一、p-RNN [2016]
《Parallel Recurrent Neural Network Architectures for Feature-rich Session-based Recommendations》
传统的推荐系统算法中,通常假设用户历史日志(如点击、购买、或浏览)是可用的。但是这种假设在许多现实世界的推荐场景中并不成立:许多电商网站不需要用户认证也可以下单购买(无法获取历史行为信息),在视频流服务中用户也很少登录,许多网站的回头客占比很少(因此没有历史行为信息)。用户跟踪(
user tracking)可以部分解决跨session的用户识别问题(例如,通过指纹技术、cookies等等),但是这通常不可靠并且通常会引发隐私问题。因此,在这种情况下,典型的解决方案是采用item-to-item推荐。这里,论文《Parallel Recurrent Neural Network Architectures for Feature-rich Session-based Recommendations》研究如何利用session数据来改进推荐。鉴于没有用户画像(指的是用户历史行为信息),从
session点击中获取尽可能多的信息至关重要。除了session的点击流(click-stream)数据(被点击的item-ID序列),还可以考虑被点击item的特征。item通常带有丰富的feature representation,如详细的文本描述或图像(比如缩略图)。可以预期,例如,购买特定类型item的用户会点击具有相似文本描述或相似视觉特征的item。图像、文本、甚至更丰富的特征(例如动画gif)是最终被用户所看到的,并且将决定一个item对用户的吸引力。在历史user-specific数据缺失或者不重要的session modeling的setting中,特征变得尤为重要。应该利用这些特征来帮助session modeling过程。item特征也是处理item冷启动问题的一种非常好的方法。这项工作同时利用深度学习技术从视觉信息中抽取高质量特征、以及建模
session(论文还通过bag-of-words从文本中抽取特征)。论文采用parallel RNN: p-RNN架构来联合建模click以及被点击item的特征(文本特征或图像特征)。具体而言,论文并未使用单个RNN(其中所有数据源以拼接的方式作为input使用)来联合建模被点击的item及其特征,而是代替以并行架构(parallel architecture),因为数据的性质非常不同:图像特征往往比item-ID的one-hot representation或文本的bag-of-words representation要稠密得多。论文介绍了3种不同的p-RNN架构,它们将click数据与被点击item的特征相结合。不同的架构有不同的共享模型参数,以及不同的隐状态交互。论文还指出,训练
p-RNN并非易事。标准的同时训练(standard simultaneous training)会浪费网络的容量,因为同一个网络的不同部分可能会从数据中学习相同的关系。因此,论文设计了3种替代的优化程序来训练p-RNN。论文在实验中评估了所提出的p-RNN架构,并与item-kNN进行对比。相关工作:
用于推荐系统的神经模型(
neural model):大多数关于深度模型和推荐的工作都集中在经典的协同过滤(collaborative filtering: CF)上。受限玻尔兹曼机(
