一、RRN [2017]
《Recurrent Recommender Networks》
在推荐系统中,一种常见的方法是研究
Netflix竞赛中介绍的问题形式:给定由用户、电影、时间戳、评分组成的元组所构成的数据集,目标是在给定用户、电影、时间戳的条件下预估评分。然后通过预估评分和实际评分的偏离(deviation)来衡量预测的效果。这个公式很容易理解,并导致了许多非常成功的方法,如概率矩阵分解(
Probabilistic Matrix Factorization: PMF)、基于最近邻的方法、聚类。此外,很容易定义适当的性能度量,只需要选择数据集的一个子集进行训练,并用剩余的数据用于测试。但是,当涉及数据中固有的时间方面(
temporal aspect)和因果方面(causal aspect)时,这些方法是存在不足。下面的例子更详细地说明了这一点:电影观念(
Movie Perception)的变化:由于社会观念的变化,曾经被认为很糟糕的电影可能现在变得值得观看。为了适当地捕获这一点,电影属性的参数(parameter)必须随时间变化从而跟踪到这种趋势。季节性变化:虽然没有那么极端,但是人们对于浪漫喜剧、圣诞电影、夏季大片的欣赏相对而言是季节性(
seasonal)的。而且,用户不太可能在夏天观看关于圣诞老人的电影。用户兴趣:用户的偏好会随着时间而改变。这在在线社区中得到了很好的证实(
《No country for old members: User lifecycle and linguistic change in online communities》),并且可以说也适用于在线消费。由于更成熟或生活方式的改变,用户对特定节目的兴趣可能会变化。任何这方面的变化都会使得现有的用户画像失去意义,但是很难显式地对所有这类变化进行建模。
除了需要建模时间演变(
temporal evolution)之外,事后评估也违反了因果关系的基本要求。例如,假如知道用户将在未来一个月内对Pedro Almodfiovar产生好感,那么就可以更容易地估计该用户对La Mala Educacifion的看法。换句话讲,当我们使用未来评分来估计当前的review时,我们在统计分析中违反了因果关系。这使得我们在benchmark上报告的准确性无法作为有效评估,从而确定我们的系统能否在实践中运行良好。虽然Netflix prize产生了一系列研究,但是评估不同模型的未来预测(future prediction)受到训练数据和测试数据的混合分布(mixed distribution)的阻碍,如下图所示。相反,通过显式建模画像动态(profile dynamic),我们可以根据当前趋势来预测未来的行为。下图为
Netflix竞赛中的数据密度。注意,测试数据在近期的评分上的密度要大得多,而训练数据的评分密度要更为均匀。这说明竞赛中提出的问题更多的是利用事后诸葛亮的插值评分(interpolating rating)(泄露了未来的评分来评估当前评分),而不是预测未来的用户行为。这段话的意思是说:对于真实世界的推荐,测试集不应该是随机选择的,而只能是未来预测(
future prediction)。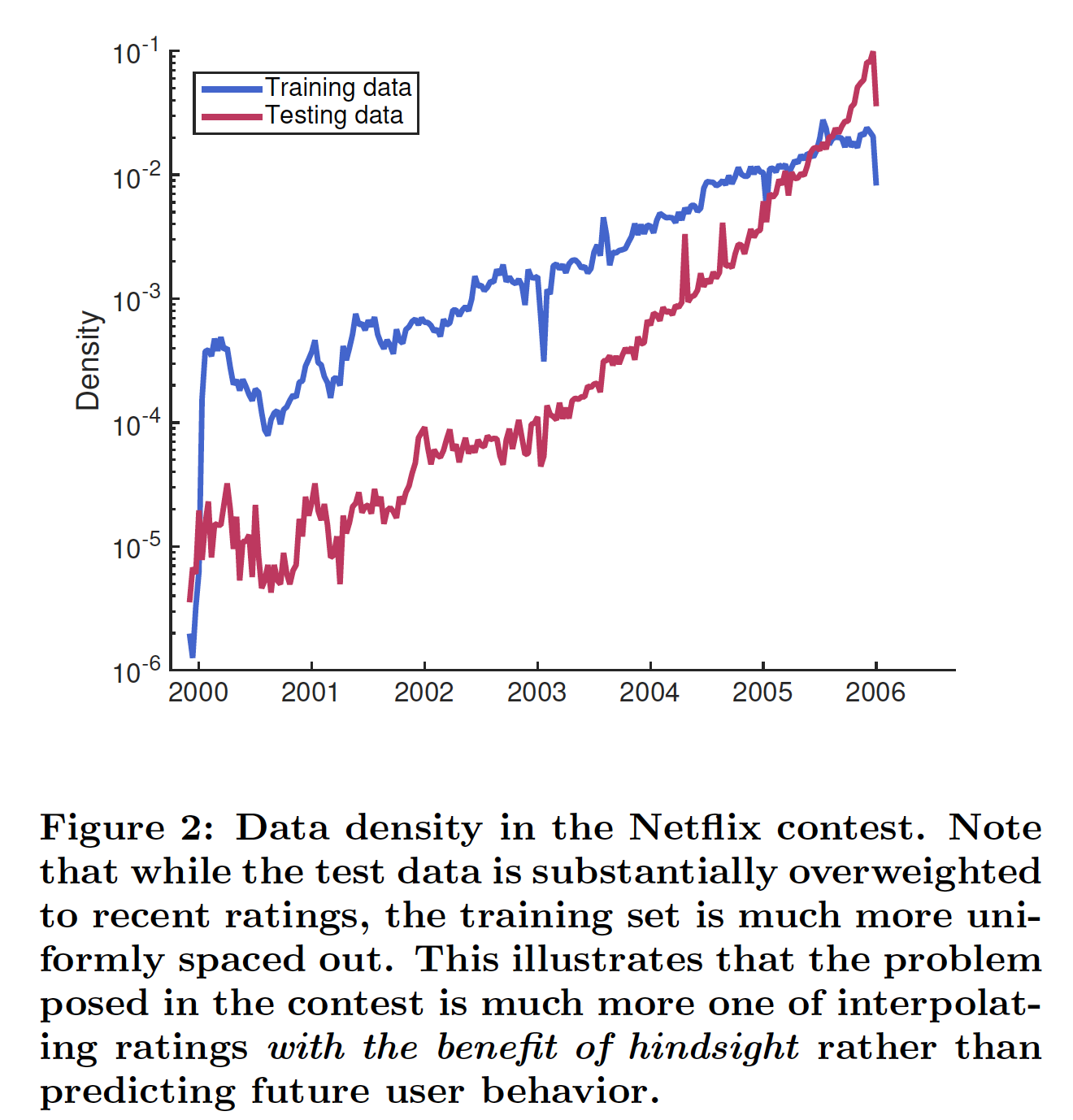
一个能够捕获推荐系统中固有的实际数据分布的模型,除了同时捕获用户集合和电影集合的评分交互之外,还需要能够同时建模每个用户和电影的时间动态(
temporal dynamic)。这意味着使用潜在变量模型(latent variable model)来推断控制用户行为和电影行为的、unobserved的状态。下图所示为这类模型的一个例子,该模型与《Collaborative filtering with temporal dynamics》提出的时间模型(temporal model)之间的区别在于:temporal model使用特定的参数化(parametrization)来插值时间行为(interpolate temporal behavior)。相反,前者使用非参数化模型(
nonparametric model),该模型能够通过学习固有的用户动态(user dynamic)和电影动态(movie dynamic),从而将行为外推(extrapolate)到未来。这使得该模型更适合true dynamic,对实验者的统计建模技能要求更低。这段话的意思是:
temporal model显式采用带时间戳的user parameter、带时间戳的movie parameter来建模user representation和movie representation,是transductive learning,它无法应用到未见过的时间戳。而前者采用模型(如马尔科夫链模型)来建模
user representation和movie representation,它将时间戳作为模型输入,是inductive learning,能够应用到见过的时间戳。
下图左侧为时间无关(
time-independent)的推荐,用户parameter和电影parameter都是静态(stationary)的。右侧为时间相关(time-dependent)的推荐,用户模型和电影模型都遵循马尔科夫链。
给定模型的整体结构,我们可以自由地为潜在变量(
latent variable)设定一种特定类型的状态(state)。流行的选择是假设一个离散的潜在状态(即离散的状态空间)。同样地,我们也可以求助于谱方法(spectral method)或非参数估计(nonparametric estimator),如循环神经网络(Recurrent Neural Network: RNN)。为了解决梯度消失问题,论文《Recurrent Recommender Networks》使用LSTM。论文
《Recurrent Recommender Networks》的贡献如下:非线性(
