一、SASRec [2018]
序列推荐系统的目标是将用户行为的个性化模型(
personalized model)(基于历史活动)与基于用户最近行为的context概念相结合。从序列动态 (sequential dynamic)中捕获有用的模式(pattern)具有挑战性,主要是因为输入空间的维度随着作为context的历史行为的数量呈指数增长。因此,序列推荐的研究主要关注如何简洁地捕获这些高阶动态(high-order dynamic)。马尔科夫链(
Markov Chains: MC)是一个典型的例子,它假设next action仅依赖于前一个(或者前几个)行为,并已成功用于刻画短程(short-range)的item转移(transition)从而用于推荐。另一项工作使用循环神经网络(RNN)通过隐状态summarize所有先前的行为,从而用于预测next action。这两种方法虽然在特定情况下很强大,但是在某种程度上仅限于某些类型的数据。MC-based方法通过作出强有力的简化假设,在高度稀疏的setting中表现良好,但可能无法捕获更复杂场景的复杂动态(intricate dynamic)。相反,
RNN虽然具有表达能力,但是需要大量数据(特别是稠密数据)才能超越更简单的baseline。
最近,一种新的序列模型
Transfomer在机器翻译任务中实现了SOTA的性能和效率。与现有的使用卷积模块或循环模块的序列模型不同,Transformer完全基于一种叫做self-attention的注意力机制,该机制非常高效并且能够揭示句子中单词之间的句法模式(syntactic pattern)和语义模式(semantic pattern)。受到这种方法的启发,论文
《Self-Attentive Sequential Recommendation》寻求将自self-attention机制应用于序列推荐问题。论文希望这个想法可以解决上述两个问题:一方面能够从过去的所有行为中提取上下文(类似于RNN),但另一方面能够仅根据少量行为来构建预测(类似于MC)。具体而言,论文构建了一个Self-Attention based Sequential Recommendation: SASRec模型, 该模型在每个time step自适应地为先前的item分配权重(如下图所示)。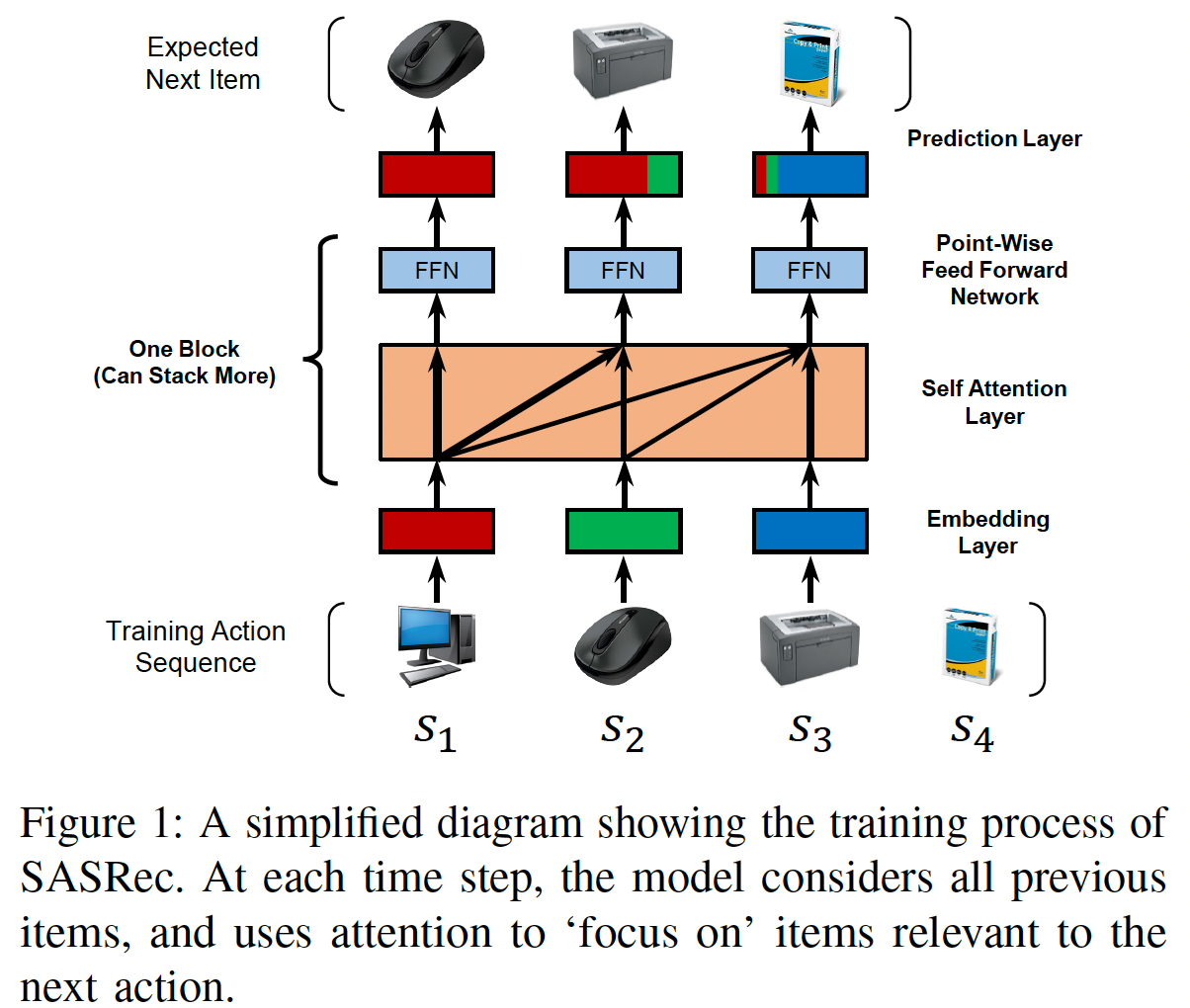
所提出的模型在几个
benchmark数据集上显著优于SOTA的、MC/CNN/RNN-based的序列推荐方法。具体而言,论文将模型性能作为数据集稀疏性的函数来进行检查,其中模型性能与前面描述的pattern密切相关。由于self-attention机制,SASRec倾向于在稠密数据集上考虑长期依赖,而在稀疏数据集上关注最近的行为。而这被证明对于自适应地处理不同密度(density)的数据集至关重要。此外,
SASRec的核心组件(即self-attention block)适用于并行加速,从而使得模型比CNN/RNN-based的替代方案快一个数量级。此外,论文分析了SASRec的复杂性和可扩展性,进行了全面的消融研究以展示关键组件的效果,并将注意力权重可视化从而定性地揭示模型的行为。相关工作:有一些工作与我们密切相关。在讨论序列推荐之前,我们首先讨论通用推荐(
general recommendation),然后是时间推荐(temporal recommendation)。最后我们介绍了注意力机制,尤其是我们模型核心的self-attention模块。通用推荐(
General Recommendation):推荐系统专注于根据历史反馈(如点击、购买、喜欢)来建模用户对
item的偏好。用户反馈可以是显式的(如评分)或隐式的(如点击、购买、评论)。由于解释non-observed数据的模糊性(ambiguity),建模隐式反馈可能具有挑战。为了解决这个问题,
《Collaborative filtering for implicit feedback datasets》提出了point-wise方法、《BPR: bayesian personalized ranking from implicit feedback》提出了pairwise方法来解决这些挑战。Matrix Factorization: MF方法试图发现潜在维度来表示用户的偏好和item的属性,并通过user embedding和item embedding之间的内积来估计交互。此外,另一个方向的工作基于
Item Similarity Models: ISM,并没有显式地使用潜在因子建模每个用户(如FISM)。他们学习一个item-to-item的相似度矩阵,然后用户对item的偏好是通过该item与该用户历史交互item之间的相似性来衡量。最近,由于深度学习在相关问题上的成功,深度学习技术已被引入推荐领域。一个方向的工作旨在使用神经网络来抽取
item特征(如图像特征、文本特征等等)从而进行content-aware推荐。另一个方向的工作旨在取代传统的
MF。例如NeuMF通过多层感知机来估计用户偏好,而AutoRec使用自编码器来预测评分。
时间推荐(
Temporal Recommendation):追溯到Netflix Prize时代,时间推荐通过显式建模用户活动的时间戳,从而在各种任务上显示出强大的性能。TimeSVD++通过将时间分成若干区间(segment),并在每个区间中分别对用户和item进行建模,从而取得了很好的效果。 此类模型对于理解那些表现出显著时间漂移(temporal drift)的数据集(例如,过去10年电影偏好如何变化、用户在下午4点访问什么样的企业)至关重要。序列推荐(或
next-item推荐)与此不同,因为序列推荐仅考虑操作的顺序,并且建模与时间无关的顺序模式(sequential pattern)。本质上,序列模型试图根据用户最近的活动建模用户行为的context,而不是考虑temporal pattern本身。序列推荐(
Sequential Recommendation):许多序列推荐系统试图建模item-item转移矩阵,并将其作为捕获连续item之间的序列模式的一种手段。例如,FPMC融合了一个MF项、以及一个item-item项从而分别捕获长期偏好和短期转移。本质上,被捕获的短期转移是一阶马尔科夫链(Markov Chain: MC),而高阶马尔科夫链假设next action与之前的几个行为有关。由于最近一个访问的item通常是影响用户next action的最关键因素(本质上是提供context),因此基于一阶马尔科夫链的方法表现出强大的性能,尤其是在稀疏数据集上。还有一些方法采用考虑更多先前
item的高阶马尔科夫链。具体而言,Convolutional Sequence Embedding: Caser是一种CNN-based方法,将item的embedding矩阵视为image,并运用卷积运算来抽取转移(transition)。除了基于马尔科夫链的方法之外,另一个方向的工作采用
RNN来建模用户序列。利用GRU4Rec使用GRU建模点击序列从而用于session-based推荐,而《Recurrent neural networks with top-k gains for session-based recommendation》改进了GRU4Rec并进一步提高了Top-N推荐的性能。在每个time step,RNN将last step的状态和当前行为作为输入。尽管人们已经提出了诸如session parallelism之类的技术来提高效率,但是step之间的依赖关系使得RNN的效率更低。注意力机制:注意力机制已被证明在各种任务中是有效的。本质上,这种机制背后的思想是:序列输出
sequential output中的每个输出都依赖于某些输入的relevant部分,而这些输入部分是模型应该持续关注的。 基于注意力的方法的额外好处是,方法更容易解释。最近,注意力机制已被引入推荐系统,例如Attentional Factorization Machine: AFM学习每个特征交互对于content-aware推荐的重要性。然而,上面使用的注意力技术本质上是原始模型的附加组件 (
