一、HRNN [2017]
《Personalizing Session-based Recommendations with Hierarchical Recurrent Neural Networks》
session是在给定时间范围(time frame)内发生的一组交互。同一个用户的不同session可以发生在同一天,也可以发生在数天内、数周内、甚至数月内。一个session通常有一个目的(goal),例如找到一家好餐馆、或者听到某种风格的音乐。在这些领域提供推荐带来了独有的挑战(
unique challenge),直到最近,这些挑战主要通过在最近一次交互、或者最近一个session上应用传统的推荐算法来解决。在session-based推荐中,仅基于当前的user session来提供推荐,因为假定用户是匿名的。但是在许多此类系统中,用户可能已经登录、或者存在某种形式的user id(如cookie)。在这些情况下,可以合理地假设:同一个用户的历史session行为可能会为next session中的推荐提供有价值的信息。在
session-based算法中,结合历史的user session信息的一种简单方法是:简单地拼接历史的user session和当前的user session。虽然这似乎是一种合理的方法,但论文《Personalizing Session-based Recommendations with Hierarchical Recurrent Neural Networks》将在实验部分看到这不会产生最佳效果。在论文
《Personalizing Session-based Recommendations with Hierarchical Recurrent Neural Networks》中,作者描述了一种基于RNN的新算法,该算法可以同时处理如下两种case:session-aware推荐:当存在user id时,将信息从前一个user session传播到下一个user session从而提高推荐准确率。session-based推荐:当没有历史的user session时(例如没有user id)。
该算法基于
Hierarchical RNN,其中当一个user session结束时,lower-level RNN的hidden state作为输入而传递给higher-level RNN。而这个higher-level RNN旨在为用户下一个user session的lower-level RNN的hidden state提供良好初始化。论文在来自行业内的两个数据集上评估了
Hierarchical RNN,结果表明论文的方法优于普通的session-based RNN、以及item-based协同过滤。相关工作:
session-based推荐:当没有用户画像时(因此也没有user id,从而无法获取该用户的所有历史行为),那么经典的CF方法(如矩阵分解)在session-based setting中失效。这个问题的一个自然解决方案是item-to-item推荐方法。在这个setting中,从可用的session数据中预先计算出一个item-to-item相似度矩阵,并且在session中经常一起被点击的item被认为是相似的。然后使用这些相似性来执行推荐。这种方法虽然简单,但是已被证明是有效的,并且被广泛采用。但是,这些方法仅考虑用户的最近一次点击,而忽略了用户之前的点击信息。递归神经网络模型:
RNN是处理序列数据的首选深度模型。LSTM网络已被证明是工作良好的RNN模型,其略微简化的版本是GRU。我们在这项工作中使用GRU。在
《Session-based recommendations with recurrent neural networks》中,RNN被首次用于对session数据进行建模。RNN在session中item ID的one-hot representation上使用ranking loss进行训练。然后,RNN用于在新的session中每次点击之后提供推荐。该方法仅关注当前session,而我们的目标不仅考虑当前session也考虑跨session的用户行为建模。在
