一、Improved GRU4Rec [2016]
《Improved Recurrent Neural Networks for Session-based Recommendations》
传统的个性化推荐方法通常需要用户画像(指的是用户历史行为信息),至关重要的是,这些方法要求在推荐时识别用户。然而这可能是不可行的,例如:网站的新用户没有任何画像信息,或者用户没有登录,或者用户删除了他们的
tracking信息。这导致了基于用户历史的推荐方法的冷启动问题。另一种替代方法依赖于历史数据,并提供
session-based推荐。在这个setting中,推荐系统仅根据用户在当前session中的行为进行推荐。这避免了上述冷启动问题,但我们必须确保系统保持准确率和及时响应(即,预测不会耗费太长时间)。最近,《Session-based recommendations with recurrent neural networks》提出了RNN用于session-based推荐。作者展示了RNN相对于传统模型在session-based推荐上的显著改进。在论文
《Improved Recurrent Neural Networks for Session-based Recommendations》中,论文进一步研究了RNN在session-based推荐中的应用。具体而言,作者检查和采纳了文献中的各种技术来完成这项任务,包括:通过序列预处理(
sequence preprocessing) 和embedding dropout来增强数据,从而提升训练并减少过拟合。通过模型预训练,从而考虑数据分布的时间偏移(
temporal shift)。使用
privileged information的蒸馏,从而从小数据集中学习。
此外,论文提出了一种新颖的替代模型,该模型通过直接预测
item embedding来减少预测的时间成本和空间成本。这使得RNN更容易在real-time setting中部署 。论文在
RecSys Challenge 2015数据集上进行了评估,并证明了作者所提出方法的有效性。相关工作:
矩阵分解和基于邻域的方法在文献中被广泛应用于推荐系统。
矩阵分解方法基于稀疏的
user-item交互矩阵,其中推荐问题被公式化为矩阵补全任务(matrix completion task)。在分解矩阵之后,每个用户都由一个潜在因子向量来表示,每个item也都由一个潜在因子向量来表示。然后可以通过对应的user latent vector和item latent vector内积来补全user-item矩阵的缺失值。由于这需要我们同时识别用户向量和
item向量,因此矩阵分解方法无法直接适用于用户未知的session-based推荐。解决这个冷启动问题的一种方法是使用成对偏好回归(pairwise preference regression)。基于邻域的方法利用
target item和用户购买历史item之间的相似性。通过比较session similarity,基于邻域的方法可以应用于session-based推荐。
深度学习最近在图像识别、语音识别、自然语言处理等领域取得了非常成功的应用。在
《Session-based recommendations with recurrent neural networks》中,作者提出RNN来用于session-based推荐。作者将RNN(带有自定义的ranking loss)与现有的session-based预测方法进行比较,发现RNN-based方法的性能相比baseline要提升20% ~ 30%。我们的工作与之密切相关,我们研究该RNN模型的扩展。在
《Sequential click prediction for sponsored search with recurrent neural networks》中,作者还使用RNN进行点击序列预测。他们考虑了历史用户行为,也考虑了每个用户和每个item的、手工设计的特征。在这项工作中,我们完全依赖于自动学习的feature representation。也有许多工作提出了方法来提高
