一、HRM [2015]
《Learning Hierarchical Representation Model for Next Basket Recommendation》
购物篮分析(
market basket analysis)可以帮助零售商更好地了解用户的购买行为,从而作出更好的决策。购物篮分析最重要的任务之一是next basket recommendation:根据每个用户的序列交易数据来推荐用户下一次访问时可能想要购买的item。其中,交易(transaction)是在某个时刻购买的一组item(如鞋子、包包)。该问题有两种建模范式:序列推荐器(
sequential recommender):主要依赖于马尔科夫链。它根据最近的动作预测next purchase来探索序列交易数据。该模型的一个主要优点是它能够捕获序列行为从而用于良好的推荐。例如,对于最近购买手机的用户,它可能会推荐该用户购买手机配件,其中这些手机配件是其它用户购买手机后也来购买的。通用推荐器(
general recommender):丢弃任何序列信息并学习用户感兴趣的item。这类方法中最成功的方法之一是基于模型的协同过滤 (如矩阵分解模型)。显然,通用推荐器擅长通过学习用户的整个购买历史来捕获用户的通用兴趣(general taste)。
next basket recommendation的更好的解决方案是同时考虑序列行为和用户的通用兴趣。个性化的马尔科夫链(personalized Markov chain: FPMC)朝着这个方向迈出了一步,它能够同时建模序列行为(通过前一个交易中的item与后一个交易中的item之间的交互)、以及用户的通用兴趣(通过用户与next basket中的item之间的交互),因此比单独的序列推荐器或者单独的通用推荐器表现更好。然而,FPMC的一个主要问题在于它的所有组件都是线性组合的,表明它在多个因子之间做出了强独立性假设(即,每个组件都是独立地影响用户的next purchase)。不幸的是,根据论文《Learning Hierarchical Representation Model for Next Basket Recommendation》的分析,作者表明独立性假设不足以提供良好的推荐。为解决上述问题,论文