nonlinear)的、非参数化(nonparametric)的推荐系统已被证明有些难以理解。具体而言,使用非线性函数来代替内积公式在论文的实验中仅显示有限的前景。据作者所知,这是第一篇以完全因果(fully causal)的、整体(integrated)的方式解决电影推荐的论文。也就是说,作者相信这是第一个试图捕获用户动态和电影动态的模型。此外,论文的模型是非参数(nonparametric)的。这使得我们能够建模数据,而不必假设状态空间(state space)的特定形式。Recurrent Recommender Network: RRN非常简洁,因为模型仅学习动态(dynamic)而不是状态(state)。这是与经典的潜在变量模型(latent variable model)的关键区别之一,其中潜在变量模型花了相当大的精力来用于估计潜在状态(latent state)。在这个方面上,RRN非常类似于《Autorec: Autoencoders meet collaborative filtering》提出的神经自编码器(neural autoencoder)。事实上可以将神经自编码器视为RRN模型的一个特例。state:即user representation和movie representation。实验表明,论文的模型优于所有其它模型。例如在现实场景中,作者尝试在给定数据的情况下估计未来的评分。实验表明,论文的模型能够非常准确地捕获外生动态(
exogenous dynamic)和内生动态(endogenous dynamic)。此外,论文证明该模型能够准确地预测用户偏好在未来的变化。外生动态:电影收到外界因素(如电影获得大奖)导致电影评分发生变化。内生动态:电影随着上映时间的增加从而导致评分发生变化。
相关工作:
推荐系统:基础(
basic)的推荐系统忽略时间信息(temporal information)。这是一个合理的近似,特别是对于Netflix竞赛,因为在大多数情况下,关于电影的意见(opinion)和用户的意见不会发生太快、太剧烈的变化。Probabilistic Matrix Factorization: PMF可能最流行的模型之一。PMF尽管简单,但是它在评分预测方面取得了鲁棒的、强大的结果。我们提出的模型采用了与PMF相同的分解来建模稳态效应(stationary effect)。从这个意义上讲,我们的模型是PMF的一个严格的泛化。TimeSVD++是SVD++矩阵分解算法的时间扩展(temporal extension)。这里的关键创新是使用一个单独的模型来捕获时间动态,即允许数据中显式的时间偏差(temporal bias)。这使得TimeSVD++能够以整体的方式(integrated fashion)来捕获由于评分label的变化以及流行度(popularity)的变化而导致的时间不均匀性(temporal inhomogeneity)。注意,
TimeSVD++的特征是手工设计的,依赖于对数据集的深入了解,这使得模型难以移植到新问题,如从电影推荐到音乐推荐或书籍推荐。其次,该模型显式地不估计未来的行为,因为
Netflix比赛不需要估计未来的行为。相反,该模型仅仅在过去的observation之间进行插值。相比之下,我们的模型不依赖于特征工程,并且能够在未看到未来的用户行为的情况下(看到未来的用户行为本来就是不切实际的)预测未来的评分。
可能与我们的方法最密切相关的是
AutoRec,它是少数用于推荐的神经网络模型之一。AutoRec将矩阵分解视为编码问题:找到用户活动(user activity)的低维representation,以便我们可以从该向量重构所有的用户评分。就评分预测而言,AutoRec是迄今为止最好的神经网络模型之一,并在多个数据集上取得了SOTA的结果。
循环深度网络:下图描述的(
graphical model)的关键挑战之一是:它要求我们根据observation推断未来的状态,例如通过消息传递(message passing)或粒子滤波(particle filtering)(粒子滤波通过非参数化的蒙特卡洛模拟方法来实现递推贝叶斯滤波)。这是昂贵且困难的,因为我们需要将评分的mission model与latent state相匹配。换句话讲,将关于评分的信息feed back到latent state的唯一方法是通过likelihoodSequential Monte Carlo sampling)。这种方法需要学习
latent state(作为模型的parameter),这是昂贵且困难的。或者,我们可以简单地学习
mapping作为非参数的状态更新的一部分,即通过Recurrent Neural Network: RNN。关键思想是使用潜在变量自回归模型(latent variable autoregressive model),如下所示:其中:
time stepobservation,observationrepresentation,time stepestimate。time steplatent state。
所谓的 ”非参数“ 指的是
latent state不是作为模型的parameter来学习的,而是通过某个函数来生成的。通过函数来生成并更新latent state,然后通过训练数据来学习这个函数,这就是论文的核心思想。上式给出了通用的函数形式,但是还可以引入非线性以及一些解决稳定性和梯度消失的工具。一个流行的选择是
Long Short-Term Memory: LSTM,它捕获时间动态。我们将LSTM作为协同过滤系统的building block。 整体模型如下图所示。状态更新如下:其中:
forget gate,input gate),output gate)。sigmoid非线性激活函数。
LSTM中有两种类型的非线性激活函数:用于遗忘门、输入门、输出门的
