一、Latent Cross [2018]
《Latent Cross: Making Use of Context in Recurrent Recommender Systems》
推荐系统长期以来一直用于预测用户会喜欢什么内容。随着
Facebook, Netflix, YouTube, Twitter等在线服务的不断增长,拥有一个高质量的推荐系统来帮助用户筛选不断扩大和日益多样化的内容变得越来越重要。推荐系统的大部分研究都集中在有效的机器学习技术上:如何最好地从用户的行为(如点击、购买、观看、评分)中学习。在这个方向上,有大量关于协同过滤(
collaborative filtering)和推荐算法的研究。与此同时,人们越来越显著地认识到对推荐的上下文(
context)进行建模的重要性:不仅仅是正在寻找视频的用户,还包括一天中的时间(time of day)、位置(location)、用户的设备(device)等。人们已经在分解(factorization)的setting中提出了许多相关的模型,例如用于location的张量分解、用于不同类型的用户动作的unfolding tensor、或者关于时间效应的手工制作的特征。随着深度学习的日益普及,如何将这些上下文特征(
contextual feature)整合到神经推荐系统中的直接研究较少。先前关于deep neural network: DNN推荐系统的工作在很大程度上依赖于将上下文作为模型中的直接特征、或者依赖于具有多任务的目标。一个值得注意的例外是使用recurrent neural network: RNN来建模时间模式(temporal pattern)。 在论文《Latent Cross: Making Use of Context in Recurrent Recommender Systems》中,作者将contextual collaborative filtering文献和神经推荐器文献联系起来。作者探索了如何在深度神经推荐器(尤其是在RNN模型中)中利用上下文数据(contextual data),并证明主流技术遗漏了这些特征中的大量信息。作者探索了在
YouTube使用的RNN-based的推荐系统中,使用上下文数据的能力。与大多数生产(production)的setting一样,YouTube拥有大量重要的上下文数据,其中包括:请求和观看时间(request and watch time)、设备类型、网站或移动app上的页面(page)。在论文中,首先作者对建模上下文作为直接特征的局限性提供了理论解释,尤其是使用feed-forward neural network: FFN作为示例的baseline DNN方法。然后作者提供了一种易于使用的技术来整合这些上下文特征,从而提高预测准确性,即使在更复杂的RNN模型中也是如此。论文的贡献是:
一阶挑战(
First-Order Challenges):论文展示一阶神经网络建模低秩关系(low-rank relationship)的挑战。生产模型(
Production Model):论文描述了如何为YouTube构建了一个大规模的RNN推荐系统。潜在交叉(
Latent Cross):论文提供了一种简单的技术,称作Latent Cross,以便在模型中更expressively包含上下文特征。具体而言,latent cross在context embedding和神经网络hidden state之间执行逐元素乘积(elementwise product)。经验结果(
Empirical Result):论文提供的经验结果证实了所提出方法提高了推荐的准确性。
相关工作:我们首先对各种相关研究进行调研,
overview参考下表。
上下文推荐(
Contextual Recommendation):大量研究集中在推荐过程中使用上下文数据。具体而言,某些类型的上下文数据已被深入探索,而其它类型的上下文数据已被抽象地处理(treated abstractly)。例如,推荐中的时间动态(
