一、BreakingHourglass [2024]
《Breaking the Hourglass Phenomenon of Residual Quantization: Enhancing the Upper Bound of Generative Retrieval》
生成式检索(
Generative Retrieval: GR)已成为搜索和推荐系统中的变革性范式,其利用numeric-based的identifier representations来提升效率和泛化能力。值得注意的是,诸如TIGER等方法采用Residual Quantization-based Semantic Identifiers: RQ-SID,通过有效管理item IDs,在电子商务场景中展现出了巨大潜力。然而,RQ-SID中存在一种关键问题,称为“沙漏”("Hourglass")现象——中间层码本tokens(intermediate codebook tokens)过度集中,这阻碍了生成式检索方法的充分利用。本文通过识别路径稀疏性(path sparsity)和长尾分布(long-tailed distribution)为主要成因,对该问题进行了分析并提出解决方案。通过全面的实验和详细的消融研究,我们分析了这些因素对码本利用率(codebook utilization)和数据分布的影响。研究结果表明,“沙漏” 现象显著影响了生成式检索中RQ-SID的性能。我们提出了有效的解决方案来缓解这一问题,从而显著提升了生成式检索在实际电子商务应用中的效果。近年来,生成式检索(
Generative Retrieval: GR)作为一种突破性的检索范式逐渐兴起,在推荐系统、搜索问答、以及电子商务检索等搜索和推荐领域取得了重大进展。在该范式中,target items首先被表示为identifiers(例如数字、子词subwords、n-grams、token IDs、URLs、semantic codes)。随后,利用queries和user details等输入信息,采用大型模型以端到端的方式输出final items。这种方法不仅提高了检索效率,还增强了模型的泛化能力。在生成式检索中,
numeric-based identifier representation方法因其简洁性、高效性和强泛化能力而被工业界广泛采用,尤其是在长行为序列推荐(long behavior sequence recommendations)中。这些方法显著缩短了序列长度并加速了推理过程。典型方法包括DSI(《Transformer memory as a differentiable search index》)、NCI(《A neural corpus indexer for document retrieval》)、TIGER(《Recommender systems with generative retrieval》)、GDR(《Generative dense retrieval: Memory can be a burden》)和GenRet(《Learning to tokenize for generative retrieval》)。