sigmoid非线性激活函数:由于门控单元的性质,门的输出必须是0.0 ~ 1.0之间。因此,如果要替换为新的非线性激活函数,则该激活函数的输出范围也必须满足0.0 ~ 1.0之间。用于
tanh非线性激活函数:用于对输入数据进行非线性变换,因此也可以替换为relu等其它非线性激活函数。但是对于RNN网络需要注意梯度消失和梯度爆炸,这也是为什么通常选择tanh非线性激活函数的原因。但是,也有论文和网上材料指出,通过仔细挑选合适的权重初始化(权重初始化为1附近),那么relu非线性激活函数的模型效果会更好。
为简单起见,在本文中我们使用
LSTM不是唯一的选择,例如也可以选择GRU(GRU的计算成本更低且结果通常相似)。在本文中,我们使用LSTM因为它稍微更通用。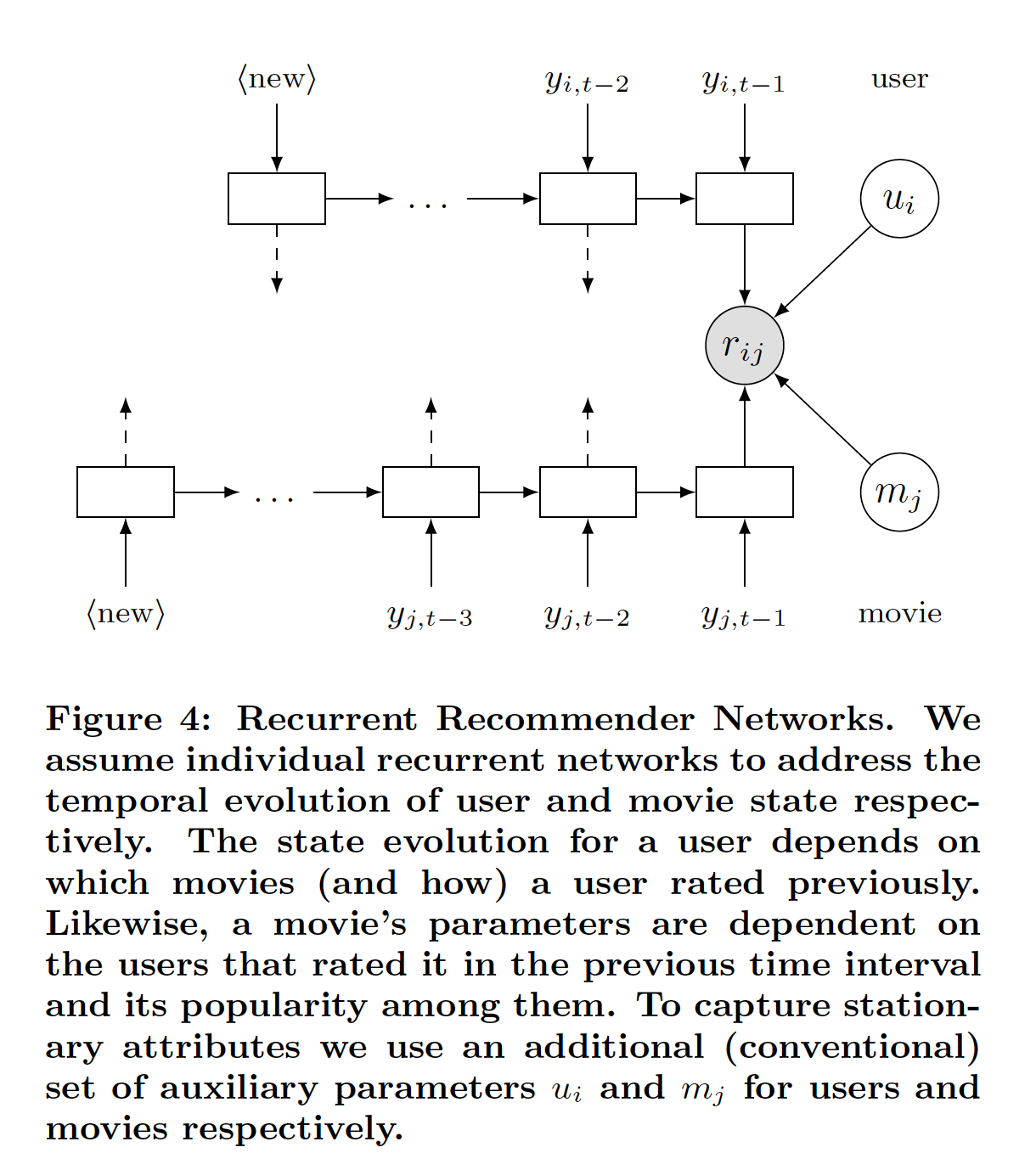
《Session-based recommendations with recurrent neural networks》没有考虑个性化,也没有尝试建模user state transition和item state transition。
1.1 模型
我们使用
LSTM RNN来捕获用户的时间依赖性(temporal dependency)和电影的时间依赖性。通过这种方式,我们能够融合(incorporate)过去的observation并以整体的方式预测未来的轨迹。令用户
latent state为latent state为temporal dynamic),我们给两者赋予时间索引,即latent state的更新函数(update function)。我们将更新函数定义为:其中:
time step函数
latent state。
我们不是解决优化问题来找到
user parameter/ movie parameter,而是解决优化问题来找到生成user parameter/movie parameter的函数。这方面类似于深度自编码器,其中深度自编码器学习一个编码器函数来编码过去的评分。然而深度自编码器的目标是最小化重构误差,而这里的问题是最小化预测评分与真实评分之间的误差。
用户状态和电影状态:为简单起见,我们首先描述
user-state RNN,因为movie-state RNN也是以相同的方式来定义的。给定一个包含
time steptime steptime stepwallclock,并且使用其中:
source information投影到embedding空间中的、待学习的变换(transformation)。注意:
由于评分序列的时间跨度很长,因此这里的
time step可以按照天粒度、月粒度、甚至年粒度来进行。此时RNN序列的长度,降低计算复杂度。粒度越长则越反应长期的趋势(短期趋势被抹平)。这种线性投影的方式本质上是:将用户在
time stepembedding进行sum聚合。也可以进行self attention聚合、max pooling聚合等等其它非线性聚合。embedding的方式添加到field:评分向量field、newbie field、wallclock field。这三个field的投影结果直接拼接在一起。也可以采用更复杂的融合方式(如MLP或者attention)。
LSTM在time step注意,如果在
time steptime step(即no-rating step)不应该包含在RNN中,这可以节省计算。尽管如此,wallclock的引入为模型提供了考虑no-rating step所需的信息,并且额外捕获了诸如rating scale变化、电影年龄之类的效果。rating scale变化指的是,比如某个时刻之前的评分范围是1 ~ 5分,之后的评分范围是1 ~ 10分。为了区分不同的用户,我们添加了用户
评分发射
rating emission(即,评分函数):尽管用户状态和电影状态可以随时间变化,但是我们推测仍然存在一些静态分量(stationary component)来编码固定属性,例如用户画像、用户的长期偏好、电影的题材。为了实现这一点,我们分别用固定的time-varying的dynamic state和stationary state的函数,即:简而言之,标准的分解模型仅考虑了静态效应(
stationary effect),而我们使用LSTM从而考虑了更长期的动态更新(dynamic update)。这使得我们的模型成为矩阵分解(matrix factorization)模型的严格超集(strict superset)。这里通过
dynamic user state和dynamic movie state映射到公共的空间。另外,上式等价于经
dynamic state和stationary state拼接之后再内积,即:评分预测(
rating prediction):与传统的推荐系统不同,在预测时我们使用外推状态(extrapolated state)(即通过LSTM生成的state)而不是估计状态(estimated state)来进行评分预测。也就是说,我们将最新的observation作为输入,更新状态,并根据更新后的状态进行预测。通过这种方式,我们自然会考虑到之前评分带来的因果关系。例如,我们能够解决享乐适应(
hedonic adaptation),它指的是在电影推荐的背景下,用户观看了一部令人满意的电影之后,用户对电影的满意度的level会降低。对于令人失望的电影也是类似的。训练:模型的优化目标函数是找到合适的
parameter从而产生最接近实际评分的预测,即:其中:
parameter,(user, movie, timestamp)元组的集合,虽然我们模型中的目标函数和
building block都是相当标准的,但是朴素的反向传播无法轻易地解决这个问题。关键的挑战在于每个单独的评分都同时取决于user-state RNN和movie-state RNN。对于每个单独的评分,通过2个序列的反向传播在计算上是很难进行的。我们可以通过仅考虑user-state RNN的反向传播来稍微缓解这个问题,但是每个评分仍然取决于movie state。反过来,我们也可以仅考虑movie-state RNN,但是每个评分仍然取决于user state。相反,我们提出了一种解决该问题的交替子空间下降策略(
