一、RepeatNet [2019]
《RepeatNet: A Repeat Aware Neural Recommendation Machine for Session-Based Recommendation》
传统的推荐方法基于
last interaction来处理session-based推荐。《Using temporal data for making recommendations》和《An MDP-based recommender system》研究如何使用马尔科夫模型抽取序列模式(sequential pattern)从而预测next item。《Playlist prediction via metric embedding》提出logistic Markov embedding来学习歌曲的representation从而进行playlist预测。
这些模型的一个主要问题是:当试图在所有
item上包含所有可能的潜在用户选择序列时,状态空间很快变得难以管理。RNN最近被用于session-based的推荐,并引起了人们的极大关注。《Session-based recommendations with recurrent neural networks》引入了带GRU的RNN,从而用于session-based推荐。《Parallel recurrent neural network architectures for feature-rich session-based recommendations》引入了许多parallel RNN: p-RNN架构来基于被点击item的click和feature(如,图片、文本)来建模session。《Personalizing session-based recommendations with hierarchical recurrent neural networks》通过跨session信息迁移来个性化RNN模型,并设计了一个Hierarchical RNN模型。这个Hierarchical RNN模型在user session中,中继(relay)和演变(evolve)RNN的潜在状态。《Neural attentive session-based recommendation》在session-based推荐中引入了注意力机制并表现出色。
尽管将深度学习应用于
session-based推荐的研究越来越多,但是没有人强调所谓的重复消费(repeat consumption),这是许多推荐场景(如电商、音乐、电视节目等等场景的推荐)中的普遍现象。重复消费的意思是:随着时间的推移,相同的item被重复消费。重复消费之所以存在,是因为人们有规律性的习惯(
regular habit)。例如,我们经常重复购买相同的东西,我们经常去相同的餐厅吃饭,我们经常听相同的歌曲和歌手。下表展示了相关研究中常用的三个benchmark数据集的重复消费率。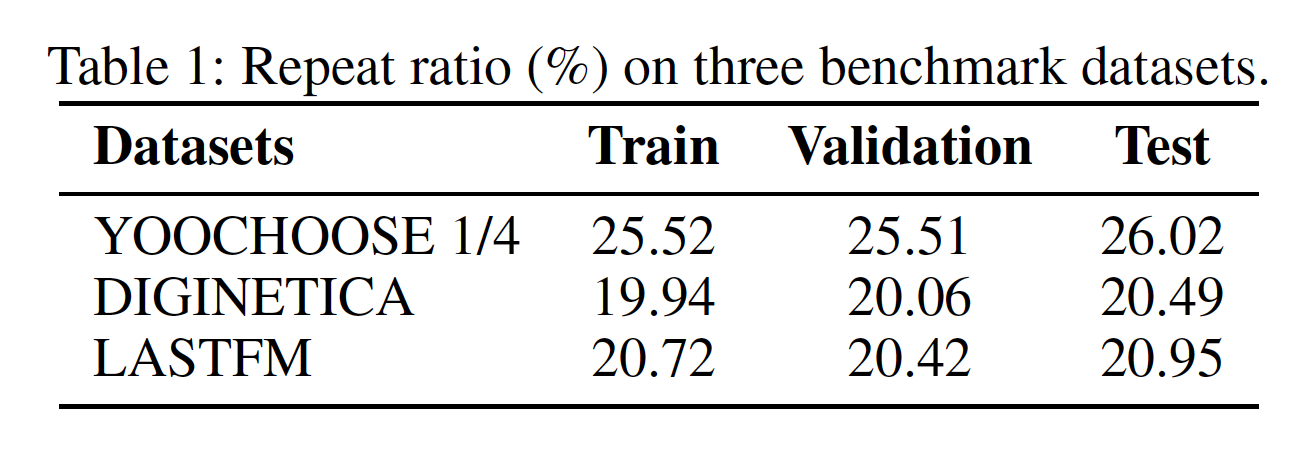
重复消费率占比不大,那么是否意味着在这方面的改进没有多大意义?毕竟
RepeatNet是针对 “少数派” 进行的优化。RepeatNet的效果严重依赖于具体的数据集,只有较高重复消费率的数据集的效果较好。因此使用之前需要先通过数据集来评估重复消费率。而这个重复消费率又依赖于
user ID,因此也无法应用到匿名session中。在论文