《Learning Hierarchical Representation Model for Next Basket Recommendation》为next basket recommendation引入了一种新颖的hierarchical representation model: HRM。具体而言,HRM将每个用户和每个item表达为连续空间中的一个向量,并使用two-layer结构来构建用户、以及上一次交易的item的hybrid representation:第一层通过聚合上一次交易的
item向量,从而形成transaction representation。第二层通过聚合用户向量和
transaction representation从而构建hybrid representation。
然后,论文使用得到的
hybrid representation来预测next basket中的item。注意,transaction representation对序列行为进行建模,而user representation捕获了用户的通用兴趣。HRM允许我们在不同的层灵活地使用不同类型的聚合函数。具体而言,通过采用非线性运算(而不是线性运算),我们可以建模不同因子之间更复杂的交互,而不是独立性假设。例如,通过使用最大池化操作,我们可以比较来自不同因子的特征,并且仅选择那些最重要的特征来形成更高level的representation从而用于未来的预测。论文还表明,通过选择适当的聚合函数,
HRM包含了几种现有的方法,包括马尔科夫链模型、矩阵分解模型、FPMC模型的变体。为了学习模型参数,论文使用负采样程序作为优化方法。论文对三个真实世界的交易数据集进行了实验,结果证明了HRM与SOTA baseline方法相比的有效性。主要贡献:
为
next basket recommendation引入了一个通用模型,该模型可以捕获序列行为和用户的通用兴趣,并灵活地结合多个因子之间的不同交互。在
hierarchical model中引入了两种类型的聚合函数,即均值池化和最大池化,并研究了这些函数的不同组合的效果。理论上表明
HRM模型在选择适当聚合函数的情况下,包含了几种现有的推荐方法。实验表明,
HRM模型在next basket recommendation的不同评估指标下始终优于SOTA baseline。