DNN的预测性能。流行的方法包括:数据增强、dropout、batch normalization、残差连接。我们寻求应用其中一些方法来提升我们模型的训练。人们提出
learning using privileged information: LUPI框架来利用一些额外的feature representation,这些feature representation仅在训练期间可用但是在测试期间不可用。当训练数据量有限时,人们发现使用此类信息是有益的。在广义蒸馏方法中,
student模型从teacher模型提供的soft label中学习。如果我们在privileged dataset上训练teacher模型,那么这种方法可以应用于LUPI。在这项工作中,我们提出使用LUPI框架来用于点击序列的预测,其中我们使用每个点击序列的未来部分作为privileged information。
1.1 模型
session-based推荐的RNN:session-based推荐问题可以公式化为基于序列的预测问题:令所有item集合的大小为click session,其中item的索引并且click session中的任何前导点击序列itemitem的概率。我们将
item成为session中next click的排序分。由于我们通常需要为用户选择一个以上的推荐,因此这里推荐top-k item(根据next click,则我们用一个one-hot编码pairwise ranking loss。我们遵循下图所示
RNN模型的通用结构。对于recurrent layer,我们使用Gated Recurrent Unit: GRU,因为《Session-based recommendations with recurrent neural networks》中发现它优于LSTM单元。但是,我们没有使用stateful RNN训练过程,在stateful RNN训练过程中模型以session-parallel、sequence-to-sequence的方式进行训练。相反,我们的网络处理每个序列next click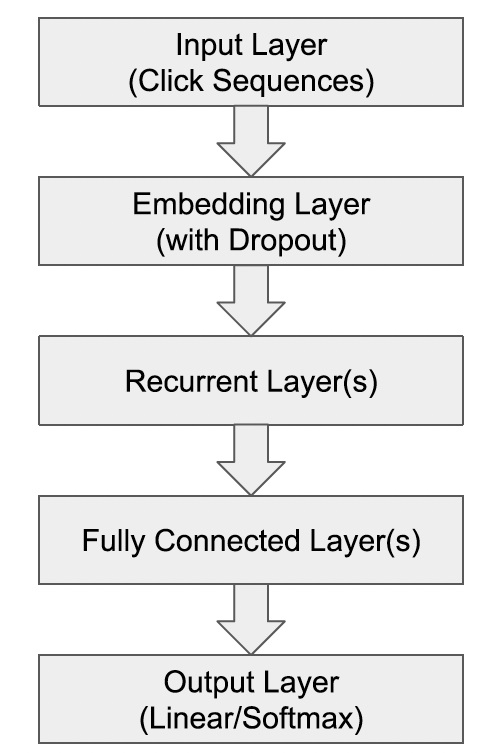
我们还使用可训练的
embedding来表示所有input。我们的网络可以通过Back-Propagation-Through-Time: BPTT算法在固定数量的time step上,使用交叉熵损失来执行标准的mini-batch随机梯度下降从而进行训练。如下图所示为一条序列的训练示意图,梯度沿着灰色箭头的反向传播,蓝色为input序列,橙色为target output。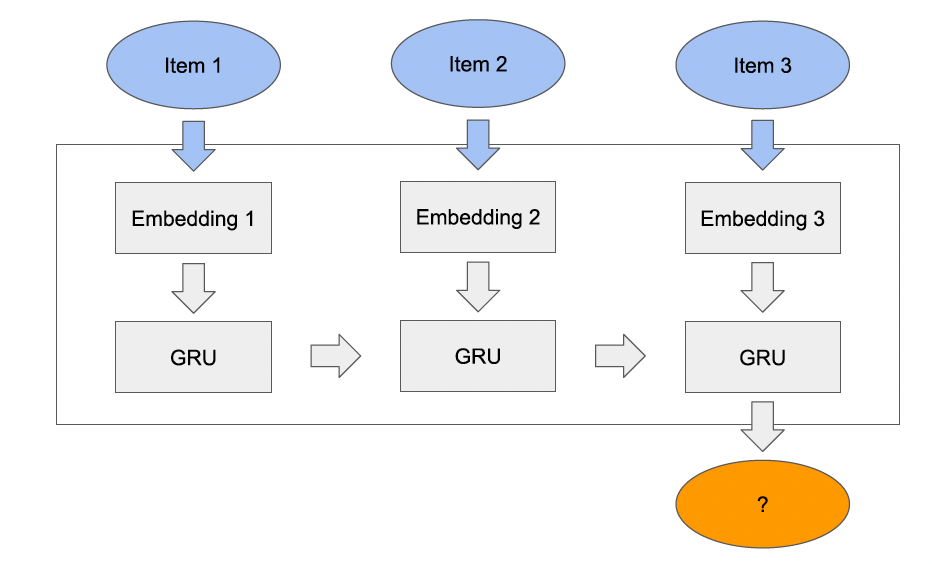
数据增强(
data augmentation):数据增强技术已被广泛应用于图像领域,这里我们提出两种方法来增强点击序列:第一个方法是
《Artificial neural networks applied to taxi destination prediction》中提出的序列预处理方法的应用。原始input session的所有前导(prefix)都被视为新的训练序列。给定一个训练sessionlabel来用于训练:第二个方法是
dropout,它是应用于input sequence的正则化形式。对点击序列应用dropout相当于随机删除部分click的预处理步骤。直观而言,这使得我们的模型对noisy click不太敏感,例如用户可能不小心点击了不感兴趣的item。因此,dropout使模型不太可能过拟合特定的noisy序列。dropout也可以被视为一种数据增强形式,它生成更短的、被裁剪的序列来用于模型训练。这里是
dropout输入序列中原始的item id,而不是dropout对应的item embedding。在本论文里二者是相同的,但是需要实验来验证?
