一、TiSASRec [2020]
《Time Interval Aware Self-Attention for Sequential Recommendation》
有两个重要的方向旨在挖掘用户的历史交互:时间推荐(
temporal recommendation)和序列推荐(sequential recommendation)。时间推荐侧重于建模绝对时间戳从而捕获用户和
item的时间动态(temporal dynamics)。例如,一个item的热门程度可能会在不同的时间段内发生变化,或者一个用户的平均评分可能会随着时间的推移而增加或减少。这些模型在探索数据集中的时间变化(temporal change)时很有用。它们不考虑序列模式(sequential pattern),而是考虑依赖于时间的时间模式(temporal pattern)。大多数以前的序列推荐器通过交互时间戳对
item进行排序,并聚焦于序列模式挖掘来预测next item。一种典型的解决方案是基于马尔科夫链的方法,其中
L阶马尔科夫链根据L个先前的动作而作出推荐。基于马尔科夫链的方法已经成功应用于捕获短期item transition从而用于推荐。这些方法通过作出很强的简化假设并在高度稀疏场景下表现良好,但是在更复杂的场景中可能无法捕获到复杂的动态(intricate dynamics)。RNN也可用于序列推荐。虽然RNN模型对用户的偏好有很长的“记忆”,但是模型需要大量数据(尤其是稠密数据)才能超越更简单的baseline。为了解决马尔科夫链模型和
RNN-based模型的缺点,受到Transformer的启发,SASRec提出将自注意力机制应用于序列推荐问题。基于自注意力机制的模型显著优于SOTA的MC/CNN/RNN based序列推荐方法。
一般而言,以前的序列推荐器会丢弃时间戳信息并且仅保留
item的顺序。即,这些方法隐式地假设序列中的所有相邻item具有相同的时间间隔。影响后续的item的因素仅有前面item的id和位置。然而,直观而言,具有most recent时间戳的item将对next item产生更大的影响。例如,两个用户具有相同的交互序列,其中一个用户在一天之内完成了这些交互而另一个用户在一个月之内完成了这些交互。因此,这两个用户的交互对于next item的影响应该是不同的,即使他们具有相同的交互序列。然而,先前的序列推荐技术将这两种情况视为相同,因为它们仅考虑sequential position(而未考虑sequential timestamp)。在论文
《Time Interval Aware Self-Attention for Sequential Recommendation》中,作者认为应该将用户交互序列建模为具有不同时间间隔的序列。下图表明:交互序列具有不同的时间间隔,其中一些时间间隔可能很大。以前的工作忽略了这些时间间隔对被预测的item的影响。为了解决上述限制,受到Self-Attention with Relative Position Representation的启发,作者提出了一种time-aware self-attention机制,即TiSASRec模型。该模型不仅像SASRec一样考虑了item的绝对位置(absolute position),还考虑了任意两个item之间的相对时间间隔。从论文的实验中可以观察到,论文提出的模型在稠密数据集和稀疏数据集上都优于SOTA算法。
