一、CSRM [2019]
《A Collaborative Session-based Recommendation Approach with Parallel Memory Modules》
传统的推荐方法通常基于显式的
user-item偏好(如,评分),其中关于用户的信息和item的信息是必不可少的。例如,content-based方法通过评估用户画像(user profile)(即,用户历史行为记录)和item特征之间的相似性来生成推荐列表。然而,在许多现实场景中,用户没有登录,并且也不知道用户历史的交互:没有显式的偏好,只有positive的观察(如,点击)可用。在这种情况下,传统的推荐方法表现不佳。为了解决这个问题,人们已经提出了session-based推荐,从而仅基于匿名行为session来生成推荐。给定用户在当前session中的行为的短期历史,session-based推荐旨在预测该用户可能感兴趣的next item。session-based推荐的早期研究主要基于item-to-item的推荐,并产生的预测依赖于计算session内item之间相似性(如,基于共现co-occurrence),而忽略了当前session中点击序列的序列信息(sequential information)。后续的工作研究了使用马尔科夫链来利用序列行为数据并根据用户的最近动作(last action)来预测用户的next action。然而,这些工作仅建模相邻item之间的局部顺序行为(local sequential behavior)。基于马尔科夫链的方法的一个主要问题是,当试图在所有item上包含所有潜在的、用户选择(user selection)的序列时,状态空间很快变得难以管理。最近的研究将深度学习(如
RNN)用于session-based的推荐,因此可以考虑整个session的信息。例如:《Session-based recommendations with recurrent neural networks》使用Gated Recurrent Unit: GRU来建模session中的动作序列。《Neural attentive session-based recommendation》通过引入注意力机制来捕获用户在当前session中的主要意图(main purpose),从而实现进一步的改进。
尽管这些
RNN-based方法比传统的推荐方法有了显著的提升,但它们的短期记忆(short-term memory)通常有限,并且难以执行记忆(memorization)。人们已经将memory network引入推荐系统,其动机是拥有一个长期记忆(long-term memory)模块的优势。《Sequential recommendation with user memory networks》通过首次引入user memory network,利用用户的历史记录,显式地捕获item-level和feature-level的序列模式(sequential pattern),从而改进序列推荐。《Improving sequential recommendation with knowledge-enhanced memory networks》提出了一种知识增强(knowledge enhanced)的序列推荐器,它将RNN-based网络与Key-Value Memory Network: KV-MN相结合。
现有的
memory network-based的推荐方法取得了令人鼓舞的结果。但是它们仅利用了用户自己的信息,而忽略了所谓的neighborhood session中协同信息(collaborative information)的潜力。neighborhood session是由任何用户(不一定是当前session的同一用户,因为这里的session是匿名的)生成的session,它们显示出与当前session相似的行为模式(similar behavior pattern),并反映出与当前session相似的用户意图(similar user intent)。例如,考虑sessionsessionsession的用户都点击了某些手机,因此可以推测他们具有类似的兴趣,可以进行比较。这两个用户可能有相似的意图来寻找合适的手机,因此,生成第二个session的用户可能对《A Collaborative Session-based Recommendation Approach with Parallel Memory Modules》假设neighborhood session可能有助于改善当前session中的推荐。论文
《A Collaborative Session-based Recommendation Approach with Parallel Memory Modules》提出了一种新颖的神经网络框架,即Session-based Recommendation Machine: CSRM,用于session-based推荐。该框架由两个并行模块组成:一个Inner Memory Encoder: IME模块、一个Outer Memory Encoder: OME模块。IME在RNN固有的dynamic memory的帮助下对当前session中包含的信息进行建模。它学习一个统一的representation来结合两种编码方案:一个全局编码器(global encoder)和一个局部编码器(local encoder)。IME其实就是《Neural attentive session-based recommendation》提出的NARM。OME利用协同过滤技术通过利用一个external memory模块来研究(investigate)neighborhood session从而更好地预测当前session的意图。OME包含一个关联的寻址机制(associative addressing mechanism)来自动识别neighborhood session。
最后,
CSRM引入了一种融合门控机制(fusion gating mechanism)来组合IME和OME产生的representation,并根据fused representation来计算每个候选item的推荐分。论文对三个
benchmark数据集进行了广泛的实验。结果表明,CSRM在所有三个数据集上的Recall和MRR均优于SOTA的session-based的推荐baseline。论文进行了进一步的实验以深入分析IME和OME,从而探索CSRM的推荐过程,并确定协同邻域信息(collaborative neighborhood information)和融合门控机制如何影响session-based推荐的性能。论文的贡献如下:
据作者所知,论文是第一个考虑在
session-based推荐中用端到端的神经网络模型进行协同建模(collaborative modeling)的。论文提出了一种新颖的
CSRM模型,该模型集成了IME和OME,从而将来自current session和neighborhood session的信息纳入session-based的推荐。论文引入了一种融合门控机制,以选择性地结合
current session和neighborhood session的信息从而获得更好的推荐。论文对三个
benchmark数据集进行了广泛的实验。在session-based的推荐任务上,CSRM在Recall和MRR方面显著优于SOTA模型。
相关工作:
协同过滤(
collaborative filtering):协同过滤是一种广泛使用的推荐方法。它通过建模user-item交互来识别用户偏好,并基于 “具有相似偏好的人倾向于作出相似选择” 的假设来向用户推荐item。先前关于协同过滤的工作可以分为两类:KNN-based方法、model-based方法。KNN-based方法使用预定义的相似性函数来查找相似的用户或item,从而促进(promote)推荐。它们可以进一步分为user-based KNN和item-based KNN。user-based KNN计算用户之间的相似性,并推荐相似用户可能喜欢的item。《An automatic weighting scheme for collaborative filtering》提出了一种算法,用于在识别两个用户之间的相似性时学习不同item的权重。《A new user similarity model to improve the accuracy of collaborative filtering》提出了一种启发式相似性度量方法来改进协同过滤,该方法结合了用户评分的上下文信息以及用户行为的偏好。