其中,TIGER方法通过残差量化(Residual Quantization: RQ)生成语义标识符(Semantic Identifiers: SID),有效捕获了语义信息(semantic information)和层次结构(hierarchical structures)。这种方法在item-dominated的电子商务场景中尤为有利,能够准确反映电子商务数据中固有的复杂层次关系(hierarchical relationships)和语义特征(semantic features),从而显著提升推荐性能。需要强调的是,
RQ-based的方法的性能上限关键取决于SID的生成。然而,我们发现通过RQ生成的SID中存在显著的“沙漏”("hourglass")现象,如Figure 1所示。具体而言,中间层(intermediate layers)的codebook tokens过度集中,形成了 “一对多“ 和 “多对一“ 的映射结构。这种集中导致了:路径稀疏性(
path sparsity):item的匹配路径(matching paths)仅占总路径空间的极小部分。以及中间层
tokens的长尾分布:大多数SID集中在少数head tokens上。
这种沙漏效应在具有长尾特性的数据集上尤为严重,极大地限制了生成式检索方法的表示能力。该问题的根本原因在于对高维向量残差进行逐步量化(
progressively quantizing)时的固有特性。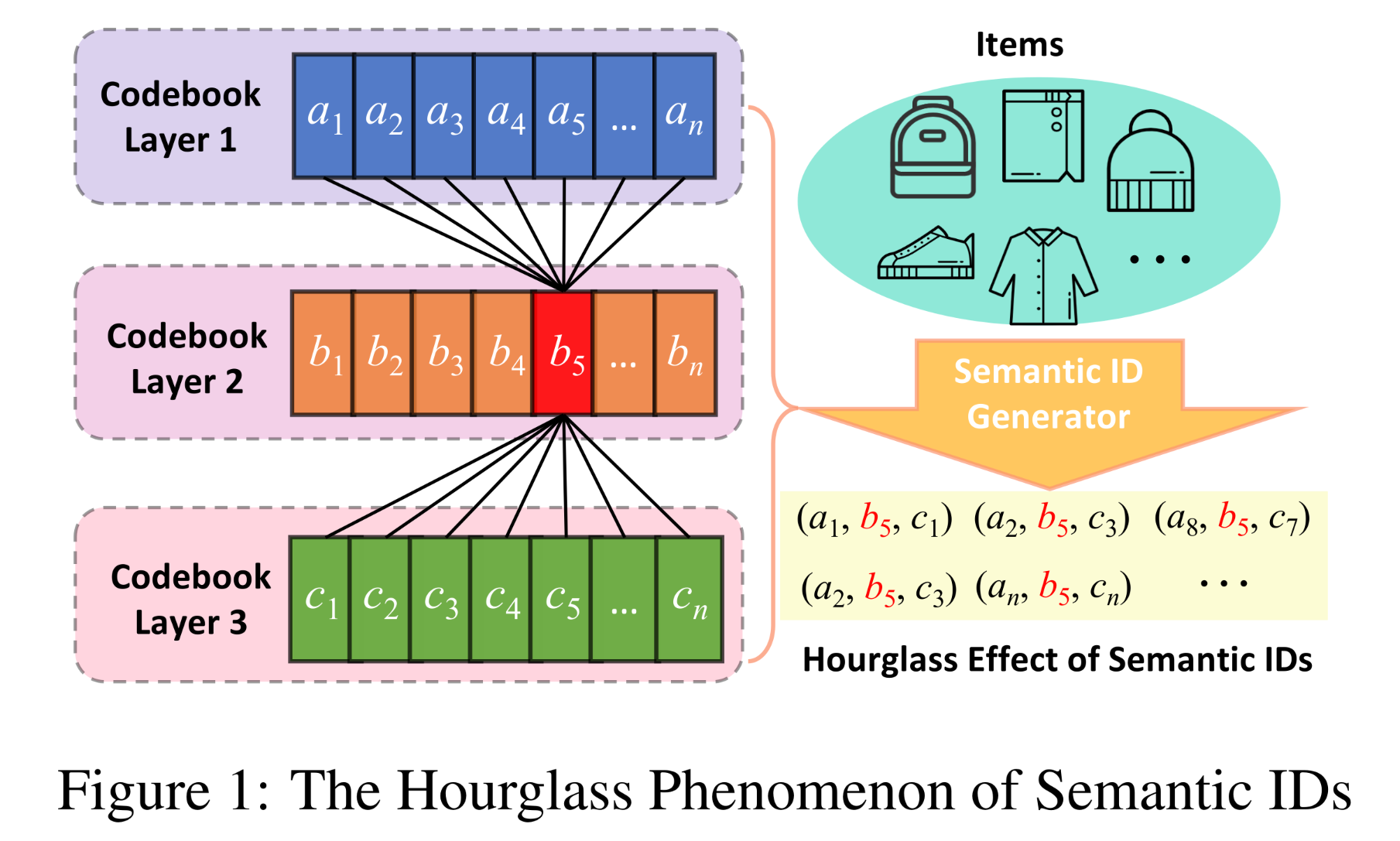
此外,我们分析了从残差(
residuals)生成SID的过程,表明稀疏性(sparsity)和长尾分布(long-tail distributions)是不可避免的。为了评估SID对下游生成式检索任务的普遍影响,我们基于RQ-SID训练了不同规模(如0.8B/7B)和不同类型(Qwen1.5/Baichuan2/LLaMA2)的模型。通过一系列实验(包括通过交互first and second layers、以及交换first and second layers来改变Semantic IDs的分布),我们不仅证实了沙漏效应的存在,还详细阐述了其对模型性能的具体影响。该分析为未来的模型优化提供了坚实基础。为了缓解沙漏效应,我们提出了两种简单而有效的方法:启发式方法、以及自适应变长
token策略(adaptive variable-length token strategy)。启发式方法:直接移除第二层,在减少长尾影响的同时,可能导致空间容量(
spatial capacity)不足。自适应变长
