一、 SemanticIDInYouTube [2024]
《Better generalization with semantic ids : A case study in ranking for recommendations》
随机哈希的
item ids在推荐模型中被广泛使用。然而,随机哈希(random hashing)所学到的representations会阻碍similar items之间的泛化,导致难以对unseen items和long-tail items进行有效学习,尤其是在item corpus规模庞大、呈幂律分布、以及动态演变的场景下。本文提出使用
content-derived features来替代random ids。研究发现,简单地将ID features替换为content-based embeddings会因记忆能力(memorization capability)下降而导致模型性能变差。为了在记忆能力(memorization)和泛化能力(generalization)之间取得良好平衡,我们提出采用Semantic IDs(《Recommender systems with generative retrieval》)来替代random item ids。Semantic IDs是一种通过RQ-VAE从frozen content embeddings中学得到的紧凑的discrete item representation,能够捕获items中概念的层次结构(hierarchy of concepts)。与
content embeddings类似,Semantic IDs的紧凑性(compactness)给推荐模型的适配(adaption)带来了挑战。为此,我们提出了新颖的方法,通过对Semantic-ID sequences的子片段(sub-pieces)进行哈希处理,从而将Semantic IDs适配到工业级规模的ranking models中。特别地,我们发现常用于大语言模型(LLM)分词的SentencePiece model(《Subword regularization: Improving neural network translation models with multiple subword candidates》),其性能优于N-grams等人工设计的pieces。最后,我们在YouTube推荐系统的真实ranking model中对所提方法进行了评估。实验结果表明,Semantic IDs能够替代video IDs的直接使用(direct use),在不牺牲模型整体性能的前提下,提升了对new items和long-tail items的泛化能力。带有
large embedding tables的神经模型(neural models)在工业级推荐系统中被广泛应用,用于海量的items进行评分和排序。这些embedding tables通常包含数百万甚至数十亿行数据,通过对randomly-hashed item ids进行建模,能够快速记忆item quality。值得注意的是,学习良好的item representations对于个性化推荐至关重要,因为用户通常被建模为a sequence of items。具体而言,本文研究的是YouTube视频推荐系统中的neural ranking model。在该模型中,每个视频都有一个唯一的标识符,即video ID,它是一个无意义的随机字符串。这种方法在众多工业级推荐系统中被广泛采用。本文旨在研究
content-based item representations,该representations能够在保持模型记忆能力且不牺牲整体性能的前提下,提升对new items和long-tail items的泛化能力,重点关注recommendation ranking models。encoding item id的常用技术是学习one-hot embeddings。然而,对于包含数十亿视频的超大规模item corpus而言,为每个视频学习一个embedding vector不仅耗费资源;更重要的是,这种方法容易受到torso and tail items的数据稀疏性(data sparsity)的影响。为了使用有限数量的embeddings,一种替代方法是采用哈希技巧(hashing trick)(《Feature hashing for large scale multitask learning》),将多个items映射到同一行。但当原始item IDs不具有语义意义时,这种方法会产生随机冲突(random collisions)。对于使用来自