相关工作:
next basket recommendation是基于隐式反馈的推荐系统的典型应用,其中用户没有显式的偏好(如评分),而只有正向的观察(positive observation)(如购买或点击)。序列推荐器:主要基于马尔科夫链模型,通过在给定最近一个动作的情况下预测用户的下一步动作来利用序列数据。我们的工作与之前方法的主要区别在于:除了序列行为之外,我们还包含了用户的通用兴趣。以外,以前的序列推荐器很少解决因子中
item之间的交互。通用推荐器:根据用户的整个购买历史进行推荐 ,而不考虑序列行为。通用推荐器的关键思想是协同过滤(
collaborative filtering: CF),它进一步可以分为基于内存的CF(通过某些相似性度量找到k近邻的用户或item来进行推荐)、以及基于模型的CF(通过分解user-item相关性矩阵来进行推荐)。通用推荐器擅长捕获用户的通用兴趣,但是如果没有建模序列行为,那么很难将其用于用户最近的购买行为。混合模型(
hybrid model):结合了序列行为建模和用户通用兴趣建模。一个
SOTA模型是FPMC,它构建了一个概率转移立方体(transition cube),其中立方体的每一项给出了用户itemitemlast item、next item之间的三个pairwise交互来解释这个概率。以这种方式,FPMC通过last item与next item之间的交互来建模序列行为,通过用户与next item之间的交互来建模用户的通用兴趣。实验表明,这种混合模型可以比单独的序列推荐器、或者单独的通用推荐器实现更好的性能。
1.1 模型
动机:
next basket recommendation的一个简单的解决方案是:线性组合序列因子(sequential factor)(来自序列行为模型)和通用因子(general factor)(来自用户通用兴趣模型)。然而,这种线性组合假设多个因子之间是独立的。真实世界的结果表明,不同因子之间的独立性假设可能不足以提供良好的推荐。我们需要一个能够更复杂地集成多个因子之间交互的模型。这成为我们工作的主要动机。令
item集合,item数量。对于每个用户
