一、HoME [2025]
《HoME: Hierarchy of Multi-Gate Experts for Multi-Task Learning at Kuaishou》
本文介绍了
Kuaishou短视频业务中遇到的实际问题及经验教训。在工业界,混合专家(Mixture-of-Experts: MoE)范式是一种广泛应用的多任务学习框架,该框架通常为每个任务引入一些shared experts和一些specific experts,再通过门控网络(gate network)衡量related experts的贡献度。尽管MoE取得了显著的性能提升,但在迭代过程中我们发现了三个严重影响模型性能的异常现象:(1)专家崩溃(Expert Collapse):我们发现experts的输出分布(output distributions)存在显著的差异,某些experts使用ReLU激活函数时zero activations比例超过90%,导致gate networks难以分配公平的权重(fair weights)以平衡各个experts。即,某个
expert能力退化为零。(2)专家退化(Expert Degradation):理想情况下,shared-expert应同时为所有任务提供predictive information。但我们发现:某些shared-experts仅被单个任务所占用,这表明shared-experts丧失了其共享能力,退化为specific-experts。即,某个
shared expert被某个任务独占。(3)专家欠拟合(Expert Underfitting):在我们的业务场景中,需要预测数十种任务,但发现某些data-sparse的预测任务往往忽略其specific-experts,而将较大权重分配给shared-experts。其原因可能是shared-experts能从data-dense任务中获得更多梯度更新和知识,而specific-experts由于数据稀疏,容易陷入欠拟合状态。即,某个任务仅仅依赖于某些
shared experts。
基于上述观察,我们提出了
Hierarchy of Multi-Gate Experts: HoME模型,旨在构建一个简单、高效的、且平衡的MoE系统从而用于多任务学习(multi-task learning)。具体而言,我们进行了三项具有洞察力的改进:(1):专家归一化与Swish机制(Expert normalization & Swish mechanism),用于对齐expert output distributions,避免专家崩溃(expert collapse)。(2):层次掩码机制(Hierarchy mask mechanism),提升任务间的共享效率,减少shared-experts occupancy问题,避免专家退化(expert degradation)。所谓的层次掩码,就是引入
category-shared experts,从而有三组experts:global-shared experts, category-shared experts, task-specific experts。(3):特征门控与自门控机制(Feature-gate & Self-gate mechanisms),确保每个experts都能获得适当的梯度,以最大化其效用。
据我们所知,本文是首个专注于提升多任务
MoE系统稳定性的研究工作。我们通过大量离线和在线实验(离线GAUC平均提升0.52%,在线play-time per user提升0.954%)及消融分析,验证了HoME的有效性。目前,HoME已部署在Kuaishou短视频业务中,每日服务400 million用户。近年来,抖音(
Tiktok)、 快手(Kuaishou)等短视频应用发展迅速。对于其他平台,用户具有明确的意图;例如,用户在谷歌(Google)上会输入关键词搜索,在亚马逊(Amazon)上会购买服装、食品等。而与这些平台不同,Kuaishou主要承担娱乐功能,用户无需输入任何概念性信息(concept inputs)。如Figure 1所示,用户使用Kuaishou时,通常只需在屏幕上上下滑动,即可连续观看多个自动播放的短视频;有时还会进行一些互动(interactions),例如长时间观看(Long-view)、评论(Comment)等。在该场景中,隐式反馈(implicit feedback)的占比远高于其他场景。因此,Kuaishou能够发展成为拥有全球400 million用户的大型应用,其核心原因在于我们的系统能够提供个性化的、有趣的短视频内容,为用户带来满意的体验。为此,充分利用由用户留下的稀少但多样的行为线索(behavior cues),精准捕获用户兴趣,是我们的核心任务。通常,业界普遍采用多任务学习(multi-task learning)范式来构建模型,该模型能够同时输出用户不同interactions的预测概率,并通过真实的用户行为日志进行监督训练。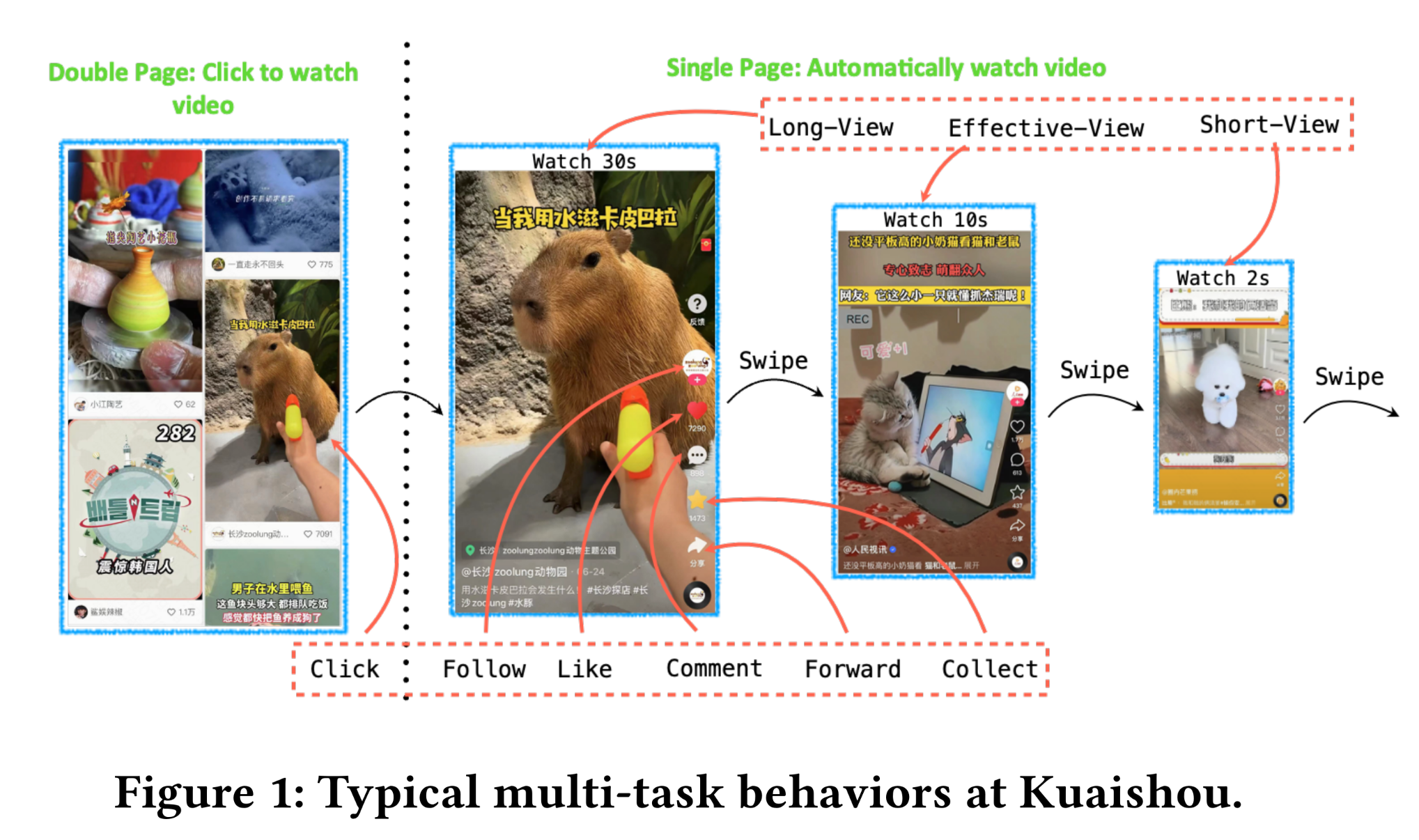
作为一种典型的多任务解决方案,
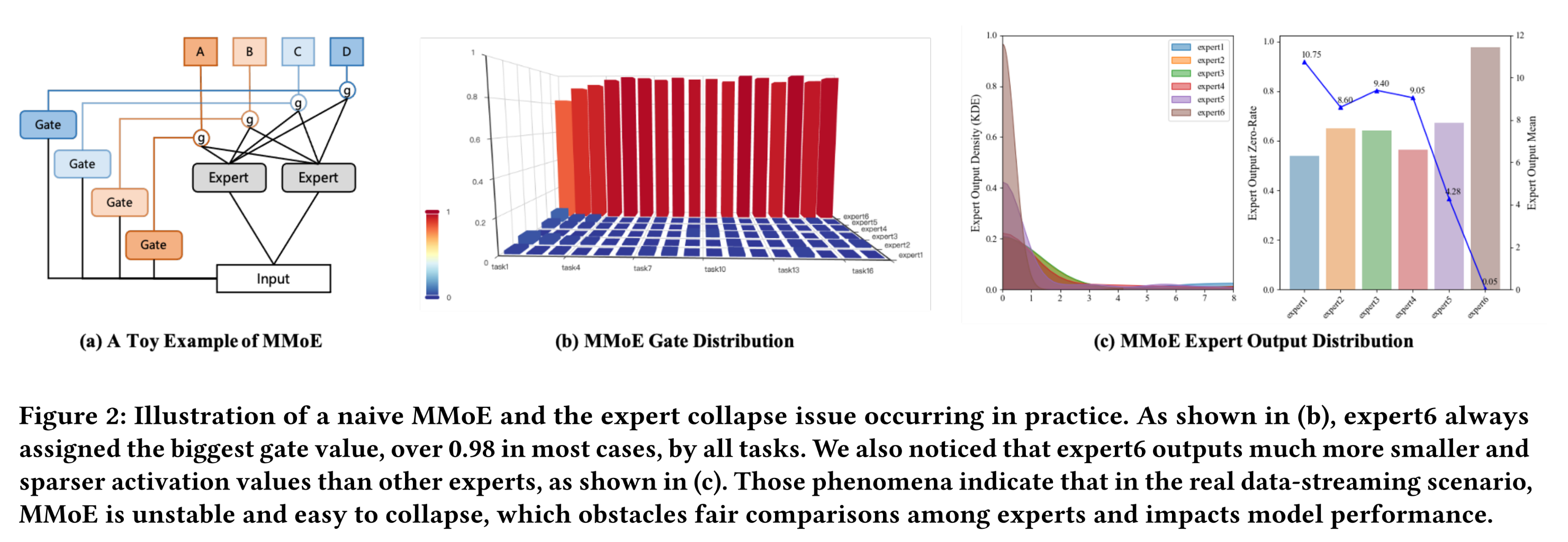
MoE的思想在工业界被广泛用于实现参数软共享(parameter soft-sharing)。其中最著名的方法是多门混合专家(Multi-gate Mixture-of-Experts: MMoE)(《Modeling Task Relationships in Multi-task Learning with Multi-gate Mixture-of-Experts》),该方法由两个核心组件构成(如Figure 2(a)所示):专家网络(