additional component),如attention+RNN、attention+FM等等。最近,一种纯粹基于注意力的sequence-to-sequence,叫做Transfomer,在之前RNN/CNN-based方法主导的机器翻译任务上实现了SOTA的性能和效率。Transformer模型在很大程度上依赖于所提出的self-attention模块来捕获句子中的复杂结构,并检索relevant word(在source language)从而生成next word(在target language)。受
Transformer的启发,我们试图建议一个基于self-attention方法的、新的序列推荐模型,然而序列推荐问题与机器翻译问题有很大不同因此需要专门设计的模型。
1.1 模型
令用户集合为
item集合为setting下,给定用户next item。在训练过程中,在time stepitem来预测next item(即,第item)。如下图所示,可以方便地将模型的输入视为
shifted版本:embedding layer、若干个self-attention block、以及一个prediction layer来构建序列推荐模型。我们还分析了它的复杂性,并进一步讨论了SASRec与相关模型的不同之处。
1.1.1 Embedding Layer
我们将训练序列
如果训练序列长度超过
如果训练序列长度小于
padding item直到序列长度为注意,训练序列按照发生时间从远到近的顺序排列,因此
padding item填充在左侧(代表最远时刻)。
对于每个
itemembedding向量embedding维度。所有item的embedding向量构成了embedding矩阵itemembedding向量。对于序列
itemembedding向量postion的item的embedding。序列input embedding matrix记做positionitem的embedding,并且对于padding item采用常数Positional Embedding:我们将在后面章节看到,由于self-attention模型不包含任何循环模块或卷积模块,因此它对于先前item的position是无感知的。因此,我们将一个可学习的position embedding矩阵input embedding中:其中:
position的position embedding,它是我们还尝试了
《Attention is all you need》中使用的固定的position embedding,单发现这在我们的case中导致性能更差。我们在实验中定量和定性地分析了position embedding的影响。
1.1.2 Self-Attention Block
《Attention is all you need》中定义的scaled dot-product attention为:其中:
query矩阵,key矩阵,value矩阵。item数量(每一行代表一个item),query/key embedding的维度,value embedding的维度,并且直观而言,
attention layer计算所有value的加权和,其中queryvaluequerykeyinteraction)有关。比例因子softmax的计算出现数值不稳定从而影响效果。也可以用超参数
Self-Attention layer:在机器翻译等NLP任务中,注意力机制通常采用《Attention is all you need》提出了一个self-attention方法,它使用相同的对象作为query、key、以及value。在我们的case中,self-attention操作将embeddingattention layer:其中:
self-attention的representation,第representation(对应于time step
引入投影可以使得模型更加灵活。例如,模型可以学习非对称交互(
asymmetric interaction),即<query i, key j>和<query j, key i>可以有不同的交互。因果关系(
Causality):由于序列的性质,模型在预测第item时,只能考虑开始的前item。然而,self-attention layer的第item的embedding的输入信息,这不符合真实的情况。因此,我们通过禁止attention。即:
key的时刻不能超过query的时刻。Point-Wise Feed-Forward Network:尽管self-attention能够使用自适应权重聚合所有先前item的embedding,但是它仍然是一个线性模型。为了赋予模型非线性并考虑不同潜在维度之间的交互,我们应用一个point-wise的、双层的feed-forward network: FFN到所有的FFN是跨time step共享权重的:其中:
注意,
注意,这里只有一个
ReLU,为什么?个人猜测是为了方便后面直接接入output layer。
1.1.3 Stacking Self-Attention Blocks
在第一层
self-attention block之后,item的embedding,即self-attention block来学习更复杂的item transition可能是有益的。具体而言,我们堆叠self-attention block(即,一个self-attention layer和一个FFN),并且第block(然而,当网络更深时,有几个问题变得更加严重:
增加的模型容量导致模型过拟合。
训练过程变得不稳定(由于梯度消失等)。
具有更多参数的模型通常需要更多的训练时间。
受到
《Attention is all you need》的启发,我们执行以下操作来缓解这些问题:其中:
self attention layer或FFN。也就是说,对于
block中的每个layer我们在输入到
layer normalization。我们对
dropout。此外,我们将输入
我们接下来依次介绍这些操作。
残差连接(
Residual Connections):在某些情况下,多层神经网络已经证明了分层(hierarchically)地学习有意义特征的能力。然而,在提出残差网络之前,简单地添加更多层并不容易得到更好的性能。残差网络背后的核心思想是:通过残差连接将low-layer特征传播到更高的层。因此,如果low-layer特征有用,模型可以轻松地将它们传播到最后一层。同样地,我们假设残差连接在我们的
case中也很有用。例如,现有的序列推荐方法表明,最近一个访问的item对预测next item起着关键作用。然而,经过几个self-attention block之后,最近一个访问的item的embedding与之前的所有item纠缠在一起。添加残差连接从而将最近一个访问的item的embedding传播到最后一层将使模型更容易利用low-level信息。假设在
time stepnext item,那么self attention layer的残差连接为:这里有一个细节:是采用
position embedding)、还是采用position embedding)?论文并未提及。这可以通过实验来验证。Layer Normalization:layer normalization用于跨特征对输入进行归一化(即,零均值和单位方差),这有利于稳定和加速神经网络的训练。和batch normalization不同,layer normalization中使用的统计数据独立于同一个batch中的其它样本。具体而言,假设输入是包含了一个样本中所有特征的向量
layer normalization定义为:其中:
Hadamard积)。
Dropout:为了缓解深度神经网络中的过拟合问题,Dropout正则化技术已被证明在各种神经网络架构中是有效的。Dropout的思想很简单:在训练期间以概率turn off神经元,并在测试期间使用所有神经元。除了在
