一、 QARM [2025]
《QARM: Quantitative Alignment Multi-Modal Recommendation at Kuaishou》
近年来,随着多模态大模型的快速发展,推荐系统研究者逐渐意识到多模态信息(
multi-modal information)在用户兴趣建模(user interest modeling)中的潜力。在工业界,下述级联式(cascading paradigm)建模架构被广泛应用:(1):先预训练一个多模态模型,为下游服务提供通用表征(omnipotent representations)。(2):下游推荐模型将该多模态表征(multi-modal representation)作为额外输入,从而拟合real user-item behaviours。
尽管该范式取得了显著效果,但仍存在两个限制模型性能的核心问题:
(1)表征失配(Representation Unmatching):pre-trained multi-modal model通常以经典的NLP/CV tasks为监督目标,而推荐模型以real user-item interaction为监督信号。两类任务的目标是本质不同的,导致representations缺乏一致的目标(consistent objective)。(2)表征固化(Representation Unlearning):generated的multi-modal representations被存储在缓存中,作为推荐模型的fixed input,无法通过推荐模型的梯度进行更新,不利于下游任务的训练。
本研究受下游任务应用中的这两大挑战的启发,提出一种量化多模态框架(
quantitative multi-modal framework),即QARM,为不同下游模型定制专用的且可训练的多模态信息。具体而言,我们通过两项关键改进来增强框架性能:(1) Item Alignment:将原始multi-modal representations转换为与real user-item behaviours distribution匹配的形式;(2) Quantitative Code:将aligned multi-modal representations转换为trainable code ID,从而用于下游任务训练。
我们通过详细的离线实验、消融分析验证了
QARM的有效性,该方法已在Kuaishou的多个业务线部署,日均服务400M用户。Kuaishou是中国最大的短视频和直播平台之一。作为新型信息分享媒介,Kuaishou吸引了海量用户观看/创作短视频,部分用户还会在观看电商带货短视频(或直播后)完成商品购买。为从数十亿短视频库中筛选出用户最感兴趣的内容、提升用户体验,强大的推荐系统(recommender system: RecSys)是支撑Kuaishou业务发展的核心基石。通常,构建高性能推荐模型的核心思路是:基于海量的real-time user-item interaction data,结合大量人工设计的input features进行模型训练。过去几年,推荐领域研究者提出了诸多里程碑式工作,对ID-based features进行精细化设计以支撑model input,例如cross ID features(如FM、DCN)、list-wise ID features(如DIN、TWIN)等。近年来,随着多模态大模型(如GPTs)的快速演进,推荐领域研究者逐渐意识到多模态信息在推荐系统中的潜力——通过理解item的语义信号(semantic signal),实现更智能的推荐。尤其在Kuaishou平台,短视频和直播是高度集成的多模态媒体,仅通过ID embedding难以充分理解其语义。然而,尽管多模态大模型(
multi-modal large language models: MLLMs)能力强大,但其训练和推理的计算成本极高。考虑到工业级推荐服务需处理海量在线请求(online requests),直接将大型多模态module添加到推荐模型并不现实(《Advertising with Multimodal Representations: Challenges, Approaches and Insights》)。为缓解计算压力,据我们所知,许多企业采用two-step部署方案将多模态语义信息融入推荐模型(如Figure 1所示):(1):预训练一个多模态大模型(MLLM),将item的文本、视觉、以及音频信息压缩为通用表征(omnipotent representation),存储在缓存中,为下游模型提供语义知识(semantic knowledge)。(2):下游模型根据训练样本信息,提取对应的multi-modal representation作为input features的一部分,提升预测能力。
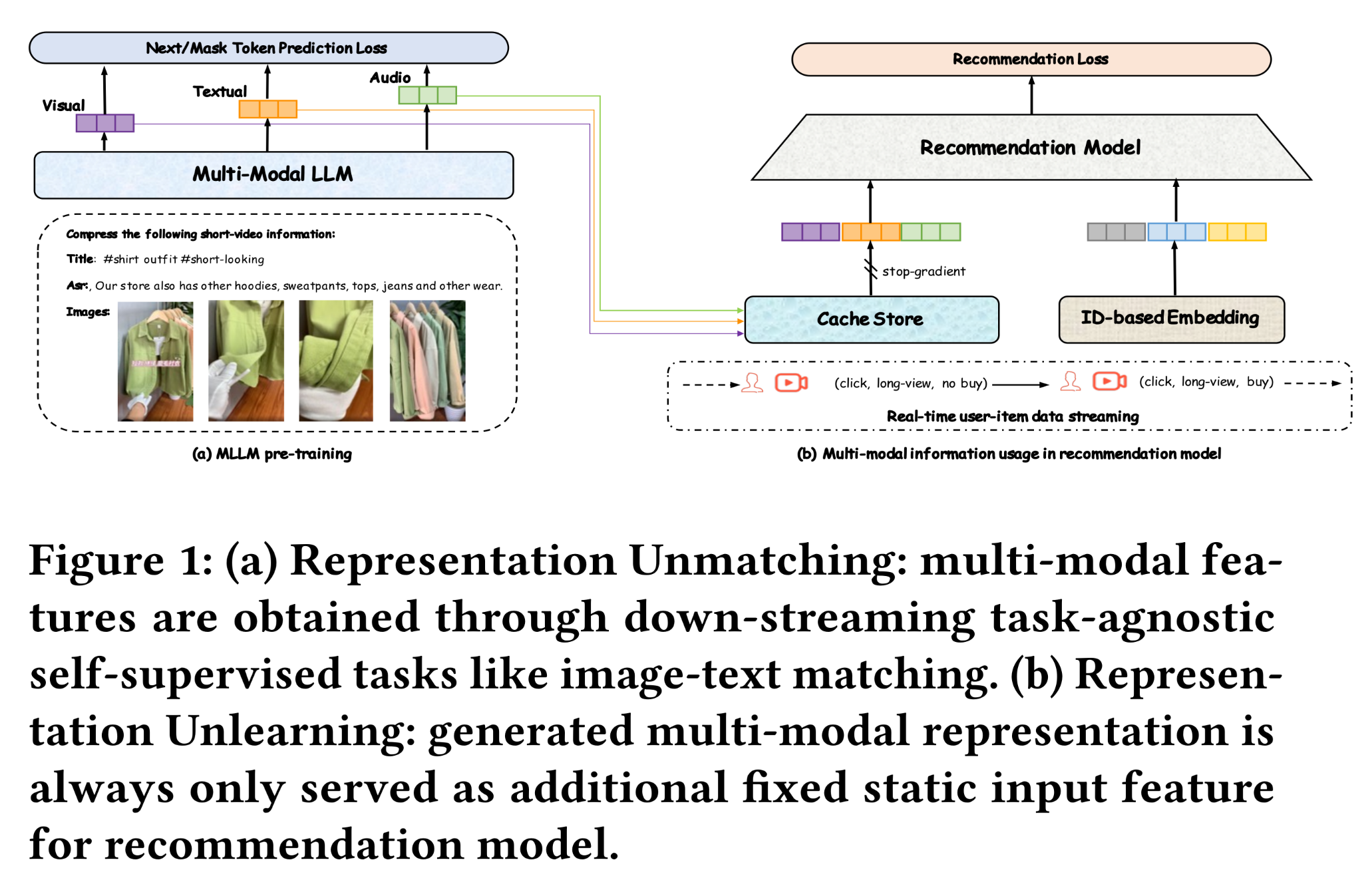
Kuaishou的推荐模型同样采用了该部署方案,并在电商、广告短视频、以及直播推荐等多个业务中取得了显著的online A/B增益。然而,这种非端到端框架存在两个明显问题,限制了模型性能上限:(1)表征失配(Representation Unmatching):常见的多模态特征通过自监督任务(如image-text matching)来获取,而ID-based features以user interaction history为监督信号。这种差异导致多模态信息与推荐知识难以在下游训练中统一,进而影响模型效果。由此引发一个关键问题:如何增强multi-modal representation与下游任务的一致性?(2)表征固化(Representation Unlearning):实际应用中,新增的多模态特征不会随推荐系统的训练而更新。相比之下,离散的ID-based features(如user ID, item ID)可通过推荐模型分配对应的embedding spaces,利用real-time user-item interaction data进行端到端的优化。因此,静态的multi-modal representations限制了模型的拟合能力,阻碍了训练的收敛。这引出了第二个关键问题:如何端到端地优化multi-modal representations?