我们将这两种方法应用于我们的所有模型。下图展示了一个示例:图中是一个包含了四个点击的
session,虚线轮廓表示训练期间被dropout的点击,灰色表示训练序列,橙色表示output label,蓝色表示privileged information(它们不用于标准的训练过程)。注意,相同序列在不同的训练
epoch会丢弃不同的点击item。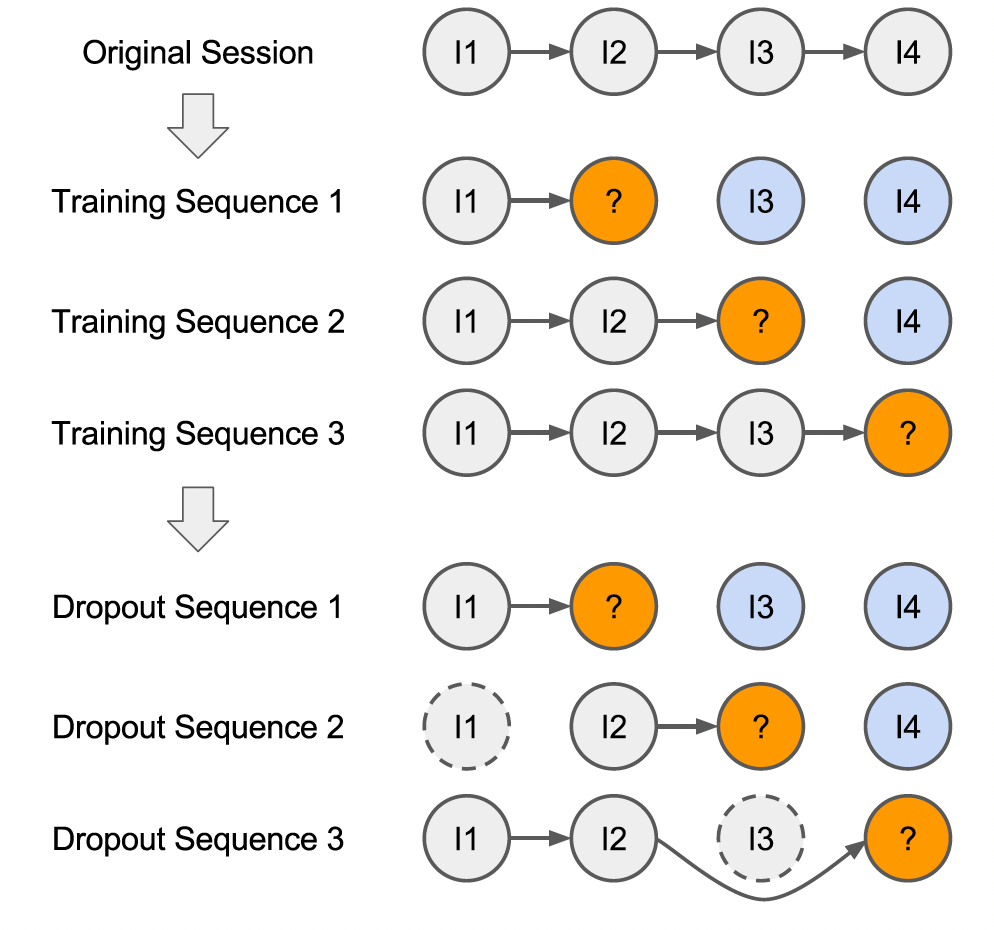
适应时序变化(
adapting to temporal changes):许多机器学习模型的一个关键假设是:输入是独立且同分布的。这在item recommendation setting中并非严格如此,因为新的商品只会出现在该商品发布之后的session中,并且用户行为/偏好也可能随着时间而改变。此外,推荐系统的目标是对新序列进行预测,即那些来自用户最近行为的序列。因此,在整个数据集上学习推荐模型可能会导致性能下降,因为模型最终会关注一些与最近序列无关的过时属性。解决这个问题的一种方法是定义一个时间阈值,并在构建模型时丢弃早于该阈值的点击序列。但是,这种方法减少了可供模型学习的训练数据量。
我们提出了一个简单的解决方案:通过预训练获得两全其美的效果。我们首先在整个数据集上训练一个模型,然后使用训练好的模型来初始化一个新模型。这个新模型仅使用近期数据(整个数据集的子集)进行训练,例如从一年点击数据中使用最近一个月的数据来训练。这使得模型能够使用大量数据进行良好的初始化,并聚焦于近期的点击序列。通过这种方式,这类似于在图像领域中使用的
fine-tuning过程。使用长期数据训练意味着学习用户的长期兴趣,使用短期数据训练意味着学习用户的短期兴趣。这里的方法通过初始化使得用户长期兴趣作为先验知识:当短期数据丰富时,学到的用户短期兴趣占主导;当短期数据匮乏时,初始的用户长期兴趣占主导。
使用