《RepeatNet: A Repeat Aware Neural Recommendation Machine for Session-Based Recommendation》中,作者通过融合一个repeat-explore机制到神经网络中从而研究重复消费,并提出了一个叫做RepeatNet的、具有encoder-decoder的新模型。与使用单个解码器来评估每个item的分数的现有工作不同,RepeatNet使用两个解码器分别在repeat mode和explore mode下评估每个item的推荐概率。在
repeat mode下,模型推荐用户历史记录中的old item。在
explore mode下,模型推荐new item。
具体而言:
首先,模型将每个
session编码为一个representation。然后,模型使用
repeat-explore机制来学习repeat mode和explore mode之间的切换概率。之后,作者提出了一个
repeat recommendation decoder来学习在repeat mode下推荐old item的概率,以及提出了一个explore recommendation decoder来学习在explore mode下推荐new item的概率。两个
decoder(相比较于传统的单个decoder)会大幅度增加资源消耗以及inference time。最后,作者将模式切换概率、以及两种模式下的每个
item的推荐概率以概率性的方式结合起来,最终确定item的推荐分。
mode prediction和item推荐在统一框架内以端到端的方式共同学习。论文对三个
benchmark数据集进行了广泛的实验。结果表明:在MRR和Recall指标上,RepeatNet在所有三个数据集上都优于SOTA baseline。此外,论文发现:随着数据集大小和重复率的增加,RepeatNet相对于baseline的改进也增加了,这证明了它在处理重复推荐场景方面的优势。综上所述,论文的主要贡献是:
论文提出了一种新的、基于深度学习的模型,叫做
RepeatNet。该模型考虑了重复消费现象。据作者所知,该论文是第一个在使用神经网络的session-based推荐背景下考虑重复消费现象的。论文为
session-based推荐引入了repeat-explore机制,从而自动学习repeat mode和explore mode之间的切换概率。与使用单个解码器的现有工作不同,论文提出了两个解码器来学习两种模式下每个item的推荐概率。论文对三个
benchmark数据集进行了广泛的实验和分析。结果表明:RepeatNet通过显式建模重复消费来提高session-based推荐的性能,从而超越了SOTA方法。
相关工作:
session-based推荐:传统的
session-based推荐方法通常基于马尔科夫链,这些方法在给定last action的情况下预测next action。《Using temporal data for making recommendations》提出了一种基于马尔科夫链的序列推荐器,并研究如何使用概率性的决策树模型来抽取序列模式从而学习next state。《Using sequential and non-sequential patterns in predictive web usage mining tasks》研究了不同的序列模式(sequential pattern)用于推荐,并发现连续(contiguous)的序列模式比通用(general)的序列模式更适合序列预测任务。