一、HyperRec [2020]
《Next-item Recommendation with Sequential Hypergraphs》提出在超图hypergraph
从电商平台到流媒体服务再到信息分享社区,推荐系统旨在根据用户的历史交互(如购买、浏览、以及关注)准确推断用户的偏好。
next-item推荐(根据用户的历史的序列交互来预测用户的next action)是一个有前景的方向,并且人们在这方面的努力最近取得了很好的成功。一个关键问题是如何在这类模型中处理
item。具体而言,在next-item推荐的某个时间段内,我们认为item的含义可以通过相关性(correlation)来揭示,这个相关性是在短期内由用户交互(user interaction)来定义的。如下图所示:iPhone8是在2017年发布并且它与其它几款最新的设备(如Nintendo Switch)一起购买的,表明它是当时的hot new technology item。一旦像
iPhone11这样的新版本在2019年发布,iPhone8就成为一个budget choice,因为它可以与其它价格合理的设备一起购买(如,Nintendo Switch的Lite版本,或者早先版本的AirPods)。同样,我们可以推断用户
A购买的花束是用于婚礼的,因为她还购买了通常与婚礼相关的其它tiem。
为了捕获
item语义的这些变化,论文《Next-item Recommendation with Sequential Hypergraphs》提出在超图(hypergraph)中对这类短期item相关性建模,其中在超图中每个超边(hyperedge)可以连接多个节点。在这方面,虽然超图中的每个节点都表示一个item,但是超边可以将用户在短时间内交互的一组item连接起来。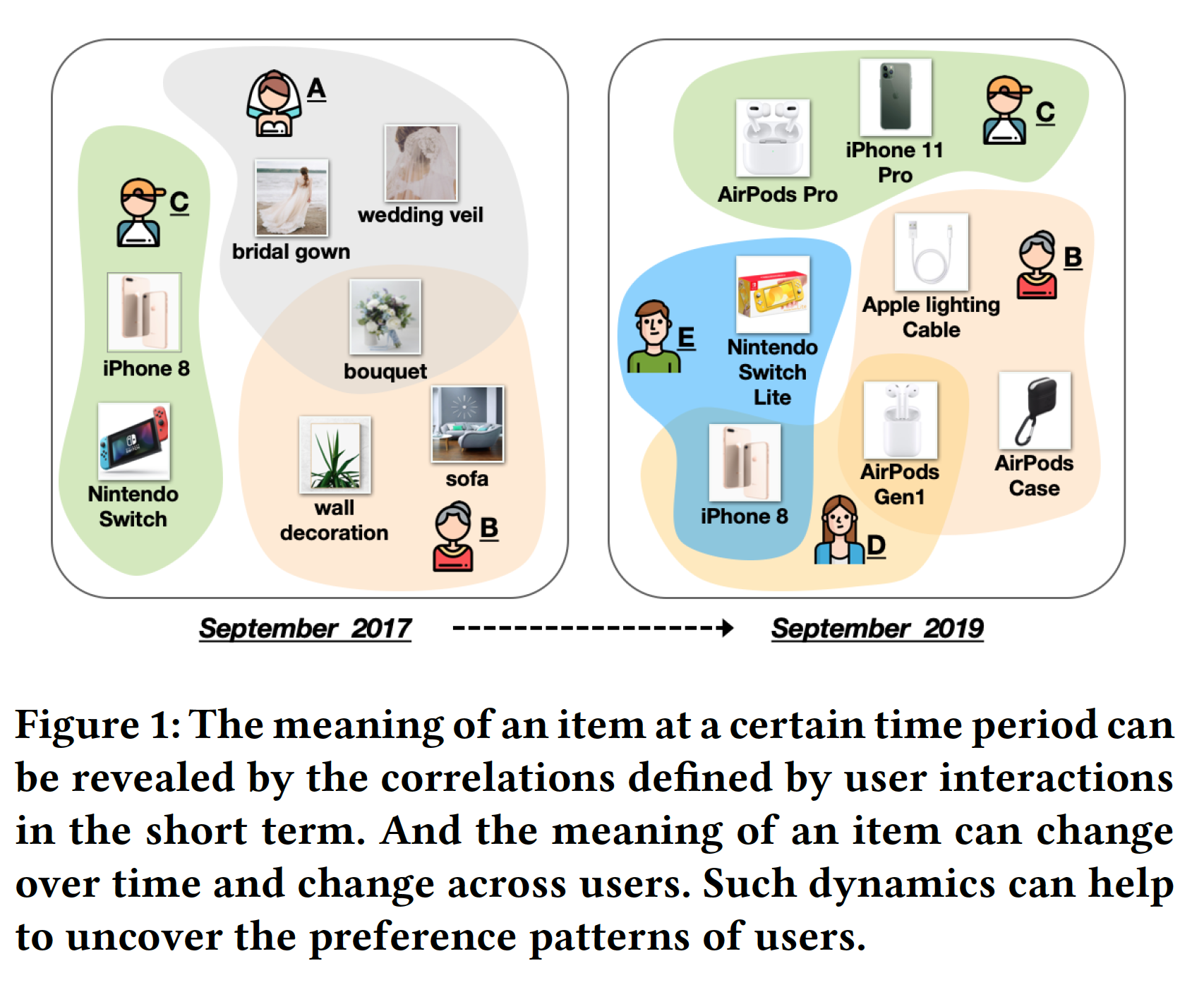
然而,从
item相关性超图(item-correlation hypergraph)中抽取有表达力的item语义并非易事。一方面,由超边编码的
item相关性不再是二元(pairwise)的,而是三元、四元、甚至是高阶的。这种复杂的关系不能用传统的方法处理,因为这些传统方法仅关注pairwise association。另一方面,
item语义可以通过multiple hops传播。例如,在上图中(2019年9月),虽然不是由某个用户共同购买,但是iPhone8也和Apple Lightning cable相关(具有2-hop连接 )。
因此,需要一种设计来有效地利用超图从而学习有表达力的
item语义。此外,如何为
next-item推荐捕获item的动态含义是另一个挑战,因为item的语义会随着时间和用户的变化而变化。这种变化有助于揭示用户的偏好模式(preference pattern)。如上图所示,用户
C在2017年购买iPhone8证明用户C追逐最新设备;而用户D在2019年购买iPhone8表明用户D追求性价比。尽管在这两种情况下的item是相同的,但是iPhone8的基本语义已经发生改变。即使在同一个时间点,一个
item也可以为不同的用户带来不同的含义。如上图中的用户B的一束鲜花可以反应家居装饰(home decoration),而用户A的同样一束鲜花可以反应一场婚礼。
尽管在
next-item推荐中存在将item视为动态dynamic的早期工作,但是它们通常将item的变化建模为时间的函数。如何捕获上述两个观点(随时间变化、以及跨用户变化)对于高质量的next-item推荐至关重要,但是仍然有待探索。为了应对上述挑战,论文
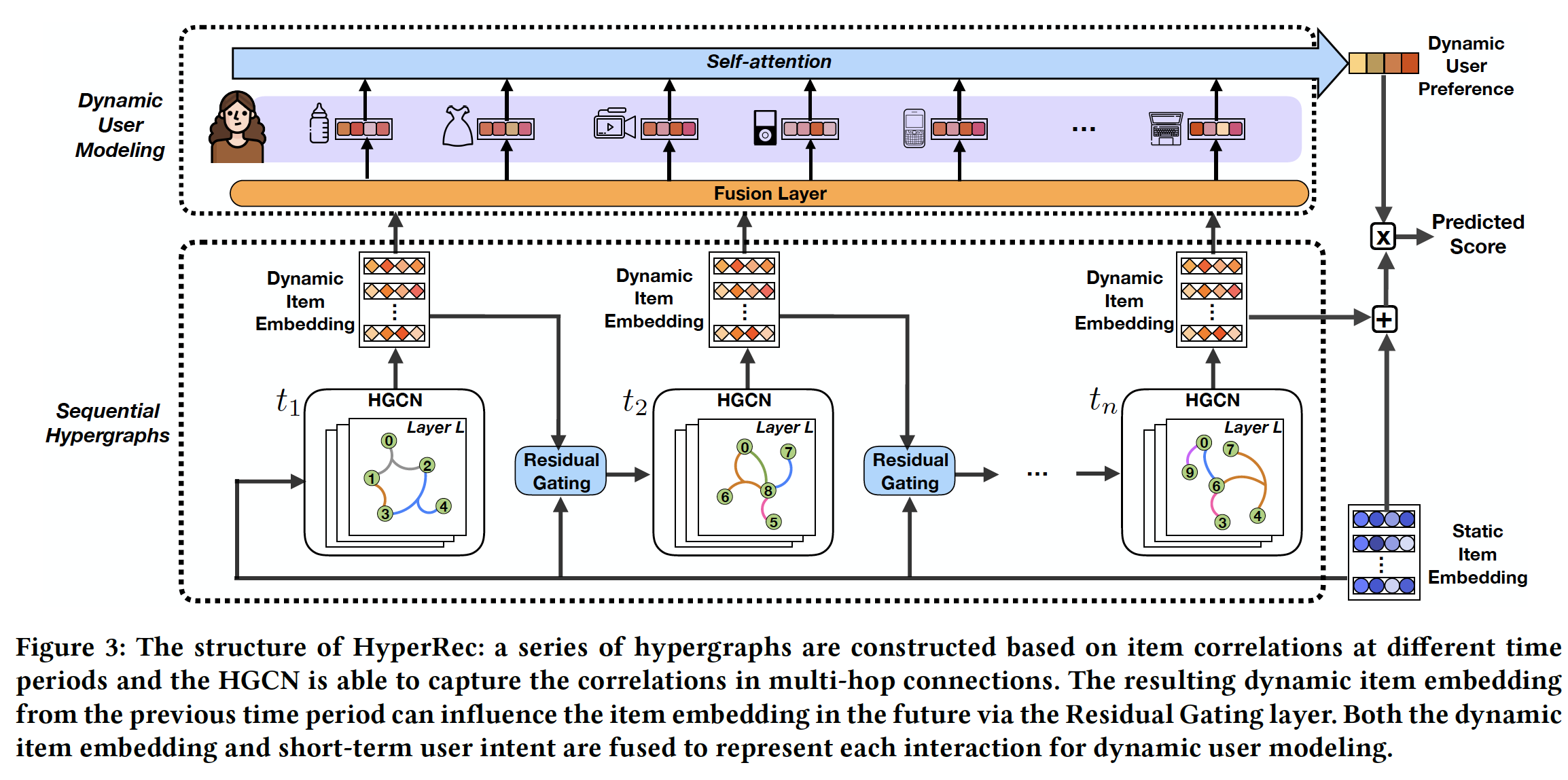
《Next-item Recommendation with Sequential Hypergraphs》提出了HyperRec,这是一种新颖的端到端框架,该框架具有序列超图(sequential Hypergraph)从而增强next-item推荐。为了解决不同时间段的短期相关性,
HyperRec根据时间戳截断用户交互从而构建一系列超图。借助超图卷积网络(hypergraph convolutional network: HGCN),HyperRec能够聚合具有直接或高阶连接的相关item,从而在每个时间段生成dynamic embedding。分时间段建模,从而捕获时间变化。
为了建模历史时间段内
item embedding的影响,HyperRec开发了一个残差门控层(residual gating layer),从而将前一个时间段的dynamic item embedding和static item embedding相结合,从而生成HGCN的输入。捕获历史时间段对于当前时间段的影响。
随着时间和用户发生变化,来自
HGCN的embedding将被馈入一个fusion layer来生成同时包含了dynamic item embedding和短期用户意图(short-term user intent)的final representation,从而用于每个特定的user-item interaction。在个性化的
next-item推荐中,动态用户偏好可以从用户的交互序列中推断出来。因此,HyperRec使用self-attention layer从交互序列中捕获动态用户模式(dynamic user pattern)。从当前