privileged information:用户在某个item之后点击的item序列也可能包含有关该item的信息,如下图所示的蓝色item。这些信息不能用于执行预测,因为我们在进行推荐时无法查看到未来的序列。然而,我们可以利用这些未来的序列用作privileged information,以便为我们模型的正则化和训练来提供soft label。为此,我们使用广义蒸馏框架。形式上,给定一个序列
session的labelprivileged information定义为:session的长度。privileged sequence仅仅是发生在第item之后的、逆序的未来序列。我们现在可以在privileged sequenceteacher模型,它也具有相同的label接下来我们通过最小化以下形式的损失函数来调优我们的
student模型其中:
label之间的重要性。注意:这里的
teacher序列为未来序列的逆序,它提供soft label。这使得
label中学习,也可以从teacherlabel(即soft label)中进行学习。当可用的训练数据很小的时候,这种学习过程很有用。论文并未说明
teacher模型用于快速预测的
output embedding:我们输出层需要输出所有item的排序分,这不仅消耗内存,也使得预测很慢。在NLP中也研究了类似的问题,典型的方法包括 使用hierarchical softmax layer、以及采样最高频的item。hierarchical softmax并不适用于我们的场景,因为我们需要进行top-k预测,而不仅仅是top-1预测。相反,我们将item embedding视为将item从one-hot编码空间到低维空间的投影。基于这个观点,我们建议训练模型直接预测next click的embedding。使用真实输出的embedding和预测的embedding之间的余弦损失来调优模型。该方法的灵感来自于word2vec,其中相似的单词具有更接近的embedding(以余弦距离来衡量)。同样地,我们预期用户在给定序列之后可能点击的item应该在item embedding空间中接近。使用这种类型的输出将
