一、NextItNet [2019]
《A Simple Convolutional Generative Network for Next Item Recommendation》
Introduction:RNN模型的问题:依赖于包含了整个历史信息的一个hidden state,无法充分利用序列中的并行计算。因此,它们的速度在训练和评估中都受到限制。相比之下,训练
CNN不依赖于前一个time step的计算,因此允许多序列中的每个元素进行并行化。Caser:一个卷积序列embedding模型,其基本思想是:将embedding矩阵视为前面image,并将序列模式(sequential patten)视为image的局部特征。Caser执行最大池化操作来仅仅保留卷积层的最大值,从而增加感受野以及处理输入序列的可变长度。下图描述了Caser的关键架构。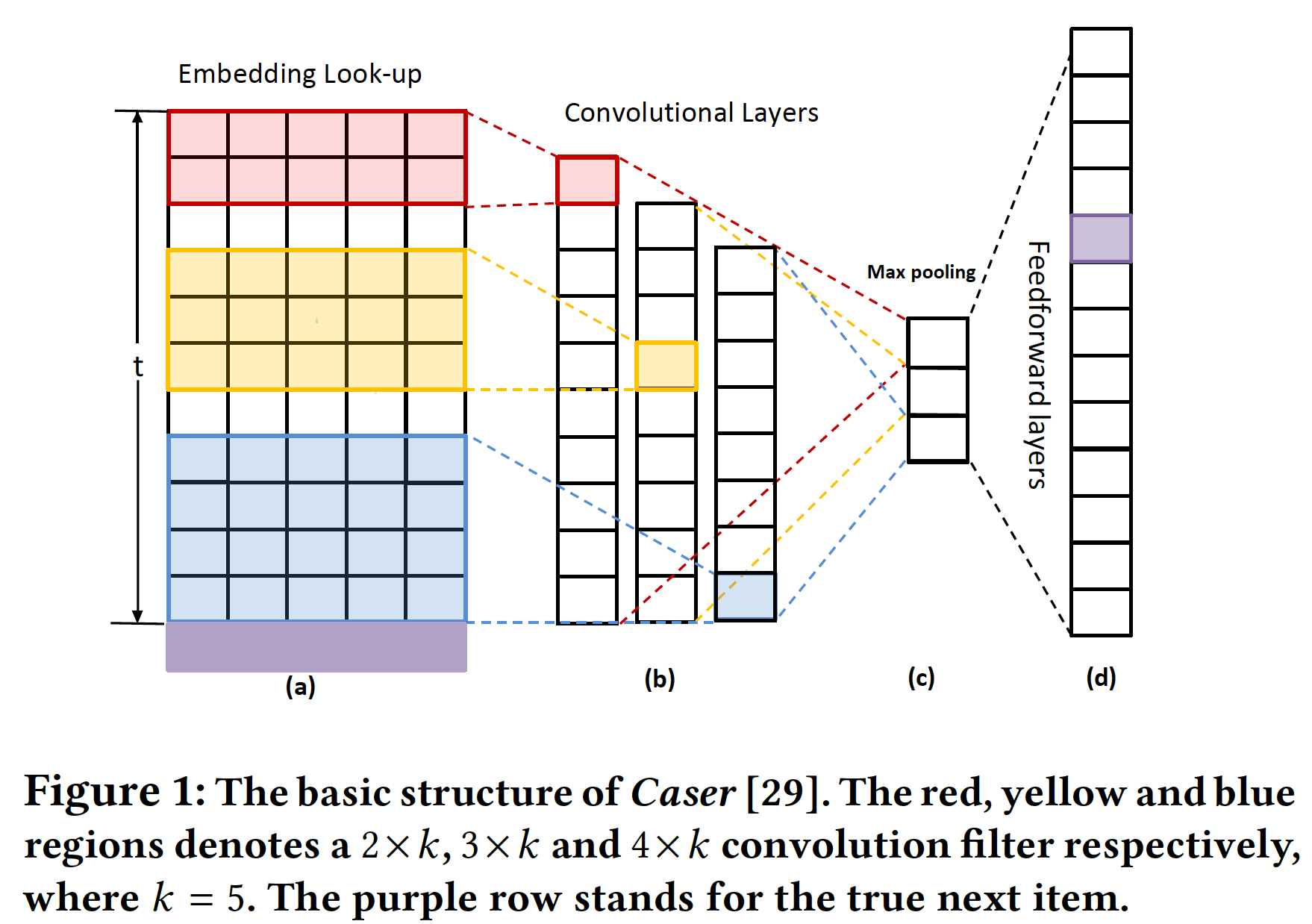
Caser的缺陷:计算机视觉中安全使用的最大池化方案在建模长距离序列数据时,可能会丢弃重要的位置信号(
position signal)和循环信号(recurrent signal)。仅为目标
item生成softmax分布无法有效地使用完整的集合的依赖性set of dependency。NextItNet建模的是item序列的联合分布(即,集合的依赖性),而Caser建模的是单个item的分布。
随着
session个数和session长度的增加,这两个缺点变得更加严重。Caser缺陷的解决方案:《A Simple Convolutional Generative Network for Next Item Recommendation》引入了一个简单的但是完全不同的CNN-based序列推荐模型NextItNet,该模型对复杂的条件分布进行建模。具体而言:首先,
NextItNet被设计为显式编码item相互依赖关系,这允许在原始item序列上直接估计输出序列的分布(而不是目标item)。这不是
NextItNet的独有优势,很多RNN-based模型都可以做到(通过拆分为subsession的方式)。NextItNet的优势在于速度(训练速度、推断速度)。其次,
NextItNet没有使用低效的大滤波器,而是将一维空洞卷积层(1D dilated convolutional layer)堆叠在一起,从而在建模远程依赖时增加感受野。因此在NextItNet的网络结构中可以安全地删除池化层。值得注意的是,虽然空洞卷积(
dilated convolution)是为图像生成任务中的稠密预测(dense prediction)任务而发明的,并已被应用于其它领域(如,声学任务,翻译任务),但是它在具有大量稀疏数据的推荐系统中尚未得到探索。此外,为了更容易优化
deep generative architecture,NextItNet使用残差网络通过残差块(residual block)来wrap卷积层。据作者所知,这也是采用残差学习来建模推荐任务的首个工作。
贡献:一个新颖的推荐生成模型(
recommendation generative model)、一个完全不同的卷积网络架构。
相关工作:
序列推荐的早期工作主要依赖于马尔科夫链和
