一、FPMC [2010]
《Factorizing Personalized Markov Chains for Next-Basket Recommendation》
在
next basket recommendation任务中,我们已知用户在各个时刻购买的basket的item,目标是向用户推荐该用户下一次访问时可能想要购买的item。基于马尔科夫链(
Markov Chain: MC)模型的推荐系统通过上一个动作来预测下一个动作,从而利用这种序列数据。MC估计了一个概率转移矩阵(transition matrix),它给出了已知上一个动作的情况下,发生下一个动作的条件概率。预测时,模型对每个用户的最近一次行为应用概率转移矩阵从而进行推荐。然而,
MC模型的概率转移矩阵对所有用户都是相同的,即非个性化的。另一方面,协同过滤方法(如矩阵分解
matrix factorization: MF)学习了个性化的、用户的一般兴趣(general taste),而忽略了序列信息。
MC和MF各有优势:MC可以通过非个性化的概率转移矩阵来及时地捕获序列效果(即,概率转移矩阵是在所有用户的所有数据上学习的),而MF可以通过所有数据来学习个性化的、每个用户的一般兴趣。在论文
《Factorizing Personalized Markov Chains for Next-Basket Recommendation》中,论文提出了一个基于个性化MC的模型,其中概率转移矩阵是user-specific的。具体而言,论文建模了一个概率转移立方体(transition cube),这个立方体的每个切面都是user-specific概率转移矩阵。通过这种个性化,论文将MC和MF的优点结合在一起:序列数据由概率转移矩阵捕获;由于所有概率转移矩阵都是user-specific的,因此模型捕获了个性化的用户兴趣。除了引入个性化
MC之外,这项工作的核心贡献是估计概率转移张量(transition tensor)(即概率转移立方体)。由于数据的稀疏性,不可能通过在完全参数化(complete parametrization)上使用标准计数方法(即,最大似然估计的估计Maximum Likelihood Estimator: MLE)来获得个性化概率转移矩阵的良好估计。相反,论文通过一个分解模型(factorization model)来建模概率转移张量。这允许在相似的用户、相似的item、以及相似的转移之间传播信息。通过使用基于pairwise interaction的MF,模型能够处理高度稀疏性。论文表明,该模型包含了个性化的MF模型、以及非个性化的MC模型。为了学习模型参数,论文将Bayesian Personalized Ranking: BPR框架扩展到next basket recommendation。最后,论文将所提出的方法应用到真实的电商数据集,实验结果表明所提出的方法优于
MF和MC模型。总而言之,论文的贡献如下:
论文引入了依赖于个性化的概率转移矩阵的个性化
MC,这允许我们同时捕获序列效应和长期用户兴趣。论文证明这是标准MC和MF的推广。为了处理转移概率估计的稀疏性,论文引入了一个可以应用于个性化概率转移矩阵的分解模型。这种分解方法导致参数更少,并且由于泛化能力导致它比完全参数化的模型更好的质量。