《An MDP-based recommender system》提出了一个马尔科夫链决策过程Markov decision process: MDP从而以session-based方式提供推荐。最简单的MDP是一阶马尔科夫链,其中next recommendation可以简单地通过通过item之间的转移概率来计算。《Effective next items recommendation via personalized sequential pattern mining》在个性化序列模式挖掘中引入了一种竞争力得分(competence score)指标,用于next-item推荐。《Playlist prediction via metric embedding》将playlist建模为马尔科夫链,并提出logistic Markov embedding来学习歌曲representation从而用于playlist预测。
将马尔科夫链应用于
session-based推荐任务的一个主要问题是:当试图在所有item上包含所有可能的潜在用户选择序列时,状态空间很快变得难以管理。RNN已被证明对序列点击预测很有用。《Session-based recommendations with recurrent neural networks》将RNN应用于session-based推荐,并相对于传统方法取得了显著改进。他们利用session-parallel的mini-batch训练,并使用ranking-based损失函数来学习模型。《Parallel recurrent neural network architectures for feature-rich session-based recommendations》引入了许多parallel RNN: p-RNN架构来基于被点击item的click和feature(如,图片、文本)来建模session。他们提出了比标准训练更适合的、用于p-RNN的替代训练策略。《Improved recurrent neural networks for session-based recommendations》提出了两种技术来提高其模型的性能,即:数据增强、以及一种考虑输入数据分布漂移(shift)的方法。《When recurrent neural networks meet the neighborhood for session-based recommendation》表明,在大多数测试的setup和数据集中,针对session的、基于启发式最近邻的方案优于GRU4Rec。《Personalizing session-based recommendations with hierarchical recurrent neural networks》提出了一种通过跨session信息迁移来对RNN模型进行个性化的方法,并设计了一个Hierarchical RNN模型,该模型在user session之间中继(relay)和演变(evolve)RNN的潜在状态。《Neural attentive session-based recommendation》探索了具有注意力机制的混合编码器以建模用户的序列行为和意图,从而捕获用户在当前session中的主要意图。
与上面列出的研究不同,我们强调模型中的重复消费现象。
