一、BERT4Rec [2019]
《BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer》
准确描述用户的兴趣是有效推荐系统的核心。在许多现实世界的
application中,用户当前的兴趣本质上是动态(dynamic)的和演变(evolving)的,受到用户的历史行为的影响。例如,一名用户可能在购买一个Nintendo Switch后不久就购买配件(如,Joy-Con控制器),然而该用户在正常情况下不会购买console配件。为了建模用户行为中的这种序列动态(
sequential dynamics),人们已经提出了各种方法来根据用户的历史交互(historical interactions)进行序列推荐(sequential recommendations)。这些方法的目标是:预测用户在给定该用户历史交互的情况下,该用户接下来可能交互的下一个item。最近,大量工作采用序列神经网络(sequential neural networks),如Recurrent Neural Network: RNN,用于序列推荐并获得有前景的结果。先前工作的基本范式是:使用从左到右的序列模型将用户的历史交互编码为向量(即,用户偏好的hidden representation),并基于该hidden representation进行推荐。尽管它们的流行性和有效性,
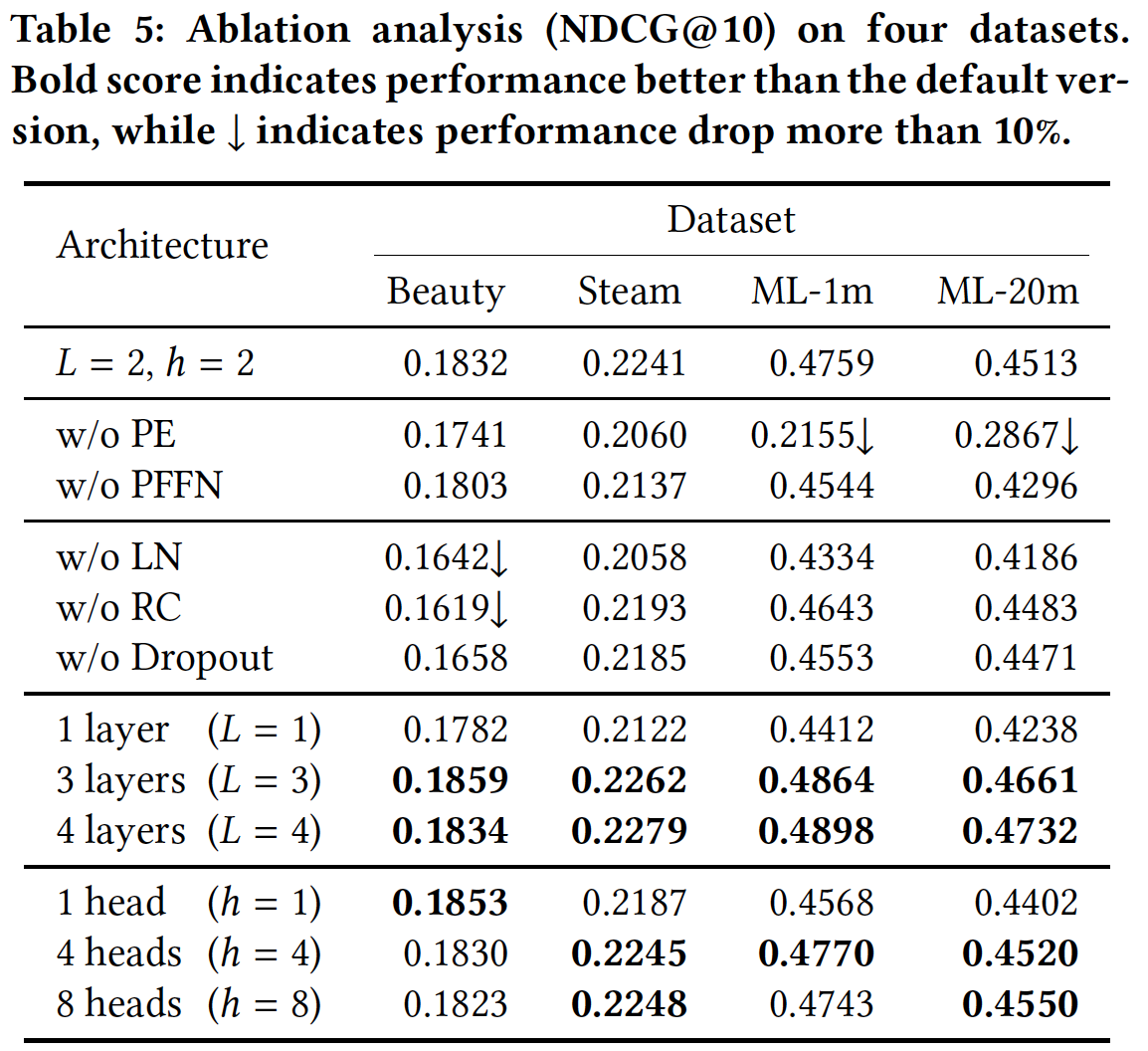
BERT4Rec的作者认为这种从左到右的单向模型不足以学到用户行为序列的最佳representation。如下图
(c)和(d)所示,主要限制是:对于历史行为序列中item,此类单向模型限制了item的hidden representation的能力,其中每个item只能对来自previous items的信息进行编码。另一个限制是:以前的单向模型最初是针对具有自然顺序(
natural order)的序列数据(sequential data)引入的,如文本序列数据(text series data)、时间序列数据(time series data)。它们通常假设数据上的严格排序的序列 (ordered sequence),这对于真实世界的application并不总是正确的。事实上,由于各种不可观察(
unobservable)的外部因素,用户历史交互中的item选择可能不遵循严格的顺序假设(order assumption)。在这种情况下,在用户行为序列建模中同时结合来自两个方向的上下文(context)至关重要。
为了解决上述限制,
BERT4Rec寻求使用双向模型来学习用户历史行为序列的representation。具体而言,受BERT在文本理解方面的成功所启发,《BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer》提出将深度双向自注意力模型(deep bidirectional self-attention model)应用于序列推荐,如上图(b)所示。在representation power方面,深度双向模型在文本序列建模任务上的优异结果表明:将双向的上下文结合起来对sequence representations learning是有益的。对于严格的顺序假设,BERT4Rec比单向模型更适合建模用户行为序列,因为双向模型中的所有item都可以利用左右两个方向的上下文。然而,为序列推荐训练双向模型并不简单,也不直观。传统的序列推荐模型通常通过预测输入序列中每个位置的
next item来从左到右进行训练。如上图所示,在深度双向模型中同时联合调节(jointly conditioning)左侧和右侧的上下文,会导致信息泄露,即允许每个位置间接see the target item。这可能会使预测未来变得没有价值,并且网络不会学到任何有用的东西。为了解决这个问题,
BERT4Rec引入了完形填空任务(Cloze task)来代替单向模型中的目标(即,序列地预测next item)。具体而言,BERT4Rec在输入序列中随机地mask一些item(即,用特殊token[mask]来替换它们),然后根据它们周围的上下文来预测这些masked item的id。 通过这种方式,BERT4Rec通过允许输入序列中每个item的representation同时融合左侧和右侧上下文,从而避免信息泄露并学习bidirectional representation mode。除了训练双向模型之外,完成填空目标的另一个优点是:它可以产生更多的样本来在多个epoch中训练更强大的模型。例如,完形填空目标可以
mask掉一个item,也可以一次mask掉多个item。而传统的session-based推荐一次只能预测一个目标。然而,完形填空任务的一个缺点是:它与最终任务(即序列推荐)不一致。为了解决这个问题,在测试过程中,我们在输入序列的末尾附加了特殊的
token[mask]来指示我们需要预测的item,然后根据其final hidden vector进行推荐。对四个数据集的广泛实验表明,我们的模型始终优于各种SOTA baselines。即,测试期间用
[mask]替代target item。论文的贡献如下:
作者提出通过完形填空任务用双向自注意力网络来建模用户行为序列。据作者所知,这是第一个将深度双向序列模型和完形填空目标引入推荐系统领域的研究。
作者将
BERT4Rec与SOTA的方法进行比较,并通过对四个benchmark数据集的定量分析证明双向架构和完形填空目标的有效性。作者进行了一项全面的消融研究,从而分析所提出模型中关键组件的贡献。
相关工作:这里我们简要回顾与我们密切相关的几个工作,包括通用推荐(
general recommendation)、序列推荐、以及注意力机制。通用推荐:推荐系统的早期工作通常使用协同过滤(
Collaborative Filtering: CF)从而根据用户的交互历史来建模用户偏好。在各种协同过滤方法中,矩阵分解(
Matrix Factorization: MF)是最流行的一种,它将用户和item投影到一个共享的向量空间中,并通过user向量和item向量之间的内积来估计用户对item的偏好。协同过滤的另一个方向是