论文的实验表明,所提出的模型在序列数据上优于其它
SOTA方法。
相关工作:
一些研究人员已经研究了马尔科夫链或推荐系统。我们没有使用启发式方法来改善最大似然估计,而是使用为优化
ranking(而不是优化MLE)而学习的分解模型。总体而言,我们的工作与之前所有方法的主要区别在于使用个性化的概率转移矩阵,这结合了序列的好处(如时间感知、具有时不变用户兴趣的马尔科夫链)。此外,转移概率的分解和用于ranking的参数优化准则是新提出的。另一方面,大多数推荐系统未考虑序列模式,而是基于整个用户历史进行推荐。最近,来自隐式反馈的
item推荐已经开始成为热点。item推荐是相比评分预测更难的问题,因为只有正反馈而没有负反馈,因此无法直接应用标准的回归方法或分类方法。最近人们提出了一些基于矩阵分解的模型,这些模型分解了user-item相关性矩阵(correlation matrix)。在这项工作中,我们将这些MF模型的优点与MC模型结合起来。
1.1 模型
生成推荐的最常见方法是丢弃任何序列信息并学习用户的一般兴趣。另一方面,序列方法(主要依赖于马尔科夫链)的推荐仅基于最近的用户事件来学习相邻购买行为的关联。这两种方法都各有优缺点。
令
item集合,item数量。假设用户
busket为busket集合为busket为next basket recommendation任务是:在用户下次访问商店的时候向用户推荐item。注意,我们处理的不是绝对时间,而是关于用户的相对时间,如用户busket、第二个busket等等。因此该方法未考虑时间信息(绝对时间、相对时间间隔),仅考虑相对次序。
next basket recommendation推荐任务可以公式化为:为用户busket中的所有item创建个性化的ranking函数ranking函数,我们可以向用户推荐top n item。首先,我们为顺序的集合(
sequential set)引入MC,并将其扩展到个性化MC。然后,我们讨论概率转移立方体(transition cube)的最大似然估计的弱点。然后,为解决这个问题 ,我们引入了分解的概率转移立方体 ,其中转移之间的信息被传播。最后,我们结合了所有的思想从而得到FPMC模型。
1.1.1 用于集合的个性化马尔科夫链
a. 用于集合 Set 的马尔科夫链
通常,阶次为
其中:
在非集合的推荐场景中,随机变量是在
itembasket上的,因此其状态空间大小是basket,它包含不同item的组合有为了处理这个巨大的状态空间,我们做了两个简化:
我们使用长度为
对于
basket场景,在非集合的推荐场景中,通常可以选择更长的马尔科夫链(如
item。在我们的case中,即使长度为basket包含很多item。例如,在我们评估的application中,平均每个basket大约有10个item。我们简化了转移概率 (
transition probability)。长度为
basket上建模转移,而是在描述了basket状态的item是否包含在当前basket中)上建模转移:itembasket的情况下,下一个basket中出现item这种建模方式意味着:
状态空间现在是
状态空间的元素是二元变量,因此
因为下一个
basket可能包含很多item,使得