《Parallel recurrent neural network architectures for feature-rich session-based recommendations》中,RNN还被用于联合建模item的内容以及点击序列。通过包含诸如缩略图或文本描述等item特征,该论文提出的所谓的parallel-NN提供了优于普通RNN的推荐质量。在
《Improved recurrent neural networks for session-based recommendations》中,作者提出了数据增强技术来提高session-based推荐的RNN性能。因为单个session被分为几个sub-session进行训练,因此该方法具有增加训练时间的副作用。RNN也被用于标准的user-item协同过滤setting,其目的是对user factor和item factor的演变进行建模。结果虽然不那么突出,该方法几乎没有优于标准的矩阵分解方法。在
《A hierarchical recurrent encoder-decoder for generative context-aware query suggestion》中,Hierarchical Recurrent Neural Network的seq-to-seq模型被用于生成上下文感知的query suggestion。
1.1 模型
1.1.1 Session-based RNN
我们的模型基于
《Session-based recommendations with recurrent neural networks》中提出的session-based RNN模型,其中RNN基于单层GRU layer来建模用户在session内的交互。RNN将session中的当前item ID作为输入,并为每个item输出一个得分表示成为session中next item的可能性。形式上,对于第
sessionsession的item数量,session中的第item,RNN将计算如下所示的session-level representation:其中:
session-level GRU,GRU在step t的hidden state并且null vector),step t item IDone-hot向量。RNN的输出是item集合中每个item的得分item成为session中next item(即第item集合。其中
softmax或tanh),具体取决于损失函数。在训练期间,将得分
next item IDonehot向量进行比较来计算损失函数。网络可以使用多种ranking loss function进行训练,如交叉熵、BPR、TOP1。在这项工作中,TOP1损失总是优于其它ranking loss,因此我们在本文的剩余部分仅考虑该损失函数。TOP1损失是relevant item(即next item)的相对排名的正则化近似。relevant item的相对排名定义为:其中:
relevant item的得分。irrelevant item的得分,sigmoid来近似。
为了迫使
negative item(即irrelevant item)的分数趋于零,在损失函数中添加了一个正则化项。最终的损失函数为:RNN通过session-parallel的mini-batch来进行有效地训练。在每个训练step,batch的current item ID of sessions(以one-hot向量来表示)。session-parallel机制在mini-batch中保留指向每个session的当前item的指针,并会在session结束时重置RNN的hidden state。为了进一步降低计算复杂度,损失函数是在