final layer中的参数数量从embedding的维度。这种方法的一个缺点是:它需要为每个
item提供高质量的embedding。获得这种embedding的一种方法是从上述模型中抽取和重用经过训练的item embedding。这种方式的
label是一个embedding向量,而不再是一个类别。还有一种解决方案:利用负采样技术,从而将
softmax layer转换为一个双塔架构。
1.2 实验
数据集:
RecSys Challenge 2015数据集,其中最后一天的session为测试集(包含15234个session),其它天的session作为训练集(包含7966257个session)。预测的候选item数量为37483。在预处理session之后,我们有23670981个训练序列。为了更好地评估我们的模型(如
privileged information和预训练),我们按时间对训练序列进行排序,然后报告我们在训练序列的最近部分上(评估方式:每个
session被item-by-item地输入到模型,计算模型在session的next click的排名。评估指标是Recall@20和Mean Reciprocal Rank (MRR)@20。对于
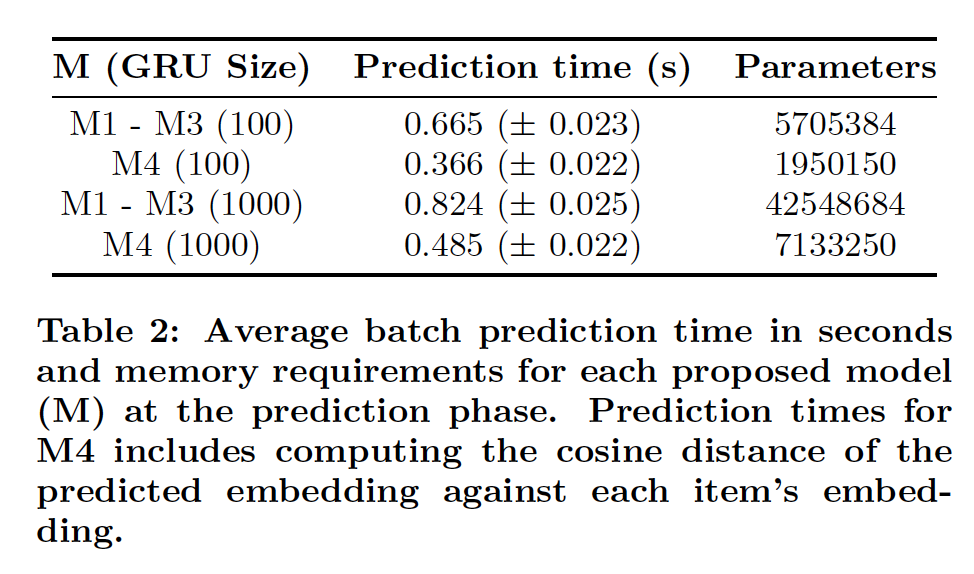
M1 ~ M3,我们直接从softmax输出中选取top 20个最可能的item。对于M4,我们计算模型输出与item embedding的余弦距离,然后选取top 20个最接近的item。最后,我们还报告了每个模型的模型大小和
batch预测时间。如果模型要部署在真实的推荐系统中,那么这些都是重要的考虑因素。配置:
所有模型对
item使用50维的embedding,embedding的dropout rate为25%。我们使用
