一、GC-SAN [2019]
《Graph Contextualized Self-Attention Network for Session-based Recommendation》
推荐系统在帮助用户缓解信息过载问题、并在许多应用领域(如电商、音乐、社交媒体)中选择有趣的内容方面发挥着重要作用。大多数现有的推荐系统都是基于用户历史交互。然而,在许多应用场景中,
user id可能是未知的。为了解决这个问题,人们提出了session-based推荐,从而根据用户在当前session中的previous behaviors序列来预测用户可能采取的next action(如点击一个item)。由于
session-based推荐的高度的实际价值,人们提出了多种session-based的推荐方法。马尔科夫链(
Markov Chain: MC)是一个经典的例子,它假设next action是基于前一个action。在如此强的假设下,历史交互的独立结合(independent combination) 可能会限制推荐的准确性。最近的研究强调了在
session-based推荐系统中使用recurrent neural network: RNN,并且取得了有前景的成果。例如:《Session-based recommendations with recurrent neural networks》提出使用GRU(RNN的一种变体)来建模短期偏好。它的改进版本《Improved recurrent neural networks for session-based recommendations》进一步提高了推荐性能。最近,
NARM旨在通过采用全局RNN和局部RNN同时捕获用户的序列模式(sequential pattern)和主要意图(main purpose)。
然而,现有方法通常对
consecutive items之间的单向转移(transition)进行建模,而忽略了整个session序列之间的复杂转移。最近,一种新的序列模型
Transformer在各种翻译任务中实现了SOTA的性能和效率。Transformer没有使用递归或卷积,而是利用由堆叠的self-attention网络所组成的encoder-decoder架构来描绘input和output之间的全局依赖关系。self-attention作为一种特殊的注意力机制,已被广泛用于建模序列数据,并在许多应用中取得了显著成果,如机器翻译、情感分析、序列推荐。Transformer模型的成功可以归因于它的self-attention网络,该网络通过加权平均操作充分考虑了所有信号。尽管取得了成功,但是这种操作分散了注意力的分布,导致缺乏对相邻item的局部依赖性(local dependency),并限制了模型学习item的contextualized representation的能力。而相邻item的局部上下文信息(local contextual information)已被证明可以增强建模neural representations之间依赖关系的能力,尤其是对于注意力模型。self-attention的注意力分布是作用在全局的,因此相对而言会忽略相邻item的重要性。即,对self-attention而言,通常难以学到一个相邻item的重要性为1.0、其它item的重要性全零的注意力分布。在论文
《Graph Contextualized Self-Attention Network for Session-based Recommendation》中,作者提出通过graph neural network: GNN来增强self-attention网络。一方面,
self-attention的优势在于通过显式关注所有位置来捕获长期依赖关系(long-range dependency)。另一方面,
GNN能够通过编码边属性或节点属性来提供丰富的局部上下文信息。
具体而言,论文引入了一个叫做