Expert Networks):一组expert networks(例如MLP with ReLU),用于建模input features和implicit high-level feature crossing,从而得到multiple representations。门控网络(
Gate Networks):task-specific gate networks(例如MLP with Softmax),用于评估不同experts的重要性,进而针对相应的任务来融合experts' outputs。
近年来,已有多项研究通过引入
task-specific experts(例如CGC《Progressive Layered Extraction (PLE): A Novel Multi-Task Learning (MTL) Model for Personalized Recommendations》)、或堆叠更多experts layers(例如PLE《Progressive Layered Extraction (PLE): A Novel Multi-Task Learning (MTL) Model for Personalized Recommendations》、AdaTT《AdaTT: Adaptive Task-to-Task Fusion Network for Multitask Learning in Recommendations》)等方式扩展expert networks,以增强MMoE系统的能力。Kuaishou此前的在线多任务模块采用的正是MMoE,与baseline模型相比,其A/B test指标取得了显著提升。然而,在部署MMoE后的几年里,我们尝试对multi-task modeling模块进行了多种修改;但均以失败告终,包括升级为two or more expert layers、增加更多shared-experts、引入额外的specific-experts等。因此,我们开始进行深入分析,以找出阻碍模型迭代的潜在原因。不出所料,我们发现了三个严重影响多任务性能的异常现象。专家崩溃(
Expert Collapse):我们首先检查了
MMoE的gate output情况,并在Figure 2(b)中展示了major tasks对6 shared-experts所分配的gate weight。可以明显看出,所有gates都将更大的权重分配给了shared-expert 6,而几乎忽略了其他shared-experts。随后,我们检查了
shared experts的output value distribution,发现它们存在显著差异。如Figure 2(c)所示,experts 1∼5的均值和方差处于相近水平,但expert 6的均值仅为其他experts的1/100。这种不一致的output distributions导致gate network难以分配公平的权重(fair weights)来平衡不同experts,进而使得处于不同数值水平(numerical levels)的experts相互排斥。此外,我们还发现
expert output存在过多的0 activations(即超过90%的output为0),导致其平均导数较小,参数训练不充分。
专家退化(
Expert Degradation):在解决了上述严重的expert collapse问题后,我们成功将多任务模块升级为一种shared-specific MoE变体——CGC。因此,我们好奇gating weights是否能达到预期效果,即所有task gate networks都能为shared-experts和specific-experts分配可感知的分数(perceivable scores),以实现平衡状态。不幸的是,我们发现了另一种意想不到的
expert degradation现象(如Figure 3所示)。图中展示了某些major towers的gating机制的平均得分。我们观察到:shared-expert几乎无法为所有任务做出贡献,而是退化为仅属于少数任务的specific-expert。因此,这一观察结果表明,naive shared and specific experts的架构难以收敛到理想状态。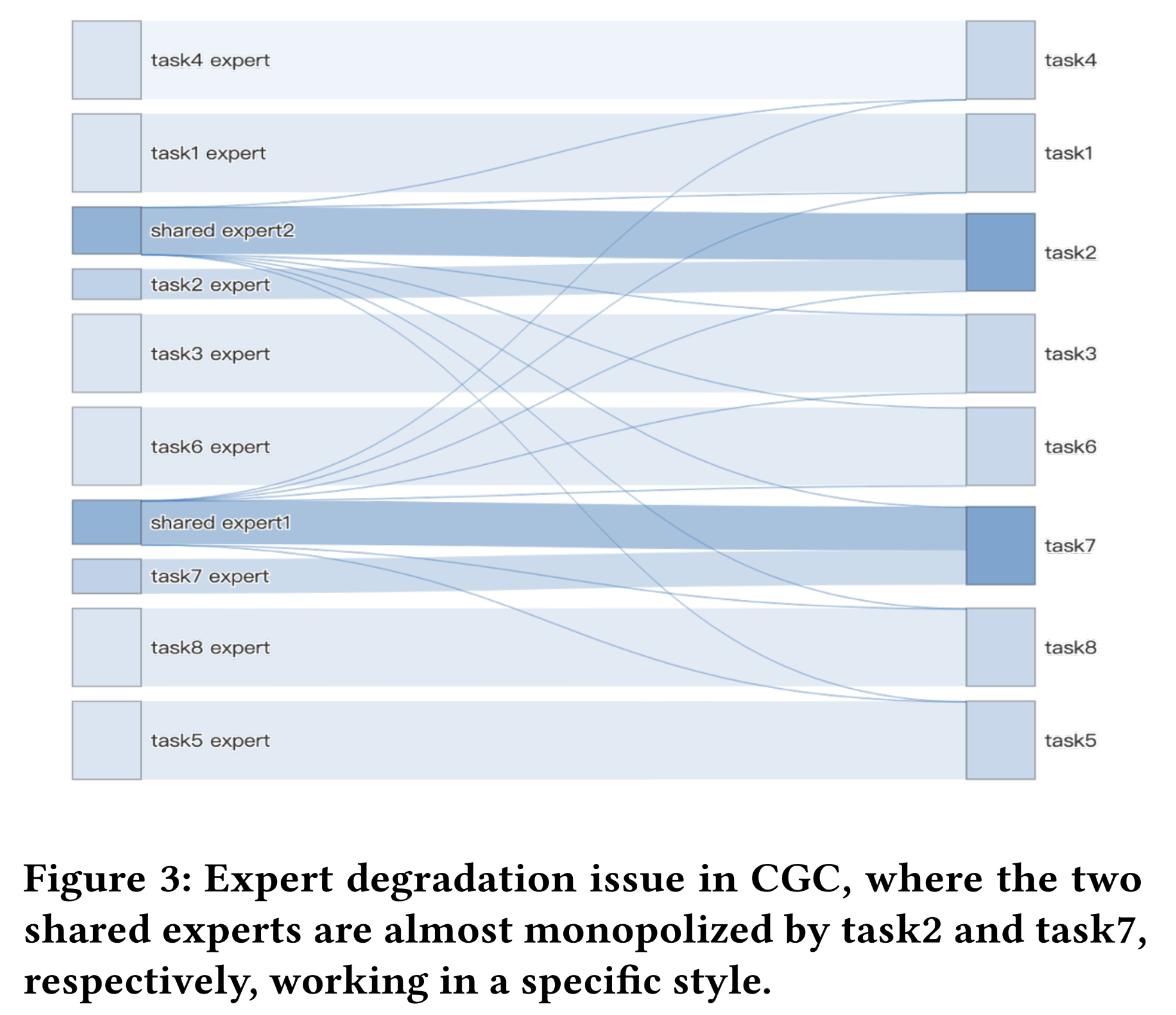
专家欠拟合(
Expert Underfitting):在进一步解决了expert degradation问题并提升了shared-experts对所有任务的效用后,我们发现某些specific-experts被分配到的gate value较小,导致对应任务仅依赖共享的知识(shared knowledge),而较少利用specific parameters。实际上,我们的模型需要同时预测数十种不同的任务,这些任务的数据密度(即正样本率)差异极大。
dense tasks的正样本率可能是sparse tasks的100倍,例如点击(Click)与收藏(Collect)任务。与能够从多个dense tasks中获得多次梯度更新的shared-experts相比,specific-experts容易陷入欠拟合状态;进而导致sparse task更多地依赖shared-experts,而忽略该任务的specific-experts,造成specific parameters的浪费。如Figure 4所示,task 6的gate network为shared-experts分配了较大的权重,而忽略了该任务的specific-experts。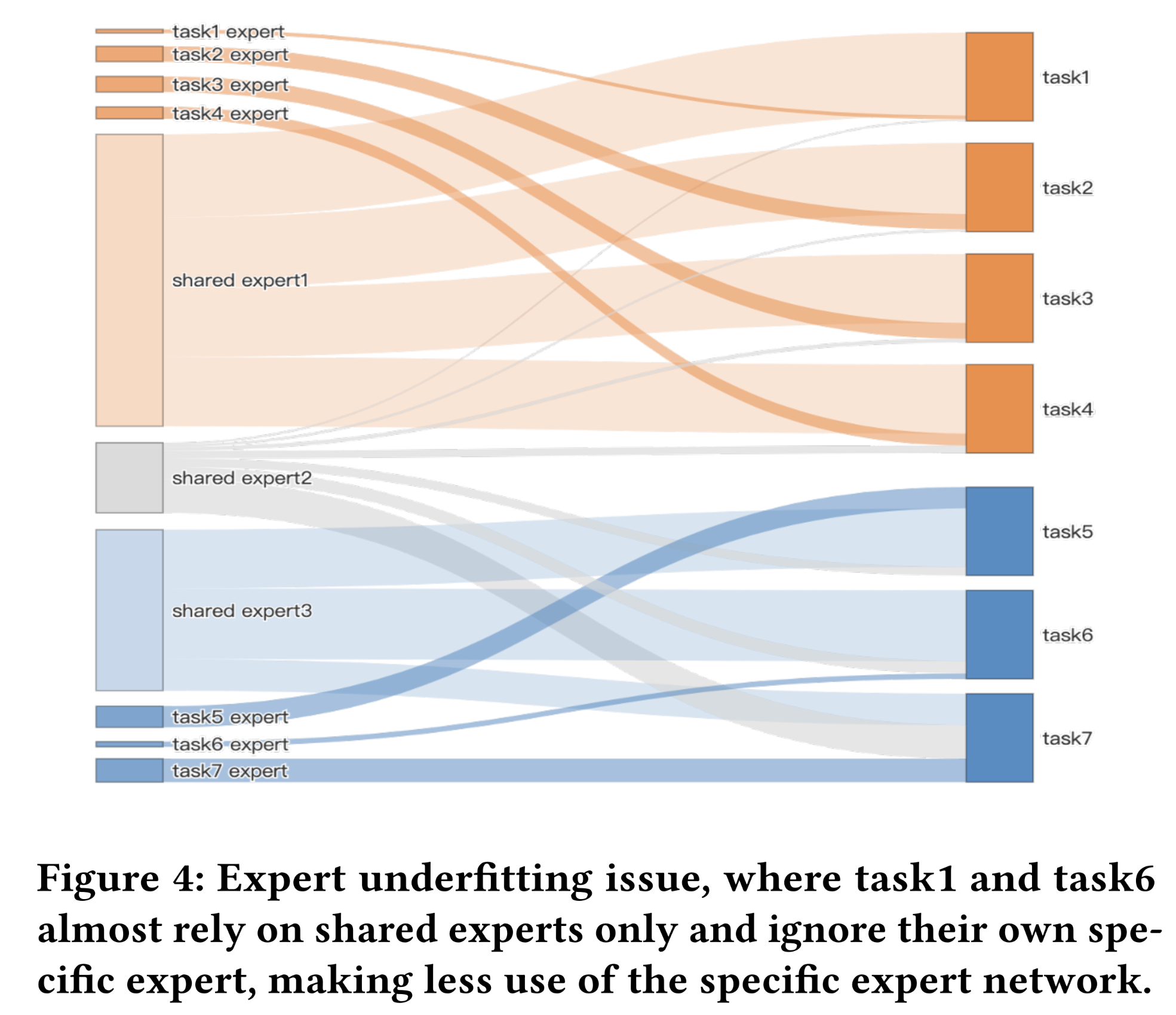
为了解决这些异常现象并提升