最后,论文的贡献如下:
作者提出将用户的交互历史视为具有不同时间间隔的序列,并将不同时间间隔建模为任意两个交互之间的关系(
relation)。作者将绝对位置编码(
absolute position encoding)和相对时间间隔编码(relative time interval encoding)的优势相结合从而用于self-attention,并且设计了一种新颖的time interval aware的self-attention机制来学习不同item, absolute position, time interval的权重从而预测next item。作者进行了彻底的实验来研究绝对位置和相对时间间隔以及不同组件对
TiSASRec性能的影响,并表明TiSASRec在两个指标上优于SOTA的baseline。
相关工作:
序列推荐:序列推荐系统挖掘用户交互序列中的模式。
一些方法捕获
item-item转移矩阵来预测next item。例如:FPMC通过矩阵分解和转移矩阵(transition matrix)来建模用户的长期偏好和动态转移(dynamic transition)。转移矩阵是一阶马尔科夫链,它仅考虑当前
item和前一个item之间的关系。Fossil使用基于相似性的方法和高阶马尔科夫链,假设next item和前面几个item相关,而《Translation-based Recommendation》证明了基于高阶马尔科夫链的模型在稀疏数据集上具有强大的性能。人们也提出了
CNN-based方法(如,Caser,《3D Convolutional Networks for Session-based Recommendation with Content Feature》)从而将先前的若干个item视为 “图像”,然后通过union-level的CNN来挖掘item之间的转移。MARank通过结合残差网络和多阶注意力来统一individual-level和union-level的previous item transitions。SHAN通过两层注意力机制来建模用户的previous several items和长期历史,从而获得用户的短期偏好和长期偏好。RNN-based模型(如,《Latent Cross: Making Use of Context in Recurrent Recommender Systems》、GRU4Rec、《Neural Survival Recommender》、《Context-Aware Sequential Recommendation》) 使用RNN来建模整个用户序列。这些方法在稠密数据集上表现良好,但是在稀疏数据集上通常表现不佳。
注意力机制:注意力机制已被证明在