item集合,next basket recommendation任务是推荐用户item。next basket recommendation任务可以公式化为对用户rankingranking我们可以向每个用户推荐top n items。为解决上述推荐问题,我们提出了
HRM模型。HRM的思想是学习一个可以同时包含序列行为和用户通用兴趣的推荐模型,同时建模这些因子之间的复杂交互。具体而言,
HRM将每个用户和每个item表达为连续空间中的一个向量,并采用两层结构来构建用户和最近一次交易的item的hybrid representation:第一层通过聚合最近一次交易的
item向量从而形成transaction representation。第二层通过聚合用户向量和
transaction representation来构建hybrid representation。
然后使用得到的
hybrid representation来预测next basket中的item。HRM的整体结构如下图所示。正如我们所见,HRM通过对连续购买进行建模从而捕获序列行为,通过在序列推荐中集成个性化的user representation从而建模了用户的通用兴趣。该模型有两个不足:
首先,模型无法捕获用户的所有历史,只能“看到 “最近” 一次发生的交易,所以无法捕获用户的长期兴趣。
其次,模型没有捕获用户兴趣的动态演变。
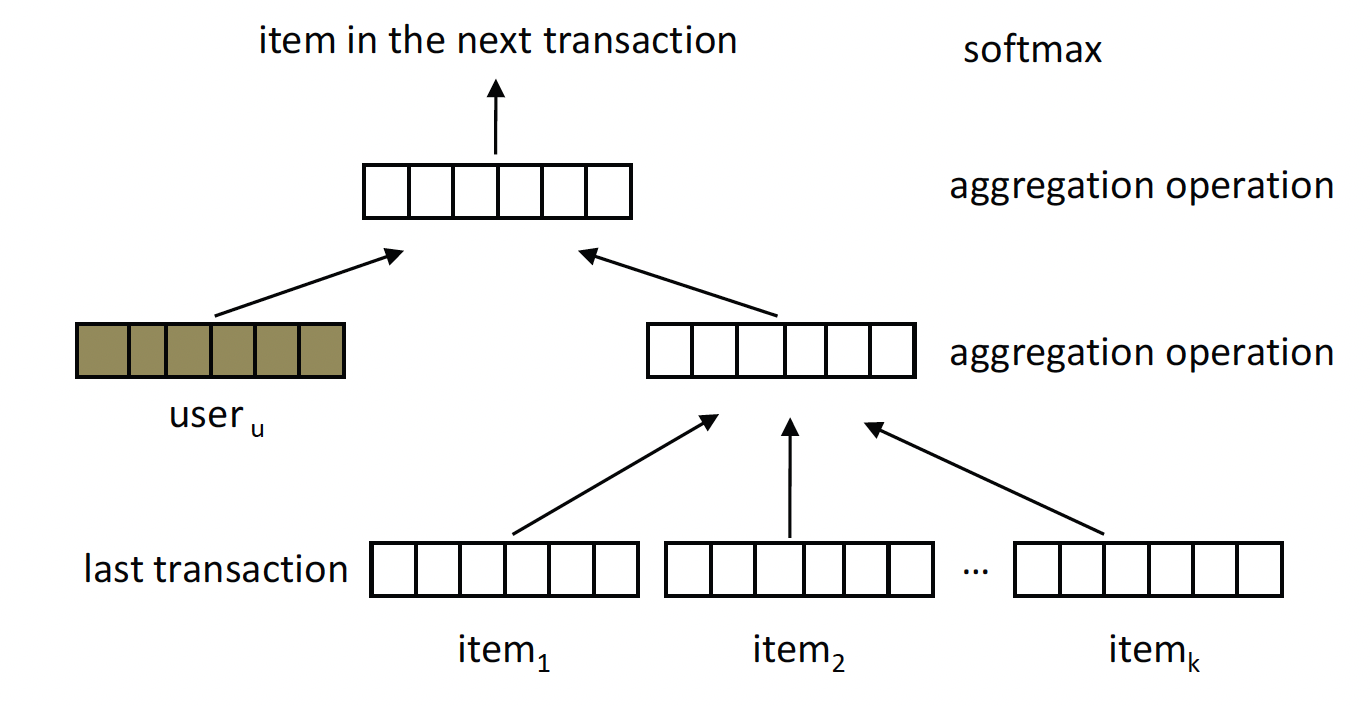
更正式而言,令
representation矩阵,第representation向量,item representation矩阵,第itemrepresentation向量。给定用户
HRM通过一个softmax函数定义用户next item其中
hybrid representation,它被定义为:其中
HRM的一个优点是我们可以引入各种聚合函数来从lower level形成higher level的representation。通过这种方式,我们可以对不同层的多个因子之间的不同交互进行建模,即在第一层对构成了transaction representation的item之间的交互进行建模,在第二层对user represetnation和transaction representation之间的交互进行建模。在这项工作中,我们研究了均值池化(
