一、Caser [2018]
《Personalized Top-N Sequential Recommendation via Convolutional Sequence Embedding》
大多数推荐系统根据用户的一般偏好(
general preference)来推荐item,但是没有关注用户最近交互的item。例如,一些用户总是更喜欢苹果的产品(而不是三星的产品),这反应了用户的一般偏好。一般偏好代表用户的长期(long term)的、静态(static)的行为。另一种类型的用户行为是序列模式(
sequential pattern),其中next item或者next action更可能取决于用户最近互动的item或action。序列模式代表了用户的短期(short term)的、动态(dynamic)的行为。序列模式源自在相近时间内互动的item之间的某种关系(relationship)。例如,用户可能会在购买iPhone之后不久购买手机配件,但是通常而言用户是不会突然购买手机配件的(没有人会对手机配件产生长期兴趣)。在这种情况下,仅考虑一般偏好的推荐系统将错过在销售iPhone之后向用户推荐手机配件的机会,因为购买手机配件不是长期的用户行为。top-N序列推荐(Sequential Recommendation):令用户集合item集合item序列,记做item在用户行为序列order。注意,absolute timestamp)。给定所有用户的行为序列
top-N序列推荐的目标是:通过考虑一般偏好和序列模式,向每个用户推荐一个item list,从而最大化用户的未来需求(future need)。与传统的
top-N推荐不同,top-N序列推荐将用户行为建模为item的序列(sequence),而不是item的集合(set)(序列是有序的,集合是无序的)。先前工作的局限性:基于马尔科夫链的模型是一种早期的
top-N序列推荐方法,其中action进行推荐。一阶马尔科夫链使用最大似然估计(
maximum likelihood estimation)来学习item-to-item的转移矩阵(transition matrix)。Factorized personalized Markov chain: FPMC及其变体通过将转移矩阵分解为两个潜在(latent)的、低秩(low-rank)的子矩阵来改进该方法。Factorized Sequential Prediction with Item Similarity Models: Fossil通过对先前的item的latent representation进行加权的sum聚合,从而将该方法推广到高阶马尔科夫链。
但是,现有方法受到两个主要限制:
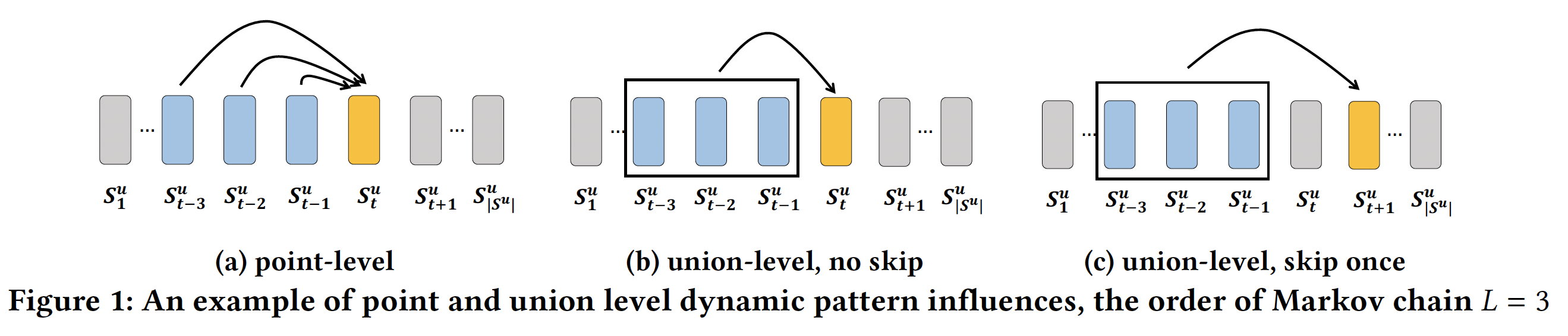
无法建模
union-level的序列模式。如下图(a)所示,马尔科夫链仅建模point-level序列模式,其中每个先前的action(蓝色)独自地(individually)(而不是协同地collectively)影响target action(黄色)。FPMC和Fossil就属于point-level序列模式。尽管Fossil考虑了一个高阶马尔科夫链,但是它的总体影响(overall influence)是:从一阶马尔科夫转移矩阵分解的、先前的item latent representation的加权和。这种point-level影响不足以建模下图(b)中的union-level影响,其中若干个先前的action以给定的顺序共同影响target action。例如,同时购买牛奶和黄油之后再购买面粉的概率,要比单独购买牛奶(或者单独购买黄油)之后再购买面粉的概率更高。再例如,同时购买内存和硬盘之后再购买操作系统的概率,要比单独购买其中一个配件之后再购买操作系统的概率更高。假设同时购买牛奶和黄油之后再购买面粉的概率为
