一、DSSRec [2020]
《Disentangled Self-Supervision in Sequential Recommenders》
为了学习序列推荐器,现有方法通常采用
sequence-to-item(seq2item)的训练策略,该策略将用户过去的行为序列作为输入,以用户的next behavior作为label来监督训练序列模型。然而,seq2item策略目光短浅,通常会生成缺乏多样性的推荐列表。在本文中,我们研究了通过关注更长远的未来从而来挖掘额外的监督信号的问题。这存在两个挑战:第一,重构包含许多行为的
future sequence比重构单个next behavior要困难得多,这可能导致收敛困难。第二,所有未来行为构成的序列可能涉及许多意图,而并非所有意图都可以从早期的行为序列中预测出来。
为了解决这些挑战,我们提出了一种基于潜在自监督(
latent self-supervision)和解耦的sequence-to-sequence(seq2seq)训练策略。具体来说,我们在潜在空间中进行自监督,即整体地重构future sequence的representation,而不是单独重构future sequence中的items。我们还解耦了任何给定行为序列背后的意图(intentions),并仅使用涉及共同意图的pairs of sub-sequences来构建seq2seq训练样本。在真实基准数据集和合成数据上的实验结果证明了seq2seq训练带来的改进。推荐系统中的用户行为序列在现代互联网应用和移动应用流量中占很大一部分。与这类序列数据相关的核心任务是,基于目标用户过去的点击、收藏等行为序列,为其推荐可能感兴趣的
next item。受深度学习在描述序列数据方面强大表现力的启发,最近的研究工作利用深度序列模型,如循环神经网络和自注意力网络(即Transformer),在该任务上取得了显著成果。训练序列模型的标准方法是,将用户过去的行为序列作为输入,并将用户的
next behavior作为监督信号,即进行从sequence-to-item(seq2item)的训练。然而,seq2item训练目光短浅,很容易导致推荐列表缺乏多样性。例如,“衬衫,衬衫,衬衫,衬衫,衬衫,裤子” 这个序列中,对应label为 “衬衫” 的连续子序列数量远远多于label为 “裤子” 的子序列。因此,通过seq2item策略训练的算法,在用户点击衬衫后,更倾向于频繁推荐衬衫;而在实际的top-k推荐系统中,我们希望算法在生成包含items的推荐页面时,能更均衡地推荐 “衬衫” 和 “裤子”。其次,如果训练数据中的next immediate behavior与此前的行为序列无关,seq2item训练就会变得很脆弱。如今,用户的意图多样且多变,甚至可能仅仅出于好奇就点击新的items,而不考虑之前的意图。在本文中,我们研究序列推荐问题,并通过关注更长远的未来从而挖掘额外的监督信号,以补充标准的
