一、 VQ-Rec [2023]
《Learning Vector-Quantized Item Representation for Transferable Sequential Recommenders》
近年来,自然语言文本的通用性(
generality)被用于开发可迁移的推荐系统。其核心思想是:利用预训练语言模型(pre-trained language model: PLM)将item text编码为item representations。尽管该方法具有良好的可迁移性(transferability),但item text与item representations之间的绑定(binding)可能过于紧密,导致过度强调text features的作用、放大domain gap的负面影响等潜在问题。为解决这一问题,本文提出
VQ-Rec,一种学习Vector-Quantized item representations的新型方法用于可迁移的序列推荐器(transferable sequential Recommenders)。该方法的核心创新在于新的item representation方案:首先将
item text映射为a vector of discrete indices(称为item code)。然后通过这些索引(
indices)来查询code embedding table以生成item representations。
该方案可表示为
"text => code => representation"。基于此表示方案,本文进一步提出一种增强型对比预训练(enhanced contrastive pre-training)方法,将semi-synthetic and mixed-domain code representations作为难负样本(hard negatives)。此外,本文设计了一种differentiable permutation-based network的cross-domain fine-tuning方法。在六个公开基准数据集上的大量实验表明,该方法在cross-domain and cross-platform settings下均具有有效性。代码和预训练模型可在以下地址获取:https://github.com/RUCAIBox/VQ-Rec。当迁移到
new domain时,需要同时更新PQ质心、以及embedding table(因为item id含义发生了变化),从而解决cross domain的语义gap(及,code-embedding alignment)。本论文在更新embedding table这个环节,复用了现有embedding table:将现有embedding table进行排列置换。而不是重新训练embedding table。序列推荐系统(
sequential recommender systems)已被广泛部署在各类application平台中,用于向用户推荐感兴趣的items。通常,此类推荐任务被建模为序列预测(sequence prediction)问题,即基于用户的历史交互序列(historical interaction sequences)推断其可能接下来交互的items。尽管不同的序列推荐系统采用了相似的任务建模方式,但将已训练好的recommender迁移到新的推荐场景中仍存在困难。例如,对于具有特定interaction characteristics的新domain,可能需要从头训练recommender,这不仅耗时,还可能面临冷启动问题。因此,开发能够快速适应新domains或新场景的transferable sequential recommenders具有重要意义。为此,推荐系统领域的早期研究主要通过跨域推荐(
cross-domain recommendation)方法,将从existing domains学到的知识迁移到new domain。这些研究通常假设存在shared information(如overlapping users/items或common features),以学习cross-domain映射关系。然而,在实际应用中,不同domains(尤其是cross-platform setting)中的用户或items往往只是部分重叠或完全不重叠,这使得有效的cross-domain transfer难以实现。此外,以往content-based transfer方法通常针对data format of shared features设计了特定方案,难以适用于各类推荐场景。作为一种近期提出的方法,多项研究提出利用自然语言文本(即
items的标题和描述文本,称为item text)的通用性(generality)来弥合推荐系统中的domain gap。其核心思想是:将通过预训练语言模型(pre-trained language models: PLM)学到的text encodings作为universal item representations。基于此类item representations,在a mixture of multiple domains的interaction data上预训练好的sequential recommenders已展现出良好的可迁移性。该范式可表示为"text => representation"。尽管该方法具有有效性,但本文认为,现有方法中item text与item representations之间的绑定(binding)过于紧密,导致两个潜在问题:首先,由于这些方法直接使用
text encodings来生成item representations(不使用item IDs),文本语义(text semantics)会直接影响推荐模型,可能导致推荐系统过度强调text features的作用(例如,生成文本相似性极高的推荐结果),而忽略了interaction data中反映的序列特性(sequential characteristics)。其次,不同
domains的text encodings(具有不同的分布和语义)在统一语义空间(unified semantic space)中并非自然地对齐(naturally aligned),text encodings中存在的domain gap可能导致multi-domain pre-training过程中的性能下降;而text encodings与item representations之间的紧密绑定(tight binding)会进一步放大这种domain gap的负面影响。
针对上述问题,本文的解决方案是在
item representation方案中引入中间的离散物品索引(intermediate discrete item indices)(本文称为codes),以放松item text与item representations之间的强绑定,该方案可表示为"text => code => representation"。不同于直接将text encodings映射为item representations,本文采用two-step item representation方案:对于给定item:首先将