GC-SAN的graph contextual self-attention network用于session-based的推荐。该网络得益于GNN和self-attention的互补的优势。首先,
GC-SAN从所有历史的session序列构建有向图(每个session构建一个session graph)。基于session graph,GC-SAN能够捕获相邻item的转移 ,并相应地为图中涉及到的所有节点生成latent vector。然后,
GC-SAN应用self-attention机制来建模远程依赖关系,其中session embedding vector由图中所有节点的latent vector生成。最后,
GC-SAN使用用户在该session的全局兴趣和该用户的局部兴趣的加权和作为embedding vector,从而预测该用户点击next item的概率。
GC-SAN和SR-GNN非常类似,主要差异在于:GC-SAN采用attention机制来建模远程依赖关系,而GC-SAN采用self-attention机制。除此之外,其它部分几乎完全相同。这项工作的主要贡献总结如下:
为了改进
session序列的representation,论文提出了一种新的、基于graph neural network: GNN的graph contextual self-attention ntwork: GC-SAN。GC-SAN利用self-attention网络和GNN的互补优势来提高推荐性能。GNN用于建模separated的session序列的局部图结构依赖关系,而多层self-attention网络旨在获得contextualized non-local representation。论文在两个
benchmark数据集上进行了广泛的实验。通过综合的分析,实验结果表明:与SOTA方法相比,GC-SAN的有效性和优越性。
相关工作:
session-based推荐是基于隐式反馈的推荐系统的典型应用,其中user id是未知的,没有显式的偏好(如评分)而只仅提供positive observation(如购买或点击)。这些positive observation通常是通过在一段时间内被动跟踪用户记录而获得的序列形式的数据。在这种情况下,经典的协同过滤方法(如矩阵分解)会失效,因为无法从匿名的历史交互中构建user profile(即用户的所有历史交互)。这个问题的一个自然解决方案是
item-to-item推荐方法。在session-based的setting中,可以从可用的session数据中,使用简单的item co-occurrence pattern预计算pre-computed一个item-to-item相似度矩阵。《Item-based collaborative filtering recommendation algorithms》分析了不同的item-based推荐技术,并将其结果与基础的k-nearest neighbor方法进行了比较。此外,为了建模两个相邻
action之间的序列关系,《Factorizing personalized markov chains for next-basket recommendation》提出了将矩阵分解和马尔科夫链(Markov Chain: MC)的力量结合起来进行next-basket推荐。
尽管这些方法被证明是有效的且被广泛使用,但是它们仅考虑了
session的most recent click,而忽略了整个点击序列的全局信息。最近,针对
session-based推荐系统,研究人员转向神经网络和attention-based模型。例如:《Session-based recommendations with recurrent neural networks》最早探索Gated Recurrent Unit: GRU(RNN的一种特殊形式)用于预测session中的next action,《Improved recurrent neural networks for session-based recommendations》后续提出了改进版本从而进一步提高推荐性能。如今,人们已经提出