seq2item训练策略。然而,用多个未来行为组成的序列,而不只是单个next behavior,来监督序列模型,带来了巨大的挑战:首先,重构包含多个行为的
future sequence比重构单个next behavior要困难得多。而且,逐个地重构行为(例如点击某个item)效率很低,因为future sequence中可能存在冗余的监督信号,比如许多点击可能反映的是同一个意图。其次,作为训练样本的
label的future sequence,可能涉及用户多个不断变化的意图。值得注意的是,并非所有隐藏在future sequence中的意图都与作为训练样本输入的早期行为序列相关。在这种情况下,除非我们能识别出future sequence中哪些部分与早期行为相关且可预测,否则将面临低信噪比的问题。
为了应对这些挑战,本文提出了一种全新的
sequence-to-sequence(seq2seq)训练策略。我们的seq2seq训练策略与标准的seq2item训练策略并行执行,通过从整个future sequence中进一步挖掘监督信号来补充后者。所提出的seq2seq策略分别采用潜在自监督(latent self-supervision)和意图解耦(intention disentanglement)的思想,来解决上述两个挑战。我们的第一个核心思想是在潜在空间而非数据空间中进行自监督。换句话说,我们的
seq2seq训练策略让模型根据早期序列的representation,来预测未来子序列的representation。这种设计避免了逐个地重构future sequence中的所有行为,有助于seq2seq训练过程的收敛。要被预测的representation有效地充当了向量空间中的distilled pseudo behavior(例如点击一个pseudo item),它总结了future sequence中的主要意图。我们的第二个核心思想是设计一个序列编码器,能够推断和解耦给定行为序列所反映的潜在意图。