session来捕获用户变化。在预测用户对某个
item的偏好时,static item embedding和most recent dynamic item embedding都被考虑在内。
总体而言,论文的贡献如下:
作者从两个角度研究了
item的动态性(随时间变化、以及跨用户变化),并揭示了利用item之间的短期相关性来改进next-item推荐的重要性。作者开发了一种具有序列超图的、新型的
next-item推荐框架,从而生成包含item之间短期相关性的dynamic item embedding。该框架的两个特色是:用于控制来自历史残差信息(
residual information)的残差门控层。用于编码每个交互的
fusion layer,该层同时采用dynamic item embedding和短期用户意图从而用于序列模式建模(sequential pattern modeling)。
通过在各种数据集上的实验,证明了所提出的模型在
Top-K next-item推荐方面优于SOTA模型。
相关工作:
next-item推荐:与将用户视为静态的推荐系统相比,next-item推荐通常在用户每次交互之后更新用户的state,并根据顺序地消费的item之间的关系来生成预测。一些工作聚焦于没有
user id的情况下为短期的interaction session提供推荐,这通常假设session中的item彼此高度相关,并且以一个强烈的意图(intent)为中心。另一类研究使用跨较长时间的历史
item序列来建模用户偏好。开创性的工作采用马尔科夫链(
《Factorizing personalized markov chains for next-basket recommendation》)和基于翻译的方法(《Translation-based recommendation》)来建模用户序列交互的item之间的转移(transition)。最近,人们在应用不同的神经网络从用户的序列行为中捕获用户的动态偏好(
dynamic preference)方面做出了很多努力。GRU4Rec利用GRU来研究用户的序列交互。然后人们提出了
GRU4Rec+(《Recurrent neural networks with top-k gains for session-based recommendations》)作为GRU4Rec的修改版本,它具有新设计的一族损失函数从而用于Top-K推荐。同时,
Caser和NextItNet采用卷积神经网络来捕获用户历史交互的序列模式(sequential pattern)。SASRec利用self-attention layer从而从历史交互中抽取用户偏好。
然而,这些方法侧重于建模序列模式而没有考虑时间效(
temporal effect),从而导致在不同时间段或来自不同用户的相同交互产生相似的latent representation。先前有一些工作聚焦于推荐系统设计中的时间效应。
在
TimeSVD++中,为了保持时间动态,他们训练了各种SVD模型从而在不同时间段进行评分。考虑到用户和
item都随着时间的推移而演变,《Coupled Variational Recurrent Collaborative Filtering》、《Recurrent Recommendation with Local Coherence》、《Recurrent recommender networks》中的工作利用并行RNN分别建模用户序列模式和item序列模式,并旨在预测用户将如何在不同的时间戳来对item进行评分。《Recurrent coevolutionary latent feature processes for continuous-time recommendation》建议使用结合RNN和point proess的模型来为用户和item生成co-evolutionary的feature embedding。
这些方法是为显式反馈序列(
explicit feedback sequence)(如,评分)而设计的,需要依赖精确的时序信息。因此,它们不适合处理具有隐式反馈和稀疏时间戳的场景。
Neural Graph-based推荐:随着neural graph embedding算法的最新进展,人们越来越关注在各种推荐场景中利用图结构。其中许多工作利用静态图中的高阶链接从而为user或item生成丰富的latent representation。在社交推荐中,可以用
GNN来研究用户之间的社交联系,从而建模社交网络中用户偏好的传播。不同的是,
PinSage提出使用item-item链接构建的图上生成item embedding,从而用于下游推荐。此外,还有一些工作聚焦于
user-item交互图(《Graph convolutional matrix completion》、《Neural Graph Collaborative Filtering》),他们基于user-item交互从而构建了一个链接了user和item的静态图。
然而,这些方法并不是为捕获推荐系统中的序列模式而设计的。
为了建模时间动态模式(
