning场景下,如果训练样本比较多(如256-shot),那么alpaca tuning几乎没什么用;当训练样本比较少(如16-shot, 64-shot),那么alpaca tuning才有价值。对于
rec-tuning,我们可以利用如Table 2所述的rec-tuning样本,类似于alpaca tuning的方式微调LLM。
alpaca tuning和rec-tuning的唯一区别在与构造样本的方式不同:alpaca tuning的数据格式是通用的。这个阶段让模型学会理解和执行各种形式的指令,而不是专门针对推荐任务。该阶段使用的数据集特指斯坦福大学
Alpaca项目发布的alpaca_data.json数据集。它是一个包含52,000条由text-davinci-003模型生成的 “指令-输入-输出” 三元组的数据集,采用了Self-Instruct方法,并由官方在GitHub上发布。rec-tuning的数据格式完全是针对推荐任务的。这个阶段的目标是让模型学会推荐任务
Lightweight Tuning:然而,直接微调LLM计算量巨大且耗时。因此,我们建议采用轻量级微调(lightweight tuning)策略来执行alpaca tuning和rec-tuning。轻量级微调的核心前提是,现代语言模型可能拥有过多的参数,其信息集中在低本征维度(low intrinsic dimension)上(《LoRA: Low-Rank Adaptation of Large Language Models》)。因此,通过仅微调一小部分参数的子集,我们可以达到与微调整个模型相当的性能。具体来说,我们采用
LoRA(《LoRA: Low-Rank Adaptation of Large Language Models》),它涉及冻结pre-trained model parameters,并在Transformer架构的每一层中引入可训练的低秩分解矩阵(rank decomposition matrices),以促进轻量级微调。因此,通过优化rank decomposition matrices,我们可以有效地整合补充的信息,同时保持原始参数处于冻结状态。总的来说,最终的学习目标可以计算为:其中:
LoRA参数,我们仅在训练过程中更新LoRA参数。通过
LoRA,我们仅用原始LLM参数的千分之一即可完成训练过程。Backbone Selection:目前,有大量的LLM发布,例如GPT系列、PaLM、CHinchilla和LLaMA。其中,相当多的LLM(例如PaLM和Chinchilla)不提供其模型参数或API的访问权限,这使得它们难以用于研究或其他应用。此外,数据安全问题是推荐领域的重要问题。因此,我们利用第三方API(例如ChatGPT和text-davinci-003)来利用LLM需要进一步讨论。为了模拟实际推荐场景中需要考虑的问题,我们打算模拟使用公开的
LLM并更新其参数以用于推荐目的。经过仔细考虑,我们选择使用LLM-LLaMA进行实验,LLaMA是目前性能最佳的开源LLM,其训练数据也是公开可用的(《LlaMA: Open and efficient foundation language models》)。
1.3 实验
在本节中,我们进行实验以回答以下研究问题:
RQ1:与当前LLM-based的推荐模型和传统的推荐模型相比,TALLRec的表现如何?RQ2:TALLRec中的不同组件如何影响其有效性?RQ3:TALLRec在跨域推荐中的表现如何?
数据集:我们在两个数据集上进行实验。统计数据和更多细节可以在我们发布的数据中找到。