受下游任务应用中的这两大挑战的启发,本文提出一种高效的多模态信息增强(
multi-modal information enhancement)方案——量化对齐多模态推荐算法(Quantitative Alignment Multi-Modal Recommendation: QARM)。具体而言,QARM通过两大核心流程解决上述问题:item对齐机制(Item Alignment)增强representation consistency,量化编码机制(Quantitative Code)生成learnable code ID用于下游任务。Item Alignment机制:为解决representation unmatching问题并增强representation consistency,我们为pre-trained multi-modal model设计了定制化的fine-tuning方案。原因在于,不同业务具有独特属性,下游任务所需的multi-modal representation应反映对应的业务特性(business characteristics)。例如:电商短视频推荐中,
different categories of goods之间的因果关系更为重要。而通用短视频推荐中,
same category内物品的关联更关键。
因此,
fine-tuning范式需针对不同下游业务来定制。为了实现这一点,我们插入了一个pre-order item alignment机制,以使用相应的business data来微调多模态模型,以确保MLLM representation能够准确反映在每个场景中观察到的actual user-item interaction patterns。Quantitative Code机制:为解决representation unlearning问题从而实现多模态信息的充分适配,受code hashing和straight-through estimator思想的启发,我们考虑为下游任务生成Semantic IDs。具体而言,在获得fine-tuned multi-modal representation后,我们提出两种简单有效的启发式方法构建quantization codebooks。codebooks被训练完成后固定不变,用于度量fine-tuned multi-modal representation并计算对应的Semantic IDs。最终,在下游推荐模型训练中,为Semantic IDs分配对应的embedding space,结合real user-item interaction data进行端到端的训练。
综上,本文的主要贡献如下:
提出
QARM算法,有效解决工业界多模态信息applications的两大核心限制。item alignment机制为下游业务生成一致性的multi-modal representations,quantitative code机制进一步将其压缩为learnable semantic IDs从而用于端到端训练。进行了全面的离线实验和消融分析,验证了
QARM各组件的有效性;线上实验显示,QARM使广告业务收入提升9.704%,电商业务商品交易总额(GMV)提升2.296%。QARM自2024年3月起已在Kuaishou多个业务线广泛部署,支撑400 million日均活跃用户。
1.1 相关工作
基于
multi-modal information fusion的contrastive learning:早期方法将 “现成” 的multimodal representations作为fixed features或conjunction with structural relationships融入推荐框架。例如:VBPR(《VBPR: visual Bayesian Personalized Ranking from implicit feedback》)通过线性变换核(linear transform kernel)将视觉特征(visual features)融入矩阵分解(Matrix Factorization),再与ID embedding进行拼接。LATTICE(《Mining Latent Structures for Multimedia Recommendation》)利用视觉embedding和文本embedding构建亲和图(affinity graphs),为协同过滤模型(collaborative filtering model)提供多模态item-item relationships。BM3(《Bootstrap Latent Representations for Multi-modal Recommendation》)通过自监督学习在协同过滤任务(collaborative filtering task)中对齐模态间和模态内的representations。