Graph Neural Network: GNN以RNN的形式来学习图结构化的数据的representation,并广泛应用于不同的任务,如图像分类、脚本事件(script event)预测、推荐系统(《Session-based recommendation with graph neural networks》)。另一方面,人们已经在各种应用(如,自然语言处理
natural language processing: NLP和计算机视觉computer vision: CV)中引入了几种attention-based机制。标准的普通的注意力机制已经被纳入推荐系统(NARM、STAMP)。最近,《Attention is all you need》提出了完全基于self-attention来建模单词之间的依赖关系,无需任何递归或卷积,并且在机器翻译任务上取得了SOTA的性能。基于简单的和并行化的self-attention机制,SASRec提出了一种基于self-attention的序列模型,其性能优于MC/CNN/RNN-based的序列推荐方法。《Csan: Contextual self-attention network for user sequential recommendation》提出了一个在feature level的、 统一的contextual self-attention network,从而捕获异质用户行为的多义性(polysemy),从而进行序列推荐。大多数现有的序列推荐模型都用
self-attention机制来捕获序列中的远距离item-item transition,并且取得了SOTA性能。然而,在相邻item之间建立复杂的上下文信息仍然具有挑战性。在本文中,我们通过GNN来增强self-attention network,同时保持模型的简单性和灵活性。据我们所知,这是对session-based推荐的self-attention network和GNN的首次尝试,其中:self-attention network可以建模session的全局item-item信息,GNN可以通过对构建的图的属性特征进行编码从而学习局部上下文信息。
1.1 模型
这里我们介绍了基于
GNN的contextualized self-attention推荐模型GC-SAN。我们首先公式化session-based推荐问题,然后详细描述我们模型的架构(如下图所示)。GC-SAN结合了GNN和SASRec,只是将SASRec的embedding layer替换为GNN生成的embedding。相比之下,
SR-GNN和GC-SAN都使用了GNN,二者区别在于SR-GNN使用了last click item embedding作为query的attention,而GC-SAN使用了self-attention。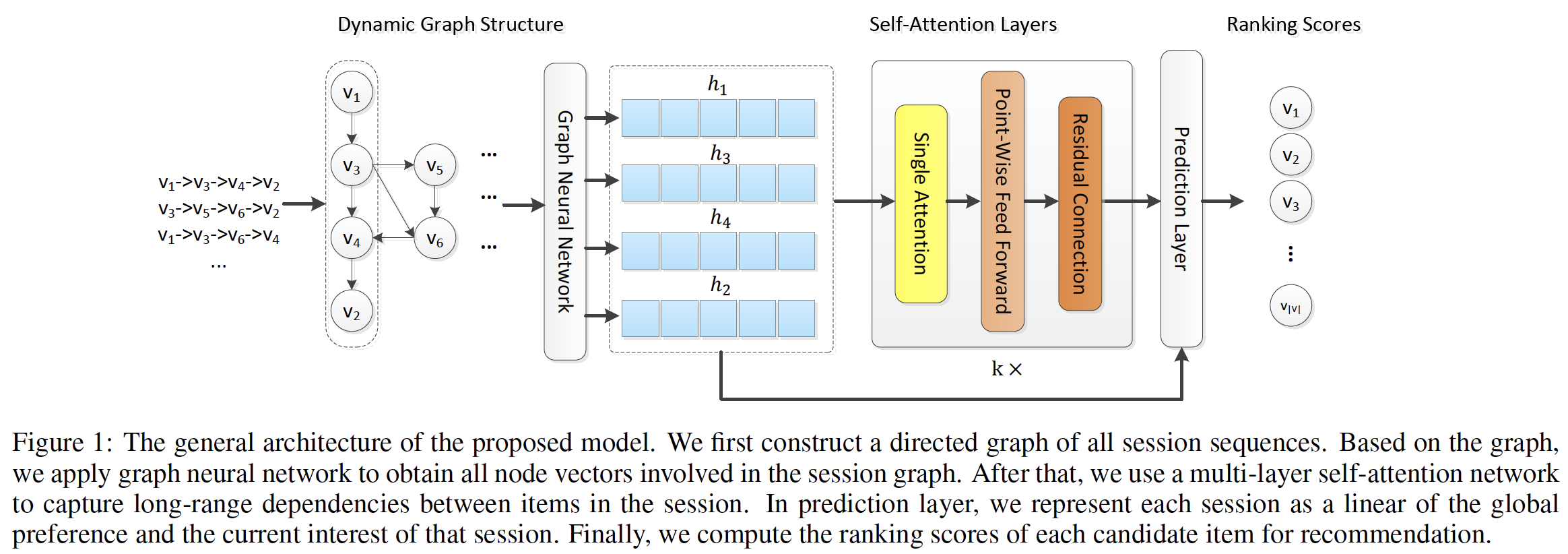
session-based推荐旨在仅基于用户当前的交互序列来预测用户接下来想点击哪个item。这里我们给出session-based推荐问题的公式如下。令
session中涉及的所有unique item的集合。对于每个匿名session,用户点击action的序列记做time stepitem。正式地,给定action序列在时刻prefixitem的排序列表(ranking list)。item的输出概率,其中itemtop-N个item进行推荐。
1.1.1 动态图结构
图构建:
GNN的第一部分是从所有session中构建一个有意义的图。给定一个sessionitemsessionitemsession序列都可以建模为有向图。可以通过促进不同节点之间的通信来更新图结构。具体而言,令
session graph中的入边incoming edge加权链接、出边outgoing edge加权链接。例如,考虑一个sessiongraph和矩阵(即session序列中可能会重复出现多个item,因此我们为每条边分配归一化权重,其计算方法为:边的出现次数除以该边的起始节点的out-degree。注意,我们的模型可以支持各种构建