alternating subspace descent strategy)。也就是说,我们仍然考虑user-state RNN的反向传播,但现在我们假设电影状态是固定的,因此不需要将梯度传播到这些电影序列中。然后我们交替更新用户序列和更新电影序列。这样,我们可以为每个用户(电影)执行一次标准的前向传播和反向传播。这种策略被称作子空间下降(subspace descent)。
1.2 实验
数据集:
IMDB数据集:包含1998年7月到2013年9月期间收集的140万个评分。Netflix数据集:包含1999年11月到2005年12月期间收集的1亿个评分。
每个数据点是一个
(user id, item id, time stamp, rating)元组,时间戳的粒度为1 day。为了更好地理解我们模型的不同方面,我们在具有不同训练和测试周期的几个不同时间窗口上测试我们的模型。详细的数据统计如下表所示。注意,我们根据时间来拆分数据从而模拟实际情况:我们需要预测未来的评分(而不是对以前的评分插值
interpolate)。测试期间的评分被平均拆分为验证集和测试集。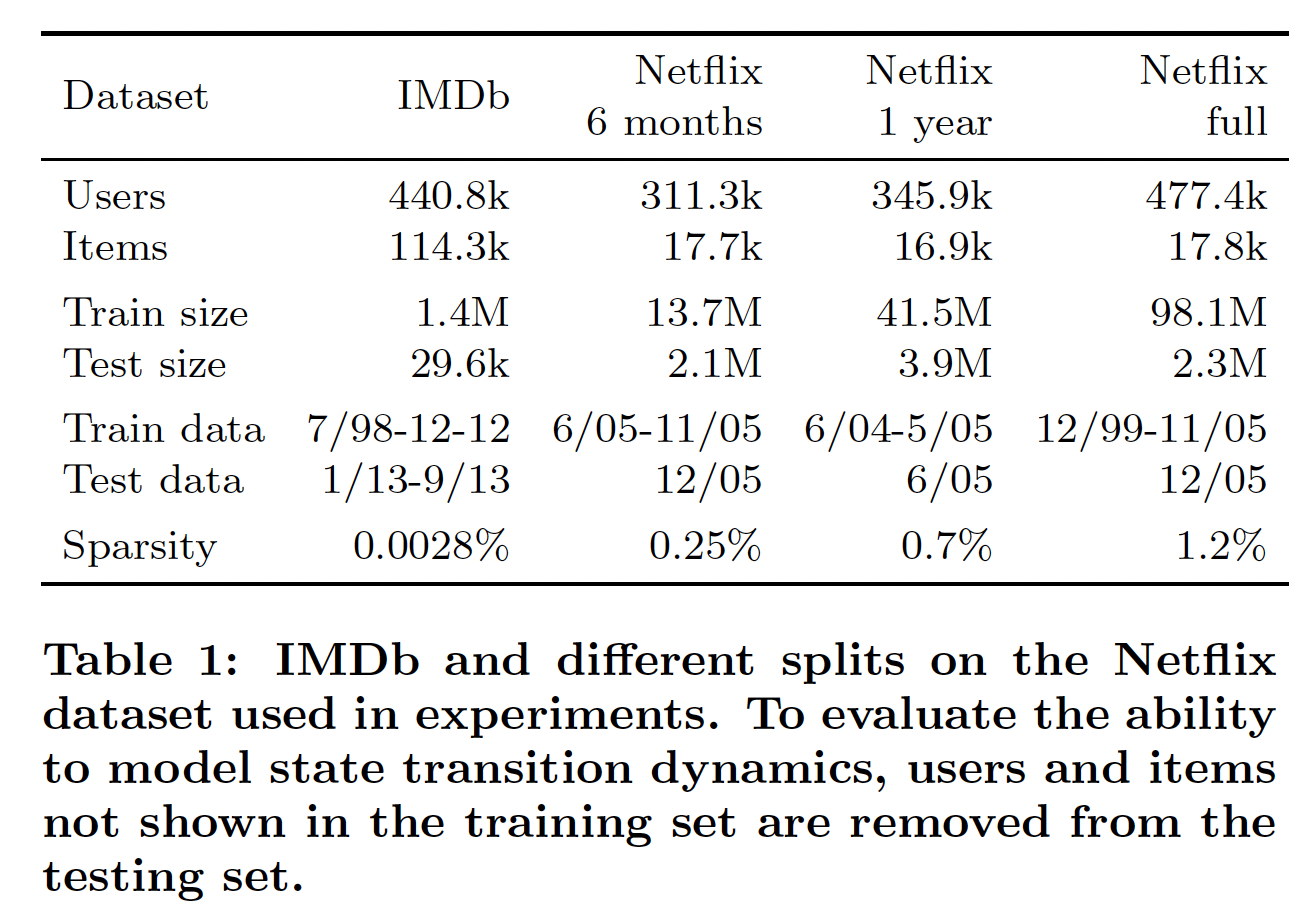
配置:
我们发现即使使用非常少的参数,我们的模型也能够达到良好的准确性。
在以下的实验中,我们使用具有
40个隐单元(即input embedding维度40维(即dynamic state维度20维(即LSTM。我们分别对
Netflix和IMDB数据集使用20维和160维的stationary latent factor。
我们的模型在
MXNet上实现。我们使用
ADAM来优化神经网络参数、使用SGD来更新stationary latent factor。我们通过交叉验证调优超参数。
我们发现:如果我们首先仅训练
stationary state,然后联合训练完整的模型,则通常可以获得更好的结果。在接下来的实验中,stationary latent state分别由一个小的预训练的PMF初始化(对于Netflix数据集)、以及一个U-AutoRec模型来初始化(对于IMDB数据集)。wallclock
baseline方法:PMF:尽管简单,然而PMF在评分预测方面取得了鲁棒的、强大的结果。由于我们的模型采用与PMF相同的因子分解来建模静态效应,因此和PMF比较的结果直接展示了我们的方法建模temporal dynamic的好处。我们使用LIBPMF,并使用网格搜索(grid search)来搜索正则化系数factor sizeTimeSVD++:TimeSVD++是捕获temporal dynamic的最成功的模型之一,并在Netflix竞赛中展示了强大的结果。我们使用网格搜索(grid search)来搜索正则化系数factor sizeAutoRec:AutoRec学习一个自编码器从而将每个电影(或每个用户)编码到低维空间,然后解码从而进行预测。就评分预测而言,它是迄今为止最好的神经网络模型之一,并在多个数据集上取得了SOTA结果。我们使用原始论文中的超参数(latent state维度
我们的评估指标是标准的
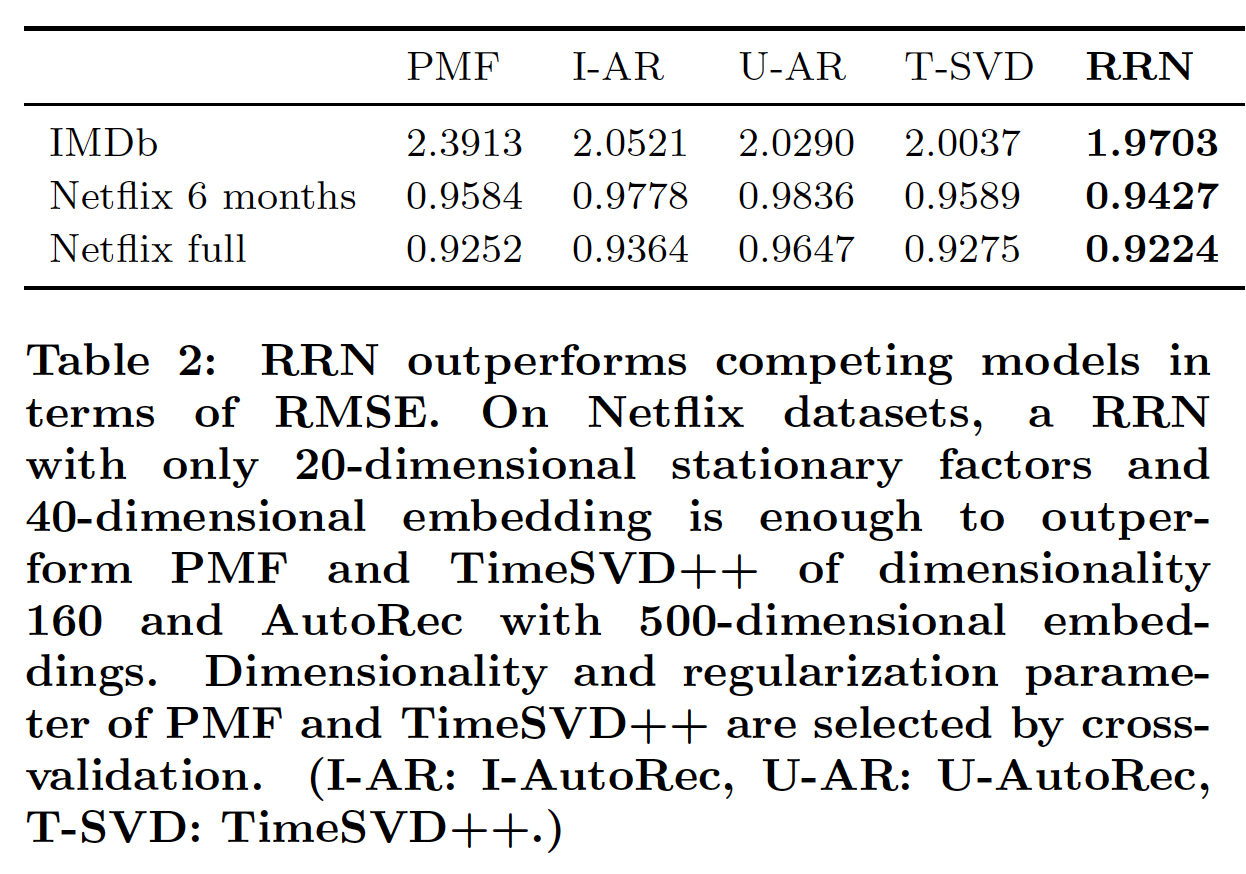
root-mean-square error: RMSE。不同数据集的结果如下表所示。这里,我们对Netflix full和IMDB使用2个月粒度的time step,对6-month Netflix数据集使用1day/7 days(对应于user/movie)粒度的time step。我们将在后续讨论time step粒度的选择。我们将模型运行10个epoch,在每个epoch结束之后计算验证集的RMSE。我们报告在验证集上效果最好的模型在测试集上的测试RMSE。模型准确性(
accuracy)和大小(size):在所有方法中,我们的模型在所有数据集上均达到了最佳的准确性。和
PMF相比,RRN在IMDB上提供了1.7%的改进,在6-month Netflix上提供了1.6%的改进。注意,下表展示的
RMSE高于Netflix竞赛的RMSE,因为我们测试的纯粹是未来的评分。此外,我们的模型非常简洁,因为我们存储转移函数(
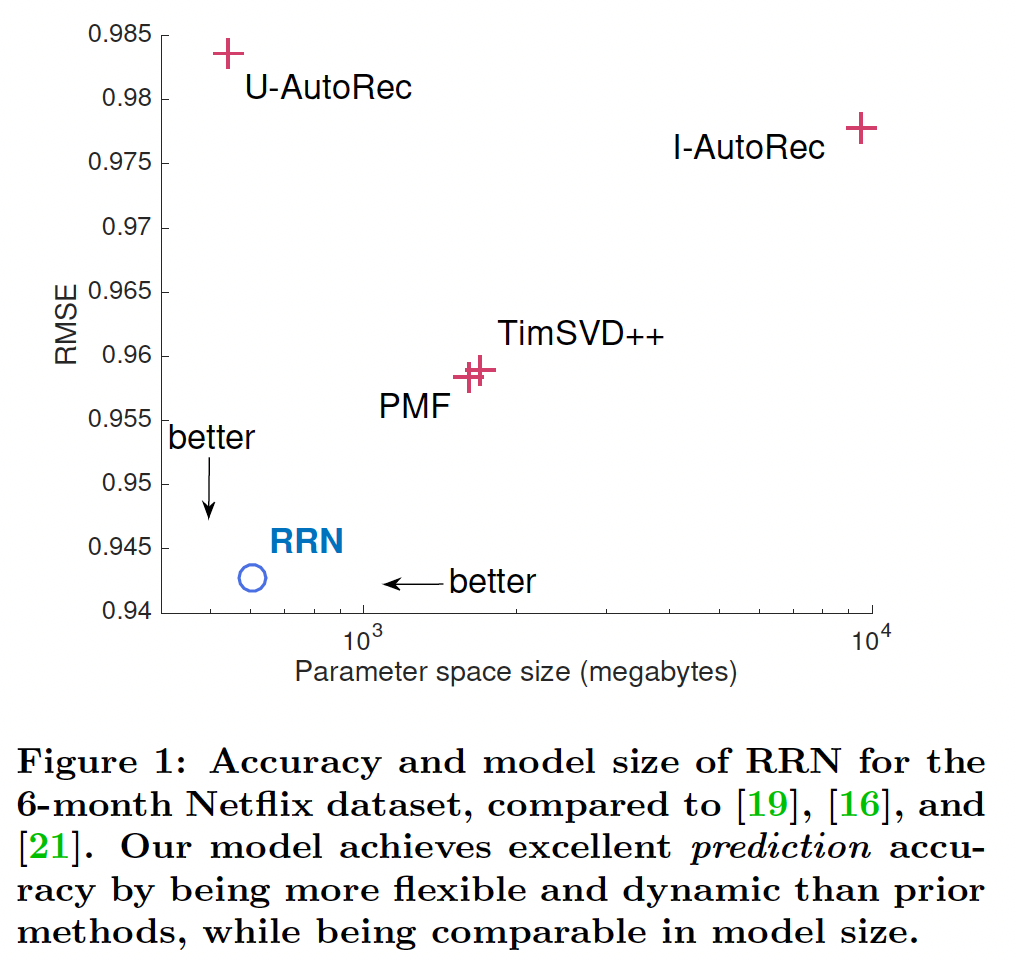
transition function)而不是实际状态从而建模temporal dynamic。虽然RRN优于所有baseline,但是RRN比PMF和TimeSVD++小2.7倍、比I-AutoRec小15.8倍。具体而言,具有40维embedding和20维stationary state的RRN足以超越160维的PMF、160维的TimeSVD++、500维的AutoRec。下图展示了
6-month Netflix数据集上的模型大小和RMSE。对于
IMDB,RRN的大小与PMF, TImeSVD++, U-AutoRec相当,但是比I-AutoRec小得多。这是因为RRN使用与分解模型相同维度的stationary state,并且包含一个相对较小的模型来捕获temporal dynamic。我们看到RRN在灵活性和准确性方面的明显优势,而不会牺牲模型大小。
鲁棒性(
robustness):RNN在不同数据集上显示出一致的改进,而其它方法在不同数据集上的排名在变化。PMF在IMDB数据集上的表现要比Time-SVD++差得多,这再次强调了对temporal dynamic建模的必要性。但是
PMF在Netflix full和Netflix 6 months上的表现要比Time-SVD++更好,是否说明建模temporal dynamic是无用的?