average pooling)和最大池化(max pooling)这两种典型的聚合函数。显然,均值池化是一种线性运算,它假设输入的representation之间相互独立。相反,最大池化是一种非线性操作,它对输入的representation之间的交互进行建模,只有那些最重要的特征才会被保留下来。注意,还可以定义其它类型的聚合函数,如
top-k均值池化或者Hadamard product。我们可能会在将来的工作中研究这些聚合函数。此外,还可以考虑在深度神经网络中引入非线性层,然而我们求助于简单的模型,因为这样的计算复杂度较低从而可以用于非常大的数据集。由于
HRM中有两个聚合,因此我们根据不同的操作组合得到四个版本的HRM,即:HRM版本实际上假设多个因子之间的交互程度不同。通过仅使用均值池化,
FPMC的某种变体。item之间、要么在user represetnation和transaction representation之间。
HRM的损失函数是负的对数似然:其中:
然而直接优化上述目标函数是不现实的,因为计算完整的
softmax的代价与item数量其中:
sigmoid函数,noise distribution)。正如我们所看到的的,带负采样的
HRM的目标旨在最大化观察到的itemitem我们使用随机梯度下降算法来最小化
Dropout技术来避免过拟合。在我们的工作中,我们为每个单元设置了一个固定的dropout rate(即,0.5)。一旦学到
user representation和item representation,则HRM的next basket recommendation过程如下:给定用户
item然后根据
item的未归一化概率对item进行排序,并选择top n个结果来推荐给用户。
注意,由于排序只需要考虑相对大小,因此没有必要计算完整的
softmax值。
1.2 和之前模型的关系
HRM和马尔科夫链的关系:HRM可以简化为某种类型的马尔科夫链模型。我们选择特殊的聚合函数:
对于第一层聚合,我们随机选择一个
item向量作为transaction representation。对于第二层聚合,我们选择
transaction representation作为hybrid representation。