MoE范式的模型稳定性,我们提出了一种简单、高效的且平衡的神经网络架构用于多任务学习——Hierarchy of Multi-gate Experts: HoME。具体而言,我们从三个角度提供了具有洞察力和深度的解决方案:value distribution alignment用于实现公平的expert weights,hierarchy meta expert structure用于重新组合任务(re-assemble tasks),gate networks用于提升sparse task expert and deep multi-layer MMoE training:专家归一化与
Swish机制(Expert normalization & Swish mechanism):为了平衡experts outputs的方差并避免expert collapse,我们首先为每个expert引入了归一化操作,将expert output投影到近似正态分布;即,expert outputs distribution近似于标准正态分布然而,在这种设置下,我们发现直接进行归一化后,后续
ReLU函数的输出中仍会出现过多的零值。这可能是因为normalized expert output的均值接近0,因此有一半的outputs会小于0,从而在ReLU激活函数之后变为0。为了缓解梯度为零的现象,我们使用Swish函数替代ReLU函数,以提高参数利用率并加速训练过程。通过归一化和Swish函数的组合设置,所有experts的输出能够对齐到相似的数值量级(numerical magnitude),这有助于gate network分配具有可比性的权重。层次掩码机制(
Hierarchy mask mechanism):为了减少expert occupancy问题并避免expert degradation(也称为任务冲突跷跷板问题task conflict seesaw issue),本文提出了一种简单有效的级联层次掩码(cascading hierarchy mask)机制来缓解此类冲突。具体而言,我们插入了一个前置的元专家网络(
pre-order meta expert network)对不同任务进行分组,以扩展标准的MoE系统。如Figure 1所示,根据任务的先验相关性(prior relevance),我们可以将Kuaishou的短视频行为任务(short-video behaviors tasks)手动分为两个元类别(meta categories):(1):被动观看时长类任务(passive watching-time tasks),例如长时间观看(Long-view)。(2):主动互动类任务(proactive interaction tasks),例如评论(Comment)。
因此,我们可以先建模粗粒度的元类别专家(
meta-category experts),然后通过以下思路为每个任务提供支持:每个任务不仅应拥有完全共享的global experts,还应拥有category内部共享的in-category experts。其实就是在
task-specific experts、global-share experts这两种experts中再添加一种in-category experts。特征门控与自门控机制(
Feature-gate&Self-gate mechanisms):为了增强sparse-task experts的训练效果,我们提出了两种gate机制,以确保它们能获得适当的梯度,从而最大化其效用:特征门控(feature-gate)和自门控(self-gate)机制。考虑到
the same layer experts通常共享相同的input features,但不同experts会接收不同的梯度,因此相同的feature input可能会给multiple expert parameter optimization带来梯度冲突(gradient conflicts)的潜在风险。为此,我们首先提出feature-gate机制,为experts生成私有化的灵活输入,以保护sparse-task expert的训练。此外,最新的
MoE研究表明,堆叠更深的expert networks能够带来更强的预测能力。然而,在我们的实验中发现,原始的gate network容易逐层地稀释梯度,这对sparse-task expert的训练不利。我们进一步设计了self-gate,以残差方式连接相邻的related experts,以确保top layers gradient能够有效传递到底层并且稳定deeper MMoE system training。
本文的主要贡献如下:
深入分析了当前
MoE系统存在的expert issues,并提出了具有里程碑意义的HoME模型。据我们所知,本文是首个专注于增强多任务MoE系统稳定性的研究,为其他研究者探索更稳健的多任务MoE系统提供了思路。在
Kuaishou短视频业务中进行了大量离线和在线实验。离线实验表明,所有预测任务的性能都得到了显著提升;在线实验中,Kuaishou and Kuaishou-Lite applications的用户播放时长分别提升了0.636%和0.735%。HoME已在Kuaishou的多个业务中广泛部署,每日支持400 million活跃用户。
1.1 相关工作
本节简要回顾多任务学习(
multi-task learning)的发展历程。多任务学习在多个研究领域中发挥着越来越重要的作用,助力模型感知多种信号,包括推荐系统、自然语言处理、计算机视觉、以及普适计算(ubiquitous computing)等。早期的一些研究工作利用了
hard expert sharing架构,该架构包含多个task-specific towers,这些towers由相同的expert output作为输入,从而实现了最简单的多任务学习系统。,包括shared-bottom(《Multitask Learning》)、mixture-of-expert: MoE(《Adaptive Mixtures of Local Experts》)等。之后,