为进一步提升
modality-driven recommendations的性能,multi-modal pre-training至关重要。DVBPR(《Visually-Aware Fashion Recommendation and Design with Generative Image Models》)扩展VBPR,将CNN visual encoder与Matrix Factorization任务联合训练;AlignRec(《AlignRec: Aligning and Training in Multimodal Recommendations》)以BEiT3(《Image as a Foreign Language: BEiT Pretraining for All Vision and Vision-Language Tasks》)为backbone,,通过mask-then-predict策略预训练visual-text alignment任务,再基于fixed multimodal representations与ID representation进行对齐。《Enhancing Taobao Display Advertising with Multimodal Representations: Challenges, Approaches and Insights》在预训练阶段采用semantic-aware contrastive learning,利用user’s search query and subsequent purchase item构建positive sample pairs,基于fixed multimodal representations通过SimTier和MAKE来提取特征。
与现有方法不同,本文通过
pre-training阶段将multimodal representation与下游业务特定的item-item relationships进行对齐,并利用quantitative code mechanisms实现推荐模型的端到端训练。推荐系统中的
quantitative multi-modal representation:discrete quantization representations通过将向量分解为多个discrete code representations来精确逼近原始向量,已在多个领域被广泛应用。乘积量化(
Product Quantization: PQ)将高维向量划分为子向量并独立地量化每个子向量(《Vector quantization》)。残差量化(
Residual Quantization: RQ)是PQ的扩展,专注于量化前一次量化后的残差(《Regularized Residual Quantization: a multi-layer sparse dictionary learning approach》、《Stacked quantizers for compositional vector compression》),以提升quantized representation的准确性。
在推荐系统中,
content discrete representations(又被称为semantic IDs)被广泛应用。semantic IDs能促进语义相关items的碰撞(collisions),提升推荐模型的泛化能力。TIGER(《Recommender systems with generative retrieval》)采用RQ-VAE(《Autoregressive image generation using residual quantization》)对item的content embedding presentations进行离散化,再通过自回归模型来预测用户感兴趣的next item的semantic ID。《Better generalization with semantic ids: A case study in ranking for recommendations》证明,hierarchical Semantic IDs可替代ranking模型中的item IDs,实现更优的泛化效果。
1.2 方法
本节详细介绍
QARM的核心组件,包括item alignment机制和quantitative code机制。
1.2.1 Item Alignment of QARM
Multi-modal representations能显著增强推荐模型中的user-side features、item-side features和target-aware historical item lists。然而,由于表征失配(Representation Unmatching)问题的持续存在,多模态信息的效用受到限制。现有方法通常通过额外的对比学习模块将item IDS与其multi-modal representations对齐。然而,这类contrastive loss的ground-truth不够diverse(例如,一个item的MLLM representation仅与自身item ID embedding作为正样本pair),导致能力较弱且易过拟合。不同于
