一、RUM [2018]
《Sequential Recommendation with User Memory Networks》
在许多现实世界的
application中,用户当前的兴趣受到他们历史行为的影响。例如,人们在购买智能手机之后可能会购买手机壳或耳机等配件,人们可能会继续购买他们以前有过良好体验的同一品牌的衣服。为了建模这种现象,人们已经提出了一些方法来使用用户历史记录(
user historical record)进行序列推荐。例如,《Factorizing personalized markov chains for next-basket recommendation》采用马尔科夫链对用户行为序列进行建模,《Context-aware sequential recommendation》和《dynamic recurrent model for next basket recommendation》利用RNN来嵌入先前购买的商品从而进行当前兴趣预测(current interest prediction)。现有方法取得了令人振奋的结果,但是它们倾向于将用户以前的所有记录(
record)压缩为一个固定的hidden representation。如下图所示,用户购买手机壳(item E)的关键原因可能是他之前购买了一部手机(item B),而之前其它购买的商品不一定与这个new purchase(即,手机壳)有关。然而,RNN(和其它的latent representation方法)会强制将所有先前的item(即item A到item D)summarize到一个向量(即,next interest。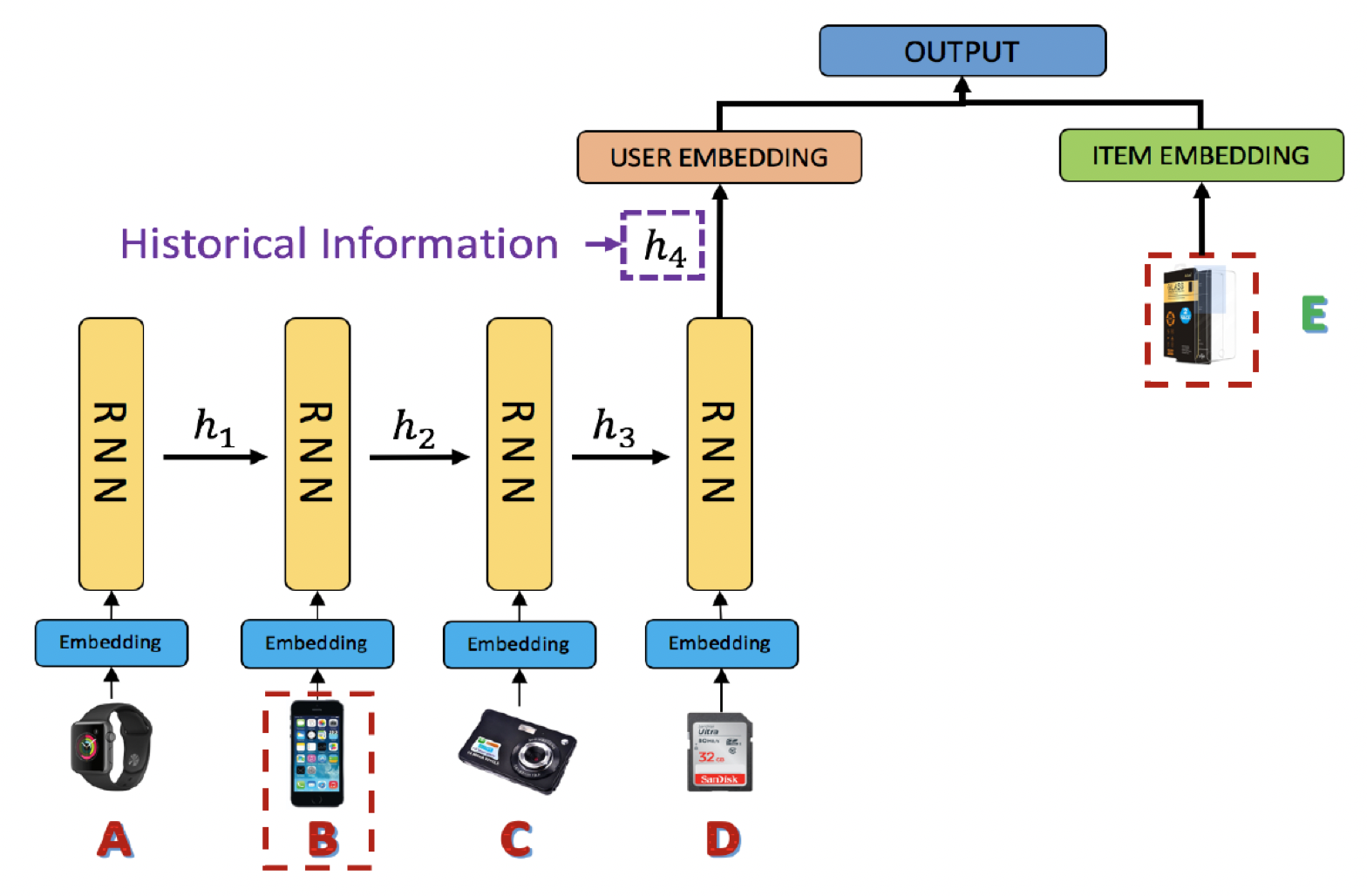
不同历史记录(它们用于
next interest prediction)的这种区分性的缺乏导致了两个不利的后果:在序列推荐中弱化了高相关
item的信号。忽略这样的高相关性信号使我们难以理解和解释序列推荐。
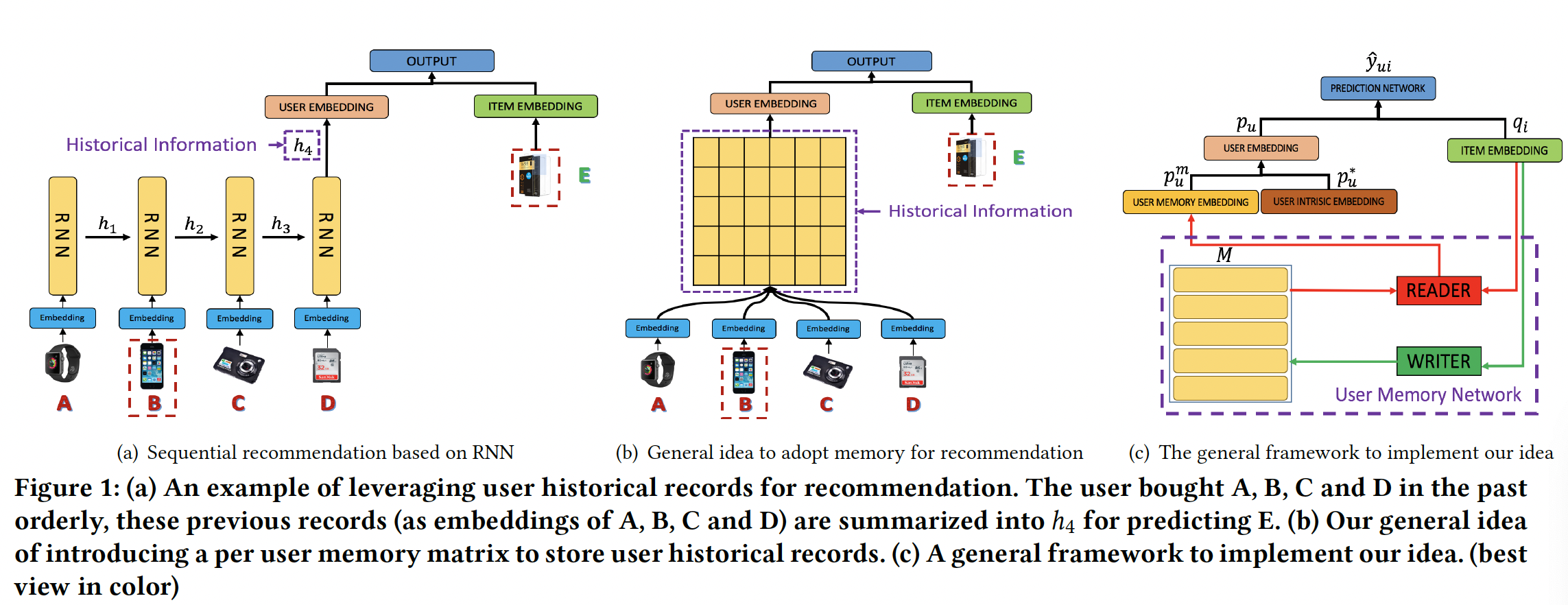
为了缓解这些问题,论文
《Sequential Recommendation with User Memory Networks》将用户行为视为描述神经图灵机(neural turing machine: NTM)的决策程序,并提出使用external memory来建模用户历史记录。凭借显式地、动态地、和有效地表达、存储和操作记录的能力,external memory network: EMN已经在许多序列预测任务中展示出良好的性能,例如知识问答(question answering: QA)、natural language transduction: NLT、knowledge tracking: KT。EMN架构不是合并先前的状态(state)来进行预测,而是引入了一个memory matrix来将状态分别存储在memory slot中。然后通过在这个矩阵上设计适当的操作,EMN与传统的RNN/LSTM模型相比在许多任务中实现了显著的提升。受到
EMN的启发,论文《Sequential Recommendation with User Memory Networks》提出了一种将Recommender system和external User Memory network相结合的新颖框架,简称RUM。然后论文进一步研究RUM在top-N推荐任务上的直觉和性能。下图(b)和(c)说明了论文提出的框架的基本思想:对于每个用户,引入一个
external user memory matrix来维护该用户的历史信息。与传统的RNN hidden vector相比,这丰富了representation capacity。在进行预测时,
memory matrix被注意力地(attentively)读出(read out)从而生成一个embedding来作为user representation,其中注意力机制学习先前记录对于当前推荐的不同重要性。在处理完序列中的每个
item后,将重写memory从而更新用户历史(user history)。
为了更好地探索论文的想法,作者提供了框架的两个规范(