temporal dynamics)已被广泛探索。在Netflix Prize期间,《Collaborative filtering with temporal dynamics》在Netflix数据集中发现了重要的长期时间动态(long-ranging temporal dynamics),并在他的协同过滤模型中添加了时间特征(temporal features)来解释这些影响。研究人员还探索了偏好(
preference)如何在较短的时间尺度内(如session)演(evolve)。更一般的抽象已被用于对推荐的偏好演变进行建模,如point processes和RNN。类似地,使用概率模型、矩阵分解、张量分解来建模带地理数据(geographical data)的用户行为也得到了广泛的探索。各种方法都建立在矩阵分解和张量分解的基础上,用于跨域学习(
cross domain learning)。分解器(factorization machine)和其它上下文推荐器等方法提供了这些协同过滤方法的推广。神经推荐系统(
Neural Recommender Systems):随着神经网络在计算机视觉和自然语言处理(natural language processing: NLP)任务中的普及,推荐系统的研究人员已经开始将DNN应用于推荐。早期的迭代侧重于将协同过滤直接应用于神经网络,例如通过自编码器、或者联合
deep and CF models。人们已经设计出更复杂的网络来融合更广泛的输入特征。《Wide & deep learning for recommender systems》在模型的DNN部分之外,通过线性模型处理上下文特征之间的交互(interaction)从而解决这个问题。最近,使用
RNN进行推荐的情况越来越多:《Neural Survival Recommender》和《Rurrent Recommender Networks》在他们的模型中包括时间信息(temporal information)作为特征和监督(supervision),而《Modelling Contextual Information in Session-Aware Recommender Systems with Neural Networks》包含一般上下文特征。然而,在这两种情况下,这些特征都与输入相拼接(concatenated),我们将展示这种方式提供的好处有限。并行的、独立的研究
《What to Do Next: Modeling User Behaviors by Time-LSTM》通过乘法性地融合(multiplicatively incorporate)时间信息来改善LSTM,但是它没有将这种方法推广到其它上下文数据。
二阶神经网络(
Second-order Neural Networks):本文的一个主要重点是神经推荐器中乘法关系(multiplicative relation)的重要性。这些二阶单元(second-order unit)出现在神经网络的一些地方。循环单元(
recurrent unit),如LSTM和GRU,是常见的带逐元素乘法(elementwise multiplication)的门控机制的二阶单元。此外,用于分类的、网络顶部的
softmax layer是DNN产生的embedding与label class embedding之间的显式双线性层(bi-linear layer)。该技术已在多篇论文中得到扩展,包括DNN之上的user-item双线性层。
与本文中描述的技术类似的是乘法模型(
multiplicative model)。这些乘法结构最常用于NLP。这些NLP方法被应用于评论的个性化建模(具有稍微不同的数学结构)。最近,《Neural Survival Recommender》不是在上下文数据上,而是直接在用户上使用乘法技术,类似于张量分解。PNN和NFM将这一思想推向了一个极端,将输入端的所有的特征pair对进行相乘,并在通过前馈神经网络之前拼接、或者平均相乘的结果。这些模型的直觉与我们的相似,但不同之处在于:我们关注上下文数据和用户动作之间的关系。