Restricted Boltzmann Machines: RBMs)是最早用于经典CF和推荐系统的神经网络之一。最近,降噪自编码器(denoising autoencoder)已被用于以类似的方式执行CF。深度学习也被用于跨域推荐,其中使用深度学习技术将item映射到联合潜在空间。Recurrent Neural Models: RNNs:在处理序列数据时,RNN是首选的深度模型。Long Short-Term Memory: LSTM网络是一种已被证明工作得特别好的RNN,它能够解决经常困扰标准RNN模型的梯度消失问题。LSTM的略微简化的版本是我们在这项工作中使用的Gated Recurrent Units: GRUs。session-based推荐:当无法从过去的用户行为构建用户画像时,经典的CF方法(例如矩阵分解)在session-based的setting中失效。这个问题的一个自然解决方案是item-to-item推荐。在这个setting中,从可用的session数据中预先计算出一个item-to-item相似度矩阵,其中在session中经常被一起点击的item被认为是相似的。然后这些相似性被用于推荐。虽然简单,但是这种方法已被证明是有效的并被广泛采用。但是,该方法仅考虑用户的最后一次点击,实际上忽略了之前点击的信息。session中,两个item“共现”的前提是 “兼容”。例如,用户可以在同一个session(比如一个小时内)内点击两篇不同的新闻,但是用户通常难以在同一个session内消费两个不同的马桶(例如该用户最近有装修房子的需求),即使这两个马桶非常相似。马尔科夫决策过程(
Markov Decision Processes: MDPs)是另一种方法,旨在以session-based方式来提供推荐,同时考虑到最后一次点击之外的信息。最简单的MDP可以归结为一阶马尔科夫链,其中next recommendation可以简单地通过item之间的转移概率 (transition probability)来计算。在session-based推荐中应用马尔科夫链的主要问题是:当试图在所有item上包含所有可能的、潜在的用户行为序列时,状态空间很快变得难以管理。《Session-based Recommendations with Recurrent Neural Networks》是神经模型在session-based推荐中的首次应用,它使用RNN来建模session数据。这项工作仅关注被点击的item ID,而这里我们的目标是建模被点击item的更丰富的representation。feature-rich的推荐:深度模型已被用于从音乐或图像等非结构化内容中抽取特征。在推荐系统中,这些特征通常与更传统的协同过滤模型一起使用。深度卷积网络已被用于从音乐中抽取特征,然后将其用于因子模型。
最近,
《Collaborative deep learning for recommender systems》引入了一种更通用的方法,其中使用深度网络从item中抽取通用内容特征,然后将这些特征融合到标准CF模型中从而提高性能。这种方法似乎在没有足够user-item交互信息的环境中特别有用。一些工作使用卷积网络抽取图像特征并用于经典的矩阵分解模型从而提高推荐质量。
1.1 模型
作为
