一、SHAN [2018]
《Sequential Recommender System based on Hierarchical Attention Network》
不同于传统的推荐系统,在序列推荐场景存在新的挑战:
首先,用户行为仅反映了他们的隐式反馈(如,是否购买),而不是显式反馈(如,评分)。这种类型的数据会带来更多的噪音,因为我们无法区分用户是不喜欢
unobserved item、还是仅仅因为没有意识到它们。因此,通过传统的潜在因子模型(latent factor model)直接优化这样的one-class分数(如1或0)是不合适的。其次,越来越多的数据来源于
session或交易(transaction),形成了用户的序列模式(sequential pattern)和短期偏好。例如,用户离开机场后更喜欢在酒店休息而不是运动,用户在购买相机后更可能购买相机相关的配件而不是衣服。然而,以前的方法主要关注用户的通用品味(general taste),而很少考虑序列信息,这导致重复的推荐(repeated recommendation)。
在文献中,研究人员通常分别使用独立的模型来分别刻画用户的长期偏好(即,通用品味)和短期偏好(即序列模式),然后将它们集成在一起。例如,
FPMC分解观察到的user-item矩阵从而学习用户的长期偏好,并利用item-item转移信息来建模序列信息(sequential information),然后将二者线性相加从而获得最终分数。然而,这些模型忽略了用户通用品味的动态变化,即,用户的长期偏好会随着时间的推移而不断演变。为每个用户学习一个静态的、低维的向量来建模该用户的通用品味是不够的。此外,这些模型主要通过线性模型来为
user-item交互、item-item交互分配固定权重,这限制了模型的表达能力。已有研究表明,非线性模型可以更好地建模用户活动中的user-item交互。为此,论文
《Sequential Recommender System based on Hierarchical Attention Network》提出了一种新颖的方法,即Sequential Hierarchical Attention Network: SHAN,从而解决next item推荐问题。注意力机制可以自动为用户分配item的不同影响(即,权重)从而捕获动态特性(dynamic property),而层次结构(hierarchical structure)结合了用户的长期偏好和短期偏好。具体而言:首先将用户和
item嵌入到低维稠密空间中。然后使用
attention layer计算用户长期行为中每个item的权重,并使用这个权重对长期行为中的item vector进行加权和从而生成用户的long-term representation。之后,使用另一个
attention layer将近期的用户序列行为与long-term representation相结合。
同一个
user embedding向量在两个attention network中作为context信息,从而计算不同用户的不同权重。为了学习模型参数,论文采用Bayesian personalized ranking: BPR优化准则来生成一个pair-wise损失函数。从实验中,可以观察到论文所提出的模型在两个数据集上优于SOTA的算法。最后,论文的贡献如下:
论文引入注意力机制来建模用户动态(
user dynamic)、个人偏好从而进行序列推荐。通过层级结构,论文结合用户的长期偏好和短期偏好来生成用户的
high-level hybrid representation。论文对两个数据集进行了实验,结果表明所提出的模型在召回率和
AUC指标上始终优于SOTA方法。
相关工作:
为了联合建模用户的个性信息(
individual information)和序列信息,人们引入了马尔科夫链来用于传统的推荐。《Factorizing personalized markov chains for next-basket recommendation》结合了分解方法(用于建模用户的通用品味)、以及马尔科夫链(用于挖掘用户序列模式)。遵从这个思想,研究人员利用不同的方法来抽取这两种不同的用户偏好。《Playlist prediction via metric embedding》和《Personalized ranking metric embedding for next new poi recommendation》使用metric embedding从而将item投影到低维欧氏空间中的点(point),从而用于play list预测、以及successive location预测。《Factorization meets the item embedding: Regularizing matrix factorization with item co-occurrence》利用word embedding从item-item共现中抽取信息,从而提高矩阵分解性能。