repeat recommendation:《The dynamics of repeat consumption》在多个领域研究了用户随着时间的推移重复消费同一个item的模式,从同一个门店的重复check-in到同一个视频的重复观看。他们发现:消费的新近程度(recency)是重复消费的最强预测器predictor。《Will you “reconsume” the near past? Fast prediction on short-term reconsumption behaviors》得出了影响人们短期重复消费行为的四个一般特征。然后,他们提出了两种具有线性核和二次核的快速算法,从而预测在给定context的情况下,用户是否会在特定时间执行短期重复消费。
推荐系统的一个重要目标是帮助用户发现
new item。除此之外,许多现实世界的系统将推荐列表用于不同的目标,即:提醒用户他们过去查看或消费的item。《On the value of reminders within e-commerce recommendations》通过一个现场实验(live experiment)对此进行了调查,旨在量化在推荐列表中此类提醒的价值。《Modeling user consumption sequences》确定了重复消费的两种宏观行为模式:首先,在给定用户的生命周期(
lifetime)中,很少有item能够存活(live)很长时间。其次,一个
item的last consumption表现出越来越大的inter-arrival gap,这与如下概念保持一致:无聊递增导致最终放弃。即,用户消费相同
item的周期越来越长,最终放弃消费该item(因为越来越无聊,没有新的吸引力)。
我们的工作与之前关于重复推荐的工作之间的主要区别在于:我们是第一个提出神经推荐模型的人,从而显式强调传统的推荐任务以及
session-based推荐任务中的重复消费。
1.1 模型
给定一个
action sessionitem,session-based推荐尝试预测next event是什么,如以下方程所示。不失一般性,本文以点击action为例:其中:
整体框架:我们提出
RepeatNet从而从概率性的角度来建模其中:
repeat mode),explore mode)。repeat mode的概率,explore mode的概率。repeat mode中推荐explore mode中推荐
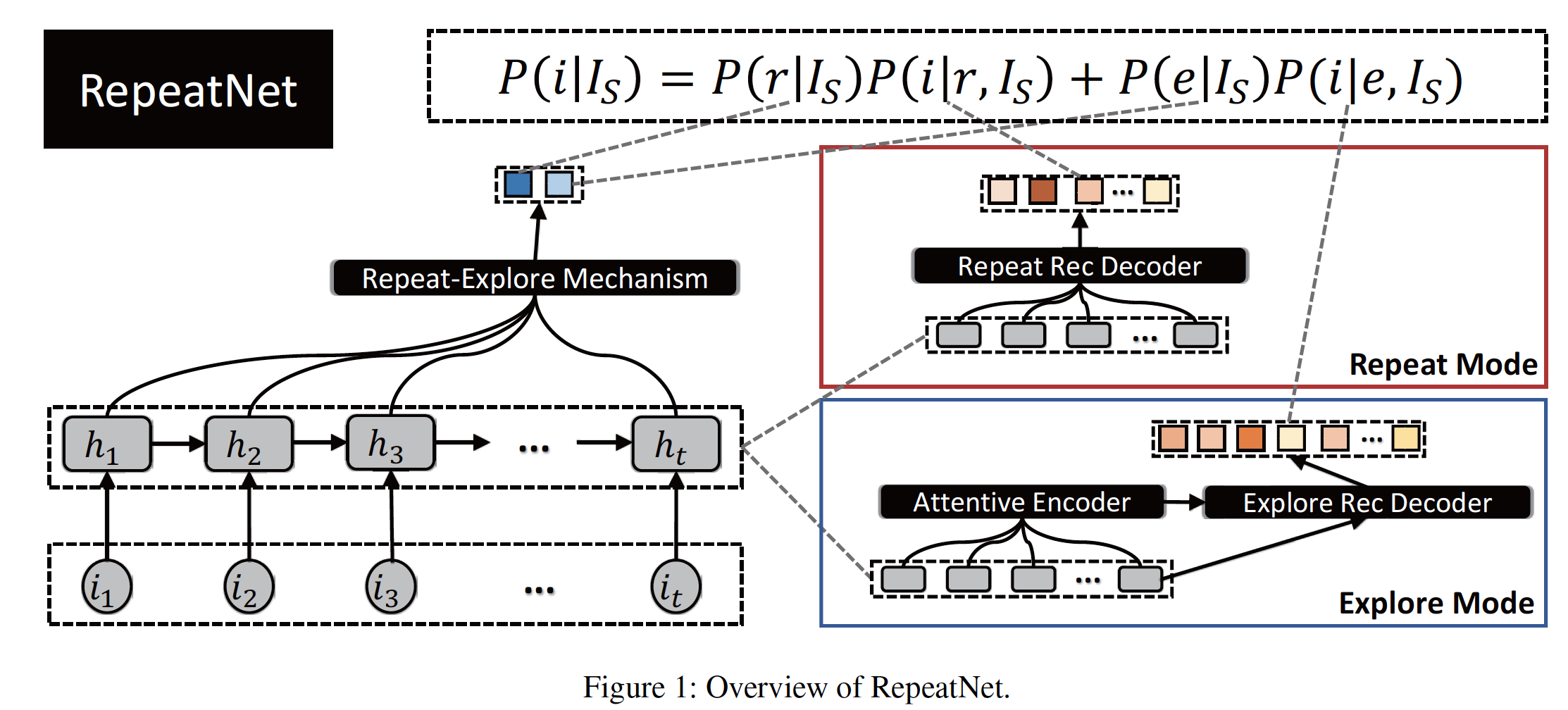
如下图所示,
RepeatNet由四个主要组件组成:一个session encoder、一个repeat-explore机制、一个repeat recommendation decoder、一个explore recommendation decoder。session encoder:它将给定的sessionrepresentationtimestampsession representation。representation,而是截止到session representation。repeat-explore机制:它以repeat mode或explore mode的概率,对应于方程中的注意:
repeat recommendation decoder:它以item的重复推荐概率,对应于方程中的explore recommendation decoder:它以item的探索推荐概率,对应于方程中的item。
session encoder:遵从先前的工作,我们使用GRU来编码GRU定义为:其中:
embedding向量。sigmoid函数,tanh函数。update gate,reset gate。