temporally dynamic pattern),《Temporal recommendation on graphs via long-and short-termp reference fusion》提出了Session-based Temporal Graph: STG,从而在一个图中链接user, item, session。通过从不同类型的节点(user/session)开始的随机游走过程,它能建模用户的长期偏好和短期偏好从而用于推荐。《Session-based Social Recommendation via Dynamic Graph Attention Networks》的工作包括一个用于捕获动态用户行为的RNN、以及一个用于建模static user-user graph上的社交影响力(social influence)的graph attention layer。SR-GNN建议使用session序列来构建session graph,然后使用GNN从这些session graph中抽取item co-occurrence。它基于session中item embedding的注意力聚合(attentive aggregation)从而生成next-click prediction。
超图(
hypergraph):超图是常规图的推广,其中每个超边(hyperedge)可以编码各种数量的对象之间的相关性。超图已被用于统一各种类型的内容从而用于context-aware recommendation。在建模各种类型对象之间的相关性方面,早期的工作应用超图来辅助传统的协同过滤从而融合上下文信息。在
《Music recommendation by unified hypergraph: combining social media information and music content》中,为了融合社交关系和音乐内容从而用于音乐推荐,他们提出使用超图来建模music social community中各种类型的对象(如,user, group, music track, tag, album)之间的关系。类似地,
《News recommendation via hypergraph learning: encapsulation of user behavior and news content》的工作使用超图来建模reader, article, entity, topic之间的相关性,从而用于个性化新闻推荐。
这些方法是根据特定社区的属性而设计的,无法轻易地推广到其它的
next-item推荐的任务。
1.1 模型
1.1.1 背景
Motivation:这里我们对来自三个在线平台(Amazon, Etsy, Goodreads)的数据进行初步调研。我们同时从长期和短期的角度探讨item的动态模式(dynamic pattern)以及item之间的相关性。item经常出现和消失:首先,我们检查了
Etsy中item的“生命周期”(lifecycle)。Etsy是销售手工制品的最大电商平台之一。在下图(a)中,我们总结了Etsy上列出的所有item从2006年到2018年的活跃时间(即,从第一次购买和最后一次购买之间的时间gap)。我们发现
Etsy中超过一半的商品在不到一年的时间内就成为inactive(即,断货或被升级的型号所取代)。在其它在线平台上也可以找到类似的模式。随着item的频繁出现和消失,短期关系(short-term relationship)可能对item建模至关重要。因为从长期角度来看,item之间的关系是不稳定的。item的热门程度随着时间的推移而迅速变化:其次,我们检索了
2001年到2005年每个月在Amazon上的Bestsellers(即,在购买排名top 1%的商品)。然后我们计算每个月的Bestsellers列表和一个月后/两个月后/三个月后/或者更长时间之后的Bestsellers列表之间的Jaccard Similarity,结果如图(b)所示。从蓝色曲线可以看到,前后相邻两个月的
Bestsellers的交集仅有30%左右。从绿色曲线可以看到,间隔六个月的
Bestsellers之间几乎没有交集(accard similarity小于10%)。
由于一个
item的热门程度可以反应社区对该item的看法,而Bestsellers列表随时间的变化表明:社区中item的含义可以随时间变化。item共现随时间变化:最后,我们转向
Goodreads中的item。Goodreads是一个平台,在该平台上用户分享他们对书籍的想法。每个用户都有一个交互的item序列,其中用户以时间顺序对序列中的item进行评分、tagging、或者评论。我们根据时间戳(按年份)拆分这些交互的item序列,并使用不同年份的序列训练不同的item embedding模型。具体而言,我们采用word2vec根据item的共现来生成book embedding。基于这些embedding,我们找到了每本书在不同年份的top-10邻居。然后我们计算每本书在2012年的邻居与1 ~ 5年后的邻居之间的Jaccard similarity,并在下图(c)中展示平均结果。我们发现:书籍的
2012年邻居和2013年邻居之间的相似度为40%,并且随着时间间隔越大而相似度越低。即,item之间的关系随着时间的推移而变化,时间间隔越长,则变化越大。
综上所述,从长期角度来看,