baseline,我们采用《Session-based recommendations with recurrent neural networks》中的最佳RNN的setting:单层GRU layer,没有前馈层,采用TOP1 pairwise loss函数,采用session-parallel的mini-batch。网络的输入是被点击的item ID。在训练期间,将预测分数的分布与
session中真实的next event对应的target item id(以one-hot的形式)进行比较,从而计算TOP1损失。为了降低计算成本,在训练期间仅计算target item的分数以及一小部分negative item。于给定的session,我们使用当前mini-batch中其它session中的item作为negative item。target item即真实被点击的那个item,也是我们要预测的ground truth。一个
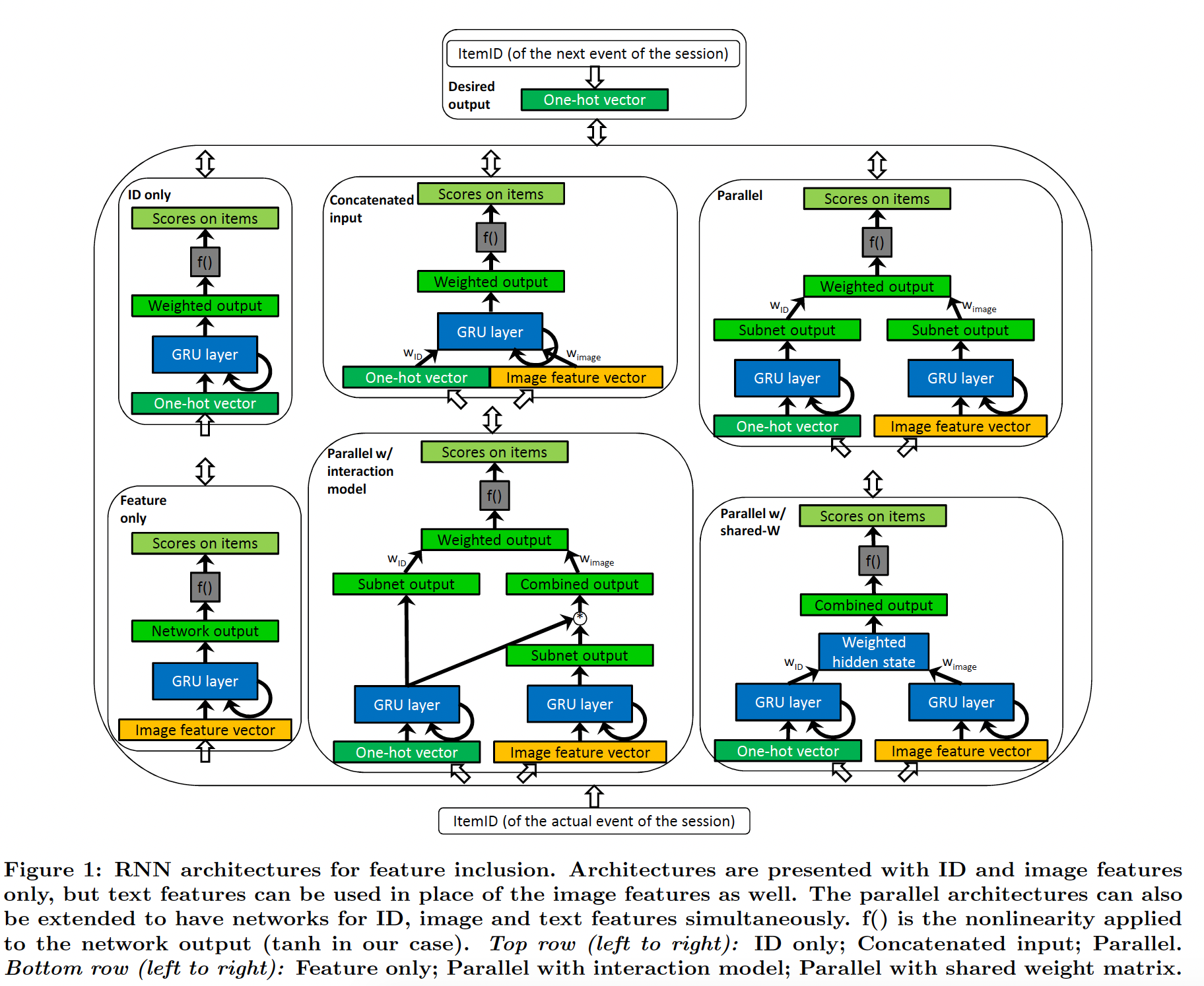
p-RNN由多个RNN子网组成,每个RNN子网用于item的某个representation/aspect,如一个RNN用于item ID、另一个RNN用于item image、还有一个RNN用于item text。模型有三个输入源:一个
one-hot ID vector代表item ID输入源、一个预先计算的稠密的image feature vector代表item image输入源、一个稀疏的unigram+ bigram text feature vector代表image text输入源。关于特征提取,本文后面将详细介绍。p-RNN架构如下图所示,由于篇幅有限,我们仅展示具有ID和图像特征的架构。对于文本特征,可以与图像特征类似地进行。p-RNN架构还可以同时处理ID、图像特征、文本特征。架构分为两组:
baseline架构:ID only:此架构仅使用one-hot ID vector作为输入,与《Session-based recommendations with recurrent neural networks》中使用的相同。它作为我们实验的baseline。output就是GRU的最后一个hidden state经过一个投影矩阵(即hidden to output权重矩阵)之后的结果。Feature only:此架构的输入是内容特征向量之一(图像或文本)。其它的工作方式与ID only网络类似。Concatenated input:组合不同item representation的最简单方法是将它们拼接起来。该架构的输入是one-hot ID vector和内容特征向量的拼接。input level的融合,不同数据源融合之前,需要分别乘以
p-RNN架构:Parallel:该架构为每个representation训练一个GRU子网,output是从子网hidden layer的拼接中计算出来的(等价于独立计算每个子网的output score并加权output score,然后通过激活函数f())。output level的融合,每个子网的output融合之前,需要分别乘以Parallel shared-W:这种架构与Parallel架构的不同之处在于,每个子网具有共享的hidden to output的权重矩阵 。这种架构中不会为每个子网单独计算output,相反,hidden state的加权和乘以单个权重矩阵来产生output。采用一个共享的权重矩阵大大减少了参数的数量,从而减少了训练时间和过拟合。hidden state level的融合,每个子网的hidden state融合之前,需要分别乘以它的模型容量相比