我们的
latent crossing机制可以应用于、并且已经被应用于整个模型。我们证明了这些交互的重要性,即使是在一个
RNN推荐系统内。
更复杂的模型结构(如注意力模型
attention model、记忆网络memory network、元学习meta-learning)也依赖于二阶关系,并且越来越受欢迎。例如,注意力模型使用通过乘法调制(modulate)hidden state的注意力向量。然而,这些方法在结构上明显更加复杂,并且通常更难训练。相比之下,我们发现本文提出的latent cross技术在实践中易于训练并且有效。
1.1 模型
1.1.1 基础知识
考虑一个推荐系统,其中我们有一个包含事件(
event)k-way元组。我们定义例如,
Netflix Prize的setting将由元组注意,每个值可以是离散(
discrete)的categorical变量(例如,用户编号continuous)的变量(例如,时间unix时间戳)。连续变量通常在预处理步骤中进行离散化,例如将day) 。有了这些数据,我们可以将推荐系统构建为:试图在给定事件其它值的情况下预测该事件中的某一个值。例如,在
Netflix Prize中,我们使用我们可以通过定义
categorical value)的还是实数值 (real value),机器学习问题分别是分类问题或回归问题。在分解模型中,所有输入值都被认为是离散的,并且被嵌入(
embedded)、被相乘(multiplied)。当我们embed一个离散值时,我们学习一个稠密的latent representation,例如,用户latent vectoritemlatent vector在矩阵分解模型中,通常基于
embedding向量。为了符号简便,我们用神经网络通常还嵌入离散的输入。即,给定一个输入
我们稍后将扩展此定义,从而允许模型将相关的
previous events也作为网络的输入,就像在序列模型中一样。
1.1.2 动机:一阶 DNN 的挑战
为了了解神经推荐器如何利用拼接的特征,我们首先探查(
inspecting)这些网络的典型构建块(building blocks)。如上所述,神经网络,尤其是前馈神经网络,通常建立在一阶运算(first-order operation)之上。更准确而言,神经网络通常依赖于matrix-vector product)。其中,last layer的输出)。在前馈神经网络中,全连接层通常具有以下形式:其中:
sigmoid或ReLU),我们认为这是一个一阶单元,因为该
layer仅仅将即,输入
尽管具有此类
layer的神经网络已被证明能够逼近任何函数,但它们的核心计算在结构上与协同过滤的直觉有很大不同。如前所述,矩阵分解模型采用一般形式 (general form)item、时间等等)之间的低秩关系(low-rank relationship)。鉴于低秩模型(low-rank model)已在推荐系统中取得成功,我们提出以下问题:一阶神经网络对低秩关系的建模效果如何?为了测试一阶神经网络是否可以建模低秩关系,我们生成人工合成的低秩数据并研究不同大小的神经网络对这些数据的拟合程度。更具体而言,我们考虑一个
m-mode的张量(即,m个输入),每个输入都是离散的并且取值空间大小都是结果是我们的数据是一个秩
scale(均值为零、经验方差接近1)。例如,当embedding来表示形式为注意,这里的
embedding,而是用于生成label。我们尝试使用这些数据来拟合不同大小的模型。具体而言,我们考虑一个将离散特征嵌入并拼接为输入的模型。该模型有一个带