item text映射为离散索引向量(a vector of discrete indices)(即item code)。然后根据
item code聚合对应的embeddings,得到item representation。
该
representation方案具有两大优势:第一,
item text主要用于生成离散编码(discrete codes),既可以减少item text对推荐模型的直接影响,又能注入有用的文本语义(text semantics)。第二,
two mapping steps可根据下游domains或任务进行学习或调优,使其更灵活地适应新的推荐场景。
为实现该方法,需要解决两个关键挑战:
(i):如何学习具有足够区分度的discrete item codes,以实现准确的推荐。(ii):如何在考虑跨不同domains上差异巨大的distribution and semantics的情况下,有效地pre-train and adapt the item representations。
为此,本文提出
VQ-Rec,一种新颖的方法来学习Vector-Quantized item representations从而用于transferable sequential Recommenders。与现有的基于PLM encoding的transferable recommenders不同,VQ-Rec将每个item映射为a discrete D-dimensional code,作为embedding lookup的索引(indices)。为获得语义丰富且具有区分度的item codes,本文利用optimized product quantization: OPQ技术对items的text encodings进行离散化处理。通过这种方式,保留了文本语义(textual semantics)的discrete codes在item set上分布更均匀,从而具有更高的区分度。由于该representation方案不修改底层骨干网络(即Transformer),因此可广泛适用于各类序列模型架构。为了捕获
transferable patterns based on item codes,本文在a mixture of multiple domains上采用对比学习(contrastive learning)方法对推荐系统进行预训练,并同时将mixed-domain code representations和semi-synthetic code representations作为hard negatives,以增强contrastive training的效果。为将
pre-trained model迁移到下游domain,本文提出一种differentiable permutation-based网络来学习code-embedding alignment,并进一步更新code embedding table以适应这个下游domain。该fine-tuning过程具有极高的参数效率,仅需调整与item representations相关的参数。这里作者并没有重新训练
code embedding table,而是排列置换。
在实验方面,本文在六个基准数据集上进行了大量实验,包括
cross-domain和cross-platform场景。实验结果表明,该方法具有强大的可迁移性(transferability)。特别是,纯基于item text的inductive recommenders无需重新训练即可推荐new items,同时在已有items上也能获得更优性能。
1.1 相关工作
序列推荐(
Sequential recommendation):序列推荐旨在基于历史交互序列(historical interaction sequences)来预测next interacted items。早期工作遵循马尔可夫链假设(
Markov Chain assumption)(《Factorizing personalized Markov chains for next-basket recommendation》),而近期研究主要关注设计不同的神经网络模型,包括循环神经网络(Recurrent Neural Network: RNN)(《Session-based Recommendations with Recurrent Neural Networks》、《Neural Attentive Session-based Recommendation》)、卷积神经网络(Convolutional Neural Network: CNN)(《Personalized Top-N Sequential Recommendation via Convolutional Sequence Embedding》)、Transformer(《Locker: Locally Constrained Self-Attentive Sequential Recommendation》、《CORE: Simple and Effective Session-based Recommendation within Consistent Representation Space》、《Self-Attentive Sequential Recommendation》、《BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer》)、图神经网络(Graph Neural Network: GNN)(《Sequential Recommendation with Graph Neural Networks》、《Session-Based Recommendation with Graph Neural Networks》)、以及多层感知机(Multilayer Perceptron: MLP)(《Filter-enhanced MLP is All You Need for Sequential Recommendation》)。然而,这些方法大多基于特定domain来定义的item IDs or attributes,难以利用其他domains或platforms的behavior sequences。最近,已有研究尝试将文本特征或视觉特征用作