Parallel更小,并且实验表明其效果相比Parallel更差。Parallel interaction:在该架构中,item feature subnet的隐状态在计算子网的分数之前以逐元素乘积的方式乘以ID subnet的隐状态 。混合session的不同方面来计算item分数,这类似于context-aware偏好建模。类似于
Parallel架构,但是融合发生了两次:一次是output level的融合(和Parallel相同),另一次是对item feature subnet隐状态的加权融合。论文中的图表可能有误(或者论文对该架构的描述有误),这里逐元素乘积的时刻应该是在
subnet output和GRU layer之间,而不应该是subnet output和combined output之间。
读者注:
p-RNN的核心就在于,信息源融合的时机(输入时?hidden state时?输出时?)、融合的方式(拼接?加权和?逐元素乘积?)、融合几次(一次?两次?)。该论文并未评估所有的这些可能性,因此不太完善。并且实验表明仅在输出时进行信息源融合的效果是最佳的(独立处理每一路,并在预测之前融合)。读者注:本文的主要贡献是两点:验证信息源如何融合、以及不同子网的训练方式(交替训练)。最佳的方式是
Parallel架构加Residual或Interleaving训练方式。这种残差式的训练模式,可以作为一种多模型ensemble训练的范式:后续子模型在残差上训练,然后ensemble在一起。
训练
p-RNN:训练p-RNN架构并非易事。由于架构的不同组件从数据中学习相同的关系,整个架构的标准反向传播可能会产生次优结果。这可以通过预训练网络的某些组件并在后续训练剩余组件来避免。这种循环的训练可以进行多次,这得益于交替方法(如ALS) 在矩阵分解中的成功。我们为p-RNN制定了以下训练策略:Simultaneous:每个子网的每个参数都是同时训练的。它作为baseline。Alternating:每个epoch以交替的方式训练子网。如,ID subnet在第一个epoch进行训练,而其它子网是固定的。然后我们在下一个epoch固定ID subnet并训练image subnet,以此类推。当每个子网都被训练一个epoch之后,循环往复。Residual:在先前训练的子网的ensemble的残差上,子网一个接一个地被训练。不会重新循环往复,但是与Alternating方法相比,每个子网的训练时间更长。例如,ID subnet训练10个epoch,然后image subnet在ID subnet的残差上继续训练10个epoch,等等。Interleaving:每个mini-batch交替训练。例如,ID subnet训练一个mini-batch,然后image subnet在ID subnet的残差上继续训练一个mini-batch,以此类推。更频繁的交替允许跨子网进行更平衡的训练,而没有Simultaneous训练的缺点。
读者认为后两种残差式的更新方式是存在一定问题的。
如果两个子网之间几乎是独立的(如