item-based邻域方法。它通过使用预计算(precomputed)的item-to-item相似度矩阵,通过测量目标item与用户交互历史中的item的相似性从而评估用户对目标item的偏好。最近,深度学习已经极大地改变了推荐系统。早期的先驱工作是用于协同过滤的两层(
Restricted Boltzmann Machine: RBM),在Netflix Prize中由论文《Restricted Boltzmann Machines for Collaborative Filtering》提出。基于深度学习的一个方向旨在通过将从辅助信息(如文本、图像、声音)中学到的
distributed item representation集成到协同过滤模型中,从而提高推荐性能。基于深度学习的另一个方向试图取代传统的矩阵分解模型。例如,
Neural Collaborative Filtering: NCF通过多层感知机而不是内积来估计用户偏好,而AutoRec和CDAE使用自编码器框架来预测用户的评分。
序列推荐:不幸的是,上述方法都不适用于序列推荐,因为它们都忽略了用户行为的顺序(
order)。早期的序列推荐工作通常使用马尔科夫链(
Markov chain: MC),从而从用户历史交互中捕获序列模式(sequential pattern)。例如:《An MDP-Based Recommender System》将recommendation generation形式化为序列优化问题(sequential optimization problem),并采用马尔科夫决策过程(Markov Decision Processe: MDP)来解决它。后来,
《Factorizing Personalized Markov Chains for Next-basket Recommendation》结合马尔科夫链和矩阵分解的能力,通过分解个性化马尔科夫(Factorizing Personalized Markov Chain: FPMC)来建模序列行为和通用兴趣。除了一阶马尔科夫链之外,
《Translation-based Recommendation》和《Fusing Similarity Models with Markov Chains for Sparse Sequential Recommendation》还采用高阶马尔科夫链来考虑更多previous items。
最近,
RNN及其变体Gated Recurrent Unit: GRU、Long Short-Term Memory: LSTM在建模用户行为序列方面变得越来越流行。这些方法的基本思想是:将用户以前的记录通过各种循环架构和损失函数,编码为一个向量(即,用于执行预测的、用户偏好的representation),包括具有ranking loss的session-based GRU(GRU4Rec)、Dynamic REcurrent bAsket Model: DREAM、user-based GRU(《Sequential User-based Recurrent Neural Network Recommendations》)、attention-based GRU(NARM)、以及具有新的损失函数(即BPR-max和TOP1-max)和改进的采样策略的improved GRU4Rec(《Recurrent Neural Networkswith Top-k Gains for Session-based Recommendations)。除了循环神经网络(
recurrent neural network)之外,人们还引入了各种深度学习模型来进行序列推荐。例如:《Personalized Top-N Sequential Recommendation via Convolutional Sequence Embedding》提出了一个卷积序列模型Caser,它同时使用水平卷积滤波器和垂直卷积滤波器来学习序列模式。《Sequential Recommendation with User Memory Networks》和《Improving Sequential Recommendation with Knowledge-Enhanced Memory Networks》使用Memory Network来改善序列推荐。STAMP使用具有注意力的MLP网络来同时捕获用户的通用兴趣(general interest)和当前兴趣 (current interest)。
注意力机制:注意力机制在建模序列数据方面显示出巨大的潜力,例如机器翻译和文本分类。最近,一些工作尝试使用注意力机制来提高推荐性能和可解释性。例如,
NARM将注意力机制融合到GRU中,从而在session-based推荐中同时捕获用户的序列行为和主要意图(main purpose)。上述工作基本上将注意力机制视为原始模型的附加组件(
additional component)。相比之下,Transformer和BERT仅建立在multi-head self-attention之上,并且在文本序列建模上取得了SOTA结果。最近,人们越来越热衷于应用单纯的attention-based神经网络来建模序列数据,从而提高模型的效果和效率 (effectiveness and efficiency)。对于序列推荐,《Self-Attentive Sequential Recommendation》引入了一个名为SASRec的、两层的Transformer解码器(即,Transformer语言模型)来捕获用户的序列行为,并在几个公共数据集上实现了SOTA的结果。SASRec与我们的工作密切相关。然而,它仍然是一个使用因果注意力掩码(casual attention mask)的单向模型。而我们使用双向模型在完形填空任务的帮助下,编码用户的行为序列。
1.1 模型
问题定义:令
item集合。interaction sequence)(按时间顺序排列),time stepitem,给定历史交互序列
time stepitem。该问题可以形式化为:建模用户time stepitem的概率:这里我们介绍了一种新的序列推荐模型,称作