transferable item representations(《Zero-Shot Recommender Systems》、《Towards Universal Sequence Representation Learning for Recommender Systems》、《ID-Agnostic User Behavior Pre-training for Sequential Recommendation》、《TransRec: Learning Transferable Recommendation from Mixture-of-Modality Feedback》)。此外,多项研究提出基于PLM构建a unified model,解决多个推荐相关任务(《M6-Rec: Generative Pretrained Language Models are Open-Ended Recommender Systems》、《Recommendation as Language Processing (RLP): A Unified Pretrain, Personalized Prompt & Predict Paradigm (P5)》)。本文的研究基于这些工作,但重点不同:通过引入discrete codes来解耦text encodings与item representations之间的绑定,并通过专门设计的pre-training和fine-tuning策略增强表征容量(representation capacity)。推荐系统中的迁移学习(
transfer learning):为缓解推荐系统中广泛存在的数据稀疏性(data sparsity)和冷启动(cold-start)问题,研究人员探索了从其他domains、markets或platforms迁移知识的思路。现有方法主要依赖source domains和target domains之间的共享信息进行迁移,如common users、common items或common attributes。近年来,
pre-trained language models: PLM已被证明是连接不同任务或domains的通用语义桥梁,多项研究提出通过PLM对items的关联文本进行编码,作为universal item representations(《Zero-Shot Recommender Systems》、《Recommendation as Language Processing (RLP): A Unified Pretrain, Personalized Prompt & Predict Paradigm (P5)》、《Towards Universal Sequence Representation Learning for Recommender Systems》)。基于pre-training universal item representations,可以在没有overlapping users or items的情况下,将fused knowledge迁移到下游domains。然而,这些研究通常强制PLM的text encodings与final item representations之间的紧密绑定,可能导致过度强调text features的作用。相比之下,本文提出了一种基于discrete codes的新型的two-step representation方案,具有更强的表征容量(representation capacity),可增强cross-domain recommendation性能。推荐系统中的
sparse representation:learning sparse representation是机器学习中广泛采用的数据对象表示方法,启发了一系列相关研究,如product quantization、multi-way compact embedding、semantic hashing等。与continuous representation不同,sparse representation旨在通过sparse方案捕获最显著的representation dimensions。具体来说,discrete representations也被应用于推荐系统,现有研究主要旨在基于sparse representations开发内存和时间效率高的推荐算法,以构建大规模推荐系统。与这些研究不同,本文的目标是利用文本语义(text semantics)的通用性,通过pre-trained方法学习transferable item representations。
1.2 方法
本节将详细介绍所提出的基于
Vector-Quantized item indices的可迁移序列推荐方法VQ-Rec。
1.2.1 方法概述
任务定义:本文考虑的序列推荐任务场景中,
multi-domain interaction data可用作训练(或pre-training)数据。形式上,用户在某个domain的interaction data可表示为交互序列interacted itemitem ID和text data(如标题或描述,即item text)。由于一个用户可能与多个domains的items进行交互,因此可为每个用户生成多个交互序列(interaction sequences)。考虑到不同domains之间存在较大的语义差异(semantic gap)(《Towards Universal Sequence Representation Learning for Recommender Systems》),本文不将单个用户的多个交互序列合并为单个序列,而是保留每个domain对应的交互序列。需要注意的是,本文方法在生成item representations时不直接使用item IDs。任务目标是预训练一个transferable sequential recommender,使其能够有效适配new domains(训练数据中未见过的domains)。解决方案概述:为构建
sequential recommender,本文采用主流的Transformer架构作为骨干网络(backbone)。该架构基于自注意力机制,在每个time step接收item embeddings和positional embeddings作为输入。与以往相关研究(《Towards Universal Sequence Representation Learning for Recommender Systems》)不同,本文未在Transformer架构中添加任何额外组件(如adaptors),而是通过transferable item representations来为骨干网络提供输入。该方法的核心创新在于为
sequential recommenders设计的new item representation scheme:首先将
item text映射为a vector of discrete indices(称为item code)。然后通过这些索引(
indices)来查询code embedding table以生成item representations。
该方案可表示为
"text => code => representation",打破了item text与item representations之间的紧密绑定(tight binding)。为学习和迁移此类item representations,本文进一步提出了特定策略来进行contrastive recommender pre-training和cross-domain recommender fine-tuning。所提出的
