一、FDSA [2019]
《Feature-level Deeper Self-Attention Network for Sequential Recommendation》
序列推荐旨在预测用户在不久的将来可能与之交互的
next item,这在各种互联网应用中至关重要。现有方法通常考虑items之间的转移模式(transition patterns),但忽略了features of items之间的转移模式。我们认为,仅item-level sequences无法揭示完整的序列模式(sequential patterns),而显式的和隐式的feature-level sequences有助于提取完整的序列模式。在本文中,我们提出了一种名为Feature-level Deeper Self-Attention Network: FDSA的序列推荐新方法。具体来说:FDSA首先通过普通注意力机制将items的各种异构特征以不同权重整合到feature sequences中。然后,
FDSA分别在item-level sequences和feature-level sequences上应用独立的self-attention blocks,对item transition patterns和feature transition patterns进行建模。接着,我们将这两个模块的输出整合到一个全连接层(
fully-connected layer)中,以进行next item recommendation。
最后,综合实验结果表明,考虑特征之间的转移关系可以显著提高序列推荐的性能。
随着互联网的快速发展,序列推荐在
ad click prediction、purchase recommendation和web page recommendation等各种应用中变得至关重要。在这些应用中,每个用户行为都可以被建模为按时间顺序排列的activities的序列,用户后续的activities会受到之前activities的影响。序列推荐旨在通过从用户历史行为中捕获有用的序列模式(sequential patterns),来推荐用户可能与之交互的next item。 人们对序列推荐的研究兴趣日益浓厚,并提出了各种模型。为了对序列模式进行建模,经典的
Factorizing Personalized Markov Chain: FPMC模型通过考虑马尔可夫链来分解user-specific的转移矩阵。然而,马尔可夫假设在构建因子之间更有效的关系方面存在困难。随着深度学习的成功,
Recurrent Neural Network: RNN方法在序列推荐中得到了广泛应用。这些RNN方法通常使用RNN的最后一个hidden state作为user representation,用于预测next action。尽管取得了成功,但即使使用Long Short-Term Memory: LSTM和Gated Recurrent Units: GRU等先进的memory cell结构,这些RNN模型也难以保持长程依赖关系(long-range dependencies)。此外,RNN-based的方法需要学习前向地step by step地传递relevant information,这使得RNN难以并行化。最近,自注意力网络(