current item ID和负采样的item ID上计算而来。具体而言,在计算损失函数时,将每个session的current item ID作为postive item、将mini-batch中其它session的所有item ID作为negative item。这使得无需执行显式的negative item采样,并执行了基于流行度(popularity-based)的采样。然而,由于user id在纯的session-based场景中是未知的,因此negative item很有可能被同一个用户在其它session中交互的postive item所“污染”。这种方式称作
in-batch负采样。另外,既可以将其它session的current item ID作为negative item(实现更简单),也可以将其它session的所有item ID作为negative item(效果更好)。
1.1.2 个性化的 Session-based Hierarchical RNN
我们的
HRNN模型在RNN之上通过以下方式构建:添加一个额外的
GRU layer来建模跨user session的信息。使用强大的
user-parallel mini-batch机制进行高效地训练。
架构:除了
session-level GRU之外,我们的HRNN模型还添加了一个user-level GRU(session的用户活动。下图展示了HRNN的结构示意图。在每个
time step,由RNN中的一样。但是,当
session结束时,user-level representation通过当一个新的
session开始时,hidden state(即user-level representation)用于初始化
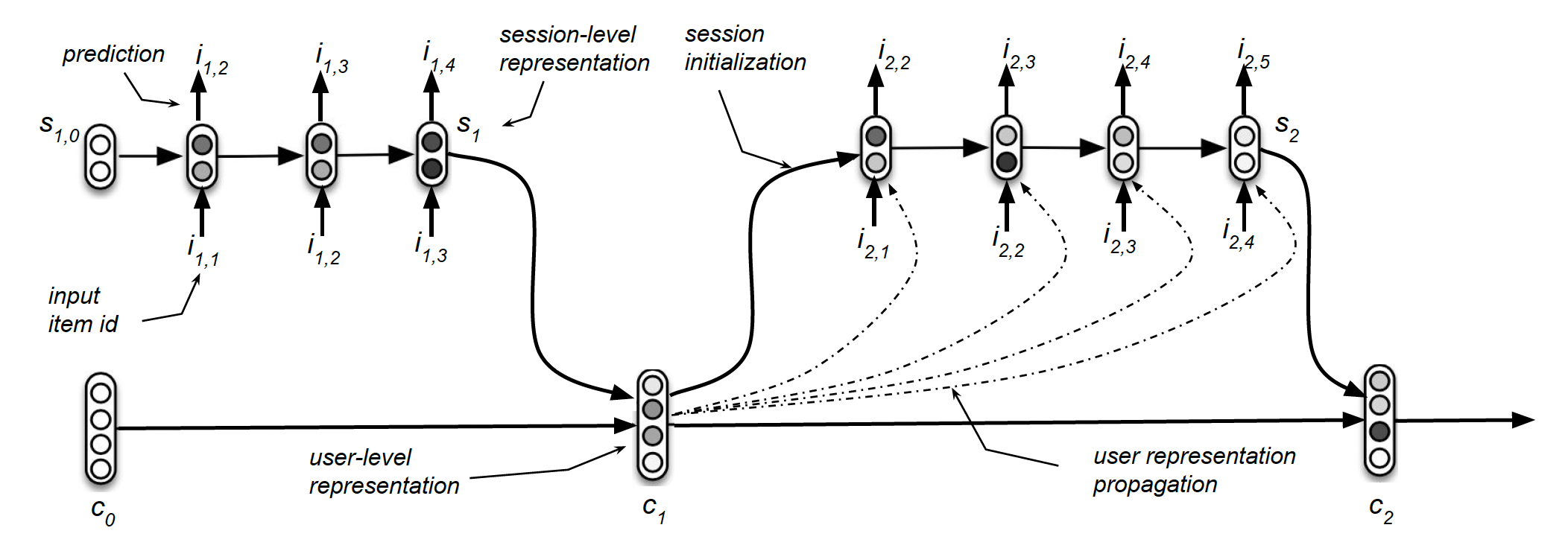
形式上,对于每个用户
session集合user-level GRU将session-level representationuser-level representationsession数量,user sessionlast hidden state。接下来为了便于表述,我们移除了
user上标user-level representation其中
null vector)。session-level GRU的last hidden state作为user-level GRU的输入。通过这种方式,user-level GRU可以跨session跟踪用户的演变,从而无缝地建模动态的用户兴趣。注意,user-level representation在整个session期间保持固定,并且仅在session结束时更新。然后使用
user-level rerepsentation来初始化session-level GRU的hidden state。给定session的session-level GRU的初始hidden state其中:
initialization权重矩阵,initialization偏置向量。通过这种方式,用户在先前session中表达的偏好相关的信息在session-level被传递。session-level representation更新为:其中方括号表示
session-level GRU的输入。如果仅仅是为了跨
session来传递用户的偏好,那么可以简单地将上一个session的last hidden state传递给下一个session。那么user-level GRU的价值在哪里?论文的解释是:user-level GRU建模了user-session如何随着时间的演变,即 “计算并演变了用户画像” 。此外论文还在实验部分评估了这种做法的效果(即
RNN Concat这个baseline),实验发现RNN Concat和HRNN在小型数据集上的效果相差无几,但是在大型数据集上HRNN效果显著优于RNN Concat。所以HRNN需要更大规模的数据才能体现其优势,因为HRNN的模型容量更大。模型使用反向传播进行端到端训练。
如果
user-level rerepsentationsession之间更新,即session结束时以及接下来的session开始时。如果