VQ-Rec方法的整体框架如Figure 1所示。本文认为,开发transferable recommenders需要三个关键组件:(i):如何通过vector-quantized code representation来表示items。(ii):如何基于新的representation方案来训练recommenders。(iii):如何将pre-trained recommender迁移到新的domains。
整体框架分为
pre-training和fine-tuning两个阶段:pre-training:通过对比学习来预训练code emb tablesequence encoder。此外,还需要独立地训练一个PQ。fine-tuning:首先独立地在
new domain上训练一个新的PQ。然后,固定
code emb tablesequence encoder,训练一个排列矩阵然后,固定排列矩阵
sequence encoder,微调code emb table
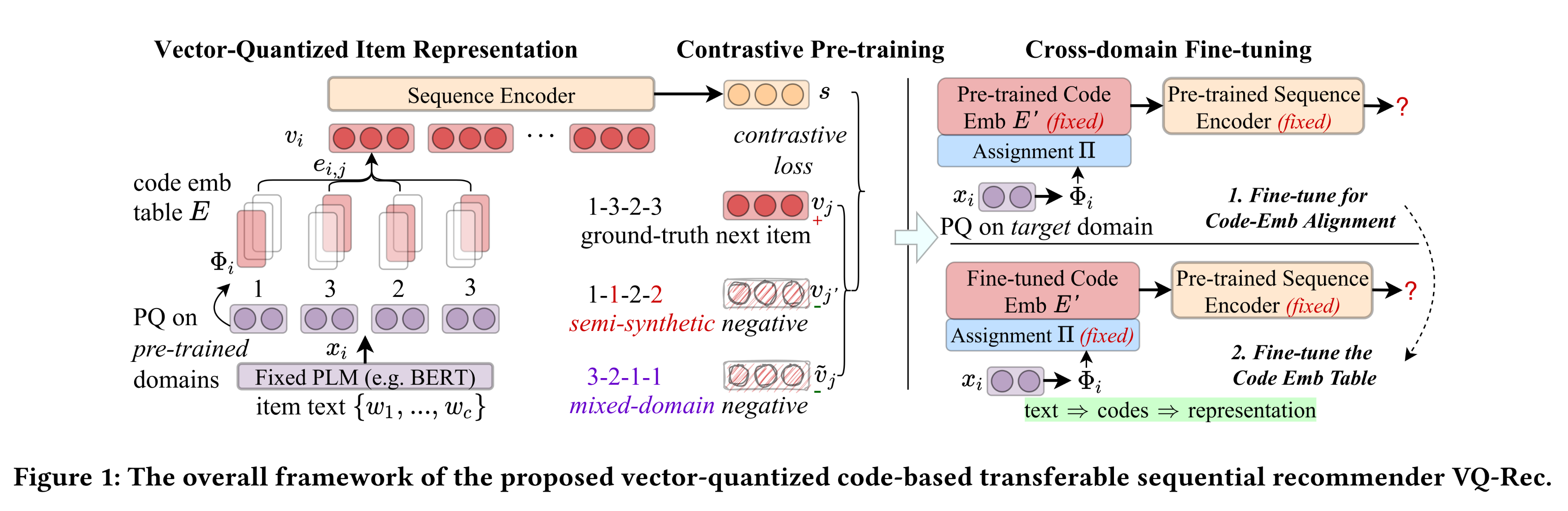
1.2.2 Vector-Quantized Item Representation
如前所述,本文提出
two-step item representation方案:(i):通过PLM将item text编码为a vector of discrete codes。(ii):利用discrete codes来查询code embedding table以生成item representation。
以下将详细介绍该
representation方案。Vector-Quantized Code Learning:本节首先研究如何将item text映射为a discrete code。为利用自然语言文本的通用性,首先通过PLM将items的描述性文本(descriptive text)编码为text encodings;然后基于optimized product quantization来构建text encodings与discrete codes之间的映射。具体过程如下:(1):基于PLM的item text => text encodings。本文采用广泛使用的BERT模型对items的文本信息进行编码。对于itemitem texta special tokenextended text馈入BERT,得到itemtext encoding:其中:
input token(即,final hidden vector;需要注意的是,本文中
BERT encoder的参数是固定的。为什么选择
BERT?其它PLM是否可行?作者并未详细说明。(2):基于PQ的text encodings => discrete codes。接下来,对于itemproduct quantization: PQ(《Product Quantization for Nearest Neighbor Search》)将text encodinga vector of discrete codes。PQ定义了centroid embeddings。形式上,用centroid embedding。对于text encodingPQ首先将其分割为centroid embedding的索引,组成discrete code(即a vector of indices)。对于itemselected index的形式化定义为:其中:
itemdiscrete code representation的第为学习这些
PQ centroid embeddings(即optimized product quantization: OPQ(《Optimized product quantization》)方法,并基于所有training domains的items的text encoding来优化centroid embeddings。centroid embeddings学习完成后,可通过上述公式独立地为每个维度分配index,得到itemdiscrete code representation
PQ的问题与OPQ的优势:传统PQ假设各子空间相互独立,但实际数据中不同维度之间可能存在相关性,直接拆分会导致量化误差较大。OPQ的核心思想:在量化之前,先对原始向量空间进行一个正交变换(旋转),使得变换后的子空间之间更接近独立,从而降低量化误差。如何通过
PQ学习k-means来直接优化每个子空间,为每个子空间得到如何通过
OPQ学习正交变换:设有一个正交矩阵
训练目标:最小化重构误差:
其中:
Quantize表示PQ量化操作(类似于k-means)。迭代:通常采用交替优化策略:固定
k-means);固定质心,优化
Code Embedding Lookup as Item Representations:给定学到的discrete item codes,可直接通过embedding lookup来生成item representations。由于本文方法使用
discrete indices(表示为item codes,因此设置了code embedding matrices(称为code embedding table)用于查询,每个矩阵对应code representation的一个维度。对于第items的discrete codes共享一个common code embedding matrixfinal item representations的维度。通过embedding lookup,可得到itemcode embeddings为什么要用
embedding table而不是共享一个?PQ结构要求:乘积量化本质是多子空间独立量化。语义独立性:不同维度编码不同方面的语义。
需要注意的是,
code embeddingPQ centroid embeddingpre-training阶段,得到
itemcode embeddings后,进一步对其进行聚合,生成final item representation:其中:
item representations;mean pooling function)。也可以考虑其它聚合函数(例如