然而,这些方法在捕获
high-level的user-item交互方面的能力有限,因为不同组件(component)的权重是固定的。最近,研究人员转向推荐系统中的图模型和神经网络。
《Unified point-of-interest recommendation with temporal interval assessment》提出了一种双加权(bi-weighted)的低秩(low-rank)的图构建模型(graph construction model),该模型将用户的兴趣和序列偏好,与时间间隔评估(temporal interval assessment)相结合。《Wide & deep learning for recommender systems》将wide linear model与cross-product feature transformation相结合,并采用深度神经网络来学习feature embedding之间的高度非线性交互。然而,该模型需要特征工程来设计交叉特征,而交叉特征在高度稀疏的真实数据中很少观察到。为解决这个问题,
《Neural factorization machines for sparse predictive analytics》和《Attentional factorization machines: Learning the weight of feature interactions via attention networks》分别设计了B-Interaction layer和attentional pooling layer,从而基于传统的分解机(factorization machine: FM)技术自动学习二阶特征交互。《Sessionbased recommendations with recurrent neural networks》和《Recurrent recommender networks》采用循环神经网络RNN来挖掘轨迹数据(trajectory data)中的用户动态(user dynamic)和item偏好。然而,在许多实际场景中,session中的item可能不会遵守严格的顺序(例如,在线购物中的交易),此时RNN不太适用。除此之外,
《Learning hierarchical representation model for nextbasket recommendation》和《Diversifying personalized recommendation with user-session context》学习了user hierarchical representation,从而结合用户的长期偏好和短期偏好。我们遵循这个
pipeline,但是有以下贡献:我们的模型建立在
hierarchical attention network之上,可以捕获动态的长期偏好和短期偏好。一些
RNN-based推荐方法也是捕获动态的长期偏好,而MF-based推荐方法才是捕获静态的长期偏好。我们的模型利用
user-item交互的非线性建模。它能够学习不同用户对相同item的不同的item influence(即,权重)。
1.1 模型
令
item集合,user-item反馈数据(如,用户的连续check-in记录、连续的购买交易记录)中抽取信息。对于每个用户
time step的总数,time stepitem集合。对于给定的
time stepitem集合next item的重要因素。另一方面,在
time stepitem集合,记做
在后面的内容中,我们将
time stepitem set,将time stepitem set。形式上,给定用户
next item。我们根据用户偏好的以下特点,提出了一种基于
hierarchical attention network的新方法,如下图所示。这些特点为:用户偏好在不同的
time step是动态(dynamic)的。不同的
item对将要被购买的next item有不同的影响。对于不同的用户,相同的
item可能对next item prediction产生不同的影响。例如,用户
A/B的行为序列都是A和B之间存在差异(例如年龄、性别、收入水平等等),导致相同的行为序列得到不同的注意力权重。
我们方法的基本思想是:通过联合学习长期偏好和短期偏好从而为每个用户生成一个
hybrid representation。更具体而言,我们首先将稀疏的user input和item input(即,one-hot representation)嵌入到低维稠密向量中。之后,我们通过结合长期偏好和短期偏好的双层结构来学习每个用户的hybrid representation。为了捕获
