一、LESSR [2020]
《Handling Information Loss of Graph Neural Networks for Session-based Recommendation》
在许多在线服务中,用户的行为天然地是按时间排序的。为了预测用户未来的行为,
next-item推荐系统通过从用户的历史行为中挖掘序列模式(sequential pattern)来学习用户的偏好。session-based推荐是next-item推荐的一个特例。与使用固定数量的previous action来预测next action的通用next-item推荐系统不同,session-based推荐系统将user action分组到不相交的session中,并使用当前session中的previous action来进行推荐。这里,session是在时间上非常接近的item的一个序列。session-based推荐的思想来自于这样的一个观察:intra-session的依赖关系对next item的影响,要比inter-session的依赖关系更大。具体而言,同一个session中的用户行为通常具有一个共同的目标(如,购买一些手机配件),而不同session中的用户行为的相关性较弱。用户可能在一个session中购买手机配件,但是在另一个session中购买与手机配件关系不大的商品,如衣服。因此,通用的next-item推荐系统可能会遇到组合不相关的session、以及抽取不完整的session这两个问题。session-based推荐系统不存在这些问题,因此它可以做出更准确的推荐,并部署在许多在线服务中。由于具有很高的实用价值,
session-based推荐引起了研究人员的高度重视,并在过去几年中开发了许多有效的方法。之前提出的大多数方法都是基于马尔科夫链或RNN。最近,GNN变得越来越流行,并在许多任务中实现了SOTA的性能。也有一些工作尝试将GNN应用于session-based推荐。尽管这些GNN-based方法取得了令人振奋的结果,并为session-based推荐提供了一个新的和有前途的方向,但是我们观察到这些方法中存在两个信息丢失问题information loss problem。现有的
GNN-based方法中的第一个信息丢失问题称作有损(lossy)的session encoding问题。这是由于它们将session转换为graph的有损编码方案(lossy encoding scheme)。要使用GNN处理session,需要首先将session转换为graph。在这些方法中,每个session都将被转换为一个有向图,边是item之间的转移(transition)。边可以加权或不加权。例如,
sessiongraph。但是,这种转换是有损操作,因为它不是一一映射。不同的sessiongraph,因此我们无法在给定graph的情况下重建原始session。尽管在特定数据集中,这两个session可能产生相同的next item。但是也可能存在一个数据集,其中这两个session产生不同的next item。在后一种情况下,这些GNN模型不可能为这两个session都作出正确的推荐。因此,这些模型的建模能力有限。本质上这两个
session是不同的,而GNN-based会为这两个session作出相同的推荐,因为这两个session转换后的graph是相同的。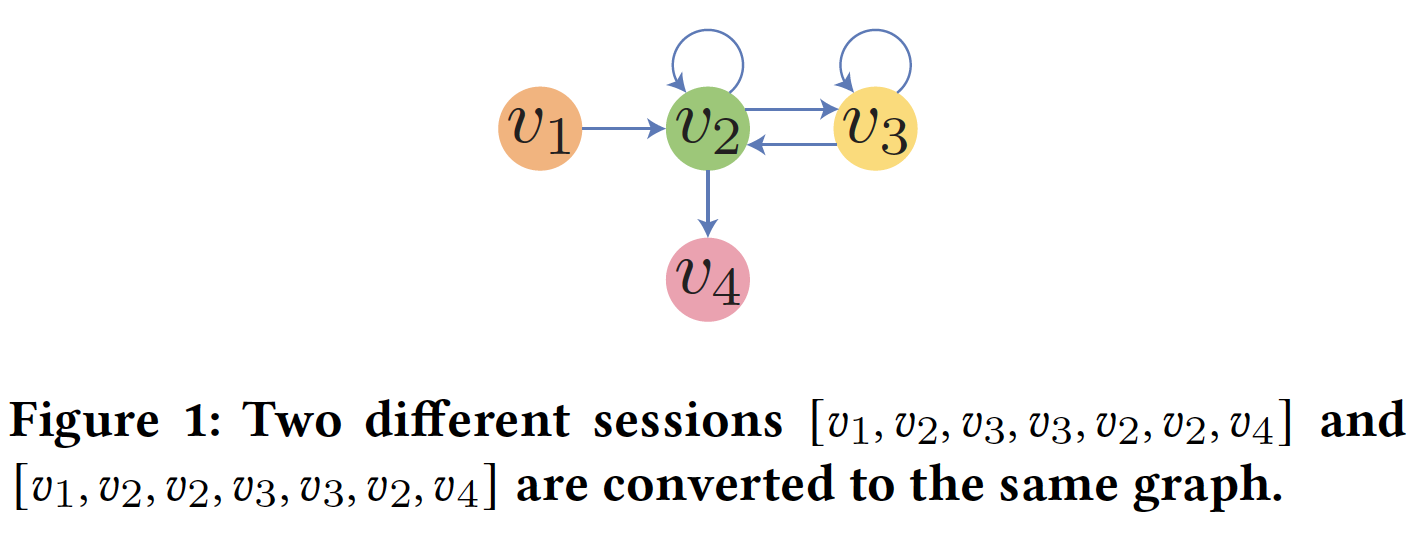
第二个信息丢失问题称为无效的远程依赖捕获问题(
ineffective long-range dependency capturing problem),即,这些GNN-based方法无法有效地捕获所有远程依赖。在GNN模型的每一层中,节点携带的信息沿着边传播一个step,因此每一层只能捕获1-hop关系。通过堆叠多个层,GNN模型可以捕获多达L-hop关系,其中L等于层数。由于过拟合(overfitting)和过度平滑(over-smoothing)问题,堆叠更多层不一定会提高性能,因此这些GNN模型的最佳层数通常不大于3。因此,模型只能捕获3-hop关系。然而,在实际应用中,
session长度很容易大于3。因此,很可能存在一些重要的、长度大于3的序列模式(sequential pattern)。然而,由于网络结构的限制,这些GNN-based模型无法捕获此类信息。
为了解决上述问题,论文
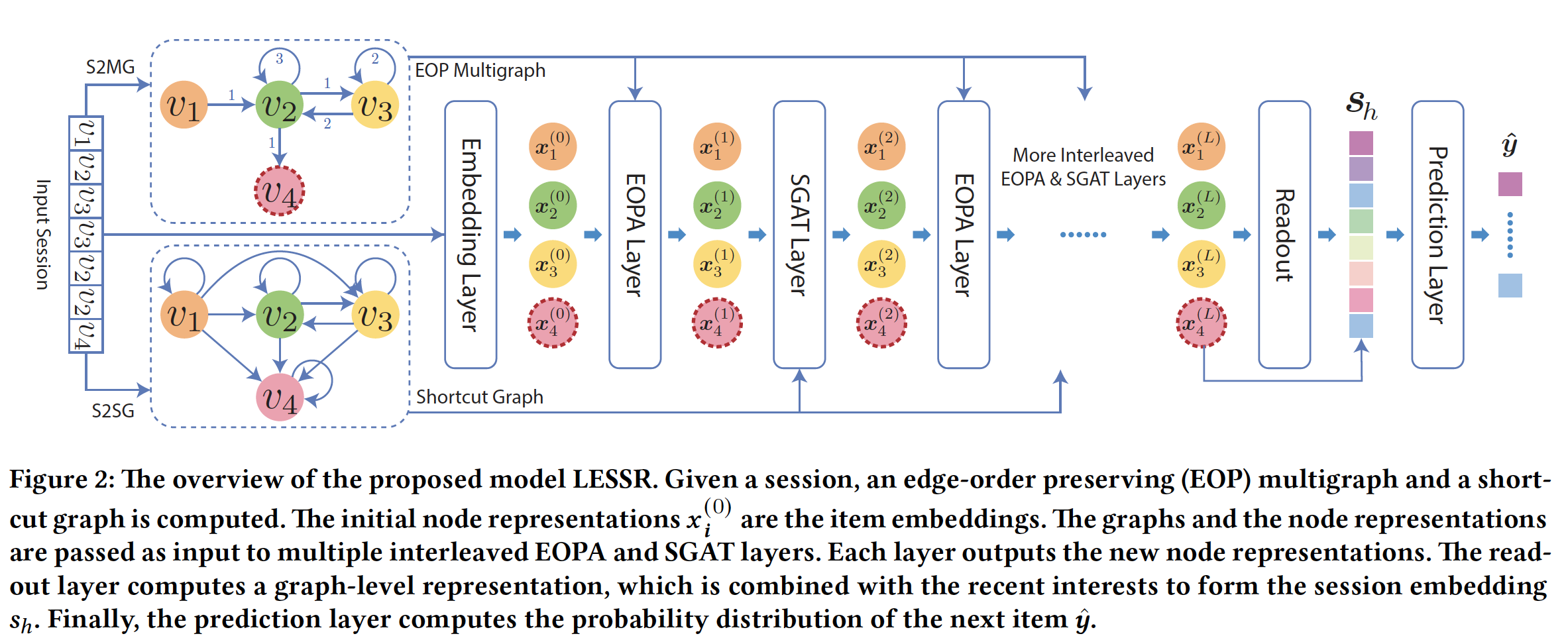