时间动态:
电影中的外生动态(
exogenous dynamic):外生动态指的是电影的评分如何随着外部效应(exogenous effect)(如电影获奖或得到提名)而变化。我们的目标是了解我们的模型如何对外生动态作出反应。具体而言,我们在
1-year数据集上运行RNN,time step粒度为一个月,并且查看平均预测评分如何沿着时间序列而演变。平均预测评分是根据1000名随机抽样的用户计算而来。这个平均预测评分代表了电影在当时的平均预测评分,并避免了当时谁选择给该电影评分的bias。这里评估的是全体用户中随机选择的,而不是从对某个电影有评分的用户中选择的。后一种方式存在选择偏差
select bias,使得仅评估未来review过该电影的用户。下图展示了获奖电影的平均预测评分。可以看到,当一部电影获奖或得到提名时,预测评分会显著上升,这与数据趋势相符。这证实了我们的预期,即
RNN应该自动适应外生变化(exogenous change)并调整预测。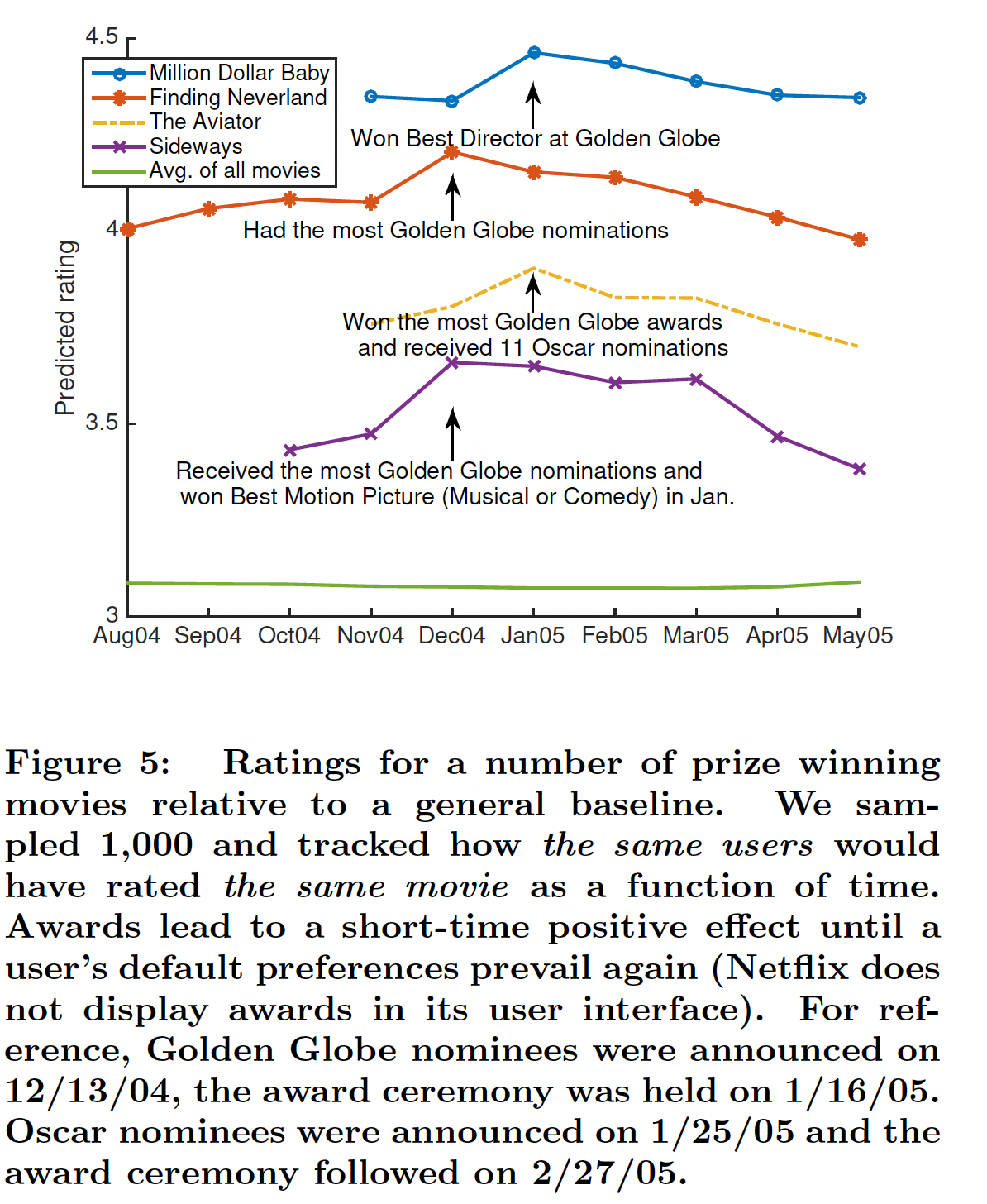
电影中的内生动态(
endogenous dynamic):除了外生事件之外,电影还可能由于内生原因而随着时间的推移而发生变化。为了了解RRN如何对内生原因的影响进行建模,我们以2个月粒度的time step对完整的6-year数据集进行了测试。实验与前一个实验相同的方式进行,但是考虑到大多数用户仅在系统上活跃一段时间这个事实,这里对每个time step我们随机采样了5000个当时活跃的用户(因此这里采用的是time step粒度随机选择的用户)。如果用户在time step内对任何电影进行了评分,那么我们认为该用户是活跃的。我们观察评分变化较大的电影,并观察RRN如何建模它的temporal dynamic。首先,我们观察到年龄效应(