attention-based聚合)。Representation Distinguishability vs. Code Uniformity:为实现准确的推荐,item representations在large candidate space中应具有良好的区分度,尤其是对于具有similar text encodings的items。在本文方法中,应尽量避免任意两个items的discrete codes发生碰撞(即分配相同的code)。《Learning Discrete Representations via Constrained Clustering for Effective and Efficient Dense Retrieval》的研究表明,当vectors被均匀量化为所有可能的discrete codes时,碰撞概率(collision probability)最小。因此,理想情况下,discrete codes应均匀分布以获得最大区分度,即code《K-means clustering versus validation measures: a data distribution perspective》、《Jointly Optimizing Query Encoder and Product Quantization to Improve Retrieval Performance》、《Learning Discrete Representations via Constrained Clustering for Effective and Efficient Dense Retrieval》),training OPQ所使用的技术(即K-means)倾向于生成cluster sizes相对均匀的聚类结果。这表明OPQ能够为items生成具有强区分度的discrete code representations。
1.2.3 Contrastive Recommender Pre-training
与直接文本映射(
direct text mapping)方法(《Zero-Shot Recommender Systems》、《Towards Universal Sequence Representation Learning for Recommender Systems》)相比,本文的item representation方法更难优化,因为它涉及discrete codes并采用two-step representation mapping。以下首先介绍
sequential encoder架构,然后提出所设计的对比预训练(contrastive pre-training)任务。为改进sequential recommenders training,本文提出同时使用mixed-domain负样本和semi-synthetic负样本。Self-attentive Sequence Encoding:给定从vector-quantized item codes中导出的a sequence of item representations,我们使用a sequential encoder获取sequence representation。借鉴SASRec,本文采用主流的self-attentive Transformer架构。具体来说,典型的Transformer encoder由multi-head self-attention layers(记作multilayer perceptron networks(记作index representationsabsolute position embeddingsTransformer encoder在位置其中:
hidden states,encoder数量。我们将对应于第
final hidden statesequence representation。Enhanced Contrastive Pre-training:为optimize the sequential recommender,一种常用方法是采用对比学习(contrastive learning)执行batch-level optimization objective。具体来说,对于包含batch,每个样本由sequential context(即历史交互序列)和ground-truth next item(即正样本)组成。将这些样本编码为representationsnormalized sequence representations(即,该序列最后一个位置的final hidden state)。positive item的normalized representation(即,positive item的code embeddings经过池化的final item representation)。
进行
contrastive training的关键步骤是采样多个负样本从而与正样本进行对比,这通常通过随机采样(random sampling)实现。然而,由于以下两个主要原因,随机负采样在本文方法中效果不佳:首先,由于本文的
representation方案涉及discrete code,会生成discrete indices的指数级别的组合(discrete indices的集合要小得多,导致representation sparsity问题。其次,在
multi-domain training data上学习时,需要有效缓解domain gap。
针对这两个问题,本文相应设计了两种增强型负样本。
semi-synthetic negatives:除了训练集中存在的item indices外,本文还考虑合成增强型item indices作为负样本,以缓解representation sparsity问题。然而,完全合成(fully-synthesized)的indices在sparse code representation space中可能与ground-truth items距离过远,无法为对比学习提供有效指导(《Hard negative mixing for contrastive learning》)。因此,本文基于true item codes生成半合成编码(semi-synthetic codes)作为hard negatives。给定一个
true item codeindex,同时保持其余indices不变。通过这种方式,由semi-synthetic code导出的item representations可定义为:其中:
semi-synthetic hard negative样本的representation。embedding lookup and aggregation操作。point-wise生成函数:其中:
item code。
需要注意的是,均匀采样(
uniform sampling)确保了semi-synthetic indices的codes与true items具有相似的分布;如前面章节所述,这些codes具有良好的区分度。这里是否可以考虑非均匀采样:根据训练集中出现的频率来采样。可以试试。
Mixed-domain negatives:与以往使用in-domain negatives的next-item prediction models(《Session-based Recommendations with Recurrent Neural Networks》、《Self-Attentive Sequential Recommendation》)不同,本文采用mixed-domain items作为负样本,以增强pre-training过程中的multi-domain fusion。考虑到效率问题,直接使用in-batch items作为负样本(即与其他sequential contexts配对的ground-truth items)。由于batch是从multiple domains中采样而构建的,in-batch sampling自然可以生成mixed-domain negatives。