《Handling Information Loss of Graph Neural Networks for Session-based Recommendation》提出了一种新的GNN模型,称作Lossless Edge-order preserving aggregation and Shortcut graph attention for Session-based Recommendation: LESSR。下图说明了LESSR的工作流程:首先,将给定的
input session转换为一个无损编码图(称作edge-order preserving: EOP的multigraph),以及一个shortcut graph。EOP multigraph可以解决lossy session encoding问题,shortcut graph可以解决无效的远程依赖捕获问题。然后,这些
graph和item embedding一起被传递给multiple edge-order preserving aggregation: EOPA层和shortcut graph attention: SGAT层,从而生成所有节点的latent feature。EOPA层使用EOP multigraph来捕获局部上下文信息,SGAT层使用shortcut graph有效地捕获远程依赖关系。然后,模型应用带注意力机制的
readout函数从所有的node embedding中生成graph-level embedding。最后,模型将
graph-level embedding与用户最近的兴趣相结合从而生成推荐。
论文的贡献总结如下:
论文首先确定了用于
session-based推荐的GNN-based方法的两个信息丢失问题,包括有损的session encoding问题、以及无效的远程依赖捕获问题。为了解决有损的
session encoding问题,论文提出了一种将session转换为有向multigraph的无损编码方案,以及一个使用GRU来聚合所传播的信息的EOPA层。为了解决无效的远程依赖捕获问题,作者提出了一个
SGAT层,该层使用注意力机制沿着shortcut connection有效地传播信息。通过结合这两种解决方案,作者构建了一个
GNN模型,该模型没有信息丢失问题并且在三个公共数据中优于现有的方法。
相关工作:
受到邻域模型在传统推荐任务中流行的启发,其中在传统推荐任务中
user id可用,早期的session-based推荐的研究工作大多基于最近邻(nearest neighbor)。这些方法需要一个相似度函数来衡量item或session之间的相似度。《The YouTube Video Recommendation System》提出了一种方法,该方法根据item的共现模式(co-occurrence pattern)来计算item相似度,并推荐最可能与当前session中的任何item共现的item。《Session-based Collaborative Filtering for Predicting the Next Song》提出了一种模型,该模型首先将每个session转换为一个向量,然后测量session向量之间的余弦相似度。基于
《Session-based Collaborative Filtering for Predicting the Next Song》的工作,《Improving Music Recommendation in Session-based Collaborative Filtering by Using Temporal Context》提出在计算余弦相似度之前使用聚类方法,将稀疏的session向量转换为稠密向量。
虽然简单有效,但是
neighborhood-based方法存在稀疏性问题,并且未考虑session中item的相对顺序。为了更好地捕获序列属性,人们采用了基于马尔科夫链的方法。
最简单的基于马尔科夫链的方法使用训练集中的转移概率来启发式地计算转移矩阵(
transition matrix)(《An MDP-Based Recommender System》)。但是,该方法无法处理未观察到的转移模式。一种解决方案是
《Factorizing Personalized Markov Chains for Next-basket Recommendation》中提出的FPMC方法,该方法使用张量分解技术来分解个性化的转移矩阵。另一种解决方案称作潜在马尔科夫