time steplong-term user representation,它是长期的item setitem embedding的加权和,权重由user embedding导出的、attention-based pooling layer来生成。为了进一步结合短期偏好,
final hybrid user representation将long-term user representation和短期item set中的item embedding相结合,其中权重根据另一个attention-based pooling layer学习而来。
如上所述,我们的模型同时考虑了动态的长期用户偏好和动态的短期用户偏好。此外,通过使用不同的、学到的权重,长期用户偏好和短期用户偏好对将要购买的
next item具有不同的影响。最后,值得指出的是,相同
item在不同用户上的影响也是不同的,因为attention layer中权重的学习过程是由user embedding指导的,而user embedding是个性化的。接下来我们详细介绍我们模型的各个部分。
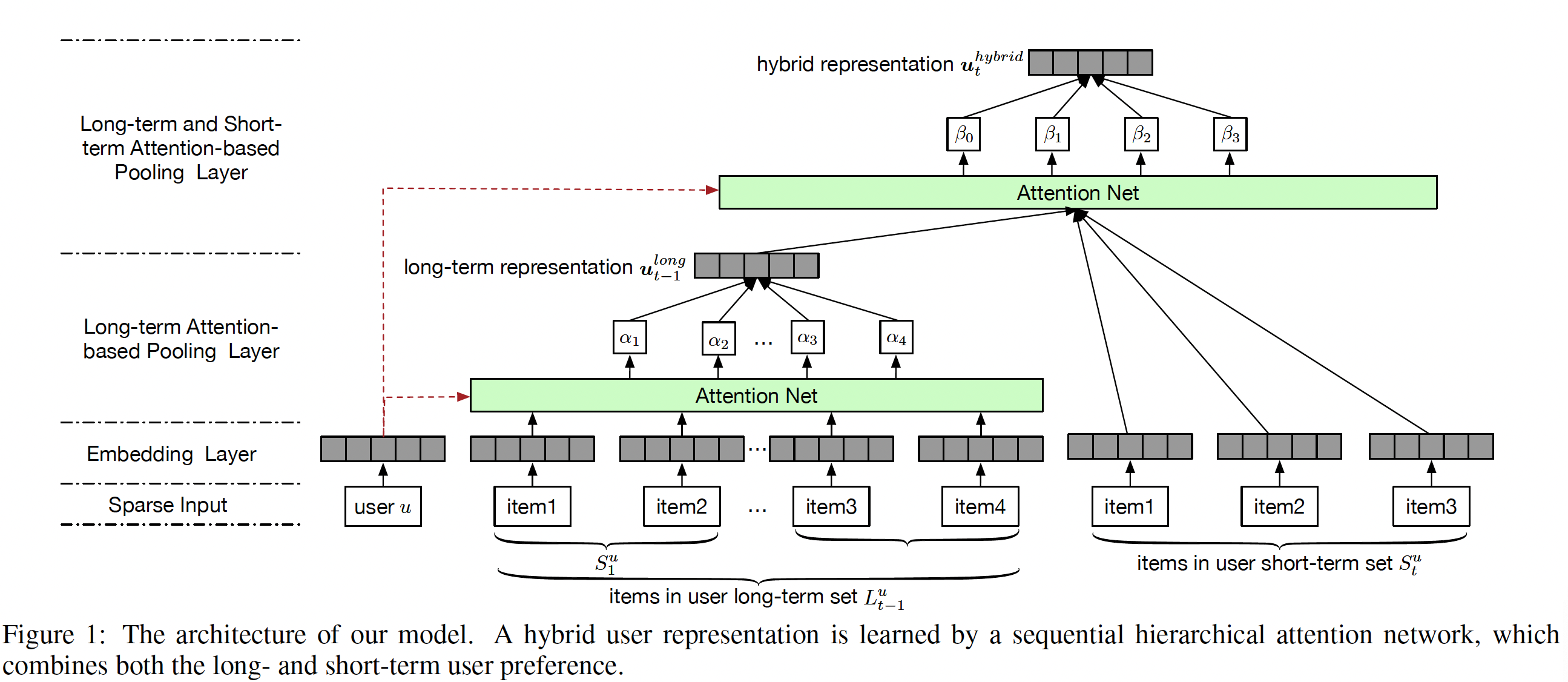
Embedding Layer:与自然语言处理中的、离散的word symbol类似,原始的user ID和item ID的表达能力非常有限。因此,我们的模型首先采用embedding layer将user ID和item ID(即,one-hot representation)嵌入到两个连续的低维空间中。形式上,令
user embedding矩阵,令item embedding矩阵,其中embedding空间的维数。user embedding向量。itemitem embedding向量。从理论上讲,传统的矩阵分解相当于一个双层神经网络:第一层为
user和item构建低维的embedding,第二层执行内积运算。然而,通过矩阵分解的embedding只能捕获low-level、bi-linear、以及静态的representation,这限制了模型的表达能力。不同的是,我们的模型基于这些basic embedding来学习high-level、非线性的、动态的user representation,这些将在后面解释。Long-term Attention-based Pooling Layer:在序列推荐系统中,长期偏好和短期偏好分别对应于用户的通用品味和序列行为。由于用户的长期
item set通常会随着时间而变化,因此为每个用户学习静态的长期偏好rerepsentation并不能完全表达长期偏好的dynamic。另一方面,从最新的长期
item set中重构long-term user representation更为合理。此外,我们认为相同的
item可能在不同用户上产生不同的影响。例如,假设用户itemitemnext item时,item
为了满足上述要求,我们提出使用已经成功应用于许多任务的注意力机制。注意力机制首先计算给定用户的长期
item set中每个item的重要性,然后聚合这些item的embedding从而形成long-term user preference representation。形式上,注意力网络定义为:其中:
user embedding向量,item set中itemitem embedding。ReLU非线性激活函数。
与传统的注意力模型对每个用户的每个
input使用相同的context向量不同(即,global的),我们将用户embeddingcontext向量(因此不同用户的context向量不同,即personalized的)。注意,和
DIN/RUM不同,这里的attention并不是将target item与历史item进行注意力计算,而是将用户静态偏好(以item进行注意力计算。对于
DIN/RUM,相同用户的、不同的target item会得到不同的注意力权重,因此在推断期间对于每个候选item都需要重新计算。此外,不同用户的、相同的
target item会得到相同的注意力权重,因此它是non-personalized的。对于
SHAN,相同用户的、不同的target item会得到相同的注意力权重,因此在推断期间对于每个候选item无需重新计算。此外,不同用户的、相同的
target item会得到不同的注意力权重,因此它是personalized的。
本质上,