image captioning和机器翻译等任务上是有效的。本质上,注意力机制背后的思想是:output依赖于input中相关的特定部分。这种机制可以计算input的权重并使得模型更易于解释。最近,人们将注意力机制纳入推荐系统(《Attentive Collaborative Filtering: Multimedia Recommendation with Item- and Component-Level Attention》、《Attention-Based Transactional Context Embedding for Next-Item Recommendation》、《Attentional Factorization Machines: Learning the Weight of Feature Interactions via Attention Networks》)。Transformer是一种纯粹基于注意力的sequence-to-sequence方法,并且在机器翻译任务上取得了SOTA性能。Transformer使用缩放的内积注意力,其定义为:其中:
query, key, value。在self-attention中,这三个输入通常使用相同的object。Transformer的自注意力模块也被用于推荐系统(如,SASRec),并在序列推荐上取得了SOTA的结果。由于自注意力模型不包含任何循环模块或卷积模块,因此它不知道前面所有item的位置。一种解决方案是向
input添加positional encoding,其中positional encoding可以是确定性函数或者可学习的参数。另一种解决方案是使用
relative position representation。该方法将两个input之间的相对位置建模为pairwise relationship。
受到带有相对位置的
self-attention的启发,我们结合absolute position和relative position来设计time-aware self-attention从而建模item的位置和时间间隔。目前已有一些工作探索了时间间隔对序列推荐的影响,如
Time-LSTM。但是作者这里尚未提及。
1.1 模型
我们的
TiSASRec包含个性化的时间间隔处理(personalized time interval processing)、一个emebdding layer、几个time-aware self-attention块 、以及一个prediction layer。我们嵌入item、item的绝对位置、以及item之间的相对时间间隔。我们通过这些emebdding来计算注意力权重。如下图所示,即使先前的几个item相同,我们的模型也会在不同的时间间隔下提供不同的predicted item。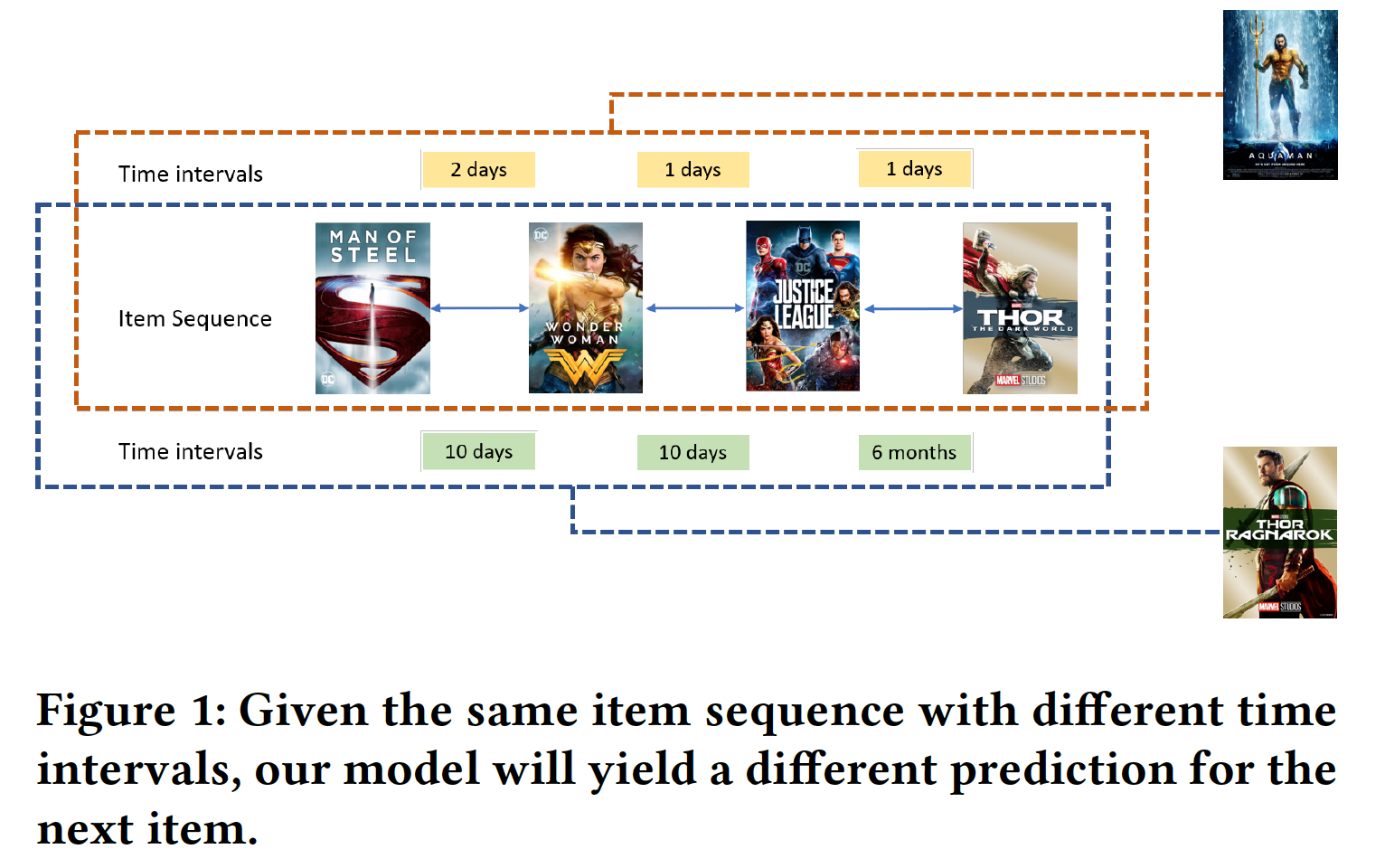
为了学习模型参数,我们采用二元交叉熵作为损失函数。
TiSASRec的目标是捕获序列模式并探索时间间隔对序列推荐的影响,而这是一个尚未探索的领域。TiSASRec的模型结构如下图所示。论文的核心就是在
SASRec上增加了相对时间间隔embedding。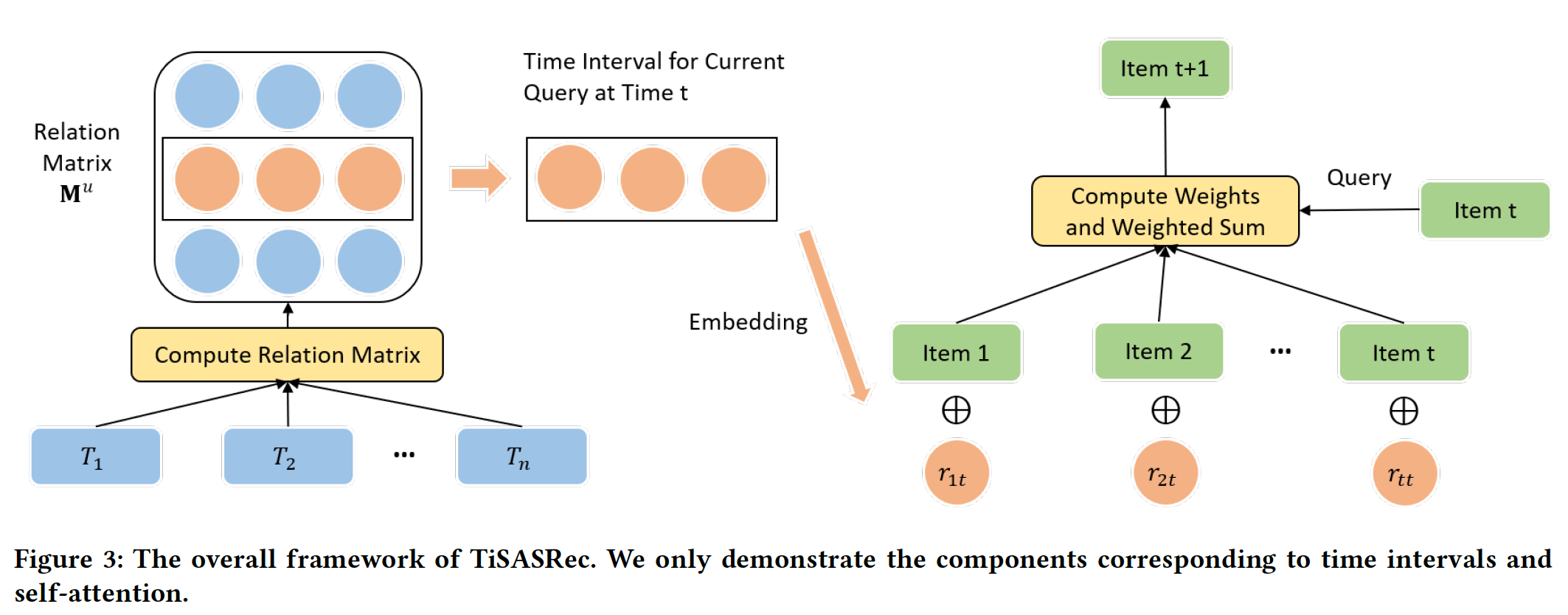
令
item集合。在time-aware序列推荐的setting中,对于每个用户action序列action发生时间的时间序列time stepitem以及itemnext item。我们模型的输入是
item之间的时间间隔矩阵time step的next item:time stepnext item的信息。事实上也可以考虑