token策略:通过an adaptive token distribution adjustment来移除第二层的top tokens,从而将semantic ID转换为变长结构(variable-length structure)。该策略在确保整体分布保持一致的同时,通过选择性的token移除(selectively token removal)从而有效缓解了沙漏效应。
大量实验结果表明,尽管两种方法都较为简单,但它们在不同程度上成功减轻了沙漏效应的影响。值得注意的是,自适应变长
token策略方法的效果最为显著。本文的贡献可总结如下:
据我们所知,这是首次系统性地研究生成式检索中
residual quantization-based semantic identifiers的缺陷,明确识别了“沙漏”现象:即,中间层codebook tokens过度集中。我们进行了全面的实验和消融研究,揭示路径稀疏性(
path sparsity)和长尾分布(long-tail distributions)是沙漏效应的主要成因,限制了生成式模型的表示能力和性能。我们提出并验证了一种缓解沙漏效应的新方法,通过提高
codebook利用率、以及解决token长尾分布问题,显著提升了模型性能。
1.1 相关工作
生成式检索的最新进展已对多个领域产生了重大影响,例如推荐系统、搜索问答和电子商务检索。如相关研究所示,这种范式转变涉及使用
numbers、sub-words和semantic codes等identifiers来表示target items。在工业界,基于
numbers的identifier representation方法因其简洁性和高效性而被广泛采用。这些方法(包括DSI、NCI、TIGER、GDR和GenRet)在长行为序列推荐中特别有效,能够缩短序列长度并加速推理过程。值得注意的是,TIGER方法采用RQ来生成SID,捕获语义信息和层次结构。这在item-dominated的电子商务环境中尤为有利,因为复杂的层次关系和语义特征对于提升推荐性能至关重要。然而,RQ-based的方法的性能上限在很大程度上取决于SID的生成,这也是本文分析和讨论的核心重点。
1.2 预备知识
1.2.1 Residual Quantization
残差量化(
Residual Quantization)是一种multi-level vector quantizer,通过对残差(residuals)进行量化来生成a tuple of codewords(即Semantic IDs)。Residual-quantized variational AutoEncoder: RQ-VAE通过更新quantization codebook和encoder-decoder reconstruction parameters进行联合训练。假设存在向量
codebooks(即,codebook包含codebooks可表示为codebookembedding向量组成。当
initial residual)定义为然后,通过将
codebookembedding来对其进行量化:其中:
codeword(semantic ID);embedding向量。注意,在第
递归重复上述过程
Semantic ID的a tuple of L codewords,记为为了重建原始向量
codebook elements求和:
该方法通过残差范数(
norm of residuals)的减小,能够从粗到细地逼近原始向量codebooksSemanticIDInYouTube中的内容:使用以下损失函数训练RQ-VAE模型:其中:
stop-gradient算子。content embeddingencoder和codebook vectors进行训练,使得
1.2.2 Generative Retrieval
生成式检索已在推荐领域、搜索领域和问答领域中被提出。这些模型主张通过自回归语言模型(
autoregressive language models)直接生成target passages/items的identifiers。在个性化搜索场景中,核心任务是根据用户给定的
query和用户的historical interaction behaviors,提供用户可能购买的most relevant candidates。在本文中,我们将该任务重新构建为利用大型语言模型(LLM)和Semantic ID的Next Token Prediction: NTP问题。具体而言,给定用户
queryhistorical item sequence,我们首先将序列转换为a Semantic ID sequence,记作:其中:
Semantic ID;historical item sequence长度为然后训练
LLM来预测Semantic ID,表示为generation objective可表述为:其中:
Semantic IDprefix)。supervised fine-tuning: SFT)模型,
1.3 Problem of GR based on RQ
1.3.1 Hourglass Phenomenon
为了生成基于残差量化的
semantic IDs,我们首先利用公司内部数十亿条搜索日志中的query-item data训练双塔模型(如DSSM和BERT)。随后,通过item tower获取数亿个items的embeddings。最后,采用残差量化为所有items生成semantic IDs。成功生成
semantic IDs后,我们对所有items的three-layer distribution maps进行聚合和计算。如Figure 2所示,Semantic ID架构的第二层集中了大量路由节点(routing nodes),three-layer code的整体分布呈现出沙漏现象(hourglass phenomenon)。这里采用三层量化,即
codebooks数量为3。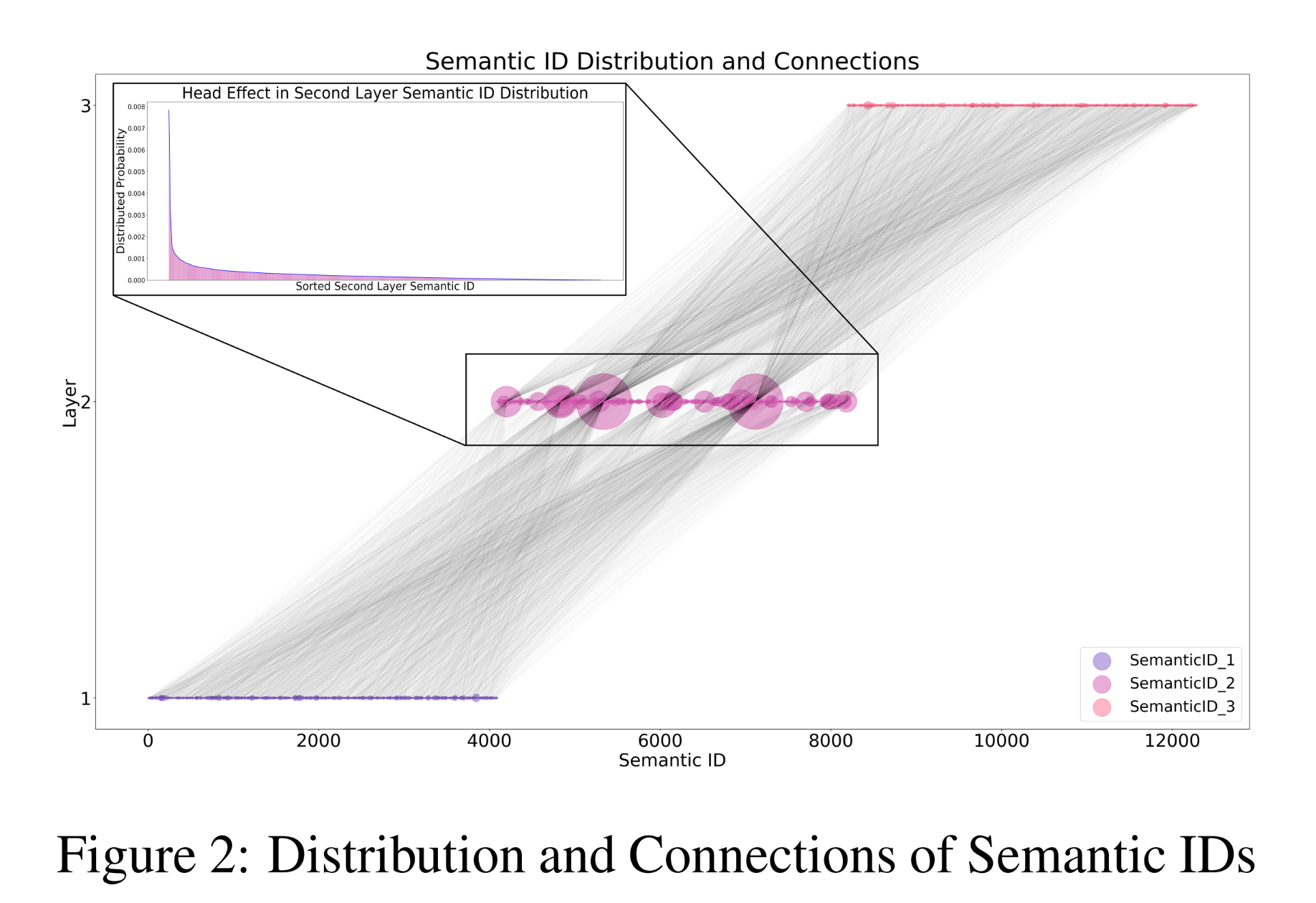
为了研究该现象的泛化性,我们在不同参数组合(如