specification),即item-level RUM和feature-level RUM,它们分别建模item-level的用户记录和feature-level的用户记录。与现有方法相比,论文的方法基于memory network对用户历史记录进行了更细粒度的使用,提高了推荐性能,同时基于注意力分析抽取了消费者行为的直观的因果关系(intuitive causality)。总之,这项工作的主要贡献包括:
论文提出将协同过滤的洞察(
insight)与memory-augmented neural network: MANN相结合从而进行推荐。这种结合以更有效的方式利用了用户历史记录。据作者所知,这是将MANN引入推荐系统领域的首次尝试。论文研究了两个具有不同
representation和operation设计的潜在memory network(item-level和feature-level)。论文进一步研究并比较了它们在序列推荐和top-N推荐任务中的表现。论文还将所提出的模型与
SOTA的方法进行了比较,并通过对现实世界数据集的定量分析来验证所提出模型的优越性。分析结果表明论文的方法能够更有效地利用用户历史记录。论文进一步提供实证分析(
empirical analyse)来解释所提出的模型如何、以及为什么推荐一个item。分析结果表明通过memory network中的注意力机制,所提出的模型能够直观地解释用户历史记录如何影响该用户当前的和未来的决策。
相关工作:我们的工作本质上是序列推荐和
memory-augmented neural network的集成。接下来我们回顾一下这两个研究方向的相关工作。序列推荐:在文献中,人们已经提出了许多模型以序列方式利用用户历史记录来进行
future behavior的预测和推荐。通过集成矩阵分解和马尔科夫链,
factorized personalized Markov chain: FPMC将相邻行为之间的转移信息(transition information)嵌入到item latent factor从而进行推荐。而
hierarchical representation model: HRM通过利用representation learning作为latent factor从而进一步扩展了这个想法。这些方法主要对每两个相邻记录之间的局部序列模式(
local sequential pattern)进行建模。为了建模
multiple-step序列行为,《Fusing Similarity Models with Markov Chains for Sparse Sequential Recommendation》采用马尔科夫链来提供稀疏序列的推荐。《A dynamic recurrent model for next basket recommendation》提出了dynamic recurrent basket model: DREAM来捕获全局序列模式(global sequential pattern)并学习基于recurrent neural network: RNN的dynamic user interest representation。在DREAM中,用户的所有历史记录都被嵌入到RNN的final hidden state中,从而代表该用户的当前偏好。DREAM这种方法取得了相对于HRM和FPMC的显著改进。类似地,
《Session-based recommendations with recurrent neural networks》、《Improved recurrent neural networks for session-based recommendations》利用用户之前的点击和购买行为,使用RNN对短期偏好进行建模,从而用于session-based推荐。《Translation-based recommendation》采用度量空间学习(metric space learning)方法来学习用于序列推荐的、加性(additive)的user-item关系。除了电商之外,序列推荐也被应用于
POI推荐、音乐推荐、浏览(browsing)推荐等各种application场景。
现有模型通常将用户先前的记录隐式编码为一个