对于
item推荐,我们感兴趣的是:在给定用户最近一个basket的情况下购买某个item的概率。这可以定义为从最近一个basket到该item的所有转移概率的均值:这里假设最近一个
basket中所有item对于next itemattention的DNN模型,从而得到交互的、非线性的、自适应权重的模型。basket上完全的马尔科夫链可以表示为:注意,我们的目标是寻求
item ranking list,因此对完全的马尔科夫链item概率
b. 转移概率的估计
给定所有用户的所有历史
busket其中:
分子为所有历史
busketbasket、basket的basket pair数量。分母为所有历史
busketbasket的basket pair数量。
这里基于统计的方法来估计
item的存在对于概率的影响。即,认为basket中所有item对于next item
c. 用于集合的个性化马尔科夫链
上述的马尔科夫链是非个性化的,即与用户无关。现在我们将其扩展到个性化马尔科夫链
item的转移概率来表示每个马尔科夫链,但是现在是user-specific的:同样地,预测结果也是
user-specific的:同样地,这里假设最近一个
basket中所有item对于next item这意味着对于每个用户
下图展示了个性化概率转移矩阵的一个例子。许多参数无法估计(图中以
?标记 ),因为没有对应的观察数据。此外,估计的转移概率仅基于少量观察数据,这意味着这些估计是不可靠的。乍一看,使用个性化马尔科夫链似乎是不合理的,接下来我们将讨论导致错误估计的原因是什么,并展示如何解决它。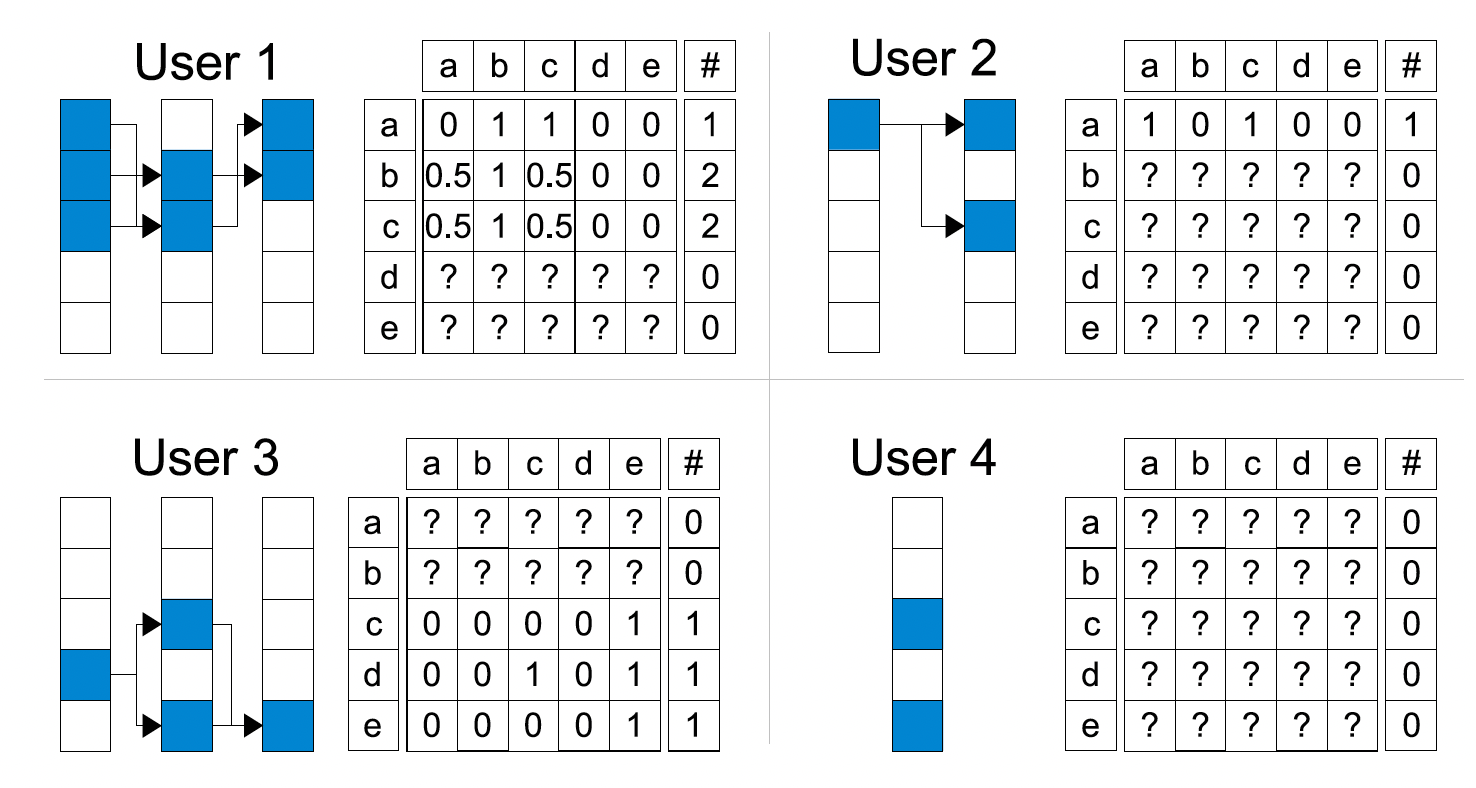
d. 最大似然估计和完全参数化的局限性
非个性化马尔科夫链和个性化马尔科夫链的不可靠转移概率的问题在于:它们使用完全参数化(
full parametrization)的转移图(transition graph)(即转移矩阵、转移立方体)、以及参数估计的方式。完全参数化意味着我们分别有
此外,最大似然估计独立地估计每个转移概率参数
此外,最大似然估计的重要性质(如高斯分布、无偏估计、无偏估计的最小方差)仅存在于渐进理论中。当数据较少的情况下,最大似然估计会遭受欠拟合。由于我们的场景中数据非常稀疏,因此最大似然估计很容易失败。
即模型的容量空间太大,数据量太少,导致模型欠拟合。
为了得到更可靠的转移概率估计,我们分解了概率转移立方体。这种方式打破了参数的独立性、以及估计的独立性。这样,每个转移概率都受到相似用户、相似
item、以及相似转移的影响,这是因为信息通过该分解模型进行传播。
1.1.2 分解转移图
我们对概率转移立方体
概率转移立方体的分解:用于估计概率转移立方体
Tucker Decomposition: TD:其中:
core tensor,item的特征矩阵(outgoing节点)。item的特征矩阵(ingoing节点)。
Tucker Decomposition包含其它分解模型,如Canonical Decomposition: CD(也称作并行因子分析parallel factor analysis: PARAFAC)。CD假设core tensor是对角矩阵,即:并且因子分解的维度相等,即