SHAN的注意力机制是类似于self-attention,它仅用到了target user侧的信息,而并没有使用target item侧的信息。由于没有进行user-item的信息交互,因此有利于模型的在线推断(类似于双塔模型的架构比较容易在线部署,例如将target user侧的emebdding离线计算好并推送到线上,target item侧的embedding实时计算并基于embedding向量的相似度来做召回)。最后,我们计算
long-term user representationitem embedding的加权和,即:Long- and Short-term Attention-based Pooling Layer:除了用户的通用品味之外,还需要考虑用户的序列行为(即,短期偏好)。短期偏好对于预测next item很重要,并且已有研究将长期偏好和短期偏好相结合从而进行序列推荐。然而,在这些早期工作中,短期偏好和长期偏好的交互仍然是线性的。并且,item被分配以相同的权重,这无法反映item对next item prediction的影响,因此限制了模型的性能。与建模用户长期偏好类似,我们也采用注意力网络,从而为
long-term representation和短期item set中的item的embedding分配权重,进而捕获用户high-level representation。正式地,其中:
user embedding向量,item set中itemitem embedding。注意,当long-term user representation。
类似地,
user embedding被作为context vector从而实现个性化的注意力(即,相同item在不同用户上分配不同的权重)。在获得归一化的注意力分数之后,hybrid user representation计算为:其中
总而言之,
item对预测next item的贡献。此外,两个层级的注意力网络可以捕获user和item之间的非线性交互。这里的注意力机制并不是基于向量内积的,而是基于
MLP的,因此引入了非线性交互。注意,
《Learning hierarchical representation model for nextbasket recommendation》还可以通过使用最大池化聚合final representation来实现非线性的目的。但是,它同时丢失了很多信息。我们将通过实验证明我们的模型可以实现比它更好的性能。注意力加权和聚合的方式是介于
sum池化和max池化之间的版本:当注意力均匀分布时,注意力加权和聚合退化为
sum池化。当注意力极度不均时,注意力加权和聚合退化为
max池化。
此外,还可以通过
CNN/RNN来进行聚合,它们是与sum池化、max池化完全不同的聚合方式。模型推断(
Model Inference):当计算出hybrid user representationitem但是,用户交易记录是一种隐式数据。由于数据稀疏性问题和
unobserved data的模糊性(ambiguity),我们很难直接优化偏好分我们模型的目标是在给定用户在时刻
item set和短期item set的情况下,提供一个ranked list。因此,我们更感兴趣的是item的排名而不是真实的偏好分。遵循BPR优化准则,我们为我们的模型提出一个pair-wise ranking目标函数。我们假设用户更喜欢next purchased item而不是unobserved item,并在itemitemranking order)其中
time stepnext item,bootstrap sampling生成的unobserved item。对于每个
observationpairwise preference order的一个集合maximizing a posterior: MAP)来训练我们的模型:其中:
user embedding和item embedding待学习参数集合,logistic function),为什么使用不同的正则化系数?用一个正则化系数不行吗?猜测的原因是不同的参数的取值不同,这可以通过后面的消融实验来验证。如果使用同一个正则化系数,那么该系数的选择被取值较大的参数所主导(可以通过统计参数范数的均值来观察)。进一步地,是否需要针对每个参数设置一个正则化系数?
SHAN算法:输入:
长期
item setitem set学习率
输出:模型参数集合
算法步骤:
从正态分布
从均匀分布
为什么采用不同的权重初始化策略?论文并未解释。
重复以下过程直到算法收敛:
混洗
observation集合observation随机从
unobserved item计算
计算
使用梯度下降来更新参数集合
返回参数集合
1.2 实验
我们进行实验回答以下几个问题:
与其它
SOTA方法相比,我们的模型的性能如何?在我们模型中,长期偏好和短期偏好的影响是什么?
超参数(如正则化参数、
embedding维度)如何影响模型性能?