item之间的关系正在发生变化,从而导致item语义的变化。因此,这些启发了我们利用item之间的短期相关性,同时建模它们的动态模式从而用于next-item推荐。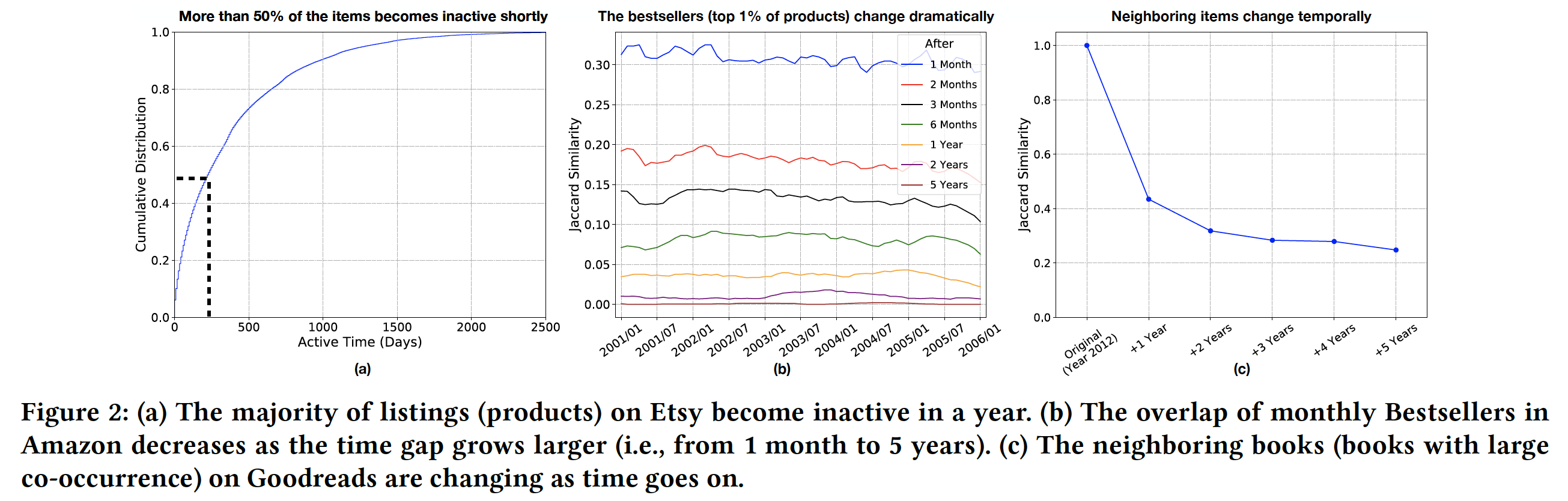
Question:我们提出了一种新颖的端到端的next-item推荐框架(即,HyperRec),该框架利用了序列超图(sequential hypergraph)从而融合了短期的item相关性,同时建模随时间的动态(dynamics over time)和跨用户的动态(dynamics across users)。我们的HyperRec围绕三个指导性的研究问题来展开:RQ1:如何定义超图结构中的item之间的相关性,以及如何通过考虑item之间的multi-hop链接从而将短期item相关性有效地融合到dynamic item embedding中?即,如何定义和捕获
item之间的相关性。RQ2:历史的item的意义可以暗示它们未来的特性,但是如何将不同时间段的embedding process联系link起来,以及连续时间段之间的residual information如何流动?即,如何考虑历史的
item信息。RQ3:如何将短期用户意图与dynamic item embedding融合从而表达用户交互序列中的每个交互,以进行动态用户偏好建模?即,得到的
dynamic item embedding怎么用。
令
item的集合。我们考虑item列表按照时间顺序排序为item这里的序列指的是比
session更长的序列,称作sequence。如果仅仅是session,那就没有必要划分时间段了。这也意味着我们必须知道
user id,否则没有办法获取用户所有的历史交互数据。因此该方法难以应用到匿名的场景中。每个
itemstatic latent embeddingitem的static latent embedding构成static embedding矩阵static embedding对于不同的用户和不同的时间戳而言是不变的。next-item推荐的目标是:给定用户item。
1.1.2 序列超图
由于用户在短时间内购买的
item是相关的,因此定义item之间的适当链接(appropriate connection)是至关重要的。用户可能与不同数量的item进行交互,而传统的图结构通常仅支持item之间的pairwise关系,因此不适合这种情况。因此,我们提出使用超图来建模这种短期相关性。在超图中,多个
item可以与一条超边(hyperedge)链接。例如下图中,2017年9月的超图由7个节点(即,item)和3条超边组成。用户A购买的三个item通过一条超边链接在一起。此外,除了超图中的直接链接之外,item之间的高阶链接也可以暗示它们之间的相关性。例如,下图中(2019年9月),虽然不是由同一个用户购买,但是iPhone8也与Apple Lightning caple有关因为它们之间存在2-hop链接。使用超图卷积网络(
hypergraph convolutional network: HGCN),我们可以利用直接链接和高阶链接来提取item之间的短期相关性。同时,一个item不应该被视为在不同时间段是不连续(discrete)的,因为item过去的特征可以暗示它未来的特征。例如,虽然iPhone8在上图中从2017年到2019年在含义上发生了根本性的变化,但是它在2019年的representation应该继承了iPhone8在2017年的representation的一些特性。接下来,以超图为主要的拓扑结构,我们将讨论如何有效地生成这种动态的
item representation,并同时考虑item在短期内的相关性和不同时间段之间的联系(connection)。短期超图(
Short-term Hypergraph):为了捕获不同时间段的item相关性,我们可以根据时间戳将user-item交互拆分为多个子集。令user-item交互来构建的:item。user。一个超边代表一个
sequence,有多少个sequence就有多少个超边。通常一个sequence对应于一个用户的所有历史行为序列(比session更长),因此user。因此,有多少个用户就有多少个超边。每个
incidence matrix)item每个
在这项工作中,我们让所有超边共享相同的权重并让
定义
degree matrix),即:节点
degree等于它连接的所有用户的加权和,权重由超边
degree等于它连接的所有节点的加权和,权重由在不同的时间段,会有一组不同的
user-item交互,从而导致拓扑结构变化的超图。我们的目标是通过捕获item相关性,从而从每个短期的超图中抽取item语义。不同的时间段除了能够捕获随时间变化的语义之外,还能够降低超图的规模从而有利于内存。如果不区分时间段,那么超图会包含所有的用户(即,超边),可能需要很大的内存来处理。
超图卷积网络(
Hypergraph Convolution Network: HGCN):在每个时间段,我们的目标是利用item之间的相关性来实现它们的temporally dynamic embedding,其中在这个短的时间段内,相关的item应该彼此接近。为了实现这一点,一个item应该从它的所有相邻item中聚合信息(即,latent representation)。这天然地符合卷积运算的假设,即,应该在被链接的item之间进行更多的传播。鉴于