我们将这种模型称作
其中
item的representation。类似于
《distributed representations of sentences and documents》中的推导,我们得到上式的最优解:这意味着
factorized Markov chain model: FMC,它通过分解item(这些item来自于两个连续的交易)之间的转移矩阵(transition matrix),这个转移矩阵与shifted PMI矩阵相关联。当PMI矩阵。事实上,如果我们采用噪声对比估计进行优化,则最优解为:
这意味着
shifted的对数条件概率矩阵。HRM和矩阵分解模型:HRM可以简化为矩阵分解模型。我们选择特殊的聚合函数:对于第二层聚合,我们选择
user representation作为hybrid representation(此时第一层完全被移除掉)。我们将这种模型称作
其最优解为:
通过这种方式, shifted PMI 矩阵。
这个
shifted PMI矩阵和的 shifted PMI矩阵在公式上不相同。
HRM和FPMC的关系:HRM可以简化为FPMC模型的某种变体。基于
S-BPR优化准则和最大后验估计的FPMC,其损失函数为:其中
prediction model):对于
HRM模型,如果我们选择负样本数量考虑到每一层都是均值池化,则有:
因此有:
可以看到:
FPMC共享相同的预测模型(即,pairwise优化准则(optimization criteria):FPMC使用pairwise ranking损失函数,即itemranking高于未观察到的itempairwise ranking损失函数,即itemranking、最小化未观察到的itemranking。
实际上,我们也可以采用
S-BPR准则来定义FPMC相同的模型。基于上述分析,我们可以看到
HRM实际上是一个非常通用的模型。通过引入不同的聚合函数,我们可以包含已有方法。此外,我们还可以探索其它预测函数以及优化准则,从而展现HRM的灵活性和潜力。
1.3 实验
数据集:我们使用三个真实交易数据集来评估不同的推荐方法。