self attention layer或FFN上应用dropout之外,我们还在embeddingdropout layer。
1.1.4 Prediction Layer
在
self-attention block之后,给定开始的item我们基于next item。具体而言,我们采用一个MF layer来预测与itemrelevance):其中:
item的条件下,itemnext item的relevance,也称作交互分(interaction score)。item embedding矩阵。
因此,一个更高的
itemnext item。我们根据Shared Item Embedding:为了降低模型大小并缓解过拟合,我们考虑在MF layer中使用item embedding注意:
使用同一套
item embedding的一个潜在问题是:它们的内积不能表示非对称的item转移,例如itemitemFPMC这样的方法倾向于使用异质(heterogeneous)的item embedding(即,然而,我们的模型没有这个问题,因为它学习了非线性变换。例如,
FFN可以通过同一套item embedding轻松实现不对称:embedding显著提高了我们模型的性能。Explicit User Modeling:为了提供个性化推荐,现有方法通常采用以下两种方法之一:学习一个显式的
user embedding从而表达用户的偏好(如MF、FPMC、Caser)。考虑用户之前的行为,并从之前访问的
item的embedding中导出一个隐式的user embedding(如FSIM、Fossil、GRU4Rec)。
我们的方法属于后者,因为我们通过考虑用户的所有行为来生成
embeddinguser embedding,例如:其中
user embedding矩阵。然而,我们根据经验发现添加显式的
user embedding并不能提高性能(可能是因为模型已经考虑了所有用户的行为)。
1.1.5 Network Training
回忆一下我们通过截断或填充从而将每个用户行为序列(排除最后一个行为)
output:其中
<pad>表示padding item。我们的模型以序列
next item)。我们采用二元交叉熵损失作为目标函数:其中:
session所组成的集合。注意,我们忽略当
上式本质是
softmax交叉熵损失的负采样版本,它是pointwise loss。我们也可以考虑pairwise loss。网络通过
Adam优化器进行优化。在每个epoch中,我们为每个序列中的每个time step随机生成一个negative item
1.1.6 复杂度分析
空间复杂度:我们模型中待学习的参数来自
embedding,以及self-attention layer、FFN、layer normalization中的参数,参数的总数为FPMC的时间复杂度:我们模型的计算复杂度主要来自于
self-attention layer和FFN,即self-attention layer的self-attention layer中的计算是完全可并行的,这适合GPU加速。相反,RNN-based方法(如GRU4Rec)依赖于time step(即,time steptime step我们经验性地发现我们的方法比采用
GPU的RNN/CNN-based方法快十倍以上(结果类似于《Attention is all you need》中机器翻译任务的结果),并且最大长度benchmark数据集,在测试阶段,对于每个用户,在计算
embeddingMF方法相同。评估每个item的计算复杂度为处理长的序列:尽管我们的实验从经验上验证了我们方法的效率,但最终它无法扩展到非常长的序列。我们有望在未来调查一些方向:
使用
restricted self-attention(《A time-restricted self-attention layer for asr》),它仅关注最近的行为而不是所有行为,并且可以在更高的layer考虑远距离行为distant action。如
《Personalized top-n sequential recommendation via convolutional sequence embedding》中那样将长序列分段 。
未来工作:
结合丰富的上下文信息(如停留时长、行为类型
action type、location、设备等等)来扩展模型。通过这些上下文信息,我们不仅知道行为序列中每个行为作用的
item,还知道发生该行为的上下文。研究处理非常长的序列。
1.1.7 讨论
我们发现
SASRec可以视为某些经典协同过滤模型的推广(generalization)。我们还在概念上讨论了我们的方法和现有方法如何处理序列建模。SASRec可以简化为一些现有模型:Factorized Markov Chains: FMC:FMC分解一阶的item转移矩阵,并且依赖于最近的一个itemnext item如果我们将
self-attention block设为零、使用非共享的item embedding、并且移除position embedding,SASRec将简化为FMC。此外,
SASRec还与Factorized Personalized Markov Chains: FPMC密切相关,后者融合MF和FMC从而分别捕获用户偏好和短期动态:其中:
遵从上面类似于
FMC的简化操作,并添加显式的user embedding(通过向量拼接),SASRec等效于FPMC。Factorized Item Similarity Models: FISM:FISM通过考虑itemitem之间的相似性来估计对item如果我们使用一个
self-attention layer(不包含FFN)、在item上设置均匀的注意力权重(即item embedding、并移除position embeddnig,则SASRec将简化为FISM。因此,我们的模型可以被视为用于next item推荐的自适应的、分层的、序列的item similarity model。
MC-based推荐:马尔科夫链(Markov Chains: MC)可以有效地捕获局部序列模式(local sequential pattern),它假设next item仅依赖于前面的item。现有的MC-based的序列推荐方法要么依赖于一阶马尔科夫链(如FPMC, HRM, TransRec)、要么依赖于高阶马尔科夫链(如Fossil, Vista, Caser)。基于一阶马尔科夫链方法往往在稀疏数据集上表现最好。相比之下,基于高阶马尔科夫链的方法有两个限制:需要在训练之前指定马尔科夫链的阶次
效率和效果无法很好地随阶次
scale,因此
我们的方法解决了第一个问题,因为
SASRec可以自适应地关注相关的前面的item(如,在稀疏数据集上仅关注最近一个item,以及在稠密数据集上关注更多的item)。此外,对于第二个问题,我们的模型建模了前面
item,并且RNN-based推荐:另一个方向的工作使用RNN来建模用户行为序列。RNN通常用于建模序列,但是最近的研究表明:CNN和self-attention在某些序列的setting中表现得比RNN更强。我们的
self-attention based模型可以从item similarity model中推导出来,这是用于推荐的序列建模的合理替代方案。对于RNN,除了并行计算效率低下外,它们的最大路径长度(从输入节点到相关的输出节点)为long-range dependency)。
1.2 实验
我们进行实验并回答以下几个问题:
RQ1:SASRec是否超越了SOTA方法(包括CNN/RNN-based方法)?RQ2:SASRec架构中各种组件的影响是什么?RQ3:SASRec的训练效率和可扩展性(关于n的)如何?RQ4:注意力权重是否能够学到与position相关的、或者与item属性相关的有意义的pattern?