point-level的加权和的形式,则有:一种缓解方案是调整加权的权重范围,如选择
不允许
skip行为(behavior)。现有模型不考虑skip行为的序列模式,如下图(c)所示,其中过去的行为可能会skip几个step之后仍然产生影响。例如,游客在机场、酒店、餐厅、酒吧以及景点依次进行check-ins。虽然机场check-ins和酒店check-ins并不是景点check-ins的直接前驱,但是它们也与景点check-ins密切相关。另一方面,餐厅check-ins和酒吧check-ins对景点check-ins的影响很小(因为到访景点之前不一定需要到访餐厅或到访酒吧,但是几乎一定意味着到访机场和酒店)。skip行为,因为它假设前面的step对紧接的next step有影响。
为了提供关于
union-level影响以及skip行为的证据,论文《Personalized Top-N Sequential Recommendation via Convolutional Sequence Embedding》从两个现实生活数据集MovieLens和Gowalla中挖掘了以下形式的序列关联规则(sequential association rule):对于上述形式的规则
support count)confidenceitem对于通过将右侧调整为
skip 1 step或者skip 2 step的影响。下图总结了找到的有效规则数量(过滤掉无效的规则)与马尔科夫阶次
skip步数的关系。过滤条件为:支持度>= 5、置信度>= 50%(作者还尝试了最小置信度为10%, 20%, 30%,但是这些趋势是相似的)。可以看到:大多数规则的阶次为
可以看到
point-level规则,union-level规则。该图还表明,相当多的规则是
skip一步或两步的。
这些发现支持
union-level以及skip行为的影响。注意,这里并不意味着
>= 50%的规则。通常而言,因此下图仅能说明
union-level和skip行为比较重要,但是并不能说明point-level行为不重要,更不能说明union-level和skip行为比point-level行为更重要。事实上,在现实世界的数据集中,point-level行为才是占据统治地位。从论文后面的实验部分(
Caser组件分析)也能验证这一点:point-level行为比union-level行为更重要。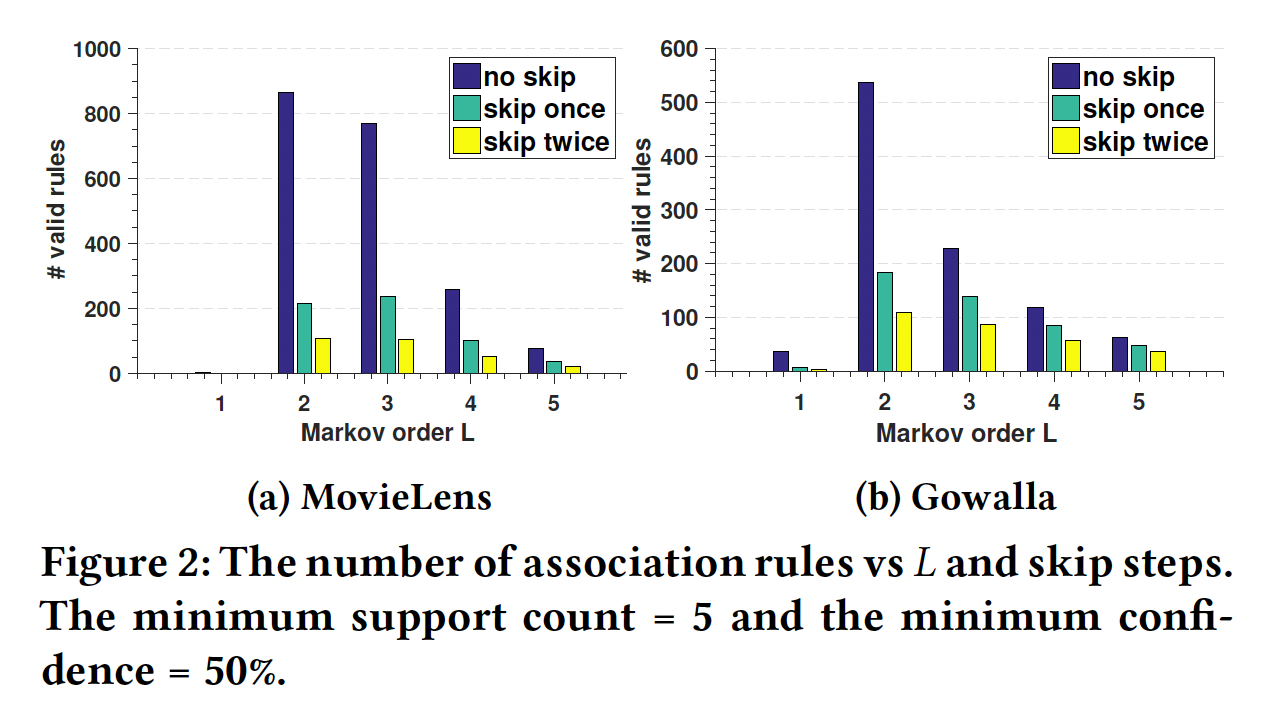
为了解决现有工作的上述限制,论文
《Personalized Top-N Sequential Recommendation via Convolutional Sequence Embedding》提出了一个ConvolutionAl Sequence Embedding Recommendation Model: Caser模型 作为top-N序列推荐的解决方案。Caser利用卷积神经网络,其创新之处在于:将前面item表示为一个embedding矩阵embedding的维度,并且矩阵的行保留了item之间的次序(order)。论文将这个embedding矩阵视为潜在空间中由item构成的image,并使用各种卷积filter来搜索序列模式从而作为该image的局部特征。然而,与图像识别不同的是,这个image并不是通过input直接给出的,而是必须与所有filter同时学习。论文主要贡献:
Caser使用水平卷积filter和垂直卷积filter来捕获point-level、union-level、以及skip行为的序列模式。Caser同时建模一般偏好以及序列模式,并在单个统一框架中概括了几种现有的SOTA方法。在现实生活的数据集上,