Ta-Feng数据集:RecSys会议发布的公开数据集,涵盖了从食品、办公用品到家具产品。BeiRen数据集:来自中国的大型零售企业BeiGuoRenBai,记录了2013年1月到2013年9月期间的超市购买记录。T-Mall数据集:淘宝发布的一个公共的在线电商数据集,以品牌(而不是商品)的方式记录了在线交易。
我们首先对数据集进行预处理。对于
Ta-Feng和BeiRen数据集,我们删除了用户量少于10个的商品、以及商品量少于10个的用户。对于较小的T-Mall数据集,我们删除了用户量少于3个的商品、以及商品量少于3个的用户。处理后的数据集如下表所示。最后,我们将所有数据集拆分为训练集和测试集,其中测试集仅包含每个用户的最后一笔交易,而剩余所有交易都放入训练集中。

baseline方法:TOP:将训练集中最流行的item作为每个用户的推荐。MC:马尔科夫链模型(即序列推荐器),它根据用户的最后一笔交易来预测next purchase。预测模型为:其中转移概率
Nonnegative Matrix Factorization: NMF:是一种SOTA的协同过滤方法。它是基于user-item矩阵的非负矩阵分解,该矩阵是通过丢弃序列信息从交易数据集构造而来。FPMC:next basket recommendation的SOTA混合模型,预测时同时考虑了序列行为和用户的通用兴趣。
对于
NMF, FPMC, HRM方法,我们在Ta-Feng数据集和BeiRen数据集上设置维度T-Mall数据集上设置评估指标:我们在测试集中对每个用户
item(item列表item。我们使用以下指标来评估推荐列表与实际购买的item:F1-Score:它是precision和recall的调和平均值,是广泛应用的指标。Hit-Ratio:如果实际购买的item至少有一项也出现在推荐列表中,则称之为命中。命中的推荐列表占所有推荐列表的比例称之为命中率。命中率关注推荐系统的召回率,即所有用户中有多少比率的人获得至少一个正确的推荐。NDCG@k:Normalized Discounted Cumulative Gain: NDCG是一种基于排名的指标,它考虑了列表推荐中的item顺序。
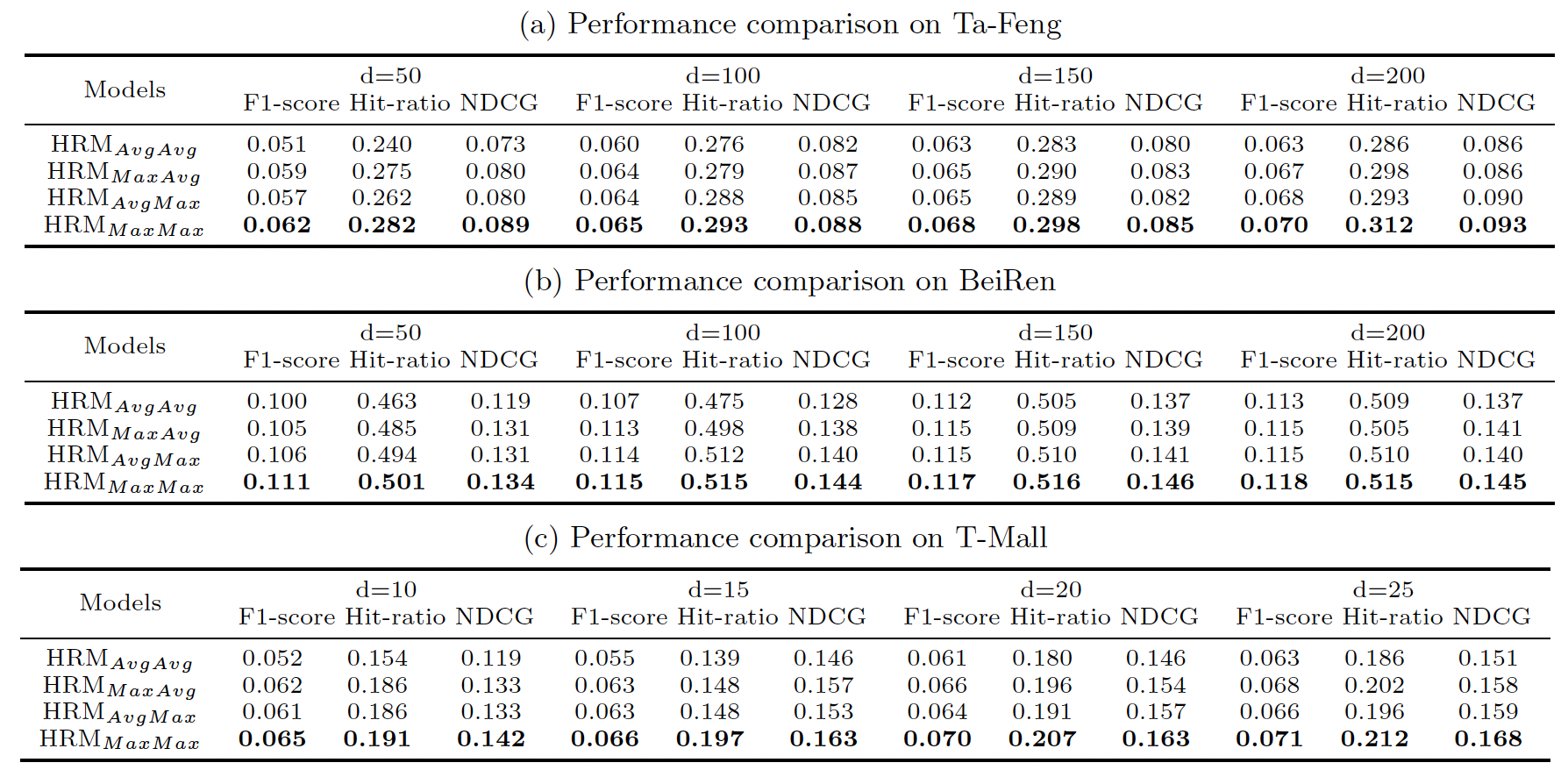
不同
HRM变体的比较:在聚合中仅使用均值池化操作的
仅使用一次最大池化操作的
在聚合中全部使用最大池化操作的