cross-stitch network(《Cross-Stitch Networks for Multi-Task Learning》)和sluice network(《Sluice Networks: Learning What to Share Between Loosely Related Tasks》)被提出,用于构建deep expert information fusion network来生成task-specific inputs,以实现soft expert knowledge sharing。除了复杂的纵向的
deep expert crossing之外,横向的expert weight estimating是另一种定制task-specific tower input的方法。近年来提出的multi-gate mixture-of-expert: MMoE(《Modeling Task Relationships in Multi-task Learning with Multi-gate Mixture-of-Experts》)采用multi-gate机制,为不同experts分配不同权重,以平衡不同任务。
随着基于神经网络的推荐系统兴起,
MMoE变体方法在提升模型能力和准确性方面也发挥了重要作用。代表性工作来自
YouTube的ranking系统(《Recommending What Video to Watch Next: A Multitask Ranking System》),该系统通过不同的gating networks利用多个shared experts,建模real user-item interactions。为了缓解任务冲突的跷跷板问题,
MMoE变体CGC(《Progres-sive Layered Extraction (PLE): A Novel Multi-Task Learning (MTL) Model for Personalized Recommendations》)和PLE(《Progres-sive Layered Extraction (PLE): A Novel Multi-Task Learning (MTL) Model for Personalized Recommendations》)不仅利用shared-experts,还引入了额外的specific-experts,以实现更灵活的expert sharing。基于
shared-/specific-experts的思想,已有大量MMoE变体被提出,包括:MSSM(《MSSM: A Multiple-level Sparse Sharing Model for Efficient Multi-Task Learning》)通过采用field-level and cell-level特征选择机制,扩展了PLE方法,能够自动确定input features的重要性。AdaTT(《AdaTT: Adaptive Task-to-Task Fusion Network for Multitask Learning in Recommendations》)在PLE的基础上利用自适应融合门控机制(adaptive fusion gate mechanism),建模specific-expert and shared-expert之间复杂的任务关系。STAR(《One Model to Serve All: Star Topology Adaptive Recommender for Multi-Domain CTR Prediction》)采用星形拓扑结构,包含一个shared expert network和多个specific expert networks,用于融合expert parameters。MoLA(《Exploring Training on Heterogeneous Data with Mixture of Low-rank Adapters》)借鉴了大语言模型(LLM)中的低秩微调技术(low-rank fine-tuning technique),设计了轻量级的low-rank specific-expert adapters,以替代复杂的specific-expert。
1.2 方法论
本节将介绍我们的模型
HoME的组成部分。首先,我们回顾
MoE系统在工业级推荐系统(RecSys)中的工作原理,包括feature engineering、MoE神经网络细节、以及prediction scores。随后,我们将详细阐述针对三个问题的解决方案:
用于克服专家崩溃问题(
expert collapse issue)的expert normalization & swish机制。用于缓解专家退化问题(
expert degradation issue)的hierarchy mask机制。用于解决专家欠拟合问题(
expert underfitting issue)的两种门控机制。
1.2.1 预备知识:工业级推荐系统中的多任务学习
工业级推荐系统通常采用两阶段设计:
(1):生成数百个candidate items。(2):对所生成的candidate items进行排序,从而筛选出数十个最优items来推荐给用户。
由于这两个阶段的目标不同,所采用的技术也完全不同:
candidate generation阶段侧重于user-side feature modeling,以及粗粒度的item sampling。ranking阶段侧重于user and item feature fusion,以及细粒度的user multi-interaction fitting。
因此,多任务学习模型(