session graph的策略,并生成相应的链接矩阵(connection matrix)。然后我们可以将两个加权的链接矩阵与图神经网络一起应用来捕获session序列的局部信息。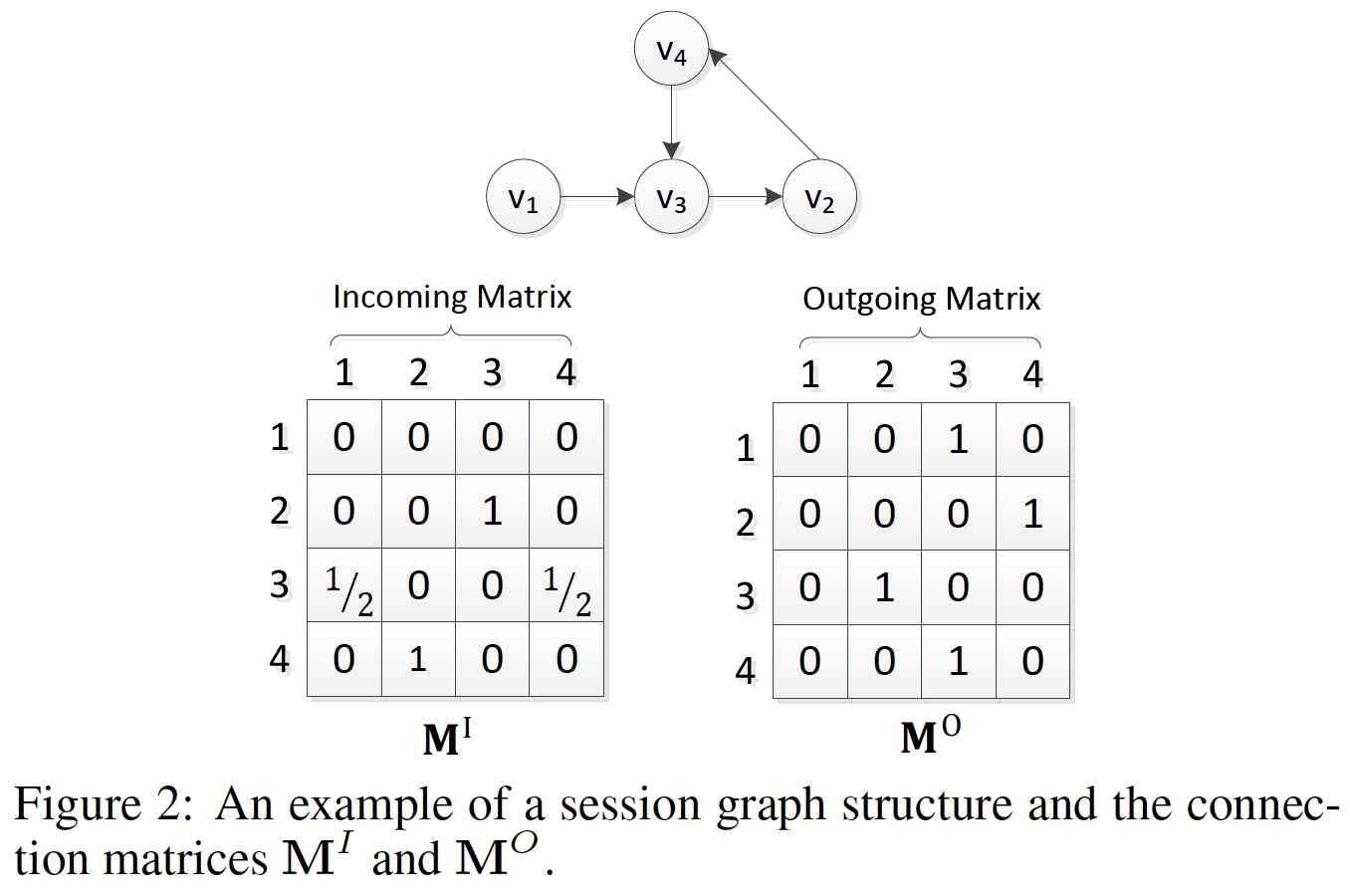
节点向量更新:接下来我们介绍如何通过
GNN获得节点的潜在特征向量(latent feature vector)。我们首先将每个itemitemgraph session中时刻其中:
embedding经过然后我们将
previous stateGNN的输入。因此,GNN layer的final output其中:
sigmoid函数,
事实上这里是单层
GNN的更新公式。在SR-GNN中给出了多层GNN的更新公式。在SR-GNN中,GNN不断迭代直到达到不动点。
1.1.2 自注意力层
self-attention是注意力机制的一个特例,并已成功应用于许多研究主题,包括NLP和QA。self-attention机制可以抽取input和output之间的全局依赖关系,并捕获整个input序列和output序列本身的item-item转移,而不考虑它们的距离。Self-Attention Layer:将session序列输入GNN之后,我们可以得到session graph中所有节点的潜在向量,即:self-attention layer从而更好地捕获全局session偏好:其中:
因为
attention矩阵是softmax位于右侧。Point-Wise Feed-Forward Network:之后,我们应用两个带ReLU激活函数的线性变换来赋予模型非线性,并考虑不同潜在维度之间的交互。然而,在self-attention操作中可能会发生transmission loss。因此,我们在前馈网络之后添加了一个残差连接,这使得模型更容易利用low-layer的信息。其中:
此外,为了缓解深度神经网络中的过拟合问题,我们在训练期间应用了
Dropout正则化技术。为简单起见,我们将上述整个self-attention机制定义为:多层
self-attention:最近的工作表明,不同的层捕获不同类型的特征。在这项工作中,我们研究了哪些level的层从特征建模中受益最多,从而学习更复杂的item transition。第一层定义为:
self-attention layer(其中:
multi-layer self-attention network的final output。
1.1.3 预测层
在若干个自适应地提取
session序列信息的self-attention block之后,我们实现了long-term的self-attentive representationnext click,我们将session的长期偏好和当前兴趣结合起来,然后使用这种组合的embedding作为session representation。对于
sessionSASRec,我们将embedding作为global embedding。local embedding可以简单地定义为last clicked-item的embedding向量,即final session embedding:其中:
embedding,SR-GNN使用的是投影矩阵来投影:最后,在给定
session embeddingitemnext click的概率为:其中:
itemsessionnext click的概率。注意:
GNN的output,即它和embedding。然后我们通过最小化以下目标函数来训练我们的模型:
其中:
ground truth item的one-hot encoding向量,
1.2 实验
我们进行实验来回答以下问题:
RQ1:所提出的推荐模型GC-SAN是否实现了SOTA的性能?RQ2:关键的超参数(如权重因子、embedding size)如何影响模型性能?