结合这两种负样本,
pre-training objective可形式化为:其中:
为简化符号,
mixed-domain samples中包含正样本,即1个正样本和
1.2.4 Cross-domain Recommender Fine-tuning
在
pre-training阶段,我们优化(optimize)code embedding matrices and Transformer中的参数,而BERT encoder保持固定,PQ操作独立于pre-training。接下来,将讨论如何在cross-domain or cross-platform setting中进行fine-tuning。在fine-tuning阶段,我们固定Transformer sequence encoder(在不同domains之间迁移),仅优化与item representations相关的参数,实现参数高效的fine-tuning。为进一步利用来自
pre-trained recommenders的learned knowledge,我们考虑学习如何迁移code representation scheme(PQ indices)和code embedding table(embedding矩阵)。基于这两个方面,我们将fine-tuning optimization分解为两个阶段,即fine-tuning code-embedding alignment和fine-tuning code embedding table。Fine-tuning for Code-Embedding Alignment:为迁移item representation scheme,一种直接的方法是直接复用discrete index set and corresponding embedding。然而,这种简单方法忽略了不同domains之间的巨大语义差异(semantic gap),导致对下游domains的迁移能力较弱。本文的解决方案是仅复用discrete index set,重新构建indices to embeddings的映射。这里分为两步:
第一步,重新训练新的
PQ质心,然后为new domain的每个item得到item code。第二步,这里没有重新训练
item code的embedding,而是将pretrained item code embedding重新排列并赋值给new domain的item code。为什么用排列而不是重新训练?这是为了知识迁移从而在
new domain数据不足的情况下提升效果。
Permutation-based code-embedding alignment:为生成下游domain的item codes,我们重新训练新的PQ centroids,以捕获domain-specific semantic characteristics。通过共享code set,使用相同的set numnew itemdiscrete indices和code embeddings,我们采用基于置换(permutation-based)的方法重新学习映射关系(即新的lookup方案),以关联indices和code embeddings。对于discrete indices的每个维度embedding alignment形式化为矩阵bijection alignment),permutation matrix),即每行和每列恰好有一个1,其余为0。形式上,new domain下对齐后的code embedding table能否考虑用
pretrained embedding的线性组合,而不是排列置换?线性组合的表达能力更强,可以试一试。Alignment optimization:为了得到code-embedding alignment矩阵next-item prediction objective来优化相应参数。给定sequential context,可根据以下概率预测next item:其中:
pre-trained sequential encoder的输出,其输入为item representationscode
为使置换矩阵(
permutation matrices)Birkhoff定理(《Sparse sinkhorn attention》)启发:任何双随机矩阵(doubly stochastic matrix)都可视为置换矩阵的凸组合。基于此思想,我们使用双随机矩阵模拟置换矩阵。具体而言:首先为每个维度随机初始化参数矩阵
然后通过
Gumbel-Sinkhorn算法(《Learning Latent Permutations with Gumbel-Sinkhorn Networks》)将其转换为双随机矩阵。这一步是为了得到置换矩阵。
双随机矩阵:所有元素非负;每一行的和为
1.0;每一列的和为1.0。
之后,基于
next item probabilitypre-trained recommender中的其余参数。Fine-tuning the Code Embedding Table:code-embedding alignment之后,我们继续微permuted code embedding table,以提高其适配下游domains的representation capacity。具体来说,基于公式next-item prediction loss,优化参数VQ-Rec不依赖item IDs,可应用于inductive setting,即无需重新训练模型即可推荐new items。当出现new item时,可将其item text编码为discrete indices,然后通过embedding lookup获得对应的item representations。
1.2.5 讨论
本节从以下三个方面强调所提出的
VQ-Rec方法的优势:容量:通过利用文本语义(
text semantics)的通用性,学到的discrete codes和code embeddings能够有效捕获不同domains间的可迁移模式(transferable patterns)。与现有的相关研究(《Zero-Shot Recommender Systems》、《Towards Universal Sequence Representation Learning for Recommender Systems》)不同,本文方法不直接将text encodings映射为item representations,因此可以避免过度强调文本相似性(text similarity),同时对文本数据中的噪声更具鲁棒性。此外,如前面章节所述,本文方法能够生成具有高区分度的code representations。灵活性:与以往研究的另一个区别是,本文不修改底层的