multi-task learning model)通常应用于ranking阶段,用于估计a specific user-item pair的各种interactions的概率。为简洁起见,model-generated的概率通常有简称(xtr),例如点击概率(ctr)、有效观看概率(evtr)、点赞概率(ltr)、评论概率(cmtr)等。Label&Feature:形式上,这种ranking learning过程通常组织为多个二分类任务,每个learning user-item samples包含两类信息——supervised label和input features:监督信号(
Supervised Signals):user-item观看体验的真实标签,例如点击特征输入(
Feature Inputs):MoE的输入旨在从多个角度描述user和item的状态,大致可分为四类:(1):ID and category features,通过直接lookup操作获取其embeddings向量,例如user ID、item ID、tag ID、is active user、is follow author、Scenario ID等等。(2):统计特征,需要设计分桶策略(bucketing strategies)将其离散化并分配ID,例如过去一个月观看短视频的数量、过去一个月的短视频观看时长等等。(3):反映用户短期兴趣和长期兴趣的序列特征,通常采用one-stage或two-stage注意力机制来建模,例如DIN、DIEN、SIM、TWIN等等;(4):pre-trained的多模态embeddings向量,例如text embedding、asr embeddings、video embedding等等。
综合以上所有特征,我们可以得到
multi-task training samples。例如标签为inputs为Mixture-of-Experts for XTR prediction:给定training user-item sample的标签shared/specific experts范式MoE变体CGC为例,详细介绍其原理:其中:
ReLU-activated shared experts networks;ReLU-activated specific experts networks。input features数量,expert output size。Softmax-activated gate network用于对应的任务;related shared and specific experts总数。gate-generated weights来聚合experts的输出。Sigmoid-activated task-specific network,用于衡量对应的interaction probabilitytower network、expert network、gating network的MLP。
在得到所有
estimated scoresmulti-task learning model:注意:这里对每个任务的
loss采用等权重的融合。也可以对不同任务采用不同的loss weight:其中:
loss weight。在
online serving中,一个常见的操作是设计一个可控的复杂方程,将多个XTR组合为一个ranking score:其中:
这里是加法融合。也可以采用乘法融合:
实际上,在工业级推荐系统中,
ranking-score非常复杂,包含多种策略,此处仅展示一个简化示例。在后续章节中,我们将重点关注公式multi-task learning过程,以提升其稳定性。
1.2.2 Expert Normalization & Swish Mechanism
尽管公式
MMoE系统取得了显著的性能提升,但仍存在严重的expert collapse问题。设experts的MLP_E函数所生成的representation为Transformer的启发,归一化操作是成功支持训练very deep神经网络的关键技术之一。我们同样为每个expert引入batch normalization,使HoME能够生成具有可比性的输出其中:
experts的MLP_E output。scale参数和bias参数,用于调整distribution。batch中same expert的输出的均值和方差。
经过
expert normalization后,0,在ReLU激活函数后变为0,使其梯度均为0,阻碍模型收敛。因此,我们使用Swish函数替代Expert函数中的ReLU激活函数,得到HoME Expert:其中:
HoMEExpert(·)就是HoME中使用的final structures。通过归一化和
Swish函数的组合设置,所有experts的输出能够对齐到相似的数值量级,这有助于gate network分配具有可比性的权重。为简洁起见,在后续章节中,我们仍使用Expert(·)表示HoMEExpert(·)。
1.2.3 Hierarchy Mask Mechanism
针对
expert degradation问题,已有一系列研究通过引入新颖的specific-expert架构和shared-expert架构来缓解任务冲突。然而,遵循specific and shared experts范式,我们发现shared expert degradation问题仍然存在。我们认为,考虑先验的任务相关性(prior task relevance)可能会有所帮助。如Figure 1所示,我们可以将prediction task分为两类,例如主动互动类任务(如点赞、评论等)和被动观看时长类任务(如有效观看、长时间观看等)。本节提出了一种简单有效的级联层次掩码机制(cascading hierarchy mask mechanism),用于建模任务之间的先验归纳偏置(prior inductive bias)。具体而言,我们插入了一个前置的元专家网络(
