一、 LLMRec [2024]
《Large Language Models are Zero-Shot Rankers for Recommender Systems》
最近,大型语言模型(
large language model: LLM)(例如,GPT-4)已展现出令人印象深刻的通用任务解决能力,包括处理推荐任务的潜力。沿着这一研究方向,本工作旨在研究LLM作为推荐系统排序模型的能力。我们首先将推荐问题形式化为一个条件排序任务(conditional ranking task),将sequential interaction histories视为conditions,并将items retrieved by other candidate generation models视为candidates。为了通过LLM解决排序任务,我们精心设计了prompting template,并在两个广泛使用的数据集上进行了大量实验。我们表明,LLM具备有前景的zero-shot ranking能力,但:(1):难以感知historical interactions的顺序。(2):可能会受到prompts中popularity或item positions的bias所影响。
我们证明,这些问题可以通过专门设计的
prompting策略和bootstrapping策略得到缓解。具备这些洞察后,当ranking candidates由多个candidate generators检索而来时,zero-shot LLMs甚至可以挑战传统的推荐模型。代码和处理后的数据集可在https://github.com/RUCAIBox/LLMRank获取。在推荐系统文献中,大多数现有模型使用来自特定领域或场景的
user behavior data进行训练,这存在两个主要问题。首先,仅通过建模
historical behaviors(例如,clicked item sequences)难以捕获用户偏好,这限制了表达能力来建模更复杂但更明确的用户兴趣(例如,用自然语言表达的意图)。其次,这些模型本质上是“狭窄的专家”(
"narrow experts"),在解决依赖背景知识或常识知识的复杂推荐任务时缺乏更全面的知识(《survey on knowledge graph-based recommender systems》)。
为了提高推荐性能和交互性(
interactivity),越来越多的努力探索在推荐系统中使用预训练语言模型(pre-trained language models: PLMs)。它们旨在用自然语言明确捕获用户偏好(《Recommendation as language processing (RLP): A unified pretrain, personalized prompt & predict paradigm (P5)》)、或从文本语料库中迁移丰富的世界知识(《Towards universal sequence representation learning for recommender systems》、《Learning vector-quantized item representation for transferable sequential recommenders》)。尽管有效,但在task-specific data上彻底微调推荐模型仍然是必需的,这使得它们解决多样化的推荐任务的能力较弱(《Towards universal sequence representation learning for recommender systems》)。最近,大型语言模型(large language model: LLM)已展现出作为zero-shot task solvers的巨大潜力(《Finetuned language models are zero-shot learners》、《Multitask prompted training enables zero-shot task generalization》)。确实,有一些初步尝试使用LLM来解决推荐任务。这些研究主要关注讨论利用LLM来构建推荐系统的可能性。尽管有前景,但对使用LLM进行推荐时的新特性的理解不足,可能会阻碍这一新范式的发展。在本文中,我们进行实证研究以探究决定了
LLM作为推荐模型能力的因素。通常,推荐系统以pipeline的架构开发(《Deep neural networks for youtube recommendations》),包括candidate generation(检索relevant items)和ranking(将relevant items排在更高位置)过程。本工作主要关注推荐系统的ranking阶段,因为LLM在大规模candidate set上运行成本更高。此外,排序性能对retrieved candidate items敏感,这更适合检查LLM推荐能力的细微差别。为了进行这项研究,我们首先将
LLM的推荐过程形式化为一个条件排序任务(conditional ranking task)。给定prompts,其中prompts包含sequential historical interactions作为"conditions",LLM被指示根据LLM的内在知识对一组"candidates"(例如,由candidate generation models检索到的items)进行排序。然后,我们通过分别为"conditions"和"candidates"设计特定配置,进行控制实验以系统研究LLM作为rankers的实证性能。总体而言,我们试图回答以下关键问题:哪些因素影响
LLM的zero-shot ranking性能?LLM进行推荐依赖哪些数据或知识?