latent factor或hidden state,而不区分每条记录在预测当前兴趣时可能扮演的不同角色。然而,在这项工作中,我们利用user memory network来存储和操作每个用户先前的记录,这有助于增强用户历史的表达能力。Memory-Augmented Neural Network:近年来出现了能够有效处理序列数据的external memory network: EMN。简而言之,EMN利用一个memory matrix来存储历史的hidden state。通过正确读取和更新这个memory matrix,EMN可以在许多面向序列的任务上获得更好的性能。遵循这个思想,《End-to-end memory networks》设计了一个端到端的memory-augmented model,它在训练期间需要的监督信息显著减少从而使其更好地适用于real-world setting。最近,研究人员已经成功地将EMN的概念应用于多个领域,如question answering: QA、natural language transduction: NLT、knowledge tracking: KT。通常,
EMN由两个主要组件构成:一个memory matrix用于维护state、一个controller用于操作(包括读取和写入)。更具体而言:对于读取过程,大多数方法采用注意力机制来读取
memory matrix。即,对于输入memory matrix中每个memory slotsimilarityslot的注意力权重为:其中
memory被注意力(attentively)地读出(read out)。对于写入过程,
《Neural turing machines》通过考虑内容和slot location来更新user memory,从而促进(facilitate)memory的所有location。然而,
《Meta-learning with memory-augmented neural networks》提出了一种单纯地content-based的写入策略,称之为least recently used access: LRUA,从而将memory写入到最少使用的memory location、或者最近使用的memory location。
在本文中,我们旨在将
EMN的思想应用于推荐系统,从而更有效地利用用户历史行为。这种应用方式还有待学术界探索。
1.1 模型
在本节中,我们首先介绍我们的通用框架,详细说明如何将
user memory network与协同过滤相结合。然后,我们通过描述通用框架的两个具体实现(即,item-level user memory network和feature-level user memory network)来聚焦于设计memory component,从而从不同的角度审视我们的框架。
1.1.1 通用框架
为了更好地理解,我们首先将广泛使用的矩阵分解 (
matrix factorization: MF)模型重新描述为神经网络。假设有item(item集合为one-hot格式的user ID/ item ID可以作为输入并馈送到架构中,然后look-up layer将这些sparse representation投影到稠密向量中(即user embedding/ item embedding)。假设用户
user embedding为itemembedding为MF模型中likeness score)memory enhanced user embedding:为了在我们的框架中利用用户历史记录,我们从两部分生成一个用户的embedding:一个部分与用户的
memory component有关,该组件对用户以前的记录进行编码(称作memory embedding,记做另一个部分是一个
free vector,用于编码不受用户先前行为影响的内在偏好(intrinsic preference)(称作intrinsic embedding,记做
memory embedding类似于传统的RNN-based方法中的hidden vector。然而,hidden vector盲目地将用户的所有历史记录压缩成一个固定的向量,而在我们的框架中,用户记录通过更具表达能力的结构(个性化的memory matrix这种方式内存消耗大(每个用户分配一个
memory matrix,内存需求为memory slot个数,memory embedding维度)。此外,模型的mini-batch训练也是一个难点。具体而言:
对于用户
memory embeddingitem embedding其中
然后,通过将