ReLU激活函数的hidden layer,这在神经推荐系统中很常见,然后是一个final linear layer。我们使用TensorFlow实现该模型,使用Adagrad优化器来优化均方误差(mean squared error: MSE)损失,并且训练模型直到收敛。我们通过训练数据和模型预测之间的Pearson correlation (R)来衡量和报告模型的准确性。我们使用
Pearson相关性,使其不受数据方差的微小差异的影响。我们针对训练数据报告准确性,因为我们正在测试这些模型结构与低秩模式(
low-rank pattern)的匹配程度。
即,我们在训练数据上评估(而不是测试数据),因为我们想评估这些模型对训练数据的拟合程度。
我们使用
Pearson correlation指标(而不是MSE),因为该指标不受数据方差的影响。为了建模低秩关系,我们想看看模型对单个乘法(
individual multiplication)(代表了变量之间的交互interaction)的逼近程度。所有数据都是在hidden layer必须有多大时才能建模两个标量的乘法。在hidden layer必须有多大时才能建模三个标量的乘法。我们使用
embedding维度无关。我们测试hidden layer的隐层维度label,我们需要多少个乘法。实验结果如下图和下表所示,我们发现:
首先,随着隐层维度的增加,模型地更好地逼近数据。鉴于网络逼近乘法的直觉,更宽的网络(即隐层维度更高)应该给出更好的逼近(
approximation)。其次,我们观察到,当我们将数据的秩
更有趣的是,我们发现即使对于
relation(即,layer来学到单个two-way relation。此外,我们发现建模超过
two-way relation会增加逼近的难度。也就是说,当我们从MSE或Pearson correlation。
总之,我们观察到
ReLU layer可以逼近乘法交互(multiplicative interaction)(即,cross),但是这样做的效率很低。这激发了对能够更轻松地表达和处理乘法关系(multiplicative relation)的模型的需求。我们现在将注意力转向使用RNN作为baseline。这是一个更强的baseline,因为与前馈神经网络相比,RNN可以更好地表达乘法关系。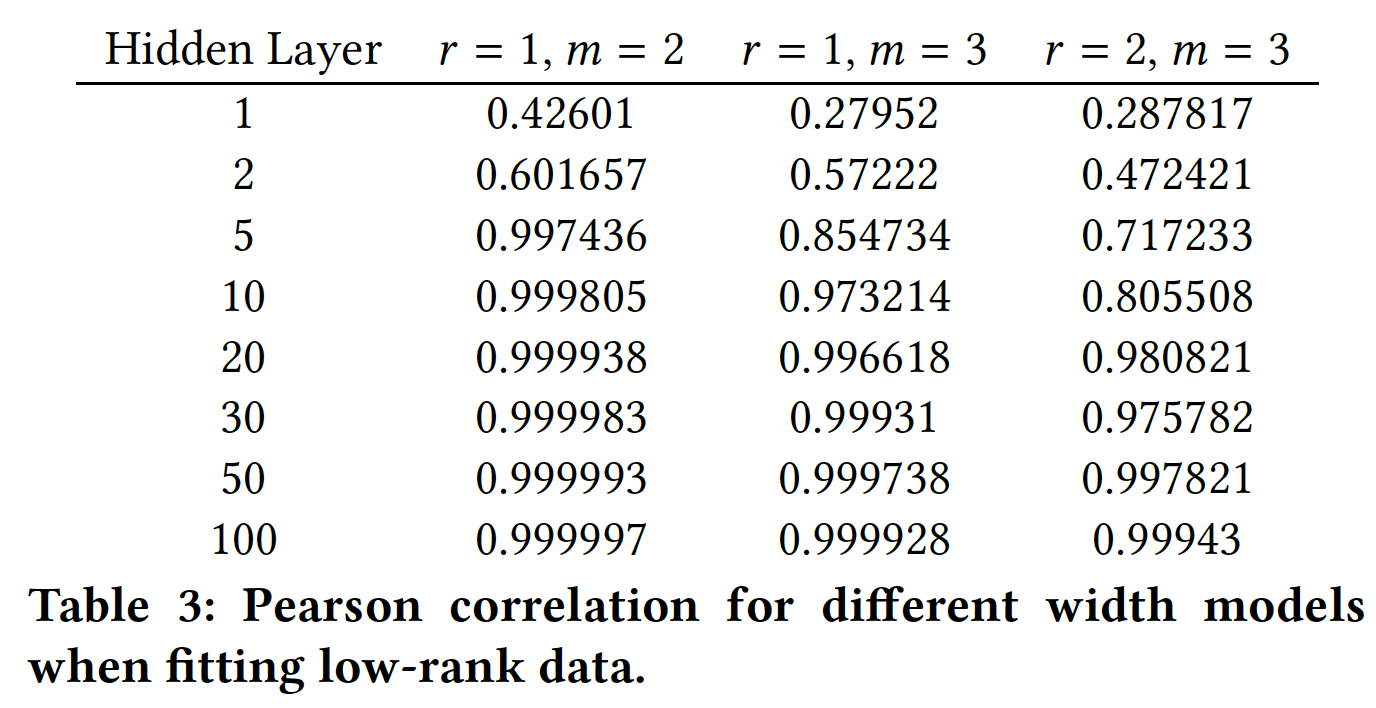
1.1.3 Youtube Recurrent Recommender
以上述分析为动力,我们现在描述对
YouTube的RNN推荐系统的改进。RNN是优秀的baseline模型,因为它们已经是二阶神经网络,比上面探索的一阶神经网络复杂得多,并且处于动态推荐系统(dynamic recommender system) 的前沿。我们首先概述我们为
YouTube构建的RNN推荐器,然后描述我们如何改进这个推荐器从而更好地利用上下文数据。公式描述:在我们的
setting中,我们观察到用户recurrent neural network: RNN模型,其中模型的输入是用户该模型经过训练以产生序列预测
在上面的例子中,如果
video embedding,uploader embedding,context embedding。注意,这里
RNN的输入。对于RNN而言,这意味着我们基于当预测
label作为输入,但是我们可以使用来自Baseline RNN模型的结构:我们的RNN模型diagram如下图所示。RNN对一系列动作进行建模。对于每个事件hidden state vector更准确而言:
每个事件首先由神经网络
input)。在我们的setting中,这将是一个恒等映射或者全连接的ReLU layer。网络的循环部分是函数:
即,我们使用循环单元(如,
LSTM或GRU)从而将上一步的state和变换后的输入为了预测
setting中,该网络将RNN的输出、以及即将进行预测的上下文作为该网络的输入,最后以所有视频的softmax layer而结束。这个网络可以包括多个全连接层。output network越简单越好还是越复杂越好?个人感觉,如果output network越复杂,那么迫使GRU学到的representation越简单。