Movie:这是一个从MovieLens 100K(《The MovieLens Datasets: History and Context》)处理得到的数据集,包含用户对电影的评分以及丰富的电影文本描述,如"title"和"director"。因为我们在需要有限微调样本的few-shot training setting下进行实验,我们通过采样最近的10,000个interactions来处理原始数据集,并按8:1:1的比例划分为训练集、验证集和测试集。为了构建一个rec-tuning sample,我们保留target item之前的10 interactions作为historical interactions。遵循《Lightgcn: Simplifying and powering graph convolution network for recommendation》、《Reformulating CTR Prediction: Learning Invariant Feature Interactions for Recommendation》,我们仅将ratings > 3的interactions视为"likes",ratings ≤ 3的视为"dislike"。Book:这是一个从BookCrossing(《Improving Recommendation Lists through Topic Diversification》)处理得到的图书推荐数据集。BookCrossing数据集包含用户评分(1-10)和图书的文本描述,例如"Book-Author"和"Book-Title"信息。对于每个用户,我们随机选择该用户交互过的一个item作为prediction target,并采样10 interacted items作为historical interactions。随后,我们将构建好的rec-tuning samples按相同的8:1:1比例划分为训练集、验证集和测试集。此外,我们根据阈值5对评分进行二值化。
Few-shot Training Setting:我们采用few-shot training setting,其中仅从训练集中随机选择有限数量的样本进行模型训练。这被称为"K-shot" training setting,其中64,我们可以测试一种方法是否能够在训练数据严重有限的情况下,从LLM中快速获得推荐能力。Baseline:我们将TALLRec与LLM-based的方法和传统推荐方法进行比较。1):现有的LLM-based的方法采用In-context Learning直接生成推荐(《Chat-REC: Towards Interactive and Explainable LLMs-Augmented Recommender System》、《Zero-Shot Next-Item Recommendation using Large Pre-trained Language Models》)。为了公平比较,我们通过使用相同的指令使这些方法与TALLRec对齐。具体来说,我们在不同的
LLM上执行In-context Learning:Alpaca-LoRA、Text-Davinci-002、Text-Davinci-003、ChatGPT。Alpaca-LoRA是一个通过使用LoRA和alpaca tuning来复现LLaMA model的Alpaca results的模型。后三个是来自OpenAI的GPT系列模型。2):传统方法。由于我们的方法利用historical interactions来预测后续interaction,类似于sequential recommendation,我们考虑以下序列模型:(i) GRU4Rec(《Session-based Recommendations with Recurrent Neural Networks》):是一个RNN-based sequential recommender,它使用GRU来编码historical interactions。(ii) Caser(《Personalized top-n sequential recommendation via convolutional sequence embedding》):利用CNN来编码historical interaction sequences。