disentangled encoder输出给定行为序列的multiple representations,每个representation聚焦于该序列的不同子序列。multiple representations中的每一个都刻画了用户与不同latent category相关的一个意图。然后,我们仅使用意图相关(即涉及相同latent category)的pairs of sub-sequences来构建seq2seq训练样本。这是为了解决如下的问题:并非所有隐藏在
future sequence中的意图都与作为训练样本输入的早期行为序列相关。
我们在真实世界的基准数据集和合成数据上进行了广泛的实验。实证结果表明,我们的
seq2seq训练策略通过发现seq2item训练未涵盖的额外监督信号,相比基线方法有性能提升。我们将主要贡献总结如下:
我们提出了一种新颖的
seq2seq训练策略,通过关注更长远的未来而不仅仅是next immediate behavior来提取额外的监督信号。我们建议在潜在空间中进行自监督以促进收敛,并提出
intention disentanglement来判断在选择seq2seq训练样本时两个子序列是否相关。我们通过实证证明了我们的
seq2seq训练策略的有效性,它补充了seq2item训练。
论文整体感觉不太流畅,思想是个中间状态:还不如直接用自监督学习来建模用户的潜在意图,正如
《Intent Contrastive Learning for Sequential Recommendation》所做的。
1.1 方法
序列数据:设
items的有序序列,其中item的索引,item空间的大小。我们关注现代推荐系统的候选生成阶段(candidate generation phase),其任务是基于观察到的序列next item(或多个items)。深度序列推荐器:用于
candidate generation的深度序列模型通常有一个序列编码器item embedding tablerepresentationrepresentation。文献中的大多数编码器latent categories下的意图。然后,模型通过测量user representationitem的representationitem的概率。其中,Sequence-to-item: seq2item训练:到目前为止,训练深度序列推荐器最常见的做法是训练模型,基于截断的序列next clicktraining loss为:其中,概率
1.1.1 序列到序列的自监督
在本小节中,我们描述我们的
seq2seq训练策略。我们的seq2seq loss的目的是补充,而不是取代传统的seq2item loss。换句话说,在使用mini-batch梯度下降来处理每个mini-batchseq2item loss和seq2seq loss。每个