我们的实证实验在两个公开的推荐系统数据集上进行。结果得出了几个关键发现,这些发现可能揭示如何将
LLM发展为推荐系统的强大排序模型。我们将关键发现总结如下:LLM难以感知给定的sequential interaction histories的顺序。通过采用专门设计的promptings,可以触发LLM感知顺序,从而提高排序性能。LLM在排序时存在position bias和popularity bias,这可以通过bootstrapping策略或专门设计的prompting策略来缓解。LLM优于现有的zero-shot推荐方法,展现出有前景的zero-shot ranking能力,尤其是在处理由多个采用不同实际策略的candidate generation models所检索到的candidates时。
LLM的latency太大导致它无法应用于推荐系统的online inference,因此只能应用于offline。而ranking阶段通常必须是online进行的,而retrieval阶段可以是offline进行的。因此,LLM通常仅用于retrieval阶段。
1.1 相关工作
推荐系统的
Transfer Learning:由于推荐系统大多在从单一来源收集的数据上训练,人们试图从其他领域、市场或平台迁移知识。典型的推荐系统transfer learning方法依赖于锚点(anchors),包括shared users/items、或来自共享空间的representations。然而,这些锚点在不同场景之间通常很稀疏,使得推荐系统之间迁移变得困难。最近,有研究旨在通过微调或
prompting将语言模型中存储的知识迁移到推荐任务中。在本文中,我们进行zero-shot推荐实验,以检验从LLM迁移知识的潜力。用于推荐系统的大型语言模型:推荐模型,特别是
sequential recommendation models的设计,长期以来一直受到语言模型设计的启发,从word2vec到最近的神经网络。近年来,随着预训练语言模型(pre-trained language model: PLM)的发展,人们试图将PLM中存储的知识迁移到推荐模型中,要么通过使用items' text features来表示items,要么以自然语言格式表示behavior sequences。最近,大型语言模型(
LLM)已被证明具有卓越的语言理解能力和生成能力。已有研究通过将LLM与传统推荐模型集成或使用专门设计的指令进行微调,使推荐系统更具交互性。也有早期探索表明LLM具有zero-shot推荐能力。尽管在一定程度上有效,但很少有工作探索决定LLM推荐性能的因素。
1.2 LLMs as Rankers 的通用框架
为了研究
LLM的推荐能力,我们首先将推荐过程形式化为一个条件排序任务。然后,我们描述了一个通用框架,该框架使LLM适用于解决推荐任务。
1.2.1 Problem Formulation
给定一个用户的
historical interactionsconditions,任务是对candidate itemsitems被排在更高的位置。在实践中,candidate items通常由candidate generation models从整个item set《Deep neural networks for youtube recommendations》)。此外,我们假设每个item《Towards universal sequence representation learning for recommender systems》的做法。
1.2.2 Ranking with LLMs Using Natural Language Instructions
我们按照
instruction-following范式(《Finetuned language models are zero-shot learners》),使用LLM作为排序模型来解决上述任务。具体来说,对于每个用户,我们首先构建两个自然语言patterns,分别包含sequential interaction historiesconditions)和retrieved candidate itemscandidates)。然后将这些patterns填入一个自然语言模板final instruction。通过这种方式,我们期望LLM理解指令并按照指令的建议来输出排序结果。我们排序方法的整体框架如Figure 1所示。接下来,我们描述我们方法中详细的instruction design。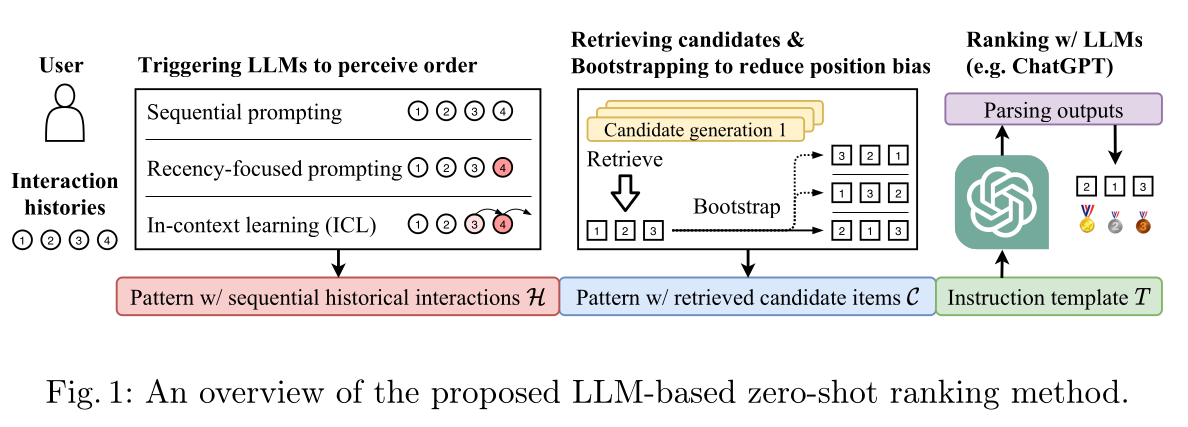
Sequential historical interactions:为了研究LLM能否从historical user behaviors中捕获用户偏好,我们将sequential historical interactionsLLM的输入包含在指令中。为了让LLM感知historical interactions的时序特性,本文提出三种指令构建方式:Sequential prompting:将historical interactions按时间顺序排列,该方法也已在过往研究(《Uncovering chatgpt’s capabilities in recommender systems》)中得到应用。示例:"I’ve watched the following movies in the past in order: ’0. Multiplicity’, ’1.Jurassic Park’, ..."Recency-focused prompting:在保留sequential interaction记录的基础上,额外增加语句来强调most recent interaction。示例:xxxxxxxxxx"I’ve watched the following movies in the past in order: ’0. Multiplicity’, ’1. Jurassic Park’, ... . Note that my most recently watched movie is Dead Presidents. ..."In-context learning (ICL):In-context learning是LLM完成各类任务的主流prompting方法(《A survey of large language models),核心是在prompt中加入示范样例。针对个性化推荐任务,直接引入其他用户的样例容易引入噪声,因为不同用户的偏好存在差异。因此本文选择对input interaction sequence本身进行增强(augmenting)来构建示范样例:将input interaction sequence的prefix与对应的successor组合为样例。示例:xxxxxxxxxx"If I’ve watched the following movies in the past in order: ’0. Multiplicity’, ’1. Jurassic Park’, ..., then you should recommend Dead Presidents to me and now that I’ve watched Dead Presidents, then ..."注意:这里的示范样例的构造,与
