一、Time-LSTM [2017]
《What to Do Next: Modeling User Behaviors by Time-LSTM》
循环神经网络(
Recurrent Neural Network: RNN)解决方案已经成为序列数据建模的SOTA方法。越来越多的工作试图在推荐系统(recommender system: RS)领域找到RNN solution。RNN在推荐任务中表现良好的insight是:在用户的动作序列中存在一些内在模式(intrinsic pattern),例如一旦一个人购买了羽毛球拍那么该用户往往在以后倾向于购买一些羽毛球,而RNN在建模此类模式时已被证明表现极好。然而,推荐系统中的上述
RNN解决方案都没有考虑用户相邻动作(action)之间的时间间隔(time interval),而这些时间间隔对于捕获用户动作之间的关系很重要。例如,间隔时间很短的两个动作往往是相关的,而间隔时间很长的两个动作往往是针对不同的目标。因此,在建模用户行为时,利用时间信息来提高推荐性能非常重要。我们使用下图来展示时间间隔是什么、以及它如何使得推荐系统与语言模型等传统领域不同。具体而言,在语言模型中没有相邻词之间的间隔的概念(如RNN架构擅长对下图(a)中的序列数据(sequential data)的顺序信息(order information)进行建模,但是无法很好地对下图(b)中的时间间隔进行建模。因此,需要提出新的模型来解决这个问题。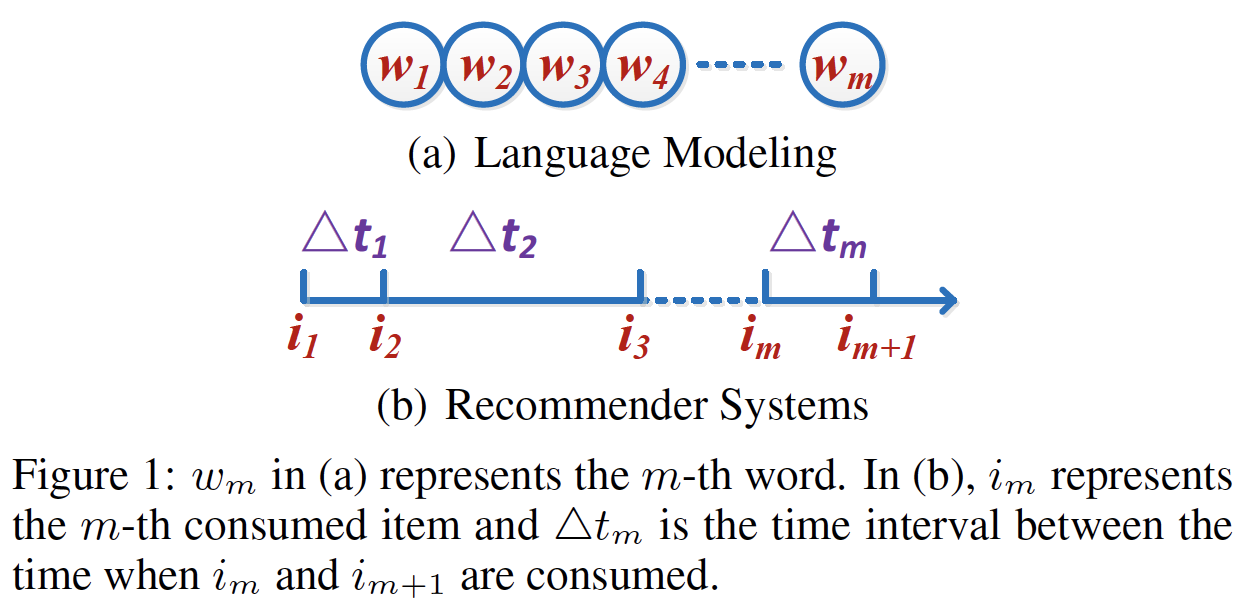
人们最近提出的一种模型,即
Phased LSTM,该模型试图通过向LSTM添加一个time gate来建模时间信息。在这个模型中,时间戳timestamp是time gate的输入,其中time gate控制了cell sate, hidden state的更新从而控制最终输出。同时,仅使用处于模型激活状态(model’s active state)的样本,导致训练期间的稀疏更新(sparse update)。因此,Phased LSTM在训练阶段可以获得相当快的学习收敛速度。然而,有一些挑战使得Phased LSTM难以成为最适合推荐任务的方法。首先,
Phased LSTM对时间戳进行建模。时间戳是单个动作的特征,而不是两个动作之间的时间间隔。因此,Phased LSTM可能无法正确建模动作之间的关系。其次,在大多数推荐系统中,用户的行为数据通常非常稀疏,而
Phased LSTM会忽略用户在非激活状态(inactive state)下的行为,无法充分利用行为信息进行推荐。第三,之前的研究已经指出,用户的短期兴趣和长期兴趣对于推荐都非常重要,但传统的
RNN架构(包括Phased LSTM)并没有旨在同时区分和同时利用这两种兴趣。在这里:短期兴趣意味着,推荐的