BERT4Rec。BERT4Rec采用来自Transformer的Bidirectional Encoder Representation来完成一个新任务,即序列推荐。BERT4Rec建立在流行的self-attention layer(即,Transformer layer)的基础之上。如下图
(b)所示,BERT4Rec由Transformer layer堆叠而成。在每一层,BERT4Rec通过Transformer layer并行地修改每个位置的representation,这种修改是通过交换前一层所有位置的信息来实现的。不像图(d)中RNN-based方法那样step-by-step地学习forward相关的信息,self-attention机制赋予BERT4Rec直接捕获任何距离的依赖关系的能力。这种机制导致全局感受野,而像Caser这样的CNN-based方法通常具有有限的感受野。此外,与RNN-based方法相比,self-attention可以直接并行化。比较下图
(b), (c), (d),最明显的区别是:SASRec-based和RNN-based方法都是left-to-right的单向结构,而我们的BERT4Rec使用双向自注意力来建模用户的行为序列。通过这种方式,我们提出的模型可以获得用户行为序列更强大的representation,从而提高推荐性能。
1.1.1 Transformer Layer
如上图
(b)所示,给定长度为《Attention is All you Need》中的Transformer layer,在每一层hidden representationrepresentation维度。这里,我们将step-by-step地计算)。如上图
(a)所示,Transformer layerTrm包含两个子层:一个Multi-Head Self-Attention子层、一个Position-wise Feed-Forward Network。Multi-Head Self-Attention:注意力机制已经成为各种序列建模任务中不可或缺的一部分,它允许捕获representation pair之间的依赖关系,而无需考虑representation pair在序列中的距离。 以前的工作表明,联合处理来自不同位置的、不同representation子空间的信息是有益的。因此,我们在这里采用multi-head self-attention而不是执行单个注意力函数。具体而言:multi-head attention首先将然后并行采用
output representation。最后这
output representation被拼接成单个representation并再次进行线性投影。
其中:
每个
head的投影矩阵Attention()函数是Scaled Dot-Product Attention:其中:
querykeyvalue注意:由于这里的
Position-wise Feed-Forward Network:如前所述,自注意力子层主要基于线性投影。为了赋予模型非线性(nonlinearity)、以及不同维度之间的交互(interaction),我们将Position-wise Feed-Forward Network应用于注意力子层的输出,在每个位置独立(separately)地、且等同地(identically)应用。Position-wise Feed-Forward Network由两个仿射变换组成,中间有一个Gaussian Error Linear Unit: GELU激活函数:其中:
在这项工作中,遵循
OpenAI GPT和BERT的工作,我们使用更平滑的GELU激活函数而不是标准的ReLu激活函数。注意,这里通过
representation先膨胀,然后再通过堆叠
Transformer Layer:如前所述,我们可以使用self-attention机制轻松地捕获整个用户行为序列中的item-item交互。通过堆叠self-attention layer来学习更复杂的item transition pattern通常是有益的。然而,随着网络的加深,网络变得更加难以训练。因此,我们在两个子层的每个子层周围使用一个残差连接,然后是layer normalization,如上图(a)所示。此外,我们还将
dropout应用于每个子层的输出,dropout发生在layer normalize之前。即,每个子层的输出为:MH()、或逐位置的前向反馈网络PFFN()。layer normalization函数。我们使用LN对同一层中的所有隐单元的输入进行归一化,从而稳定和加速网络训练。
总之,
BERT4Rec将每一层的hidden representation调整为:
1.1.2 Embadding Layer
如前所述,由于没有任何递归模块或卷积模块,因此
Transformer layer Trm不知道输入序列的顺序(order)。为了利用输入的序列信息,我们将Positional Embedding注入到Transformer layer stack底部的input item embedding中。对于给定的iteminput representationitem embedding和positional embedding相加得到:其中:
itemembedding向量,positional embedding。所有
item的embedding构成item embedding矩阵embedding构成positional embedding矩阵在这项工作中,我们使用可学习的
positional embedding而不是固定的正弦embedding,从而获得更好的性能。positional embedding矩阵positional embedding矩阵item。如果是固定的正弦
embedding作为positional embedding,那么模型没有最大序列长度的限制。
1.1.3 输出层
在
Transformer Layer之后,我们得到输入序列的所有item的final outputtime stepmask了itemmasked的itemGELU激活的两层前馈网络来生成target item的输出分布:其中:
bias项,item的embedding矩阵。我们在输入层和输出层使用共享的