embedding(《Playlist Prediction via Metric Embedding》),它将item嵌入到欧氏空间,并通过embedding的欧氏距离来估计item之间的转移概率。
当考虑更多
previous items时状态空间的规模很快就变得难以管理,因此大多数基于马尔科夫链的方法仅使用一阶转移来构建转移矩阵,这使得它们无法捕获更复杂的高阶序列模式。由于强大的序列建模能力,
RNN是对上述基于马尔科夫链方法的限制的自然解决方案。GRU4Rec是第一个RNN-based的session-based推荐方法,它简单地堆叠了多个GRU layer。受计算机视觉和自然语言处理中注意力机制成功的启发,
NARM采用带注意力机制的混合编码器来建模用户的序列行为和主要意图。结果证明这是学习session representation的有效方法。遵从
NARM工作,几乎所有后续的RNN-based方法都包含了注意力机制(LINet、RepeatNet、ISLF)。
卷积神经网络也是强大的序列建模工具。
《Personalized Top-N Sequential Recommendation via Convolutional Sequence Embedding》提出了一种基于CNN的方法(即,Caser),该方法将item序列嵌入到二维潜在矩阵中,并对矩阵进行水平卷积和垂直卷积从而抽取sequence representation。《A Simple Convolutional Generative Network for Next Item Recommendation》提出使用空洞卷积层(dilated convolutional layer)来有效地增加感受野,而不依赖于有损的池化操作,从而使模型与GRU4Rec和Caser相比更能捕获远程依赖关系。
在过去的几年里,
GNN越来越受欢迎,并在许多任务中取得了SOTA的性能。有一些工作将GNN应用于session-based推荐。SR-GNN首先将session编码为无权有向图,其中边表示session中的item转移。然后使用gated GNN: GGNN在节点之间沿着边的两个方向传播信息。基于
SR-GNN,《Graph Contextualized Self-Attention Network for Session-based Recommendation》提出了一种方法,该方法使用GGNN来提取局部上下文信息,并使用self-attention network: SAN来捕获远距离位置之间的全局依赖关系。FGNN将session转换为加权有向图,其中边的权重是item转移的计数。它使用一个适配的multi-layered graph attention network来抽取item特征,并使用一个修改过的Set2Set池化算子来生成session representation。
这些
GNN-based方法为session-based推荐展示了一个新的和有前景的方向。然而,正如我们即将讨论的那样,这些方法在代表了session有损编码的图上操作,并且它们无法有效地捕获长期依赖关系。
1.1 模型
GNN是直接对graph数据进行操作的神经网络。它们用于学习诸如图分类、节点分类、链接预测等问题的任务。这里我们仅关注图分类问题,因为session-based推荐可以被表述为图分类问题。给定图
node representation传递给GNN的第一层。大多数GNN可以从消息传递的角度来理解。在GNN的每一层中,node representation通过沿着边来传递消息从而得到更新。该过程可以表述为:其中:
node representation。incoming edge)集合。message function),它计算要从相邻节点aggregation function),它聚合传递给目标节点update function),它根据原始的node representation和聚合后的信息来计算新的node representation。这里的消息函数、聚合函数、更新函数都与
layer-specific的。如果层之间共享,那么这三个函数可以表示为:
令
GNN的层数。经过GNN的final node representation捕获了L-hop community内的有关图结构和节点特征的信息。对于图分类任务,
readout functionrepresentation来生成graph level representationsession-based推荐的目标是给定当前session的一个item序列(历史点击的item),预测用户最有可能点击的next item。正式地,令