mini-batchmini-batchmini-batchfuture sequence我们假设我们有一个序列编码器
items的latent categories下的偏好。我们还假设,如果序列latent category下的任何items,那么pseudo item,它总结了属于第latent category的clicked items。方法的概览如
Figure 1所示。注意:模型的
seq2i训练部分,也使用了Sequence Encoder + Intention Disentanglement。未来序列的长度是否有限制?过去序列的长度是否有限制?从经验上讲,用过去的长度为
1的序列,来预测未来的长度为实验部分表明,该模型对短序列效果较好,对长序列(比如,序列长度超过
140)的效果提升一般。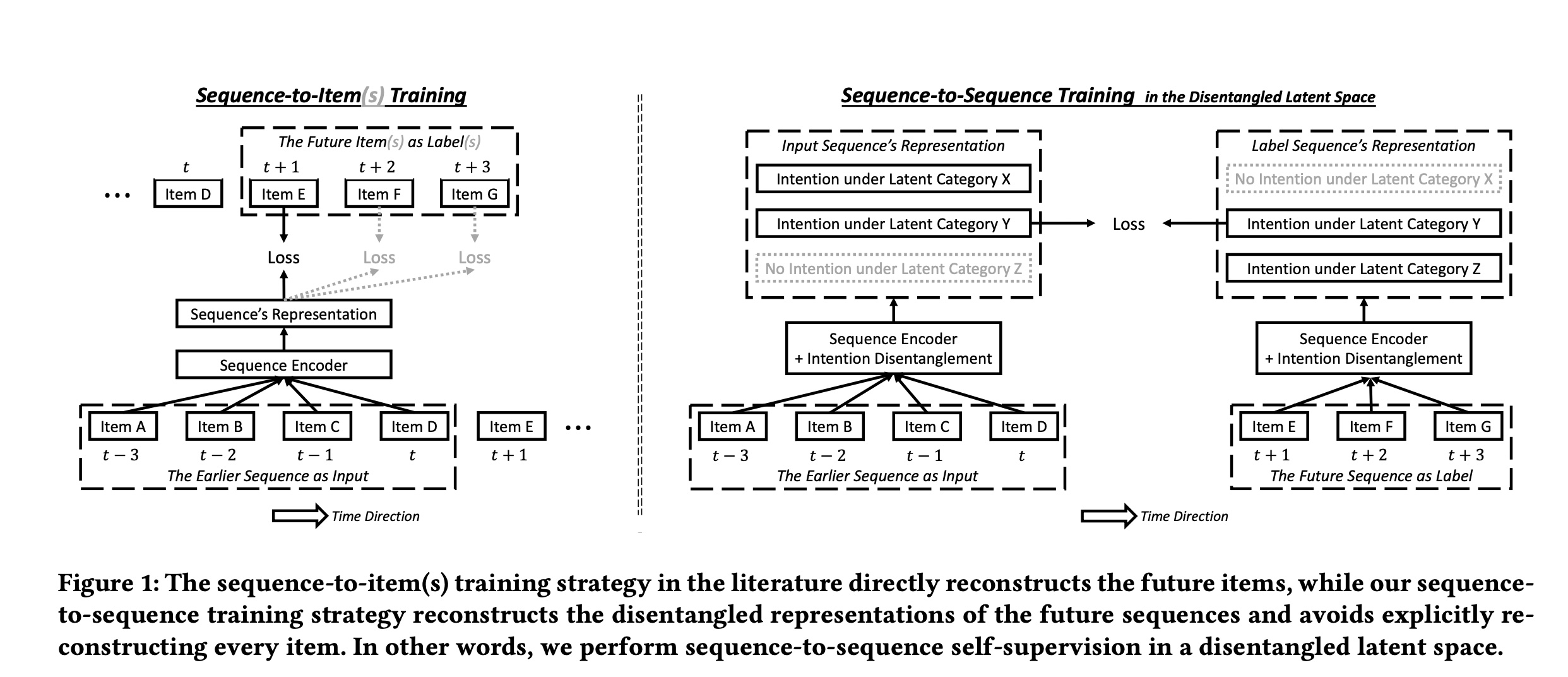
Sequence-to-sequence: seq2seq损失:我们为这个样本定义sequence-to-sequence loss为:positive pair:latent category、当前子序列的未来序列的第latent category。negative pairs:latent category、batch内所有用户的所有未来序列的相同的latent category。这里面可能会有false negative。对于每个序列,一共有
我们将点积得分缩放了
layer-normalization layer,这个缩放因子有助于收敛。这里的
softmax是在当前mini-batch我们使用反向序列
encoder根据时间顺序对序列中的items进行加权,我们希望更接近位置items获得更多权重。为什么用反向序列?这里的解释讲不通。当使用
position embedding的时候,并不能保证靠近位置items具有更大的权重。
选择高置信度的样本进行
seq2seq训练:然而,我们应该只使用latent categoryfuture sequencecategorymini-batchloss。具体来说,sequence-to-sequence loss计算为:其中
sequence-to-sequence训练样本。Sequence-to-item: seq2item损失:传统的sequence-to-item训练策略对于在相对较短的时间内学习一个合适的编码器,以及对齐序列的向量空间和item的向量空间是必要的。我们的sequence-to-item loss定义如下:其中