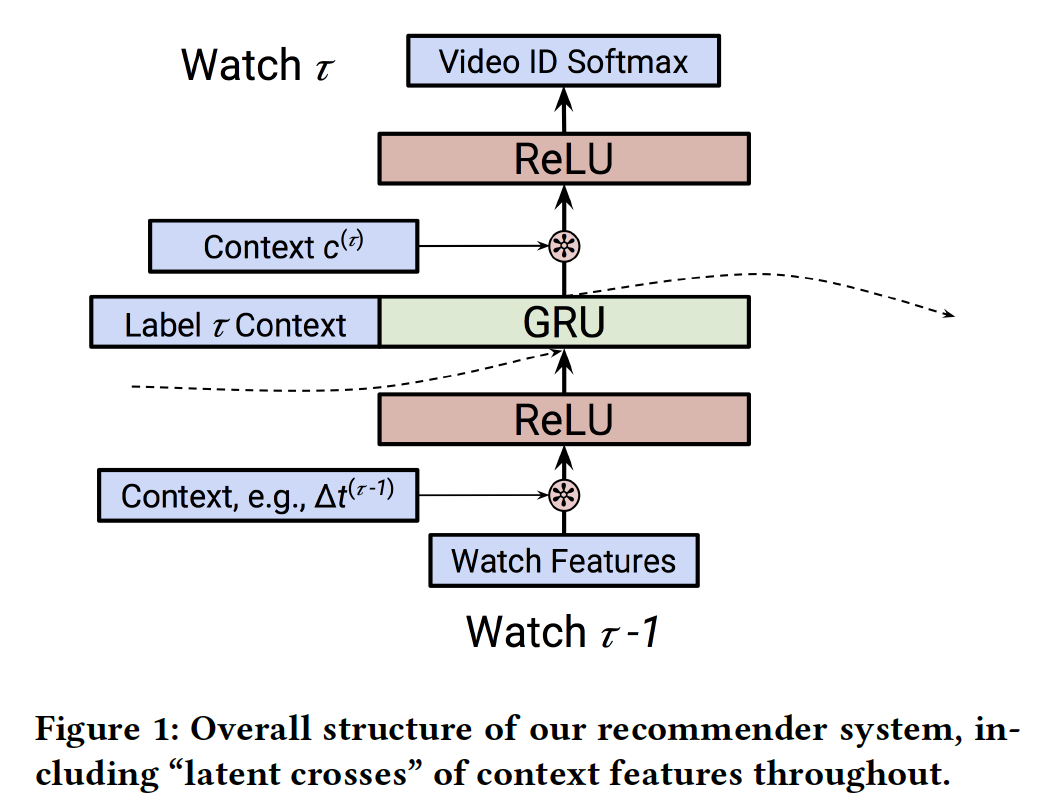
上下文特征:该模型成功的核心是结合上下文数据,而不仅仅是观看的视频序列。我们将在下面讨论我们如何利用这些特征。
TimeDelta:在我们的系统中,有效地结合时间对我们RNN的准确性非常有价值。从历史上看,时间上下文time context已经以多种方式被纳入协同过滤模型中。在这里,我们使用一种称为timedelta的方法:也就是说,在考虑事件
《Neural Survival Recommender》和《What to Do Next: Modeling User Behaviors by Time-LSTM》中描述的time representation。这里是
action对未来的影响(而不是对过去的影响)。Software Client:YouTube视频可以在各种设备上观看,如浏览器、iOS、Android、Roku、Chromecast等。将这些上下文视为等同(equivalent)的,则会错失相关的关系(relevant correlation)。例如,与通过Roku设备相比,用户不太可能在手机上观看完整的故事片。类似地,像预告片这样的短视频可能相对更有可能在手机上观看。对software client进行建模,特别是它如何与观看决策watch dicision交互,这一点很重要。不同设备上呈现不同的交互特色。
Page:我们还会在我们的系统中记录观看是从哪里开始的。例如,我们区分从主页开始的观看(即,Home Page Watches),以及作为被推荐的follow-up watch来初始化的观看(即,Watch Next Watches)。Watch Next Watches:当用户已经在观看一个视频时,系统提供一个推荐列表,然后用户从推荐列表选择一个视频并进行观看。这一点很重要,因为
Home Page Watches可能对新内容更加开放open,而Watch Next Watches可能是因为用户想要更深入地挖掘某个主题。
Pre-Fusion和Post-Fusion:我们可以通过两种方式将这些上下文特征(统称为RNN cell的输出相结合。我们把在
RNN cell之前包含上下文特征称作pre-fusion,把在RNN cell之后包含上下文特征称作post-fusion。尽管可能是一个精巧的点(subtle point),但这个决定可能会对RNN产生重大影响。具体而言:通过
pre-fusion包含一个特征,该特征将通过它如何修改RNN的state来影响预测。但是,通过
post-fusion包含一个特征,该特征可以更直接地对该time step的预测产生影响。
为了解决这个问题,在预测
post-fusion的特征,并使用pre-fusion的特征。这意味着RNN状态,但pre-fusion特征,并且开始影响RNN的状态。由于
GRU的递归特性,这里相当于是:cell state捕获了序列实现&训练:我们的模型在
TensorFlow中实现,并在许多分布式workers和parameter servers上进行了训练。训练使用一种可用的反向传播mini-batch随机梯度下降算法,即Adagrad或ADAM。在训练期间,我们使用周期100次观看)。这通常会优先考虑最近的观看,因为当学到的模型将被应用于实时流量(live traffic)时,这种方式(即,优先考虑最近的观看)与预测任务更为相似。由于可用的视频数量非常多,因此我们限制了我们要预测的可能的视频集合、以及我们建模的这些
uploaders的数量。在下面的实验中,这些集合的规模从50万到200万 。softmax layer使用sampled softmax进行训练,每个batch采样2万个负样本。我们在针对batch内所有label的交叉熵损失中使用这个sampled softmax的预测。即,每个
batch内的所有样本共享同一组负样本。