feature-based矩阵分解方法。与神经网络模型相比,基于马尔科夫链的方法无法建模序列数据中的复杂关系。例如,在
Caser中,作者表明马尔科夫链方法无法建模union-level的序列模式,并且不允许item序列中的skip behavior。基于分解的方法(如分解机),通过
sum序列的item vector来建模序列。然而,这些方法不考虑item的顺序,也不是专门为序列推荐而发明的。
最近,与传统模型相比,深度学习模型展示出
SOTA的推荐准确性。此外,RNN几乎在序列推荐领域占据主导地位。例如,GRU4Rec提出了一个带ranking loss的GRU架构,用于session-based推荐。在后续论文中,人们设计了各种RNN变体来适应不同的应用场景,如:添加个性化:
《Personalizing Session-based Recommendations with Hierarchical Recurrent Neural Networks》。添加内容特征:
《Learning to refine text based recommendations》。添加上下文特征:
《Contextual Sequence Modeling for Recommendation with Recurrent Neural Networks》。添加注意力机制:
《A Hierarchical Contextual Attention-based GRU Network for Sequential Recommendation》、《Neural Attentive Session-based Recommendation》。使用不同的
ranking loss函数:《Recurrent Neural Networks with Top-k Gains for Session-based Recommendations》。
相比之下,
CNN-based序列推荐模型更具挑战性并且探索较少,因为卷积不是捕获序列模型的自然方式。据我们所知,迄今为止仅提出了两种类型的、CNN-based的序列推荐架构:标准二维CNN的Caser、旨在建模高维特征的三维CNN(《3D Convolutional Networks for Session-based Recommendation with Content Feature》)。与上述例子不同,我们计划使用有效的空洞卷积滤波器和残差块来研究一维
CNN的效果,从而构建推荐架构。
1.1 模型
Top-N session-based推荐:令user-item交互序列(或session),也可记做item在长度为序列推荐的目标是:寻找一个模型,使得对于给定的前缀
item序列(prefix item sequence)item生成ranking或分类分布(classification distribution)item。其中:item作为该session的第item的可能性。item的规模。
在实践中,我们通常从
top-N个item来提供推荐,称作top-N session-based的推荐。Caser的局限性:Caser的基本思想是:通过embedding look-up操作将前面的item嵌入为一个矩阵(a)所示。矩阵的每个行向量对应一个item的潜在特征。embedding矩阵可以视为item在image。直观而言,在计算机视觉中成功应用的各种