item embedding矩阵来缓解过拟合并减小模型大小。一方面,由于
mask了,因此在所有Transformer Layer中都不会泄露另一方面,位置
final representationitem的信息从而用于预测
1.1.4 模型学习
训练阶段:传统的单向序列推荐模型通常通过预测输入序列的每个位置的
next item来训练模型。具体而言,输入序列targetconditioning)左右上下文会导致每个item的final output representation包含target item的信息。这使得预测未来变得没有意义,并且网络不会学到任何有用的东西。假如
target item为序列中最后一个item,那么在双向模型中,序列中第一个item、第二个item、... 其它所有位置item都能访问到target item的信息。这个问题的一个简单解决方案是:从原始长度为
next item作为label的子序列,如target item。然而,这种方法非常耗时和耗资源,因为我们需要为序列中的每个位置创建一个新样本并分别预测它们。为了有效地训练我们提出的模型,我们将一个新目标,即完形填空任务(
Cloze task)(也被称作Masked Language Model: MLM),应用于序列推荐。这是一项由一部分语言组成的测试,其中某些单词被删除,模型需要预测缺失的单词。在我们的例子中,对于每个training step,我们随机mask输入序列中所有item的token"[mask]"替换),然后仅根据左右上下文预测被masked item的原始ID。例如:与
"[mask]"相对应的final hidden vector被馈送到一个output softmax,就像在传统的序列推荐中一样。最终,我们将每个masked inputmasked target的负对数似然:其中:
masked版本,如masked的item集合,如masked itemground truth,如ground truth的概率。
完形填空任务的另一个优点是它可以生成更多样本来训练模型。假设一个长度为
BERT4Rec可以在多个epoch中获得maskitem)。这允许我们训练更强大的双向representation模型。测试阶段:如前所述,我们在训练和最终的序列推荐任务之间造成了不匹配 (
mismatch),因为完形填空任务的目标是预测当前的masked item,而序列推荐任务的目标是预测未来。为了解决这个问题,我们将特殊token"[mask]"附加到用户行为序列的末尾,然后根据该token的final hidden representation来预测next item。为了更好地匹配序列推荐任务(即,预测
next item),在训练期间我们还生成mask输入序列中最后一个item的样本。它的作用类似于用于序列推荐的微调,可以进一步提高推荐性能。mask输入序列中最后一个item的样本是否可以给予更大的样本权重?这样可以让模型更focus这类样本,从而缓解训练阶段和测试阶段不匹配的问题。或者直接使用domain adaption方法。因为机器学习有一个核心假设:训练样本和测试样本的分布要保持一致。
1.1.5 讨论
我们讨论我们的模型与之前相关工作的联系。
SASRec:显然,SASRec是我们的BERT4Rec的从左到右的单向版本,具有single head attention以及causal attention mask。不同的架构导致不同的训练方法。
SASRec预测序列中每个位置的next item,而BERT4Rec使用完形填空目标来预测序列中的masked item。CBOW& SG:另一个非常相似的工作是Continuous Bag-of- Word: CBOW和Skip-Gram: SG。CBOW使用target word上下文中所有的词向量(同时使用左侧和右侧)的均值来预测target word。它可以视为BERT4Rec的一个简化案例:如果我们在BERT4Rec中使用一个self-attention layer、对所有item使用均匀的注意力权重、取消共享的item embedding、移除positional embedding、并且仅mask center item,那么我们的BERT4Rec就变成了CBOW。与
CBOW类似,SG也可以看作是BERT4Rec在化简之后的、类似的简化案例(除了保留一个item之外,mask所有其它item)。
从这个角度来看,完形填空可以看作是
CBOW和SG目标的通用形式。此外,
CBOW使用简单的聚合操作来建模单词序列,因为它的目标是学习良好的word representation,而不是sentence representation。相反,我们寻求学习一个强大的行为序列representation模型(即,本文中的深度自注意力网络)来进行推荐。BERT:虽然我们的BERT4Rec受到NLP中的BERT的启发,但是它仍然与BERT有几个不同之处:最关键的区别是:
BERT4Rec是用于序列推荐的端到端模型,而BERT是用于sentence representation的预训练模型。BERT利用大规模的、任务无关的语料库为各种文本序列任务训练sentence representation模型,因为这些任务共享相同的、关于语言的背景知识。然而,这个假设在推荐任务中并不成立。因此,我们针对不同的序列推荐数据集,端到端地训练BERT4Rec。与
BERT不同,我们移除了next sentence loss和segment embedding,因为在序列推荐任务中,BERT4Rec仅将用户的历史行为建模为一个序列。
未来方向:
将丰富的
item特征(如商品的类别和价格、电影的演员表)引入到BERT4Rec中,而不仅仅是建模item ID。将用户组件引入到模型中,以便在用户有多个
session时进行显式的用户建模。
另外,也可以将
SR-GNN中的GNN组件代替这里的item embedding。
1.2 实验
数据集:我们在四个真实世界的代表性数据集上评估所提出的模型,这些数据集在领域和稀疏性方面差异很大。