数据集:我们在来自现实世界应用程序的四个数据集上评估我们的方法。数据集在领域(
domain)、平台(platform)、稀疏性(sparsity)方面差异很大:Amazon:来自于Amazon.com的数据集,其中Amazon上的top-level产品类别被视为单独的数据集。我们考虑两个类别,美妆(Beauty) 、游戏(Games)。该数据集以高度的稀疏性和可变性(variability)而著称。Steam:来自于一个大型在线视频游戏分发平台Steam。数据集包含2567538名用户、15474款游戏、7793069条英文评论,时间跨度从2010年10月到2018年1月。该数据集还包含可能对未来工作有用的丰富信息,如用户游戏时长(小时)、游戏定价信息、媒体评分(对游戏的评分)、游戏类别 (category)、游戏开发者(developer)等等。MovieLens:用于评估协同过滤算法的、广泛使用的benchmark数据集。我们使用包含100万用户评分的版本MovieLens-1M。
我们遵循与
《Factorizing personalized markov chains for next-basket recommendation 》、《Translation-based recommendation》、《Fusing similarity models with markov chains for sparse sequential recommendation》相同的预处理程序:对于所有数据集,我们将评论或评分的存在视为隐式反馈(即,用户和
item的交互),并使用时间戳来确定行为的顺序。对于评分,如果太低是不是要移除?否则高分和低分没有差异。
我们丢弃频次低于
5的用户、以及频次低于5的item。我们将每个用户
这个和
GRU4Rec的不同。在GRU4Rec中,仅在用户之间完整的session划分数据集(即,user-level),而不对session内部进行拆分(即,session-level)。区别在于:user-level的划分:测试用户是全新的,相当于冷启动cold-start。session-level的划分:测试用户不是全新的,已经在训练期间见过用户前面的
数据集的统计特性参考下表。我们看到:两个
Amazon数据集的actions per user和actions per item更少,Steam的actions per item更高,而MovieLens-1m是最稠密的数据集。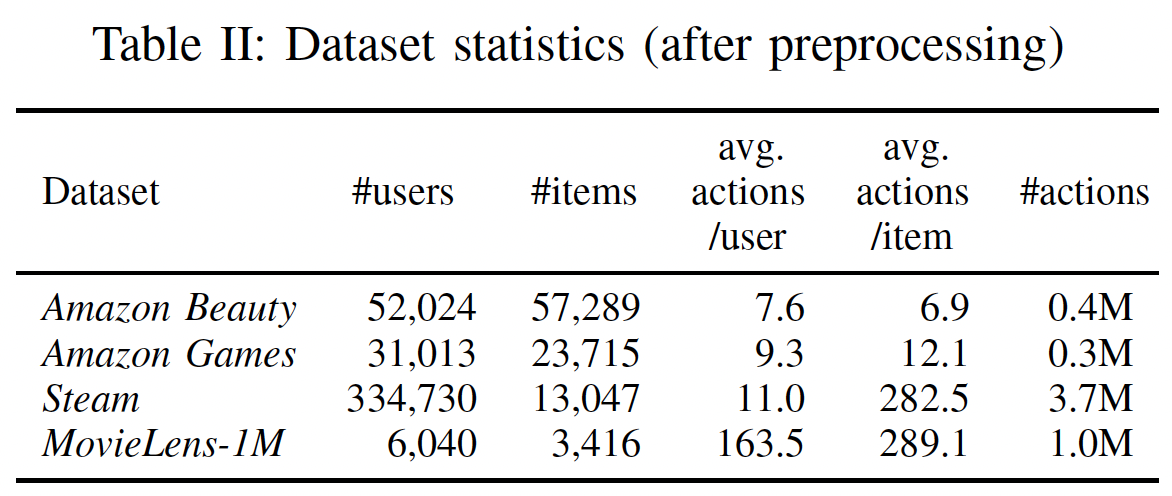
baseline方法:我们考虑三组baseline。第一组
baseline仅考虑用户反馈而不考虑行为顺序的通用推荐方法(general recommendation method):PopRec:这是一个简单的baseline,根据item的热门程度(即数据集中的频次)对item进行排名。Bayesian Personalized Ranking: BPR:是一种从隐式反馈中学习个性化排名的经典方法。biased的矩阵分解模型作为底层的推荐器(recommender)。
第二组