Adam优化器,batch size = 512。我们将
item序列的长度截断为19,因为99%的原始训练session的长度小于等于19。为简单起见,短于19个item的序列用零填充,RNN将忽略这些零。我们使用
10%的训练数据作为每个模型的验证集来早停,从而设置每个模型的epoch数量。我们在所有模型中都使用单层
recurrent layer,因为我们发现更多的层并未提高性能。每个模型的GRU设置为100个隐单元或1000个隐单元。
模型是在
GeForce GTX Titan Black GPU上,在keras和theano中定义和训练的。每个模型的详细信息(以及它们的label)如下:M1:具有softmax输出、序列预处理、embedding dropout的RNN模型。recurrent layer全连接到输出层。M2:与M1相同,但是针对数据集的最近时间段的部分重新训练了模型。预训练是在整个数据集上进行的,重新训练是在最近部分上进行的(下图的
x轴)。M3:在每个数据中可用的privileged information(未来序列)上训练的M1模型。这用于为参数softmax的温度超参数) 和M1模型提供soft label。我们并没有广泛调优这两个超参数。M4:模型的输出直接预测item embedding。我们在recurrent layer和输出层之间添加了一个全连接的隐层,因为我们发现这提高了模型的稳定性。我们为这些模型使用了embedding,这些embedding是由M1在整个训练数据集上训练得到的。
下图总结了每个模型在评估指标上的性能。
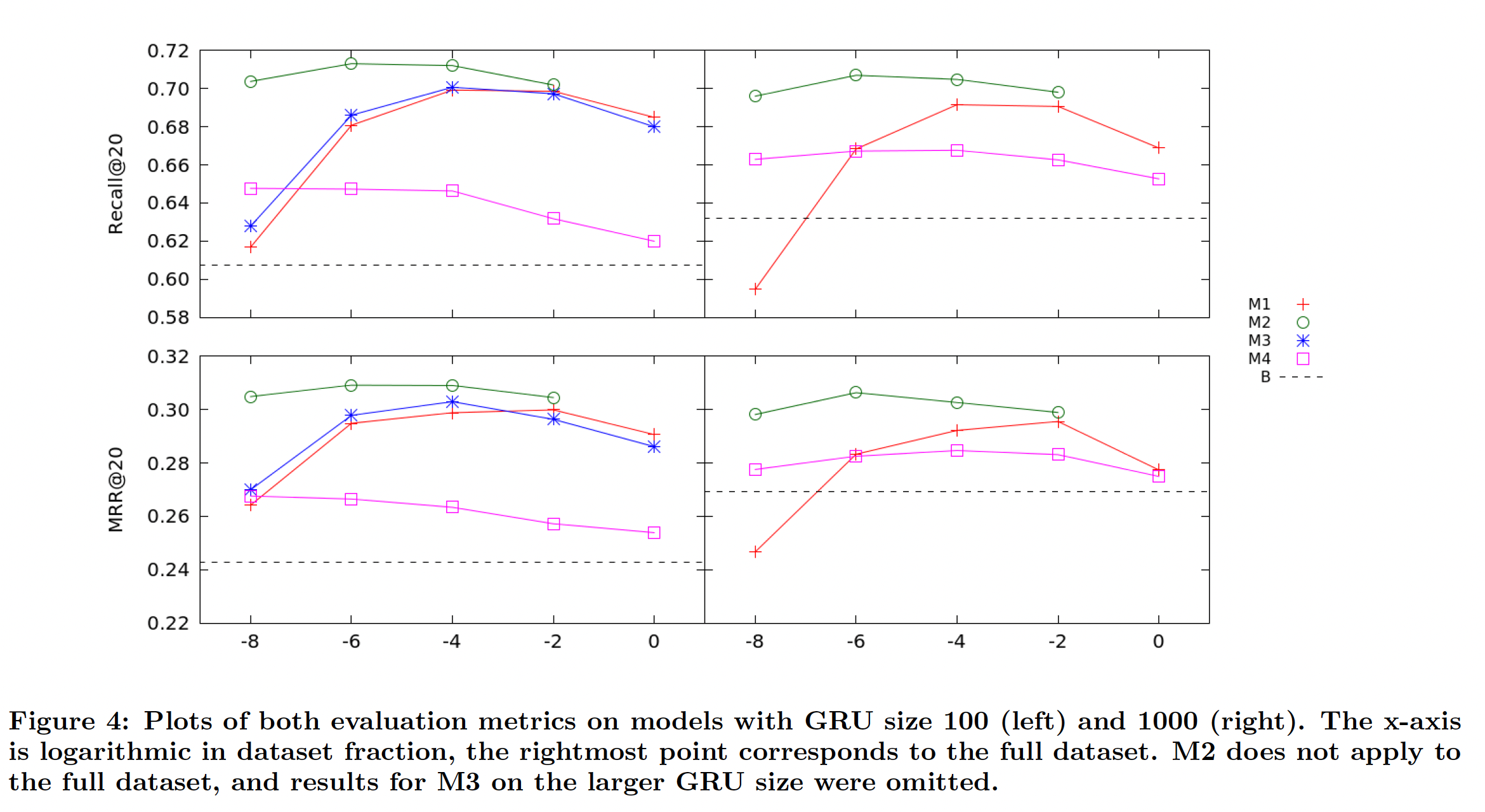
M1和M2比报告的baseline RNN模型产生了显著的性能提升。从
M1的结果中,我们看到使用整个数据集进行训练的结果,要比使用使用数据集最近部分重新训练的结果稍差。这表明我们的推荐模型确实需要考虑随时间变化的用户行为。下表还报告了我们表现最好的模型,我们还列出了