item-based KNN计算item之间的相似性,并使用这些相似性来预测user-item pair对的评分。《Item-based collaborative filtering recommendation algorithms》提出使用correlation-based和cosine-based技术来计算item之间的相似性。《Item-based top-n recommendation algorithms》将item-to-item相似性扩展到用户的所有消费(consumed)的item与候选item之间的相似性概念从而用于top-N推荐。
给定
user-item评分矩阵,model-based方法将用户和item映射到共享的潜在因子空间(shared latent factor space)中从而表征用户和item,并通过用户和item的潜在因子(latent factor)之间的内积来生成预测。这些方法的例子包括矩阵分解(matrix factorization)、奇异值分解(Singular Value Decomposition: SVD)、SVD++。《Collaborative denoising auto-encoders for top-n recommender systems》通过将一个user-specific bias集成到自编码器中来推广协同过滤模型。《Neural collaborative filtering》通过使用深度学习而不是内积来建模user-item交互。
尽管这些方法通过探索协同过滤取得了可喜的成果,但是它们都有局限性。
一方面,
KNN-based方法无法识别序列信号(sequential signal)。另一方面,当用户画像(即,用户历史行为序列)不可用时,
model-based方法不能用于session-based推荐。
最近,
《When recurrent neural networks meet the neighborhood for session-based recommendation》结合了一个GRU模型和co-occurrence-based KNN模型来探索session-based推荐中的协同信息。他们的方法与我们的工作之间的差异至少有两个方面。首先,我们的模型是一个端到端的
memory network,而他们使用简单的加权方案将GRU模型和KNN模型的分数以手工制作的超参数结合起来。其次,我们的模型中用于查找
k近邻k-nearest neighbor的相似性是自动学习到的,而他们使用一个启发式的、co-occurrence-based相似性度量。
记忆增强的神经网络(
memory augmented neural network):Memory Augmented Neural Network: MANN通常由两个组件组成:一个存储长期历史信息的memory、一个在memory上执行read/write操作的控制器(controller)。最近,用于推荐系统的
memory network因其SOTA的性能而受到了相当大的关注。《Sequential recommendation with user memory networks》首个提出将矩阵分解与MANN集成从而进行序列推荐(sequential recommendation)。他们提出了具有两种变体的Recommendation with User Memory network: RUM:item-level RUM和feature-level RUM。item-level RUM将每个item视为一个单元(unit),并将item embedding直接存储在memory matrix中。feature-level RUM将用户在不同潜在特征上的偏好的embedding存储在memory matrix中。
《Improving sequential recommendation with knowledge-enhanced memory networks》提出了一种知识增强(knowledge enhanced)的序列推荐器,它结合了知识库(knowledge base)信息来捕获attribute-level的用户偏好。《Mention recommendation for multimodal microblog with cross-attention memory network》将MANN与交叉注意力机制(cross-attention mechanism)相结合,为多模态推文(tweet)执行mention推荐任务,其中他们使用MANN来存储图片和推文的历史兴趣。
尽管这些方法都取得了可喜的成果,但他们都忽略了协同的邻域信息。
与我们最相似的工作涉及协同记忆网络
Collaborative Memory Network: CMN(《Collaborative memory network for recommendation systems》)。它统一了两类协同过滤模型:矩阵分解、neighborhood-based方法。CMN利用三种memory state来建模user-item交互,包括:一个内部的user-specific memory state、一个内部的item-specific memory state、以及一个collective neighborhood state。我们的工作与CMN之间的差异至少有三点:首先,
CMN不能直接应用于session-based的推荐,因为没有可用的用户信息。尽管我们可以对CMN进行一些改变,但我们发现它对session-based推荐没有效果。其次,
CMN通过寻找相似的user-item交互模式(interaction pattern)找执行协同过滤。相比之下,我们的模型通过探索neighborhood session来利用协同信息。第三,
CMN简单地结合协同特征(collaborative feature)和user-item潜在特征来预测评分。相反,我们引入了一种融合门控机制来学习选择性地组合(selectively combine)不同的特征源。
1.1 模型
令
item的集合。令session,其中每个session期间所交互的item,如听一首歌、看一个视频。给定一个sessionsession-based推荐系统的任务是预测用户可能交互的next item。正式地,给定当前sessionitemtop-N item(我们提出了一个
Collaborative Session-based Recommendation Machine: CSRM框架来生成session-based的推荐。CSRM背后的关键思想是:利用来自neighborhood session的信息来提高current session的推荐性能。neighborhood session是展示与current session相似的行为模式的session。具体而言,我们将最近
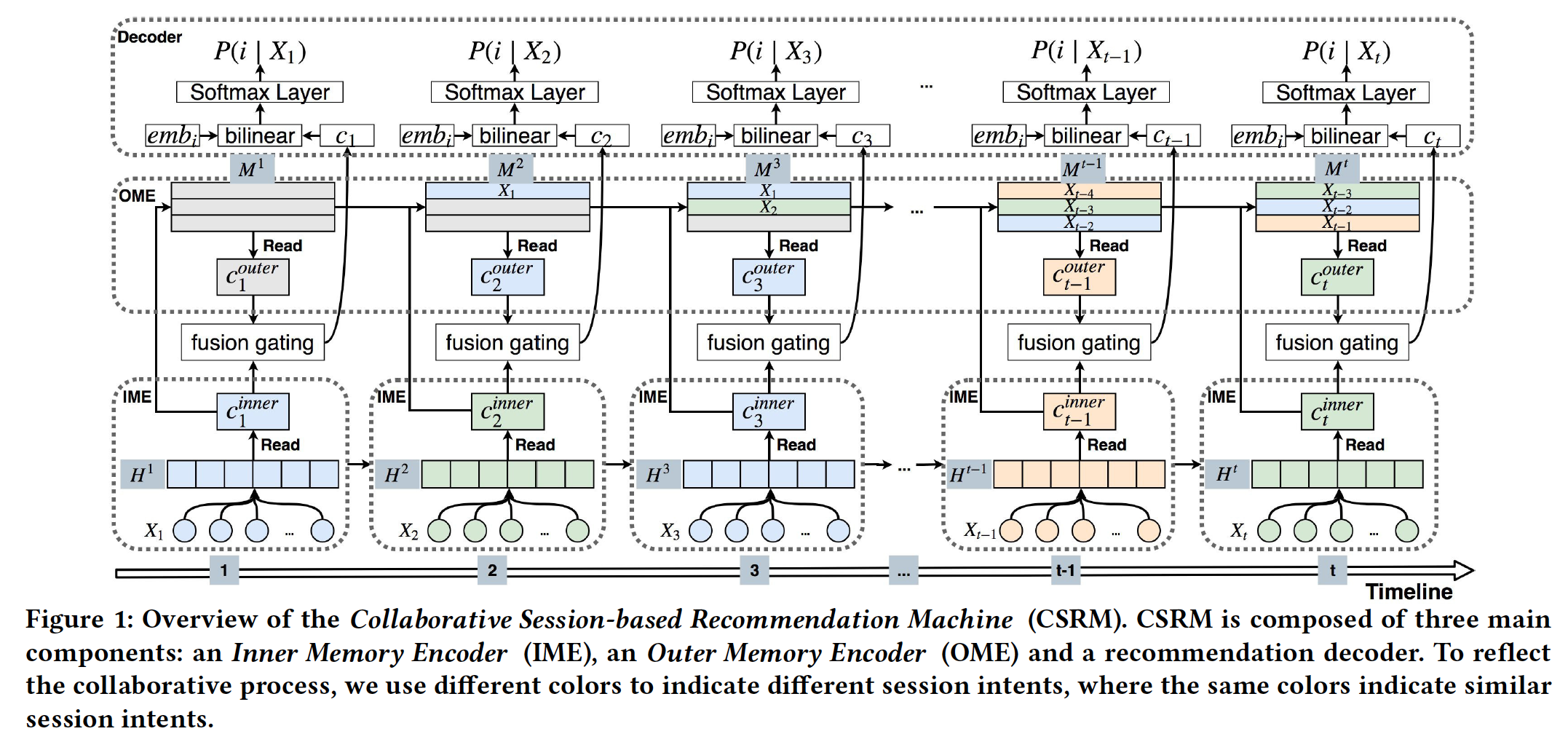
session存储在一个outer memory中作为潜在的neighborhood session。给定当前session,CSRM会自动从outer memory中查找neighborhood session并抽取有用的特征来提升针对当前session的推荐。如下图所示,
CSRM由三个主要组件组成:一个Inner Memory Encoder: IME、一个Outer Memory Encoder: OME、一个推荐解码器(recommendation decoder)。融合门控机制(fusion gating mechanism)用于控制IME和OME组件之间的信息流。首先,
IME将input session转换为两个高维的hidden representation:一个用于summarize整个session,另一个用于在当前session中选择相对重要的item(因为当前session中可能包含意外或出于好奇而点击的item)。这两个session被拼接成一个统一的session representation。其次,