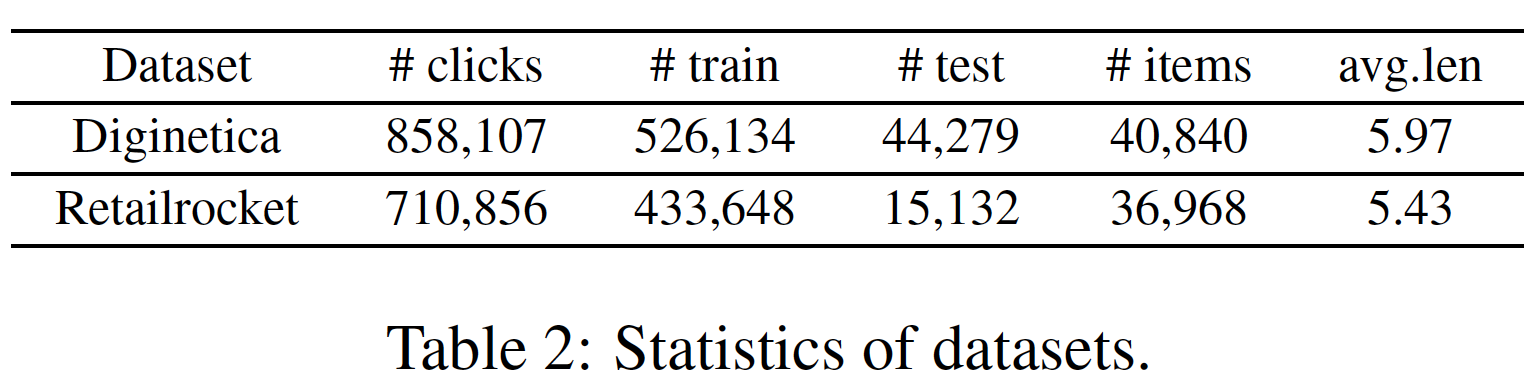
数据集:
Diginetica:来自于CIKM Cup 2016,这里仅使用交易数据。Retailrocket:来自一家个性化电商公司,其中包含六个月的用户浏览记录。
对于这两个数据集,为了过滤噪音,我们过滤掉出现频次少于
5次的item,然后删除item数量少于2的所有session。此外,对于session-based的推荐,我们最后一周的session数据设为测试集,剩余数据作为训练集。类似于
《Improved recurrent neural networks for session-based recommendations》和《A simple convolutional generative network for next item recommendation》,对于session序列input和相应的label为:预处理之后,数据集的统计数据如下表所示:
评估指标:为了评估所有模型的推荐性能,我们采用三个常见指标,即
Hit Rate(HR@N)、Mean Reciprocal Rank(MRR@N)、Normalized Discounted Cumulative Gain(NDCG@N)。HR@N是对unranked的检索结果进行评估,MRR@N和NDCG@N是对ranked list进行评估。这里我们考虑top N推荐,baseline方法:Pop:一个简单的baseline,它根据训练数据中的流行度来推荐排名靠前的item。BPR-MF:SOTA的non-sequential的推荐方法,它使用一个pairwise ranking loss来优化矩阵分解。IKNN:一种传统的item-to-item模型,它根据余弦相似度来推荐与候选item相似的item。item向量的生成参考SR-GNN的baseline介绍部分。FPMC:一个用于next-basket推荐的经典的混合模型,结合了矩阵分解和一阶马尔科夫链。注意,在我们的推荐问题中,每个basket就是一个session。作者描述有误,应该是每个
