一、GRU4Rec [2015]
《Session-Based Recommendations With Recurrent Neural Networks》
有些电商推荐系统、新闻网站、媒体网站不会跟踪用户
ID。虽然cookie和浏览器指纹技术可以提供一些程度上的用户识别,但是这些技术通常不可靠并且容易引发隐私问题。即使可以跟踪用户ID,但是用户在一些小型电商网站上可能只有一两个会话(session),并且在某些领域(如分类网站classified site)中,用户的行为通常表现出session-based的特征。因此,同一个用户的每个会话应该独立地处理。在中国的互联网早期,存在大量的、可以匿名访问的网站或
APP,因此不会跟踪用户ID。随着移动互联网浪潮的兴起,中国互联网大多数网站或APP需要登录才能访问,典型的例子是淘宝,因此可以跟踪到用户ID。即使能够跟踪到用户ID,我们也无法保证操作手机的是同一个用户。目前大多数电商的
session-based的推荐系统都使用相对简单的方法,如item-to-item相似性、item共现、转移概率等等。虽然有效,但是这些方法仅考虑用户的最后一次行为,而忽略了用户的历史行为。此外,推荐系统中最常用的是因子模型(
factor model)和邻域方法(neighborhood method)。因子模型将稀疏的
user-item交互矩阵分解为一组user潜在因子向量和item潜在因子向量来完成矩阵补全问题(例如用潜在因子向量的内积)。由于无法跟踪用户ID(导致无法获取用户历史交互的item),所以因子模型很难应用于session-based的推荐。邻域方法依赖于会话内的
item共现,因此被广泛应用于session-based推荐中。
RNN在翻译、对话建模、图像标注(image captioning)等领域取得了显著成功,但是很少有人将其用于推荐领域。在论文《Session-Based Recommendations With Recurrent Neural Networks》中,作者认为RNN可以应用于session-based推荐并取得了显著效果。作者处理了在建模这类稀疏序列数据进行时出现的问题,并通过引入适当的、新的ranking loss function来使得RNN模型适应推荐setting。session-based推荐问题在建模方面与一些NLP-related问题相似,比如它们都处理序列数据。在session-based推荐中,我们可以将用户在会话中的第一个交互item作为RNN的初始输入,然后我们根据这个初始输入来query模型从而获得推荐。然后,用户的每次后续交互都会产生一个推荐,这个推荐取决于所有先前的、同一个会话内的交互。item集合可能是数万甚至数十万,另外交互行为可能非常频繁,因此训练时间和可扩展性非常重要。和大多数信息检索和推荐
setting一样,论文主要关注于建模用户最感兴趣的top item,为此论文使用ranking loss function来训练RNN。相关工作:
session-based推荐:推荐系统领域的大部分工作都集中在当user ID可用并且可以获取用户画像时的模型上。这种情况下,矩阵分解模型、邻域模型在文献中占据主导地位。session-based推荐中采用的主要方法之一是item-to-item推荐,此时item-to-item相似度矩阵是从可用的会话数据中预计算而来,也就是说,在同一个会话中共现的item被认为是相似的。这种方法虽然简单但是已被证明有效,并被广泛采用。但是,该方法仅考虑用户的最近一次行为,忽略了用户历史行为信息。session-based推荐的另一个稍微不同的方法是马尔科夫决策过程(Markov Decision Processes: MDP)。MDP是序列随机决策问题的模型,最简单的MDP本质上是一阶马尔科夫链,其中next推荐可以简单地根据item之间的转移概率来计算。 在session-based推荐中应用马尔科夫链的主要问题是:当试图包含所有可能的用户行为序列时,状态空间很快变得无法管理。通用分解框架(
General Factorization Framework: GFM)的扩展版本能够使用会话数据来推荐。该方法通过事件(event)的sum来建模会话,并对item使用两种潜在representation:一种代表item本身、另一种代表item是会话的一部分。然后将会话中所有item的第二种representation取平均从而作为会话的representation。但是,该方法不考虑会话中的行为顺序。推荐系统中的深度学习:在推荐系统中最早应用深度学习的相关方法之一是
《Restricted boltzmann machines for collaborative filtering》,它使用RBM来对user-item交互进行建模并执行推荐。此外,深度模型也用于从音乐或图像等非结构化内容中提取特征,然后与更传统的协同过滤模型一起使用,如《Deep content-based music recommendation》。最近,《Collaborative deep learning for recommender systems》引入了一种更通用的方法,该方法使用深度网络从任何类型的item中抽取通用的内容特征,然后将这些特征集成到标准的协同过滤中从而提高推荐性能。这些方法在缺乏足够user-item交互的setting中特别有用 。
1.1 模型
1.1.1 模型
标准的
RNN:其中:
hidden state),sigmoid函数)。Gated Recurrent Unit: GRU是一个更精细的RNN模型,旨在处理梯度消失问题。GRU gates本质上是学习何时更新单元的隐状态、以及更新多少:其中:
update gate,reset gate,sigmoid激活函数,candidate activation)。我们在模型中使用
GRU-based RNN来进行session-based推荐。网络的输入是每个时刻会话的实际状态(actual state),输出是会话中下一个事件的item。会话的状态可以是最新的事件(即当前事件)。此时使用
OneHot编码,即输入向量的长度为item为1而其它位置为0,其中item集合大小。会话的状态也可以是截止到当前的所有事件(即累计事件)。此时对每个事件的
OneHot编码进行加权和,权重根据事件发生时刻距离当前时间间隔进行衰减。为了稳定性,我们对输入向量进行归一化。我们希望这种累计事件的方式会有所帮助,因为它增强了记忆效应(