OME在outer memory network的帮助下将当前session的collaborative neighborhood information编码为collaborative session representation。这个过程可以被看作是一种session-based的最近邻方法,它对与当前session具有相似行为模式的特定session子集赋予更高的权重。最后,
IME和OME的输出作为推荐解码器的输入,其中使用融合门控机制来选择性地组合来自IME和OME的信息从而进行推荐。输出是基于双线性解码方案(bi-linear decoding scheme)的、每个候选item的推荐分。
接下来我们详细介绍每个部分。
1.1.1 Inner Memory Encoder
IME尝试对当前session中包含的有用信息进行编码。遵从《Neural attentive session-based recommendation》的做法,它由两个组件组成:全局编码器(global encoder)和局部编码器(local encoder)。全局编码器用于建模整个
session中的序列行为。局部编码器用于关注特定的行为,这体现在当前
session中相对重要的item。
我们使用
GRU作为全局编码器,因为已经有论文表明:GRU在session-based的推荐方面表现出比LSTM更好的性能。GRU的activation是previous hidden statehidden state其中:
update gate) 。更新门
item embedding,sigmoid激活函数。候选的
hidden statereset gate),tanh激活函数。复位门
最后,我们使用
final hidden statesession的序列行为的representation:注意,所有的
gate通常都使用sigmoid激活函数,因为gate的输出必须在0到1之间。尽管全局编码器考虑了整个序列所反映的行为,但是由于噪音(
noise)的item,很难准确地捕获当前session的行为模式。为此,我们使用另一个具有item-level注意力机制的GRU作为局部编码器。在全局编码器之后,当前sessioninner memory matrixinner memory network)。局部编码器仅依赖session自己的信息从inner memory network动态读取。注意力机制通过强调某些特定行为而忽略其它行为来密切关注当前session的意图。我们为相对更重要的item分配更高的权重。对于当前
sessionitem对session意图的贡献。具体而言,权重因子final hidden state向量item的representation其中:
sigmoid激活函数,这里也可以使用其他的非线性激活函数,如
relu。然后我们可以通过自适应地关注更重要的
item(即,对部分item分配更高的权重)来捕获当前session中的session意图:总之,当前
session可以通过从inner memory networkrepresentationsession representation:其中
也可以考虑其它融合方式,如最大池化、均值池化、门控融合机制等等。
1.1.2 Outer Memory Encoder
IME中的全局编码器和局部编码器仅利用当前session中包含的信息,而忽略了neighborhood session中协同信息的重要性。为解决这个问题,我们提出了一个Outer Memory Encoder: OME。outer memory matrixsession的representation(它也被称作outer memory network) 。OME从session具有更多相似行为模式的previous neighborhood session。这些neighborhood session用作辅助信息,从而帮助了解当前session。OME使用以下read/write操作来访问read操作:直观而言,读取session-based最近邻方法,它可以选择性地对检索到的、与当前session相关的neighborhood进行加权。给定当前
sessionsession最相似的previous session。具体而言,我们计算当前session的memory矩阵previous session的每个其中
为什么不使用
根据
session的subsamplesession的然后,我们通过
softmax函数对k largest相似度值进行处理,得到reading权重:其中
这些
reading权重还反映了每个neighbor对当前session的独特影响(unique impact),这允许模型对neighborhood中更相似的session分配更高的权重。最后,我们根据
neighborhood session对当前session的影响,通过访问neighborhood memory network中其它session的representation,从而得到OME模块的输出,即
write操作:在我们实验的每个epoch开始时,outer memory matrix是空的。我们采用first-in-first-out: FIFO机制来更新outer memory matrix,因此该矩阵总是存储最近的session。写入outer memory的时候,最早的session从memory中移除,新的session被添加到memory中。注意,当
outer memory matrix未填满时,我们直接添加session而不删除任何现有的session。存储的
session的session的session的
1.1.3 Recommendation Decoder
推荐解码器根据
IME和OME的输出来评估点击next item的概率。为了选择性地组合来自
IME和OME的信息,我们使用融合门控机制来构建final session representation,从而平衡当前session信息和collaborative neighborhood information的重要性:其中
fusion gate)并被定义为:然后我们使用双线性解码方案和
softmax来计算推荐分。假设item的representation,我们根据当前sessionfinal sesssion representationitem的最终推荐概率:其中:
item embedding的维度,final session representation
我们的目标函数是:给定当前
session的情况下最大化actual item的预测概率。因此,我们采用交叉熵损失函数:其中:
session的集合。sessionnext item的概率。ground truth函数。如果itemground truth,那么
在学习过程中,我们采用
Back-Propagation Through Time: BPTT方法来优化CSRM。
1.1.4 讨论
未来工作:
CSRM的outer memory network的slot有限,因此只能从少数最近的session中选择neighbor。在未来的工作中,我们希望结合一种retrieval-based机制,使得OME能够根据之前的所有session来查找neighbor。我们还希望通过引入用户偏好信息、以及
item属性来改善CSRM,例如用户评论和item类别等等。此外,注意力机制和
memory机制具有很强的泛化能力。所以我们想探索这个框架在其它application领域的使用。
1.2 实验
我们旨在回答以下研究问题:
RQ1:CSRM在session-based推荐任务中的表现如何?它在Recall和MRR指标上是否优于SOTA的方法?RQ2:CSRM使用不同的编码器(而不是结合IME和OME)的性能如何?RQ3:CSRM使用不同的聚合操作(而不是融合门控机制)的性能如何?RQ4:CSRM在OME中具有不同数量的neighbor时表现如何?RQ5:session长度如何影响session-based推荐性能?RQ6:collaborative neighborhood information如何影响session-based推荐性能?