Parallel架构),那么一个子网的更新不会影响另一个子网的能力,那么一个子网去学习另一个子网的残差是合理的。这使得两个子网之间能力。如果两个子网之间是耦合的(如
Parallel interaction架构),那么一个子网的更新会影响另一个子网的能力,那么一个子网在学习另一个子网残差的过程中,也会影响这个残差本身。即,子网参数的更新会改变子网学习的目标(即,残差)。这使得模型很难学习(没有固定的目标)。
最终实验部分的效果也验证了这一点:在
Residual和Interleaving学习策略上,Parallel iinteraction架构的效果不如Parallel架构的效果。特征抽取:图像特征(
image feature)是从视频缩略图(thumbnail)中抽取的,而文本特征(text feature)是基于产品描述的。编码图像:我们使用
Caffe深度学习框架实现的GoogleNet从视频缩略图中抽取特征。该网络在ImageNet ILSVRC 2014数据集上被预训练。视频缩略图首先必须按比例缩小和裁剪,以便适应网络的输入。我们从最后一个均值池化层中抽取图像特征。特征向量被归一化为l2范数为1。我们最终得到的image feature representation是一个长度为1024的实值向量。下图通过显示与两个
query image最相似的3个图像来说明图像特征的质量,其中相似度被定义为图像特征向量之间的余弦相似度。鉴于图像特征的质量良好,我们不会将CNN直接插入RNN,因为这会给训练带来不必要的复杂性,而且也不实用。因为:这使得网络的收敛速度会慢得多,因为它需要在变化的
item representation上学习模型。网络不适合
item数量较少的数据集,因为1万个item不足以充分利用CNN的潜力。retraining需要更长的时间(因为模型更复杂、计算复杂度更高)。
另一种可能的选择是在
RNN训练期间微调image feature representation。这对我们的实验没有太大影响,因此我们没有使用微调(fine tuning)。
编码文本:鉴于在线分类广告平台对描述文本长度的严格限制,广告主通常为其
item提供相当简洁的文本。描述文本的主要目的是吸引潜在感兴趣的用户的注意。因此,描述文本通常仅包含item的主要特点,并使用语法错误的句子。此外,用多种语言编写描述文本从而吸引更广泛的受众也很常见。我们的数据集的大部分描述文本使用了3种主要语言,另外也有少数不太常见的语言。鉴于我们数据中非结构化文本和多种语言的固有噪声,我们采用经典的
bag-of-words representation来编码产品描述文本。首先,我们将
item的标题和描述文本拼接起来。然后,我们过滤停用词
stopword并从文本中抽取unigram和bigram,并丢弃所有仅出现一次的项。最后,我们使用
TF-IDF对生成的bag-of-words进行加权。
最终的
text feature representation是一个长度为1099425的稀疏向量,平均有5.44个非零元素。我们尝试了其它方法从非结构化文本中抽取特征,例如
distributed bag-of-word、Language Modeling with RNN。然而,我们发现带有TF-IDF的经典bag-of-words最适合我们的数据。我们将此归因于用户生成内容(user generated content: UGC)的噪音。由于缺乏英文的文本、以及存在多种语言,所以我们无法使用预训练的word representation,如来自word2vec的word embedding。我们尝试在输入特征和网络之间插入