memory effect)。但是实验发现,这种方式并不会带来额外的准确率增益。这毫不奇怪,因为GRU像LSTM一样,同时具有长期记忆和短期记忆。
我们尝试添加一个额外的
embedding layer,但是发现OneHot编码总是表现得更好。如果没有
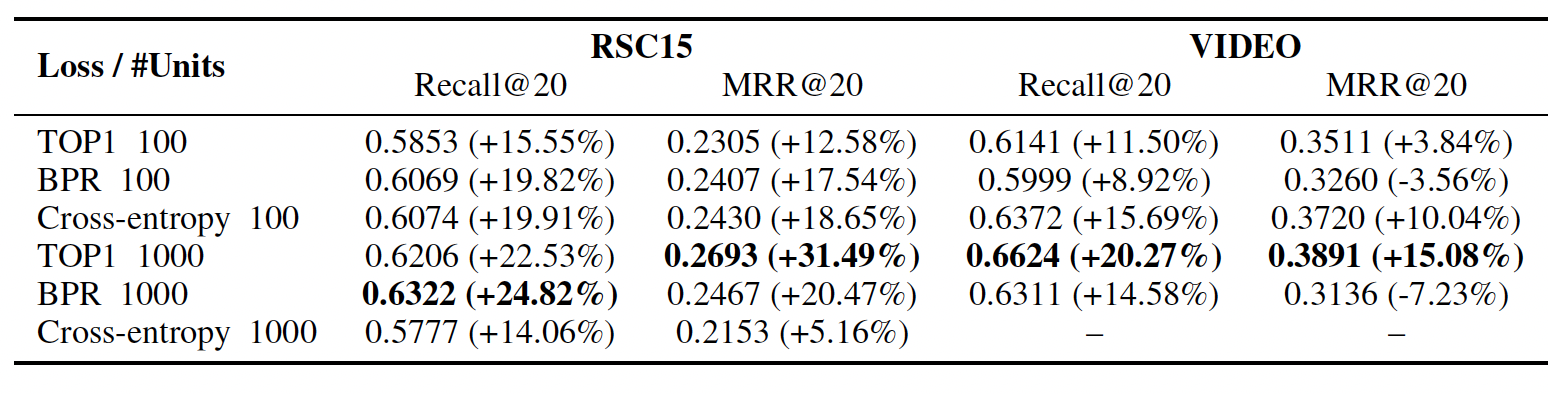
embedding layer,则embedding矩阵; 如果添加额外的embedding layer,则embedding矩阵之上的投影矩阵。网络的核心是
GRU layer。可以使用多层GRU layer,其中前一层的hidden state是下一层 的输入。最后一个GRU layer和输出层之间添加了额外的前馈层(Feedforward layer)(但是实验发现增加这个额外的前馈层对于效果提升没有帮助)。输出是每个item在当前会话中成为next的可能性。input层也可以选择连接到网络中更深的GRU layer,因为我们发现这可以提高性能。完整的架构如下图所示,该架构描述了事件时间序列中单个事件的
representation。图中包含了
embedding layer和feedforward layer,但是根据实验描述,这两个layer是无益的,需要移除。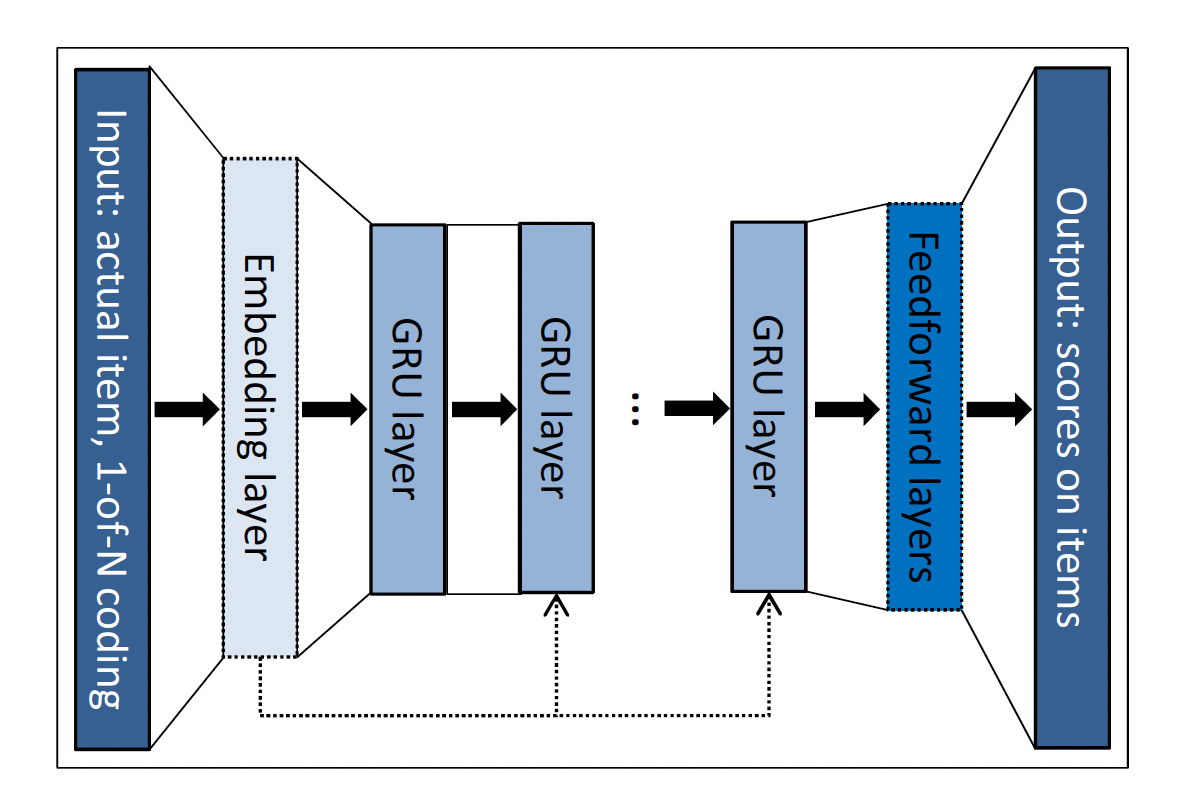
1.1.2 调整
由于推荐系统不是
RNN的主要应用领域,我们修改了基础网络从而更好地适应任务。我们还考虑了实际场景,以便我们的解决方案可以应用于现场环境。session-parallel mini-batch:用于NLP任务的RNN通常使用in-sequence mini-batch。例如,通常在句子的单词上使用滑动窗口,并将这些窗口片段彼此相邻从而形成mini-batch。这不适合于我们的任务,因为:首先,会话之间长度的差异非常大(远远大于
NLP中的句子)。一些会话仅包含一到两个事件,而另一些会话可能包含超过数百个事件。其次,我们的目标是捕获会话如何随时间的演变,因此将会话分解为片段是没有意义的。
因此,我们使用
session-parallel mini-batch,如下图所示。具体而言:首先,我们将所有会话进行排序。
注意,这里是以会话为基本单元进行排序,而不是对会话内的事件进行排序。
然后,我们使用前
X个会话的第一个事件来构成第一个mini-batch的输入(所需的输出是这些会话的第二个事件)。第二个mini-batch是由这些会话的第二个事件形成的,依次类推。如果任何一个会话结束了,则下一个可用的会话将填补该结束会话的位置。假设会话之间是相互独立的,因此我们在发生这种会话切换的时候重置对应的
hidden state。这种训练方式可以支持任意长度的
session,而无需将session进行长度限制(比如截断为固定长度)。
sampling on the output:当item集合规模太大时,在每个step计算每个item在当前会话中成为next的可能性是不现实的。因此我们需要负采样技术。我们根据
item的流行程度进行负采样:item越流行,那么用户就越可能知道它,那么用户未对该item交互则意味着用户更有可能不喜欢该流行item。我们没有为每个训练样本生成单独的负采样,而是使用来自