basket就是一个item。GRU4Rec:一种RNN-based的深度学习模型,用于session-based推荐。它利用session-parallel的mini-batch训练过程来建模用户行为序列。STAMP:一种新颖的short-term memory priority模型,用于从previous点击中捕获用户的长期偏好、以及从session中的last click来捕获当前兴趣。SR-GNN:最近提出的session-based的GNN推荐模型。它使用GNN生成item的潜在向量,然后通过传统的attention network来表达每个session。
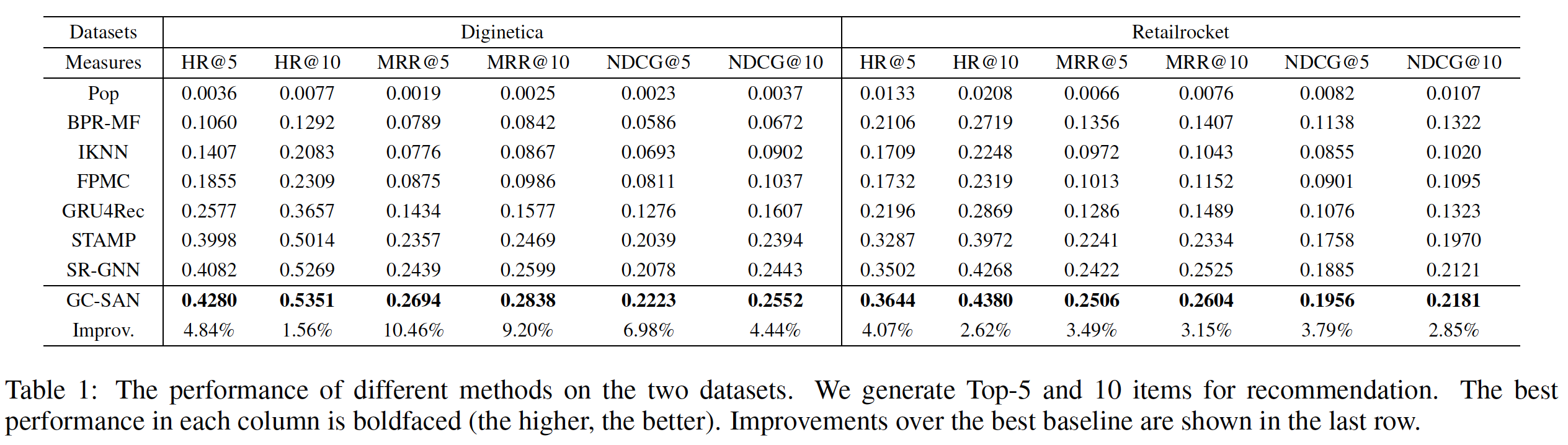
性能比较(
RQ1):为了展示我们的模型GC-SAN的推荐性能,我们将其与其它SOTA方法进行比较。实验结果如下所示:非个性化的、基于流行度的方法(即,
Pop)在两个数据集上的效果最差。通过独立地处理每个用户(即,个性化)并使用pairwise ranking loss,BPR-MF比Pop表现更好。这表明个性化在推荐任务中的重要性。IKNN和FPMC在Diginetica数据集上的性能优于BPR-MF,而在Retailrocket数据集上的性能差于BPR-MF。实际上,IKNN利用了session中item之间的相似性,而FPMC基于一阶马尔科夫链。所有神经网络方法,如
GRU4Rec和STAMP,几乎在所有情况下都优于传统的baseline(如:FPMC和IKNN),这验证了深度学习技术在该领域的实力。GRU4Rec利用GRU来捕获用户的通用偏好(general preference),而STAMP通过last clicked item来改善短期记忆。不出所料,STAMP的表现优于GRU4Rec,这表明短期行为对于预测next item问题的有效性。另一方面,通过将每个