item的集合。一个sessionitem序列,其中time stepitem,next itemsession-based推荐系统会生成next item的一个概率分布,即top概率的一批item将作为候选集合用于推荐。遵从之前的工作,我们在本文中不考虑额外的上下文信息,如
user ID和item属性。item ID被嵌入在item feature。这是session-based推荐的文献中的常见做法。然而,很容易调整我们的方法来考虑额外的上下文信息。例如:
user ID embedding可以作为graph-level的属性,并且可以附加到每一层中的item ID embedding。item特征可以与item ID emebdding相结合,或者直接替换后者。
1.1.1 Session 到 Graph 的转换
要使用
GNN处理session,必须首先将session转换为图。这里我们首先介绍一种叫做S2MG的方法,该方法将session转换为EOP multigraph。然后我们介绍另一种叫做S2SG的方法,该方法将session转换为shortcut graph。
a. S2MG: Session to EOP Multigraph
在
session-based推荐的文献中,有两种常用的方法可以将session转换为图。第一种方法由
SR-GNN提出,它将session转换为无权有向图session中的unique item组成,边集合第二种方法由
FGNN提出。与第一种方法不同,该方法转换后的图是加权的,其中边session中出现的频次。
在接下来的内容中,我们称第一种方法为
Session-to-Graph: S2G,第二种方法为Session-to-Weighted-Graph: S2WG。我们声称
S2G和S2WG都是有损的转换方法,因为在给定转换后的图的情况下,并不总是可以重建原始的session。为了证明这一点,我们只需要证明S2WG是有损的,因为它比S2G捕获更多的信息,即item transition的出现次数。因此,S2WG is lossy意味着S2G is lossy。为了了解为什么
S2WG是有损的,我们举一个反例如下。给定两个不同的session:S2WG将这两个session转换为相同的图,如下图(a)所示。注意,我们省略了边的权重,因为它们都是1。因此,给定下图(a)中的转换后的图,我们不清楚session。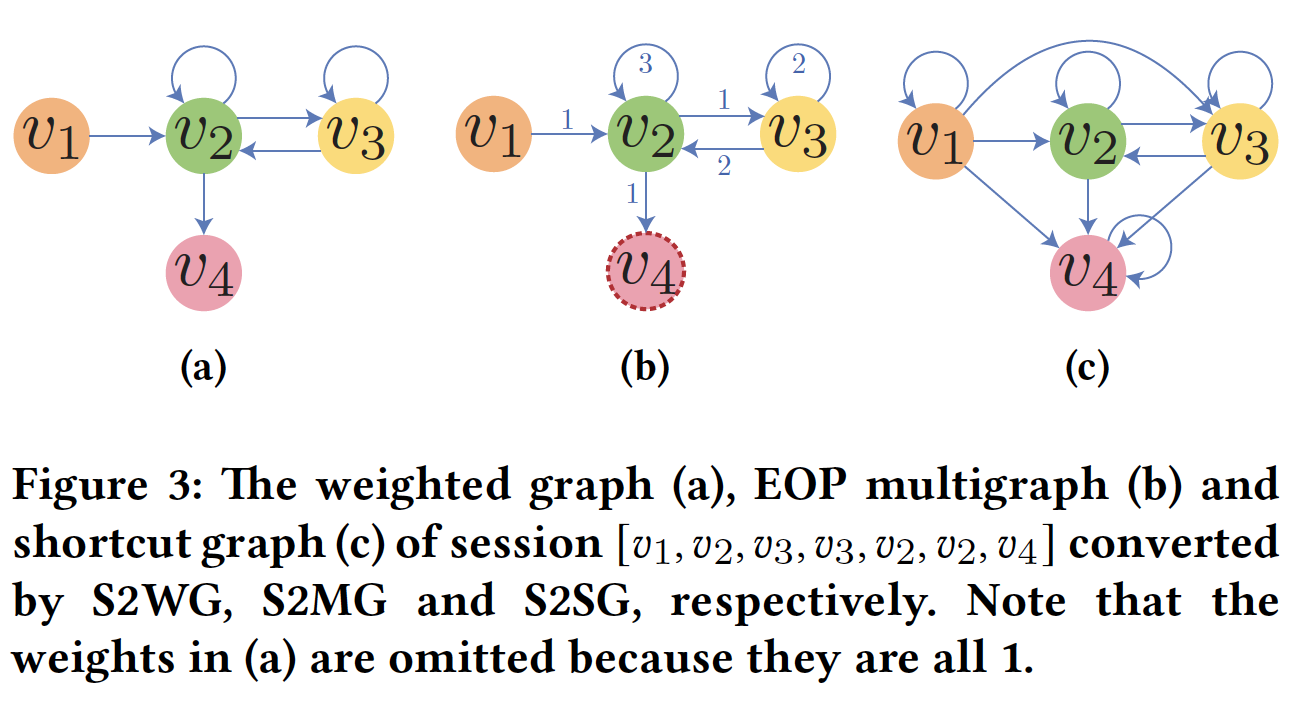
有损转换可能会出现问题,因为被忽略的信息对于确定
next item可能很重要。我们应该让模型自动学习决定哪些信息可以被忽略,而不是使用有损转换方法 “盲目地” 作出决定。否则,该模型不够灵活,无法适应复杂的数据集,因为模型的建模能力受到有损转换方法的限制。为了解决这个问题,我们提出了一种叫做
session to EOP multigraph: S2MG的方法,该方法将session转换为保留了边顺序的有向multigraph。对于原始
session中的每个转移multigraph,因为如果存在从然后,对于每个节点
session中出现的时间来排序。我们通过给首先出现在
1。接下来出现的边,其属性值为2。以此类推。
例如,
session(b)中的图,用last item,即sessionsession的edge-order preserving: EOP的multigraph。现在,我们通过展示如何在给定一个
EOP multigraph(即,使用S2MG转换得到的图)的情况下重建原始的session来证明S2MG是一种从session到graph的无损转换方法。基本思想是:按照item在session中出现的相反顺序来恢复item。我们以
last item是被标记的节点由于我们知道
last item,并且我们知道last edge是倒数第二个
item就是last edge的源节点,即然后我们可以迭代地执行该操作并确定倒数第三个
item,以此类推。
通过这种方式,我们可以从图
sessiongraph,可以应用相同的过程来重建原始的session。因此,S2MG是一种从session到图的无损转换方法。
b. S2SG: Session to Shortcut Graph
为了处理现有的
GNN-based的session-based推荐模型中无效的远程依赖问题,我们提出了shortcut graph attention: SGAT层(见后面的内容描述)。SGAT layer需要一个不同于上述EOP multigraph的输入图。这个输入图采用称作session to shortcut graph: S2SG的方法从input session中转换而来。给定一个