CNN模型都可以用于对item序列构建的image进行建模。但是,序列建模和图像处理有两方面的区别,这使得CNN-based模型的使用不是很直接:首先,现实世界场景中的可变长度的
item序列可能会产生大量不同大小的image,而传统的具有固定大小滤波器的卷积架构可能会失败。其次,用于图像的最有效的滤波器,例如
3 x 3和5 x 5,不适用于序列image,因为这些小的滤波器(就行方向而言)无法捕获full-width embedding vector的representation。
为了解决上述限制,
Caser中的滤波器通过大滤波器滑过序列image的完整列。也就是说,滤波器的宽度通常与输入image的宽度相同。高度通常是一次滑动2 ~ 5个item。不同大小的滤波器在卷积后会生成可变长度的feature map(如下图(b))。为了确保所有feature map具有相同的大小,Caser对每个feature map执行最大池化(仅保留每个feature map的最大值),产生一个1 x 1的feature map(如下图(c))。最后,这些来自所有滤波器的1 x 1的feature map被拼接起来构成一个特征向量,然后是一个softmax layer(如下图(d))。注意,我们省略了垂直卷积,因为它无助于解决下面讨论的主要问题。
基于以上对
Caser中卷积的分析,我们发现可能存在的几个缺陷:首先,最大池化算子有明显的缺陷。它无法区分
feature map中的重要特征是仅出现一次还是出现多次,并且忽略了重要特征出现的位置。在图像处理中安全使用的最大池化算子可能对建模远程序列有害。其次,
Caser中的仅适用于一个hidden卷积层的浅层网络结构在建模复杂关系或远程依赖时可能会失败。最后一个重要的缺陷来自于
next item的生成过程。我们将在后文中详细描述。
为了解决上述局限性,我们引入了一种新的概率生成模型,该模型由堆叠的一维卷积层组成。一般而言,我们提出的模型在几个关键方面与
Caser有根本的不同:我们的概率估计器一次性地显式地建模序列中每个
item的分布,而不仅仅是last item的分布。我们的网络具有深层结构而不是浅层结构。
我们的卷积层是基于高效的一维空洞卷积而不是标准的二维卷积。
我们的网络移除了池化层。
1.1.1 一个简单的生成模型
这里介绍一个简单的、但是非常有效的生成模型(
generative model),该模型直接对先前交互item的序列进行操作。我们的目标是估计原始item交互序列上的联合概率分布。令
item序列其中:
session中第一个item的概率。itemitem
NADE,PixelRNN/CNN在生物领域和图像领域都探索了类似的设置。因为
GRU4Rec建模条件概率,因此它是判别模型。我们通过堆叠一维卷积网络来建模
user-item交互的条件分布。具体而言,网络接收这是一个典型的
seq-to-seq的自回归模型。注意,虽然网络接收例如,如下图所示,
Caser, GRU4Rec),它们仅建模单个条件分布Caser这样的模型仅估计next itemsoftmax),而我们的生成方法估计item的分布。生成过程的对比如下:
其中:
predict。显然,我们的模型在捕获所有序列关系的集合方面更有效,而
Caser和GRU4Rec未能显式地建模在实践中,为了解决这个缺点,
Caser和GRU4Rec这类模型通常会生成很多子序列(subsession),用于通过数据增强技术(如,填充、拆分、或移位input序列)进行训练,如以下公式所示(NARM、HRNN、Caser、3D-CNN):虽然有效,但是由于每个
subsession的单独优化,上述生成subsession的方法无法保证最佳结果。此外,单独优化这些subsession将会导致相应的计算成本。本文实验部分也进行了详细的比较。session的联合概率的最大似然,分解为每个subsession的条件概率的最大似然。由于线性关系,因此每个subsession是可以单独优化的。NextItNet是CNN-based,因此可以在所有subsession中并行地、共享地利用卷积计算结果,所以它的优势在于计算效率,而不是作者提到的联合优化。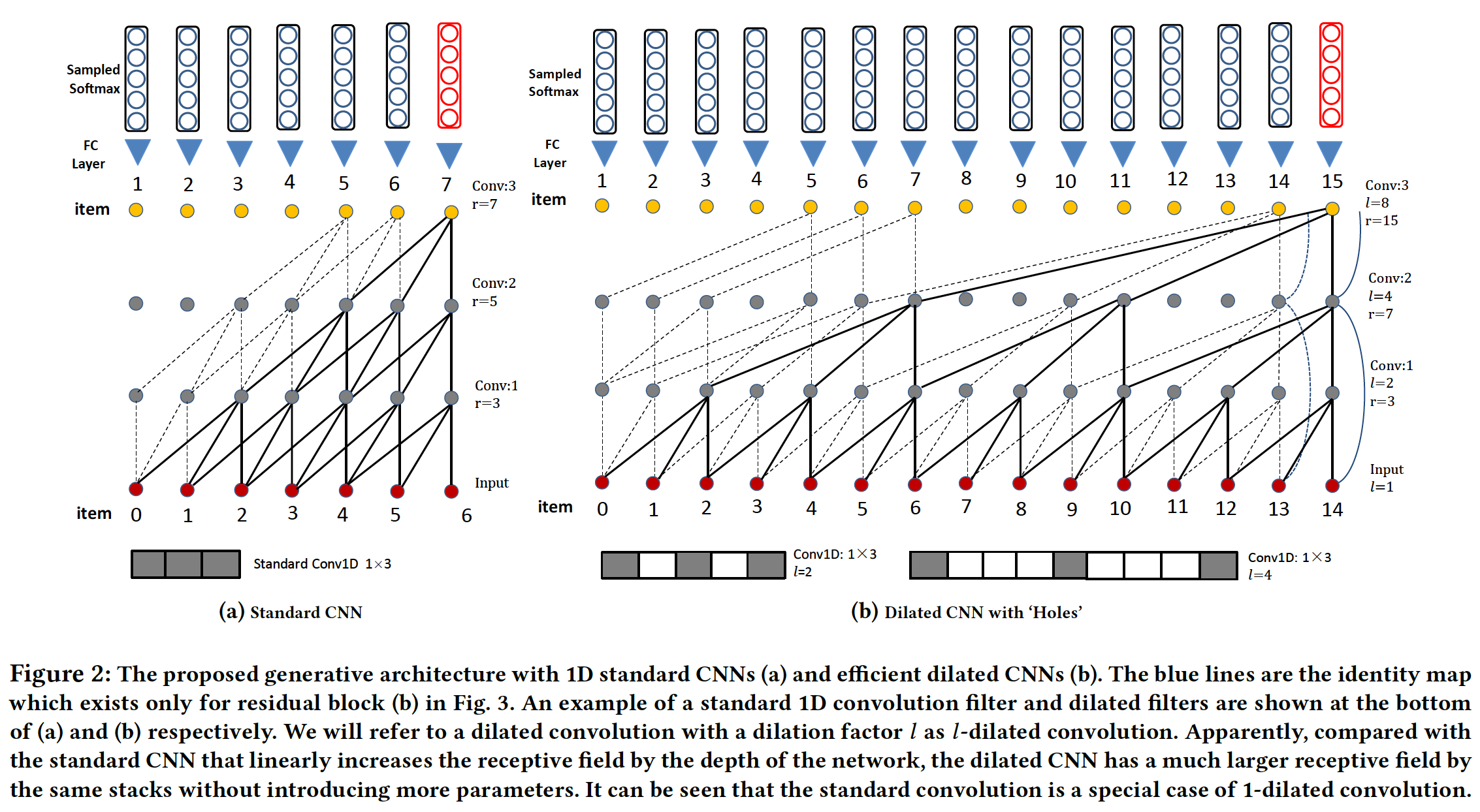
1.1.2 网络架构
Embedding Look-up Layer:给定一个item序列lookup table检索前面itemitem embedding堆叠在一起。假设embedding维度为inner通道数,这将导致大小为item对应于embedding向量注意,与
Caser在卷积期间将输入矩阵视为二维image不同,我们提出的架构通过一维卷积滤波器来学习embedding layer,我们将在后面描述。Dilated layer:如上图(a)所示,标准滤波器只能通过以网络深度呈线性关系的感受野来进行卷积。这使得处理long-range序列变得困难。与WaveNet类似,我们使用空洞卷积来构建所提出的生成模型。空洞卷积的基本思想是:通过使用零值的空洞来将卷积滤波器应用于大于其原始长度的区域。因此,由于使用更少的参数所以它更高效。另一个好处是,空洞卷积可以保留输入的空间维度,这使得卷积层和残差结构的堆叠操作更加容易。
常规卷积通过
padding也可以保留输入的空间维度。因此,保留输入空间维度并不是空洞卷积的优势。上图展示了所提出的序列生成模型在标准卷积和空洞卷积上实现时,模型之间的对比。
(b)中的空洞因子(dilation factor)是:1 / 2 / 4 / 8。令感受野大小为
如果卷积为标准卷积,则感受野是线性的,即
如果卷积为空洞卷积,则感受野是指数的,即
给定空洞因子
location则
item序列为了防止信息泄露,这里仅使用左侧的数据点来进行卷积。
其中:
locationembedding矩阵。
显然,空洞卷积结构更有效地建模
long-range的item序列,因此在不使用更大的滤波器或模型变得更深的情况下更有效。如果把
attention-based聚合操作(并且使用长度为在实践中,为了进一步增加模型容量和感受野,需要堆叠多次一维空洞卷积层,如
一维变换(
One-dimensional Transformation):尽管我们的空洞卷积算子依赖于二维输入矩阵embedding输入进行建模,我们执行了一个简单的reshape操作,这是执行一维卷积的先决条件。具体而言,将二维矩阵
reshape为大小为image的通道,而不是Caser中标准卷积滤波器的宽度。下图