session建模为图并应用GNN和注意力机制,SR-GNN在两个数据集上都优于所有其它baseline。这进一步证明了神经网络在推荐系统中的强大能力。与
SR-GNN相比,我们的方法GC-SAN采用self-attention机制自适应地为previous item分配权重,而无论它们在当前session中的距离如何,并捕获session中item之间的长期依赖关系。我们以线性方式将long-range self-attention representation和short-term interest of the last-click相结合,从而生成final session representation。正如我们所看到的,我们的方法在HR, MRR, NDCG指标在所有数据集上超越了所有baseline。这些结果证明了GCSAN对session-based推荐的有效性。
模型分析(
RQ2):这里我们深入分析研究GC-SAN,旨在进一步了解模型。限于篇幅,这里我们仅展示HR@10和NDCG@10的分析结果。我们在其它指标上也获得了类似的实验结果:GNN的影响:虽然我们可以从上表中隐式地推断出GNN的有效性,但是我们想验证GNN在GC-SAN中的贡献。我们从GC-SAN中移除GNN模块,将其替代为随机初始化的item embedding,并馈入self-attention layer。下表展示了使用
GNN和不使用GNN之间的效果。可以发现:即使没有GNN,GC-SAN在Retailrocket数据集上仍然可以超越STAMP,而在Diginetica数据集上被GRU4Rec击败。事实上,
Retailrocket数据集的最大session长度几乎是Diginetica数据集的四倍。一个可能的原因是:短序列长度可以构建更稠密的session graph,提供更丰富的上下文信息,而self-attention机制在长序列长度下表现更好。这进一步证明了self-attention机制和GNN在提高推荐性能方面发挥着重要作用。GNN在短序列的session-based推荐中的作用更大(相比长序列的session-based推荐)。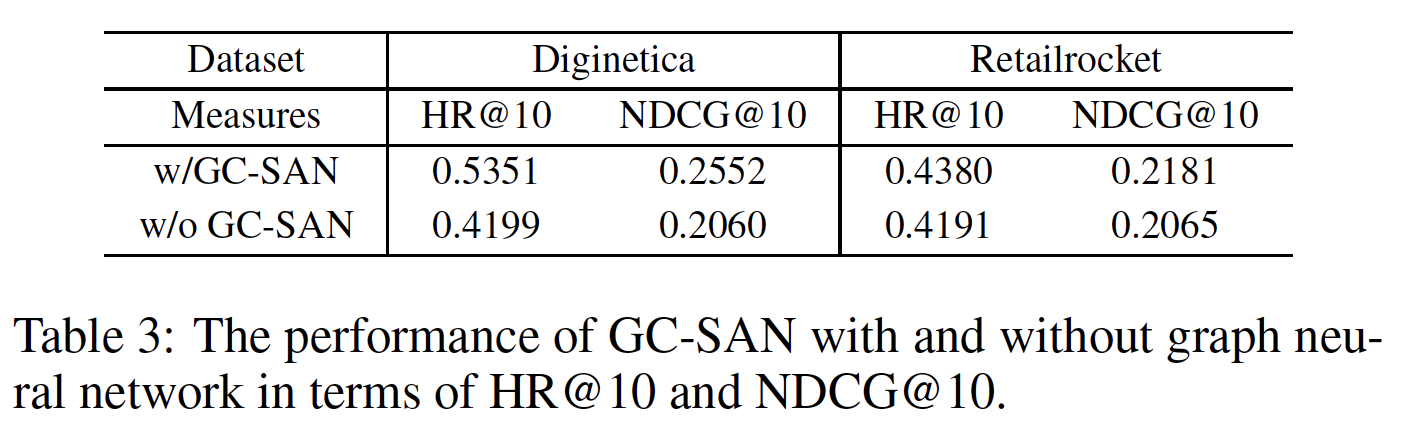