sessionunique item。对于每对有序的节点pairpairshortcut graph,因为它连接了一对item而不经过中间的item。我们还在图中添加了
self-loop,以便稍后在SGAT层执行消息传递时,可以组合update function和aggregate function,这是GAT模型中的常见做法。采用了
self-loop之后,更新函数和聚合函数可以用一个统一的函数来替代。因此,
sessionshortcut graph如下图(c)所示。在接下来的内容中,我们展示了
SGAT层如何通过在shortcut graph上执行消息传递从而解决无效的远程依赖问题。
1.1.2 LESSR
LESSR的整体框架如下图所示。首先我们介绍EOPA layer,然后我们介绍SGAT layer,接下来我们描述如何堆叠这两种类型的层,然后我们展示如何获取session embedding。最后,我们给出了我们如何进行预测和训练。
a. EOPA layer
给定从
session无损转换的EOP multigraph,GNN仍然需要正确地处理图,以便可以将不同的session映射到不同的representation。这在现有的GNN-based的session-based推荐模型中是不可能的,因为它们使用排列不变(permutation-invariant)的聚合函数,忽略了边的相对顺序。因此,这些模型仅适用于边之间的排序信息不重要的数据集,这意味着这些模型的建模能力存在限制。因为
EOP multigraph中,每条边有一个整数属性值来保留边的相对顺序,那么将这个属性值作为聚合函数的特征(比如,position embedding),是否就可以保留边之间的排序信息?为了填补这个
gap,我们提出了edge-order preserving aggregation: EOPA层,该层使用GRU来聚合从相邻节点传递的信息。具体而言,令degree。EOP multigraph中边的整数属性从其中:
GRU的hidden state。初始的状态消息函数的结果作为
GRU的输入。
GRU聚合器是一种RNN聚合器。我们选择GRU而不是LSTM,因为已经有工作表明:在session-based推荐任务中GRU优于LSTM。尽管在现有工作中人们已经提出了RNN聚合器,如GraphSAGE中提出了LSTM聚合器,但是应该注意到这些RNN聚合器的工作方式与我们的不同。具体而言,现有的
RNN聚合器通过对这些边的随机排列执行聚合来故意忽略入边(incoming edge)的相对顺序,而我们的GRU聚合器以固定的顺序执行聚合。这是因为在session-based推荐设置中,边自然是按时间排序的。但是,我们要强调的是,
GRU聚合器并不是我们的主要贡献。我们的主要贡献是应用GRU聚合器来解决前面描述的信息丢失问题。来自已有
GNN模型的消息函数和更新函数可以与GRU聚合器一起使用,但是考虑到GRU强大的表达能力,我们简单地对消息函数和更新函数使用线性变换。因此,将所有内容放在一起,我们模型的EOPA层定义为:其中:
这里消息函数
至于最后一个节点的信息,将在后面描述的
readout函数中使用,以便将不同的session映射到不同的representation。
b. SGAT layer
一般而言,每一层都传播一个
step的信息,因此一层只能捕获节点之间的1-hop关系。为了捕获multi-hop关系,可以堆叠多个GNN层。不幸的是,这会引入过度平滑问题(over-smooth problem),即,node representation收敛到相同的值。由于过度平滑问题通常发生在层数大于3时,因此堆叠多个层并不是捕获multi-hop关系的好方法。此外,即使可以堆叠多个层,
GNN也只能捕获最多k-hop关系,其中application中,session长度大于session-based推荐的GNN模型无法有效地捕获very long range内的依赖关系。为了解决这个问题,我们提出了
shortcut graph attention: SGAT层,它本质上是利用S2SG得到的shortcut graph中的边来进行快速的消息传播。具体而言,
SGAT层使用以下注意力机制沿着shortcut graph中的边来传播信息:其中:
shortcut graph中的入边(incoming edge)集合。