Caser优于SOTA的top-N序列推荐方法。
相关工作:
传统的推荐方法,如协同过滤、矩阵分解、以及
top-N推荐,都不适合捕获序列模式,因为它们没有建模action的顺序。序列模式挖掘的早期工作基于统计共现来找到显式的序列关联规则(
sequential association rule)。这种方法依赖于模式的显式表示(explicit representation),因此可能会错过未观察到的状态(unobserved state)下的模式。此外,这种方法还存在:过大的搜索空间、阈值设置的敏感性(置信度阈值)、大量的规则(大多数规则是冗余的)等等问题。observed state下的模式指的是训练数据中已经观察到的序列模式,unobserved state下的模式指的是所有可能的序列模式。受限玻尔兹曼机(
Restricted Bolzmann Machine: RBM)是首个成功应用于推荐问题的2层神经网络。自编码器(autoencoder)框架及其变体降噪自编码器(denoising autoencoder)也产生了良好的推荐性能。卷积神经网络已用于从用户的评论中提取用户的偏好。这些工作都不是用于序列推荐的。循环神经网络
RNN已被用于session-based推荐。虽然RNN在序列建模方面已展示出卓越的能力,但是其顺序地连接的网络结构在序列推荐setting下可能无法正常工作。因为在序列推荐的问题中,并非所有相邻的action都有依赖关系,例如,用户在购买itemitem1RNN-based方法表现更好。这也意味着,如果数据集中包含的序列模式较少,那么
RNN-based方法的表现会很差。所以应用RNN-based方法之前首先需要评估数据集中序列模式的占比。然而我们提出的方法没有将序列模式建模为邻接(
adjacent)的action,我们的方法采用了来自CNN的卷积filter,并将序列模式建模为先前item的embedding的局部特征(local feature)。这种方法在单个统一框架中提供了灵活性,从而同时建模point-level序列模式、union-level建模序列模式、以及skip行为。事实上,我们将展示Caser概括了几种SOTA方法。一个相关的、但是不同的问题是时间推荐(
temporal recommendation),例如应该在早晨而不是在晚上推荐咖啡。而我们的top-N序列推荐会在用户购买iPhone后不久推荐手机配件,这与时间无关。显然,这两个问题是不同的,需要不同的解决方案。
1.1 模型
我们提出的
ConvolutionAl Sequence Embedding Recommendation: Caser模型结合了卷积神经网络(Convolutional Neural Network: CNN)来学习序列特征、以及Latent Factor Model: LFM来学习user specific特征。Caser网络设计的目标是多方面的:同时捕获一般偏好以及序列模式、同时在union-level和point-level进行捕获、捕获skip行为、所有一切都在unobserved space中进行。如下图所示,
Caser由三个组件构成:Embedding Look-up、Convolutional Layers、Fully-connected Layers。为了训练CNN,对于每个用户action序列item作为输入,并将它们的next T items作为target(如下图左侧所示)。这是通过在用户的action序列上滑动一个大小为(u, previous L items, next T items)来表示。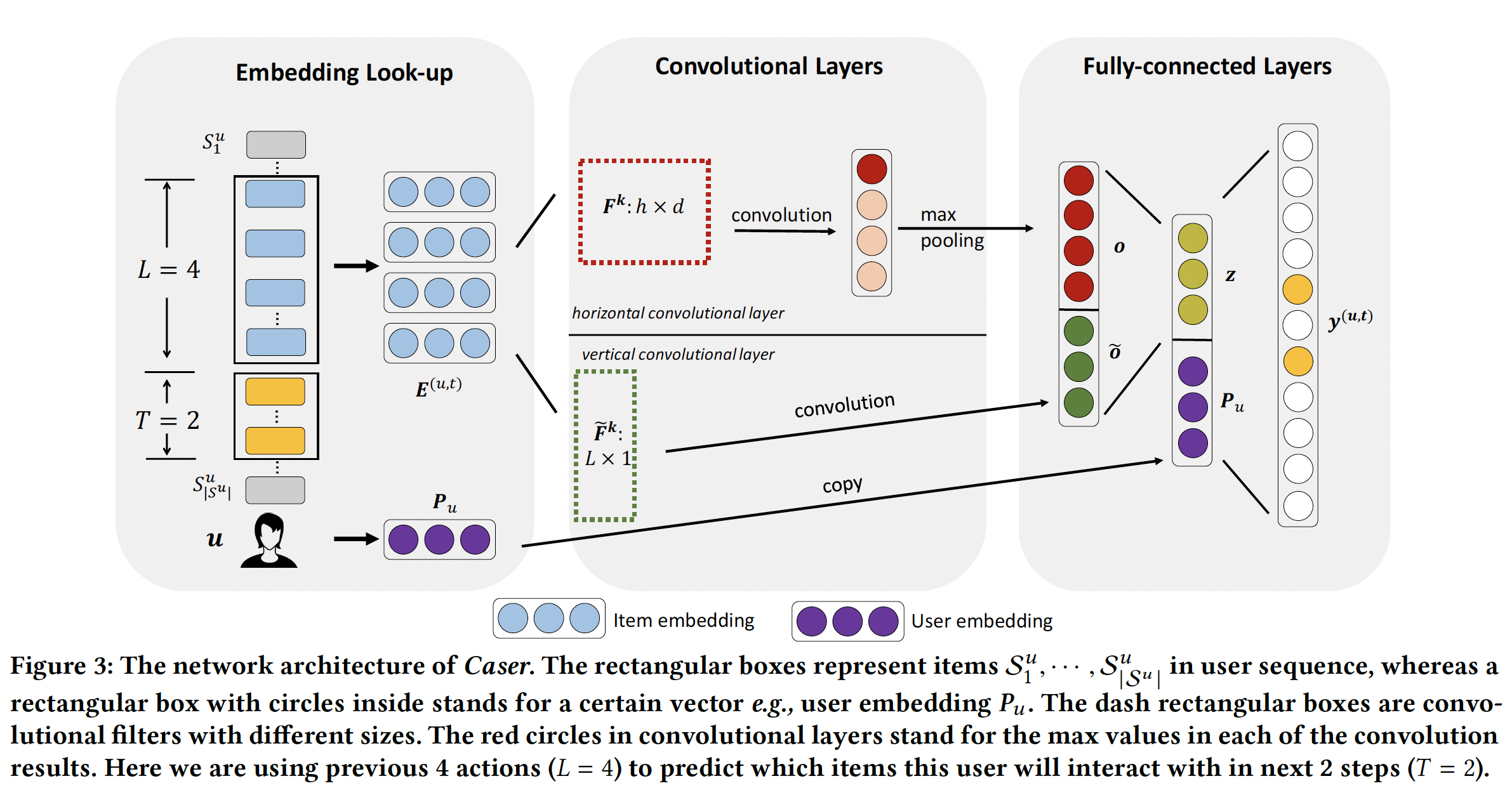