(iii) SASRec(《Self-attentive sequential recommendation》):是一个经典的transformer-based sequential recommender。(iv) DROS(《A Generic Learning Framework for Sequential Recommendation with Distribution Shifts》):是一个SOTA的sequential recommender model,它利用distributionally robust optimization来实现robust recommendations。我们使用作者提供的由GRU4Rec实现的版本。
上述
sequential models依赖于item ID features,没有考虑items的文本描述。然而,在我们的设置中,我们假设item的文本描述可用于LLM微调。为了确保公平比较,我们进一步考虑比较GRU4Rec和DROS的以下变体:(v) GRU-BERT:是GRU4Rec的一个变体,它结合了pre-trained BERT来编码文本描述。具体来说,BERT编码文本描述并输出一个CLS embedding,然后将其与GRU4Rec的原始ID embedding拼接起来作为item representations。(vi) DROS-BERT:与BERT集成,类似于GRU-BERT。
评估指标:由于
TALLRec旨在预测用户对target item的偏好,即一个二分类问题,我们采用推荐中常用的评估指标:AUC。实现细节:
为了确保统一的序列长度,我们使用用户
last interacted item来填充长度小于阈值(10)的historical interaction sequences。通常是填充
0。这里采用不同的填充方式?对于所有方法,我们使用
Adam with MSE loss(学习率为1e-3)来优化参数。我们在
{1e-3, 1e-4, 1e-5, 1e-6, 1e-7}中搜索所有方法的weight decay。遵循
《A Generic Learning Framework for Sequential Recommendation with Distribution Shifts》,对于基线的特定超参数,我们坚持其原始设置。对于GRU-BERT和DROS-BERT,我们使用Hugging Face发布的BERT,同时将GRU层数设置为4,hidden size = 1024,以与BERT的embedding size对齐。最后,我们使用不同的随机种子将所有方法运行五次,并报告平均结果。
1.3.1 性能比较 (RQ1)
我们旨在研究各种方法在
few-shot training setting下的推荐性能,这使我们能够评估如何通过有限的rec-tuning样本快速调整LLM以适配推荐。与传统方法的评估结果如Table 3所示,而与LLM-based的方法的比较如Figure 3 (a)所示。从
Figure和Table中,我们得出以下观察结果:我们的方法显著优于传统方法和
LLM-based的方法,验证了通过我们的TALLRec框架微调LLM的优越性。TALLRec成功解锁了LLM的知识和泛化能力以用于推荐。LLM-based的方法表现与随机猜测相似(AUC ≈ 0.5)。然而,通过TALLRec训练的LLM取得了显著的提升。这些结果表明推荐任务和语言任务之间存在巨大差距,显示了使用推荐数据对LLM进行rec-tuning的重要性。在我们的
few-shot training settings下,传统推荐方法始终表现不佳,这意味着传统方法无法用有限的训练样本快速学习推荐能力。GRU-BERT和DROS-BERT相比于它们的后端模型GRU4Rec和DROS没有显示出显著改进。这表明在few-shot training setting中,仅仅添加文本描述并不能增强传统推荐模型。