user-level rerepsentationsession内保持不变),session内更新。我们也尝试将
user-level representation传播到final prediction layer,即RNN而言,新模型的性能严重下降。因此,我们在本次讨论中放弃了这种setting。
注意,
user session的hidden state传递给下一个user session,而且还学习(在训练期间)user session如何随时间的演变。我们将在实验部分看到,这对于提高性能至关重要。实际上,user session),因此实际上个性化了RNN中,具有相同点击item序列的user session,模型将为这些用户提供相同的推荐。在HRNN中,情况不再如此,推荐结果也会受到用户历史session的影响。总之,我们考虑了以下两种不同的
HRNN setting,具体取决于公式user representationHRNN Init:其中next session的representation。HRNN All:其中next session的representation,也用作next session的输入。HRNN All相比于HRNN Init的模型复杂度稍高。
正如我们将在实验部分看到的,根据推荐场景,这两种
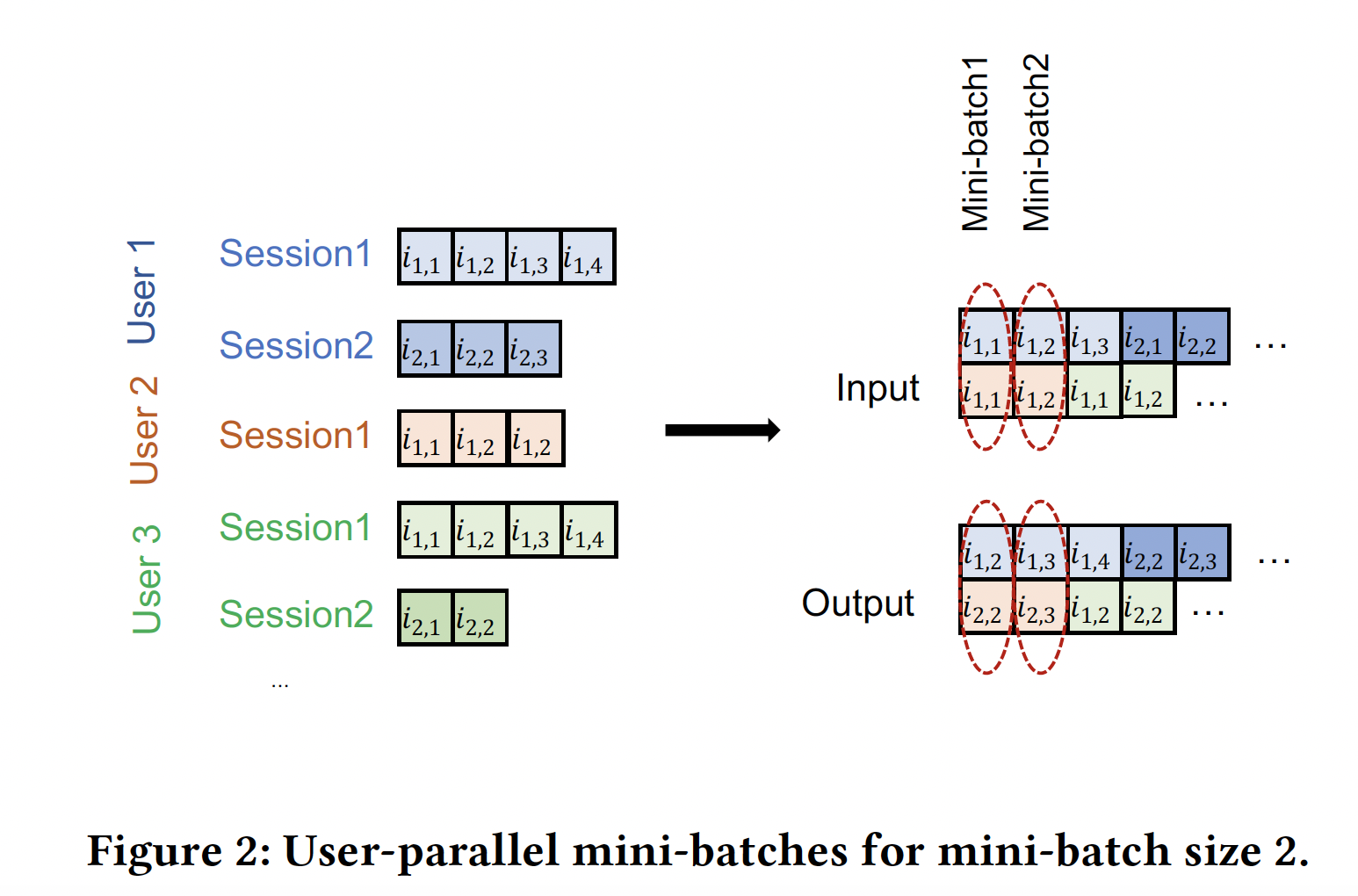
setting可能会导致截然不同的结果。学习:为了提高训练效率,我们调整了
《Parallel recurrent neural network architectures for feature-rich session-based recommendations》中描述的session-parallel mini-batch机制,从而考虑训练期间的user id,如下图所示。我们首先根据用户对
session进行分组,然后按照时间戳对每个分组内的session事件进行排序。然后我们对用户进行随机排序。在第一次迭代中,前面session的第一个item构成了HRNN的输入,对应session的第二个item构成了HRNN的输出。然后我们将HRNN的输出作为下一次迭代的输入,依此类推。当
mini-batch中的session结束时,更新hidden state、并为下一个session来初始化hidden state。当一个用户被完全处理之后,hidden state都被重置,mini-batch中下一个用户将被放到这个被处理完的用户的位置进行处理。使用
user-parallel mini-batch,我们可以有效地训练HRNN从而满足不同session数量、以及session内不同长度的用户。此外,这种机制允许以独立于用户的方式对负样本进行采样,从而减少负样本被实际正样本“污染” 的机会。采样过程仍然是基于流行度
popularity的,因为一个item出现在mini-batch中的可能性与其流行度成正比。众所周知,这两个特点都有利于基于隐式用户反馈的pairwise learning。因为负样本是从其它用户那里采样到的,因此可以减少污染机会。
未来工作:
使用注意力模型、
item特征、用户特征,从而进一步改善user representation并进一步提升session-based推荐方法。在其它领域研究
session-based个性化模型,例如音乐推荐领域、电商领域、在线广告领域。
1.2 实验
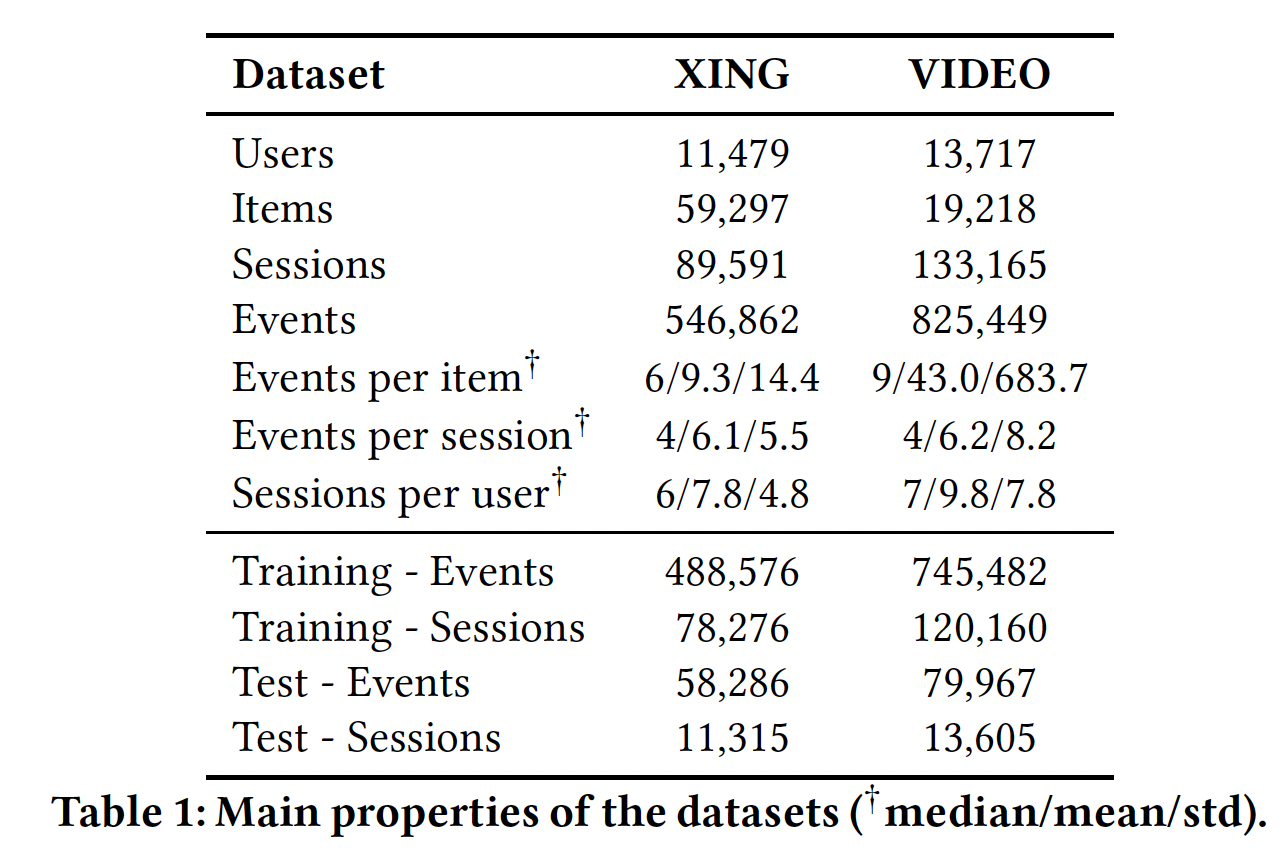
数据集:
XING数据集:XING Recsys Challenge 2016数据集,包含80天内77万用户的job posting交互信息。用户交互带有时间戳和交互类型(点击、添加书签、回复、删除)。VIDEO数据集:来自类似于Youtube的视频点播网站的专属数据集,包含13k用户在2个月内观看的视频。观看时长小于指定阈值的事件被丢弃。
我们使用
30分钟空闲阈值来手动地将交互数据拆分为session。对于XING数据集,我们丢弃了 “删除” 类型的交互。我们还丢弃了session中相同类型的重复交互从而减少噪音(例如在session中重复点击同一个job posting)。然后我们对两个数据集进行如下预处理:
我们删除了
XING数据集中出现频次低于20的item,删除了VIDEO数据集中出现频次低于10的item,因为低频item不是建模的最佳选择。我们删除了交互次数少于
3次的session从而过滤太短且信息量不足的session。我们删除了
session总数低于5个的用户,从而使得用户具有足够多的cross-session信息,以便对用户进行正确的建模。
我们使用每个用户的最后一个
session构建测试集,剩余的session构成训练集。我们还过滤了测试集中不属于训练集的item。这种划分允许针对具有不同历史session数量的用户进行评估,从而衡量模型对不同活跃程度的用户的推荐质量。我们使用相同的程序进一步划分验证集从而调优算法的超参数。数据集的统计信息如下表所示。
baseline方法:Personal Pop: PPOP:推荐用户交互次数最多(而不是全局交互次数最多的item)。Item-KNN:根据session内item的共现来计算item-to-item的余弦相似度。RNN:采用《Session-based recommendations with recurrent neural networks》中提出的模型,该模型使用TOP1损失函数以及session-parallel mini-batch(来自同一个用户的session彼此独立地馈入RNN)。RNN Concat:与RNN相同,但是来自同一个用户的所有session被拼接为单个session。这相当于
配置:
我们使用
AdaGrad来优化TOP1损失函数的神经网络模型,训练10个epoch。在所有模型中,增加epoch数量并未显著改善损失。我们对
RNN和HRNN的hidden state使用了dropout正则化。我们还将dropout应用于HRNN的我们在
hierarchy的两个level中都采用了单层GRU,因为使用多层GRU layer并没有提高性能。为了评估网络容量如何影响推荐质量,我们考虑了每个
GRU layer具有100个隐单元的小型网络、以及具有500个隐单元的大型网络。我们使用随机搜索(
random search)在验证集上调优了每个模型(包括baseline模型)的超参数。为了帮助我们实验的可复现性,我们在下表中报告了我们在XING数据集上的、在实验中使用的超参数。HRNN中的user-level GRU、session-level GRU、以及初始化都使用了dropout,因此下表中给出的dropout概率按照这个顺序提供。对于所有的数据集,Item-KMM的最佳邻域大小都是300。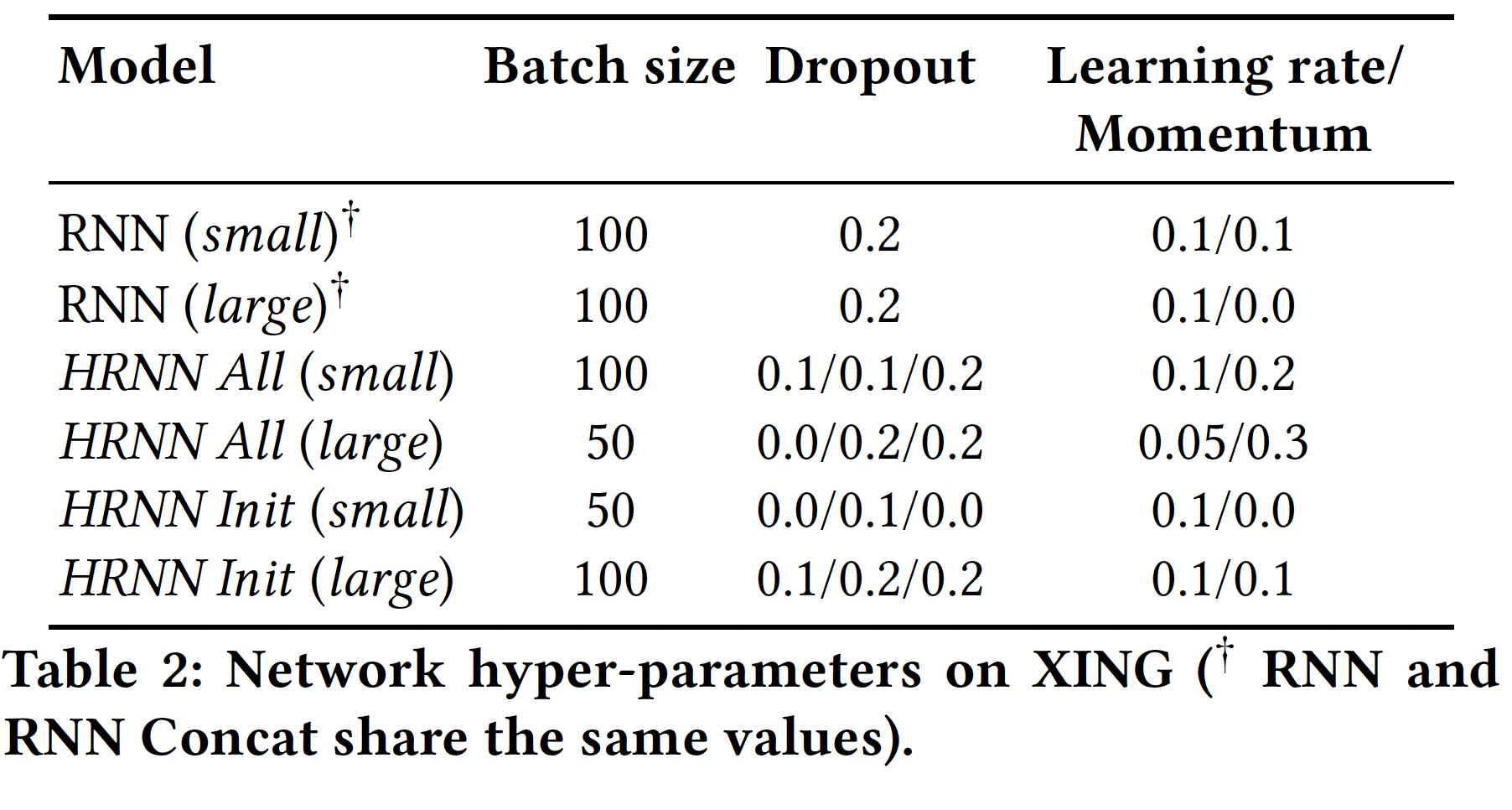
神经网络模型在
12GB GPU内存的Nvidia K80 GPU上进行训练。训练时间从XING上的小型RNN模型的5分钟,到VIDEO上的大型HRNN All的30分钟不等。所有实验的评估时间不超过2分钟。我们要强调的是,
RNN和HRNN之间的训练时间没有显著差异,其中HRNN All是计算成本最高的模型,因为其架构的复杂性更高。
评估方式:我们评估序列的
next-item prediction task,即给定user session的事件,我们评估算法预测后续事件的效果。所有RNN-based模型都一个接一个地在session中输入事件,我们检查next item的预测排名。此外,
HRNN模型和RNN Concat使用测试session之前的所有历史session,这会降低评估速度,但是有必要在评估开始之前正确地设置个性化模型的internal representation(如HRNN的user-level representation)。注意,评估指标仍然仅针对测试集中的事件进行计算,因此评估仍然是公平的。此外,我们在每个测试
session中丢弃了由RNN Concat baseline计算的第一个预测,因为它是唯一的、能够推荐user session中首个事件的方法。其它方法都只能最早预测