1.1.1 Embedding Look-up
Caser通过将前面item的embedding馈入神经网络中来捕获潜在空间中的序列特征。itemembeddinglatent factor的概念,这里embedding维度。embedding look-up操作检索前面item对应的item embedding,并将它们拼接在一起,从而为用户time stepembedding matrixitem中的第item的embedding。除了
item embedding之外,我们还为用户embedding向量user feature。item embedding和user embedding分别由上图中Embedding Look-up方框中的蓝色圆圈和紫色圆圈来表示。
1.1.2 卷积层
参考在文本分类中使用
CNN的思想,我们的方法将embedding矩阵item组成的image,并将序列模式视为该image的局部特征。这种方法可以使用卷积filter来搜索序列模式。下图展示了两个
horizontal filter(不同颜色的方块代表不同的参数值,颜色越深则数值越大),它们捕获两个union-level的序列模式。这些filter(表示为embedding维度(称作full width)。它们通过在row上滑动从而筛选序列模式的信号。例如,第一个filter通过在潜在维度中具有更大的值(其中酒店和机场具有更大的值)来选择序列模式(Airport, Hotel) -> Great Wall。Latent Space给出的是embedding矩阵,颜色越深则数值越大。Horizontal FIlters给出的是filter矩阵,颜色越深则数值越大。第一个filter主要捕获前面3个维度(filter末尾2个维度的取值几乎为零),而Airport和Hotel的embedding在前面3个维度取值较大、末尾2个维度取值几乎为零。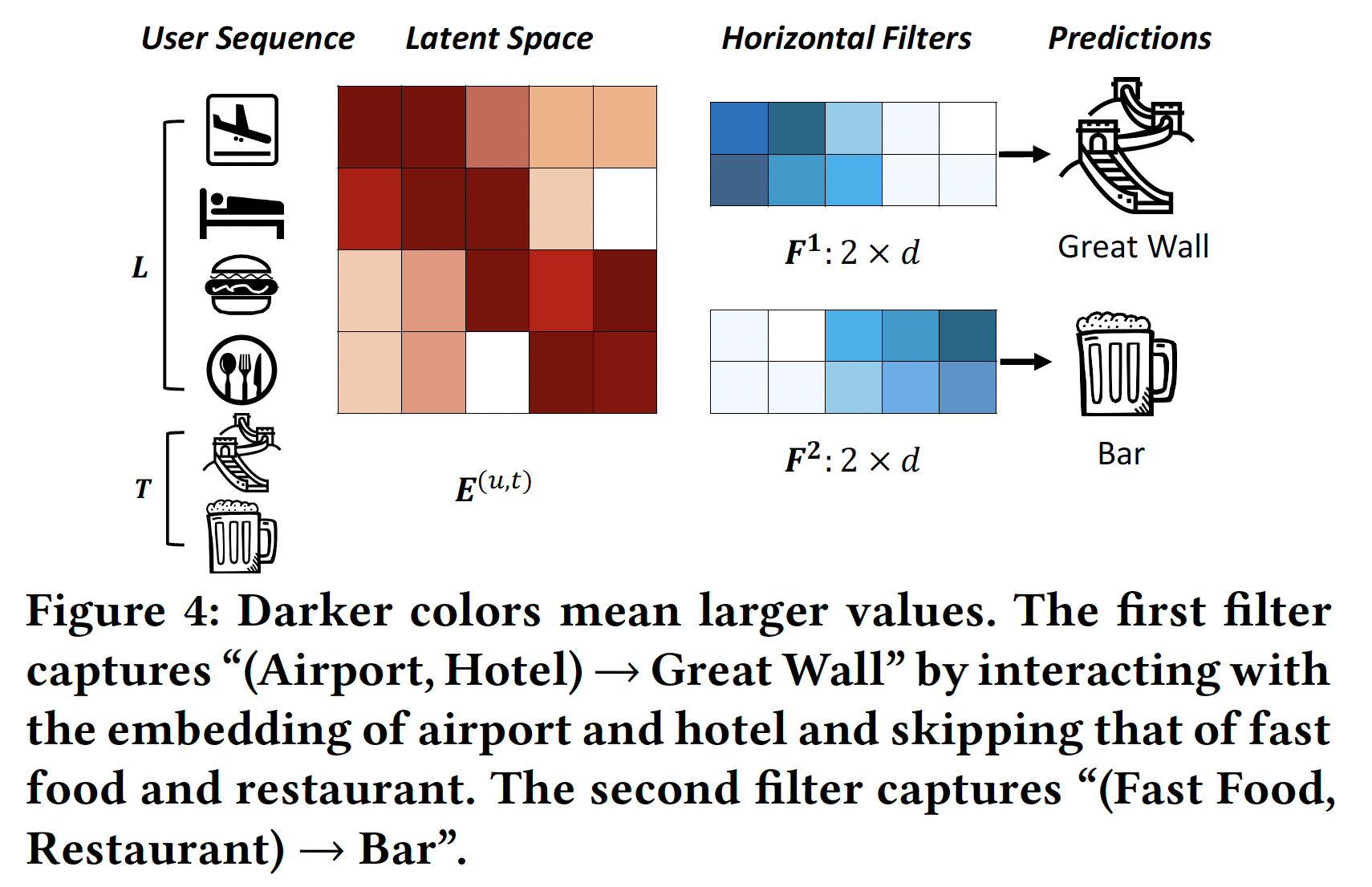
类似地,
vertical filter是一个与图像识别不同,这里的
imageitemembedding向量filter一起同时学习。水平卷积层(
Horizontal Convolutional Layer):该层有horizontal filterfilter的高度。例如,如果filter,然后可以选择horizontal dimension)(每个水平的行表示一个item的embedding)交互。第其中:
inner product operator),item到第item的embedding。卷积值是
然后我们对
max pooling操作,从而从该特定filter产生的所有卷积值中提取最大值。这个最大值捕获了filter抽取的最重要的特征。因此,对于卷积层的filter,它们最终总的输出为horizontal filter通过embeddingitem交互。模型同时学习embedding和filter从而最小化目标函数,这个目标函数编码了target item的预测误差(prediction error)。通过滑动不同高度的
filter,模型将会接收到重要的信号,无论这些信号处在什么位置。因此,可以训练horizontal filter从而捕获具有多种union size的union-level序列模式。这
filter可以采用不同的高度,因此这些filter的垂直卷积层(
Vertical Convolutional Layer):我们用tilde符号filterfilter其中:
inner product operator),由于内积算子的性质,可以很容易地证明:
其中