itemrepresentation,即item embedding tablepositive pair:latent category、当前子序列的next item的embedding。negative pairs:latent category、batch内所有用户的所有next item的embedding。这里面也可能会有false negative。我们在使用
mini-batch梯度下降训练模型时,优化以下损失:
1.1.2 解耦的序列编码
目前推荐领域最先进的序列编码器是基于多头自注意力编码器,即
Transformer编码器。例如,SASRec编码器是Transformer的一个最新变体,它使用一组可训练的position embeddings,而不是原来手工制作的position embeddings,来编码序列中items的顺序。此外,SASRec在编码序列时,复用item embedding tableitem embedding table。换句话说,在编码序列然而,单独的
SASRec编码器并不能完全满足我们对序列编码器SASRec的作者报告说,多头版本的SASRec为相同的输入序列输出多个vector representations,但似乎并没有比single-head implementation有明显的优势。从经验上看,单头和多头的SASRec都倾向于推荐与输入序列中最近点击的item属于同一category的items,即使用户之前点击过其他categories的items。因此,我们在这里提出一个意图解耦层(
intention-disentanglement layer),它附加在单头SASRec编码器之后,以便重用SASRec的表达能力。设SASRec编码器在输入序列item意图聚类:我们的
intention-disentanglement layer首先根据意图与一组intention prototypes的距离从而对意图进行聚类:其中:
这里
latent categories下的prototypical intention representations,它们是模型参数layer-normalization layer,我们使用下标layer-normalization layers之间的混淆,因为每个层都有自己参数来缩放输出。
由于归一化,我们实际上使用的是余弦相似度,而不是点积,来衡量给定意图
intention prototypelatent category)之间的相似性。先前的工作(《Learning disentangled representations for recommendation》)发现,在处理模式崩溃mode collapse(即模型忽略大多数prototypes的退化情况)时,余弦相似度比点积更具鲁棒性。latent category意图加权:上述注意力权重