mini-batch的其它训练样本的item作为负采样。这种方法的好处是我们可以减少计算时间、降低代码复杂性、并且也易于实现。同时,该方法也是一种基于流行程度的采样,因为一个item出现在mini-batch中的可能性与其流行程度成正比。ranking loss:推荐系统的核心是item的relevance-based ranking。尽管该任务也可以解释为分类任务,但是learning-to-rank方法通常优于其它方法。ranking可以是point-wise、pair-wise、或者list-wise的。point-wise ranking彼此独立地估计item的score或者ranking,并且损失函数的定义方式使得相关的item的排名应该靠前。pair-wise ranking比较一个positive item和一个negative item组成的ranking pair对,损失函数强制positive item的排名应该比negative item的排名更靠前。list-wise ranking使用所有item的score或ranking,并将它们与完美排序进行比较。它通常在计算上代价太大,因此不经常使用。
此外,如果仅有一个相关的
item(例如我们这里的例子),list-wise ranking可以通过pair-wise ranking来解决。我们在我们的解决方案中包含了几个point-wise ranking loss和pair-wise ranking loss。我们发现模型的point-wise ranking loss不太稳定,而pair-wise ranking loss表现良好,最终我们使用以下两个pair-wise ranking loss:BPR:贝叶斯个性化排名(Bayesian Personalized Ranking: BPR)是一种矩阵分解方法,它使用pair-wise ranking loss。它比较一个positive item和一个负采样的negative item的score。这里,我们将positive item的score和几个负采样的negative item的score进行比较,并将它们的均值作为损失。具体而言,pair-wise ranking loss为:其中:
sigmoid函数,s中itemscore,positive item,negative item。TOP1:这个ranking loss是我们为这项任务而设计的,它是relevant item的相对排名(relative rank)的正则化近似。relevant item其中
sigmoid函数来代替示性函数,优化这个相对排名将会修改parameter从而使得itemscore会很高。然而,这个目标函数不稳定,因为某些
positive item也会扮演负样本角色,因此score往往会变得越来越高。为避免这种情况,我们希望强制
negative item的score在零左右,这是negative item的score的自然预期。为此,我们在损失函数中添加了一个正则化项。重要的是,这一项与相对排名在同一取值区间并且作用与其相似。最终的损失函数为:.