age effect)。也就是说,一部电影的评分往往在上映后的第一年略有下降,然后随着年龄的增长而上升。在下图中,我们看到我们的模型显著地捕获到这种年龄效应并有效地适应。下图为精心挑选的某部电影的平均预测评分。论文并未讲述这种效应产生的原因,只是说明有这种现象。
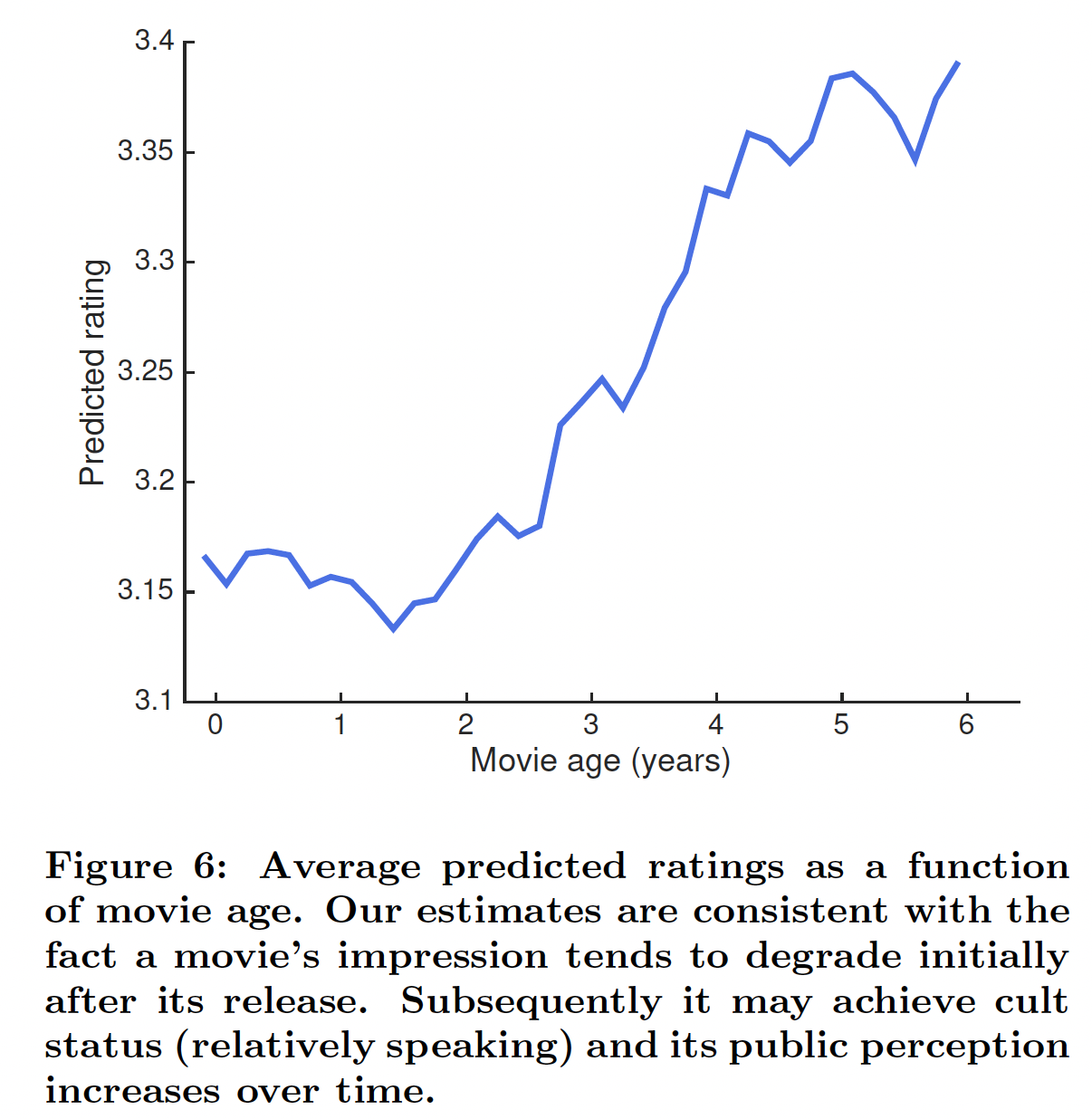
此外,我们还注意到
RRN如何对具有不同反响的电影进行不同的建模。下图展示了奥斯卡最佳影片提名(蓝色曲线)、以及金酸莓最差影片提名(红色曲线)的预测评分。我们看到每个分组中的电影都显示出符合直觉的一致模式:金酸莓提名电影最初经历了平均评分下降,然后上升;而奥斯卡提名电影在开始时平均评分上升,然后保持相对稳定。注意,这些模式不是简单地通过一个bias项来捕获的shift。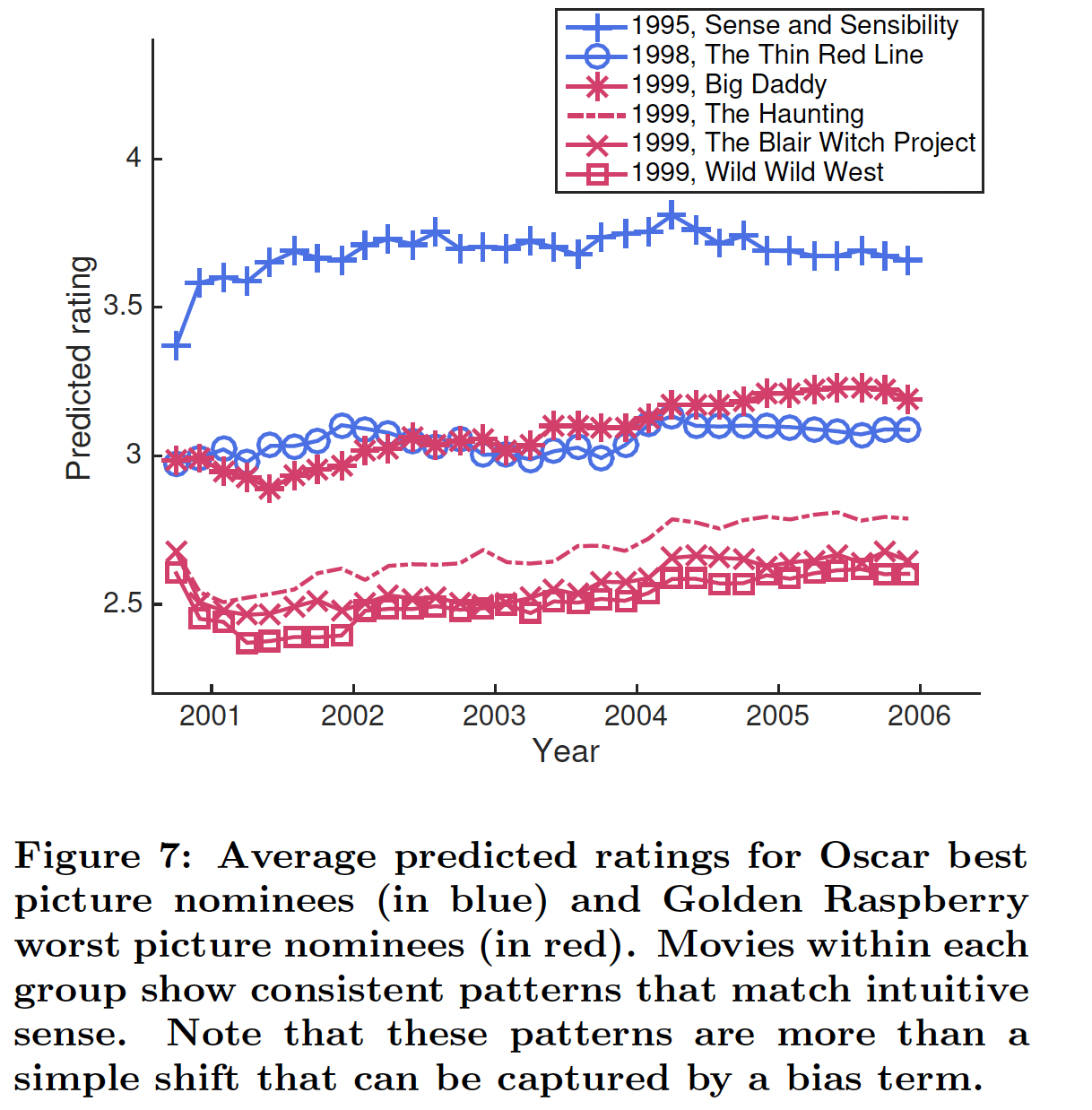
用户偏好(
User Interface)改变:正如《Collaborative filtering with temporal dynamics》中所指出的,2004年初评分的scale发生了改变。显然,没有考虑到这一点的系统将具有较差的估计准确性。我们在完整的Netflix数据集上测试我们的模型,time step粒度为2个月,并查看每个time step上随机选择的用户所生成的平均评分。注意,由于我们计算随机用户随时间的平均预测,因此我们观察模型的dynamic embedding如何随时间变化。下图显示了按电影发行年份分组的平均预测评分。我们看到所有的曲线在