embedding layer,实验结果发现性能更差。因此我们使用经典的bag-of-words/TF-IDF特征作为text feature representation,并直接用于RNN的输入。
1.2 实验
数据集:
VIDXL数据集:该数据集是从2个月内从类似YouTube的视频网站收集的,其中包含至少具有预定时长的视频观看事件。在收集期间,item-to-item的推荐展示在精选视频旁边,由一系列不同的算法生成。CLASS数据集:该数据集由在线分类网站的商品查看事件组成。该网站在收集期间也展示了不同算法给出的推荐。
在原始
event-stream的预处理过程中,我们过滤掉了不切实际的长session,因为这些session可能是由于机器人(bot)流量造成的。我们删除了单个事件的session,因为它们对session-based推荐没有用。我们还删除了频次低于五次的item,因此低频的item不适合建模。每个数据集最后一天的
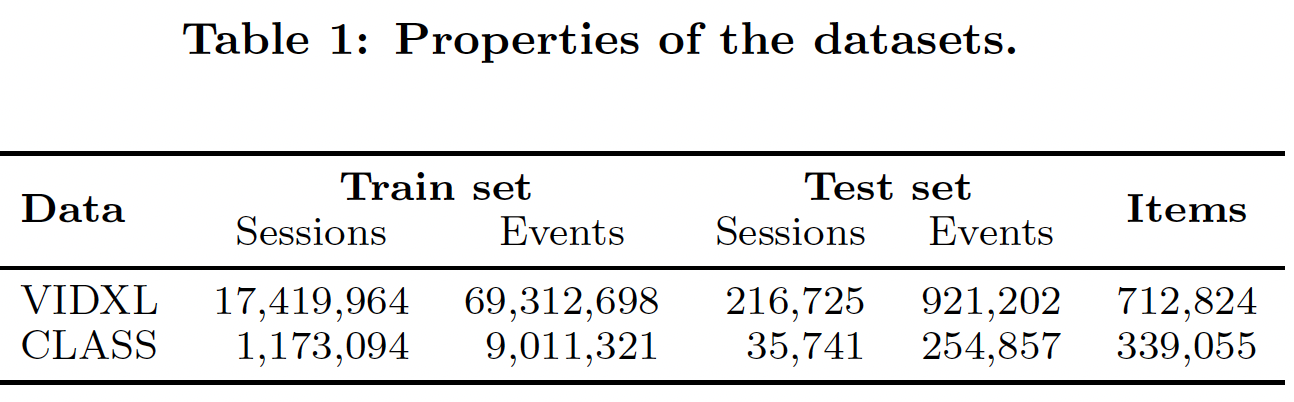
session作为 测试集,其它session作为训练集。每个session要么分配给训练集、要么分配给测试集,我们不在session中间拆分数据。对于测试集session中的item,如果它们不在训练集中那么我们也会将它们过滤掉。数据集的统计信息如下表所示。
评估方式:我们评估
next-event prediction task,即,给定session事件,算法预测session的next event。我们将测试集session中的事件一个接一个地馈入训练好的模型,然后检查next event的item的排名。当session结束后,网络的隐状态重置为零。由于推荐系统一次只能推荐几个
item,用户选择的实际item(即next item,也称作target item)应该包含在推荐列表的前面几个item中。因此,我们的主要评估指标是recall@20,即:在所有test case的推荐列表的top-20中,具有target item的case的比例。召回不考虑target item的实际排名,只需要它位于推荐列表的top-N。这很好地建模了某些实际场景,在这些场景中推荐位置和顺序无关紧要。召回率通常也与重要的在线KPI密切相关,如点击率CTR。实验中使用的第二个指标是
Mean Reciprocal Rank: MRR@20,它是target item的排名倒数(reciprocal rank)的均值。如果target item的rank > 20,那么排名倒数设为零。MRR考虑target item的排名,这适用于推荐顺序很重要的场景,例如尾部排名的item仅在屏幕滚动之后才可见。
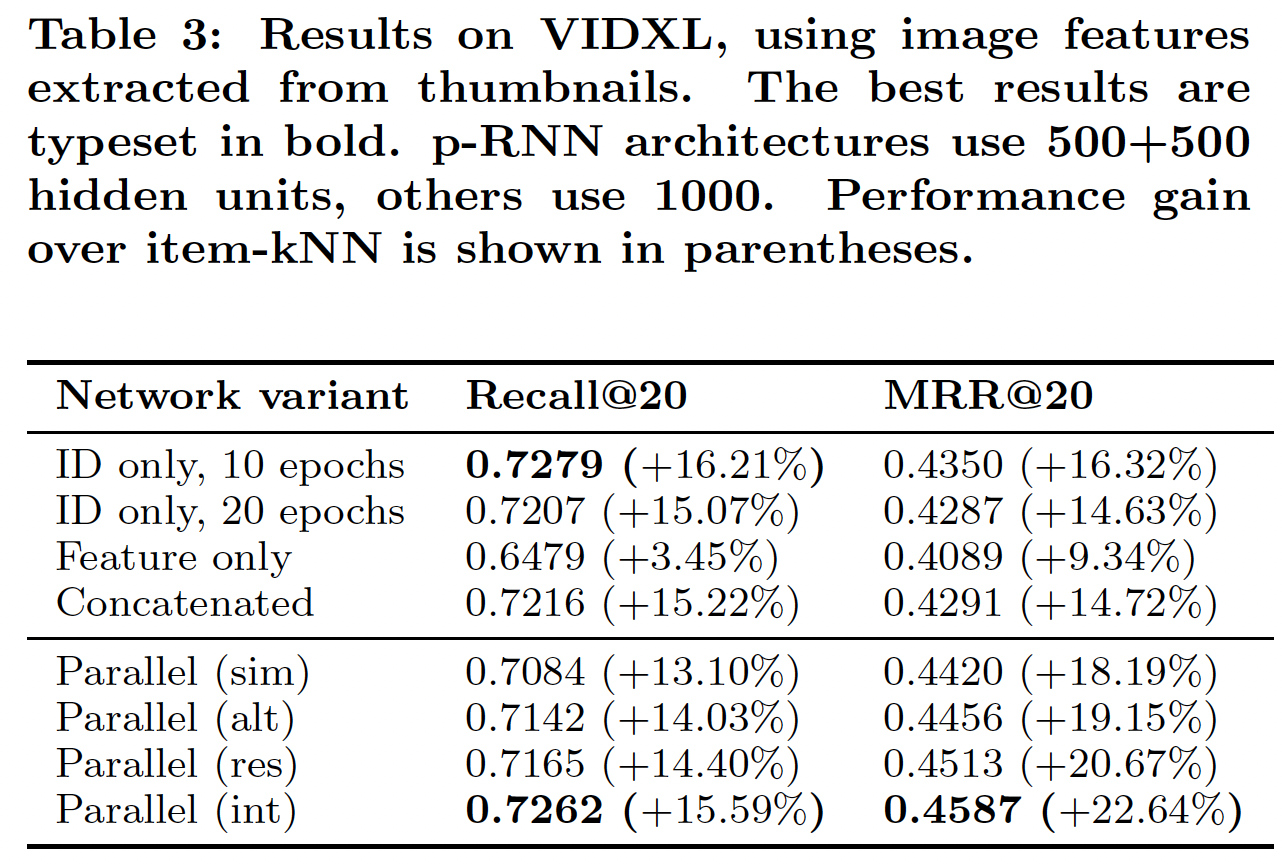
1.2.1 基于缩略图的视频推荐
我们从视频的缩略图中抽取图像特征。我们对不同架构和训练策略进行了实验,从而了解图像数据如何有助于提高推荐准确性。
和
《Session-based Recommendations with Recurrent Neural Networks》类似,所有网络使用adagrad来优化TOP1损失。ID only网络和feature only网络的参数(如dropout、学习率、动量、batch size等等)在留出(hold out)的验证集上进行了优化。然后在完整的训练集(包括验证集)上重新训练网络,并在测试集上测量最终结果。由于