next basket recommendation中对多个因子之间的交互进行建模的优势。
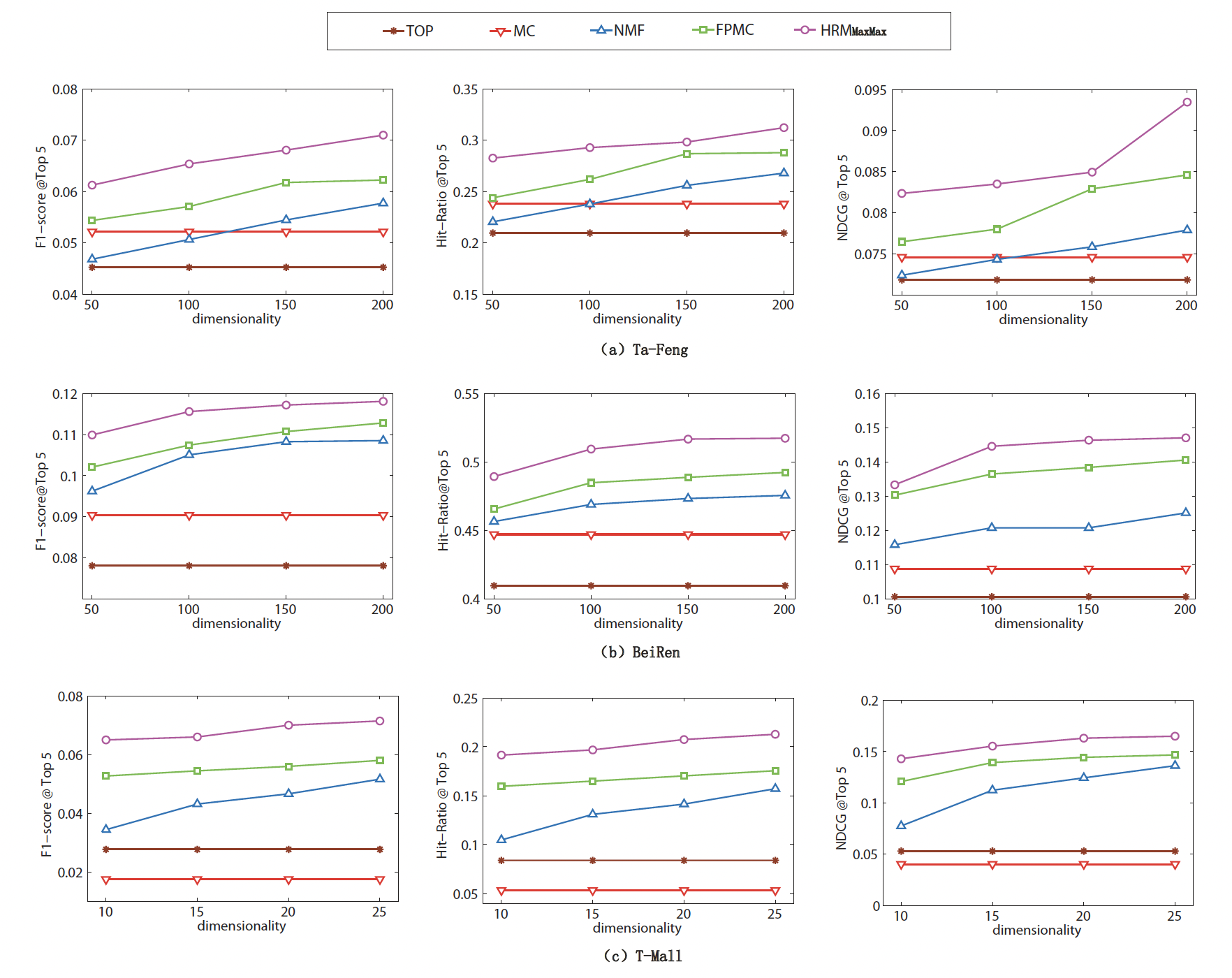
不同方法之间的比较:我们选择
HRM版本与baseline方法进行比较。总体而言,
TOP方法效果最差。然而我们发现Top方法在T-Mall数据集上优于MC。这可能是由于T-Mall数据集中的商品实际上是品牌。因此流行品牌在训练集和测试集上的分布非常接近,这符合Top方法的假设并导致更好的性能。NMF方法在大多数情况下优于MC方法。一个主要原因是MC方法中估计的转移矩阵相当稀疏,直接应用它进行推荐可能导致效果不佳。提高MC方法性能的一种方法是分解转移矩阵从而缓解稀疏性问题。通过结合序列行为和用户的通用兴趣,
FPMC可以获得比MC和NMF更好的结果。通过进一步引入多个因子之间的交互,
baseline方法。
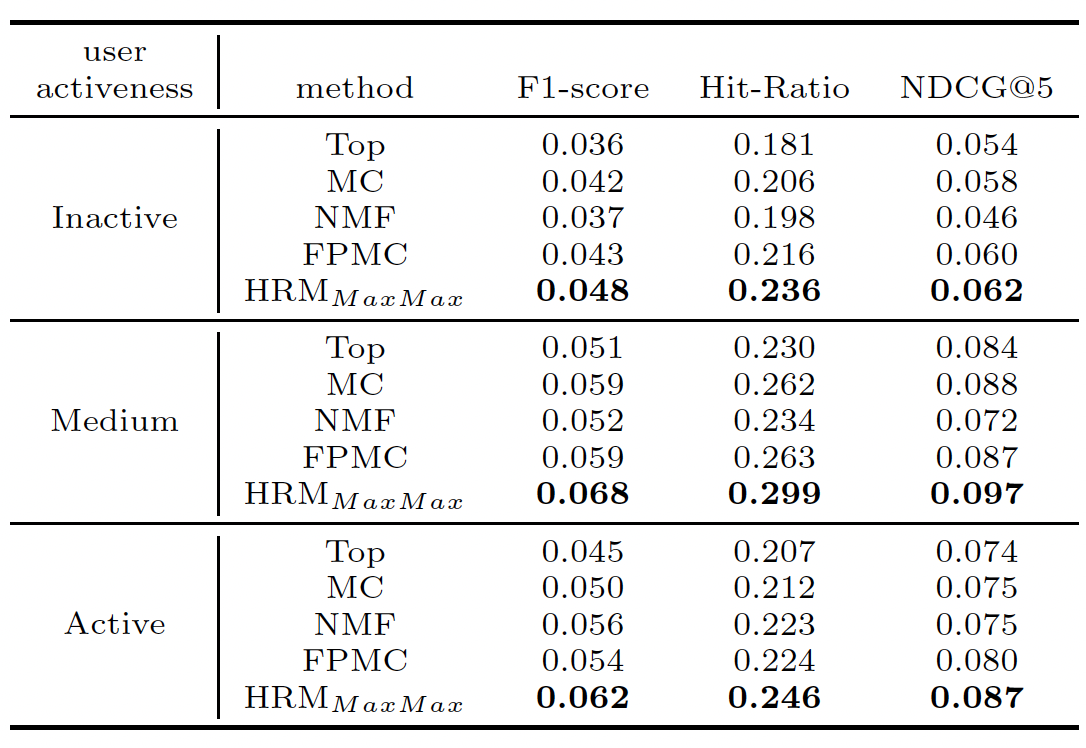
为进一步研究不同方法的性能,我们根据用户的活跃度将用户分为三组(即,不活跃、中等活跃、活跃)并对不同用户组进行比较。以
Ta-Feng数据集为例,如果用户购买历史少于5次则为不活跃、超过20次则为活跃、否则为中等活跃。这样,不活跃、中等活跃、活跃用户的占比分别为40.8%, 54.5%, 4.7%。由于篇幅所限我们仅报告Ta-Feng数据集的结果,其它数据集的结果也是类似的。Top方法仍然是所有用户组中表现最差的。MC在非活跃用户和中等活跃用户上的效果都优于NMF,而在活跃用户上比NMF更差。这表明,NMF很难通过很少的交易来学习良好的user representation从而进行推荐。通过将序列行为和用户的通用兴趣来线性组合,
FPMC在非活跃用户和活跃用户上的性能优于MC、在非活跃用户和中等活跃用户上的性能优于NMF。但是,我们可以看到不同用户组的改进并不是很一致。
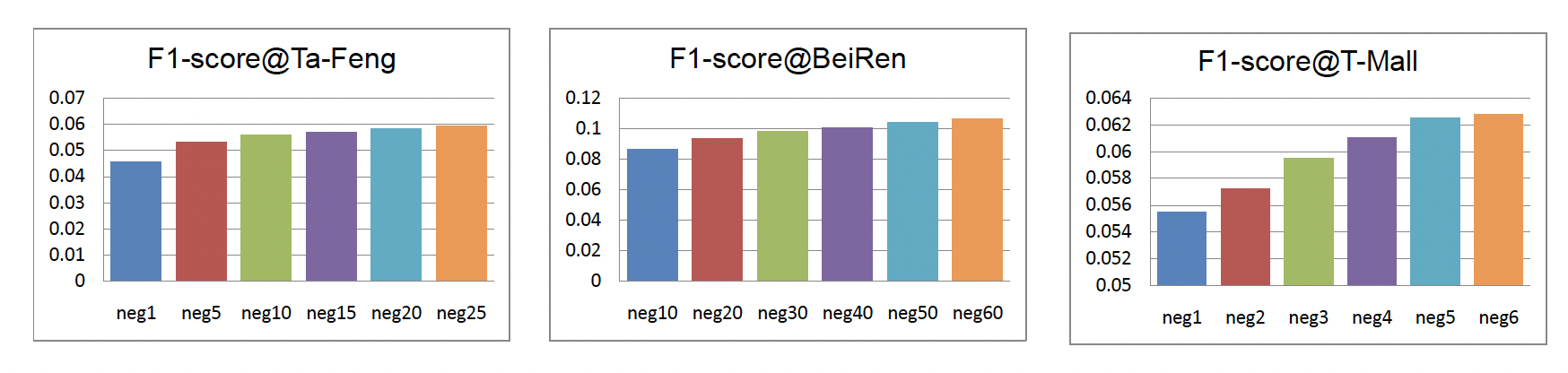
负采样的影响:这里我们研究负采样数量
Ta-Feng数据集和BeiRen数据集上T-Mall数据集上随着
F1-Score也随之提升,并且三个数据集的趋势非常一致。随着
baseline比较实验中,我们在Ta-Feng, BeiRen, T-Mall数据集中,分别将25, 60, 6。