code table size和层数)下进行了多次可视化实验。如附录中的Figure 6所示,结果表明沙漏效应非常显著,且tokens跨code table跨三层之间的path distribution相对稀疏。RQ LxM,其中第一个数字代表层数,第二个数字代表每个codebook包含多少个向量。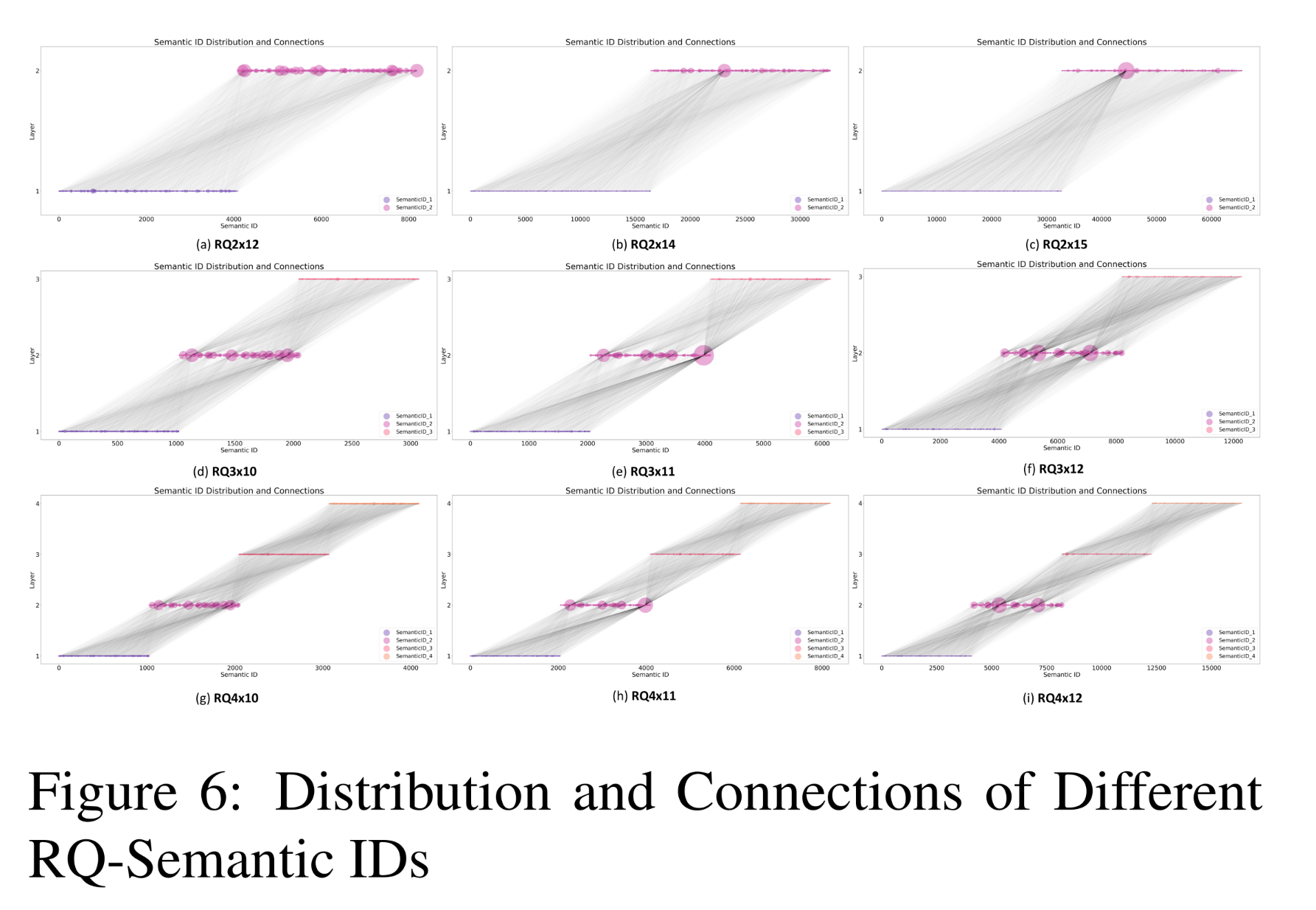
此外,基于上述实验,我们使用三种指标(熵
entropy、基尼系数Gini coefficient、以及标准差standard deviation)对第二层的token distribution进行了统计分析,如Figure 3所示。结果表明,第二层的token distribution具有低熵、高基尼系数、以及大标准差的特点,说明该分布高度倾斜并呈现出长尾效应。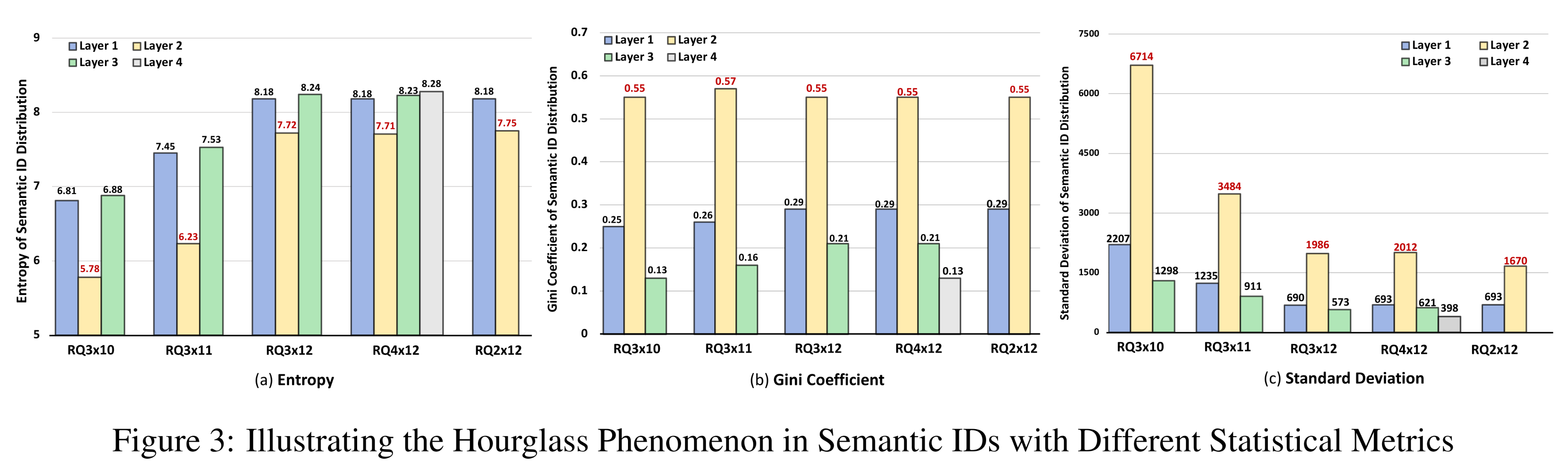
总体而言,这种沙漏现象在
code table中通过path sparsity和a long-tail distribution of tokens得到了统计验证:1):由Semantic ID结构导致的path sparsity,使得code table利用率较低。2):长尾分布表明,在中间层(intermediate layer),绝大多数路由(routes)汇聚到单个token上。
1.3.2 Analysis of Residual Quantization
为了探究沙漏现象的成因,我们将基于残差量化的运行机制进行深入分析和讨论。不失一般性,我们考虑原始
embedding的两种分布:非均匀分布和均匀分布首先考虑均有分布。记为
semantic ID。在第一层,所有候选点(
candidate's points)被划分到cluster buckets。每个cluster bucket包含对于均匀分布,
tokens的in-degree相等。在第二层,所有
input embedding是第一层的残差magnitude存在差异,该层的input distribution是非均匀的。存在大量
magnitudes较小的点(来自前一层每个桶中cluster center附近的点),其数量为同时,存在少量
magnitudes较大的点,这些点被视为异常值。
为了减少
clustering loss,该层的聚类过程聚焦于这些异常值。结果,大量的magnitudes较小的点将占据少数cluster centers,而少量的magnitudes较大的点(即,异常值)将占据单个cluster center或多个cluster centers。因此,该层的semantic IDs将形成大型路由节点(large routing nodes),呈现出长尾现象,这也在Figure 4的第二层中得到了体现。在第三层,所有输入点的