baseline包含基于一阶马尔科夫链的序列推荐方法,它考虑最近一个访问的item:Factorized Markov Chains: FMC:一阶马尔科夫链方法。FMC使用两个item embedding来分解item转移矩阵,并根据最近一个访问的item生成推荐。Factorized Personalized Markov Chains: FPMC:FPMC组合了矩阵分解和分解的一阶马尔科夫链,从而捕获了用户的长期偏好以及item-to-item的转移。Translation-based Recommendation: TransRec:一种SOTA的一阶序列推荐方法,它将每个用户建模为一个翻译向量(translation vector)从而捕获从current item到next item的转移。
最后一组
baseline包含基于深度学习的序列推荐方法,这些方法考虑了最近访问的一些item或者所有访问的item:GRU4Rec:一种开创性的、使用RNN来建模用户行为序列的session-based推荐方法。我们将每个用户的反馈序列视为一个session。一个用户只有一个
session。理论上最好进行时间间隔的拆分,将用户行为序列基于时间间隔拆分为多个session,使得每个session集中体现用户的某个意图。GRU4Rec+:GRU4Rec的改进版本(《Recurrent neural networks with top-k gains for session-based recommendations》),它采用不同的损失函数和采样策略,并在Top-N推荐上显示出显著的性能提升。Convolutional Sequence Embeddings: Caser:最近提出的一种CNN-based方法,它通过对item的embedding矩阵应用卷积运算来捕获高阶马尔科夫链,并实现了SOTA的序列推荐性能。
由于其它序列推荐方法(如
PRME, HRM, Fossil)在类似数据集上的性能逊色于上述baseline,因此我们不考虑与它们进行比较。我们也不包含TimeSVD++, RRN等时间推荐方法(temporal recommendation method),因为它们的setting与我们这里考虑的不同。配置:
为了公平地比较,我们使用带
Adam优化器的TemsorFlow来实现BPR, FMC, TransRec。对于GRU4Rec, GRU4Rec++, Caser,我们使用相应作者提供的代码。对于除了
PopRec之外所有方法,我们从{10, 20, 30, 40, 50}中考虑潜在维度对于
BPR, FMC, FPMC, TransRec,我们考虑L2正则化并且正则化系数从{0.0001, 0.001, 0.01, 0.1, 1}之间选择。所有其它超参数和初始化策略都是对应方法的作者所建议的。我们使用验证集调优超参数,如果验证集性能在
20个epoch内没有提高,那么终止训练。
SASRec实现细节:对于默认版本的
SASRec中的架构,我们使用两个self-attention block(positional embedding。embedding layer和prediction layer中的item embedding是共享的。我们使用
TensorFlow实现了SASRec。优化器是Adam,学习率为0.001,batch size = 128。MovieLens-1m的dropout rate = 0.2,而其它三个数据集由于稀疏性因此dropout rate = 0.5。数据集越稀疏所以
dropout rate越大?可能需要进行超参数调优来观察实验效果。MovieLens-1m的最大序列长度
我们在后面检查
SASRec的不同变体以及不同超参数的性能。SASRec的代码公布在https://github.com/kang205/SASRec。评估指标:我们使用两个常见的