item的embedding。因此,通过vertical filter我们可以学习聚合前面item的embedding,类似于Fossil的加权sum来聚合前面item的latent representation。不同之处在于每个filterFossil类似,这些vertical filter通过对前面item的latent representation的加权和来捕获point-level序列模式。然而Fossile对每个用户使用a single weighted sum,我们的方法使用vertical filter为所有用户生成其中
注:
原始论文中,垂直卷积层没有使用激活函数,理论上也可以添加激活函数。
垂直卷积层并没有使用最大池化,而是直接将不同
filter产生的卷积结果进行拼接。
虽然
vertical filter和horizontal filter的用途都是聚合,但是二者稍有不同:每个
vertical filter的尺寸固定为latent)的,单次与多个连续的列进行交互是没有意义的。不需要对垂直卷积的结果应用最大池化操作,因为我们希望对每个潜在维度(
latent dimension)保留聚合结果。
1.1.3 全连接层
我们将两个卷积层的输出拼接起来,并将它们馈入一个全连接层,从而获得更
high-level、更抽象的特征:其中:
bias向量,convolutional sequence embedding,它对前面item的各种序列特征进行编码。为了捕获用户的一般偏好,我们还
look-up了user embeddingoutput layer,即:其中:
bias向量。输出层的值
time stepitemuser embeddinguser embedding正如我们将在后文看到的,这使得我们的模型具有概括(
generalize)其它模型的能力。我们可以用其它被概括模型的参数来预训练(
pre-train)我们模型的参数。正如《Neural collaborative filtering》所述,这种预训练对模型性能至关重要。
1.1.4 模型训练和推断
为了训练模型,我们将输出层的值
其中:
sigmoid函数。这里本质上是通过负采样技术将
softmax输出转换变sigmoid输出。令
time step的集合。数据集中所有序列的似然likelihood为:其中
为进一步捕获
skip行为,我们通过用next itemnext T target items。采用负的对数似然之后,我们得到目标函数(即二元交叉熵损失):参考已有的工作,对于每个
target item3)。模型参数
grid search调优得到。我们使用Adam优化算法,batch size = 100。为了控制模型复杂度并避免过拟合,我们使用了两种正则化方法:应用于所有参数的
drop ratio = 50%的Dropout技术。我们使用
MatConvNet实现了Caser。整个训练时间与训练样本数量成正比。例如,在4-cores i7 CPU和32 GB RAM的机器上,MovieLens数据大约需要1小时、Gowalla数据需要2小时、Foursquare数据需要2小时、TMall数据需要1小时。这些时间与Fossil的运行时间相当,并且可以通过使用GPU进一步减少。在训练好模型之后,为了在
time steplatent embeddingitem的embedding作为网络的输入。我们向用户item。向所有用户进行推荐的复杂度为注意,
target item数量item数量。读者注:
Caser模型的几个不足的地方:水平卷积虽然 “宣称” 捕获了
union-level序列模式,但是卷积操作本身是non-sequential的。更准确的说法是:水平卷积捕获了union-level的局部模式(local mode)。如果需要捕获序列模式,那么可以用
RNN代替水平卷积。超参数