magnitudes再次变得一致且相对均匀。因此,该层的code distribution与第一层类似,呈均匀分布。结果,可以直接观察到第二层的large routing nodes在第三层分化为多个较小的节点,形成一对多的情况,如Figure 4的第三层所示。同时,如果第二层的残差趋近于零,第三层仍会存在一定的聚类现象。然而,由于此时所有
magnitudes都非常小,聚类效应(clustering effect)的影响有限。
随着层数的不断迭代,这种非均匀分布、长尾聚类随后均匀分布(
long-tail clustering followed by uniform distribution)的现象将交替出现。然而,随着层数的增加,残差变得越来越小(参考Figure 4的第四层),聚类效应减弱,因此可以忽略不计。最终,这导致形成沙漏状结构:输入数据首先被压缩到少数的clusters中,然后扩展回大量的clusters,最后收敛到均匀分布。SID构建完成后,残差量化方法的影响,再加上中间层head tokens的主导地位,自然导致了路径的稀疏性。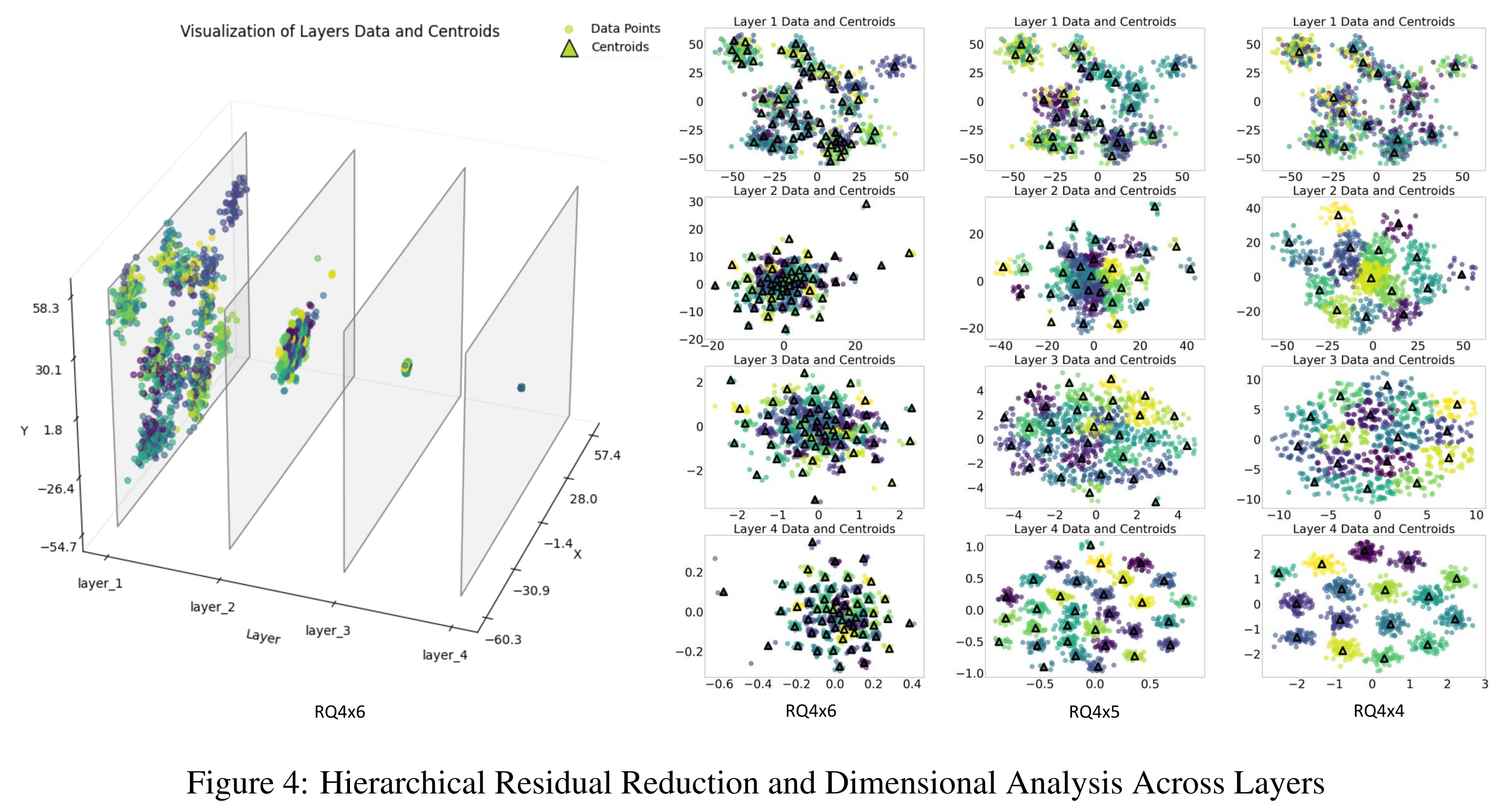
类似地,对于非均匀分布(如长尾分布),残差分布变得更加不均匀,导致沙漏现象更为严重。
1.3.3 Impact on the GR
在上述部分中,我们讨论了
Semantic ID在第二层的长尾分布,指出了其 “一对多“ 和 ”多对一“ 的结构。我们认为这种现象显著影响下游任务的generation,尤其是生成式检索任务。为了衡量这种影响,我们进行了各种实验。首先,通过交互第一层和第二层来改变
Semantic ID的分布。在此基础上,我们固定第一层的tokens,仅预测第二层和第三层的tokens。什么是 “交互第一层和第二层”?作者并未说明。
在评估过程中,我们根据第二层
tokens的分布将测试集分为两组:head token test set和tail token test set。如Table 1所示,head token test set的性能显著提升,而tail token test set的性能则明显较差。这种性能差异可归因于前面分析的路径稀疏性和tokens长尾分布,导致结果存在bias。在不同规模(
LLaMA2、Baichuan2和Qwen1.5)和不同parameters of RQ的模型中均观察到了这种现象,突显了long-tail token distribution和path sparsity对模型性能的广泛影响。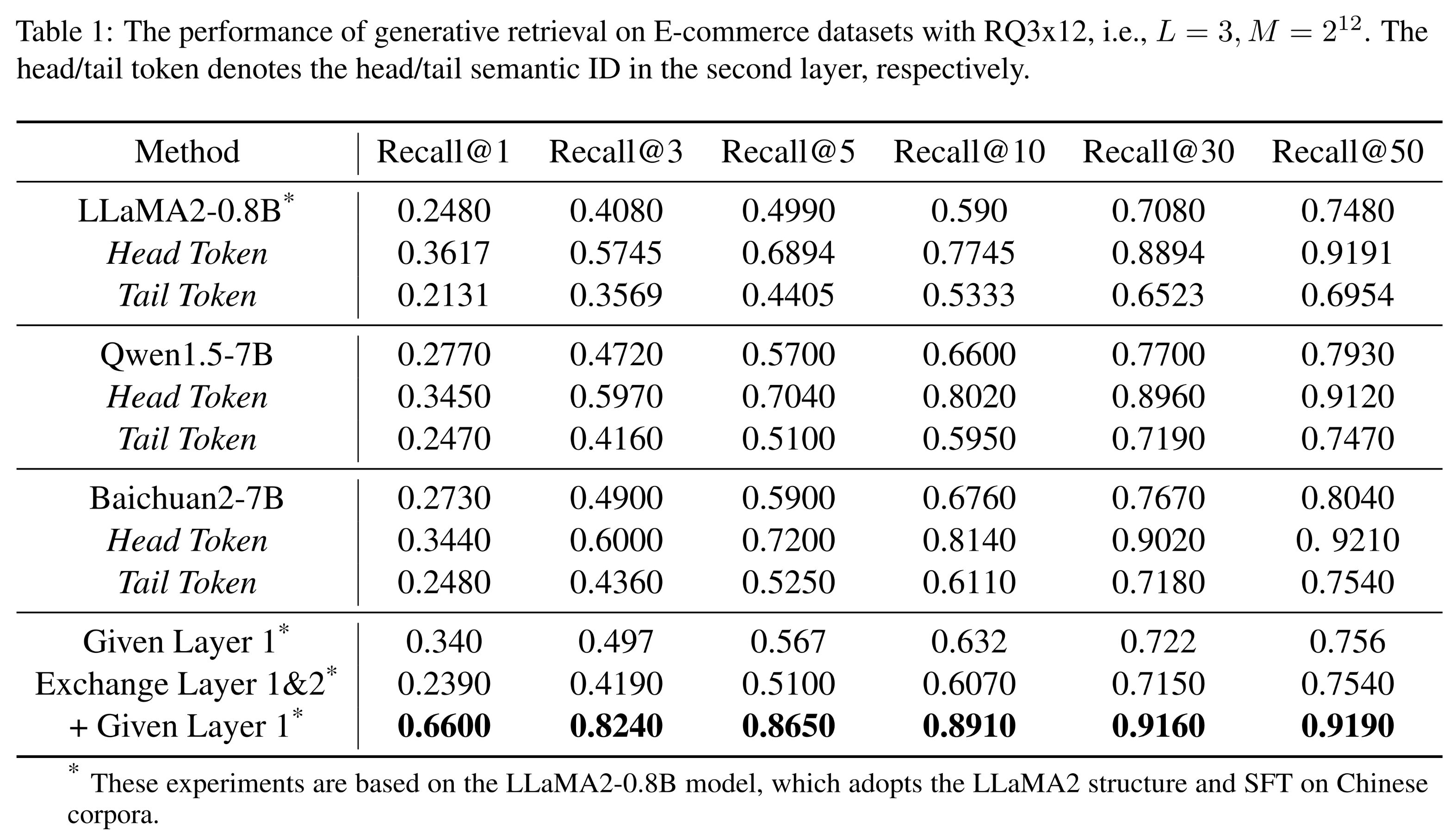
为了进一步探究沙漏现象对模型性能的影响,我们进行了三项关键实验:
1):直接将第一个token作为输入。即,
first token作为已知条件,仅仅召回second/third token。2):交换第一层和第二层的tokens。即,将所有