权重因子
self-attention representation和last-clicked action之间的贡献,如下图(a)。可以看到:仅将全局
self-attention作为final session embedding(即,0.4 ~ 0.8之间的效果更好。
这表明:虽然带
GNN的self-attention机制可以自适应地分配权重从而关注长期依赖关系、或更近期的行为,但是短期兴趣对于提高推荐性能也是必不可少的。这个权重可以通过数据来自适应地学到。
self-attention block数量level的self-attention layer从GC-SAN中受益最多。下图(b)展示了应用不同数量的self-attention block的效果,其中1 ~ 6。在这两个数据集上,我们可以观察到增加GCSAN的性能。然而,当
block(GC-SAN更容易丢失low-layer的信息。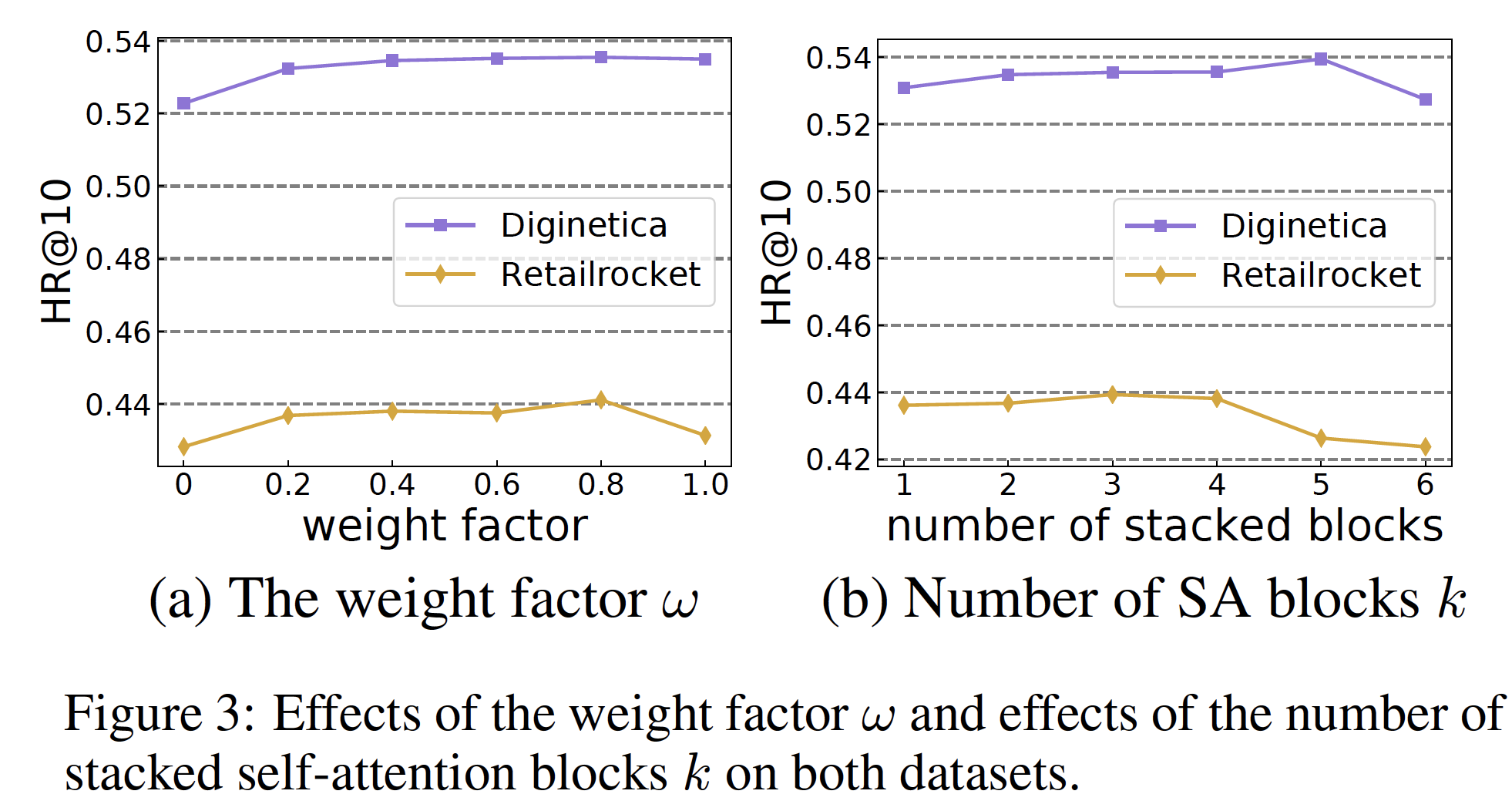
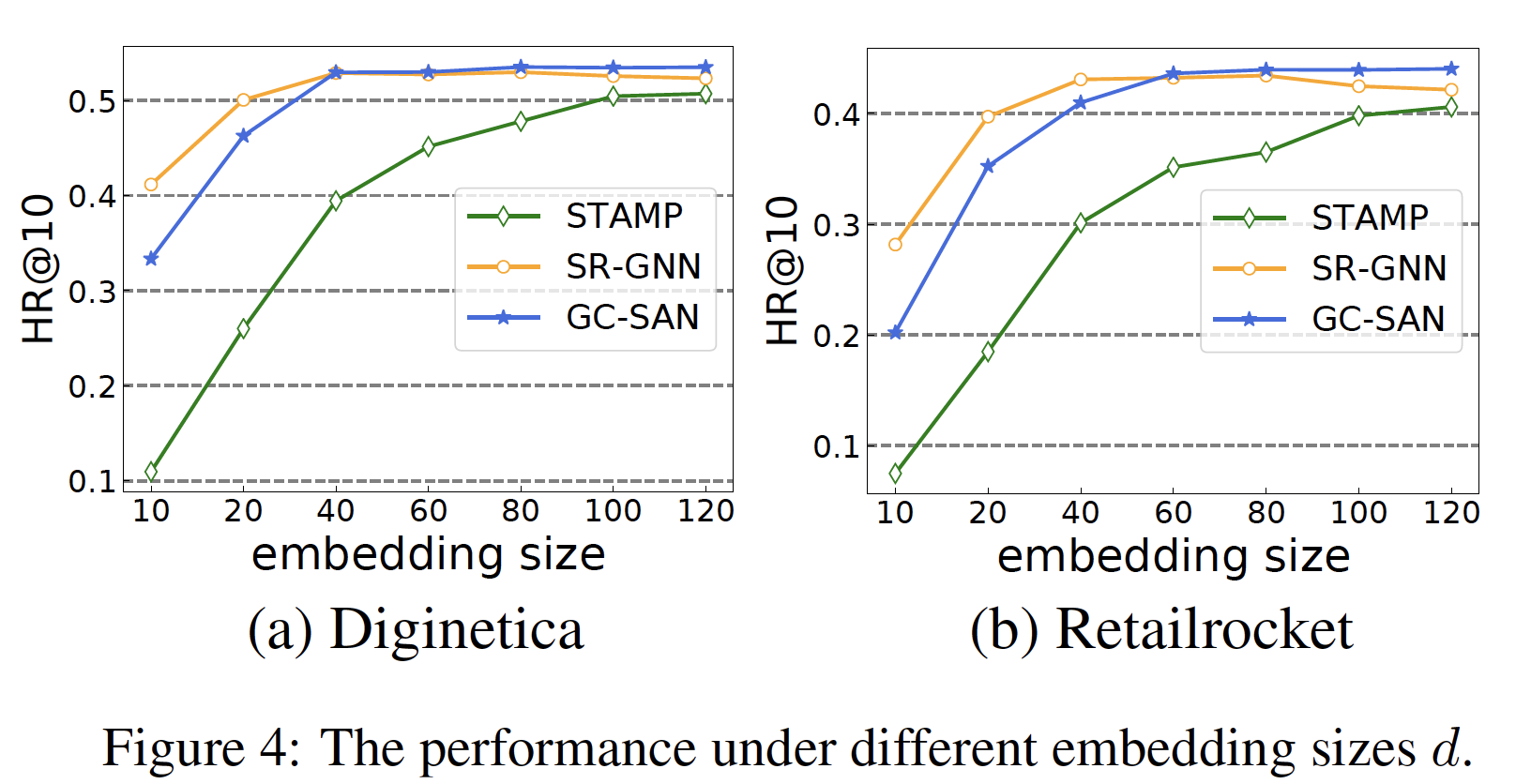
embedding sizeemebdding size10 ~ 120。在所有
baseline中,STAMP和SR-GNN表现良好且稳定。因此,为了便于比较,我们使用STAMP和SR-GNN作为两个baseline。从图中可以观察到:我们的模型
GC-SAN在所有STAMP。当
SR-GNN的性能优于GC-SAN。一旦超过这个值,GC-SAN的性能仍然会增长并且最终在SR-GNN的性能会略有下降。这可能是因为相对较小的GC-SAN捕获item潜在因子之间的复杂transition,而SR-GNN可能会因为较大的