1.2 实验
数据集:
RecSys Challenge 2015数据集(RSC15):该数据集包含电商网站上的click-streams,其中某些stream以购买事件而结束。我们仅保留点击事件,并且过滤掉长度为1的会话。我们使用前6个月的数据进行训练,使用第二天的会话进行测试。每个会话要么是训练集要么是测试集,我们不会在会话中拆分数据。由于协同过滤方法的性质,我们从测试集中过滤掉训练期间
unseen的item,并且删除测试集中长度为1的会话。VIDEO数据集:包含某个视频服务平台收集的视频观看事件。预处理步骤如前所述,但是也过滤掉了很长的会话,因为这些会话可能是由机器人生成的。训练数据集包含最后一天除外的所有数据,测试数据集包含最后一天的数据。
评估方式:通过
one-by-one提供会话的事件并检查下一个事件的item排名来完成评估。GRU的隐状态在会话结束之后重置为零。item按照score降序排名。对于
RSC15数据集,我们对训练集中出现的37483个item进行排名。对于VIDEO数据集,因为item集合太大因此我们将next item和最流行的30000个item进行排名。这种评估的影响可以忽略不计,因为冷门的item通常score很低。此外,基于流行度的预过滤在实际推荐系统中很常见。recall@20:在top 20排名的item中,召回的next item占所有next item的比例。召回不考虑
item的实际排名,只要它位于top N的位置。这很好地建模了某些实际场景,其中绝对顺序无关紧要。此外,召回率通常还与重要的在线指标密切相关,如点击率CTR。MRR@20:Mean Reciprocal Rank: MRR是next item的排名的倒数的均值。如果排名在20之后则排名的倒数置为零。MRR考虑item的排名,这在推荐顺序很重要的场景下很重要(如排名靠后的item仅在滚动屏幕之后才可见)。
baseline方法:POP:流行度的predictor,它总是推荐训练集中的流行item。尽管简单,但是它通常是某些领域的强大baseline。S-POP:推荐当前会话中最流行的item(而不是全局最流行的item)。该baseline在具有高重复性的领域中很强。Item-KNN:基于item相似性来推荐和当前item最相似的item。相似度定义为此外,我们还使用正则化从而避免冷门
item的偶然发生导致的高度相似性。该
baseline是实际系统中最常见的item-to-item解决方案之一。尽管简单,它通常也是一个强大的baseline。BPR-MF:它通过SGD优化pair-wise ranking目标函数,是最常用的矩阵分解方法之一。矩阵分解无法直接应用于session-based推荐,因为新会话没有预先计算的特征向量。然而,我们可以通过使用会话中出现的item的特征向量的均值作为user特征向量来克服这个问题。换句话讲,我们对next item的特征向量、迄今为止会话中item特征向量的相似性进行平均。