pre-order meta expert network)对不同任务进行分组,其中包含三种元任务知识(meta-task knowledge),以支持两类任务:其中:
macro-level meta representation),分别用于提取:(1)互动类任务的类别内知识;(2)观看时长类任务的类别内知识;(3)共享的知识。Swish-activated shared experts networks。Softmax-activated gate network用于对应的任务;experts总数。gate-generated weights来聚合experts的输出。
获得这些
meta representations后,我们根据其对应的meta knowledge和shared meta knowledge进行多任务预测。具体而言,我们利用meta knowledge构建三种类型的experts:(1):基于globally shared experts。(2):基于locally shared experts。(3):基于specific experts。
对于
task-specific gate networks,我们直接使用shared meta knowledgemeta knowledge的拼接结果来生成weights of experts。此处以点击(Click)和有效观看(Effective-view)这两个任务为例:其中:
shared experts;interaction类别内任务的shared experts;watch类别内任务的shared experts;ctr任务的task-specific experts。
这里是两层的
MMoE:第一层根据原始输入
meta representationsMMOE完全相同。第二层根据
meta representations来获取prediction。gating network的输入不是shared meta knowledge + category meta knowledge。gating network聚合的experts有:global shared experts、category shared experts、task-specific experts。experts的输入不是meta representations。
值得注意的是,
HoME第一层的元抽象(meta abstraction)(与PLE的主要架构差异)是基于我们在Kuaishou真实多任务推荐场景中的观察(见Figure 5)。基于HoME中的先验语义(prior semantics)(由meta expert network划分而来),我们可以最大限度地避免任务之间的冲突,同时最大化任务间的共享效率(sharing efficiency)。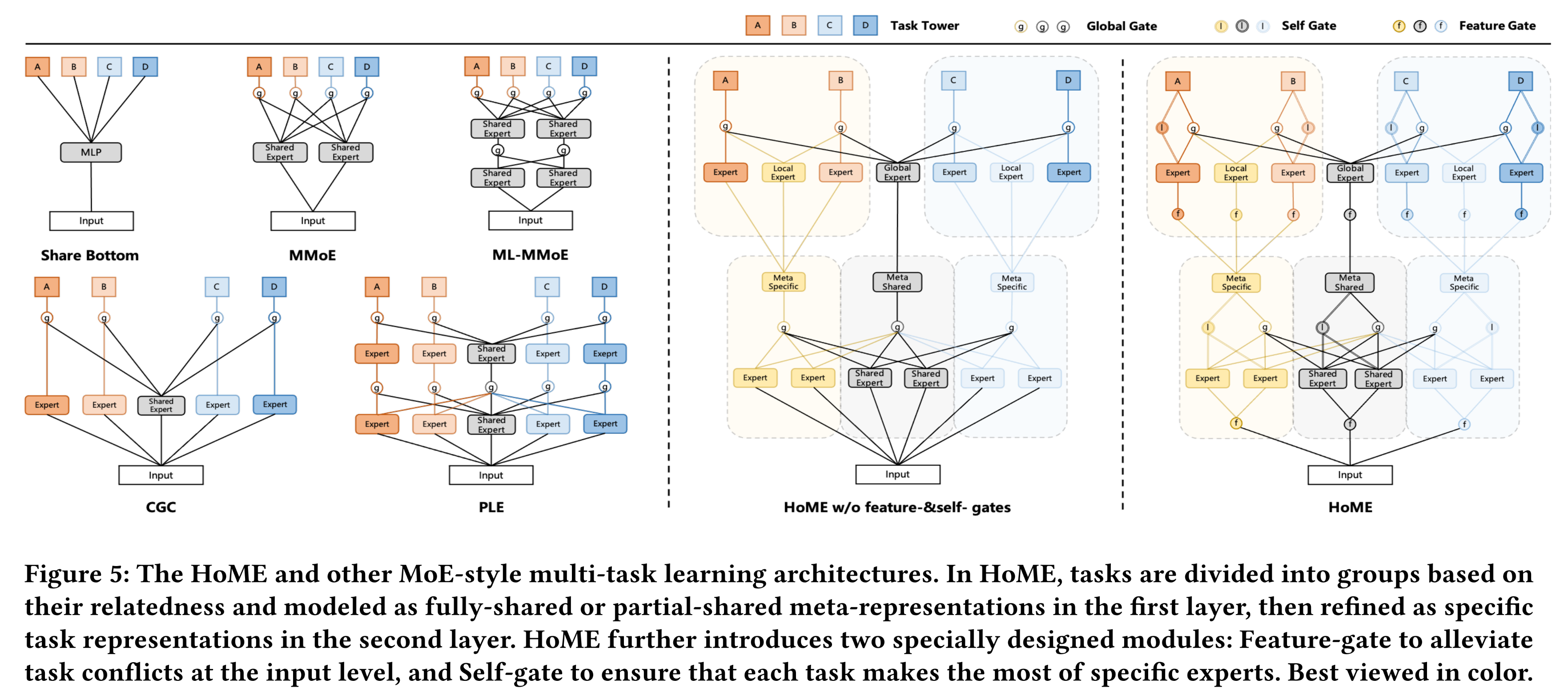
1.2.4 Feature-gate & Self-gate mechanisms
针对
expert underfitting问题,我们发现某些data-sparse tasks的gate-generated weights往往忽略该任务的specific experts,而将较大的gate weights分配给shared experts。这可能是因为我们的模型需要同时预测20多个不同的任务,而这些任务的数据密度(data density)差异极大,dense tasks的数据密度可能是sparse tasks的100倍。为了增强sparse task expert training,我们提出了两种门控机制,以确保它们能获得适当的梯度,从而最大化其效用:feature-gate机制和self-gate机制。对于
feature-gate,其目的是为不同任务的experts生成不同的representations of input features,以缓解潜在的梯度冲突(gradient conflicts)。当所有experts共享相同的input features时,可能出现梯度冲突。形式上,
feature-gate旨在提取每个input feature element的重要性。例如,给定输入为meta experts会带来较高的计算成本。受大语言模型(LLM)高效微调技术LoRA(《LoRA: Low-Rank Adaptation of Large Language Models》)的启发,我们同样引入两个小型矩阵来近似一个大型矩阵,以生成element importance:其中:
需要注意的是,我们在
Sigmoid函数后应用了一个FeaLoRA函数是生成私有化的expert inputs的有效方法。在迭代过程中,我们发现可以通过多任务思想进一步增强该函数,即引入更多的FeaLoRA从多个角度生成feature importance,作为我们的FeaGate:其中:
FeaLoRA数量,每个FeaLoRA的FeaLoRA的维度FeaLoRA的重要性。
因此,我们的
expert input可以通过以下方式获得(此处以第一层meta shared experts input其中:
通过这种方式,不同的
experts拥有各自的特征空间,这有助于降低梯度冲突的风险,从而保护sparse tasks。此外,最新的
MoE研究表明,堆叠更深的expert networks能够带来更强的预测能力(《AdaTT: Adaptive Task-to-Task Fusion Network for Multitask Learning in Recommendations》、《Progressive Layered Extraction (PLE): A Novel Multi-Task Learning (MTL) Model for Personalized Recommendations》)。不幸的是,在我们的实验中发现,原始的gate network容易逐层地稀释梯度,这对sparse task expert training尤为不利。除了在expert-input level引入FeaGate外,我们还在expert-output level添加了residual idea-based self-gate,以确保top layers的梯度能够有效传递到bottom layers。具体而言,