item应该取决于最近消费的item。例如,如果用户刚买了一台尼康相机,那么该用户很可能在不久的将来会购买存储卡、镜头、保护套。长期兴趣是指被推荐的
item也应该受到用户历史行为的影响,其中历史行为反映了用户的一般兴趣(general interest)。
为了应对上述挑战,论文
《What to Do Next: Modeling User Behaviors by Time-LSTM》提出了具有三个版本的Time-LSTM来建模用户在推荐系统中的序列动作(sequential action)。Time-LSTM中的time gate建模动作的时间间隔,从而捕获动作之间的关系。第一个版本的
Time-LSTM只有一个time gate,这个time gate利用时间间隔来同时捕获短期兴趣和长期兴趣。第二个版本的
Time-LSTM有两个time gate。第一个
time gate旨在利用时间间隔来捕获当前item recommendation的短期兴趣。第二个
time gate是保存时间间隔,以便建模长期兴趣用于之后的推荐。
第三个版本的
Time-LSTM使用coupled input and forget gates减少参数数量,这使得模型更加简洁。
具有这些
time gate的Time-LSTM可以很好地同时捕获用户的短期兴趣和长期兴趣,从而提高推荐性能。此外,Time-LSTM没有忽略动作的非激活状态,因此与Phased LSTM相比,它可以更好地利用行为信息。论文的实验结果证明了Time-LSTM的有效性。本文的贡献如下:
所提出的模型
Time-LSTM为LSTM配备了精心设计的time gate,因此它不仅擅长建模序列数据中的顺序信息,还可以很好地捕获对象之间的时间间隔。这是一个一般(general)的思想(不限于推荐系统),可以开发Time-LSTM的其它变体来建模其它任务中event-based的序列数据。请注意,与考虑时间戳并可能隐式捕获间隔信息的
Phased LSTM不同,论文显式地建模时间间隔。此外,与Phased LSTM相比,Time-LSTM利用了更多的样本。提出了三个版本的
Time-LSTM。与现有的RNN解决方案相比,这些Time-LSTM版本可以更好地同时捕获用户的短期兴趣和长期兴趣,从而提高推荐性能。所提出的模型在两个真实世界的数据集上进行了评估,实验结果表明使用
Time-LSTM的推荐方法优于传统方法。
相关工作:
LSTM及其变体:LSTM:LSTM最常用的更新方程如下:其中:
input gate),forget gate),output gate),cell activation vector,hidden state vector,input feature vector。sigmoid非线性激活函数,而tanh非线性激活函数。LSTM的实现并未引入这一项)。Hadamard product。