memory embeddingintrinsic embeddingfinal user embedding为:其中
其中
我们还测试了逐元素乘法合并、以及向量拼接合并,但是它们的效果都不如加权加法合并。加权加法合并的另一个优点是:我们可以调整权重超参数
memory机制进行推荐的效果,这将在实验部分展示。
预测函数:在进行预测时,我们将
final user embeddingitem embedding其中
《Neural collaborative filtering》中的prediction neural network。在这里,我们选择sigmoid内积训练:我们采用二元交叉熵作为模型优化的损失函数,要最大化的目标函数为:
其中:
ground truth,如果用户item1,否则取值为0。item的集合,item的集合。我们从unobserved的item集合negative item。应该注意的是,非均匀采样策略可能会进一步提高性能,我们将非均匀采样策略留待未来的工作。
在这个等式中,我们通过前两项来最大化我们预测结果的可能性,最后一项对所有模型参数正则化从而避免过拟合。在训练阶段,我们通过随机梯度下降 (
stochastic gradient descent: SGD)来学习模型参数。memory updating:在每次购买行为之后,我们通过以下方式更新user memory matrixdynamic nature):在接下来的内容中,我们将描述个性化的
memory matrixitem-level和feature-level设计
1.1.2 Item-level RUM
在本节中,我们首先通过简单的方式扩展以前的方法来实现我们的思想(如下图
(a))。与现有模型类似,我们将每个item视为一个单元(unit),并建模先前购买的item对下一个item的影响。许多工作表明(《Factorizing personalized markov chains for next-basket recommendation》、《Learning hierarchical representation model for next-basket recommendation》),用户最近的行为可能对当前决策更重要。因此,对于每个用户memory matrixitem的embedding,如下图(a)中的紫色虚线框所示。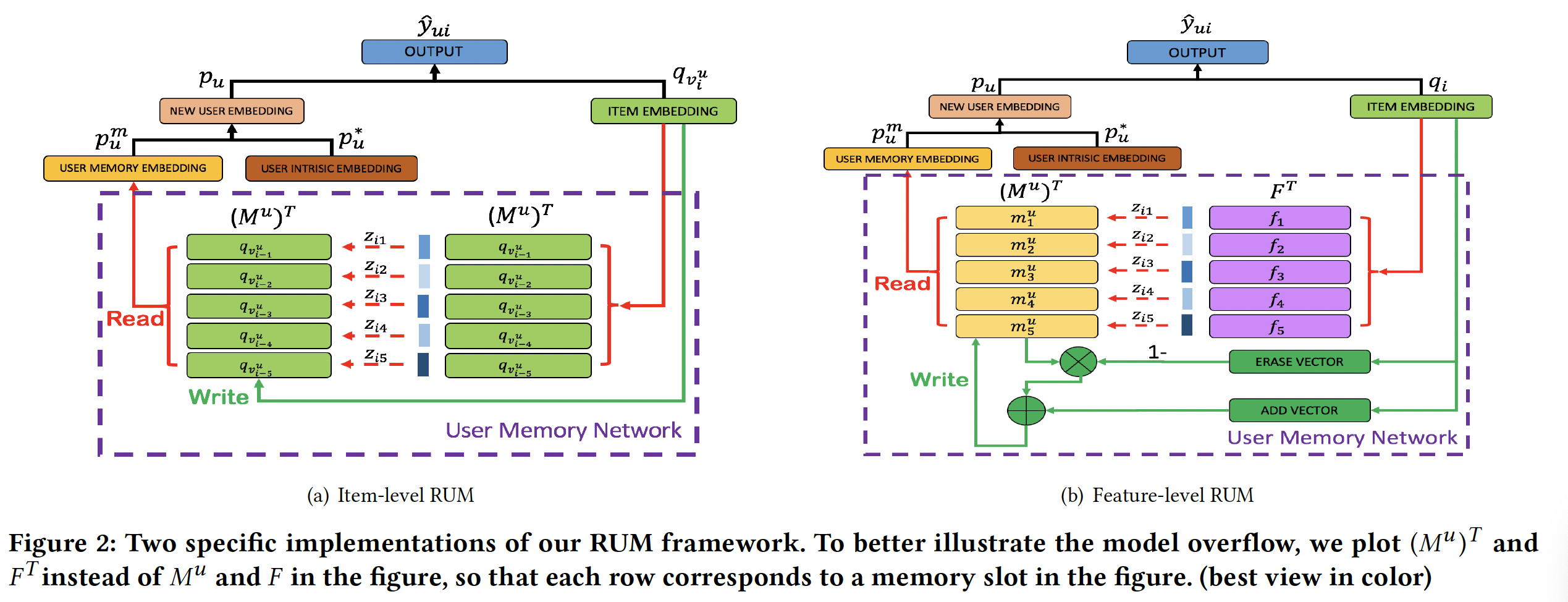
假设用户
item集合定义为:item。令
itemembedding。假设memory matrix有memory slot),即column vector)。我们设计reading操作和writing操作如下:reading操作:直观上看,之前的item可能对当前的item有不同的影响,影响越大的item在final memory embedding中应该越重视。形式上,在我们的模型中,当对user-item pairFPMC类似的方式来计算user memoryitem与当前item其中
strength)超参数。然后我们使用
memory embedding,这为我们提供了一个能力:根据用户历史行为对当前item的影响来访问用户历史行为。即:与之前的模型不同,我们不会在
reading过程中强行合并所有item embedding。相反,我们现将这些item embedding单独存储在item给予更多的关注。这为我们提供了一种更细粒度的方法来利用用户历史记录。writing操作:如前所述,用户最近的行为通常对当前的预测起着更重要的作用。因此,我们采用简单的first-in-first-out: FIFO机制来维护user memory matrixitem。具体而言,用户
memory matrixitem。假设当前item是memory matrix为:memory时,最早的item将被替换,memory未满时,直接添加item而不必替换memory内的任何其它item。
这种做法的思想类似于
DIN。由于DIN。但是,与
DIN相比,这里的size的,因此需要进行序列padding或截断,因此会一定程度上损害性能。
1.1.3 Feature-level RUM
受到经典潜在因子模型(