latent category的相关程度。我们现在引入另一个注意力权重其中:
这里
我们可以将
intention-disentanglement layer使用的一组position embeddings。我们根据query向量,基于以下假设:最近的点击更有价值,并且在向量空间中与latest intention接近的早期意图更可能是重要的。然而,这些假设并不总是正确的,这就需要引入可训练参数意图聚合:我们现在可以根据
其中:
这里
output我们使用两组不同的
seq2seq样本输入的序列,即label的序列,即
latent category的相关程度。因此,latent category的加权聚合,权重与latent category和未来意图的重要程度相关。在损失函数中促进解耦:在文献中,提出了许多正则化方法来促使
disentanglement引入任何额外的正则化项。
1.2 实验
在本节中,我们评估我们的方法与
SOTA的序列推荐器相比的性能,并展示seq2seq训练的优势。然后,我们进行消融研究,并分析超参数的影响。数据集:我们在经过
SASRec和BERT4Rec处理的数据集上进行实验。这四个数据集分别是Amazon Beauty(40,226个用户和54,542个items)、Steam(281,428个用户和13,044个items)、MovieLens-1M(6,040个用户和3,416个items)和MovieLens-20M(138,493个用户和26,744个items),它们的平均序列长度分别为8.8、12.4、163.5和144.4。序列中的items按时间排序,最后一个位置对应最近的点击。我们按照先前工作(SASRec, BERT4Rec)的相同方式分割数据集,即每个用户序列的最后一个item用于测试,倒数第二个item用于验证,其余items用于训练。future序列的长度是多少?这里没讲。评估指标:我们根据召回率(
recall)、归一化折损累计增益(normalized discounted cumulative gain: NDCG)和平均倒数排名(mean reciprocal rank: MRR)来评估所有方法。这些指标的值越高,表明推荐性能越好。我们遵循BERT4Rec的建议,将测试集中的每个ground-truth item与根据流行度来随机采样的100个negative items进行配对,这是文献中的常见做法。然后,推荐任务就变成了在这101个items中识别出哪个item是每个用户的ground-truth next item。实现和超参数:
我们在
TensorFlow中实现我们的模型,并使用TensorFlow推荐的默认初始化方法来初始化参数。我们使用
Adam优化器进行mini-batch梯度下降,将学习率设置为0.001,batch size为128。我们使用单头版本的
SASRec作为我们编码器的一部分。对于
MovieLens-1M和MovieLens-20M,我们将最大序列长度限制为200,而对于其他两个数据集,将其限制为50,这与SASRec和BERT4Rec使用的配置相同。然后,通过随机搜索来调优其他超参数。具体来说:我们遵循
BERT4Rec,从{16, 32, 64, 128, 256}中选择item embedding维度从
{1, 2, 3}中选择自注意力块的数量,这部分是我们从SASRec借用的编码器组件。超参数
{0.05, 0.10, . . . , 1.0}中选择。潜在类别的数量
{1, 2, . . . , 8}中选择。dropout rate从{0, 0.1, 0.2, . . . , 0.9}中选择。而
{0, 0.0001, 0.001, . . . , 1}中选择。
1.2.1 推荐性能
在本小节中,我们报告与
SOTA的序列推荐器相比,我们方法的整体性能。基线方法:
我们将我们的方法与一系列有代表性的基线方法进行比较:
一个简单的基线,即推荐最受欢迎的
items(POP)。经典贝叶斯个性化排序算法的矩阵分解变体(
BPR-MF) 。著名的神经协同过滤(
NCF)。
然后,我们考虑利用用户行为数据序列性的强大基线,包括:
将序列建模为马尔可夫链的因子化个性化马尔可夫链(
FPMC)。基于循环神经网络的
GRU4Rec及其改进版本GRU4Rec+。基于卷积神经网络的
Caser。基于
Transformer的SASRec。SOTA的深度序列推荐器BERT4Rec,它使用BERT的完形填空目标来训练双向Transformer编码器。
分析:
Figure 2和Figure 3展示了所有方法在四个数据集上的整体推荐性能。我们可以看到:我们的方法将传统的
seq2item训练策略与disentangled latent seq2seq training相结合,始终优于所有基线方法。在Beauty和Steam数据集上的改进尤为显著,相比最强的基线方法,相对提升通常超过35%。然而,我们也注意到,在另外两个数据集