coupled input and forget gates:LSTM的一种变体是使用coupled input and forget gates,而不是单独决定要遗忘什么、以及什么新信息要被添加。这个变体丢弃了forget gate,并调整Phased LSTM:Phased LSTM是一种SOTA的RNN架构,用于建模event-based的序列数据。Phased LSTM通过添加time gateLSTM。time gatetotal period)时长,open period和total period的比值,phase shift。time gate其中:
leak rate(在训练阶段取值几乎为零,在测试阶段直接设为零)。leak rateLeaky ReLU,用于传播梯度信息。注意,这里的
time gate。考虑到通常有多个特征维度,因此time gate是个向量。time gatephases:在第一个phase0上升到1,在第二个phase1下降到0(前两个phase,模型为激活状态),在第三个phasephase,模型为非激活状态inactive state)。仅在time gate激活状态下才更新Phased LSTM的cell state和hidden state更新方程为:由于设置了
inactive state,Phased LSTM在应用于推荐系统时无法充分利用用户的动作。
推荐系统中的
RNN解决方案:《Session-based recommendations with recurrent neural networks》在old sessions中对item-ID的one-hot representation训练了带ranking loss的RNN。然后,训练好的RNN用于在新的user session上提供推荐。《Parallel recurrent neural network architectures for feature-rich session-based recommendations》是《Session-based recommendations with recurrent neural networks》的扩展,它提出了两项技术(数据增强、以及一种考虑输入数据分布变化的方法)来提高模型的性能。此外,它考虑了一个稍微不同的setting,其中存在item的丰富特征。它引入了parallel RNN架构来建模clicks以及item特征。《A dynamic recurrent model for next basket recommendation》为next-basket recommendation设计了一种RNN方法。
在本文中,我们探索了在推荐系统社区中具有更常见