latent factor model: LFM)推荐的启发,我们进一步探索在feature-level上实现RUM框架。在LFM中,我们假设用户在作出购买决策时可能会考虑一组产品特征(product feature),并且LFM中的每个embedding维度代表了产品域(product domain)中的一个潜在特征,其中所有的潜在特征张成了一个latent representation space。然后,LFM将用户对这些特征的偏好估计为该空间中的向量。在这项工作中,我们使用
memory network的能力来显式地建模这些潜在特征。直观而言,用户对这些特征的偏好应该动态地反映在该用户的购买行为中。例如,如果用户在新购买的iPhone上体验非常好,那么该用户未来可能会继续在品牌(brand)特征上选择苹果的产品。受这些直觉的启发,我们维持用户对
memory matrix中不同特征的偏好。这些特征将被读取从而生成user memory embedding, 并由该用户购买的每个item来写入。更具体而言,我们将我们的方法形式化为一个key-value memory neural network,如下图(b)所示。我们首先设计了一个
global latent feature table: GLFT来存储每个feature的embedding,并且在进行预测时,item将与这个table交互从而识别其相关的特征。对于每个用户,我们利用
user memory matrixGLFT上特征的偏好。基于上述识别的特征,该用户会注意力attentively地合并memory embedding。与
LFM中的全局特征空间一样,这里的global latent feature table在所有用户之间共享,而memory matrix以个性化的方式进行per-user level的维护。最后,我们使用
item embedding更新user memory matrix
形式上,令用户
embedding为itemembedding为global latent feature table为embedding。对于用户memory matrix定义为embedding。reading操作:为了使得读取过程可微,我们采用soft-attention机制来读取user memory matrix。具体而言,在对user-item pairitemglobal latent feature table中每个特征的相关性:其中
strength)超参数。我们也使用
memory matrix中的slot,从而计算该用户的memory embedding:这里的
reading操作和Item-level RUM的reading操作的区别在于注意力权重的生成:Item-level RUM中,Feature-level RUM中,Feature-level RUM的参数更多、模型容量更高。writing操作:受神经图灵机(neural turing machine: NTM) 的启发,在写入user memory matrix擦除:我们首先从
erase vector)sigmoid函数,erase parameter)。给定注意力权重和擦除向量,feature preference memory更新为:其中:
因此:仅当该
location的注意力权重和erase element均为1时,这个memory location才会被重置为零;当该location的注意力权重为零或者erase element为零,那么memory vector保持不变。添加:当擦除操作之后,我们使用一个
add vectorfeature preference memory:其中:
add parameter。
这种
erase-add更新策略允许在学习过程中遗忘和加强user feature preference embedding,并且模型可以通过学习erase parameter和add parameter来自动地决定哪些信号需要减弱、哪些信号需要加强。这种更新方式类似于
RNN,按顺序地馈入RNN之后一个状态而feature-level RUM有feature-level RUM每次更新的是不同的slot,那么一定程度上丢失序列信息。甚至feature-level RUM不知道哪个item是最近购买的,而根据现有的研究表明,最近购买的item是相当重要的。
1.1.4 讨论和分析
为了提供对我们的方法的更多洞察,我们分析了