(c)说明了reshape的过程。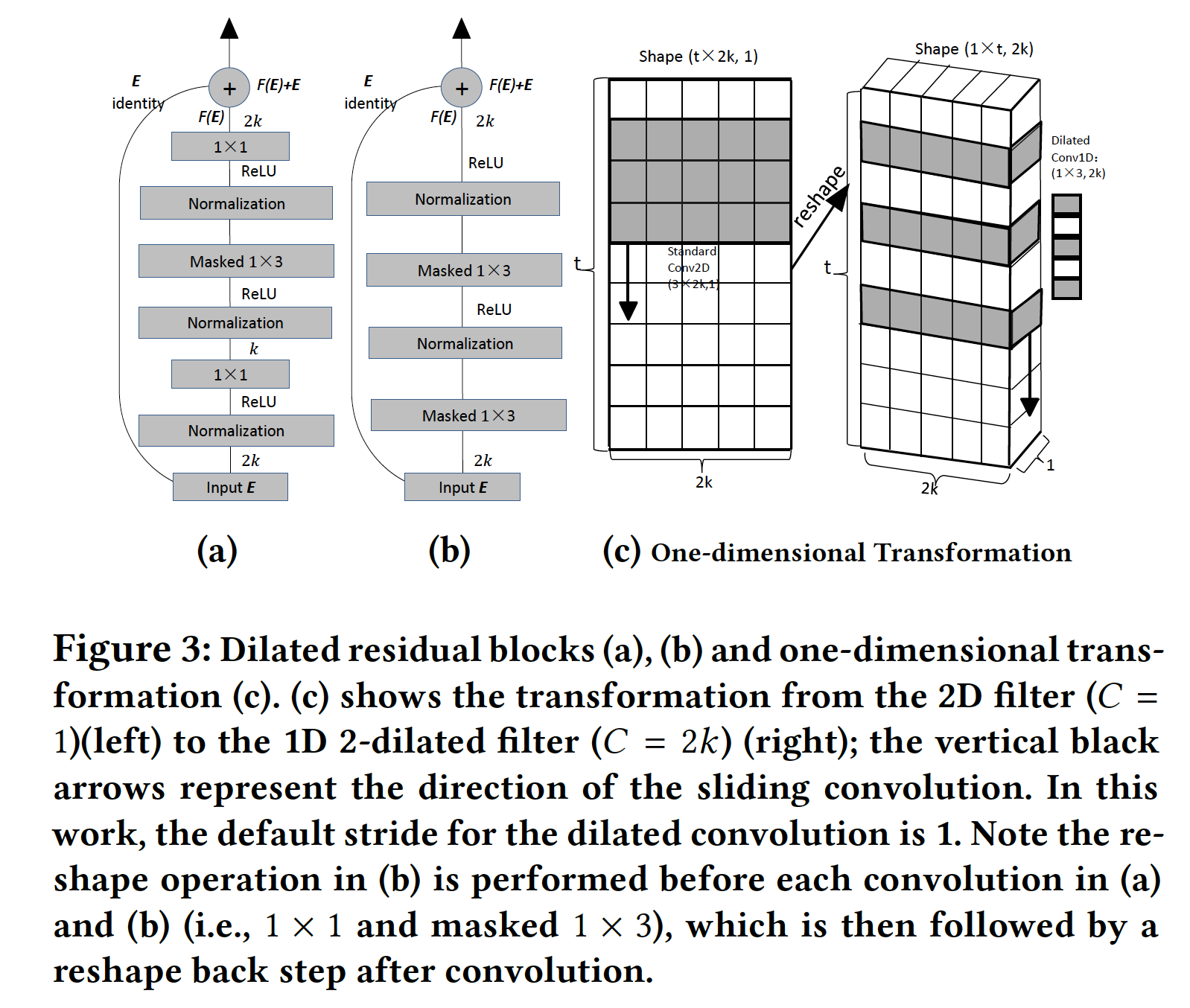
1.1.3 Masked Convolutional Residual Network
虽然增加网络层的深度有助于帮助获得
higher-level feature representation,但是也容易导致梯度小的问题,这使得学习过程变得更加困难。为了解决退化问题(degradation problem),深度网络引入了残差学习。残差学习的基本思想是将多个卷积层作为一个
block堆叠在一起,然后采用skip connection将前一层的特征信息传递到后一层。skip connection允许显式拟合残差映射(而不是原始的恒等映射),这可以维持输入信息从而增大传播的梯度。假设所需要的映射为
block拟合另一个映射:所需要的映射现在通过逐元素加法重写为:
ResNet中所证明的,优化残差映射受到
《Identity mappings in deep residual networks》和《Neural machine translation in linear time》的启发,我们在下图(a)和(b)中引入了两个残差模块。在
(a)中我们用一个残差块(residual block)来wrap每个空洞卷积层(即,Masked 1 x 3),而在(b)中我们用一个不同的残差块来wrap每两个空洞卷积层。也就是说,对于(b)中的block的设计,输入层和第二个卷积层通过skip connection来连接。具体而言,每个
block都由归一化层、激活(例如ReLU)层、卷积层、skip connection以特定的顺序组成。在这项工作中,我们在每个激活层之前采用了SOTA的layer normalization,因为与batch normalization相比,它非常适合序列处理和在线学习。(a)中的residual block由三个卷积滤波器组成:一个大小为1 x 3的空洞卷积滤波器和两个大小为1 x 1的常规滤波器。引入1 x 1滤波器主要是改变feature map的通道数,从而减少1 x 3卷积要学习的参数。第一个
1 x 1滤波器(靠近图(a)中的输入第二个
1 x 1滤波器进行相反的变换从而保持下一次堆叠操作的空间维度。
(b)中的residual block包含两个卷积滤波器,它们都是1 x 3的空洞卷积滤波器。这里没有1 x 1的常规滤波器。并且input之后没有跟随Normalization。
为了展示
(a)中的1 x 1滤波器的有效性,我们计算了(a)和(b)中的参数数量。为简单起见,我们忽略了激活层和归一化层。正如我们所见:在
(b)中,由于没有1 x 1滤波器,所以1 x 3滤波器的参数数量为:而在
(a)中,要学习的参数数量为:
(a)和(b)中的残差映射的公式为:其中:
ReLU层,layer-normalization。1 x 1卷积的权重权重函数。1 x 3大小的l-dilated卷积滤波器的权重函数。
注意,为了简化公式,这里省略了偏置项。
Dropout-mask:为了避免未来信息泄露的问题,我们为一维空洞卷积提出了一种masking-based的dropout技巧,从而防止网络看到未来的item。具体而言,在预测因为默认的卷积操作会以当前位置为中心,同时使用左侧和右侧的数据点。