time stepcurrent timestamp作为时间上下文。
1.1.1 个性化时间间隔
我们将训练序列
如果训练序列长度
item。如果训练序列长度
padding item直到长度为
类似地,我们对于时间序列
我们将交互序列中的时间间隔建模为两个
item之间的关系。一些用户有更频繁的交互,而另一些用户则没那么频繁,我们仅关心用户序列中时间间隔的相对长度。因此,对于所有时间间隔,我们除以用户序列中最短的时间间隔(0除外)来获得个性化的时间间隔。具体而言,给定用户
item缩放后的时间间隔
其中
根据定义有:
因此,用户
relation matrix)为什么用个性化的时间间隔,而不使用绝对的时间间隔,例如
我们考虑的两个
item之间的最大相对时间间隔被截断为sparse relation encoding)(即,裁剪后的关系矩阵大多数元素为零),并且使得模型能够泛化到训练期间unseen的时间间隔。因此,裁剪后的矩阵为:其中:矩阵的
1.1.2 Embedding Layer
我们为所有
item创建一个item embeddingembedding维度。对于padding item,它的embedding固定为零向量。给定固定长度的序列
embedding look-up操作查找这item的embedding,将它们堆叠在一起从而得到一个矩阵其中
itemembedding向量。遵从
《Self-Attention with Relative Position Representations》,我们使用两个不同的可学习的positional embedding matrix,即self-attention机制中的key和value。给定固定长度的序列
item的位置检索得到emebdding矩阵其中:
positionkey的positional embedding。positionvalue的positional embedding。
用两组
embedding来表达positional embedding会增强模型的容量从而提高模型的表达能力,但是效果是否更好?这个可以通过实验来比较。类似于
positional embedding,相对时间间隔embedding matrix为self-attention机制中的key和value。在检索裁剪后的关系矩阵embedding张量其中:
key的embedding。value的embedding。
这两个相对时间间隔
embedding矩阵是对称矩阵(其实是张量),并且主对角线上的元素全为零。类似地,这里用两组
embedding来表达相对时间间隔embedding会增强模型的容量从而提高模型的表达能力,但是效果是否更好?这个可以通过实验来比较。
1.1.3 Time Interval-Aware 自注意力
受相对位置自注意力机制的启发,我们提出了对自注意力的扩展从而考虑序列中两个
item之间的不同时间间隔。但是,仅考虑时间间隔是不够的,因为用户交互序列可能有许多具有相同时间戳的item。在这种情况下,模型将成为没有任何位置信息或关系信息的self-attention。因此,我们还考虑了item在序列中的位置。例如,假设时间间隔都是相等的,那么