Amazon Beauty:这是从Amazon.com爬取的一系列商品评论数据集。人们根据Amazon上的top level商品类别将数据拆分为单独的数据集。在这项工作中,我们采用Beauty类别。Steam:这是从大型的在线视频游戏分发平台Steam收集的数据集。MovieLens:这是一个用于评估推荐算法的、流行的benchmark数据集。在这项工作中,我们采用了两个版本,即MovieLens 1m: ML-1m和MovieLens 20m: ML-20m。
对于数据集预处理,我们遵循
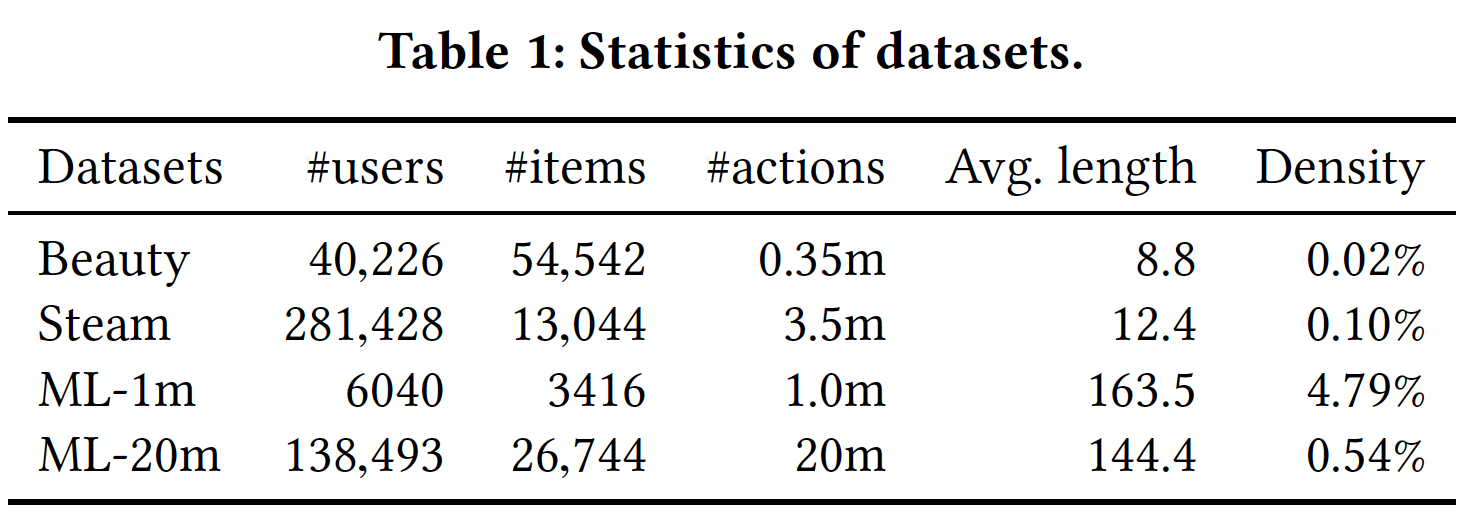
SASRec、FPMC、Caser中的常见做法。对于所有数据集,我们将所有数字评分、或者存在评论转换为数值为1的隐式反馈(即,用户与item存在交互)。此后,我们将交互记录按用户分组,并根据时间戳对这些交互记录进行排序,从而为每个用户构建交互序列。为了确保数据集的质量,按照惯例,我们仅保留至少存在五个反馈的用户。处理后的数据集的统计数据如下表所示。
任务设置:为了评估序列推荐模型,我们采用了
leave-one-out评估(即,next item推荐)任务,该任务在SASRec、FPMC、Caser中已被广泛使用。对于每个用户,我们将行为序列的最后一个item作为测试数据,将倒数第二个item作为验证集,并利用剩余的item进行训练。为了简单的、公平的评估,我们遵循
SASRec、FPMC、Caser中的通用策略,将测试集中的每个ground truth item与100个随机采样的、用户未与之交互的negative item进行配对。为了使采样可靠和具有代表性,这100个negative item根据流行度进行采样。因此,任务变成将这些negative item与每个用户的ground truth item进行排名。每个
ground truth item独立地采样100个negative item,而不是所有ground truth item共享相同的negative item。评估指标:为了评估所有模型的排名,我们采用了多种评估指标,包括
Hit Ratio: HR、Normalized Discounted Cumulative Gain: NDCG、Mean Reciprocal Rank: MRR。考虑到每个用户仅有一个ground truth item,因此HR@k等价于Recall@k且与Precision@k成正比,MRR相当于Mean Average Precision: MAP。在这项工作中,我们使用
HR和NDCG。对于所有这些指标,值越高则代表性能越好。baseline:POP:它是最简单的baseline,根据item的热门程度来排序,其中热门程度根据交互次数来判断。BPR-MF:它使用pairwise ranking loss来优化带隐式反馈的矩阵分解。NCF:它使用MLP而不是矩阵分解中的内积来建模user-item交互。FPMC:它通过将矩阵分解与一阶马尔科夫链相结合,从而捕获用户的通用口味(general taste)以及序列行为。GRU4Rec:它使用带ranking based loss的GRU来建模用户行为序列从而用于session-based推荐。GRU4Rec+:它是GRU4Rec的改进版本,具有新的损失函数和新的采样策略。Caser:它同时以水平卷积和垂直卷积两种方式来使用CNN来建模高阶马尔科夫链,从而进行序列推荐。SASRec:它使用从左到右的Transformer语言模型来捕获用户的序列行为,并在序列推荐上实现了SOTA的性能。
配置:
对于
NCF、GRU4Rec、GRU4Rec+、Caser、SASRec,我们使用相应作者提供的代码。对于BPR-MF和FPMC,我们使用TensorFlow实现它们。对于所有模型中的通用超参数,我们考虑隐层维度
所有其它超参数(如
Caser中的马尔科夫阶次)和初始化策略,要么遵循原始论文作者的推荐,要么根据验证集进行调优。我们报告每个baseline在其最佳超参数设置下的结果。我们使用
TensorFlow实现BERT4Rec。所有参数都使用[−0.02, 0.02]范围内的截断正态分布进行初始化。我们使用
Adam训练模型,学习率为当梯度的
为了公平比较,我们设置层数
head数量SASRec中相同的最大序列长度,即:对于ML-1m和ML-20m数据集,Beauty和Steam数据集,对于
head的设置,我们根据经验将每个head的维度设置为32(如果single head)。我们使用验证集调优
mask比例Beauty为Steam为ML-1m和ML-20m为所有模型都是在单个
NVIDIA GeForce GTX 1080 Ti GPU上从零开始训练的而没有任何预训练,batch size = 256。
1.2.1 整体性能比较
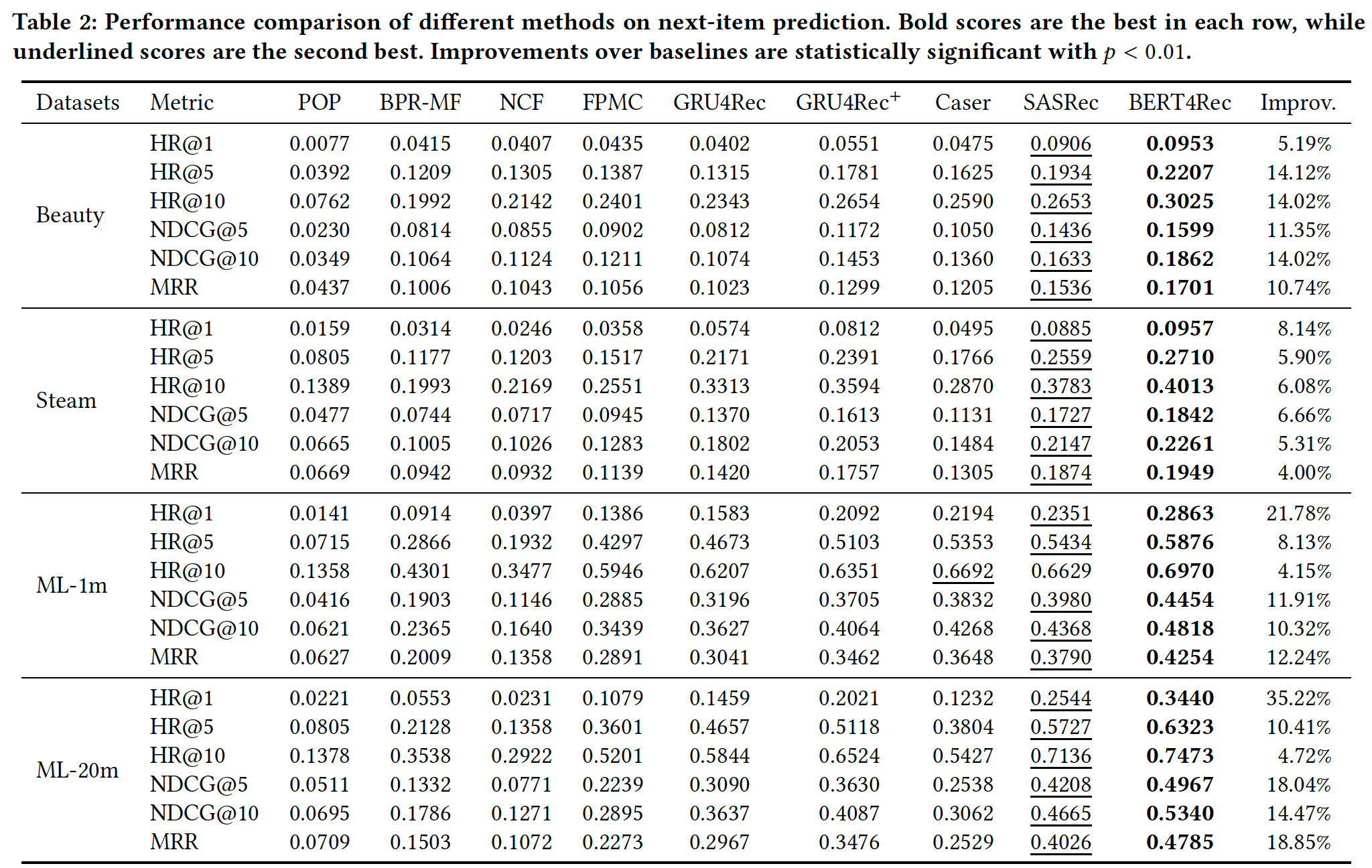
下表总结了所有模型在四个
benchmark数据集上的最佳结果。最后一列是BERT4Rec相对于最佳baseline的提升。我们省略了NDCG@1的结果,因为在我们的实验中它等于HR@1。可以看到:非个性化
POP方法在所有数据集上的性能最差,因为它没有使用历史行为记录来建模用户的个性化偏好。在所有
baseline方法中,序列方法(如,FPMC和GRU4Rec+)在所有数据集上始终优于非序列方法(如,BPR-MF和NCF)。与BPR-MF相比,FPMC的主要改进在于它以序列的方式来建模用户的历史行为记录。这一观察结果验证了:考虑序列信息有利于提高推荐系统的性能。
在序列推荐
baseline中,Caser在所有数据集上都优于FPMC,尤其是在稠密数据集ML-1m上,这表明高阶马尔科夫链有利于序列推荐。然而,高阶马尔科夫链通常使用非常小的阶次scalable的。这导致Caser的性能比GRU4Rec+和SASRec更差,尤其是在稀疏数据集上。此外,
SASRec的性能明显优于GRU4Rec和GRU4Rec+,这表明self-attention机制是一种更强大的序列推荐工具。根据结果,很显然
BERT4Rec在所有方法中,在四个数据集上的所有指标都是最佳的。与最强的baseline相比,它平均而言获得了7.24%的HR@10相对提升、11.03%的NDCG@10相对提升、11.46%的MRR相对提升。
问题一:收益是来自于双向自注意力模型还是来自于完形填空目标?