pre-trained multimodal item encoders的content embeddings,由于会损失item-level memorization,目前尚不清楚是否能够完全替代large item ID table。在《Where to go next for recommender systems? id- vs. modality-based recommender models revisited》的研究中,作者发现对于规模达150k-size的item corpus,在SASRec(《Self-attentive sequential recommendation》)上,frozen item embeddings的性能优于item ID baselines;但是,在双塔模型(《Neural collaborative filtering vs. matrix factorization revisited》)上并非如此。在我们针对YouTube更大corpus的实验中,当用content embeddings替代video IDs时,观察到模型性能显著下降。最近的一项研究(《A content-driven micro-video recommendation dataset at scale》)表明,通过端到端训练的video encoders(VideoRec)替代短视频推荐模型中的video ID是有效的,但该方法的计算成本是ID baseline的10-50倍。我们提出了一种新的框架,用于在
ranking models中适配content embeddings,该框架能够灵活控制generalization和memorization。我们的方法基于item Semantic IDs(Semantic IDs: SIDs)。SIDs概念最初在TIGER模型(《Recommender systems with generative retrieval》)中提出,是一种用于生成式检索(generative retrieval)的hierarchical, sequential and compact representation。SID的hierarchical nature允许通过使用不同levels的前缀来灵活控制粒度(granuality);其序列特性(sequential property)则与subword tokenization相关联,例如大语言模型中的SentencePiece model: SPM(《Improving neural network translation models with multiple subword candidates》)。值得注意的是,TIGER模型将SIDs用于生成式检索,而效率并非其首要考虑因素;而我们的研究重点是在资源受限且对延迟敏感的生产级ranking models中使用Semantic IDs,其中hashing和adaptation through embeddings是关键。本文的具体贡献如下:
(1):提出了两种将SIDs适配到推荐模型中以替代item IDs的方法:N-gram方法和SentencePiece Model: SPM方法。两种方法的核心思想都是通过item SIDs的sub-pieces创建content-based hashing;其中SPM方法通过将长度不一的sub-pieces分组,提供了一种从item distribution中学习的方法。即,当已经从
content embedding中获得了item code之后,如何根据item code来生成item representation?作者提出了N-gram方法和SPM方法。(2):在YouTube数据集上进行了大量实验,以验证所提方法的有效性。结果表明,SID-based adaption方法优于直接使用content embeddings的方法;并且在每个item的embedding lookups相同的情况下,使用large embedding tables时,SPM方法的性能优于N-gram方法。(3):展示了SIDs在YouTube数十亿个视频的corpus中的生产化(productionization),并举例说明了有意义且细粒度的hierarchical relationships,以及在生产场景中成功替换video IDs的情况。
1.1 相关工作
Embedding learning:Recommender models依赖于学习categorical features的good representation。编码categorical features的常用技术是通过one-hot embeddings来训练embeddings。Word2vec(《Distributed representations of words and phrases and their compositionality》)在language models领域普及了这种方法。当类别基数(
category cardinality)较大时,通常会采用哈希技巧(hashing trick)(《Feature hashing for large scale multitask learning》),但这种方法会产生随机冲突(random collisions)。多重哈希(
multiple hashing)(《Model size reduction using frequency based double hashing for recommender systems》)在一定程度上缓解了这一问题,但仍然会导致随机冲突。Deep Hash Embedding(《Learning to embed categorical features without embedding tables for recommendation》)通过不维护embedding tables来规避这一问题,但代价是增加了hidden layers的计算量。