shortcut graph中的边直接将每个item连接到其所有后续item,而无需经过中间的item。因此,shortcut graph中的边可以看做是item之间的shortcut connection。SGAT层可以有效地捕获任意长度的长期依赖关系,因为它在一个step中沿着item之间的shortcut connection传播信息,而无需经过中间的item。它可以与现有的GNN-based方法中的原始层相结合,从而提高GNN-based方法捕获远程依赖关系的能力。如何与现有的
GNN-based方法中的原始层相结合?可以参考本文中的 “堆叠多层” 部分。
c. 堆叠多层
EOPA层和SGAT层用于解决之前GNN-based的session-based推荐方法的两个信息丢失问题。为了构建没有信息丢失问题的GNN模型,我们堆叠了许多EOPA层和SGAT层。我们没有将所有EOPA层放在所有SGAT层之后,也没有将所有的SGAT层放在EOPA层之后。我们将EOPA层与SGAT层交错,原因如下:shortcut graph是原始session的有损转换,因此不断堆叠多个SGAT层会引入有损session encoding问题。SGAT层越多,问题就越严重,因为信息丢失量会累积。通过交错
EOPA层和SGAT层,丢失的信息可以保留在后续的EOPA层中,SGAT层可以仅专注于捕获远程依赖关系。交错两种层的另一个优点是:每种层都可以有效地利用另一种层捕获的特征。由于
EOPA层更能捕获局部上下文信息,而SGAT层更能捕获全局依赖关系,将这两种层交错可以有效地结合两者的优点,提高模型学习更复杂依赖关系的能力。
为了进一步促进特征重用(
feature reuse),我们引入DenseNet中提出的稠密连接。每层的输入由所有previous layers的输出特征组成。具体而言:第
采用稠密连接之后,第
previous layers输出的拼接。
结果表明:具有稠密连接的深度学习模型的参数效率更高,即,用更少的参数实现相同的性能,因为每个较高的层不仅可以使用它的前一层的抽象特征,还可以使用更低层的
low-level feature。
d. 生成 Session Embedding
在所有层的消息传递完成之后,我们得到所有节点的
final representation。为了将当前session表示为embedding向量,我们应用了SR-GNN中提出的readout函数,该函数通过注意力机制聚合node representation来计算graph-level representation。令
session中last item的final node representation。graph-level representation其中:
session转换后的图的节点集合,它的规模远远小于全量item集合graph-level representation捕获当前session的全局偏好,记做local preference vector),记做然后,我们将
session embedding计算为全局偏好和局部偏好的线性变换:其中:
e. 预测和训练
在获得
session embedding之后,我们可以使用它来计算next item的概率分布从而进行推荐。对于每个
itemembeddingsession embedding来计算一个分数:实际上
然后,
next item是item对于
top-K推荐,我们可以仅推荐概率最高的ietm。令
next item的真实概率分布,它是一个one-hot向量。损失函数被定义为预测分布和真实分布的交叉熵:然后,所有参数以及
item embedding都被随机初始化,并通过端到端的反向传播来联合学习。
1.2 实验
数据集:
Diginetica数据集:来自CIKM Cup 2016。我们使用它的交易数据来进行session-based推荐。遵从之前的工作(NARM, STAMP, RepeatNet, SR-GNN),我们使用最近一周的session作为测试集。Gowalla数据集:是一个广泛用于point-of-interest: POI推荐的check-in数据集。遵从之前的工作(《Streaming Session-based Recommendation, Caser),我们保留了top 30000个最受欢迎的location,并通过1天的时间间隔来拆分用户的check-in记录从而将这些记录分组到不相交的session中。最近的20%的session用作测试集。Last.fm数据集:是一个广泛用于许多推荐任务的数据集。我们将该数据集用于音乐艺术家推荐。遵从之前的工作(《Streaming Session-based Recommendation》, RepeatNet),我们保留了top 40000名最受欢迎的艺术家,并将拆分间隔设置为8小时。与Gowalla类似,最近的20%的session用作测试集。