latent representation初始的
latent representation是通过残差门控组件得到的,其中该组件会利用前一个时间段HGCN得到的dynamic item embedding。其中:
ReLu)。
上式的括号内可以重新组织为:
内层:对于每条超边
representation。其中权重为0/1的二元值),并且节点representation经过外层:聚合节点
1,因此权重等于0/1二元值)。
可以看到,这里可以视为一个异质图的
meta-path,即V-E-V,其中异质图包含两种类型的节点:V为超图中的节点、E为超图中的超边(作为异质图中的节点)。因此这里考虑的是超图节点之间的一阶关系。这个卷积操作将对每条超边进行编码:首先聚合每条超边包含的所有节点信息到该超边,然后聚合目标节点所在的每条超边的信息从而得到该节点的
embedding。对于不同的目标节点,第一步是共享的(即,聚合每条超边包含的所有节点信息到该超边)。
我们可以将这个卷积过程表示为矩阵形式:
为了防止堆叠多个卷积层引起的数值不稳定性,我们需要添加堆成归一化。最终我们得到:
这里
one-hop邻居来更新节点从而用于单层hypergraph convolutional layer。我们可以堆叠多个卷积层从而聚合来自超图中高阶邻居的信息。在这样的hypergraph convolutional network: HGCN中,第从第
embedding,从而捕获超图中item相关性的传播。而在不同的时间段dynamic item embedding反映了不同时间段的短期相关性。超图卷积网络和传统的
GCN的核心区别在于:超图卷积网络在信息传递时,传递了整个用户(即,超边)的信息,即:其中节点
high-level的)。相比较而言,传统
GCN在节点残差门控(
Residual Gating):虽然item正在发生改变,但是item在不同时间段的特征之间仍然存在联系。item的某些特征会从上一个时间段保留到下一个时间段。例如,item可能具有一些平滑变化、或者始终不变的固有特征。为了将residual information从先前的时间段传播到未来,我们引入了residual gating从而将dynamic embedding与static embedding拼接来产生每个节点的initial embedding。iteminitial embedding可以计算为:其中:
gate的转换矩阵和转换向量,是待学习的参数。tanh非线性激活函数。itemdynamic embedding。如果itemresidual component并让itemstatic embedding。residual information信息的比例。
通过这个
residual gating,我们按时间顺序连接超图,从而得到HyperRec的主要组件:序列超图(sequential hypergraph)(如下图所示)。在每个时间段,每个item都将从static item embedding以及来自过去的residual information来初始化。然后,HGCN可以结合短期item相关性来生成有表达力的dynamic item embedding。使用残差门控的一个局限性在于:不同时间段的超图需要串行地计算而无法并行计算,因此计算速度会更慢(相比较于并行计算)。
1.1.3 Dynamic User Modeling
短期用户意图(
Short-term User Intent):如下图所示,短期用户意图可以根据用户在特定时间段内交互的所有item中推断出来。这天然地属于超边的定义,超边完全解释了用户在短期内交互的所有item。具体而言,我们可以通过以下操作聚合每个超边上的dynamic node embedding来推断每个用户的短期意图:这里用到的是每个节点
HGCN中最后一层(即,第dynamic item embedding。结果矩阵
这里的
user实际上指的是sequence,它是比item更高level的概念。融合层(
Fusion Layer):然后,我们希望将dynamic item embedding和短期用户意图结合起来,从而更好地表达序列中的每个交互。我们提出如下融合层来生成useritemrepresentation:其中:
itemstatic item embedding,itemdynamic item embedding。
现在
为了避免过拟合,在训练期间,对于在与我们想要预测的
item所相同时间段内发生的交互,我们将fusion layer从而生成这是因为:如果使用
next item,因此会发生信息泄露。self-attention:我们采用self-attention作为基础模型来捕获交互序列中的动态模式。itemembedding。即,现在我们有了更优表达力的
item embedding,因此需要获得当前时刻的用户偏好。假设我们有用户
positionposition embedding,用于刻画顺序信息。给定
embedding序列self-attention旨在根据序列中每个元素与最后一个元素aggregation。其中,其中:
embedding维度。attentive aggregation可以计算为:其中:
生成的
item交互之后的动态偏好(dynamic preference)。
1.1.4 偏好预测
在预测用户对