1,因此会丢失位置信息。Time Interval-Aware Self-attention Layer:对于每个长度为itemitem embedding,我们计算一个新的序列其中:
value的待学习的投影矩阵。每个权重系数
softmax函数来计算:其中:
query和key的待学习的投影矩阵。缩放因子
因果性(
Causality):由于交互序列的性质,模型在预测第item时应该仅考虑前面item。然而,time-aware self-attention layer的第SASRec,我们通过禁止Point-Wise Feed-Forward Network:尽管我们的Time Interval-Aware Self-attention Layer能够将所有先前的item、绝对位置、相对时间信息以自适应权重的方式结合起来,但是它是通过线性组合来实现的。在每个time-aware attention layer之后,我们应用两个线性变换,这两个线性变换之间有一个ReLU非线性激活函数从而赋予模型非线性:其中:
item,这里使用相同的参数(同层之间);对于不同层的相同item,这里使用不同的参数(跨层之间)。正如
SASRec所讨论的,在堆叠自注意力层和前馈层之后,会出现更多的问题,包括过拟合、训练过程不稳定(如,梯度消失)、以及需要更多的训练时间。类似于《Attention Is All You Need》以及SASRec,我们也采用layer normalization、残差连接、以及dropout正则化技术来解决这些问题:其中:
1.1.4 Prediction layer
在堆叠
self-attention block之后,我们得到了item, position, time interval的组合的representation。为了预测next item,我们采用latent factor model来计算用户对item其中:
itemembedding。item(即,item的时间间隔(即,representation。
在每个位置预测的是
next item,因此是
1.1.5 模型推断
给定一个时间序列和一个
item序列,我们定义其中:
<pad>表示一个padding item。因为用户交互是隐式反馈数据,我们无法直接优化偏好分数
ranked item list。因此,我们采用负采样来优化item的排名。对于每个预期的positive outputnegative itempairwise preference orders我们通过
sigmoid函数0.0 ~ 1.0之间,并采用二元交叉熵作为损失函数:其中:
embedding矩阵的集合,Frobenius范数,注意,我们丢弃了
padding item的损失。模型通过
Adam优化器优化。由于每个训练样本mini-batch SGD来加快训练效率。
1.2 实验
我们的实验旨在回答以下研究问题:
RQ1:我们提出的方法是否在序列推荐中优于SOTA的baseline?RQ2:对于序列推荐,绝对位置或相对时间间隔,哪个更重要?RQ3:超参数如何影响模型性能,如embedding维度RQ4:个性化的时间间隔在这个模型中有用吗?
数据集:我们在六个数据集上评估,这些数据集具有不同的领域、规模、以及稀疏性,并且它们都是可以公开访问的。