遵从之前的工作(
NARM, STAMP, FGNN, RepeatNet, SR-GNN),我们首先过滤了短的session和低频的item,然后应用了NARM, STAMP, SR-GNN中描述的数据增强技术。预处理后数据集的一些统计数据如下表所示: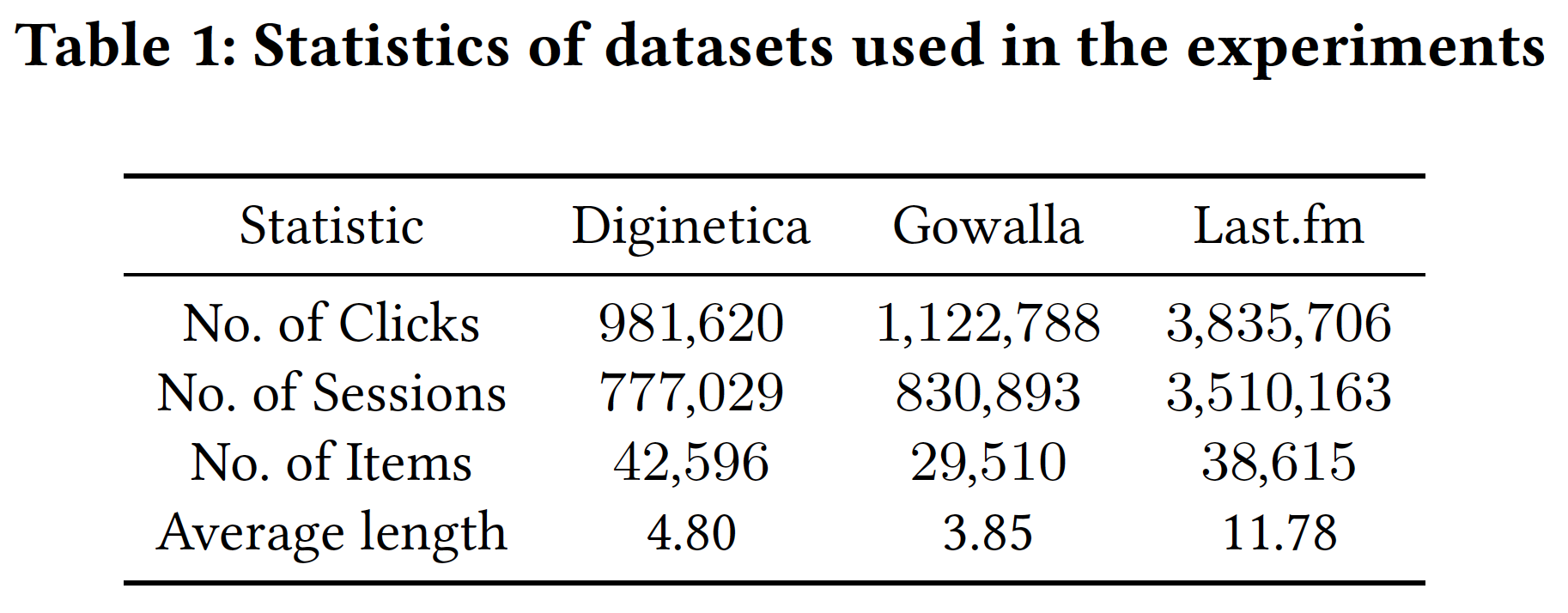
baseline方法:Item-KNN:一种邻域方法,它推荐与当前session中的previous items相似的item,其中两个item之间的相似度由它们的session余弦相似度所定义。FPMC:一种用于next-basket推荐的基于马尔科夫链的方法。为了适配session-based推荐,我们将next item视为next-basket。NARM:使用RNN来捕获用户的主要意图和序列行为。NextItNet:一种用于next-item推荐的CNN-based方法。它使用空洞卷积来增加感受野,而且不使用有损的池化操作。SR-GNN:将session转换为有向无权图,并通过GNN来沿边的两个方向传播信息从而提取item特征。FGNN:将session转换为有向加权图,并使用适配的GAT来学习item representation。GC-SAN:首先使用GGNN来抽取局部上下文信息,然后使用self-attention network: SAN来捕获全局依赖关系。
配置:遵从
STAMP和Caser之后,对于每种方法,我们应用网格搜索并使用训练集的最后20%作为验证集从而找到最佳超参数。超参数的范围是:embedding维度学习率
对于
GNN-based方法,我们也搜索层数
我们使用
Adam优化器来训练模型,batch size设置为512。我们报告每个模型在其最佳超参数配置下的结果。评估指标:
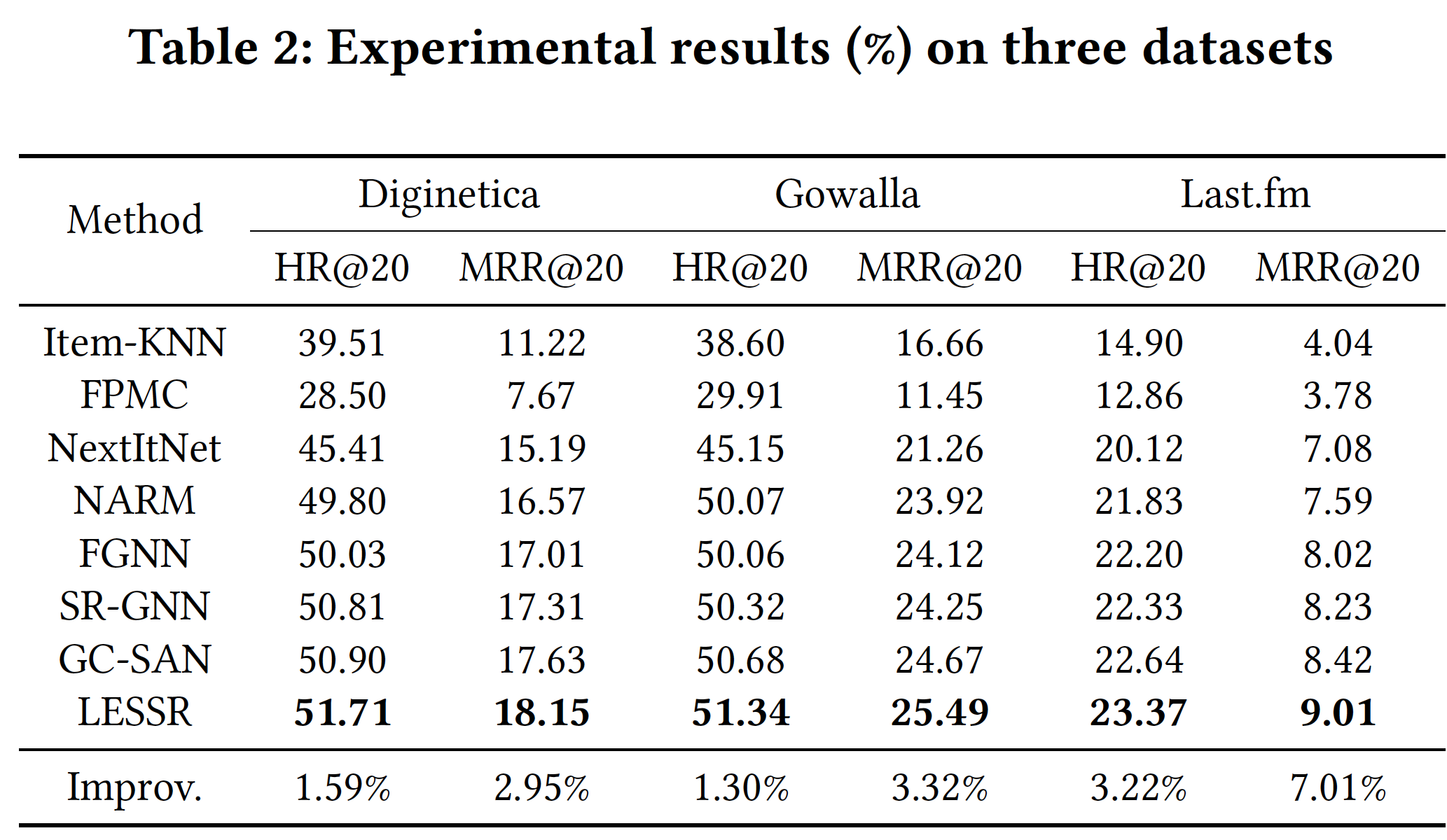
Hit Rate: HR@20、Mean Reciprocal Rank: MRR@20。所有方法的实验结果如下表所示,可以看到:
包括
Item-KNN和FPMC在内的传统方法的性能没有竞争力。这些方法仅基于item的相似性、或者仅基于item转移进行推荐,而不考虑其它重要的序列信息,如,当前session中previous items之间的相对次序。所有基于神经网络的模型都大大优于传统方法,证明了深度学习技术在
session-based推荐中的有效性。基于神经网络的模型能够捕获复杂的序列模式从而进行推荐。然而,它们的序列建模能力并非同样地强大。
CNN-based的方法NextItNet的性能低于其它RNN-based和GNN-based方法。一个可能的原因是:CNN仅擅长捕获连续的序列模式,而不擅长捕获长期依赖。NARM取得了具有竞争力的性能,因为它使用RNN来捕获序列行为以及使用注意力机制来捕获全局偏好。
GNN-based方法通常优于其它方法,这表明GNN为session-based推荐提供了一个有前途的方法。虽然
FGNN使用的转换方法conversion method比SR-GNN使用的方法捕获更多的信息,但是FGNN的性能并不优于SR-GNN,这表明选择强大的消息传递方案的重要性。GC-SAN优于SR-GNN,因为它使用SAN来捕获远距离item之间的全局依赖关系,展示出显式考虑长期依赖关系的有效性。LESSR使用强大的EOPA来抽取局部上下文,并使用SGAT来捕获任意长度的远程依赖关系,因此它可以显著优于所有的baseline方法,证明了所提出方法的效果。在三个数据集中,
LESSR在Last.fm数据集上获得了最大的性能提升,因为这个数据集的平均长度最大,所以LESSR从保留边次序(edge order)和捕获长期依赖关系中获益最多。
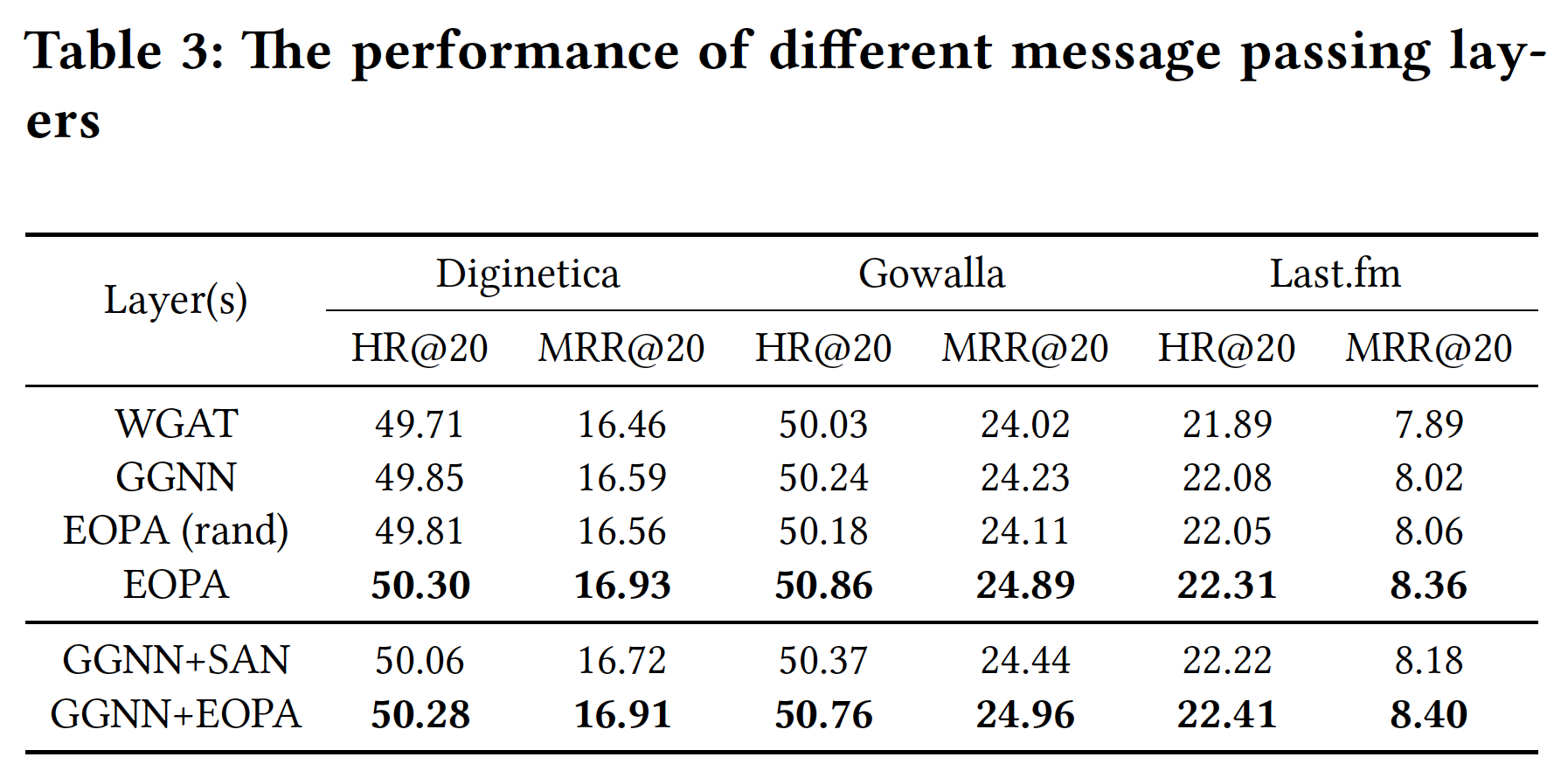
消融研究:
EOPA Layer的有效性:为了评估EOPA层的有效性,我们将它与来自其它GNN-based方法的message passing: MP层进行比较,包括:来自SR-GNN的GGNN、来自FGNN的WGAT、来自GC-SAN的SAN。我们使用前述描述的相同的