GRU的初始状态为零,即经过
session encoder编码之后,每个sessionrepeat-explore机制:repeat-explore机制可以视为一个基于representation。具体而言:我们首先使用
last hidden statehidden state其中:
然后我们归一化重要性分数,并获得
hidden state的加权和从而作为context vector:然后我们使用
softmax回归将其中:
这里的
softmax其实可以退化为sigmoid,因为这是个二分类问题。
repeat recommendation decoder:repeat recommendation decoder评估item被重复点击的概率。受到CopyNet的启发,我们使用一个修改的注意力模型来实现这一点。item其中:
itemitem可能在
explore recommendation decoder:explore recommendation decoder评估那些不在new item被点击的概率。具体而言:首先,为了更好地捕获用户对
sessionitem-level注意力机制,允许解码器动态选择和线性组合输入序列中的不同部分:其中:
在计算重要性分数
query,key。然后我们将
last hidden stateattentive statehybrid representation其中:
最后,
item其中:
itemexplore mode下它被点击的概率为零。
目标函数:我们的目标是给定
input session的情况下最大化ground truth的预测概率。因此,我们优化负对数似然损失函数:其中:
RepeateNet的参数,session的集合,ground truth item的预测概率,RepeatNet包含了一个额外的repeat-explore机制从而在repeat mode和explore mode之间软切换(softly switch)。我们假设:如果next item已经在repeat mode,否则切换到explore mode。因此,我们可以联合训练另一个损失,即mode prediction损失,它也是负对数似然损失:其中:
1,否则为0。在联合训练的情况下,最终的损失是两种损失的线下组合:
注意:
这里可以考虑加权,如:
然后,作者在实验中表明,联合训练的效果要比单独训练
首先,
next item已经完美地预测了,那么mode prediction也百分之百正确。其次,
RepeatNet(仅使用
因此,实验部分主要采用
最后,为了缓解联合训练效果较差的问题,并同时利用模式预测的监督信息,可以考虑一种
warmup训练策略:在前面epoch(比如50%的epoch)优化50%比例的epoch去优化这是因为预测
next item是否重复点击的任务,要比预测next item是哪个item要更简单。那么我们把容易的任务作为warm up从而先把模型预热到一个良好的状态,然后再去训练困难的任务。
RepeatNet的所有参数及其item embedding都是端到端通过反向传播来训练的。未来方向:
首先,可以结合人们的先验知识来影响
repeat-explore mechanism。其次,可以考虑更多的信息(如元数据、文本)和更多因子(如协同过滤)来进一步提高性能。
此外,
RepeatNet的变体可以应用于其它推荐任务,如content-based推荐。
读者点评:
RepeatNet本质上是把困难的next item预测任务拆分成两阶段的子任务:
第一阶段子任务:预测
next item是否是重复购买。这个任务相对而言要更简单。第二阶段子任务:分别预测
repeat mode或explore mode下的next item。这个任务相对而言更难。基于类似的原理,我们也可以把
next item预测任务按照不同的维度拆分为:
第一阶段子任务:预测
next item是属于哪个category。第二阶段子任务:计算给定
next category的条件下,预测next item的概率。甚至我们可以拆分为三个阶段:
第一个阶段子任务:预测
next category是否重复出现。第二个阶段子任务:基于
repeat mode和explore mode,预测next category的概率。第三个阶段子任务:计算给定
next category的条件下,预测next item的概率。取决于具体的任务,我们还有更多的拆分方式。
这类拆分能提升效果的原因,读者觉得主要是:把困难的任务拆分成相对简单的子任务。
另外,这种拆分还引入了更多的监督信息。这些额外的监督信息来自于
next item的属性。例如RepeatNet中的额外监督信息来自于属性:next item是否重复出现。而category的例子中,监督信息来自于属性:next item的category。虽然论文的实验结果表明:这种监督信息的联合训练效果不佳。但是读者认为,这是因为作者没有很好地利用这种监督信息,理论上引入这种监督信息的效果更好。
这种方式是否有效,关键是评估:如果用传统的方法预测,那么
repeat mode的概率是否接近ground truth。如果传统的方法(如
BERT4REC)预测的next item中,计算到的repeat mode预测概率等于repeat mode真实出现的概率,那么说明传统方法已经能很好地捕获repeat mode,此时无需使用RepeatNet这种方法。否则,可以考虑使用RepeatNet这种方法。
1.2 实验
数据集:
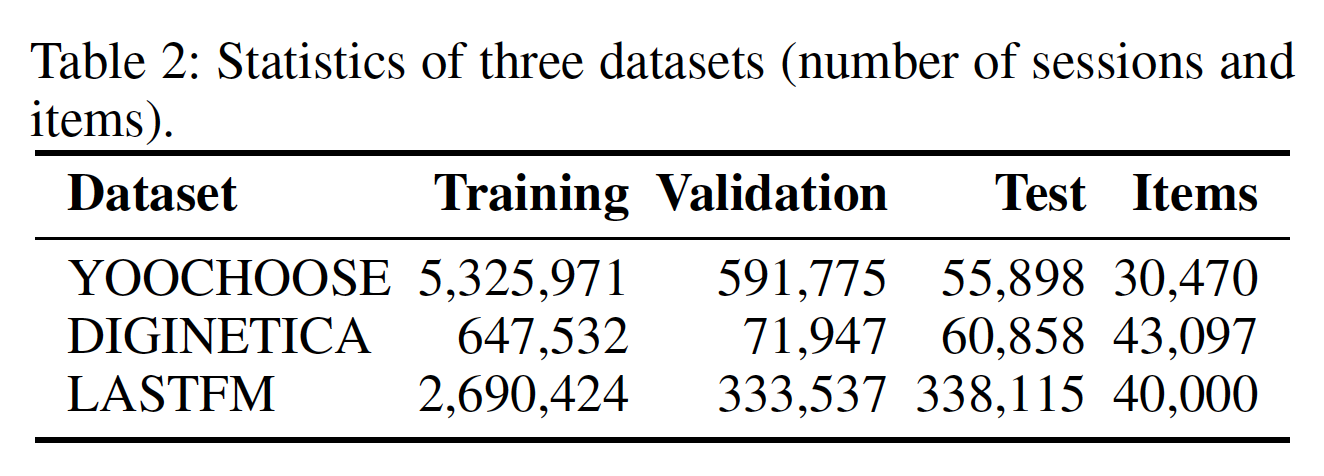
YOOCHOOSE、DIGINETICA、LASTFM数据集,其中YOOCHOOSE、DIGINETICA是电商数据集,LASTFM是音乐数据集。数据集的拆分与《Neural attentive session-based recommendation》相同。YOOCHOOSE数据集:是RecSys Challenge 2015发布的公共数据集。我们遵循《Session-based recommendations with recurrent neural networks》和《Neural attentive session-based recommendation》,并过滤掉长度为1的session以及出现频次少于5次的item。他们注意到1/4的数据集足以完成任务,增加数据量不会进一步提高性能。DIGINETICA数据集:是CIKM Cup 2016发布的公共数据集。我们再次遵循《Neural attentive session-based recommendation》并过滤掉长度为1的session以及出现频次少于5次的item。LASTFM:是Celma 2010发布并广泛应用于推荐任务。我们将数据集用于音乐艺术家推荐。我们保留top 40000名最受欢迎的艺术家,并过滤掉超长的session(item数量超过50)、以及超短的session(item数量低于2)。