Ranking with large language models这里用到的final examples的格式不同。这里的ICL的样例仅仅用于增强input interaction sequence。
Retrieved candidate items:待排序的candidate items一般先由candidate generation models完成召回(《Deep neural networks for youtube recommendations》)。本研究设置小规模candidate set,最终保留20 candidate items(即LLM对candidates进行排序时,我们将candidate setxxxxxxxxxx"Now there are 20 candidate movies that I can watch next: ’0. Sister Act’, ’1. Sunset Blvd’, ..."参照经典的
candidate generation方案(《Deep neural networks for youtube recommendations》),召回得到的candidate items没有固定顺序。为此,我们在prompts中对candidate items采用不同的排列次序,以此进一步探究:LLM的排序结果是否会受candidates排列顺序影响(即position bias),以及如何通过bootstrapping来缓解该bias。Ranking with large language models:现有研究表明,LLM可在zero-shot setting下遵循自然语言指令完成多种任务(《Finetuned language models are zero-shot learners》、《A survey of large language models》)。利用LLM实现排序时,我们将上述各类patterns填充至instruction templateinstruction template示例如下:xxxxxxxxxx"[pattern that contains sequential historical interactions H] [pattern that contains retrieved candidate items C] Please rank these movies by measuring the possibilities that I would like to watch next most, according to my watching history."Parsing the output of LLMs:LLM的输出为自然文本,本文采用启发式的text-matching方法来解析输出结果,并将推荐结果限定在指定的item set内。具体而言,我们使用KMP等高效的substring matching算法,对LLM outputs与text of candidate items进行匹配。 实验发现,LLM偶尔会生成candidate set以外的items;对于GPT-3.5,这类异常输出占比仅为3%。针对该问题,既可对异常结果重新处理,也可直接将out-of-candidate items判定为无效推荐。
1.3 实证研究
数据集:实验在两个广泛使用的公开推荐系统数据集上进行:
(1):电影评分数据集MovieLens-1M(简称ML-1M),其中user ratings被视为interactions。(2):来自Amazon Review数据集的一个名为Games的类别,其中reviews被视为interactions。
我们筛选出
interactions次数少于5次的users和items。然后,我们按时间戳对每个用户的interactions进行排序,最早的interactions在前,以构建相应的historical interaction sequences。movie/product标题用作item的描述性文本。我们在这项研究中使用item titles有两个原因:(1):为了确定LLM是否能在仅提供最少信息的情况下,利用其内在的世界知识做出推荐。(2):为了节省计算资源。探索LLM如何使用更广泛的文本特征进行推荐将是我们未来工作的重点。
评估和实现细节:
遵循现有工作(
《Self-attentive sequential recommendation》、《Towards universal sequence representation learning for recommender systems》),我们采用留一法(leave-one-out)进行评估。对于每个
historical interaction sequence,最后一个item用作测试集中的ground-truth item。倒数第二个item用于验证集(用于训练baseline方法)。我们采用广泛使用的指标
NDCG@K(简称N@K)来评估在给定candidates上的排序结果,其中为了便于复现本工作,我们的实验使用流行的开源推荐库
RecBoLe(《Towards a unified, comprehensive and efficient framework for recommendation algorithms》)进行。historical interaction sequences被截断在50长度以内。我们在
ML-1M数据集上的所有用户以及Games数据集上默认随机抽样的6,000名用户上评估LLM-based的方法。除非另有说明,被评估的LLM通过调用OpenAI的API gpt-3.5-turbo访问。调用LLM的超参数温度设置为0.2。所有报告的结果是至少三次重复运行的平均值,以减少随机性的影响。