1.1.4 带 Latent Cross 的上下文建模
在上面对我们的
baseline模型的描述中应该很清楚,上下文特征的使用通常是作为简单的全连接层的拼接输入(concatenated input)来进行的。然而,正如我们在前面所解释的,神经网络在建模拼接输入特征之间的交互(interaction)方面效率很低。这里我们提出一个简单的替代方案。单个上下文特征:我们从包含单个上下文特征的情况开始。为了清楚起见,我们将时间作为上下文特征的一个例子。我们并不是将该特征与其它相关特征拼接起来作为输入从而执行融合,而是在网络的中间执行一个逐元素乘积(
element-wise product)。也就是说,我们执行:其中,我们使用零均值的高斯分布来初始化
1的高斯分布。乘法项的均值为
1,这可以解释为在representation上提供一个mask机制或者一个注意力机制的上下文。但是,它也enable了输入的previous watch与time之间的低秩关系(矩阵分解代表了一种低秩关系)。注意,我们也可以在
RNN之后应用这个操作:《A multiplicative model for learning distributed text-based attribute representations》中提供的技术可以被视为一种特殊情况,其中乘法关系(multiplicative relation)与softmax函数一起被包含在网络的最顶部,从而改善NLP任务。在这种情况下,该操作可以被视为张量分解,其中一种模态的embedding是由神经网络产生的。多个上下文特征:在许多情况下,我们想要包含不止一个上下文特征。当包含多个上下文特征时,例如时间
我们使用这种形式有几个不同的原因:
使用零均值的高斯分布来初始化
1,因此可以类似地充当hidden state的mask/atttention机制。通过将这些项相加,我们可以捕获
hidden state和每个上下文特征之间的2-way关系。这遵循了分解机(factorization machine)设计中的观点。使用简单的加法函数易于训练。像
根据前文的结论,我们是否可以把常规的
input field也视为上下文,然后进行latent cross,从而更好地捕获2-way关系?更进一步地,我们是否可以将
input拆分为多个field,网络的每一层利用一个field并进行latent cross,并且最重要的field靠近输出、最不重要的field靠近输入?甚至更进一步,我们是否可以用
attention机制自动筛选出哪些是最重要的、哪些是不重要的,然后每一层选择不同的field进行latent cross?效率:我们注意到使用
latent cross的一个显著优势是:它们的简单性和计算效率。使用embedding,可以在latent cross,并且不会增加后续layer的宽度。
1.2 实验
我们进行两个实验:
第一个实验是在时间作为唯一上下文特征的数据集上,我们比较了几个模型。
第二个实验是在我们的生产模型上,并根据我们如何融合上下文特征来探索相对的效果提升。
1.2.1 对比分析
数据集:我们使用一个数据集,该数据集的观看序列来自于数亿用户。用户被拆分为训练集、验证集、测试集,其中验证集和测试集都有数千万的用户。
观看被限制在
50万个流行视频的集合中。所有用户的序列中至少有50个观看。序列是由观看视频的列表、以及每个观看的时间戳给出的。任务是预测用户序列中最近5次观看。评估指标:在测试集上的
Mean-Average-Precision-at-k (MAP@k),其中模型配置:对于这个实验,我们使用带
LSTM的RNN。我们在循环单元之前或之后没有ReLU cell,并使用一个pre-determined的hierarchical softmax: HSM来预测视频。在这里,我们使用序列中除了第一个观看之外的所有观看作为训练期间的监督。模型使用ADAM优化算法来训练。由于时间是该数据集中唯一的上下文特征,我们使用视频