相比之下,我们使用
Semantic IDs——一种在item IDs的embedding learning过程中避免随机冲突的高效计算方法。Semantic IDs通过使语义相关的items产生冲突,提升了recommender models的generalization。即,在
Semantic IDs中,只有语义相关的items才产生冲突。Cold-start and content information:content-based recommender models已被提出用于解决冷启动问题(例如《Methods and metrics for cold-start recommendations》、《Content-based neighbor models for cold start in recommender systems》)并实现可迁移推荐(《Transrec: Learning transferable recommendation from mixture-of-modality feedback》、《Learning vector-quantized item representation for transferable sequential recommenders》、《A content-driven micro-video recommendation dataset at scale》)。近年来,基于内容信息的embeddings也受到了广泛关注(例如,DropoutNet《Dropoutnet: Addressing cold start in recommender systems》、CCCC《Adaptive feature sampling for recommendation with missing content feature values》、《How to learn item representation for cold-start multimedia recommendation?》)。PinSage(《Graph convolutional neural networks for web-scale recommender systems》)聚合了视觉信息、文本信息和engagement信息来表示items。此外,
PinnerFormer(《Pinnerformer: Sequence modeling for user representation at pinterest》)使用与item history对应的sequences of PinSage embeddings构建一个sequential recommendation model。
与这些研究不同,我们的目标是开发一种基于内容的
representations,不仅具有良好的泛化能力,还能相对于使用item ID features提升性能。这是一项极具挑战性的任务。《A content-driven micro-video recommendation dataset at scale》成功解决了将video encoders生成的content embedding替代video ID的问题,该video encoders与短视频recommendation model进行端到端的训练。类似地,
TransRec(《Transrec: Learning transferable recommendation from mixture-of-modality feedback》)也采用端到端的训练,并利用多模态信息来表示items,以实现可迁移推荐(transferable recommendations)。
然而,这两种方法都显著增加了训练成本,使其难以在实际生产中部署。
Semantic IDs能够将content embeddings高效压缩为discrete tokens,使得在生产级推荐系统中使用content signals成为可能。此外,与用于offline inference的PinnerFormer不同,我们的重点是提升用于real-time inference的ranking model的泛化能力。因此,显著增加资源成本(包括存储、训练和服务成本)的方法在生产环境中是不可行的。《A content-driven micro-video recommendation dataset at scale》引入了一个大规模短视频数据集,并表明现有的video encoders生成的embeddings对于推荐任务并非有效。Discrete representations:目前存在多种将embeddings离散化的技术,包括VQ-VAE(《Neural discrete representation learning》)、VQ-GAN(《Taming transformers for high-resolution image synthesis》)、以及它们在生成式建模中的变体(例如,《Scaling autoregressive models for content-rich text-to-image generation》、《Soundstream: An end-to-end neural audio codec》)。TIGER模型(《Recommender systems with generative retrieval》)在recommender applications场景中使用了RQ-VAE。许多推荐模型采用了传统的量化技术,如