item-level RUM和feature-level RUM之间的关系。然后通过将其与matrix factorization: MF和factorized personalized Markov chain: FPMC进行比较,我们进一步将我们的方法与以前的方法联系起来。Item-level RUM和Feature-level RUM:一般而言,item-level RUM和feature-level RUM都是下图(c)所示同一框架的特定实现。但是,它们从不同的角度管理用户历史信息。item-level RUM将每个item视为一个单元(unit),并将item embedding直接存储在memory matrix中,其中memory matrix旨在捕获item-to-item的转移模式 (transition pattern)。然而在
feature-level RUM中,历史信息以feature-centered的方式被利用。memory matrix用于存储用户偏好在不同潜在维度上的embedding,并且每个item都被间接用于改变这些embedding。
在实际应用中使用这些模型时,实际上存在
explanation-effectiveness的trade-off:item-level RUM可以明确地告诉我们过去哪些item对于当前决策更重要,这为系统提供了一定的可解释能力。然而,
feature-level RUM在black box中通过更细粒度的建模可以获得更好的性能。
我们将在后的内容讨论更多细节和实验结果。
RUM和MF的关系:当user memory network设置为不可用时(即,user memory embedding设置为全零的向量),RUM将简化为传统的MF。然而,通过启用user memory network,RUM可以从历史行为中收集有价值的信息,这可以提高Top-N推荐任务的性能,如后面的实验所示。RUM和FPMC的关系:RUM和FPMC都利用用户的历史行为来预测当前行为。为了对每个用户建模item-to-item转移模式,FPMC构建张量分解模型,并在Bayesian personalized ranking: BPR准则下进行优化。目标函数如下:其中:
basket,basket中购买item
当应用于序列推荐时,
FPMC中的每个basket仅包含一个item,因此有:其中:
item(即时刻item) 的embedding。为展示我们模型与
FPMC的区别,我们考虑item-level RUM并且仅使用一个memory slot(即,通过将
RUM的user intrinsic embeddingFPMC中的user embeddingRUM的损失函数可以重写为:对比
FPMC与一阶的item-level RUM共享相同的预测函数(即,observed的交互、unobserved的交互:FPMC通过最大化margin来学习模型。RUM分别尝试最大化
实际上,我们也可以使用
Bayesian personalized ranking: BPR来优化RUM,此时,FPMC相当于一个一阶的item-level RUM从而用于序列推荐。基于以上分析,我们可以看出
RUM是一个非常通用的推荐框架。一方面,RUM是许多现有推荐模型的推广。另一方面,RUM可以通过将merge函数、predict函数、以及reading/writing策略修改为其它的形式,从而为我们提供机会来探索其它有前景的模型。未来工作:
通过引入用户评论、产品图像等辅助信息,我们可以将
feature-level RUM中的memory unit与不同的语义对齐,因此我们可以构建一个更可解释的推荐系统。此外,我们的
RUM模型是一个具有灵活泛化能力的框架,因此我们可以研究其它类型的memory network设计(而不仅限于这里的item-level RUM和feature-level RUM),从而使得我们的框架适应不同的应用场景。
13.2 实验
数据集:我们在
Amazon数据集上进行了实验。该数据集包含1996年5月至2014年7月亚马逊的user-product购买行为。我们在四个产品类别上评估我们的模型,包括即时视频 (Instant Video)、乐器(Musical Instrument)、汽车(Automotive)、婴儿护理 (Baby Care)。为了提供序列推荐,我们选择至少有
10条购买记录的用户进行实验,最终数据集的统计数据如下表所示: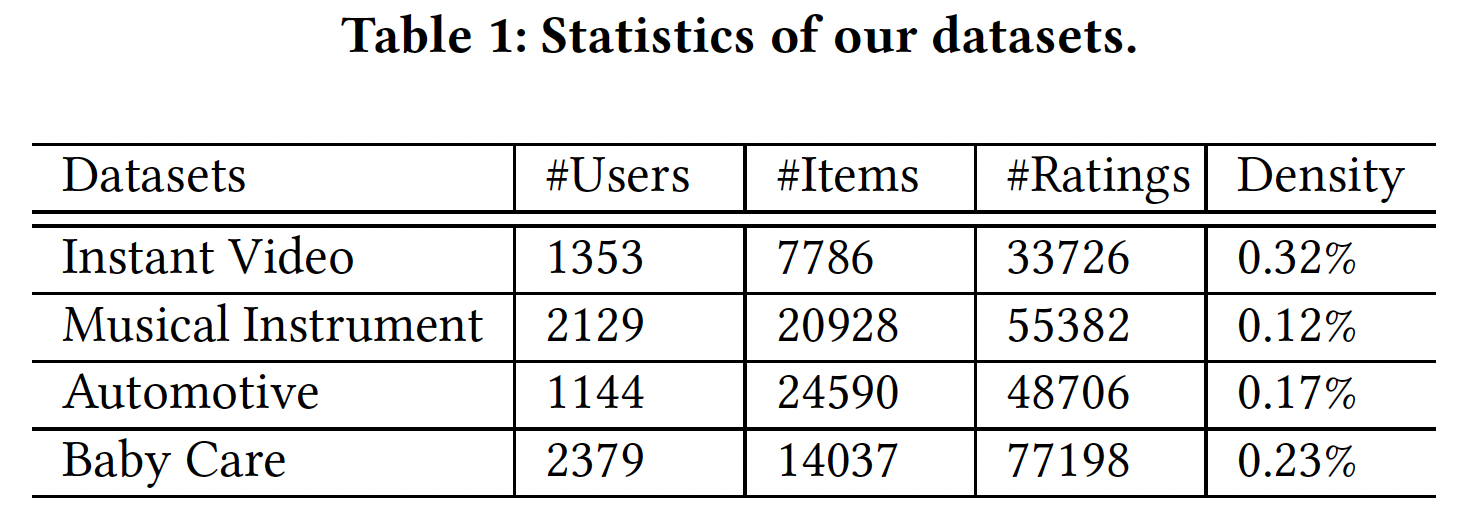