embeddingtimedelta值latent cross,使得LSTM的输入为pre-fusion的例子,我们称之为RNNLatentCross。注意,这里仅评估了
pre-fusion的效果。baseline方法:我们将上述RNNLatentCross模型与其它baseline方法进行比较:RRN:使用RNN的输入。RNN:直接在RNN,没有时间信息作为输入。BOW:作用在用户观看历史的视频集合、以及用户的人口统计学特征上的bag-of-watches模型。BOW+Time:一个三层的前馈神经网络模型,将bag-of-watches、最近观看的三个视频中的每一个、week这些特征的拼接作为输入。该模型使用softmax对与最近观看last watch共现次数最多的50个视频进行训练。Paragraph Vector (PV):使用《Document embedding with paragraph vectors》学习每个用户的无监督embedding(基于用户人口统计,以及历史的观看)。使用学到的embedding以及最后一个观看的embedding作为一个单层前馈神经网络分类器的输入,其中该分类器通过sampled softmax来训练。Cowatch:根据序列中的last watch推荐共现次数最多的其它视频。
除非另有说明,否则所有模型都使用一个
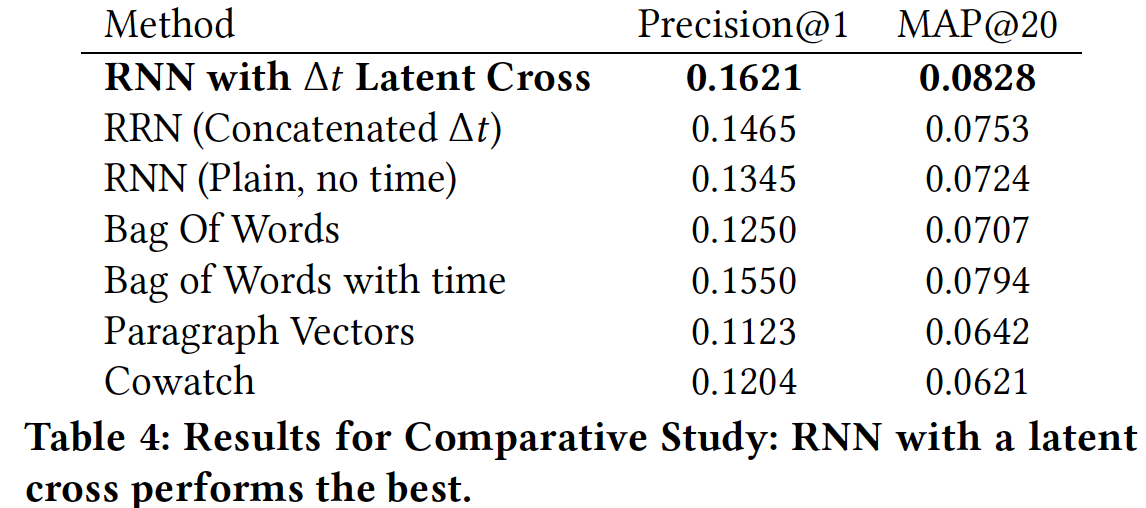
hierarchical softmax。所有模型及其超参数都进行了调优。注意,只有BOW和PV模型使用了用户人口统计学数据。实验结果:我们在下表中报告了该实验的结果。从中可以看到,我们的模型在
Precision@1和MAP@20上都表现最佳(注意,MAP@1就是Precision@1)。可能更有趣的是模型的相对性能。我们在
BOW模型(对比BOW with time)和RNN模型(对比RNN with time)中都观察到建模时间的重要性。此外,我们观察到执行
latent cross而不是仅仅拼接
1.2.2 YouTube 模型
配置:在这里我们使用用户观看的生产数据集(
production dataset)。我们的序列由观看的视频以及视频创建人(即uploader)组成。我们使用了百万级最近流行的视频和uploader的更大的vocabulary。我们根据用户和时间将数据集拆分为训练集和测试集。
首先,我们将用户分为两组:
90%的用户在我们的训练集中,10%在我们的测试集中。其次,为了根据时间来拆分,我们选择截止(
cut-off)时间vocabulary是基于
我们的模型考虑嵌入和拼接上面定义的所有特征作为输入,然后是一个
256维的ReLU层、一个256维的GRU cell,然后是另一个256维的ReLU层,最后再输入到softmax层。如前所述,我们使用区间100个观看作为监督信息。在这里,我们使用Adagrad优化器在多个workers和parameter servers上进行分布式训练。为了测试我们的模型,我们仍然使用
MAP@k指标。对于不在我们vocabulary中的观看,我们总是将预测标记为不正确。这里报告的评估MAP@k得分是使用大约45000个观看来度量的。Page作为上下文的价值:我们通过以不同方式融合Page来开始分析准确性的改善。具体而言,我们比较了不使用Page、使用Page与其它特征拼接来作为输入、使用Page来执行post-fusion latent cross。注意,当我们将Page作为被拼接的特征时,它在pre-fusion和post-fusion都被拼接。如下图所示,使用
Page来执行latent cross可以提供最佳准确性。此外,我们看到同时使用latent cross和特征拼接并没有额外提高准确性,这表明latent cross足以捕获Page的信息。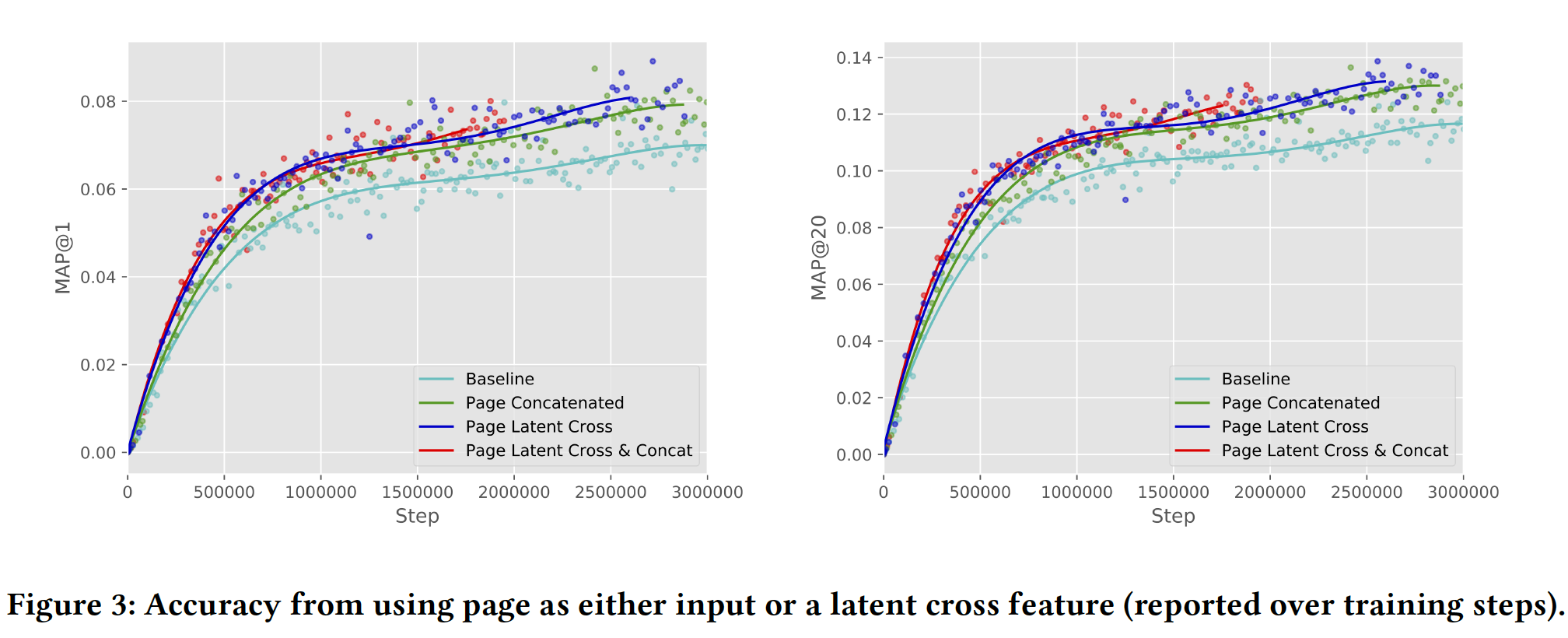
整体提升:最后,我们测试了在完整生产模型之上添加