self-attention networks: SANs)在机器翻译、自然语言推理和问答等各种自然语言处理任务中取得了有前景的实证结果。自注意力网络的一个优点是能够通过计算序列中每对items之间的注意力权重来捕获长程依赖关系。受自注意力网络的启发,《Self-attentive sequential recommendation》提出了自注意力序列推荐模型(Self-Attentive Sequential Recommendation: SASRec),该模型应用自注意力机制取代传统的RNN进行序列推荐,并取得了SOTA的性能。然而,它只考虑了items之间的序列模式,忽略了features之间的序列模式,而后者对捕获用户细粒度偏好是有益的。
实际上,我们的日常活动通常在
item feature level(即,类别等显式特征、或其他隐式特征)呈现转移模式。例如,用户在购买衣服后更有可能购买鞋子,这表明next product的类别与current product的类别高度相关。这里,我们将用户对结构化的属性(如
categories)的演变的偏好(evolving appetite)称为显式特征转移(explicit feature transition)。此外,一个
item可能还包含一些其他非结构化的属性,如描述文本或图像,这些属性提供了item更多细节。因此,我们希望从这些非结构化属性中挖掘用户潜在的feature-level patterns,我们称之为隐式特征转移(implicit feature transition)。
然而,现有方法往往忽略了
item features之间的显式的和隐式的特征转移。我们认为,仅item-level sequences无法揭示完整的序列模式,而feature-level sequences可以更好地帮助实现这一目标。为此,在这项工作中,我们提出了一种新颖的feature-level deeper self-attention network用于序列推荐。为了捕获
explicit feature-level transition patterns,我们没有使用combined representation of item and its features,而是分别在item sequences和feature sequences上应用独立的self-attention blocks,以捕获item-item和feature-feature之间的关系。然后,我们结合item-level和feature-level的context进行推荐。此外,我们进一步研究如何从