2004年初都有一个与scale change相匹配的显著上升。这与PMF形成对比,PMF的embedding是静态的,因此随着时间的推移平均预测是恒定的。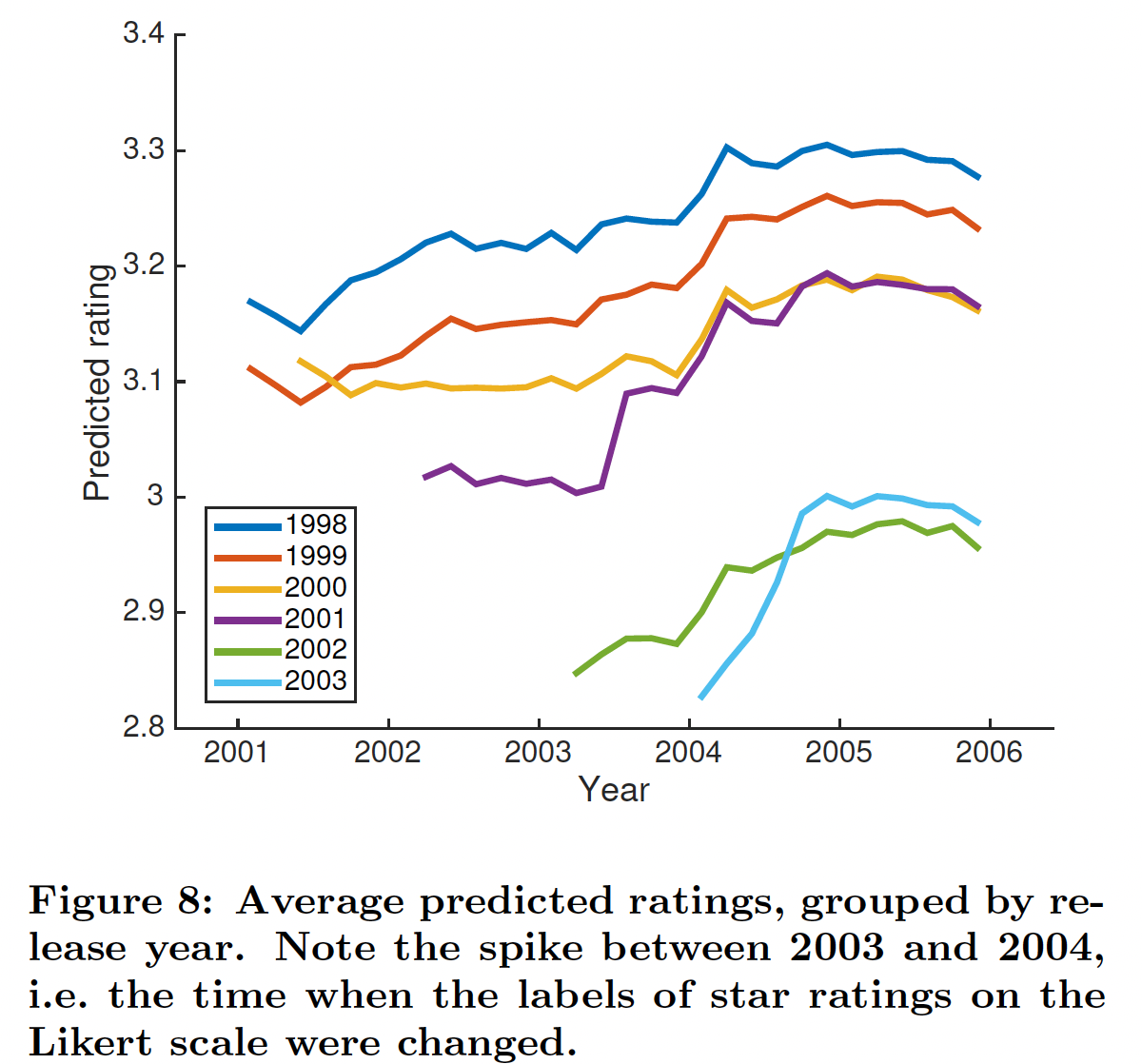
冷启动:为了了解我们模型的优势和劣势,我们在训练集中评分很少的用户和电影上与静态
PMF模型进行了比较。如下图所示,对于训练集中评分很少的用户,
RRN比PMF有所改进。对于训练集中评分非常少的用户,RRN(相比较PMF)的相对改进最大。整体而言,训练集中评分数量越多,则相对改进越小。
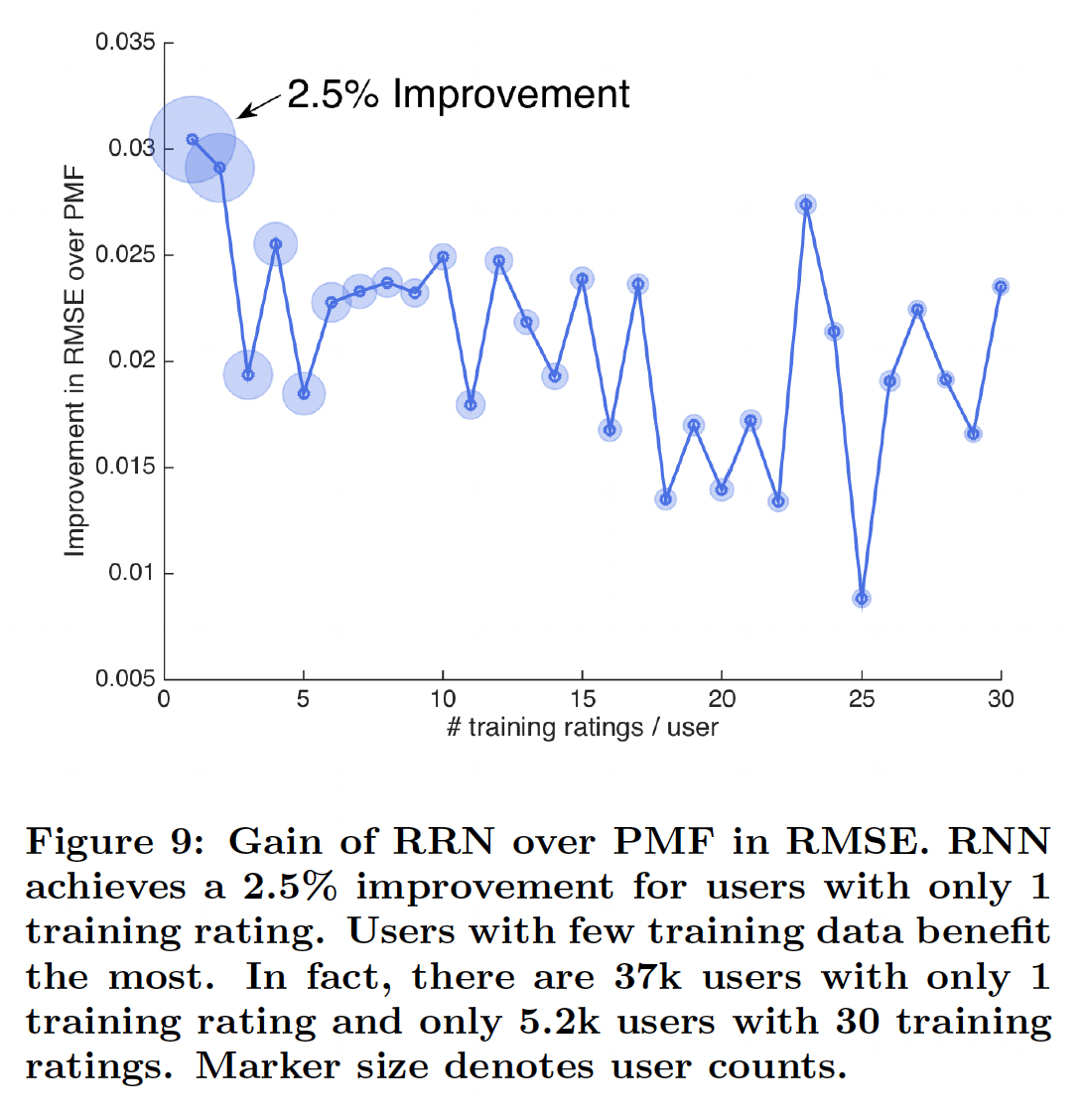
如下图所示,我们发现
RRN仍然一致性地为评分很少的电影提供改进,但是改进幅度与观察次数之间的关系更加noisy。这可能是由于这些电影在测试集中的评分相对较少。这个理由缺乏数据的支撑,因为前面关于评分数量少的用户的结论中,这些用户也可能在测试集中的评分很少。
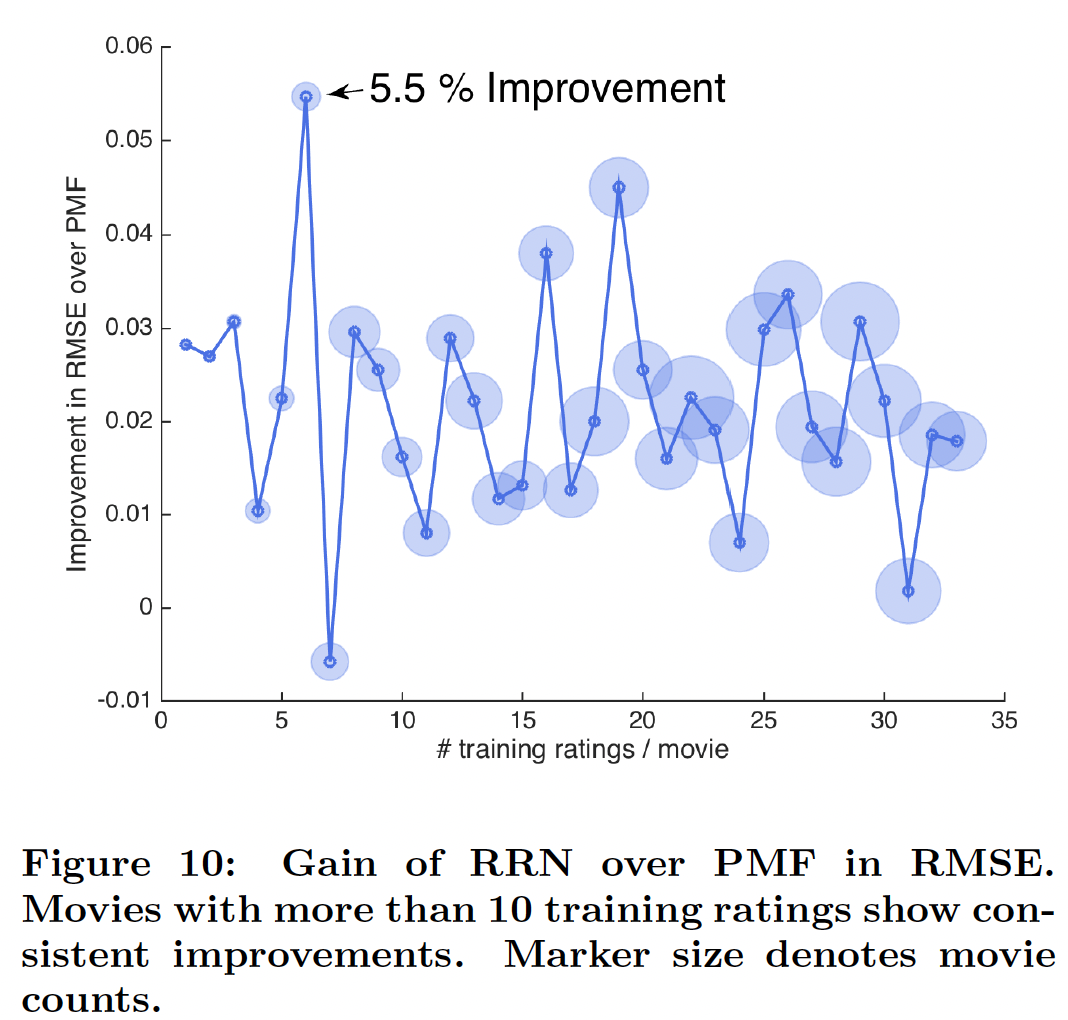
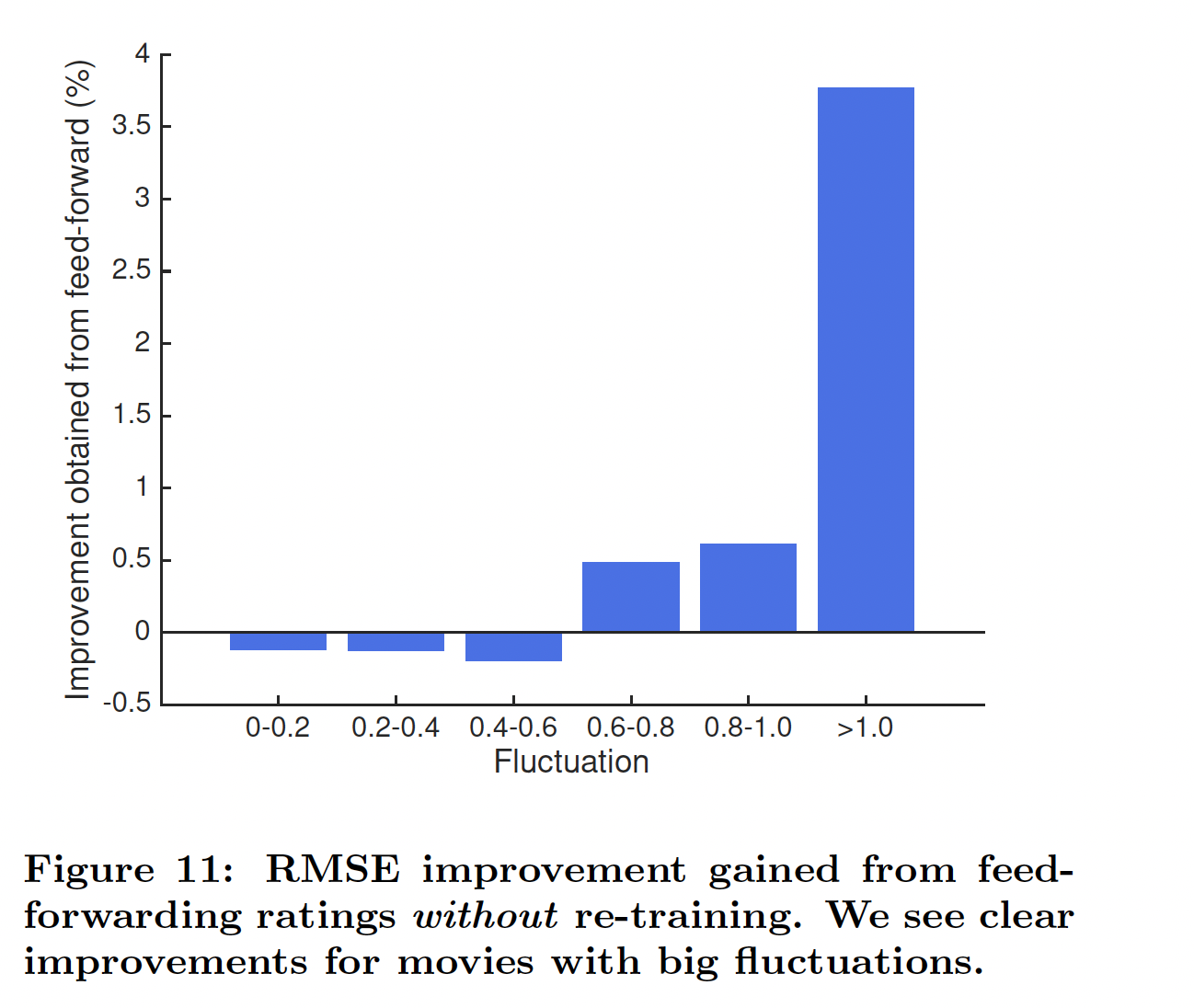
无需重新训练(
re-training)从而融合新数据:估计转移函数(transition function)而不是估计状态本身的一个优势是:即使没有重新训练(re-training),我们也能够融合新观察到的评分信息从而更新状态(只需要将新的评分输入到网络中)。这里,我们在