MovieLens:用于评估协同过滤算法的广泛使用的benchmark数据集。我们使用包含100万用户评分的版本,即MovieLens-1M。Amazon:该数据集包含从Amazon.com抓取的大量商品评论数据。我们考虑了四个类目,包括CDs and Vinyl、Movies and TV、Beauty、Video Games。该数据集高度稀疏。Steam:该数据集是从大型在线视频游戏分发平台Steam上抓取的,包含用户的游戏时间、媒体评分、以及开发人员等信息。
所有这些数据集都包含时间戳或交互的特定日期。
为了预处理,我们遵循
《Translation-based Recommendation》、SASRec、FPMC中的过程:对于所有数据集,我们将评论或评分视为隐式反馈(即,用户与
item交互),并按时间戳对item进行排序。对于所有用户,我们在他们自己的序列中减去最小的时间戳,让时间戳从零开始。
我们过滤掉冷启动用户和冷启动
item,即互动少于5次的user和互动少于5次的item。遵从
SASRec之后,我们使用最近的item用于测试集,使用第二近的item用于验证集,剩余的item用于训练集。
数据集的统计结果如下表所示。
MovieLens-1m是最稠密的数据集,具有最长的平均action和最少的用户和最少的item。Amazon Beauty和Amazon Games具有最短的平均action。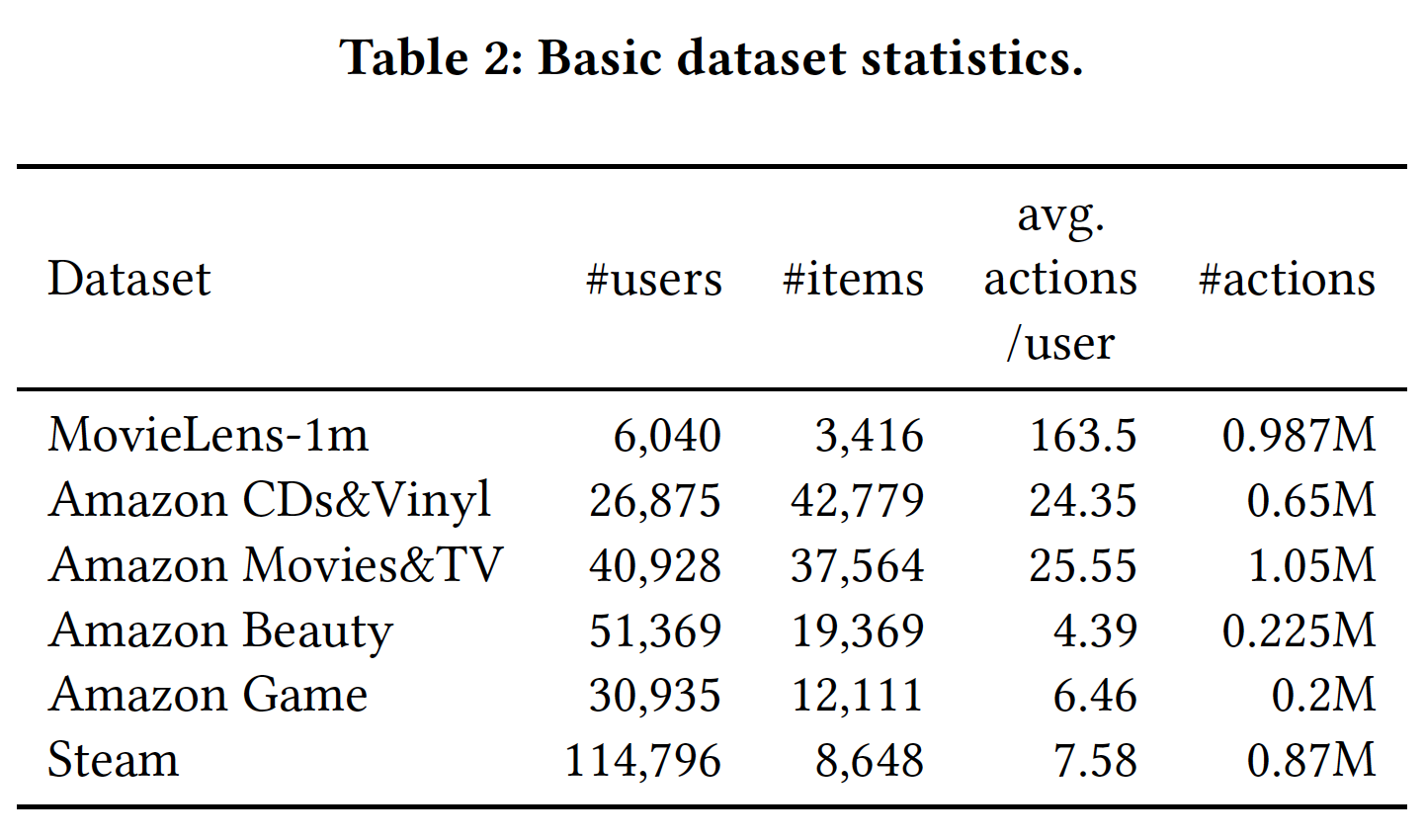
评估指标:
Hit@10和NDCG@10。Hit@10评估了在top 10 item list中有多少比例的ground-truth item。NDCG@10考虑排名信息并将更高的权重分配给更靠前的排名。遵从
《Factorization meets the neighborhood: a multifaceted collaborative filtering model》,对于每个用户100个negative item,并将这些item与ground-truth item进行排序。我们根据这101个item的排名来计算Hit@10和NDCG@10。baseline方法:不考虑序列模式的经典的通用推荐(
general recommendation):POP:所有item根据它们在训练集中的流行度来排序。流行度是根据互动频次来统计的。BPR:贝叶斯个性化排名(bayesian personalized ranking)是通用推荐的经典方法,其中矩阵分解用作推荐器。
基于一阶马尔科夫链的方法:
FPMC:该方法结合了矩阵分解和一阶马尔科夫链,分别捕获了长期偏好和动态转移(dynamic transition)。TransRec:该方法将每个用户建模为item到item的翻译向量(tanslation vector)。这是捕获转移的一阶方法。
基于神经网络的方法:
GRU4Rec+:建模用户行为序列从而用于session-based推荐。与GRU4Rec相比,GRU4Rec+采用了不同的损失函数和采样策略,相比于GRU4Rec表现出显著的提升。Caser:将最近item的序列嵌入到潜在空间的 ”图像“ 中。该方法可以捕获考虑了最近item的高阶马尔科夫链。MARank:最近提出的SOTA模型。该方法考虑最近的一些item并应用multi-order attention来捕获individual-level和union-level的依赖关系。SASRec可以视为一种仅考虑绝对位置的方法,将在实验部分与我们的模型进行比较和讨论。其它序列推荐方法,如