items的异构属性中捕获有意义的implicit feature transition patterns。我们额外利用普通注意力机制来辅助feature-based self-attention block,从items的各种类型属性中自适应地选择重要特征,并进一步学习潜在的implicit feature transition patterns。然后,我们将
item transition patterns与implicit feature transition patterns组合到一个全连接层中进行推荐。
最后,我们在一个著名电子商务平台的两个真实数据集上进行了广泛的实验。实验结果表明,考虑
feature-level transition patterns可以显著提高推荐性能。本文的主要贡献总结如下:
我们提出了一种新颖的框架用于序列推荐,即
Feature-level Deeper Self-Attention Network: FDSA。FDSA应用self-attention networks将item-level transitions与feature-level transitions相结合,从而对用户的序列意图进行建模。通过分别在
item sequences和feature sequences上应用不同的self-attention blocks,我们对explicit and implicit feature transitions进行建模。为了获得implicit feature transitions,我们添加了普通注意力机制来辅助feature-based self-attention block,从item的各种属性中自适应地选择重要特征。我们在两个真实数据集上进行了广泛的实验,以证明我们提出的方法的有效性。
1.1 模型
1.1.1 问题描述
在详细介绍我们提出的模型之前,我们首先介绍本文中使用的符号,并定义序列推荐问题。我们用
item集合,其中items数量。我们使用items序列,其中itemitemitems上的历史活动的情况下,推荐用户可能采取行动的next item。
1.1.2 FDSA
如前所述,日常人类活动通常呈现
feature-level(如category-level)的转移模式(transition patterns)。在本文中,我们提出了一种新颖的用于序列推荐的feature-level deeper self-attention network(FDSA)。FDSA不仅利用item-based self-attention block来学习item-level sequence patterns,还利用feature-based self- attention block来搜索feature-level transition patterns。如