contrastive learning objective,为确保多模态特征与特定业务的用户行为决策(user behavior decisions)相关,我们考虑在representation馈入下游模型前,利用下游业务的真实interaction data对multi-modal representation进一步微调。具体实现上,我们构建了一个pure multi-modal representation input only alignment模型,并利用现有retrieval model的知识监督其学习,以反映真实的业务特性(business characteristics)。具体步骤如下:首先,通过如下步骤构建高质量的
item2item pairs dataset基于
User2Item retrieval model,对于每个user positive clicked target item,从该用户最近点击的50个positive clicked items中,选择ID representation space中相似度最高的item作为trigger item。User2Item retrieval model可以导出item embedding table。对于每个user positive clicked target item,然后在historical positive clicked items中,根据item embedding选择相似度最高的一个item作为对比学习的positive pair。问题:为什么必须从用户最近点击的
50个items中选择,而不是在全局item embedding space中选择?回答这个问题需要从业务逻辑和模型目标出发。以下是可能的原因:
保证正样本对的相关性:用户最近点击的
50个items代表了该用户的短期兴趣,从这些items中选择与target item最相似的item作为trigger,可以确保trigger和target在用户兴趣层面是相关的。如果在全局空间中选择最相似的item,可能虽然item在内容上相似,但与用户当前的兴趣无关,这样的positive pair可能无法很好地反映用户的行为模式。避免引入全局热门物品:全局
item embedding space中最相似的item可能是全局热门的item,这些item可能与许多item都相似,导致positive pair缺乏区分度。而从用户最近点击的items中选择,可以保证trigger item是用户实际感兴趣的,避免热门item的干扰。模拟真实用户行为序列:推荐系统中的用户行为往往具有序列性,用户当前的点击往往受到最近行为的影响。从最近点击的
items中选择trigger,可以更好地建模用户兴趣的演变,使对齐后的多模态表征能够捕捉到这种序列依赖关系。增强个性化:不同用户对相似
item的偏好可能不同。从用户自身的历史中选择,可以保证trigger item是个性化的,与用户的兴趣偏好一致。全局选择可能会忽略用户的个性化偏好。减少噪声:全局
item embedding space可能包含大量用户从未接触过的items,这些items可能与target item在内容上相似,但用户可能对它们不感兴趣,甚至可能是无关的。从用户历史中选择,可以保证trigger item是用户已经认可的item,减少噪声。与下游任务一致:下游推荐模型通常利用用户历史行为来预测下一个点击(
target item)。因此,在构建对齐模型时,使用用户历史行为作为trigger的来源,可以使多模态表征更适应下游任务。
总结:从用户最近点击的
50个items中选择trigger item,是为了保证positive pair具有用户兴趣相关性和个性化,同时减少全局热门item和噪声的影响,更好地模拟真实用户行为,从而使学习到的多模态表征更适合下游推荐任务。基于
Item2Item retrieval model,利用现有模型学到的稳定的高相似度的item pairs作为data sources,例如从Swing retrieval model中导出数据。Swing算法是一种基于图的协同过滤算法,主要用于计算item之间的相似度。其核心思想是:如果两个item被很多用户同时交互过,且这些用户之间的兴趣相似度较低(即用户之间的重叠行为较少),那么这两个item的相似度应该更高。这样的设计能更好地捕获
item之间的非流行性关联,避免因为热门item而被过度推荐。数学公式:
其中:
itemitem集合。user-level overlap。user-level overlap的影响。
然后,基于高质量的
item2item pairs dataseta item2item style alignment models with pure multi-modal representation。对于a random batch data其中:
batch中的generated的trigger/target item MLLM representation,representation dimension,batch size。trigger/target item的用于MLLM的raw input text, audio and image tokens。QARM的alignment training loss。
值得注意的是,我们的
contrastive learning objective更具泛化性,每个item拥有多个diverse的contrastive learning正样本。通过优化item alignment loss,MLLM representations被引导从而与下游业务知识对齐,最大化表征一致性(representation consistency)。论文没有提及如何构建负样本。根据经验,
Batch-Contrastive中,每个样本的负样本来自于batch内,其它样本的positive样本集合。
1.2.2 Quantitative Code of QARM
当获得
alignment multi-modal representation后,下一步需利用MLLM的world knowledge提升下游模型的prediction accuracy。然而,与直接将pre-trained representation作为model input相比,推荐模型更适合使用ID style features进行端到端的训练。受code hashing和straight-through estimator思想在计算机视觉(CV)(《Taming transformers for high-resolution image synthesis》)和数据挖掘(DM)(《Recommender systems with generative retrieval》)领域的成功应用启发,我们考虑生成a series of quantitative code IDs来替代MLLM representation。具体而言,我们设计了两种简单有效的量化机制——Vector-Quantized: VQ(《Neural discrete representation learning》)和Residual-Quantized: RQ(《Autoregressive image generation using residual quantization》),将learned item alignment MLLM representationquantitative code,其中item集合,item总数。论文同时采用
VQ code和RQ code,因为这两种code捕获了不同的特性。VQ code通过TopK similar item neighbors来表征target item information。然而,
RQ code通过a hierarchical residual path来编码整个MLLM representation。
VQ code: 作为应用最广泛的量化技术(quantitative technique),VQ首先训练一个大型的codebook matrix,然后通过top-k nearest neighbor search对representation进行哈希编码。在QARM中,由于pre-trained MLLM representations已能反映复杂的items’ correlation;为简化流程,我们不训练a new codebook matrix,而是直接将所有items的alignment representations作为codebook:其中:
QARM的VQ codebook。基于该
codebook,任意MLLM representationVQ code list:其中:
TopKCode()函数用于从codebookrepresentationrepresentations的索引(即code)。VQ quantitative codes数量的超参数。每个
code满足
这就是基于
representation similarity,为每个target representation寻找最相似的source item。这种做法使得相似的item具有相似的code。例如:假设
item1的top-3相似items为:item 4/6/8,那么item1的code为(4, 6, 8)。假设