item的偏好时,我们应该同时考虑dynamic item embedding和static item embedding:其中:
dynamic user preference。dynamic item embedding。
这里并没有使用交互的
representationitem为了训练模型,我们采用
Bayesian Pairwise Loss,其中我们假设用户更喜欢该用户交互过的item而不是未交互过的item。损失函数为:其中:
L2正则化,sigmoid函数。训练集
ground truth tupleitemitemitem(负样本)。
1.2 实验
数据集:我们遵从先前的工作(
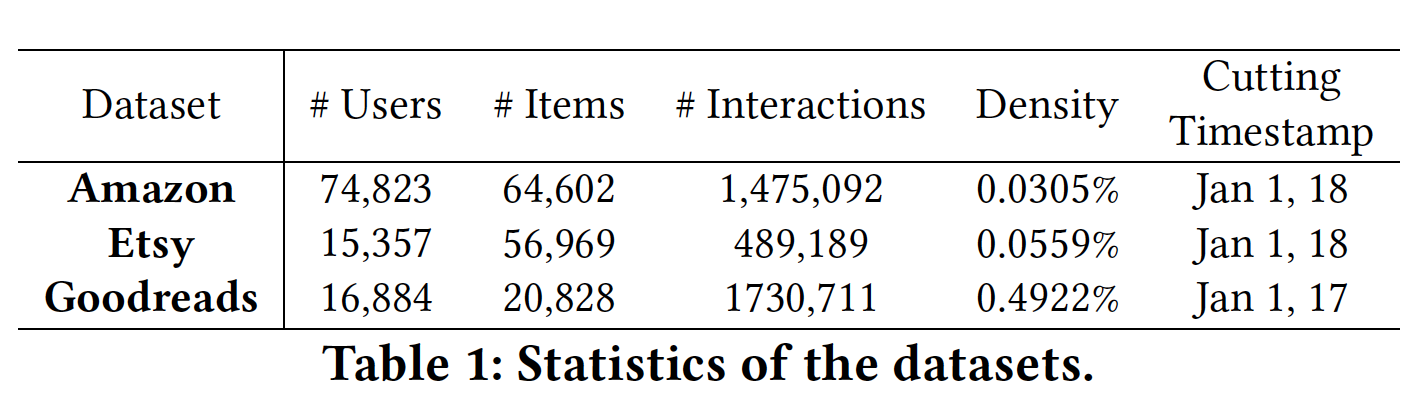
SASRec、BERT4Rec)一样在leave-one-out setting下评估next-item推荐问题,并按照《Recurrent Recommendation with Local Coherence》和《Recurrent recommender networks》中的真实场景拆分训练集和测试集。注意,模型仅使用cutting timestamp之前的交互进行训练。对于每个用户,我们使用cutting timestamp之后的第一个交互作为验证集,第二个交互作为测试集。为了探索模型的泛化能力,我们评估了三个不同的在线平台采样到的数据。
Amazon:这是一个公开的Amazon数据集的更新后的版本,覆盖了从1996年5月到2018年10月的Amazon评论。为了探索一组多样化产品之间的短期item相关性,我们混合了来自不同类目的购物数据,而不是对每个类目进行实验。我们使用评论时间戳来估计购买的时间戳。我们移除少于
50次购买的item。我们保留在cutting timestamp之前购买至少5个item且在cutting timestamp之后购买至少2个item的用户。Etsy:Etsy数据集包含2006年11月到2018年12月期间,销售手工艺品的最大电商网站之一的购买记录。我们移除交易少于50笔的item,然后过滤掉2018年之前少于5笔交易、或2018年少于2笔交易的用户。Goodreads:Goodreads数据集来自一个图书阅读社区,用户可以在其中对图书进行tag、评分、撰写评论。我们将不同类型的交互视为对item的隐式反馈。我们保留了2017年之前交互5本书以上且2017年交互2本书以上的用户。这个数据集要比
Amazon和Etsy都更稠密,因为这样一个信息共享平台中的item(即,书籍)更稳定,并且不太可能像电商平台中那样被新的item替换(如,商品可能被升级后的版本所替代)。
这些数据集的统计结果如下表所示。
评估指标:
遵从
leave-one-out setting,在测试集中,每个用户仅关联一个item,这个item就是该用户在cutting time之后的item。我们采用常见的
next-item推荐指标来评估每个模型在Top-K推荐中的性能,包括:Hit Rate: HIT@K、Normalized Discounted Cumulative Gain: NDCG@K、Mean Reciprocal Rank: MRR。遵从之前的
Top-K推荐工作(《Neural collaborative filtering》、SASRec),我们为每个用户随机选择100个negative item,并将测试集的item(即,positive item)与negative item进行排名rank。排名是基于推荐系统生成的预测偏好分。由于每个用户的测试集仅有一个
item,因此hit rate等于recall,表明测试的item是否出现在Top-K列表中。Ideal Discounted Cumulative Gain对于所有用户而言都是一个常数,因此在计算NDCG@K时可以忽略(因为对于每个用户,测试集仅有一个item)。在基于预测分数的排序中,假设用户
item的排序为如果
如果
根据这个计算,在
leave-one-out setting中,NDCG@1 = HIT@1。MRR衡量测试item的平均倒数排名,即,
我们报告每个数据集上所有用户的平均
NDCG和平均Hit Rate,其中baseline:PopRec:热门度推荐。这种简单的方法根据item的受欢迎程度来排序,并推荐最热门的item。TransRec:基于翻译的推荐。TransRec使用user-specific翻译操作来建模交互序列中不同item之间的转移。GRU4Rec+:具有Top-k Gains的RNN。作为GRU4Rec的改进版,该模型采用GRU来建模序列行为,并使用一族新的损失函数来提高Top-K增益。TCN:用于next-item推荐的简单卷积生成网络(《A Simple Convolutional Generative Network for Next Item Recommendation》)。该模型改进了典型的CNN-based的next-item推荐,使用masked filter和堆叠的一维空洞卷积层,从而建模远程依赖关系。HPMN:Lifelong Sequential Modeling with Personalized Memorization(《Lifelong Sequential Modeling with Personalized Memorization for User Response Prediction》)。