数据集:我们在两个公开可用的数据集上进行了实验,即
YOOCHOOSE和LastFM。我们通过以下步骤对数据集进行预处理:首先,我们确保所有
session都是按照时间顺序排列。其次,我们过滤掉仅出现在测试集中的
item。第三,我们执行数据增强来考虑
session中的时间漂移(temporal shift)。
数据集的细节如下:
YOOCHOOSE:YOOCHOOSE数据集是RecSys Challenge 2015发布的公开可用数据集。它包含电商网站中六个月的click-streams。我们使用最后一天的session进行测试,用所有其它session进行训练。我们遵循《Improved recurrent neural networks for session-based recommendations》的做法,过滤掉长度为1的session以及出现次数少于5次的item。《Improved recurrent neural networks for session-based recommendations》发现YOOCHOOSE的最近部分(more recent fraction)足以完成任务,并且增加数据量不会进一步提高性能。我们使用最近的1/64和1/4部分的训练session,分别称作YOOCHOOSE 1/64数据集和YOOCHOOSE 1/4数据集。经过预处理之后:
YOOCHOOSE 1/64数据集包含17702个item的637226次点击,随机分为124279个训练session、12309个验证session、以及15236个测试session。YOOCHOOSE 1/4数据集包含30672个item的8253617次点击,随机分为1988471个训练session、12371个验证session、以及15317个测试session。
LastFM:LastFM是一个音乐推荐数据集,包含从2004年到2009年通过LastFM API获得的(user, time, artist, song)元组。为了简化数据集,我们将数据集用于音乐艺术家推荐。在我们的实验中,我们选择
top 40000名最受欢迎的艺术家作为item集合。然后,我们以8小时的时间间隔手动将收听历史(listening history)划分为session。也就是说,如果两个连续的动作发生在8小时时间间隔以内,那么它们就属于同一个session。否则,我们认为它们属于不同的session。这个时间间隔使得每个session不仅包含足够的交互,而且不同的session在一定程度上相互独立。最后,在我们过滤掉少于2个item、以及超过50个item的session之后,剩下281614个session和39163个item。该数据集称作LastFM。经过预处理之后,
LastFM数据集包含对39163个item的3804922次点击,随机分为269847个训练session、5996个验证session以及5771个测试session。
数据集的统计结果如下表所示。

baseline:我们考虑了三组baseline方法,即传统的方法、RNN-based的方法、memory network-based的方法。传统的方法:
POP:POP总是推荐训练集中最流行的item。这是一个非常简单的baseline,但它可以在某些领域表现良好。S-POP:S-POP推荐当前session中最流行的item,而不是全局最流行的item。Item-KNN:在这种方法中,推荐与last item相似的item。相似性定义为:其中:
occurrence表示出现了指定item的session的数量,co-occurrence表示出现了指定两个item的session的数量。另外,也可以包含正则化项从而避免低频
item之间的偶然高度相似性。BPR-MF:BPR-MF通过使用随机梯度下降来优化pairwise ranking目标函数。与之前的研究一样,我们将这种方法应用于session-based推荐,方法是对session中截止到当前为止出现的item的latent factor取平均从而作为session的representation。FPMC:Factorizing Personalized Markov Chain: FPMC结合马尔科夫链模型和矩阵分解模型,用于next-basket推荐任务。为了使其适用于session-based推荐,我们在计算推荐分的时候忽略了user latent representation。
RNN-based方法:GRU-Rec:我们将《Recurrent neural networks with top-k gains for session-based recommendations》和《Session-based recommendations with recurrent neural networks》提出的模型表示为GRU-Rec,它使用session-parallel的mini-batch训练过程,还使用ranking-based损失函数来学习模型。RNN-KNN:RNN-KNN将heuristics-based的最近邻方案和人工制作权重参数(weighting parameter)的GRU结合起来,用于session-based推荐,并取得了比GRU-Rec更好的性能。RNN-KNN使用item co-occurrence来决定k近邻session。Improved GRU-Rec:我们将《Improved recurrent neural networks for session-based recommendations》中提出的模型表示为Improved GRU-Rec。Improved GRU-Rec采用两种技术:数据增强、以及一种考虑输入数据分布偏移shift的方法,从而提高GRU-Rec的性能。NARM:Neural Attentive Recommendation Machine: NARM是一种改进的encoder-decoder架构,用于session-based推荐。它通过将注意力机制融合到RNN中来改善Improved GRU-Rec。
memory network-based方法:RUM:RUM有两种具体的实现方式。item-level RUM: RUM-I直接将item嵌入到memory matrix中,而feature-level RUM: RUM-F将用户在不同潜在特征latent feature上的偏好的embedding存储到memory matrix中。我们将RUM-I应用于session-based推荐任务,通过RNN-based方法用序列中的item的latent factor来表示一个新的session。但是,RUM-F无法应用于session-based推荐,因为很难获得一个新的session对特定特征的偏好。CMN:CMN利用memory network来解决带隐式反馈的协同过滤问题。我们通过在进行预测时使用session中出现的item的平均latent representation来表示一个session,从而使得这种方法适用于session-based推荐。CMN在测试的时候需要对每个候选item一个一个地打分,比较耗时。我们不评估所有的item,而是采样了1000个negative item从而加快进程。