Product Quantization(《Product quantization for nearest neighbor search》)及其变体(例如,MGQE《Learning multi-granular quantized embeddings for large-vocab categorical features in recommender systems》和《Learning vector-quantized item representation for transferable sequential recommenders》)。
然而,这些技术不具备层次语义(
hierarchical semantics),而我们的研究正是利用了这一特性。
1.2 提出的方法
1.2.1 概述
给定
a corpus of items的content embeddings,与直接将embeddings用作input feature的方法不同,我们提出了一种高效的两阶段方法,以在下游推荐模型中利用content signal:Stage 1:将content embeddings高效压缩为discrete Semantic IDs。我们提出使用残差量化(Residual Quantization)技术(称为RQ-VAE)(《Recommender systems with generative retrieval》、《Autoregressive image generation using residual quantization》、《Soundstream: An end-to-end neural audio codec》),将dense content embeddings量化为discrete tokens,以捕获视频的语义信息(semantic information)。这种压缩至关重要,因为每个item可以被高效地表示为几个整数,而不是高维embeddings,从而能够高效地表示用户的历史行为。训练完成后,我们冻结trained RQ-VAE model,并在Stage 2中用于训练下游ranking model。Stage 2:使用Semantic IDs来训练ranking model。我们使用Stage 1训练好的模型将每个item映射到其对应的Semantic ID,然后训练Semantic ID的embeddings以及ranking model的其他部分。在实际场景中,ranking model通常使用最近logged data进行训练。
我们方案中的一个关键设计选择是训练
Stage 1的RQ-VAE model,然后将其冻结。frozen RQ-VAE model用于生成Semantic IDs,这些Semantic IDs被用于ranking model的training和serving。Recent data可能包含不在RQ-VAE model的training distribution中的items,这就引发了一个潜在问题:freezing the model可能会随着时间的推移影响ranking model的性能。如附录
A.2所述,我们分别对两种Semantic IDs对应的YouTube ranking models进行了分析:基于
older data来训练的RQ-VAE models所生成的Semantic IDs。基于
recent data来训练的RQ-VAE models所生成的Semantic IDs。
结果表明两者性能相当。这说明
learned semantic representations具有时间稳定性。
1.2.2 用于 Semantic ID 的 RQ-VAE
SIDs是通过残差量化变分自编码器(Residual-Quantized Variational AutoEncoder: RQ-VAE)(《Autoregressive image generation using residual quantization》、《Soundstream: An end-to-end neural audio codec》、《Recommender systems with generative retrieval》)从item content embeddings生成的。RQ-VAE在multiple levels上对残差(residuals)进行量化,如Figure 1所示。RQ-VAE包含三个联合训练的组件:(1):一个encodercontent embeddinga latent vector(2):一个具有levels的残差量化器(residual quantizer),每个level都有一个码本(codebook)codebook大小。quantizer在每个levelnearest codebook vector(3):一个解码器(decoder)quantized latentembedding space
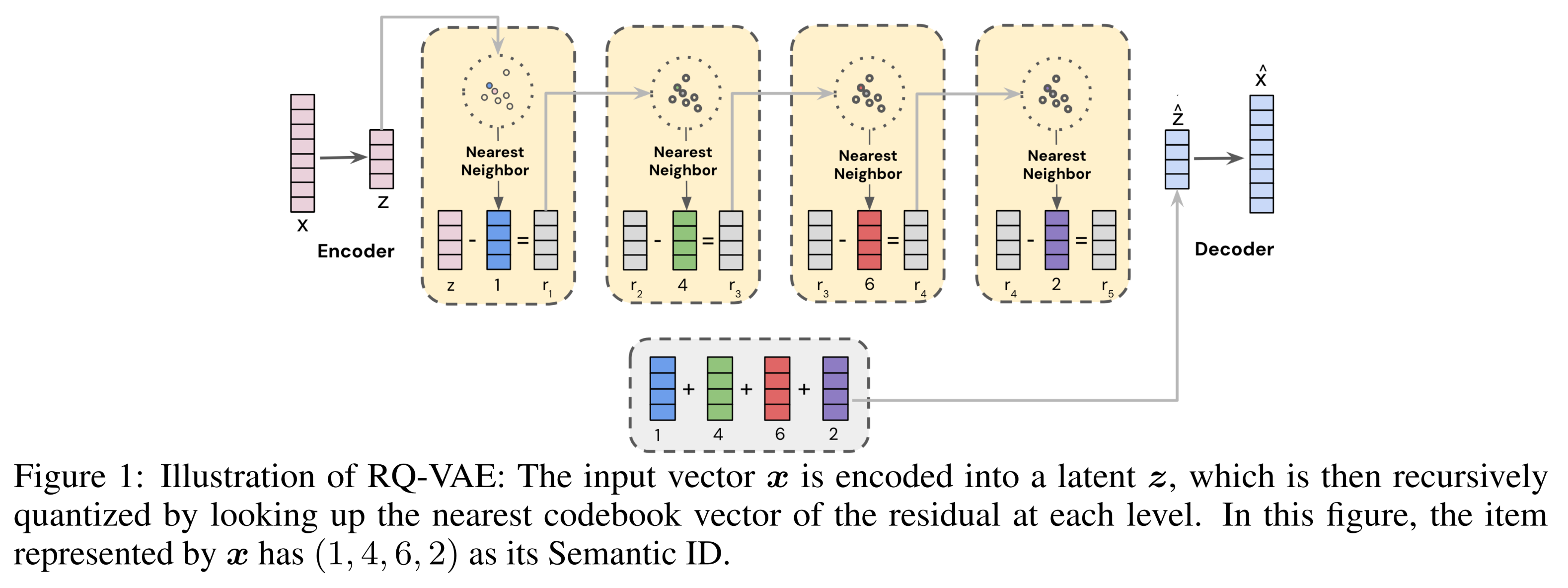
我们使用以下损失函数训练
RQ-VAE模型:其中:
stop-gradient算子。content embeddingencoder和codebook vectors进行训练,使得
1.2.3 Ranking Model 中的 Semantic ID Representation
本节将讨论如何对基于
SIDs的item representations进行建模,以用于ranking models。对于给定的iteman RQ-VAE model with L levels生成了一个SID,该SID是一个序列adaptation)的核心思想是:创建子词(subwords),从而将SID sequence哈希为多个learnable embeddings。我们提出了两种适配技术:N-gram-based:N-gram item representations利用SID codes,通过将其分组为长度为subwords。每个subword都与一个learnable embedding相关联,从而有效捕获N-gram内的语义关系(semantic relationships)。item representation通过对该item内所有N-gram subwords的embeddings求和来构建。例如:一个
unigram representation包含subwords,每个subword包含一个单独的code:具有
non-overlapping codes的一个bigram representation包含subwords,每个subword包含两个连续的codes:
为了将
learnable embeddings与这些N-gram-based subwords相关联,我们为每个subgroup学习一个独立的embedding table。由于每个code的基数为an N-gram group的embedding table包含embedding tables与ranking model的其他参数一起进行联合训练,使网络能够学习在ranking task背景下有效捕获semantic codes之间关系的representations。以
unigram representation为例,一共subwords,因此需要学习embedding tables。总的emebdding参数规模为VQ-Rec模型就是采用的N-gram-based方法,且SPM-based:虽然N-gram-based video representations提供了一种直接捕获Semantic ID中sequential codes之间关系的方法,但它们存在一些限制,影响了其有效性。首先,它们依赖于
predefined N-gram sizes的fixed grouping,这限制了其适应Semantic ID corpus的specific characteristics的能力,导致embedding table lookups的效果不佳。其次,
N-gram的embedding tables的行数随
这些挑战促使我们采用
SentencePiece Models: SPM(《Improving neural network translation models with multiple subword candidates》)对Semantic IDs进行适配。SPM为representing item content提供了一种更具适应性和高效性的解决方案。我们提出使用
SPM基于distribution of impressed items来动态学习Semantic ID subwords。这允许生成变长子词(dynamic length subwords),使得popular co-occuring codes被自动合并为一个subgroup,而很少共现的codes则可能退化为unigram。对于SPM-based representation,我们学习一个embedding table,其中每行对应一个特定的variable-length subpieces。通过在固定的embedding table size的情况下自适应地构建subword vocabularies,SPM vocabulary能够在generalization和memorization之间取得平衡。N-gram方法通过为每个subgroup使用独立的embedding table,能够捕获位置特定的语义;而SPM方法使用单一的embedding table,因此无法区分相同子词在不同位置的情况。但这并不一定是缺点,因为SPM方法在其他方面更有优势(如自适应长度、更好的泛化等)。
1.3 实验
Ranking Model:我们在一个multitask production ranking model(《Improving training stability for multitask ranking models in recommender systems》、《Recommending what video to watch next: A multitask ranking system》)上进行实验,该模型用于:给定用户当前观看的视频以及用户历史行为的基础上,推荐用户接下来要观看的视频。该模型使用O(10) million buckets进行随机哈希,以容纳corpus中的O(100) millions个视频,并使用logged data进行训练。在baseline中,random hashing of video IDs用于三个关键特征:用户的观看历史、当前观看的视频、以及待排序的候选视频。我们在trained model未见过的数据上评估所提出的方法,以了解video corpus的data-distribution shift情况下的性能。ranking models固有的scale和实时性要求使得embedding tables必须具备特定的特性,以确保高效且有效的性能。首先,