Top-N指标Hit Rate@10, NDCG@10来评估推荐性能。Hit@10计算了ground-truth的next item出现在推荐列表的top 10个item比例(分母为推荐列表的个数,即推荐结果中有多少是命中的)。注意,由于我们对每个用户仅有一个
test item,因此Hit@10相当于Recall@10,并且与Precision@10成正比(Precision@10还要除以推荐列表长度,这里是10)。而
NDCG@10是一个position-aware的指标,它在排名靠前的位置分配更大的权重。
为了避免对所有
user-item pair进行大量的计算,我们对每个用户随机采样100个negative item,并将这些negative item与ground-truth item进行排名。我们根据这101个item的排名来评估Hit@10和NDCG@10指标。
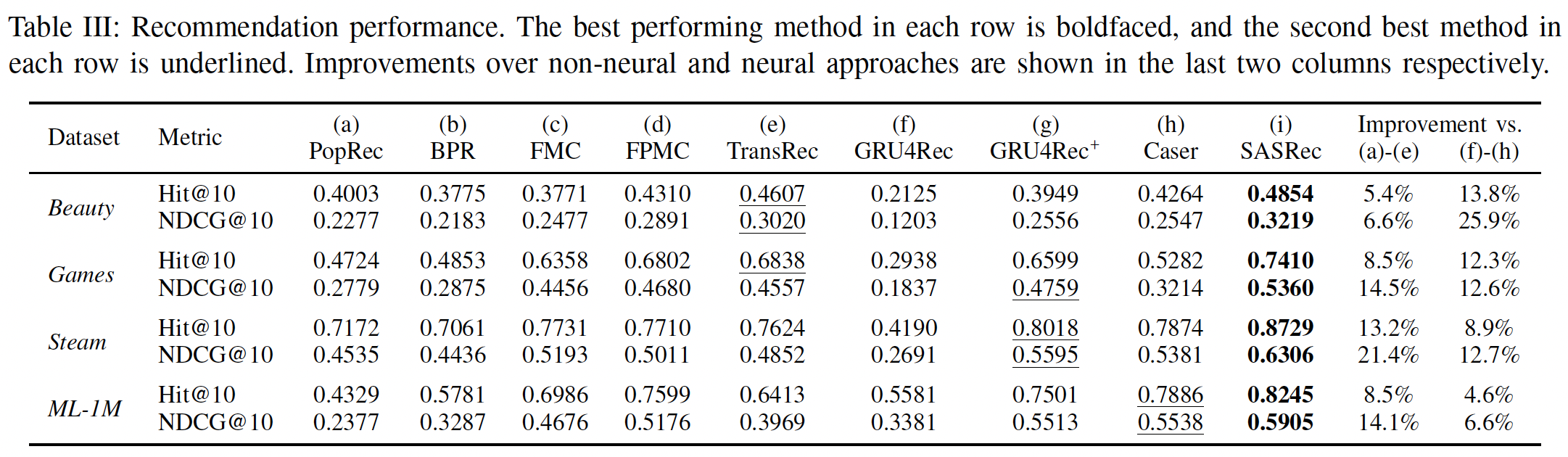
1.2.1 不同方法结果比较
下表展示了所有方法在四个数据集上的推荐性能(用于回答问题
RQ1)。考虑排除
SASRec以外的其它方法在所有数据集上的表现,我们发现一种通用模式,即:non-neural方法((a) ~ (e))在稀疏数据集上表现更好,而神经网络方法((f) ~ (h))在稠密数据集上表现更好。这可能是由于神经网络方法具有更多参数来捕获高阶转移(
high order transition)(即,它们具有表达能力但是容易过拟合),而精心设计但更简单的模型在高度稀疏的setting中更有效。我们的方法
SASRec在稀疏数据集和稠密数据集上都优于所有baseline,并且相对于最强的baseline在Hit Rate上平均提升6.9%、在NDCG上平均提升9.6%。一个可能的原因是我们的模型可以自适应地关注不同数据集上不同范围内的
item(例如,在稀疏数据集上仅关注前一个item,在稠密数据集上关注更多的item)。我们在后面内容进一步分析了这种行为。
在下图中,我们还通过展示
10到50的变化时所有方法的NDCG@10指标,从而分析关键超参数SASRec在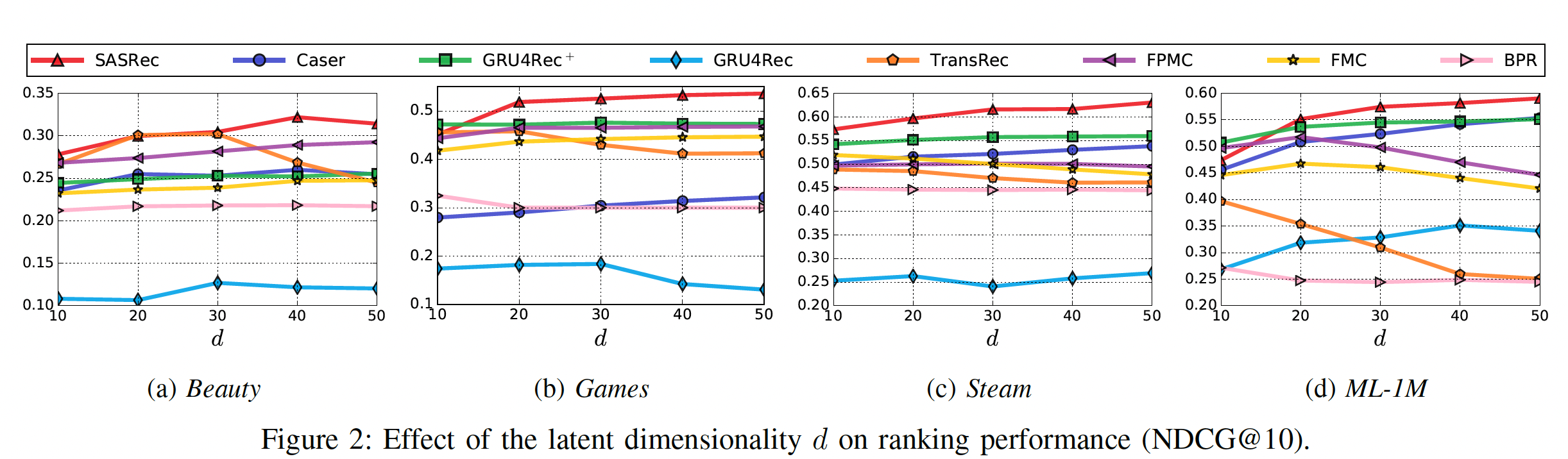
1.2.2 消融研究
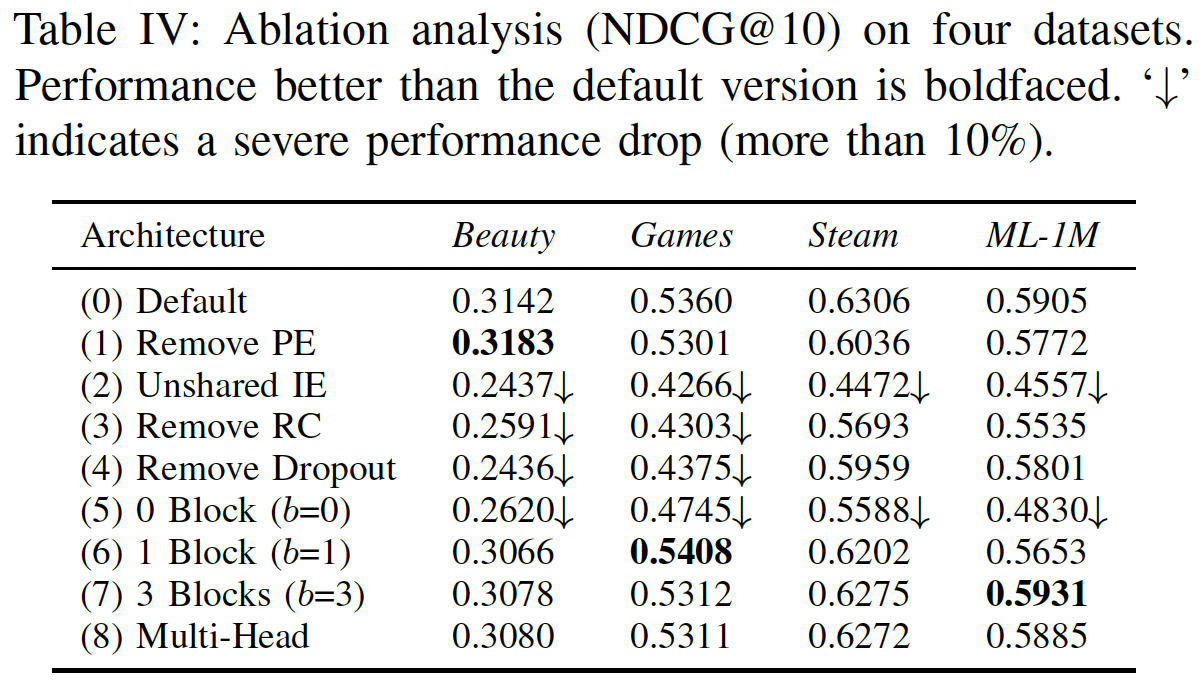
由于我们的架构中有许多组件,我们通过消融研究来分析它们的影响(用于回答问题
RQ2)。下表显示了我们的默认方法及其8个变体在所有四个数据集上的性能(Remove PE(Positional Embedding):没有positional embeddingitem的注意力权重仅取决于item embedding。也就是说,该模型根据用户过去的行为进行推荐,但是行为的顺序并不重要。该变体可能适用于用户行为序列通常较短的稀疏数据集。该变体在最稀疏的数据集
Beauty上的表现优于默认的模型,但是在其它更稠密的数据集上的表现更差。移除