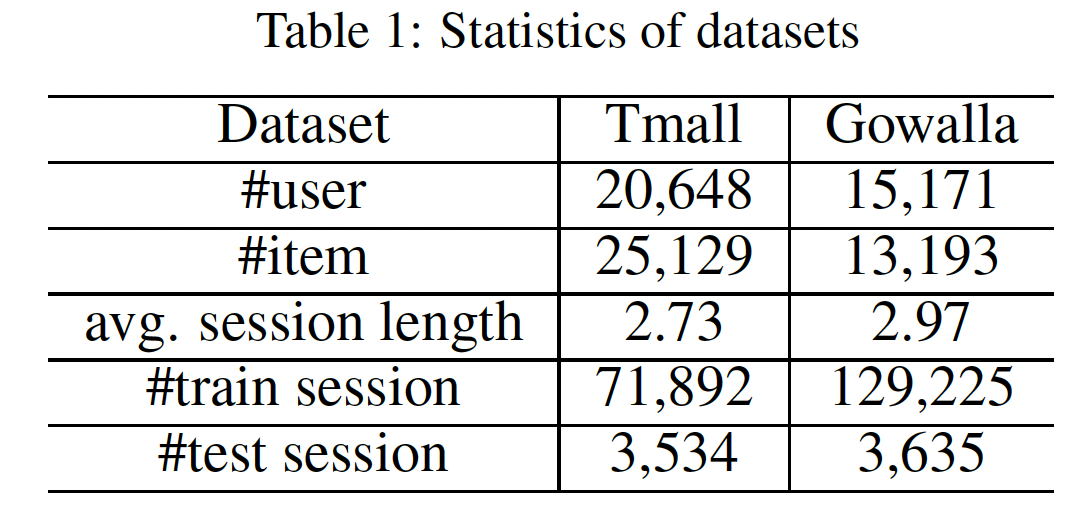
数据集:
Tmall数据集:包含中国最大的在线购物网站(即,Tmall.com)上的用户行为日志。Gowalla数据集:记录了用户在location-based社交网站Gowalla中check-in的时间的point-of-interest: POI信息。
我们专注于这两个数据集上过去七个月生成的数据。在此期间,少于
20个交互的item被剔除。此后,将一天内的用户记录视为一个session(即,交易transaction)来表示短期偏好,并删除所有的singleton session(即,session中仅有一个item)。类似于
《Diversifying personalized recommendation with user-session context》,我们随机选择最近一个月20%的session进行测试,其余的用于训练。我们还在每个session中随机保留一个item作为待预测的next item。预处理之后,这两个数据集的基本统计信息如下表所示:
评估指标:我们采用两个广泛使用的指标
Recall@N和AUC。Recall@N指标评估在所有测试session中,ground truth item排在top-N的case占所有ground truth item的比例。AUC指标评估ground truth item在所有item中的排名有多高。这里将
ranking list中非ground truth的其它item视为负样本,将ground truth item视为正样本,因此AUC指标严重依赖于负样本的采样方式。事实上,
Recall@N指标也会依赖于负样本的采样方式。
baseline方法:TOP:基于流行度的推荐,其中流行度通过训练集中item的出现频次来统计。BPR:BPR是一种用于隐式用户反馈数据的、SOTA的pairwise learning to rank框架。我们选择矩阵分解作为internal predictor。