数据集的统计结果如下表所示。
评估指标:
MRR@20、MRR@10、Recall@20、Recall@10。Recall@k:ground truth item位于top k推荐列表的case,占所有test case的比例。MRR@k:ground truth item位于推荐列表的排名倒数(reciprocal rank)的均值。如果排名落后于
实验配置:
item embedding size和GRU hidden state size均设为100。使用
dropout,并且dropout rate = 0.5。使用
Xavier方法来随机初始化模型参数。使用
Adam优化算法,其中学习率我们每隔三个
epoch将学习率我们还在训练期间应用范围为
为了加快训练速度和快速收敛,我们通过
grid search使用mini-batch size = 1024。我们对每个
epoch在验证集上评估模型性能。RepeatNet是用Chainer编写的,并在一个GeForce GTX TitanX GPU上训练。
另外,这里没有采用联合训练,而是仅训练
baseline方法:传统的
session-based推荐方法:POP:推荐训练集中最流行的item。它经常被用作推荐系统领域的baseline。S-POP::推荐当前session中最流行的item。它使用session粒度的流行度而不是全局流行度。Item-KNN:推荐与session中历史互动item相似的item。item相似度定义为:其中还可以包括正则化项从而避免稀疏
item的偶然的高度相似性。BPR-MF:是一种常用的矩阵分解方法。我们使用当前session中截至目前为止互动的item的潜在因子的均值来表达一个session,将其应用于session-based推荐。FPMC:用于next-basket推荐的SOTA混合模型。为了使其适用于session-based推荐,我们在计算推荐分时忽略了user latent representation。PDP:号称是第一个建模序列重复消费(sequential repeat consumption)的方法。据我们所知,这是唯一考虑序列重复消费的推荐模型。
deep learning的session-based推荐方法:先前的研究工作都没有考虑建模序列重复消费。GRU4REC:使用session-parallel mini-batch的训练过程,并且还使用ranking-based损失函数来学习模型。Improved-GRU4REC:通过两种技术来改进GRU4REC,即:数据增强、以及一种考虑输入数据分布漂移shift的方法。GRU4REC-TOPK:通过top-k based ranking loss进一步改进了GRU4REC。NARM:通过神经注意力机制进一步改进了Improved-GRU4REC。
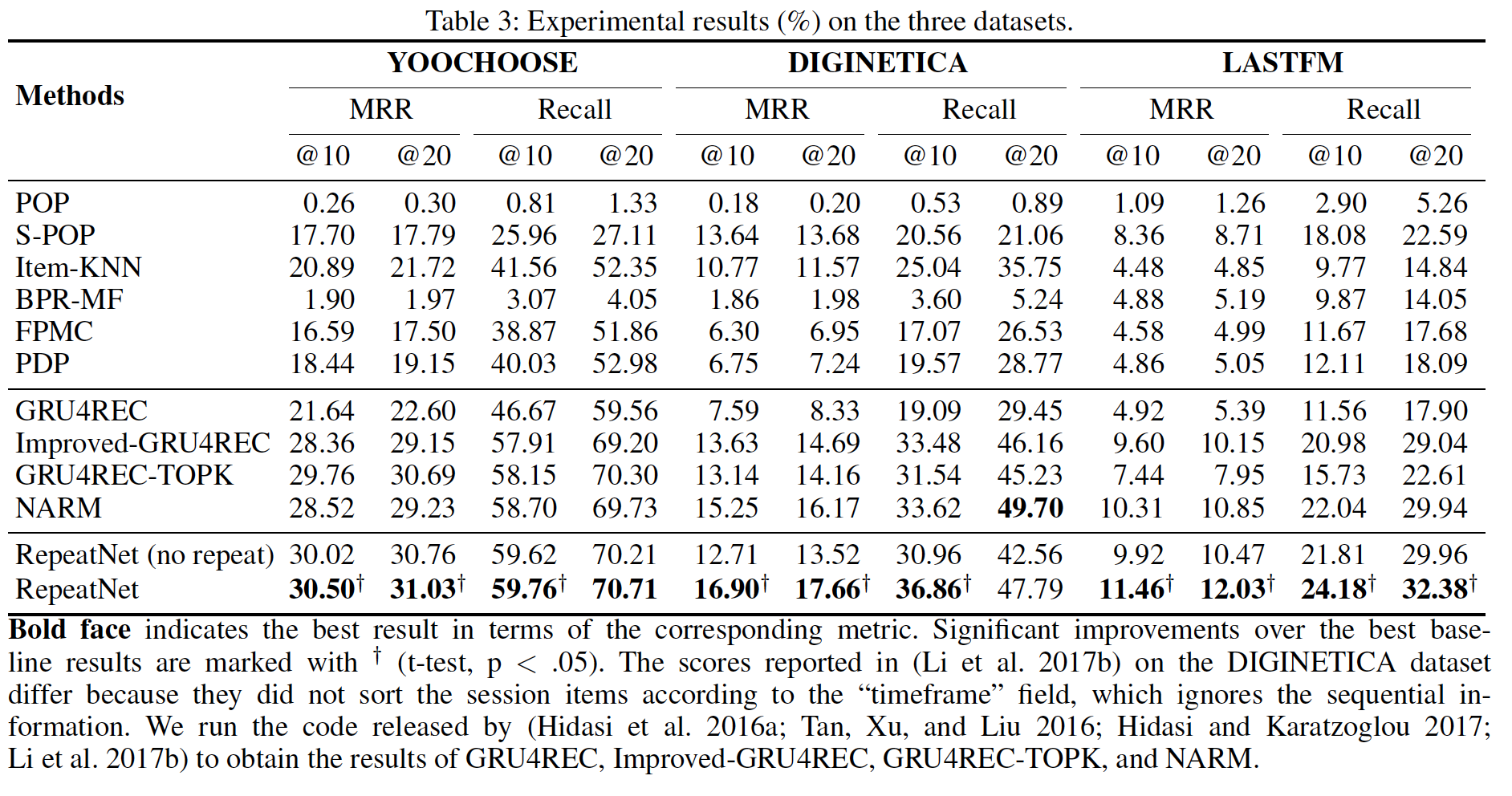
所有方法的实验结果如下表所示。我们运行
GRU4REC和NARM发布的代码来报告GRU4REC和NARM的结果。可以看到:首先,
RepeatNet优于传统方法和神经网络方法,包括最强的baseline,即GRU4REC-TOPK和NARM。RepeatNet对NARM的改进甚至大于NARM对Improved-GRU4REC的改进。这些改进意味着显式建模重复消费是有帮助的,这使得
RepeatNet在session-based推荐中建模复杂情况的能力更强。其次,随着重复率的增加,