评估指标:对于每个模型,我们定义为用户
item的预测分数(根据预测分数进行降序排列,分数越高排则名越靠前)。假设测试集中用户
item集合为Precision (P), Recall (R), F1-score:我们采用per-user的均值而不是全局均值从而为了更好的可解释性:Hit-ratio(HR):命中率HR给出了可以收到至少一个正确推荐的用户占比:其中:
normalized discounted cumulative gain(NDCG):NDCG通过考虑ground truth item的排名来评估性能:其中:
DCG@N所有可能取值的最大值,此时每个grount-truth都排在非ground-truth之前)。DCG@N是位于推荐列表中的ground-truth收益的加权和,其中收益固定为1,权重为ground-truth的排名。最大的DCG@N需要推荐列表满足两个条件:所有
ground-truth都位于DCG@N中,即累加的项足够多。所有
ground-truth的排名都最低,即
Baseline方法:MostPopular: MP:非个性化的、基于热门item的推荐。其中item的热门程度根据它在数据集中出现的频次来得到。BPR:bayesian personalized ranking,一种流行的top-N推荐方法。我们采用矩阵分解作为BPR的prediction component。FPMC:factorized personalized Markov chains,它是基于马尔科夫链的、SOTA的序列推荐模型之一。在我们的数据集中,每个item都被视为一个basket。DREAM:dynamic recurrent basket model,它是RNN-based的、SOTA的序列推荐方法。
配置:
在实现我们的方法时,模型参数首先根据均匀分布随机初始化,然后通过随机梯度下降
SGD进行更新。SGD的学习率是在{1, 0.1, 0.01, 0.001, 0.0001}的范围内通过网格搜索来确定的。memory slot数量20。merge函数中设置权重超参数对于每个购买的
item(即,positive instance),我们从用户未交互的item中均匀采样一个negative instance。embedding维度{10, 20, 30, 40, 50}范围内网格搜索来确定。正则化系数
{0.1, 0.01, 0.001, 0.0001}范围内网格搜索来确定。在我们的实验中,每个用户的购买记录按照购买时间排序,每个用户的前
70%的item用于训练、剩余的item用于测试。我们为每个用户推荐
5个item,即推荐列表长度
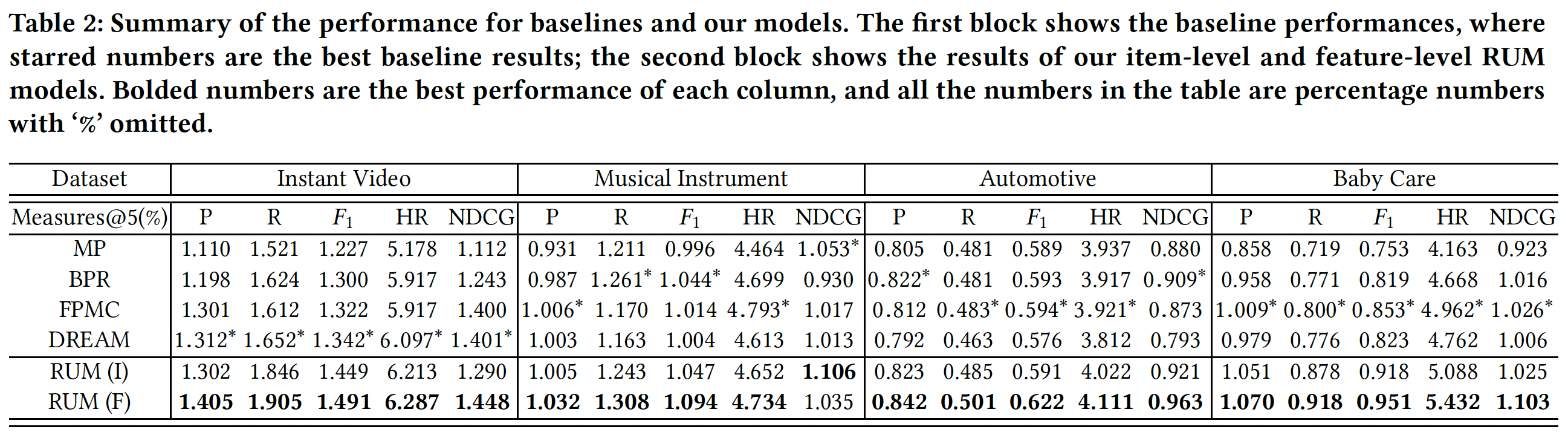
模型整体性能:我们首先研究默认设置(
item-level RUM和feature-level RUM的性能,如下表所示。可以看到:非个性化的
Most Popular方法几乎在所有情况下都给出了最差的性能。由于它没有考虑用户的个性化信息,因此这一观察突出了个性化在推荐任务中的重要性。正如预期的那样,通过单独分析用户并直接优化
ranking-based目标函数,在大多数情况下BPR的性能优于Most Popular。FPMC和DREAM在大多数指标上都可以达到比BPR更好的性能,而这两种方法之间的差异不是很明显。考虑到BPR和FPMC之间的主要区别在于后者以序列方式对用户历史记录进行建模,这一观察结果验证了序列推荐有助于提高推荐性能。有趣的是,
DREAM在instant video上获得了比FPMC更好的性能。DREAM建模用户的multi-step behavior而不是pair-wise behavior,能够更好地捕获用户对视频偏好的长期兴趣。然而,在其它数据集上,
pair-wise的短期影响可能更有助于预测next behavior,但是DREAM通过RNN将之前的所有item均等(equally)地合并为单个hidden vector,这可能会削弱序列推荐的pair-wise信号。这突出了我们动机的重要性,即需要一个精心设计的机制来自动地确定哪些先前的
item对当前兴趣预测很重要。在稠密数据集上,
multi-step behavior可能更重要;在稀疏数据集上,pair-wise behavior可能更重要。而instant video数据集是这四个数据集中最稠密的。令人振奋的是,我们发现在大多数情况下,