user session中第二个事件。由于推荐系统一次只能推荐几个
item,因此relevant item应该在推荐列表中排名靠前。因此我们选择Recall@5、Precision@5、Mean Reciprocal Rank (MRR@5)等指标来评估推荐质量。Recall@5:相当于命中率指标,它衡量所有测试case中,relevant item在top-5的case的占比。对于推荐顺序无关紧要的场景,这是一个良好的指标,并且该指标与CTR等重要KPI密切相关。Precision@5:衡量所有推荐列表的top-5位置中正确推荐的比例。MRR@5:relevant item的排名的倒数(reciprocal rank),如果排名大于5则排名的倒数被手动置为零。MRR会考虑item的排名,这在推荐顺序要紧的情况下很重要。
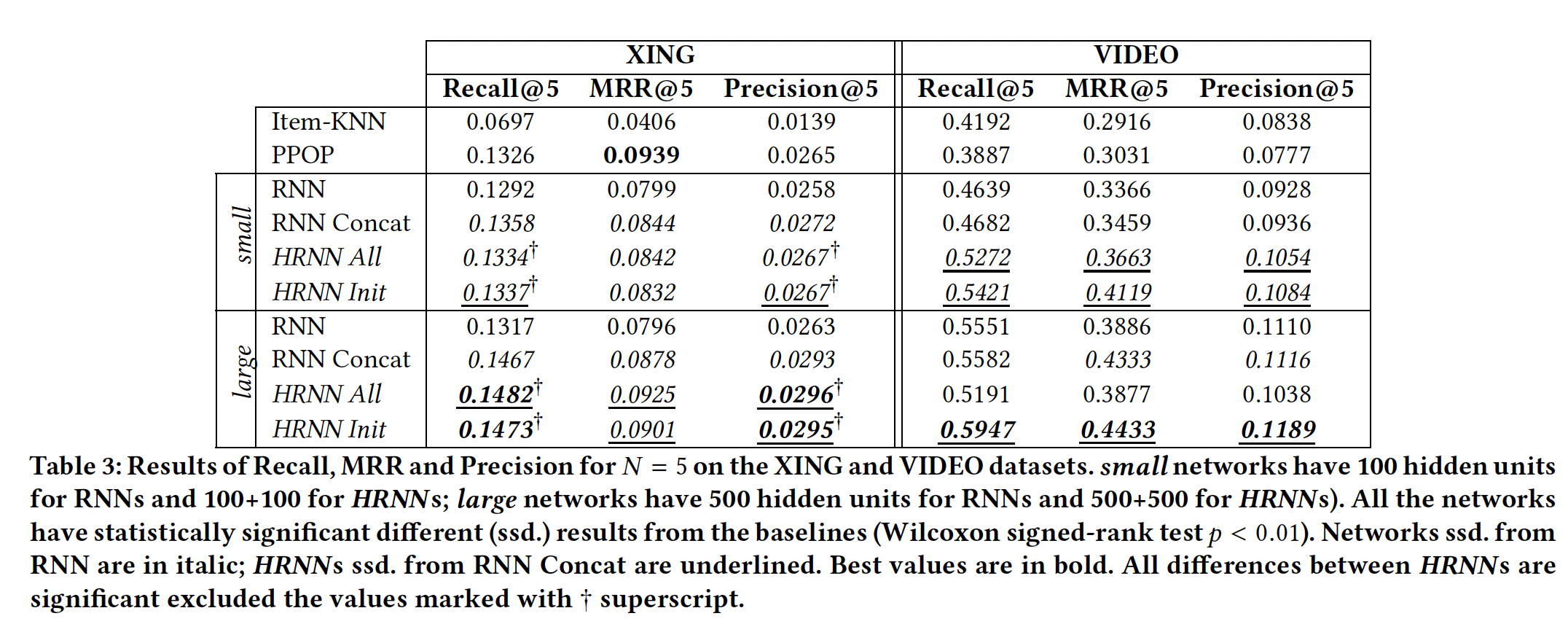
实验结果:下表给出了
XING和VIDEO数据集的结果。我们使用不同的随机数种子对每个神经网络模型进行了10次训练,并报告了平均结果。我们使用Wilcoxon signed-rank test来评估HRNN模型与baseline方法之间差异的显著性。XING数据集的结果:简单的
PPOP baseline就是一种非常有竞争力的方法,能够大大超越更复杂的Item-KNN baseline。正如前人工作对数据集的研究已经表明,用户在sessoin内和跨session之间的活动具有高度的重复性。这使得在这种情况下生成non-trivial的个性化推荐非常具有挑战性。session-based RNN较差的性能进一步突出了这一点,无论网络容量如何,它总是比PPOP差得多。尽管如此,
session-based个性化推荐可以克服其局限性,并在小型网络和大型网络的Recall和Precision指标上实现卓越的性能。HRNN在Recall和Precision指标上显著优于RNN Concat,并且在大型网络上提供显著更好的MRR。此外,
HRNN在Recall和Precision指标上显著优于强大的PPOP baseline大约11%,同时获得了可比的MRR。两个
HRNN变体之间并没有显著的差异,除了在MRR指标上HRNN All比HRNN Init略有优势。Recall和Precision指标上的差异并没有统计显著性。RNN Concat与HRNN All, HRNN Init相差无几,但是在文章末尾的大型数据集上,HRNN效果要好得多。这是符合预期的,因为HRNN的模型复杂度更高,所以需要更大量的数据才能体现其能力。
VIDEO数据集的结果:该数据集上显示出与XING数据集截然不同的结果。Item-KNN baseline显著优于PPOP,而session-based RNN可以大大优于这两个baseline。这与过去一些工作在类似数据集上的实验结果一致。RNN Concat相比较于session-based RNN具有可比的Recall和Precision。有趣的是,RNN Concat大型网络的MRR指标明显更好。这表明直接拼接session不会增强RNN推荐器的检索能力,但是会增强其正确排序item的能力。HRNN Init的性能显著优于所有baseline。换句话讲,在相同的情况下,由HRNN建模的更复杂的cross-session dynamic在整体推荐质量方面提供了显著的优势。我们将在后面研究这些结果的可能原因。值得注意的是,
HRNN All在这种情况下表现不佳。我们将推荐质量的严重下降归因于该setting中使用的context-enforcing policy。一种可能的解释是:多媒体内容(在我们的例子中是视频)的消费是一个session-based场景,比XING中代表的求职场景强得多。用户可能会遵循通用群体趋势 (general community trend)并且具有长期兴趣(该长期兴趣由user-level GRU来捕获)。但是,session中的用户活动可能与该用户最近的session完全断开,甚至与用户的一般兴趣(general interest)无关(如,对极限运动视频有强烈兴趣的用户可能偶尔也会观看卡通电影预告片)。HRNN Init让session-level GRU根据session中用户兴趣的实际演变来自由地利用这些用户兴趣动态。其更大的灵活性带来了卓越的推荐质量。即该场景中的兴趣更多的是