Figure 1所示,FDSA由五个组件组成,即Embedding layer、Vanilla Attention layer、Item-based self-attention block、Feature-based self-attention block、以及Fully-connected layer。具体来说:我们首先将
items的sparse representation和items的discrete attributes(即onehot representation)投影到低维稠密向量中。对于items的文本属性,我们使用topic model提取这些文本的topical keywords,然后应用Word2vector获得这些关键词的word vector representation。由于
items的特征(属性)通常是异构的,并且来自不同的领域和数据类型。因此,我们利用普通注意力机制来辅助self-attention network,从items的各种特征中自适应地选择重要特征。之后,通过两个
self-attention networks学习用户的sequence patterns,其中item-based self-attention block用于学习item-level sequence patterns、feature-based self-attention block用于捕获feature-level transition patterns。最后,我们将这两个模块的输出整合到一个全连接层中,以获得
final prediction。
接下来,我们将介绍
FDSA每个组件的详细信息。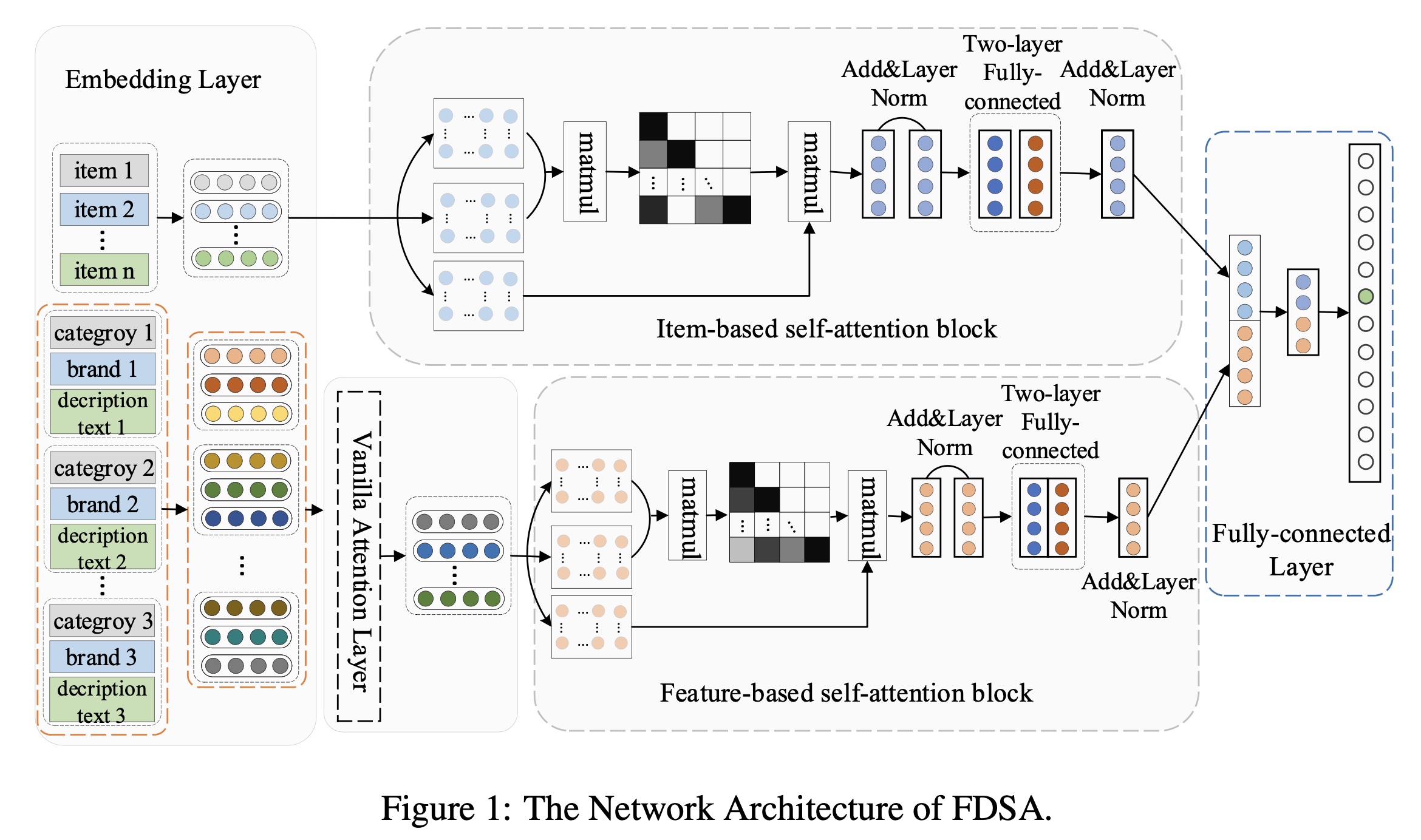
Embedding layer:由于用户行为序列的长度不固定,我们从用户历史序列中选取一个固定长度的序列如果用户的行为序列长度小于
如果用户的行为序列长度大于
同样地,我们以相同的方式处理
feature sequence。以类别信息为例,由于每个item都对应一个类别,我们得到一个固定长度的category sequencelookup layer将行为序列category sequenceone-hot向量转换为稠密向量。对于其他categorical features(如品牌、卖家),也采用相同的方法。对于文本特征(即描述文本、标题),我们首先利用广泛使用的
topic model提取文本的topical key-words,然后应用Word2vector模型来学习文本的semantic representations。在本文中,我们从每个item的描述文本和标题中提取五个topical keywords,然后应用均值池化方法将五个topical keyword vectors融合为一个向量。Vanilla attention layer:由于items的特征通常是异构的,很难知道哪些特征将决定用户的选择。因此,在捕获用户对属性(如类别、品牌)多样化偏好的过程中,我们采用普通的注意力机制来辅助feature-based self-attention block。给定itemembeddings为:其中:
itemitemrepresentation。
形式上,注意力网络定义如下:
其中:
注意,这个公式应该是:
最后,我们将
itemfeature representation计算为itemattribute vector representations的加权和,权重为注意力分数,如下所示:值得注意的是,如果
itemitemfeature representation就是上述公式描述有问题,读者认为应该是这样的:
其中:
DenseLayer。这个DenseLayer的输入单元为sigmoid。
Feature-based self-attention block:由于item-based self-attention block和feature-based self-attention block仅在输入上有所不同,我们重点详细说明feature-based self-attention block的过程。从上述注意力层中,我们可以得到itemfeature representationfeature sequence:为了对
feature-level transition patterns进行建模,我们利用自注意力网络,该网络可以保留序列上下文信息,并捕获类别序列中类别之间的关系,而不管它们之间的距离。虽然自注意力网络可以确保计算效率并导出长程依赖关系,但它忽略了序列输入的位置信息。因此,我们将一个位置矩阵input embedding中。即feature-based self-attention block的输入矩阵为:scaled dot-product attention: SDPA为:其中:
query, key, value;这里,
the feature-based self-attention block中的query, key, value都来自SDPA中,如下所示:其中:
representation subspaces的信息,自注意力采用multi-head attention: MH。multi-head attention定义如下:其中:
feature-based self-attention block中的head数量。此外,自注意力网络采用残差连接、
layer normalization和带有ReLU激活函数的两层全连接层来增强自注意力网络的性能。最后,feature-based self-attention block的输出定义如下:其中:
为了简单起见,我们将整个自注意力模块定义如下:
在第一个
self-attention block之后,embeddings。然而,它可能需要通过另一个基于feature transitions。因此,我们堆叠self-attention block,第block定义如下:其中:
Item-based self-attention block:item-based self-attention block的目标是学习有意义的item-level transition patterns。对于给定的用户,我们可以得到一个item action sequenceitem-based self-attention block的输出为:其中:
Fully-connected layer:为了同时捕获items的和特征的transition patterns,我们将item-based self-attention block的输出feature-based self-attention block的输出其中:
注意:
position上进行广播。最后,我们通过点积运算计算用户对
item的偏好:其中:
position的representation。item embedding matrix,item的embedding。items(即,itemnext item的relevance。
值得注意的是,在训练过程中,模型输入一个序列
next item。
1.1.3 损失函数
在本小节中,为了从训练过程中有效地学习,我们采用二元交叉熵损失作为
FDSA模型的优化目标函数,定义如下:此外,对于每个行为序列中的每个
target itemnegative item
1.2 实验
在本节中,我们进行实验以评估所提出的
FDSA方法在两个真实数据集上的性能。我们首先简要介绍数据集和基线方法,然后将FDSA与这些基线方法进行比较。最后,我们分析实验结果。数据集:我们在两个公开可用的数据集上进行实验,即
Amazon数据集和Tmall数据集。Amazon是一个电子商务平台,广泛用于product recommendation的评估。我们采用其中一个子类别:玩具和游戏(Toys and Games)。对于Toys and Games数据集,我们过滤掉评分少于5个items的用户、以及被少于10个用户评分的items。该数据集中,每个item的特征集合包含类别、品牌和描述文本。Tmall是中国最大的B2C平台,我们使用的是从IJCAI 2015竞赛中获得的user-purchase数据。我们移除了被少于30个用户观察到的items,并剔除了评分少于15个items的用户。Tmall数据集中每个item的特征是类别、品牌和卖家。
两个数据集的统计信息总结在
Table 1中。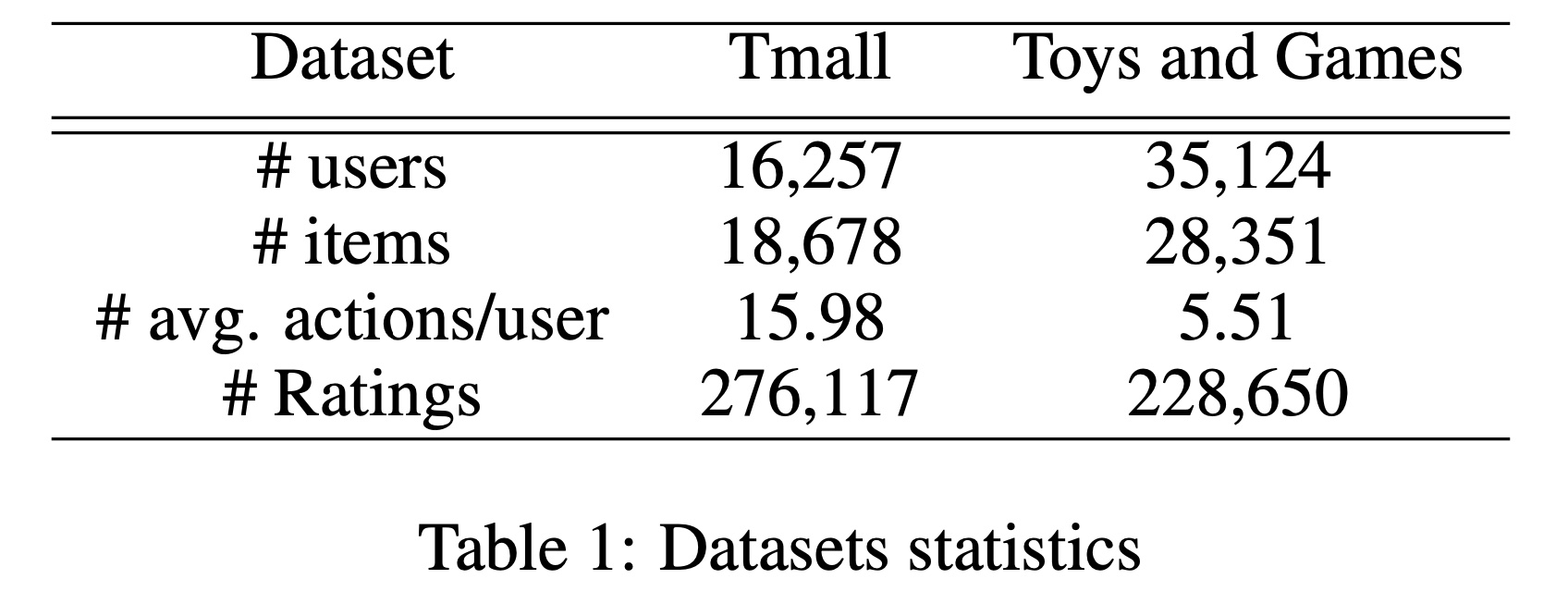
评估指标:为了评估每个模型在序列推荐中的性能,我们采用两个广泛使用的评估指标,即:
hit ratio: Hit、normalized discounted cumulative gain: NDCG。Hit ratio衡量推荐的准确性;NDCG是一种位置感知指标,对较高位置赋予更大的权重。在我们的实验中,我们选择Hit@K和NDCG@K的不同结果。实现细节:除非文中另有说明,我们将所有模型的
embedding维度固定为100,batch size固定为10。此外,在两个数据集上,最大序列长度50。基线方法:我们将我们的模型