如图所示,我们的
dropout-masking操作有两种方式(假设卷积核大小为padding & masking:如图(d)所示,在输入序列左侧填充CNN的padding填充),并在卷积时masking卷积窗口右侧部分。shifting & padding:如图(e)所示,将输出序列左移这种方法
(e)中的方法很可能导致序列中的信息丢失,特别是对于短序列。因此,在这项工作中我们在(d)中应用填充策略。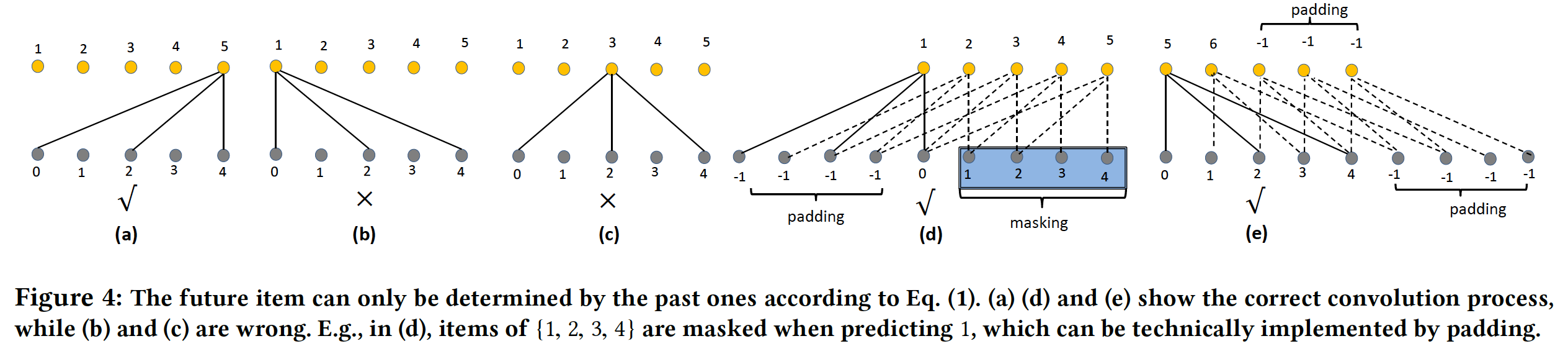
1.1.3 训练和预测
如前所述,卷积架构的最后一层中的矩阵(由
item的概率分布,其中top-N推荐。为此,我们可以简单地在最后一个卷积层之上再使用一个
1 x 1卷积层,滤波器大小为item总数。遵从一维变换过程,我们得到想要的输出矩阵softmax操作之后的每个行向量表示categorical distribution,优化的目标是最大化训练数据关于
item的二元交叉熵损失之和。对于具有数千万个item的实际推荐系统,可以应用负采样策略来绕过full softmax分布的生成,其中1 x 1卷积层被一个具有权重矩阵sampled softmax或kernel based sampling。经过适当调优的采样大小,这些负采样策略的推荐准确性与full softmax方法几乎相同。这里,
1 x 1卷积层和全连接层几乎是等价的,所以替代的意义是什么?读者认为这里表述有误,应该是output都采样相同的一组负样本。另外,这里没有把
input emebddingoutput embedding预测阶段:为了与现有模型进行比较,我们仅预测
next item,然后停止生成过程。然而,该模型能够简单地通过将预测的next item(或序列)输入网络来预测下一个,从而生成一个预测序列,因此是序列生成模型。这与大多数现实世界的推荐场景相匹配。在这些场景中,当观察到当前action时,紧跟着next action。但是在训练和评估阶段,所有
time step的条件预测都可以并行进行,因为完整的输入item序列出于比较的目的,我们没有在我们的模型或
baseline中考虑其它上下文。然而,我们的模型可以灵活地结合各种上下文信息。例如,如果我们知道user idlocation其中:
user embedding,location的location matrix。我们可以通过逐元素操作(如乘法、加法、或拼接)将
1.2 实验
数据集:
Yoochoosebuys: YOO:来自RecSys Challenge 2015。我们使用购买数据集进行评估。对于预处理,我们过滤掉长度小于3的session。同时,我们发现在处理后的YOO数据中,96%的session长度小于10,因此我们简单地删除了长度大于等于10的session(占比4%),并将其称作short-range序列数据。Last.fm:我们从该数据集中分别随机抽取20000和200000首歌曲,分别称作MUSIC_M数据集和MUSIC_L数据集。在