VIDXL数据集太大,更复杂网络的子网使用对应的ID only网络或feature only网络的最佳超参数。子网的权重被设置为相等,因为我们没有得到显著不同的结果(除非任何一个子网的权重设为零,此时才会有显著不同的结果)。为了加快评估速度,我们计算了
target item与50000个最热门item的排名。评估列表的长度会影响评估指标,列表越长则
recall指标越高、precision指标越低。但是对于相同的评估列表,不同算法之间的比较仍然是公平的。下表总结了不同架构和训练策略的效果。在本实验中,对于
baseline架构,隐单元数量设为100。对于p-RNN,每个子网的隐单元设为100。网络训练了10个epoch,因为之后的损失没有显著变化。我们将这些网络与item-kNN算法进行了比较。由于额外的信息源和网络整体容量的增加,具有
100 + 100个隐单元的p-RNN可以轻松超越具有100个单元 的ID only网络。因此,我们还评估了200个隐单元的ID only网络的准确性从而作为一个强大的baseline。结论:
baseline方法之间:与
《Session-based Recommendations with Recurrent Neural Networks》类似,RNN(即,ID only网络)的性能大大优于item-kNN baseline。RNN在这项任务上的召回率非常高,因此更先进的架构很难显著改善这一结果。仅在图像特征上训练的网络(即,
Feature only网络)明显比ID only网络更差,甚至比item-kNN更差,这表明item特征序列本身并不足以很好地建模session。将
ID和图像特征拼接起来作为网络的输入,因为在训练期间更强的输入占主导地位,因此该网络(即Concatenated网络)的性能与ID only网络的性能相差无几。单个
GRU layer很难同时处理两种类型的输入,导致性能与ID only网络的性能非常相似。使用朴素的方法添加item特征没有明显的好处,因此我们建议改用p-RNN架构。
p-RNN架构之间:若干个
p-RNN架构的性能显著优于ID only网络这个强大的baseline。由于baseline的高召回率,这些新颖的架构主要提升了MRR,即:它们没有找到更多的target item,但是它们对target item进行了更合适的排名。性能最好的架构是经典的
Parallel架构。通过简单的Simultaneous训练,它在MRR指标上显著优于ID only网络,但是在recall指标上稍差。通过
Simultaneous训练,p-RNN的不同组件从数据中学习相同的关系,因此没有利用网络的全部容量。因此,我们建议使用其它训练策略。
训练策略之间(对于
Parallel架构):最好的训练策略是
Residual训练,紧随其后的是Interleaving训练,但Alternating训练也紧随其后。使用
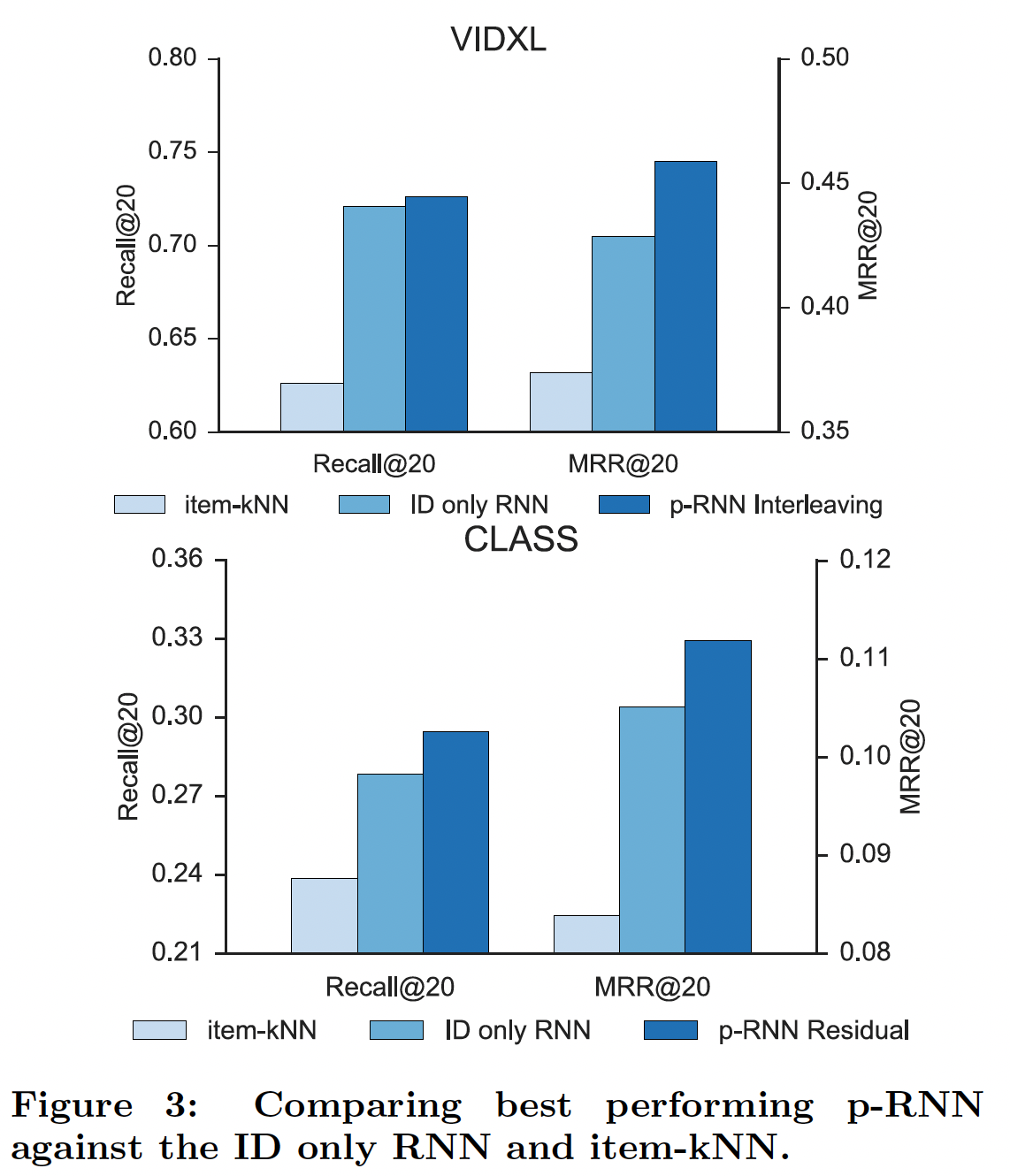
Risidual训练的Parallel架构在MRR指标上比ID only网络显著提升,同时实现了类似的召回率。和item-kNN相比,Risidual训练的Parallel架构的改进更大,召回率提升12.21%、MRR提升18.72%。