FDSA与以下基线方法进行比较,简要介绍如下:PopRec:根据items的流行度对items进行排名。将最受欢迎的items推荐给用户。BPR:是一种从隐式反馈数据中构建推荐系统的经典方法,它提出了一种pair-wise损失函数来建模用户的相对偏好。FPMC:融合矩阵分解和一阶马尔可夫链,分别捕获长期偏好和短期item-item transitions,用于next item的推荐。TransRec:将用户视为连接items的relational vector。GRU4Rec:应用GRU对用户点击序列进行建模,用于session-based的推荐。CSAN:基于自注意力网络对多种类型的行为和多模态内容进行建模。在这里,我们仅考虑数据集中的内容和行为。SASRec:是一种基于自注意力的序列模型,它可以考虑consumed items来推荐next item。SASRec+:是我们对SASRec方法的扩展,它将item vector representations和category vector representations拼接在一起,作为item-level自注意力网络的输入。SASRec++:是我们对SASRec方法的扩展,它将item representation和items的各种异构特征拼接在一起,作为item-level自注意力机制的输入。CFSA:是我们提出的方法的简化版本,它仅考虑类别特征。它分别在item-level sequences和category-level sequences上应用独立的self-attention blocks。
有没有考虑将各种异构特征
sum起来而不是拼接起来,类似于position embedding的使用方式?性能比较:我们将
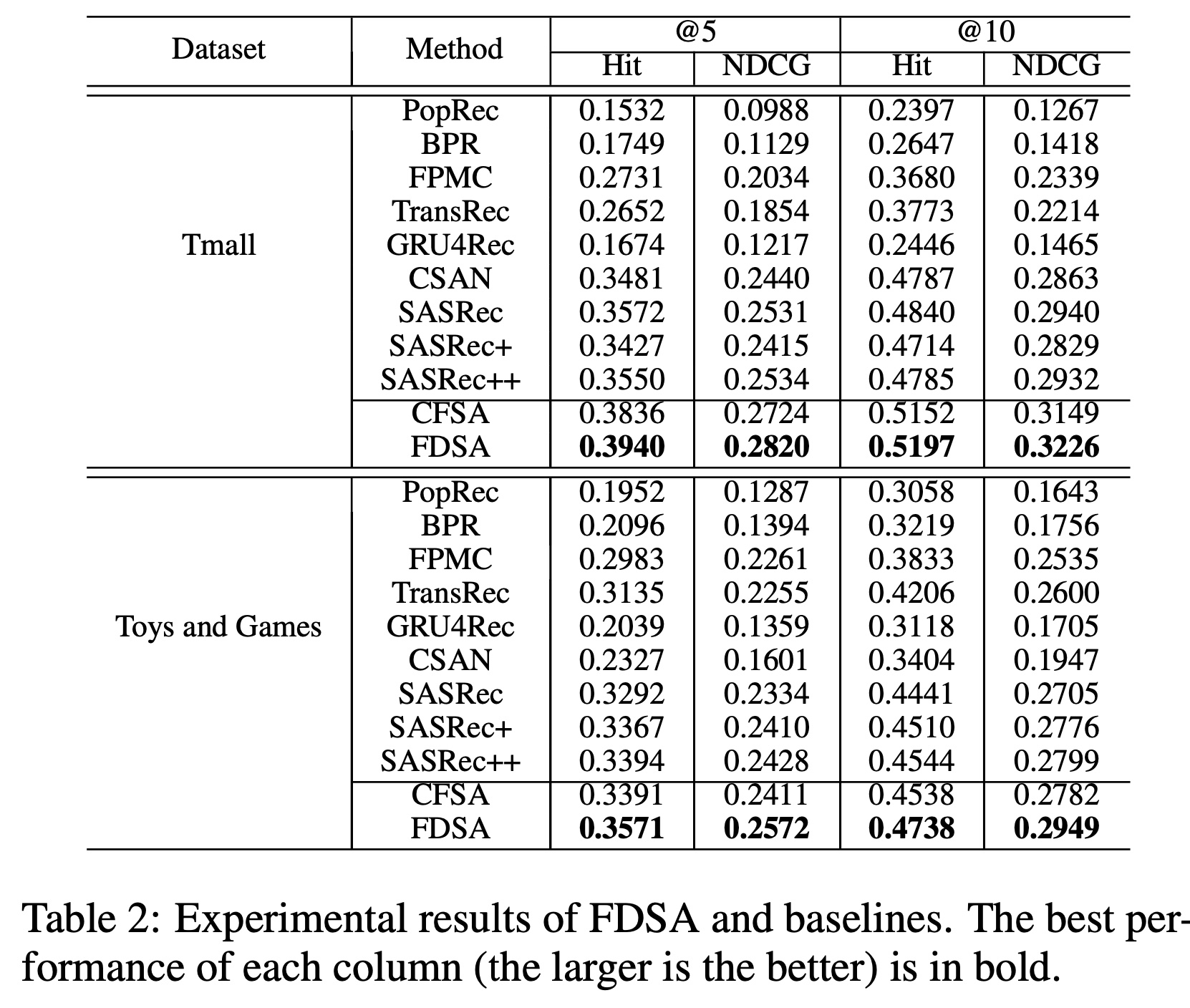
FDSA的性能与十个基线方法在Hit和NDCG指标上进行比较。Table 2报告了它们在两个数据集上的整体实验性能。我们对实验分析总结如下:首先,在两个数据集上,
BPR和GRU4Rec的性能均优于PopRec。这表明了个性化推荐方法的有效性。在基线方法中,序列模型(如
FPMC和TransRec)在两个数据集上的表现通常优于非序列模型(即BPR)。这证明了在next item recommendation时考虑序列信息的重要性。其次,与
FPMC和TransRec相比,SASRec在两个指标上表现更优。这证实了使用自注意力机制对序列模式进行建模的优势。尽管
CSAN将items的异构特征拼接在item representation中,以帮助自注意力机制学习序列模式,但自注意力机制可能只能更好地建模时间顺序信息。然而,SASRec不仅使用自注意力机制捕获长期偏好,还通过残差连接考虑了短期偏好(即最近一个行为)。第三,