session内的,而求职场景中的兴趣更多的是跨session的。对于session内的兴趣建模,用HRNN Init效果更好;对于跨session的兴趣建模,用HRNN All效果更好。
用户历史长度分析:我们预计用户历史长度会对推荐质量产生影响,因此我们按照用户历史中的
session数量对evaluation进行细分。为此,我们将用户历史分为两组:具有<= 6个session的short用户历史、具有> 6个session的long用户历史。下表中报告了这些数据集中不同分组占比的统计数据。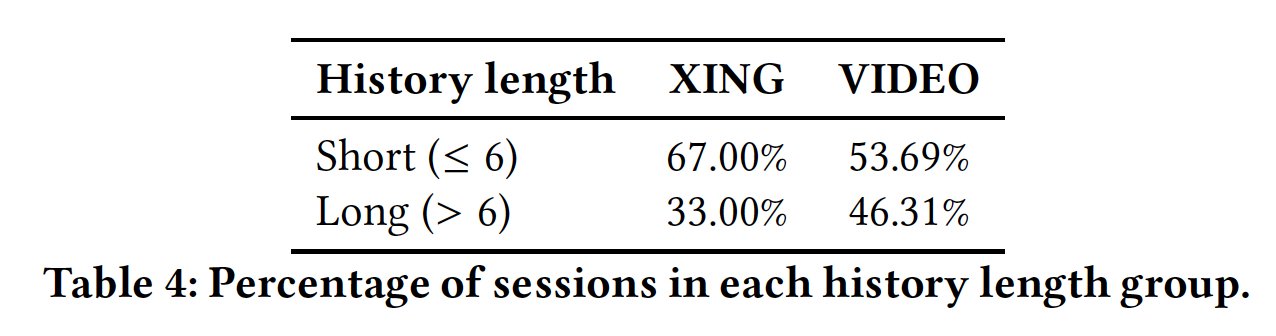
由于我们的目标是衡量
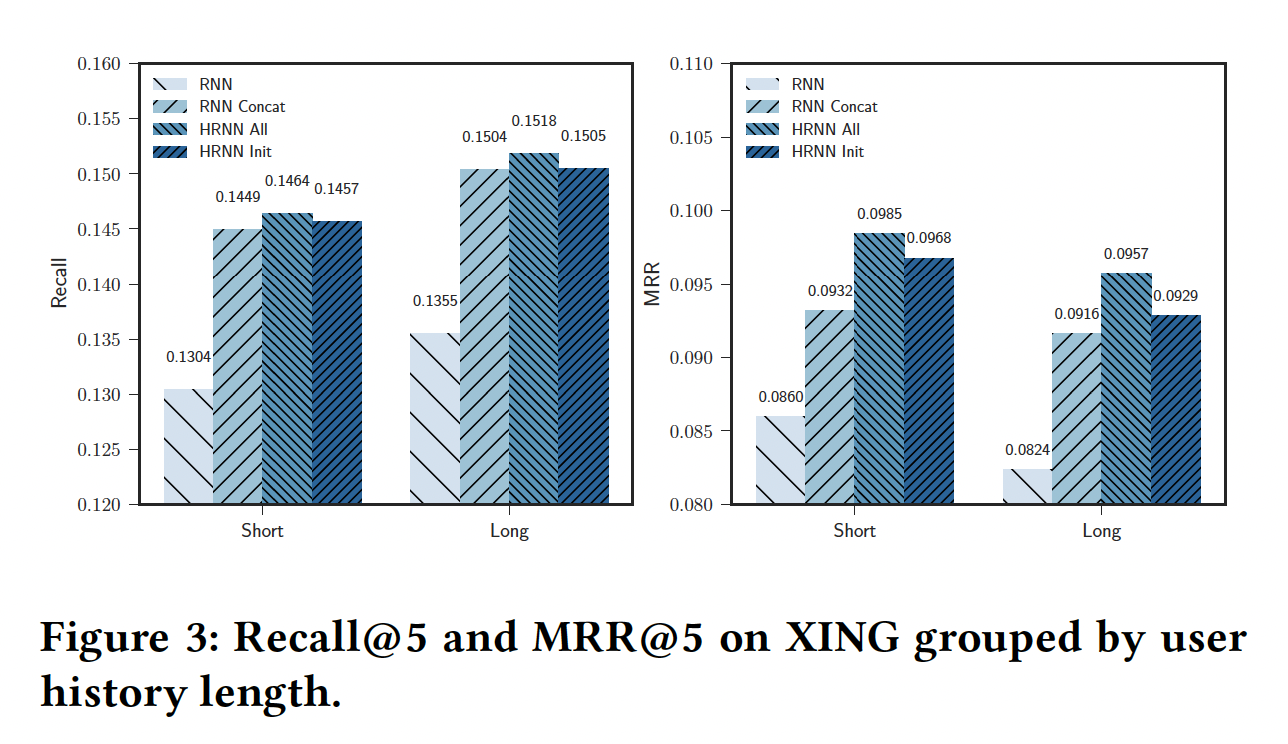
HRNN中使用的复杂的cross-session dynamic对于传统RNN的影响,因此我们将这些分析限制在大型配置中RNN-based推荐器上。对于每种算法,我们计算测试集中不同分组中test session的平均Recall@5和MRR@5。由于Precision@5的分析结论与Recall@5相似,因此由于篇幅有限我们在此省略。为了增强实验结果的鲁棒性,我们使用不同的随机数种子运行10次评估,并报告每个算法的median value(而不是均值)。XING数据集的结果如下所示。可以看到:随着用户历史长度的增加,我们注意到所有方法(包括
session-based RNN)的Recall略微增加、MRR略微下降。不同方法的
short用户历史和long用户历史的效果之间并没有显著变化。HRNN All是性能最好的模型,与session-based RNN相比,其Recall@5提高了12%、MRR@5提高了14~16%。根据我们之前的发现,
HRNN Init的性能与RNN Concat、HRNN All相当。
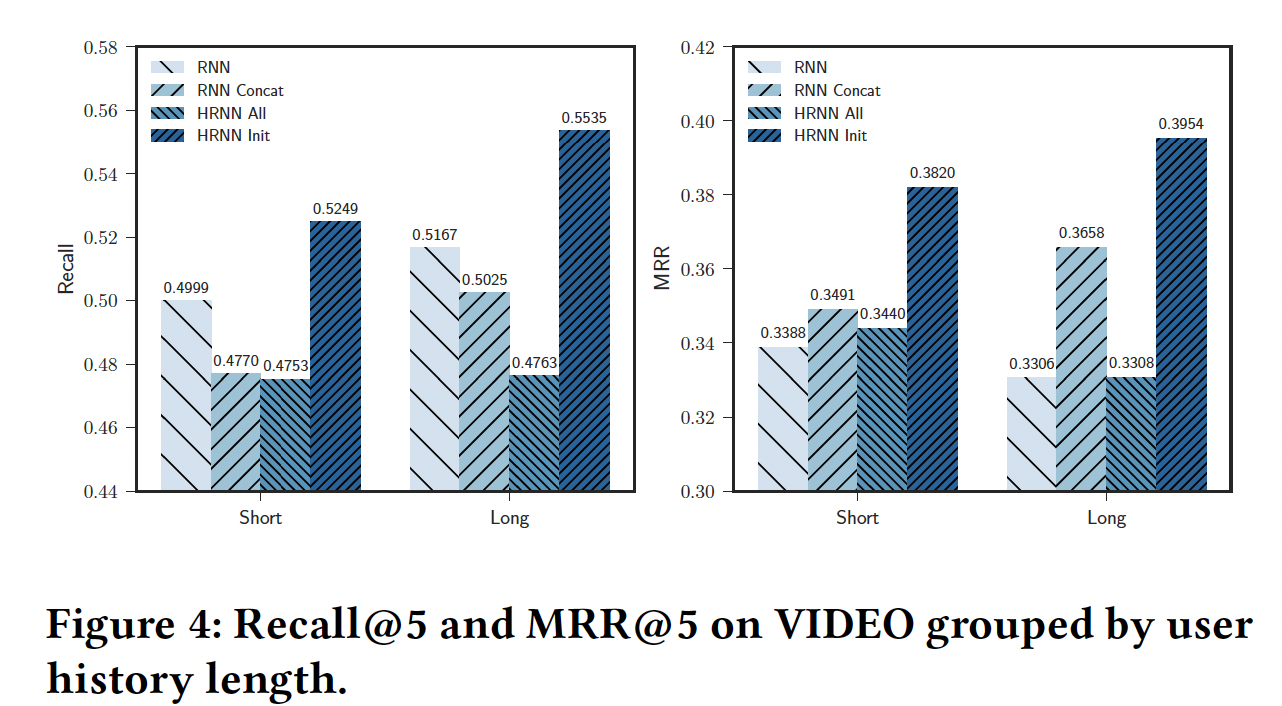
VIDEO数据集的结果如下所示。可以看到:所有方法(包括
session-based RNN)的Recall都随着用户历史长度的增加而提升。MRR仅在RNN Concat、HRNN Init方法上随着用户历史长度的增加而提升。这凸显了需要有效的个性化策略从而在session-level获得卓越的推荐质量。此外,
HRNN Init相对于session-based RNN在Recall@5/MRR@5指标上分别提升5%/12% (short)到7%/19% (long),这进一步凸显了我们个性化策略的推荐质量。与我们之前的发现一致,
HRNN All在这种情况下表现不佳。
综上所述,正如预期的那样,用户历史的长度对推荐质量有很大的影响。在像
XING这样松散的session-bounded领域,其中用户活动高度重复并且跨session的多样性较少,那么将user representation强制提供给session-level输入,将得到比initialization-only方法更好的性能。然而,在更强的session-based场景中,跨session的用户活动具有更高程度的变化性,并且可能很大程度上偏离了用户的历史兴趣和偏好,那么更简单有效的HRNN Init变体将具有更好的推荐质量。session分析:这里我们按session中事件数量进行细分,从而衡量个性化在user session中的影响。我们仅分析长度>= 5的session(XING数据集中仅为6736个session、VIDEO数据集中仅为8254个session)。我们根据session中的位置(开始Beginning、中间Middle、结束End)计算每个指标的均值。开始指的是session的前2个事件,中间指的是session的第3和第4个事件,结束指的是session第5个及其之后的任何事件。与之前的分析一样,我们关注