items的code map映射关系中,将第二个token与第一个token互换。例如,item 1 -> (c1, c2, c3)现在变为:item 1 -> (c2, c1, c3)。3):将swapped sequence的第一个token作为输入。
可以看到:
仅交换第一层和第二层会导致第一层出现显著的长尾分布,且长尾分布问题仍未解决。如
Table 1所示,指标变化极小。然而,如果我们交换第一层和第二层并提供第一个
token,任务将转变为预测第二层和第三层。由于真实的第一层已被给出,这简化了任务,减轻了长尾分布的影响,显著提升了性能。相反,如果不交换层数但仍提供第一个
token,第二层的SID仍保持其长尾分布。Table 1中的这些结果高于基线,但低于交换第一层和第二层并提供第一个token的情况。
这些方法旨在减轻长尾分布的影响,结果验证了性能的显著提升。这一发现表明,沙漏现象对模型性能具有实质性的负面影响。通过上述实验,我们不仅证实了沙漏效应的存在,还阐明了其对模型性能的具体影响,从而为未来的优化提供了坚实基础。
1.4 方法与实验
为了缓解沙漏效应,我们提出了两种简单而有效的方法。
启发式方法(
Heuristic Method):一种启发式方法是直接移除第二层,消除长尾的影响。然而,这可能导致空间容量(spatial capacity)不足,即L-layer SID,然后再移除第二层;这与直接生成two-layer SID不同——直接生成two-layer SID可能仍然存在large routing nodes。这是强行改变映射关系:从
变长的
SID(Variable Length of SID):另一种简单方法是自适应地移除第二层的top tokens,使semantic ID成为变长结构。这里采用top@K策略,其中tokens来减少沙漏效应的影响。此外,空间容量充足,即top-K的选择取决于实际数据分布,因此需要进行消融测试。总之,该方法简单高效,但并非最优,只能缓解而非完全解决沙漏现象。核心思想是自适应地移除第二层中频率最高的
token,使原本固定长度的SID变为可变长度结构,从而缓解第二层的长尾分布问题。具体做法是:统计第二层中token的分布,然后将阈值超过token直接抹掉(或者将最大的token直接抹掉),使得对应的tokens只有第一层和第三层。
为了进一步验证该方法的有效性,我们在
LLaMA模型和真实的大规模电子商务平台上进行了实验。我们从近60天的数据中随机选择了数亿个训练样本,用户基数达到数千万,产品目录包含200 million items。用户行为序列的平均长度为100。结果表明,通过应用
adaptive token removal策略,与base模型相比,该模型的性能得到了提升,同时计算成本保持相似。此外,在Focal Loss和Mile Loss等几个objective optimizations方面也相对baseline取得了进步。具体而言,实验结果显示:
移除
top@400 tokens的模型在大多数评估指标上优于基线模型。这表明该方法有效减少了长尾效应的影响。随着移除