FPMC:该方法通过矩阵分解建模用户偏好、通过一阶马尔科夫链建模序列信息,然后通过线性方式将它们组合起来进行next basket recommendation。FOSSIL:该方法将factored item similarity和马尔科夫链相结合,从而建模用户的长期偏好和短期偏好。注意,我们将session的长度是可变的。HRM:该方法生成user hierarchical representation来捕获序列信息和通用品味。我们使用max pooling作为聚合操作,因为这样可以达到最佳效果。SHAN:这是我们提出的模型,它使用两个注意力网络来挖掘长期偏好和短期偏好。我们还展示了简化版本的性能(叫做
SAN),它忽略了层次结构,并通过单个注意力网络从长期item set和短期item set中计算item的权重。
为了公平地比较,所有
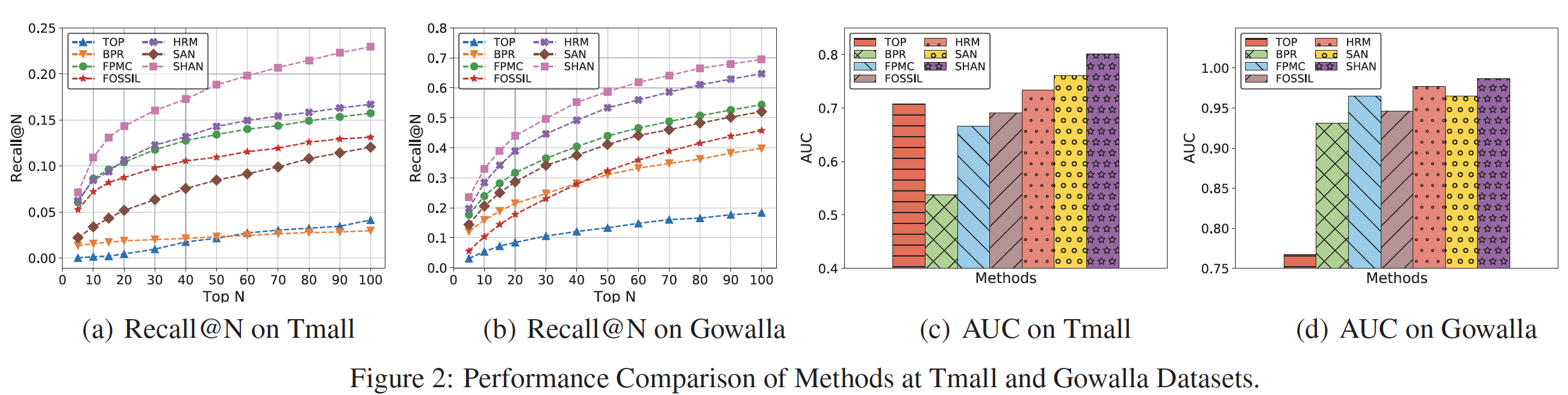
model-based方法都基于BPR优化准则来优化一个pair-wise ranking目标函数。对比结果:下图展示了所有方法在
Tmall和Gowalla数据集上的Top-5 to Top-100的召回率和AUC指标。从结果可以看到:SHAN在Tmall数据集的所有指标下始终以较大的优势优于所有其它方法。具体而言,与第二好的方法(即
HRM)相比,SHAN在Tmall数据集上和Gowalla数据集上的召回率指标分别提高了33.6%和9.8%。这表明:我们的模型通过注意力网络为long-term representation和short-term representation捕获了更high-level的、更复杂的、非线性的信息,而HRM可能会通过hierarchical max pooling操作丢失很多信息。此外,
SHAN的性能优于SAN,可能是因为长期item set的item数量远远多于短期item set。因此,单个注意力网络很难为属于短期item set的较少、但是更重要的item分配适当的权重。
HRM在大多数情况在这两项指标下的表现普遍优于FPMC。具体而言,