实验配置:
我们使用
Tensorflow实现CSRM,并在一个GeForce GTX TitanX GPU上进行实验。为了缓解过拟合,我们采用了两个
dropout layer:第一个
dropout layer位于item embedding layer和GRU layer之间,dropout rate = 25%。第二个
dropout layer位于final representation layer和bilinear decoding layer之间,dropout rate = 50%。
在训练期间,我们使用高斯分布(均值为
0、标准差为0.01)来随机初始化模型参数。我们使用
mini-batch的Adam优化器,分别设置了动量超参数batch size根据经验设置为512。我们学习率由
[0.001, 0.0005, 0.0001]范围内的网格搜索确定。GRU的item embedding维度和hidden unit由[50, 100, 150]范围内的网格搜索确定。我们将
OME中最近邻的数量根据[128, 256, 512]来变化,从而研究该超参数的影响。所有超参数都根据验证集进行调优,其中验证集是训练数据的一小部分。
评估指标:我们的任务是在给定当前
session的情况下预测用户接下来会点击什么。推荐系统在每个时刻为每个session生成一个推荐列表,该列表通常包含N个 根据预测分进行排序的item。用户接下来点击的实际item应该包含在推荐列表中。因此我们使用以下指标来评估top-N推荐:Recall@20:ground-truth item排在top-20 item中的case的比例。该指标不考虑ground-truth item的实际排名。MRR@20:Mean Reciprocal Rank: MRR考虑item排名倒数(reciprocal rank)。如果排名弱于20,则排名倒数置为零。MRR会考虑ground-truth item的实际排名,这在推荐顺序很重要的场景中很重要(如,排名靠后的item仅在屏幕滚动后才可见)。
对于显著性检验,我们使用
paired t-test。性能对比 (
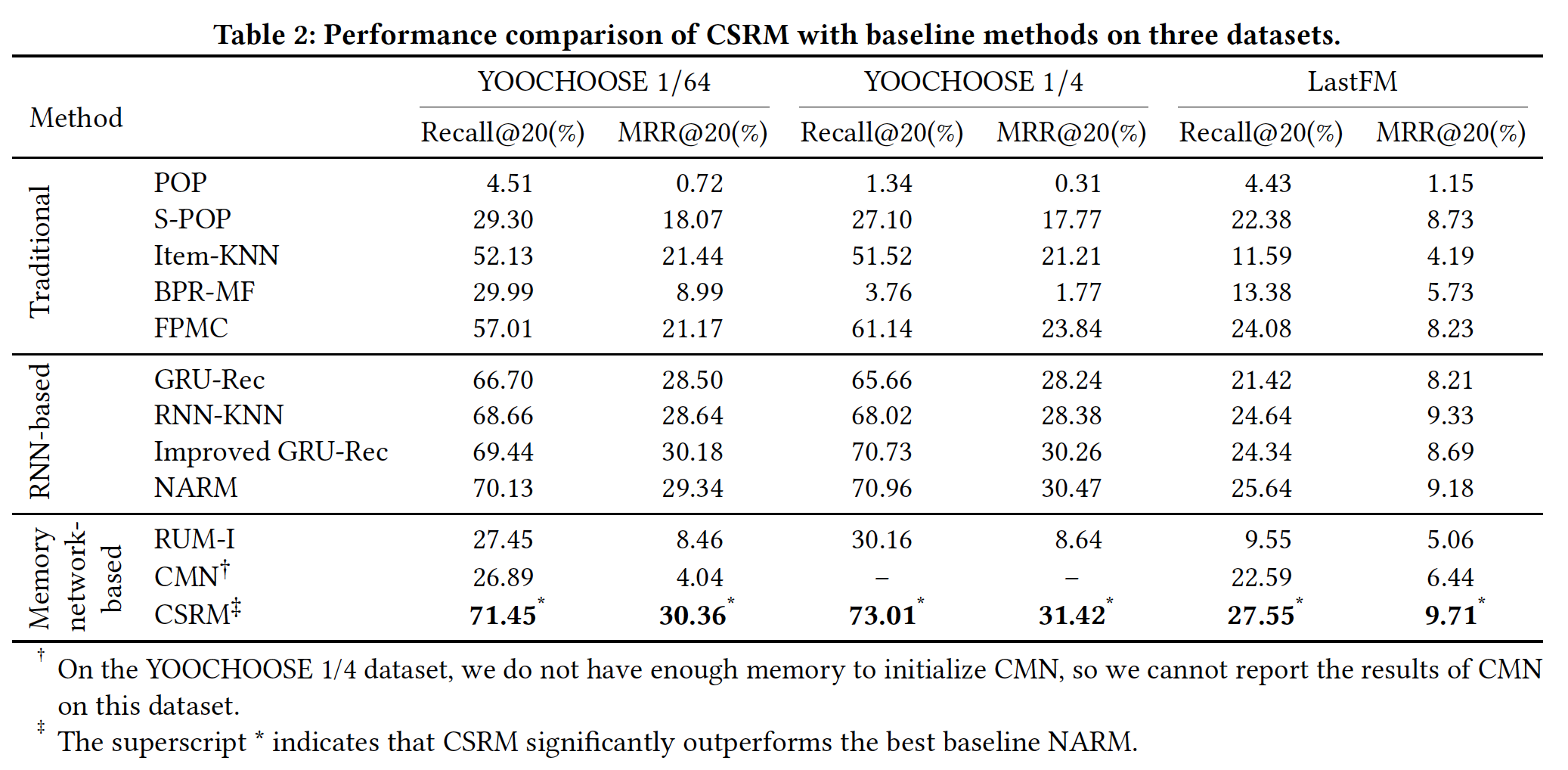
RQ1):下表说明了在三个数据集上CSRM和baseline方法的性能。结果表明,CSRM在所有数据集的Recall@20和MRR@20指标方面始终达到最佳性能。从结果中,我们有四个主要观察结论:在传统方法中,
Item-KNN在大多数情况下都要比POP、S-POP、BPR-MF取得显著的提升。这意味着KNN-based的协同过滤方法可以帮助改善session-based的推荐。至于
FPMC,考虑到BPR-MF和FPMC之间的主要区别在于后者以序列的方式建模用户的历史记录,因此FPMC比BPR-MF获得更好结果的观察(observation)证实了序列信息有助于推荐性能。我们观察到五种
RNN-based的方法(GRU-Rec、Improved GRU-Rec、RNN-KNN、NARM、CSRM)优于传统方法。这表明RNN-based的模型擅长处理session中的序列信息。CSRM显著优于所有RNN-based的baseline方法。一般而言,相对于最佳baseline NARM,CSRM在三个数据集上的Recall@20指标分别提高了1.88%, 2.89%, 7.45%,MRR@20指标分别提高了3.48%, 3.12%, 5.77%。尽管