embedding table size需要能够轻松放入内存,这是我们在确定N-gram-based Semantic ID representations中embedding tables的行数随N-gram-based representations的分析限制在其次,
embedding lookups需要快速执行,从而对user requests提供近乎即时的responses。
我们的分析基于上述两个特性展开。
Content Embeddings:Semantic IDs是使用dense content embeddings来生成的。我们使用一个video encoder为每个YouTube视频生成dense content embeddings。该video encoder是一个基于Video-BERT(《Videobert: A joint model for video and language representation learning》)的Transformer模型,以音频特征和视觉特征作为输入,输出2048维的embeddings,该embeddings能够捕获视频的主题信息(topicality)。该模型采用《Large scale video representation learning via relational graph clustering》中描述的技术进行训练。Experimental Settings:我们将所提出的两种Semantic ID-based representations与两种baseline representation技术进行比较:直接使用原始
content embeddings,称为"Dense Input"。以及常用的
randomized hashed IDs,称为"Random Hashing"。
由于直接使用
dense input embeddings作为item representation无需embedding table parameters,为了进行公平比较,我们还为Dense Input方法引入了额外的baselines,将ranking model layers数量增加1.5倍和2倍,以研究增加model depth对ranking性能的影响。为了生成
Semantic IDs,我们使用depth,使得每个视频的Semantic ID包含8 codes。RQ-VAE的codebook size设置为评估指标:
ranking model使用前trained sequentially),其中每天的数据包含当天user interactions产生的logged data。我们使用第
CTR的AUC来评估模型性能。我们还在第new items上对该指标进行细分,称为CTR/1D。CTR AUC和CTR/1D AUC指标分别评估了模型由于数据分布偏移(data distribution shifts)和cold-start items带来的时间上的泛化能力。对于我们的ranking model而言,CTR AUC提升0.1%被认为是显著的。
1.3.1 Semantic ID 的性能
为用户观看历史中的每个视频存储
content embeddings非常消耗资源。因此,训练一个使用content embeddings来表示用户观看历史中每个视频的baseline large-scale ranking model是不可行的。为了更好地理解哪种representation方法性能更佳,我们考虑了ranking model的两种设置。在第一种设置中,我们将
SID-based representation与原始content embeddings和random hashing based ID进行比较,其中用户观看历史不作为输入特征(Figure 2)。在这种设置下,ranking model使用两种视频特征(即当前视频、候选视频)作为输入特征。在第二种设置中,我们使用用户的观看历史作为输入特征(以及当前视频和候选视频),并将
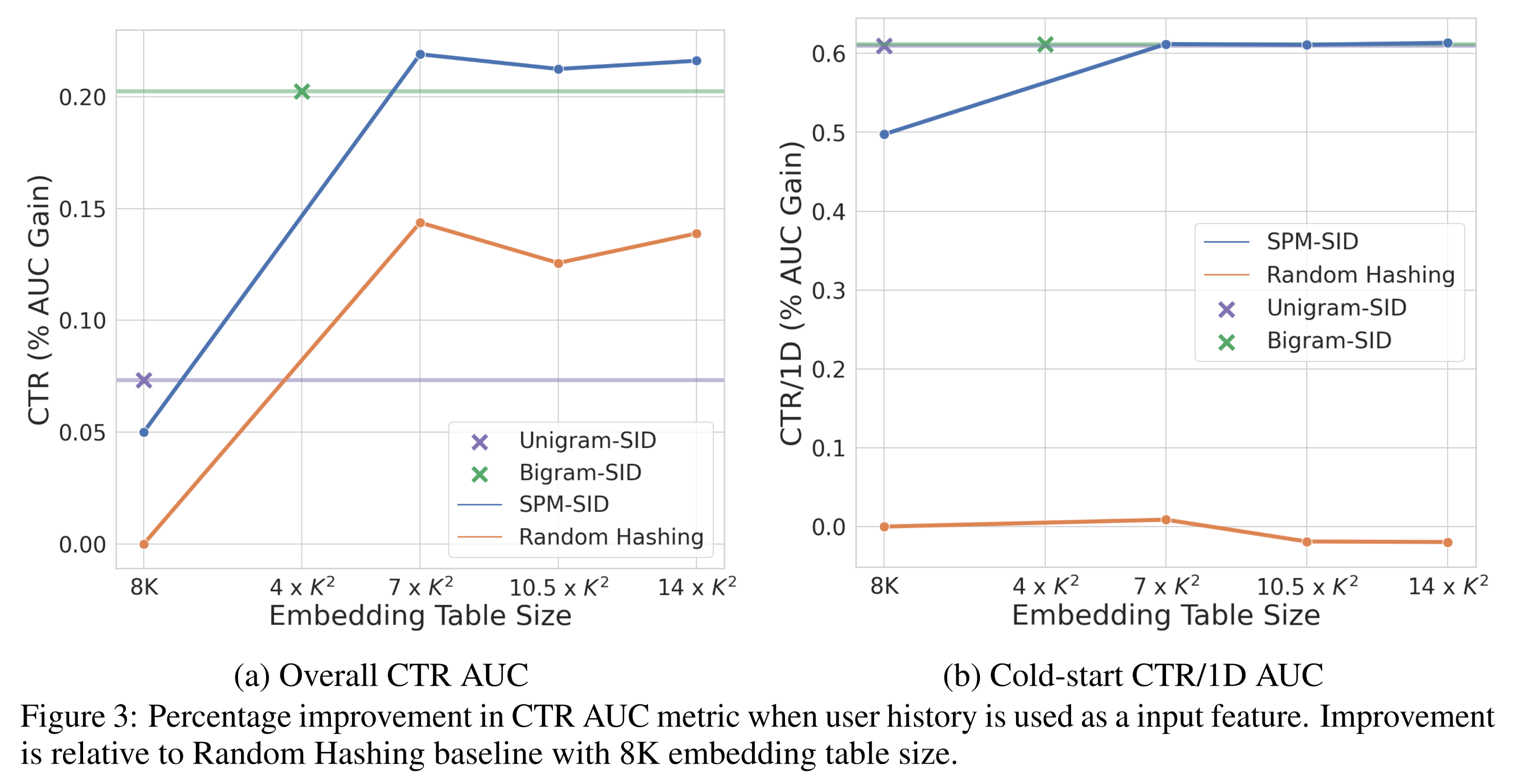
SID-based representation与random hashing based ID进行比较(Figure 3)。
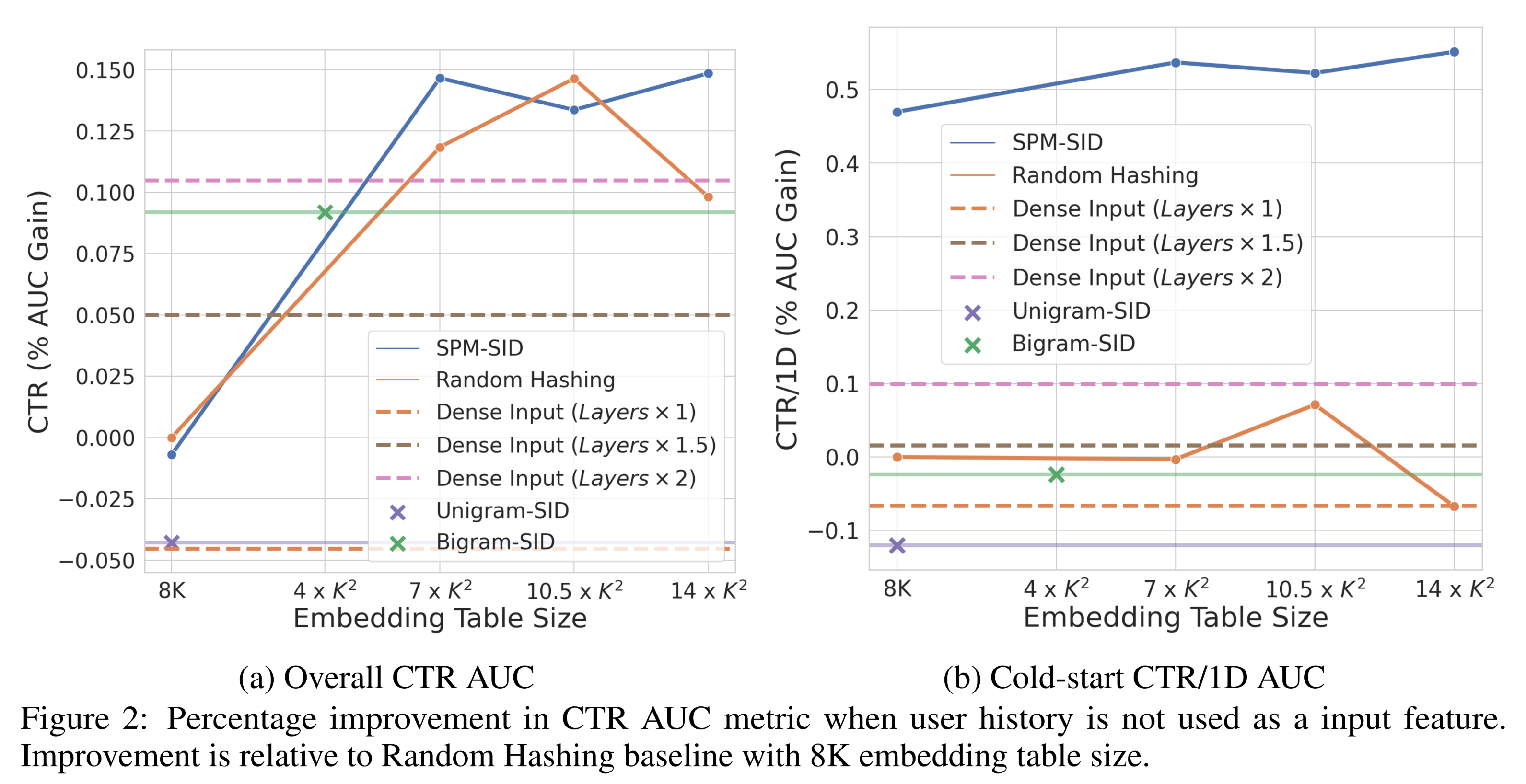
Dense Content Embedding vs. Random Hashing:我们观察到,在不对模型架构进行额外修改的情况下,直接使用content embeddings(Dense Input)替代random hashing-based IDs并不会带来更好的性能。如Figure 2a-2b,Dense Input baseline的性能不如video-ID based baseline。我们推测,ranking models严重依赖于来自ID-based embedding tables的memorization;用fixed dense content embeddings作为特征来替代embedding table会导致CTR变差。能否结合