可以看到
Shared-W的效果不如Parallel的效果,这是可以预期的,因为Shared-W的模型容量更低。在
Residual和Interleaving学习策略上,Parallel interaction架构的效果不如Parallel架构的效果,原因如前所述。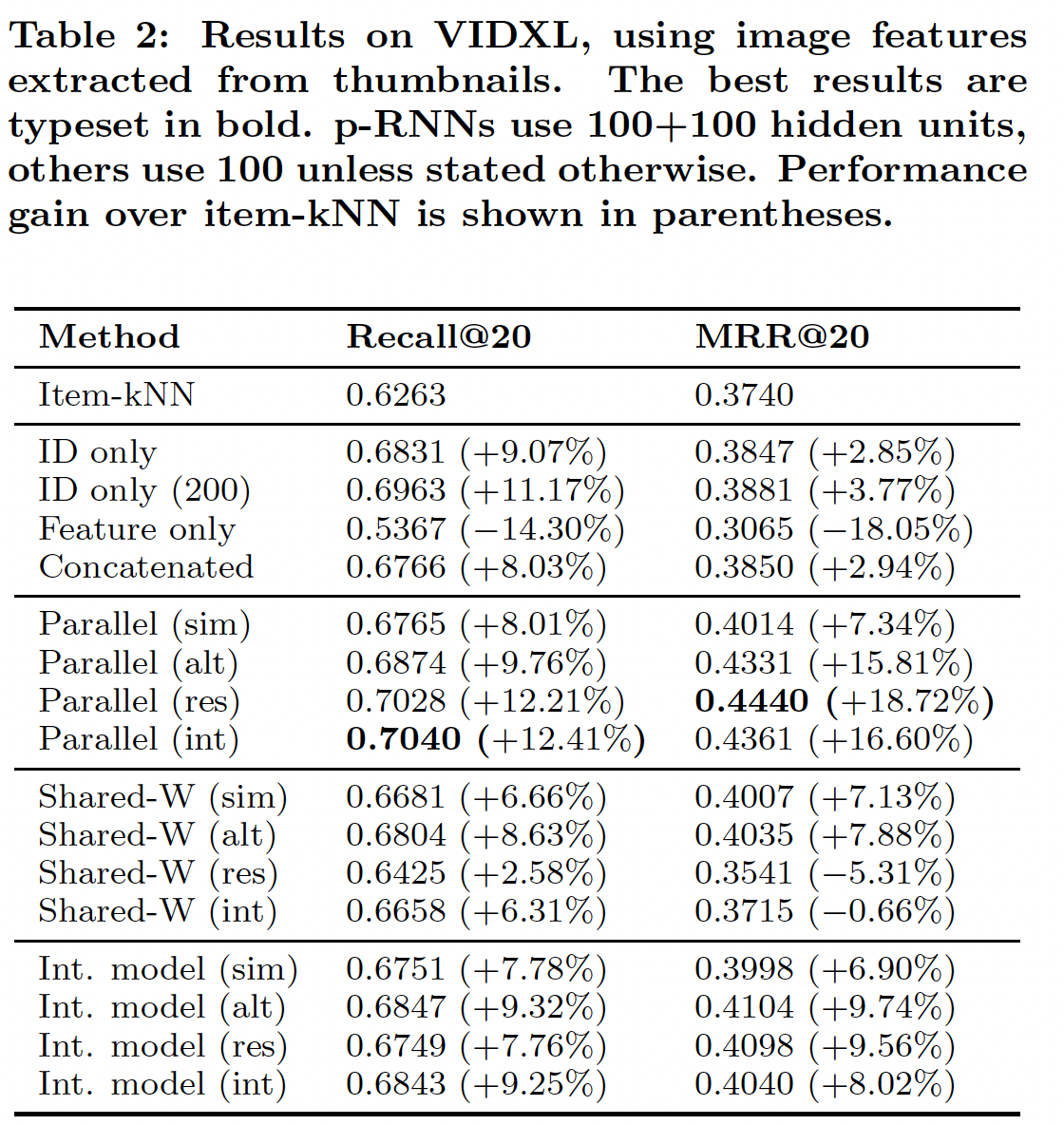
通过增加隐单元数量,
RNN的模型容量增加,因此这个参数对模型性能有很大的影响。然而,这个参数也遵循收益递减规模 。我们发现超过1000个隐单元的结果并没有显著改善,因此我们实验了具有1000个隐单元的non-parallel架构,以及具有500 + 500个隐单元的性能最好的Parallel架构,从而确认在增加网络容量和/或epoch数量的收益递减时,添加item特征也可以使得session modeling受益。下表给出了实验结果。随着隐单元的增加,网络性能会提高,甚至
Feature only网络的性能也优于item-kNN baseline,因为网络的容量足以利用图像特征中的信息。但是除此之外,结果之间的关系与前面的实验结果相似。进一步增加隐单元的数量和/或
epoch的数量并没有显著提高任何网络的性能,但是Parallel架构在MRR方面显著优于更大模型容量的ID only网络,并且具有相似的召回率。这意味着我们的架构以及我们的训练策略可以显著提高网络性能,即使随着网络容量的增加而收益递减。换句话讲,添加额外的数据源(
item特征)可以提高推荐的准确性。然而,处理多个数据源需要特殊的架构(Parallel架构)和训练策略(Residual或Interleaving)。
1.2.2 使用产品描述
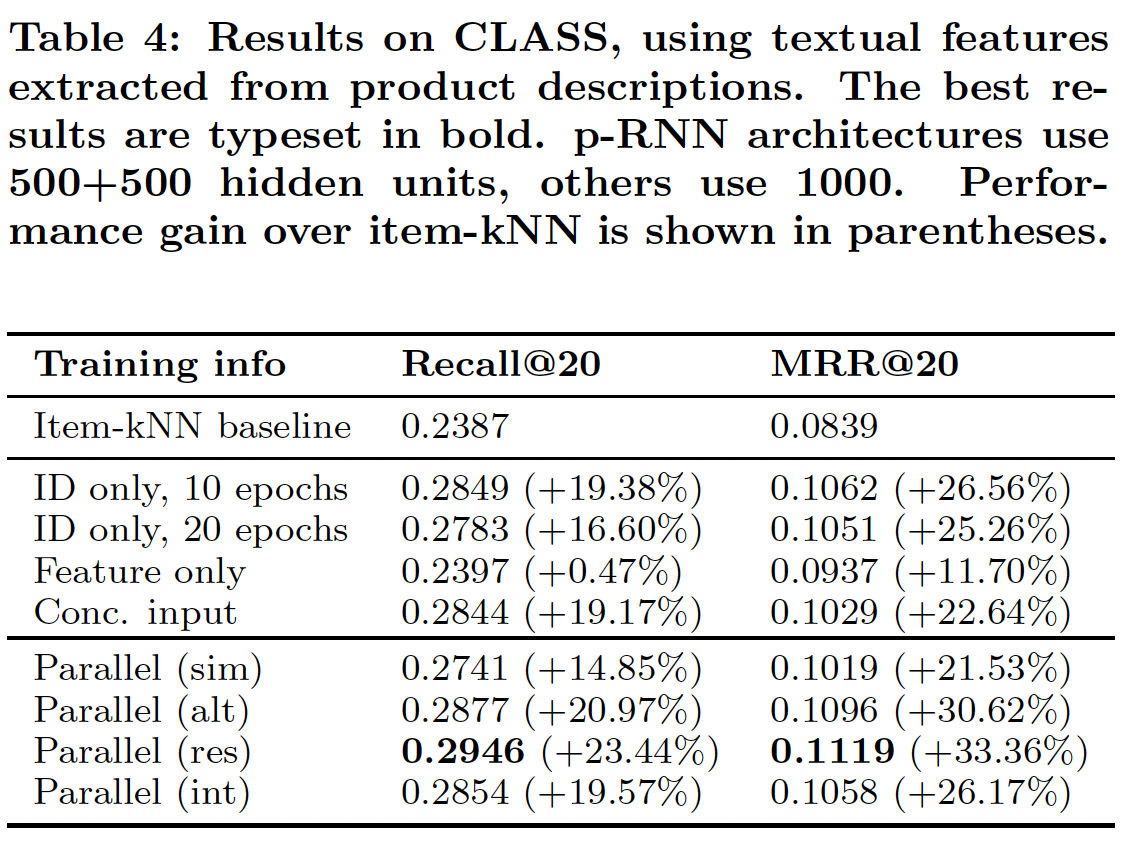
我们在
CLASS数据集上重复了上一个实验,即baseline RNN有1000个隐单元、Parallel架构每个子网有500个隐单元,其中特征是从产品描述文本而不是图像中抽取的。实验设置与前面相同,只是我们选择在评估期间对所有item排名,因为该数据集的item set规模明显更小(相比VIDXL数据集),因此可以在合理的时间内进行全面的评估。结果如下表所示,可以看到结果与前面图像特征实验的结果一致。
在
MRR指标上,Feature only网络明显优于item-kNN baseline。这证实了可以有效地利用文本特征来产生更好的排名。但是,与
ID only的网络相比,Feature only网络的效果较差。这表明单独的文本特征是不够的。在文本特征和
ID拼接作为输入的情况下,Concatenated网络的性能类似于ID only网络,类似于前面的实验 。我们提出的
non Simultaneous训练策略在训练Parallel架构时至关重要,Simultaneous训练策略在推荐准确性方面显然不是最佳的。Residual训练策略被证明是该实验中的最佳训练策略,相比ID only网络,其召回率提高了6%、MRR提高 了6.5%。注意,进一步增加
baseline RNN的隐单元数量或epoch数量并没有进一步改善结果。
在下图中,通过我们的方法与
item-kNN和具有1000个隐单元的ID only网络进行比较,从而说明了我们的解决方案(每个子网500个隐单元)的能力。