由于观察到
CD的一种特殊情况来建模pairwise交互:这里类似于
FFM的思想,每个field都有两个embedding从而与不同的其它field进行交互。此外,这里的
core tensor对角线为1,意味着不同的field交互的重要性都是相同的。能否自动学习不同field交互的重要性?该模型直接建模张量的所有三种模式之间的
pairwise交互,即user和next item之间、user和last item之间、以及last item和next item之间的交互。对于每种模式,我们有两个分解矩阵:对于
user和next item之间的交互:next item特征。对于
user和last item之间的交互:last item特征。对于
last item和next item之间的交互:next item特征,last item特征。
该模型优于
TD的一个优点是:预测和学习复杂度远远低于TD。此外,即使TD和CD包含了上述pairwise交互模型,但是它们无法识别到pairwise交互模型。我们提出的分解概率转移立方体的模型也可以用于非个性化的概率转移矩阵
总结:将个性化的、集合的马尔科夫链与分解的概率转移立方体相结合,则得到分解的个性化马尔科夫链(
factorized personalized Markov chain: FPMC):其中我们通过被分解的立方体
因为
user和next item之间的交互可以看到
FPMC的预测结果可以分为几个部分:user和next item之间的交互,建模next item与用户长期偏好的关系,因为这部分与时间last item和next item之间的交互,建模next item与用户短期偏好的关系。user和last item之间的交互,这一部分可以建模了用户长期偏好和用户短期偏好的关系。随后的章节中,论文证明这个部分可以被移除。
所有的这些部分都可以用更复杂的模型(如
DNN)、引入更多的辅助信息(如用户画像、item画像)来刻画。在接下来的章节中,我们将
FPMC模型应用于item推荐任务。我们将证明,在这种情况下模型可以进一步简化,此时user和last item之间的交互可以移除。与完全参数化的概率转移立方体相比,分解模型的泛化性能更好、且参数更少。
完全参数化的模型需要
分解模型只需要
对于具有大量
item的application而言,使用
1.1.3 Item 推荐
前面已经介绍了个性化马尔科夫链的分解模型,接下来我们将该模型应用于
item推荐任务中。这意味着模型参数应该针对ranking进行优化。首先,我们从
sequential set数据中导出S-BPR,它是item推荐的通用优化准则。该优化准则不仅可用于我们的FPMC模型,还可用于其他模型,如kNN或标准MF模型。其次,我们将
S-BPR应用于FPMC,并展示了在使用S-BPR进行item推荐的情况下如何简化模型。最后,我们提出了一种基于
bootstrap采样的随机梯度下降学习算法,用于使用S-BPR优化模型参数。这个
bootstrap采样的随机梯度下降学习算法就是mini-batch随机梯度下降学习算法。
a. S-BPR 优化准则
如前所述,从