1.3.1 LLM 能理解包含 Sequential Historical User Behaviors 的 Prompts 吗 ?
在
LLM-based方法中,historical interactions自然地按有序序列排列。通过设计LLM是否能利用这些historical user behaviors并感知其顺序性以做出准确的推荐。LLM难以感知给定historical user behaviors的顺序。在本节中,我们检验LLM是否能理解包含有序historical interactions的prompts并给出个性化推荐。任务是对一个包含20 items的candidate set进行排序,其中包括一个ground-truth item和19 randomly sampled negatives。通过分析historical behaviors,感兴趣的items应被排在更高的位置。这里的
candidate generator是一种规则:检索ground-truth item、以及19 randomly sampled negatives。我们比较了三种
LLM-based方法的排序结果:(a)我们的方法:按照前面正文描述的方式进行排序。historical user behaviors使用"sequential prompting"策略被编码到prompts中。(b)随机顺序:其中historical user behaviors在输入模型前会被随机打乱,(c)虚假历史:我们将原始historical behaviors中的所有items替换为随机采样的items作为fake historical behaviors。
从
Figure 2(a)可以看出,我们的方法比使用fake historical behaviors的变体表现更好。然而,我们的方法和随机顺序的表现相似,表明LLM对给定的historical user interactions的顺序不敏感。此外,在
Figure 2(b)中,我们改变了用于构建prompt的latest historical user behaviors的数量5到50。结果表明,增加historical user behaviors的数量并不能提高排序性能,反而会对排序性能产生负面影响。我们推测,这种现象是由于LLM难以理解顺序,而是平等地考虑所有historical behaviors。因此,过多的historical user behaviors(例如,LLM不堪重负,导致性能下降。相比之下,相对较小的LLM能够专注于most recently interacted items,从而获得更好的推荐性能。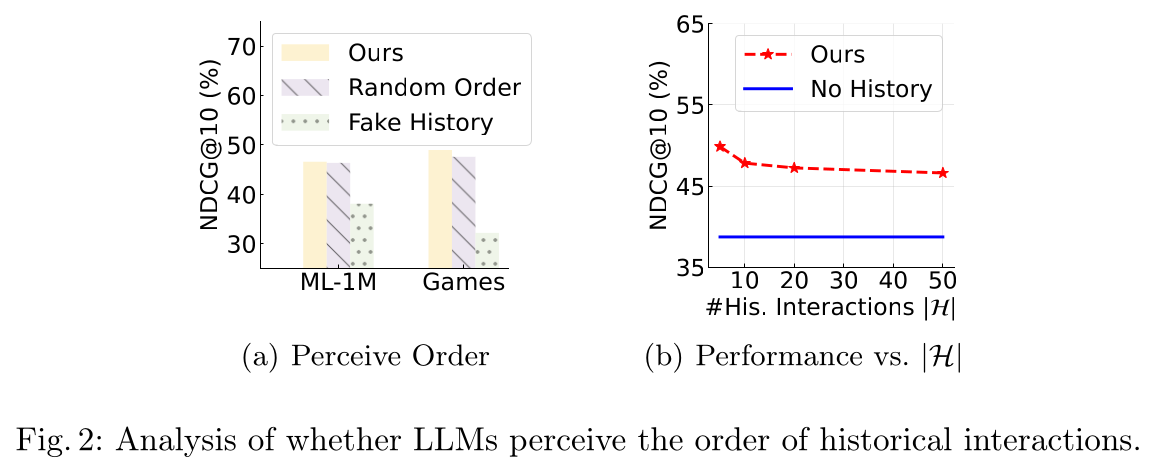
触发
LLM感知interaction order:基于上述观察,我们发现LLM难以通过默认的prompting策略来感知interaction histories中的顺序。因此,我们旨在通过提出两种替代的prompting策略并强调recently interacted items,来激发LLM的顺序感知能力。前面正文章节中已详细描述了所提出的策略。在Table 2中,我们可以看到,recency-focused prompting和in-context learning通常都能提高LLM的排序性能,尽管最佳策略可能因数据集而异。上述结果可以总结为以下关键observation:Observation 1:LLM难以感知给定的sequential interaction histories的顺序。通过采用专门设计的promptings,可以触发LLM感知historical user behaviors的顺序,从而提高排序性能。