RNN-KNN和CSRM都考了了协同过滤信息,但是我们注意到CSRM在RNN-KNN上取得了一致的提升。原因是RNN-kNN通过人工制作的超参数将RNN与co-occurrence-based KNN相结合,缺乏能够捕获更复杂关系的非线性交互。这些观察证实,利用带
memory network的collaborative neighborhood information可以显著提高session-based推荐的性能。对于
MANN-based方法,我们发现CSRM在所有数据集上都优于RUM和CMN。这是因为在session-based推荐中没有可用的用户信息,并且RUM和CMN在这种case中根本不适用、也没有效果。一个自然的疑问是:在用户信息可用的场景下,
RUM、CMN、CSRM的效果对比如何?
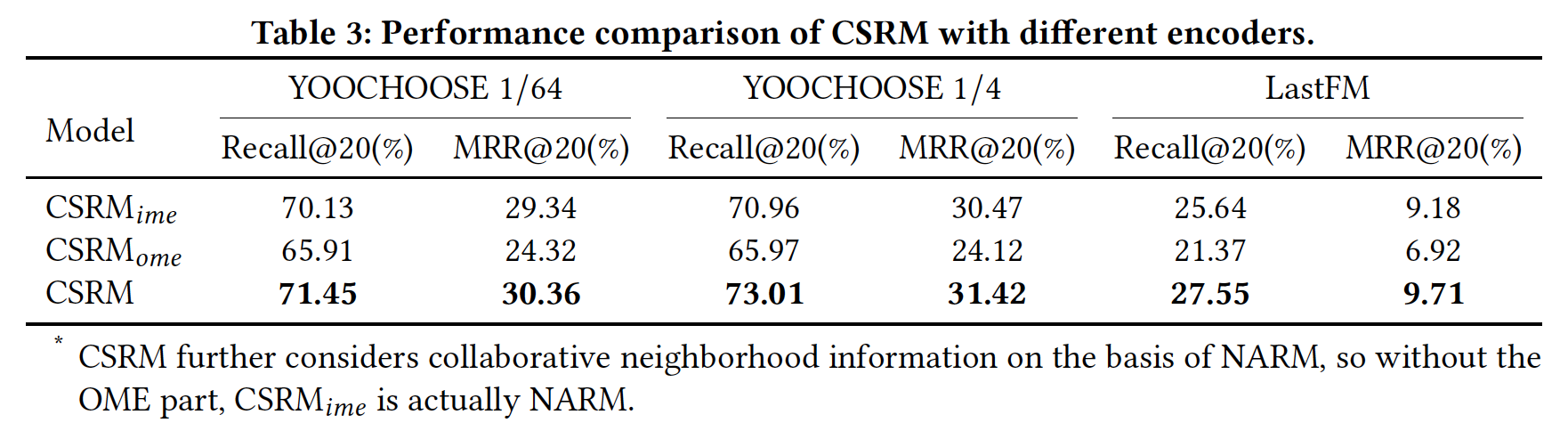
Encoder影响(RQ2):为了进一步说明协同信息和memory network的效果,我们比较了CSRM、以及两种CSRM变体之间的性能:OME的CSRM。它使用RNN的固有memory来建模当前session中的序列行为。它实际上相当于NARM模型,因为CSRM在NARM的基础上进一步考虑了collaborative neighborhood information。在本节中,我们使用NARM的结果来表示IME的CSRM。它使用external memory来编码collaborative neighborhood information。
下表总结了这几个模型在三个数据集上的实验结果。
首先,我们发现
session自身的序列信息对于session-based的推荐任务更重要。其次,
CSRM在三个数据集上的所有指标都要比session自己的信息、以及collaborative neighborhood information来获得更好的推荐的有效性。以YOOCHOOSE 1/64数据集为例,与CSRM在Recall@20指标上分别相对提升1.88%和8.41%左右,在MRR@20指标上分别相对提升3.48%和24.84%左右。
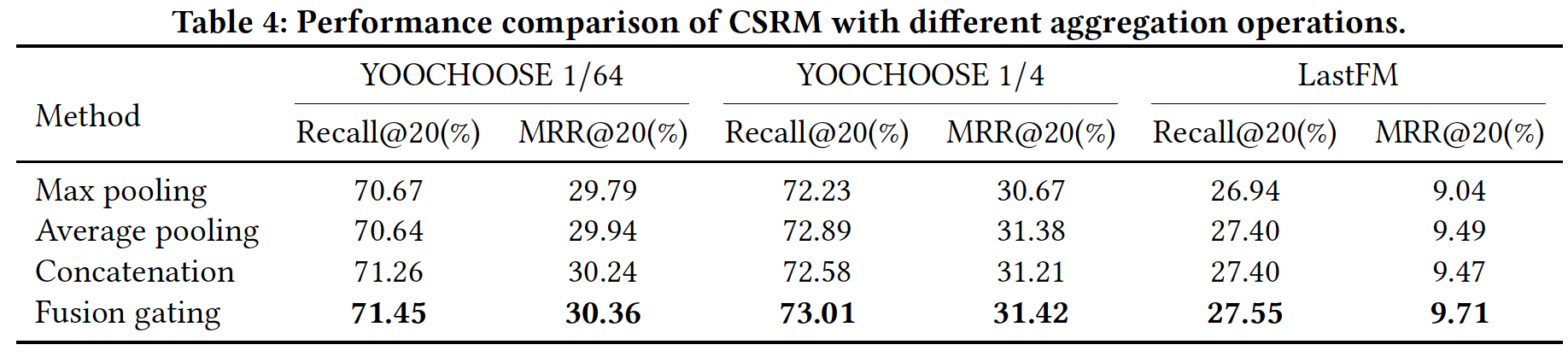
聚合操作的影响(
RQ3):接下来,我们带不同聚合操作的CSRM进行相互比较。这些聚合操作包括:最大池化、均值池化、拼接、融合门控机制。对于最大池化聚合,
final session representation定义为max的操作。对于均值池化聚合,
final session representation定义为对于拼接聚合,
final session representation定义为对于融合门控机制聚合,
final session representation如正文部分所示,定义为:其中
如下表所示:
在
Recall@20和MRR@20指标上,带融合门控机制的CSRM在三个数据集上均优于其它三种聚合操作。这表明融合门控机制更有助于建模IME和OME之间的交互。在大多数情况下,带拼接操作的
CSRM和带均值池化的CSRM实现了相似的性能,并且在三个数据集上均优于带最大池化的CSRM。这表明在建模多个因子之间的交互时,均值池化和拼接操作要比最大池化更有利。
邻居数量的影响(
RQ4):为了研究collaborative neighborhood information对session-based推荐的影响,我们在下表中展示了CSRM关于不同邻居数量的性能。对于