sequential basket数据中推荐item的目标是推导出item的ranking函数ranking,我们假设有一个估计量ranking:其中
由于
total order),所以item集合接下来我们导出类似于通用
BPR方法 的sequential BPR: S-BPR优化准则。用户raking其中
假设
basket和用户独立,这导致模型参数的最大后验(maximum a posterior: MAP)估计:对所有
item pairbasket内的next item之间是相互独立的(来自于BPR原始论文的假设),则然后我们用模型定义
这里我们忽略参数
sigmoid函数,则有:进一步地,我们假设模型参数
S-BPR的MAP估计:其中
S-BPR和BPR的核心区别在于:BPR的(positive, negative) pair中,negative是用户item之外选取,即全局负样本。S-BPR的(positive, negative) pair中,negative是用户basket item(即positive所在的basket)之外选取,即局部负样本。
b. 采用 FPMC 的 Item 推荐
首先,我们用
FPMC模型来表示S-BPR:引理一(
user和last item之间分解的不变性):对于使用S-BPR的item排序和优化,FPMC模型对于user和last item之间的分解是不变的,即证明过程见原文。主要思路:令
则可以证明:
两个模型
两个采用
S-BPR的模型最优化得到相同的参数解
因此对于采用
FPMC的item推荐,我们使用新的然后,我们将展示简化的
FPMC模型与标准的矩阵分解(matrix factorization: MF)和分解马尔科夫链(factorized Markov chain: FMC)的关联。用于
item推荐的标准MF模型为:其中
非个性化的分解马尔科夫链
FMC模型为:
因此,
FPMC是MF模型和FMC模型的线性组合:这意味着
FPMC可以包含这两种模型:通过将
user和next item之间分解的维度设为0,即FMC。通过将
last item和next item之间分解的维度设为0,即MF模型。
需要注意的是:
item推荐中,即使FPMC的模型方程可以通过MF和FMC模型的线性组合来表示,但是FPMC不同于单个MF模型和单个FMC模型的线性组合。因为FPMC模型的参数是联合学习的,而不是每个子模型(如MF模型和FMC模型)单独学习的。这在FPMC的通用情况下更为明显,其中FPMC的模型方程 无法由MC和FMC的线性组合来表示,如:当
FPMC优化另一个准则(如最小平方误差)而不是S-BPR准则时,其中user和last item之间的分解不能被丢弃,因为这个准则下的不变性(即引理一)不成立。此时FPMC的模型方程无法由MC和FMC的线性组合来表示。当
FPMC中为张量TD或CD)而不是pairwise交互时,此时即使采用S-BPR优化准则,则FPMC的模型方程也无法由MC和FMC的线性组合来表示。
c. 最优化
FPMC包含MF和FMC,而这两个模型也可以使用它们各自所提供的的算法针对S-BPR准则进行优化。尝试直接优化