LLM zero-shot的性能与Pop方法差不多,也就是推荐热门item。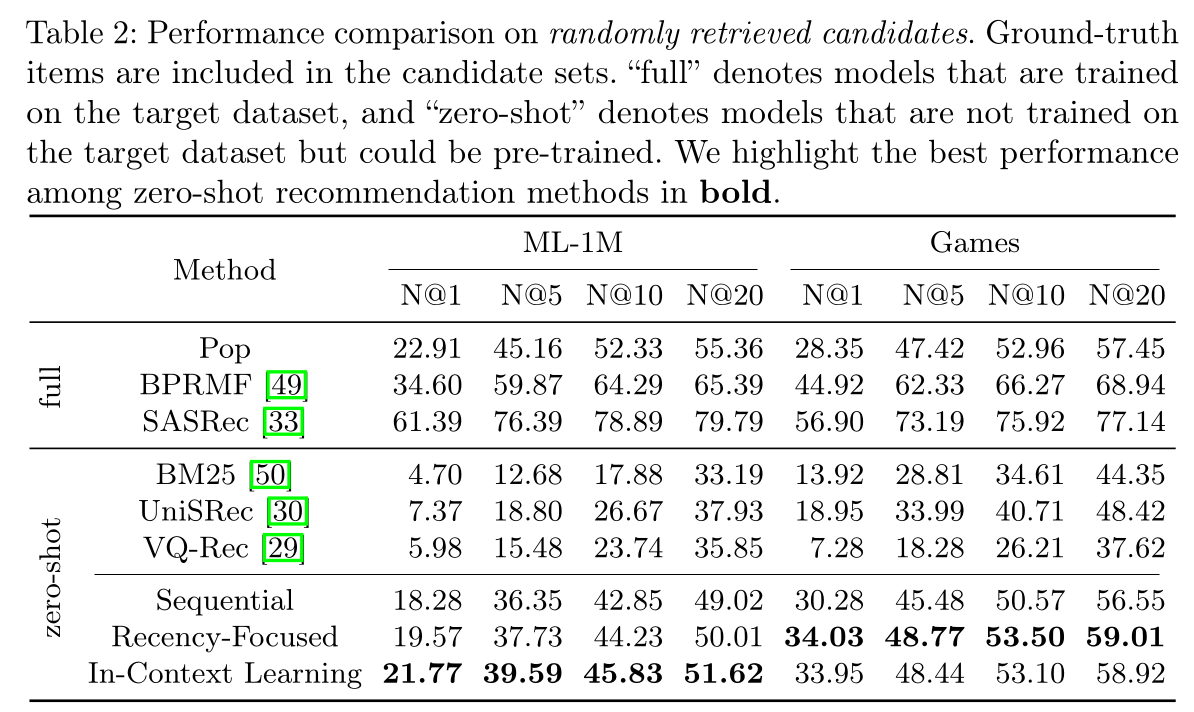
1.3.2 LLM 在排序时会受到 biases 影响吗?
传统推荐系统中的
biases和debiasing methods已被广泛研究(《Bias and debias in recommender system: A survey and future directions》)。对于LLM-based的推荐模型,input和output都是自然语言文本,将不可避免地引入新的biases。在本节中,我们讨论LLM-based的推荐模型遭受的两种biases。我们还讨论了如何减轻这些biases。candidates的顺序影响LLM的排序结果:对于传统的排序方法,retrieved candidates的顺序通常不会影响排序结果(《Self-attentive sequential recommendation》、《Session-based recommendations with recurrent neural networks》)。然而,对于正文章节中描述的LLM-based的方法,candidates以序列方式排列并填入prompt中。已经证明,对于NLP任务,LLM通常对prompt中示例的顺序敏感(《Calibrate before use: Improving few-shot performance of language models》、《Fantastically ordered prompts and where to find them: Overcoming few-shot prompt order sensitivity》)。因此,我们也进行实验来检验candidates的顺序是否影响LLM的排序性能。我们采用与第1.3.1节相同的实验设置。唯一的区别是我们控制了prompts中这些candidates的顺序,使ground-truth items出现在特定位置。我们将ground-truth items的位置在{0,5,10,15,19}中变化,结果如Figure 3(a)所示。我们可以看到,当
ground-truth items出现在不同位置时,性能会发生变化。特别是,当ground-truth items出现在最后几个位置时,排序性能显著下降。结果表明,LLM-based rankers受到candidates顺序的影响,即position bias,而这可能不会影响传统的推荐模型。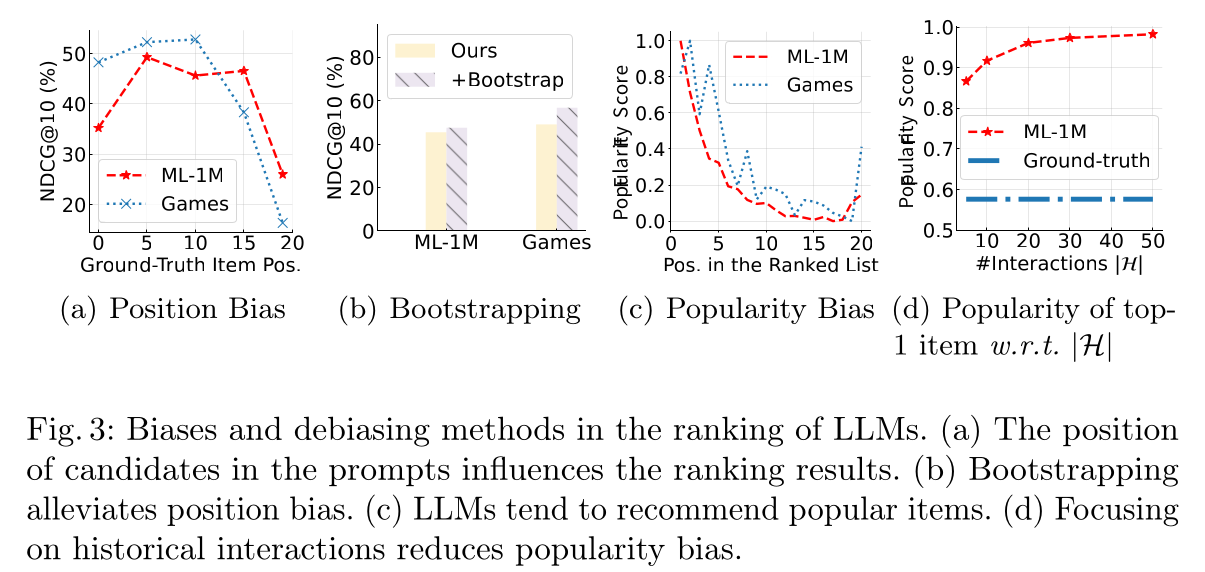
通过
bootstrapping减轻position bias:一种减轻position bias的简单策略是bootstrap the ranking process。我们可以重复对candidate set进行排序candidates的顺序。这样,一个candidate可能出现在不同的位置。然后我们合并每轮的结果以得出final ranking。从Figure 3(b)中,我们遵循第1.3.1节的设置,将bootstrapping策略应用于我们的方法。每个candidate set将被排序3次。我们可以看到,bootstrapping提高了两个数据集上的排序性能。“合并每轮的结果”:如何合并?论文并未说明。可以采用平均投票法:
LLM推荐哪个candidate item最多,则返回这个candidate item。candidates的流行度影响LLM的排序结果:对于popular items,其关联的文本也可能频繁出现在LLM的预训练语料中。例如,一本畅销书会在网络上被广泛讨论。因此,我们旨在检验排序结果是否受the popularity of candidates的影响。然而,直接衡量the popularity of item text是困难的。这里,我们假设text popularity可以间接地通过一个推荐数据集中的item frequency来衡量。在Figure 3(c)中,我们报告了ranked item lists中每个位置的item popularity score(通过训练集中出现的normalized item frequency来衡量)。我们可以看到,popular items倾向于被排在更高的位置。让
LLM关注historical interactions有助于减少popularity bias:我们假设,如果LLM关注historical interactions,它们可能会给出更个性化的推荐,而不是更popular的推荐。从
Figure 2(b)中,我们知道,当使用较少的historical interactions时,LLM能更好地利用historical interactions。从
Figure 3(d)中,我们比较了随着historical interactions数量变化时,best-ranked items的popularity scores。可以观察到,随着popularity score也降低。
这表明,当
LLM更多地关注historical interactions时,可以减少popularity bias的影响。通过以上实验,我们可以得出以下结论:Observation 2:LLM在排序时存在position bias和popularity bias,这可以通过bootstrapping策略或专门设计的prompting策略来缓解。
这意味着采用较短的
historical interactions(即较小的popularity bias。或者采用recency-focused prompting和in-context learning。