setting的RNN解决方案:我们知道user id,但是不知道session信息。此外,前述方法不考虑时间间隔,而我们在LSTM中添加time gate,可以利用时间间隔来推高推荐性能。短期兴趣和长期兴趣:
推荐系统中的大多数现有算法,如
Bayesian Personalized Ranking: BPR、矩阵分解(matrix factorization)、张量模型(tensor models),聚焦于建模用户的长期兴趣。《Personalized news recommendation based on click behavior》通过content-based方法来适配(adapt)一种协同过滤方法(collaborative filtering)从而挖掘用户的当前兴趣。一些方法应用协同过滤和关联规则(
association rule)来match用户最近的行为。《Adaptation and evaluation of recommendations for short-term shopping goals》提出用户的短期兴趣和长期兴趣在在线购物场景中都很重要,并量化了几种组合策略(combining strategy)。半马尔可夫过程(
Semi-Markov Process: SMP)和马尔可夫更新过程(Markov Renewal Process: MRP)还旨在建模具有时间间隔的序列过程(sequential process)。然而,由于SMP和MRP的马尔科夫特性,它们无法捕获在我们任务中的长期兴趣。
1.1 模型
令
item集合。对每个用户item。我们的任务是在给定用户
我们通过两种方法使得
LSTM适配(adapt)我们的任务:第一种方法是,我们仅记录
item的顺序,而不考虑时间信息。因此在我们的任务中,LSTM更新方程中的one-hot)。这也是大多数现有方法的做法。
第二种方法是,考虑时间信息。我们首先将
那么在我们的任务中,
LSTM更新方程中的one-hot representation,对也可以对
day/week/month等离散化,然后转换为embedding。这里用下一个时间戳减去当前时间戳,而不是当前时间戳减去上一个时间戳,是因为我们想捕获当前消费的
item对未来的影响。
为了适配
LSTM及其所有变体,模型的输出是由item的概率分布。损失函数基于模型的输出和对于
Phased LSTM的适配,在我们的任务中,one-hot representation),time gate中的当将
LSTM及其变体应用于推荐系统时:last item的信息。由于这是用户最近(most recent)的动作,我们可以利用另一方面,
previous actions)的信息,因此
然而,
consuming goal)。在Time-LSTM中,我们使用time-gate来控制last consumed item此外,这些