positional embedding不一定效果下降,主要还是要看数据集的性质。Unshared IE(Item Embedding):我们发现,使用两种item embedding(非共享的item embedding)会一致性地损害性能,可能是由于过拟合。Remove RC(Residual Connections):我们发现,移除残差连接之后模型性能显著更差。这大概是因为lower layer中的信息(如,最近一个item的embedding,第一个block的output)无法轻易地传播到最后一层,而这些lower layer中的信息对于推荐非常有用,尤其是在稀疏数据集上。Remove Dropout:我们的结果表明,dropout可以有效地正则化模型从而实现更好的性能,尤其是在稀疏数据集上。结果还暗示了:过拟合在稠密数据集上不严重。过拟合在稠密数据集上也比较严重,只是相对稀疏数据集而言不太严重。
因为稀疏数据集更容易陷入过拟合,因此更需要正则化。
Number of blocks:毫不奇怪, 零个
block的结果较差,因为模型效果仅取决于最近一个item。带有一个
block的变体的表现相当不错。带有两个
block的变体(即default模型)的表现仍然进一步提升,尤其是在稠密数据集上,这意味着hierarchical self-attention structure有助于学习更复杂的item转移。带有三个
block的变体可以获得与default模型(即两个block)相似的性能。
Multi-head:Transformer的作者发现使用multi-head的注意力很有用,它将注意力应用于case中,two head attention的性能始终比single-head attention稍差。这可能是由于我们的问题中的Transformer中,
1.2.3 训练效率和可扩展性
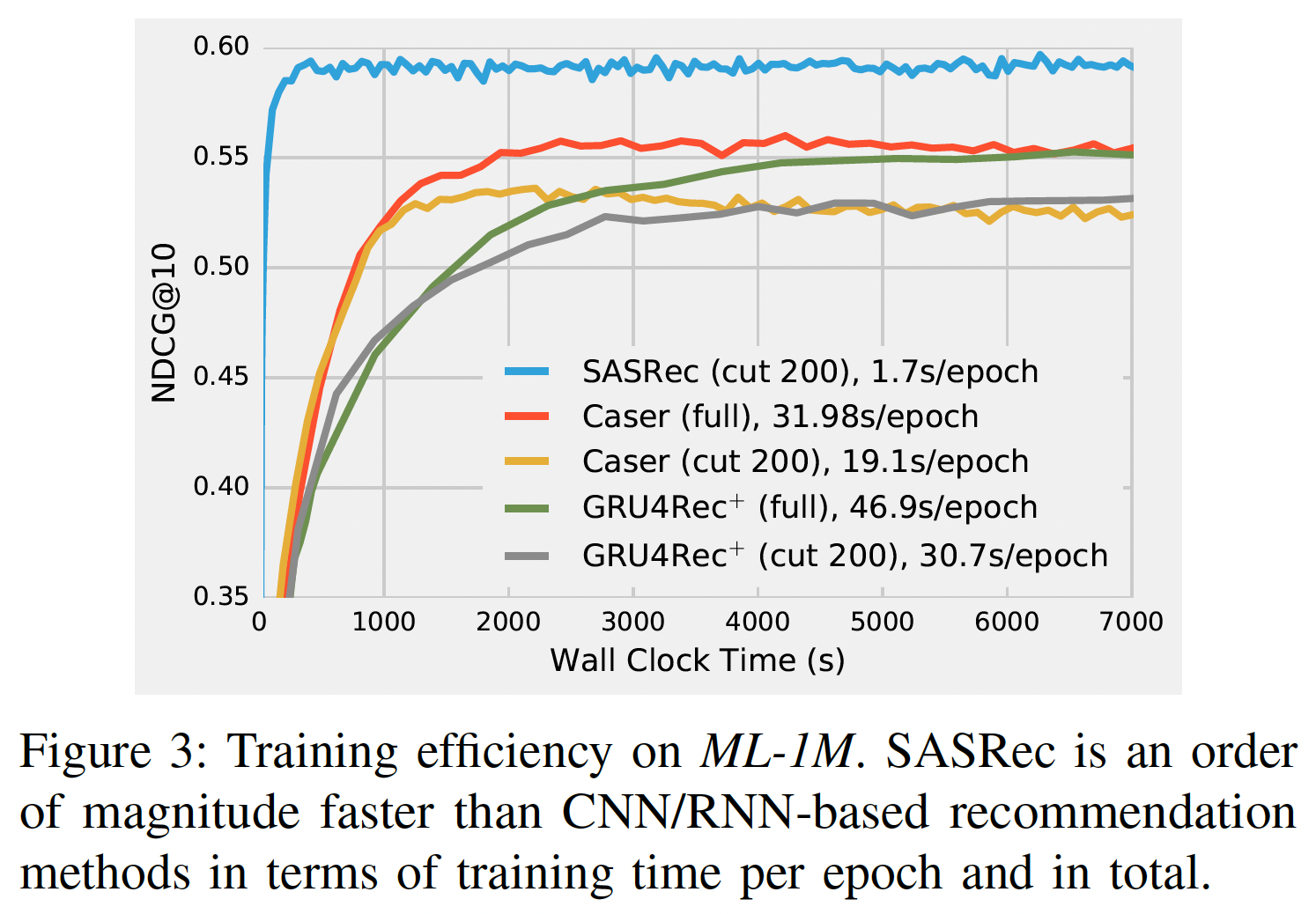
我们评估了我们模型的训练效率的两个方面(用于回答问题
RQ3):训练速度(一个训练epoch所花费的时间)、收敛时间(达到令人满意的性能所花费的时间)。我们还根据最大长度GTX-1080 Ti GPU进行。训练效率:下图展示了使用
GPU加速的、基于深度学习的方法的效率。GRU4Rec由于性能较差而被省略。为公平比较,Caser和GRU4Rec+有两种训练选项:使用完整的训练数据、或仅使用最近的200个行为(SASRec中就是使用最近的200个行为)。在计算速度上,
SASRec一个epoch的模型更新时间仅为1.7秒,比Caser快11倍(19.1 s/epoch))、比GRU4Rec+快18倍(30.7s/epoch)。在收敛速度上,
SASRec在ML-1M数据集上大约在350秒内收敛到最佳性能,而其它模型需要更长的时间。我们还发现,使用完整数据可以提高
Caser和GRU4Rec+的性能。
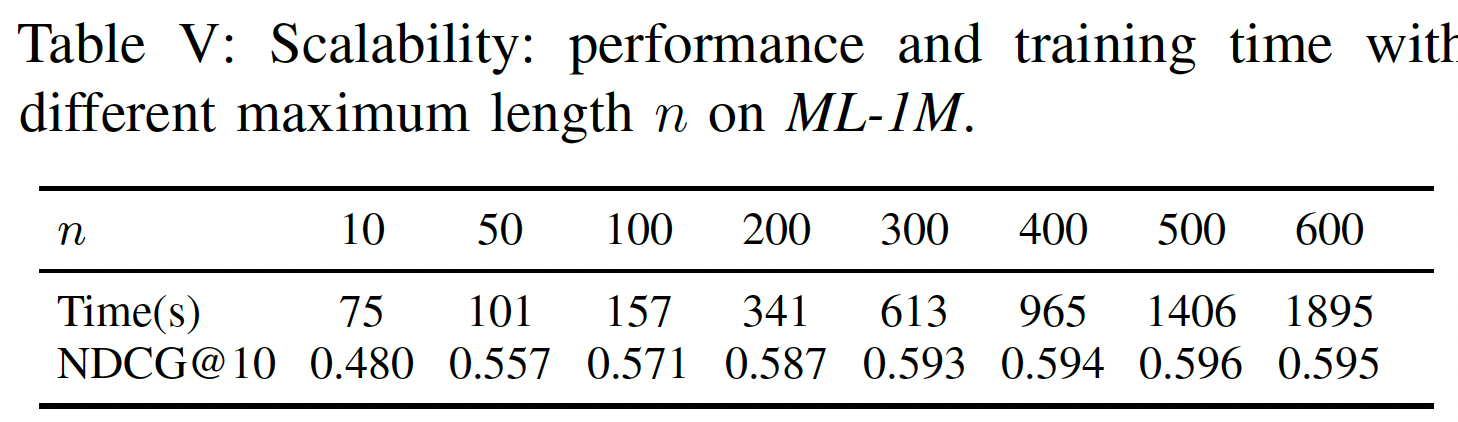
可扩展性:与标准
MF方法一样,SASRec与用户总数、item总数、action总数呈线性关系。一个潜在的可扩展性问题是最大长度GPU并行化。这里我们测量SASRec在不同SASRec的可扩展性,并分析它是否可以在大多数情况下处理序列推荐。下表显示了具有不同序列长度的
SASRec的性能和效率。较大的
99.8%的行为序列)。然而,即使
2000秒内完成训练,这仍然比Caser和GRU4Rec+更快。
因此,我们的模型可以轻松地扩展到多达数百个行为的用户行为序列,这适用于典型的评论数据集和购买数据集。我们计划在未来研究处理非常长的序列的方法。
1.2.4 可视化
回想一下,在