SelfGate仅关注该任务的specific experts的输出。以watching-time meta experts output为例:其中:
related Expert的数量。如果SelfGate的激活函数为Sigmoid;否则SelfGate的激活函数为Softmax。类似地,
representations相加(例如,SelfGate与常规Gate的唯一区别在与:SelfGate仅仅聚合task-specific experts,而常规Gate聚合shared experts and task-specific experts。HoME的细粒度结构细节如Figure 5所示。
1.3 实验
本节:
首先在
offline settings下将HoME与多种广泛使用的multi-task learning方法进行对比。然后通过模型变体验证
HoME各项改进的有效性。接着测试
HoME超参数(experts数量和feature-gate LoRA数量)的鲁棒性。此外,还提供了模型的
expert network gate weights graph,以展示HoME是一个平衡的系统。最后,将
HoME部署到online A/B test中,验证其为Kuaishou带来的业务收益。
Experiments Setup:实验基于Kuaishou短视频数据流场景(Kuaishou最大的推荐场景),该场景包含超过400 Million用户和每日50 Billion logs。为了保证对比的公平性,我们仅修改公式具体而言,我们实现了
MMoE、CGC、PLE、AdaTT等模型变体作为baselines。评估指标采用广泛使用的排序指标AUC和GAUC,以反映模型的预测能力。在Kuaishou短视频业务中,GAUC是最重要的离线指标,其核心思想是先计算每个用户的AUC,然后加权聚合所有用户的AUC:其中:
1.3.1 Offline Experiments
主要实验结果如
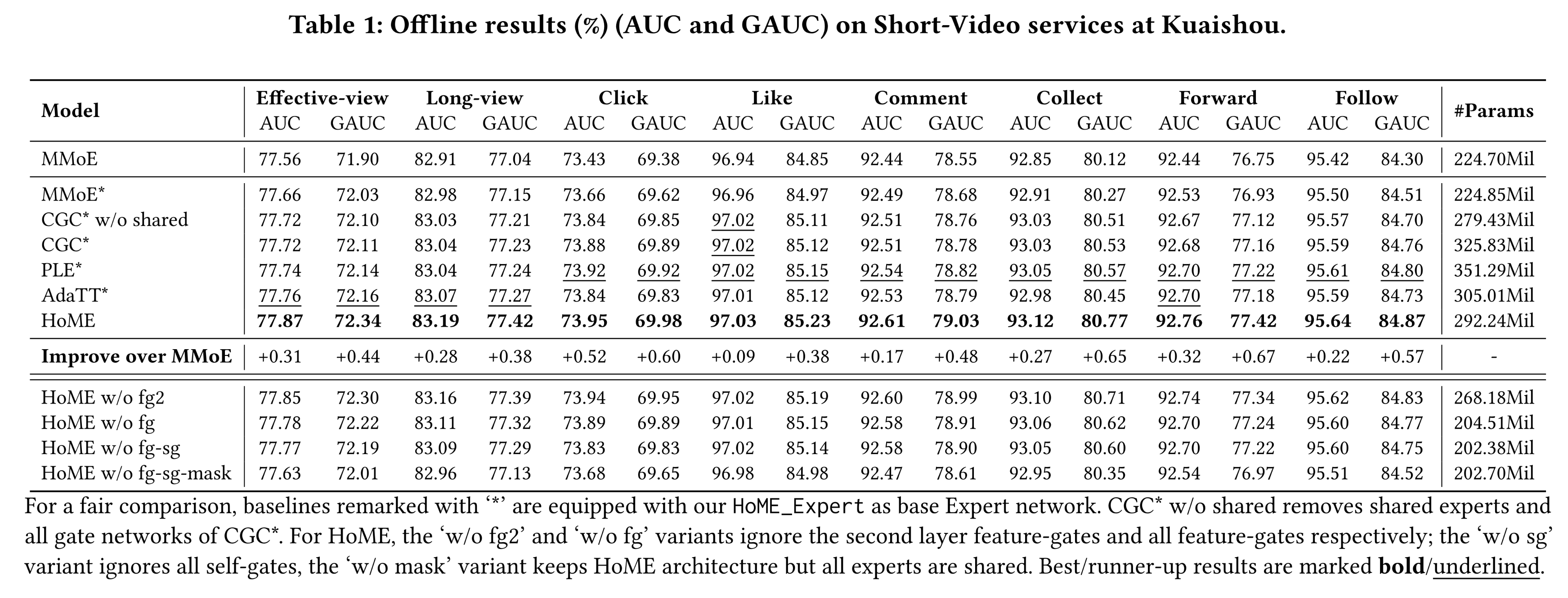
Table 1所示。需要注意的是,在离线评估中,AUC或GAUC提升0.03%~0.05%就足以给业务带来可观的online revenue。我们首先展示了基于
HoMEExpert的MMoE(即MMoE*)的性能。然后我们将
HoME与同样配备HoMEExpert的improved baselines进行对比。例如'CGC* w/o shared':CGC的变体,忽略shared experts和所有gate network。此外,我们还实现了
HoME的消融变体:'w/o fg2'和'w/o fg'分别表示忽略第二层feature-gates、以及忽略所有feature-gates。'w/o sg'表示忽略所有self-gates。'w/o mask'表示保持HoME架构,但所有experts均为shared experts。
注:最佳/次佳结果分别以粗体/下划线标注。
基于实验结果,我们得出以下观察结论:
(1):MMoE*的性能大幅优于朴素MMoE。这表明我们的Expert normalization & Swish机制能够有效克服expert collapse问题,平衡expert outputs,并促使expert networks发挥应有的作用。(2):'CGC* w/o shared'可视为每个任务配备a specific-expert的共享底部模型(Shared-bottom)。在实验中,'CGC* w/o shared'的参数比MMoE*多24%,且性能优于MMoE*。这表明在真实的大规模数据流场景中,MMoE系统较为脆弱,容易退化。(3):与'CGC* w/o shared'相比,CGC*并未表现出显著的性能提升。这表明CGC*的shared-experts已退化为some specific-experts。(4):与MMoE*相比,PLE*和AdaTT*取得了更好的性能。这表明在解决expert collapse问题后,堆叠多个expert network layers并增加model parameters是释放multi-task modules潜力的有效途径。(5):HoME在所有任务上的性能均显著优于其他strong baselines,同时引入的参数更少,取得了最佳结果。这表明我们的改进能够增强多任务MoE系统的稳定性,并最大化expert efficiency。
对于
HoME的消融实验,我们得出以下结论:(1):'w/o fg-sg-mask'变体的性能与MMoE*相当,而'w/o fg-sg'变体在所有任务上均取得了显著提升(大多数情况下AUC提升0.15%)。这表明我们的Hierarchy Mask机制是一种强大的且低资源消耗的策略,能够在不引入大量额外参数的情况下缓解expert degradation问题。(2):'w/o fg'变体的性能优于'w/o fg-sg'变体,且更稳定。这表明在不同layer experts之间添加残差连接(residual connection)有助于训练experts。(3):对比HoME和'w/o fg2'变体可以发现,第二层feature-gates能够提升模型能力,但第一层feature-gates的提升效果更稳健、更显著。这可能是因为第一层作为信息源的输入,并且第一层被用于coarsen meta layer中,其任务梯度冲突(tasks gradient conflict)问题比第二层fine-grained layer更为严重。