sequence encoder(即Transformer)架构,也不进行任何微小改动(如添加adaptors)。此外,text encoder和PQ与底层的sequence encoder在optimization方面是独立的。这些解耦的设计使得该方法可以灵活扩展,适用于各类PLM、sequential encoder和discrete coding方法。效率:本文方法通过三个
specific designs来实现高效的model training and utilization:(1):固定的text encoder。(2):独立学习的discrete codes。(3):微调阶段固定了sequence encoder。
此外,与
UniSRec(《Towards Universal Sequence Representation Learning for Recommender Systems》)等现有方法相比,VQ-Rec在生成transferable item representations时具有更优的时间复杂度(VQ-Rec不需要像以往基于adaptors的方法那样进行任何矩阵乘法运算。
1.3 实验
本节通过实验验证所提出的
VQ-Rec方法的有效性和可迁移性。数据集:实验使用公开基准数据集评估
transferable recommender。预训练数据采用
Amazon评论数据集中的五个domains(食品Food、家居Home、CD、Kindle、电影Movies)。然后,我们将
pre-trained model迁移到五个下游cross-domain datasets(科学Scientific、食品储藏室Pantry、乐器Instruments、艺术Arts、以及办公Office,均来自Amazon)和一个cross-platform dataset(Online Retail,一个基于英国的在线零售平台)。
借鉴
《Towards Universal Sequence Representation Learning for Recommender Systems》的方法,我们过滤掉交互次数少于5次的users and items。然后,在每个子数据集中,我们对interactions按照用户进行分组,并按时间顺序排序。对于descriptive item text,Amazon子数据集拼接title、categories和brand字段,Online Retail dataset使用Description字段。item text截断为长度512。preprocessed datasets的统计信息如Table 1所示。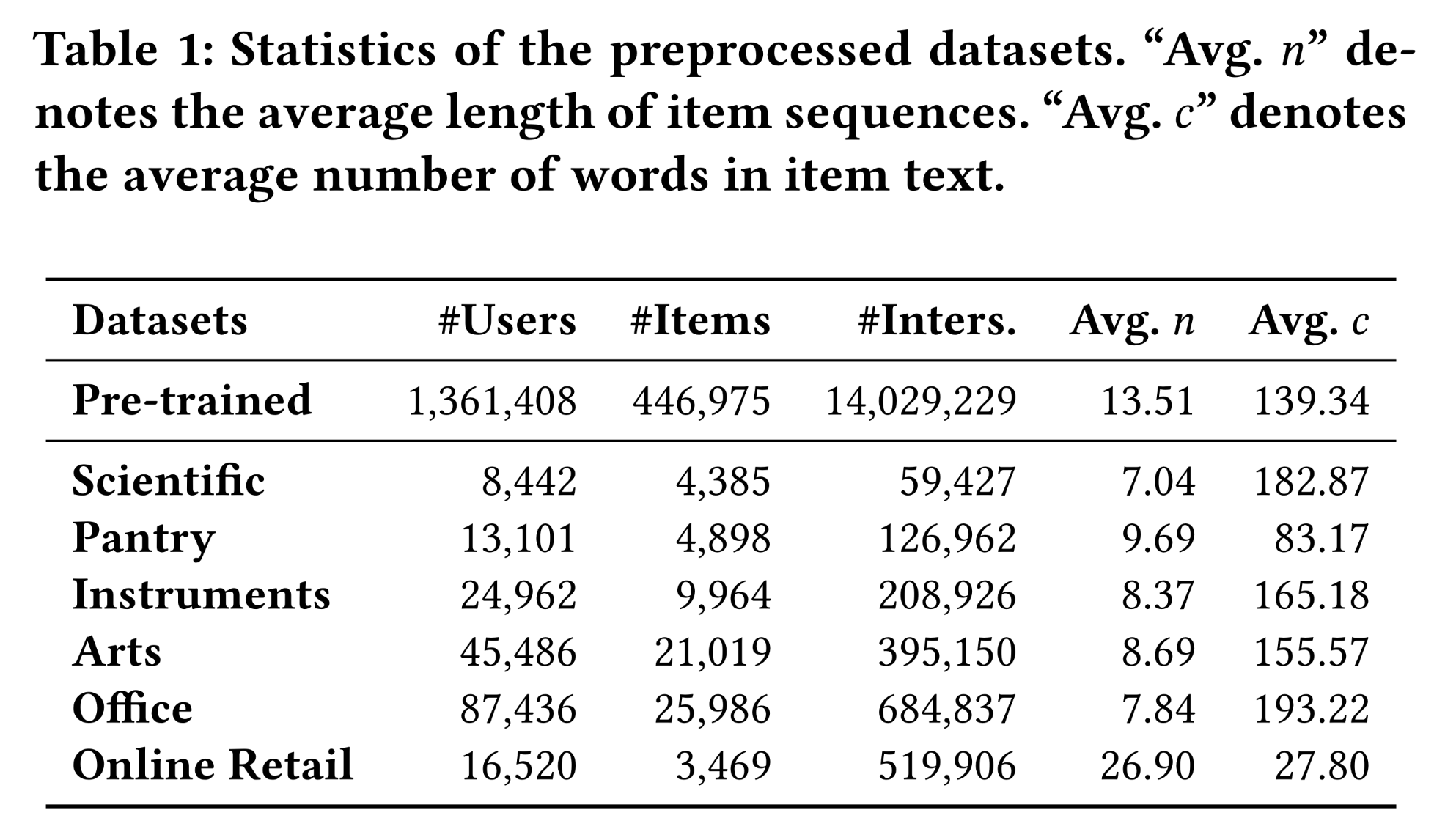
baseline方法:我们将所提出的方法与以下基准方法进行比较:SASRec:采用self-attentive model来捕获item correlations。我们实现两个版本:(1):使用传统的ID embeddings。(1):将item text的fine-tuned BERT representations作为basic item representations。
BERT4Rec:采用bi-directional self-attentive model,结合cloze objective进行sequence modeling。FDSA:使用独立的self-attentive sequential models对item sequence和feature sequence进行建模。S3-Rec:在预训练阶段通过互信息最大化目标(mutual information maximization objectives)来捕获feature-item correlations。RecGURU(《RecGURU: Adversarial Learning of Generalized User Representations for Cross-Domain Recommendation》):提出对抗性学习范式(adversarial learning paradigm),通过auto-encoder来pre-train user representations。ZESRec(《Zero-Shot Recommender Systems》):使用PLM来编码item text从而作为basic item representations。为保证公平比较,ZESRec与VQ-Rec在相同数据集上进行预训练。UniSRec(《Towards Universal Sequence Representation Learning for Recommender Systems》):为textual item representations配备一个MoE-enhanced adaptor,用于domain fusion and adaptation。设计了item-sequence and sequence-sequence contrastive learning tasks,用于预训练transferable sequence representations。
对于本文方法,首先在来自预训练数据集的
mixture of item sequences上预训练一个VQ-Rec模型,然后将预训练模型微调到每个下游数据集。评估指标:借鉴以往研究,我们采用两个广泛使用的排序指标:
Recall@K和NDCG@K(leave-one-out),即latest interacted item作为测试数据,倒数第二个item作为验证数据。评估时,将每个序列的ground-truth item与所有其他items进行排序,最终报告所有测试用户的平均分数。实现细节:
我们基于
Faiss ANNS库和REcBoLE实现模型。我们采用
PQ indices作为code representation方案。VQ-Rec预训练300 epochs,温度semi-synthetic ratio)Gumbel-Sinkhorn算法的迭代次数设置为3。主要基准方法的结果直接取自
《Towards Universal Sequence Representation Learning for Recommender Systems》的研究。对于其他模型,通过搜索超参数获取最优结果。
batch size = 2048。学习率在permutation learning epochs在验证集上
NDCG@10分数最高的模型被选中从而进行测试集评估。我们采用早停策略,
patience值设置为10 epochs。
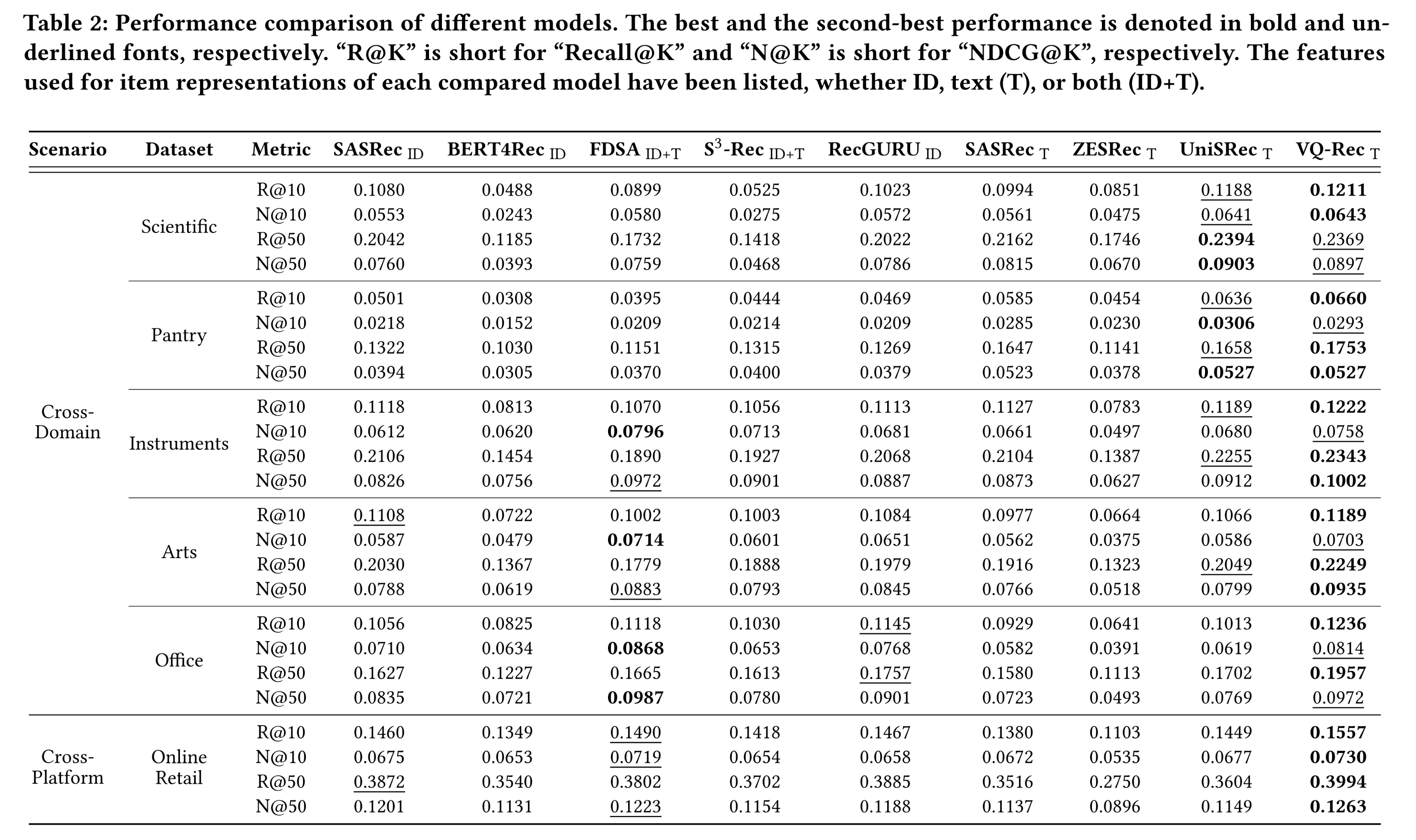
1.3.1 整体性能
将
VQ-Rec与基准方法在六个基准数据集上进行比较,结果如Table 2所示。对于
baseline方法:基于文本的模型(即