6-month Netflix数据集上评估该策略。具体而言,我们使用从第一个测试time step观察到的评分来外推状态(extrapolate state),并使用外推到的状态来预测第二个time step的评分。我们测试了具有不同的评分波动水平的电影。波动(fluctuation)被定义为:评分最高的time step的平均评分,与评分最低的time step的平均评分之间的差异。下图总结了该策略的
RMSE改进。我们观察到:虽然我们的预训练模型没有捕获到小的波动,但是它成功地捕获了大的波动,从而显著提高了预测准确性。也就是说,使用RRN不仅缓解了频繁昂贵的重新训练的需要,而且还开辟了提供实时推荐的新途径。通常小的波动不太重要,此时这些电影的评分比较稳定,甚至直接将它们的评分预估为一个恒定值就足够可以。
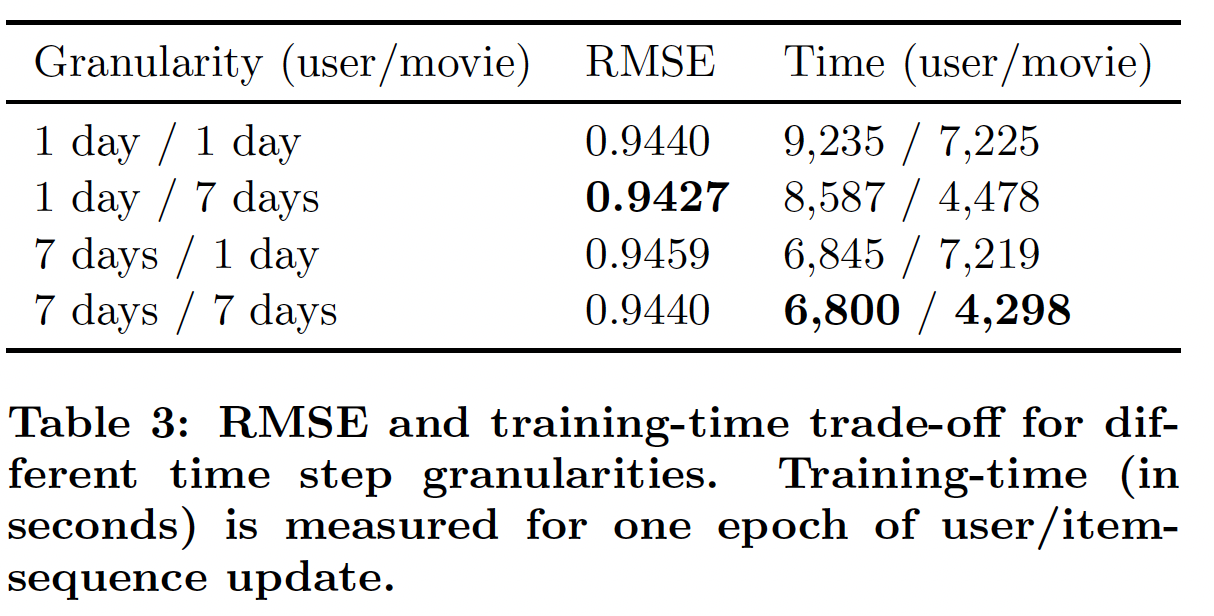
time step粒度(granularity)和敏感性(sensitivity):较小的time step允许模型频繁地更新并捕获短期影响。然而,这也会导致更长的LSTM序列,从而进一步导致更高的训练成本。下表总结了
6-month数据集上不同粒度(user和movie采用不同的粒度)的训练时间和测试RMSE。这里我们看到了RMSE和训练时间之间的trade-off。可以通过更长的训练时间为代价来获得更好的准确性。注意,性能对粒度不是特别敏感,即使采用最差RMSE的粒度,它也优于所有的baseline模型。这可能是因为RRN是完全通用的,因为它没有假设数据的特定形式或分布。