latent cross对准确性的影响。在这种情况下,模型知道每次观看的page、设备类型、时间(the time)、观看时长(watch time)、视频年龄(watch age)(即,视频从上传到现在过了多久)、uploader。具体而言,我们的baseline YouTube模型使用page、设备类型、观看时长、timedelta数据作为pre-fusion的拼接特征,并且还使用page、设备类型、视频年龄作为post-fusion的拼接特征。为什么
pre-fusion特征和post-fusion特征不同、latent-cross的特征也不同?个人猜测是经过反复实验得到的结论。我们测试包含
timedelta和page作为pre-fusion的latent cross,以及设备类型和page作为post-fusion的latent cross。从下图可以看到,尽管所有这些特征都已通过拼接包含在内,但将它们作为latent cross可以进一步提高baseline模型的准确性。这也证明了具有多个特征的pre-fusion和post-fusion能够共同工作并提供强大的准确性提升。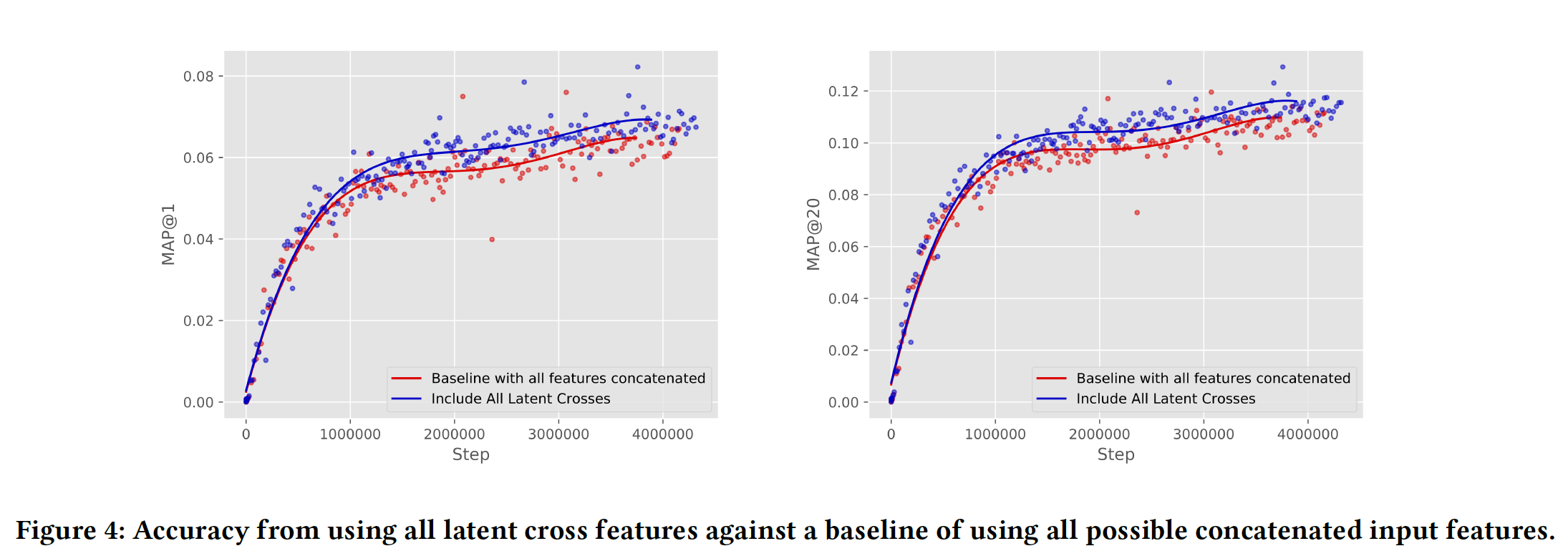
1.3 讨论
我们在下面讨论了这项工作提出的一些问题以及对未来工作的影响。
DNN中的离散关系(Discrete Relation):虽然本文的大部分内容都集中在enable特征之间的乘法交互(multiplicative interaction),但是我们发现神经网络也可以逼近离散交互(discrete interaction),这是factorization模型更困难的领域。例如,在《Improving User Topic Interest Profiles by Behavior Factorization》中,作者发现当用户item与 “一阶DNN的挑战” 的实验类似,我们按照
pattern1的矩阵。我们遵循与 “一阶DNN的挑战” 相同的实验程序,测量具有不同隐层深度、不同隐层宽度的网络的Pearson correlation (R)。我们以0.01的学习率训练这些网络,比上面使用的学习率小十倍。作为baseline,我们还测量了不同秩的张量分解(Pearson相关性。从下图可以看出:
在某些情况下,深度模型获得了相当高的
Pearson相关性,这表明它们实际上能够逼近离散交叉(discrete cross)。同样有趣的是,学习这些交叉需要具有宽隐层的深度网络,对于数据规模而言特别大(即,对于小数据集就需要很宽的网络了)。此外,我们发现这些网络很难训练。baseline张量分解性能很有趣。我们观察到分解模型可以很好地逼近数据,但是需要相对较高的秩。然而,即使在这么高的秩下,张量分解模型需要的参数也比DNN少,而且更容易训练。
因此,与前面的结果一样,
DNN可以逼近这些pattern,但这样做可能很困难,并且模型包含低秩交互(low-rank interaction)有助于提供易于训练的逼近(approximation)。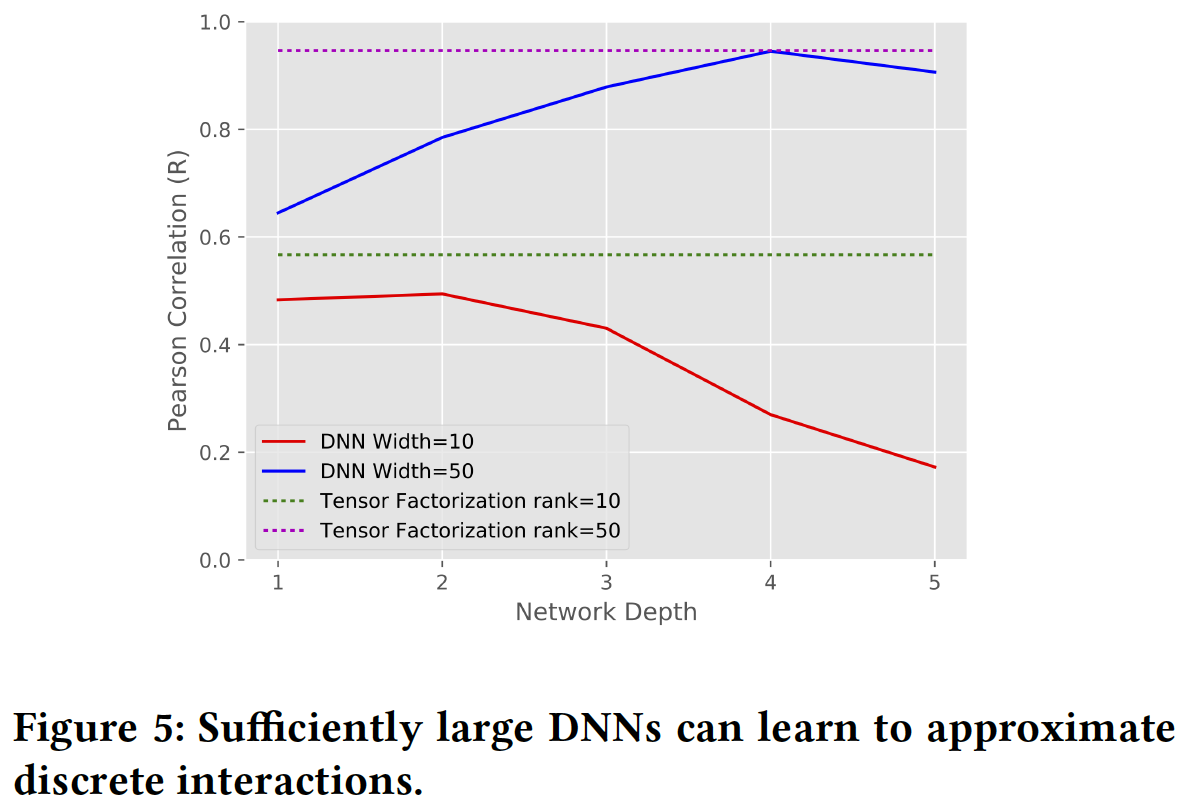
二阶
DNN:阅读本文时自然要问的一个问题是,为什么不尝试更宽的层、或者更深的模型、或者更多的二阶单元(second-order unit)(如GRU和LSTM)?所有这些都是合理的建模决策,但根据我们的经验,模型的训练变得更加困难。latent cross方法的优点之一是它易于实现和训练,同时仍然提供显著的性能提升,即使与LSTM和GRU等其它二阶单元结合使用也是如此。整个深度学习的趋势似乎是使用更多的二阶交互。例如,这在注意力模型(
attention model)和记忆网络(memory network)中很常见。虽然更多二阶交互导致更难训练,但我们相信这项工作展示了神经推荐系统在这个方向上的前景。如果将加法类比于
or操作、将乘法类比于and操作,那么这意味着推荐算法会涉及大量的and,而and难以设计和优化?