fixed dense content embeddings和ID-based embedding tables?这两个特征可以互补:将它们拼接起来。作者并未尝试这个方法。为了验证这一假设,我们还进行了实验,将
ranking model的层数增加1.5倍或2倍,以提升Dense Input baseline的memorization能力。结果发现,与random hashing-baseline相比,增加depth确实提升了整体性能和cold-start items的性能。事实上,Dense Input Model with 2x layers的CTR提升高于Dense Input with 1.5x layers,这表明层数越多,memorization(Overall CTR)和generalization(cold-start CTR/1D)越好。然而,增加层数会导致serving成本大幅增加。如下文所述,SIDs能够保留原始content embeddings中的语义信息,同时通过learned embedding tables灵活高效地提供memorization。SID vs. Baselines:我们将两种类型的SID representations(N-gram和SPM)与baselines进行比较。其中,对于N-gram-SID,我们使用Unigram (N=1)和Bigram (N=2)。当使用N-gram时,embedding table size基于相应N-gram的所有可能组合,即Unigram-SID有Bigram-SID有我们发现:
当不将用户历史作为输入特征时,
Unigram-SID和Bigram-SID的overall CTR均低于Random Hashing(Figure 2)。这可能是由于训练数据中的内容分布不均衡,导致embedding table的sparse usage。而在random hashing中,由于视频被随机分配到embedding table中的embeddings,embeddings的使用是均匀的,因此不会出现这一问题。另一方面,当将用户历史作为输入特征时(
Figure 3),Unigram-SID和Bigram-SID的性能都明显优于random hashing,因为用户观看历史中的视频内容可能涵盖更多样化的内容,从而使得embedding table的使用更加均匀。
接下来,我们展示了
SPM-SID-based的视频representations带来的显著性能提升。当使用更大的
embedding tables时,SPM-SID始终优于N-gram representations,这一点在CTR/1D AUC指标的提升中尤为明显(见Figure 2b和Figure 3b),表明其对cold-start items具有更强的泛化能力。但对于较小的
embedding tables,我们观察到了一些细微的差异。具体而言,当embedding table size有限时(N-gram方法的性能略优于SPM-SID。这是因为在这些受限的table sizes下,SPM学到的subword vocabulary较小,可能无法充分捕获复杂的语义关系(semantic relationships)。
需要注意的是,对于大多数生产级
ranking models而言,大型embedding table是保证良好性能的必要条件。因此,SPM-SID based representation更适合大规模生产级ranking models。总体而言,在我们的大规模ranking models实验中,Bigram-SID和SPM-SID都显著优于random hashing,这突出了结构化表征(structured representations)在捕获语义关系、提升cold-start video recommendations方面的重要性。Efficiency in SPM-SID vs. N-gram-SID:与具有fixed embedding table sizes的N-gram SID representations不同,SPM-SID能够灵活适配给定的embedding table size。这种适配(adaptation)是通过直接基于训练数据构建的subwords来实现的。给定一个
fixed embedding table,SPM动态地生成subwords,每个subword映射到一个唯一的table entry。这在size constraint内优化了Semantic ID representation,提升了video representation的效率。此外,在
embedding table lookups方面,SPM-SID比N-gram-SID更优。我们在Figure 4中绘制了每个视频的embedding lookups次数与embedding table size的关系。该图突出了SPM的自适应特性:对于训练数据中的head/common videos,lookups次数动态减少,而平均lookups次数与N-gram中的fixed number of lookups相当。