filter的大小,它刻画了local mode究竟有多local。目前Caser模型中,fixed。这使得模型不够灵活,因为不同的样本可能需要不同的可以通过
self attention机制自适应地选择相关的item,从而得到自适应的、soft的超参数
local mode影响到未来的第几个target item。目前Caser模型中,fixed。这使得模型不够灵活,因为不同的样本可能需要不同的此外,
Caser模型考虑local mode会影响未来的多个target item。这会引入大量的噪声,因为很可能当前的local mode仅与其中的某个(而不是连续的多个)target item相关。可以通过
target attention机制自适应地选择与target item最相关的item,从而过滤掉无关的item。然后对剩下的item应用CNN或RNN。
1.1.5 和现有模型的联系
Caser vs MF:通过丢弃所有卷积层,我们的模型变成一个普通的LFM,其中user embedding作为user latent factor,它们关联的权重作为item latent factor。MF通常包含bias项,在我们的模型中为MF相同:其中:
Caser vs FPMC:FPMC将分解的一阶马尔科夫链与LFM融合,并通过Bayesian personalized ranking : BPR进行优化。尽管Caser使用了不同的优化准则(即,交叉熵),但是它能够通过将前一个item的embedding复制到hidden layerbias项来概括FPMC:由于
FPMC使用BPR作为准则,因此我们的模型与FPMC并不完全相同。然而,BPR被限制为在每个time step仅有一个target样本和一个negative样本。我们的交叉熵损失没有这些限制。Caser vs Fossil:通过忽略水平卷积层并使用单个vertical filter(即hidden layer正如垂直卷积层中所讨论的那样,这个
vertical filter将前面item的embedding进行加权和,就像在Fossil中一样(然而Fossil使用Similarity Model而不是LFM) ,并将其分解在与马尔科夫模型相同的潜在空间中。另一个区别是
Fossil对每个用户使用一个局部权重,而我们通过vertical filter使用多个全局权重。
1.2 实验
数据集:仅当数据集包含序列模式时,序列推荐才有意义。为了识别这样的数据集,我们对几个公共数据集应用了序列关联规则挖掘(
sequential association rule mining),并计算了它们的序列强度(sequential intensity: SI):分子是
1到5)找到的,并对支持度(最小支持度为5)和置信度(最低置信度为50%)进行过滤。分母是用户总数。我们使用SI来估计数据集中序列信号(sequential signal)的强度。下表描述了四个数据集及其
SI。MovieLens是广泛使用的电影评分数据集。Gowalla和Foursquare包含通过user-venue check-ins得到的隐式反馈。Tmall是从IJCAI 2015竞赛中获得的用户购买数据,旨在预测重复的购买者(buyer)。
根据前人的工作,我们将所有数字评分转换为取值为
1的隐式反馈。我们还删除了冷启动(cold-start)的用户和item(反馈数量少于item) ,因为处理冷启动推荐通常在文献中被视为一个单独(separate)的问题。对于MovieLens, Gowalla, Foursquare, Tmall,5, 16, 10, 10。前人的工作所使用的的