HRM在Tmall和Gowalla数据集上的Recall@50的相对性能(相对于FPMC方法)提升分别为6.7%和4.5%。这证明了多个因子(factor)之间的交互可以通过最大池化操作来学习。此外,尽管是简单的最大池化,该操作引入的非线性交互将提高模型性能。另外,
SHAN实现了比HRM更好的性能,这表明注意力网络在建模复杂交互方面比最大池化更强大。在大多数情况下,所有混合模型(即,
FPMC, FOSSIL, HRM, SHAN)在两个数据集的不同指标下均优于BPR。以AUC为例,混合模型相对于BPR的性能提升持续保持在非常高的水平。这表明序列信息对于我们的任务非常重要,而BPR忽略了它。另外,SHAN在这些混合模型中获得了最佳性能。令人惊讶的是,在
Tmall数据集上,当50继续增加时,TOP方法在召回率方面超越了BPR,甚至在AUC指标上超越了FPMC。这种现象可以解释为:
用户在网上购物时可能倾向于购买热门
item。因此,当TOP方法可以达到更好的性能。相反,由于
Gowalla数据集中的用户check-in数据更加个性化,因此TOP方法的性能要比其它方法差很多。
最后,我们的模型可以在不同的
baseline。
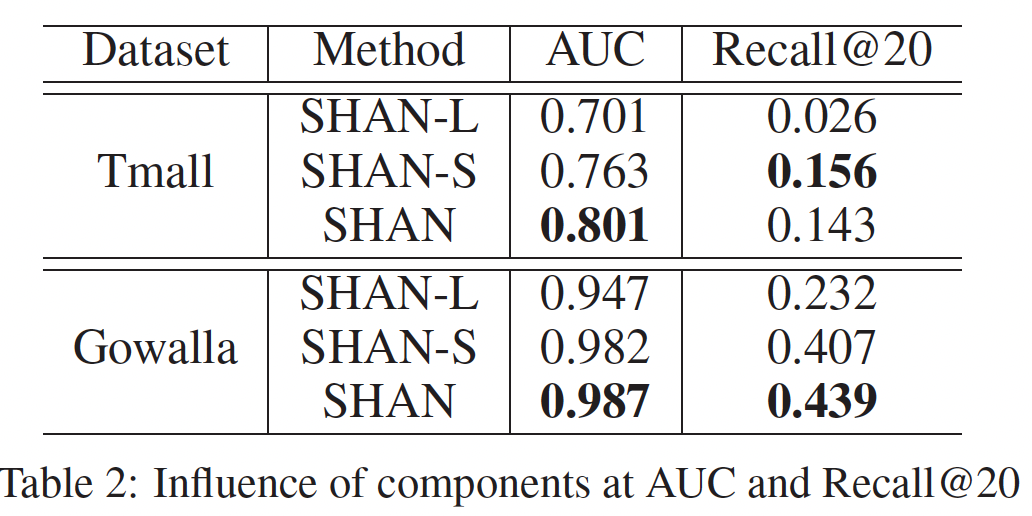
不同组件的影响:为了评估每个组件对
final user hybrid representation的贡献,我们进行实验来分析下表中每个组件。SHAN-L表示仅建模用户的通用品味,SHAN-S表示仅建模用户的短期偏好。与同样仅建模长期偏好的
BPR相比,SHAN-L实现了更好的性能。例如,BPR在Tmall数据集和Gowalla数据集上的Recall@20指标分别为0.019和0.204。这表明通过动态方式dynamic way来建模通用品味,要比通过固定的embedding向量更好。SHAN-S在很大程度上优于SHAN-L,这表明短期序列信息在predicting next item task上更为重要。令人惊讶的是,