time stepself-attention机制根据前面item的position embedding和item embedding自适应地为它们分配权重。为了回答RQ4,我们检查所有训练序列,并通过展示position上的平均注意力权重、以及item之间的平均注意力权重来揭示有意义的pattern。position上的注意力:下图展示了最近15个time step在最近15个position上的平均注意力权重的四种热力图。注意,我们在计算平均权重时,分母是有效权重的个数,从而避免短序列中padding item的影响。我们考虑了不同热力图之间的一些比较:
(a) vs (c):这种比较表明:对于稀疏数据集
Beauty,SASRec倾向于关注更近(more recent)的item。对于稠密数据集
ML-1M,SASRec倾向于关注不那么近(less recent)的item。
这是使我们的模型能够自适应地处理稀疏数据集和稠密数据集的关键因素,而现有方法往往仅侧重于某一头。
即,表明我们的
self-attention机制的行为是自适应的。(b) vs (c):这种比较展示了使用positional embedding: PE的效果。没有
positional embedding(即,(b),注意力权重基本上均匀分布在先前的item上。有
positional embedding(即,(c),也是默认的模型),模型对position更敏感,因为模型倾向于关注最近的item。
即,表明我们的
self-attention机制的行为是position-aware的。(c) vs (d):由于我们的模型是分层(hierarchical)的,这里展示了不同block之间的注意力是如何变化的。显然,high layer的注意力往往集中在更近(more recent)的position上。这大概是因为第一个self-attention block已经考虑了所有之前的item,而第二个block不需要考虑很远的position。即,表明我们的
self-attention机制的行为是hierarchical的。此外,既然第二个
block不需要考虑很远的position,那么是否使用简单的last representation就可以?毕竟self-attention block的计算复杂度比直接引入last representation更高。
总而言之,可视化表明我们的
self-attention机制的行为是自适应的、position-aware的、以及hierarchical的。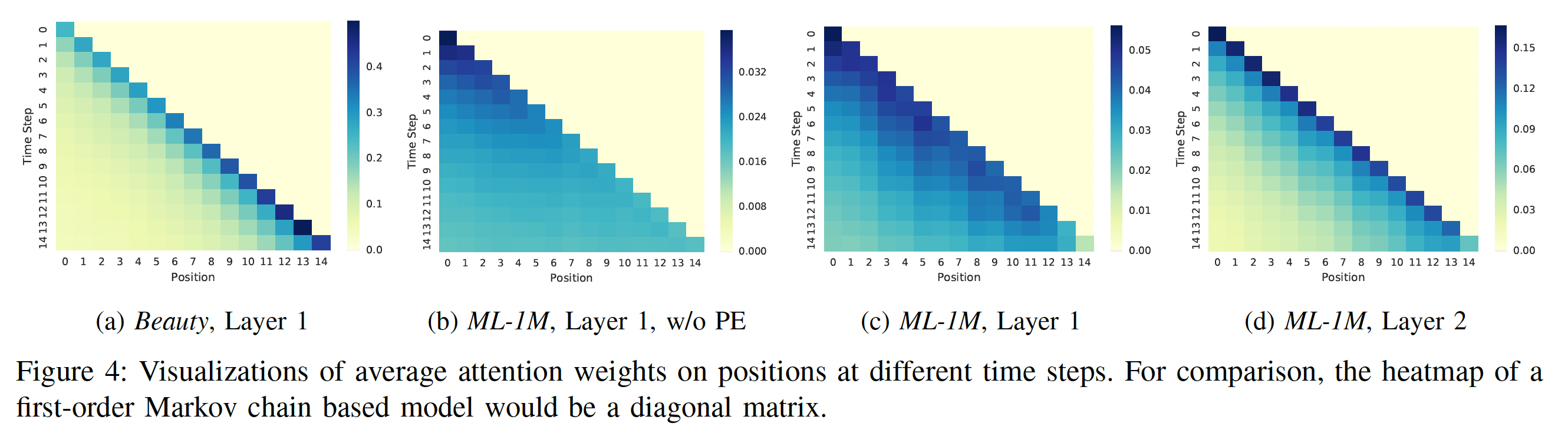
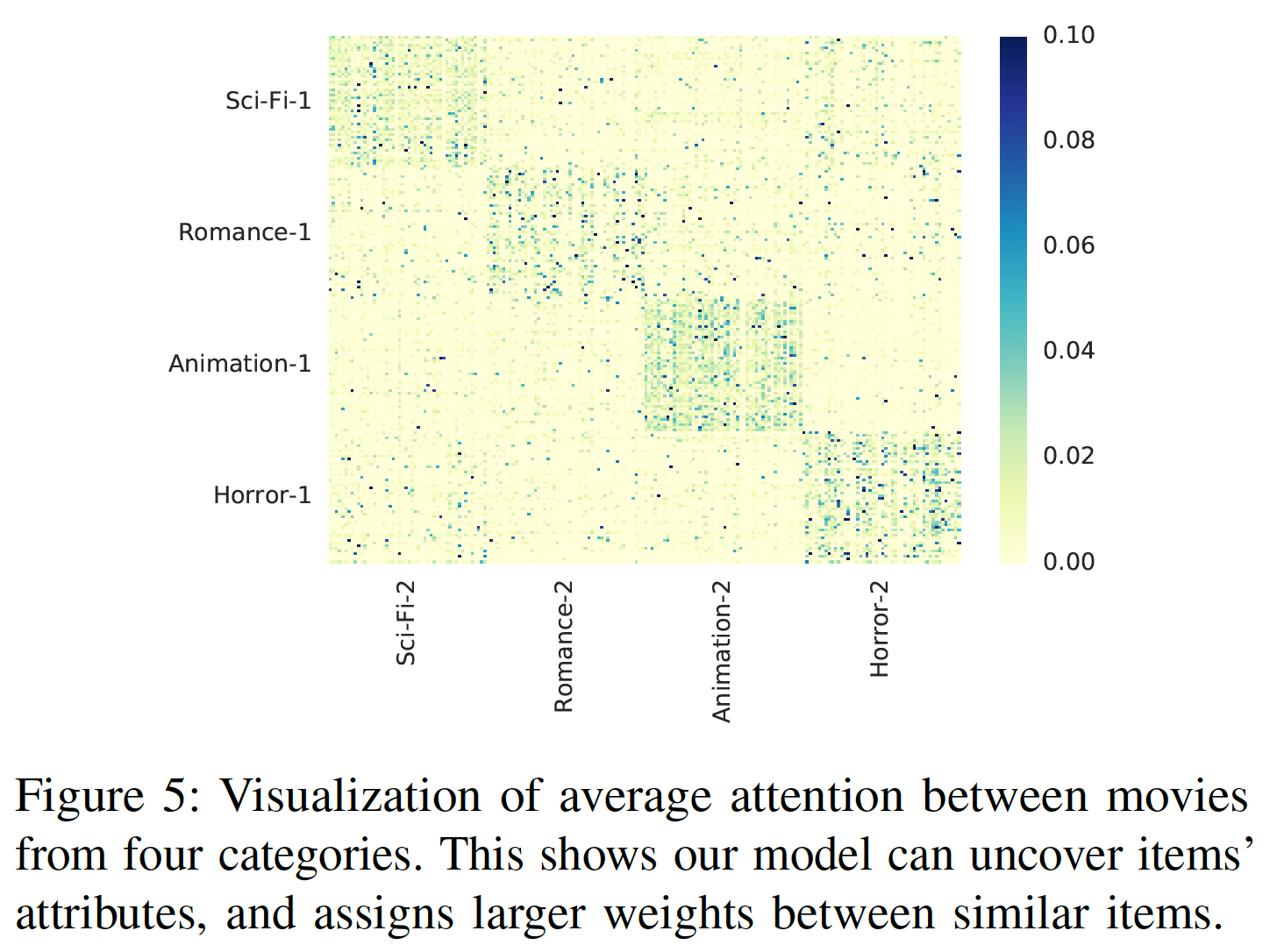
item之间的注意力:展示几个精心挑选的item之间的注意力权重可能没有统计学意义。在MovieLens-1M上,每部电影都有多个类别。为了进行更广泛的比较,我们随机选择两个不相交的集合,每个集合包含来自4个类别的200部电影:科幻(Sci-Fi)、浪漫(Romance)、动画(Animation)、恐怖(Horror) (注,这两个集合共享相同的四个类别)。第一个集合用于query,第二个集合用于key。下图展示了两个集合内不同
item之间的平均注意力权重的热力图(item粒度的,而不是类别粒度的),每个集合内的item根据类别进行分组。我们可以看到:热力图大概是一个块对角矩阵(block diagonal matrix),这意味着注意力机制可以识别相似的item(如,同一个类别的item),并倾向于在相似item之间分配更大的权重(SASRec事先不知道类别,我们也没有将item类别作为特征馈入模型)。