time gate有助于将时间间隔存储在later recommendation)中的长期兴趣。因此,在建模用户的长期兴趣时,不仅要考虑用户以前消费过的item,还要考虑相应的时间间隔。我们设计了三个版本的Time-LSTM,如下图所示。在
attention-based模型(如STAMP中),是否可以将last item对当前推荐的影响?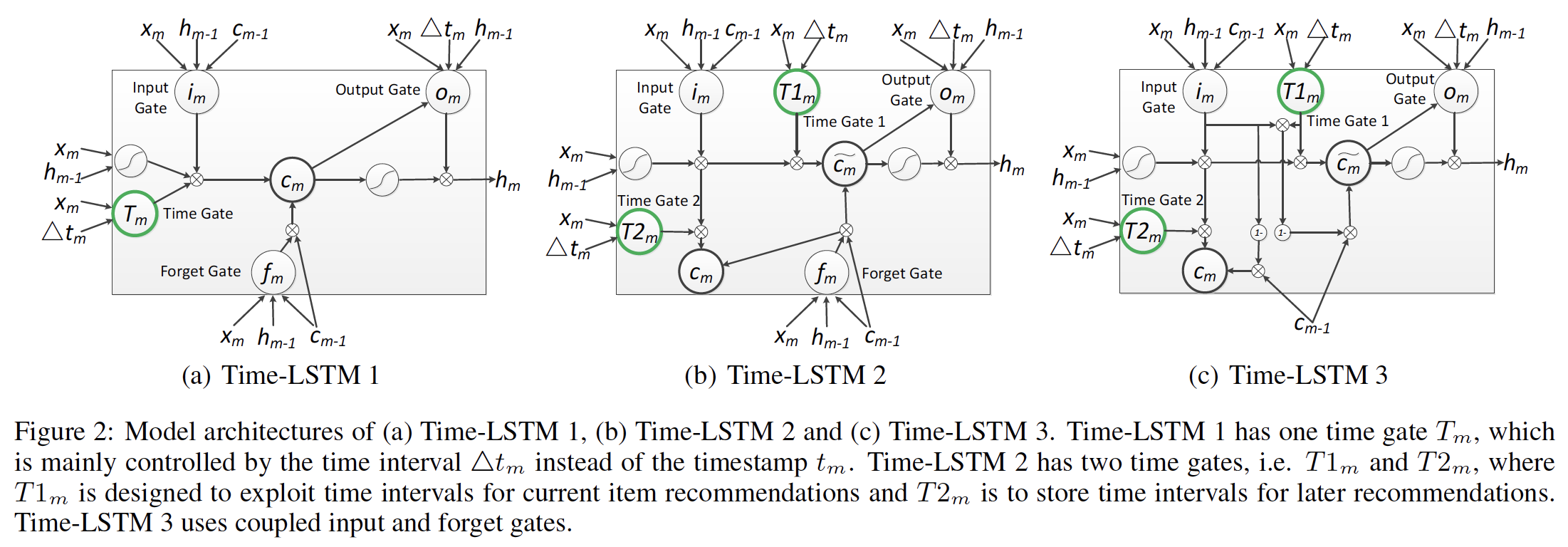
1.1.1 Time-LSTM 1
第一个版本的
Time-LSTM添加了一个time gateLSTM的更新方程,我们添加了一个time gate的更新,同时调整了其中:
sigmoid函数,time gate。
可以看到,
time gate一方面,
input gatetime gate另一方面,
later recommendation)来建模用户的长期兴趣
注意,我们能够以类似的方式将
RNN架构,如GRU。last consumed item,如果它是非常近期消费(more recently consumed)的,则这个item应该对当前推荐有更大的影响。我们希望将这些先验知识融入到time gate的设计中。
1.1.2 Time-LSTM 2
第二个版本的
Time-LSTM添加了两个time gatelast consumed item对当前item recommendation的影响。而
基于
LSTM的更新方程,我们首先添加了两个time gate的更新:然后我们调整
其中:
input gatecell stateoutput gatehidden stateitem recommendation。
通过方程中的约束条件
item recommendation的影响。具体而言:如果
item recommendation产生更大的影响。即,另一方面,如果
然而,对于
time gate,即区分和定制化了用于当前推荐的角色(role for current recommendation)(time gaterole for later recommendation)(time gate
1.1.3 Time-LSTM 3
受
《Lstm: A search space odyssey》的启发,第三个版本的Time-LSTM使用了coupled input and forget gates。具体而言,基于Time-LSTM 2,我们移除了forgate gate,并修改由于
forget gate。而forget gate。
1.1.4 训练
在我们的任务中,我们使用
Time-LSTM的方法类似于第二种LSTM适配:首先将
然后在
Time-LSTM中,one-hot representation),而
我们使用随机梯度下降(