SASRec +和SASRec++在Toys and Games数据集上的结果优于SASRec,但在Tmall数据集上的表现比SASRec差。这种现象可以解释为,将items’ representations和items’ feature representations拼接在一起作为自注意力机制的输入向量,可能无法稳定地对序列模式进行建模。此外,
CFSA的性能优于SASRec+,FDSA的性能超过SASRec++。这表明,分别在item-level sequences和feature-level sequences上应用独立的self-attention blocks来捕获item transition patterns和feature transition patterns(即CFSA和FDSA),比将item representations及其feature representations的拼接作为自注意力机制的输入(即SASRec +和SASRec++)更有效。上述实验表明,通过两个独立的
item-level sequences和feature-level sequences对item transition patterns和feature transition patterns进行建模,对于序列推荐是有价值且有意义的。最后,无论数据集和评估指标如何,我们提出的
FDSA都取得了最佳性能。我们的简化模型
CFSA始终优于大多数基线方法。这表明了使用自注意力网络对独立的category-level sequences进行建模的有效性。FDSA的性能优于CFSA,这表明在feature-level sequences中对更多特征进行建模的有效性。
超参数的影响:我们研究了超参数的影响,如
embedding维度item-based self-attention block中的head数feature-based self-attention block中的head数NDCG@10的实验结果。在Hit@10指标上,我们也获得了类似的实验结果。没有分析
self-attention block层数的影响。也没有分析Vanilla attention layer的消融研究。embedding维度Figure 2展示了我们的模型在两个数据集上使用不同embedding维度Figure 2中可以看出,高维度可以为items建模更多信息,但当维度超过100时,FDSA和CFSA的性能会下降。这表明当模型的embedding维度过高时,可能会发生过拟合。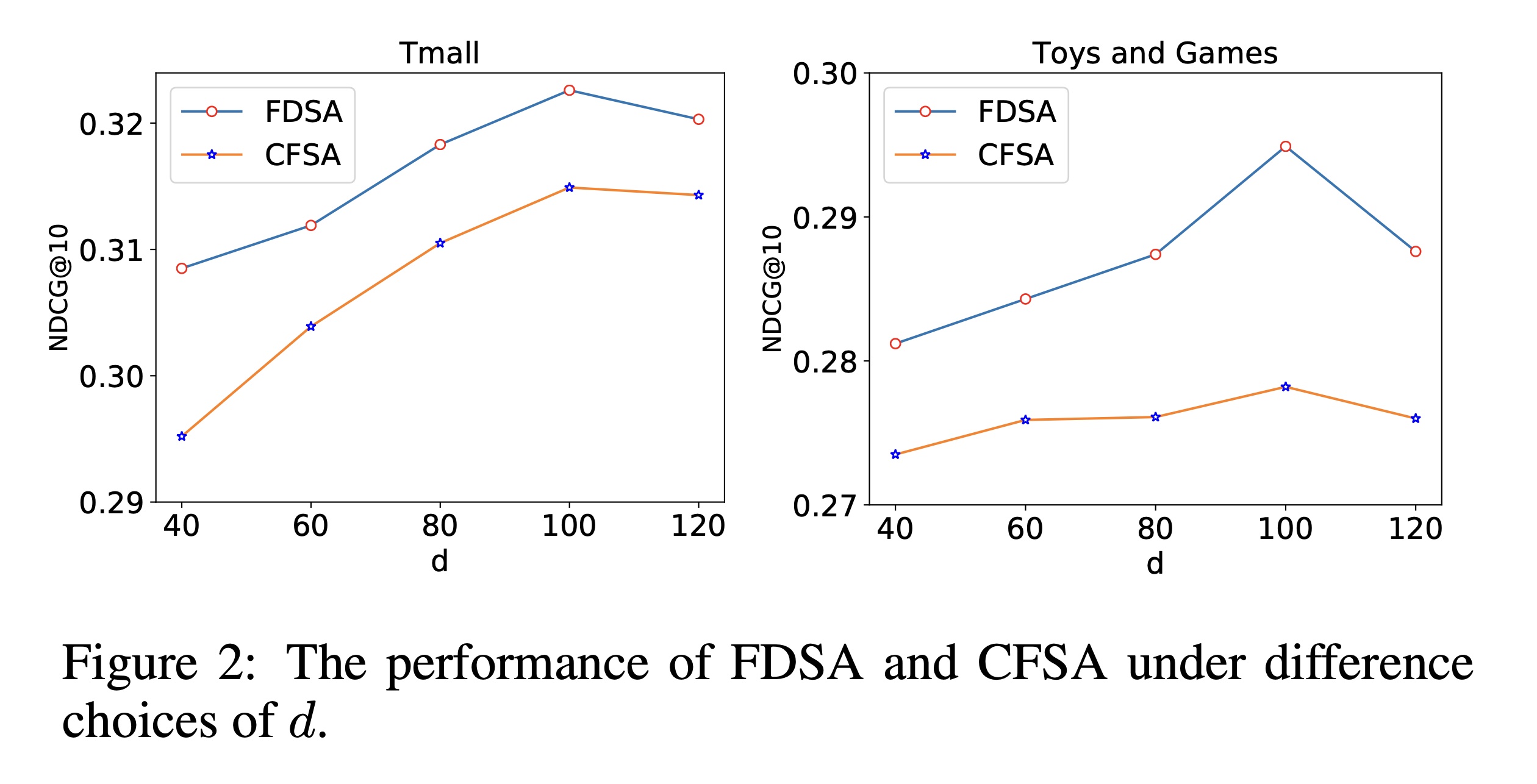
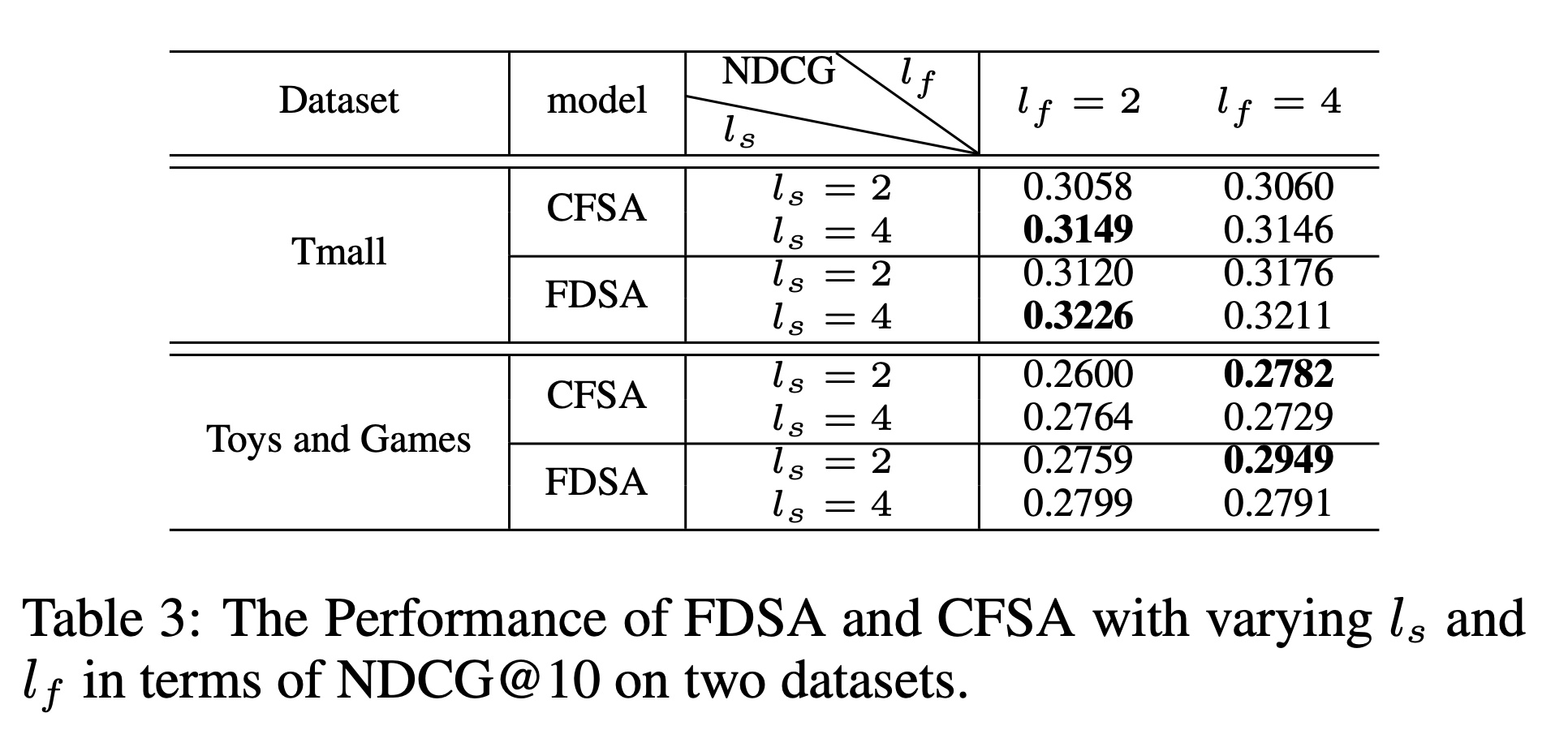
head数量Table 3展示了NDCG@10的实验结果。我们可以观察到:在
Tmall数据集上,CFSA和FDSA在而在
Toys and Games数据集上,它们在Toys and Games数据集中,每个items都包含描述文本和标题,我们的模型需要更多的heads来捕获特征之间的转移关系;而Tmall数据集中这些items的特征数据类型单一,可能不需要太复杂的结构来对特征之间的关系进行建模。