item2的top-3相似items为:item 4/5/8,那么item2的code为(4, 5, 8)。
考虑到
item1和item2都与item 4/8非常相似,所以item1与item2之间也存在一定的相似性。所以,item1与item2也是相似的,它们的code也是相似的。RQ code:与VQ使用a larger codebook size进行哈希编码不同,RQ采用固定size的codebook,以粗到细的方式递归地量化一个representation。具体而言,RQ训练具有级联关系(cascading relationships)的L levels codebooks,然后为每一层的residual representation搜索nearest neighbor index。在QARM中,我们利用启发式的Kmeans算法为每一层生成size = N的codebook:其中:
cluster,即codebookrepresentation执行nearest representation search方法,从而获取残差RQ的trained codebook list,每一层的codebook
基于该
codebook list,任意item的MLLM representation其中:
code,返回该code的索引。codebookcode vector。representationRQ codes,每个code满足
VQ and RQ codebook generation的伪代码如Algorithm 1所示。通过该算法,任意alignment MLLM representations可转换为两类编码:VQ code:RQ code:
随后将这些
codes存储在缓存中,用于推荐模型的端到端的representation learning。
1.2.3 Usage of QARM
基于
quantitative codes,我们设计了多种简单有效的特征构建方式,支撑下游推荐模型的端到端的MLLM information training。具体包括retrieval and ranking model的item-side feature, user-side feature,以及ranking model的target item-aware feature:Item-side feature:直接将VQ code和RQ code作为item ID feature,并为这些codes分配对应的embedding spaces,通过lookup来获取end-to-end learnable embeddings。对于
VQ code(或者RQ code)一个item对应codes,从而lookup得到多个embedding。那么如何使用它们?拼接还是池化?作者并未说明。此外,
《Better generalization with semantic ids : A case study in ranking for recommendations》提出使用SPM-based或者N-gram-based来构建embedding。User-side feature:为描述用户兴趣,将用户最近交互的sequence of positive interacted items的quantitative codes作为模型输入的一部分。假设获取最近的
positive interacted items,每个item有RQ code,那怎么从这个codes中获得sequence representation?Target item-aware feature:除直接学习code representation外,还利用target item quantitative code来搜索若干个item sequences,从而构建target item-aware cross features。例如,基于RQ code,可生成latest first one-code matching item sequence、latest two-code matching item sequence等。latest first one-code matching item sequence可以类比于:与target item相同一级类目的item sequence作为输入的sequence featuere。
上述特征建模方式与工业界常见方案一致,整体学习流程如下(流程如
Figure 2所示):其中:
itemselected embedding;IDLookUP表示embedding lookup;embedding size。每个