item-level RUM或feature-level RUM的性能都优于最佳baseline。这些结果表明了我们提出的序列推荐方法的有效性。这实际上并不惊讶,因为我们模型中的
memory机制和reading/writing设计为建模用户历史记录提供了更好的表达能力。通过在更细粒度的
level上建模item关系,feature-level RUM在大多数指标上都优于item-level RUM。这很直观,因为两个item的功能可能不直接相关,但是它们可能具有一些共同的特征,这些特征可能会影响用户的决策,例如它们都属于同一个品牌。
权重超参数
memory是否有助于、以及如何帮助序列推荐。为此,我们分析权重超参数merge函数中memory embedding相对于intrinsic embedding的重要性。具体而言,我们通过在
0 ~ 1的范围内以0.1的步长调整F1@5上的性能。结果如下图所示。可以看到:当
memory component不可用(即feature-level RUM和item-level RUM都简化到相同的模型并共享相同的性能。在这种情况下,它们都在所有数据集中给出了不利的结果(但不一定是最差的)。加入了
memory network之后,模型性能大幅提升,并且在然而,当
memory embedding的权重继续上升时,模型性能下降。这一观察在四个数据集上是一致的。
这些结果表明:考虑用户历史行为记录的序列影响(
sequential influence)确实有助于提供更好的推荐,但是过分关注这个最近购买信号(recent purchase signal)可能会削弱用户的内在偏好(intrinsic preference)。这些结果进一步验证了学术界经常观察到的现象:短期用户偏好和长期用户偏好对于个性化推荐都很重要。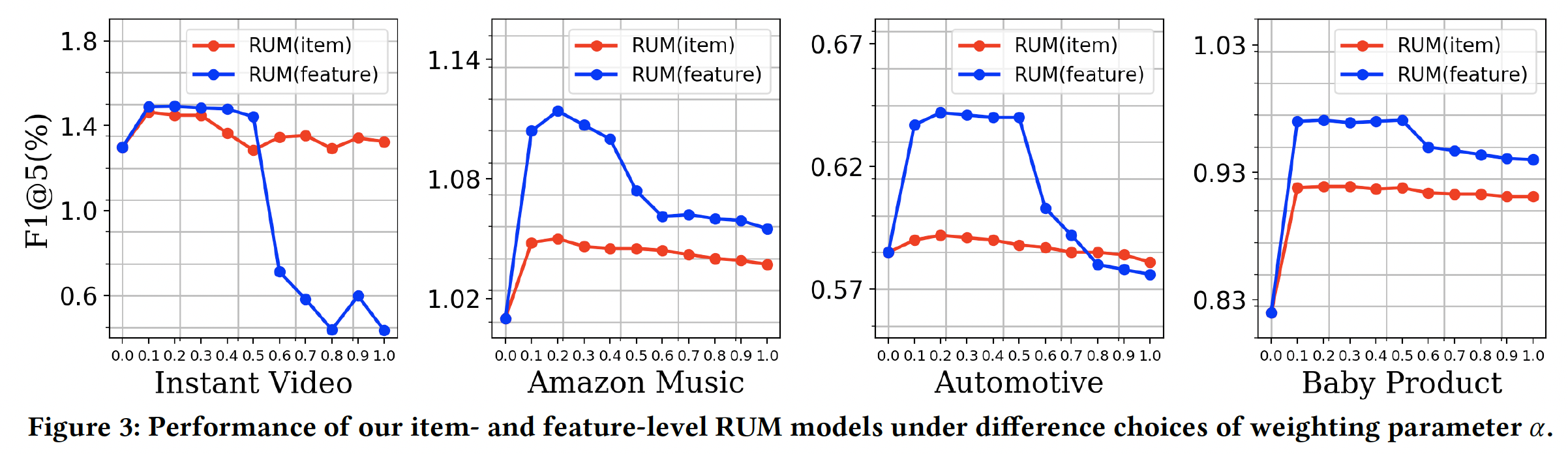
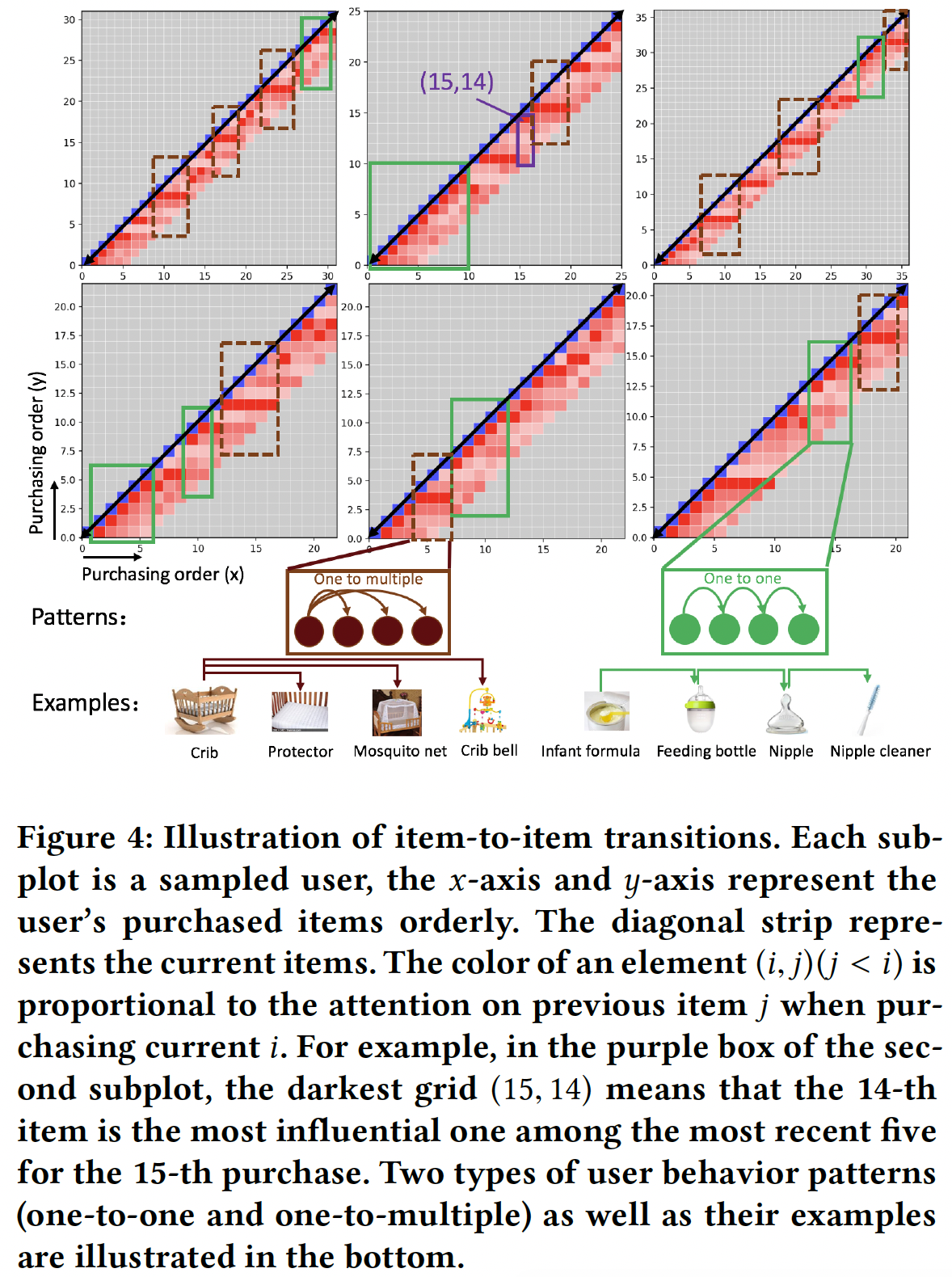
Item-level RUM中的AttentionWeights的直觉:为了说明item-to-item转移的直觉(intuition),我们在下图展示了一些示例用户(每个用户一个子图),这些用户是从Baby Care数据集上带5个memory slot的item-level RUM(即,这里只有
6个case,所以一些结论不具备说服力?最好给出一批case的统计结果。当用户购买第
item时(对应于x轴,用蓝色小网格表示),我们在该用户的子图中绘制一个长度为5的列向量(如上面中间子图中,(15,14)对应处的、高度为5的细长条)。这个列向量对应于y轴的位置item上的注意力权重item的注意力越高。当用户继续购买item时,最近购买的5个item被保留在memory中,因此列向量填充的位置从左下角到右上角。基于这幅图,我们得到以下有趣的观察:通常,靠近对角线的网格的颜色较深。这意味着历史最有影响力的
item通常是距离当前行为附近的item。这进一步证实了item-level RUM背后的假设,即:最近的行为对当前的决策更为重要。然而,最有影响力的
item的具体位置并不总是最近的,这可以解释为什么FPMC仅通过建模pair-wise相邻行为并未取得良好的性能。此外,我们发现了两种有趣的用户行为模式:
某些行为序列是由最近行为连续触发的(用绿色实线框来表示),这符合
FPMC的假设。我们称之为one-to-one的行为模式。一个真实的例子是用户购买了一些婴儿配方奶粉,然后购买了奶瓶,这导致该用户接下来购买了奶嘴,而这些奶嘴导致该用户进一步购买了奶嘴清洁器。
某些行为序列中,多个行为主要受到相同的历史行为的影响(用棕色虚线框来表示),而这多个行为之间的关系并不那么重要。我们称之为
one-to-multiple的行为模式。一个真实的例子是用户购买了婴儿床,然后该用户为婴儿床购买了防水床垫保护套、蚊帐,然后又购买了床铃来装饰婴儿床。在这种情况下,我们的带注意力机制的
RUM模型可以根据大规模的用户购买记录自动学习先前item的重要性。这优于假设相邻影响(adjacent influence)的FPMC,也优于合并所有先前行为的RNN。
基于这些发现的模式,
item-level RUM可以从序列行为的角度解释推荐系统,这与以前通常利用辅助信息(如用户文本评论)进行解释的方法不同。