在
few-shot training settings下,传统推荐方法效果几乎等于随机,这是可以预期的,因此模型参数远远大于样本数量,模型没有得到充分学习。因此,与传统方法进行比较是没有什么价值的。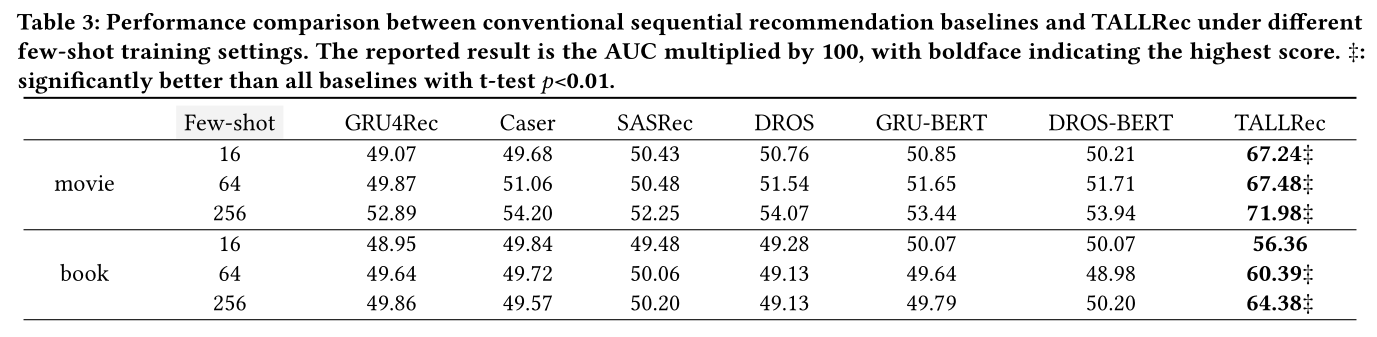
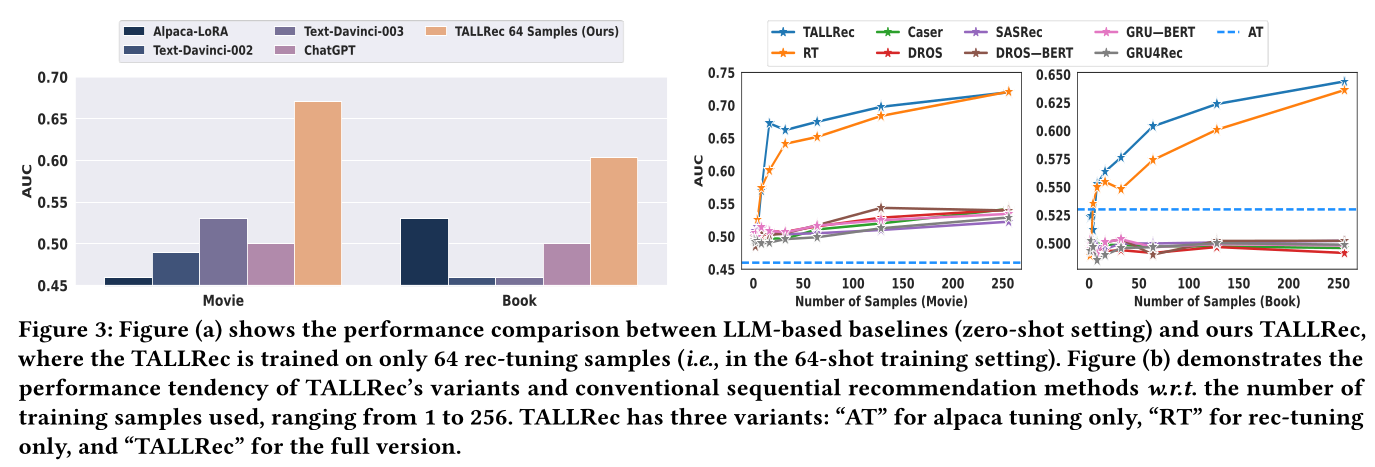
1.3.2 消融研究 (RQ2)
为了证明
TALLRec中alpaca tuning和rec-tuning的有效性,我们K-shot training setting下对不同的TALLRec与其两个变体"AT"和"RT"的性能进行比较,其中"AT"仅进行alpaca tuning,而"RT"仅实施rec-tuning。通过改变我们将结果总结在
Figure 3 (b)中,从中我们得到以下观察结果:"AT"的性能与"RT"和TALLRec相比显著下降,表明了rec-tuning的关键作用,它有效地激发了LLM的推荐能力。在有限的
rec-tuning样本(<= 128)下,TALLRec通常优于"RT",这证实了alpaca tuning可以增强LLM在新任务上的泛化能力,尤其是在新任务的训练数据不足时。随着rec-tuning样本数量的增长,TALLRec和"RT"的结果变得更加接近。这是有道理的,因为当新任务有充足的训练数据时,来自其他任务的泛化能力的重要性就会减弱。随着
rec-tuning样本数量的增加,TALLRec的表现始终优于基线。这归功于rec-tuning,它可以利用有限的样本激发LLM的推荐能力。
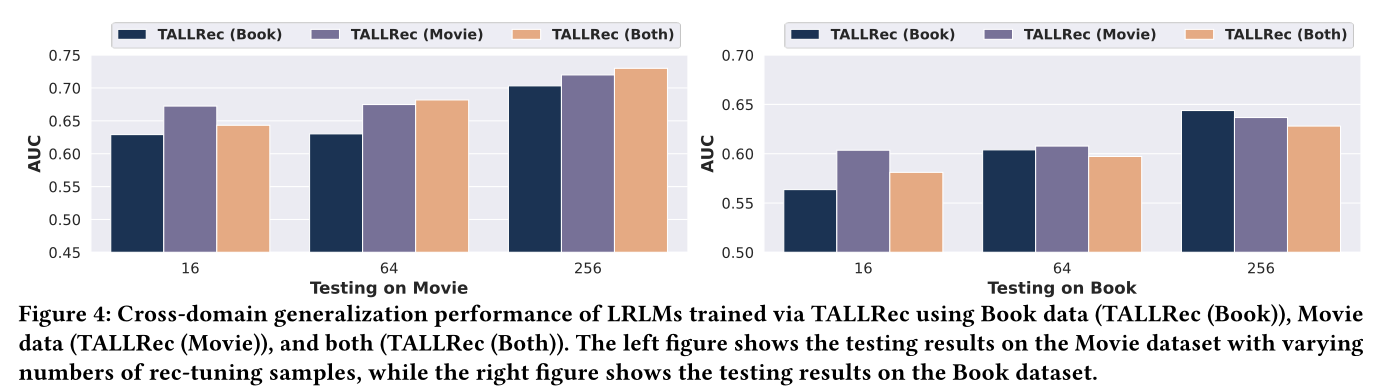
1.3.3 跨域泛化分析 (RQ3)
为了进一步研究
TALLRec的泛化能力,我们进行了跨域推荐的实验。具体来说,我们使用不同的rec-tuning样本来微调TALLRec,包括:"TALLRec (Book)":仅使用来自Book数据集的样本。"TALLRec (Movie)":仅使用来自Movie数据集的样本。"TALLRec (Both)":同时使用Book和Movie数据集的样本进行微调。
我们在
few-shot training setting下,令{16, 64, 258}中变化,并分别在Book和Movie的测试集上评估模型。结果总结在Figure 4中,从中我们可以发现:TALLRec展示了卓越的跨域泛化能力。例如,仅在Movie样本上微调后,"TALLRec (Movie)"在Book数据上也表现出良好的性能,与"TALLRec (Book)"相当。这令人印象深刻,表明TALLRec具有跨域泛化能力,而不是像传统推荐器那样仅拟合单一领域。当
rec-tuning样本数量超过64时,"TALLRec (Both)"在两个测试集上都超过了"TALLRec (Movie)"和"TALLRec (Book)"。这一发现表明TALLRec可以无缝整合来自不同领域的数据以增强其泛化性能。在未来的工作中,使用来自异构领域的大规模推荐数据对TALLRec进行预训练是很有前景的。
1.4 结论
随着
LLM的进步,人们逐渐认识到它们在推荐系统中的潜力。在这项工作中,我们探索了使用LLM进行推荐的可行性。我们的初步发现表明,即使是现有的最佳LLM模型在推荐任务中也表现不佳。为了解决这个问题,我们提出了一个TALLRec框架,该框架可以通过两个微调阶段(alpaca tuning和rec-tuning)有效地将LLM与推荐任务对齐。我们的实验结果表明,使用我们的TALLRec框架训练的LLM优于传统模型,并展现出强大的跨域泛化能力。展望未来,我们计划探索更有效的方法来激活更大模型的推荐能力,并微调LLM以同时处理多个推荐任务。