PRME, HRM, Fossil, GRU4Rec的性能弱于上述baseline,因此我们省略了与它们的比较。
配置:
为了公平比较,我们使用带
Adam优化器的TensorFlow来实现BPR, FPMC, TransRec。对于GRU4Rec+, Caser, MARank,我们使用作者提供的代码。我们在
20个epoch内没有提高,则终止训练。对于
TiSASRec:我们使用两层
Time Interval-Aware Self-attention Layer。所有数据集的学习率为
0.001,batch size为128,dropout rate为0.2。
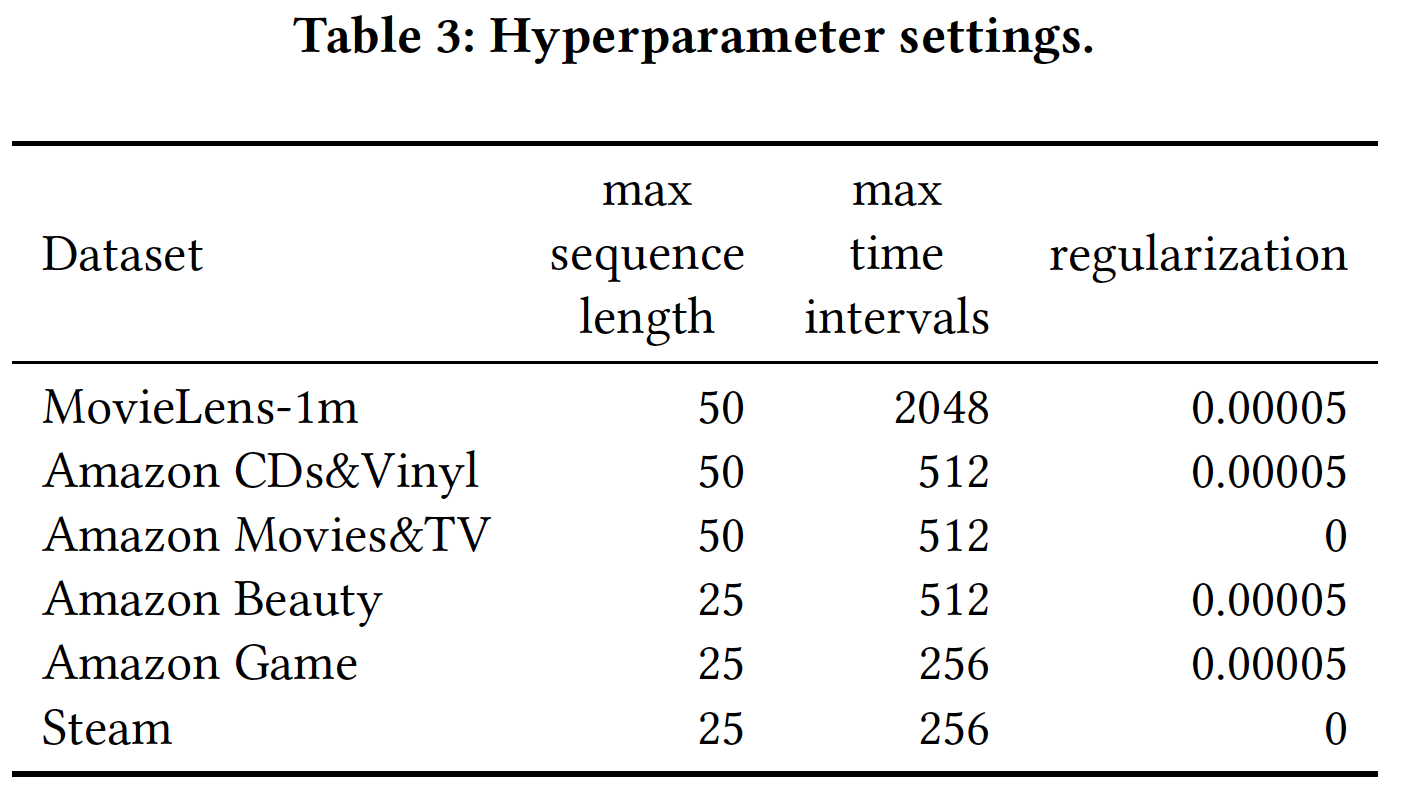
剩余的超参数设置如下表所示。所有实验均使用单个
GTX-1080 Ti GPU进行。
推荐性能(
RQ1):下表给出了所有方法在六个数据集上的推荐性能。可以看到:在所有
baseline中,MARank超越了其它baseline。MARank可以捕获individual-level和union-level的用户交互,并且很好地处理稀疏数据集。对于稠密数据集,基于神经网络的方法(即,
GRU4Rec+, Caser)比基于马尔科夫链的方法具有显著更好的性能,因为这些方法具有更强的能力来捕获长期序列模式,而这对于稠密数据集很重要。由于基于马尔科夫链的方法(即,
FPMC, TransRec)聚焦于item的动态转移,因此它们在稀疏数据集上表现更好。TiSASRec在所有稠密数据集和稀疏数据集上都超越了所有的baseline方法。
其它方法都没有考虑时间信息,而
TiSASRec考虑了时间信息,那么这篇论文仅仅证明了时间信息的价值,并不能证明模型架构是好的。为了证明模型架构是好的,论文应该和同时考虑了时间信息的模型去比较。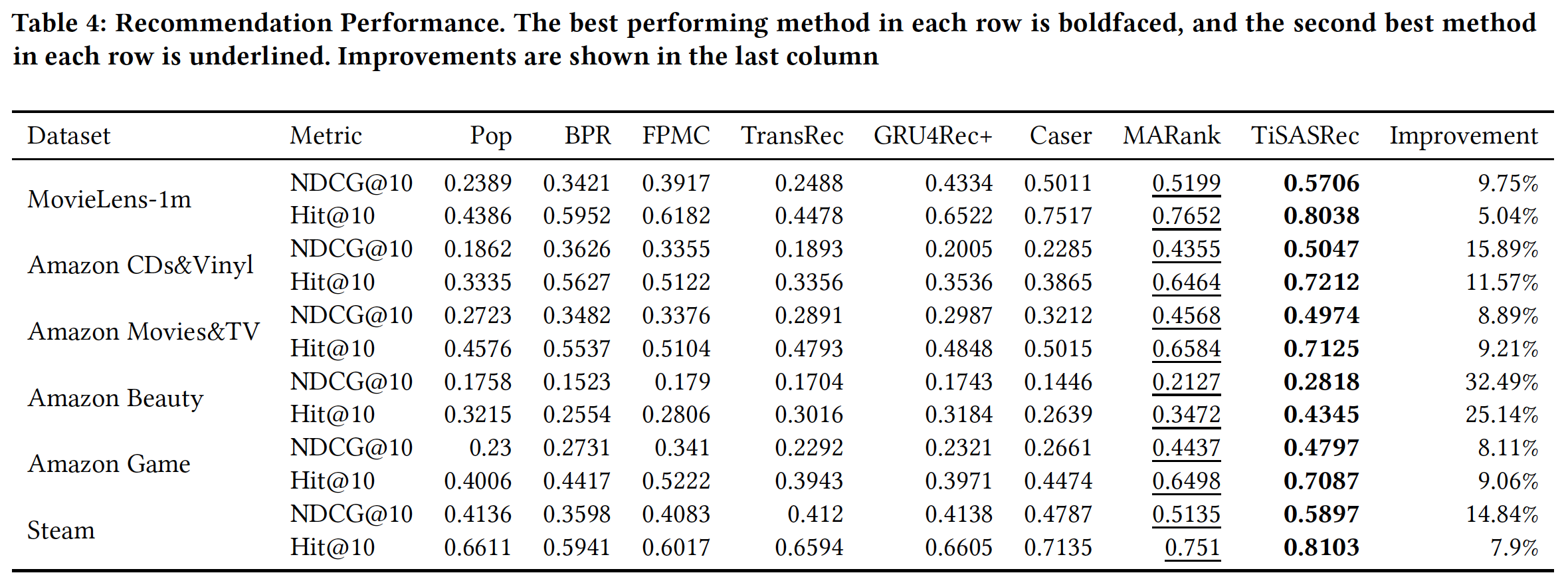
相对时间间隔(
RQ2):为了比较仅有绝对位置、或者仅有相对时间间隔的模型的性能,我们修改Time Interval-Aware Self-attention Layer的输出 ,使得TiSASRec仅考虑相对时间间隔而不考虑绝对位置。具体而言,我们修改Time Interval-Aware Self-attention Layer的输出为:即,我们移除了该方程中的
positional embedding,从而得到一个新的模型,称作TiSASRec-R。此外,我们将
SASRec视为一种仅考虑绝对位置的self-attention方法。我们在这六个数据集上应用SASRec, TiSASRec-R, TiSASRec来比较它们。为公平比较,我们对SASRec使用与TiSASRec相同的最大序列长度。实验结果如下表所示。可以看到:TiSASRec-R在Movie-Lens, CDs&Vinyl, Beauty数据集上比SASRec具有更好的性能,但是在其它三个数据集上则不然。总体而言,
TiSASRec-R(仅使用相对时间间隔)将具有与SASRec(仅使用绝对位置)相似的性能。结合了