1.3.3 LLM 在 Zero-Shot Setting 中对 Candidates 进行排序的效果如何?
我们进一步评估
LLM-based的方法在由不同策略检索的、包含hard negatives的candidates上的表现,以进一步研究LLM的排序依赖于什么。然后,我们展示了不同方法在由多个candidate generation models检索到的candidates上的排序性能,以模拟一个更实际和困难的设置。LLM具有有前景的zero-shot ranking能力:在Table 2中,我们进行实验,将LLM-based方法的排序能力与现有方法进行比较。我们采用与第1.3.1节相同的设置,其中candidate items是随机检索的。我们包括了三个在训练集上训练的传统模型,即Pop(根据item popularity进行推荐)、BPRMF(《BPR: bayesian personalized ranking from implicit feedback》)和SASRec(《Self-attentive sequential recommendation》)。我们还评估了未在
target datasets上训练的三个zero-shot recommendation methods,包括BM25(《The probabilistic relevance framework: BM25 and beyond》)(根据candidates与historical interactions之间的文本相似度进行排序)、UniSRec(《Towards universal sequence representation learning for recommender systems》)和VQ-Rec(《Learning vector-quantized item representation for transferable sequential recommenders》)。对于UniSRec和VQ-Rec,我们使用它们公开可用的pre-trained models。我们未包含ZESRec(《Zero-shot recommender systems》),因为没有发布pre-trained model。此外,我们在Table 3中比较了不同LLM的zero-shot ranking性能。对于LLM-based rankers,我们使用了"Recency-Focused"的prompting策略。从
Table 2和Table 3可以看出,参数更多的LLM通常表现更好。最佳的LLM-based方法大大优于现有的zero-shot推荐方法,展现出有前景的zero-shot ranking能力。我们强调,在ML-1M数据集上进行zero-shot推荐是困难的,因为仅仅通过电影标题的相似性来衡量电影之间的相似性具有难度。然而,LLM可以利用其内在知识来衡量电影之间的相似性并做出推荐。我们要强调的是,评估zero-shot推荐方法的目标不是为了超越传统模型。目标是展示pre-trained base models的强大推荐能力,这些模型可以进一步适配和迁移到下游场景。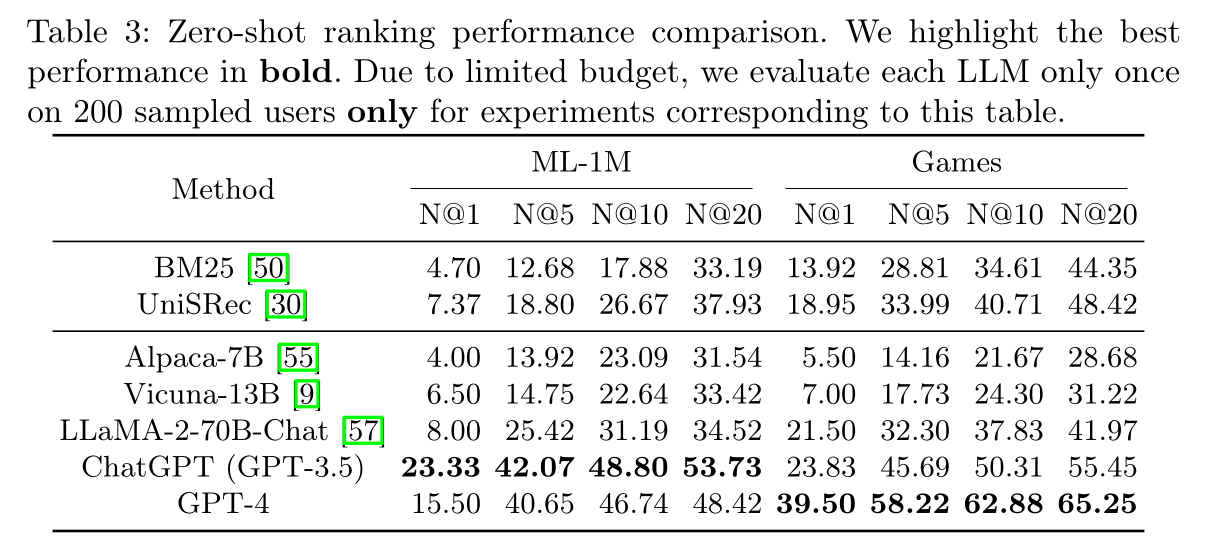