1.3.2 Discussion of Hyper-Parameter Sensitivity
本节探讨
experts数量和feature-gate LoRA数量对HoME性能的影响,以验证模型的鲁棒性。对于
experts数量,我们基于'HoME w/o fg'变体进行实验,因为第一层feature-gate是计算成本较高的参数消耗(parameter-consuming)操作。从
Table 2可以看出,HoME存在scaling-law现象:随着experts数量的增加,预测准确性随参数数量的增加而稳步提升。这一现象也表明HoME是一个平衡的MoE系统,能够充分释放所有experts的能力。
对于
feature-gate LoRA数量,我们基于'HoME w/o fg2'变体进行实验。该变体仅包含第一层feature-gate,且在Table 1中表现出显著的性能提升。具体而言,在我们的实现中,增加LoRA数量只会降低hidden size,而不会增加额外参数,这可能会降低单个LoRA的建模能力。从
Table 3可以看出,采用2 LoRA的变体取得了最佳结果。这表明存在一个平衡点,需要在LoRA数量和LoRA建模能力之间进行权衡。
1.3.3 Discussion of HoME Situation
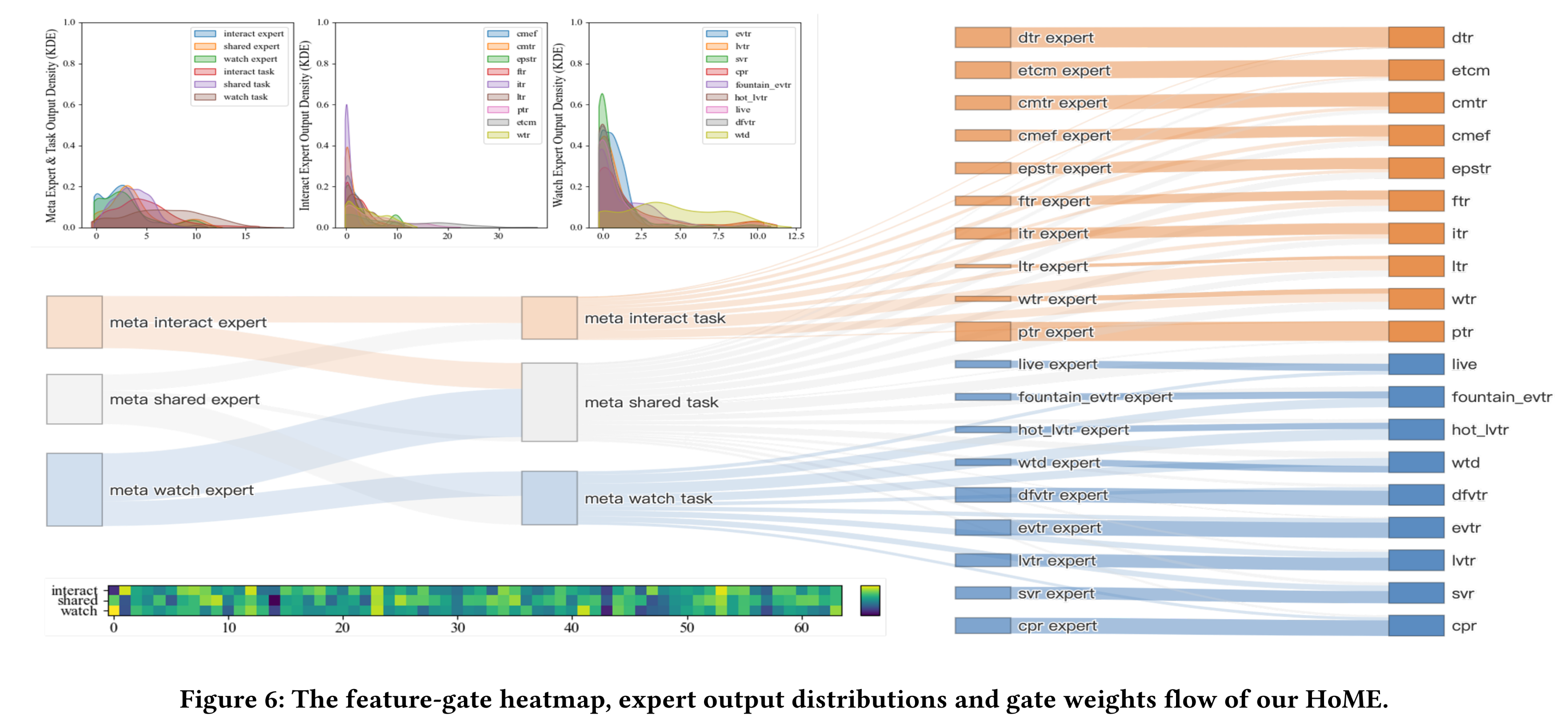
Figure 6展示了HoME的expert output distributions和graph weights flow。从图中可以看出,HoME实现了平衡的gate weight均衡状态:(1):根据feature-gate的热力图(随机可视化64个维度),我们可以得出结论:feature-gate能够为每个expert实现灵活的element-wise feature selection。(2):所有shared and specific expert outputs都对齐到相似的数值量级。此外,meta-shared-expert distributions与specific-expert distributions不同。这表明shared-knowledge倾向于由meta networks编码,而difference-knowledge则由specific experts编码。(3):所有experts都发挥了预期的作用,the shared and specific experts都贡献了可感知的权重(perceivable weights)。
1.3.4 Online A/B Test
本节将
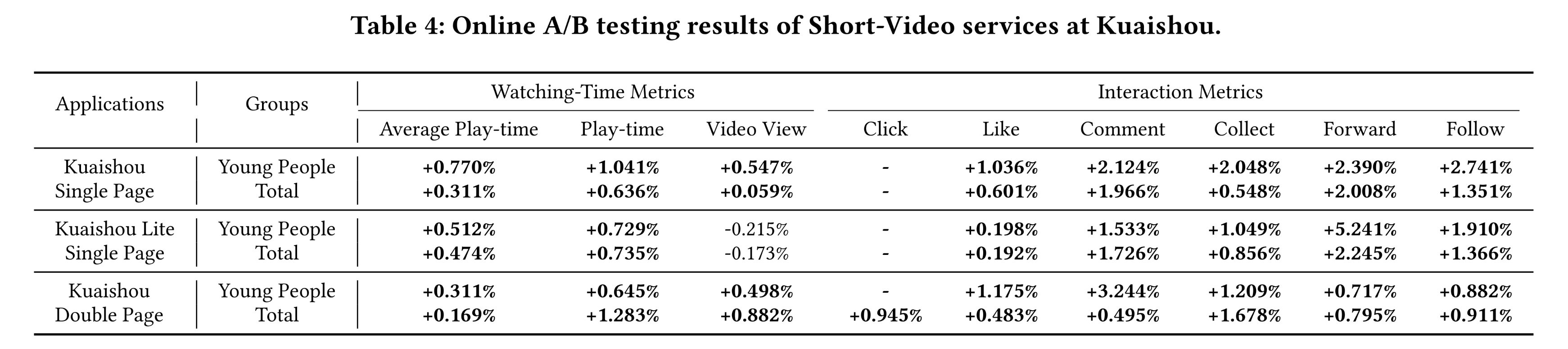
HoME部署为online ranking model,应用于三个短视频场景:Kuaishou Single/Double Page(如Figure 1所示)和Kuaishou Lite Single Page。在我们的业务中,核心指标是观看时长相关指标(例如人均播放时长),反映用户在Kuaishou平台上的总停留时间。同时我们还展示了视频观看量指标,衡量用户观看的短视频总数。Young用户组和Total用户组的online A/B test结果如Table 4所示。实际上,在Kuaishou平台上,播放时长提升约0.1%就属于具有统计显著性的改进。我们提出的
HoME在三个场景中分别为所有用户带来了+0.311%、+0.474%和+0.169%的显著提升,这是过去一年中最显著的改进。此外,
HoME在所有交互指标(如点击、点赞、评论等)上都取得了显著的业务收益,这表明HoME能够使多任务系统收敛到更平衡的均衡状态(equilibrium state),而不会出现跷跷板现象。此外,我们还发现稀疏行为任务(
sparse behavior tasks)的提升更为明显,这表明HoME能够使所有shared or specific experts获得适当的梯度,以最大化其效果。
1.4 结论
本文聚焦于解决
Kuaishou短视频业务(全球最大的推荐场景之一)中多任务学习方法面临的实际问题及经验教训。我们首先发现,当前广泛使用的多任务学习家族(即
Gated Mixture-of-Expert)容易出现多个严重问题,限制了模型的预期能力。从
expert outputs来看,存在expert degradation问题,即experts的output distributions差异显著。从
shared-expert learning来看,存在expert degradation问题,即某些shared experts仅服务于一个任务。从
specific-expert learning来看,存在expert underfitting问题,即某些sparse tasks specific-experts几乎无法提供任何信息。
为了解决这些问题,我们提出了三项具有洞察力的改进:
(1):Expert normalization & Swish机制,用于对齐expert output distribution。(2):Hierarchy mask机制,用于规范任务之间的关系,以最大化shared-expert efficiency。(3):Feature-gate和Self-gate机制,用于生成更灵活的experts私有化的输入,并连接相邻的related experts,确保所有experts都能获得适当的梯度。
此外,通过在全球最大的短视频平台之一
Kuaishou进行的大量离线和在线实验,我们证明了HoME相较于其他广泛使用的多任务方法取得了显著的性能提升。目前,HoME已在Kuaishou的多个在线模型中广泛部署,为多项业务提供支持,每日服务400 Million活跃用户。