HPMN采用分层周期记忆网络(hierarchical periodic memory network),可以同时捕获用户的多尺度序列模式,从而可以将近期用户行为与长期模式相结合。HGN:用于序列推荐的Hierarchical Gating Network(《Hierarchical Gating Networks for Sequential Recommendation》)。该方法包含一个特征门控(feature gating)以及一个实例门控(instance gating),用于分层地选择item特征和item实例,从而用于为next-item推荐来建模用户。SASRec:Self-attentive Sequential Recommendation。它采用self-attention layer来捕获用户交互序列中的动态模式。它可以被视为HyperRec中动态用户建模组件的简化版本,该简化版本使用static item embedding来表示每个交互。BERT4Rec:带有来自于Transformer的双向编码器representation的序列推荐。该方法利用双向自注意力模块从左右两侧捕获用户历史行为序列中的上下文信息。除了上述
baseline之外,我们还将所提出的模型与后文介绍的变体进行比较,作为我们的消融实验案例。
HyperRec要求user ID的信息从而可以得到完整的用户历史行为序列。然而,这里的有些baseline方法是针对匿名session进行的(如GRU4Rec+、SASRec、BERT4Rec。这些方法既可以用于匿名session也可以用于非匿名session(提供了user id),但是它们并没有针对非匿名session进行优化,如,建模user embedding。所以这里的比较不一定公平。配置:
实验是在配备了
12GB Nvidia TITAN Xp GPU的服务器上进行的。所有数据集的最大序列长度设置为
50。为了公平比较,训练过程中所有模型的负采样率都设置为
1。即,对于每个ground-truth tuple,我们都将它与一个随机采样的negative item相结合。对于
HPMN, GRU4Rec+, HGN, BERT4Rec,我们使用原始论文中提供的实现和配置。对于TCN和SASRec,我们使用《Session-based Social Recommendation via Dynamic Graph Attention Networks》中提供的实现。为了获得每个模型的最佳性能,我们执行超参数搜索,其中:
dropout rate搜索范围:在
HyperRec的哪一层执行dropout?作者并未讲明。正则化系数
embedding size搜索范围:对于特定于模型的超参数,我们根据验证集来微调。
我们在
TensorFlow中实现了HyperRec及其所有变体,并采用Adam作为优化器。在实验中,经过grid search之后,学习率设为0.001、batch size = 5120。我们将所有数据集的embedding size设为100。我们微调了每个数据的层数,范围在
实验结果:我们将
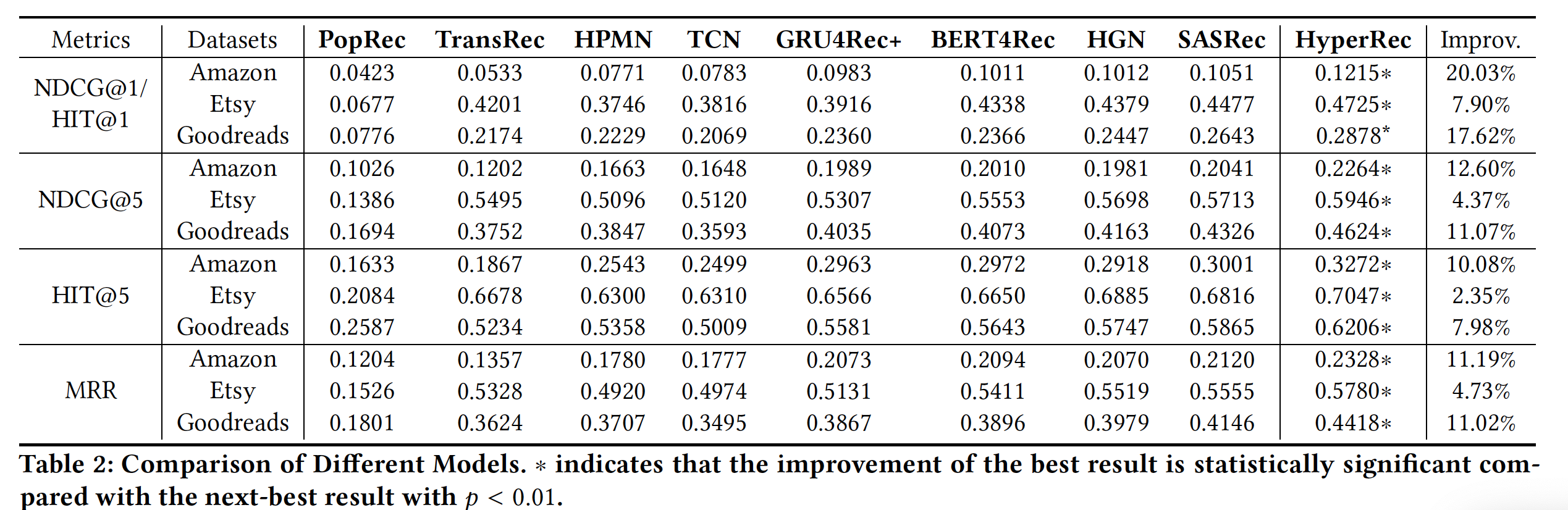
HyperRec与baseline进行比较,结果如下表所示。可以看到:在所有评估指标下,
HyperRec在每个数据集中都显著优于所有baseline。这证明了HyperRec在真实环境(其中item随着时间演变)中改进next-item推荐的有效性。TransRec相比于简单地推荐热门item相比,可以提供有前景的改进。然而,TransRec将用户视为他们购买的consecutive items之间的线性翻译,这限制了模型处理现实问题的能力,其中用户和item都在改变。HPMN由分层记忆网络组成并为用户创建lifelong profile,其中记忆网络的每一层都旨在捕获特定时期的周期性用户偏好(periodic user preference)。我们发现HPMN在Amazon中的表现优于TransRec在30%以上,但是在Etsy和Goodreads上似乎较弱。TCN建立在一维空洞卷积之上,展示出它在建模短期行为方面的优势。TCN在Etsy中优于HPMN,但是它似乎不太适合像Goodreads这样长期偏好很重要的场景。作为针对
GRU4Rec的高级版本,在Amazon和Goodreads数据集上,GRU4Rec+可以通过GRU来进行动态用户建模并采用针对RNN模型定制化的损失函数,从而改进TCN和HPMN。HGN配备了新颖的特征门控和实例门控从而增强短期用户建模,因此优于上述baseline。SASRec和BERT4Rec都使用self-attention layer来建模序列用户模式。在BERT4Rec中,通过随机屏蔽用户序列中的item,它能够训练一个双向模型用于推荐。然而,它并没有像原始的BERT一样为NLP带来巨大的提升,因为序列中从右到左的模式不一定能够提供预测用户动态偏好的信息。与
SOTA相比,HyperRec在Amazon中可以实现比其它数据集最大的改进。原因可能是HyperRec能够从极其稀疏的具有超图拓扑的user-item交互中完全地抽取item特性。
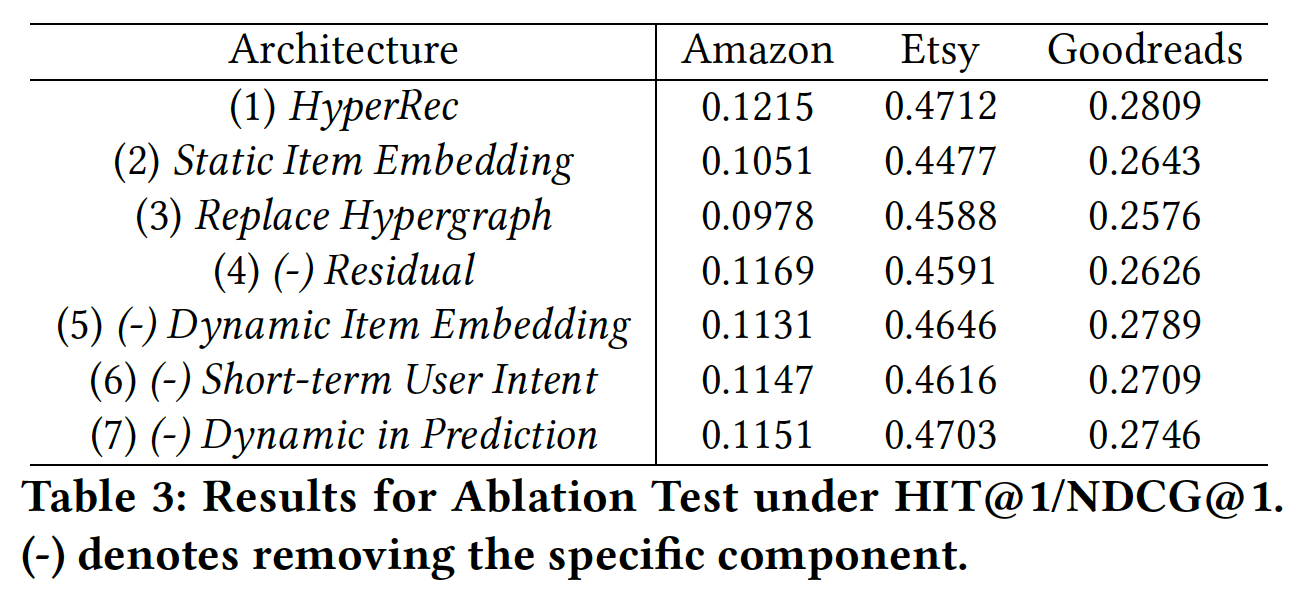