Last.fm数据集中,我们观察到大多数用户每周听音乐数百次,而有的用户甚至一天内听了一百多首歌曲。因此,我们能够通过切分这些long-range的听歌session来测试我们的模型在short-range和long-range序列上的性能。在
MUSIC_L中,我们定义最大session长度5 / 10 / 20 / 50 / 100(每种长度定义一个数据集),然后提取每item作为我们的输入序列。这是通过在整个数据集上滑动一个大小和步长为item之间的时间跨度超过2小时的session。这样,我们创建了5个数据集,称之为RAW-SESSIONS。此外,MUSIC_M5和YOO也是RAW-SESSIONS。我们将这些RAW-SESSIONS数据随机划分为训练集、验证集、测试集,划分比例为50%-5%-45%。是否要根据时间跨度来切分?这种滑动窗口的方法会导致一些
session内部的item之间,存在较大的时间跨度。此外,这里训练集太小,测试集太大?
如前所述,
Caser和GRU4Rec的性能对于长序列输入应该会显著降低,例如当Caser和GRU4Rec将使用item相互依赖关系。为了弥补这个缺陷,当NARM和《Improved recurrent neural networks for session-based recommendations》,通过从RAW-SESSIONS的训练集中手动创建额外的session,以便Caser和GRU4Rec可以在很大程度上利用full dependency。假设session将通过填充头部和移除尾部从而创建45个sub-session,即:关于
MUSIC_M,我们仅展示我们在下表中展示了
RAW-SESSIONS和SUB-SESSIONS(即SUB-SESSIONS-T)的训练数据集的统计信息。为什么对于
YOO, MUSIC_M5, MUSIC_L5,SUB-SESSIONS-T反而要比RAW-SESSIONS更少?读者猜测,这里SUB-SESSIONS-T不包含原始的RAW-SESSIONS,因此真实训练集是二者的并集。
配置:
所有模型均使用
TensorFlow在GPU(TITAN V)上进行训练。baseline方法的学习率和batch size是根据验证集中的性能手动设置的。对于所有数据集,
NextItNet使用0.001的学习率和batch size = 32。如果没有特别的说明,那么所有模型的
embedding大小我们报告了使用残差块
(a)和完整softmax的结果,我们也独立地验证了 残差块(b)的性能结果。残差块
(a):每个残差块来wrap每个空洞卷积层。残差块
(b):每个残差块来wrap每两个空洞卷积层。为了进一步评估两种残差块的有效性,我们还在另一个数据集中测试了我们的模型,即
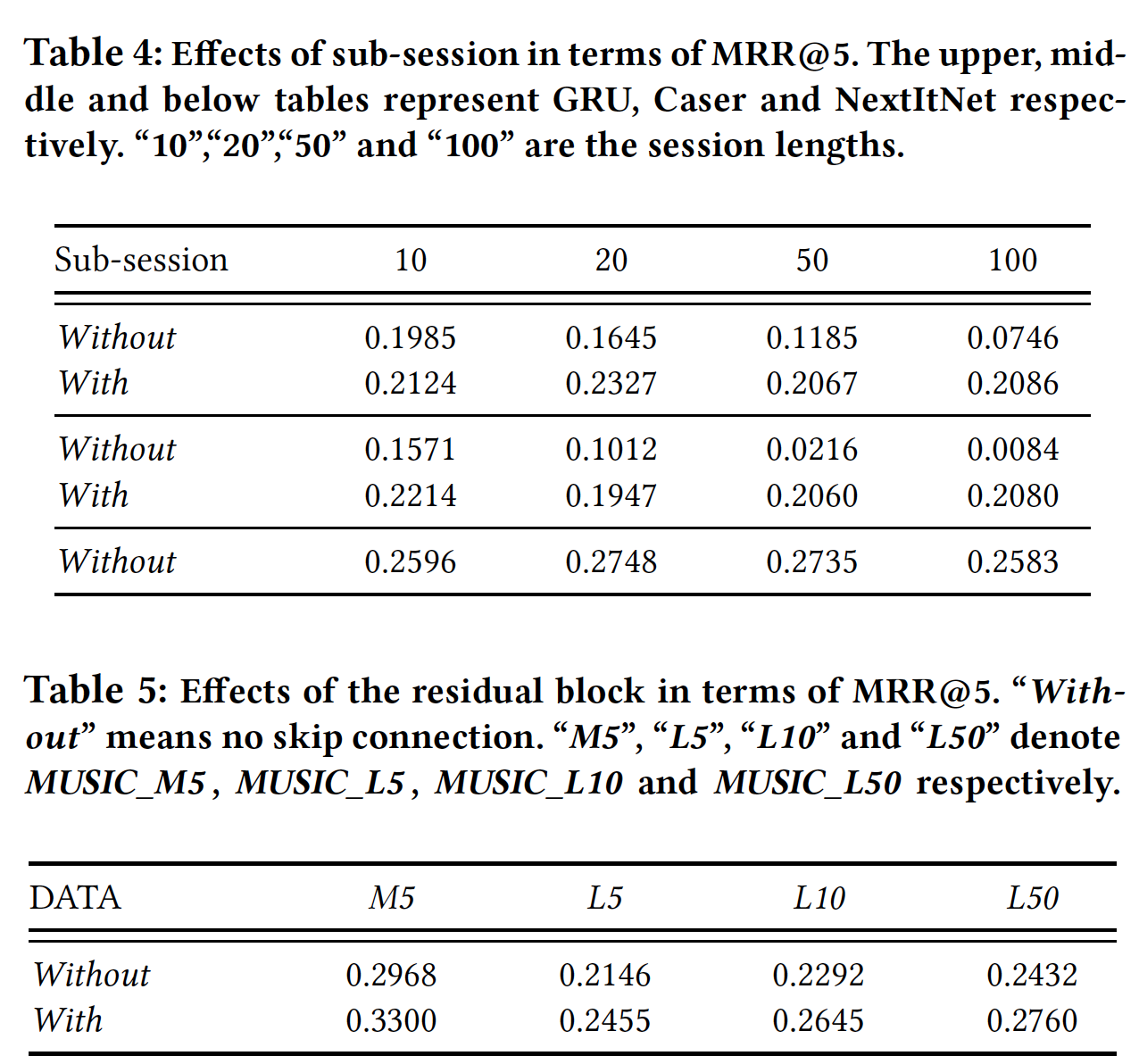
Weishi。与没有残差块的相同模型相比,improvement大约是两倍。
评估指标:
Mean Reciprocal Rank: MRR@N、Hit Ratio: HR@N、Normalized Discounted Cumulative Gain: NDCG@N。5和20。我们评估测试集中每个序列的
last item的预测准确性。论文这里省略了
baseline的介绍。所有方法的总体性能如下表所示。可以看到:神经网络模型(即,