SASRec(T)、ZESRec和UniSRec)在小规模数据集(如Scientific和Pantry)上的性能优于其他方法。对于这些interactions不足以训练强大ID-based recommender的数据集,基于文本的方法可能受益于text characteristics。而对于融合
item IDs的模型(即SASRec和BERT4Rec),在interactions较多的数据集(如Arts、Office和Online Retail)上表现更优,这表明过度强调text similarity可能导致次优结果。
所提出的
VQ-Rec方法在所有数据集上均取得了最佳或次佳性能。在小规模数据集上,结果表明所提出的
discrete indices能够保留文本语义,提供合适的推荐。在大规模数据集上,
VQ-Rec能够很好地训练,捕获sequential characteristics。
需要注意的是,
VQ-Rec可应用于inductive setting,无需重新训练模型即可推荐new items。实验结果还表明,通过精心设计的encoding方案和large-scale pre-training,inductive recommenders也能优于传统的transductive models。
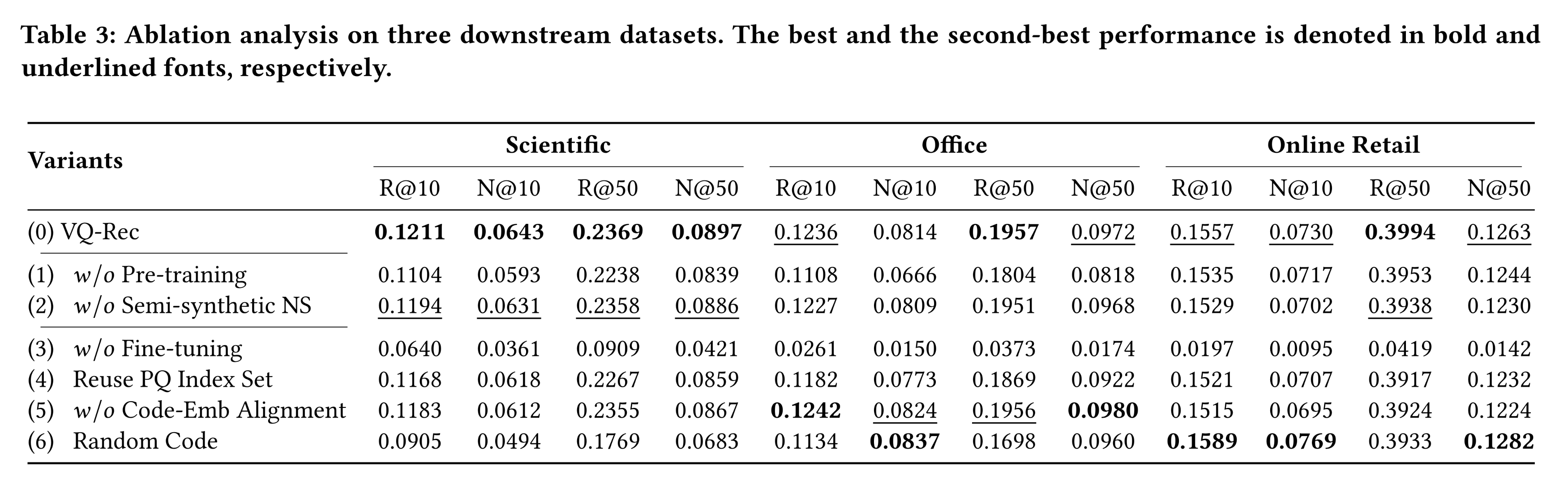
1.3.2 消融实验
我们分析每个提出的组件对最终性能的影响。
Table 3展示了默认方法及其六个变体在三个代表性数据集上的性能,包括一个小规模数据集(Scientific)、一个大规模数据集(Office)和一个cross-platform数据集(Online Retail)。(1) w/o Pre-training:不在multiple domains上进行预训练,该变体在所有数据集上的性能均低于VQ-Rec。结果表明,VQ-Rec能够学习并迁移discrete codes的通用序列模式(general sequential patterns)到下游domains or platforms。(2) w/o Semi-synthetic NS:从pre-training loss中移除半合成负样本(semi-synthetic negative samples),VQ-Rec可能会受到稀疏性问题的影响,导致结果次优。(3) w/o Fine-tuning:如果不对pre-trained model进行微调,性能会急剧下降,这进一步表明迁移到语义不同的domains具有挑战性。(4) Reuse PQ Index Set:我们直接使用pre-training的PQ centroids对下游item indices进行编码。巨大的语义差异(semantic gap)使得indices呈现长尾分布。由于区分度降低,该变体的性能更差。(5) w/o Code-Emb Alignment:该变体移除了矩阵pre-trained embeddings与下游codes进行对齐)。结果表明,permutation-based alignment network通常能够提高性能。(6) Random Code:我们将pre-trained embeddings随机分配给下游items。该变体的性能通常低于默认方法,表明学到的vector-quantized codes能够保留text characteristics。需要注意的是,在Online Retai数据集上,该变体的性能略好,主要因为该数据集的item text相对较短(平均仅27.8 words)。结果表明,informative item text对于部署此类text-based recommenders至关重要。
1.3.3 进一步分析
训练数据量对
capacity的影响分析:为验证所提出的discrete code embeddings是否具有更优的capacity,我们模拟了训练数据量增加的场景。具体来说,使用不同比例的training interactions(即20% ~100%)来训练模型,并在测试集上展示性能,结果如Figure 2所示。可以看出,随着训练数据的增加,
VQ-Rec的性能始终能够提升,且优于对比方法。结果表明,VQ-Rec具有更好的拟合training sequences的capacity。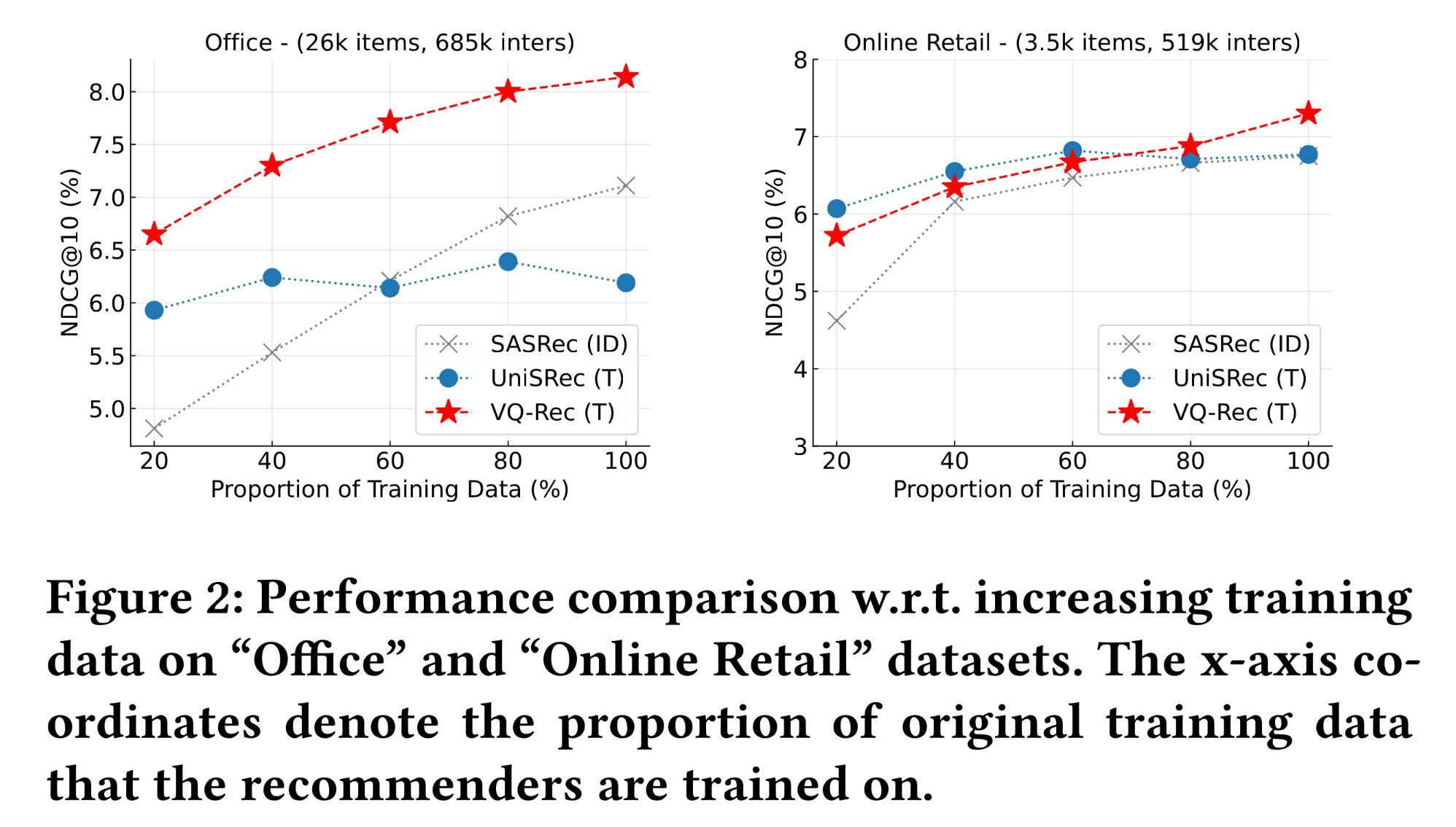
下游数据集对可迁移性的影响分析:本节展示了每个下游数据集上的相对迁移改进(
relative transferring improvements),即有预训练与无预训练的性能对比。结果如Figure 3所示。可以看出:
由于基于
PLM的item representations存在capacity问题,UniSRec在多个数据集(即Arts、Office、以及Online Retail)上可能会出现负向迁移。相比之下,
VQ-Rec在所有六个实验数据集上都能从预训练中受益,最大改进幅度超过20%。
结果表明,所提出的技术能够帮助
recommenders迁移到语义不同的下游场景。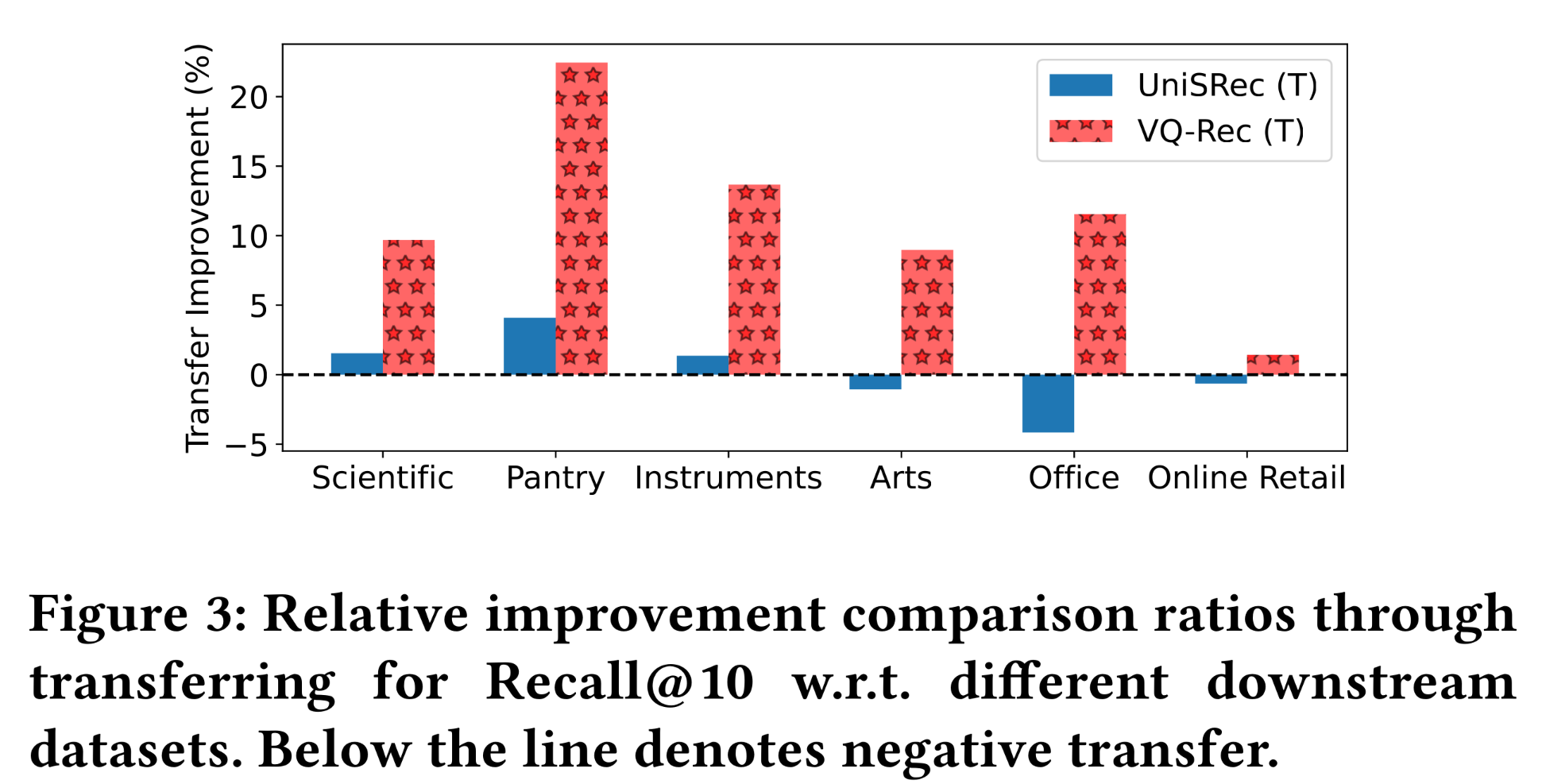
冷启动
Item分析:开发transferable recommenders的动机之一是缓解冷启动推荐问题。根据ground-truth items的流行度将测试数据分为不同组,结果如Figure 4所示。尽管直接将文本映射为
textual item representations的recommenders在冷启动组(如Office的[0,5)、在Online Retail的[0,20))上表现良好,但在流行组(popular groups)上的性能会下降。相比之下,
VQ-Rec在所有组上的性能都优于SASRec,尤其是在冷启动组。
结果表明,这些长尾
items的推荐可能受益于所提出的预训练技术。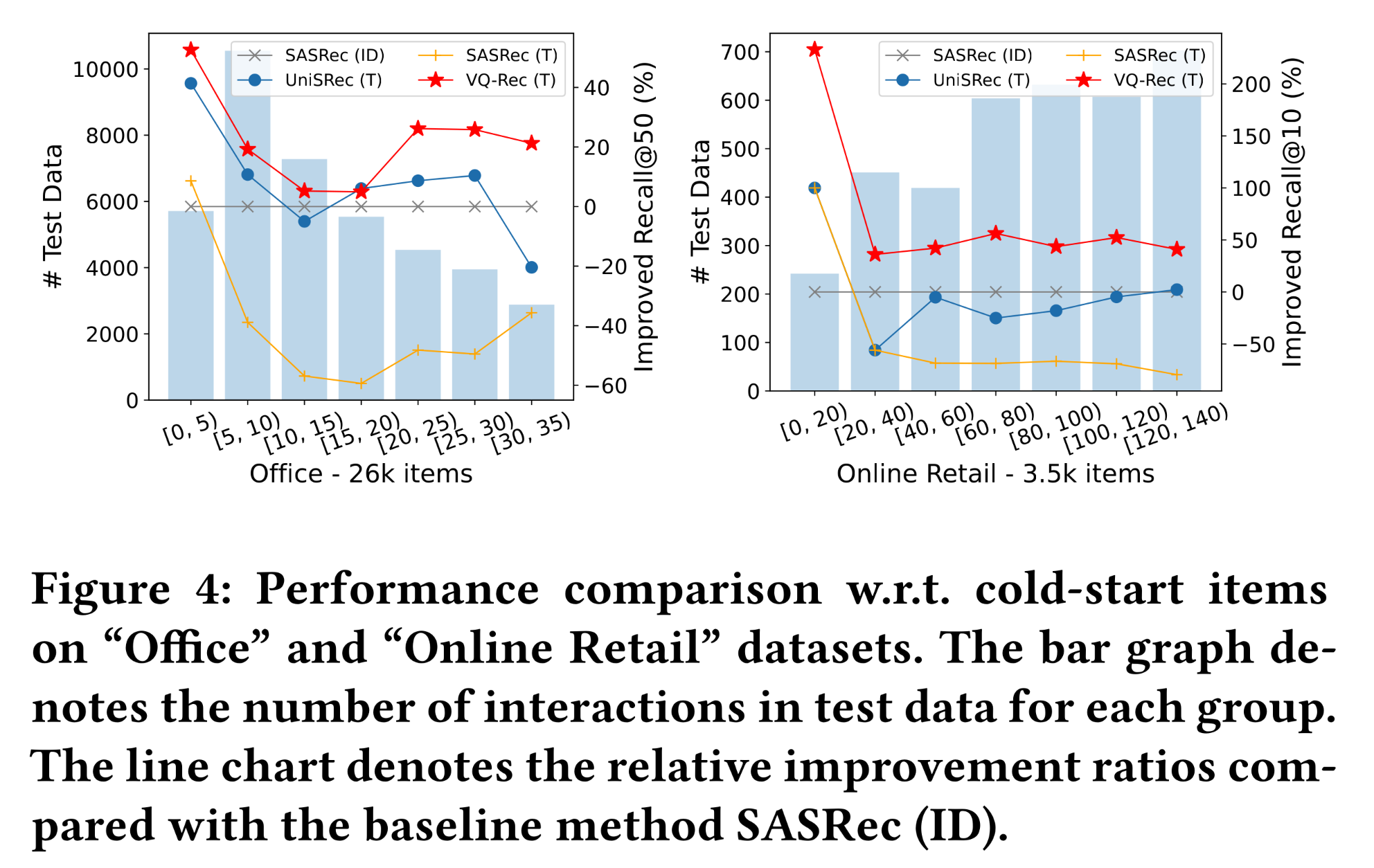
1.4 结论
本文提出
VQ-Rec,一种学习vector-quantized item representations的transferable sequential Recommenders。与现有直接将来自PLM的text encodings映射为item representations的方法不同,本文建立了two-step item representation方案:首先将text encodings映射为discrete codes,然后通过embedding lookup生成item representations。为在
multi-domain interaction data上预训练该方法,我们采用mixed-domain code representations和semi-synthetic code representations作为hard negatives。我们进一步提出了一种permutation-based network,学习domain-specific code-embedding alignment,能够有效适配下游domains。在六个transferring benchmarks上的大量实验表明,VQ-Rec具有良好的有效性。