tokens数量的增加,模型的性能提升遇到瓶颈。特别是当第二层所有tokens都被移除时,这种限制尤为明显;推测这是由于缺少long-tail tokens导致召回率损失。同时,直接移除第二层会导致一个SID对应多个items。
这种细粒度分析为所提出方法的有效性提供了有力证据——该方法选择性地移除不太重要的
tokens,同时保留most informative tokens,即使移除了大量数据,仍能提升模型性能。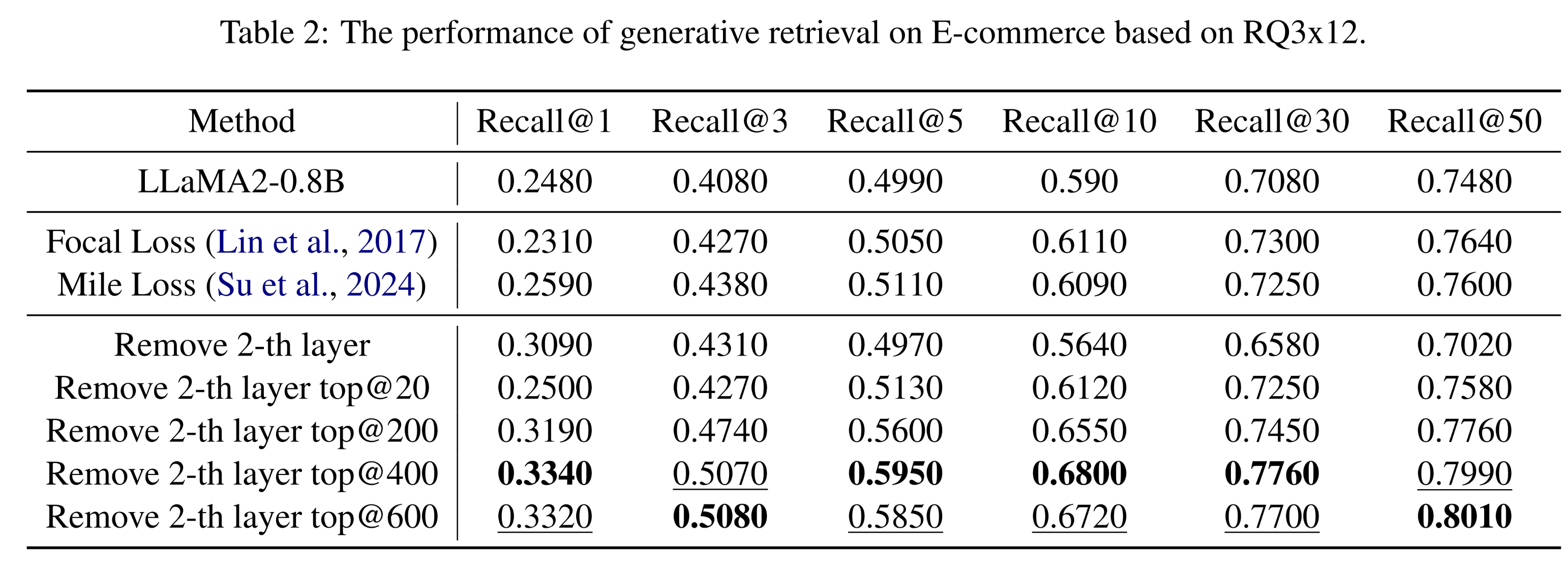
Valid Ratio:在自回归解码(autoregressive decoding)过程中,当模型解码target SID的next token时,可能会预测出无效的SIDs(即不在SID's vocabulary中、或与full dataset中任何item都不对应的SID)。因此,我们计算了基于RQ3x12的LLaMA2-0.8B模型上无效SIDs的比例。如
Figure 5所示,我们可以看到:与
base模型相比,所提出方法的invalid ratio更低,表明generation的质量更高,幻觉比例更低。此外,当召回数量小于
10时,无效率低于5%。因此,generation的有效性能够满足实际需求。在其他需要更高召回数量的情况下(
invalid ratio更高。
在不同规模的
base模型和不同的RQ parameter setting下,结果趋向于得出相同的结论。因此,在推理过程中需要采用retrieval augmented generation: RAG进行处理,例如前缀树(prefix-tree)和FM_Index。当需要召回更多的
candidates时,Remove 2-th Layer top@400的invalid ratio几乎与baseline相同。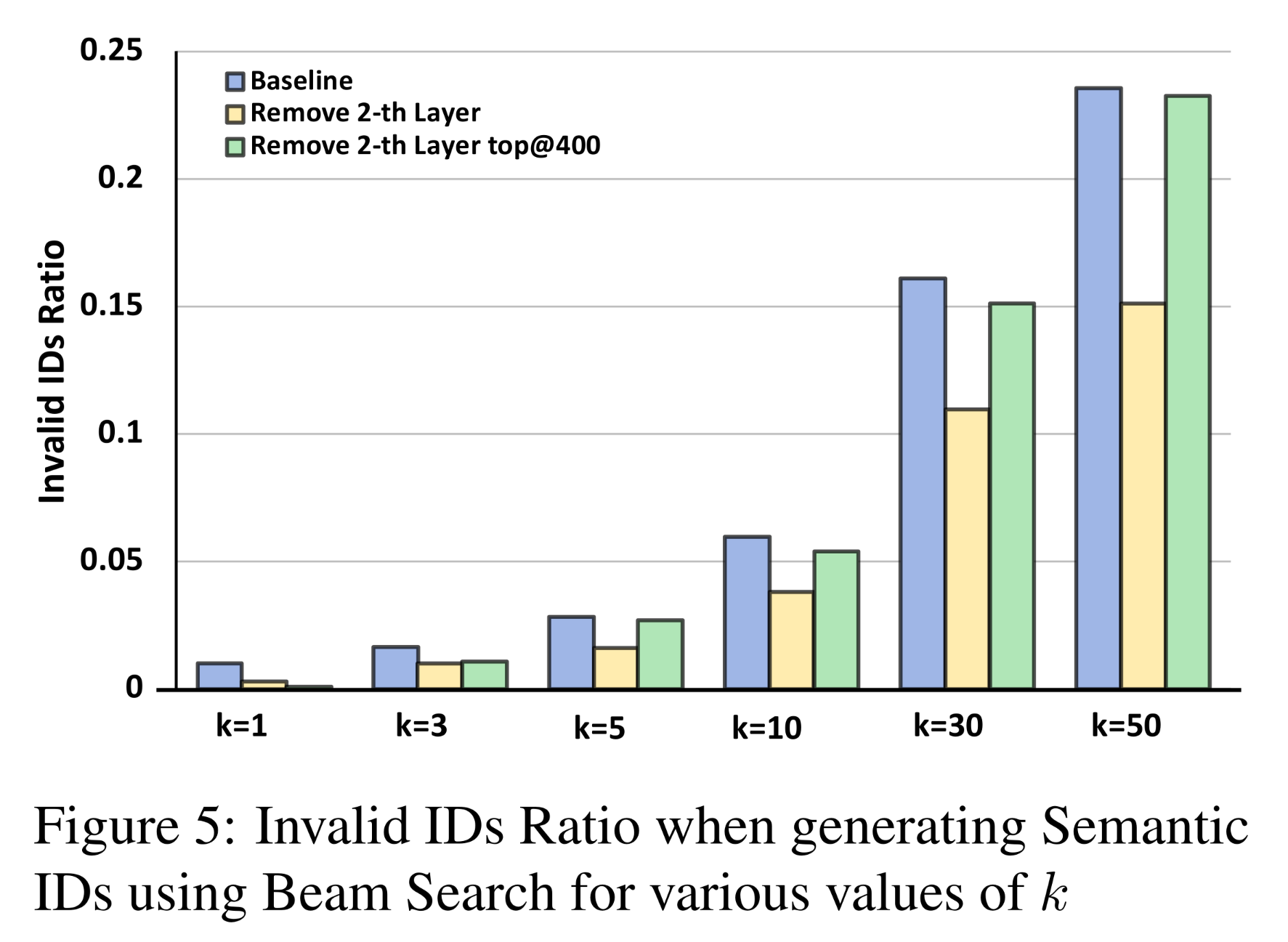
1.5 结论
本研究系统性地探讨了生成式检索中
RQ-SID的局限性,特别地识别了intermediate layer中的沙漏现象:codebook tokens过度集中。沙漏现象导致了路径稀疏性和长尾分布。通过大量实验和消融研究,我们证实了该现象的存在,并深入分析了其根本原因在于residuals的特性。为了缓解这一问题,我们提出了两种方法:
一种启发式方法:直接移除第二层。
一种
variable-length token策略:自适应地调整token distribution。
实验结果表明,两种方法都有效缓解了瓶颈效应(
bottleneck effect),其中自适应token distribution adjustment的效果最佳。尽管该方法简单高效,但并非最优,只能缓解而非完全解决沙漏现象。据我们所知,这是首次系统性地探索生成式检索中RQ-SID的缺陷,为未来的模型优化提供了坚实基础,并通过提高codebook利用率来显著提升了模型性能。