positional embedding和相对时间间隔embedding的TiSASRec在所有数据集上超越了SASRec, TiSASRec-R。
限制
TiSASRec-R性能的主要原因是:用户序列中有许多相同的时间戳。在这种情况下,TiSASRec-R将在没有任何位置信息的情况下降级为self-attention。为了缓解这个问题,我们结合了相对时间间隔和绝对位置。这样,TiSASRec结合了更丰富的item关系来计算注意力权重。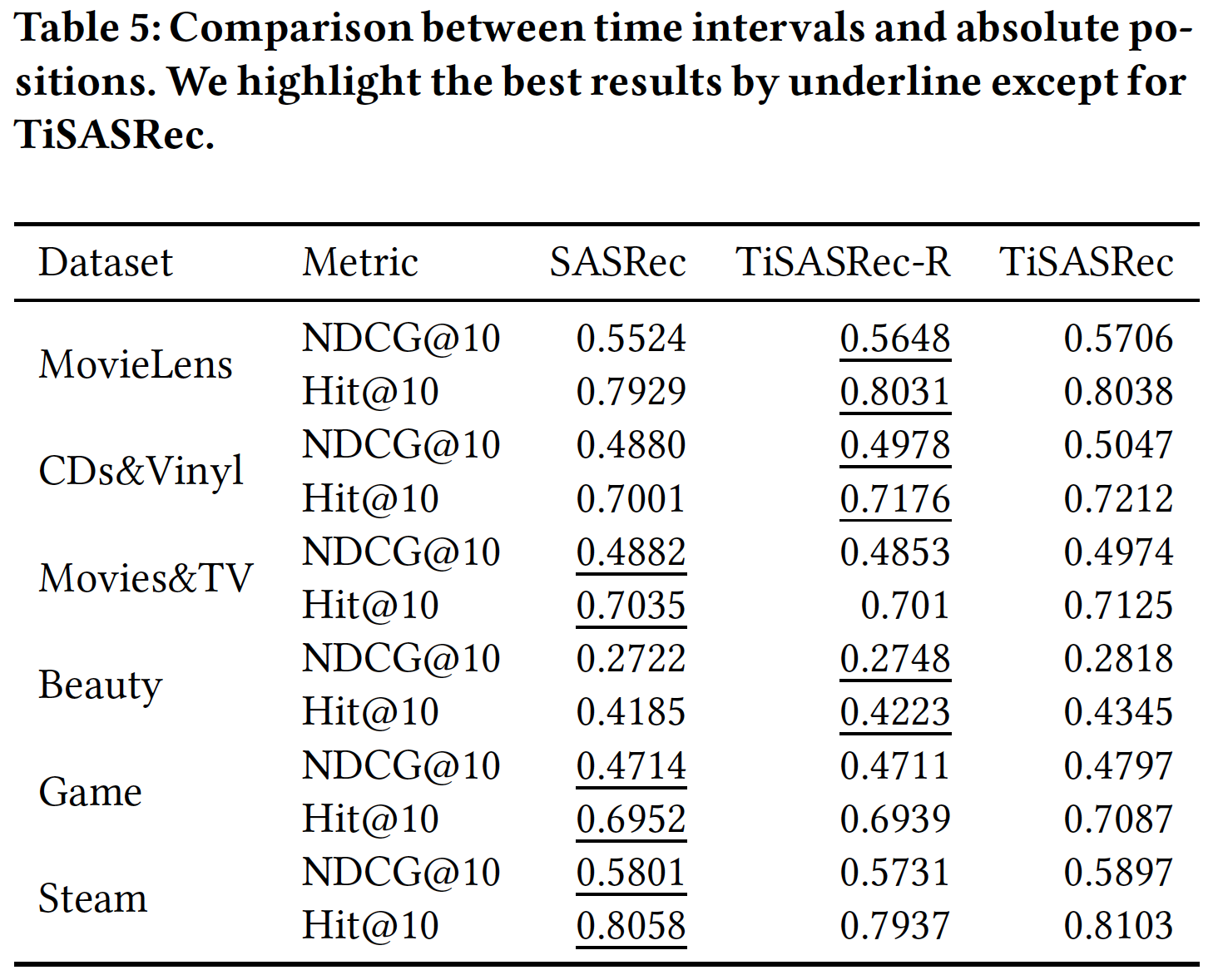
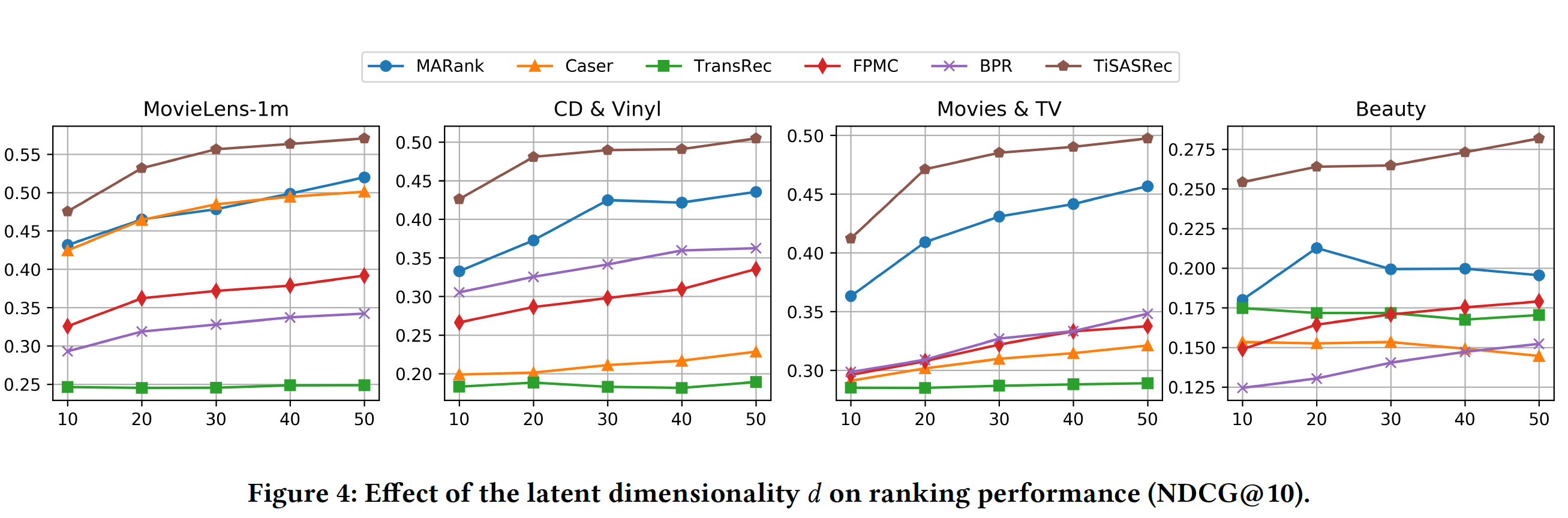
超参数影响(
RQ3):embedding维度10到50对NDCG指标的影响。可以看到:在大多数情况下,较大的
TransRec的影响有限。对于数据集
Amazon Beauty,当Caser, MARank, TransRec的性能较差。
最大序列长度
10到50对NDCG指标的影响。可以看到:更大的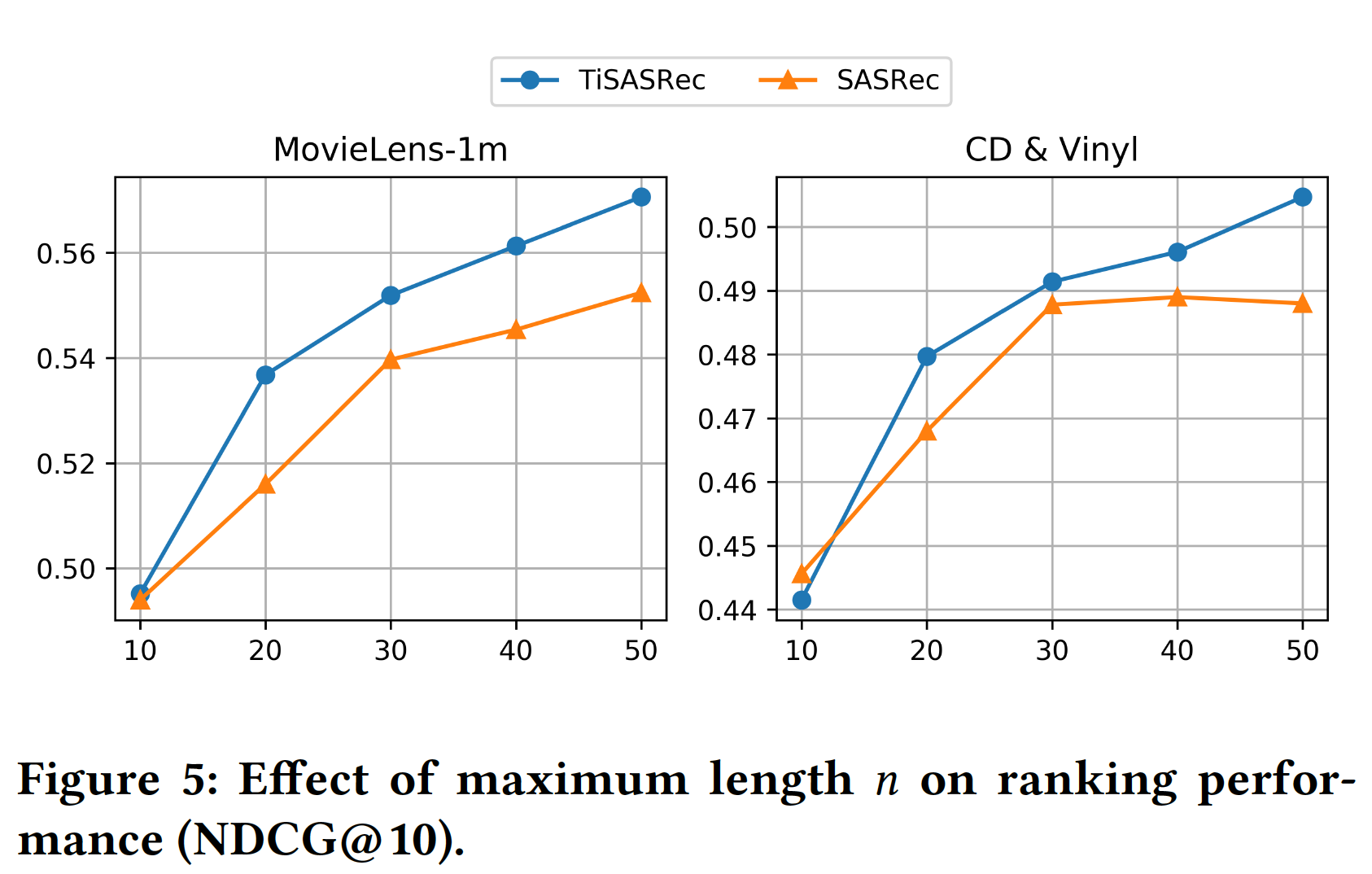
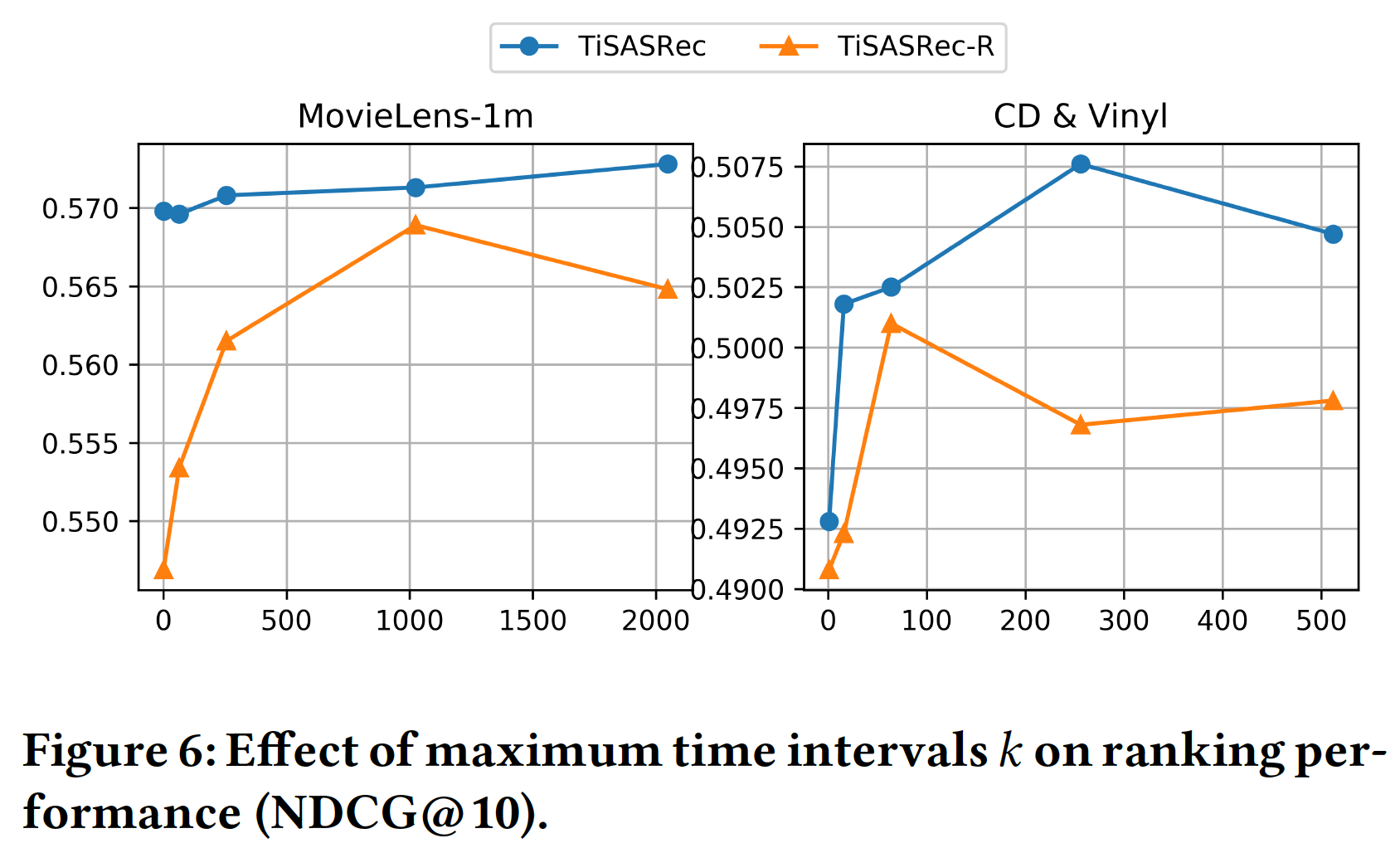
最大时间间隔
NDCG指标的影响。我们为MovieLens数据集选择时间间隔{1, 64, 256, 1024, 2048},为Amazon CDs & Vinyl数据集选择时间间隔{1, 16, 64, 256, 512}。可以看到:TiSASRec在不同的最大时间间隔下具有更稳定的性能。当
TiSASRec-R实现最佳性能,而对于较大的
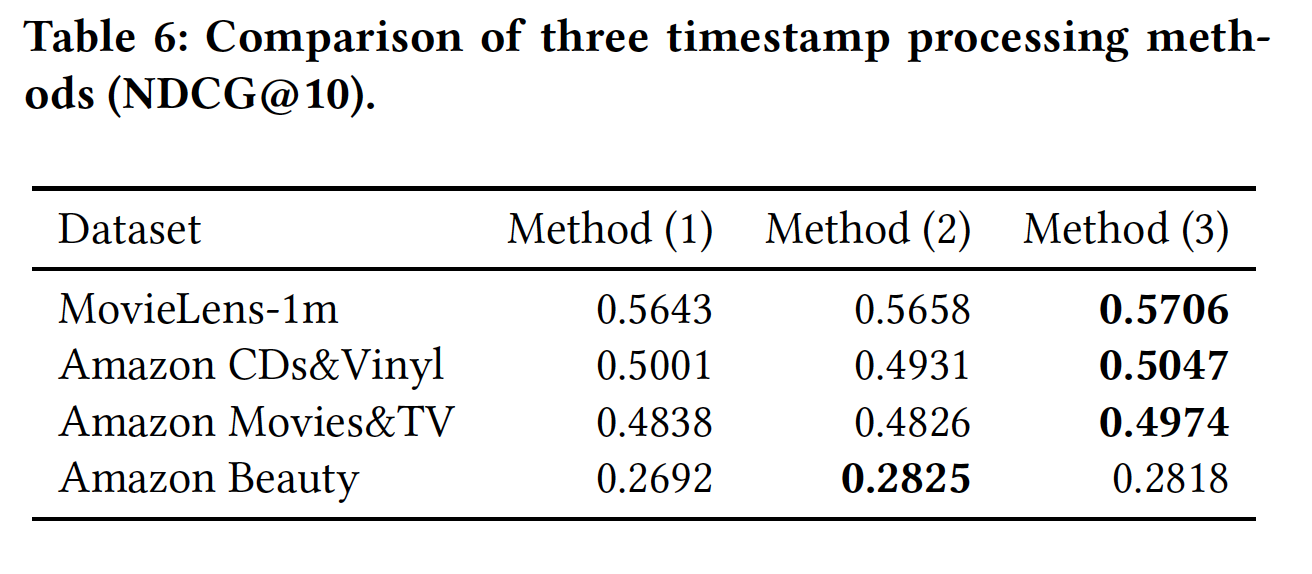
个性化的时间间隔(
RQ4):我们讨论不同的时间戳处理方法,具体而言为以下三种方法:直接使用时间戳作为特征。我们会减去数据集中最小的时间戳(全局粒度的),让所有时间戳从
0开始。使用未缩放的时间间隔。对于每个用户,我们减去序列中的最小时间戳(用户粒度的),让用户的时间戳从
0开始。使用个性化的时间间隔。对于每个用户,我们减去序列中的最小时间戳(用户粒度的),然后除以该序列的最小时间间隔。
下表给出了时间戳不同处理方法的结果。注意,我们不会在前两种方法中裁剪时间戳。可以看到:第三种方法(即,个性化的时间间隔)在前三个数据集中获得了最佳性能。
可视化:我们使用
TiSASRec来预测用户可能交互的next item。然后,我们将所有时间间隔设为相同从而获得另一个预测。如下图所示,可以看到时间间隔影响了预测结果。
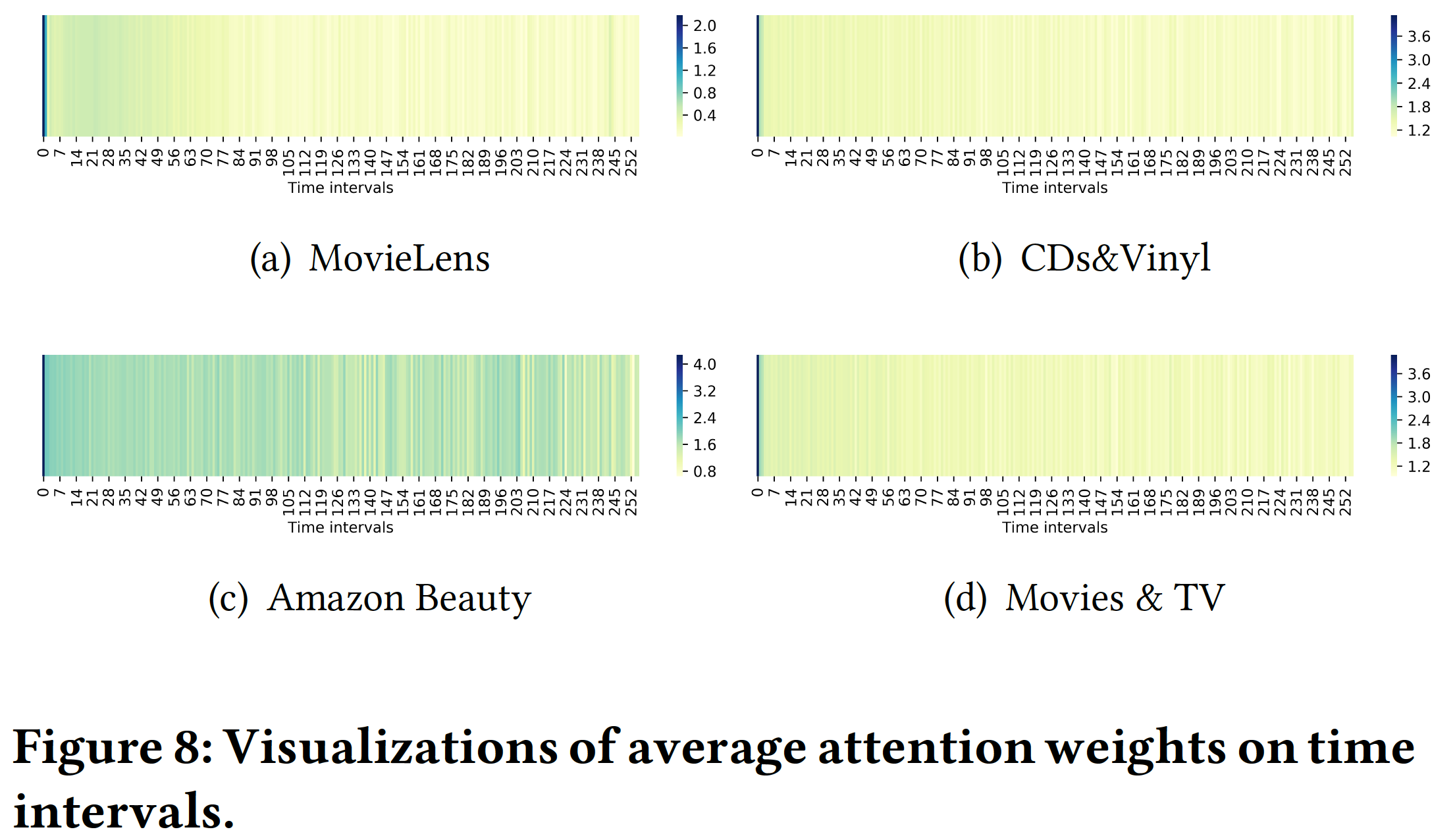
下图展示了前
256个时间间隔的平均注意力权重padding item的影响。从这四个热力图中我们可以看到:小的时间间隔通常比大的时间间隔具有更大的权重,这意味着最近的
item对next item的预测具有更大的影响。稠密数据集(如
MovieLens)比稀疏数据集(如CDs&Vinyl)需要更大范围的item(即,间隔更大),因为MovieLens热力图左侧有一个较大的绿色区域同时右侧是黄色区域。Amazon Beauty数据集的热力图没有明显的绿色区域或黄色区域,可能是因为该数据集没有明显的序列模式。这就解释了为什么几种序列方法在这个数据集上表现不佳。