RepeatNet的性能普遍提高。我们基于对YOOCHOOSE和DIGINETICA的不同改进得出这一结论。两个数据集都来自电商领域,但是YOOCHOOSE的重复率更高。第三,
RepeatNet的性能因领域而异。实验结果表明,RepeatNet在音乐领域比电商领域具有更大的优势。我们认为这是由于不同领域的不同特性造成的。人们更愿意重复消费曾经听过的歌。
在
LASTFM数据集上,S-POP的表现要比Item-KNN好得多,这意味着流行度在LASTFM数据集上非常重要。但是,Item-KNN在YOOCHOOSE数据集上的表现要比S-POP好得多,这意味着协同过滤在YOOCHOOSE数据集上更重要。此外,神经网络模型在所有数据集的所有评估指标上都比传统方法有很大的进步。最近的其它研究也得出了类似的结论。
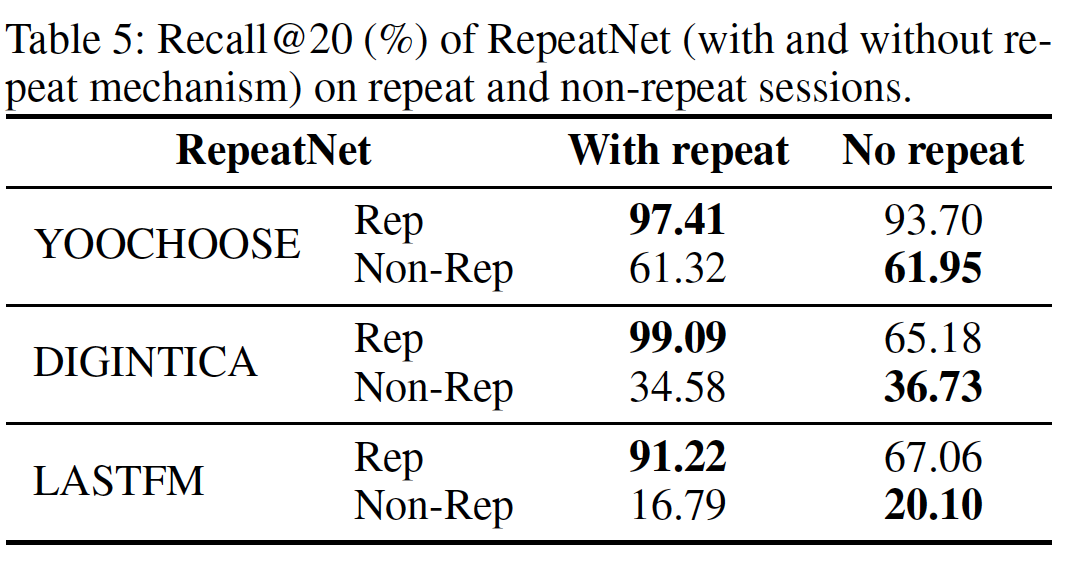
repeat mechanism的分析:如上表所示,一般而言,RepeatNet with repeat在所有数据集上都优于RepeatNet without repeat。作者并未解释
no repeat模型是如何实现的。个人猜测,是认为explore mode来构建模型。RepeatNet (with and without repeat)在repeated session和non-repeated session上的表现如下表所示。可以看到:
RepeatNet的改进主要来自repeated session。具体而言,在DIGINTICA和LASTFM数据集上,RepeatNet在repeated session上分别提高了33.91%和24.16%的Recall@20。但是,RepeatNet在non-repeated session上的效果有所下降。实验结果表明,
RepeatNet通过显式建模repeat mode和explore mode从而具有更大的潜力。但是,结果也显示了RepeatNet的局限性:如果我们让它完全从数据中学习mode probability,它似乎倾向于过多地重复推荐。应该增加一种机制来集成先验知识(即,不要过多地重复推荐)。因为
RepeatNet在Non-Rep session上的效果不佳,这表明它倾向于过多地重复推荐。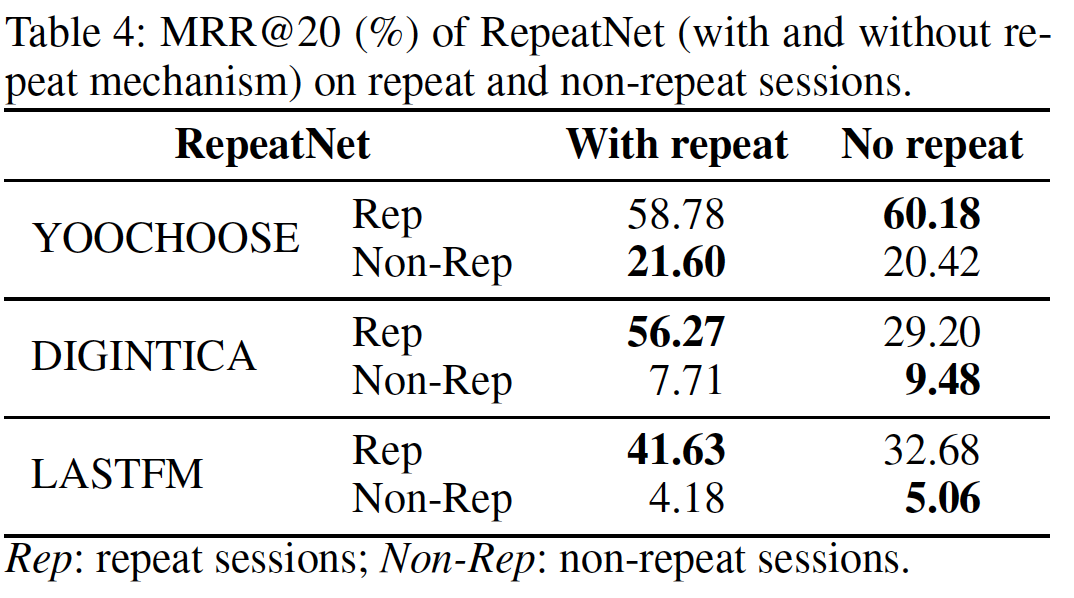
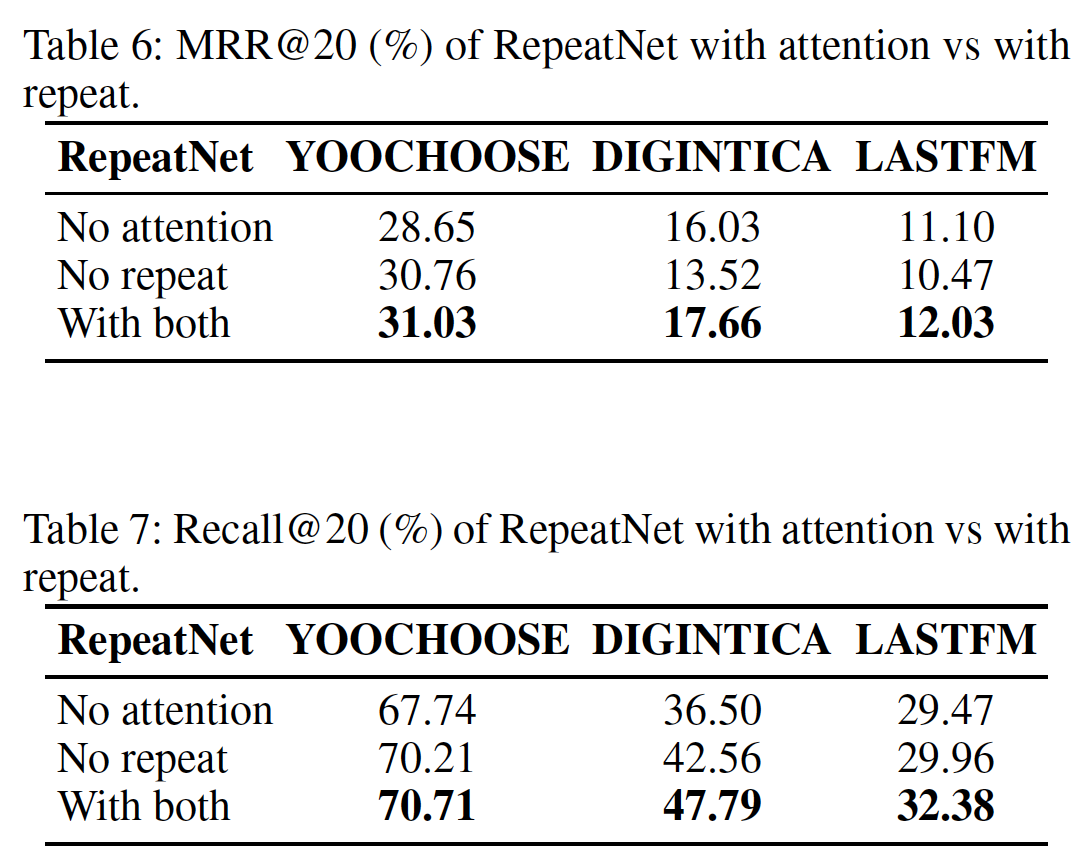
attention mechanism和repeat mechanism的分析:我们在下表中比较了with and without attention、with and without repeat的RepeatNet的结果。结果表明:attention mechanism和repeat mechanism都可以改善RepeatNet。重要的是,attention mechanism和repeat mechanism的贡献是相辅相成的,因为这种组合在所有数据集的所有指标上都带来了进一步的提升,这证明了二者的必要性。此外,我们可以看到
attention mechanism更有助于提高Recall,而repeat mechanism更有助于提高MRR。
联合学习的分析:有趣的是,如果我们联合训练推荐损失
首先,
RepeatNet(仅使用repeated session上取得了很大的改进。并且repeated session的改善余地相对较小(因为重复购买的比例不高)。其次,
RepeatNet(仅使用