MovieLens-1M和MovieLens-20M上的性能提升不太明显,相比最强的基线方法,相对提升约为5%。这可能是因为后两个数据集包含长得多的序列,平均长度分别为163.5和144.4,而Beauty和Steam数据集包含的序列平均长度分别为8.8和12.4,要短得多。长度超过140的长序列可能特别难以解耦。
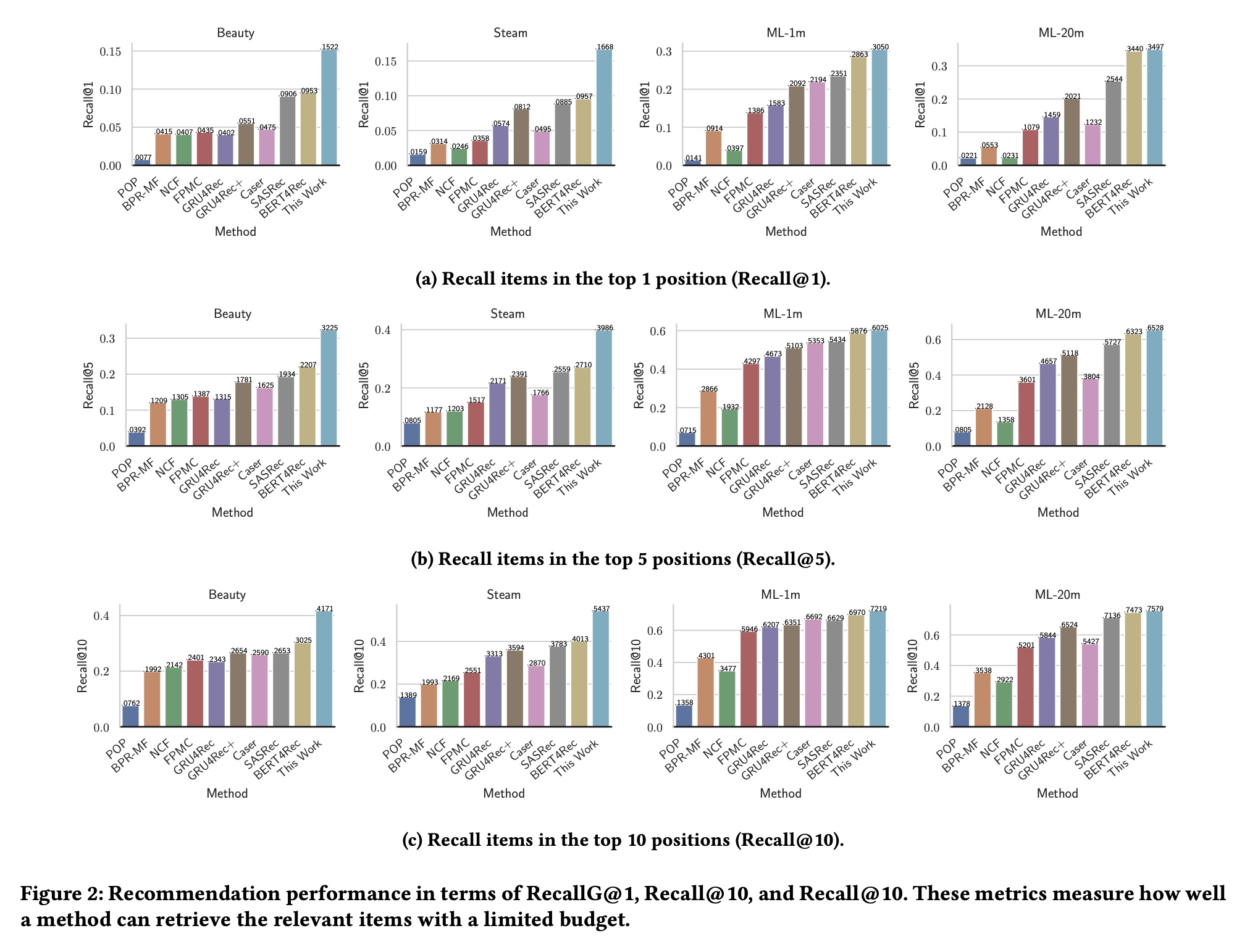
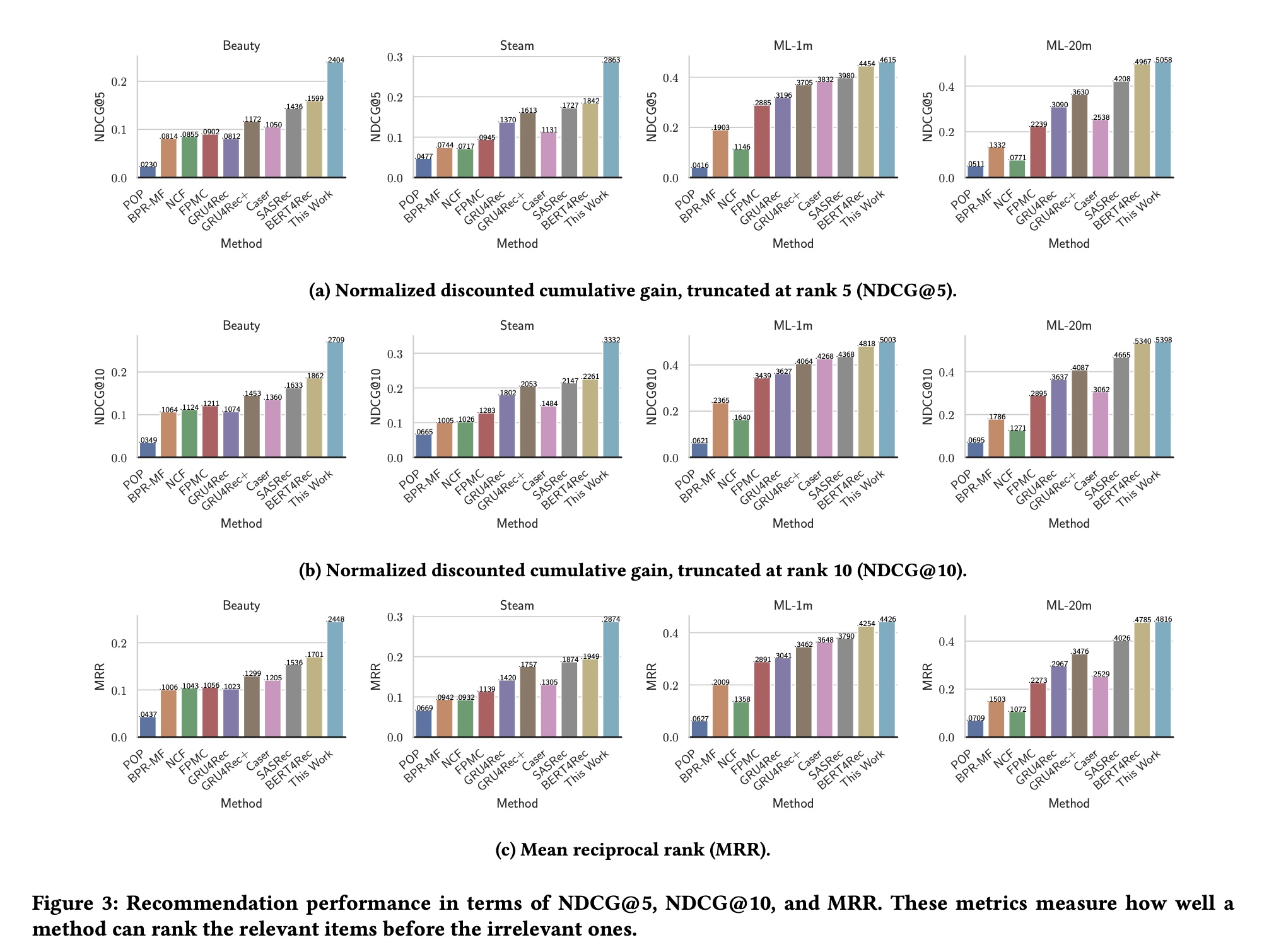
1.2.2 对合成噪声的鲁棒性
我们现在分析与仅使用
seq2item训练的传统策略相比,我们的seq2seq训练策略的鲁棒性如何。具体来说,我们通过用均匀采样的item来随机替换训练集中观察到的部分clicks来破坏训练数据。我们在Beauty数据集上进行这个实验,将被破坏的训练数据的百分比从10%到50%进行变化。我们在
Figure 4中展示了我们方法的两个变体。一种方法如正文所述,同时优化
seq2item损失和seq2seq损失。另一种方法仅优化
seq2item损失。
我们可以看到,只要噪声水平相对较低(例如,噪声
< 20%),使用seq2seq训练策略时,推荐性能下降得更慢。这表明我们的seq2seq训练策略通过从更长远的未来中挖掘额外的监督信号,并从高置信度的seq2seq样本中进行选择性学习,确实有可能带来更高的鲁棒性。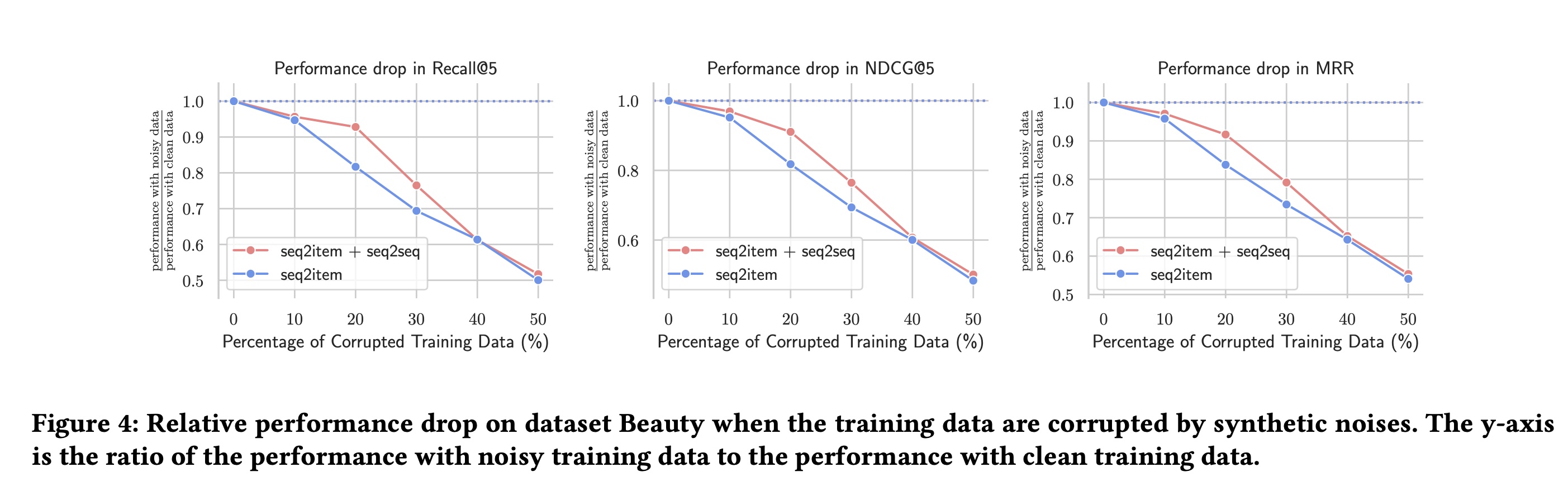
1.2.3 消融研究
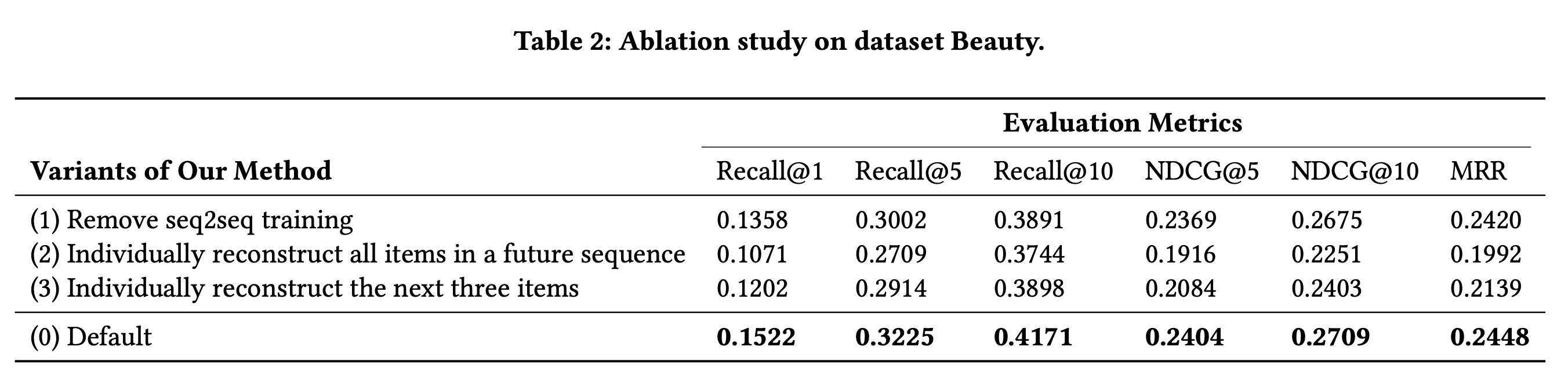
Table 2列出了消融研究的结果。我们方法的变体
1去掉了seq2seq损失,只使用seq2item损失。我们观察到性能下降,这证明了我们seq2seq损失的有效性。变体
2和3直接重构future sequence中的每个items,即针对future sequence中的每个item优化seq2item损失,而不是使用我们的seq2seq损失。变体2和3的性能甚至比只考虑一个future item的变体1更差。性能下降可能是由于长期未来中存在许多不相关的items。
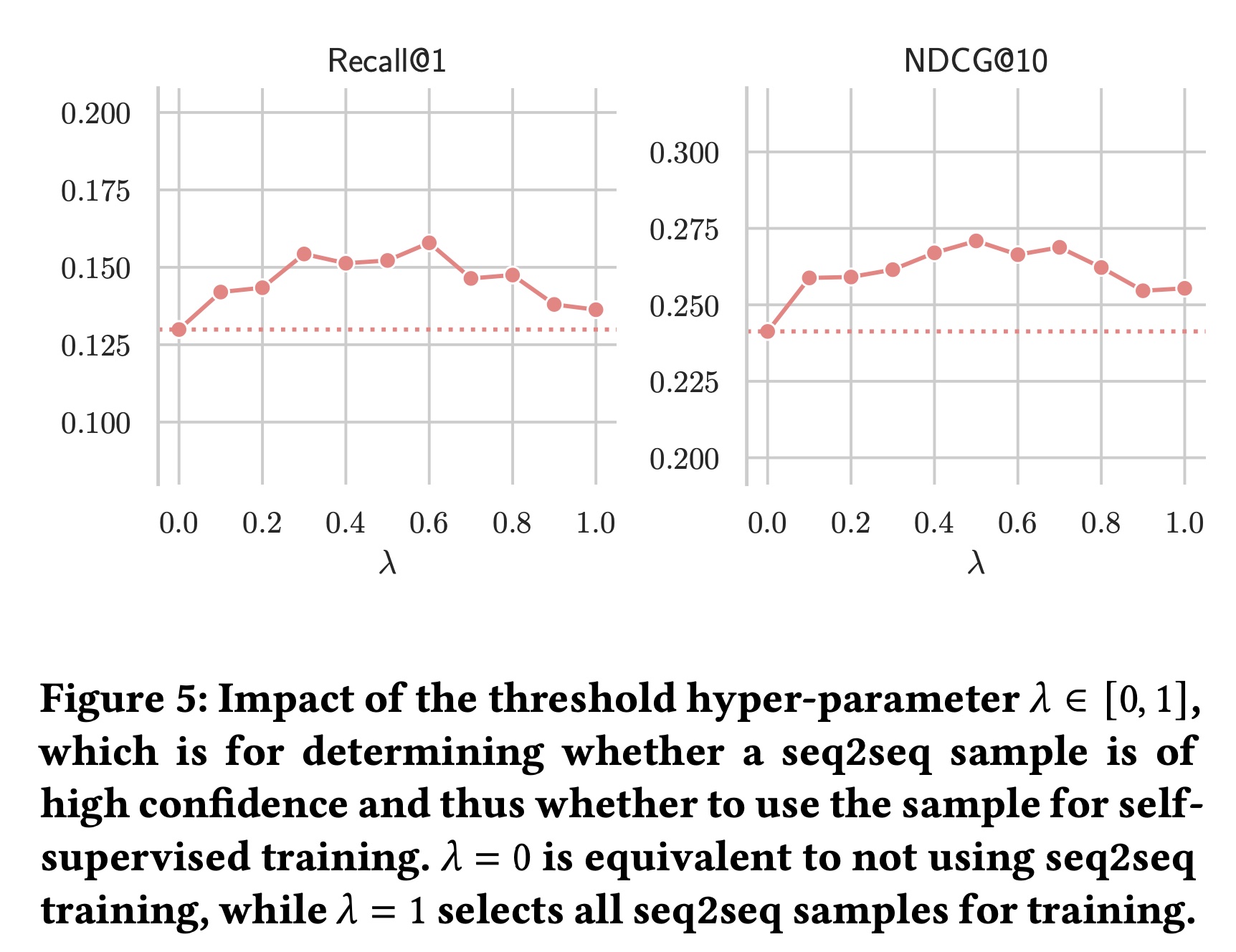
1.2.4 超参数敏感性
我们的
seq2seq损失涉及一个关键的超参数seq2seq样本是否具有高置信度,从而决定是否使用该样本进行训练。我们在Beauty数据集上进行实验,并在Figure 5中展示了这个超参数的影响。Figure 5表明seq2seq样本数量,而阈值太宽松会引入太多不相关的seq2seq样本。其他数据集上的结果也遵循类似的趋势,尽管最优值可能因数据集而异。