Caser, GRU4Rec, NextItNet)在top-N序列推荐任务中获得了非常有前景的准确性。例如,在
MUSIC_M5数据集中,三个神经网络模型在MRR@5上的表现比广泛使用的baseline MostPop好120倍以上。在这个数据集中,我们通过NextItNet获得的最佳MRR@20结果是0.3223,这大致意味着目标item在20000个候选item中平均排名第3位(1/0.3223大致等于3)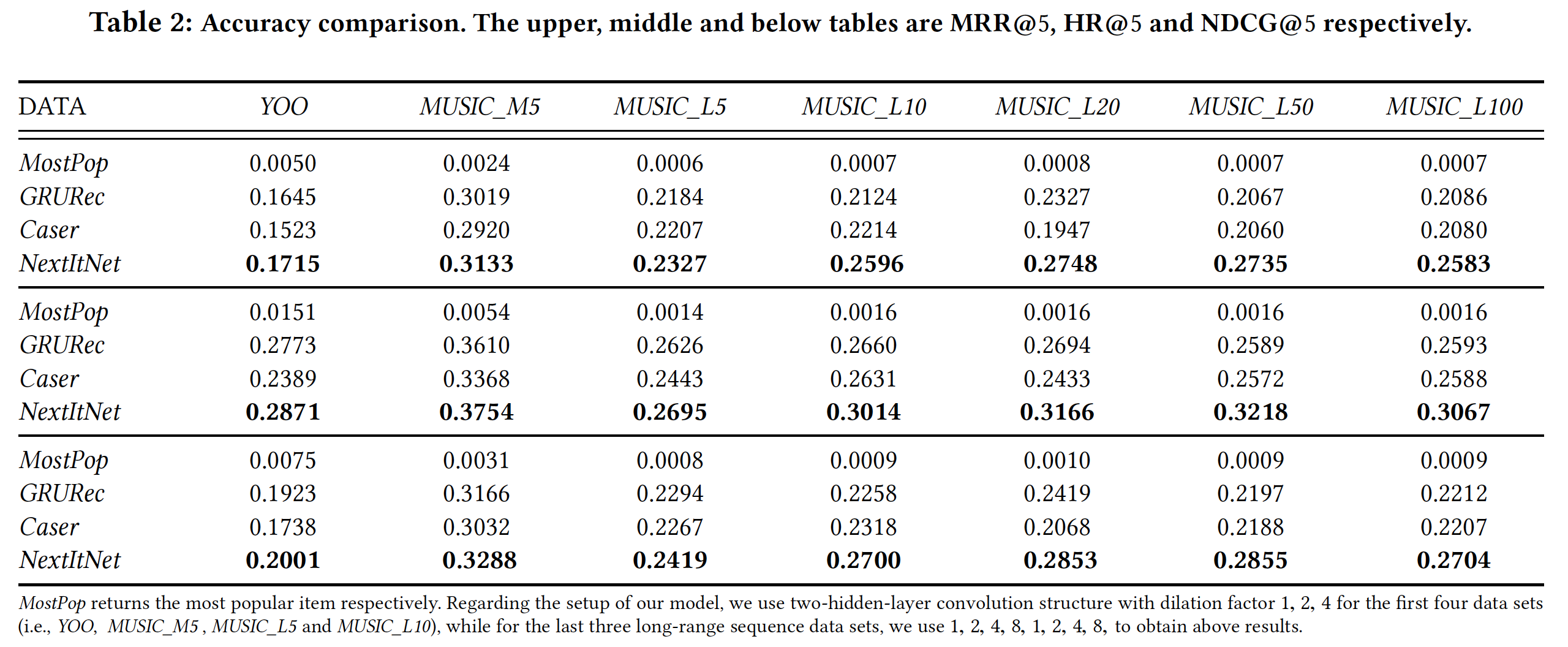
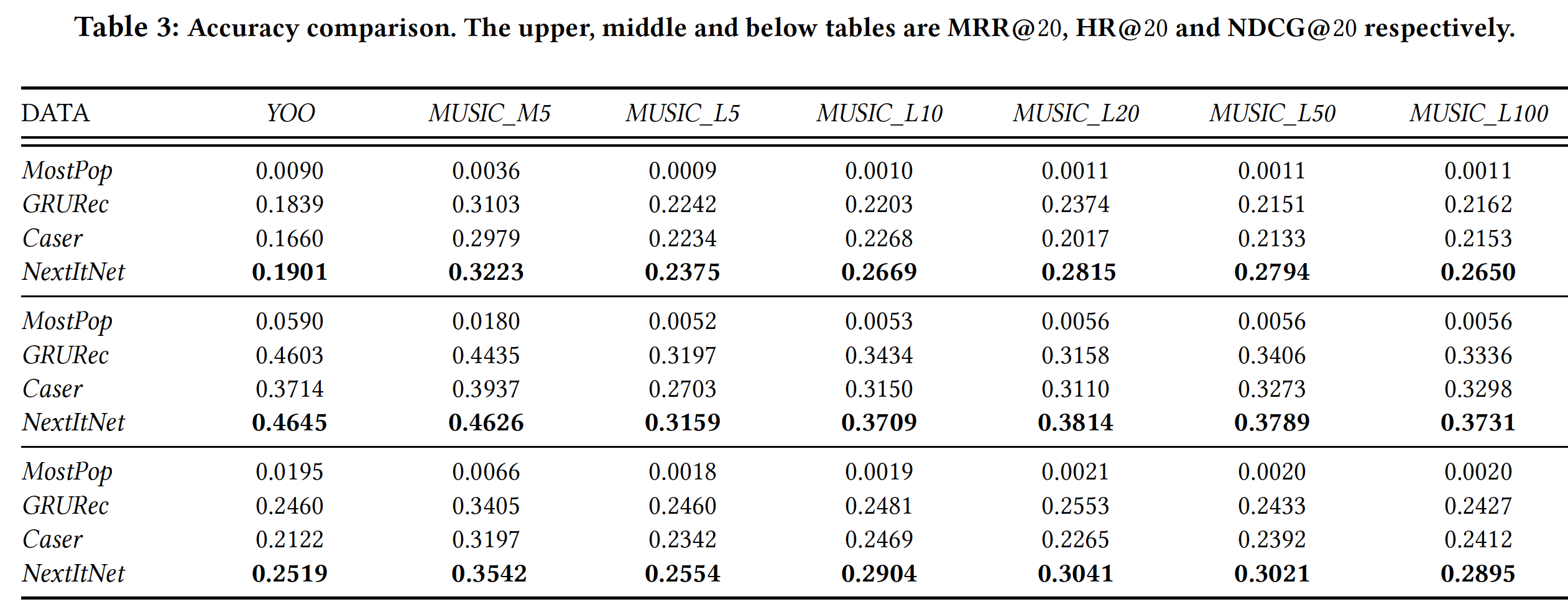
我们发现,在这些基于神经网络的模型中,
NextItNet在很大程度上优于Caser和GRU4Rec。我们认为有几个原因促成了这个SOTA的结果。首先,正如前文所强调的那样,
NextItNet充分利用了完整的序列信息。这可以在下表中轻松地验证,我们观察到没有subsession的Caser和GRU4Rec在long session中的表现非常糟糕。此外,即使使用
subsession,Caser和GRU4Rec仍然展示出比NextItNet差得多的结果。因为与NextItNet利用完整session相比,每个subsession的独立优化显然是次优suboptimal的。“每个
subsession的独立优化显然是次优suboptimal的” 个人觉得不成立,因为本质上由于subsession单独优化的最大化。其次,与
Caser不同的是,NextItNet没有池化层,尽管它也是CNN-based模型。因此,NextItNet保留了原始embedding矩阵第三,
NextItNet可以通过使用残差学习来支持更深的层,这更适合建模复杂的关系和长期依赖关系。我们独立地验证了残差块(b)的性能,并将结果展示在下表中。可以观察到:通过残差块设计可以显著提高NextItNet的性能。
下表展示了
embedding size的影响。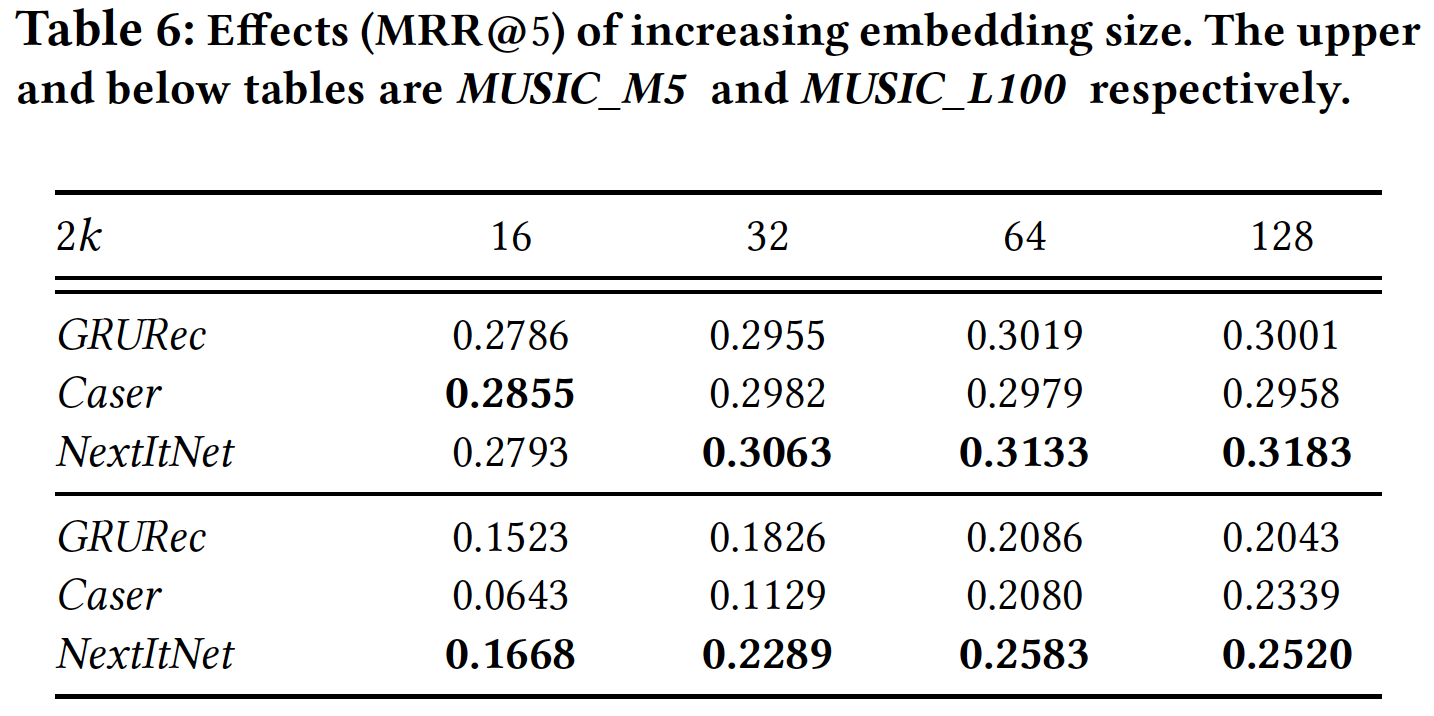
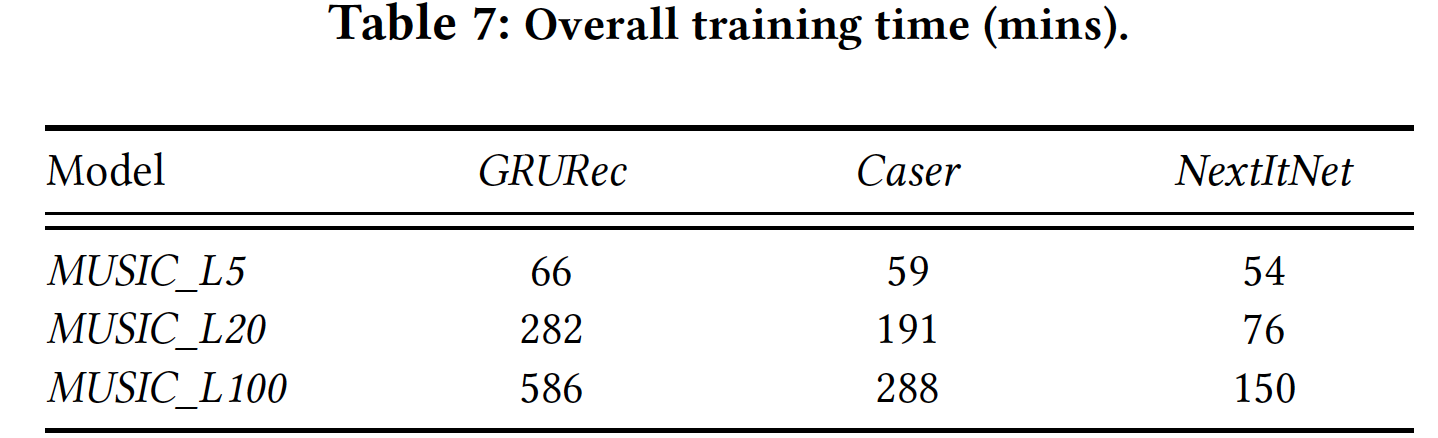
除了推荐准确性的优势,我们还在下表中评估了
NextItNet的效率。可以看到:首先,
NextItNet和Caser在所有三个数据集中都需要比GRU4Rec更少的训练时间。CNN-based模型可以更快训练的原因是由于卷积的完全并行机制。显然,具有训练速度优势的CNN模型更受现代并行计算系统的青睐。其次,
NextItNet与Caser相比,其训练效率得到进一步的提升。更快的训练速度主要是因为NextItNet在训练期间利用了完整的序列信息,然后通过更少的训练epoch来更快地收敛。个人觉得
NextItNet训练速度快的其中一个原因是:卷积运算的结果在多个subsession之间共享,所以节省了大量的计算。
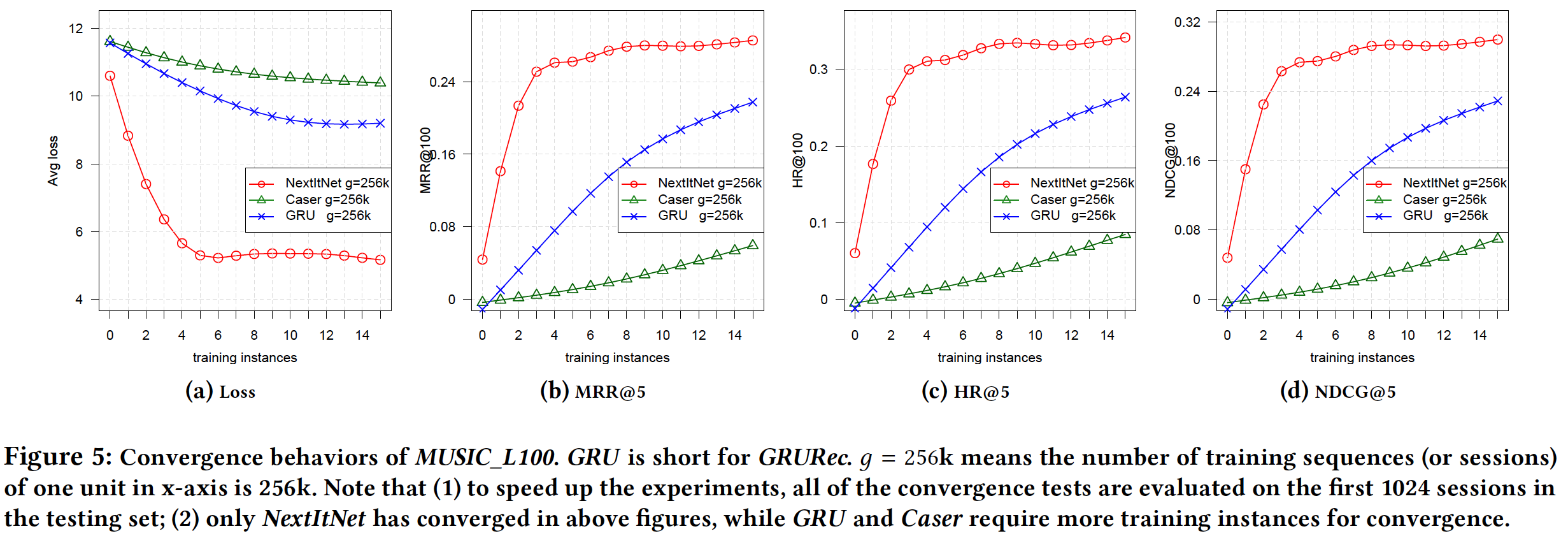
为了更好地理解收敛行为,我们在下图中展示了它们。可以看到:在具有相同数量的训练
session的情况下, 和Caser, GRU4Rec相比,NextItNet的收敛速度更快。这证实了我们前面的观点,因为Caser和GRU4Rec无法充分利用session中的内部序列信息。