LLM基于item popularity、文本特征、以及user behaviors对candidates进行排序:为了进一步研究LLM如何对给定的candidates进行排序,我们在由不同candidate generation methods检索到的candidates上评估LLM。这些candidates可以被视为ground-truth items的hard negatives,可用于衡量LLM对specific categories of items的排序能力。我们考虑了两类策略来检索candidates:(1):基于内容的方法,如BM25(《The probabilistic relevance framework: BM25 and beyond》)和BERT(《Bert: Pre-training of deep bidirectional transformers for language understanding》),根据文本特征相似度来检索candidates。(2):基于interaction的方法,包括Pop、BPRMF(《BPR: bayesian personalized ranking from implicit feedback》)、GRU4Rec(《Session-based recommendations with recurrent neural networks》)和SASRec(《Self-attentive sequential recommendation》),使用在user-item interactions上训练好的神经网络来检索items。
给定
candidates,我们比较了LLM-based的模型(我们的方法)和代表性方法的排序性能。从
Figure 4中,我们可以看到LLM-based的方法的排序性能在不同的candidate sets和不同的数据集上有所不同。(1):在ML-1M上,LLM-based的方法无法在包含popular items的candidate sets(例如Pop和BPRMF)上很好地排序,表明在ML-1M数据集上,LLM-based的方法在很大程度上依赖于item popularity来推荐item。(2):在Games上,我们可以观察到我们的方法在popular candidates和textual similar candidates上都有相似的表现,表明item popularity和文本特征对LLM的排序能力上贡献相似。(3):在这两个数据集上,我们的方法的性能都受到hard negatives(由interaction-based candidate generation models检索而来)的影响,但不像那些interaction-based rankers(如SASRec)那样严重。
上述结果表明,
LLM-based的方法不仅仅考虑单一方面进行排序,而是利用了item popularity、文本特征、甚至user behaviors。在不同的数据集上,这三个方面影响排序性能的权重也可能不同。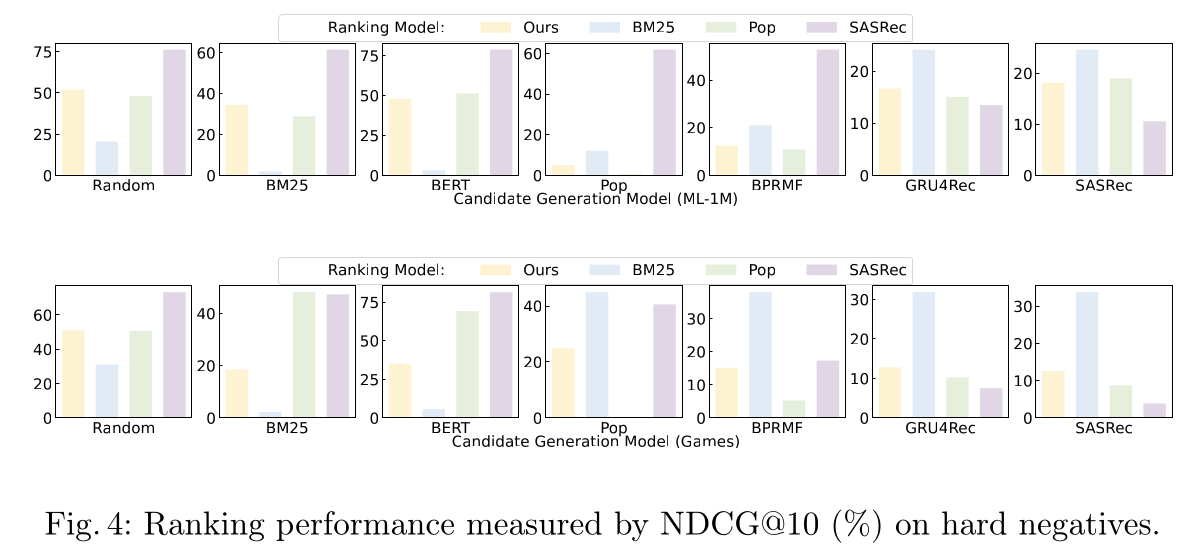
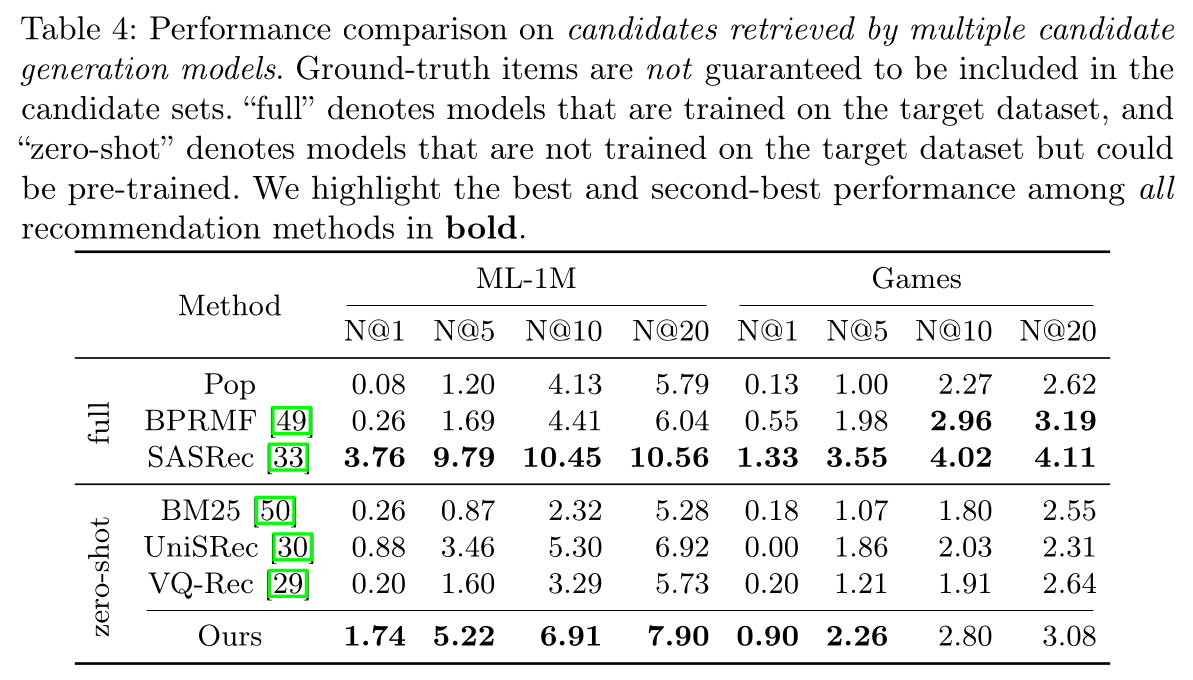
LLM可以有效地对由多个candidate generation models检索而来的candidates进行排序:对于现实世界的推荐系统(《Deep neural networks for youtube recommendations》),待排序的items通常由多个candidate generation models检索而来。因此,我们还在一个更实际和更困难的设置下进行了实验。我们使用上述七个candidate generation models来检索items。每个candidate generation model检索到的top-3 best items将被合并到一个包含总共21 items的candidate set中。作为一个更实际的设置,我们不将ground-truth item补充到每个candidate set中。