为了回答这个问题,我们尝试通过将完形填空任务限制为一次仅
mask一个item来隔离这两种因素的影响。通过这种方式,我们的BERT4Rec(带有一个mask)和SASRec之间的主要区别在于:BERT4Rec通过联合地调节(jointly conditioning)左右上下文来预测target item。注意,这里要求被
masked的item是随机的,不能固定为最后一个item。如果固定地mask最后一个item,那么BERT4Rec就等价于SASRec。由于篇幅有限,我们在下表中报告了
Beauty和ML-1m的实验结果,其中mask的BERT4Rec在所有指标上都显著优于SASRec。这证明了bidirectional representation对于序列推荐的重要性。此外,最后两行表明完形填空目标也提高了性能。完形填空任务以及
mask比例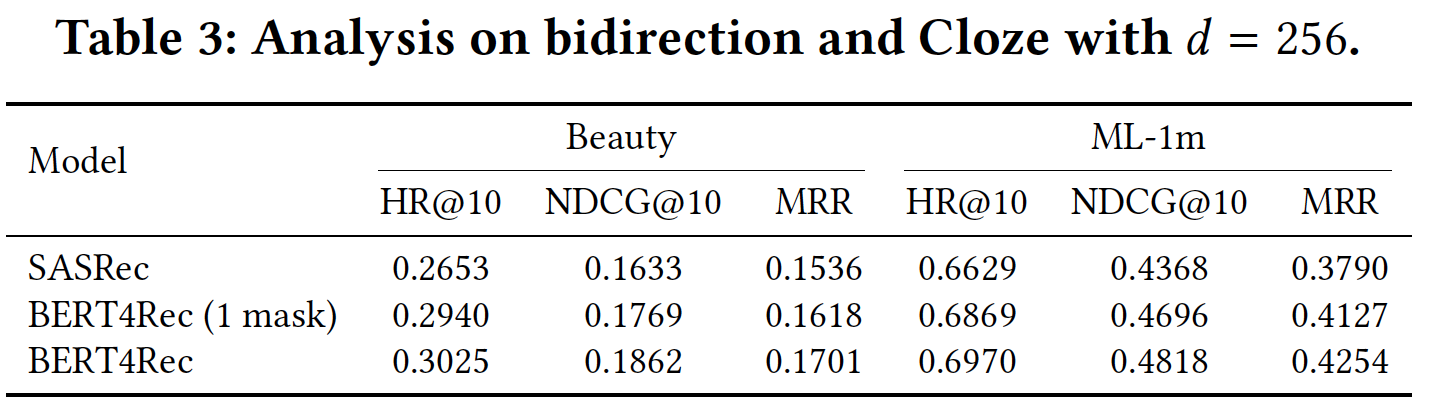
问题二:双向模型为何、以及如何优于单向模型?
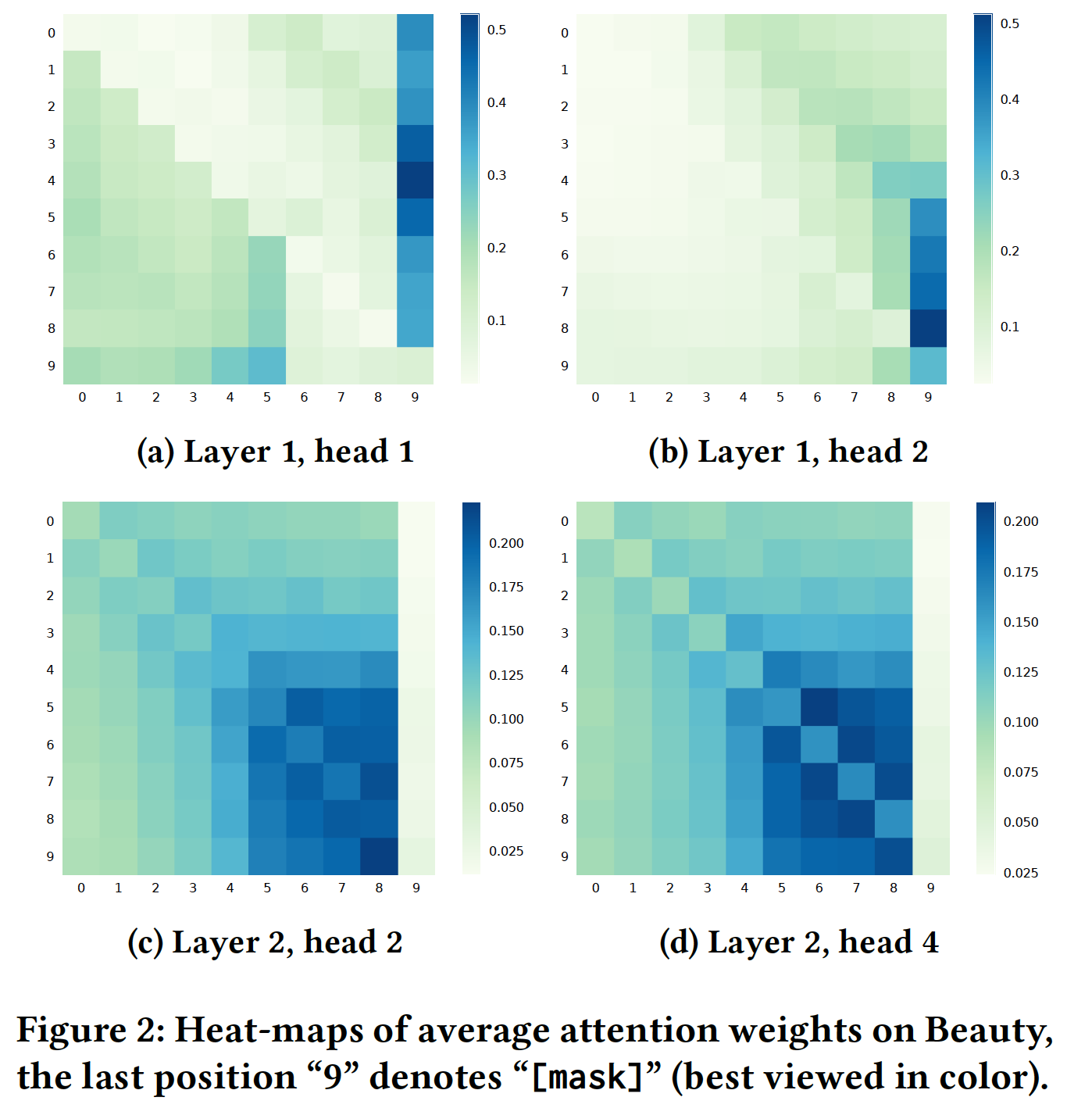
为了回答这个问题,我们试图通过在
Beauty测试期间可视化the last 10 items的平均注意力权重来揭示有意义的模式,如下图所示。由于篇幅有限,我们仅报告了不同层和不同head的四个具有代表性的注意力热力图。从结果中可以看到:不同
head的注意力不同。例如,在layer 1中,head 1倾向于关注左侧的item,而head 2更喜欢关注右侧的item。不同层的注意力不同。显然,
layer 2的注意力往往集中在更近(more recent)的item上。这是因为layer 2直接连接到输出层,而recent item在预测未来方面起着更重要的作用。另一个有趣的模式是:图
(a)和(b)中的head也倾向于关注[mask](因为最后一个item是被masked的)。这可能是self-attention将sequence-level state传播到item level的一种方式。最后也是最重要的一点,与单向模型只能关注左侧的
item不同,BERT4Rec中的item倾向于同时关注两侧的item。这表明双向对于用户行为序列建模是必不可少且有益的。
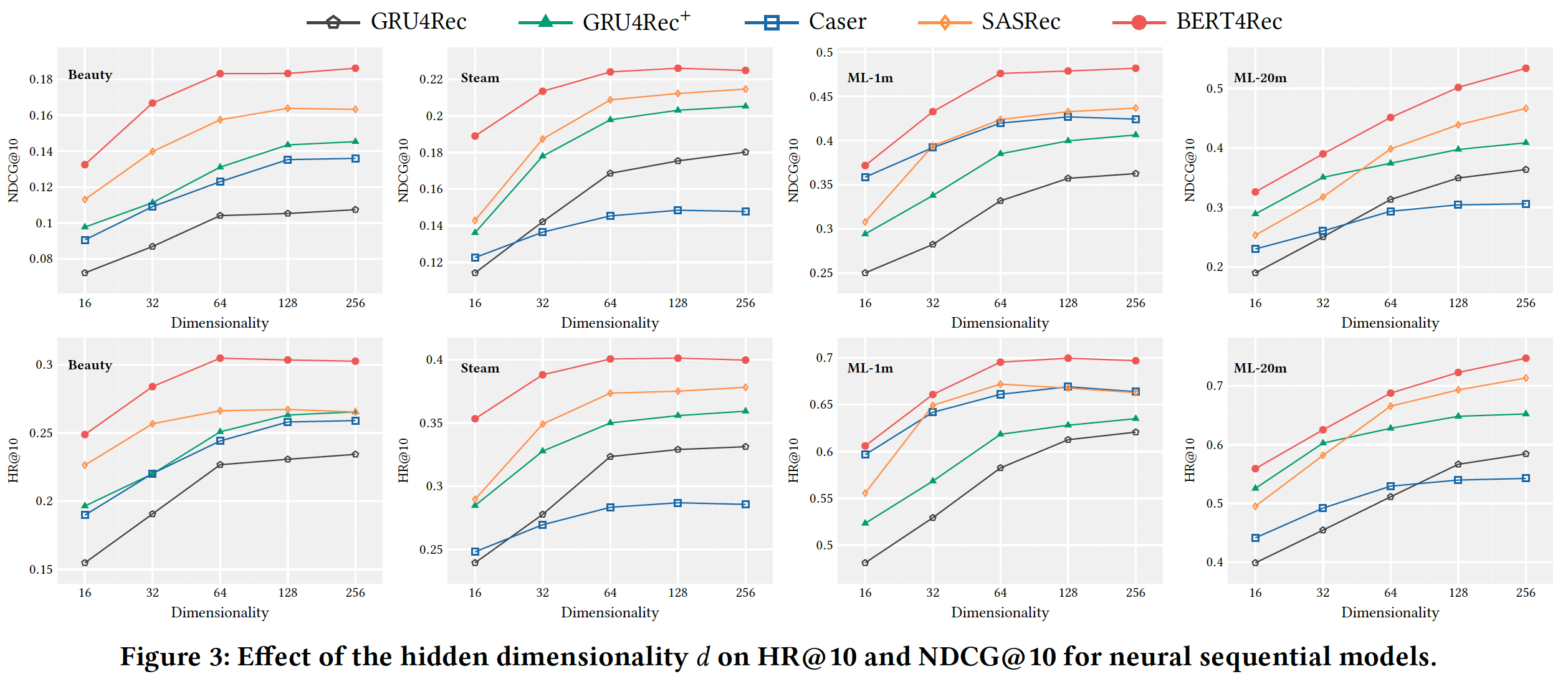