《Session-based recommendations with recurrent neural networks》中报告的baseline结果,包括他们最好的、基于RNN的模型(即TOP1和BPR)以及两种传统算法(即S-POP和Item-KNN)。令人惊讶的是,从GRU 100到GRU 1000,我们模型的性能(M1 ~ M3)并未显著提升。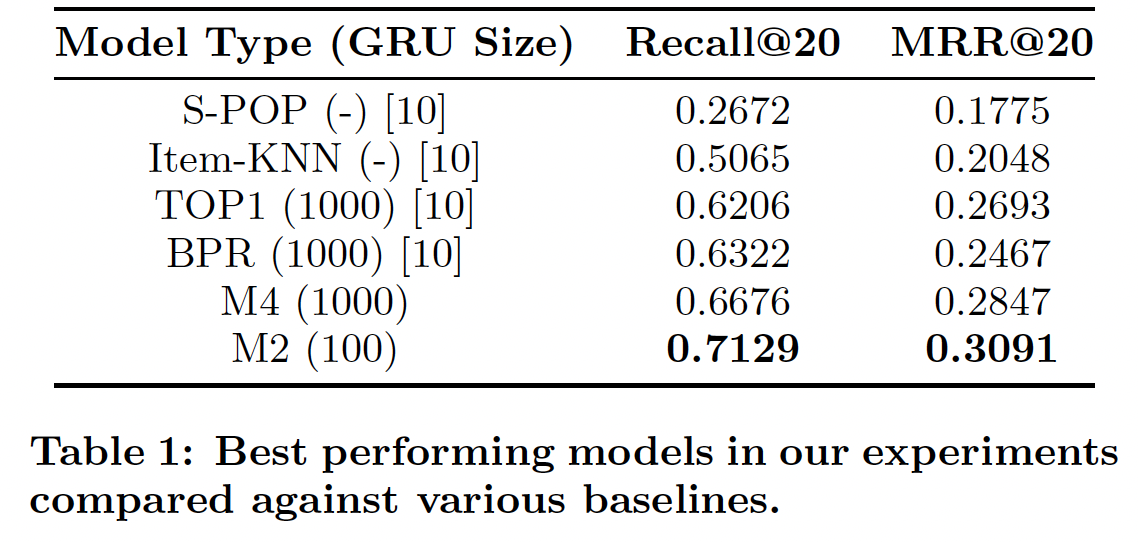
我们发现
privileged information模型(M3)的训练时间非常长。我们省略了GRU size 1000的结果,因为它无法在合理的时间内进行训练。我们认为训练时间急剧增加的主要原因是:需要计算soft label、以及为每个mini-batch计算针对这些soft label的相应交叉熵损失。当可能的soft label数量很大时,这种扩展性很差,就像这里的情况一样。尽管如此,在最小的数据集上(即仅使用最近1/8的训练数据),M3相比M1产生了适度的性能提升。这与《Unifying distillation and privileged information》中privileged information的使用是一致的,并且表明它在可用数据很少的环境中可能很有用。最后,与我们的其它模型相比,
M4在预测准确性方面表现不佳(尽管它仍然比baseline有所提高)。如果可以使用质量更好的embedding作为目标,我们或许能够进一步提升M4的准确性。例如我们没有使用item的任何辅助信息,如类别、品牌。另一方面,
batch prediction时间和模型大小如下表所示。对于M4模型,仅使用基于分类的模型(M1 ~ M3)的大约60%的预测时间就可以在M4中进行预测。M4的参数也少得多,因此需要的内存更少。总之,这些都是使RNN能够部署在真实推荐系统中的步骤。