item映射为一个token sequence。ItemCodeRep为item-side code feature,它通过ItemNet网络编码而来。UserCodeRep为user-side code feature,它通过UserNet网络编码而来。CrossCodeRep为target item-aware multi-modal feature,它通过CrossNet网络编码而来。OtherFeaRep为其他的user/item features’ representations。multi-task prediction模块。ranking模型的training objective。
ItemNet/UserNet/CrossNet的网络结构是什么?作者没有讲。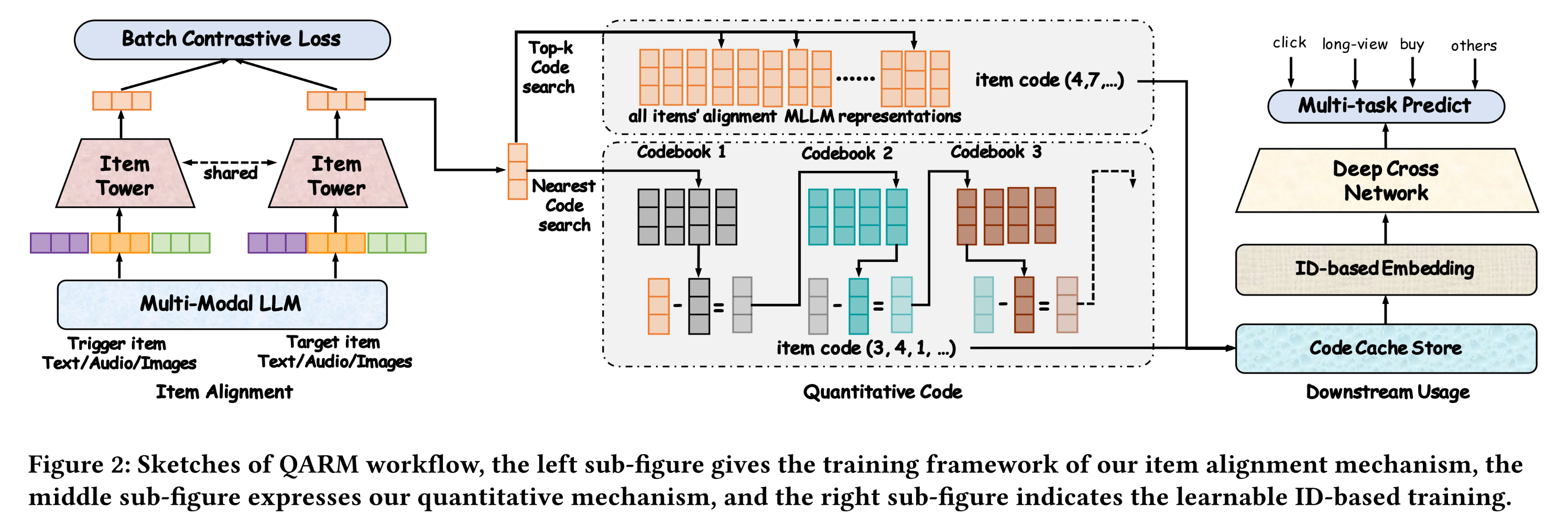
1.3 实验
本节在
Kuaishou电商和广告业务中进行了详细的离线/在线实验及消融分析,验证QARM的有效性。评估指标:
AUC:反映一个positive user-item pair的得分高于negative user-item pair得分的整体概率。UAUC:所有用户的AUC的平均值。GAUC:UAUC的加权版本,结合不同用户的interaction样本占比,提供更精准的评估。
其中:
user-item pair交互样本数;all_sample为总样本数。baseline方法:两个strong baseline models,它们已经采用了cached MLLM representation,如Figure 1所示。没有数据集的描述?没有模型配置?
1.3.1 离线性能
Table 1报告了电商和广告业务的离线实验结果(VQ code lengthRQ code lengthembedding size与
baseline模型相比,直接融入item alignment MLLM representation(+ IA Rep)能进一步提升广告业务的模型预测准确性,表明缓解表征失配(representation unmatching)问题从而使MLLM representation与real bussiness interaction distribution knowledge对齐具有积极作用。与
"+ IA Rep"变体相比,使用VQ code或RQ code替代items’ MLLM representation能带来更显著的性能提升,表明解决表征固化(representation unlearning)问题,并分配learnable embedding从而进行端到端训练,对推荐模型收敛至关重要。同时融入
VQ code和RQ code(+ VQ & RQ Code)的性能优于单独的+VQ Code和+RQ Code,原因在于两种codes侧重不同的MLLM knowledge:VQ code通过TopK similar item neighbors来表征target item information。然而,
RQ code通过a hierarchical residual path来编码整个MLLM representation。
这里缺少同时添加
+ IA Rep + VQ & RQ Code的变体(即,最终的模型)。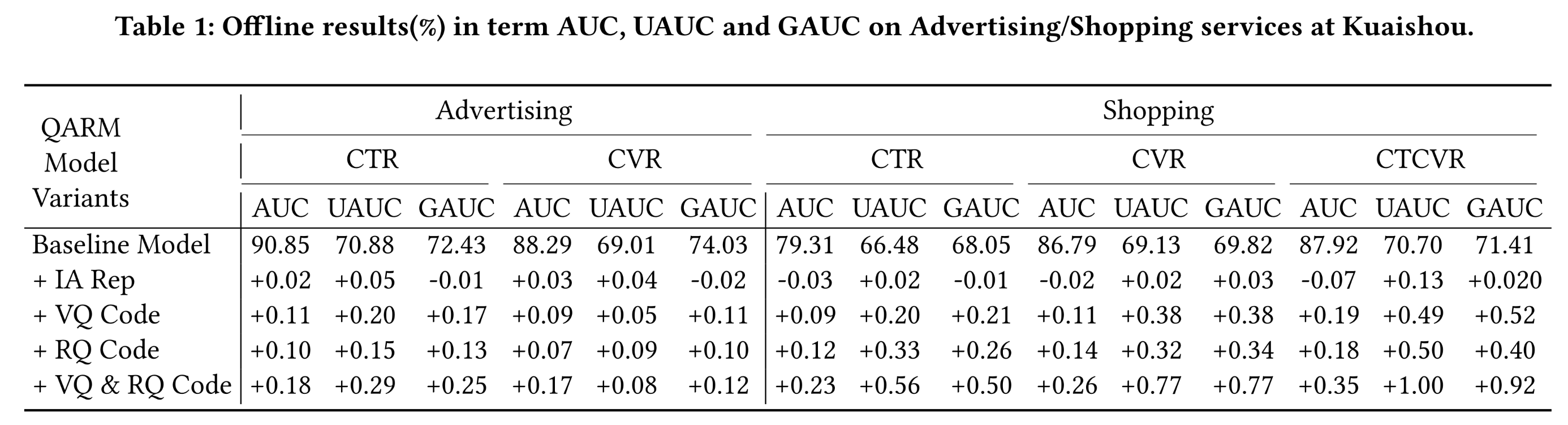
1.3.2 Online A/B Test
为衡量
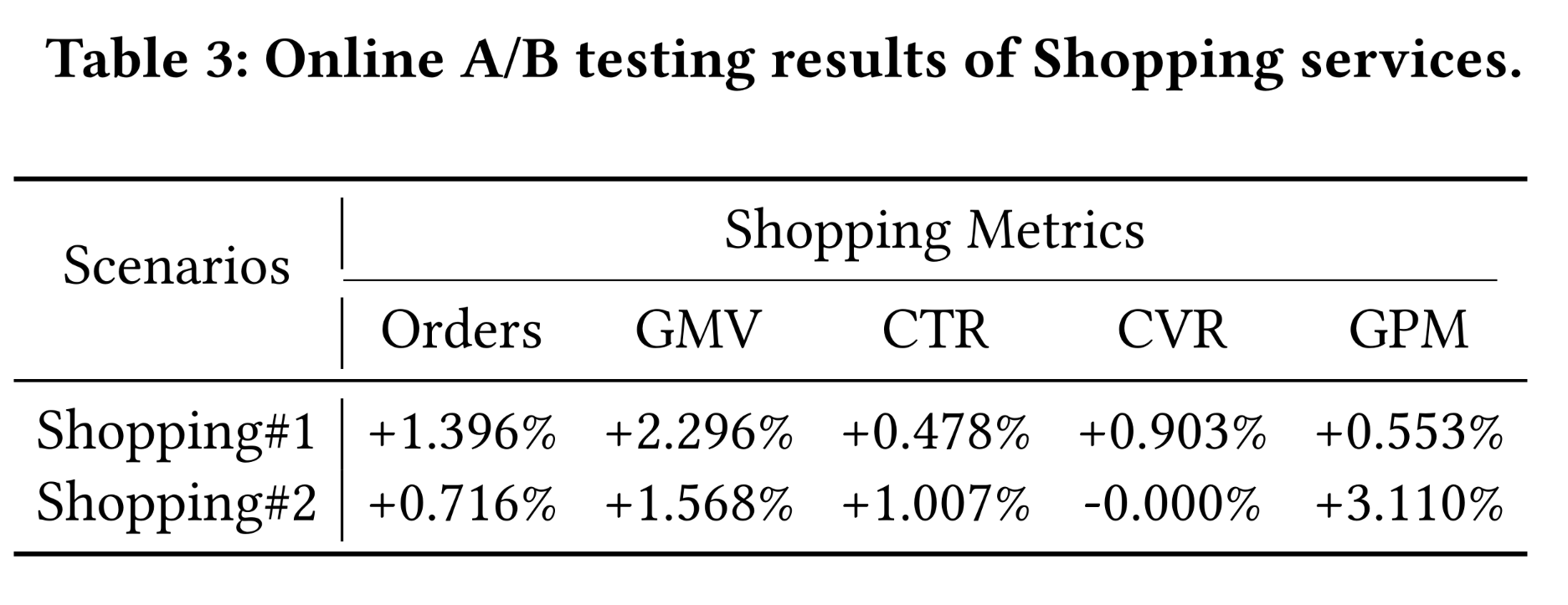
QARM对线上业务的实际贡献,我们将'+ VQ & RQ Code'变体部署到online A/B test系统,处理真实用户的电商和广告请求。不同业务的核心指标不同:广告业务关注收入(Revenue),电商业务关注商品交易总额(GMV)。Table 2和Table 3分别报告了广告和电商业务的线上结果("#1"和"#2"表示对应业务的不同应用场景,如短视频场景或商城场景)。结果显示:
广告业务中,
Cold-start item group和Others group的收入分别提升9.704%/3.147%和9.555%/1.950%。电商业务中,
GMV提升2.296%/1.568%。
这表明,通过
QARM理解multi-modal item semantic signal,能显著改善我们的系统。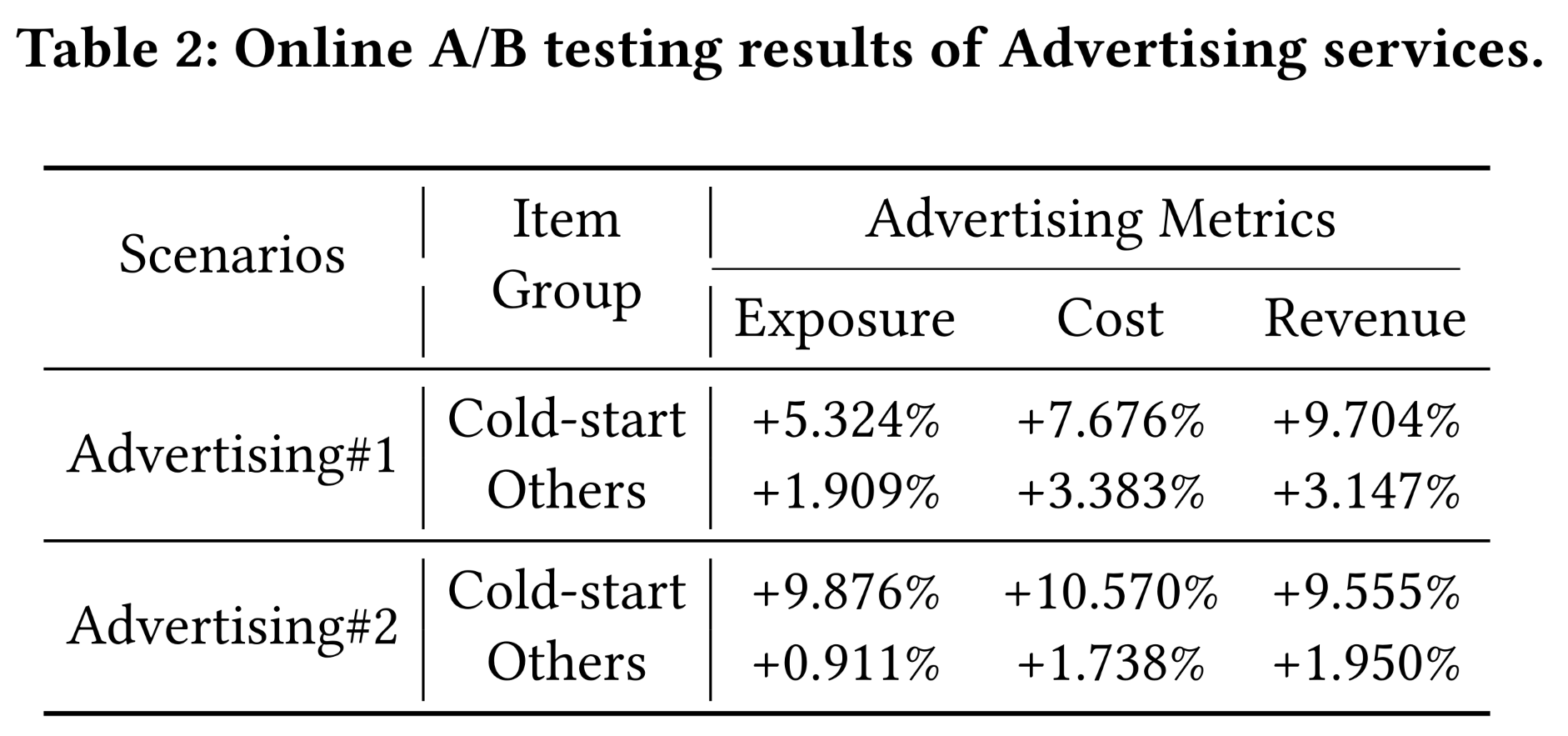
1.3.3 Case Study of QARM
本节探究多模态信息对系统内容分发的影响。直观来看,多模态信息对长尾
items更友好——因为多模态信息不受item popularity的影响。因此,长尾items性能的提升可在一定程度上证明QARM引入多模态信息的合理性。为验证QARM对长尾items的有效性,我们根据item的购买频率将其分为6组(L1至L6):L1为购买频率最低的长尾items,后续groups的购买频率依次递增。首先我们进行离线评估。
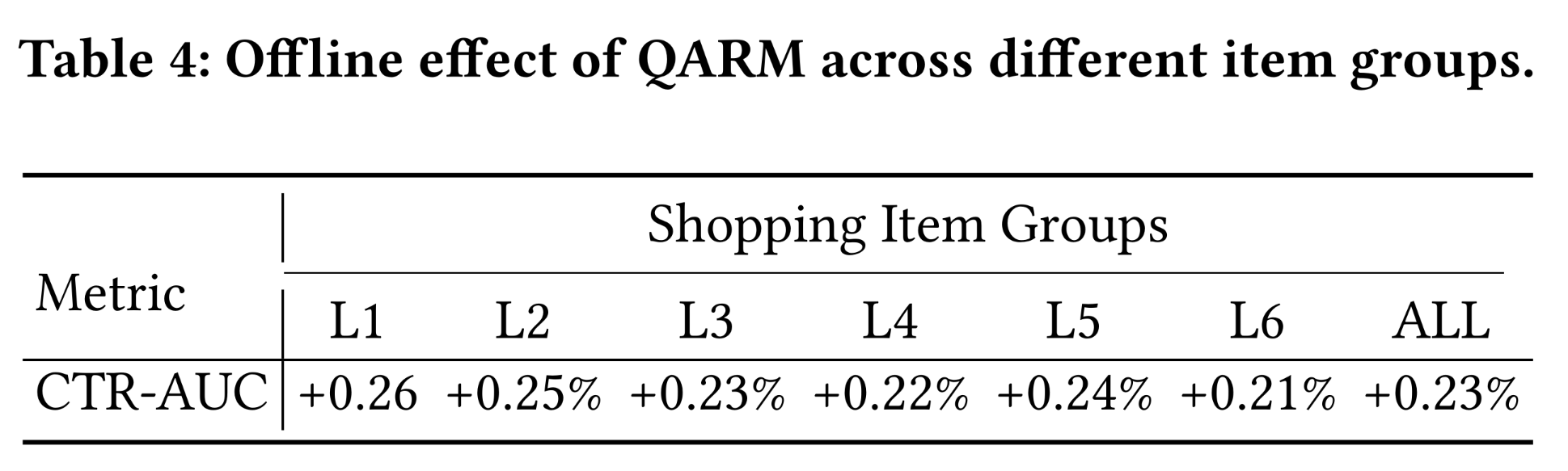
Table 4显示了不同groups的离线CTR-AUC指标。结果表明:长尾