SHAN-S在两个数据集上都优于HRM。例如,HRM在Tmall数据集和Gowalla数据集上的AUC指标分别为0.734和0.966。原因可能是SHAN-S中的basic user embedding vector(它融合了user basic preference)是通过短期item set中每个item的权重从而计算得到的。因此,SHAN-S还考虑了用户的静态通用品味、以及序列信息从而生成hybrid representation。结果还表明:一层的注意力网络优于两层的最大池化操作。
SHAN-S在Tmall数据集上的Recall@20指标要好于SHAN。这表明在该数据集上,用户在上一个session中的点击行为对当前session中的next clicked item没有太大影响。最后,在大多数情况下,
SHAN的性能优于两个单组件的模型。这表明:将动态的用户通用品味添加到SHAN-S有助于预测next item。因为SHAN-S仅仅是结合了用户的basic的、fixed的偏好以及序列行为。
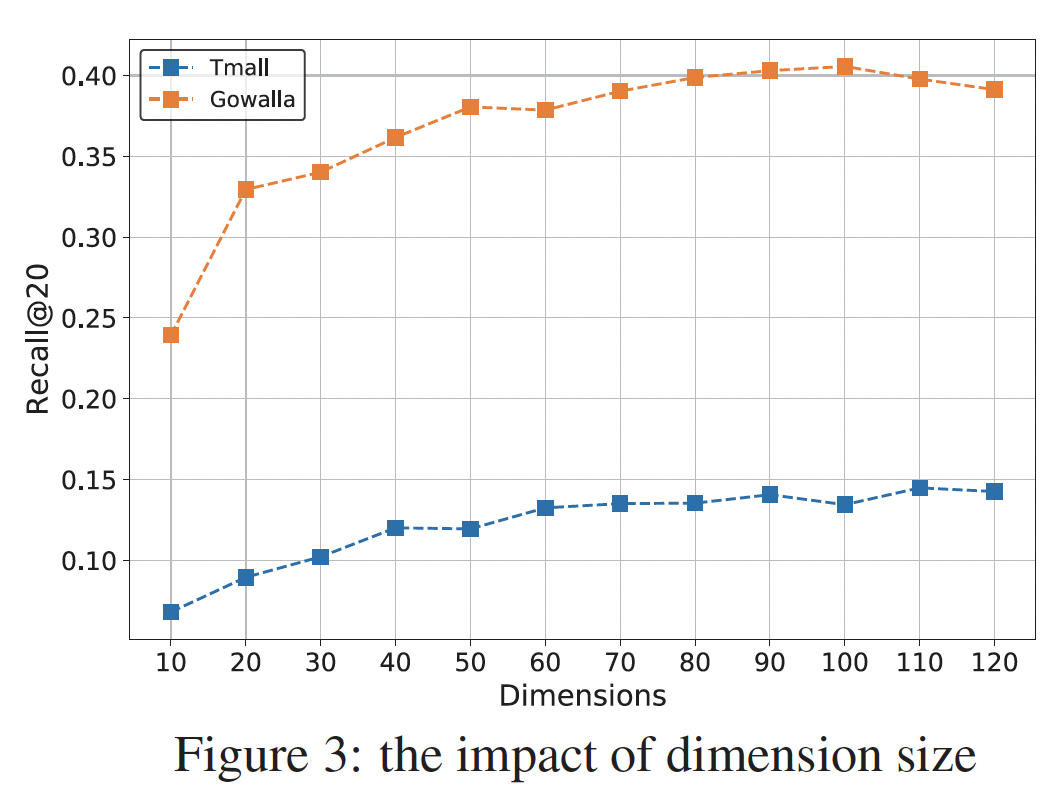
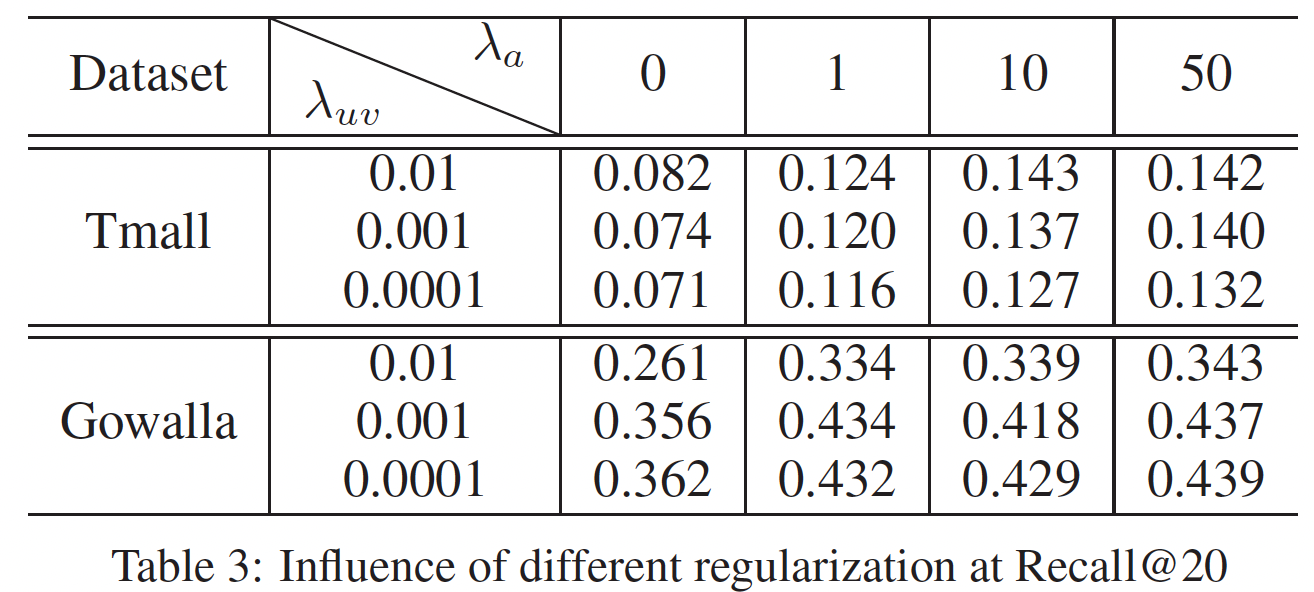
超参数的影响:这里我们研究正则化系数和
embedding size对模型的影响。由于篇幅所限,我们仅展示Recall@20指标下的结果。在我们的模型中,我们利用
user embedding和item embedding正则化系数Recall@20指标的影响。可以看到:当
可以看到,
我们进一步研究了维度大小
user embedding和item embedding的size有关,还与注意力网络中的MLP参数有关。为简单起见,user embedding和item embedding的size是相同的。可以看到:大的
item,并且将更有利于通过注意力网络构建high-level的因子交互(factor interaction)。这种现象类似于传统的潜在因子模型。在实验中,我们将100,从而平衡两个数据集的计算成本和推荐质量。