1.2.2 超参数研究
接下来我们检查了超参数的影响,包括隐层维度
mask比例NDCG@10和HR@10。隐层维度
NDCG@10和HR@10指标,可以看到:最明显的观察是:每个模型的性能随着维度
Beauty和Steam等稀疏数据集上。这可能是由于过拟合造成的。在细节方面,
Caser在四个数据集上的表现不稳定,这可能会限制其有用性(usefulness)。self-attention based方法(即,SASRec,BERT4Rec)在所有数据集上都取得了卓越的性能。最后,我们的模型在所有数据集上始终优于所有其它
baseline,即使在隐层维度
考虑到我们的模型在
mask比例mask比例mask比例masked item。为了验证这一点,我们研究了mask比例下图展示了
mask比例0.1到0.9之间变化的结果。考虑
从前两列的结果中,很容易看出
这些结果验证了我们上面所说的。
此外,我们观察到最优
对于具有短序列长度的数据集(如
Beauty和Steam),在Beauty) 和Steam) 时获得最佳性能。对于具有长序列长度的数据集(如
ML-1m和ML-20m),在
这是合理的,因为与短序列数据集相比,长序列数据集中的大
item更多。以ML-1m和Beauty为例,对于
ML-1m我们需要平均每个序列预测item。对于
Beauty我们仅需要平均每个序列预测item。
前者对于模型训练而言太难了。
注:下图的
x轴文字有误,应该是Mask proportion而不是Dimensionality。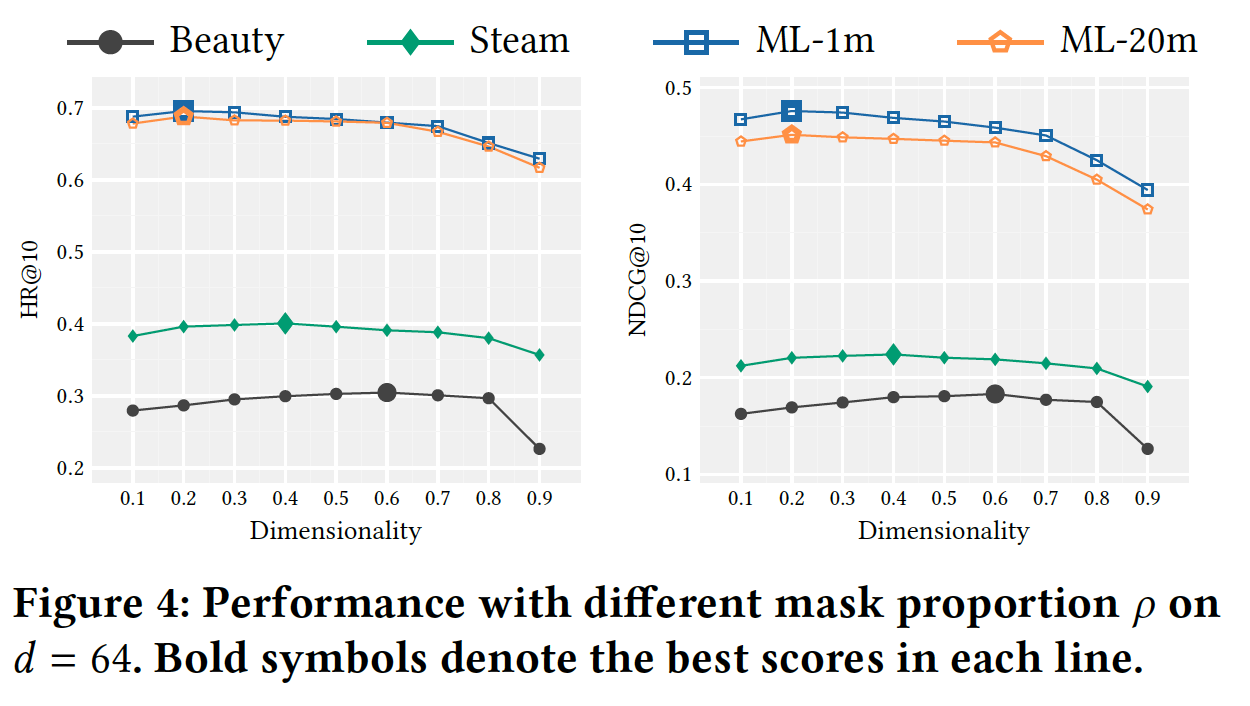
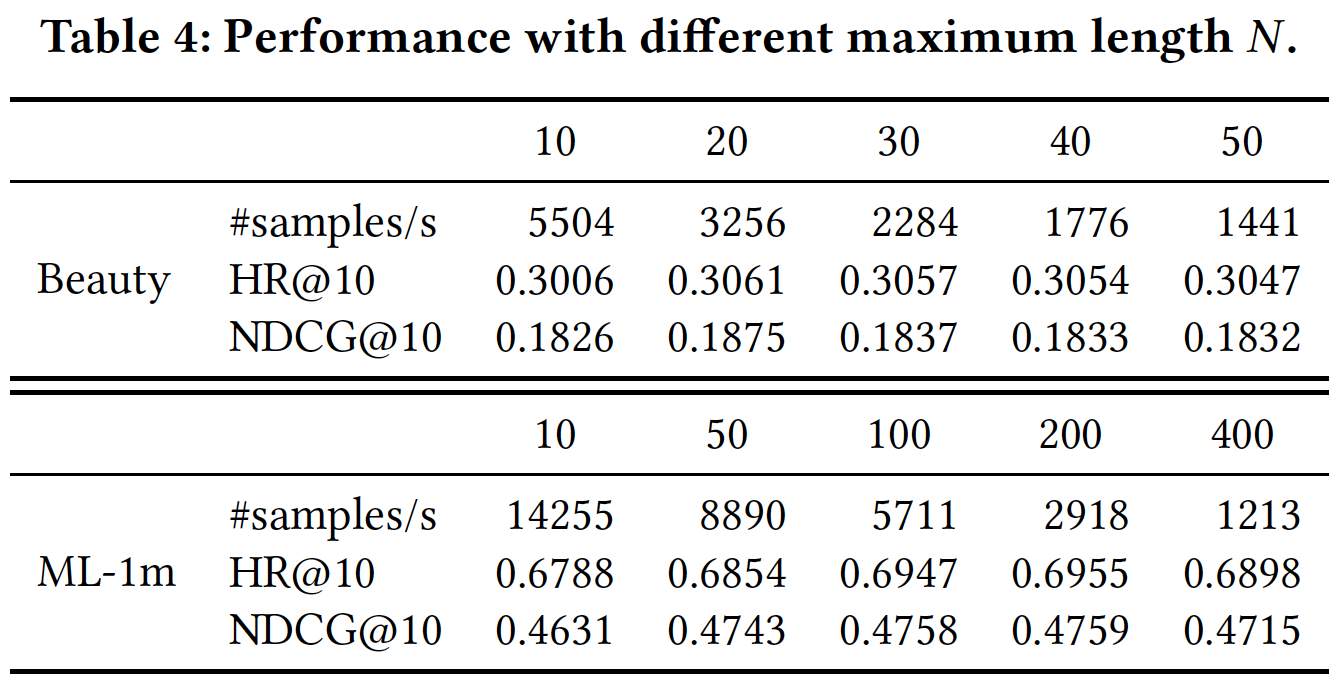
最大序列长度
Beauty和ML-1m数据集上不同的最大长度适当的最大长度
Beauty更喜欢较小的ML-1m在more recent items的影响、受到长序列数据集上less recent items的影响。这是因为
Beauty数据集的平均序列长度很短,而ML-1m数据集的平均序列长度很长。因此,二者的最佳20和200。通常而言,模型不能一致地从较大的
informative items。BERT4Rec的一个可扩展性问题是:每层的计算复杂度为GPU可以有效地并行化self-attention layer。
1.2.3 消融研究