Stochastic Gradient Descent: SGD)的变体AdaGrad来优化Time-LSTM模型中的参数。由于方程中存在约束projection operator)来处理它,即: 如果我们在训练迭代期间得到在现实世界的
application中,用户的新消费行为不断地被产生。因此,我们希望利用所有可用的消费历史(包括新生成的动作)进行推荐,即online learning setting。非
online learning setting策略是:在推断期间冻结模型,使用固定的参数进行推断。oneline learning setting策略会根据新的消费行为来更新模型参数,使用新的参数进行推断。为了实现这一点,我们将
《Recurrent neural network based language model》中的动态更新模型应用于我们的任务,如下所示:第一步,我们的模型根据用户现有的消费历史进行训练,直到收敛。
第二步,我们重复以下过程:当
AdaGrad应用于用户更新后的消费历史从而更新previous parameters一次。我们可以增大online learning的效率。也可以根据时间周期性地更新(如每隔
1小时)。
我们可以周期性重复以上两个步骤。可以综合考虑推荐性能和计算成本来选择合适的周期。
1.2 实验
数据集:我们在
LastFM和CiteULike这两个数据集上进行评估。对于
LastFM数据集,我们抽取元组<user id, song id, timestamp>,其中每个元组代表用户user id在 时刻timestamp听歌曲song id的动作。对于
CiteULike数据集,一个用户在某个时刻注释一篇论文时可能有几条记录从而区分不同的tag。我们将这些记录合并为单条记录并抽取元组<user id, papaer id, timestamp>。注意,与
《Heterogeneous hypergraph embedding for document recommendation》不同,我们没有将tag用于推荐。
我们过了掉低频的用户和
item。这些元组都按照user id组织并根据timestamp进行排序。下表展示了这些数据集的统计数据。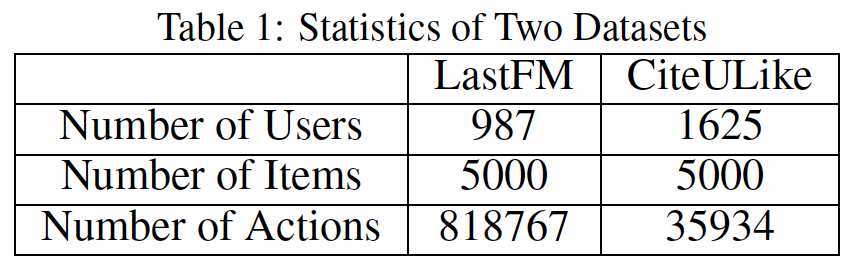
对于每个数据集,我们随机选择
80%的用户作为训练用户,并使用他们的元组进行训练。剩余的20%用户作为测试用户。对于每个测试用户test case,其中第test case是在给定ground truth为baseline方法:CoOccur+BPR:这是《Adaptation and evaluation of recommendations for short-term shopping goals》中提出的一种组合策略,其中CoOccur是为了捕获短期兴趣,而BPR是为了捕获长期兴趣。具体而言,