请注意,这里的实验是在implicit preference setup下进行的(《A revisiting study of appropriate offline evaluation for top-n recommendation algorithms》),表明the retrieved items中可能存在implicit positive instances(未显示地标记为正样本)。更忠实的评估可能需要人工研究,我们打算在未来的工作中进行探索。对于我们的方法,我们总结了从第1.3.1节和第1.3.2节获得的经验。我们使用recency-focused prompting策略将sequential historical interactions编码到prompts中,并使用bootstrapping策略重复排序3轮。从
Table 4中,我们可以看到,在大多数指标上,LLM-based的模型(我们的方法)在被比较的推荐模型中取得了第二佳的性能。结果表明,LLM-based zero-shot ranker甚至优于已在target datasets上训练好的传统推荐模型Pop和BPRMF,进一步证明了LLM强大的zero-shot ranking能力。我们假设LLM可以利用其内在的世界知识,综合考虑item popularity、文本特征、以及user behaviors来对candidates进行排序。相比之下,现有模型(作为narrrow experts)可能缺乏在复杂环境中排序items的能力。上述发现可以总结为:Observation 3:LLM具有有前景的zero-shot ranking能力,尤其是在由多个candidate generation models with different practical strategies检索到的candidates上。
这种人工构造的数据集,可能不是那么有说服力。
1.4 结论
在这项工作中,我们研究了
LLM作为推荐系统的zero-shot ranking model的能力。为了使用LLM进行排序,我们构建了包含historical interactions、candidates、和instruction templates的自然语言prompts。然后,我们提出了几种专门设计的prompting策略,以触发LLM感知orders of sequential behaviors的能力。我们还引入了bootstrapping策略和prompting策略,以减轻LLM-based ranking models可能遭受的position bias和popularity bias问题。大量的实证研究表明,
LLM具有有前景的zero-shot ranking能力。实证研究证明了将知识从LLM迁移为强大推荐模型的强大潜力。我们旨在阐明进一步提高LLM排序能力的几个有前景的方向,包括:(1):更好地感知the order of sequential historical interactions。(2):减轻position bias和popularity bias。
对于未来的工作,我们考虑开发技术方法来解决在部署
LLM作为推荐模型时上述关键挑战。我们也希望开发LLM-based的推荐模型,可以在下游user behaviors上进行高效调优,以实现有效的个性化推荐。
1.5 局限性
在本文的大部分实验中,
ChatGPT被用作主要的target LLM从而用于评估。然而,作为一个闭源商业服务,ChatGPT可能在其核心大型语言模型之上集成了额外的技术来提高性能。虽然有可用的开源LLM,例如LLaMA 2和Mistral,但它们与ChatGPT相比表现出显著的性能差距(例如,Table 3中的LLaMA-2-70B-Chat与ChatGPT)。这种差距使得仅使用开源模型评估LLM在推荐任务上的涌现能力(emergent abilities)变得困难。此外,我们应该注意,observations可能受到特定prompts和数据集的bias所影响。