S-BPR非常耗时,因为basket-wise随机梯度下降方法的收敛速度非常慢。相反,我们通过bootstrapp独立地随机抽取四元组,并对这些样本进行随机梯度下降。在每次迭代中,我们随机抽取一个四元组basketitembasket中的itemS-BPR执行梯度下降。算法的复杂度为basket大小。感觉这就是常规的
mini-batch随机梯度下降。
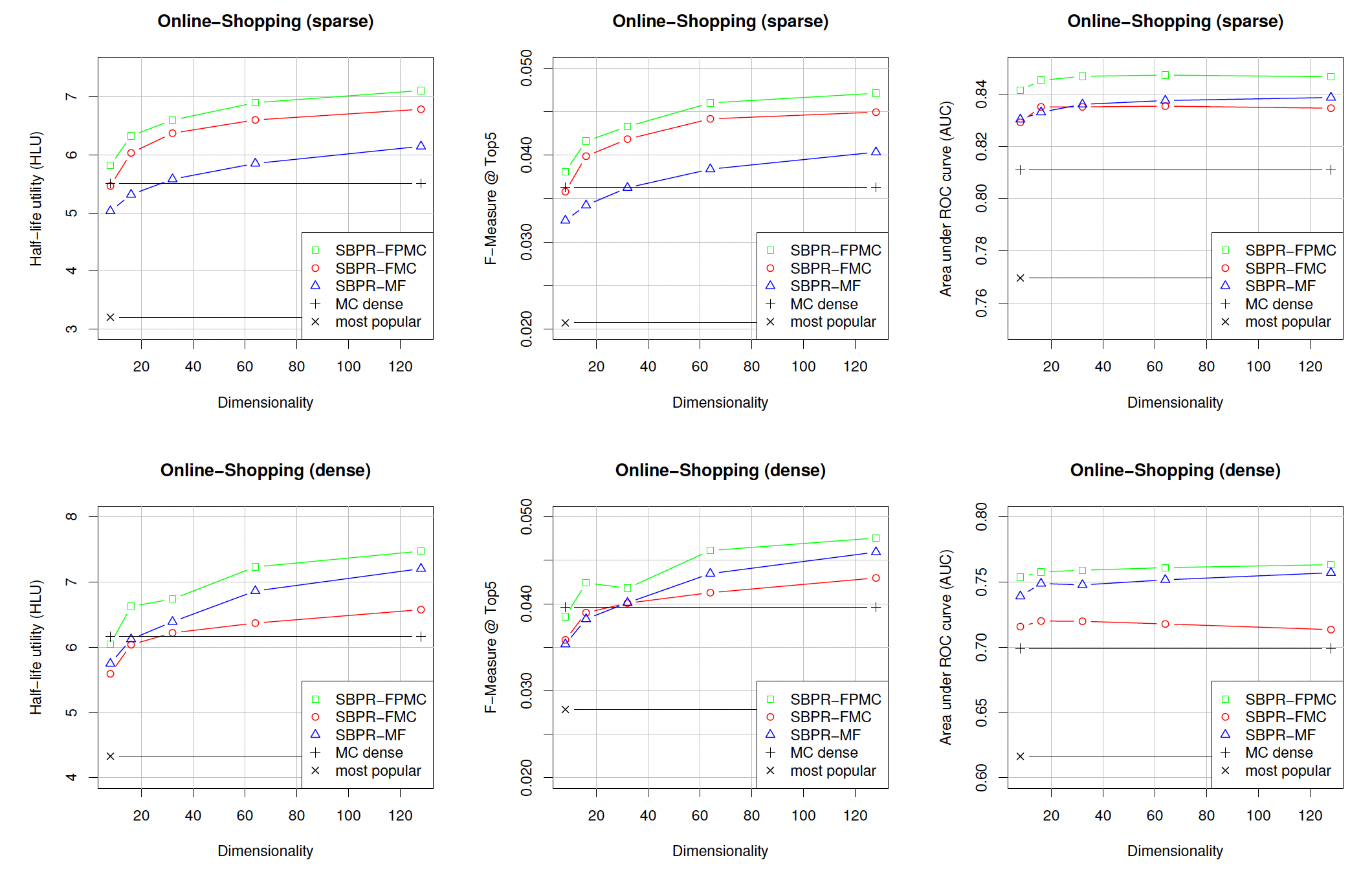
1.2 实验
baseline方法:factorized Markov chain: FMC、non-factorized Markov chain: MC dense、matrix factorization: MF、最流行most-popular: MP。注意,这里包含很强的
baseline方法BPR-MF。由于MF和FMC都是FPMC的特例,因此对于这三种方法我们都是用FPMC的学习算法。数据集:我们使用在线药店的匿名购买数据集。我们使用的数据集是一个
10 core子集,其中每个用户总共至少购买了10个item,每个item至少被10个用户购买。我们还创建了它的一个子集,其中包含10000个最多购买的用户、以及1000个最多购买的item,从而评估稀疏性对方法的影响。

评估方式:我们将每个用户的最后一个
basket作为测试集,并将剩余的basket作为训练集。我们从测试集中删除了过去购买少于10种不同item的用户。对于每个用户,我们从测试集中删除该用户已经购买过的所有
item,这是因为我们希望向用户推荐其不知道的新品。这使得预测任务变得更加困难。否则,对于牙刷、清洁剂等药店中的非耐用品,仅重复推荐已购买商品将是一个简单的、但是非常成功的策略。然而,这不是推荐系统的任务,因为推荐系统应该帮助用户发现新事物。我们针对每个用户
basket来测试不同模型的质量。评估指标:Half-life-utility: HLU:测试basket中每个next item的归一化衰减因子之和。其中,归一化衰减因子为:next item在所有我们报告所有测试
basket的HLU均值。Precision:top K预估结果中,命中next item的item数量除以Recall:top K预估结果中,命中next item的item数量除以测试basket的大小。这里我们选择此外,我们还报告
F-measure指标,它是Precision和Recall的调和均值。AUC:Area under the ROC curve。
实验结果如下图所示。对于分解方法,我们使用
正如预期的那样,所有其它方法都优于
most-popular方法。其次,在合理的分解维度(如
32)下,所有其它分解方法都优于标准MC方法(即MC dense)。总体而言,
FPMC优于所有其它方法。
我们比较
FMC和MC。结果表明:学习分解的概率转移矩阵相比通常的计数方案(counting scheme)产生更好的估计。分解方法有两个优点:它的参数规模更小,并且通过使用低秩近似来防止过拟合。我们比较
FMC和MF。可以看到:在稠密场景下MF似乎优于FMC,而在稀疏场景下FMC似乎更胜一筹。原因可能是:在稠密场景中,每个用户的信息要多得多,因此使用所有全部用户购买信息的
MF方法,要优于仅使用最后一次购买的FMC方法。反之,
FMC在稀疏数据集上具有优势。而结合了这两种方法优点的FPMC在两个数据集上都优于它们。