Amazon数据集由于其SI太小(Office Products的SI为0.0026,Clothing, Shoes, Jewelry和Video Games的SI为0.0019)而未被使用。换句话讲,该数据集的序列信号远远低于前面的四个数据集。我们将每个用户序列中前
70%的action作为训练集,使用接下来的10%的action作为验证集来调优所有模型的最佳超参数,使用最后的20%的action作为测试集来评估模型性能。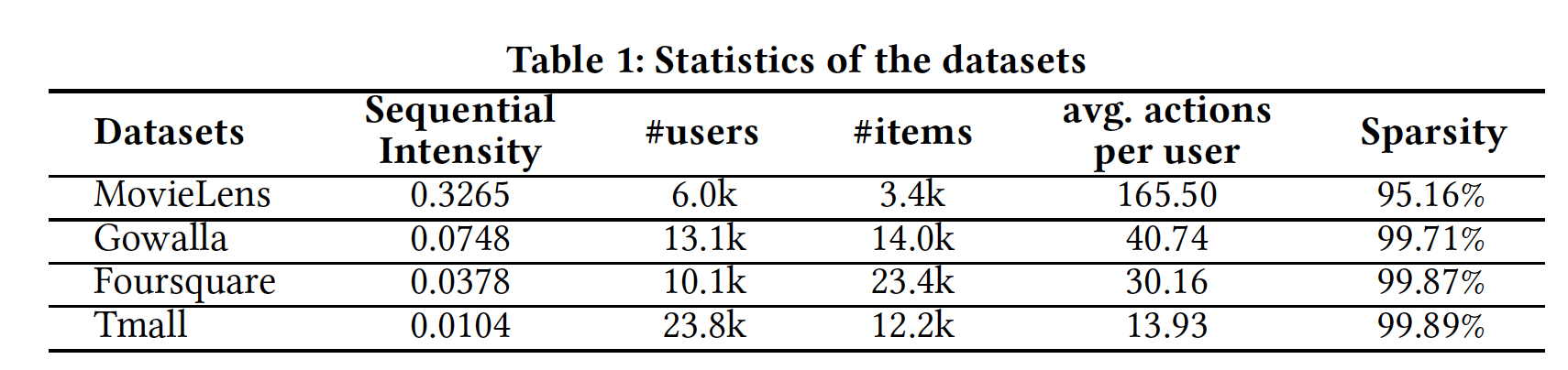
评估指标:
Precision@N和Recall@N:给定一个用户的、长度为action记做action序列中最后20%的action)。则Precision@N、Recall@N定义为:我们报告所有用户的平均
Precision@N和平均Recall@N,并且选择Mean Average Precision: MAP:给定用户的、全量item的推荐列表,记做其中:如果
item位于也有文献移除了
MAP是所有用户的AP均值。
baseline方法:POP:根据item的流行度popularity进行推荐,而流行度取决于item的交互次数。BPR:结合了矩阵分解模型的Bayesian personalized ranking: BPR是对隐式反馈数据进行非序列推荐的SOTA方法。FMC和FPMC:FMC将一阶马尔科夫转移矩阵分解为两个低维子矩阵,而FPMC是FMC和LFM的融合。它们都是SOTA的序列推荐方法。FPMC在每一步都允许推荐一个basket的若干个item。对于我们的序列推荐问题,每个basket都只有一个item。Fossil:Fossil对高阶马尔科夫链进行建模,并使用Similarity Model而不是LFM来建模一般用户偏好。GRU4Rec:GRU4Rec使用RNN来捕获序列依赖性并进行预测。
配置:对每种方法,都在验证集上使用
grid search调优最佳超参数。调优的超参数包括:对所有模型(除了
POP):潜在因子维度对
Fossil, Caser, GRU4Rec:马尔科夫链阶次对于
Caser:horizontal filter的高度target数量{identity, sigmoid, tanh, relu}。对于每个高度horizontal filter的数量vertical filter的数量
我们报告每种方法在其最佳超参数
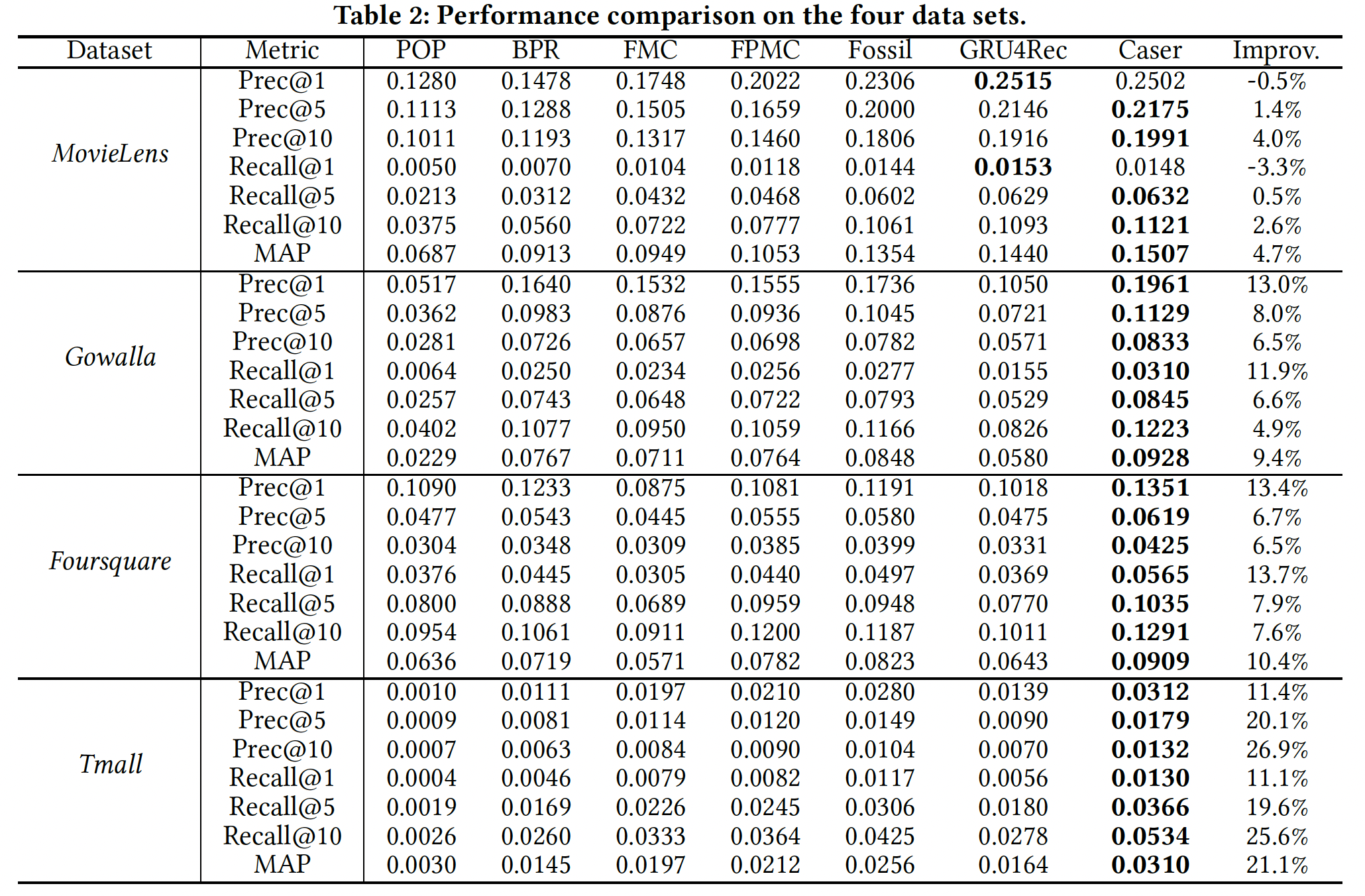
setting下的结果。实验结果:下表总结了所有方法的最佳结果。每一行中表现最好的结果以粗体突出显式。最后一列是
Caser相对于最佳baseline的改进,定义为(Caser-baseline)/baseline。结论:除了
MovieLens之外,Caser在所有指标上相对于最佳baseline都取得了大幅提升。在
baseline方法中,序列推荐器(如FPMC和Fossil)通常在所有数据集上都优于非序列推荐器(即BPR),这表明考虑序列信息(sequential information)的重要性。FPMC和Fossil在所有数据集上的表现都优于FMC,这表明个性化的有效性。在
MovieLens上,GRU4Rec的性能接近于Caser,但在其它三个数据集上的性能要差得多。事实上,
MovieLens比其它三个数据集具有更多的序列信号,因此RNN-based的GRU4Rec可以在MovieLens上表现良好,但是在其它三个数据集上效果不佳。此外,GRU4Rec的推荐是session-based的,而不是个性化的,这在一定程度上扩大了泛化误差。
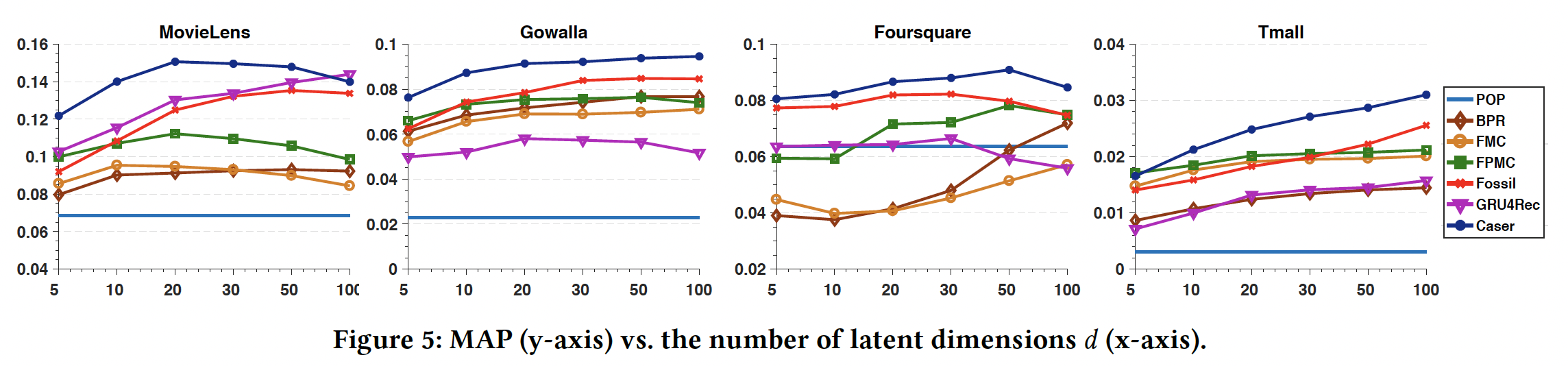
接下来我们研究超参数
setting。我们聚焦于MAP超参数,因为它是一个整体的性能指标,并且与其它指标一致。维度
在更稠密的