large配置中RNN-based模型,并报告使用不同随机数种子在10次运行中均值的median。Recall@5和MRR@5的结果如下图所示。在
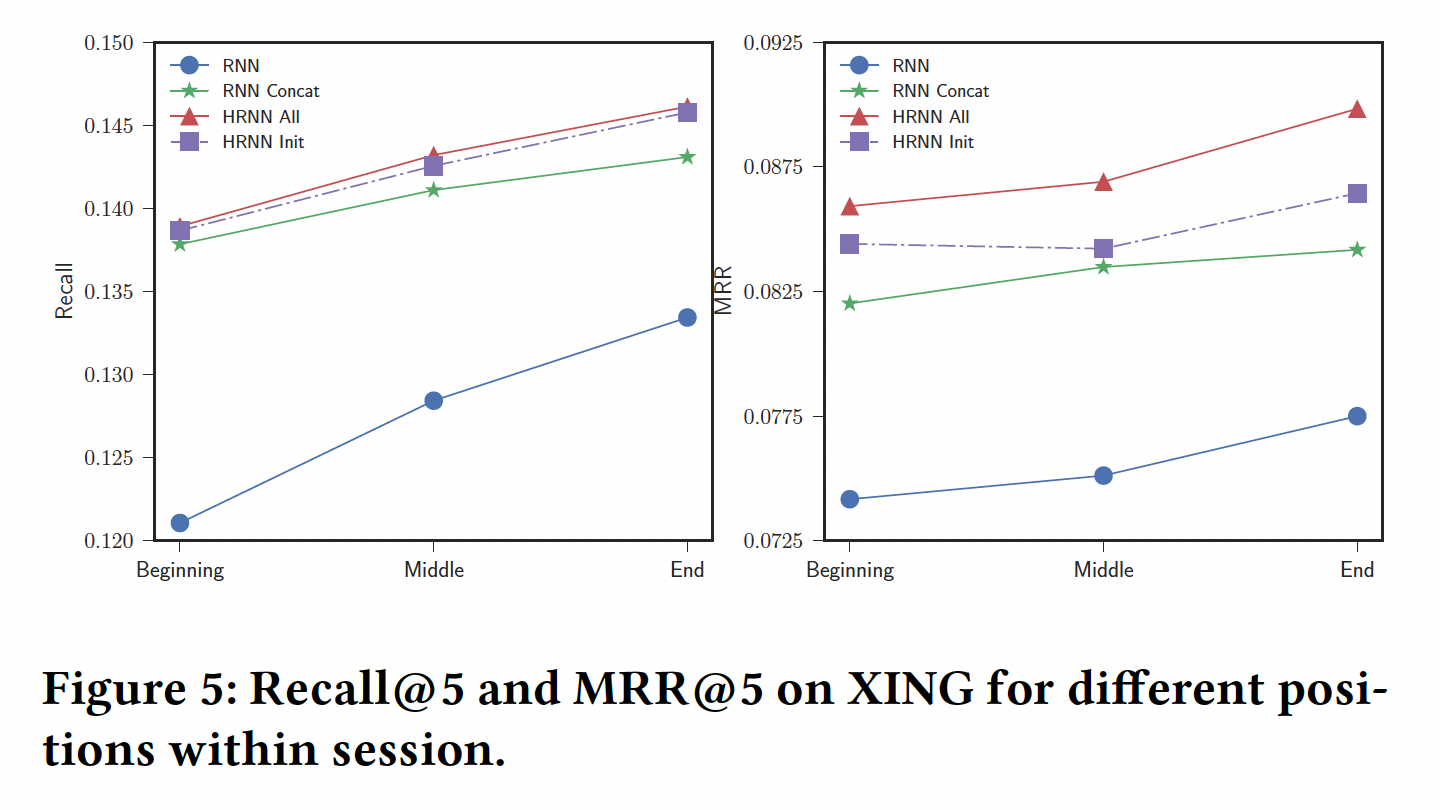
XING数据集上:所有方法的性能随着
session中previous item的数量增加而增加,这表明session-level的user context被所有RNN-based方法所正确利用。但是,个性化的
session-based模型和pure session-based模型之间存在很大差距。两个HRNN都具有相似的Recall@5,并且与RNN Concat相当。有趣的是,HRNN All的MRR@5相对于RNN和RNN Concat的增益随着处理的item数量增加而增加,这意味着在这种情况下,随着user session的继续,历史用户信息变得更加有用。HRNN Init的MRR一直都比RNN Concat更好,在Begining和End具有更高的增益。
在
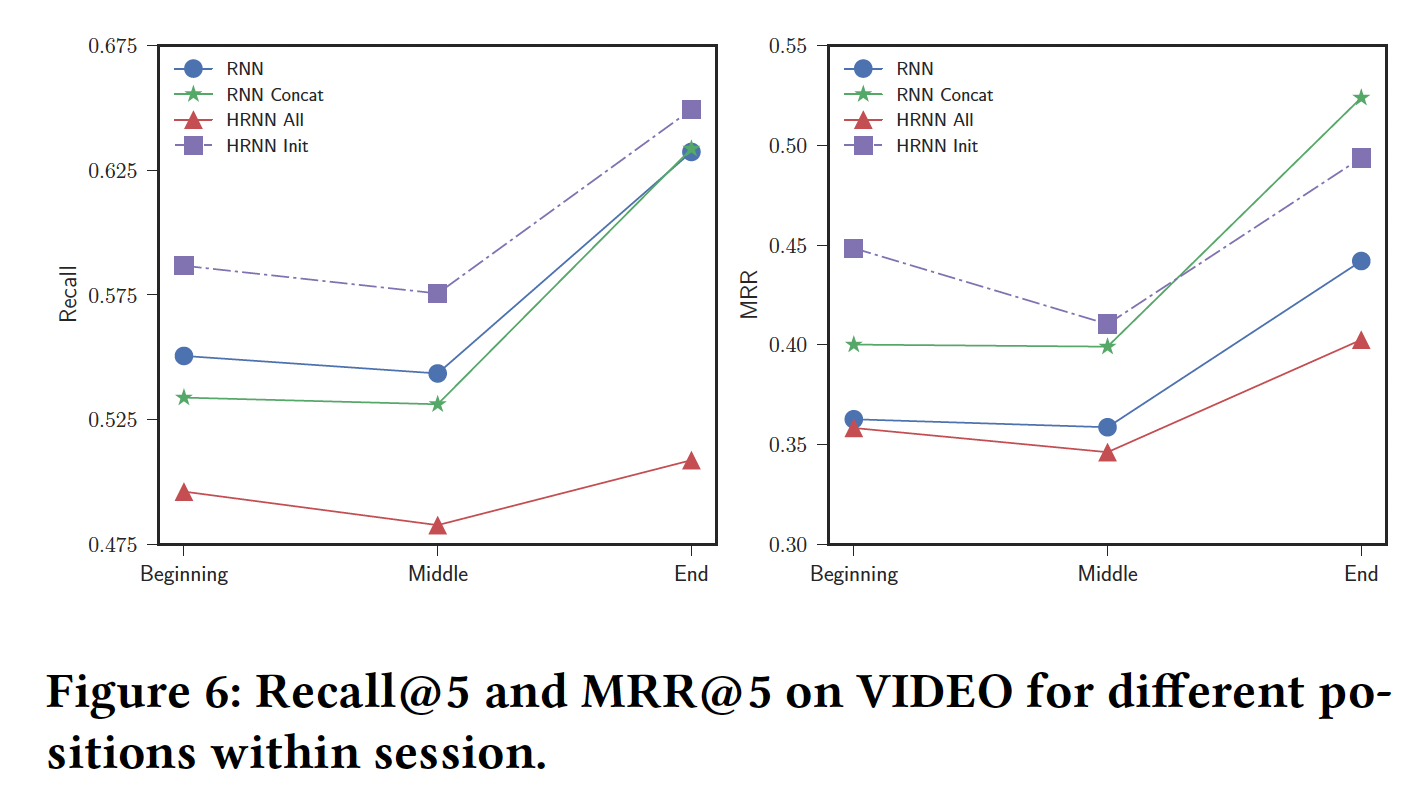
VIDEO数据集上:在
session开始和结束之间,Recall和MRR都如预期的增加。HRNN Init在session开始时比RNN和RNN Concat有很大的提升。这符合直觉,即过去的用户活动也可以有效地用于更准确地预测用户在接下来session中的首个行为。在最初的几个事件之后,个性化的
session-based模型相对于pure session-based模型的Recall增益在减少,而MRR的增益保持稳定。换句话讲,在经历一些事件之后,session-level dynamic开始压制longer-term user interest dynamic,从而降低了个性化策略的有效性。然而,个性化仍然在整个
session中提供了卓越的排序质量,正如HRNN Init和RNN Concat都比RNN有更高的MRR所证明的那样。更重要的是,在session开始时更好的推荐,要比session后期更好的推荐更具有影响力,因为前者更有可能增加留住用户的机会。最后,
HRNN All总是更差的方法,这进一步巩固了HRNN Init变体的优越性。
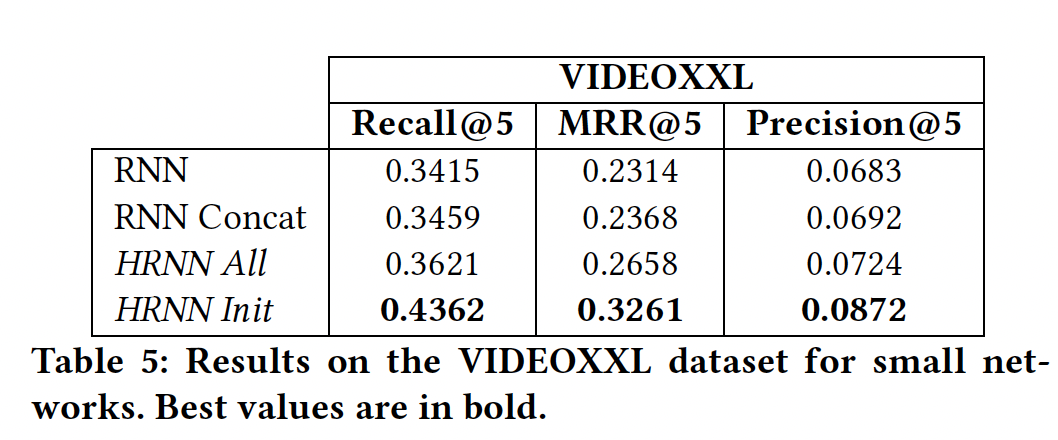
大型数据集上的实验:我们在更大版本的
VIDEO数据集(由先前的论文所使用)上验证了HRNN。该数据集由81万用户在2个月期间对38万个视频的交互组成,总共包括3300万个事件、850万个session。然后我们应用了与VIDEO数据集相同的预处理步骤。我们将这个数据集命名为VIDEOXXL。由于我们的计算资源有限,因此我们只能在这个大型数据集上测试
small网络(对于RNN和HRNN采用100维的隐层)。我们使用在小型VIDEO数据集上学到的相同超参数运行一次所有的RNN和HRNN。虽然这不是最优的,但是这种方法在更一般的setting下提供了我们解决方案的初步近似。出于同样的原因,我们没有像对小型数据集所做的那样对实验结果进行详尽的分析。为了加快评估速度,我们计算了相关item与5万个最热门item相比的排名,如《Parallel recurrent neural network architectures for feature-rich session-based recommendations》中所做的那样。结果在下表中所述,这证实了我们之前在小型
VIDEO数据集上的发现:RNN Concat无效,其性能类似于session-based RNN。另一方面,
HRNN的性能优于session-based RNN。具体而言,HRNN Init相比session-based RNN,其Recall@5高了28%、MRR@5高了41%。这些结果进一步证实了本文提出的HRNN模型的有效性。在更大的数据集上,
HRNN体现了其优势。