items(L1)的预测性能提升最高。而且,随着
items的购买频率增加,性能提升幅度逐渐下降。
然后,我们执行在线评估。
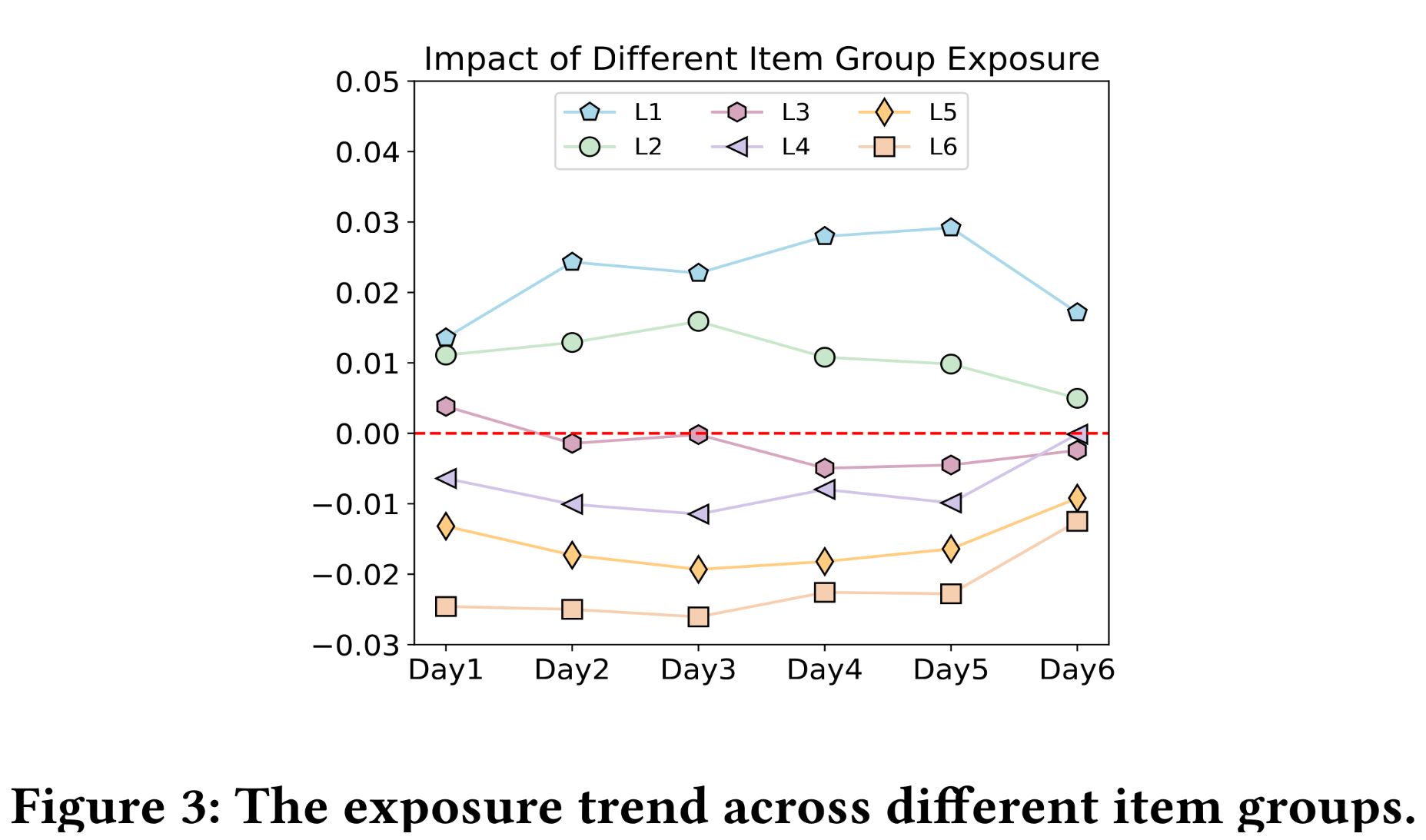
Figure 3展示了不同groups的日均曝光量提升趋势。Table 5给出了汇总的统计结果。与baseline模型相比:L1, and L2 items的曝光次数得到显著提升。而更热门的
L4, L5, and L6的曝光次数有所减少。
这两种现象表明,我们的
QARM是一种值得信赖的方式,可以为RecSys注入多模态信息,不仅为用户带来更好的体验,而且为new-uploaded items构建了一个公平的环境。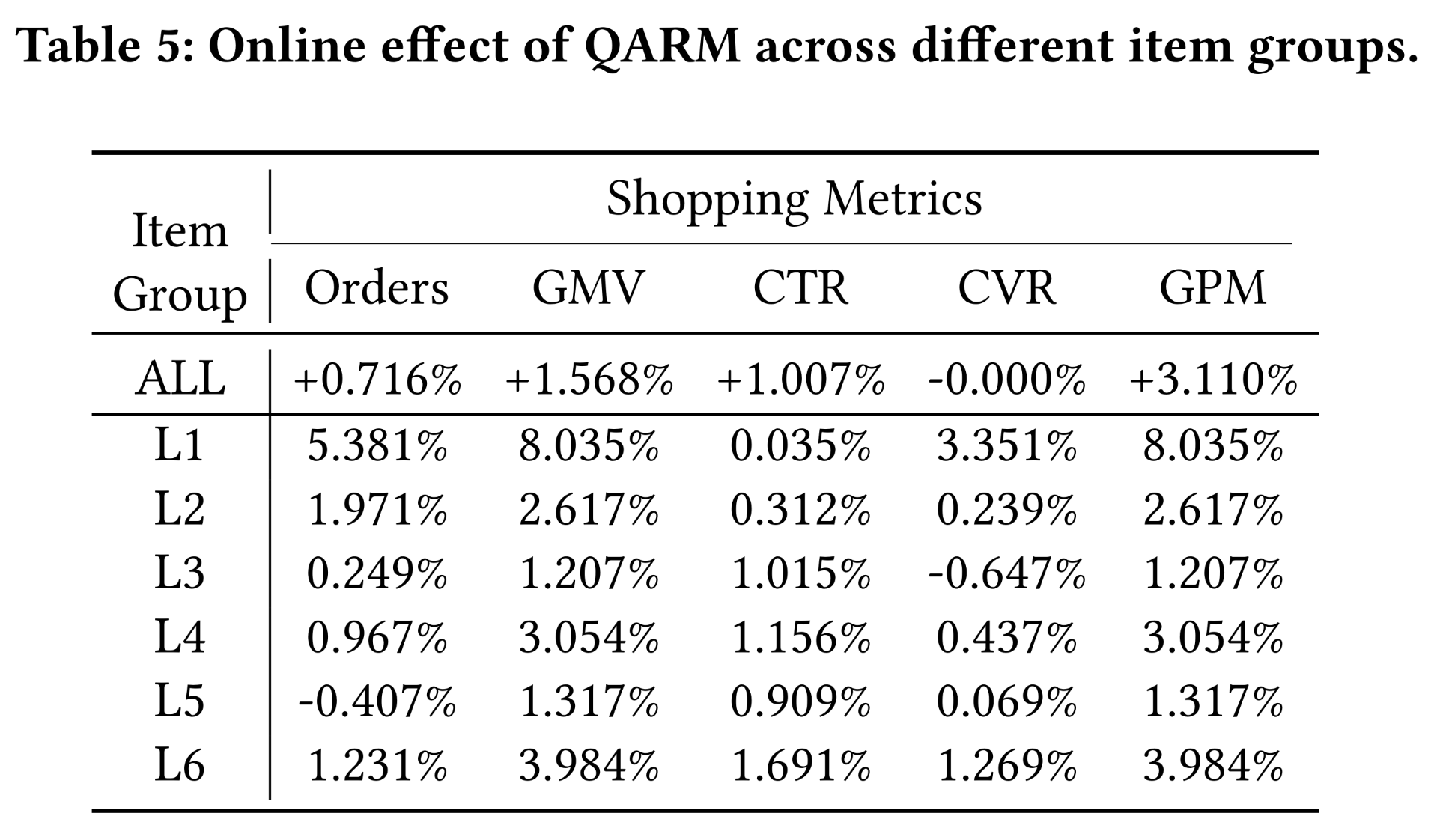
接下来,我们进一步通过实验来可视化
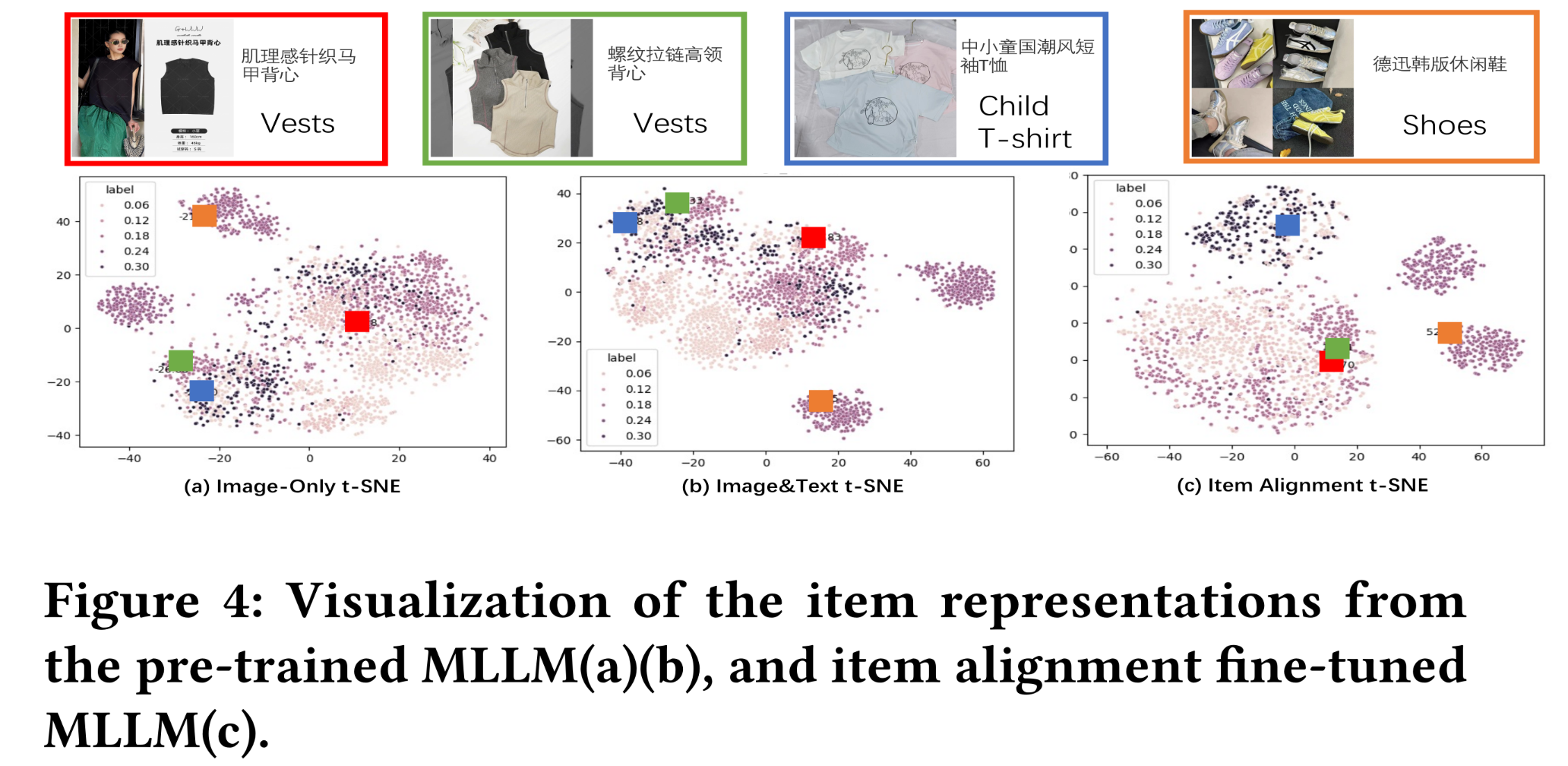
item alignment MLLM representations的影响。Figure 4展示了电商商城场景下三种不同representations的t-SNE可视化结果:(1):原始image-only representation的t-SNE。(2):原始image-text representation的t-SNE。(3):item alignment representation的t-SNE。
同时,随机选取了四个
items(两件背心vests、一件儿童T-shirt、以及一双鞋子shoes)展示item alignment效果。结果显示:
三种方法均能较好地区分鞋子和衣物。
原始
MLLM representations无法准确区分两件背心,且蓝色儿童T-shirt因图像风格与绿色背心相似从而在t-SNE中它们两更接近。item alignment representation将两件不同背心映射到最接近的位置,表明QARM的item alignment机制能成功捕获业务特性,最大化表征一致性(representation consistency)。
1.3.4 Parameter Analysis of Quantitative Code
默认设置
VQ code lengthRQ code lengthembedding sizequantitative codes的超参数对QARM鲁棒性的影响,我们针对VQ code lengthembedding size对于
VQ code length4种Table 6所示。根据实验结果,我们可以观察到,VQ code length的增加能够为我们的QARM模型带来相对稳定的性能提升。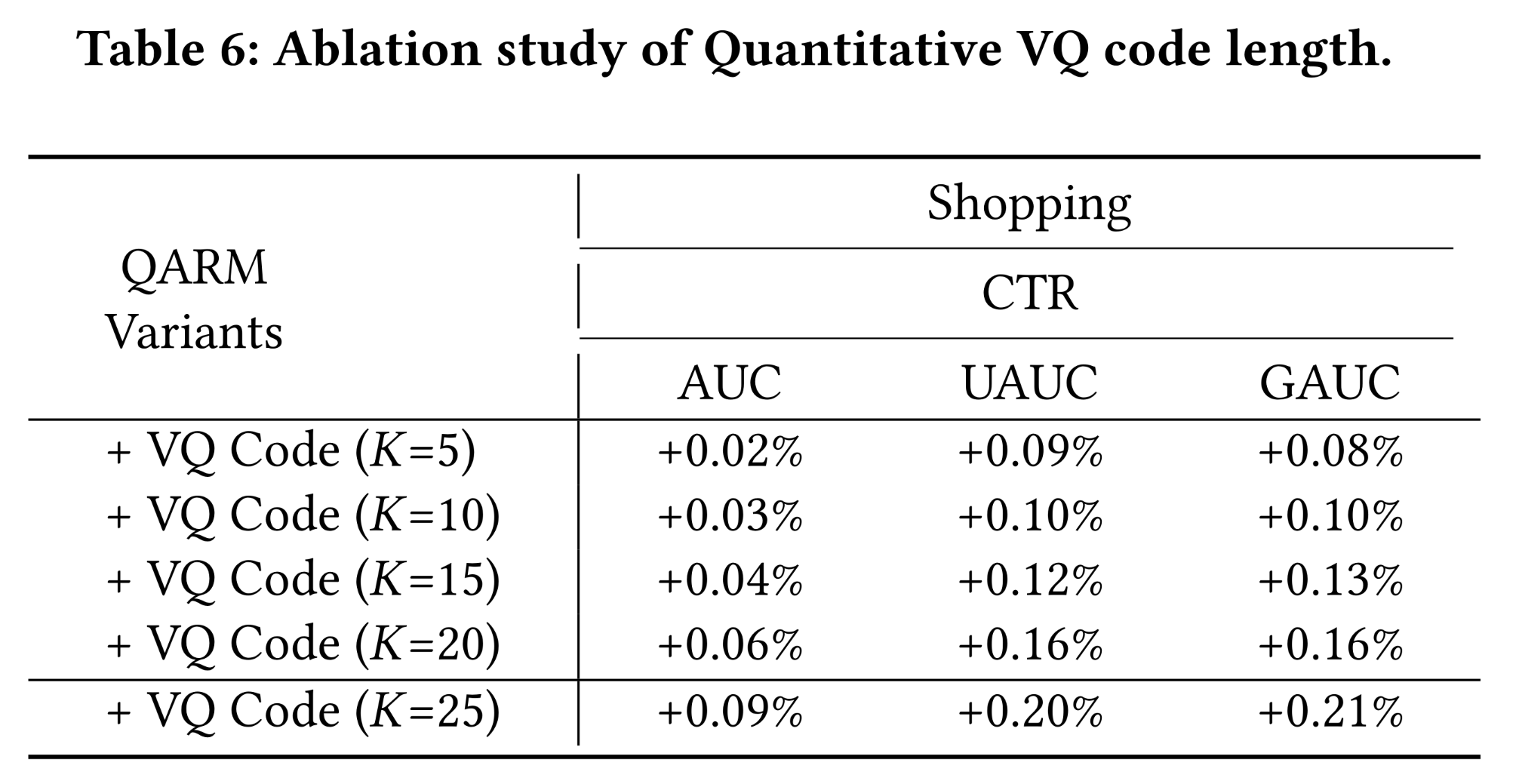
对于
code embedding的embedding sizeTable 7中。结果表明,增加code embedding size也是提升模型性能的有效方法。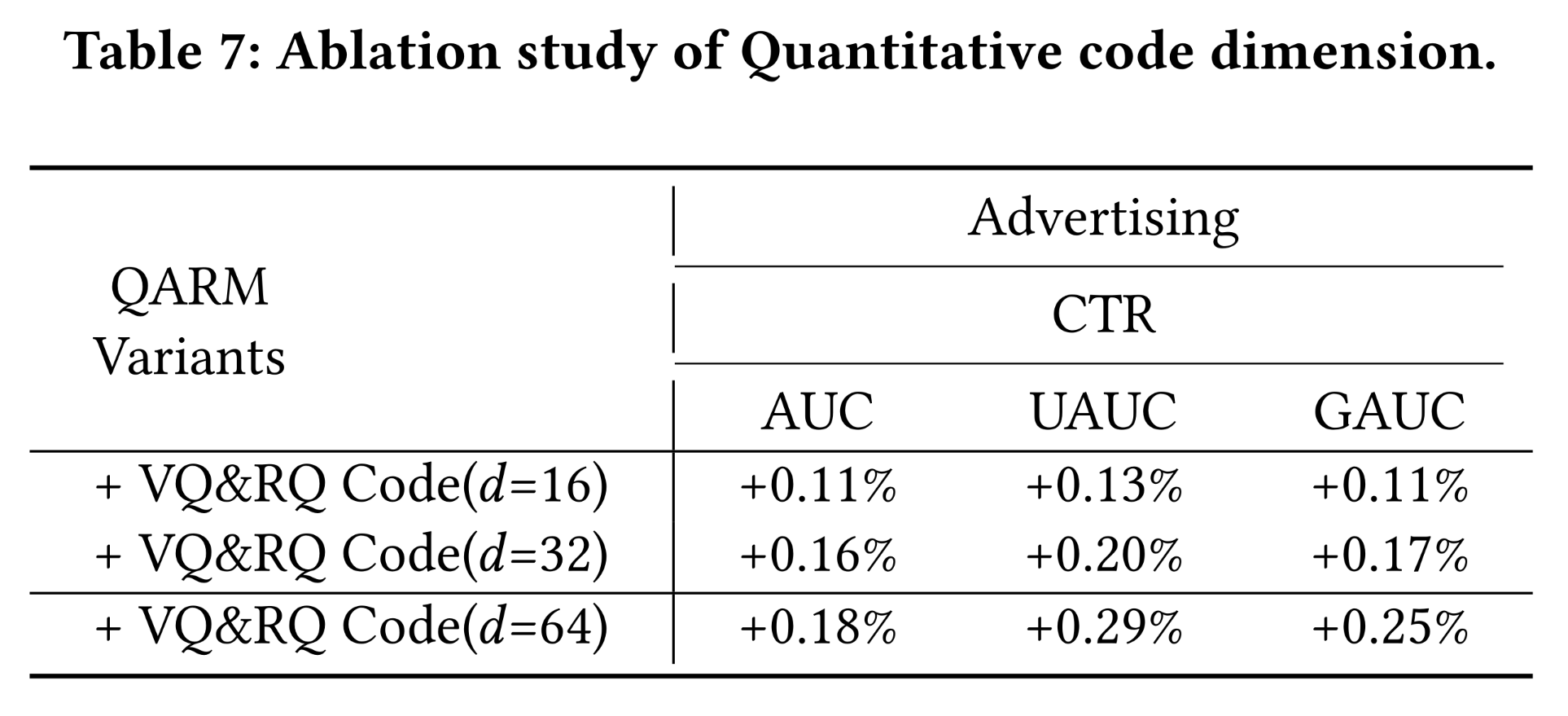
总之,实验结果表明,学习下游任务自适应的
representation对于理解多模态信息至关重要。
1.4 结论
本文提出了一种将多模态信息注入推荐模型的新方法——
QARM。与常用的部署范式(使用fixed unlearnable pre-trained MLLM representation)不同,我们的QARM利用down-streaming task alignment fine-tuned MLLM representations的quantitative code,实现了端到端的MLLM information training。具体而言:在
item alignment机制中,我们首先挖掘一组高质量的下游任务的item-item pairs,并利用它们来指导MLLM fine-tuning。对于
quantitative code机制,我们设计了两种启发式编码方法(VQ code和RQ code)来量化这些representations,从而构建user-side features、item-side features和target item-aware features,实现端到端优化,以获得更好的收敛性。
在
Kuaishou广告和购物场景上的实验结果表明,QARM在多模态信息融合方面具有显著的有效性。此外,详细分析表明,我们的QARM对冷启动items和长尾items更加友好,这符合multi-modal information usage的需求。QARM已于2024年3月在Kuaishou部署,支持各项服务,服务用户达400 million。
1.5 生成式AI使用声明
本文仅使用
AI工具修正语法错误。研究动机、方法设计和实验结果均来自Kuaishou真实业务场景的一手实验与分析,所有数据和观察结果均通过online A/B tests和离线分析进行了严格验证。