MovieLens数据集上,更大的但是对于其它三个更稀疏的数据集,每个模型都需要更大的
对于所有数据集,
Caser通过使用较小的baseline方法。
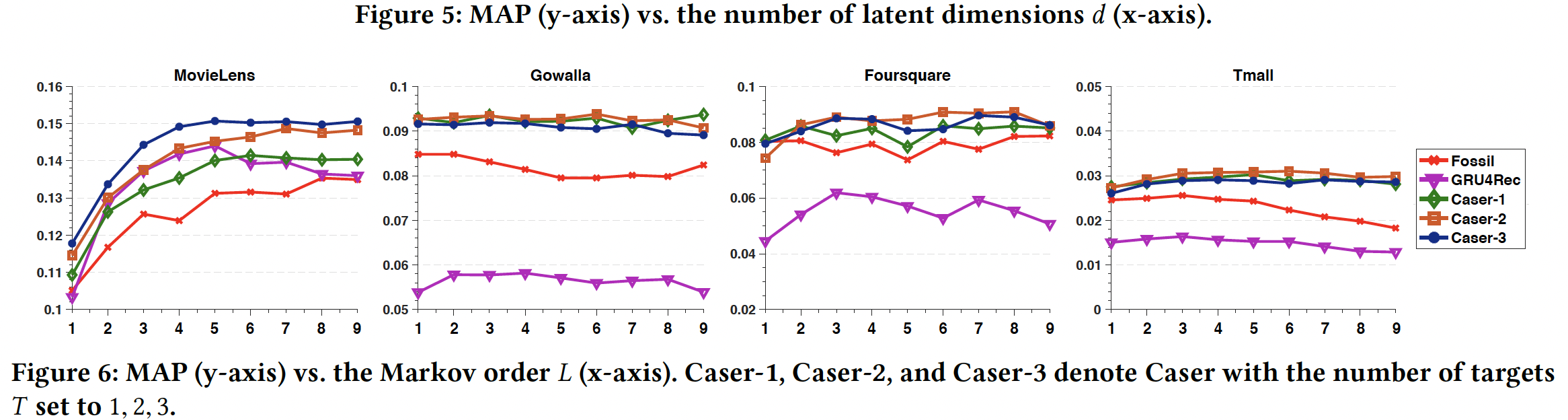
马尔科夫阶次
target数量Caser-1, Caser-2, Caser-3表示target数量Caser,从而研究skip行为的影响。在更稠密的
MovieLens数据集上,Caser较好地利用了较大Caser-3表现最好,这表明skip行为的好处。然而,对于稀疏的数据集,并非所有模型都始终受益于较大的
在大多数情况下,
Caser-2在这三个稀疏数据集上的表现略优于Caser-1和Caser-3。
Caser组件分析:现在我们评估Caser每个组件,水平卷积层(即setting。MovieLens和Gowalla的结果如下表所示,其它两个数据集的结果是类似的因此没有列出。对于Caser-x表示启用了组件x的Caser,其中h表示水平卷积层,v表示垂直卷积层,p表示个性化。任何缺失的组件都通过将其对应的位置填充零向量来解决。例如,vh表示采用垂直卷积层和水平卷积层,同时将结论:
Caser-p表现最差,而Caser-h、Caser-v、Caser-vh显著提高了性能,这表明将top-N序列推荐视为传统的top-N推荐将丢失有用的信息(如序列信息),并且同时在union-level和point-level建模序列模式有助于改进预测。对于这两个数据集,通过联合使用
Caser的所有组件(即Caser-pvh)可以获得最佳性能。
Caser-pvh与Caser-pv之间的gap刻画了水平卷积层的收益,Caser-pvh与Caser-ph之间的gap刻画了垂直卷积层的收益。可以看到,垂直卷积层要远比水平卷积层更重要,这也间接说明了point-level序列模式要比union-level序列模式更重要。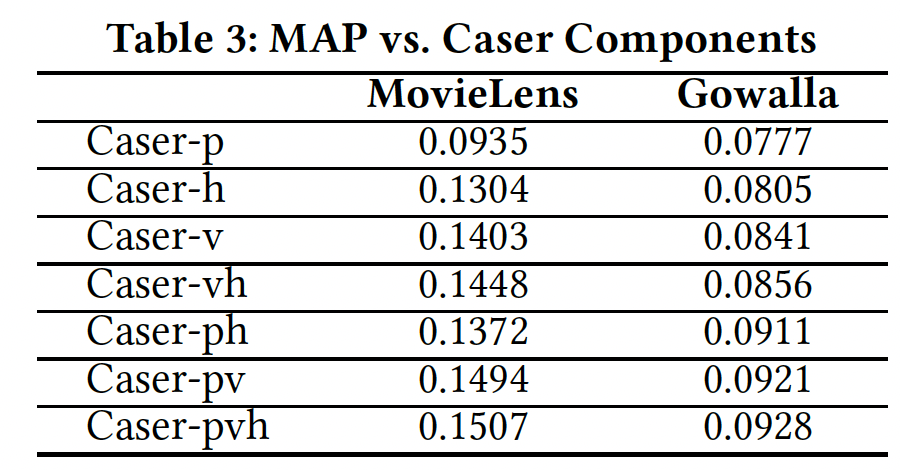
网络可视化:我们仔细研究了一些训练好的网络及其预测。
vertical filter:下图显示了在MovieLens数据集上训练Caser之后,四个vertical filter的值(指的是卷积核的权重)。在微观上四个filter被训练为多样化(diverse)的,但是在宏观上它们遵循从过去位置(past position)到最近位置(recent position)的上升趋势。由于每个vertical filter都是作为对前面action的embedding进行加权的一种方式,这一趋势表明Caser更加重视最近的action,这与传统的top-N推荐有很大不同(传统的top-N推荐认为每个action的重要性是相同的)。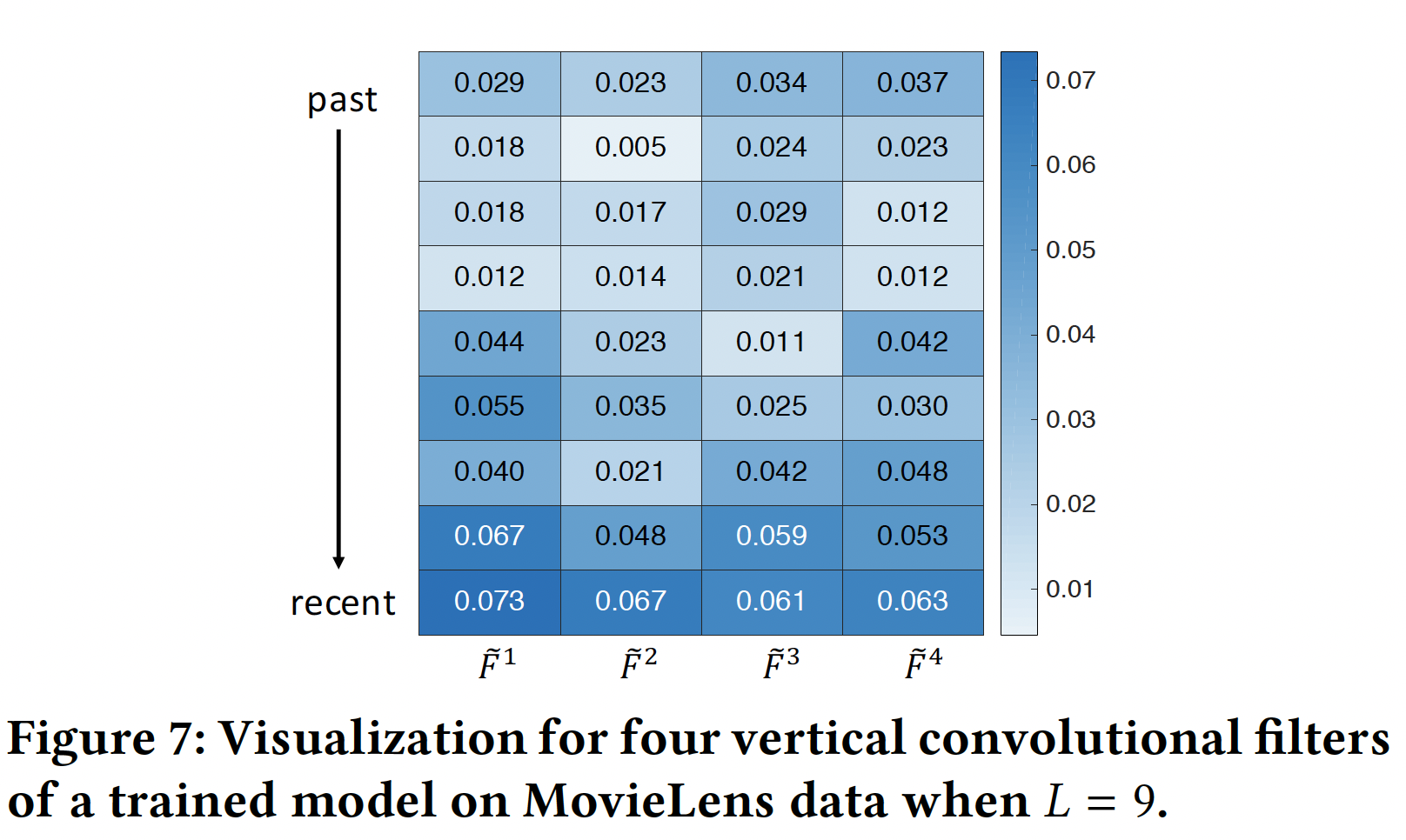
horizontal filter:为了查看horizontal filter的有效性,下图(a)显示了Caser针对一名用户推荐的、排名top N = 3的电影,即:(Mad Max)、Star War)、Star Trek)。该用户的前面13th Warrior)、American Beauty)、Star Trek II)、Star Trek III)、Star Trek IV)。ground truth(即用户序列中的next movie)。注意,下图
(b)显示了将该用户前面embedding屏蔽为全零之后(即item mask),模型预测屏蔽
2(从排名第3)。事实上既然如此,为什么不屏蔽
target attention机制对历史action序列过滤掉与target item无关的action。屏蔽
当同时屏蔽
这项研究清晰地表明:我们的模型正确地捕获到了
union-level序列特征。