消融研究:我们通过移除或替换
HyperRec中的基础组件来进行一系列消融测试,从而评估这些组件的有效性。消融测试的结果如下表所示。为了公平地比较,当模型中有超图时,结果是以12个月为粒度并且两层的HGCN来实现的。首先,在所有数据集上,
HyperRec与所有变体相比都实现了最佳的性能,这证明了HyperRec设计的有效性。为了评估超图结构的有效性,我们在
(3)中为每个用户和每个item在不同时间段分配不同的latent embedding作为dynamic item embedding和短期用户意图。也就是说,我们没有像HyperRec那样利用超图来建模短期item相关性,而是使用这些time-dependent embedding来编码数据集中的变化。我们发现性能有很大的下降。在Amazon和Goodreads数据集中,(3)的性能甚至比使用static item embedding的(2)更差。一个原因是:每个时间段的
user-item交互过于稀疏,无法直接充分训练time-dependent embedding。但是带HGCN的超图能够在每个时间段从multi-hop链接中充分抽取item之间的有效的相关性。然后我们转向
HyperRec中dynamic item embedding所赋予的每个组件,从而检查它们的贡献。在
(4)中,通过移除residual component,超图的initial embedding仅由static item embedding组成。虽然在所有数据集上的性能下降,但是我们发现它在Goodreads中带来了最大的性能损失。因此,通过控制过去的residual information来连接不同时间段的dynamic item embedding是很重要的。对于
(5)和(6),我们分别移除fusion layer中的dynamic item embedding和短期用户意图如何影响动态用户偏好建模中的特定交互的含义。由于(5)和(6)在所有数据集上都实现了相似的性能,因此我们可以得出结论:这两个组件对于捕获交互的含义(meaning of an interaction)都很重要。在
(7)中,我们使用公式dynamic item embeddingAmazon和Goodreads有很大贡献。然而,在Etsy上,item对即时送礼事件(instant gifting event)(如,圣诞节、纪念日)更为敏感,因为上一个时间段的dynamic item embedding可能无法提供对当前时间段的深入洞察。
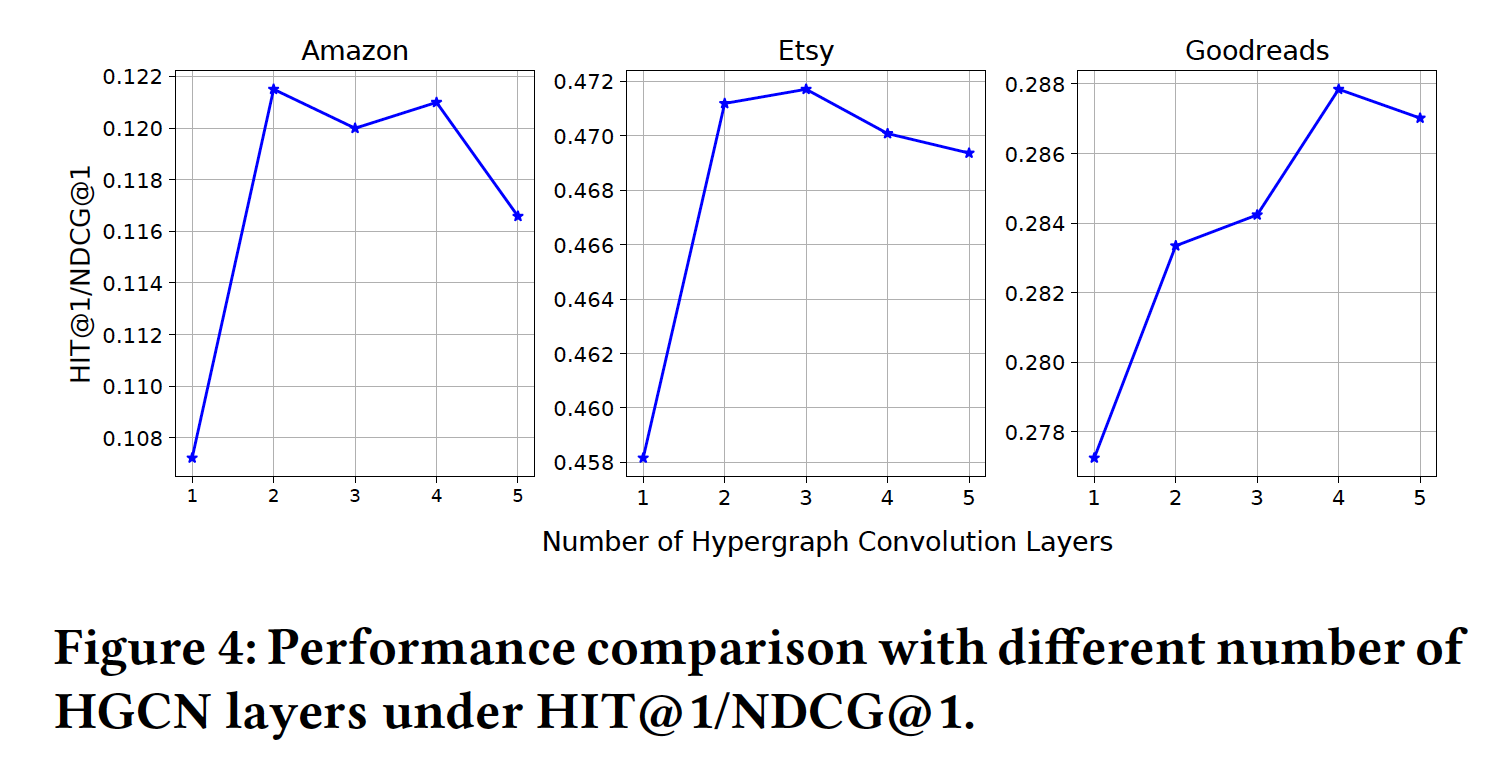
超参数分析:我们探索
HyperRec在不同数量的卷积层、以及不同的时间段粒度下的性能。HGCN层数:我们通过改变超卷积层的数量来比较HyperRec的性能,结果如下图所示。当仅有一个卷积层时,每个
dynamic item embedding仅聚合来自通过超边与其直接相连的item的信息。在这个阶段,HyperRec可以超越它的仅考虑static item embedding的变体,这说明了在next-item推荐中探索短期item相关并且采用dynamic embedding的必要性。与仅有一层相比,堆叠两个卷积层可以带来显著的提升。我们可以推断:超图和
HGCN是一种有效选择从而用于抽取短期的有表达力的item语义。并且在超图中考虑高阶邻域的信息很重要。但是,对于
Etsy和Amazon而言,由于数据非常稀疏,因此没有必要进一步增加卷积层的数量。2 ~ 3层的HGCN足以抽取不同时间段的item语义。然而,由于
Goodreads在每个超图中包含相对更多的交互,因此更多的卷积层可以进一步改善embedding过程。
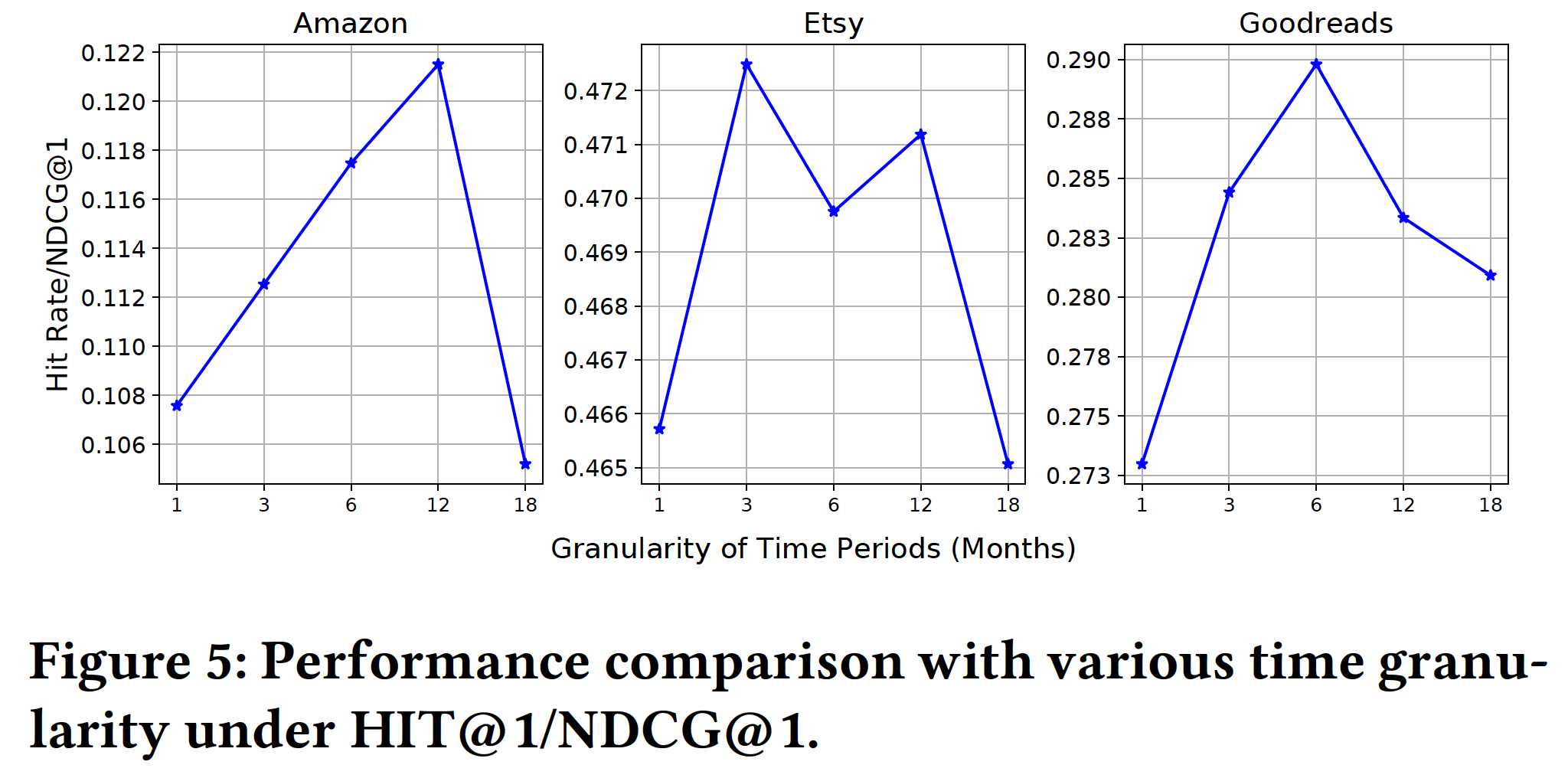
时间粒度(
Time Granularity):时间段的粒度控制了HyperRec对随时间变化的敏感程度。在下图中,我们通过将粒度从1 ~ 18个月来展示模型的性能。可以看到:当时间粒度较小时,我们发现模型无法达到最佳性能,因为交互非常稀疏,不足以构建一组有表达能力的
item embedding。当扩大粒度时,我们发现
HypereRec的性能在所有数据集上都有所提高。在
Amazon数据集上,当粒度设置为12个月时,模型性能达到最佳。在
Etsy数据集上,最佳的粒度较小,因为Etsy上销售的商品(即手工制品)的波动性高于Amazon上的商品。在
Goodreads数据集上,最佳的粒度约为6个月。因为在Goodreads中,对于每个时间段都有更多的交互从而用于dynamic item embedding。
如果我们进一步扩大粒度,则模型性能会下降,因为这会低估
item的变化并且可能会给模型带来噪声。
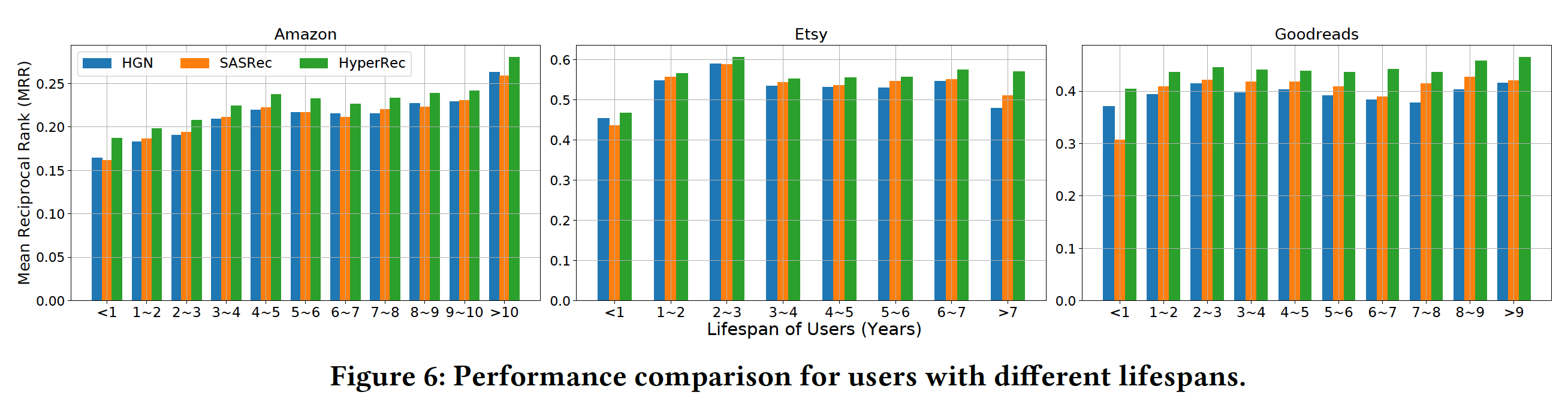
用户生命周期:我们评估具有不同生命周期的用户,其中生命周期指的是用户的最后一次交互和第一次交互之间的时间间隔。实验结果如下图所示。可以看到:
对于生命周期较短(不到一年)的用户,
HGN比SASRec效果更好;而对于生命周期更长的用户,SASRec比HGN更好。我们发现
HyperRec显著优于所有生命周期的baseline。对于生命周期较长的用户,HyperRec可以实现较大的提升,这表明HyperRec在捕获长期用户模式并同时考虑短期相关性方面具有优势。