这些
baseline的效果如下表所示,其中item-KNN方法显著优于其它baseline方法。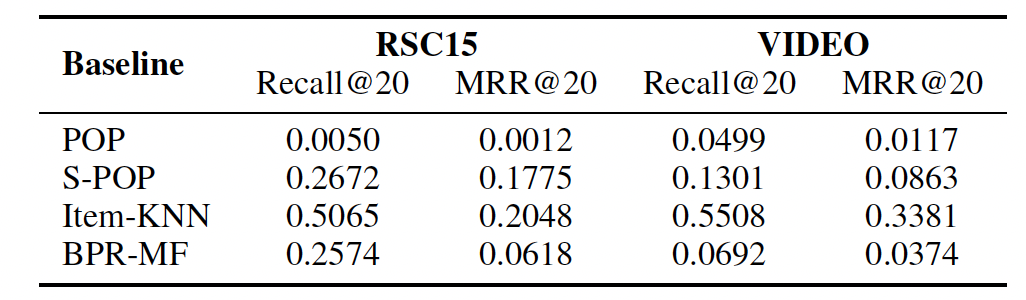
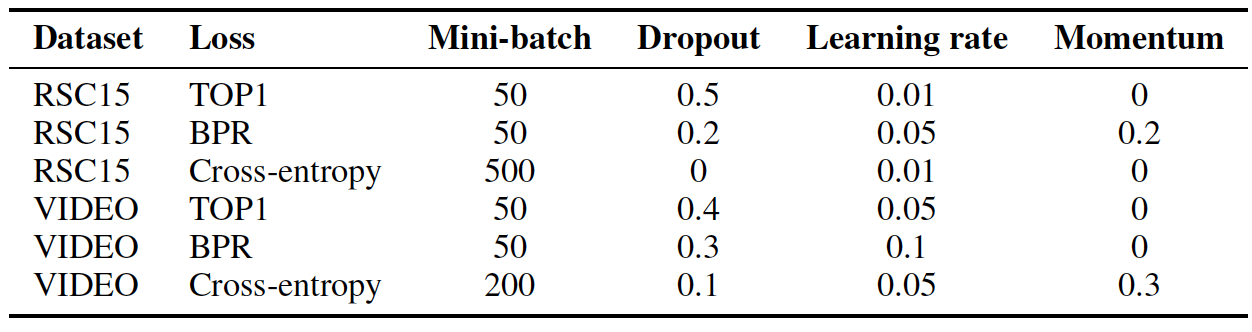
参数配置:我们通过单独优化每个超参数来进行超参数调优,其中调优是在单独的验证集上进行的。然后我们在训练集和验证集上对网络进行重新训练,并最终在测试集上进行评估。下表给出了最佳的超参数。
此外还有一些探索如下:
权重矩阵从
我们评估了
rmsprop和adagrad优化器,发现adagrad效果更好。我们对
GRU以外的其它RNN单元进行了简单的实验,发现常规的RNN单元和LSTM单元的效果都更差。我们尝试了几种损失函数。
point-wise ranking loss(如交叉熵和MRR)优化通常是不稳定的,即使添加正则化也是如此。我们认为:这是由于这种方法试图为positive item获得高分,而负样本的negative push太小。另一方面,
pair-wise ranking loss表现良好。
我们检查了几种架构,发现:
单层
GRU表现最好。我们假设这是由于会话的生命周期通常都很短,不需要表达不同分辨率的多个时间尺度。然而,确切原因尚不明确,需要进一步研究。使用
item embedding得到的效果稍差,因此我们仅使用OneHot编码。此外,将会话的所有历史事件(而不是最新的事件)作为输入并不能带来额外的准确率增益。这毫不奇怪,因为
GRU像LSTM一样,同时具有长期记忆和短期记忆。在
GRU layer之后添加额外的前馈层也没有帮助。然而,增加
GRU layer的大小提高了性能。我们还发现使用
tanh作为输出层的激活函数是有益的。
实验结果:下表给出了性能最佳的网络的结果(括号表示相对于
item-KNN中的提升。)。具有1000个隐单元的VIDEO数据集的交叉熵在数值上不稳定,因此我们没有提供结果。结论:即使隐单元数量为
100,GRU-based的方法在两个数据集上都显著优于item-KNN。增加隐单元数量进一步改善pair-wise loss的结果,但是降低了交叉熵损失(即point-wise loss)的准确率。在隐单元数量为
100时,尽管交叉熵损失给出了更好的结果,但是随着隐单元数量的增加,pair-wise loss超过了该结果。尽管增加隐单元数量会增加训练时间,但是我们发现
GPU上从隐单元100提升到1000的代价不太昂贵。交叉熵损失在数值上不稳定,因为网络独立地尝试增加
positive item的score,而其它item的negative push相对较小。因此,我们建议使用上述两个pair-wise loss中的任何一个。