CoOccur根据item在user session中共现(co-occurring)的条件概率对item进行排序(关联规则)。如果推荐列表尚未填满,则根据BPR的推荐继续填充推荐列表。我们不使用原始论文中的
FeatureMatching和RecentlyViewed。原因是:FeatureMatching需要item的属性信息,这在我们的任务中是不可用的。RecentlyViewed只是推荐最近查看过的item,然而大多数情况下,我们希望推荐系统为我们提供那些我们忽略(ignore)的、但是仍然喜欢的item。因为即使没有推荐系统的帮助,我们仍然可以自己找到我们熟悉的item(例如我们最近浏览过的item、或者最近消费过的item)。
该方法需要
session信息。我们使用一种常用的方法,即timeout,来识别用户消费历史中的session。如果两个动作的间隔时间超过了指定的阈值,则认为它们属于不同的
session;否则属于相同的session。Session-RNN:《Session-based recommendations with recurrent neural networks》使用RNN在session-based推荐中基于session中的item来捕获短期兴趣。该方法不考虑长期兴趣。session信息的抽取如CoOccur + BPR中所述。我们使用该方法的公开可用的python实现。Session-RNN虽然是序列模型(类似于LSTM),但是它仅考虑当前session的信息而不是历史所有item的信息,因此仅捕获短期兴趣。LSTM:前文介绍的LSTM的第一种适配方式。LSTM + time:前文介绍的LSTM的第二种适配方式。Phased LSTM:前文介绍的Phased LSTM的适配。我们并没有对比
《A dynamic recurrent model for next basket recommendation》,因为该方法的setting不同于我们的方法,并且该方法的某些操作(如池化)无法应用于我们的方法。
前文介绍的
online learning setting应用于LSTM及其变体(包括Phased LSTM和Time-LSTM),其中训练training users的元组用于训练step one的模型。类似的更新策略应用于CoOccur + BPR和Session-RNN以确保公平地比较。LSTM及其变体(包括Phased LSTM和Time-LSTM)的unit数量设置为512。所有方法中的其它超参数都通过交叉验证进行调优,或者按照原始论文进行设置。评估指标:每个
target itemground truth)与100个其它随机item进行组合。然后推荐算法对这101个item进行排名,top 10个item构成推荐列表。Recall@10:Recall@10的定义为:其中:
test case的数量,test case的数量。MRR@10(Mean Reciprocal Rank):这是reciprocal rank)的均值。如果10,则排名倒数置为零。MRR@10考虑item的排名。
每个指标评估
10次并取均值。实验结果如下表所示:
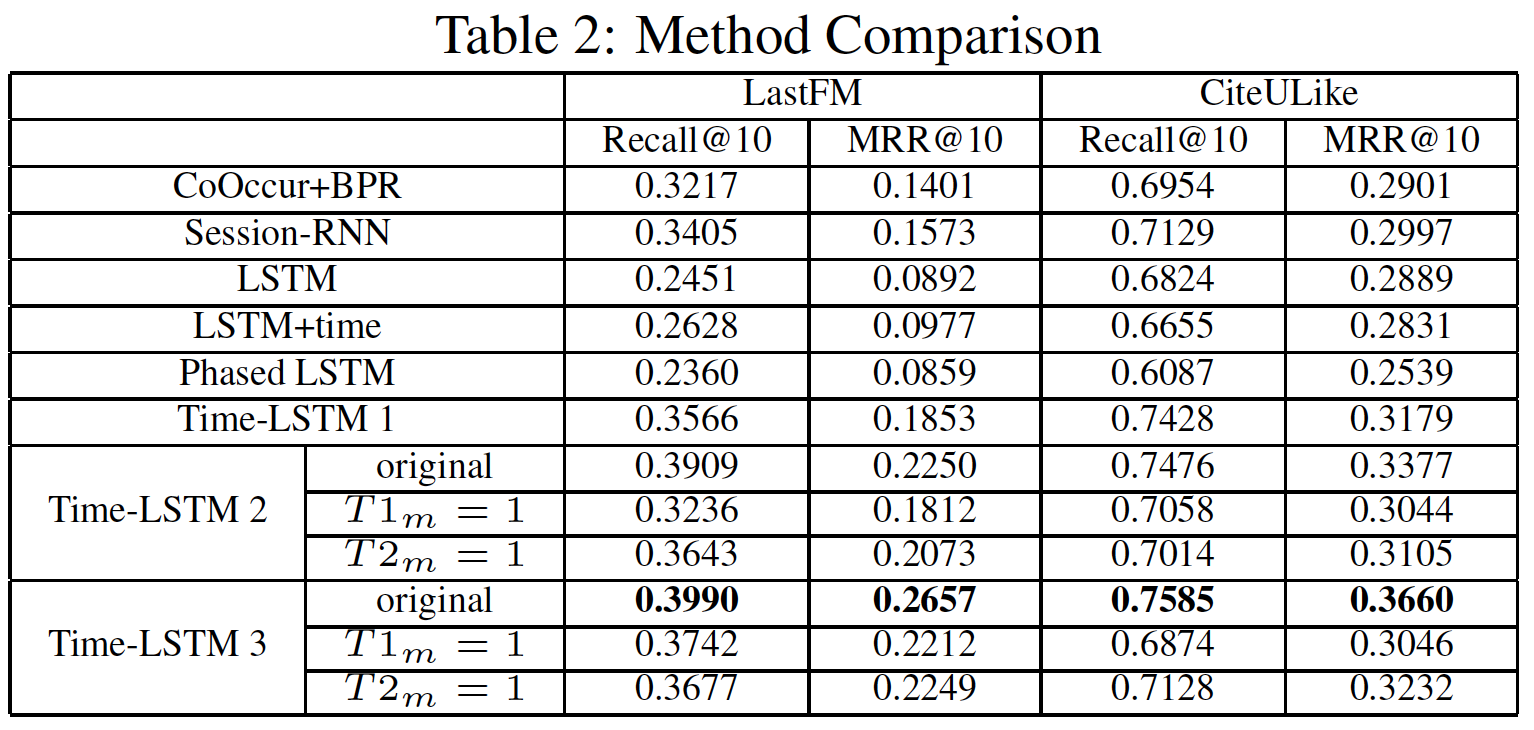
Time-LSTM模型通常优于其它baseline。Time-LSTM 2和Time-LSTM 3的性能优于Time-LSTM 1,这证明了使用两个time gate而不是一个time gate的有效性。T1m=1和T2m=1分别是我们将1、将1的结果。它们的性能比原始版本更差,这表明使用我们设计的T1m来过滤输入、T2m来存储时间间隔都可以提高性能。LSTM+time在CiteULike中的表现略逊于LSTM,这可能是由于CiteULike中的时间间隔通常很大(归一化之后,它的性能有所提高,但仍然比Time-LSTM模型更差)。
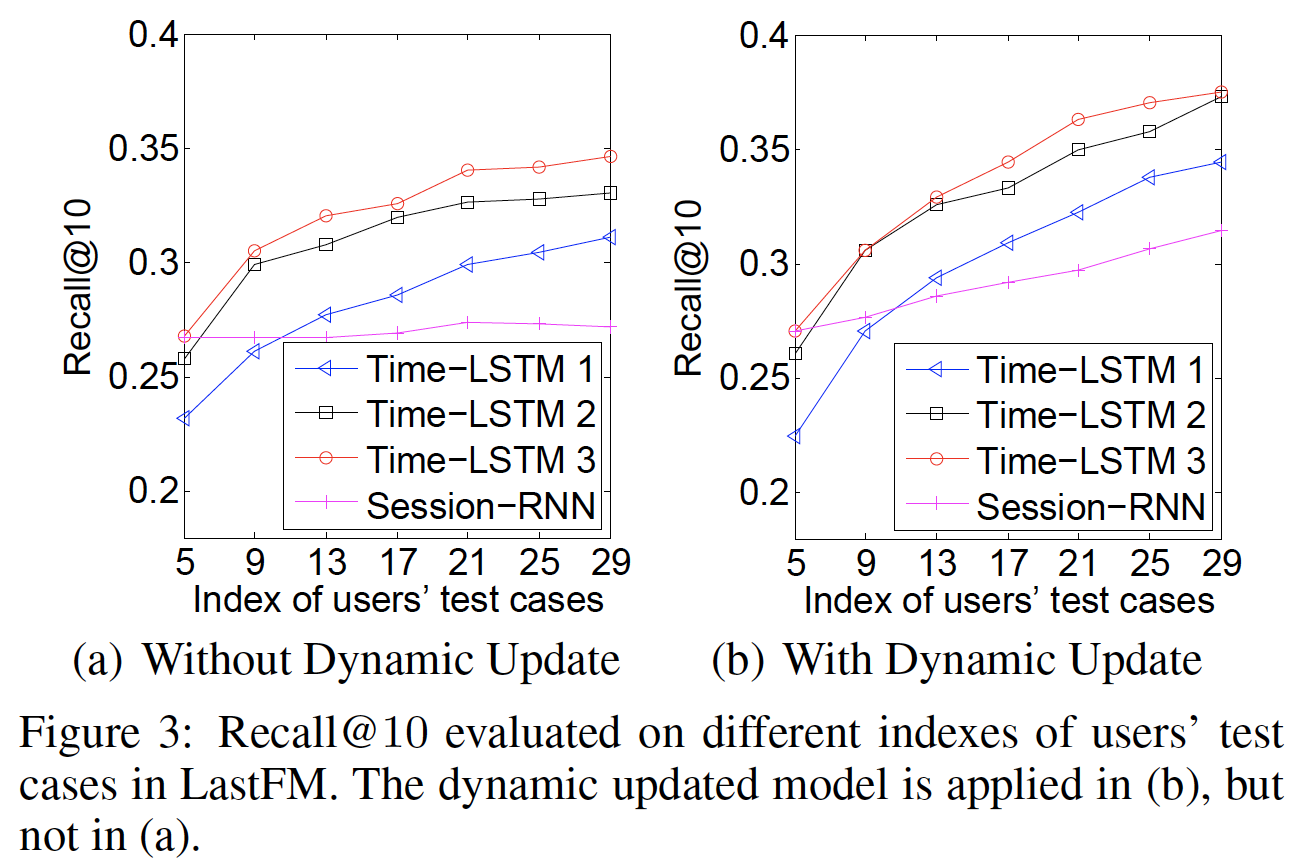
Cold User和Warm User的性能:如果用户消费的item很少,则我们认为用户是cold的;否则我们认为用户是warm的。由于篇幅有限,我们只在LastFM中展示Recall@10的结果。如下图所示,x轴上的索引test case。在给定training user的所有动作、以及test user的前test user的第图
(a)表明Time-LSTM对warm user表现更好(较大的索引表明用户消费了更多的item)。原因是Time-LSTM可以更好地建模长期兴趣用于推荐。对于
cold user,Time-LSTM的性能与Session-RNN相当。这是因为尽管消费行为很少,但是Time-LSTM仍然可以通过捕获短期兴趣来很好地执行推荐。图
(b)中的性能优于(a),这证明了动态更新模型的有效性。对于warm user而言,从(a)到(b)的性能提升更为显著,因为warm user的模型更新次数要比cold user更多。
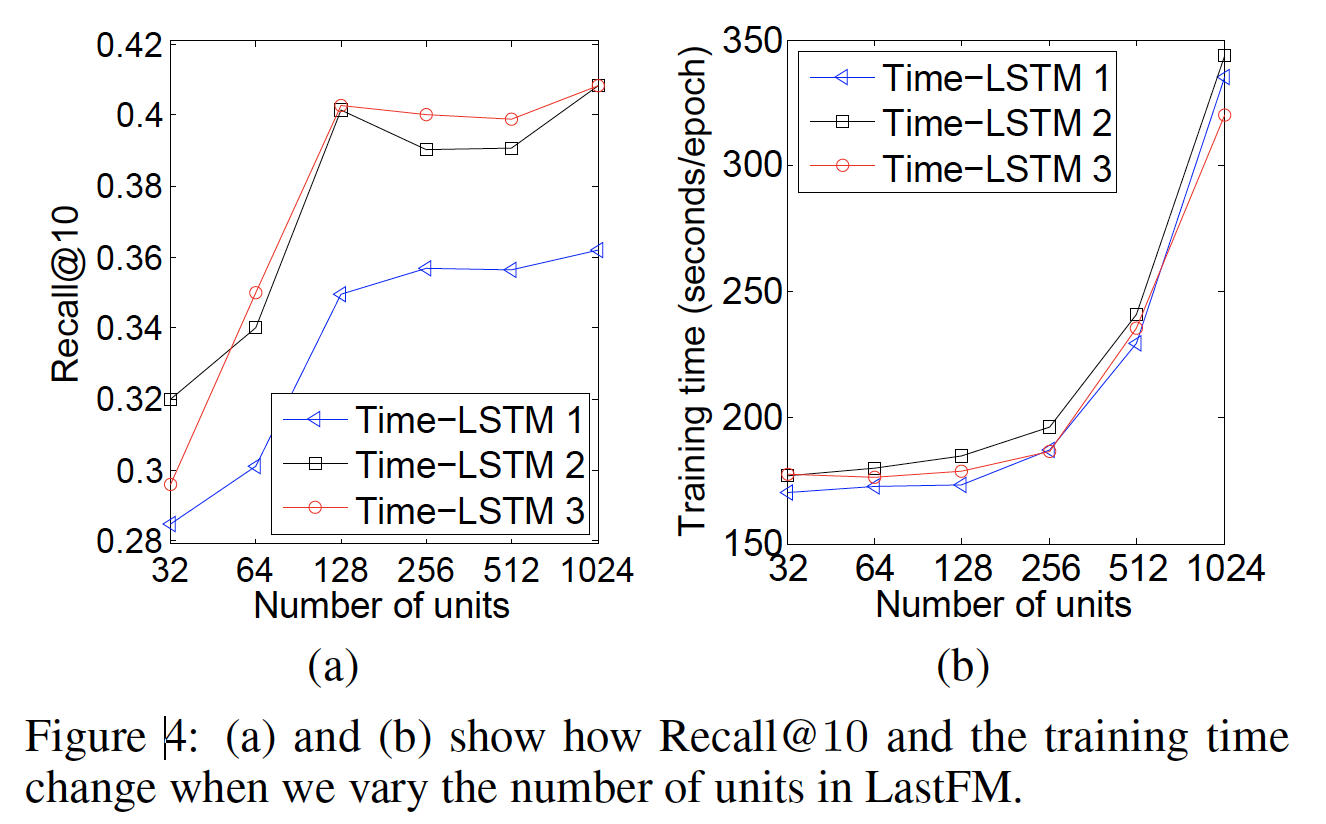
单元数量(
unit number)和效率:我们改变单元数量GeForce GTX Titan Black GPU上进行评估。限于篇幅,我们仅展示在LastFM数据集上的Recall@10、以及训练时间。如下图
(a)所示,增加Recall@10。但是当另一方面,如下图
(b)所示,增加128和512之间比较合适。当
Time-LSTM 3的训练时间总是比Time-LSTM 2更少。原因是Time-LSTM 3中的coupled input and forget gates减少了参数数量,并加快了训练过程。