SPM的这种自适应特性使其效率和可扩展性得到提升,使其更适合大规模ranking models。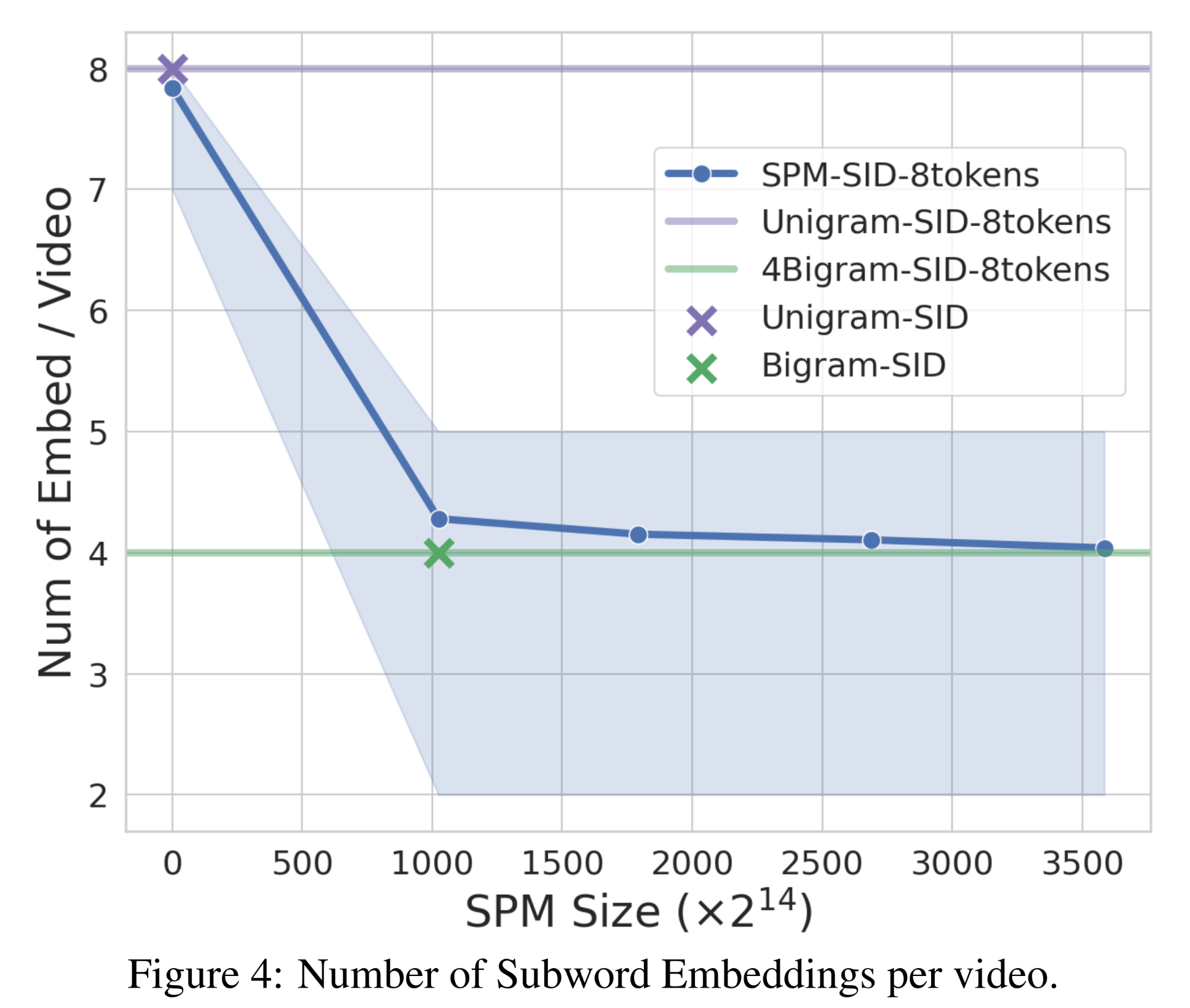
1.4 结论
本文旨在解决推荐模型中对广泛使用的
item IDs的依赖这一难题。我们以YouTube ranking model为例,探讨了在大规模生产级推荐模型中使用item ID features的弊端。利用RQ-VAE算法,我们从frozen content embeddings中为数十亿个YouTube视频生成Semantic IDs,以捕获corpus中语义丰富的hierarchical structures。我们提出并验证了Semantic IDs作为一种有效的替代video IDs的方法,通过引入有意义的冲突(collisions)来提升模型的泛化能力。
二、附录
2.1 附录 A
2.1.1 RQ-VAE 的 Training and Serving Setup
模型超参数:对于
RQ-VAE模型,我们使用一个1-layer encoder decoder model,维度为256。我们使用level的codebook sizeRQ-VAE Training:我们在随机采样的impressed videos上训练RQ-VAE模型,直到reconstruction loss稳定(对于我们的corpus,约为数千万steps)。已知
vector quantization技术在训练过程中会遇到码本崩溃(codebook collapse)问题(《Jukebox: A generative model for music》),即模型仅使用一小部分codebook vectors。为了解决这一挑战,我们在每个training step中将unused codebook vectors重置为batch中随机抽样的视频的content embeddings(《Soundstream: An end-to-end neural audio codec》),这显著提高了码本的利用率(codebook utilization)。我们使用training loss。训练完成后,我们冻结RQ-VAE模型,并使用encoder生成视频的Semantic IDs。RQ-VAE Serving/Inference:当新视频被添加到corpus中时,我们使用frozen RQ-VAE model生成其Semantic IDs。然后,Semantic IDs被存储并像其他用于ranking model的特征一样被served。
2.1.2 Semantic IDs 的时间稳定性
为了研究
Semantic IDs的稳定性,我们训练了两个RQ-VAE模型:RQ-VAE_v0和RQ-VAE_v1,使用的数据相隔6个月。Figure 5显示,使用最近的engagement data所训练的production ranking model(使用SID-3Bigram-sum),其性能在基于RQ-VAE_v0和RQ-VAE_v生成的Semantic IDs上是相当的。这证实了通过RQ-VAE学到的视频的semantic token space在下游production ranking model中具有时间稳定性。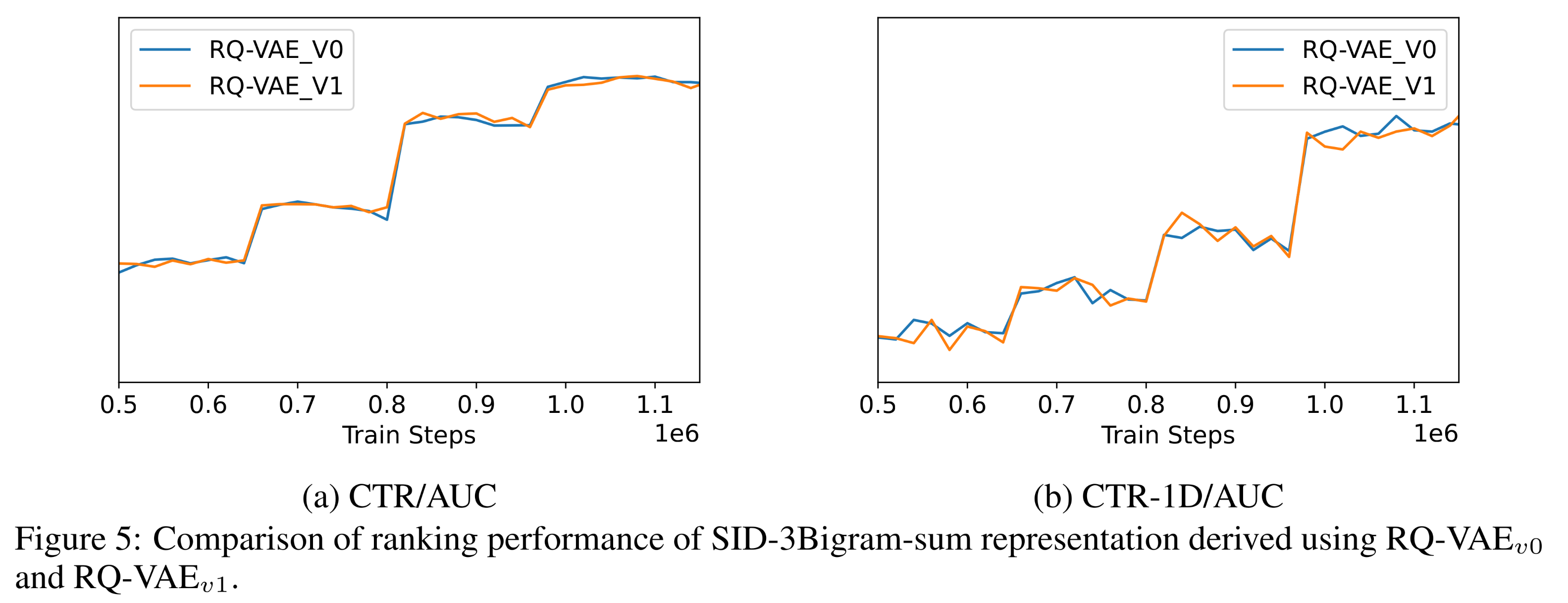
2.1.3 作为 Hierarchy Of Concepts 的 Semantic IDs
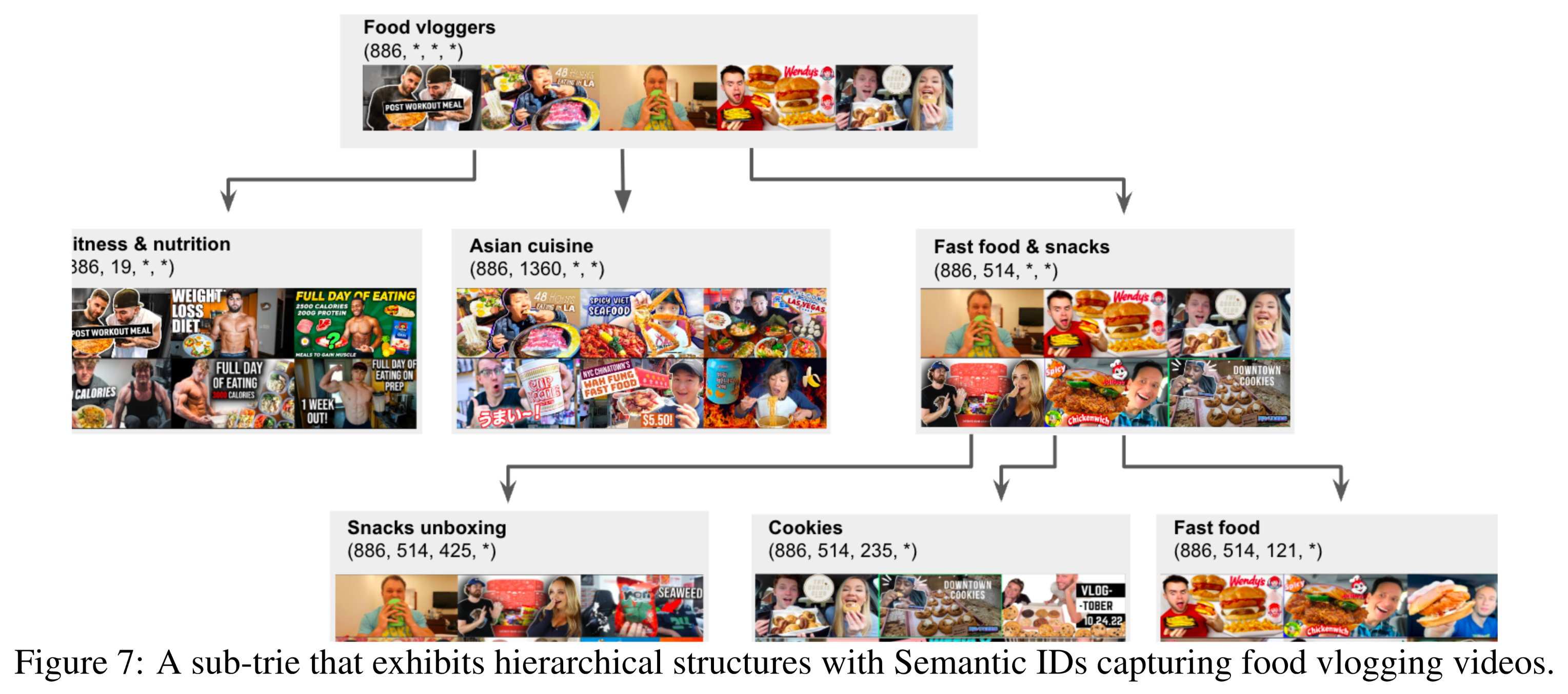
我们展示了
corpus中视频的Semantic IDs所捕获的概念层级结构(hierarchy of concepts)。实验章节详细介绍了用于训练RQ-VAE模型的超参数。直观地说,我们可以将Semantic IDs视为视频上的一个trie树,其中higher levels代表较粗粒度的概念、lower levels代表较细粒度的概念。Figure 6和Figure 7展示了我们训练的RQ-VAE模型中两个包含4 tokens的sub-tries示例,它们分别捕获了体育(sports)和美食(food)vlog视频中的概念层级结构。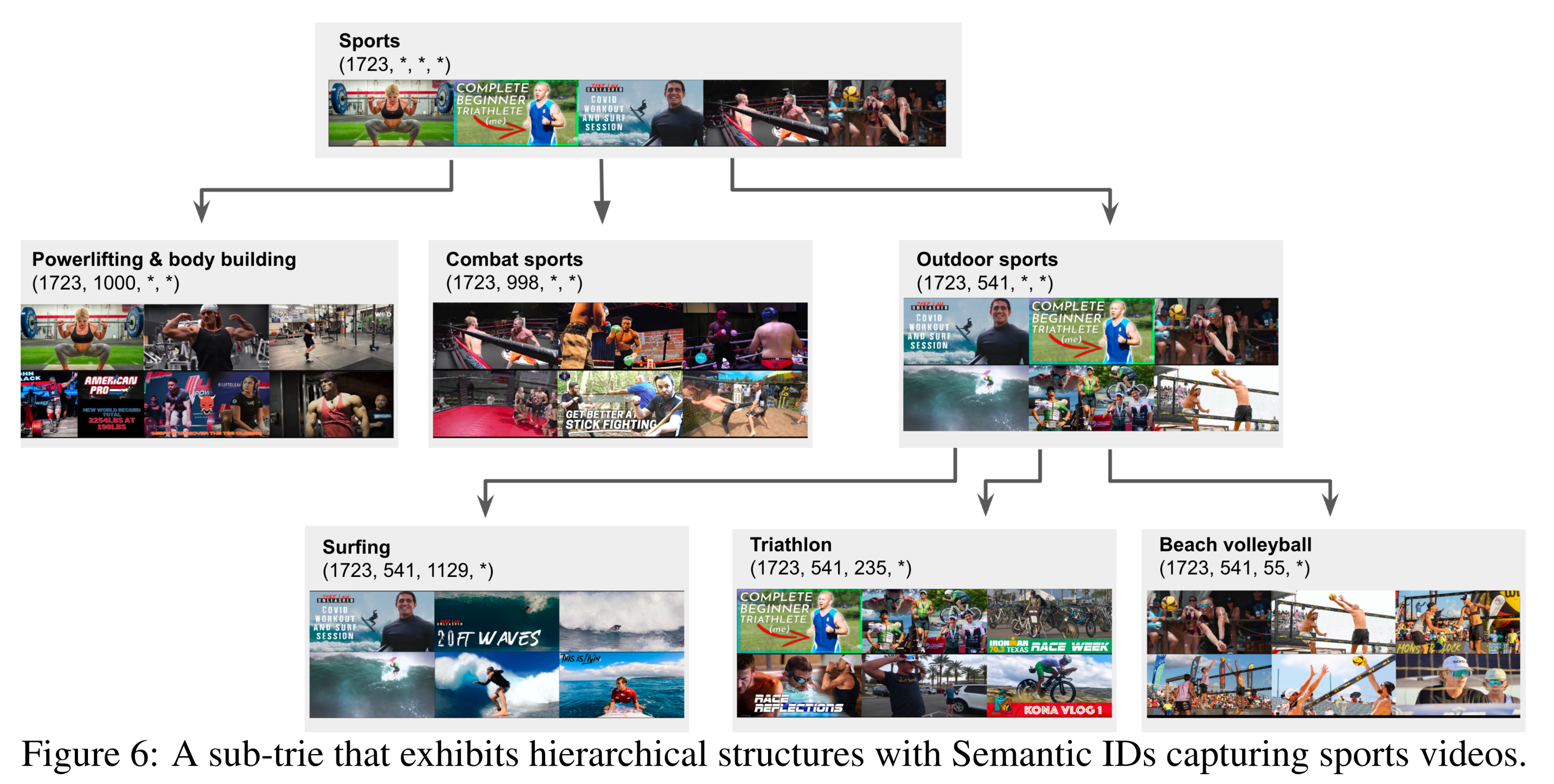
2.1.4 Semantic ID 的相似性分析
Table 1显示了满足条件的所有视频在content embedding space中的pairwise cosine similarity的均值、以及它们对应的sub-trie sizes:这些视频具有长度为shared Semantic ID prefix。我们考虑Semantic IDs分别为(1, 2, 3, 4)和(1, 2, 6, 7)的两个视频,它们shared prefix长度为2。我们观察到,随着
shared prefix length的增加,平均pairwise cosine similarity增加,而sub-trie size减小。这表明,随着Semantic ID prefixes长度的增加,它们所代表的概念粒度(granular concepts)越来越细。