最后,我们对
BERT4Rec的一些关键组件进行了消融实验,从而更好地了解它们的影响,包括positional embedding: PE、position-wise feed-forward network: PFFN、layer normalization: LN、residual connection: RC、dropout、self-attention的层数multi-head attention的head数量下表显示了我们的默认版本
PE:结果表明,移除positional embedding会导致BERT4Rec在长序列数据集(即ML-1m和ML-20m)上的性能急剧下降。如果没有
positional embedding,每个itemhidden representationitem embedding。此时,模型无法获得序列的顺序信息,例如模型对于不同位置的"[mask]",使用相同hidden representation来预测不同的target item(假设unmask的item保持不变) 。这使得模型有问题。这个问题在长序列数据集上更为严重,因为它们有更多的masked item需要预测。PFFN:结果表明,长序列数据集(如ML-20m)从PFFN中获益更多。这是合理的,因为PFFN的目的是整合来自多个head的信息。正如关于head数量head的信息是长序列数据集所偏好的。LN, RC, Dropout:引入这些组件主要是为了缓解过拟合。显然,它们在Beauty等小型数据集上更有效。为了验证它们在大型数据集上的有效性,我们在ML-20m上进行了实验。结果表明:当没有RC时,NDCG@10降低了约10%(这个结果不在下表中)。层数
Transformer layer可以提高性能,尤其是在大型数据集(如ML-20m)上。这验证了通过深度自注意力架构学习更复杂的item transition pattern是有益的。在数据集Beauty上,head数量ML-20m)受益于较大的Beauty)更喜欢较小的《Why Self-Attention? A Targeted Evaluation of Neural Machine Translation Architectures》中的实验结果一致,即大multi-head self-attention捕获长距离依赖关系至关重要。