readout函数。embedding size设置为96,因为大多数模型在这个embedding size下实现了最佳性能。对于
GGNN和WGAT,层数设置为1,并与具有一个EOPA层的模型进行比较。为了展示
EOPA的重要性,我们还将EOPA层与其修改后的变体进行了比较,该变体对入边(incoming edge)的随机排列执行聚合。换句话讲,修改后的EOPA层忽略了EOP multigraph中边的顺序属性。我们用变体EOPA(rand)来表示。对于
SAN,由于它是为与GGNN一起工作而设计的,因此我们比较了由GGNN和SAN组成的模型,以及由GGNN和EOPA组成的模型。
结果如下表所示。每个模型都由其包含的
MP layer的名称来表示。可以看到:EOPA始终优于所有其它类型的MP layer,证明了EOPA的有效性。其它类型的
MP layer表现更差,因为它们使用有损编码方案将session转换为图,并且它们的聚合方案不考虑边的相对顺序。注意,尽管
EOPA和EOPA(rand)使用相同的编码方案,即S2MG,但是EOPA优于EOPA(rand),因为EOPA(rand)在执行聚合时会随机排列入边(incoming edge)。因此,仅保留边顺序的转换方案是不够的。聚合方案还需要保留边顺序。
SGAT Layer的有效性:为了展示SGAT的有效性,我们将每个现有的GNN-based方法的最后一个MP layer替换为SGAT layer,并检查是否替换后是否提高了性能。由于
SR-GNN和FGNN只有一种MP layer,因此将层数设置为2,以便修改后的模型有一个原始MP layer、有一个是SGAT layer。对于
GC-SAN,层数设为3,因为它有两种MP layer。对于
LESSR,我们比较了一个具有两层EOPA layer的模型,以及一个具有一层EOPA layer和一层SGAT layer的模型。
emebdding size设为96。由于篇幅有限,我们仅报告了Diginetica数据集上的HR@20的性能,因为它更常用于session-based的推荐。结果如下表所示。可以看到:替换有助于提高模型性能。这是因为原始层仅擅长捕获局部上下文信息,而不是复杂的远程依赖关系。通过SGAT layer替换原始层,模型捕获远程依赖关系的能力得到提升。GC-SAN中的SAN层也能够捕获远程节点之间的全局依赖关系。但是,它们在每对节点之间传播信息,这完全丢弃了原始session中的连接信息。相反,我们的SGAT层仅当SAN layer替换为我们的SGAT layer时,模型的性能提升是可以理解的。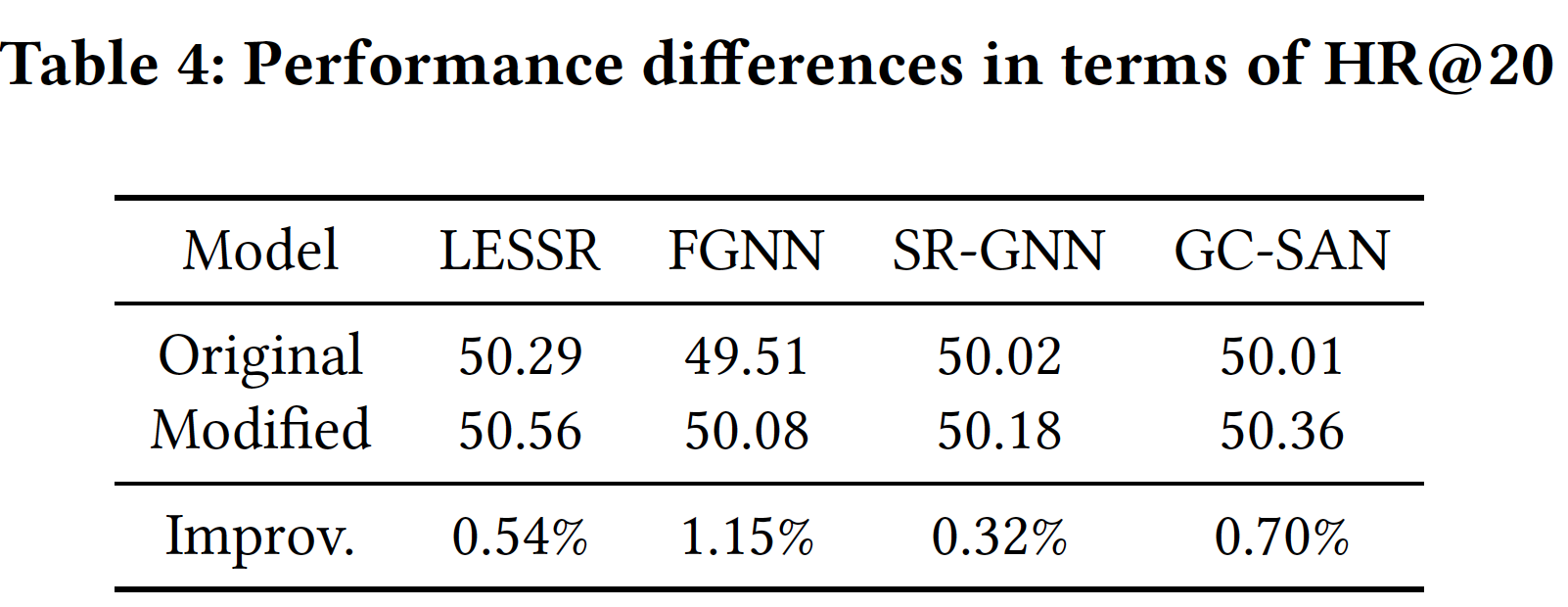
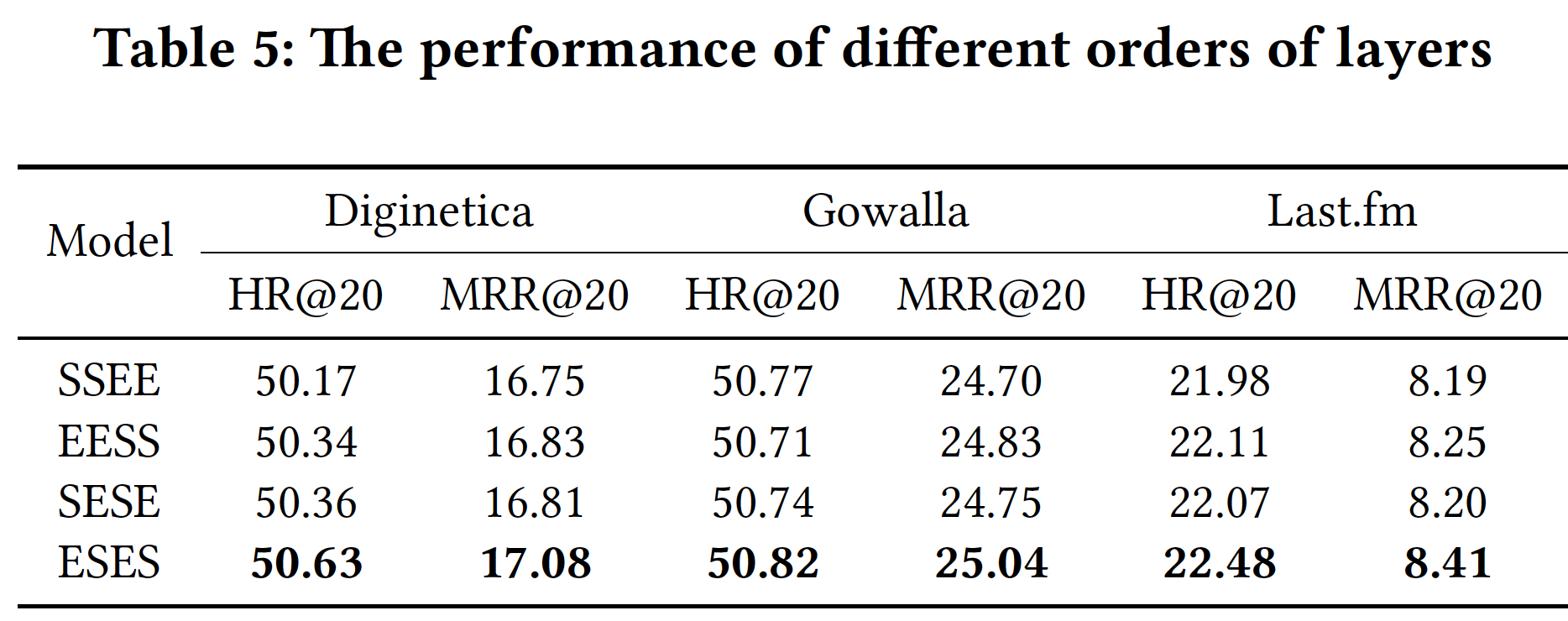
EOPA层和SGAT层的顺序:为了展示层顺序的优势,我们比较了四种模型,包括:EESS, SSEE, ESES, SESE。每个模型包含两个EOPA layer和两个SGAT layer,其中E代表EOPA layer,S代表SGAT layer,字符的顺序代表层之间的顺序。例如,EESS有两个EOPA layer,后面跟着两个SGAT layer。embedding size设置为96,并使用残差连接。下表展示了实验结果。可以看到:SSEE表现最差,因为它不能利用任何一种层的优点。SESE和EESS具有相似的性能,这表明交错两种层、或者将EOPA层放在SGAT层之前的好处。ESES优于所有其它模型,证明该顺序是利用这两种层的优势的最有效方式。
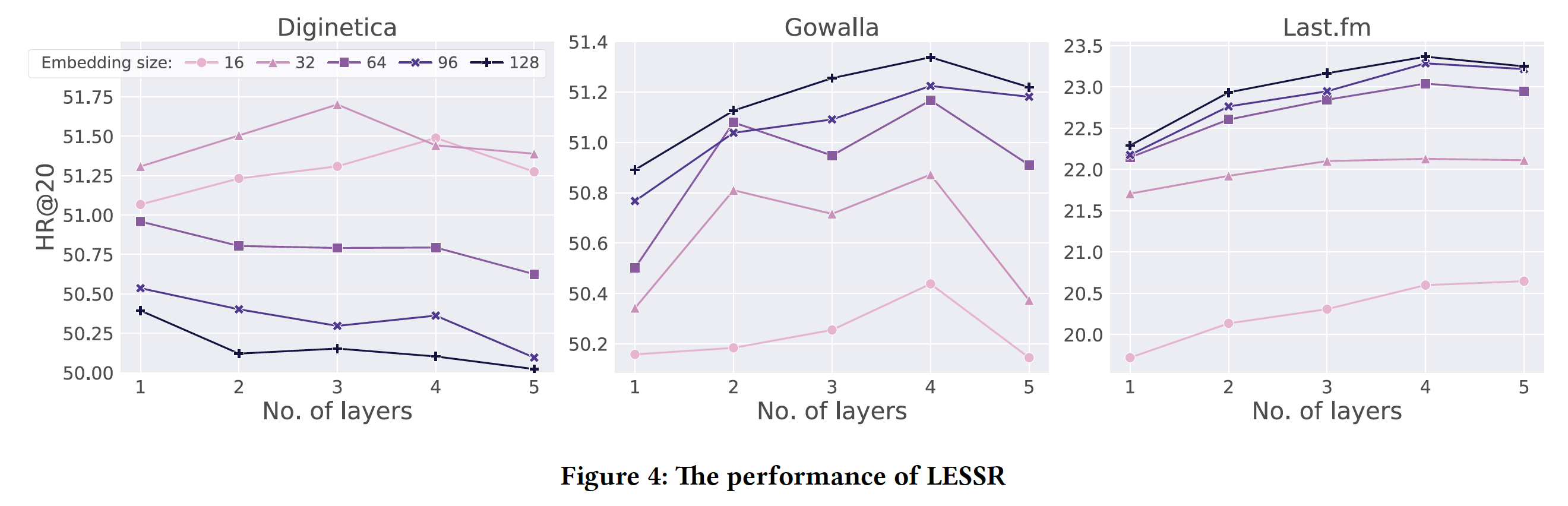
超参数调优:这里我们研究
embedding size和层数如何影响所提出方法的性能。由于篇幅有限,这里我们仅给出HR@20的结果,如下图所示。可以看到:增加
embedding size或层数并不总是会带来更好的性能。对于较小的数据集
Diginetica,最佳的embedding size为32。当embedding size超过该最佳值时,性能会迅速下降,因为模型过拟合。对于另外两个较大的数据集,增加
embedding size通常会提高性能,因为较大的embedding size会增加模型的学习能力。
如果
embedding size小于最优值,那么随着层数的增加,模型性能先提高后下降。这是因为随着层数变大,模型的学习能力会增加。但是过多的层数也无济于事,因为会出现过度平滑的问题,即使模型没有过拟合。因此,堆叠更多的层并不是捕获远程依赖的有效方法,而采用替代方法(如
SGAT layer)来提高模型捕获远程依赖的能力是有意义的。