YOOCHOOSE 1/64和YOOCHOOSE 1/4数据集,CSRM在Recall@20指标上的性能随着邻居数量的增加而提高,在MRR@20指标上的性能随着邻居数量的增加而小幅波动。对于
LastFM数据集,当
这表明,准确地预测
session intent取决于推荐系统将collaborative neighborhood information纳入模型的程度。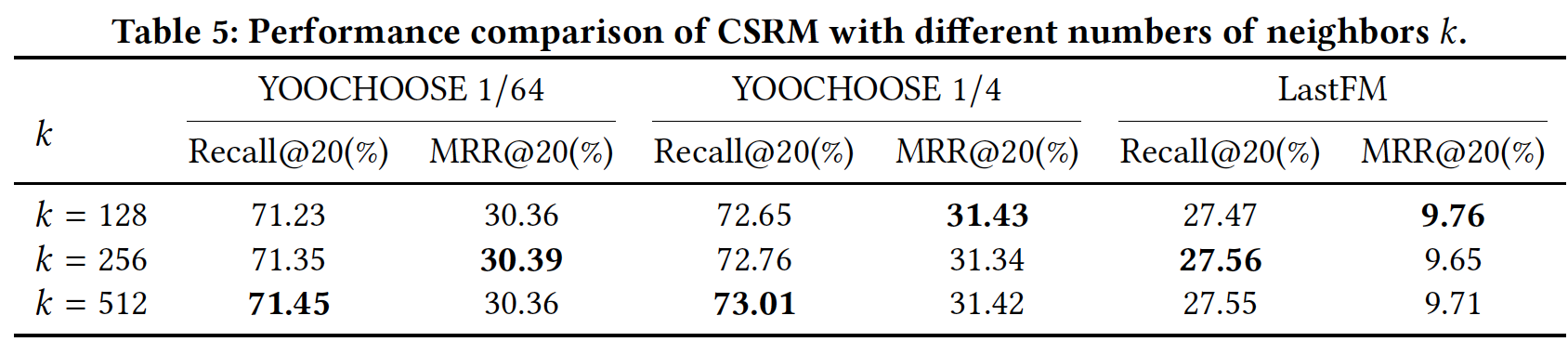
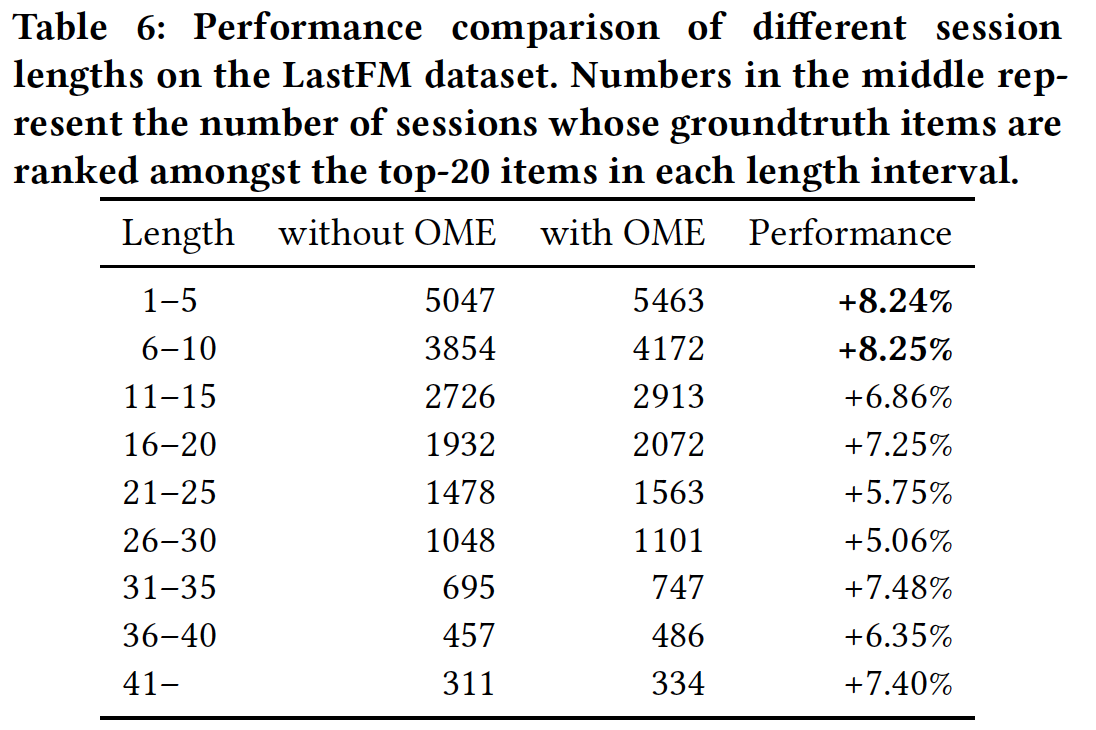
session长度的影响(RQ5):为了了解session长度对利用collaborative neighborhood information的影响,我们在LastFM上比较了不同长度的、各种各样的session。我们在下表中展示了与session长度相关的性能。注意,由于session长度的范围较广,我们将测试集根据每个session的长度划分为不同的分组。从结果中我们可以观察到:CSRM整体上表现更好。这表明collaborative neighborhood information确实有助于捕获session意图并作出更好的预测。一般而言,
session长度在1到10之间时,CSRM的性能提升更强。这可能是因为当session很短时,每个session的点击item有限,因此很难捕获session的意图。在这种情况下,CSRM擅长通过collaborative neighborhood information来捕获session的意图。
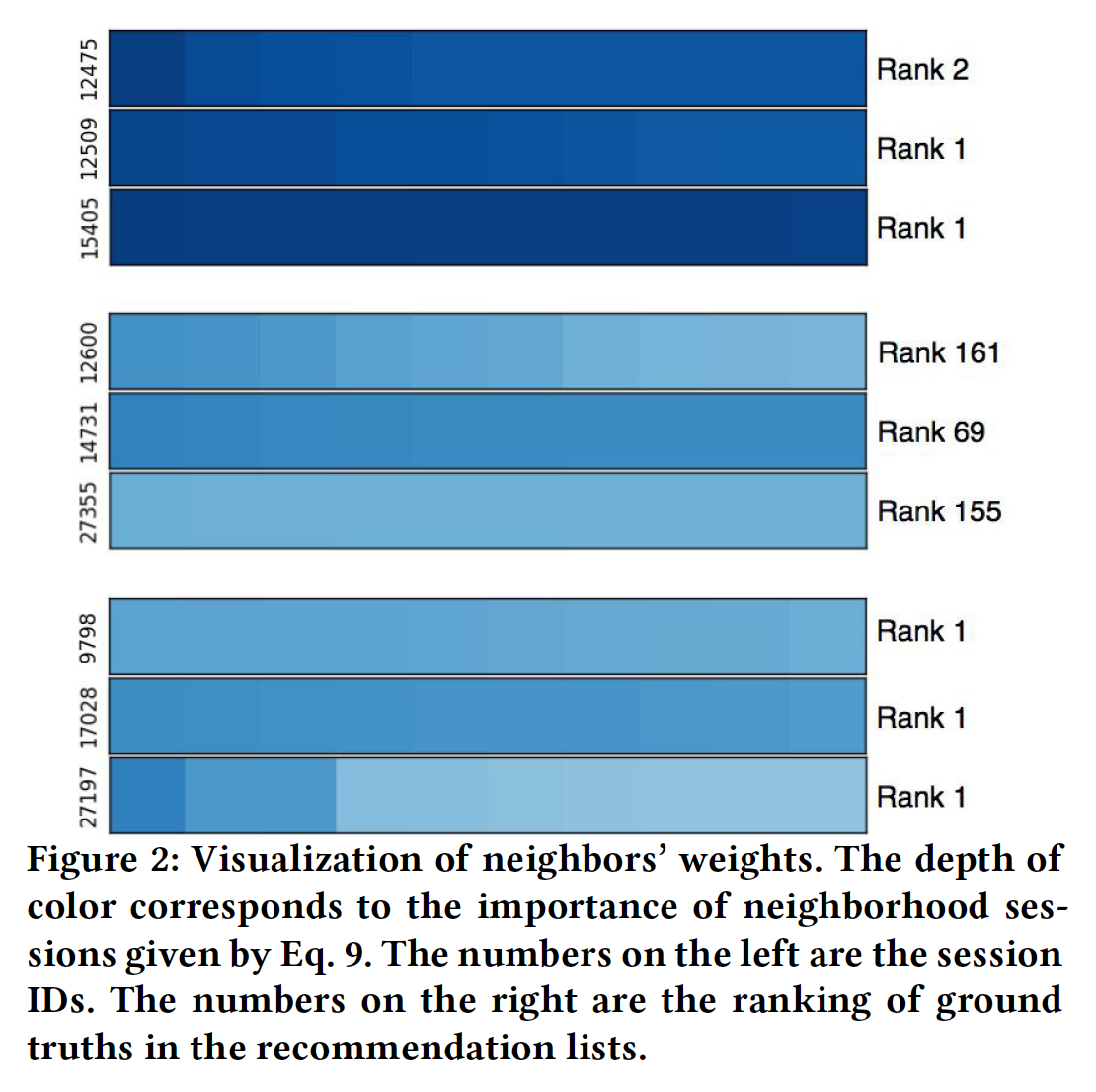
案例研究(
RQ6):为了直观地掌握协同信息的效果,我们从YOOCHOOSE 1/64数据集中选择了一些good case和bad case,如下图所示。左侧的数字是current session ID,右侧的数字是推荐列表中ground truth的排名。颜色程度表示neighbor similarity)的强度,其中较浅的颜色表示较低的值、较深的颜色表示较高的值。图中的每一行代表当前session的top 10 neighbor。相似性之间的差异可能非常小,因此在视觉上难以区分。这里的横坐标表示不同的
neighborhood session(而不是current session中的不同item)。总体而言,显然具有高度相似
neighbor的session获得了更好的推荐性能,即下图中的session 12475, 12509, 15405。分配了都是低相似度
neighbor的session获得了更差的推荐性能,即下图中的session 12600, 14731, 27355。这证实了
collaborative neighborhood information对session-based推荐的用户意图有很大影响。并非当前
session的所有neighbor都同等重要。例如,session 12475的neighbor具有非常不同的权重。并非所有
session都需要依赖collaborative neighborhood information来获得良好的性能。一些session将相同的低相似性(equal low similarity)分配给neighbor,这意味着它们使用较少的协同信息。但是它们仍然取得了良好的推荐性能,如下图中的session 9798, 17028, 27197。